
Abstract
The giant ladybug Megalocaria dilatata (Fabricius) is a potential biocontrol agent and a valuable model for coccinellid genomics and evolutionary biology. However, the lack of a reference genome for M. dilatata has impeded further explorations into its evolution and constrained its use in pest management. Here, we assembled and annotated a high-quality, chromosome-level genome of M. dilatata. The resulting assembly spans 772.3 Mb, with a scaffold N50 of 72.48 Mb and a GC content of 34.23%. The Hi-C data aided in anchoring the assembly onto 10 chromosomes ranging from 43.35 to 108.16 Mb. We identified 493.33 Mb of repeat sequences, accounting for 63.88% of the assembled genome. Our gene prediction identified 25,346 genes, with 81.89% annotated in public protein databases. The genome data will provide a valuable resource for studying the biology and evolution of Coccinellidae, aiding in pest control strategies and advancing research in the field.
Similar content being viewed by others
Background & Summary
The family Coccinellidae, consisting of small beetles, is widely distributed and recognized by various common names, such as ladybugs, ladybirds, or lady beetles. Worldwide, there are over 6,000 described species classified across approximately 360 genera1. Coccinellids undergo complete metamorphosis, a holometabolous development that encompasses distinct stages, including the egg, larva, pupa, and adult stages2. The adult ladybugs exhibit an oval shape with a rounded back and a flat underside. Notably, there is sexual dimorphism within this family, with adult females being larger than males. Many species within this family possess eye-catching aposematic colors and patterns, such as a red body with black spots, serving as warning signs to potential predators, indicating their unpalatability3. Ladybugs are renowned for their beneficial predatory nature, particularly in gardens, agricultural fields, orchards, and similar environments4. Both the adult and larval stages of ladybugs actively consume various pest insects5. Primarily, ladybirds feed on aphids, while coccids, mites, honeydew, pollen, nectar, and mildew are documented as secondary food sources6.
Megalocaria dilatata (Fabricius, 1775)7 belongs to the subfamily Coccinellinae and tribe Coccinellini (Fig. 1a). This species was originally named Coccinella dilatata7 and later described as Caria dilatata8, but the widely used name for this species was Anisolemnia dilatata9. However, the use of the name Anisolemnia was subsequently restricted to its type species, and the other species, including M. dilatata, were transferred to the genus Megalocaria10. The giant ladybug M. dilatata is known for its large body size and preference for feeding on woolly aphids, which infest bamboo plants and sugarcane11. Its distribution is limited to South Asia and the Asia-Pacific regions11. The species’ longer lifespan compared to other ladybug species, high reproductive potential, and efficient predation on aphids indicate its significant potential as a biological control agent against pest insects12.

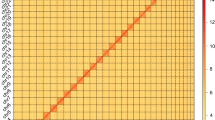
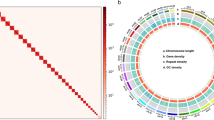
Summary of the final genome assembly results of Megalocaria dilatata. (a) Photos of M. dilatata. (b) The K-mer distribution of Illumina paired-end reads using GenomeScope based on a k value of 19. (c) A Circos atlas of the chromosomal genome of M. dilatata. From the outside to inside rings: (A) Chromosome ideograms (Mb scale); (B) Single-nucleotide polymorphism (SNP) density; (C) Insertion or deletion (INDEL) density; (D) PCG density; (E) GC content. Window size = 500 kb. Syntenic blocks are depicted by connected lines.
Ladybugs have been studied as genetic models since the early 20th century, primarily due to their genetically polymorphic color patterns. The majority of genetic research has focused on color pattern polymorphism in coccinellids1. Despite the high species diversity within Coccinellidae, the genomes of only a few species have been sequenced, such as Coccinella septempunctata, Propylea japonica, Harmonia axyridis, Adalia bipunctata, Halyzia sedecimguttata, Cryptolaemus montrouzieri, and Henosepilachna vigintioctomaculata13,14,15,16,17,18,19,20. Estimations of genome size in Coccinellidae, based on haploid nuclear DNA content or C-value, have revealed greater variation compared to other beetle families21. However, there is minimal intraspecific variation in genome size21. Genome size in Coccinellidae does not correlate with body size or chromosome number, but larger genomes appear to be associated with longer development periods1. Regarding chromosome numbers in Coccinellidae, the diploid count varies across subfamilies and tribes, ranging from 12 to 28 chromosomes22,23. The most common diploid number consists of 18 autosomes and a sex chromosome pair, which is considered the ancestral state for Coleoptera24,25. Despite these efforts, the lack of genomic data for ladybugs hinders our understanding of their evolution and limits their use as biological control agents.
In this study, we sequenced and assembled a high-quality chromosome-level genome for M. dilatata. To achieve this, we employed a comprehensive approach that involved short-read sequencing from Illumina HiSeq, SMRT (single molecule real-time) sequencing from PacBio (Pacific Biosciences), and Hi-C (high-throughput/resolution chromosome conformation capture) scaffolding technology. Our assembly demonstrates remarkable completeness, offering an invaluable genomic asset for future investigations in the field of Coccinellidae, including molecular and evolutionary studies, as well as potential applications in biological control. Additionally, we conducted a comparative analysis incorporating genomes of other related beetle species to identify genes that have undergone rapid evolution within the M. dilatata genome.
Methods
Sample preparation
The specimens of M. dilatata used in this study were cultivated under controlled laboratory conditions at the Sichuan Academy of Agricultural Sciences in Chengdu, China. Genomic DNA for de novo sequencing was extracted from a female adult of M. dilatata. The adult specimen was carefully rinsed with 75% ethanol and subsequently dissected on a sterile workbench. Muscle tissue was carefully collected and promptly preserved in liquid nitrogen, with the samples subsequently stored at −80 °C until further analysis. The extraction of high molecular-weight genomic DNA from the muscle tissue was performed using the TIANGEN Blood & Tissue Kit (Tiangen, Beijing, China) in accordance with the manufacturer’s guidelines.
The female adult of M. dilatata was used to extract total RNA, which was promptly preserved by freezing it in liquid nitrogen. For library construction, the SMRTbell™ Template Prep Kit 1.0 (Illumina Inc., San Diego, CA, USA) was employed following the recommended protocols provided by the manufacturer. The library was sequenced on an Illumina PacBio platform, generating paired-end reads of 300 base pairs as per the manufacturer’s instructions. The RNA library preparation and sequencing procedures were conducted at Shanghai Personal Biotechnology Co., Ltd. (Shanghai, China). Subsequently, all reads obtained underwent quality control measures, and the Trinity software package26 was utilized with default parameters to assemble the transcripts.
Illumina sequencing and genome size estimation
We prepared a paired-end library with an insert size of 400 bp using the Illumina TruSeq DNA PCR-free prep kit (Illumina Inc., San Diego, CA, USA). To assess the quality of the library, we employed the Agilent 2100 Bioanalyzer (Agilent Technologies, Santa Clara, CA, USA) along with the Agilent High Sensitivity DNA Kit (Agilent Technologies, Santa Clara, CA, USA). Quantification of the library was carried out using the Promega QuantiFluor in conjunction with the Quant-iT PicoGreen dsDNA Assay Kit (Thermo Fisher Scientific, Waltham, MA, USA). Subsequently, the library underwent sequencing on an Illumina NovaSeq 6000 platform (Illumina Inc., San Diego, CA, USA), generating paired-end reads of 150 base pairs in accordance with the manufacturer’s instructions. The DNA library preparation and sequencing procedures were performed at Shanghai Personal Biotechnology Co., Ltd. (Shanghai, China). We initially obtained approximately 62.3 Gb of Illumina DNA raw data27 (Table S1).
We performed a quality assessment of the raw data using Fastqc v0.11.8 (http://www.bioinformatics.babraham.ac.uk/projects/fastqc/). To eliminate any undesirable data, we utilized Fastp v0.20.028, employing a base-calling strategy. This process involved the removal of reads with adapter contamination, as well as the exclusion of low-quality reads with a mean PHRED score below 20%. Additionally, any paired reads with a length shorter than 150 bp and reads containing poly-N were also filtered out. To prevent any potential external contamination, a subset of 10,000 high-quality reads was randomly selected. These reads were then subjected to a homologous alignment with publicly available data in GenBank, focusing on identifying closely related species to M. dilatata. After quality control, we obtained approximately 60 Gb of high-quality data (Table S2).
For genome size estimation, a total of 59.9 Gb of data obtained from the 400-bp paired-end Illumina library was utilized. The distribution of k-mer copy number (KCN) was calculated to perform this estimation. Specifically, we conducted a 19-mer frequency distribution analysis using Jellyfish v2.3.029, resulting in a count of 682,724,594 19-mers. Based on the unique k-mer depth observed (Fig. 1b), we estimated the genome size of M. dilatata to be 0.682 Gb using the GenomeScope package30. Furthermore, the sequenced individual exhibited an estimated repetitive fraction of 49.9% and a heterozygosity rate of 0.8% (Table S3).
PacBio library preparation and sequencing
Whole-genome sequencing was conducted using the PacBio Sequel II platform (Pacific Biosciences, Menlo Park, CA, USA), which utilizes long-read technology. A 15-kb library was prepared following the standard PacBio Template Prep Kit 1.0 preparation protocol (Pacific Biosciences, Menlo Park, CA, USA). For genome sequencing, a SMRT cell was utilized on the PacBio Sequel II sequencing platform, resulting in a total of 34,806,299 long sequencing reads (Table S4), which included 2,767,560 HiFi reads31 (Table S5).
Hi-C library preparation and sequencing
The Hi-C library was prepared using the TruSeq DNA PCR-free prep kit (Illumina Inc., San Diego, CA, USA) following a standard procedure. This process involved various steps, such as DNA crosslinking, restriction enzyme cutting, end filling and biotin marking, ligation, DNA purification and shearing, biotin pull-down, and sequencing using paired ends. Subsequently, the Hi-C library was quantified and sequenced on the Illumina NovaSeq platform, generating paired-end reads of 2 × 150 bp. We obtained approximately 49.6 Gb of sequencing data from the Hi-C library (Table S6). To ensure data quality, a quality check of the Hi-C raw data32 was performed using Fastqc v0.11.8, which included assessments of base quality distribution, sequence content, GC distribution, and sequence base quality across all sequences. Furthermore, to generate high-quality Hi-C data, Fastp v0.20.0 was employed with a base-calling strategy, enabling the removal of low-quality reads. Following data filtering with Fastp, we obtained approximately 44.5 Gb of high-quality data (Table S7). In addition, we obtained approximately 89 Gb of transcriptomic data33 to assist in genome annotation (Table S8).
Genome assembly and Hi-C scaffolding
The M. dilatata genome was assembled using sequencing reads from Illumina, PacBio, and Hi-C technologies. PacBio sequence data were utilized for the initial de novo assembly, and subsequent polishing was performed using Illumina sequence data to enhance the quality of the contigs. Hi-C reads were employed to scaffold the draft genome. To align the Hi-C data, HiC-PRO v2.5.034 was employed. The junction site of the enzyme was set as ‘GATCGATC’, and default parameters were used for the alignment. The HiC-PRO software conducted two alignment steps. First, the clean paired-end reads were mapped to the draft assembled genome using Bowtie v2.3.235. Second, the unmapped reads with junction fragments were mapped to the draft genome after removing the 3′ end. The results of both mapping steps were merged into a single alignment file. The alignment process of Hi-C data generated approximately 61.8 million uniquely mapped paired-end reads, of which 79% were determined to be valid interaction pairs (Table S9) according to the HiC-Pro pipeline34.
Using the valid Hi-C data, the Endhic de novo assembly pipeline36 was employed to generate chromosome-level scaffolds. Endhic was chosen due to its suitability for larger contigs (>1 Mb), providing higher accuracy, fewer parameters, and faster processing compared to other commonly used software. A total of 716,341,908 base pairs were successfully mapped to the chromosomes by Endhic, accounting for 92.21% of the total genome length. To improve the accuracy of the assembly, two rounds of error correction were performed using Illumina reads and the PILON program37. As a result, we were able to accurately anchor the Hi-C-assisted genome assembly onto 10 pseudochromosomes (chromosomes), with lengths ranging from 43.35 to 108.16 Mb (Figs. 1c, 2, Table S10). The diploid chromosome number of M. dilatata (2n = 20) is consistent with the prevailing chromosome count found in Coccinellidae, which includes 18 autosomes and a pair of sex chromosomes. Notably, this chromosome number is identical to that observed in recently sequenced ladybugs, namely, C. septempunctata, H. sedecimguttata, and P. japonica13,14,20. The conservation of this chromosome number across these ladybug species suggests potential evolutionary significance and a shared genetic foundation among members of Coccinellidae.

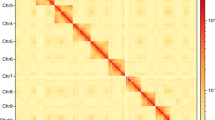
Genome‐wide Hi‐C heatmap for Megalocaria dilatata showing interactions among the 10 chromosomes. The number of log2 links was calculated. The color bar indicates the frequency of Hi‐C interaction links from yellow (low) to dark (high) in the plot.
After applying various refining techniques, such as Pilon polishing, redundancy and contaminant removal, as well as Hi-C scaffolding, we determined the final genome size of M. dilatata to be ca. 772.3 Mb, with a scaffold N50 length of ca. 72.48 Mb and a GC content of ca. 34.23% (Table 1). These results closely match the earlier estimations of genome size based on k-mer analysis, validating the accuracy and reliability of our assembly process.
Repetitive element analysis
Repetitive elements (REs) were detected through two approaches: homology search and de novo annotation. The homology-based search was conducted against RepBase-20150807, utilizing RepeatMasker v4.0.538. For de novo repeat library construction, RepeatModeler v1.0.438 was employed. Protein-coding-like sequences that exhibited similarity to those in the Swiss-Prot database were eliminated from the de novo library. Finally, RepeatMasker v4.0.538 was used to search the constructed de novo library. We identified a total of 493.33 Mb of repeat sequences (Table S11), which accounted for 63.88% of the genome. The M. dilatata genome had a much higher level of repetitive sequence than the genomes of other sequenced coleopterans14, which raises intriguing questions about the evolutionary forces shaping genome architecture in this species. Among these repeats, DNA elements were the most prevalent, constituting 175.13 Mb (22.68%). This finding aligns with previous studies on Aedes albopictus (Skuse, 1894)39,40 and P. japonica14, which also reported DNA elements as the predominant repetitive elements. Additionally, 113.97 Mb (14.76%) were attributed to long interspersed nuclear elements (LINEs), 9.54 Mb (1.23%) to long terminal repeat elements (LTRs), and 3.11 Mb (0.4%) to short interspersed nuclear elements (SINEs). The DNA elements and LINEs may contribute to genomic plasticity and adaptation. Their abundance might be linked to specific biological features, such as responses to environmental changes, host-pathogen interactions, or other ecological factors. Moreover, we observed 191.59 Mb (24.81%) of unclassified repeat elements that could not be categorized into known repeat elements. The remaining repeats included 1 Kb of small RNA, 312.05 Kb of satellites (0.04%), 375.87 Kb of simple repeats, and 2 Kb of low complexity repeats. These repeats could be utilized in population genetics, phylogenetics, or association studies, providing a bridge between the observed genomic composition and phenotypic traits. Notably, DNA elements and LINEs were the two most abundant repeat categories in the M. dilatata genome, collectively accounting for 37.44% of the genome assembly.
Protein-coding gene prediction
The prediction of protein-coding genes (PCGs) within the genome involves multiple approaches, including ab initio prediction, homology-based prediction, and evidence from transcriptome-based prediction. Ab initio gene prediction was carried out using Augustus v3.0341, GeneID v1.442, and GeneMark v4.3543. In the homology-based approach, amino acid sequences from related ladybugs were aligned to the M. dilatata assembly using Exonerate v2.2.044. Transcriptome-based prediction methods utilized RNA-seq data. The assembled transcripts from Trinity were used as inputs for gene model prediction using PASA45. To integrate all the gene prediction results, EVidenceModeler (EVM) vr2012-06-2546 was employed to generate consensus gene models. We predicted a total of 25,346 genes in M. dilatata, with an average gene length of 16,245 bp (Table S12). These genes comprised 101,803 exons, with an average of 4 exons per gene. The genome contained 101,803 coding sequences (CDSs), with an average CDS length of 305.1 bp. The total length of CDSs reached 31,069,524 bp, representing 4.0229% of the genome.
Noncoding RNA prediction
The identification of transfer RNA (tRNA) genes within the genome was performed using tRNAscan-SE v1.3.147. For the prediction of ribosomal RNA (rRNA) genes, RNAmmer v1.248 was utilized. To identify the remaining noncoding RNA (ncRNA) genes, a search was conducted against the Rfam database using the Infernal v1.1.3 program49. We identified 15,915 ncRNAs in the genome, including 1,327 8 S rRNAs, 1,418 18 S rRNAs, 1,314 28 S rRNAs, 9,328 tRNAs, and 2,528 other ncRNAs (Table S13).
Gene function annotation
Gene functions were assigned based on the most significant alignments against the Swiss-Prot and NCBI nonredundant protein sequence (NR) databases using local Blastp with a threshold E-value of 1e-5. Additionally, the Pfam database was searched through InterProScan50 for gene function annotation. InterProScan50 was also employed to obtain domain information and perform GO (Gene Ontology) term annotation. The predicted protein sequences were submitted to KAAS (KEGG Automatic Annotation Server) to obtain KEGG (Kyoto Encyclopedia of Genes and Genomes) pathway annotations51. For the prediction of carbohydrate-active enzymes (CAZy), Hmmer v3.052 was utilized. An E-value cut-off of 1e-5 was used for sequences longer than 80 amino acids, and an E-value cut-off of 1e-3 was used for sequences shorter than 80 amino acids.
Among the 25,346 predicted genes, 20,397 (80.47%) exhibited hits to proteins in the Nr database, 11,148 (43.98%) in the Swiss-Prot database, and 14,751 (58.20%) in the Pfam database (Table S14). Additionally, 10,663 (42.07%) genes were annotated with GO terms (Fig. S1), while 6,505 (25.66%) genes were annotated with KEGG Orthology (KO) terms (Fig. S2). Overall, a total of 20,756 (81.89%) genes were annotated by at least one of the public databases, indicating substantial functional annotation coverage.
Furthermore, CAZy annotation predicted the presence of various carbohydrate-active enzymes in the genome (Fig. S3). Specifically, we identified 150 genes of glycosyl transferases (GT), 3 genes of polysaccharide lyases (PL), 71 genes of carbohydrate esterases (CE), 40 genes of auxiliary activities (AA), 59 genes of carbohydrate-binding modules (CBM), and 136 genes of glycoside hydrolases (GH). The identification of carbohydrate-active enzymes through CAZy annotation suggests their involvement in various metabolic processes related to carbohydrate metabolism, potentially reflecting the dietary preferences and ecological niche of M. dilatata.
Data Records
The genomic (Illumina, PacBio, Hi-C) and transcriptomic sequencing data was deposited at the NCBI Sequence Read Archive (SRA) database under BioProject ID PRJNA102934153. The accession numbers of the Illumina sequencing data, HiFi sequencing data, Hi-C sequencing data, and transcriptomic data are SRR2642579327, SRR2642579231, SRR2642579132, and SRR2642579033, respectively. The accession number of the genome assembly is JAWQEH00000000054. The genome assembly and raw sequencing data are also available at the China National GeneBank DataBase (CNGBdb) under Project ID CNP000448255.
Technical Validation
To assess the completeness and continuity of the M. dilatata genome assembly, we employed Benchmarking Universal Single-Copy Orthologues (BUSCO) v.3.0.256, utilizing the Insecta database comprising 75 species and 1,367 universal single-copy orthologous genes, which evaluates the presence of conserved insect genes. This analysis allows us to assess the comprehensiveness and representation of the insect gene set within the M. dilatata genome. By comparing our assembly to a set of 1,367 conserved genes, we identified a remarkable 1,330 genes (97.29%) present in the M. dilatata genome (Table S15). This high BUSCO score signifies the robustness and completeness of our assembly, suggesting that a significant majority of the conserved insect genes are accurately represented within the M. dilatata genome.
BUSCO v.3.0.256 was also used to assess the completeness of the annotated protein-coding genes, which revealed that 98.76% of the conserved orthologous genes were complete in the predicted PCGs, with 96.27% single-copy and 2.49% duplicated (Table S16). This indicates a comprehensive prediction and annotation of the gene set. The comprehensive results obtained from BUSCO assessment and functional annotation collectively demonstrate that the genes in the newly assembled M. dilatata genome are well annotated. This robust annotation provides a solid foundation for further investigations into the functional genomics and comparative studies of this giant ladybug.
Code availability
The bioinformatic analyses were performed using the manuals and protocols by the software developers. If manually adjusted parameters were used, the software version and method used are described in the Methods.
References
Hodek, I., Honek, A. & Van Emden, H. F. Ecology and behaviour of the ladybird beetles (Coccinellidae) (John Wiley & Sons, 2012).
Hodek, I. in Biology of Coccinellidae (ed. Hodek, I.) (Dr W. Junk Publishers, 1973).
Aslam, M. Conspicuousness and toxicity of Coccinellidae: An aposematic review. Arthropods 9, 85–91 (2020).
Kundoo, A. A. & Khan, A. A. Coccinellids as biological control agents of soft-bodied insects: A review. J. Entomol. Zool. Stud. 5, 1362–1373 (2017).
Schwarz, T. & Frank, T. Aphid feeding by lady beetles: higher consumption at higher temperature. BioControl 64, 323–332 (2019).
Ali, A. & Rizvi, P. Q. Development and predatory performance of Coccinella septempunctata L. (Coleoptera: Coccinellidae) on different aphid species. J. Biol. Sci. 7, 1478–1483 (2007).
Fabricius, J. C. Systema Entomologiae, sistens Insectorum Classes, Ordines, Genera, Species, adjectis Sysnonymis, Locis, Descriptionibus, Observationibus. Kortii, Flensburgi et Lipsiae 8, 375–390 (1775).
Mulsant, E. Species des Coleopteres trimeres securipalpes. Annales des Sciences Physiques et Naturelles, d’Agriculture et d’Industrie, Lyon 2, 1–1104 (1850).
Korschefsky, R. Coleopterorum Catalogus, pars 120 Coccinellidae II (W Junk, 1932).
Iablokoff-Khnzorian, S. M. Les Coccinelles Coleopteres-Coccinellidae Tribu Coccinellini des regions Palearctique et Orientale (Boubée, 1982).
Agarwala, B. K. & Majumder, J. Life history fitness of giant ladybird predator (Coleoptera: Coccinellidae) of woolly aphids (Hemiptera: Aphididae) in varying prey densities from northeast India. Curr. Sci. 110, 434–438 (2016).
Ponnusamy, N., Gurung, B. & Pal, S. Biology and feeding potential of giant ladybird beetle, Anisolemnia dilatata (Fab.) (Coleoptera: Coccinellidae) on some aphids (Aiceona sp.) (Hemiptera: Aphididae). Pest Management in Horticultural Ecosystems 27, 61–64 (2021).
Crowley, L. M. The genome sequence of the seven-spotted ladybird, Coccinella septempunctata Linnaeus, 1758. Wellcome Open Res. 6, 319–328 (2021).
Zhang, L. et al. Chromosome-level genome assembly of the predator Propylea japonica to understand its tolerance to insecticides and high temperatures. Mol. Ecol. Resour. 20, 292–307 (2020).
Chen, M. et al. A chromosome‐level assembly of the harlequin ladybird Harmonia axyridis as a genomic resource to study beetle and invasion biology. Mol. Ecol. Resour. 21, 1318–1332 (2021).
Gautier, M. et al. The genomic basis of color pattern polymorphism in the harlequin ladybird. Curr. Biol. 28, 3296–3302 (2018).
Ando, T. et al. Repeated inversions within a pannier intron drive diversification of intraspecific colour patterns of ladybird beetles. Nat. Commun. 9, 3843 (2018).
Li, H. S. et al. Horizontally acquired antibacterial genes associated with adaptive radiation of ladybird beetles. BMC Biol. 19, 1–16 (2021).
Goate, Z. The genome sequence of the two-spot ladybird, Adalia bipunctata (Linnaeus, 1758). Wellcome Open Res. 7, 288 (2022).
Crowley, L. M. et al. The genome sequence of the orange ladybird, Halyzia sedecimguttata (Linnaeus, 1758). Wellcome Open Res. 8, 186 (2023).
Gregory, T. R., Nedvěd, O. & Adamowicz, S. J. C-value estimates for 31 species of ladybird beetles (Coleoptera: Coccinellidae). Hereditas 139, 121–127 (2003).
Smith, S. G. Cytogenetic pathways in beetle speciation. Can. Entomol. 94, 941–955 (1962).
Yadav, J. S. & Gahlawat, S. Chromosomal investigations on five species of ladybird beetles (Coccinellidae, Coleoptera). Folia Biol. 42, 139–143 (1994).
Smith, S. G. & Virkki, N. Animal Cytogenetics. Vol. 3: Insecta 5. Coleoptera (Gebrüder Borntraeger, 1978).
Lyapunova, E. A. et al. Karyological investigations on seven species of coccinellid fauna of USSR (Polyphaga: Coleoptera). Zool. Anz. 212, 185–192 (1984).
Grabherr, M. G. et al. Full-length transcriptome assembly from RNA-Seq data without a reference genome. Nat. Biotechnol. 29, 644–652 (2011).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR26425793 (2023).
Chen, S., Zhou, Y., Chen, Y. & Gu, J. fastp: an ultra-fast all-in-one FASTQ preprocessor. Bioinformatics 34, i884–i890 (2018).
Marcais, G. & Kingsford, C. A fast, lock-free approach for efficient parallel counting of occurrences of k-mers. Bioinformatics 27, 764–770 (2011).
Vurture, G. W. et al. GenomeScope: Fast reference-free genome profiling from short reads. Bioinformatics 33, 2202–2204 (2017).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR26425792 (2023).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR26425791 (2023).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR26425790 (2023).
Servant, N. et al. HIC‐PRO: An optimized and flexible pipeline for Hi‐C data processing. Genome Biol. 16, 259 (2015).
Langmead, B. & Salzberg, S. L. Fast gapped-read alignment with Bowtie 2. Nat. Methods 9, 357–359 (2012).
Wang, S. et al. EndHiC: assemble large contigs into chromosome-level scaffolds using the Hi-C links from contig ends. BMC bioinformatics 23, 1–19 (2022).
Walker, B. J. et al. Pilon: An integrated tool for comprehensive microbial variant detection and genome assembly improvement. PLoS ONE 9, e112963 (2014).
Tarailo-Graovac, M. & Chen, N. Using RepeatMasker to identify repetitive elements in genomic sequences. Curr. Protoc. Bioinformatics 25, 4–10 (2009).
Skuse, F. A. A. The banded mosquito of Bengal. Indian Museum Notes 3, 20 (1894).
Chen, X. G. et al. Genome sequence of the Asian Tiger mosquito, Aedes albopictus, reveals insights into its biology, genetics, and evolution. Proc. Natl. Acad. Sci. 112, 5907–5915 (2015).
Stanke, M., Diekhans, M., Baertsch, R. & Haussler, D. Using native and syntenically mapped cDNA alignments to improve de novo gene finding. Bioinformatics 24, 637–644 (2008).
Blanco, E., Parra, G. & Guigó, R. Using geneid to identify genes. Curr. Protoc. Bioinformatics 18, 4–30 (2007).
Borodovsky, M. & Lomsadze, A. Eukaryotic gene prediction using GeneMark.hmm-E and GeneMark-ES. Curr. Protoc. Bioinformatics 35, 4.6.1–4.6.10 (2011).
Slater, G. S. C. & Birney, E. Automated generation of heuristics for biological sequence comparison. BMC Bioinformatics 6, 31 (2005).
Haas, B. J. et al. Improving the Arabidopsis genome annotation using maximal transcript alignment assemblies. Nucleic Acids Res. 31, 5654–5666 (2003).
Haas, B. J. et al. Automated eukaryotic gene structure annotation using EVidenceModeler and the program to assemble spliced alignments. Genome Biol. 9, R7 (2008).
Lowe, T. M. & Eddy, S. R. tRNAscan‐SE: A program for improved detection of transfer RNA genes in genomic sequence. Nucleic Acids Res. 25, 955–964 (1997).
Lagesen, K. et al. RNAmmer: Consistent and rapid annotation of ribosomal RNA genes. Nucleic Acids Res. 35, 3100–3108 (2007).
Griffiths-Jones, S. et al. Rfam: Annotating non-coding RNAs in complete genomes. Nucleic Acids Res. 3, 121–124 (2005).
Jones, P. et al. InterProScan 5: Genome-scale protein function classification. Bioinformatics 30, 1236–1240 (2014).
Moriya, Y., Itoh, M., Okuda, S., Yoshizawa, A. C. & Kanehisa, M. KAAS: An automatic genome annotation and pathway reconstruction server. Nucleic Acids Res. 35, 182–185 (2007).
Meng, X. & Ji, Y. Modern computational techniques for the HMMER sequence analysis. ISRN Bioinform 2013, 252183 (2013).
NCBI BioProject https://www.ncbi.nlm.nih.gov/bioproject/PRJNA1029341 (2023).
NCBI GenBank https://identifiers.org/ncbi/insdc:JAWQEH000000000 (2023).
CNGBdb Project https://db.cngb.org/search/project/CNP0004482 (2023).
Seppey, M., Manni, M. & Zdobnov, E. M. in Gene Prediction: Methods and Protocols (ed. Kollmar, M.) (Springer, 2019).
Acknowledgements
This work was supported by the National Key R & D Program of China (2023YFD1400600), Tobacco Company of Sichuan (SCYC202212) and the Tea Innovation Team of National Modern Agricultural Industry Technology System (sccxtd-2020-10).
Author information
Authors and Affiliations
Contributions
D.Q.P. conceived and designed the study. X.L.W. collected and identified the samples. X.L.W., Z.T.C. and S.J.W. performed the analyses. D.Q.P. and X.L.W. drafted the manuscript. P.C. and H.L.L. revised the manuscript. All authors have read and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Pu, DQ., Wu, XL., Chen, ZT. et al. Chromosome-level genome assembly of the giant ladybug Megalocaria dilatata. Sci Data 11, 117 (2024). https://doi.org/10.1038/s41597-024-02990-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-024-02990-1
