





Abstract
Determining accurate redshift distributions for very large samples of objects has become increasingly important in cosmology. We investigate the impact of extending cross-correlation based redshift distribution recovery methods to include small-scale clustering information. The major concern in such work is the ability to disentangle the amplitude of the underlying redshift distribution from the influence of evolving galaxy bias. Using multiple simulations covering a variety of galaxy bias evolution scenarios, we demonstrate reliable redshift recoveries using linear clustering assumptions well into the non-linear regime for redshift distributions of narrow redshift width. Including information from intermediate physical scales balances the increased information available from clustering and the residual bias incurred from relaxing of linear constraints. We discuss how breaking a broad sample into tomographic bins can improve estimates of the redshift distribution, and present a simple bias removal technique using clustering information from the spectroscopic sample alone.
1 INTRODUCTION
Cosmological measurements require distance estimates in order to map the large scale structure of the Universe. In the past this has most often been done on an object-by-object basis by obtaining spectroscopic redshifts for individual sources. Surveys of large samples of galaxies such as the Sloan Digital Sky Survey and its extensions (York et al. 2000; Abazajian et al. 2009) have been instrumental in improving cosmological measurements. However, a number of current and upcoming missions [Dark Energy Survey (DES), Large Synoptic Survey Telescope (LSST), etc.] will attempt to measure the fundamental properties of cosmology, and particularly dark energy, using a variety of methods (e.g. weak gravitational lensing, baryon acoustic oscillations, etc.). Fundamental to all of these surveys is the assumption that the millions, or even billions, of galaxies observed by these instruments will be separable into redshift bins, despite the fact that the number of objects involved makes spectroscopic follow-up wildly impractical. Photometric redshift techniques show a good deal of promise towards this goal (e.g. Connolly et al. 1995; Benítez 2000; Cunha et al. 2009), but there remain questions as to whether or not they can meet the stringent requirements outlined in these surveys and avoid systematic biases that could leak into dark energy constraints (e.g. Ma, Hu & Huterer 2006; Cunha et al. 2012). In this paper, we examine a technique that uses clustering between spectroscopic and photometric samples to accurately determine a photometric sample's redshift distribution. The applications of such a technique are much more general than the aforementioned large surveys: this technique can be used to estimate the redshift distribution of nearly any data set. Even single-band detections that lack photometric redshift estimates can be used, as long as they have reliable astrometric information for the calculation of cross-correlation functions.
The technique described in this paper uses the physical associations due to large-scale clustering to probe redshift distributions. Such ideas are not new: Seldner & Peebles (1979) cross-correlated quasars and galaxy counts to test for physical association, though they found no trend with redshift. Roberts & Odell (1979) similarly cross-correlated quasars and rich galaxy clusters. More recently, Quadri & Williams (2010) counted pairs of galaxies at small angular separations between photometric redshift-selected samples, taking advantage of physically associated pairs of galaxies in order to determine an empirical measure of the photometric redshift errors. Similarly, Benjamin et al. (2010) cross-correlated photometric redshift bins to determine the relative contamination fraction between redshift bins based on the magnitude of the induced angular cross-correlations.
These previous techniques do not require any spectroscopic sample and rely solely on photometric redshift information. Schneider et al. (2006) discuss using cross-correlations of objects sorted into redshift bins in order to determine their redshift distribution. They mention that having a subset of objects with more accurately determined redshifts would enable tighter constraints than photometric redshifts alone. Expanding on this idea, Newman (2008) (hereafter N08) and Matthews & Newman (2010, 2012) describe a technique that requires a spectroscopic sample that spans the redshift range of interest. In simple terms, the method measures the amount of overlap between the spectroscopic sample divided into redshift bins and an unknown sample (which we will refer to as the ‘photometric’ sample, though photometric redshifts are not necessary for sample selection). As galaxies cluster on all scales, if a spectroscopic bin overlaps in redshift with the photometric sample, we expect to see an excess number of objects, whereas if there is no overlap we expect to simply see the average number of objects that overlap spatially due to projection. By measuring the strength of the spatial cross-correlations as a function of redshift we can recover the redshift distribution of the photometric sample. A major component of the N08 technique is an iterative method to correct for bias evolution that may occur in the sample. Schulz (2010) implemented a very similar technique on mock data and reported difficulty in disentangling the galaxy bias from the redshift distribution, a point which we will examine in this paper. It is only very recently that this technique has been used with real data (Mitchell-Wynne et al. 2012; Nikoloudakis, Shanks & Sawangwit 2013), including the exact technique described in this work (Morrison et al. 2012, Ménard et al., in preparation).
The N08 technique is designed to work with large-scale correlations where the galaxy bias can be treated as linear. However, the increasing amount of power in galaxy correlation functions due to large-scale clustering means that there is considerable signal that is not being fully utilized at smaller scales (this is particularly relevant given the small angular extent of many deep spectroscopic surveys.). Further study of the spectroscopic sample's non-linear bias properties may enable us to account for the effects of bias in the redshift recovery. In this paper we explore the impact of retaining the linear assumptions while expanding the procedure to include smaller physical scales, where the galaxy bias becomes non-linear in the density field. In this regime evolution of the galaxy bias will modulate the amplitude of the recovered redshift distribution. We test the efficacy of using the linear assumptions well into the non-linear regime.
Additionally, in some instances we are only interested in the existence or absence of galaxies in a redshift interval, and the detailed shape of the redshift distribution is not the main concern. As an example, when selecting objects based on photometric redshifts, parameter degeneracies can lead to inclusion of a secondary population of objects far outside the intended redshift range. In such a case the exact shape of the redshift distribution, which can be distorted by the presence of evolving galaxy bias, may be secondary to detecting the presence or absence of an interloper population. For these reasons we examine the relative amount of information contained at a range of physical scales around our spectroscopic samples.
The layout of the paper is as follows. In Section 2 we discuss the algorithms used to determine the redshift distributions. A summary of the mock data sets is given in Section 3. Results are presented in Section 4. We conclude and present future work in Section 5.
2 METHOD
Our main goal is to measure the redshift probability density function (PDF), ϕ(z), for a specific sample of objects that we will refer to as the ‘photometric’ sample. As mentioned in Section 1, we do not necessarily need a photometric redshift measurement for our samples. However, as we will discuss, a sample that is selected to cover a narrow range in redshift leads to a more accurate recovery than that of a broad distribution. So, while the method can be applied to almost any arbitrary data set, in practice it will most often use samples selected with photometric redshifts. We estimate these redshift distributions by measuring the amplitude of the cross-correlation signal between our photometric sample and a sample of objects with known redshifts.
In computing the projected overdensities, proper treatment of the survey area, including complicated selection and masks, is essential. To accomplish this goal we develop a code which employs the astro-stomp software package.1 The software uses a pixelization of the sky to encode both the galaxy positions and the survey footprint for fast computation of galaxy density and has the ability to encode complex masking and selection.
2.1 Bias correction
Measuring the overdensity of galaxies around objects in the spectroscopic sample does not immediately give us the underlying redshift distribution: cross-correlations measure the object overdensity within a fixed real space annulus, but the clustering length of both the spectroscopic and ‘photometric’ samples is not necessarily constant with redshift. We must account for any such evolution in order to recover the redshift distribution. We will examine using the clustering length calculated from the spectroscopic sample alone to account for bias evolution in Section 4.4, but will mainly use the iterative method introduced by N08. This technique describes an iterative correction to the redshift distribution using estimates of the mean clustering length for the photometric sample and the (presumably known) clustering evolution of the spectroscopic sample. Thus, the method requires that we have sufficient data to calculate the clustering evolution of the spectroscopic sample, and assumes that the bias in the photometric sample varies linearly with the bias in the spectroscopic sample. This assumption will break down as we include measurements at small radii as the clustering moves in to the non-linear regime. Finding the scales at which the bias evolution becomes too great for effective correction is the subject of this paper.
2.2 Choice of rmin and rmax
The photometric overdensity is measured over a constant range of projected physical scales around each spectroscopic object, bounded by an inner and an outer radius, rmin and rmax. The choice of these radii affects the recovery in a number of ways and the values for rmin and rmax serve as the primary tuning parameters for the fidelity of the recovered redshift distribution.
For cases where the photometric catalogue contains some fraction of the spectroscopic catalogue a complication can arise. Excess signal from the cross-matches between objects in the catalogues may boost the recovery signal if we allow for rmin = 0, or if astrometric uncertainties lead to mismatch of spectroscopic and photometric objects. For our simulations, we have explicitly excluded such objects, so small radius matches are unaffected by such contamination. More broadly, at small physical separations (below ∼1 Mpc) the clustering of objects will become stronger and increasingly non-linear. This increased amplitude is a strong indicator that there is more information to be extracted from the cross-correlation, albeit at the cost of bending some of the linear assumptions described in Section 2.1. We will discuss this issue further in Section 5. For the outer boundary of the annulus, as rmax increases, more physically associated galaxies will be included in the annulus, but so will an increasing number of unassociated background sources. The clustering signal declines as radius increases, so increasing rmax can degrade the signal-to-noise ratio (S/N) of the measurement. The optimum rmax will depend on both the clustering of the sample and the density of the photometric source catalogue.
3 SIMULATED GALAXY CATALOGUES
The redshift recovery procedure is sensitive to the evolution of galaxy bias. In order to test this sensitivity we employ two sets of simulations: mocks based on Millennium light cones with a limited field of view (Springel et al. 2005; Croton et al. 2006) and larger area mocks based on LasDamas simulations (McBride et al., in preparation). To cover a wide variety of possible scenarios we will examine four mock data sets.
No galaxy bias evolution.
Evolving galaxy bias as expected for a realistic, magnitude-limited sample.
A magnitude-limited selection with an additional stellar mass cut used to recover the magnitude-limited sample, as might be expected if our spectroscopic catalogue was a particular galaxy type.
A mixed case with constant bias at low redshift and a magnitude-limited selection at higher redshift used to recover a sample with smooth bias evolution. Such a distribution might arise from multiple populations or complex selection criteria.
The first two cases have spectroscopic and photometric data drawn from the same underlying distribution, and thus identical galaxy bias properties. Cases (iii) and (iv) have different bias properties for the spectroscopic and observed samples, as will be discussed in the following subsections. We use the LasDamas simulations for the constant bias (item i) and mixed evolution samples (item iv), and the Millennium simulations for the magnitude-selected and stellar mass selected samples (items ii and iii).
3.1 LasDamas-based mock catalogues
The LasDamas catalogues used in this paper are a customized galaxy data set generated from the dark matter simulations of the LasDamas project (McBride et al., in preparation).2 These galaxy mocks were constructed for testing this method, and do not explicitly fit to observed SDSS data, as is done in the full LasDamas simulations. This enabled us to extend the redshift range beyond z > 1, with samples spanning 0.03 ≤ z ≤ 1.33, and covering a 9° × 14° degree patch of sky. The galaxy mocks are constructed from a static redshift output of one of the four large LasDamas boxes (the Carmen simulations) at z = 0.5. We defined friends-of-friends haloes (Davis et al. 1985) with a linking length of 20 per cent of the mean inter-particle separation. We assigned mock galaxies based on a simple three-parameter halo occupation distribution model (i.e. HOD; Berlind & Weinberg 2002). To achieve the variable bias, the HOD is varied to reduce the number density as a function of redshift (thereby increasing the bias). The LasDamas simulations assume a flat Λcold dark matter cosmology with Ωm = 0.25, ΩΛ = 0.75, h = 0.70 and σ8 = 0.8.
We construct two spectroscopic catalogues, populating the same dark matter halo catalogues with two different types of galaxy bias applied to generate the data:
A constant bias for the whole redshift range consisting of approximately 120 000 galaxies over 125 deg2.
A constant bias over (0.2 ≤ z ≤ 0.77), then mimicking an apparent magnitude-limited selection for z > 0.77 with about 235 000 galaxies over 500 deg2.
We refer to the first as the ‘constant bias’ sample and the second as the ‘mixed bias evolution’ sample. For the photometric samples we create distributions drawn from the same constant bias case, as well as an additional data set with bias chosen such that the density decreases linearly with redshift over the range 0.2 ≤ z ≤ 1.33 (referred to as the ‘linear density evolution’ sample. For these samples we create the following.
A bimodal sample with galaxies in the ranges 0.4 < z < 0.6 and 0.8 < z < 1.1 containing about 350 000 for the constant bias sample and about 592 000 galaxies for the linear density evolution sample.
A Gaussian centred at z = 0.75 and width σz = 0.10 with ∼145 000 for the constant bias case and ∼410 000 galaxies for the linear density evolution sample.
3.2 Millennium galaxy mock catalogues
The Millennium simulation galaxy mock catalogues of Croton et al. (2006)3 are light cones populated with galaxies generated from semi-analytic models that follow the prescriptions of Croton et al. (2006) and Kitzbichler & White (2007). We use the four 2° × 2° ‘DLS’ cones, designed to match the footprints of the Deep Lens Survey (Wittman et al. 2002). The light cones contain 17.4 million galaxies with redshifts spanning 0 < z < 3 over 16 deg2 with a magnitude-limited r-band depth of r = 29.0, which cover a redshift range large enough that significant galaxy bias evolution will occur. Areal coverage is limited enough that sample variance will be a significant factor in some measurements. The Millennium simulation assumes cosmological parameters Ωm = 0.25, ΩΛ = 0.75, h = 0.73 and σ8 = 0.9.
We construct two ‘spectroscopic’ catalogues with known redshifts, and two ‘photometric’ catalogues, where no redshift information is retained. For the spectroscopic sets we do the following. We refer to the first as the ‘bias evolution’ sample and the second as the ‘masscut’ sample. Each has a surface density of approximately 5.6 galaxies arcmin−2. For the photometric samples, we draw from the same underlying magnitude-limited distribution used in the evolving bias scenario, thus they have identical bias evolution properties to the evolving bias case. We construct two samples from the simulation data:
We randomly select ∼2 per cent (approximately 325 000 galaxies) of the magnitude-limited sample that will have a galaxy bias evolution matching that of the underlying sample.
We design a galaxy sample of roughly the same size as the previous sample (335 000 galaxies) which contains all galaxies with stellar mass greater than 2.3 × 1010 M⊙.
a bimodal distribution with 1.9 million galaxies covering the ranges 0.9 < z < 1.1 and 1.9 < z < 2.1.
a Gaussian distribution of about 690 000 galaxies centred at z = 1.5 with width σz = 0.15.
As will be shown in later sections, despite similar redshift spans and identical spectroscopic catalogues, the effects of evolving bias on the recovered redshift distribution for these two samples can be quite dissimilar. The stellar mass selection gives our spectroscopic sample different bias properties than the photometric samples, enabling us to test the efficacy of the recovery algorithm in the presence of stronger, non-representative bias. The evolving bias scenario has identical bias in the spectroscopic and photometric samples. The iterative procedure should perfectly recover the redshift distribution when the biases are the same; however, we will see that this is not the case when we measure the clustering length based on the large linear regime scales but use non-linear clustering information to reconstruct the distribution.
3.3 Clustering measurements
The recovery procedure requires fits to the projected correlation function of the spectroscopic data sets, as well as the slope and amplitude of the two-point autocorrelation functions of the photometric samples. For the Millennium data sets the projected correlation functions of the spectroscopic samples are well fitted by a power-law form, and lack a strong one-halo break. As the slope of the power law shows little variation, we fix it at γss = 1.8 when fitting for the correlation length, r0, ss, and use only projected separations greater than rp > 300 kpc. Thus, non-linear evolution in the one-halo regime will not be reflected in the clustering lengths used in the iterative corrections. We fit a parabolic form to the r0, ss data to smooth small-scale redshift dependence induced by the measurement errors. For the angular correlation function fits of the photometric samples, we measure best-fitting power-law slopes of γpp = 1.75 ± 0.13 for bimodal and γpp = 1.68 ± 0.11 for the Gaussian distribution.
For the LasDamas data, both the constant bias and mixed bias data sets show a strong one-halo component and a break in their projected correlation functions, with slopes of γss = 1.45 for the constant bias data set and γss = 1.8 for the mixed bias case, nearly independent of redshift, at rp > 300 kpc beyond the one-halo break. Once again we fit for r0, ss using only this ‘quasi-linear’ regime.
4 RESULTS
The effectiveness of cross-correlation methods in recovering redshift distributions is dependent of many factors. Some of these (e.g. spectroscopic completeness or galaxy bias evolution) are determined by the survey data itself. Others (the scale used for the cross-correlations, the redshift binning of the spectroscopic samples and weighting of the cross-correlation pairs) are nearly free parameters that can be used to tune the recovery. Of these free parameters, the choice of scale has the most significant effect on the recovery due to its direct linkage to the galaxy bias dependence of the recovery. In the N08 iterative technique, measurements are made on large enough scales (several Mpc) that the linear bias can be removed. For the purposes of our analysis, we consider a much broader range of scales, from the linear to the quasi-linear (∼1 Mpc) down to the non-linear scales of a few kiloparsec. Our full analysis tests a wide range of scales, covering 3 ≤ rmin≤ 3000 kpc and 10 ≤ rmax ≤ 5000 kpc, but for illustrative purposes we will show results only for three representative decade-width scales: 3 < r < 30 kpc, 30 < r < 300 kpc and 300 < r < 3000 kpc.
Before examining the redshift recoveries for these scales, a word about the smallest scales: since we are using simulated data with perfect astrometry, we can distinguish perfectly between galaxies at scales where real data sets with noise from astrometric calibration and atmospheric blurring would likely struggle. Applying these techniques to real data on those scales would likely mean that cross-contamination between the spectroscopic and photometric samples would dominate the recovered signal. We have experimented with differing levels of cross-contamination between our simulated samples and found that the behaviour of the recovered distributions is highly dependent on the choice of simulated spectroscopic sample. To avoid this additional complication, we have chosen to eliminate all spectroscopic objects from our photometric catalogues and vice versa and defer further exploration of this effect to a future publication.
4.1 Recovery scales and populations
In practical terms, several different bias scenarios may arise depending on the type of data selected. We might select a population with very little expected bias evolution (e.g. Luminous Red Galaxies), slowly evolving bias over a broad redshift interval (e.g. field galaxies), or complex evolution due to the presence of multiple populations (e.g. a tomographic redshift bin with outliers). For this reason we study the redshift reconstruction in several bias scenarios. The shape of the redshift distribution of the photometric sample also plays a role: even a sample with strong galaxy bias evolution will not show significant relative bias change if the redshift interval of the recovery is sufficiently narrow. Conversely, even slight bias evolution over a broad redshift interval may become significant when we include additional information from non-linear scales. We test the recovery algorithm on two types of distributions to explore these effects: a centrally peaked Gaussian distribution and a bimodal distribution.
Fig. 1 shows the recovered redshift distributions of the Gaussian photometric samples for both the LasDamas constant bias scenario and the Millennium evolving bias at our three representative scales. Red points show the distribution before the iterative correction of equations (2) and (3) is applied, while black points show the results after the correction. In the constant bias case the iterative correction should have almost no effect, which is seen in the small difference between the pre- and post-iteration recoveries. Interestingly, the method performs extremely well in the absence of bias evolution, down to the smallest scales, and including scales that span the break in the LasDamas correlation function.
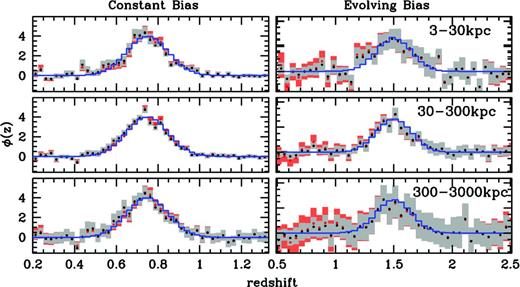
Recovered Gaussian redshift distributions for the LasDamas constant bias (left) and Millennium evolving bias (right) spectroscopic samples for three decade width sets of rmin and rmax. Red points are the results before the iterative bias correction is applied, while black points with grey errors are after the iteration. The blue histogram shows the actual redshift distribution of the photometric sample. The more centrally peaked distribution is less sensitive to bias evolution than the broader bimodal distribution.
The centrally peaked Gaussian distribution, with most galaxies close to the mean redshift where our r0, pp estimate is most accurate, shows little sensitivity to effects of the evolving bias. More compact and symmetric photometric distributions will be less affected by galaxy bias evolution, which enables us to push the recovery to smaller scales. We will discuss this further in Sections 4.2 and 4.3. For the constant bias scenario the best fit is 50 ≤ r ≤ 100 kpc with a reduced χ2 = 1.42, though the change in χ2 is not particularly sensitive to the exact values of rmin and rmax (i.e. the likelihood surface is very flat).
For the evolving bias the best fit occurs for 100 ≤ r ≤ 300 kpc with a reduced χ2 = 0.107. The χ2 value significantly below 1.0 shows that we are overestimating our error bars for the Millennium sample, which is not unexpected: with only 16 deg2 available in the Millennium light cones we use only 32 jackknife samples to estimate the errors on fits for 99 bins. This appears to only affect the amplitude of the errors, and not the overall structure of the covariance matrix. The centrally peaked distribution shows little sensitivity to bias evolution even down to the smallest scales probed, and we accurately recover the distribution at all scales.
Fig. 2 shows the recovered redshift distributions of the bimodal samples for the constant bias and evolving bias spectroscopic samples. The best fit for the bimodal sample occurs at 10 ≤ r ≤ 50 kpc with a reduced χ2 of 1.16. The χ2 values are similar for the bimodal and Gaussian distributions, showing that in the absence of bias evolution the recovery performs accurately regardless of the shape of the redshift distribution. The most notable feature in the evolving bias scenario is the relative amplitude of the two peaks. The bimodal sample shows a clear bias before the iterative correction is applied, with larger discrepancies as the annulus moves to smaller physical scales. This is as expected, since this bimodal configuration is particularly sensitive to bias evolution. Because the iterative correction estimates a single, average value of r0, pp for the sample the bias correction is most accurate near the mean redshift of the photometric distribution. The bimodal sample has a mean redshift of z = 1.59, between the two peaks where no galaxies are located. Also of note is the fact that even with identical bias evolution we introduce error into the recovered distributions even after iterative correction. This is mainly due to the fact that we (purposely) measure the clustering length using only large (>300 kpc) scales, and to a lesser extent due to the empirical estimation of the clustering length with finite samples that can also introduce errors. We note, however, that the iterative technique does accurately recover the distributions when only the large-scale clustering information is used, as expected.
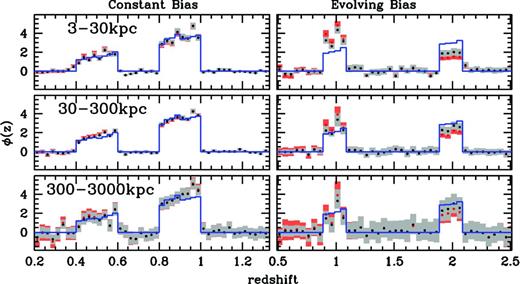
Recovered bimodal redshift distributions for the LasDamas constant bias (left) and Millennium evolving bias (right) spectroscopic samples for three decade width sets of rmin and rmax. Red points are the results before the iterative bias correction is applied, while black points with grey errors are after the iteration. The blue histogram shows the actual redshift distribution of the photometric sample. In the case of no bias evolution the recovery works well on all scales, while evolving bias induces a skew in the recovered distribution.
The effectiveness of the iteration in correcting for the bias is obviously reduced as the radius of the annulus decreases, though errors due to covariance between bins also increase as rmax grows and more unassociated galaxies are included in the estimate. The best-fitting values are for intermediate scales, with a minimum at 200 ≤ r ≤ 300 kpc and χ2 = 0.334. The best fits at intermediate scales balance the increasing influence of the bias at small scales with the concurrent increase in S/N and decreased bin-to-bin covariance that comes with smaller physical apertures. It is clear that small-scale information greatly increases bias in the recovery, and should not be used to recover broad redshift distributions.
Table 1 lists the reduced χ2 values for the representative scale distributions both before and after the N08 iteration is applied. The success of the iterative technique in aiding the recovery procedure is varied. The iteration improves the recovery for every case in the evolving bias scenario, mixed results in the constant bias and mass cut scenarios, and mainly degrades results in the mixed/linear case.
Reduced χ2 for distributions before and after the N08 iterative correction.
| Annulus | χ2/ND | χ2/ND | χ2/ND | χ2/ND |
|---|---|---|---|---|
| pre- | post- | pre- | post- | |
| iteration | iteration | iteration | iteration | |
| Bimodal | Gaussian | |||
| LD constant bias | ||||
| 3–30 kpc | 3.34 | 3.11 | 1.55 | 1.59 |
| 30–300 kpc | 1.99 | 1.47 | 2.12 | 3.33 |
| 300–3000 kpc | 1.86 | 1.64 | 1.35 | 2.06 |
| 3–3000 kpc | 1.97 | 1.79 | 1.43 | 2.61 |
| Evolving bias | ||||
| 3–30 kpc | 1.12 | 0.67 | 0.274 | 0.201 |
| 30–300 kpc | 0.566 | 0.258 | 0.229 | 0.148 |
| 300–3000 kpc | 0.400 | 0.216 | 0.264 | 0.215 |
| 3–3000 kpc | 0.496 | 0.270 | 0.237 | 0.207 |
| Mass cut | ||||
| 3–30 kpc | 7.11 | 7.20 | 0.279 | 0.276 |
| 30–300 kpc | 1.99 | 2.04 | 0.156 | 0.155 |
| 300–3000 kpc | 0.381 | 0.376 | 0.215 | 0.204 |
| 3–3000 kpc | 0.743 | 0.783 | 0.514 | 0.521 |
| LD mixed bias | ||||
| 3–30 kpc | 228.2 | 513.1 | 366.08 | 122.8 |
| 30–300 kpc | 10.99 | 27.90 | 3.26 | 4.92 |
| 300–3000 kpc | 5.98 | 10.01 | 2.05 | 1.78 |
| 3–3000 kpc | 131.6 | 340.3 | 20.71 | 34.44 |
| Annulus | χ2/ND | χ2/ND | χ2/ND | χ2/ND |
|---|---|---|---|---|
| pre- | post- | pre- | post- | |
| iteration | iteration | iteration | iteration | |
| Bimodal | Gaussian | |||
| LD constant bias | ||||
| 3–30 kpc | 3.34 | 3.11 | 1.55 | 1.59 |
| 30–300 kpc | 1.99 | 1.47 | 2.12 | 3.33 |
| 300–3000 kpc | 1.86 | 1.64 | 1.35 | 2.06 |
| 3–3000 kpc | 1.97 | 1.79 | 1.43 | 2.61 |
| Evolving bias | ||||
| 3–30 kpc | 1.12 | 0.67 | 0.274 | 0.201 |
| 30–300 kpc | 0.566 | 0.258 | 0.229 | 0.148 |
| 300–3000 kpc | 0.400 | 0.216 | 0.264 | 0.215 |
| 3–3000 kpc | 0.496 | 0.270 | 0.237 | 0.207 |
| Mass cut | ||||
| 3–30 kpc | 7.11 | 7.20 | 0.279 | 0.276 |
| 30–300 kpc | 1.99 | 2.04 | 0.156 | 0.155 |
| 300–3000 kpc | 0.381 | 0.376 | 0.215 | 0.204 |
| 3–3000 kpc | 0.743 | 0.783 | 0.514 | 0.521 |
| LD mixed bias | ||||
| 3–30 kpc | 228.2 | 513.1 | 366.08 | 122.8 |
| 30–300 kpc | 10.99 | 27.90 | 3.26 | 4.92 |
| 300–3000 kpc | 5.98 | 10.01 | 2.05 | 1.78 |
| 3–3000 kpc | 131.6 | 340.3 | 20.71 | 34.44 |
Reduced χ2 for distributions before and after the N08 iterative correction.
| Annulus | χ2/ND | χ2/ND | χ2/ND | χ2/ND |
|---|---|---|---|---|
| pre- | post- | pre- | post- | |
| iteration | iteration | iteration | iteration | |
| Bimodal | Gaussian | |||
| LD constant bias | ||||
| 3–30 kpc | 3.34 | 3.11 | 1.55 | 1.59 |
| 30–300 kpc | 1.99 | 1.47 | 2.12 | 3.33 |
| 300–3000 kpc | 1.86 | 1.64 | 1.35 | 2.06 |
| 3–3000 kpc | 1.97 | 1.79 | 1.43 | 2.61 |
| Evolving bias | ||||
| 3–30 kpc | 1.12 | 0.67 | 0.274 | 0.201 |
| 30–300 kpc | 0.566 | 0.258 | 0.229 | 0.148 |
| 300–3000 kpc | 0.400 | 0.216 | 0.264 | 0.215 |
| 3–3000 kpc | 0.496 | 0.270 | 0.237 | 0.207 |
| Mass cut | ||||
| 3–30 kpc | 7.11 | 7.20 | 0.279 | 0.276 |
| 30–300 kpc | 1.99 | 2.04 | 0.156 | 0.155 |
| 300–3000 kpc | 0.381 | 0.376 | 0.215 | 0.204 |
| 3–3000 kpc | 0.743 | 0.783 | 0.514 | 0.521 |
| LD mixed bias | ||||
| 3–30 kpc | 228.2 | 513.1 | 366.08 | 122.8 |
| 30–300 kpc | 10.99 | 27.90 | 3.26 | 4.92 |
| 300–3000 kpc | 5.98 | 10.01 | 2.05 | 1.78 |
| 3–3000 kpc | 131.6 | 340.3 | 20.71 | 34.44 |
| Annulus | χ2/ND | χ2/ND | χ2/ND | χ2/ND |
|---|---|---|---|---|
| pre- | post- | pre- | post- | |
| iteration | iteration | iteration | iteration | |
| Bimodal | Gaussian | |||
| LD constant bias | ||||
| 3–30 kpc | 3.34 | 3.11 | 1.55 | 1.59 |
| 30–300 kpc | 1.99 | 1.47 | 2.12 | 3.33 |
| 300–3000 kpc | 1.86 | 1.64 | 1.35 | 2.06 |
| 3–3000 kpc | 1.97 | 1.79 | 1.43 | 2.61 |
| Evolving bias | ||||
| 3–30 kpc | 1.12 | 0.67 | 0.274 | 0.201 |
| 30–300 kpc | 0.566 | 0.258 | 0.229 | 0.148 |
| 300–3000 kpc | 0.400 | 0.216 | 0.264 | 0.215 |
| 3–3000 kpc | 0.496 | 0.270 | 0.237 | 0.207 |
| Mass cut | ||||
| 3–30 kpc | 7.11 | 7.20 | 0.279 | 0.276 |
| 30–300 kpc | 1.99 | 2.04 | 0.156 | 0.155 |
| 300–3000 kpc | 0.381 | 0.376 | 0.215 | 0.204 |
| 3–3000 kpc | 0.743 | 0.783 | 0.514 | 0.521 |
| LD mixed bias | ||||
| 3–30 kpc | 228.2 | 513.1 | 366.08 | 122.8 |
| 30–300 kpc | 10.99 | 27.90 | 3.26 | 4.92 |
| 300–3000 kpc | 5.98 | 10.01 | 2.05 | 1.78 |
| 3–3000 kpc | 131.6 | 340.3 | 20.71 | 34.44 |
For another more quantitative measure of the fidelity of the redshift recovery, we calculate the sample mean (average redshift) and standard deviation (square root of the sample variance, i.e. the ‘sample width’) for each distribution. Fig. 3 shows the deviation from the true redshift mean |$\bar{z}_{\rm tr}$| and true sample width σtr for the two cases shown in Figs 1 and 2. We show the three decade width bins and also results using information encompassing all three scales, with 3 ≤ r ≤ 3000 kpc as a grey shaded ellipse. As the information in each of the three annuli is independent, combining all scales should provide a higher S/N measurement of the redshift distribution.
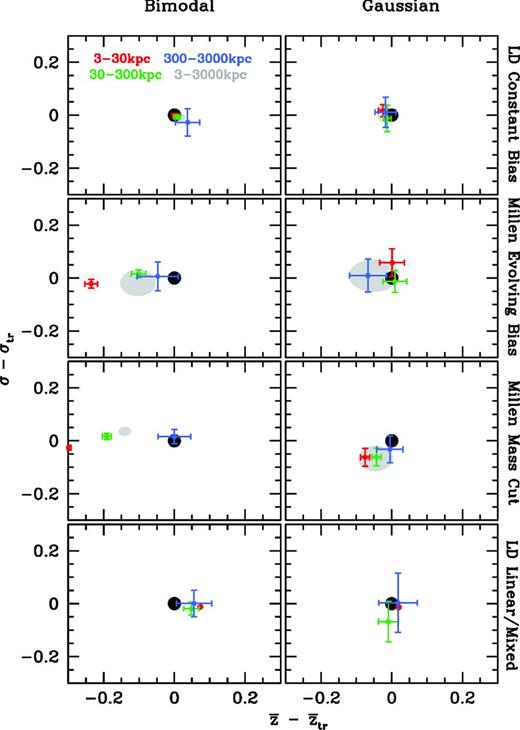
Measured deviation from the true redshift mean and width of the bimodal (left) and Gaussian (right) distributions for all four spectroscopic data sets. The truth is shown as the black dot; 3–30 kpc (red), 30–300 kpc (green), 300–3000 kpc (blue) and 3–3000 kpc (grey shaded) are shown for comparison.
The top two panels in Fig. 3 show that with little or no expected bias evolution using all scales works extremely well at recovering the photometric sample distributions. For the evolving data set, the presence of even modest bias evolution results in a misestimation of the mean redshift for the bimodel distribution, due to the relative amplitudes of the recovered peaks. However, the sample width is largely unaffected, as the lack of cross-correlation signal outside of the two bimodal bins provides a strong constraint on σ. In the centrally peaked Gaussian distribution the mean is more accurately recovered, but the uncertainty in the sample width is increased. This is due to the fact that the tails of the distribution are now more affected by the difference in bias at low and high redshift.
Unlike the top two rows, the bottom of Fig. 3 uses simulated spectroscopic samples with very different bias profiles from their respective photometric samples. The stellar mass cut sample has stronger bias evolution than the magnitude-limited sample that comprises the observed sample. The effects on the bimodel distribution in the evolving bias scenario are exacerbated by the stronger bias in the mass cut sample. Once again, the mean redshift for the bimodal sample is significantly skewed.
To illustrate the differing bias of the three LasDamas samples we calculate the linear bias explicitly and show them in Fig. 4. The mixed/linear bias case uses the ‘mixed’ bias data for the spectroscopic sample and the linear density sample for the photometric sample. In this case, the normal tendency of the method to overestimate signal at lower redshifts is counteracted by the more rapid bias evolution in the spectroscopic sample, resulting in a mean recovered redshift near the expected value for all scales. However, the difference in bias on the two sides of the Gaussian distribution results in greatly increased scatter in the recovered width. Note that we did not have access to this information when computing the recovered distributions; in fact the bias is never explicitly calculated in the N08 iteration. Instead, the clustering length of the spectroscopic sample, empirically measured from the correlation functions, is used to iteratively determine the best value for the photometric sample clustering length.
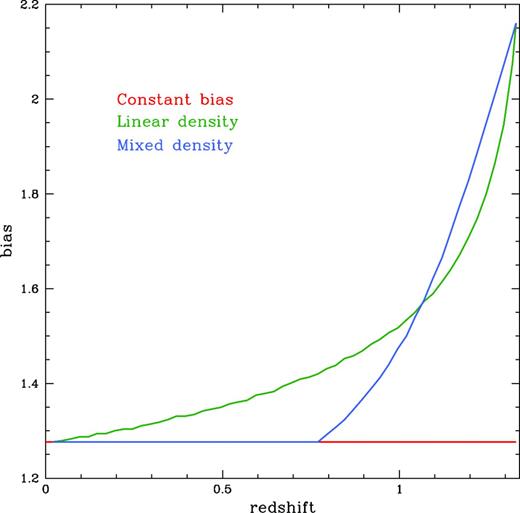
Linear galaxy bias as a function of redshift for the three LasDamas samples described in Section 3.1. Red indicates the constant bias sample, green the sample with linear density evolution and blue the sample with ‘mixed’ bias evolution.
Overall, we see several trends.
In absence of bias evolution, recovery S/N is always highest at the smallest scales.
In the presence of modest bias evolution, intermediate scales (∼100 < r < 500 kpc) offer the most reliable, highest S/N recovery.
For extreme bias evolution, larger scales (1000 < r < 3000) offer the cleanest recovery.
For all cases, a centrally peaked redshift distribution is far less sensitive to bias evolution, although outliers can affect the recovered distribution width.
Small-scale information should not be used to recover broad redshift distributions when the bias is known to evolve.
4.2 Tomographic binning
The previous section discussed the recovery of broad redshift distributions. However, most upcoming surveys will focus on determining the redshift distribution for narrow tomographic redshift bins for the purposes of measuring weak lensing and baryonic acoustic oscillations.
The main limitation of the iterative method is that it relies on a single estimated value for r0, pp. If the clustering length of the photometric sample evolves differently than the spectroscopic sample, then the assumption that r0, sp scales as |$r_{0,sp}^{\gamma _{sp}}=(r_{0,pp}^{\gamma _{pp}}r_{0,ss}^{\gamma _{ss}})^{1/2}$| will not hold. The iterative method essentially finds the best single value for r0, pp given the data. However, if we can further subdivide our photometric sample in redshift, e.g. with some photometric redshift algorithm or colour selection, we benefit in several ways: first, we may now determine a best-fitting r0, pp over a smaller redshift range for each subsample, over which the bias presumably evolves less. Secondly, having two values of r0, pp to estimate gives an additional free parameter. Thirdly, the S/N of the measurement increases, as by breaking our initial photometric data set into multiple samples in redshift, we have removed a large number of physically unassociated galaxies from the correlation measurement that were adding to the background and diluting the signal.
Fig. 5 shows the result of splitting the bimodal sample for the evolving bias data set (the same as shown in the top-right panel of Fig. 2) into two distinct redshift bins and computing the recovered distributions for each individual bin. This is done for rmin and rmax values of 3 kpc and 30 kpc, far into the non-linear regime and at much smaller scales than the best fit in the previous section. The red points show the recovery for the low-redshift bin, while the blue points show the recovery for the high-redshift bin (overlapping points have been omitted for clarity). The top panel shows the results of the same reconstruction using a single photometric sample. The change in the size of the errors on the two individual recoveries is related to the normalization factor enabled by the two independent estimates of the best-fitting clustering length, which boosts/lowers the S/N of the low-/high-redshift recoveries. In general, the more narrow the redshift range can be restricted, the smaller the optimum recovery scale will be, which results in an increase in S/N. However, the presence of catastrophic outliers in certain photometric redshift ranges may be a concern when applying tomographic selections. We address this in the following section.
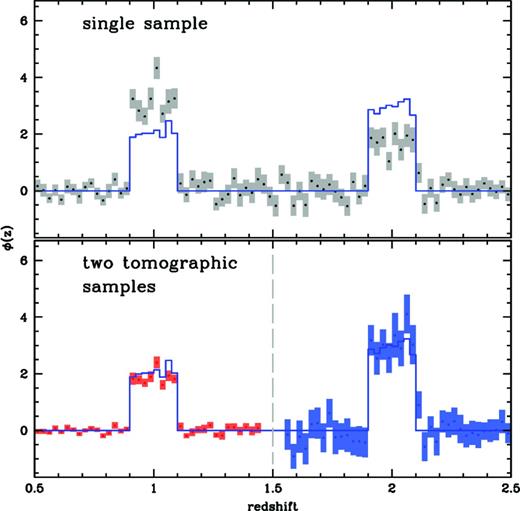
Top: recovered redshift distribution for the bimodal Millennium light cone sample for an annulus of 3–30 kpc. Bottom: the same sample split into two redshift bins (overlapping points omitted for clarity). The bottom panel shows that the amplitudes of the bimodal recovered low redshift (red) and high redshift (blue) samples are significantly less biased than the union of the two samples recovered at once.
4.3 Redshift outlier detection
Selection of tomographic redshift bins in cosmological analyses, for instance with colour cuts or photometric redshift cuts, can include data sets where degeneracies exist that include an unrelated population far outside the intended redshift range. The most prominent example in optical photometric surveys is the common Lyman/Balmer break degeneracy, where low-redshift (z ∼ 0.2–0.3) blue galaxies are mistaken for very high redshift (z ∼ 2–3) blue galaxies and vice versa, due to their similar optical colours. Such ‘catastrophic outlier’ populations often result in two bimodal peaks widely separated in redshift, which we have shown (Section 4.1) can be problematic for accurate redshift recovery. However, we can use small-scale information to diagnose the presence of such outlier populations.
In nearly all cases examined previously, reconstructing the redshift distribution at smaller physical scales results in smaller uncertainties, albeit at the expense of increased bias sensitivity. This is expected, given the power-law form of the correlation function we expect more signal on smaller scales. We also note that the method does an excellent job at returning a null signal in areas where there is no overlap between the spectroscopic and photometric samples, e.g. we see signal consistent with zero and small error bars outside the bimodal bins in Fig. 2.
We can use these features to test for the presence of interlopers, as done in Morrison et al. (2012), where the authors cross-correlate a high-redshift luminous blue galaxy sample with spectroscopically confirmed galaxies to test for the presence of intermediate-redshift elliptical galaxies with similar expected colours. We construct several data sets to test the influence of recovery scales on sensitivity to outlier populations. Using the LasDamas mixed bias evolution data set, we construct samples where we have a primary peak at the redshift of interest (0.4 ≤ z ≤ 0.6) and a secondary peak due to colour degeneracies (0.8 ≤ z ≤ 1.0) that contains between 0.5 and 10 per cent of the total number of galaxies. Fig. 6 shows detection significance (in terms of σ determined from the χ2) as a function of contamination fraction. The inset shows one recovered distribution as an example, with 10 per cent contamination and using an annulus of 30 ≤ r ≤ 300 kpc.
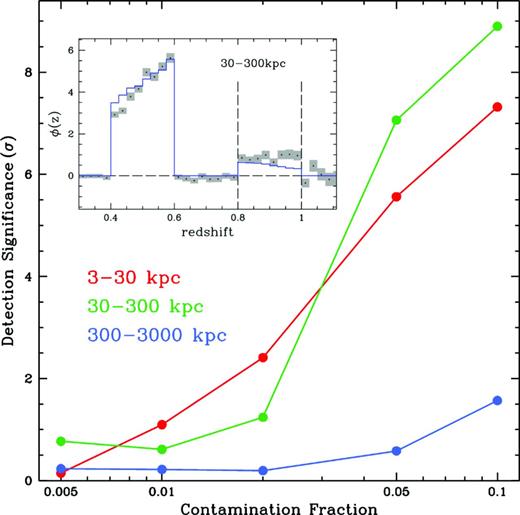
Detection significance of the secondary peak as a function of contamination fraction using the LasDamas mixed bias data set for three annuli. The inset shows an example recovery with 10 per cent of the galaxies in the second peak. The higher S/N per bin for smaller annuli enables us to detect contaminating objects at much greater significance than when using large-scale information alone.
Using the 300 ≤ r ≤ 3000 kpc annulus we cannot reliably detect the secondary peak, however at smaller scales we see nearly all bins outside of the two peaks consistent with zero, and clearly detect non-zero signal in the range 0.8 ≤ z ≤ 1.0 for contamination fractions above 2 per cent. The ability to detect secondary peaks will depend on both the redshift evolution of the bias and the amount of separation between the two peaks in redshift space. The influence of the bias evolution when using small-scale information can cause us to misestimate the overall contamination fraction, though detection of any contaminants at all may be the goal. While the recovery method does not directly inform us of which galaxies are degenerate, we can use the method to tailor photometric redshift cuts that lead to maximum purity in the sample by testing variations of the cuts and choosing those that minimize sample contamination.
4.4 Alternative bias removal technique
The application of the full iterative procedure discussed so far requires calculation of the photometric sample angular autocorrelation functions. In actual surveys, complex selection and masking often make estimation of the correlation functions difficult. We can simplify our analysis by, instead of assuming a linear relation between the spectroscopic and photometric samples, assuming that the two samples have the same bias as calculated from r0, ss (or measurements from the literature). We take the estimates of r0, ss estimated for rp > 300 kpc discussed in Section 3.2 and calculate the bias evolution of the spectroscopic sample as a function of redshift. In place of the full iterative procedure, we then simply divide our initial estimate of ϕ(z) by this relative bias and renormalize.
The top panel of Fig. 7 shows a comparison between the initial estimate (black), the final iterative correction (red) and this alternative bias removal (blue) for the Millennium light cone simulation with rmin = 30 kpc and rmax = 300 kpc (though the conclusions hold at both smaller and larger scales as well). The simple bias correction actually outperforms the iterative solution, with a χ2 = 0.40, compared to χ2 = 0.61 for the iterative method. In retrospect, this is not unexpected: the photometric samples from the Millennium simulation used in Fig. 7 were drawn from the same underlying population as the spectroscopic sample, and thus have the same galaxy bias properties. The linear bias approximation used in the iterative correction, calculating the correlation length r0, sp as the geometric mean of the spectroscopic correlation length and a single, constant value for the average photometric correlation length, actually lessens the predicted redshift evolution of the bias, particularly when using very wide redshift baseline for the photometric sample. This is related to the improvements gained from splitting the sample into subsets in redshift, where we gain both in a smaller relative evolution in bias over the shorter redshift interval, and in the ability to estimate multiple values of r0, pp in the different redshift intervals.
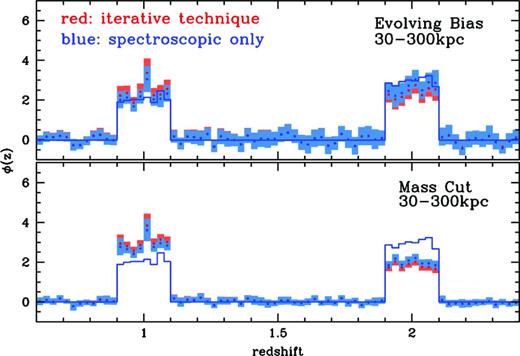
Comparing the iterative and approximate bias removal techniques for 30 ≤r ≤ 300 kpc. The top panel shows the recovered distributions for the Millennium sample with evolving bias using the full iterative technique (red), and using only the spectroscopic bias (blue). The bottom panel shows the same recovery using the stellar mass-selected spectroscopic sample. The simple bias approximation can provide as good or better estimates of the redshift distribution when the bias evolution of the two samples is similar.
Applying a stellar mass selection to the spectroscopic sample will change the galaxy bias evolution properties. The bottom panel of Fig. 7 shows the recovery of the same photometric sample using the mass-selected spectroscopic sample and corresponding bias estimate. While the difference is less pronounced, using the spectroscopic bias to correct the amplitude again outperforms the iterative method, with χ2 = 3.4 versus the χ2 = 5.1 for the iterative method. In practical terms, removing the bias evolution of the estimated sample using an estimate based solely on the spectroscopic sample can provide results competitive or better than those obtained from the full iterative technique.
5 DISCUSSION AND FUTURE WORK
In this paper we have presented a study of a simple but powerful redshift recovery algorithm applied to realistic mock data sets, testing the inclusion of information from the non-linear clustering regime. Our galaxy density estimator is equivalent to a one-bin measurement of the cross-correlation function between user adjustable physical scales of rmin and rmax. We have shown that non-linear scales contain a wealth of information that can be exploited to increase S/N in the determination of redshift distributions compared to using only large-scale information, and that the iterative technique used to mitigate the effects of bias evolution works well beyond the linear regime used to date for narrow distributions. Due to the wide variety of bias scenarios that may be present in real data we are limited to somewhat qualitative assessments. However, these general conclusions are informative in future applications of the method.
We successfully recover the redshift distributions for several evolving and non-evolving galaxy bias configurations. However, the non-linear biasing does incur increasing amounts of error as we push to smaller and smaller radii. The optimum scale depends on the details of the photometric data set, in terms of both bias properties and extent in redshift: narrow redshift distributions and those with little expected bias evolution can exploit clustering signal well into the non-linear regime, while broad redshift distributions or complex galaxy bias should be restricted to the more conservative limits at larger scales. Furthermore, in our one-bin treatment, larger values of rmax lead to increasing covariance between redshift recovery bins, which increases the relative error when using large scales. One must find the balance between the increased S/N and the accompanying increased sensitivity to galaxy bias when performing the recovery.
The iterative correction suggested by N08 and Matthews & Newman (2010) and employed in this paper has limitations. The assumption that the bias of the photometric sample scales linearly with the spectroscopic sample allows us to determine only a single value for the average cluster scaling between the spectroscopic and photometric samples via equation (3). The technique works well at correcting for galaxy bias when used for large scales, but begins to fail, as expected, as the non-linear information is included. We explored using an approximation of simply dividing by the bias of the spectroscopic sample in Section 4.4, and found that this works well in many cases, though the same caveats that apply to the use of the iterative corrections apply. The iterative correction works best at the mean redshift of the photometric sample, thus narrow redshift distributions peaked near the mean redshift are recovered much more accurately than broad distributions, as illustrated by the relative performance of the Gaussian and bimodal samples shown in Figs 1 and 2. If we are able to subdivide the distribution we wish to recover into narrower redshift ranges then we can recover the distribution more accurately, as the bias should evolve less over the smaller redshift interval (assuming a smoothly varying bias evolution). This was illustrated in the simple example of breaking one of our bimodal samples into two bins in Section 4.2. This is in line with the direction of the large future surveys (DES, LSST, etc.), where the strategy for determining cosmological parameters hinges on precisely determining the redshift distribution for a number of relatively narrow tomographic photometric redshift bins. The tomographic bins planned for such surveys are ideal samples for including non-linear information in redshift recovery. However, extra care will have to be taken if bins include any ‘catastrophic outlier’ galaxies, where photometric redshift degeneracies cause some portion of the sample to lie at very different redshifts than that targeted by the selection. Such distributions will be susceptible to biasing, particularly when including information from non-linear scales. In such cases, reverting to large rmin values may be necessary. Even in such cases, the non-linear regime can be used to accurately assess the presence or absence of catastrophic outliers in the sample, as illustrated in the tests of sample contamination discussed in Section 4.3. We plan to carry out tests on more realistic tomographic photometric redshift bins based on improved simulations in an upcoming paper.
The method could be further improved by extending beyond the simple one-bin treatment used in this paper, particularly in cases where there is obvious non-power-law form to the correlation functions, or where the slope of the power law changes substantially. For example, in the determination of r0, ss we used only information at scales greater than 300 kpc, beyond the break in the correlation function, even when testing the recovery at the smallest scales. An explicit fit to both the one-halo and two-halo portions of the correlation function would enable a more precise recovery. However, the non-linear relation between galaxies and underlying dark matter at small scales will still leave the method susceptible to the influence of galaxy bias evolution.
Having shown that the methods discussed in this paper can accurately recover redshift distributions using small-scale clustering information, we will follow up with analyses using real data sets for both known and wholly novel redshift distributions (Ménard et al., in preparation). This powerful technique will be an important and useful tool for both current and future photometric surveys.
This work was supported by NSF Grant AST-1009514. Brice Menard is supported by the NSF and the Alfred P. Sloan foundation. We thank the anonymous referee for suggestions that improved the content of the paper. We used mock catalogues based on the LasDamas project; we thank the LasDamas collaboration for providing us with these data. We thank Darren Croton for making the Millennium simulation light cones used in this work publicly available.
Alfred P. Sloan fellow.
Available at: http://code.google.com/p/astro-stomp/
We note that these mocks are not part of the ‘publicly available’ mocks accessible from the LasDamas website http://lss.phy.vanderbilt.edu/lasdamas/
Available at: http://web.me.com/darrencroton/Homepage/SDSS-DEEP2.html
REFERENCES
APPENDIX A ADDITIONAL RECOVERY PARAMETERS
While the choice of the physical annulus defined by rmin and rmax is the dominant factor in determining the redshift recovery, we have the freedom to choose both an additional radial weighting of our pixelized aperture and the bin width of the spectroscopic sample.
A1 Annulus weighting
The power-law form of the correlation function shows that there is an increasing amount of clustering information at smaller angular and physical scales; however there are also fewer galaxies due to the decreasing area of the annulus. Similarly, while larger apertures decrease shot noise in density estimates, they also increase the number of unassociated galaxies that are included due solely to line-of-sight projection. In addition to a ‘uniform’ density estimator, where we simply divide the number of galaxies within the pixelized annulus by the area in physical units of Mpc, we test an ‘inverse’ weighted density estimate, calculating the density in the pixelized annulus and weighting the density in each pixel by the inverse of the distance from the spectroscopic object. Errors are a combination of variations due to large-scale-structure (which becomes a more serious issue for surveys with small areal footprint), and Poisson shot noise. We estimate errors on the recovery empirically with a spatial jackknife, which captures both sources of error. For illustration, Fig. A1 shows the uniform versus inverse weighting recovered redshift distributions of the constant bias bimodal sample with a large outer radius of rmax = 3000 kpc. There is a clear reduction of error when using the inverse weighting, which is observed at nearly all scales and in all samples tested, thus we employ this inverse weighted estimator throughout the paper. However, because the smaller scales are now weighted more heavily, this estimator is more sensitive to evolving galaxy bias. Therefore, caution should be used when using the inverse weighting at very small scales when galaxy bias evolution is known to be large.
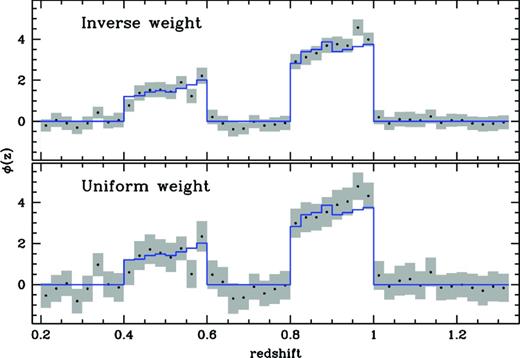
Recovered redshift distribution for bimodal sample of galaxies for the constant bias sample for the ‘uniform’ density weight (left) and ‘inverse’ density weight (right). The magenta histogram shows the actual redshift distribution of the photometric sample. The inverse weighting produces smaller error estimates, but is more sensitive to the effects of non-linear bias evolution.
A2 Redshift binning
The choice of binning for the spectroscopic sample is an additional free parameter that we must choose. To construct our redshift distribution we take each spectroscopic galaxy and estimate the density of sources within the physical aperture defined by rmin and rmax. Then, we bin all spectroscopic objects within a redshift interval Δ z and take the mean of the density estimates within each bin to determine the amplitude of the redshift distribution estimate.
Several factors influence the uncertainties resulting from a specific choice of redshift binning. Errors are a combination of Poisson fluctuations, i.e. the number of spectroscopic galaxies included in the bin, sample variance and the fractional error in the amplitude of the cross-correlation function. The sample variance is fixed by large-scale structure and the areal coverage of the survey. The amplitude of the cross-correlation function depends on the width of the redshift bin, as using broader redshift bins lowers the amplitude of the cross-correlation signal. Narrow redshift bins lead to a stronger cross-correlation signal; however this must be balanced with Poisson noise from small samples within the bin. In practice, the total S/N is not a strong function of bin-width choice for small bins. However, the total S/N is significantly lower when using a small number of very broad bins. Using a small number of bins effectively throws out information unnecessarily.
Fig. A2 shows the jackknife error estimates for several bin size choices using the LasDamas based mock data set with no bias evolution and 30 ≤ r ≤ 300 kpc. For the constant bias sample used in Fig. A2 the optimal scale occurs at Δ z ≈ 0.005 with ∼200–800 galaxies per redshift bin used to determine the mean density. We expect adjacent bins to be increasingly correlated as Δ z decreases, as shared large-scale structure near the bin boundaries should become more important.
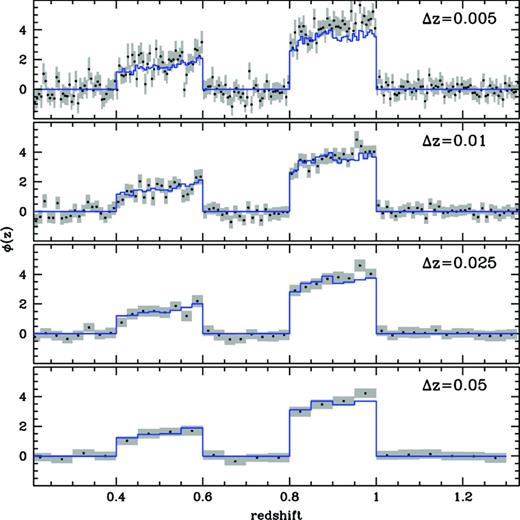
The effect of spectroscopic bin size on the recovered redshift distribution in a data set with no bias evolution. Errors are a combination of large-scale structure fluctuations and Poisson noise in the average density estimate. The effect of Poisson fluctuations can be seen as the number of galaxies per bin decreases at Δ z = 0.005.
All bins are correlated with each other, as expected, since the density estimate of background galaxies samples the distribution over the entire projected redshift range, with many galaxies falling within the physical annulus surrounding a spectroscopic object multiple times. This leads to a distinct correlation matrix structure: a strong diagonal and all off diagonal elements correlated at a similar ‘floor’ level, the amplitude of which is determined by the size of the annulus and the width of the recovery. A redshift bin of width Δ z = 0.005 corresponds to ∼10–20 Mpc in comoving distance for 0.2 ≤ z ≤ 1.33 probed in the recovery, much larger than the weighted physical distance, so the correlation matrix shows a strong diagonal component, but adjacent bins do not show excess correlation compared to widely separated bins. The projected nature of the measurement leads to highly correlated bins, and the full covariance matrix must be used for proper error estimation.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}