
Abstract
We evaluated the contribution of artificial intelligence in predicting the risk of acute cellular rejection (ACR) using early plasma levels of soluble CD31 (sCD31) in combination with recipient haematosis, which was measured by the ratio of arterial oxygen partial pressure to fractional oxygen inspired (PaO2/FiO2) and respiratory SOFA (Sequential Organ Failure Assessment) within 3 days of lung transplantation (LTx). CD31 is expressed on endothelial cells, leukocytes and platelets and acts as a “peace-maker” at the blood/vessel interface. Upon nonspecific activation, CD31 can be cleaved, released, and detected in the plasma (sCD31). The study included 40 lung transplant recipients, seven (17.5%) of whom experienced ACR. We modelled the plasma levels of sCD31 as a nonlinear dependent variable of the PaO2/FiO2 and respiratory SOFA over time using multivariate and multimodal models. A deep convolutional network classified the time series models of each individual associated with the risk of ACR to each individual in the cohort.
Similar content being viewed by others

Introduction
Lung transplantation (LTx) is a life-saving therapy that may be offered to selected patients with end-stage lung disease. However, lung transplant recipients have the lowest survival rate among solid organ transplants of 6.7 years1. Indeed, their prognosis can be hampered by numerous complications, including primary graft dysfunction2, infections3, airway complications4 and acute rejection5. Despite advances in immunosuppressive treatment strategies, 30–50% of recipients experience at least one episode of acute cellular rejection (ACR) during the first year after LTx6,7. ACR is triggered by a T lymphocyte-induced response to allogeneic human leucocyte antigen or other antigens8,9, which is characterized by the infiltration of mononuclear cells around the pulmonary capillaries and/or small airways10 that target and damage the graft tissue. ACR is a major risk factor for chronic lung allograft dysfunction, which is the leading cause of mortality beyond 1 year of LTx and accounts for over 25% of deaths11. In a multicentre, prospective study, Todd et al. reported that more than 50% of LTx recipients experienced at least one episode of ACR within the first year, with a median delay of 43 (27–100) days7. The diagnosis of ACR is suspected in the presence of respiratory deterioration but remains very challenging. Indeed, ACR has no clinical, radiological, or biological specificities with respect to other causes of decreased lung function12. Moreover, ACR can occur in asymptomatic patients or those who develop nonspecific symptoms such as cough, fever, or flu-like manifestations13,14. Once suspected, the diagnosis of ACR is confirmed by histopathological evidence on transbronchial lung biopsies15,16,17. However, there are no recommendations on how often and how to perform transbronchial lung biopsies15. In addition, the anatomopathological interpretation of acute rejection suffers from a high degree of inconsistency, partly due to the inter-observer variability18.
ACR results from the initial activation and interaction of graft endothelial cells with lymphocytes, neutrophils and platelets. Allogeneic presentation by graft endothelial cells is a primary target for circulating T cells19,20, and the association of endothelial activation with acute rejection has been previously observed in heart transplantation21. The role of platelets in acute rejection has been studied in kidney22, cardiac23 and skin allograft24. After the initiation of allograft rejection by T cells, platelets help recruit T cells and increase the plasma inflammatory mediators, which accelerates the T-cell-induced rejection24. Neutrophils also play an important role in the acute rejection of solid organ transplants25.
The development of surrogate biomarkers with the assistance of artificial intelligence technology to identify recipients at risk of developing ACR is a major diagnostic aid to the clinician26.
We hypothesized that the severity of endothelial dysfunction and impaired haematosis assessed very early after LTx might be associated with the occurrence of ACR.
CD31 is a promising biomarker of acute rejection. CD31 is a 130-kDa glycosylated transmembrane immunoglobulin-type inhibitory receptor that is constitutively and exclusively expressed on endothelial cells, leucocytes (including T- and B-lymphocytes, dendritic cells, neutrophil monocytes and macrophages)27, and platelets28,29. CD31 is involved in maintaining homeostasis at the blood/vessel interface30. CD31 is composed of an extracellular domain comprising 6 Ig-like domains numbered from 6 to 1 from the membrane part to the most distal extracellular part, a trans-membrane segment and a cytoplasmic tail containing 2 immuno tyrosine-based inhibitory motifs (ITIMs)31. CD31 molecules on interacting cells bind to each other via a trans-homophilic interaction of extracellular domain 1 that triggers protein clustering via a cis-homophilic interaction of the extracellular juxta-membrane sequences; thus, they promote the phosphorylation of the intracellular ITIMs of CD31 by tyrosine kinases. The phosphorylation of ITIMs triggers the recruitment and activation of SH2-containing phosphatase signalling pathways, which leads to an inhibitory effect on tyrosine kinase-dependent cellular functions and an activating effect on SH2 phosphatase-dependent functions. CD31 is involved in inhibiting the reactive oxygen species formation32 and inflammatory signalling by ICAM-133 and IL-1β34. In addition, CD31-mediated signalling is required for cell survival35, prostacyclin release36, regulation of arteriolar tone37, barrier integrity38 and angiogenesis39. Upon cell activation, regardless of the stimulus, the extracellular portion of CD31 is enzymatically cleaved and released from the cell surface. The shed CD31 can be detected in the plasma in a soluble form (sCD31)40,41,42,43,44,45. Truncated CD31, which remains anchored on the cell membrane, loses its primary function as a "peacemaker" and contributes to enhance the cell activation. We hypothesized that the sCD31 released from activated endothelial cells, platelets and leukocytes and detected in blood samples of lung transplant patients could be used as a predictive biomarker of ACR.
The ratio of arterial oxygen partial pressure to fractional inspired oxygen (PaO2/FiO2) is used to assess the haematosis of the lungs and classify the severity of acute respiratory distress syndrome46. Measurement of the PaO2/FiO2 ratio 24 h after LTx has been shown to correlate with mortality47.
In this study, we provide a systemic model that can connect the plasma levels of sCD31 to the PaO2/FiO2 ratio over time. The model unveils a behavioural pattern that can be used early on to stratify patients who suffer episodes of ACR using multivariate and multimodal models of time series48,49. Then, facing more limited traditional statistical models50,51, we evaluated the contribution of machine learning (see Fig. S0) in the prediction of the risk of ACR after LTx. With this goal in mind, we constructed a deep convolutional network52 that classified the time series models of each individual. Thus, we adjusted the parameters derived from every patient’s outcome modelled as a time series and improved their initial guesses. Our model successfully utilized the scarce available information. Additionally, we avoided the inadequate consequences of learning from datasets with large label imbalances due to the calibration of the trained convolutional network by weighting the patient outcomes53. Then, we encoded the pre-activation of the penultimate layer with a similar procedure to that used by the log-odds54 to build a risk predictor of ACR. Finally, this predictor was associated with a percentage of accuracy for all patients in the cohort.
Results
Demographic data and patient outcomes after lung transplantation
Forty patients were included in the study between December 2016 and February 2021. The lung transplant recipients were aged 60 (52–64) years and mainly of the male sex (70%). They were transplanted for emphysema (33%), interstitial lung disease (50%) or other aetiologies (17.5%). They received single (45%) or double LTx (55%). After LTx, patients had a median (IQR) length of stay in the intensive care unit (ICU) of 19 (13–39) days and were mechanically ventilated for a median (IQR) time of 2.5 (1–6) days. The mortality rates in the ICU and at 1 year were 5% and 15%, respectively. Seven (17.5%) patients had at least one episode of ACR within 1 year after LTx, with a median (IQR) time to onset of 18 (13–221) days. Five ACR were classified as A1 and two as A2. The median (IQR) postoperative plasma sCD31 levels were 4240 (2753–6114) pg/ml at H24, 4251 (2860–6197) pg/ml at H48 and 4285 (2950–6414) pg/ml at H72. Patients with and without ACR had median (IQR) plasma sCD31 levels of 4280 (3137–4646) and 4160 (2738–6428) pg/ml at H24, 3757 (2570–4173) and 4618 (3184–7105) pg/ml at H48, and 3259 (2753–6154) and 4773 (3099–6871) pg/ml at H72, respectively. The mean sCD31 levels of patients with ACR grades A1 and A2 were 3973 and 12,688 pg/ml at H24, 2826 and 5799 pg/ml at H48 and 3597 and 2596 pg/ml at H72, respectively.
Establishing the systematic view of sCD31 as a biomarker of reference during patient post-operational tracking
To better understand the potential of sCD31 in predicting ACR after LTx, all empirical data observed by clinicians during the post-operation period had to be formalized. Since rehabilitation tracking is a dynamic process over time, the measured plasma levels of sCD31 were treated as a time series. We approached a varied set of classical machine learning methods to complete this task. Initially, univariate time series modelling of sCD31 based on linear regression with overlaying paddings enabled us to predict the patient outcomes55,56. Using totally random tree models57 and unsupervised hierarchical machine learning, we obtained the best percentage of success in patient stratification, reaching 78% (see supplemental material and Fig. S1). This result confirms that sCD31 is a critical checkpoint for ACR complications. However, this approach missed many more false negatives than expected, potentially due to the total recall achieved by the univariate model, which was 0.70–0.83. This recall range was not sufficiently high for a cohort displaying these characteristics (see “Methods”). Thus, the univariate model did not properly reflect the physiological power of sCD31. Moreover, the spectral plots of the stationary series could not be used to discriminate between non-ACR and ACR patients.
The inclusion of the PaO2/FiO2 ratio largely ameliorates the prior univariate model reinforcing sCD31 as a unique physiological spot
The measured PaO2/FiO2 exchange ratio is an important parameter when quantifying the effects of therapeutic interventions or when specifying diagnostic criteria for acute lung injury and acute respiratory distress syndrome58.
Overall, the integration of the above in our model improved the multivariate analysis of our time series model59. Indeed, such analysis outperformed the univariate modelling of sCD31 in the previous section. The spectral analysis on both biomarkers as time series revealed a hidden bidirectional relationship between series60. In particular, the quantitative behaviour of sCD31 plasma levels over time was influenced by PaO2/FiO2 (see Fig. 1). Furthermore, sCD31 as a time series could be fully explained in terms of PaO2/FiO2 as an absolute value ratio and respiratory SOFA (Sequential Organ Failure Assessment) using a multivariable function, which followed a vector autoregression model (VAR)59,61. Then, the predictors were only the lags of sCD31 and PaO2/FiO2 series (see “Methods”).

Remarkably higher sCD31 concentration in patients who experienced ACR after LT. A relative concentration of sCD31 to ACR might be observed in (a). Whether or not the patients experienced any complication was highlighted in green or blue in the curves. The expected value predicted by our VAR model is shown in grey. A 2D projection of (a) is shown in panel (b). The grade of separation in sCD31 concentration between patients with or without complications after LT was calculated using 2d-DTW (see “Methods”) in upper panel (c). The distance function has linear space complexity but quadratic time complexity. Panel c displays the matrix with all possible warping paths (i.e., accumulated cost matrix) that resulted in a perfect match between indices of ACR time series.
At first glance, the series has a similar trend profile over time tags (i.e., 24, 48, and 72 h post-transplantation), except for PaO2/FiO2, where a slightly different profile of anti-correlation is evidenced in its amplitude (see Figs. S2a-b). The Granger’s causality test62 to check for PaO2/FiO2 causing sCD31 yielded a p value of 0.0054. However, the p value of sCD31 causing PaO2/FiO2 was 0.4005 (see Table S1 for p values associated with all possible combinations of series). In both cases, the p values were far from the standard threshold of 0.05. Consequently, the null hypothesis (see “Methods”) that stated that the coefficients were equal to zero in the autoregression process could be rejected.
Now, if a set of time series can be co-integrated63, they have a long-term, statistically significant relationship. Regarding our biomarker series, respiratory SOFA could not be co-integrated into the other two series before starting to build the VAR model. The associated statistic of respiratory SOFA lay below the bound limit identified by the cointegration test as valid (see “Methods”); this value corresponded to 4.1296 with a confidence interval of 95%.
Next, we want our selected statistical features not to vary over time, since it is a necessary condition to build the VAR model. In brief, we fitted the VAR model on a training dataset derived from the sCD31 data, and we used the trained model to forecast the next k observations (training, test = data[0:-k], data[-k:]). The augmented Dickey–Fuller63 with only differencing (see Table S2) made the trick pass the respiratory SOFA p value from 0.408 to 0.0001. Finally, actual and expected forecasts will be crossed during the testing task against those in the test set. The statistical goodness of fit of the model is approached using multiple forecast accuracy metrics such as root-mean-square error (RMSE) and mean absolute percentage error (M(A)PE).
To select the right lag order of the VAR model (see Supplemental material), we iteratively fitted increasing orders of the model. Then, we picked the order associated with the VAR model with the least Hannan-Quinn information criterion (HQIC) (see Table S3 for other tested scores). The lowest HQIC resulted at lag 3, so we trained our VAR model using that order. No serial correlation was observed in the model since the Durbin-Watson statistic (DW) remained close to 2 across the series (for further details, see supplemental material and Table S5)64. Finally, we could generate the forecast of the testing data for sCD31, PaO2/FiO2, and respiratory SOFA series, whose computing scaled the magnitude to the training data used by the model. Therefore, to bring it back up to its initial scale, we de-differenced once as noted above. The accuracy of the resulting VAR model is provided in Table S6 and Fig. S2c.
To the best of our knowledge, this is the first time that a functional influence of this type has been established in the post-operative follow-up of a pulmonary transplant. We did not claim the PaO2/FiO2 ratio to be an important physiological player in predicting the risk of ACR, but it is relevant for the stability of our VAR model of sCD31.
The modelling of sCD31 as a multivariate time series provides strong evidence of its post-transplantation predictive power
After the autoregression process, we set a decreasing order for the values of the series derived from the VAR model, which synchronised the time series profiles forecasted from the model. Surprisingly, when we plotted the model predictions for the testing data, they slammed down as expected, and they preserved a unique pattern in accordance with rejected or accepted recipients across patients of the cohort. Thus, the sCD31 vs. PaO2/FiO2 profile modelling plasma levels and haematosis over time displayed by patients in whom the surgery failed sharply dropped in those patients who were categorized as definitely accepting the transplantation (Fig. 1a,b). It was reasonable to consider it a potential good criterion to apply to differentially stratify recipients early on. Consequently, this result confirms the powerful discriminant role that our VAR model assigns sCD31 during post-operational patient tracking.
Using dynamic time warping (DTW)65, we quantified (see “Methods”) the decrease in sCD31 plasma levels exhibited in the series forecasted from our model. We measured the distance between two dependent 2-dimensional sequences with \(\left({\mathbb{R}}^{T\times P}\right.{)}^{3k}\) time steps (see “Methods”). The first dimension of the data was assumed to be the time series index. With this calculation, we qualitatively compared the temporal series per class and the complication. Thus, the normalized distance between non-ACR and ACR patients was 1.0779 (see Fig. 1c). This result indicates that an accurate qualitative distinction has been achieved between classes of patients with ACR complications (see Fig. S3).
A deep neural network classifier of the sCD31 time series accurately predicts the outcomes of patients
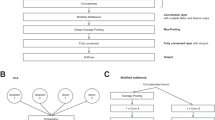
During training, we adjusted the parameters of our model to improve the guess about the input of the VAR models. Our strategy does not rely on a priori calculated derivation, but it benefits from the model processing of multivariate time series. Thus, the proposed model learns based on the underlying nonlinear behaviour of sCD31 plasma levels as a time series to be classified from multivariate and multimodal models. Then, we constructed a machine learning architecture (see Fig. 2), which preserved this premise. The time series fed into the learning model were additionally standardized to ensure the existence of an adequate probability space where to generate of our ACR risk predictor. This predictor largely ameliorated the impact of the spectral patient stratification in the previous section. In particular, with a smart design of convolutional neural network (CNN) feature extractors66, which consisted of parallel processing of different series modalities using a linearly activated dense input layer and two convolutional 1D (conv1d) layers, all three passed by batch normalization layers that were nonlinearly activated with 64 (64) + 1568 (128) + 194 (8) trainable parameters each, the resulting tensor passed through a dropout layer that randomly removed 25% of outgoing neurons to reduce overfitting, and the global average pooling1d layer was averaged among all time steps of the pool sizes. A final dense layer with a sigmoid activation function with 3 trainable parameters formed the actual time series classifier (see “Methods”). Ultimately, we implemented a personalized risk predictor of everyone experiencing an ACR in the cohort based on the cumulative probability distribution associated with the pre-activation values of the penultimate layer.

Architecture of our temporal network. Detailed design of our learning model for the feature extractor to CD31 channels when the time series takes a length of \(3P\). We used a similar schema for PaO2/FiO2 channels. If an amalgamation of both sCD31 and PaO2/FiO2 and respiratory SOFA is considered, the outputs of the dropout layers are concatenated and fed into the final classifier. Thus, the last dense layer of our temporal network is composed of a set of cardinal parameters equal to \(3\times ((\)T + T′)\(\times (3P//32)\times 2)\).
Starting from a baseline model (see Fig. S5), we applied an initial bias correction to partially improve the training performance of the model with the raw series. The baseline model reported a fair classification of ACR patients but with a difficult interpretation of the precision and recall values returned during the training task. The baseline model resulted in a loss of 0.46–0.66, an average accuracy of 75% and f1-scores, recall and precision of 0.33. This was possibly due to an imbalance in the class dataset. Thus, the model was recalibrated using class weights. Here, with the class weights, the average accuracy and precision were 0.87 and 0.93 per class, respectively, with a high ratio of false positives. Simultaneously, the recall (1 and 0.33) and area under the curve (AUC = 0.85) reached their best values because the model found more true positives than the baseline model. The weighted model achieved its maximal accuracy and recall and identified more false negatives (see Fig. 3). We additionally tested f1 and Cohen’s kappa scores67, which are especially useful (as opposed to accuracy metrics) in the presence of imbalanced classes (see “Methods”). The f1-score that combines precision and recall was 0.92 and 0.5 (recovery and ACR classes), respectively, whereas the associated Cohen’s kappa was in the range from good to excellent with a value of 0.44 (see “Methods”). The confusion matrix shows that on average, only two patients of the test data were missed. Finally, the learning surface corresponding to the weighted model was composed of 1929 trainable parameters (see Fig. 3a–c and Fig. S6 for further details on the regularisation of this variational manifold).

Results from the initial bias corrected and weighted temporal network. (a–c) Trainable parameter landscapes of the deep temporal network. The plots show the learning progression of our model across epochs and batches. (a) Contour with optimal projected trajectories in blue in the [− 1, 1] range. Those trajectories go from “mountain” values near 1 to a “valley” near − 0.73. From the green levels’ density and blue maps, we can confirm 1 and − 0.73 as the global coordinates to be travelled by the network to arrive in good convergence. (b) Grid projection exhibiting a global maximum collapsing in 1 and a stretcher option for “valleys”. (c) Surface composed of the required weights to achieve the optimal sought by the Adam algorithm, which is scaled by their z scores. (d) Training history of the corrected bias initialization and weighted model. We visualize accuracy across the chosen number of epochs and batches. A global quick look appears to show a standard training scenario with minor issues concerning the validation results in precision and recall panels at the beginning of the training task. (e) Goodness of fit of our weighted deep network during the training task. We calculated its confusion matrix where we could observe only two misclassified patients. However, we accurately detected false negatives compared to the baseline model. (f) Final heatmap associated with the metrics in the learning process of our weighted model. The balance among accuracy, recall and precision values is optimal to prevent missing false negatives. (g) Assessment of our model during the testing validation of our weighted model. We plotted it in terms of the average metrics (left) and scores of learning performance (right) on Cohen Kappa, Kullback Leibler divergence (KL Divergence) or Mean Squared Error. The formers are especially useful because we had imbalanced data. The KL divergence describes the inefficiency caused by the approximation of the true target distribution with the expected target distribution. KLDivergence does not have an upper bound; thus, a score of approximately 2.0 can be interpreted as a moderate or fair measure of how our model estimates the true target distribution.
The predictions resulting from the learning model generate a personalized risk predictor of ACR
Upon fixing the required probabilistic space by initially standardizing the series, the last dense layer of the time distributed network conformed to a valid classifier of the time series of patients. Let \(y\) be the output of that last layer resulting from applying a sigmoid function to the pre-activation vector. Then, we calculated the cumulative distribution function that provided the individual risk percentages of ACR. It is important to note that the z values or log-odds derived from the inverse of the sigmoid were used here, which stated that z could be defined as the log of the probability of the ACR patients divided by the probability of the non-ACR patients as follows:
where the distribution or probability density function (pdf) of each activation \({Y{^{\prime}}}_{i}\) of the penultimate layer is a multidimensional version of the rectified Gaussian distribution. This is a hybrid (discrete–continuous) distribution with a point mass at the origin, a multivariate Gaussian in the all-positive part of the space and 0 everywhere else. Then, the z-values transform into probability due to the following conversion:
Hence, we could associate a risk of ACR from the classification of each patient series based on their sCD31 plasma levels post-transplantation by:
Discussion
In this work, we introduce a multivariate and time-distributed learning model based on the early evaluation of sCD31 cleavage in triggering ACR after LTx. The model takes advantage of other important clinical features such as PaO2/FiO2 or respiratory SOFA to extract the best guess of sCD31 from it. The outcome of each patient is compared to their expected predictions; then, we adjust the model’s parameters by training tasks to improve the guess. To the best of our knowledge, this is a one-of-a-kind model in the literature. Beyond the limitations of any model, our predictor bridges the gap between health care management and a field where clinicians’ standards of diagnosis are still far from being computerized.
sCD31 is a prime candidate as a biomarker to predict ACR. Indeed, sCD31 results from the cleavage and shedding of CD31 into plasma following endothelial, leukocyte and/or platelet activation, which are key features in ACR. Therefore, sCD31 is used as a reflection of altered CD31.
Several studies have shown that CD31 plays a protective role in acute rejection, since the native function of this receptor is to counteract excessive activation of the endothelium, leukocytes and platelets.
Using an in vitro model of porcine cells, human CD31 suppressed neutrophil-mediated xenogenic cytotoxicity by inhibiting NETosis68. Cheung et al. showed that CD31 conferred an immune privilege to the vascular endothelium, which prevented the apoptotic death of endothelial cells induced by cytotoxic T lymphocytes and TNF-α69. In the same study, the authors compared the rejection of male-derived wild-type and CD31-deficient skin grafts by syngeneic female recipient mice. Female mice that received CD31-deficient male-derived skin grafts had significantly reduced survival compared with those that were grafted with wild-type skin. Moreover, they showed that the transduction of the CD31 gene to CD31-deficient pancreatic β cells enabled them to recover the cytoprotective mechanisms against extrinsic apoptosis. Transplantation of CD31-transduced pancreatic β-cells into allogeneic diabetic recipient mice controlled their blood glucose levels, whereas diabetes persisted in the mice that were transplanted with CD31-deficient pancreatic β-cells. Similarly, Ma et al. showed that CD31 played a nonredundant role in the regulation of T-cell immunity and tolerance. In a skin grafting model where wild-type or CD31−/− deficient female mice received wild-type male skin, HY mismatch resulted in the T-cell-mediated rejection of male skin grafts. Skin graft rejection by CD31−/− females was significantly accelerated and more pronounced than that of wild-type females70. CD31 plays a complex role in the regulation of T-cell-mediated immune responses71. One of the most studied roles of CD31 is its ability to inhibit the protein tyrosine kinase-dependent signal transduction mediated by the immunoreceptor tyrosine-based activation motif-containing T-cell receptor72. Alloreactive memory T cells are an essential component of the allograft rejection process and a major obstacle to tolerance induction in clinical transplantation73. Interestingly, CD31 selectively attenuates the chemokinesis of memory and activated T cells, which helps homeostatically regulate the effector T-cell immunity74.
In addition, sCD31 can be used as a target for in vivo molecular imaging of ACR, since our group has shown that targeting cleaved CD31 is an attractive strategy for specific in vivo imaging of inflammatory processes75.
Herein, we designed a smart architecture of a deep neural network to create a personalized risk predictor of ACR based on the sCD31 plasma level classification from multimodal and multivariate time series. The proposed model pools information from three different categories of biomarkers due to a linear spatial filtering operation76 and builds a hierarchical feature representation of the post-operational records of a lung transplant based on temporal convolutions. It pulls complementary information over different categories processed with separate pipelines, and it optimizes at maximum all available information related to a small cohort.
Our model in this work displays robust classification performances compared to the state-of-the-art, which is lacking in lung transplant track models. There are no artificial intelligence-derived models, but few results have mainly focused on less adaptable statistical models. Conveniently, our model takes a short run time and a low computational cost. Thus, the approach is a potential good candidate for use in a local device and to perform online ACR patient prediction for clinician analysis. Our approach enables the quantification of the use of multiple sCD31 plasma levels and additional categories, such as PaO2/FiO2 and respiratory SOFA. Interestingly, our model missed very few false negatives during the analysis and maximized its accuracy. In the end, this was the best indicator of our model goodness. Furthermore, using class weights boosted the model performances. We alternatively applied LSTM77 with class oversampling to classify the ACR patients. For a model with 512 layers and 0.25 dropout, we obtained quantitatively similar results as CNN but with less interpretable evidence of model accuracy, conceivably due to a null recall range achieved by the model during the training task.
The most important concern related to this study may be the limited number of patients analysed. Additionally, but to a lesser extent, the reliability of making medium-term predictions based on short-term data may be further discussed. However, to the best of our knowledge, there is no systematic learning model of surrogate biomarkers to identify recipients at risk of developing ACR. In this context, the proposed approach is a novel model that charts the outcomes of traumatic solutions related to the treatment of severe pulmonary diseases. Therefore, our model based on the time-distributed analysis of a pool of precious samples should be considered a valuable tool for anyone in the domain. Complementarily, we envisage extending our work by predicting the time to the next episode of ACR.
Another limitation is that sCD31 and haematosis parameters (PaO2/FiO2 ratio and respiratory SOFA) are dysregulated in many forms of physiological stress to the lungs, such as pneumonia and primary graft dysfunction. The predictive value is lower for primary graft dysfunction (PGD) because the measurements of sCD31, PaO2/FiO2 ratio and respiratory SOFA are performed within 72 h after LTx, which is also the time of onset of PGD in its definition. However, the specificity of the model that we use to predict the occurrence of ACR versus the occurrence of other respiratory complications should be assessed in a future study.
We minimized the effect of a “low number of samples (n = 40)” by leveraging a linear spatial filtering layer earlier on the deep network. The introduction of on-bottom frozen layers of samples resulting from linear combinations, such as that occurring in transfer learning, helped robustly train our full-scale model from scratch. The latter might be dissipated by considering a multimodal and multivariate temporal network at the base of our learning model. That structure enabled the accurate forecasting of our predictions in the medium term. Another interesting approach may be to spot the best stride between actual and forecasted time series and predict only there to prevent the model from predicting the entire series.
In conclusion, our analysis demonstrates the benefit of using the temporal context with training tasks in ACR prediction using sCD31, which is a unique biomarker that can reflect endothelial, leukocyte, and platelet activation. Furthermore, its quantification appears to significantly increase the performance when the number of biomarkers is limited. In large cohorts with a larger number of associated biomarkers, the use of temporal context as proposed here for online prediction may require adjustments. However, the flexibility of our model enables clinicians or anyone in the field to easily use it for prediction on local servers.
Methods
Design
This is an interventional, prospective, and single-centre study conducted from December 2016 to December 2018. The study was approved by an Institutional Review Board (French national ethics committee for the protection of persons undergoing research, “Comité de Protection des Personnes Sud-Est III”, number 2017-054 B), which confirmed that the study met the validation conditions set out in Article L. 1123.7 of the Public Health Code. All participants provided written informed consent. All methods were performed in accordance with relevant guidelines and regulations.
Determination of the plasma sCD31 concentration and PaO2/FiO2 ratio
For each patient, blood samples were collected at 24, 48 and 72 h after LTx, centrifuged twice at 2500g for 15 min and frozen at − 80 °C. Endothelial shed CD31 was assessed by incubating 50 µl of plasma sample with functional cytometric beads coupled to WM59 monoclonal purified antibodies directed against human CD31 domain 1 (Thermo Fischer Scientific). Positive binding of sCD31 was detected by the anti-CD31 monoclonal antibody MBC78.2 directed against human CD31 domain 6 (Thermo Fischer Scientific). The standard curves were obtained with each detecting monoclonal antibody that was simultaneously used with recombinant CD31 to overcome any bias due to differences in binding affinity of the diverse antibodies. Analyses were performed using the Bio-Plex® 200 system. The PaO2/FiO2 ratios were calculated from the arterial blood gas analysis, which was simultaneously taken with the sCD31 samples.
Diagnosis of acute cellular rejection
ACR was suspected to occur in the year following LTx when there was a combination of clinical and radiological evidence. Transbronchial lung biopsy was performed for anatomopathological analysis to confirm or deny the suspicion of ACR. ACR was graded as previously defined based on the perivascular and interstitial mononuclear infiltrates of the lung allograft10.
Adequate notation
We denote by X∈ \({\mathbb{R}}^{T\times P}\) a segment of exogenous time series with its label \(\mathcalligra{y}\in \mathcal{Y}\) that maps to the set {A, R\(\}\), where A denotes accepted and R denotes rejected. Here, X corresponds to a sample record, and \(\mathcal{Y}=\left\{\mathcalligra{y}\right.\in {\mathbb{R}}_{+}^{2} : \sum_{i=1}^{2}{\mathcalligra{y}}_{i}=\left.1\right\}\) corresponds to the probability convex simplex. Specifically, each label is encoded as a vector of \({\mathbb{R}}^{2}\) with one coefficient equal to 0 and a single coefficient equal to 1, which indicates the post-operational stage. Here, T is the number of time points P and refers to the number of samples. \({\mathcal{T}}_{t}^{k}=\left\{{X}_{t-k},\ldots ,{ X}_{t}, \cdots , {X}_{t+k}\right\}\) is a sequence of 3\(k\) variables per time point. \({\chi }_{k}=\left({\mathbb{R}}^{T\times P}\right.{)}^{3k}\) determines the space of the \(3k\) consecutive multivariate time series. Finally, \({\mathcal{B}}_{\mathcalligra{l}}\) is the binary cross entropy loss function. Given a true label \(\mathcalligra{y}\in \mathcal{Y}\) and a predicted label \(p\in \mathcal{Y}\), it is defined as \({\mathcal{B}}_{\mathcalligra{l}}=-\frac{1}{2}\sum_{i=1}^{2}{y}_{i}\mathrm{log}{p}_{i}\).
sCD31 and PaO2/FiO2as time series models
Similar to an electrocardiogram measuring the heartbeat pace of patients to diagnose heart disorders, our approach transforms the problem of tracking sCD31 activity in plasma into an analytic matter of time series. We pre-processed the raw dataset to be adequately interpreted by a multivariable model. This task consisted of determining whether sCD31 and PaO2/FiO2, which are considered variables, could influence each other depending on their past values. To prove this hypothesis, we reshaped the original \({\mathbb{R}}^{9\times 40}\) matrix as an \({({\mathbb{R}}}^{3\times 3}{)}^{40}\) one. This is the dimension of the transformed space of latent features ready to be predicted using multimodal models in the classification of time series datasets. Additionally, we set the respiratory SOFA (Sequential Organ Failure Assessment) time series, which is an invasive arterial monitoring tool to measure the arterial partial pressure of oxygen and subsequently calculate the PaO2/FiO2 ratio78. This discrete clinical indicator acts as a “categorical PaO2/FiO2 feature” with important implications in the assessment of the acute morbidity of critical illness78. Before the classification task, we used the dynamic time warping (DTW)79 to align the time series and calculate their distances between classes.
Machine learning problem
In this section, we translate the classification of patient time series into the formal language of mathematics. Thus, for every nonnegative integer \(k,\), we define the predictive model \(J:{\mathcal{X}}_{k}\to \mathcal{Y}.\) Each model is in a parametric set \(\mathcal{M}\). Model \(J\) applies an ordered sequence of \(3k\) consecutive intervals of patient time series to a probability vector \(p\in \mathcal{Y}\). For simplicity, we do not show the network parameterisation. Hence, the machine learning problem can be written as follows:
Equation (4) optimizes the parameters of the neural network \(J\) by minimizing the expected value of the binary cross entropy between the output of this network \(J(x)\) and the true label \(y\).
Multivariate network design
To stratify the evolution of patients after lung transplant, we designed a deep network that consisted of three main features: linear spatial filtering to estimate linear combinations of matrices from patient variables as transfer learning does80, convolutive layers to acquire spectral features and separate routes depending on the time variables sCD31 and PaO2/FiO2, and respiratory SOFA (see Fig. S4). This network traces the global feature extractor herein defined by \({F}_{t }: {\mathbb{R}}^{T\times P}\to {\mathbb{R}}^{D}\), where D is the dimension of the estimated feature space. Our network supports multiple combinations of input variables from patients and several categorical metrics simultaneously (see Fig. S4 for its on-top visualization). Multivariable models of sCD31 based on PaO2/FiO2 (respiratory SOFA) causality are learned using the vector of autoregression model (VAR). Later, these feature structures will be standardized and used as features of a multimodal deep convolutional network81.
Next, we explained in depth different parts of the network (for further details, see Fig. 2). We could find a primary layer that performed a time-independent linear operation to obtain a set of mixed time series, each of which resulted from a linear combination of the initial input variables. Then, it implemented a spatial filtering driven by the classification task to be executed. In particular, the usage of an appropriate 1D convolution with kernel of dimension (T,3) and a dense layer on top ensured the completion of a first layer driven in terms of spatial filters (see layer 3 in Fig. 2).
Upon the implementation of that first linear operation, we stacked two more convolution layers followed by nonlinearity and max pooling. The parameters were fixed for sCD31 plasma levels sampled at 24, 48, and 72 h. In this case, the number of time tags was \(T=3\times 40=120\). Each block first minimally convolved its input signal, maintained the size of each filter as 1 × 3 but steeply increased to 32 and decreased to 2 total learned filters with stride 1 (amounts to 24 h) before applying a rectified linear unit, i.e., the so-called ReLU nonlinearity of expression \(x \mapsto {\text{max}}\left( {x,0} \right)\)82. Then, the output size was reduced along the time axis using a global average pooling 1D layer (size of 3 without overlay). Finally, we entered the output of these two convolutional blocks in a batch normalization layer83, which randomly selected 25% of its outward neurons and put their updates in the background at each gradient step.
The sCD31 and PaO2/FiO2 time series were treated together, since their types were comparable in magnitude, and both measured similar signals, i.e., passive diffusion of soluble molecular biomarker plasma levels. This smart and recurrent idea has been used by practitioners who approach problems of other domains, such as sleeping stage classification. In that case, series with signals of similar order are kept in methodological decomposition to better reject particular series artefacts48. The respiratory SOFA time series, which have different statistical and spectral properties, are processed in a parallel pipeline.
Then, we created the feature space of dimension D by combining the resulting outputs. This asset-backed space was fed into the ending layer, which was endowed with 2 neurons and a sigmoid nonlinearity to obtain a probability vector that summed to 1. This final layer is called a sigmoid classifier84. If we consider \(a\in {\mathbb{R}}^{2}\) as the pre-activation of the last layer, the output of the network is a vector \(p\in \mathcal{Y}\). Hence, p was determined as follows: \({p}_{i}=\frac{1}{1+{e}^{-\sum_{j=1}^{2}{a}_{j}}}\).
We also weighted patient classes to prevent the classifier from being affected by the bias derived from the label’s imbalance. The class weights were injected during the training model to minimize the range of loss.
Time distributed multivariate network
In a VAR model, each variable is a linear function of its past values and the past values of all other variables. Thus, the predictors will be grounded on their lag values of the series. Thus, we leveraged VAR to quantify the bidirectional influence of sCD31, PaO2/FiO2 ratio and respiratory SOFA on each other. Early on, the Granger causality test of all possible time series combinations provided us with the p values that had to reject the null hypothesis that the coefficients of past values in the regression equation were zero. In simpler terms, the past values of PaO2/FiO2 time series do not cause the sCD31 series. Moreover, we co-integrated those time series whose linear combination ranked below their single components when the series became stationary (i.e., the mean and variance did not change over time). To this end, we performed the augmented Dickey–Fuller test on sCD31 and PaO2/FiO2 series. However, only a difference per patient was required to make the series stationaries85. Then, the VAR model was constructed by selecting its right lag order as a function of the Hannan-Quinn information criterion (HQIC) score86. For a given time series, the matrix form of the algorithm can be written as follows:
where \({a}_{i}\) are the constant terms, \({W}_{j}\) are the coefficients, and vector \(e\) amounts to multivariate white noise87 with expected value 0 for a single series and the standard deviation of the series otherwise.
After the model had been implemented, we applied Durbin-Watson test on the residuals to evaluate the error correlations. Therefore, checking for serial correlation ensures that the model can sufficiently explain the variances and patterns in the time series. A closer value to 2 indicates that there is no significant serial correlation.
Finally, a set of a few metrics was used to check the accuracy of our model, such as the RMSE, correlation or the MAPE. The entire analysis was implemented in Python using Statsmodels88.
Training the model
We minimize the expression in (4) using an in-house procedure based on the stochastic gradient descent setting mini batches of data. How to discriminate underrepresented classes (i.e., the ACR), and since we are interested in optimizing the balanced accuracy, we propose balancing the distribution of each class in minibatches of size 32. Because we have 2 classes, during training, each batch has approximately 5% of the samples of each class. The Adam optimizer89 was used for optimization with its default parameters, i.e., \(lr=1{e}^{-4}\) (learning rate), \({\beta }_{1}=\) 0.9, \({\beta }_{2}=0.999\) and \(\varepsilon =1{e}^{-7}\). An early stopping call-back on the validation loss with patience of 10 epochs was used to stop the training process when no improvements were detected. The tracking of the loss function during training initialized weights using a normal distribution with mean \(\mu\)=0 and standard deviation \(\sigma =0.1\). Simulated linear combinations of the 40 patient matrices were also included at this stage to reinforce model optimization and cross-validated test performances (e.g., transfer learning). Since our dataset was imbalanced, we used the k-fold stratified cross-validation90. During cross-validation, we maintained the same class distribution in each subset. This is known as stratified sampling, where the actual classes or targets must control the sampling procedure. For example, the application from the background of a default fivefold cross-validation task (i.e., ~ 30% of training as validation data) to our model will reinforce the class distribution of each individual data batch. Thus, we ensure correspondence with the entire distribution of the training task.
Since the initial guesses were not expected to be good due to the imbalanced dataset, we set the output layer's bias91, which improved the initial convergence. Specifically, the bias was updated according to the expression \({log}_{e}\left(\frac{pos}{neg}\right).\) where \(pos\left(neg\right)\) is the number of positive classes (resp. neg). Upon resetting the initial bias, the model returned much more reasonable initial guesses in terms of validation loss. Indeed, the fact that unlikely positive classes were not considered during the first epochs sped up its learning pace. Thus, the interpretation of the loss curves was made easier during the training history check. To ensure that we fairly compared different training runs, we applied the initial model’s weights to each model prior to the training. Next, we evaluated the loss, accuracy, precision, recall and area under the curve (AUC) metrics as measures of our model goodness. One might want to summarize the actual vs. predicted classes using the confusion matrix. We also measured the scores derived from a combination of previous metrics, such as the f1-score or Cohen’s kappa, which are especially useful in performances with label imbalance (unlike accuracy metrics). Finally, we plotted the receiver operating characteristic (ROC) curves of the test samples.
There is no ideal method to maximize both precision and recall, particularly because the classifiers handle imbalanced datasets. At this stage of the analysis, the goal is to spot false negatives (an ACR patient is missed). However, due to the limited number of ACR patients, we wanted the classifier to heavily weight the few available samples. Therefore, we passed the weights of each class through a specific parameter that was applied during the training task. Thus, we made the model focus on those samples with an underrepresented class. We retrained and evaluated the model with the class weights. Alternatively, we resampled the dataset by oversampling the minority class and reran the models. Finally, we indicate that our implementation was deployed in Keras92 with a TensorFlow backend93.
Building the risk predictor of ACR
The individual risk predictor of ACR94 is founded on the training of the time distributed network, which is divided into phases I and II. The former consists of the global training of the multivariate network, notably its feature extractor part \({F}_{t}\). Then, we set the weights of the feature extractor distributed in time according to the trained model. In the second phase, those weights remain in a latent state while we train the final sigmoid classifier with aggregated features. Finally, from the evaluation of the training model using test samples, we extract the output of the penultimate layer to construct the probability distribution per patient.
References
Chambers, D. C. et al. The registry of the international society for heart and lung transplantation: Thirty-fourth adult lung and heart-lung transplantation report—2017; focus theme: Allograft ischemic time. J. Heart Lung Transpl. 36, 1047–1059 (2017).
Snell, G. I. et al. Report of the ISHLT Working Group on Primary Lung Graft Dysfunction, part I: Definition and grading-A 2016 Consensus Group statement of the International Society for Heart and Lung Transplantation. J. Heart Lung Transpl. 36, 1097–1103 (2017).
Nosotti, M., Tarsia, P. & Morlacchi, L. C. Infections after lung transplantation. J. Thorac. Dis. 10, 3849–3868 (2018).
Crespo, M. M. et al. ISHLT Consensus Statement on adult and pediatric airway complications after lung transplantation: Definitions, grading system, and therapeutics. J. Heart Lung Transpl. 37, 548–563 (2018).
Parulekar, A. D. & Kao, C. C. Detection, classification, and management of rejection after lung transplantation. J. Thorac. Dis. 11, S1732–S1739 (2019).
Chambers, D. C. et al. The Registry of the International Society for Heart and Lung Transplantation: Thirty-fourth adult lung and heart-lung transplantation report-2017; focus theme: Allograft ischemic time. J. Heart Lung Transpl. 36, 1047–1059 (2017).
Todd, J. L. et al. Risk factors for acute rejection in the first year after lung transplant. A multicenter study. Am. J. Respir. Crit. Care Med. 202, 576–585 (2020).
Haque, M. A. et al. Evidence for immune responses to a self-antigen in lung transplantation: Role of type V collagen-specific T cells in the pathogenesis of lung allograft rejection. J. Immunol. Baltim. Md 1950(169), 1542–1549 (2002).
Martinu, T., Howell, D. N. & Palmer, S. M. Acute cellular rejection and humoral sensitization in lung transplant recipients. Semin. Respir. Crit. Care Med. 31, 179–188 (2010).
Stewart, S. et al. Revision of the 1996 working formulation for the standardization of nomenclature in the diagnosis of lung rejection. J. Heart Lung Transpl. 26, 1229–1242 (2007).
Husain, A. N. et al. Analysis of risk factors for the development of bronchiolitis obliterans syndrome. Am. J. Respir. Crit. Care Med. 159, 829–833 (1999).
Gotway, M. B. et al. Acute rejection following lung transplantation: Limitations in accuracy of thin-section CT for diagnosis. Radiology 221, 207–212 (2001).
Gordon, I. O., Bhorade, S., Vigneswaran, W. T., Garrity, E. R. & Husain, A. N. SaLUTaRy: Survey of lung transplant rejection. J. Heart Lung Transpl. 31, 972–979 (2012).
De Vito Dabbs, A. et al. Are symptom reports useful for differentiating between acute rejection and pulmonary infection after lung transplantation?. Heart Lung J. Crit. Care 33, 372–380 (2004).
Trulock, E. P. et al. The role of transbronchial lung biopsy in the treatment of lung transplant recipients. An analysis of 200 consecutive procedures. Chest 102, 1049–1054 (1992).
Sibley, R. K. et al. The role of transbronchial biopsies in the management of lung transplant recipients. J. Heart Lung Transpl. 12, 308–324 (1993).
Guilinger, R. A. et al. The importance of bronchoscopy with transbronchial biopsy and bronchoalveolar lavage in the management of lung transplant recipients. Am. J. Respir. Crit. Care Med. 152, 2037–2043 (1995).
Arcasoy, S. M. et al. Pathologic interpretation of transbronchial biopsy for acute rejection of lung allograft is highly variable. Am. J. Transpl. 11, 320–328 (2011).
Al-Lamki, R. S., Bradley, J. R. & Pober, J. S. Endothelial cells in allograft rejection. Transplantation 86, 1340–1348 (2008).
Kummer, L. et al. Vascular signaling in allogenic solid organ transplantation—the role of endothelial cells. Front. Physiol. 11, 443 (2020).
Briscoe, D. M. et al. Predictive value of inducible endothelial cell adhesion molecule expression for acute rejection of human cardiac allografts. Transplantation 59, 204–211 (1995).
Fenech, A., Nicholls, A. & Smith, F. W. Indium (111In)-labelled platelets in the diagnosis of renal transplant rejection: Preliminary findings. Br. J. Radiol. 54, 325–327 (1981).
Oluwole, S. et al. Use of indium-111-labeled cells in measurement of cellular dynamics of experimental cardiac allograft rejection. Transplantation 31, 51–55 (1981).
Swaim, A. F., Field, D. J., Fox-Talbot, K., Baldwin, W. M. & Morrell, C. N. Platelets contribute to allograft rejection through glutamate receptor signaling. J. Immunol. Baltim. Md 1950(185), 6999–7006 (2010).
Scozzi, D. et al. The Role of Neutrophils in Transplanted Organs. Am. J. Transpl. 17, 328–335 (2017).
Shigemura, N. Transforming diagnostics in lung transplantation: From bronchoscopy to an artificial intelligence-driven approach. Am. J. Respir. Crit. Care Med. 202, 486–488 (2020).
Woodfin, A., Voisin, M.-B. & Nourshargh, S. PECAM-1: A multi-functional molecule in inflammation and vascular biology. Arterioscler. Thromb. Vasc. Biol. 27, 2514–2523 (2007).
van Mourik, J. A., Leeksma, O. C., Reinders, J. H., de Groot, P. G. & Zandbergen-Spaargaren, J. Vascular endothelial cells synthesize a plasma membrane protein indistinguishable from the platelet membrane glycoprotein IIa. J. Biol. Chem. 260, 11300–11306 (1985).
Stockinger, H. et al. Molecular characterization and functional analysis of the leukocyte surface protein CD31. J. Immunol. Baltim. Md 1950(145), 3889–3897 (1990).
Newton, J. P., Buckley, C. D., Jones, E. Y. & Simmons, D. L. Residues on both faces of the first immunoglobulin fold contribute to homophilic binding sites of PECAM-1/CD31. J. Biol. Chem. 272, 20555–20563 (1997).
Newman, P. J. Switched at birth: A new family for PECAM-1. J. Clin. Invest. 103, 5–9 (1999).
Ji, G. et al. PECAM-1 (CD31) regulates a hydrogen peroxide-activated nonselective cation channel in endothelial cells. J. Cell Biol. 157, 173–184 (2002).
Couty, J.-P. et al. PECAM-1 engagement counteracts ICAM-1-induced signaling in brain vascular endothelial cells. J. Neurochem. 103, 793–801 (2007).
Cepinskas, G., Savickiene, J., Ionescu, C. V. & Kvietys, P. R. PMN transendothelial migration decreases nuclear NFkappaB in IL-1beta-activated endothelial cells: Role of PECAM-1. J. Cell Biol. 161, 641–651 (2003).
Gao, C. et al. PECAM-1 functions as a specific and potent inhibitor of mitochondrial-dependent apoptosis. Blood 102, 169–179 (2003).
Russell-Puleri, S. et al. Fluid shear stress induces upregulation of COX-2 and PGI2 release in endothelial cells via a pathway involving PECAM-1, PI3K, FAK, and p38. Am. J. Physiol. Heart Circ. Physiol. 312, H485–H500 (2017).
Bagi, Z. et al. PECAM-1 mediates NO-dependent dilation of arterioles to high temporal gradients of shear stress. Arterioscler. Thromb. Vasc. Biol. 25, 1590–1595 (2005).
Flynn, K. M., Michaud, M., Canosa, S. & Madri, J. A. CD44 regulates vascular endothelial barrier integrity via a PECAM-1 dependent mechanism. Angiogenesis 16, 689–705 (2013).
Park, S., DiMaio, T. A., Scheef, E. A., Sorenson, C. M. & Sheibani, N. PECAM-1 regulates proangiogenic properties of endothelial cells through modulation of cell-cell and cell-matrix interactions. Am. J. Physiol. Cell Physiol. 299, C1468-1484 (2010).
Fornasa, G. et al. TCR stimulation drives cleavage and shedding of the ITIM receptor CD31. J. Immunol. Baltim. Md 1950(184), 5485–5492 (2010).
Ilan, N., Mohsenin, A., Cheung, L. & Madri, J. A. PECAM-1 shedding during apoptosis generates a membrane-anchored truncated molecule with unique signaling characteristics. FASEB J. 15, 362–372 (2001).
Nguyen, V. A. et al. Adhesion of dendritic cells derived from CD34+ progenitors to resting human dermal microvascular endothelial cells is down-regulated upon maturation and partially depends on CD11a-CD18, CD11b-CD18 and CD36. Eur. J. Immunol. 32, 3638–3650 (2002).
Wang, S.-Z. et al. Shedding of L-selectin and PECAM-1 and upregulation of Mac-1 and ICAM-1 on neutrophils in RSV bronchiolitis. Am. J. Physiol. Lung Cell. Mol. Physiol. 275, L983–L989 (1998).
Eugenin, E. A. et al. Shedding of PECAM-1 during HIV infection: A potential role for soluble PECAM-1 in the pathogenesis of NeuroAIDS. J. Leukoc. Biol. 79, 444–452 (2006).
Naganuma, Y. et al. Cleavage of platelet endothelial cell adhesion molecule-1 (PECAM-1) in platelets exposed to high shear stress. J. Thromb. Haemost. JTH 2, 1998–2008 (2004).
Bernard, G. R. et al. The American-European Consensus Conference on ARDS. Definitions, mechanisms, relevant outcomes, and clinical trial coordination. Am. J. Respir. Crit. Care Med. 149, 818–824 (1994).
González-Castro, A. et al. Evaluation of the oxygenation ratio as long-term prognostic marker after lung transplantation. Transplant. Proc. 39, 2422–2424 (2007).
Chambon, S., Galtier, M. N., Arnal, P. J., Wainrib, G. & Gramfort, A. A deep learning architecture for temporal sleep stage classification using multivariate and multimodal time series. IEEE Trans. Neural Syst. Rehabil. Eng. 26, 758–769 (2018).
Courtiol, P. et al. Deep learning-based classification of mesothelioma improves prediction of patient outcome. Nat. Med. 25, 1519–1525 (2019).
Morilla, I. et al. Singular manifolds of proteomic drivers to model the evolution of inflammatory bowel disease status. Sci. Rep. 10, 19066 (2020).
Morilla, I. & Ranea, J. A. Mathematical deconvolution uncovers the genetic regulatory signal of cancer cellular heterogeneity on resistance to paclitaxel. Mol. Genet. Genomics MGG 292, 857–869 (2017).
Morilla, I. et al. Colonic MicroRNA profiles, identified by a deep learning algorithm, that predict responses to therapy of patients with acute severe ulcerative colitis. Clin. Gastroenterol. Hepatol. 17, 905–913 (2019).
Haibo He & Garcia, E. A. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 21, 1263–1284 (2009).
Cramer, J.S. The Origins and Development of the Logit Model (Cambridge University Press, 2003).
Percival, D. B. & Walden, A. T. Spectral Analysis for Univariate Time Series (Cambridge University Press, 2020). https://doi.org/10.1017/9781139235723.
Sperandei, S. Understanding logistic regression analysis. Biochem Medica https://doi.org/10.11613/BM.2014.003 (2014).
Morilla, I. et al. Computational Learning of microRNA-based prediction of pouchitis outcome after restorative proctocolectomy in patients with ulcerative colitis. Inflamm. Bowel Dis. https://doi.org/10.1093/ibd/izab030 (2021).
Karbing, D. S. et al. Variation in the PaO2/FiO2 ratio with FiO2: Mathematical and experimental description, and clinical relevance. Crit. Care Lond. Engl. 11, R118 (2007).
Lütkepohl, H. New Introduction to Multiple Time Series Analysis (Springer, Berlin, 2005).
von Sachs, R. Nonparametric Spectral Analysis of Multivariate Time Series (Annual Review of Statistics and Its Application, 2020).
Eason, E. G., Carver, N. S., Kelty-Stephen, D. G. & Fausto-Sterling, A. Using vector autoregression modeling to reveal bidirectional relationships in gender/sex-related interactions in mother-infant dyads. Front. Psychol. 11, 1507 (2020).
Chen, P. & Chih-Ying, H. Looking Behind Granger Causality (MPRA, 2010).
Dickey, D. A. & Fuller, W. A. Distribution of the estimators for autoregressive time series with a unit root. J. Am. Stat. Assoc. 74, 427–431 (1979).
Durbin, J. & Watson, G. S. Testing for serial correlation in least squares regression. I. Biometrika 37, 409–428 (1950).
Tormene, P., Giorgino, T., Quaglini, S. & Stefanelli, M. Matching incomplete time series with dynamic time warping: An algorithm and an application to post-stroke rehabilitation. Artif. Intell. Med. 45, 11–34 (2009).
Li, F. et al. Feature extraction and classification of heart sound using 1D convolutional neural networks. EURASIP J. Adv. Signal Process. 2019, 59 (2019).
Artstein, R & Poesio, M. Inter-Coder Agreement for Computational linguistics. (Computational Linguistics, 2008).
Wang, H.-T. et al. Human CD31 on porcine cells suppress xenogeneic neutrophil-mediated cytotoxicity via the inhibition of NETosis. Xenotransplantation 25, e12396 (2018).
Cheung, K. et al. CD31 signals confer immune privilege to the vascular endothelium. Proc. Natl. Acad. Sci. U. S. A. 112, E5815-5824 (2015).
Ma, L. et al. Ig gene-like molecule CD31 plays a nonredundant role in the regulation of T-cell immunity and tolerance. Proc. Natl. Acad. Sci. U. S. A. 107, 19461–19466 (2010).
Marelli-Berg, F. M., Clement, M., Mauro, C. & Caligiuri, G. An immunologist’s guide to CD31 function in T-cells. J. Cell Sci. 126, 2343–2352 (2013).
Newton-Nash, D. K. & Newman, P. J. A new role for platelet-endothelial cell adhesion molecule-1 (CD31): Inhibition of TCR-mediated signal transduction. J. Immunol. Baltim. Md. 1950(163), 682–688 (1999).
Benichou, G., Gonzalez, B., Marino, J., Ayasoufi, K. & Valujskikh, A. Role of memory T cells in allograft rejection and tolerance. Front. Immunol. 8, 170 (2017).
Kishore, M., Ma, L., Cornish, G., Nourshargh, S. & Marelli-Berg, F. M. Primed T cell responses to chemokines are regulated by the immunoglobulin-like molecule CD31. PLoS ONE 7, e39433 (2012).
Vigne, J. et al. Cleaved CD31 as a target for in vivo molecular imaging of inflammation. Sci. Rep. 9, 19560 (2019).
Griffith, D. & Getis, A. Spatial filtering. In Encyclopedia of GIS (eds. Shekhar, S., Xiong, H. & Zhou, X.) 2018–2031 (Springer, 2017). https://doi.org/10.1007/978-3-319-17885-1_1523.
Hochreiter, S & Schmidhuber, J. Long Short-Term Memory. (Neural computation, 1997).
Lambden, S., Laterre, P. F., Levy, M. M. & Francois, B. The SOFA score-development, utility and challenges of accurate assessment in clinical trials. Crit. Care Lond. Engl. 23, 374 (2019).
Giorgino, T. Computing and visualizing dynamic time warping alignments in R: The dtw Package. J. Stat. Softw. 31(7), 1–24 (2009).
Pan, S. J. & Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 22, 1345–1359 (2010).
Ismail Fawaz, H., Forestier, G., Weber, J., Idoumghar, L. & Muller, P.-A. Deep learning for time series classification: A review. Data Min. Knowl. Discov. 33, 917–963 (2019).
Nair, V & Hinton, G.E. Rectified linear units improve restricted Boltzmann machines. In ICML, 807–814 (2010).
Garbin, C., Zhu, X. & Marques, O. Dropout vs. batch normalization: An empirical study of their impact to deep learning. Multimed. Tools Appl. 79, 12777–12815 (2020).
Wang, Y., Li, Y., Song, Y. & Rong, X. The influence of the activation function in a convolution neural network model of facial expression recognition. Appl. Sci. 10, 1897 (2020).
Boshnakov, G. On first and second order stationarity of random coefficient models. Linear Algebra Appl 434, 415–423 (2011).
Hannan, E.J & Quinn, B.G. The Determination of the order of an autoregression. in Journal of the Royal Statistical Society (1979).
Baum, C.F. Applied Econometrics. http://fmwww.bc.edu/EC-C/S2013/823/EC823.S2013.nn10.slides.pdf. (2013).
Seabold S & Perktold J. Statsmodels: Econometric and Statistical Modeling with Python https://doi.org/10.25080/Majora-92bf1922-011 (2010).
Kingma, D.P & Ba, J. Adam: A Method for Stochastic Optimization. https://arxiv.org/abs/1412.6980v9 (2014).
Imbalanced Learning: Foundations, Algorithms, and Applications. (Wiley, 2013). https://doi.org/10.1002/9781118646106.
Karpathy A. A Recipe for Training Neural Networks. https://pdfcoffee.com/a-recipe-for-training-neural-networks-5-pdf-free.html (2019).
Chollet, F. Keras : https://github.com/keras-team/keras. https://github.com/keras-team/keras (2015).
Abadi, M et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. https://arxiv.org/abs/1603.04467 (2015).
Gupta, R. K. et al. Discovery and validation of a personalized risk predictor for incident tuberculosis in low transmission settings. Nat. Med. 26, 1941–1949 (2020).
Acknowledgements
This study was funded by “projet Emergence 4 du DHU FIRE”, l'Agence de la Biomédecine, la Société Francophone de Transplantation and the National Research Association (ANR) (Inflamex renewal 10-LABX-0017 to I.M.). The study funders had no role in the conceptualization, design, data collection, analysis, decision to publish or preparation of the manuscript. The authors would like to thank all research teams involved in the primary studies that contributed data for this analysis.
Author information
Authors and Affiliations
Contributions
I.M.; A.T.D., S.T, Y.C, P.M, H.M, P.M, J.M, G.C, A. conceived of the study and led the data collection. I.M., A.T.D., A.N. and G.C. wrote the study protocol and developed the analysis plan. I.M. conducted the analyses and wrote the first draft of the manuscript. I.M., A.T.D. and Q.L. performed the systematic literature review. I.M. provided statistical, systems biology and machine learning expertise. A.T.D., Q.L., G.E, A.N. and G.C. contributed primary data and assisted with interpretation. I.M. and A.T.D. contributed to the data interpretation. All authors critically reviewed and approved the manuscript before submission.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Tran-Dinh, A., Laurent, Q., Even, G. et al. Personalized risk predictor for acute cellular rejection in lung transplant using soluble CD31. Sci Rep 12, 17628 (2022). https://doi.org/10.1038/s41598-022-21070-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-21070-1
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
