
Abstract
We analyze a binary classification problem by using a support vector machine based on variational quantum-circuit model. We propose to solve a linear equation of the support vector machine by using a \(\Gamma \) matrix expansion. In addition, it is shown that an arbitrary quantum state is prepared by optimizing a universal quantum circuit representing an arbitrary \(U(2^N)\) based on the steepest descent method. It may be a quantum generalization of Field-Programmable-Gate Array (FPGA).
Similar content being viewed by others
Introduction
Quantum computation is a hottest topic in contemporary physics1,2,3. An efficient application of quantum computations is machine learning, which is called quantum machine learning4,5,6,7,8,9,10,11,12,13,14,15,16,17 . A support vector machine is one of the most fundamental algorithms for machine learning18,22,23, which classifies data into two classes by a hyperplane. A support vector machine (SVM) is a computer algorithm that learns by examples to assign labels to objects. It is a typical method to solve a binary-classification problem18. The optimal hyperplane is determined by an associated linear equation \(F|\psi _{ \text {in}}\rangle =|\psi _{\text {out}}\rangle \), where F and \(|\psi _{ \text {out}}\rangle \) are given. A quantum support vector machine solves this linear equation by a quantum computer10,13,24. Usually, the linear equation is solved by the Harrow-Hassidim-Lloyd (HHL) algorithm25. However, this algorithm requires many quantum gates. Thus, the HHL algorithm is hard to be executed by using a near-term quantum computer. Actually, this algorithm has experimentally been verified only for two and three qubits26,27,28. In addition, it requires a unitary operator to execute \(e^{iFt}\), which is quite hard to be implemented. The Kernel based SVM implementation based on the quantum is reported19,20,21.
The number of qubits in current quantum computers is restricted. Variational quantum algorithms are appropriate for these small-qubit quantum computers, which use both quantum computers and classical computers. Various methods have been proposed such as Quantum Approximate Optimization Algorithm (QAOA)29, variational eigenvalue solver30, quantum circuit learning31 and quantum linear solver32,33. We use wave functions with variational parameters in QAOA, which are optimized by minimizing the expectation value of the Hamiltonian. A quantum circuit has variational parameters in quantum circuit learning31, which are optimized by minimizing a certain cost function. A quantum linear solver solves a linear equation by variational ansatz32,33. The simplest method of the optimization is a steepest-descent method.
In this paper, we present a variational method for a quantum support vector machine by solving an associated linear equation based on variational quantum circuit learning. We propose a method to expand the matrix F by the \(\Gamma \) matrices, which gives simple quantum circuits. We also propose a variational method to construct an arbitrary state by using a universal quantum circuit to represent an arbitrary unitary matrix \(U(2^{N})\). We prepare various internal parameters for a universal quantum circuit, which we optimize by minimizing a certain cost function. Our circuit is capable to determine the unitary transformation U satisfying \(U|\psi _{\text {initial} }\rangle =|\psi _{\text {final}}\rangle \) with arbitrary given states \(|\psi _{ \text {initial}}\rangle \) and \(|\psi _{\text {final}}\rangle \). It will be a quantum generalization of field-programmable-gate array (FPGA), which may execute arbitrary outputs with arbitrary inputs.
Results
Support vector machine
A simplest example of the SVM reads as follows. Suppose that there are red and blue points whose distributions are almost separated into two dimensions. We classify these data points into two classes by a line, as illustrated in Fig. 1a.
In general, M data points are spattered in D dimensions, which we denote \({\varvec{x}}_{j}\), where \(1\le j\le M\). The problem is to determine a hyperplane,
separating data into two classes with the use of a support vector machine. We set
for red points and
for blue points. These conditions are implemented by introducing a function
which assigns \(f\left( {\varvec{x}}\right) =1\) to red points and \(f\left( {\varvec{x}}\right) =-1\) to blue points. In order to determine \(\omega _{0} \) and \(\varvec{\omega }\) for a given set of data \({\varvec{x}} _{j} \), we introduce real numbers \(\alpha _{j}\) by
A support vector machine enables us to determine \(\omega _{0}\) and \(\alpha _{j}\) by solving the linear equation
where \(y_{i}=f(x_{i})=\pm 1\), and F is a \((M+1)\times (M+1)\) matrix given by
Here,
is a Kernel matrix, and \(\gamma \) is a certain fixed constant which assures the existence of the solution of the linear equation (6) even when the red and blue points are slightly inseparable. Note that \(\gamma \rightarrow \infty \) corresponds to the hard margin condition. Details of the derivation of Eq. (6) are given in Method A.

(a) Binary classification of red and blue points based on a quantum support vector machine with soft margin. A magenta (cyan) line obtained by an exact solution (variational method). (b) Evolution of the cost function. The vertical axis is the log\(_{10}E_{\text {cost}}\). The horizontal axis is the variational step number. We have used \(r=2\), \(\xi _{1}=0.001\) and \(\xi _{2}=0.0005\) and \(\gamma =1\). We have runed simulations ten times, where each simulation is plotted in different color. (c) The saturated value of the cost function \(\log _{10}E_{\text {opt}}\) as a function of \(\xi _{2}\) ranging \(10^{-1}\le \xi _{2}\le 10^{-5}\) for various \(\xi _{1}\). The green dots indicates \(\xi _{1}=0.0001\), black dots indicates \(\xi _{1}=0.001\), magenta dots indicates \(\xi _{1}=0.01\) and cyan dots indicates \(\xi _{1}=0.1\).
Quantum linear solver based on \(\Gamma \) matrix expansion
We solve the linear equation (6) by a quantum computer. In general, we solve a linear equation
for an arbitrary given non-unitary matrix F and an arbitrary given state \( \left| \psi _{\text {out}}\right\rangle \). Here, the coefficient c is introduced to preserve the norm of the state, and it is given by
The HHL algorithm25 is a most famous algorithm to solve this linear equation by a quantum computer. We first construct a Hermitian matrix by
Then, a unitary matrix associated with F is uniquely obtained by \(e^{iHt}\) . Nevertheless, it requires many quantum gates. In addition, it is a nontrivial problem to implement \(e^{iHt}\).
Recently, variational methods have been proposed32 to solve the linear equation (9). In one of the methods, the matrix F is expanded in terms of some unitary matrices \(U_{j}\) as
In general, a complicated quantum circuit is necessary to determine the coefficient \(c_{j}\).
We start with a trial state \(|{\tilde{\psi }}_{\text {in}}\rangle \) to determine the state \(|\psi _{\text {in}}\rangle \). Application of each unitary matrix to this state is efficiently done by a quantum computer, \(U_{j}|{\tilde{\psi }} _{\text {in}}\rangle =|{\tilde{\psi }}_{\text {out}}^{\left( j\right) }\rangle \), and we obtain
where \(|{\tilde{\psi }}_{\text {out}}\rangle \) is an approximation of the given state \(\left| \psi _{\text {out}}\right\rangle \). We tune a trial state \(| {\tilde{\psi }}_{\text {in}}\rangle \) by a variational method so as to minimize the cost function32
which measures the similarity between the approximate state \(|{\tilde{\psi }}_{ \text {out}}\rangle \) and the state \(\left| \psi _{\text {out} }\right\rangle \) in (9). We have \(0\le E_{\text {cost}}\le 1\), where \(E_{\text {cost}}=0\) for the exact solution. The merit of this cost function is that the inner product is naturally calculated by a quantum computer.
Let the dimension of the matrix F be \(2^{N}\). It is enough to use N satisfying \(2^{N-1}<D\le 2^{N}\) without loss of generality by adding trivial \(2^{N}-D\) components to the linear equation. We propose to expand the matrix F by the gamma matrices \(\Gamma _{j}\) as
with
where \(\alpha \) \(=0,x,y\) and z.
The merit of our method is that it is straightforward to determine \(c_{j}\) by the well-known formula
In order to construct a quantum circuit to calculate \(c_{j}\), we express the matrix F by column vectors as
We have \(\left( \left| f_{q-1}\right\rangle \right) _{p}=F_{pq}\), where subscript p denotes the p-th component of \(\left| f_{q-1}\right\rangle \). Then \(c_{j}\) is given by
where the subscript q denotes the (\(q+1\))-th component of \(\Gamma _{j}\left| f_{q}\right\rangle \). We have introduced a notation \( \left| q\right\rangle \!\rangle \equiv |n_{1}n_{2}\cdots n_{N}\rangle \) with \(n_{i}=0,1\), where q is the decimal representation of the binary number \(n_{1}n_{2}\cdots n_{N}\). See explicit examples for one and two qubits in Method B.
The state \(\left. \left| q\right\rangle \!\right\rangle \equiv |n_{1}n_{2}\cdots n_{N}\rangle \) is generated as follows. We prepare the NOT gates \(\sigma _{x}^{\left( i\right) }\) for the i-th qubit if \(n_{i}=1\). Using all these NOT gates we define
We act it on the initial state \(\left| 0\right\rangle \!\rangle \) and obtain
Next, we construct a unitary gate \(U_{f_{q}}\) generating \(\left| f_{q}\right\rangle \),
We will discuss how to prepare \(U_{f_{q}}\) by a quantum circuit soon later; See Eq. (33). By using these operators, \(c_{j}\) is expressed as
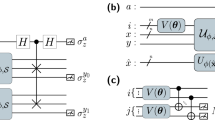
which can be executed by a quantum computer. We show explicit examples in Fig. 2.
Once we have \(c_{j}\), the final state is obtained by applying \(\Gamma _{j}\) to \(|{\tilde{\psi }}_{\text {in}}\rangle \) and taking sum over j, which leads to
The implementation of the \(\Gamma \) matrix is straightforward in quantum circuit, because the \(\Gamma \) matrix is composed of the Pauli sigma matrices, as shown in Fig. 2.

Quantum circuits determining \(c_{j}\). We show an example with (a) \( \Gamma _{yx0}=\sigma _{y}\otimes \sigma _{x}\otimes \sigma _{0}\). \(U_{X}^{\left( 6\right) }\left. \left| 0\right\rangle \!\right\rangle =\sigma _{x}^{\left( 1\right) }\sigma _{x}^{\left( 2\right) }\left| 000\right\rangle =\left| 110\right\rangle =\left. \left| 6\right\rangle \!\right\rangle \) and (b) \(\Gamma _{xyz}=\sigma _{x}\otimes \sigma _{y}\otimes \sigma _{z}\). \(U_{X}^{\left( 5\right) }\left| 0\right\rangle \!\rangle = \sigma _{x}^{\left( 1\right) }\sigma _{x}^{\left( 3\right) }\left| 000\right\rangle =\left| 101\right\rangle =\left. \left| 5\right\rangle \!\right\rangle \).
Steepest-descent method
One of the most common approaches to optimization is the steepest-descent method, where we make iterative steps in directions indicated by the gradient34. We may use this method to find an optimal trial state \(|{\tilde{\psi }}_{\text { in}}\rangle \) closest to the state \(|\psi _{\text {in}}\rangle \). To determine the gradient, we calculate the difference of the cost function \( \Delta E_{\text {cost}}\) when we slightly change the trial state \(|\tilde{\psi }_{\text {in}}(t)\rangle \) at step t by the amount of \(\Delta |{\tilde{\psi }} _{\text {in}}(t)\rangle \) as
We explain how to construct \(|{\tilde{\psi }}_{\text {in}}(t)\rangle \) by a quantum circuit soon later; See Eq. (33). Then, we renew the state as
where we use an exponential function for \(\eta _{t}\),
We choose appropriate constants \(\xi _{1}\) and \(\xi _{2}\) for an efficient search of the optimal solution, whose explicit examples are given in the caption of Fig. 1b. We stop the renewal of the variational step when the difference \(\Delta |{\tilde{\psi }}_{\text {in} }(t)\rangle \) becomes sufficiently small, which gives the optimal state of the linear equation (9).
In the numerical simulation, we discretize the time step
with a fixed \(\Delta t\). We add a small value \(\eta \left( n\Delta t\right) \) in the p-th component of the trial state \(|{\tilde{\psi }}_{\text {in} }^{\left( p\right) }(t)\rangle \) at the n step
where \(\delta ^{\left( p\right) }\) denotes a unit vector where only the p component is 1 and the other components are zero. Then, we calculate the costfunction
By running p from 1 to \(2^{N}\), we obtain a vector \(E_{\text {cost} }^{\left( p\right) }\left( \left( n+1\right) \Delta t\right) \), whose p-th component is \(E_{\text {cost}}^{\left( p\right) }\left( \left( n+1\right) \Delta t\right) \). Then, the gradient is numerically obtained as
and we set the trial state at the \(n+1\) step.
We iterate this process so that \(\Delta E_{\text {cost}}\left( n+1\right) \) becomes sufficiently small.
We denote the saturated cost function \(E_{\text {opt}}\). It depends on the choice of \(\xi _{1}\) and \(\xi _{2}\) in Eq. (27). We show \(\log _{10}E_{ \text {opt}}\) as a function of \(\xi _{2}\) for various \(\xi _{1}\) in Fig. 1c. There are some features. First, \(E_{\text {opt}}\) is small for small \(\xi _{1}\). Namely, we need to choose small \(\xi _{1}\) in order to obtain a good solution. On the other hand, the required step increases for small \(\xi _{1}\). It is natural that small \(\xi _{1}\) means that the step size is small. The required step number is antiproportional to \(\xi _{1} \). Second, there is a critical value to obtain a good solution as a function of \(\xi _{2}\) for a fixed value of \(\xi _{1}\). We find that it is necessary to set \(\xi _{2}<10^{-3}\).
A comment is in order. The cost function does not become zero although it becomes very small. It means that the solution is trapped by a local minimum and does not reach the exact solution. It is a general feature of variational algorithms, where we cannot obtain the exact solution. However, the exact solution is unnecessary in many cases including machine learnings. Actually, the classification shown in Fig. 1a is well done.
Variational universal-quantum-state generator
In order to construct the trial state \(|{\tilde{\psi }}_{\text {in}}(t)\rangle \), it is necessary to prepare an arbitrary state \(\left| \psi \right\rangle \) by a quantum circuit. Alternatively, we need such a unitary transformation U that
It is known that any unitary transformation is done by a sequential application of the Hadamard, the \(\pi /4\) phase-shift and the CNOT gates35,36. Indeed, an arbitrary unitary matrix is decomposable into a sequential application of quantum gates35,36, each of which is constructed as a universal quantum circuit systematically37,38,39,40,41,42. Universal quantum circuits have so far been demonstrated experimentally for two and three qubits43,44,45,46.
We may use a variational method to construct U satisfying Eq. (33). Quantum circuit learning is a variational method31, where angle variables \(\theta _{i}\) are used as variational parameters in a quantum circuit U, and the cost function is optimized by tuning \(\theta _{i}\). We propose to use a quantum circuit learning for a universal quantum circuit. We show that an arbitrary state \(\left| \psi \left( \theta _{i}\right) \right\rangle \) can be generated by tuning \(U\left( \theta _{i}\right) \) starting from the initial state \(\left| 0\right\rangle \!\rangle \) as
We adjust \(\theta _{i}\) by minimizing the cost function
which is the same as that of the variational quantum support vector machine. We present explicit examples of universal quantum circuits for one, two and three qubits in Method C.

Evolution of the cost function for (a) two qubits and (b) three qubits. The vertical axis is the log\(_{10}E_{\text {cost}}\). The horizontal axis is the number of variational steps. We use \(c_{1}=0.005\) and \( c_{2}=0.005\) for both the two- and three-qubit universal quantum circuits. We prepare random initial and final states, where we have runed simulations ten times. Each simulation is plotted in different color.
Quantum field-programmable-gate array
We next consider a problem to find a unitary transformation \(U_{\text {ini-fin}}\) which maps an arbitrary initial state \(\left| \psi _{\text {initial} }\right\rangle \) to an arbitrary final state \(\left| \psi _{\text {final} }\right\rangle \),
Since we can generate an arbitrary unitary matrix as in Eq. (33), it is possible to generate such matrices \(U_{\text {ini}}\) and \(U_{\text {fin}}\) that
Then, Eq. (36) is solved as
since \(U_{\text {ini-fin}}\left| \psi _{\text {initial}}\right\rangle =U_{ \text {ini-fin}}U_{\text {ini}}\left| 0\right\rangle \!\rangle =\left| \psi _{\text {final}}\right\rangle =U_{\text {fin}}\left| 0\right\rangle \!\rangle \).
An FPGA is a classical integrated circuit47,48,49,50, which can be programmable by a customer or a designer after manufacturing in a factory. An FPGA executes any classical algorithms. On the other hand, our variational universal quantum-state generator creates an arbitrary quantum state. We program by using the variational parameters \(\theta _{i}\). In this sense, the above quantum circuit may be considered as a quantum generalization of FPGA, which is a quantum FPGA (q-FPGA).
We show explicitly how the cost function is renewed for each variational step in the case of two- and three-qubit universal quantum circuits in Fig. 3, where we have generated the initial and the final states randomly. We optimize 15 parameters \(\theta _{i}\) for two-qubit universal quantum circuits and 82 parameters \(\theta _{i}\) for three-qubit universal quantum circuits. We find that \(U_{\text {ini-fin}}\) is well determined by variational method as in Fig.3.
Variational quantum support vector machine
We demonstrate a binary classification problem in two dimensions based on the support vector machine. We prepare a data set, where red points have a distribution around \(\left( r\cos \Theta ,r\sin \Theta \right) \) with variance r, while blue points have a distribution around \(\left( -r\cos \Theta ,-r\sin \Theta \right) \) with variance r. We assume the Gaussian normal distribution. We choose \(\Theta \) randomly. We note that there are some overlaps between the red and blue points, which is the soft margin model.
As an example, we show the distribution of red and blue points and the lines obtained by the variational method marked in cyan and by the direct solution of (6) marked in magenta in Fig. 1a. They agrees well with one another, where both of the lines well separate red and blue points. We have prepared 31 red points and 32 blue points, and used six qubits.
Discussion
Efficiency
The original proposal10 requires \(O\left( \log \left( N_{\text {D}}M\right) \right) \) runtime, where \(N_{ \text {D}}\) is the dimension of the feature space and M is the number of training data points. It has an advantage over the classical protocol which requires \(O\left( \text {polynomial}\left( N_{\text {D}},M\right) \right) \). There exisits also a quantum-inspired classical SVM51, which requires polynomial runtime as a function of the number of data points M and dimension of the feature space \(N_{\text {D}}\).
N qubit can represent \(2^{N-1}<N_{\text {D}}M\le 2^{N}\). Hence, the required number of qubits is \(N=\log \left( N_{\text {D}}M\right) \). We need \( 4^{N}-1\) quantum gates for an exact preparation of a universal quantum state. On the other hand, a hardware-efficient universal quantum circuit prepares an approximate universal quantum state by using the order of 4N quantum gates52,53,54. We need N quantum gates for the execution of \(U_{X}^{\left( q\right) }\) and \(\Gamma _{j}\), separately. We need \(4^{N}+2N-1\) quantum gates for exact preparation and 6N for approximate preparation. In machine learning, the exact solution is unnecessary. Thus, 6N quantum gates are enough.
On the other hand, the accuracy is independent of the number of required quantum gates. It is determined by \(\xi _{1}\) as shown in new Fig.1c.
Radial basis function
In this paper, we have used the linear Kernel function (8), which is efficient to classify data points linearly. However, it is not sufficient to classify data points which are not separated by the linear function. The radial basis function55,56 is given by
with a free parameter \(\sigma \). It is used for a nonlinear classification57. It is known58,59 that the depth of a quantum is linear to the dimension of the feature space N.
Conclusion
We have proposed that the matrix F is efficiently inputted into a quantum computer by using the \(\Gamma \)-matrix expansion method. There are many ways to use a matrix in a quantum computer such as linear regression and principal component analysis. Our method will be applicable to these cases.
Although it is possible to obtain the exact solution for the linear equation by the HHL algorithm, it requires many gates. On the other hand, it is often hard to obtain the exact solution by variational methods since trial functions may be trapped to a local minimum. However, this problem is not serious for the machine learning problem because it is more important to obtain an approximate solution efficiently rather than an exact solution by using many gates. Indeed, our optimized hyperplane also well separates red and blue points as shown in Fig. 1a.
In order to classify M data, we need to prepare \(\log _{2}M\) qubits. It is hard to execute a large number of data points by current quantum computers. Recently, it is shown that electric circuits may simulate universal quantum gates60,61,62 based on the fact that the Kirchhoff law is rewritten in the form of the Schrödinger equation63. Our variational algorithm will be simulated by using them.
Methods
Support vector machine
A support vector machine is an algorithm for supervised learning18,22,23. We first prepare a set of training data, where each point is marked either in red or blue. Then, we determine a hyperplane separating red and blue points. After learning, input data are classified into red or blue by comparing the input data with the hyperplane. The support vector machine maximizes a margin, which is a distance between the hyperplane and data points. If red and blue points are perfectly separated by the hyperplane, it is called a hard margin problem (Fig.4a). Otherwise, it is called a soft margin problem (Fig.4b).
We minimize the distance \(d_{j}\) between a data point \({\varvec{x}}_{j}\) and the hyperplane given by
We define support vectors \({\varvec{x}}\) as the closest points to the hyperplane. There is such a vector in each side of the hyperplane, as shown in Fig. 4a. This is the origin of the name of the support vector machine. Without loss of generality, we set
for the support vectors, because the hyperplane is present at the equidistance of two closest data points and because it is possible to set the magnitude of \(\left| \varvec{\omega }\cdot {\varvec{x}}+\omega _{0}\right| \) to be 1 by scaling \(\varvec{\omega }\) and \(\omega _{0}\). Then, we maximize the distance
which is identical to minimize \(\left| \varvec{\omega }\right| \).

Illustration of the hyperplane and the support vector. Two support vectors are marked by red and blue squares. (a) Hard margin where red and blue points are separated perfectly, and (b) soft margin where they are separated imperfectly.
First, we consider the hard margin problem, where red and blue points are perfectly separable. All red points satisfy \(\varvec{\omega }\cdot {\varvec{x}}_{j}+\omega _{0}>1\) and all blue points satisfy \(\varvec{ \omega }\cdot {\varvec{x}}_{j}+\omega _{0}<-1\). We introduce variables \( y_{j}\), where \(y_{j}=1\) for red points and \(y_{j}=-1\) for blue points. Using them, the condition is rewritten as
for each j. The problem is reduced to find the minimum of \(\left| \varvec{\omega }\right| ^{2}\) under the above inequalities. The optimization under inequality conditions is done by the Lagrange multiplier method with the Karush-Kuhn-Tucker condition64. It is expressed in terms of the Lagrangian as
where \(\beta _{j}\) are Lagrange multipliers to ensure the constraints.
For the soft margin case, we cannot separate two classes exactly. In order to treat this case, we introduce slack variables \(\xi _{j}\) satisfying
and redefine the cost function as
Here, \(\gamma =\infty \) corresponds to the hard margin. The second term represents the penalty for some of data points to have crossed over the hyperplane. The Lagrangian is modified as
The stationary points are determined by
We may solve these equations to determine \(\varvec{\omega }\) and \(\nu _{j}\) as
from (48), and
from (50). Inserting them into (51), we find
Since \(y_{j}^{2}=1\), it is rewritten as
Since \(\beta _{j}\) appears always in a pair with \(y_{j}\), we introduce a new variable defined by
and we define the Kernel matrix \(K_{ij}\) as
Then, \(\omega _{0}\) and \(\alpha _{j}\) are obtained by solving linear equations
which are summarized as
which is Eq. (6) in the main text. Finally, \(\varvec{\omega } \) is determined by
Once the hyperplane is determined, we can classify new input data into red if
and blue if
Thus, we obtain the hyperplane for binary classification.
\(\Gamma \) matrix expansion
We explicitly show how to calculate \(c_{j}\) in (17) based on the \(\Gamma \) matrix expansion for the one and two qubits.
One qubit
We show an explicit example of the \(\Gamma \) -matrix expansion for one qubit. One qubit is represented by a \(2\times 2\) matrix,
The column vectors are explicitly given by
The coefficient \(c_{j}\) in (17) is calculated as
Two qubits
Next, we show an explicit example of the \( \Gamma \)-matrix expansion for two qubits. Two qubits are represented by a \( 4\times 4\) matrix,
The column vectors are explicitly given by
The coefficient \(c_{j}\) in (17) is calculated as
Universal quantum circuits
Angle variables are used as variational parameters in a universal quantum circuit learning. We present examples for one, two and three qubits.
One-qubit universal quantum circuit
The single-qubit rotation gates are defined by
The one-qubit universal quantum circuit is constructed as
We show a quantum circuit in Fig. 5a. There are three variational parameters.
It is obvious that an arbitrary state is realized starting from the state \( \left| 0\right\rangle \) as

Universal quantum circuits for (a) one, (b) two and (c) three qubits.
Two-qubit universal quantum circuit
The two-qubit universal quantum circuit is constructed as43
where the entangling two-qubit gate is defined by43
The two-qubits universal quantum circuit contains 15 variational parameters. We show a quantum circuit in Fig. 5b.
Three-qubit universal quantum circuit
The three-qubit universal quantum circuit is constructed as
where \(U_{A}^{\left( 1\right) }\), \(U_{B}^{\left( 1\right) }\), \(U_{C}^{\left( 1\right) }\), and \(U_{D}^{\left( 1\right) }\) are one-qubit universal quantum circuits, while \(U_{A}^{\left( 2\right) }\), \(U_{B}^{\left( 2\right) }\), \( U_{C}^{\left( 2\right) }\), and \(U_{D}^{\left( 2\right) }\) are two-qubit universal quantum circuit and
Eplicit quantum circuits for \(U_{A}\left( 3\right) \), \(U_{B}\left( 3\right) \) and \(U_{C}\left( 3\right) \) are shown in Ref.42. The three-qubits universal quantum circuit contains 82 variational parameters. We show a quantum circuit in Fig. 5c.

Hardware-efficient universal quantum circuits for four qubits54.
Multi-qubit universal quantum circuit
General multi-qubit universal quantum circuit is constructed in Ref.39. The minimum numbers of variational parameters are \(4^{N}-1\) for N-qubit unicersal quantum circuits. However, we need more variational parameters in the currently known algorithm for \(N\ge 3\).
Actually, multi-qubit universal quantum circuits are well approximated by the hardware-efficient quantum circuit52,53,54. They are constructed as
with the use of the single qubit rotation
and the CNOT gates
where \(U_{\text {CROT}}^{n\rightarrow n+1}\) stands for the controlled rotation gate with the controlled qubit being n and the target qubit being \(n+1\). We need the order of 4N quantum gates for N-qubit universal quantum circuits. We show an example of the hardware-efficient quantum circuit with \(N=4\) in Fig. 6.
In addition, an ansatz based on the restricted Boltzmann machine requires \(N^{2}\) quantum gates, while a unitary-coupled cluster ansatz requires \( N^{4}\) quantum gates16,34.
Simulations
All of the numerical calculations are carried out by Mathematica.
References
Feynman, R. P. Simulating physics with computers. Int. J. Theor. Phys. 21, 467 (1982).
DiVincenzo, D. P. Quantum computation. Science 270, 255 (1995).
Nielse, M. & Chuang, I. Quantum Computation and Quantum Information 189 (Cambridge University Press, 2016) ISBN 978-1-107-00217-3.
Lloyd S., Mohseni M. & Rebentrost P. Quantum algorithms for supervised and unsupervised machine learning. arXiv:1307.0411.
Schuld, M., Sinayskiyv, I. & Petruccione, F. An introduction to quantum machine learning. Contemp. Phys. 56, 172 (2015).
Biamonte, J. Quantum machine learning. Nature 549, 195 (2017).
Wittek, P. Quantum Machine Learning: What Quantum Computing Means to Data Mining (Academic Press, 2014).
Harrow, A. W., Hassidim, A. & Lloyd, S. Quantum algorithm for linear systems of equations. Phys. Rev. Lett. 103, 150502 (2009).
Wiebe, N., Braun, D. & Lloyd, S. Quantum algorithm for data fitting. Phys. Rev. Lett. 109, 050505 (2012).
Rebentrost, P., Mohseni, M. & Lloyd, S. Quantum support vector machine for big data classification. Phys. Rev. Lett. 113, 130503 (2014).
Li, Z., Liu, X., Xu, N. & Du, J. Experimental realization of a quantum support vector machine. Phys. Rev. Lett. 114, 140504 (2015).
Schuld, M. & Killoran, N. Quantum machine learning in feature Hilbert spaces. Phys. Rev. Lett. 122, 040504 (2019).
Havlicek, V. et al. Supervised learning with quantum-enhanced feature spaces. Nature 567, 209 (2019).
Lamata, L. Quantum machine learning and quantum biomimetics: A perspective. Mach. Learn. Sci. Technol. 1, 033002 (2020).
Cong, I., Choi, S. & Lukin, M. D. Quantum convolutional neural networks. Nat. Phys. 15, 1273 (2019).
Sajjan, M., Sureshbabu, S. H. & Kais, S. Quantum machine-learning for eigenstate filtration in two-dimensional materials. Am. Chem. Soc. 143, 18426 (2021).
Xia, R. & Kais, S. Quantum machine learning for electronic structure calculations. Nat. Commun. 9, 4195 (2018).
Vapnik, V. & Lerner, A. Pattern recognition using generalized portrait method. Autom. Remote Control 24, 774 (1963).
Sarma A., Chatterjee R., Gili K. & Yu T. Quantum unsupervised and supervised learning on superconducting processors. arXiv:1909.04226.
Liu, Y., Arunachalam, S. & Temme, K. A rigorous and robust quantum speed-up in supervised machine learning. Nat. Phys. 17, 1013 (2021).
Date, P., Arthur, D. & Pusey-Nazzaro, L. QUBO formulations for training machine learning models. Sci. Rep. 11, 10029 (2021).
Noble, W. S. What is a support vector machine?. Nat. Biotechnol. 24, 1565 (2006).
Suykens, J. A. K. & Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 9, 293 (1999).
Zhaokai, L., Xiaomei, L., Nanyang, X. & Jiangfeng, D. Experimental realization of a quantum support vector machine. Phys. Rev. Lett. 114, 140504 (2015).
Harrow, A. W., Hassidim, A. & Lloyd, S. Quantum algorithm for linear systems of equations. Phys. Rev. Lett. 15, 150502 (2009).
Cai, X. D. et al. Experimental quantum computing to solve systems of linear equations. Phys. Rev. Lett. 110, 230501 (2013).
Barz, S. et al. A two-qubit photonic quantum processor and its application to solving systems of linear equations. Sci. Rep. 4, 6115 (2014).
Pan, J. et al. Experimental realization of quantum algorithm for solving linear systems of equations. Phys. Rev. A 89, 022313 (2014).
Farhi E., Goldstone J. & Gutmann S. A Quantum Approximate Optimization Algorithm. MIT-CTP/4610.
Peruzzo, A. et al. A variational eigenvalue solver on a photonic quantum processor. Nat. Commun. 5, 4213 (2014).
Mitarai, K., Negoro, M., Kitagawa, M. & Fujii, K. Quantum circuit learning. Phys. Rev. A 98, 032309 (2018).
Bravo-Prieto C., LaRose R., Cerezo M., Subasi Y., Cincio L. & Coles P. J. Variational Quantum Linear Solver. LA-UR-19-29101.
Xu X., Sun J., Endo S., Li Y., Benjamin S. C. & Yuan X. Variational Algorithms for Linear Algebra. arXiv:1909.03898.
Cerezo, M. et al. Variational quantum algorithms. Nat. Rev. Phys. 3, 625 (2021).
Deutsch, D. Quantum theory, the Church-Turing principle and the universal quantum computer. Proc. R. Soc. A 400, 97 (1985).
Dawson C. M. & Nielsen M. A. The Solovay–Kitaev Algorithm. arXiv:quant-ph/0505030.
Kraus, B. & Cirac, J. I. Optimal creation of entanglement using a two-qubit gate. Phys. Rev. A 63, 062309 (2001).
Vidal, G. & Dawson, C. M. Universal quantum circuit for two-qubit transformations with three controlled-NOT gates. Phys. Rev. A 69, 010301 (2004).
Mottonen, M., Vartiainen, J. J., Bergholm, V. & Salomaa, M. M. Quantum circuits for general multiqubit gates. Phys. Rev. Lett. 93, 130502 (2004).
Shende, V. V., Markov, I. L. & Bullock, S. S. Minimal universal two-qubit controlled-NOT-based circuits. Phys. Rev. A 69, 062321 (2004).
Vatan F. & Williams C. P. Realization of a General Three-Qubit Quantum Gate. arXiv:quant-ph/0401178.
Sousa P. B. M. & Ramos R. V. Universal Quantum Circuit for n-Qubit Quantum Gate: A Programmable Quantum Gate. arXiv:quant-ph/0602174.
Hanneke, D. et al. Realization of a programmable two-qubit quantum processor. Nat. Phys. 6, 13 (2009).
DiCarlo, L. et al. Demonstration of two-qubit algorithms with a superconducting quantum processor. Nature 460, 240 (2009).
Qiang, X. et al. Large-scale silicon quantum photonics implementing arbitrary two-qubit processing. Nat. Photonics 12, 534 (2018).
Roy, T. et al. Programmable superconducting processor with native three-qubit gates. Appl. Phys. Rev. 14, 014072 (2020).
Monmasson, E. & Cirstea, M. N. FPGA design methodology for industrial control systems: A review. IEEE Trans. Ind. Electron. 54, 1824 (2007).
Naouar, M.-W., Monmasson, E., Naassani, A. A., Slama-Belkhodja, I. & Patin, N. FPGA-based current controllers for AC machine drives: A review. IEEE Trans. Ind. Electron. 54, 1907 (2007).
Kuon, I., Tessier, R. & Rose, J. FPGA architecture: Survey and challenges. Found. Trends Electron. Des. Autom. 2, 135 (2007).
Shawahna, A., Sait, S. M. & El-Maleh, A. FPGA-based accelerators of deep learning networks for learning and classification: A review. IEEE Access 7, 7823 (2018).
Ding C., Bao T.-Y. & Huang H.-L. Quantum-Inspired Support Vector Machine. arXiv:1906.08902.
Kandala, A. et al. Hardware-efficient variational quantum eigensolver for small molecules and quantum magnets. Nature 549, 242 (2017).
Kardashin, A., Uvarov, A., Yudin, D. & Biamonte, J. Certified variational quantum algorithms for eigenstate preparation. Phys. Rev. A 102, 052610 (2020).
Kardashin, A., Pervishko, A., Biamonte, J. & Yudin, D. Numerical hardware-efficient variational quantum simulation of a soliton solution. Phys. Rev. A 104, 020402 (2021).
Broomhead D. S. & Lowe D. Radial Basis Functions, Multi-variable Functional Interpolation and Adaptive Networks. Tech. Rep. (Royal Signals and Radar Establishment Malvern (United Kingdom), 1988).
Broomhead, D. & Lowe, D. Multivariable functional interpolation and adaptive networks. Complex Syst. 2, 321 (1988).
Vert J.-P., Tsuda K. & Scholkopf B. A primer on kernel methods. Kernel Methods in Computational Biology (2004).
Haug, T., Bharti, K. & Kim, M. S. Capacity and quantum geometry of parametrized quantum circuits. Quantum Phys. Rev. X 2, 040309 (2021).
Haug T., Self C.N. & Kim M. S. Large-Scale Quantum Machine Learning. arXiv:2108.01039.
Ezawa, M. Electric circuits for universal quantum gates and quantum Fourier transformation. Phys. Rev. Res. 2, 023278 (2020).
Ezawa, M. Dirac formulation for universal quantum gates and Shor’s integer factorization in high-frequency electric circuits. J. Phys. Soc. Jpn. 89, 124712 (2020).
Ezawa, M. Universal quantum gates, artificial neurons, and pattern recognition simulated by LC resonators. Phys. Rev. Res. 3, 023051 (2021).
Ezawa, M. Electric-circuit simulation of the Schrodinger equation and non-Hermitian quantum walks. Phys. Rev. B 100, 165419 (2019).
Kuhn, H. W. & Tucker, A. W. Nonlinear programming. Proceedings of 2nd Berkeley Symposium 481–492 (University of California Press).
Acknowledgements
The author is very much grateful to E. Saito and N. Nagaosa for helpful discussions on the subject. This work is supported by the Grants-in-Aid for Scientific Research from MEXT KAKENHI (Grants No. JP17K05490 and No. JP18H03676). This work is also supported by CREST, JST (JPMJCR16F1 and JPMJCR20T2).
Author information
Authors and Affiliations
Contributions
M.E. conceived the idea, performed the analysis, and wrote the manuscript.
Corresponding author
Ethics declarations
Competing interests
The author declares no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ezawa, M. Variational quantum support vector machine based on \(\Gamma \) matrix expansion and variational universal-quantum-state generator. Sci Rep 12, 6758 (2022). https://doi.org/10.1038/s41598-022-10677-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-10677-z
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
