
Abstract
Study design:
Descriptive study.
Objective:
This study aimed to develop and evaluate a systematic arrangement for improvement and monitoring of data quality of the National Spinal Cord (and Column) Injury Registry of Iran (NSCIR-IR)—a multicenter hospital-based registry.
Setting:
SCI community in Iran.
Methods:
Quality assurance and quality control were the primary objectives in improving overall quality of data that were considered in designing a paper-based and computerized case report. To prevent incorrect data entry, we implemented several validation algorithms, including 70 semantic rules, 18 syntactic rules, seven temporal rules, and 13 rules for acceptable value range. Qualified and trained staff members were also employed to review and identify any defect, inaccuracy, or inconsistency in the data to improve data quality. A set of functions were implemented in the software to cross-validate, and feedback on data was provided by reviewers and registrars.
Results:
Socio-demographic data items were 100% complete, except for national ID and education level, which were 97% and 92.3% complete, respectively. Completeness of admission data and emergency medical services data were 100% except for arrival and transfer time (99.4%) and oxygen saturation (48.9%). Evaluation of data received from two centers located in Tehran proved to be 100% accurate following validation by quality reviewers. All data was also found to be 100% consistent.
Conclusions:
This approach to quality assurance and consistency validation proved to be effective. Our solutions resulted in a significant decrease in the number of missing data.
Similar content being viewed by others


Introduction
Health care system registries are important data resources, providing information regarding a patient’s condition, treatment course, and outcomes. Disease registries have been defined as regional databases of specified disease designed to simplify disease management and to improve its outcome [1]. Disease registries may have different purposes, such as disease management, tracking disease trends, disease surveillance, planning for disease control and prevention, evaluation of healthcare services, or effectiveness of treatments, research, and education. The above-mentioned aims cannot be adequately achieved using poor quality data. Registries are valuable but depend heavily on the quality of the gathered data, as previously demonstrated [2,3,4].
Despite the growing number and influence of registries, health data have been found to be underutilized and of poor quality, according to global studies [5, 6]. Most registries and health information systems have multiple reporting levels (data collection, collation, and transfer), leading to data loss or inaccuracy [3]. To optimize the quality of disease registry data, registry guidelines and frameworks should be established and followed by staff [2].
To begin, a definition of data quality and its dimensions is necessary. Determining the quality of data is multifaceted, and previous literature suggests different parameters for data quality [3, 7,8,9]. The most repeatedly and unambiguously cited terms for data quality criteria were “accuracy”, “completeness”, “timeliness”, “consistency”, and “relevancy” [3, 10,11,12,13,14]. However, the definition of data quality criteria may be different depending on registry type. For example, in epidemiologic registries that monitor incidence or prevalence, registry completeness is defined as the ability to capture all eligible cases in the specific population over a certain time period without missing a case [15, 16], while in other studies, completeness implies that all required data is recorded and there is no missing data [17, 18].
In any case, a framework for data quality improvement can include a list of mechanisms that happen prior to, concurrent with, and following processing of data collection. According to Whitney et al., mechanisms that take place before collection of data are referred to as quality assurance, and those carried out during and after data collection are recognized as quality control mechanisms [18]. Data quality control and assurance procedures become complex when one considers the magnitude and methods of collecting data, level of expertize among registrars, and the number of sources from which the data is gathered. Sometimes these items vary among participating centers in multicenter trials or studies [11].
The “National Spinal Cord Injury Registry of Iran (NSCIR-IR),” recognized by the Iranian Ministry of Health and Medical Education, was initiated in November 2014. A pilot study of the NSCIR-IR was performed to assess the practicality, conduction issues, and quality of data of the registry [19].
The potential for error in this study is large and may therefore affect the quality and usefulness of the registry. We should also consider the optimization of our framework in a way that is more sensitive to errors that can threaten the outcome of our study rather than minor ones which correspond less to the outcome. In other words, heavy spending that targets detection methods for uncommon errors is not endorsed [20]. This study aimed to develop and evaluate a systematic arrangement for improvement and monitoring of data quality of the National Spinal Cord (and Column) Injury Registry of Iran (NSCIR-IR)—a multicenter hospital-based registry.
Methods
NSCIR-IR is a national, hospital-based, prospective registry, the pilot phase of which was completed from October 2015 to May 2016 in three neurosurgery departments of three hospitals: two hospitals in Tehran (Sina and Firouzgar) and one in Rasht (Poursina) [19].
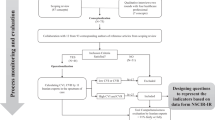
In general, seven strategies (Figs. 1 and 2) were applied in our data quality improvement program, which were categorized into (I) data quality assurance (i.e., preventive actions before starting the registry) and (II) data quality control strategies (i.e., corrective actions during execution of the registry).

Seven strategies for quality data control and assurance were applied respectively in the registry project.

Data quality dimentions.
Data quality assurance involved several steps, and began with determining the data set. To achieve this goal, at the time of data set development and case report form design, availability and accessibility of data were evaluated by an expert panel who was aware of the clinical documentation status and the content of medical records in Iranian hospitals. The authors believed that any data that was unavailable or inaccessible would lead to a decline in the percentage of data completion and increase missing data.
In the second step, reliable sources for each data item (including patient-reported items, provider-reported items, and patient medical records) were specified in the data gathering guideline and data dictionary.
In the third step, quality considerations were taken into account in the design of data collection tools such as paper-based case report forms, data dictionary, data collection guide, and software. A written data dictionary specified the characteristics of each data element/variable, including data/variable name, definition, type or format, whether the variable is mandatory/conditional or optional, source of data, and values and validations rules (such as length of field, acceptable range of value, and its association with other data/variables). Our data set included 301 data elements, including 183 items of the International Standards for Neurological Classification of Spinal Cord Injury (ISNCSCI) examination used for the acute phase of injury [21].
Other solutions for data quality assurance were considered in designing paper forms and electronic case report forms, such as using structured formats instead of free text. In addition, the software system was designed with a ruling engine that helped define the rules of data validation, further controlling for data quality. To prevent incorrect data entry, pre-defined validation rules were created and then implemented in the software. There were 70 semantic rules, 18 syntactic rules, 7 temporal rules, and 13 rules for acceptable value range. Entering invalid data would therefore result in an error/warning message appearing and the software program preventing further data entry.
In the fourth step, all registrars were trained for data collection and proper usage of software by expert staff.
For quality control, trained staff were employed as independent quality reviewers to identify any kind of defect, inaccuracy, or inconsistency in the submitted data and to double-check injury type, level, and number of injured vertebrae through assessment of medical images. Information regarding injured vertebra was double-checked by two reviewers, including one neurosurgeon, through patients’ diagnostic images (e.g., CT, MRI, bone view, etc.).
A hierarchy of functions was implemented in the software, including re-checking the data by reviewers, sending feedback to registrars, and making corrections. Functions included the following items:
-
(i)
During the review and correction process, the file is labeled as “completing” (the patient’s entire dataset has not yet been submitted by the registrar), “under review” (patient record is being reviewed by quality reviewer), “needs to be corrected” (patient record returned to registrar with comments), “confirmed” (all data in the patient record is approved) and “rejected” (patient record and data is not acceptable because the patient is not eligible).
-
(ii)
Interactive online discussion regarding inconsistencies, inaccuracies, or causes of error through a chat section in the system.
-
(iii)
Automatically locking acceptable data, returning records to the registrar for revision (only erroneous data items are editable), and additional re-check before final confirmation.
We evaluated the effects of this plan on the completeness, accuracy, and consistency of patient documents in our registry data through a seven-month pilot phase.
Data accuracy implies the correctness of data. The accuracy of NSCIR-IR registry data was cross-checked according to patient identification documents, medical images, and hospital records; missing data were distinguished from not applicable data items. Of note, the accuracy of the Pousrina Hospital, which is outside of the Tehran collaborating center, was not measurable, and the reporting there is selective. Data completeness is defined as the recording of all required data items. Data is consistent if the value of the data items were the same or accordant.
Results
A total of 81 eligible patients were identified in three hospitals. Data of 16 patients from one hospital were not recorded into the electronic system because of multiple questionable inaccuracies that required revision. The data of the remaining 65 patients were reviewed and verified.
Procedures for quality assurance and control of data resulted in a 100% completion rate for socio-demographic data except for national ID numbers (97%) and educational level (92.3%). Missing data was mainly due to patient unconsciousness during the time of data collection, lack of a responsive companion at the time of admission, or absence of identification documents for undocumented immigrants.
Incomplete emergency medical data, such as arterial oxygen saturation (SaO2) (48.9%) and arrival and transfer time (99.4%), occurred due to defects in medical documentation.
There are no clear statistics regarding the number of foreigners in Iran, and the number of Afghans in our study was relatively high, indicating the susceptibility of this group to spinal trauma. As a result of not having appropriate and complete ID for chronic re-hospitalization, there is a high likelihood of missed or incomplete data in our registry in these cases. Other parameters had 100% completeness in our registry (Table 1).
Based upon cross-reference of patient data with identification, demographic data accuracy was 100%. Since an integrated electronic medical record for patients was not available in the included hospitals, patient medical history was collected in the NSCIR-IR from paper-based medical records and from each patient’s verbal description of health status and previous diseases. Similarly, data from Poursina Hospital (located in Rasht, Iran) for vertebral injury and intervention was 100% accurate based on double-checking original medical images by two independent observers (a trained nurse and then a neurosurgeon). Evaluation of accuracy of other data in this hospital was not performed because the original source of data was not accessible for reviewers in Tehran. The consistency of data was 100% per the two-step quality control process.
Discussion
We developed and evaluated a system to improve data quality for the NSCIR-IR, which is a multicenter, hospital-based registry in Iran. With regard to information quality, we assessed data with criteria for completeness, accuracy, and consistency. All gathered information met completeness criteria except National ID number, patient education level (one of the socio-demographic variables), oxygen saturation, and transfer time to the hospital.
Accuracy and consistency criteria were fully met for all data items (100%). However, in one of the participating centers, accuracy was only checked with respect to data related to vertebral injury and surgical intervention. The accuracy for Pousrina Hospital, which is outside of the Tehran collaborating center, was not measurable, and the need for improvement in this regard is clear. However, lack of original hard copies of patient documents (except for the documents of spinal cord injuries and their related intervention) made it improbable that our study would substantially increase accuracy at Pousrina Hospital.
According to Arts et al., there are two general types of data errors: systematic errors (e.g., programming errors, unclear definitions, or failure to comply with the data collection protocol) and random errors (e.g., inaccurate data transcription) [2]. Within this context, accuracy can be evaluated in two major fields: accuracy of data located in patient documents, and accuracy of data transfer from paper to digital forms. While our study mainly focused on the former [22], application of synthetic and semantic validation rules in registry software during the data assurance phase could reduce random errors during data transfer. Double-checking in the quality control phase was used for further improvement. Although a number of papers favored data entry by two independent persons and comparing datasets afterwards [23, 24], we proposed a different method to increase data accuracy and decrease time. In our method, data entry was performed by one person and subsequently double-checked by another; discordant data were reported to maximize accuracy without the implementation of resource-intensive strategies.
We checked data in patient documents to determine accuracy. For instance, we cross-referenced relevant demographic information in patient documentation with each patient’s ID, and have reached 100% precision for these demographic factors. This process was unreliable for past medical history and related information mainly due to the patient’s (and companions’) lack of information and situations such as unconsciousness. To overcome these obstacles, we believe that designing a system to collect all patient data and medical history in every hospital readmission is crucial to improve accuracy. This system required considerable resources to be designed that are not the subject of this study. Establishment of a connected electronic health record system that allows other hospitals at remote locations to access medical data may help assess and increase data accuracy derived from local centers.
Quality control of data entry was defined in different steps. The first step was designing procedural checkpoints to create a framework of data types, units of measurement, and value ranges. The second step involved use of input masks to ensure that the values entered would match our predefined format (e.g., ten-digit format for National ID numbers). The final step included the use of drop-down menus to avoid free text input (e.g., “Male” or “Female” for gender) [1]. We used these steps to augment the quality control process and to improve the quality of data entry.
Each of these three steps was implemented in our software design. We used semantic and synthetic rules for the first two steps, and for the third step we used drop-down menus, check boxes, and radio buttons to reduce the amount of free text as much as possible. Since two other studies support reducing the number of open-ended questions, we adopted the same approach and attempted to reduce the number of such questions [1, 25, 26]. However, the expansion of natural language processing resources in the near future might change the value of free text in electronic health records.
Despite these rules, some unpredictable errors in the data could not be avoided given that medical knowledge is necessary to identify certain inconsistencies and errors. Registrars may possess insufficient professional knowledge or expertize, thereby leading to inconsistent data entry that requires oversight by a medical professional.
We attempted to overcome this problem by verifying data consistency in the quality control phase; however, the main question remained unanswered: “Who is the most appropriate person for entering and double-checking data?” Some studies suggest training individuals in data collection and interpretation [27]. The same studies indicate that to standardize training, all involved personnel should be trained at a central location [27, 28]. In our study, we trained hospital staff from all centers with different levels of medical knowledge to enter data using our pre-defined processes and protocols. This strategy both satisfies the need for clinical knowledge and the need for entering several data points into a standard form. This also reduced the misinterpretation that often occurs in multi-center registries. Data in remote registry centers is often entered by different people with different educational backgrounds and at various levels of skills and expertize. Misunderstanding often occurs for the end user secondary to these discrepancies. Using our training, we tried to minimize the effect that different personnel has on data interpretation and to create a simple framework for data entry. In this study, the consistency of data was 100%, whereas two similar studies reported a consistency of 98.7% and 99.6% [29, 30]. This higher percentage is possibly due to our data being reviewed and verified by neurosurgeons.
Despite relative ease of registry implementation in our pilot study, extension of the registry on a larger scale may not result in similar outcomes. The ultimate solution to maintaining data entry consistency may be the development of an artificial intelligence algorithm that matches data from various sources and detects inconsistencies.
In an aboriginal health registry, Harper et al. reported completeness, consistency, and accuracy of 99%, 81.7%, and 94.8%, respectively [29]. Completeness and accuracy of data in a 2017 registry of children who underwent cardiac surgery were 94.7% and 98% [16]. Data consistency and completeness of a web-based stroke registry in Italy were 92% and 68%, respectively, before the implementation of validation rules on the system. These metrics improved to 100% and 97.2%, respectively, after administering such measures [1]. In our study, the completeness for major complications (e.g., pain, pressure ulcer, fever, spasm, and wound infection) was 100%, whereas in a recent study the completion rate was 93% [31].
In this article, completeness was calculated based on cases that our trained registrars reviewed, although completeness can be defined using all cases that are submitted. Completeness of all complications is almost impossible to achieve, as this task is time-consuming and effort-consuming. Inclusion of appropriate complications that are relevant to the outcome will improve the value of the registry.
Using an evidence-based chart to improve complication evaluation and identification would likely increase the quality and efficacy of our registry system. Considering that complications of various therapeutic interventions may occur at different stages, including the acute phase, this strategy would not only help detect these complications more efficiently, but also facilitate treatment in a timely fashion. These extremely limited findings with regard to complications also suggest that there are some inconsistencies in data collection. Although human error would likely remain, increasing the precision in data collection by designing a thorough complication list would minimize the risk of underestimating complication rate.
Conclusion
Our major goals of implementation of our registry were: (i) Attain 100% consistency rate, which compares favorably to similar studies, (ii) Decrease missing data to an acceptable rate despite the challenge of undocumented immigrants and incomplete patient documentation, and (iii) Achieves 100% accuracy of data registered in collaborating Tehran registry centers. It is reasonable to conclude that our solutions for quality assurance and consistency were fully effective. Regarding completeness, our solutions led to a decrease in missing data. Although solutions for quality assurance and accuracy were effective for registry centers in Tehran, it is necessary to develop an appropriate mechanism to control accuracy of recorded data by centers outside of Tehran.
Data archiving
Anonymous data of NSCIR-IR may be accessible for research use upon written request and approval from the steering committee.
References
Lanzola G, Parimbelli E, Micieli G, Cavallini A, Quaglini S. Data quality and completeness in a web stroke registry as the basis for data and process mining. J Healthc Eng. 2014;5:163–84.
Arts DG, De Keizer NF, Scheffer G-J. Defining and improving data quality in medical registries: a literature review, case study, and generic framework. J Am Med Inform Assoc. 2002;9:600–11.
Manya A, Nielsen P. Reporting practices and data quality in health information systems in developing countries: an exploratory case study in Kenya. J Health Inform Develop Countries. 2016;10:114–126.
Sáez C, Zurriaga O, Pérez-Panadés J, Melchor I, Robles M, Garcia-Gomez JM. Applying probabilistic temporal and multisite data quality control methods to a public health mortality registry in Spain: a systematic approach to quality control of repositories. J Am Med Inform Assoc. 2016;23:1085–95.
Calle J, Saturno P, Parra P, Rodenas J, Pérez M, San Eustaquio F, et al. Quality of the information contained in the minimum basic data set: results from an evaluation in eight hospitals. Eur J Epidemiol. 2000;16:1073–80.
Corrao S, Arcoraci V, Arnone S, Calvo L, Scaglione R, Di Bernardo C, et al. Evidence-based knowledge management: an approach to effectively promote good health-care decision-making in the information era. Intern Emerg Med. 2009;4:99–106.
Nobles AL, Vilankar K, Wu H, Barnes LE (eds). Evaluation of data quality of multisite electronic health record data for secondary analysis. IEEE International Conference on Big Data (Big Data). IEEE; 2015:2612–20.
Shimakawa Y, Bah E, Wild CP, Hall AJ. Evaluation of data quality at the Gambia national cancer registry. Int J Cancer. 2013;132:658–65.
Weiskopf NG. Enabling the reuse of electronic health record data through data quality assessment and transparency. Columbia University; 2015.
Batini C, Scannapieco M. Data and information quality. Cham, Switzerland: Springer International Publishing; 2016.
Bosch‐Capblanch X, Ronveaux O, Doyle V, Remedios V, Bchir A. Accuracy and quality of immunization information systems in forty‐one low income countries. Tropical Med Int Health. 2009;14:2–10.
Ledikwe JH, Grignon J, Lebelonyane R, Ludick S, Matshediso E, Sento BW, et al. Improving the quality of health information: a qualitative assessment of data management and reporting systems in Botswana. Health Res policy Syst. 2014;12:7.
Mphatswe W, Mate KS, Bennett B, Ngidi H, Reddy J, Barker PM, et al. Improving public health information: a data quality intervention in KwaZulu-Natal, South Africa. Bull World Health Organ. 2012;90:176–82.
Uenal H, Rosenbohm A, Kufeldt J, Weydt P, Goder K, Ludolph A, et al. Incidence and geographical variation of amyotrophic lateral sclerosis (ALS) in Southern Germany–completeness of the ALS registry Swabia. PLoS ONE. 2014;9:e93932.
Fararouei M, Marzban M, Shahraki G. Completeness of cancer registry data in a small Iranian province: a capture–recapture approach. Health Inf Manag J. 2017;46:96–100.
Nathan M, Jacobs ML, Gaynor JW, Newburger JW, Masterson CD, Lambert LM, et al. Completeness and accuracy of local clinical registry data for children undergoing heart surgery. Ann Thorac Surg. 2017;103:629–36.
Ostrom QT, Gittleman H, Kruchko C, Louis DN, Brat DJ, Gilbert MR, et al. Completeness of required site-specific factors for brain and CNS tumors in the Surveillance, Epidemiology and End Results (SEER) 18 database (2004-12, varying). J Neuro-Oncol. 2016;130:31–42.
Whitney CW, Lind BK, Wahl PW. Quality assurance and quality control in longitudinal studies. Epidemiol Rev. 1998;20:71–80.
Naghdi K, Azadmanjir Z, Saadat S, Abedi A, Habibi SK, Derakhshan P, et al. Feasibility and data quality of the National Spinal Cord Injury Registry of Iran (NSCIR-IR): a pilot study. Arch Iran Med. 2017;20:449–502.
Cruz-Correia RJ, Rodrigues PP, Freitas A, Almeida FC, Chen R, Costa-Pereira A. Data quality and integration issues in electronic health records. In: Hristidis V. (ed) Information discovery on electronic health records. Chapman and Hall/CRC; 2009, pp. 55–95.
Schuld C, Franz S, Brüggemann K, Heutehaus L, Weidner N, Kirshblum SC, et al. International standards for neurological classification of spinal cord injury: impact of the revised worksheet (revision 02/13) on classification performance. J Spinal Cord Med. 2016;39:504–12.
Mrcp JWD. Acquisition and use of clinical data for audit and research. J Evaluation Clin Pract. 1995;1:15–27.
Day S, Fayers P, Harvey D. Double data entry: what value, what price? Controlled Clin Trials. 1998;19:15–24.
Gissler M, Teperi J, Hemminki E, Meriläinen J. Data quality after restructuring a national medical registry. Scand J Soc Med. 1995;23:75–80.
Blumenstein BA. Verifying keyed medical research data. Stat Med. 1993;12:1535–42.
Teperi J. Multi method approach to the assessment of data quality in the Finnish Medical Birth Registry. J Epidemiol Community Health. 1993;47:242–7.
Hilner JE, McDonald A, Van Horn L, Bragg C, Caan B, Slattery ML, et al. Quality control of dietary data collection in the CARDIA study. Controlled Clin Trials. 1992;13:156–69.
Hlaing T, Hollister L, Aaland M. Trauma registry data validation: essential for quality trauma care. J Trauma Acute Care Surg. 2006;61:1400–7.
Harper S, Edge V, Schuster-Wallace C, Ar-Rushdi M, McEwen S. Improving Aboriginal health data capture: evidence from a health registry evaluation. Epidemiol Infect 2011;139:1774–83.
Sheridan R, Peralta R, Rhea J, Ptak T, Novelline R. Reformatted visceral protocol helical computed tomographic scanning allows conventional radiographs of the thoracic and lumbar spine to be eliminated in the evaluation of blunt trauma patients. J Trauma Acute Care Surg. 2003;55:665–9.
Gassman JJ, Owen WW, Kuntz TE, Martin JP, Amoroso WP. Data quality assurance, monitoring, and reporting. Controlled Clin Trials. 1995;16:104–36.
Acknowledgements
We would like to thank the Deputy of Research and Technology, Ministry of Health and Medical Education of Iran for supporting the NSCIR-IR. Also, we thank the Office of University and Industry Communication in Tehran University of Medical Sciences, and all experts who provided insight and expertize that greatly assisted the research.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
There are no conflicts of interest in this paper except ARV. ARV has these conflicts of interest: Royalties: Aesculap; Atlas Spine; Elsevier; Globus; Jaypee; Medtronics; SpineWave; Stryker Spine; Taylor Francis/Hodder and Stoughton; Thieme. Stock Options: Advanced Spinal Intellectual Properties; Avaz Surgical; Bonovo Orthopaedics; Computational Biodynamics; Cytonics; Deep Health; Dimension Orthotics LLC; Electrocore; Flagship Surgical; FlowPharma; Franklin Bioscience; Globus; Innovative Surgical Design; Insight Therapeutics; Nuvasive; Orthobullets; Paradigm Spine; Parvizi Surgical Innovation; Progressive Spinal Technologies; Replication Medica; Spine Medica; Spinology; Stout Medical; Vertiflex. The remaining authors declare that they have no conflict of interest.
Ethical approval
This study was approved by Research Ethics Committee of Tehran University of Medical Sciences as a part of National Spinal Cord Injury Registry (NSCIR-IR) study.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Derakhshan, P., Azadmanjir, Z., Naghdi, K. et al. The impact of data quality assurance and control solutions on the completeness, accuracy, and consistency of data in a national spinal cord injury registry of Iran (NSCIR-IR). Spinal Cord Ser Cases 7, 51 (2021). https://doi.org/10.1038/s41394-020-00358-2
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41394-020-00358-2
