





Abstract
We have devised a method to select galaxies that are isolated in their dark matter halo (N = 1 systems) and galaxies that reside in a group of exactly two (N = 2 systems). Our N = 2 systems are widely separated (up to ∼200 h−1 kpc), where close galaxy–galaxy interactions are not dominant. We apply our selection criteria to two volume-limited samples of galaxies from Sloan Digital Sky Survey Data Release 6 (SDSS DR6) with Mr − 5 log10 h ≤ −19 and −20 to study the effects of the environment of very sparse groups on galaxy colour. For satellite galaxies in a group of two, we find a red excess attributed to star formation quenching of 0.15 ± 0.01 and 0.14 ± 0.01 for the −19 and −20 samples, respectively, relative to isolated galaxies of the same stellar mass. Assuming N = 1 systems are the progenitors of N = 2 systems, an immediate-rapid star formation quenching scenario is inconsistent with these observations. A delayed-then-rapid star formation quenching scenario with a delay time of 3.3 and 3.7 Gyr for the −19 and −20 samples, respectively, yields a red excess prediction in agreement with the observations. The observations also reveal that central galaxies in a group of two have a slight blue excess of 0.06 ± 0.02 and 0.02 ± 0.01 for the −19 and −20 samples, respectively, relative to N = 1 populations of the same stellar mass. Our results demonstrate that even the environment of very sparse groups of luminous galaxies influence galaxy evolution and in-depth studies of these simple systems are an essential step towards understanding galaxy evolution in general.
1 INTRODUCTION
The overall galaxy population out to z ∼ 1 divides into two distinct types: early-type and late-type galaxies (e.g. Hubble 1926; Strateva et al. 2001; Blanton et al. 2003; Bell et al. 2004; Tanaka et al. 2005; Baldry et al. 2006; Cooper et al. 2006). Although the exact definition of the two types varies in the literature, late-type galaxies tend to have spiral morphology and are blue due to a highly active recent star formation history. On the other hand, early-type galaxies tend to have elliptical morphology and are red due to a lack of recent star formation.
From observations of galaxies at different redshifts we know that the stellar mass on the red sequence has increased by a factor of 2 since z ∼ 1 (Bell et al. 2004). Along with numerous other observations this suggests that physical processes have been at work since z ∼ 1 transforming late-type galaxies into early-type galaxies. Young clusters at z ∼ 0.5 contain many spiral galaxies and very few S0 galaxies while local clusters have a ratio of S0 to elliptical galaxies greater by a factor of 5 and a similar decrease in the number of spiral galaxies (Dressler et al. 1997). Also, the galaxy luminosity function density normalization for blue galaxies has remained essentially constant, while it has doubled (∼0.5 dex) for red galaxies since z ∼ 1 (Faber et al. 2007).
In the currently favoured Λ cold dark matter (ΛCDM) picture of structure formation (Blumenthal et al. 1984), dark matter collapses into haloes, trapping baryonic matter at early epochs. In galaxy-sized dark matter haloes, cool baryonic material falls in while retaining angular momentum to form luminous spiral galaxies. Galaxy groups and cluster form hierarchically when smaller dark matter haloes combine to form larger dark matter haloes (White & Rees 1978; Kauffmann, White & Guiderdoni 1993; Cole et al. 2000). This picture motivates a number of physical processes that may alter a galaxy's morphology and/or quench star formation through the removal and/or depletion of the galaxy's gas reservoirs bringing about a late-type to early-type transition.
The merger of two dark matter haloes will eventually result in the merger of their central galaxies as a result of dynamical friction (Chandrasekhar 1943), potentially permanently altering both morphology and star formation rates. Even before the central galaxies merge they are altered by interactions, especially if a smaller dark matter halo has fallen into a large group or cluster-sized halo with a dense intracluster medium and many other un-merged satellite galaxies. These environmental interactions broadly fall into two categories: gravitational tides and gas collisions.
Tidal interactions due to the main cluster potential on the infalling satellite galaxy may strip it of stars and/or gas leading to changes in morphology and/or star formation rates (Fujita 1998). Tidal interactions from a close galaxy pass also trigger inflows of gas into the centres of galaxies, inducing short-lived starbursts (Mihos & Hernquist 1996). Once the galaxy has exhausted its supply of gas, it will quickly redden unless it can replenish its supply of gas. One mechanism that can prevent the accretion of new gas is feedback from an active galactic nucleus (AGN; e.g. Di Matteo, Springel & Hernquist 2005; Bower et al. 2006; Croton et al. 2006). The energy released by an AGN generates an outflow of gas preventing accretion, which may transform a blue, active galaxy into a red and dead galaxy although the details remain unclear. In addition to tidal interactions with the main cluster potential, a satellite galaxy will tidally interact with the other unmerged satellites within the halo. All these close high-speed encounters, which occur approximately once per Gyr, are referred to as galaxy harassment (e.g Farouki & Shapiro 1981; Moore et al. 1996) and can transform small disc galaxies into dwarf elliptical or dwarf spheroidal galaxies.
The collisional interaction of the hot gaseous intracluster medium of the larger host halo with the cold disc gas and/or the hot halo gas reservoir of the smaller halo's central galaxy may rapidly strip it of either gas reservoir in a process known as ram-pressure stripping (Gunn & Gott 1972). High-resolution hydrodynamical simulations have shown that ram-pressure stripping can remove the entire H i gas content within 100 Myr from a luminous spiral galaxy like the Milky Way leading to redder colours from a lack of star formation (Quilis, Moore & Bower 2000). However, the morphology of the original stellar disc is unaffected by ram-pressure stripping, which results in the spiral galaxy being transformed into an S0-like galaxy. If only the hot halo gas reservoir of a satellite galaxy, which replenishes the cold disc gas that is converted into stars, is removed by ram-pressure stripping or tides, the result is a gradual decline of star formation because it continues until the cold disc gas is exhausted. To distinguish it from the removal of cold disc gas, which results in a rapid truncation in star formation, this is usually referred to as strangulation (Larson, Tinsley & Caldwell 1980; Balogh, Navarro & Morris 2000). Strangulation should result in a similar transformation of a spiral into an S0-like galaxy, except on a different time-scale than ram-pressure stripping of cold disc gas.
If an infalling satellite galaxy is able to withstand the environmental interactions discussed above, a major or minor merger with another satellite galaxy (Makino & Hut 1997) or the central galaxy of the host halo may result in a merger remnant with drastically different morphology and/or star formation rate than either of the two progenitors. The severity of the change is highly dependent on the mass ratio of the two progenitors. If a spiral galaxy is involved in a minor merger, a temporary starburst may be triggered from the compression of colliding cold gas and the disc morphology may be affected. However, morphology is definitely altered when two spiral galaxies with similar masses experience a major merger. In this case, the merger remnant may have spheroidal or elliptical morphology (Toomre & Toomre 1972). If the gas reservoirs depleted in the triggered starburst are not replenished because of say AGN feedback, the major merger will have transformed two active spiral galaxies into a red and dead spheroidal or elliptical galaxy.
A fundamental goal of astrophysics is a comprehensive understanding of the role mergers and environmental processes play in building and evolving the diverse set of galaxies that exist in the Universe. Studies of galaxy evolution span a range of environments including isolated galaxies (e.g. Allam et al. 2005; Tollerud et al. 2011; Edman, Barton & Bullock 2012), close pairs (e.g. Sol Alonso et al. 2006; Barton et al. 2007; Ellison et al. 2008, 2010, 2011; Patton et al. 2011; Scudder et al. 2012), groups (e.g. Balogh et al. 2004; Gerke et al. 2005; Weinmann et al. 2006a,b, 2009; Kang & van den Bosch 2008; van den Bosch et al. 2008; Kimm et al. 2009; Skibba 2009; Iovino et al. 2010; Pasquali et al. 2010; McGee et al. 2011; Wetzel, Tinker & Conroy 2012; Knobel et al. 2013) and clusters (e.g. Balogh et al. 2002; Rines et al. 2005; Tanaka et al. 2005; von der Linden et al. 2007, 2010).
However, a general understanding of galaxy evolution requires an understanding of the simplest galactic environments, which are isolated galaxies residing alone in their dark matter halo (N = 1 system) and systems of two galaxies sharing a dark matter halo (N = 2 system), which includes galaxy pairs and groups of two galaxies. Isolated galaxies are the least ambiguous and are the most controlled environments in which to study galaxy evolution. In general, more isolated galaxies are more likely to have later type morphologies, higher star formation rates and bluer colours (e.g. Postman & Geller 1984; Blanton et al. 2005b).
In this paper, we present a preliminary study of the difference between the properties of isolated galaxies and groups of two galaxies in order to study the effects of the environment of very sparse groups. We use a cosmological model consisting of a hybrid N-body/semi-analytic substructure simulation to understand and remove the contamination from galaxies in other environments allowing us to study the full, uncontaminated distributions of star-forming and morphological parameters instead of just the average trend. This approach differs from previous studies that utilize group-finding algorithms (e.g. Yang et al. 2005), which have difficulty accounting for interloper systems. Our technique has been used previously by Barton et al. (2007) to study triggered star formation in close galaxy pairs, where galaxy–galaxy interactions are dominant. In galaxy groups, where galaxy–galaxy interactions are not dominant, the dominant mechanism responsible for star formation quenching is still an open question and a very active field of research (e.g. Weinmann et al. 2006a,b, 2009; Kang & van den Bosch 2008; van den Bosch et al. 2008; Kimm et al. 2009; McGee et al. 2009, 2011; Skibba 2009; Pasquali et al. 2010; Wetzel et al. 2012; Phillips et al. 2013). The low-mass haloes of groups of two galaxies examined in this paper represent the minimum mass where the dominant group mechanism begins to activate (McGee et al. 2009). Investigations of groups of two aim to shed light on the subject and they afford a number of other advantages including the fact that ΛCDM makes robust predictions for the merger histories of N = 2 systems (e.g. Stewart et al. 2008) and such systems are routinely studied in high-resolution hydrodynamical simulations (e.g. Cox et al. 2006) allowing for a direct comparison yielding insights into our assumptions and treatment of interactions, star formation and feedback. As such, groups of two galaxies are a valuable vehicle for the study of galaxy evolution and will contribute towards a comprehensive understanding of the topic in general.
The layout of this paper is as follows. In Section 2, we discuss the cosmological model we use throughout the paper to yield information on several important unobservable galaxy properties. Section 3 describes the selection of populations of isolated galaxies and groups of two galaxies starting with an analysis of the environment of the simulated galaxies in our cosmological model. Section 3.1 contains a description of the observational data set resulting from the application of our selection criteria to galaxies from the Sloan Digital Sky Survey (SDSS, York et al. 2000). Our method for correcting for the contamination by galaxies in other environments is explained in Section 3.2. We look at the stellar mass distribution of isolated galaxies and groups of two galaxies and discuss our Monte Carlo mass resampling technique for producing populations of the same stellar mass in Section 3.3. Results are discussed in Section 4. In Section 4.1, we concern ourselves with the difference in colour between isolated galaxies and groups of two galaxies. In Section 4.2, we discuss the red excess of satellite galaxies in a group of two and its implications on star formation quenching time-scales. The blue excess of central galaxies in a group of two and its origins are explored in Section 4.3 followed by a conclusion in Section 5.
2 COSMOLOGICAL MODEL
The main components of our cosmological model include a large N-body simulation of cold dark matter halo formation and a semi-analytic cold dark matter substructure model (Zentner & Bullock 2003; Zentner et al. 2005). This model has been previously discussed in Berrier et al. (2006) and Barton et al. (2007) and we provide a brief review here.
The model uses N-body simulations to characterize the spatial and mass distributions of ‘host’ dark matter haloes. By definition, the centres of host haloes do not lie within the virial radius of other haloes. Our N-body simulation follows the evolution of 5123 dark matter particles until z = 0 in a comoving box of volume 120 h−1 Mpc3 using the Adaptive Refinement Tree code of Kravtsov, Klypin & Khokhlov (1997) in a standard ΛCDM cosmology with |$\Omega _{\text{m}}=0.3$|, ΩΛ = 0.7, h = 0.7 and σ8 = 0.9. The implied particle mass is mp ≃ 1.1 × 109 h−1 M⊙ and the simulation grid is refined down to a minimum cell size of |$h_{\rm {peak}}\simeq 1.8$| h−1 kpc on a side. For more details regarding the N-body simulation see Zentner et al. (2005), Allgood et al. (2006) and Wechsler et al. (2006).
N-body simulations predict the substructure content of host haloes, but suffer from various numerical resolution limitations. Thus, we populate each host dark matter halo in the simulation volume with subhaloes using the semi-analytic substructure model of Zentner et al. (2005), which effectively has infinite resolution. We use the semi-analytic model to randomly generate four independently realized mass accretion histories using the stochastic method of Somerville & Kolatt (1999) for each host halo of mass M at redshift z in our simulation volume. Then, we determine the orbital evolution for each infalling subhalo in the potential of the host from accretion until z = 0, during which it loses mass and its maximum circular velocity decreases as its profile is heated by interactions. If the maximum circular velocity of a subhalo falls below 60 km s−1 at any time, it is removed to mimic the dissolution of the observable galaxy as a result of these interactions. Each mass accretion history results in a different subhalo population in the simulation volume. We interpret these realizations as four independent cosmological volumes with identical large-scale structure, but different small-scale structure. All four realizations will be used in the statistical analysis that follows.
We assume each subhalo in the simulation volume contains a luminous satellite galaxy and each host halo has a luminous central galaxy. For host haloes, we use the maximum circular velocity as a proxy for luminosity and assume a monotonic relationship between the two following previous works (e.g. Berrier et al. 2006, 2011; Conroy, Wechsler & Kravtsov 2006; Barton et al. 2007; Tollerud et al. 2011). For subhaloes, we use the maximum circular velocity at accretion (see Berrier et al. 2006), which has been shown to reproduce the galaxy two-point correlation function at many epochs (Conroy et al. 2006). In other words, all haloes above a given cutoff Vmax will correspond to a population of galaxies brighter than some absolute magnitude. By exploring the number density of haloes in the model as a function of Vmax, we find that the number density of haloes with Vmax ≥ 140 (196) km s−1 matches the observed number density of SDSS Data Release 6 (SDSS DR6, Adelman-McCarthy et al. 2008) volume-limited samples with Mr − 5 log10 h ≤ −19 (−20).
With luminous galaxies mapped on to dark matter haloes, we construct a mock volume-limited galaxy redshift survey to mimic galaxies from SDSS DR6 by placing the simulation volume the appropriate distance from the observer and computing the right ascension, declination and redshift of each simulated galaxy. This technique has been previously used to mimic galaxies from SDSS DR4 (Barton et al. 2007; Berrier et al. 2011) and DR7 (Tollerud et al. 2011) including selection effects and we refer the reader to these works for more details.
For each simulated galaxies in the mock volume-limited redshift survey, we are able to quantify the number of luminous galaxies that share the same host halo, N, which is a key measure of the environment of a galaxy but an unobservable parameter in real redshift surveys. We analyse the correlation between N and observable measures of environment, such as projected nearest neighbour distance. This analysis reveals selection criteria for defining relatively pure populations of isolated galaxies (N = 1 systems) and groups of two galaxies (N = 2 systems) from volume-limited redshift surveys and gives statistical information on other unobservables of these populations.
Note that mock redshift surveys using similar hybrid N-body/semi-analytic substructure simulations have been used previously by Barton et al. (2007) to study triggered star formation in close galaxy pairs and by Tollerud et al. (2011) to study Milky Way/Large Magellanic Cloud-like systems. The work on groups of two galaxies here is a natural extension of these studies using similar methods. It is possible to construct mock redshift surveys using high-resolution large-box simulations (e.g. Berrier et al. 2011; Tollerud et al. 2011), such as the Millennium-II simulations (Boylan-Kolchin et al. 2009), where semi-analytic models are not required because subhaloes are well resolved and these will be consider in future studies of groups of two galaxies.
3 SELECTION CRITERIA FOR N = 1 AND N = 2 SYSTEMS
First, we analyse the environment of galaxies in our mock volume-limited redshift surveys in order to define selection criteria for isolated galaxies (N = 1) and groups of two galaxies (N = 2) in SDSS. Following Barton et al. (2007), for each ‘galaxy’ (halo or subhalo with Vmax ≥ 140 or 196 km s−1) in our mock volume-limited sample, we compute DN, the comoving projected distance to the galaxy's nearest neighbour within ΔV ≤ 1000 km s−1, using periodic boundary conditions to fully sample its environment when necessary. We also compute N700, the total number of galaxies within a comoving projected distance of 700 h−1 kpc within ΔV ≤ 1000 km s−1. Lastly, we measure N, the total number of galaxies that lie within the same host dark matter halo, which is unobservable in galaxy redshift surveys. Constraints on the observables DN and N700 can identify galaxies in redshift surveys with a high probability of being in an N = 1 or N = 2 system, by applying them simultaneously to the data and the simulations.
Following Barton et al. (2007), but with a different Vmax cutoff, Fig. 1 (left) shows the fraction of galaxies with Vmax ≥ 196 km s−1 in our mock volume-limited sample that reside in a halo of a given multiplicity N as a function of DN. Galaxies that are relatively far from their nearest neighbour are overwhelmingly in N = 1 systems. Galaxies that are relatively close to their nearest neighbour are predominantly in haloes with nine or more galaxies in the same dark matter halo. The results are qualitatively similar for Vmax ≥ 140 km s−1. Thus, using DNalone does not provide a sufficient means to select for N = 2 systems in volume-limited redshift surveys.
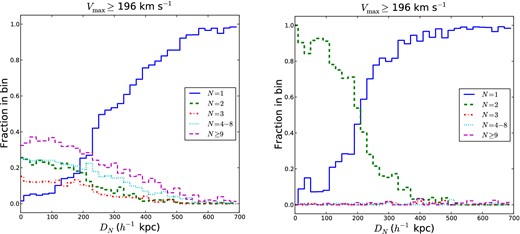
(Left) Fraction of simulated galaxies in our mock volume-limited redshift survey (Mr − 5 log10 h ≤ −20 or Vmax ≥ 196 km s−1) that reside in a dark matter halo of a given multiplicity N, as a function of the comoving projected distance to their nearest neighbour, DN. Each bin in DN is normalized to 1. DN alone cannot be used to define samples of galaxies in N = 2 systems from volume-limited redshift surveys. Galaxies with small DN values are predominantly in haloes with a total of 9 or more galaxies. (Right) Fraction of simulated galaxies with exactly one neighbour within 700 h−1 kpc (N700 = 1) that reside in a dark matter halo of a given multiplicity N, as a function of DN. Very few galaxies with N700 = 1 reside in haloes with more than two galaxies. Galaxies with N700 = 1 and large values of DN have a very high probability of being isolated in their halo and those with N700 = 1 and small values of DN have a high probability of being in an isolated galaxy pair.
However, these systems can be selected using DN and N700 together. Fig. 1 (right) shows the fraction of galaxies in our mock volume-limited sample with N700 = 1 that reside in a halo of a given multiplicity N as a function of DN. The plot shows that very few galaxies with N700 = 1 reside in haloes with N > 2. Moreover, galaxies with N700 = 1 and large values of DN are in N = 1 haloes and those with small values of DN reside almost exclusively in N = 2 haloes. Thus, we identify a population of galaxies with a high probability of residing in an N = 2 system can be defined by selecting galaxies from volume-limited redshift surveys with exactly one neighbour within a projected distance of 700 h−1 kpc and DN smaller than some maximum value. The purity and contamination by interlopers in the N = 2 sample may be determined from our mock redshift survey by quantifying the number of galaxies residing in N = 1, N = 2 and N > 2 haloes for a given maximum DN. Table 1 lists the fraction of N = 1 haloes, fN=1, the fraction of N=2 haloes, fN=2, and the fraction of N > 2 haloes, fN>2, for a maximum DN of 250, 200 and 150 h−1 kpc for both luminosities. The DN ≤ 200 h−1 kpc population is our fiducial N = 2 sample but we verify all results for the other two values.
Sample definitions, sizes and purity. Symbol definitions are as follows: DN – comoving projected distance to the nearest neighbour, N700 – number of neighbours within a comoving projected distance of 700 h−1 kpc, NSDSS – number of galaxies in the SDSS sample, Nsim – number of simulated galaxies in the cosmological model, fN=1 – fraction of simulated galaxies in N = 1 systems, fN=2 – fraction of simulated galaxies in N = 2 systems, fN>2 – number of simulated galaxies in N > 2 systems.
| Sample | Magnitude limit | DN (h−1 kpc) | N700 | |$N_{\rm {SDSS}}$| | |$N_{\rm {sim}}$| | fN=1 | fN=2 | fN>2 |
|---|---|---|---|---|---|---|---|---|
| N = 1 | ≤−20 | ≥400 | ≤1 | 26 192 | 18 030 | 0.995 | 0.001 | 0.004 |
| N = 1 | ≤−19 | ≥400 | ≤1 | 7266 | 37 309 | 0.999 | 0.000 | 0.000 |
| N = 2 | ≤−20 | ≤250 | 1 | 3229 | 2675 | 0.203 | 0.788 | 0.008 |
| N = 2 | ≤−20 | ≤200 | 1 | 2549 | 2276 | 0.144 | 0.848 | 0.007 |
| N = 2 | ≤−20 | ≤150 | 1 | 1830 | 1807 | 0.106 | 0.887 | 0.007 |
| N = 2 | ≤−19 | ≤250 | 1 | 1096 | 5634 | 0.369 | 0.629 | 0.002 |
| N = 2 | ≤−19 | ≤200 | 1 | 918 | 4786 | 0.289 | 0.709 | 0.002 |
| N = 2 | ≤−19 | ≤150 | 1 | 721 | 3769 | 0.199 | 0.799 | 0.002 |
| Sample | Magnitude limit | DN (h−1 kpc) | N700 | |$N_{\rm {SDSS}}$| | |$N_{\rm {sim}}$| | fN=1 | fN=2 | fN>2 |
|---|---|---|---|---|---|---|---|---|
| N = 1 | ≤−20 | ≥400 | ≤1 | 26 192 | 18 030 | 0.995 | 0.001 | 0.004 |
| N = 1 | ≤−19 | ≥400 | ≤1 | 7266 | 37 309 | 0.999 | 0.000 | 0.000 |
| N = 2 | ≤−20 | ≤250 | 1 | 3229 | 2675 | 0.203 | 0.788 | 0.008 |
| N = 2 | ≤−20 | ≤200 | 1 | 2549 | 2276 | 0.144 | 0.848 | 0.007 |
| N = 2 | ≤−20 | ≤150 | 1 | 1830 | 1807 | 0.106 | 0.887 | 0.007 |
| N = 2 | ≤−19 | ≤250 | 1 | 1096 | 5634 | 0.369 | 0.629 | 0.002 |
| N = 2 | ≤−19 | ≤200 | 1 | 918 | 4786 | 0.289 | 0.709 | 0.002 |
| N = 2 | ≤−19 | ≤150 | 1 | 721 | 3769 | 0.199 | 0.799 | 0.002 |
Sample definitions, sizes and purity. Symbol definitions are as follows: DN – comoving projected distance to the nearest neighbour, N700 – number of neighbours within a comoving projected distance of 700 h−1 kpc, NSDSS – number of galaxies in the SDSS sample, Nsim – number of simulated galaxies in the cosmological model, fN=1 – fraction of simulated galaxies in N = 1 systems, fN=2 – fraction of simulated galaxies in N = 2 systems, fN>2 – number of simulated galaxies in N > 2 systems.
| Sample | Magnitude limit | DN (h−1 kpc) | N700 | |$N_{\rm {SDSS}}$| | |$N_{\rm {sim}}$| | fN=1 | fN=2 | fN>2 |
|---|---|---|---|---|---|---|---|---|
| N = 1 | ≤−20 | ≥400 | ≤1 | 26 192 | 18 030 | 0.995 | 0.001 | 0.004 |
| N = 1 | ≤−19 | ≥400 | ≤1 | 7266 | 37 309 | 0.999 | 0.000 | 0.000 |
| N = 2 | ≤−20 | ≤250 | 1 | 3229 | 2675 | 0.203 | 0.788 | 0.008 |
| N = 2 | ≤−20 | ≤200 | 1 | 2549 | 2276 | 0.144 | 0.848 | 0.007 |
| N = 2 | ≤−20 | ≤150 | 1 | 1830 | 1807 | 0.106 | 0.887 | 0.007 |
| N = 2 | ≤−19 | ≤250 | 1 | 1096 | 5634 | 0.369 | 0.629 | 0.002 |
| N = 2 | ≤−19 | ≤200 | 1 | 918 | 4786 | 0.289 | 0.709 | 0.002 |
| N = 2 | ≤−19 | ≤150 | 1 | 721 | 3769 | 0.199 | 0.799 | 0.002 |
| Sample | Magnitude limit | DN (h−1 kpc) | N700 | |$N_{\rm {SDSS}}$| | |$N_{\rm {sim}}$| | fN=1 | fN=2 | fN>2 |
|---|---|---|---|---|---|---|---|---|
| N = 1 | ≤−20 | ≥400 | ≤1 | 26 192 | 18 030 | 0.995 | 0.001 | 0.004 |
| N = 1 | ≤−19 | ≥400 | ≤1 | 7266 | 37 309 | 0.999 | 0.000 | 0.000 |
| N = 2 | ≤−20 | ≤250 | 1 | 3229 | 2675 | 0.203 | 0.788 | 0.008 |
| N = 2 | ≤−20 | ≤200 | 1 | 2549 | 2276 | 0.144 | 0.848 | 0.007 |
| N = 2 | ≤−20 | ≤150 | 1 | 1830 | 1807 | 0.106 | 0.887 | 0.007 |
| N = 2 | ≤−19 | ≤250 | 1 | 1096 | 5634 | 0.369 | 0.629 | 0.002 |
| N = 2 | ≤−19 | ≤200 | 1 | 918 | 4786 | 0.289 | 0.709 | 0.002 |
| N = 2 | ≤−19 | ≤150 | 1 | 721 | 3769 | 0.199 | 0.799 | 0.002 |
A population of galaxies with a very high probability of being isolated in N = 1 systems results from selecting galaxies with N700 ≤ 1 and DN ≥ 400 h−1 kpc. The purity and contamination for this population for both luminosities are also listed in Table 1. Note that the N = 1 population defined in this way is very pure (99.5–99.9 per cent).
3.1 N = 1 and N = 2 systems in SDSS
Our goal is to identify pure samples of N = 1 and N = 2 galaxies in order to investigate the differences in their properties. We apply the selection criteria discussed in the previous section to a volume-limited sample of galaxies from the New York University Value-Added Galaxy Catalogue (NYU-VAGC, Blanton et al. 2005a) based on SDSS DR6 with Mr − 5 log10 h ≤ −19 (−20). The volume-limited samples contain galaxies from the main galaxy sample with an extinction-corrected apparent magnitude r ≤ 17.77 in regions of redshift completeness greater than 0.8. The volume-limited sample with Mr − 5 log10 h ≤ −19 (−20) contains 67 472 (107 327) galaxies.
Next, we apply our selection criteria on DN and N700 as defined from our mock volume-limited redshift survey. However, the mock volume-limited redshift survey does not suffer from incompleteness as SDSS does, which affects the N700 environment statistic as described in Berrier et al. (2011). To account for incompleteness, we follow Berrier et al. (2011) and use four random catalogues of evenly distributed galaxies, provided by the NYU-VAGC website,1 to estimate the completeness of the 700 h−1 kpc, ΔV = ±1000 km s−1 cylinder for each galaxy in the volume-limited sample. Each random galaxy is weighted by the completeness of the sector from the FGOTMAIN parameter tabulated in the NYU-VAGC and by an estimate of the fraction of the luminosity function (Blanton et al. 2005a) missed due to the limiting magnitude of the sector. Then, we sum the number of weighted random galaxies and normalize to the area searched on the sky. We use the random counts as a measure of the local completeness of the survey. In the following, we do not consider NYU-VAGC galaxies with a local completeness less than 1.5σ the mean local completeness level.
A population of N = 1 galaxies is defined by selecting all galaxies with N700 ≤ 1 and DN ≥ 400 h−1 kpc and no potential neighbours. The SDSS −19 (−20) N = 1 sample contains 7266 (26 192) galaxies. The expected purity of this population is fN=1 = 0.999 (0.995) with negligible amounts of contamination by N = 2 and N > 2 systems according to our mock volume-limited redshift survey (see Table 1).
A population of N = 2 galaxies is defined by selecting all galaxies with N700 = 1 and DN ≤ 200 h−1 kpc and no potential neighbours. The SDSS −19 (−20) N = 2 sample contains 918 (2549) galaxies. The expected purity of this sample is fN=2 = 0.709 (0.848) and the contamination is mostly from N = 1 systems, fN=1 = 0.289 (0.144), according to our mock redshift survey. The contamination by systems with N > 2, fN>2 = 0.002 (0.007), is very small and we will only directly consider and correct the contamination by N = 1 systems. If instead we take the maximum DN for the N = 2 sample to be 250 or 150 h−1 kpc, the sample then contains 1096 (3229) and 721 (1830) galaxies, respectively. However, the contamination is higher for 250 h−1 kpc with fN=1 = 0.369 (0.203) and lower for 150 h−1 kpc with fN=1 = 0.199 (0.106).
The overall N = 2 population may be further divided into satellite and central galaxies. The satellite galaxy resides within a smaller subhalo, which has fallen into the larger host halo of the central galaxy. For each N = 2 pair, the less (more) luminous galaxy in Mr is selected as the satellite (central) galaxy. Note that in some cases, the two galaxies are both central galaxies in separate dark matter haloes or may be both satellites in a richer system. We have quantified the frequency of these occurrences in Table 1. The contamination by N = 1 systems, i.e. when the two galaxies are both centrals is statistically corrected as described in Section 3.2.
3.2 Correction of N = 2 populations for contamination by N = 1 systems
In the previous section, we observed that N = 2 populations selected using our constraints on DN and N700 are primarily contaminated by N = 1 systems. Using our mock volume-limited redshift survey, we quantified the levels of contamination and the results are listed in Table 1. Below we discuss our technique to statistically correct an N = 2 population for contamination by N = 1 systems.
The satellite/central N = 2 populations are also contaminated by a population of N = 1 systems. The populations of N = 1 systems contaminating the satellite/central N = 2 populations are not the same as the population contaminating the overall N = 2 population. To apply equation (3) to the satellite/central N = 2 populations, the appropriate distributions, |$H_{N=1}^{\mathrm{pure,cen}}(x)$| and |$H_{N=1}^{\mathrm{pure,sat}}(x)$|, must be determined. When a system identified using our constraints on DN and N700 is two N = 1 systems instead of an N = 2 pair, the less (more) luminous N = 1 galaxy is placed in the satellite (central) galaxy population. As a result, the N = 1 population contaminating the satellite (central) N = 2 population is less (more) luminous than the population contaminating the overall N = 2 population. We construct the N = 1 populations contaminating the satellite and central N = 2 populations from the N = 1 population contaminating the overall N = 2 population by first randomly choosing two galaxies within the full N = 1 population. The less (more) luminous galaxy is placed in the satellite (central) N = 2 contaminant population. This process is repeated 10 000 times. Fig. 2 shows the stellar mass (top) and colour (bottom) distributions of the −19 (left) and −20 (right) N = 1 populations contaminating the overall (solid blue), satellite (dashed green) and central (dot–dashed red) N = 2 populations.
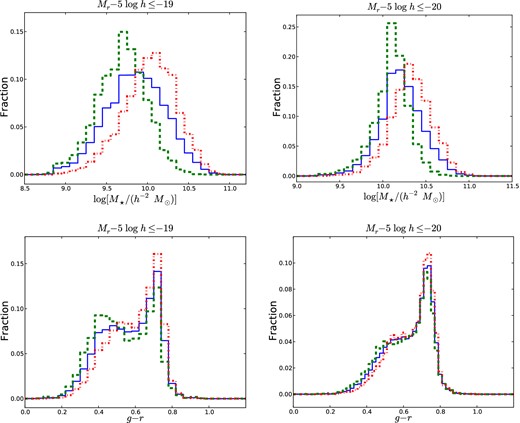
Stellar mass (top) and colour (bottom) distributions of the −19 (left) and −20 (right) N = 1 populations contaminating the overall (solid blue), satellite (dashed green) and central (dot–dashed red) N = 2 populations. Distributions are used with equation (3) to correct the N = 2 populations for interloper systems.
3.3 Stellar mass distribution and resampling
Here, we examine the stellar mass distribution of our N = 2 and N = 1 galaxy populations and discuss our procedure for resampling these populations to be of the same stellar mass. The stellar mass distributions of the −19 (left) and −20 (right) overall (top), satellite (middle) and central (bottom) N = 2 populations (dashed) are shown in Fig. 3. These distributions are contamination corrected using equation (3) and the distributions shown in Fig. 2. Also shown is the stellar mass distribution of the full N = 1 population (solid).
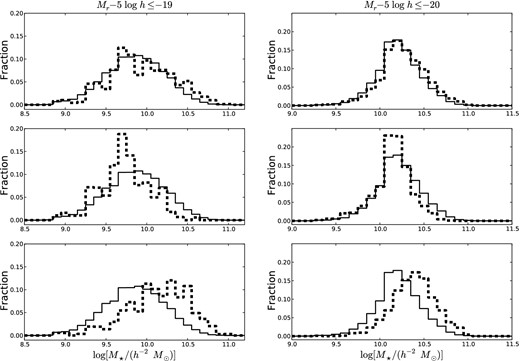
Contamination-corrected stellar mass distributions of the −19 (left) and the −20 (right) overall (top), satellite (middle) and central (bottom) N = 2 populations (dashed). Also shown is the stellar mass distribution of the full N = 1 population (solid) without Monte Carlo mass resampling. Without Monte Carlo mass resampling, differences in stellar mass contribute to difference in colour between N = 1 and N = 2 populations.
From the stellar mass distributions, we see that satellite N = 2 galaxies have less stellar mass when compared to N = 1 galaxies, on average. On the other hand, central N = 2 galaxies have more stellar mass when compared to N = 1 galaxies, on average. Galaxies with higher stellar mass content tend to be redder in colour (Kauffmann et al. 2003). Thus, differences in the colour distributions of our N = 2 and N = 1 populations are in part due to differences in stellar mass.
We remove colour differences due to differences in stellar mass by comparing populations of the same stellar mass using a Monte Carlo technique to resample the much larger N = 1 population, i.e. randomly selecting without replacement, subpopulations whose stellar mass distributions match the contamination-corrected N = 2 distributions shown in Fig. 3. We check that the resampled N = 1 population has the same stellar mass distribution as the N = 2 population using the Kolmogorov–Smirnov (K-S) test probability computed using the function K-S test in Mathematica. The K-S test probabilities when comparing the stellar mass of the −19 and −20 overall, satellite and central N = 2 populations to the full and resampled N = 2 populations are listed in Table 2 for one realization of the Monte Carlo resampling. The resampled N = 1 populations are clearly more like the various N = 2 populations in stellar mass than the full N = 1 population.
K-S test probabilities when comparing the stellar mass of various N = 2 populations with the full and resampled N = 1 populations.
| Mag | |||||
|---|---|---|---|---|---|
| Limit: | −19 | −19 | −20 | −20 | |
| N = 1: | Full | Resamp. | Full | Resamp. | |
| N = 2 Overall | 0.002 | 0.984 | 0.000 | 0.969 | |
| N = 2 Satellites | 0.000 | 0.993 | 0.000 | 0.889 | |
| N = 2 Central | 0.000 | 0.920 | 0.000 | 0.537 |
| Mag | |||||
|---|---|---|---|---|---|
| Limit: | −19 | −19 | −20 | −20 | |
| N = 1: | Full | Resamp. | Full | Resamp. | |
| N = 2 Overall | 0.002 | 0.984 | 0.000 | 0.969 | |
| N = 2 Satellites | 0.000 | 0.993 | 0.000 | 0.889 | |
| N = 2 Central | 0.000 | 0.920 | 0.000 | 0.537 |
K-S test probabilities when comparing the stellar mass of various N = 2 populations with the full and resampled N = 1 populations.
| Mag | |||||
|---|---|---|---|---|---|
| Limit: | −19 | −19 | −20 | −20 | |
| N = 1: | Full | Resamp. | Full | Resamp. | |
| N = 2 Overall | 0.002 | 0.984 | 0.000 | 0.969 | |
| N = 2 Satellites | 0.000 | 0.993 | 0.000 | 0.889 | |
| N = 2 Central | 0.000 | 0.920 | 0.000 | 0.537 |
| Mag | |||||
|---|---|---|---|---|---|
| Limit: | −19 | −19 | −20 | −20 | |
| N = 1: | Full | Resamp. | Full | Resamp. | |
| N = 2 Overall | 0.002 | 0.984 | 0.000 | 0.969 | |
| N = 2 Satellites | 0.000 | 0.993 | 0.000 | 0.889 | |
| N = 2 Central | 0.000 | 0.920 | 0.000 | 0.537 |
4 RESULTS
4.1 N = 2 colour distribution
The goal of this paper is to investigate the differences in the colour between N = 1 and N = 2 galaxies and to discuss what these differences imply in regards to star formation activity. We compare the g − r colour of N = 2 populations with N = 1 populations resampled to have the same stellar mass to remove any colour differences due to differences in stellar mass. NYU-VAGC magnitudes and colours are standard Petrosian magnitudes and colours (Petrosian 1976; Strauss et al. 2002) that are galactic extinction corrected (Schlegel, Finkbeiner & Davis 1998) and K-corrected by the template-fitting method of Blanton & Roweis (2007).
The contamination-corrected g − r distributions of the −19 (left) and −20 (right) overall N = 2 populations (dashed) and the resampled N = 1 populations (solid) of the same stellar mass are shown in the top row of Fig. 4. We separate galaxies into red (non-star-forming) and blue (star-forming) based on a cut in g − r and measure the excess of red galaxies between the two populations. The difference between the red fractions of the N = 2 and N = 1 populations as a function of the g − r value used to separate the red sequence and blue cloud is shown in the bottom row of Fig. 4. A g − r cut of 0.68 yields the maximum difference between the red fractions. This point corresponds to the ‘green valley’ and we define a red galaxy to be a galaxy with g − r ≥ 0.68 and a blue galaxy to be a galaxy with g − r < 0.68. This cut is shown as a vertical black line. The red excess is simply the difference between the two red fractions.
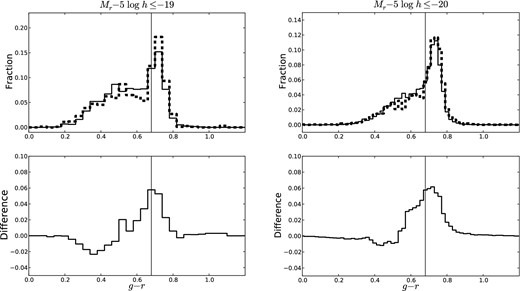
(Top) Contamination-corrected g − r distribution of the −19 (left) and −20 (right) overall N = 2 population (dashed) and a resampled N = 1 population (solid) of the same stellar mass. (Bottom) Difference between red fractions of the −19 (left) and −20 (right) N = 2 and N = 1 populations as a function of the g − r value used to separate the red sequence and blue cloud. The black vertical line shows our chosen red/blue separator value at g − r = 0.68 and the difference at this value is taken to be the red excess.
The g − r distributions of the N = 1 populations shown in Fig. 4 change as the subpopulations selected during our Monte Carlo resampling changes. Thus, the red excess is different for each Monte Carlo realization. We generate 100 independent realizations of our Monte Carlo resampling technique and compute the red excess for each realization. Taking the mean and standard deviation over all realizations, we find that the overall N = 2 population has a red excess of 0.05 ± 0.01 and 0.06 ± 0.01 for the −19 and −20 samples, respectively, relative to N = 1 populations of the same stellar mass. Thus, N = 2 galaxies in a very sparse group environment are redder than N = 1 galaxies of the same stellar mass. This is not surprising considering that galaxies in denser group environments are well known to be redder on average (e.g. Weinmann et al. 2006a).
4.2 Satellite N = 2 red excess
Following previous authors (e.g. van den Bosch et al. 2008) we now study the satellite and central N = 2 galaxy populations individually. The contamination-corrected g − r distributions of the −19 (left) and −20 (right) satellite N = 2 populations (dashed) and the resampled N = 1 populations (solid) of the same stellar mass are shown in the top row of Fig. 5. The difference in the red fractions of the satellite N = 2 population and an N = 1 population of same stellar mass as a function red/blue separator value is shown in the bottom row of Fig. 5. As before we select g − r = 0.68 as our red/blue separator value (shown by the black vertical line) and the red excess is the difference between the red fractions of the two populations.
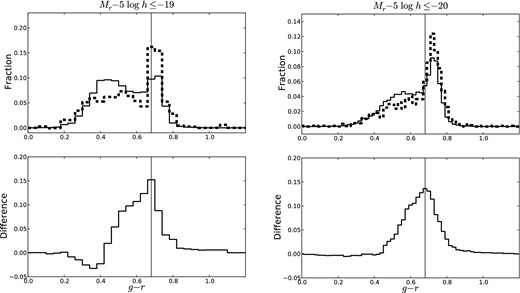
(Top) Contamination-corrected g − r distribution of the −19 (left) and −20 (right) satellite N = 2 population (dashed) and a resampled N = 1 population (solid) of the same stellar mass. (Bottom) Difference between red fractions of the −19 (left) and −20 (right) satellite N = 2 and N = 1 populations as a function of the g − r value used to separate the red sequence and blue cloud. The black vertical line shows our chosen red/blue separator value at g − r = 0.68 and the difference at this value is taken to be the red excess.
As before for the overall N = 2 population, we generate 100 independent realizations of our Monte Carlo resampling technique and compute the red excess of the satellite N = 2 population relative to N = 1 populations of the same stellar mass for each realization. Taking the mean and standard deviation over all realizations, which accounts for the variation in the red fraction of the N = 1 population, we find that satellite N = 2 populations have a red excess of 0.15 ± 0.01 and 0.14 ± 0.01 for the −19 and −20 samples, respectively, relative to N = 1 populations of the same stellar mass.
In other words, 15 per cent of satellite N = 2 galaxies have transitioned from the blue to the red sequence after being accreted into a very sparse group of two halo, assuming N = 1 galaxies are the progenitor of satellite N = 2 galaxies in a statistical sense. Tracking the merger histories in N-body simulations reveals that the differences in past major merger (<3:1) histories of N = 1 and N = 2 subhaloes are ≲ 1 per cent (Stewart et al. 2008). Additionally, our cosmological model shows that for DN ≤ 200 h−1 kpc, the fraction of N = 2 galaxies that have had a close pass within 30 h−1 kpc within the last 0.5 Gyr is ∼4 and 3 per cent for the −19 and −20 samples, respectively. Hence, mergers and galaxy–galaxy interactions are unlikely to play a significant role in these populations and the observed red excess is likely due to star formation quenching of the satellite galaxies from entering the sparse group environment as previously observed in richer and denser groups (e.g. Weinmann et al. 2006a; van den Bosch et al. 2008).
Recent studies of satellite star formation quenching in galaxy groups reveal that quenching must occur over long time-scales of order 2–3 Gyr (Kang & van den Bosch 2008; van den Bosch et al. 2008; McGee et al. 2009, 2011; Weinmann et al. 2009). These authors suggest strangulation as the physical process responsible for star formation quenching in these systems. The hot halo gas of the infalling satellite galaxy is stripped (by ram-pressure or tides) and star formation slows as the cold gas is consumed. However, semi-analytic models show that instantaneous and complete removal of hot halo gas by ram-pressure stripping leads to a passive red fraction of satellite galaxies that is much higher than the observed fraction (Weinmann et al. 2006b; Kang & van den Bosch 2008; Kimm et al. 2009). This has led some authors to simply decrease the stripping efficiency in their semi-analytic model (e.g. Font et al. 2008; Weinmann et al. 2010) or suggest tidal stripping of hot halo gas (Weinmann et al. 2010) to better match the observations.
However, strangulation of hot halo gas by any mechanism tends to produces too many galaxies in the green valley (Weinmann et al. 2010). Because of this Wetzel et al. (2012) do not support strangulation and point out that it is not clear that strangulation is efficient in low-mass haloes, such as the groups of two being studied here, as such haloes are not expected to have virial shock fronts which support hot, virialized gas within the halo (Dekel & Birnboim 2006). They also find a persistent specific star formation rate bimodality, i.e. the lack of galaxies in the green valley at all halo masses. Taken together, they argue that the satellite quenching mechanism must bring about a rapid transition from the blue cloud to the red sequence, which any form of hot halo gas strangulation struggles with. Ram-pressure stripping of cold gas is the natural quenching mechanism for a rapid blue to red transition. Although most estimates indicate that ram-pressure stripping is very inefficient in the low-mass haloes being studied here, Nichols & Bland-Hawthorn (2011) suggests that cold disc gas can be puffed up by internal star formation making the removal of cold gas by ram-pressure stripping possible even with a rarefied external medium of a low-mass halo.
Following the semi-analytic approach, we include a simple treatment of the removal of the cold gas from the infalling satellite galaxies (possibly by ram-pressure stripping) to our cosmological model. First, we consider an immediate-rapid quenching scenario where cold gas is instantaneously and completely removed immediately upon accretion. This is modelled using the population synthesis models of Bruzual & Charlot (2003) with a Chabrier (2003) initial mass function with model galaxies with exponentially decaying star formation rates with τ = 1–10 Gyr. The infalling galaxy's star formation rate is set to zero when the galaxy reaches the ‘initial’ g − r value and we record the amount of time it takes to reach to the red sequence for each τ. Fig. 6 shows the average time to reach the red sequence (g − r ≥ 0.68) after star formation has stopped as a function of g − r at accretion. The data points and error bars represent the mean and standard deviation over all values of τ.
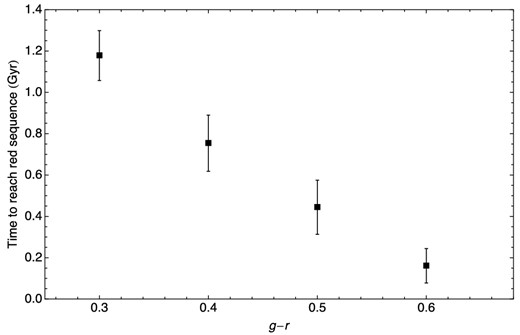
Time required to reach the red sequence after star formation stops (instantaneous and complete removal of cold gas) according to the population synthesis models of Bruzual & Charlot (2003) using model galaxies with exponentially decaying star formation rates with τ =1–10 Gyr. Data points and error bars represent the mean and standard deviation over all values of τ.
Our analysis indicates that a galaxy with g − r ∼ 0.3 will take an average of ∼1.2 Gyr after accretion to reach the red sequence in the immediate-rapid quenching scenario. Any galaxy with g − r > 0.3 will take less time. From the means and standard deviations in Fig. 6 we generate 100 realizations of the transition time, ttransition(g − r), for all g − r bins between 0.3 and 0.68 by drawing from random distributions with the appropriate mean and standard deviation and then interpolating.
Next, we determine the transition fraction, ftransition(g − r), for all g − r bins between 0.3 and 0.68. In the immediate-rapid quenching scenario, this is simply the fraction that have been within their host halo for at least the transition time computed above. The distribution of time spent in host halo for satellite galaxies in our cosmological model, f(t), is shown in the top panel of Fig. 7. The bottom panel shows the right cumulative distribution, |$F(t) = \sum _{t^{\prime }\ge t}f(t^{\prime })$|, or the fraction that have been within their host halo for at least t Gyr. The transition fraction is given by ftransition(g − r) = F(ttransition(g − r)) and is computed for each g − r bin between 0.3 and 0.68 for each realization. The satellite galaxies in our cosmological model have N700 = 1, DN ≤ 200 h−1 kpc, and N = 2. They are distinguished from central galaxies by a host/satellite flag tabulated in the catalogue. We compute the look-back time at accretion for each satellite halo from the scalefactor of the universe at accretion using |$\Omega _{\text{m}}=0.3$|, ΩΛ = 0.7, h = 0.7.
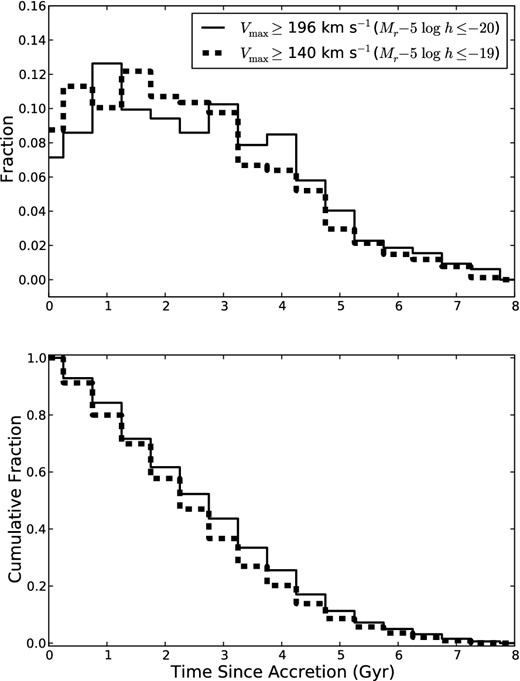
Time spent within host halo for simulated satellite N = 2 galaxies with Vmax ≥ 196 km s−1 (solid) and Vmax ≥ 140 km s−1 (dashed) in our hybrid N-body/semi-analytic cosmological model.
While Wetzel et al. (2012) argue that the quenching mechanism must be rapid, it does not need to occur immediately upon accretion, i.e. a delayed-then-rapid scenario. We can easily model such a scenario by including a delay time before truncating star formation in our model galaxies. The time to reach the red sequence (see Fig. 6) becomes ttransition → ttransition + tdelay. As the transition times get longer, the transition fractions decrease and the computed red excess decreases. The red excess predicted from the model as a function of star formation quenching delay time is shown in Fig. 8. A delay time of ∼3.3 and 3.7 Gyr predicts a red excess in agreement with the observations for the −19 and −20 samples, respectively.
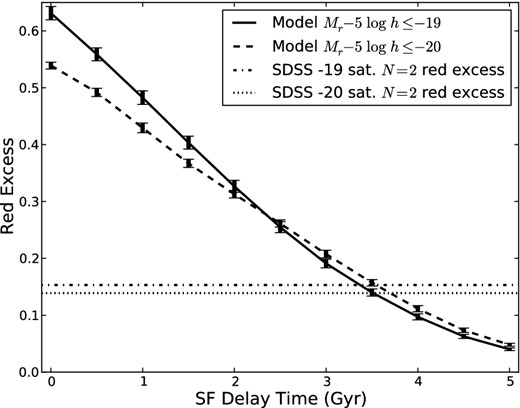
Expected red excess of satellite N = 2 galaxies as a function of the delay time in star formation quenching when the satellite is accreted into another halo for a −19 (solid) and −20 (dashed) mock redshift survey based on a model using the population synthesis models of Bruzual & Charlot (2003) and our hybrid N-body/semi-analytic cosmological simulations. Also shown are the observed satellite N = 2 red excess for the −19 (dot–dashed) and −20 (dotted) SDSS samples. The error bars represent the 1σ variation due to different star formation histories in the Bruzual & Charlot (2003) models.
A few caveats should be mentioned regarding the results above. Our observational result indicates that present-day satellite N = 2 galaxies have a higher red fraction than present-day N = 1 galaxies of the same stellar mass. In our immediate-rapid quenching model and delayed-then-rapid quenching model, we use a present-dayN = 1 population to predict the red excess of present-day satellite N = 2 galaxies assuming the former are representative of the progenitors of the latter. Ideally, we would have used an N = 1 population at the average redshift of accretion of satellite N = 2 galaxies instead of the present-day population. From Fig. 7, satellite N = 2 galaxies have been within their host haloes for 2.3 and 2.6 Gyr on average for the −19 and −20 samples, respectively. The average redshift of SDSS galaxies is z ∼ 0.1. Thus, we should be using an N = 1 population at z ∼ 0.32 and 0.34 for the −19 and −20 samples, respectively (see McGee et al. 2011). van den Bosch et al. (2008) also compared two present-day galaxy population while assuming one population is representative of the progenitors of the other. Following their arguments, we do not expect significant evolution in the red fraction of N = 1 galaxies at low redshifts and any evolution is probably towards lower red fractions at higher redshifts. As such, our model estimates are actually lower limits.
The observed red excess of satellite N = 2 galaxies with respect to N = 1 galaxies of the same stellar mass may be biased by the N = 1 population used to statistically correct the satellite N = 2 population for contamination. If the red fraction of the pure N = 1 population used in equation (3) is higher or lower, then the resulting red fraction of the satellite N = 2 population and the resulting red excess will be lower or higher than the values reported above. According to our cosmological model, the average host halo mass of the satellite N = 2 population is ∼0.4 dex greater than the average host halo mass of the N = 1 population selected using our constraints on DN and N700 (see fig. 4 of Barton et al. 2007). This means that the satellite N = 2 population is actually contaminated by an N = 1 population with an average host halo mass greater than the N = 1 population we used in equation (3) for statistical correction. Hence, we have slightly overestimated the true red fraction of the satellite N = 2 population and therefore the red excess. Based on the dependence of the early-type fraction with host halo mass at fixed luminosity for central galaxies in groups as shown by Weinmann et al. (2006a), we estimate that the red fraction of the higher host halo mass N = 1 population actually contaminating the satellite N = 2 population is ∼0.1 greater than the red fraction of the N = 1 population originally used in equation (3). If we increase the red fraction of the N = 1 population by 0.1 and recompute the satellite N = 2 red fraction using equation (3), we only find a decrease of ∼0.04 and 0.02 for −19 and −20, respectively. Thus, even when we account for the bias from the difference in host halo mass between the satellite N − 2 population and the pure N = 1 population used for statistical correction, we still find a red excess of at least ∼0.12. Thus, satellite star formation quenching is still present in N = 2 systems and the slight bias from our statistical correction does not significantly change our conclusions regarding quenching time-scales (see Fig. 8).
The observed red excess may also be biased due to the effects of galaxy harassment by fainter satellites. N = 2 haloes are expected to host more substructure suggesting that the effects of harassment by fainter satellites on satellite N = 2 galaxies is greater than for N = 1 galaxies, which implies that we have again slightly overestimated the red fraction of satellite N = 2 galaxies. However, the impact of harassment in galaxy group appears to be secondary (Weinmann et al. 2006a) and we expect that accounting for harassment by fainter satellites will not have a significant impact on our observed red fraction.
Another assumption made in our simple model is that the orbits of infalling satellites are identical for satellites that are red or blue at accretion. If satellites that are red at accretion are biased towards particular orbits, then the distribution of time spent within the host halo may differ from that shown in Fig. 7 and our red excess estimates will be affected. It is difficult to tell whether the red excess estimates would be larger or smaller without ‘a priori’ information on which orbits red satellites prefer.
Finally, in this preliminary study we have treated gas removal as instantaneous and complete and we have not included AGN feedback in contrast to more sophisticated semi-analytic galaxy formation models such as Kang & van den Bosch (2008), Font et al. (2008) and Weinmann et al. (2010). Nevertheless, our delayed-then-rapid model produces a star formation truncation time after accretion that is similar to the 3 Gyr reported by McGee et al. (2011) based on Font et al. (2008). In future work, we will study the properties of groups of two galaxies in considerably more depth and address the shortcomings of our simple semi-analytic model in order to gain a more thorough understanding of the environmental process(es) at work in the very sparse galaxy groups.
4.3 Central N = 2 blue excess
In the previous section, we explored our satellite N = 2 populations; we turn our attention to our central N = 2 populations here. The contamination-corrected g − r distributions of the −19 (left) and −20 (right) central N = 2 populations (dashed) and the resampled N = 1 populations (solid) of the same stellar mass are shown in the top row of Fig. 9. The difference in the red fractions of the central N = 2 population and an N = 1 population of the same stellar mass as a function of the g − r value used to separate the red sequence and blue cloud is shown in the bottom row of Fig. 9. As before we select g − r = 0.68 as our blue/red separator value (shown by the black vertical line) and the red excess is the difference in the red fractions of the two populations. For central N = 2 populations, we find a blue excess of 0.06 ± 0.02 and 0.02 ± 0.01 for the −19 and −20 samples, respectively, relative to N = 1 populations of the same stellar mass from mean and standard deviation of 100 independent realizations of our Monte Carlo resampling technique. Thus, for our chosen red/blue separator, central galaxies in a group of two are bluer than isolated galaxies of the same stellar mass.
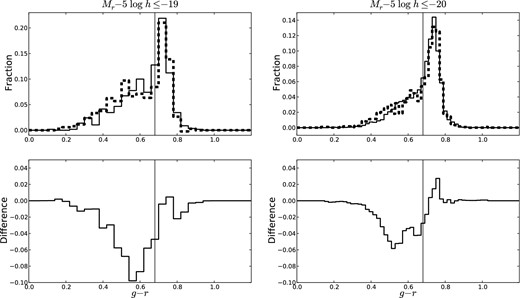
(Top) Contamination-corrected g − r distribution of the −19 (left) and −20 (right) central N = 2 population (dashed) and a resampled N = 1 population (solid) of the same stellar mass. (Bottom) Difference between red fractions of the −19 (left) and −20 (right) central N = 2 and N = 1 populations as a function of the g − r value used to separate the red sequence and blue cloud. The black vertical line shows our chosen red/blue separator value at g − r = 0.68 and the difference at this value is taken to be the red excess.
The red excess in satellite galaxies is likely due to a lack of star formation from gas loss. The gas that is lost by the satellite may be fed directly to the central, triggering star formation. This transfer could explain the observed blue excess in centrals. To investigate this hypothesis further, we examine satellite galaxies that are paired with red (blue) central galaxies and compare them with the overall satellite population. We begin by considering the stellar mass distributions of the three satellite populations: all satellites, satellites with a red central and satellites with a blue central. These distributions are not contamination corrected using equation (3) because we do not know the appropriate distributions for correction. The three satellite populations are resampled to be of the same stellar mass using our Monte Carlo resampling technique and we generate 100 independent realizations.
For each realization, we compute the g − r distribution and red fraction for all three satellite populations. Figs 10 and 11 show the results for satellites with a red and blue central, respectively, compared to the overall satellite population for one realization. The red excess of the satellite population with a red (blue) central galaxy relative to the overall satellite population is computed for each realization. From the mean and standard deviation over all realizations, satellites with a red central have a red excess of 0.05 ± 0.03 and 0.02 ± 0.02 for the −19 and −20 samples, respectively, relative to the overall satellite population of the same stellar mass. Similarly, the population of satellites with a blue central have a blue excess of 0.00 ± 0.03 and 0.03 ± 0.02 for the −19 and −20 samples, respectively, relative to the overall satellite population of the same stellar mass. In other words, red satellites slightly tend to pair with red centrals and blue satellites slightly tend to pair with blue centrals and ‘galactic conformity’ (Weinmann et al. 2006a) is somewhat present even in groups of two. However, we conclude from this analysis that direct gas exchange between the satellite and central is not a likely cause of the central blue excess.
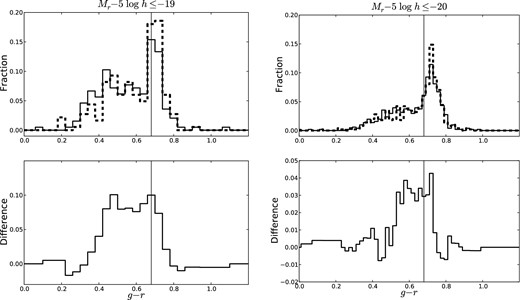
(Top) g − r distribution of the −19 (left) and −20 (right) satellite N = 2 population (dashed) with a red central galaxy and the overall satellite N = 2 population (solid) of the same stellar mass from one realization of our Monte Carlo resampling technique. (Bottom) Difference between red fractions of the −19 (left) and −20 (right) satellite N = 2 population with a red central and the overall satellite N = 2 population of the same stellar mass as a function of the g − r value used to separate the red sequence and blue cloud. The black vertical line shows our chosen red/blue separator value at g − r = 0.68 and the difference at this value is taken to be the red excess.
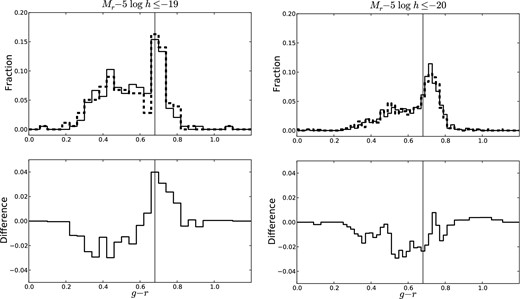
(Top) g − r distribution of the −19 (left) and −20 (right) satellite N = 2 population (dashed) with a blue central galaxy and the overall satellite N = 2 population (solid) of the same stellar mass from one realization of our Monte Carlo resampling technique. (Bottom) Difference between red fractions of the −19 (left) and −20 (right) satellite N = 2 population with a blue central and the overall satellite N = 2 population of the same stellar mass as a function of the g − r value used to separate the red sequence and blue cloud. The black vertical line shows our chosen red/blue separator value at g − r = 0.68 and the difference at this value is taken to be the red excess.
Triggered star formation from a close satellite pass (e.g. Mihos & Hernquist 1996; Barton et al. 2007) could also explain the observed blue excess in centrals, although we mentioned earlier that the frequency of such a close pass is expected to be very small. To test this hypothesis, we divide the central N = 2 population into a sample with satellite separations ≲ 100 h−1 kpc and another with satellite separations ≳ 100 h−1 kpc. This satellite separation value divides the central population into two nearly equal sized subsamples. The subsample with the closer satellites contains a red excess of 0.08 ± 0.05 and blue excess of 0.03 ± 0.03 for the −19 and −20 samples, respectively, relative to the subsample with wider satellite separations. Here, the errors are simply Poisson errors. We do not find that the central population with closer satellites to be bluer than the population with wider satellite separations. Hence, triggered star formation from a close pass is not a likely cause of the central blue excess either.
Lastly, we note that the central blue excess could also result because galaxies with satellites are also more likely to be actively accreting cold gas (see Kereš et al. 2009, and references therein), which is usually associated with larger scale filamentary overdensities in galaxy position. However, we have no means of directly testing this scenario presently and we do not attempt to substantiate any further.
5 CONCLUSION
In this paper, we used a ΛCDM cosmological model of structure formation to devise a method for selecting galaxies that are isolated in their dark matter halo (N = 1 system) and galaxies sharing their dark matter halo with exactly one neighbour (N = 2 systems) in a group of exactly two based on DN, the comoving projected distance to the nearest neighbour within ΔV ≤ 1000 km s−1 and N700, the total number of galaxies within a comoving projected distance of 700 h−1 kpc within ΔV ≤ 1000 km s−1. Our cosmological model enabled us to understand and correct for the contamination by galaxies in other environments allowing us to study the full, uncontaminated distributions of star-forming and morphological parameters instead of just the average trends. Using a Monte Carlo resampling technique, we constructed populations of isolated galaxies and groups of two galaxies with the same stellar mass distribution in order to remove any colour differences due to a difference in stellar mass. We studied the differences in g − r to determine the effects of very sparse galactic group environments and we find the following:
If galaxies are separated into a red sequence (g − r ≥ 0.68) and blue cloud (g − r < 0.68), N = 2 systems have a red excess of 0.05 ± 0.01 and 0.06 ± 0.01 for the −19 and −20 samples, respectively, relative to N = 1 systems of the same stellar mass. Thus, the environment of even a sparse group environment influences galaxy evolution to a limited extent.
Examining the less luminous member, satellite N = 2 galaxies have a red excess of 0.15 ± 0.01 and 0.14 ± 0.01 for the −19 and −20 samples, respectively, relative to N = 1 galaxies of the same stellar mass.
An immediate-rapid star formation quenching scenario, where the cold gas of the infalling satellite galaxy is instantaneously and completely removed immediately upon accretion into the sparse group of two halo yields a red excess prediction of 0.62 ± 0.01 and 0.54 ± 0.01 for the −19 and −20 samples, respectively. Thus, an immediate-rapid star formation quenching scenario is inconsistent with the observations.
A delayed-then-rapid star formation quenching scenario, as suggested by Wetzel et al. (2012), with a delay time of ∼3.3 and 3.7 Gyr for the −19 and −20 samples, respectively, yields a red excess prediction in agreement with the observed red excess for satellite N = 2 galaxies relative to N = 1 galaxies of the same stellar mass.
Examining the more luminous member, central N = 2 galaxies have a blue excess of 0.06 ± 0.02 and 0.02 ± 0.01 for the −19 and −20 samples, respectively, relative to N = 1 galaxies of the same stellar mass.
Satellite N = 2 galaxies with a red central have a red excess of 0.05 ± 0.03 and 0.02 ± 0.02 for the −19 and −20 samples, respectively, relative to the overall satellite population of the same stellar mass. Satellite N = 2 galaxies with a blue central have a blue excess of 0.00 ± 0.03 and 0.03 ± 0.02 for the −19 and −20 samples, respectively, relative to the overall satellite population of the same stellar mass. Thus, red satellites slightly tend to pair with red centrals and blue satellites slightly tend to pair with blue centrals demonstrating that galactic conformity somewhat present even in groups of two galaxies. However, the central blue excess cannot be explained by a simple direct exchange of gas between the satellite and central.
Central N = 2 galaxies whose satellite separation is ≲ 100 h−1 kpc have a red excess of 0.08 ± 0.05 and blue excess of 0.03 ± 0.03 for the −19 and −20 samples, respectively, relative to central N = 2 galaxies with satellite separations ≳ 100 h−1 kpc. Thus, triggered star formation from a close pass is unlikely to cause the observed central blue excess. The central blue excess may be due to cold flows.
Our most significant result in this preliminary study is that present-day satellite galaxies in a group of two have a higher red fraction compared to present-day isolated galaxies of the same stellar mass. Thus, star formation quenching of satellite galaxies by the yet undetermined dominant group environmental process occurs even in very sparse group environments where there are no other bright neighbours and galaxy–galaxy interactions with the central galaxy are unlikely. Taken together with our other results, we have demonstrated that environmental processes influence even the sparest groups of luminous galaxies. Furthermore, investigation of the star formation rate, AGN fraction, age, metallicity and concentrations of these simple systems and direct comparisons with predictions from ΛCDM and high-resolution hydrodynamical simulations will help undercover the causes of the trends seen here and contribute significantly towards a comprehensive understanding of galaxy evolution.
The authors thank Joss Bland-Hawthorn, Alison Coil, Jeff Cooke, Renée Pelton, Billy Robbins, and Sanjib Sharma for helpful discussions and encouragement to complete the work.
CQT gratefully acknowledges support by the National Science Foundation Graduate Research Fellowship under Grant No. DGE-1035963. EJB acknowledges support by NSF grant AST-1009999. CQT, EJB and JSB acknowledge support from the UC Irvine Center for Cosmology.
Funding for the Sloan Digital Sky Survey (SDSS) has been provided by the Alfred P. Sloan Foundation, the Participating Institutions, the National Aeronautics and Space Administration, the National Science Foundation, the US Department of Energy, the Japanese Monbukagakusho and the Max Planck Society.
The SDSS is managed by the Astrophysical Research Consortium (ARC) for the Participating Institutions. The Participating Institutions are The University of Chicago, Fermilab, the Institute for Advanced Study, the Japan Participation Group, The Johns Hopkins University, Los Alamos National Laboratory, the Max-Planck-Institute for Astronomy (MPIA), the Max-Planck-Institute for Astrophysics (MPA), New Mexico State University, University of Pittsburgh, Princeton University, the United States Naval Observatory and the University of Washington.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}