



INTRODUCTION
Recent technical developments in the area of public health information infrastructure make it realistic to collect, structure, and statistically analyse infectious disease data in close to real time and in local public health contexts [Reference Timpka1]. Early knowledge of influenza epidemics in the community allows local epidemic alerts in primary care and hospital settings before the publication of regional data and could accelerate the implementation of preventive transmission-based precautions both within the local health care services and the community [Reference Gerbier-Colomban, Potinet-Pagliaroli and Metzger2]. In the past few years, a considerable amount of research has focused on developing statistical methods to identify aberrations in disease incidence data accurately and quickly [Reference Singh3–Reference Dórea5] as well as predicting epidemic progress [Reference Ohkusa6–Reference Shaman8]. Other researchers have focused on the use of alternative data sources, such as internet search engines [Reference Kim9,Reference Timpka10], mini-blogs [Reference Nagel11,Reference Yom-Tov12], and records from over-the-counter drug sales [Reference Kirian and Weintraub13,Reference Socan, Erculj and Lajovic14] with the goal of enhancing detection and prediction outcomes. However, few studies have compared the performance of different algorithms in routine practice using prospective designs. In a meta-narrative review of influenza detection and prediction algorithm evaluations in public health settings [Reference Spreco and Timpka15], only three studies covering seven detection algorithms and five studies covering nine prediction algorithms were found to have been performed using prospective designs. We inferred that further research is needed where algorithms are comparatively evaluated in parallel in the same setting using identical data.
The aim of this study was to perform a comparative trial of algorithms for the detection and prediction of influenza activity using local data from a county-wide public health information system.
METHODS
The study applied an accuracy trial design [Reference Bossuyt16] based on two streams of data used for routine influenza surveillance in a Swedish county (population 445 000): data on clinical diagnoses recorded by physicians and syndromic chief complaint data from a national telenursing service. The latter source has been found to provide indications of increased influenza activity up to 2 weeks ahead of the former [Reference Timpka10,Reference Timpka17]. The primary criteria for inclusion of an influenza detection or prediction algorithm were that it had been evaluated using authentic prospective data and the report had been published in a peer-reviewed scientific journal before 1 February 2016. The secondary criteria were that the algorithm (1) was to be applicable in county-level influenza surveillance, i.e. on unidimensional influenza data from a population of approximately 500 000 inhabitants, (2) it was sufficiently documented to be reproduced, (3) it could be calibrated using a maximum of one season of learning data, and (4) the detailed assumptions about data characteristics were compatible with the county-level data used for the evaluation. The study design was approved by the Regional Research Ethics Board in Linköping (dnr. 2012/104-31).
Data sources
The study data were collected from an electronic health data repository maintained by a Swedish county council [Reference Timpka1]. The repository collects data from all patient visits at health care facilities in the county and from calls made by county residents to the nation-wide telenursing service. For the study, influenza diagnosis codes (International Classification of Diseases, 10th Revision (ICD-10)/International Conference on Drugs and Pharmacological Classification (ICDPC) J10.0, J10.1, J10.8, J11.0, J11.1, J11.8, and J11.0-P) and telenursing chief complaints potentially associated with influenza, i.e. fever (adult, child), cough (adult, child), headache (adult, child), dyspnea, sore throat, vertigo, lethargy, and syncope were used. Collection of learning data used to calibrate the algorithms covered the winter influenza season of 2008–2009, starting from the end of the previous winter influenza season (4 May 2008 to 25 April 2009). Immediately after the end of the learning period, the evaluation period started, covering one pandemic outbreak and two winter influenza seasons (26 April 2009 to 19 May 2012) (Fig. 1). Because the evaluation period included both the pandemic outbreak and winter influenza seasons, it was divided into two parts; one part covered the pandemic outbreak and the other part covered the winter influenza seasons. The epidemic threshold was defined as two incident influenza diagnosis cases per 100 000 population recorded during a 7-day period.

Fig. 1. Weekly rates of influenza diagnosis cases (a) and telenursing calls for fever (child, adult) (b) in Östergötland County, Sweden, during the retrospective learning period from May 2008 to April 2009 (the gray marked area) and the prospective evaluation period from April 2009 to May 2012.
Evaluation procedure
For diagnostic data, the learning dataset was used to retrospectively decide parameter settings for the different detection and prediction methods. These parameters were then formatively applied in retrospective analyses using the learning dataset. For telenursing data, the learning set was first used to determine which time lag and grouping of chief complaints had the largest strength correlation with the diagnostic data. The chief complaint grouping with the largest correlation strength and best time lag was chosen for the following analyses. Thereafter the learning set was used to determine parameter settings for the different detection and prediction methods.
Detection performance was evaluated using measurements of sensitivity (the proportion of correctly identified weeks with increased influenza activity), specificity (the proportion of correctly identified weeks with no increased influenza activity), and timeliness (the time-difference between the observed and the predicted start of a period with increased influenza activity), whereas prediction performance was compared using Pearson correlation (r) and median absolute percentage error (MedAPE), both representing the association between predicted and observed time series of influenza activity.
In ranking the detection algorithms, specificity was given priority over sensitivity because a high level of false alarms is unacceptable in public health practice. If several algorithms performed similarly with regard to specificity and sensitivity; timeliness was used to decide which algorithm was superior. The calculation for specificity was based on the 10 weeks immediately before an epidemic and the calculation for sensitivity was based on the first 10 weeks of an epidemic. The reason why these measures were not based on entire datasets was that detection methods are primarily optimized to detect epidemics. The performance of an algorithm was considered acceptable if the specificity was at least 0·85 and the sensitivity was at least 0·80.
In the evaluation of prediction algorithms, the Pearson correlation coefficient (r) was used as the primary measurement of the association between observed and predicted values. The limits used to interpret the observed values were modified from the Cohen scale [Reference Cohen18], in which the limits 0·10, 0·30, and 0·50 were defined as small, medium, and large effect sizes. In this study, the limits were set at 0·70, 0·80, and 0·90 denoting acceptable, excellent, and outstanding predictive performance. The secondary evaluation measurement, MedAPE, is a measure of the accuracy of statistical methods for constructing fitted time series values [Reference Burkom, Murphy and Shmueli19]. For a perfect fit, MedAPE is 0; it has no restriction with regard to its upper level. MedAPE gives an idea of the typical percentage error and allows comparisons across different series. The combination of correlation and absolute percentage error (MedAPE before the median is calculated) has been used previously [Reference Jiang20].
Detection algorithms
Influenza detection was defined as indicating the initiation of a prolonged period on increased influenza activity in the population under surveillance. At the time of algorithm selection, seven influenza detection algorithms were found to have been evaluated using authentic prospective data. Four of these methods did not meet the secondary inclusion criteria. The algorithm based on the Kolmogorov–Smirnov test evaluated by Closas et al. [Reference Closas, Coma and Méndez21] was excluded because it was not applicable on streams of county-level influenza diagnosis data. This test assumes that the rate of influenza diagnosis cases in non-epidemic periods can be represented by a random variable (y) that is exponentially distributed. However, influenza diagnosis case rate data in local settings are in general represented by small integers during non-epidemic periods. Therefore, it is more reasonable to assume that the observations are Poisson distributed. The time series method based on a dynamic model [Reference Cowling22], was excluded for similar reasons, i.e. it requires that data follow a normal distribution. Finally, the two hidden Markov models evaluated by Martínez–Beneito et al. [Reference Martínez-Beneito23] were excluded because the algorithms partly relied on simulated data.
The three detection algorithms meeting the study criteria were Serfling regression [Reference Martínez-Beneito23,Reference Serfling24], ‘simple regression’ [Reference Cowling22,Reference Stroup25], and cumulative sum (CUSUM) [Reference Cowling22,Reference Martínez-Beneito23]. Serfling regression [Reference Martínez-Beneito23,Reference Serfling24] monitors the period when there is no increased influenza activity to determine a baseline defined by a fixed threshold. Defining
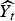 $\widehat{{Y_t}} $
as the number of influenza diagnosis cases (or telenursing calls), the model is defined as
$\widehat{{Y_t}} $
as the number of influenza diagnosis cases (or telenursing calls), the model is defined as
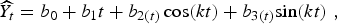 $$\widehat{{Y_t}} = b_0 + b_1 t + b_{2(t)} \cos (kt) + b_{3(t)} {\rm sin}(kt)\;, $$
$$\widehat{{Y_t}} = b_0 + b_1 t + b_{2(t)} \cos (kt) + b_{3(t)} {\rm sin}(kt)\;, $$
where b 0 is a constant intercept, b 1 is the slope of a long-term trend, and b 2(t), b 3(t) are coefficients for continuous harmonic terms representing seasonal trends, with k = (2π/(365 · 25/7)) to give a 1-year sinusoidal period of these terms. Using only the non-epidemic phases of the learning set, we first determined the coefficients mentioned above. Using these on the learning set, we searched for the optimal threshold α (the threshold that generates the highest sensitivity and specificity) which is based on the normal distribution, investigating α = 0 · 005, 0 · 010, … , 0 · 500.
Simple regression [Reference Cowling22,Reference Stroup25] raises an alarm if data from the current week fall outside a
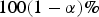 $100(1 - \alpha )\% $
forecast interval from a normal distribution with running mean
$100(1 - \alpha )\% $
forecast interval from a normal distribution with running mean
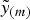 $\tilde y_{(m)} $
and running sample variance
$\tilde y_{(m)} $
and running sample variance
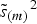 $\tilde s_{(m)}{} ^2 $
calculated from the preceding m weeks. The forecast interval is calculated as
$\tilde s_{(m)}{} ^2 $
calculated from the preceding m weeks. The forecast interval is calculated as
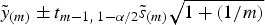 $\tilde y_{(m)} \pm t_{m - 1,\; 1 - \alpha /2} \tilde s_{(m)} \sqrt {1 + (1/m)} $
, where t
m−1,1−α/2 is the 100(1 − α)th percentile of the Student t-distribution with m − 1 degrees of freedom. Using the learning set, we searched for the parameter combination that resulted in the highest sensitivity and specificity for this algorithm, investigating all possible combinations of α = 0 · 005, 0 · 010, … , 0 · 500 and m = 3, 4, … , 10.
$\tilde y_{(m)} \pm t_{m - 1,\; 1 - \alpha /2} \tilde s_{(m)} \sqrt {1 + (1/m)} $
, where t
m−1,1−α/2 is the 100(1 − α)th percentile of the Student t-distribution with m − 1 degrees of freedom. Using the learning set, we searched for the parameter combination that resulted in the highest sensitivity and specificity for this algorithm, investigating all possible combinations of α = 0 · 005, 0 · 010, … , 0 · 500 and m = 3, 4, … , 10.
Using the CUSUM method [Reference Cowling22,Reference Martínez-Beneito23], an alarm is raised if the upper CUSUM
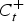 $C_t^ + $
exceeds a pre-specified threshold g. For the series of observations y
t
, t = 1, 2, … , the d-week upper CUSUM at time t,
$C_t^ + $
exceeds a pre-specified threshold g. For the series of observations y
t
, t = 1, 2, … , the d-week upper CUSUM at time t,
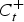 $C_t^ + $
is defined as
$C_t^ + $
is defined as
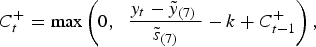 $$C_t^ + = {\rm max}\left( {0,\; \;\displaystyle{{y_t - \tilde y_{(7)} {\rm \;}} \over {\tilde s_{(7)}}} - k + C_{t - 1}^ +} \right),$$
$$C_t^ + = {\rm max}\left( {0,\; \;\displaystyle{{y_t - \tilde y_{(7)} {\rm \;}} \over {\tilde s_{(7)}}} - k + C_{t - 1}^ +} \right),$$
with
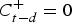 $C_{t - d}^ + = 0$
[Reference Montgomery26]. The running mean
$C_{t - d}^ + = 0$
[Reference Montgomery26]. The running mean
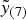 $\tilde y_{(7)} $
and running variance
$\tilde y_{(7)} $
and running variance
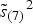 $\tilde s_{(7)}{} ^2 $
are calculated from the series of 7 weeks, y
i−d−7 , … , y
i−d−1 preceding the most recent d weeks. The d denotes the number of weeks excluded from the running mean and variance immediately before the index week. This is done in order to avoid contamination with the upswing of an epidemic [Reference Tokars27]. The parameter k represents the minimum standardized difference from the running mean, which is not ignored by the CUSUM calculation.
$\tilde s_{(7)}{} ^2 $
are calculated from the series of 7 weeks, y
i−d−7 , … , y
i−d−1 preceding the most recent d weeks. The d denotes the number of weeks excluded from the running mean and variance immediately before the index week. This is done in order to avoid contamination with the upswing of an epidemic [Reference Tokars27]. The parameter k represents the minimum standardized difference from the running mean, which is not ignored by the CUSUM calculation.
The CUSUM algorithm was evaluated in its original form and in two modified versions based on that the observations y follow a Poisson distribution. In the first modified version the variance is estimated by the sample mean, since the variance equals the expected value in a Poisson distribution. In the second modified version CUSUM at time t (C
t
) is expressed in terms of accumulated probability, namely
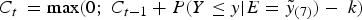 $C_{t\;} = {\rm max}(0;\;C_{t - 1} + P(Y \le y \vert E = \tilde y_{(7)} ) - \; k)$
where P is the Poisson probability function. The second suggested modification is an adaption to Poisson distributed data with so low expected values that normal approximation is inappropriate. In this case, the pre-specified alarm threshold (g) cannot be based on the normal distribution. Using the learning set, we searched for the parameter combination that generated the highest sensitivity and specificity for all three CUSUM methods, investigating all possible combinations of g = 0 · 00, 0 · 01, … , 20 · 00, k = 0 · 00, 0 · 01, … , 3 · 00 (k = 0 · 00 − 1 · 00 for the third method) and d = 0, 1, … , 4 for diagnostic data; and g = 0 · 00, 0 · 01, … , 100 · 00, k = 0 · 00, 0 · 01, … , 4 · 00 (k = 0 · 00 − 1 · 00 for the third method) and d = 0, 1, … , 4 for telenursing data.
$C_{t\;} = {\rm max}(0;\;C_{t - 1} + P(Y \le y \vert E = \tilde y_{(7)} ) - \; k)$
where P is the Poisson probability function. The second suggested modification is an adaption to Poisson distributed data with so low expected values that normal approximation is inappropriate. In this case, the pre-specified alarm threshold (g) cannot be based on the normal distribution. Using the learning set, we searched for the parameter combination that generated the highest sensitivity and specificity for all three CUSUM methods, investigating all possible combinations of g = 0 · 00, 0 · 01, … , 20 · 00, k = 0 · 00, 0 · 01, … , 3 · 00 (k = 0 · 00 − 1 · 00 for the third method) and d = 0, 1, … , 4 for diagnostic data; and g = 0 · 00, 0 · 01, … , 100 · 00, k = 0 · 00, 0 · 01, … , 4 · 00 (k = 0 · 00 − 1 · 00 for the third method) and d = 0, 1, … , 4 for telenursing data.
Prediction algorithms
Influenza prediction was defined as foretelling the amplitude and time span of a detected increase in influenza activity in a specified population. Nine influenza prediction algorithms were found to have been evaluated using authentic prospective data. Six of these did not meet the secondary inclusion criteria for this comparative trial. The Holt–Winters method (generalized exponential smoothing) [Reference Burkom, Murphy and Shmueli19] and the method of analogs [Reference Viboud28] were excluded because they required collection of learning data from more than one influenza season. The autoregressive model [Reference Viboud28] was excluded because the evaluation data did not comply with its detailed assumptions. A Bayesian network model [Reference Jiang20], a Shewhart-type algorithm [Reference Timpka17], and a multiple linear regression algorithm [Reference Yuan29] were excluded due to that they required access to multidimensional data, i.e. a syndromic data source to predict influenza case rates.
The first algorithm meeting the study criteria, non-adaptive log-linear regression, fits an ordinary least squares, log-linear model to a learning set to obtain regression coefficients [Reference Brillman30]. These coefficients are then used to forecast values beyond the learning data without adjusting for subsequent changes in time series behavior. Modified for weekly data, the model reads as follows:
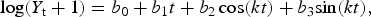 $$\log (Y_{\rm t} + 1) = b_0 + b_1 t + b_2 \cos (kt) + b_3 {\rm sin}(kt),$$
$$\log (Y_{\rm t} + 1) = b_0 + b_1 t + b_2 \cos (kt) + b_3 {\rm sin}(kt),$$
where Y t is the number of influenza diagnosis cases or telenursing calls on week t, b 0 is a constant intercept, b 1 is the slope of a long-term trend and b 2 and b 3 are coefficients for continuous harmonic terms representing seasonal trends, with
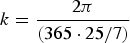 $$k = \displaystyle{{2\pi} \over {(365 \cdot 25/7)}}$$
$$k = \displaystyle{{2\pi} \over {(365 \cdot 25/7)}}$$
to give a 1-year sinusoidal period of these terms. The reason for transforming the original weekly counts into log scale is to capture a multiplicative nature of the effects of the trend and seasonal components.
The second algorithm, adaptive log-linear regression with a sliding 8-week baseline interval, recomputes the regression coefficients for each forecast using only the series values from the 8 weeks before the forecast week [Reference Burkom31]. The short baseline is intended to capture recent seasonal and trend patterns [Reference Burkom, Murphy and Shmueli19]. Modified for weekly data the model is described as follows:
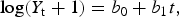 $$\log (Y_{\rm t} + 1) = b_0 + b_1 t,$$
$$\log (Y_{\rm t} + 1) = b_0 + b_1 t,$$
where Y t is the number of influenza diagnosis cases or telenursing calls in week t, b 0 is a constant intercept, and b 1 is the slope of a long-term trend. In Burkom et al. [Reference Burkom, Murphy and Shmueli19] a holiday indicator was added to avoid exaggerated holidays occurring in the short baseline interval; however, because weekly counts are used, the holiday effect are considered to be low or non-existing. Adjustments to the suggested models were made to fit weekly counts, due to that daily counts were used in Burkom et al. [Reference Burkom, Murphy and Shmueli19].
The final algorithm, the so-called naive method, predicts that a future incidence F is equal to a current incidence I, hence F(T + h) = I(T), where h ⩾ 1 and t is the current week number.
RESULTS
Retrospective algorithm calibration
When re-applied on the retrospective diagnostic data, four of the detections algorithms (Serfling regression and the three CUSUM methods) displayed a perfect performance (i.e. specificity and sensitivity 1·00 and timeliness 0 week) (Table 1), whereas the simple model performed weakly (specificity 0·90, sensitivity 0·70, and timeliness 23 weeks). Regarding the telenursing data, the grouping of telenursing chief complaints with the largest correlation strength on a weekly basis (r = 0·91; P < 0·001) and longest lead time (2 weeks) to diagnostic data in the retrospective dataset was fever (child, adult). Based on these observations, fever (child, adult) was chosen as the complaint grouping for use in the evaluations. The detection algorithms performing best on telenursing data were Serfling regression and the three CUSUM methods, although all displayed less accurate performance than for diagnostic data (specificity 1·00, sensitivity 0·80, and timeliness −2 weeks) (Table 1). The simple model also performed poorly for the telenursing data (specificity 0·90, sensitivity 0·50, and timeliness 12 weeks).
Table 1. Performance of influenza detection algorithms when retrospectively applied on the learning set of influenza diagnosis data and syndromic telenursing data

a Positive timeliness means that the alarm is raised before the epidemic has started (i.e. the alarm is raised too early) and negative timeliness means that the alarm is raised after the epidemic has started (i.e. the alarm is raised too late).
b One value stands out, otherwise the timelines would have been 0.
The prediction algorithm that performed best on the retrospective diagnostic dataset was non-adaptive log-linear regression (r = 0·72 for 2-week-ahead predictions and r = 0·57 for 4-week-ahead predictions) followed by the naive method (r = 0·62 for 2-week-ahead predictions and r = 0·29 for 4-week-ahead predictions) (Table 2). However, MedAPE for the non-adaptive log-linear regression was the poorest of the methods (0·92 for 2-week predictions and 1·00 for 4-week predictions). For the telenursing data, the algorithm with the notably best predictive performance was non-adaptive log-linear regression (r = 0·72 for 2-week predictions to r = 0·66 for 4-week predictions and MedAPE 0·15 for 2-week predictions and 0·16 for 4-week predictions) (Table 2).
Table 2. Performance of influenza prediction algorithms when retrospectively applied on the learning set of influenza diagnosis data and syndromic telenursing data

a The correlation coefficient (r) ranks the algorithms from highest (best) to lowest (worst) values, while MedAPE ranks them from lowest (best) to highest (worst) values.
b The method does not have the same learning set because it is adaptive, which means that the parameters are updated every week.
c The method has no learning set. The predicted value k weeks ahead is the same as the true value k weeks before.
Prospective evaluations of detection algorithms
In the comparative evaluation using diagnostic data, the best performing detection algorithms were Serfling regression for the winter influenza seasons (specificity 1·00, sensitivity 0·80, and timeliness −2 weeks) and the CUSUM Poisson (alternative 2) for the pandemic outbreak in 2009 (specificity 0·80, sensitivity 1·00, and timeliness 1 week) (Table 3).
Table 3. Performance of influenza detection algorithms when applied prospectively on influenza diagnosis data and syndromic telenursing data, respectively

a Positive timeliness means that the alarm is raised before the epidemic has started (i.e. the alarm is raised too early) and negative timeliness means that the alarm is raised after the epidemic has started (i.e. the alarm is raised too late).
b The mean of the absolute values.
c An alarm is never raised.
In the corresponding evaluation using the syndromic telenursing data, none of algorithms displayed a satisfactory performance. The algorithm performing best was Serfling regression with specificity 1·00, sensitivity 0·55, and timeliness −4 weeks for the winter influenza seasons and specificity 1·00, sensitivity 0·70, and timeliness −2 weeks for the pandemic outbreak (Table 3).
Prospective evaluations of prediction algorithms
The best performing prediction algorithm based on diagnostic data for the winter influenza seasons was non-adaptive log-linear regression (r = 0·77 for 2-week-ahead predictions, r = 0·76 for 4-week-ahead predictions, and MedAPE varying from 0·75 for 2-week predictions to 0·77 for 4-week predictions) (Table 4). For the pandemic outbreak in 2009, none of the algorithms provided satisfactory evaluation outcomes.
Table 4. Performance of influenza prediction algorithms when applied prospectively on influenza diagnosis data and syndromic telenursing data, respectively

a The correlation coefficient (r) ranks the algorithms from highest (best) to lowest (worst) values, while MedAPE ranks them from lowest (best) to highest (worst) values.
b The method does not have the same learning set because it is adaptive, which means that the parameters are updated every week.
c The method has no learning set. The predicted value k weeks ahead is the same as the true value k weeks before.
For the syndromic telenursing data, the best prediction algorithm for the winter influenza seasons was non-adaptive log-linear regression (r = 0·77 for 2-week predictions, r = 0·69 for 4-week predictions, and MedAPE varying from 0·17 for 2-week-ahead predictions to 0·20 for 4-week-ahead predictions) (Table 4). Acceptable performance was also displayed for 2-week-ahead predictions for the naive method (r = 0·74 and MedAPE = 0·17). For the pandemic outbreak in 2009, the algorithms produced lower correlations; the highest correlation was r = 0·52 for the naive method for 2-week-ahead predictions.
DISCUSSION
The aim of this study was to perform a comparative trial of algorithms for the detection and prediction of increases in local influenza activity using data streams from a county-wide health information system. Among the detection algorithms evaluated, we found that only the Serfling regression displayed satisfactory performance when applied to influenza diagnosis data during winter influenza seasons. Concerning the evaluated prediction algorithms, the non-adaptive log-linear regression showed acceptable performance when applied both to influenza diagnosis data as well as to syndromic telenursing data. Among the remaining two algorithms, acceptable performance was only displayed for 2-week-ahead predictions for the naive method when applied to syndromic data. It has been pointed out that parametric methods are not suitable when the parameters describing the incidence curve vary considerably from year to year [Reference Andersson, Bock and Frisén32–Reference Schiöler34], as is the case with winter influenza seasons [Reference Timpka35]. However, the results of this study show that Serfling regression, a parametric detection method, and non-adaptive log-linear regression, a parametric prediction method, displayed satisfying performance when applied to local influenza diagnosis data. These observations suggest that parametric methods may be considered, although carefully, when developing methods for use in influenza epidemic detection and prediction at local level.
Several factors could explain some of the poor performances of the algorithms observed in this study. One reason for the poor performance of the detection algorithms when applied to the syndromic telenursing data is that most of the evaluated algorithms were threshold based, whereas the baseline of the telenursing data had an increasing trend. For instance, the average number of calls to the telenursing service during the intermittent period before the winter influenza season in 2011–2012 had increased by nearly 18% compared with the corresponding number of calls during the intermittent period before the winter influenza season in 2010–2011 (Fig. 1). When using the learning set of telenursing data to calibrate the algorithms, the thresholds were set lower than would have been optimal for the algorithms to perform well during the evaluation period. In particular, this was reflected in the sensitivity outcomes because low thresholds that lack empirical foundation make the calibrated algorithms excessively sensitive for raising alarms. The need for regular pre-processing of syndromic data, correcting for issues such as daily autocorrelations, seasonal trends and day-of-the-week effects, has previously been emphasized [Reference Lotze, Murphy and Shmueli36]. For instance, in Timpka et al. [Reference Timpka17], a baseline temporal trend of telenursing calls was estimated in the retrospective data using linear regression (y = b 0 + b 1 t (where y is the incidence, b 0 is the intercept, b 1 is the slope, and t the time unit)) and corrected for. It has also been shown that algorithms applied to syndromic data demonstrate the best performance in specific settings, for example, depending on the shapes of the epidemic signal [Reference Buckeridge37]. These experiences indicate that application of detection algorithms prospectively on syndromic data is a complex enterprise that requires consideration of pre-processing the data streams and combining detection approaches, rather than aspiring to apply one best algorithm on unprocessed unidimensional data [Reference Dórea38]. However, it should be taken into account that combined detection approaches may lead to a decreased specificity for the system as a whole [Reference Dohoo, Martin and Stryhn39].
This study has both strengths and limitations that need to be taken into account when interpreting the results. It is one of the first studies to use real empirical data for side-by-side evaluation of influenza detection and prediction algorithms in a prospective setting. Use of real data for algorithm evaluations has been recommended, because the characteristics of baseline conditions in public health practice, such as temporal patterns and noise, are likely to have an influence on algorithm performance [Reference Buckeridge40]. Regarding the limitations of the study, it should be taken into consideration that although some consensus regarding measurements to be used in the evaluation of detection algorithms exists [Reference Unkel41], this is not the case for the evaluation of prediction algorithms. For the evaluation of prediction algorithms, we chose the combination of the Pearson correlation coefficient (r) and MedAPE, where the correlation measure estimated how well the predicted time series followed the observed time series and the MedAPE measure estimated the deviance of the level of the predicted time series on the y-axis from the observed level. Alternative or additional measurements include the median absolute deviation and root-mean-squared error [Reference Burkom, Murphy and Shmueli19], but we believe that the two measurements used in this study provide a sufficiently valid and accurate description of prediction performance. Moreover, because long-term data series of constant quality are seldom available at present at local public health levels, only data from one season were used for algorithm learning. Several interesting algorithms were therefore excluded, and some of the algorithms would probably show a better performance with a longer time period for collection of learning data. This scarcity of longitudinal data is a recognized problem in the evaluation of influenza detection systems [Reference Lotze, Kass-Hout and Zhang42]. Data simulation has been used to solve this data shortage problem; the main remaining challenge is replicating the complexity of both baseline and epidemic data streams [Reference Buckeridge43,Reference Buckeridge44]. Similarly, algorithms reported only from theoretical settings were excluded, with corresponding implications. In addition, the calculation of specificity was based on the 10 weeks immediately before an observed epidemic and the calculation of sensitivity was based on the first 10 weeks of an observed epidemic. The reason why these measures were not based on entire datasets was that detection methods are primarily optimized to detect epidemics. Evidently, including longer time periods before and during influenza epidemics would have generated higher evaluation values. Although other selections and computation methods could have generated dissimilar results, we believe that the definitions using fixed time periods are valid for the comparative analyses performed in the present study.
We conclude that among the algorithms evaluated, Serfling regression as detection algorithm and non-adaptive log-linear regression as prediction algorithm displayed satisfactory performance when applied on diagnostic data during winter influenza seasons in a local public health setting. When applied on syndromic data, satisfactory performance was shown only for the non-adaptive log-linear regression method among the prediction algorithms evaluated, while all of the detection algorithms evaluated showed poor performance. During the 2009 pandemic outbreak, the evaluated algorithms generally displayed poor performance. Both further evaluation research and research on combination of methods of these types in public health information infrastructures for ‘nowcasting’ (integrated detection and prediction) of influenza activity is warranted.
AUTHOR CONTRIBUTIONS
A.S., O.E., Ö.D., and T.T. conceived and designed the study. A.S., O.E., and Ö.D. analyzed the data. A.S., O.E., Ö.D., and T.T. contributed materials/analysis tools. A.S. and T.T. wrote the paper. Ö.D. and O.E. revised the manuscript and provided intellectual content. A.S., O.E., Ö.D., and T.T. gave final approval of the version to be published. T.T. is the guarantor of the content.
ACKNOWLEDGEMENTS
This study was supported by grants from the Swedish Civil Contingencies Agency (2010-2788) and the Swedish Research Council (2008-5252). The funders had no role in the study design, data collection and analysis, decision to publish, or preparation of the manuscript.
DECLARATION OF INTEREST
None.





