
Abstract
The detection precision of infrared seeker directly affects the guidance precision of infrared guidance system. To solve the problem of low target detection accuracy caused by the change of imaging scale, complex ground background and inconspicuous infrared target characteristics when infrared image seeker detects ground tank targets. In this paper, a You Only Look Once, Transform Head Squeeze-and-Excitation (YOLOv5s-THSE) model is proposed based on the YOLOv5s model. A multi-head attention mechanism is added to the backbone and neck of the network, and deeper target features are extracted using the multi-head attention mechanism. The Cross Stage Partial, Squeeze-and-Exclusion module is added to the neck of the network to suppress the complex background and make the model pay more attention to the target. A small object detection head is introduced into the head of the network, and the CIoU loss function is used in the model to improve the detection accuracy of small objects and obtain more stable training regression. Through these several improvement measures, the background of the infrared target is suppressed, and the detection ability of infrared tank targets is improved. Experiments on infrared tank target datasets show that our proposed model can effectively improve the detection performance of infrared tank targets under ground background compared with existing methods, such as YOLOv5s, YOLOv5s + SE, and YOLOV 5 s + Convective Block Attention Module.
Similar content being viewed by others


Introduction
In complex ground background, the grayscale characteristics of infrared tank targets are very similar to the background, which is easily influenced by background factors, making the target characteristics inconspicuous1. Moreover, when infrared seekers detect targets at a long distance, the targets in infrared images are often weak targets, the target scale changes greatly, and environmental interference factors are many2,3. Therefore, the seeker needs to find and detect infrared tank targets quickly from the complex battlefield environment to deal with complex, changeable situations more quickly.
Compared with visible light images, infrared images are depicted by thermal radiation, which has the characteristics of long-acting distance and can be used day and night4,5 . However, infrared images also have the characteristics of high noise and poor spatial resolution, which presents higher requirements for long-distance target detection, especially in ground background6. Traditional methods use the gray feature method7,8, the spatial filtering method9,10, the Markov random field method11,12,13, and the wavelet transform method14,15,16,17. However, these methods have some problems, such as requiring prior conditions, artificially defining features, high false alarm rate18,19,20,21,22, and inability to suppress the background to infrared targets. With the development of artificial intelligence technology, the convolutional neural network (CNN) can extract deeper image features, realize end-to-end learning, and obtain better image interpretation ability23,24,25. The methods based on CNN are mainly divided into two stages and one stage. The two-stage methods include Region-CNN (R-CNN)26, FAST R-CNN27 [27], and FAST R-CNN28. The one-stage methods include single-shot multi-box detector29 and YOLO30. Based on the YOLO method, YOLO900031, YOLOv332, YOLOv433, YOLOv534, and other methods have been developed. Although the two-stage method has high accuracy, it has a large amount of calculation and slow detection speed, whereas the one-stage method has high speed but low accuracy35,36. When an infrared seeker detects at a long distance, the target is far, the target pixels are few, and suppressing the ground background and focusing on the identified target is necessary. Moreover, due to the limitation of hardware resources, adopting a lighter network is necessary. The different network configurations of YOLOv5 model are divided into YOLOV537, YOLOv5m38, YOLOv5l39, and other structures, among which YOLOV5 model has the simplest structure, so it is considered.
With the appearance of the above detection methods, some researchers have done a lot of research on infrared target detection under complex background. In this part, we briefly review the related work of previous researchers. The related work of infrared target detection is mainly elaborated through two aspects, the traditional method and the method of convolutional neural network.
In terms of traditional methods, Gao et al. modeled the infrared target detection problem based on Mixture of Gaussians (MoG) and Markov Random field (MRF) method, and proposed a MRF guided MoG noise model under Bayesian framework to realize target detection under complex background40. Xie et al.41proposed a method of local average gray difference measurement (LAGDM) to highlight the difference between infrared target and background, and then generated a LAGDM map to enhance target features and suppress clutter. This method has good robustness to cloudy sky, sea and sky, mountains and forests and other backgrounds. Zhang et al.42 proposed an infrared target detection method based on morphology and wavelet transform, which suppresses clutter and performs wavelet decomposition, extracts high-frequency components and performs adaptive fusion to improve detection rate and reduce false alarm rate. Luo et al.43proposed an adaptive spatial filtering algorithm, which can effectively detect small infrared targets in undulating background with little loss of target information. Aiming at the problem of infrared target recognition in desert background, Li et al.44 proposed an improved kernel fuzzy clustering algorithm to cluster infrared images and polarized images to distinguish the target from the background.
In terms of convolutional neural networks, Ding et al. improved the detection accuracy of infrared targets by discarding the low-resolution layer and enhancing the high-resolution layer based on the SSD model45. Based on the convolutional neural network CNN, Du et al. designed effective small anchors in the shallow layer of ResNet50 to improve the detection accuracy of infrared small targets46. Ou et al.47 used an improved faster R-CNN target detection model to improve the feature extraction network based on VGG16 to improve the detection accuracy of infrared targets in complex backgrounds. Based on the YOLOv4 model, Du et al., proposed an FA-YOLO model, which adds a dilated convolutional block attention module to CSPdarknet53 in the backbone, and proposes a negative sample focusing mechanism to reduce the influence of useless complex background information on detection results, and improve the vehicle detection in remote sensing images with complex backgrounds48.
Motivation
The infrared seeker needs to detect the target in real-time during the working process. However, in the actual flight process, there are some problems, such as less feature information, fast scale change and complex ground background of the infrared target. In order to improve the guidance accuracy of the seeker, we need the seeker to have the ability to detect the target accurately and suppress the unfavorable factors of the complex ground background on the target detection.
In this paper, the YOLOv5s-THSE model is proposed to solve the problem of infrared seeker target detection in the ground background. Firstly, aiming at the problem of less feature information of infrared targets, we add a multi-head attention mechanism to the backbone and neck of YOLOv5s model to improve the network model's ability to mine the features in the whole image and make the extracted features more abundant. The complex and variable ground background can easily cause the false detection of the targets, leading to poor detection accuracy. Therefore, we add the CSP_SE module to the neck of the network to suppress the influence of the background on the target detection. The seeker is far away from the target in the initial stage, and the target is smaller than 16*16. In order to improve the detection accuracy of the seeker in the initial stage, a small target detection Head is introduced into the Head of the network to improve the detection accuracy of the seeker for small targets in the initial search stage, so as to improve the application range of the seeker. Through the above means, the recognition of the target itself was focused from multiple dimensions to suppress the ground background interference. On the other hand, in order to solve the problem that the predicted position is prone to deviate when the seeker is far away from the target, and to make the target frame more stable in the regression process when the target is small, In this paper, we change the GIoU (Intersection over Union) of the loss function in the YOLOv5s model to CIoU (Complete Cntersection over Union), which makes the target box more stable in the process of training and regression.
Main contributions
The main contributions of this work are as follows:
-
(1)
The multi-head attention mechanism is introduced into the YOLOv5s network model to improve the feature extraction ability of the network model for infrared targets in the image.
-
(2)
The CSP_SE module is added to the YOLOv5s model, which aims to suppress the complex ground background and make the model pay more attention to the infrared target itself.
-
(3)
The small target detection head is added to the Head of YOLOv5s model, which deals with the small target detection problem faced in the initial stage of the seeker. On the other hand, the loss function uses CIoU, which can make the training of the network, especially the training regression of small targets, more stable and easy to converge the model.
Organization of the Paper
The remainder of the text is arranged as follows: the second part introduces the proposed You Only Look Once, Transform Head Squeeze-and-Excitation model (YOLOv5s-THSE) model and then describes the network structure, including the improved small target detector, the CSP_SE model, the multi-head attention mechanism, the loss function, and the regression of the target box. The third part of this paper introduces the experimental data, compares the YOLOv5s-THSE model with the YOLOv5s, YOLOv5s + SE49, and YOLOv5s + CBAM50 models, and analyzes the experimental results. The last part presents the conclusion of this paper.
Methods and models
Network structure
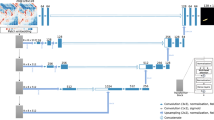
The YOLOv5 model performs well in detection speed, but its detection accuracy is low for infrared target recognition with complex ground background. Therefore, based on YOLOv5, this paper improves the network and proposes the YOLOv5-THSE model, which can effectively suppress the background and make it more accurate in detecting small targets. Its network structure is shown in Fig. 1.

Improved YOLOv5s-THSE network structure diagram.
According to the characteristics of seeker detecting complex ground targets, it is improved from three parts: backbone, neck, and head. To make the detection network pay more attention to the target itself and suppress the ground background, the CSP_SE module is used in the neck part. The CSP_SE module is an improvement of the original CSP module in YOLOv5s, with the purpose of using the Squeeze-and-Exclusion (SE) attention mechanism51 to increase the attention to the characteristics of the target itself. During the flight of the seeker, the target shows multiscale drastic changes in the infrared image of the seeker, and the seeker’s ability to detect small targets is low. To solve these two problems, an 80*80*18 small target detector is added to the network to cope with the multi-scale changes of targets and improve the detection ability of small targets. To mine the deeper image semantic information of the target in the complex ground background, inspired by Transformer, the multi-head attention trans module is introduced in the output part of the backbone and the head to mine the deeper image semantic information.
Infrared dim and small target detection head
In the initial stage of seeker searching for the target, the target is a weak infrared target because of the long distance between seeker and target. Therefore, in the head part of the network model, a detector is added to detect small, weak infrared targets, which can cope with the drastic change of the target scale in the image during the flight of the seeker. Figure 1 shows the newly added 80*80*18 detector is a high-resolution feature map, which is more accurate in detecting small, weak targets. Through the four detection heads in the network structure, the target detection can be dealt with in different scales.
CSP_SE model
The CSP structure in YOLOv5s can reduce the calculation of the model and improve the detection speed of the model52. However, infrared targets often have few features, and the CSP structure cannot effectively extract the features of infrared targets. To solve this problem, this paper proposes a CSP_SE model structure, which adds the SE attention mechanism to the CSP structure, so that the network can learn the important information of the target adaptively, thus enhancing the extraction effect of the target features.
The structural diagram of the SE attention mechanism module is shown in Fig. 2. The SE model focuses on the relationship between channels, and the model can learn the weights of different channel features. The overall structure includes two steps: compression and excitation. Specifically, the SE model first maps X to the feature map U through the mapping \({\mathbf{F}}_{tr}\), then obtains a \(1 \times 1 \times C\) feature map through pooling operation, and then calculates the \(1 \times 1 \times C\) feature map through \({\mathbf{F}}_{ex} ( \cdot ,{\mathbf{W}})\) matrix to obtain the feature weight of \(1 \times 1 \times C\). Finally, the weighted feature map can be obtained by fusion.

A squeeze-and-excitation block.
Figure 3 shows the CSP_SE model structure replaces a CBL module in the original CSP structure with an SE module, which can make the network pay more attention to the target.

Comparison between CSP model and CSP_SE model. (a) CSP model, (b) CSP_SE model.
Multi-head attention mechanism module
In the process of seeker flying at high speed, the complex ground background easily affects target recognition. Inspired by the Transformer model53, this paper introduces the multi-head attention mechanism module into the network. When the single-headed self-attention mechanism model encodes the information of the current position, it will excessively focus on its own position and get an attention. Compared with single-headed attention, multi-headed attention transforms an input object into multiple features, and then calculates the self-attention of multiple features. Because each feature is independent in theory, it can also generate multiple independent attention, thus obtaining multi-dimensional image feature information. We use the coding module in the Transformer model to obtain deeper, richer semantic information to improve the adaptability of the network to the complex ground background. On the one hand, YOLOv5s-THSE adds the multi-head attention mechanism to the front end of the detector, replacing the CSP module in the original YOLOv5s network model, to make each detector capture richer global information and semantic information. On the other hand, in the backbone of the network, a CSP module is also replaced by a multi-head attention module. The purpose is to map the original features into multiple subspaces by using the multi-head attention mechanism, so that the network can extract image features from multiple dimensions. The multi-head attention mechanism module is mainly divided into two parts, as shown in Fig. 4. One is the multi-head attention mechanism layer, and the other is the multilayer perceptron. Each layer is connected in a cross-layer way.

Structural diagram. (a) multi-head attention structure, (b) coding module in transformer.
Loss function
The loss function in YOLOv5s model consists of three parts, namely, positioning loss, confidence loss, and category loss. Among them, confidence loss and category loss are calculated by cross-entropy, and the loss function is calculated as follows.
where K indicates that the feature map finally output by the network is divided into K × K grids, m indicates the number of anchor boxes corresponding to each grid, \(I_{ij}^{obj}\) indicates the anchor box with target, \(I_{ij}^{noobj}\) indicates the anchor box without target, and \(\lambda_{noobj}\) indicates the confidence loss weight coefficient without target anchor box. The object detection problem faced by the model in this paper is a typical problem of an unbalanced number of categories. . Among K*K grids, there are usually only about three or four grids containing objects, and even fewer small targets, and the rest are all grids without objects. If the weights in the loss function are not set, the mAP of object detection will not be too high, because the model prefers grids that do not contain objects. \(\lambda_{noobj}\) is to adjust the weight, so that the grids without objects have less weight. This makes the model more biased towards the loss caused by grids containing objects. Due to the existence of some small targets in this paper, the value of \(\lambda_{noobj}\) needs to be reduced, and we take \(\lambda_{noobj}\) equal to 0.3 in the paper.
GIoU is used to calculate the positioning loss in YOLOv5s model. Compared with IoU, GIoU can better reflect the overlap between the predicted box and the real box, but GIoU always only considers the overlap rate, which cannot well describe the regression problem of the target box54. When the prediction box is inside the real box, for the prediction boxes with different positions but the same size, GIoU cannot distinguish the position relationship between the prediction boxes, especially when the seeker is far from the target, and the target is smaller, which is more likely to happen. Therefore, this paper uses CIoU instead of GIoU as the loss function of target regression, and the formula is as follows:
where α is an equilibrium parameter and does not participate in gradient calculation, and v is a parameter used to measure the consistency of aspect ratio. CIoU comprehensively considers the overlap rate, the distance from the center point, and the aspect ratio between the real box and the predicted box, which makes the regression of the target box more stable and have higher convergence accuracy, and is beneficial to improving the detection accuracy of infrared small targets.
Regression of target box
Target box regression aims to find some mapping relationship, so that the mapping of candidate target box is infinitely close to the real target box. The prediction of the real target box is to regress the relative coordinates of the target box relative to the upper left corner of a grid by means of relative position. The relationship between the prior box and the prediction box is shown in Fig. 5, where the dashed box represents the prior box, and the solid box represents the prediction box. The prediction box is obtained by translating and scaling the prior box. The original picture is divided into S × S grid cells according to the size of the feature map, and each grid cell predicts 3 prediction boxes, each containing 4 coordinate information and 1 confidence information. When the center coordinates of a target in the real box fall in a grid, the grid predicts the target.

Target box regression schematic diagram.
The coordinate prediction of the target box is calculated as follows:
where \(t_{x}\), \(t_{y}\), \(t_{w}\), and \(t_{h}\) are the offset, and \(\sigma\) is the Sigmoid activation function, which is used to map the network predicted values \(t_{x}\), \(t_{y}\), \(t_{w}\), and \(t_{h}\) to [0,1]; \(c_{x}\),\(c_{y}\) is the offset in the cell grid relative to the upper left corner of the picture; \(p_{w}\) and \(p_{h}\) are the width and height of the prior box, respectively; \(b_{x}\), \(b_{y}\) and \(b_{w}\), \(b_{h}\) are the central coordinates of the prediction target box; \(\delta (t_{0} )\) is the confidence of the prediction box, which is obtained by multiplying the probability of the prediction box and the CIoU value of the prediction box and the real box. A threshold for \(\delta (t_{0} )\) is set, the prediction boxes with low confidence are filtered out, and then the non-maximum suppression is used. The NMS algorithm for the remaining prediction boxes is used to determine the final prediction box.
In this paper, a small target detector is added to form four detectors. On the smallest feature map, because its receptive field is the largest, it should be used to detect large targets. Therefore, the large-scale feature map should use a small-scale prior frame, and the small-scale feature map should use a large-scale prior bounding box for regression of prediction boxes. In this paper, the corresponding relationship between the feature map size of four scales and the prior bounding box size is shown in Table 1.
Experiment and analysis
Infrared tank target data set
The acquisition cost of the measured infrared tank target data is high, and a large number of flight tests are needed to obtain sufficient data. The data set used in this paper includes measured infrared data and simulated infrared data. The infrared tank data set is expanded to 13,379 images by data augmentation.
The material library of infrared simulation data includes common soil, vegetation, rocks, water, roads, building materials, general paints, and pigments. Based on the physical characteristics, the infrared target is modeled, which can reflect the corresponding spectral radiation characteristics and atmospheric transmission characteristics. The real infrared characteristics analysis and image rendering are carried out by combining the real target model, material characteristics, target thermal characteristics, and environmental thermal radiation characteristics. After the infrared scene and infrared target model are built, the infrared target imaging data of seeker can be simulated and generated by adding flight parameters. The measured data are hung by infrared seeker. Some infrared images in the data set are shown in Fig. 6. Table 2 shows the image size, number of images and target number under different ground backgrounds. Table 3 shows the number of simulated infrared images and measured infrared images, as well as the number of images in training set and verification set.

Infrared data set.
Evaluation indicators
Evaluation indicators generally use the common evaluation indicators in target detection algorithms, such as mean AP, mAP, precision, and recall, to evaluate the performance of this algorithm. Precision refers to the number of correct positive samples in the prediction data set divided by the number of positive samples predicted by the model. Recall rate refers to the number of correct positive samples in the prediction data set divided by the number of actual positive samples. The above indicators are calculated as follows:
TP, FP, and FN represent the number of correct detection boxes, false detection boxes, and missed detection boxes, respectively.
In this paper, we use mAP_0.5 and mAP_0.5:0.95 evaluation indicators. mAP_0.5 refers to calculating the average accuracy of all pictures in each category when IoU is set to 0.5, and then averaging all categories. mAP_0.5:0.95 refers to the average precision values at different IoU thresholds (from 0.5 to 0.95, with a step size of 0.05).
Experimental results
Table 4 shows the experimental results on the typical infrared tank target data set in this paper and compares the YOLOv5s-THSE detection model proposed in this paper with the YOLOv5s, YOLOv5s + SE, and YOLOv5s + CBAM models. Here, the size of the input image is set to 640*640, the training period is set to 300 generations, the initial learning rate of training is 0.001, the learning rate is attenuated by 0.001 every 10 generations, and the batch size is set to 16. The training experiment is based on PyTorch, and the GPU is GeForce GTX 2080 Ti.
Table 4 shows that compared with the other models, the YOLOv5s-THSE proposed in this paper has evident improvements in precision, recall, mAP_0.5, and mAP_0.5:0.95. In terms of precision, YOLOv5s-THSE is 14.632%, 2.927%, and 11.550% higher than YOLOv5s, YOLOv5s + SE, and YOLOv5s + CBAM, respectively. In terms of recall, YOLOv5s-THSE is 13.756%, 7.847%, and 8.497% higher than YOLOv5s, YOLOv5s + SE, and YOLOv5s + CBAM, respectively. In terms of mAP_0.5, YOLOv5s-THSE is 10.425%, 4.136%, and 6.90% higher than YOLOv5s, YOLOv5s + SE, and YOLOv5s + CBAM, respectively. In terms of mAP_0.5:0.95, YOLOv5s-THSE is 6.994%, 5.215%, and 5.370% higher than YOLOv5s, YOLOv5s + SE, and YOLOv5s + CBAM, respectively. These data show that the model in this paper has a good detection effect on infrared tank targets under ground background.Figure 7 shows the target detection results of infrared images, including a variety of complex ground backgrounds. (a) The sequence pictures are the tank targets in the grassland background containing urban buildings. (b) The sequence pictures are the tank targets in the field background. (c) The sequence pictures are the tank targets in the grassland background. (d) The sequence pictures show the desert background tank targets with certain vegetation. (e) The sequence pictures are the scenes with gray levels similar to those of tanks. The first line is the detection result of YOLOv5s, the second line is the detection result of YOLOv5s + SE, the third line is the detection result of YOLOv5s + CBAM, and the fourth line is the detection result of YOLOv5s-THSE proposed in this paper. Here, the same four pictures are used to compare the test results.
Figure 7 shows that the detection results of YOLOv5s-THSE model adopted in this paper are better than those of the four other models in six different scenarios, and it has good detection accuracy at different scales.


Target detection results of different models under different opposite backgrounds.
To study the index changes of different models in training, Fig. 8 shows the change trend of mAP_0.5 and mAP_0.5:0.95 in the training of several models, such as YOLOv5s-THSE, YOLOv5s, YOLOv5s + SE, and YOLOv5s + CBAM. Figure 8a shows the change of the average detection accuracy of categories when the CIoU threshold is 0.5. Figure 8b shows the change of average detection accuracy when the CIoU threshold is between 0.5 and 0.95. Compared with the YOLOv5s model, the YOLOv5s + SE model and the YOLOv5s + CBAM model add an attention mechanism, so the detection accuracy of these two methods is higher than that of the YOLOv5s model. However, the YOLOv5s-THSE model proposed in this paper adds a small target detector and a multi-head attention mechanism. The experimental results in Fig. 9 show that the YOLOv5s-THSE model has the highest precision and recall compared with the three other models, it can quickly converge to a higher precision during the training, and it takes less training period to enter a stable state.

Comparison of mAP_0.5 and mAP_0.5:0.95 curves of different models, (a) Precision metrics, (b) Recall metrics.

Comparison of precision and recall index of different models.
As the objective function of optimization in the whole training, the smaller the loss value is, the closer the detection is to the real result, and the smaller the loss value is, the better the performance of the model. Figure 10 shows the changes of several models in this paper in the training set and the verification set. Box loss and object loss on the training set show a downward trend and finally stabilize. In Fig. 10a and b, the box loss and the object loss of the YOLOv5s-THSE model decrease most rapidly, and the minimum value after stabilization is the smallest. Similarly, in Fig. 10c and d, the box loss and the object loss of the YOLOv5s-THSE model also decrease the fastest and have the smallest values. This result shows that using CIoU in the YOLOv5s-THSE model can make the detection result closer to the real target position.

Comparison of loss function values of different models on training set and verification set. (a) Train_box_loss, (b) Train_obj_loss, (c) Val Box_loss, (d) Val Object_loss.
To verify the improvement of small target detection by adding a small target detector in YOLOv5s-THSE model, an infrared image data set with the distance between the seeker and the target greater than 5 km is constructed. At this distance, the target pixel in the infrared image is less than 15*25. Then through data enhancement, the data set is expanded to 5000, and the above models are used for training and detection.
Figure 11 shows the change trend of indicators of different models on small target data, and Fig. 11a shows the change trend of precision metrics indicators in the training. The final convergence value of precision metrics of YOLOv5s-THSE model is the highest. Figure 11a shows the changing trend of recall metrics in the training. Compared with the three other models, the YOLOv5s-THSE model has the highest convergence value, less fluctuation of training curve, and fewer training iterations required for convergence. Figure 11c shows the change of average detection accuracy of categories when the CIoU threshold is 0.5. Figure 11d shows the change of average detection accuracy when the CIoU threshold is between 0.5 and 0.95. The YOLOv5s-THSE model has higher detection accuracy under these two different threshold modes. The detection results of the three groups of small targets are given in Fig. 12. In the image of group (a), the infrared seeker is 7 km away from the target, and the target size is about 5*11 pixels. In the image of group (b), the infrared seeker is 6.5 km away from the target, and the target size is about 7*13 pixels. In the image of group (c), the infrared seeker is 5 km away from the target, and the target size is about 10*15 pixels.

Comparison of indicators on small target data sets. (a) Precision metrics, (b) Recall metrics, (c) mAP_0.5, (d) mAP_0.5:0.95.

Comparison of small target detection results.
Table 5 compares several models for small target detection. The YOLOv5s-THSE proposed in this paper has improved precision, recall, mAP_0.5, and mAP_0.5:0.95. In terms of precision, YOLOv5s-THSE is 6.023%, 4.056%, and 4.510% higher than YOLOv5s, YOLOv5s + SE, and YOLOv5s + CBAM, respectively. In terms of recall, YOLOv5s-THSE is 6.668%, 2.355%, and 4.915% higher than YOLOv5s, YOLOv5s + SE, and YOLOv5s + CBAM, respectively. In terms of mAP_0.5, YOLOv5s-THSE is 7.564%, 3.945%, and 5.156% higher than YOLOv5s, YOLOv5s + SE, and YOLOv5s + CBAM, respectively. In terms of mAP_0.5:0.95, YOLOv5s-THSE is 5.154%, 2.809%, and 4.490% higher than YOLOv5s, YOLOv5s + SE, and YOLOv5s + CBAM, respectively. These results show that the model in this paper can improve the detection of small targets in tanks.
Conclusion
Aiming at the problem of infrared tank target detection under complex ground background, this paper proposes a YOLOv5s-THSE model. After the discussion and experiments in this paper, the following conclusions can be reached: 91) the multi-head attention mechanism added in the Backbone and Neck of the network can make the network mine deeper target feature information. (2) The CSP_SE structure is added to the Neck network to suppress the background and make the model pay more attention to the target. Compared with other models mentioned in this paper, the experimental evaluation results show that introducing the multi-head attention mechanism and CSP_SE structure effectively improves the detection accuracy of infrared targets in complex ground background. 3) The small target detection Head added to the head part of YOLOv5s-THSE model can effectively improve the detection accuracy of infrared small targets, and the improvement of small target detection means that the infrared seeker has a larger detection range. On the other hand, through the experimental training curve, it can be concluded that CIoU has a smaller loss value, which is more conducive to the training and regression of object detection. These measures are of positive importance for the multiscale detection and identification of infrared seeker under complex ground. In later research, adding more measured infrared tank data will be considered to expand the data set. The model is lightweight to ensure accuracy and meet the actual use requirements.
Data availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Lei, B. et al. Signal denoising of multi element infrared signal based on wavelet transform. J. Phys. Conf. Ser. 1639(1), 012102 (2020).
Li, S. et al. Investigation of infrared dim and small target detection algorithm based on the visual saliency feature. Proc. Inst. Mech. Eng. Part G J. Aerosp. Eng. 235(12), 1630–1647 (2021).
Chen, J. et al. Snake-hot-eye-assisted multi-process-fusion target tracking based on a roll-pitch semi-strapdown infrared imaging seeker. J. Bionic Eng. 19(4), 1124–1139 (2022).
Ren, H. et al. Retrieval of land surface temperature, emissivity, and atmospheric parameters from hyperspectral thermal infrared image using a feature-band linear-format hybrid algorithm. IEEE Trans. Geosci. Remote Sens. 60, 1–15 (2021).
Yousefi, B. et al. Unsupervised identification of targeted spectra applying rank1-NMF and FCC algorithms in long-wave hyperspectral infrared imagery. Remote Sens. 13(11), 2125 (2021).
Zang, Y. et al. Pose estimation at night in infrared images using a lightweight multi-stage attention network. Signal Image Video Process. 15(8), 1757–1765 (2021).
Mangale, S. & Khambete, M. Gray level co-occurrence matrix feature based object tracking in thermal infrared imagery. J. Electron. Imaging 27(3), 0330211–0330219 (2018).
Mo, W. & Pei, J. Sea-sky line detection in the infrared image based on the vertical grayscale distribution feature. Vis. Comput. 2022, 1–13 (2022).
Morin, A., Masten, M.K., Stockum, L.A. Adaptive spatial filtering techniques for the detection of targets in infrared imaging seekers, 2000: 182–193.
Jia, J. et al. Destriping algorithms based on statistics and spatial filtering for visible-to-thermal infrared pushbroom hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 57(6), 4077–4091 (2019).
Guerrero-Pena, F. A. & Vasconcelos, G. C. Object recognition under severe occlusions with a hidden Markov model approach. Pattern Recognit. Lett. 86(15), 68–75 (2017).
Guerrero-Pea, F.A., Vasconcelos, G.C. Search-space sorting with hidden Markov models for occluded object recognition. In 2016 IEEE 8th international conference on intelligent systems (IS). IEEE, 2016.
Wang, H.Y., Su-Hang, G.U., Ji-Dong, L.V. Partially occluded object recognition based on SIFT features under hidden Markov model. Comput. Technol. Automation, 2016.
Qin, R. et al. Multilevel wavelet-SRNet for SAR target recognition. IEEE Geosci. Remote Sens. Lett. 19, 1–5 (2021).
Wei, W. & Hu, D. Target recognition algorithm based on wavelet transform method. Int. J. Simul. Syst. 16(2), 71–74 (2015).
Jiang, Z.H., Zhou, C.R. Infrared image sequence small target recognition method based on wavelet transform domain. In 2020 IEEE International Conference on Industrial Application of Artificial Intelligence (IAAI). IEEE, 2020.
Jie, W. et al. Device-free simultaneous wireless localization and activity recognition with wavelet feature. IEEE Trans. Veh. Technol. 66(2), 1659–1669 (2017).
Woo-Han, Y. et al. Real-time object recognition using relational dependency based on graphical model. Pattern Recognit. 41(2), 742–753 (2008).
Bo, W., Nevatia, R. Improving part based object detection by unsupervised, online boosting. In 2007 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2007), 18–23, Minneapolis, Minnesota, USA. IEEE, 2007.
Li, S. et al. (2021) YOLO-FIRI: Improved YOLOv5 for infrared image object detection. IEEE Access 9, 141861–141875 (2021).
Li, B. et al. Dense nested attention network for infrared small target detection. IEEE Trans. Image Process. 14(8), 1745–1758 (2015).
Zhang, H. et al. Visual fusion of network security data in image recognition. IEEE Access https://doi.org/10.1109/ACCESS.2020.3020867 (2020).
Shin, H. C. et al. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans. Med. Imaging 35(5), 1285–1298 (2016).
Ghosh, R., Mishra, A., Orchard, G., et al. Real-time object recognition and orientation estimation using an event-based camera and CNN. In Biomedical Circuits & Systems Conference. IEEE, 2014.
Wang, Y., Deng, W. Self-restraint object recognition by model based CNN learning. In 2016 IEEE International Conference on Image Processing (ICIP). IEEE, 2016.
Lee, H., Eum, S., Kwon, H. ME R-CNN: Multi-expert region-based CNN for object detection. In IEEE Transactions on Image Processing, 2017, 99.
Girshick, R. Fast R-CNN. Computer Science, 2015.
Jiang, H., Learned-Miller, E. Face detection with the faster R-CNN. IEEE, 2017:650–657.
Wei, L. et al. SSD: Single shot multibox detector (Springer, 2016).
Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 779–788.
Redmon, J., Farhadi, A. YOLO9000: Better, faster, stronger. In IEEE Conference on Computer Vision & Pattern Recognition. IEEE, 2017:6517–6525.
Redmon, J., Farhadi, A. YOLOv3: An incremental improvement. arXiv e-prints, 2018.
Bochkovskiy, A., Wang, C.Y., Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934, 2020.
Fang, Y. et al. Accurate and automated detection of surface knots on sawn timbers using YOLO-V5 model. BioResources 16(3), 5390–5406 (2021).
Liu, M. et al. UAV-YOLO: Small object detection on unmanned aerial vehicle perspective. Sensors 20(8), 2238 (2020).
Zhang, L., Liang, L., Liang, X. et al. Is faster R-CNN doing well for pedestrian detection? In European Conference on Computer Vision. Springer International Publishing, 2016
Zhang, C. et al. Grape cluster real-time detection in complex natural scenes based on YOLOv5s deep learning network. Agriculture 12(8), 1242 (2022).
Luo, S. & Liu, J. Research on car license plate recognition based on improved YOLOv5m and LPRNet. IEEE Access 10, 93692–93700 (2022).
Guo, X., Zuo, M., Yan, W., et al. Behavior monitoring model of kitchen staff based on YOLOv5l and DeepSort techniques. In MATEC Web of Conferences. EDP Sciences, 2022, 355.
Gao, C. et al. Infrared small-dim target detection based on Markov random field guided noise modeling. Pattern Recognit. 76, 463–475 (2018).
Xie, F. et al. Infrared small-target detection using multiscale local average gray difference measure. Electronics 1110, 1547 (2022).
Zhang, Y., et al. Infrared small target detection based on morphology and wavelet transform. In 2011 2nd International Conference on Artificial Intelligence, Management Science and Electronic Commerce (AIMSEC). IEEE, 2011.
Luo, J.-H., Ji, H.-B., Liu, J. An algorithm based on spatial filter for infrared small target detection and its application to an all directional IRST system. In 27th International Congress on High-Speed Photography and Photonics. Vol. 6279. SPIE, 2007.
Li, X., Huang, Q. Target detection for infrared polarization image in the background of desert. In 2017 IEEE 9th International Conference on Communication Software and Networks (ICCSN). IEEE, 2017.
Ding, L. et al. Detection and tracking of infrared small target by jointly using SSD and pipeline filter. Digital Signal Process. 110, 102949 (2021).
Du, J. et al. CNN-based infrared dim small target detection algorithm using target-oriented shallow-deep features and effective small anchor. IET Image Process. 151(1), 1–15 (2021).
Ou, J. et al. Infrared image target detection of substation electrical equipment using an improved faster R-CNN. IEEE Trans. Power Deliv. 38, 387–396 (2022).
Du, S. et al. FA-YOLO: An improved YOLO model for infrared occlusion object detection under confusing background. Wirel. Commun. Mob. Comput. 2021, 1–10 (2021).
Zhang, H., Sicong, Z. A YOLOv5s-SE model for object detection in X-ray security images.In 2021 International Conference on Control, Automation and Information Sciences (ICCAIS). IEEE, 2021.
Jiang, T. et al. An improved YOLOv5s algorithm for object detection with an attention mechanism. Electronics 1116, 2494 (2022).
Jie, H., Li, S., Gang, S. Squeeze-and-Excitation Networks. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2018.
Zhou, Z.H., Meng, Y.W., Yu, R.D. et al. An improved Yolov5s based real-time spontaneous combustion point detection method. In 2021 IEEE International Conference on Computer Science, Electronic Information Engineering and Intelligent Control Technology (CEI). 0.
Vaswani, A., Shazeer, N., Parmar, N., et al. Attention is all you need. Adv. Neural Inf. Process. Syst., 2017, 30.
Rezatofighi, H., Tsoi, N., Gwak, J.Y. et al. Generalized intersection over union: A metric and a loss for bounding box regression. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2019.
Author information
Authors and Affiliations
Contributions
C.L. and Z.Y. contributed to the conception of the study; C.L. and J.W. performed the experiment; C.L. and M.R. contributed significantly to analysis and manuscript preparation; L.T. and X.G. performed the data analyses and wrote the manuscript; C.L., M.R. and L.T. helped perform the analysis with constructive discussions. X.G., J.W. and J.L. collected some infrared data and constructed some infrared data sets.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liang, C., Yan, Z., Ren, M. et al. Improved YOLOv5 infrared tank target detection method under ground background. Sci Rep 13, 6269 (2023). https://doi.org/10.1038/s41598-023-33552-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-33552-x
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
