
Abstract
Introduction
Identifying individual characteristics or underlying conditions linked to adverse drug reactions (ADRs) can help optimise the benefit–risk ratio for individuals. A systematic evaluation of statistical methods to identify subgroups potentially at risk using spontaneous ADR report datasets is lacking.
Objectives
In this study, we aimed to assess concordance between subgroup disproportionality scores and European Medicines Agency Pharmacovigilance Risk Assessment Committee (PRAC) discussions of potential subgroup risk.
Methods
The subgroup disproportionality method described by Sandberg et al., and variants, were applied to statistically screen for subgroups at potential increased risk of ADRs, using data from the US FDA Adverse Event Reporting System (FAERS) cumulative from 2004 to quarter 2 2021. The reference set used to assess concordance was manually extracted from PRAC minutes from 2015 to 2019. Mentions of subgroups presenting potential differentiated risk and overlapping with the Sandberg method were included.
Results
Twenty-seven PRAC subgroup examples representing 1719 subgroup drug–event combinations (DECs) in FAERS were included. Using the Sandberg methodology, 2 of the 27 could be detected (one for age and one for sex). No subgroup examples for pregnancy and underlying condition were detected. With a methodological variant, 14 of 27 examples could be detected.
Conclusions
We observed low concordance between subgroup disproportionality scores and PRAC discussions of potential subgroup risk. Subgroup analyses performed better for age and sex, while for covariates not well-captured in FAERS, such as underlying condition and pregnancy, additional data sources should be considered.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
There is a lack of validated statistical methods that could help identify subgroups defined by characteristics such as age, sex and underlying conditions, and that might be at increased risk of adverse drug reactions. |
We tested one of the few available first-pass screening subgroup methods using a large, diverse dataset of spontaneous adverse event reports (US FDA Adverse Event Reporting System [FAERS]). |
Our study showed apparent low concordance between disproportionality scores calculated by subgroup analysis using FAERS and a reference set (European Medicines Agency Pharmacovigilance Risk Assessment Committee discussions of subgroup risk). |
Age and sex were better captured within FAERS and showed relatively better concordance among the different covariates tested. Covariates such as pregnancy and underlying condition might benefit from enrichment with additional data sources, such as electronic healthcare records data. |
1 Introduction
The response to a drug or vaccine includes both therapeutic effects and potential adverse drug reactions (ADRs); the magnitude of such effects can be highly heterogeneous across patient subgroups [1]. If responses are significantly associated with known subgroup characteristics, such as age, sex or underlying condition, prescribers can use this information to identify individuals who are more likely to experience ADRs, and thus optimise the benefit–risk ratio for a given patient.
Associations between patient characteristics and ADRs are well understood in some cases and can be used to inform clinical decisions. For instance, the drug rasburicase is used to prevent and treat tumour lysis syndrome, which is an oncological emergency in patients with certain solid tumours or haematological malignancies [2]. However, rasburicase is contraindicated in patients with glucose-6-phosphate dehydrogenase (G6PD) deficiency because of an increased risk of haemolysis (rupturing of red blood cells) [2]. Thus, it is recommended that clinicians screen patients at high risk for G6PD deficiency, such as those of African or Mediterranean ancestry [3]. ADRs can also be associated with the sex of the patient. For example, young adult male patients are at increased risk of myocarditis associated with coronavirus disease 2019 (COVID-19) vaccination [4,5,6]. Conversely, female sex has been identified as a risk factor for drug-induced QT prolongation and Torsades de pointes [7,8,9], as well as congenital long-QT syndrome [10]. Additionally, lower doses of the hypnotic agent zolpidem are recommended for women, who eliminate zolpidem more slowly and are more prone to impairment of daytime activities than men [11].
Early in the drug development process, preclinical pharmacodynamic and pharmacokinetic data are used to model the risk of ADRs in human subjects [12,13,14]. The focus shifts to empirical evidence once a drug or vaccine enters human trials [15, 16]. Sometimes, rare but serious ADRs are recognised only after a drug is approved and marketed and appropriate steps are taken to minimise the risk [17].
Spontaneous reporting systems for adverse events (AEs) are the mainstay of postmarketing safety surveillance [18, 19]. Because of the large volume of spontaneous reports, pharmaceutical companies and regulators use quantitative signal detection methodologies, mostly based on disproportionality analysis, to identify potential ADRs, which subsequently undergo a focused clinical review [18, 20,21,22]. Quantitative signal detection is usually broadly applied to AE reporting datasets and often adjusts for potential confounders based on stratification. However, this one-size-fits-all approach for stratification does not account for all the confounding in spontaneous AE reports and can therefore be misleading. It has been demonstrated that subgroup analyses can perform better than methods adjusted by stratification [21, 23,24,25] and potentially address modifying effects that might underly the AE data. Nevertheless, there is currently a lack of systematic subgroup analyses for first-pass screening and, when employed, subgroup analyses are often limited to specific demographic characteristics [26,27,28]. Quantitative screening for a broad range of covariates in this context has recently been proposed [29]. This approach could be burdened by limitations related to the specificity of spontaneous reporting, such as lack of certain data needed to characterise subgroups, non-random reporting of specific elements on the spontaneous report, as well as a low number of AE reports for recently launched products or products with narrow indications or low exposure. However, subgroup analysis could enable safety reviewers to efficiently screen large amounts of data to identify subgroups that may be at greater risk.
In this study, we aimed to examine the extent to which subgroup analysis can serve as a first-pass quantitative signal detection method in screening spontaneous AE reports. We also aimed to examine the potential limitations of spontaneous AE data sources that might influence the ability to identify subgroup statistical signals, such as missing data elements required for subgroup differentiation and subsequently point to ways to improve high-risk subgroup identification. To this end, we compiled a reference set of AEs, which we defined as any AE discussed within the context of differentiated subgroup risk in European Medicines Agency (EMA) Pharmacovigilance Risk Assessment Committee (PRAC) meeting minutes from 2015 to 2019. We then applied a recently published quantitative approach for subgroup analysis [29] across a large and diverse dataset of AE reports and examined whether we could detect the reference set of a priori identified AEs.
2 Methods
2.1 US FDA Adverse Event Reporting System (FAERS) Dataset
US FDA Adverse Event Reporting System (FAERS) data cumulative from 2004 through the second quarter of 2021 were used for the analyses. All records in which the product was reported as suspect or interacting (but not concomitant) were included. The analyses were performed on all events at the Medical Dictionary for Regulatory Activities (MedDRA®; version 24.0) Preferred Term (PT) level and on all mapped products at their active moiety level. The data were standardised and deduplicated. Active moieties were derived, in alignment with the FDA’s definition [30], by Commonwealth Informatics in the same manner as the commercially available signal management platform Commonwealth Vigilance Workbench.
Specifically, drug name cleaning was performed by processing their source values through successive mappings, including uppercasing; removing excess whitespace, quotes, parentheses, trailing periods and commas, outer square brackets, braces, etc.; removing certain literals and variants thereof (e.g. ‘tablet’, ‘caplet’, ‘capsule’, ‘unknown’, ‘formulation’, ‘generic’, ‘nos’, etc.); removing units such as ‘mg’ and ‘milligrams’; and changing backslashes to forward slashes. The adjusted verbatim drug names were then mapped to product active ingredients according to known verbatim-active ingredients mappings. Any remaining unmapped verbatim drug names were assigned to the literal ‘UNMAPPED’ and excluded from the analysis.
Duplicate detection was performed after all other data transformation and standardisation was complete. A large number of candidate duplicate pairs were initially generated based on a set of simple heuristic rules. These candidate pairs were then scored by implementing a quantitative method based on the hit-miss algorithm previously described [31]. Briefly, the method generates a score correlated to the statistical likelihood that two different reports represent two versions of the same underlying case. Pairs with a score above a selected threshold are considered true duplicates. Finally, the individually identified duplicate pairs are ‘coalesced’ into duplicate groups (consisting of two or more case reports) to address multiple duplicates for a given case report.
2.2 Reference Set
2.2.1 Initial Reference Set
The PRAC meeting minutes from 2015 to 2019 were downloaded from the EMA website to extract the reference set of positive controls for this study. PRAC meetings aim to evaluate data from all sources, including spontaneously reported suspected ADRs and results from interventional and observational studies that offer important data for signal detection. The PRAC discusses the prioritisation of emerging safety signals and issues recommendations required for their management, such as further investigation or drug labelling changes [32]. The minutes were reviewed independently by two healthcare professionals to identify any discussion of an AE associated with the use of a drug and the potential for a differentiated risk in particular subgroups. Neither the context of the discussion (e.g. signal detection, signal validation, signal assessment or hypothesis testing) nor the trigger (e.g. case reports, clinical trials or epidemiological studies) were considered for the purpose of identifying these subgroup examples.
Only subgroups corresponding to those defined by Sandberg et al. [29] (Table 1) were considered for inclusion in the subgroup analyses. Subgroups mentioning products in development or vaccines were excluded from the reference set as they are rarely listed in FAERS. The included subgroups will be referred to as PRAC subgroup examples.
2.2.2 Mapping of Drugs, Events and Subgroups
The drugs and events discussed in the PRAC subgroup examples did not fully correspond to the drug and medical ontologies used to code the FAERS data. For instance, a group of drugs rather than a specific drug may have been discussed or generic medical nomenclature rather than specific MedDRA® terms may have been used to describe events in PRAC examples. Additionally, the subgroups discussed by PRAC may not be readily identifiable in the AE reporting data set (e.g. pregnancy).
Where needed, events described in PRAC subgroup examples were independently mapped to MedDRA® PTs available in FAERS by two drug safety experts. The two mappings were then jointly reviewed by the experts and consensus was reached.
Where needed, drugs described in PRAC subgroup examples were independently mapped to the active moieties available in FAERS by two drug safety experts. As for events, the two mappings were then jointly reviewed by the experts and consensus was reached.
PRAC subgroups were mapped to subgroups defined by Sandberg et al. [29]. Because the raw narratives were not available in the FAERS data used for this study, identifying cases for the pregnancy subgroup was challenging. Therefore, a slightly adapted algorithm was needed. Upper case MedDRA® PTs that included the substrings of ‘PREGN’ or ‘GESTAT’ or ‘GRAVID’ or ‘MATERN’ or ‘LABOUR’ and excluded terms such as ‘Pregnancy test negative’, ‘Pregnancy test false positive’ and ‘Pregnancy test urine negative’ were used to identify potential pregnancy cases. Additionally, the reported case must have concerned a woman between the age of 15 and 44 years. However, if the MedDRA® PT fell under the MedDRA® High Level Term ‘Unintended pregnancies’, these were excluded. This algorithm was used only to identify cases for the pregnancy subgroup and not to identify pregnancy-related AEs.
2.3 Subgroup Analysis
Subgroup disproportionality scores were computed on the overall FAERS data using the method described by Sandberg et al. [29]. This method is based on the Information Component, which is the binary logarithm of a shrunk disproportionality data mining algorithm comparing the observed (O) number of reports for a given drug–event combination (DEC) with an expected (E) number of reports estimated from the overall database, and is fully described elsewhere [33]. Briefly, subgroup disproportionality scores were obtained by restricting the O/E ratio computation to the subgroups of interest. No combinations of the subgroup covariates were considered and no further adjustment was performed within the subgroups. Bayesian credibility intervals were computed and the lower limit of 95% credibility intervals was used to set the threshold for signal detection. For subgroup analyses, broader credibility intervals were used [29] compared with the intervals reported by Norén et al. [33] to control for the rate of spurious associations due to multiple comparisons [34]. The requirements reported by Sandberg et al. were used to identify subgroup signals, followed by sensitivity analyses using algorithm adaptations (Table 2). The analyses were run in Azure Databricks using PySpark.
2.4 Assessment of Concordance
Concordance was determined at two different levels: at the subgroup example level, requiring just one of the PRAC subgroup DECs to be detected in FAERS to consider the subgroup example detected; and at the subgroup DEC level, assessing for each PRAC subgroup DEC whether it was detected in FAERS or not. Because the PRAC examples included combinations of covariates (i.e. age and underlying condition, sex and underlying condition, sex and age) but no combinations were considered for the subgroup analysis in FAERS, these examples were considered independently for each covariate. For instance, an example representing age and underlying condition was tested once for age and once for underlying condition.
3 Results
3.1 Reference Set
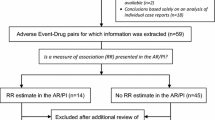
Review of the PRAC meeting minutes from 2015 to 2019 allowed retrieval of 52 subgroup examples (Fig. 1). Four PRAC subgroup examples that mentioned drugs pertaining to classes or events with different aetiology or biological mechanisms were split further, leading to the addition of seven PRAC subgroup examples and bringing the total to 59 examples.

PRAC subgroup examples (attrition diagram). FAERS Food and Drug Administration Adverse Event Reporting System, PRAC Pharmacovigilance Risk Assessment Committee
One PRAC subgroup example was excluded because it described an AE following vaccination. Twenty-four PRAC subgroup examples were excluded from the analysis, 8 because of duplicates and 16 because the subgroups mentioned in the minutes were not considered by Sandberg et al. [29], i.e. AE in offspring from exposure during pregnancy or AE resulting from concomitant use of another substance (Fig. 1). All drugs discussed in the included PRAC subgroup examples are approved for similar indications in the EU and US. After the mapping to FAERS active moieties and MedDRA® PTs, seven PRAC subgroup examples were excluded because the corresponding subgroup DECs were not reported in the FAERS database. Six of the seven were reported as DECs but not for the subgroup described in the PRAC minutes, and one was not reported as a DEC but was reported independently as a drug and an event.
Eventually, 27 PRAC subgroup examples were included in the analyses (Table 3). The drugs, medical concepts and subgroups described in these 27 examples were mapped to FAERS active moieties, MedDRA® PTs and subgroups as described in Sect. 2.2.2, resulting in 1719 subgroup DECs included in the analysis (Online Resource Table 1).
The 27 PRAC subgroup examples were dominated by age and underlying condition, with underlying condition less dominant when considering the number of subgroup DECs (Table 3). These included subgroup examples that were triggered from case reports, clinical trials and epidemiological studies (Fig. 2). Age was mentioned in 22 PRAC subgroup examples (1028 subgroup DECs), with only 11 exclusively about age (Table 4). Ten PRAC subgroup examples referred to underlying conditions (385 subgroup DECs), but only one exclusively mentioned underlying condition. Of the six PRAC examples mentioning sex as a subgroup (305 subgroup DECs), only two exclusively mentioned sex. Pregnancy was described in only one PRAC example (and only one subgroup DEC) that focused on exposure and harm to the mother. None of the PRAC subgroup examples specifically described countries or regions or referred to body mass index (BMI). Therefore, no country, region or BMI subgroupings were included in the present analysis. However, these covariates were, to some extent, available in FAERS. Country was reported in 98% of reports, and regions could be derived from countries. BMI, although not readily available in FAERS, could be approximated by the weight that was reported in 21% of reports. Height was not available in the version of FAERS used for this analysis but would be available in other spontaneous report systems.

Distribution of PRAC subgroup examples per trigger category
3.2 Availability of Subgroups in FAERS
Age was reported in 58% of FAERS cases, with adult categories being predominant (Online Resource Table 2). There were more than 5×106 subgroup DECs in FAERS for age, for approximately 7.5×106 AE reports with age known. Sex was provided in 89% of FAERS reports (Online Resource Table 2), with women representing 61% of reports where sex was known. Sex corresponded to more than 4×106 subgroup DECs in FAERS, with a total of approximately 11.6×106 reports where sex is known. The underlying condition was approximated by all-drugs indication reported in the cases and at least one drug indication was reported in 88% of FAERS cases, of which 77% reported only one drug indication (Online Resource Table 2). There were more than 19×106 drug indication subgroup DECs in FAERS, for a total of 11.5×106 reports with at least one drug indication. Finally, pregnancy cases represented 0.5% of FAERS reports (Online Resource Table 2) and translated to 129,826 subgroup DECs in FAERS.
3.3 Concordance Between FAERS Subgroup Signals and Pharmacovigilance Risk Assessment Committee (PRAC) Subgroup Examples
3.3.1 Subgroup Example Level
Overall, 2 of the total 27 PRAC subgroup examples (7%) were detected in FAERS when applying the Sandberg subgroup methodology (Table 3). Looking at each covariate, 1 of the 22 (5%) and 1 of the 6 (17%) PRAC subgroup examples for age and sex, respectively, were detected. For underlying condition and pregnancy, none of the 10 and none of the 1 PRAC subgroup examples, respectively, were detected. When relaxing the requirement for subgroup signals to not be disproportionately reported in the entire database (i.e. removal of the requirement that IC025 for the entire database ≤ 0), 14 of the 27 (52%) PRAC subgroup examples were detected, with 10 of 22 (45%), 5 of 6 (83%), 1 of 10 (10%) and 1 of 1 (100%) examples detected for age, sex, underlying condition and pregnancy, respectively (Table 3). This suggests that when a subgroup example from the PRAC discussions was a subgroup statistical signal, it could have initially been identified by an overall statistical signal, at the DEC level, and then the stratum-specific effect identified as a second step. The detected examples included subgroups triggered from case reports, clinical trials and epidemiological studies (Fig. 2). None of the other adjustments to the requirements reported by Sandberg et al. [29] for sensitivity analyses had a significant impact on detection (Table 3).
3.3.2 Subgroup Drug–Event Combination (DEC) Level
When moving from the subgroup example level to the subgroup DEC level, only 2 of the 1719 PRAC subgroup DECs (0.1%) were detected by applying the Sandberg subgroup methodology [29] to FAERS data (Table 3). One of 1028 (0.1%) and 1 of 305 (0.3%) subgroup DECs for age and sex, respectively, were detected. None of the 385 and none of the 1 PRAC subgroup DECs were detected for underlying condition and pregnancy, respectively. Increased concordance was achieved when a subgroup signal was considered detected regardless of whether it was disproportionately reported in the entire database (i.e. removal of the requirement that IC025 for the entire database ≤ 0). In this case, 170 of the 1719 PRAC subgroup DECs (10%) were detected, but at the cost of generating more subgroup signals (increased from 193,656 to 1,312,922). When relating to patient’s age, sex, underlying condition, and pregnancy status, 69 of 1028 (7%), 75 of 305 (25%), 25 of 385 (6%), and 1 of 1 (100%) subgroup DECs were detected, respectively. The poorer performance at this level compared with the subgroup example level is explained by the low specificity of the PRAC subgroup discussions that led to dilution of the effect across the many MedDRA® PTs and drug active moieties, and, subsequently, decreased detection power.
3.4 Post Hoc Sensitivity Analysis
3.4.1 Restriction of PRAC Subgroup Examples
Some of the PRAC subgroup examples could not be rigorously analysed in the same way as the subgroup statistical alerts for which the Sandberg methodology was proposed. Hypothesizing that excluding such subgroups might improve the performance, a post hoc sensitivity analysis was performed in which the following PRAC subgroup examples were excluded.
-
Any PRAC example where only one subgroup had the ability to be exposed to the drug or to experience the event (e.g. risk of developing ovarian macrocysts in women exposed to mitotane). Despite subgroup analyses being more appropriate in these situations, it cannot be argued that there is a differentiated risk in the subgroups of the same covariate.
-
Any PRAC example where the subgroups were conditional, i.e. they involved two different covariates (Table 4; e.g. adults [age] with pulmonary hypertension associated with idiopathic interstitial pneumonia [underlying condition] experiencing an increased risk of mortality when exposed to riociguat). Given that combinations of covariates were not considered in the study by Sandberg et al. [29], these were assessed independently for each covariate, thereby applying an approach using ‘OR’ instead of ‘AND’; however, this led to considerable deviation from the subgroup signals initially discussed in the PRAC meeting minutes.
3.4.2 Results at Subgroup Example Level
Applying these additional exclusion criteria, our sample of PRAC subgroup examples was reduced from 27 to a smaller sample size of 11. Of those 11, one (9%) was detected using the Sandberg methodology. When considered regardless of whether they were disproportionately reported in the entire database, two examples (18%) were detected as subgroup signals. These represented 2 of 10 PRAC examples (20%) for age and none for the one underlying condition PRAC example. The main reasons that nine subgroup examples were not detected by the latter approach were that the number of observed cases for the subgroup DECs was small and with broad credibility intervals (7 of 9), the subgroup DECs were not reported more than expected (1 of 9) and the O/E ratios for the subgroups were not substantially different from the O/E ratios for the remainder of the database (i.e. ICΔ ≤0; 1 of 9).
3.4.3 Results at Subgroup DEC Level
The remaining 11 PRAC subgroup examples represented only 70 subgroup DECs. One of 70 (1%) PRAC subgroup DECs was detected in FAERS using the Sandberg method [29]. When examined regardless of whether they were disproportionately reported in the entire database, four subgroup DECs were detected, all of which related to age (4 of 69 [6%]).
4 Discussion
Subgroup analyses can be of vital importance in postmarketing safety surveillance to identify subgroups at higher risk of developing specific ADRs. Currently, both a widely accepted gold standard to assess quantitative signal detection methods [35] and systematic assessment of the extent to which quantitative data mining on spontaneous reports correlates with subgroup safety risk differences are lacking. In this study, we applied a recently published method [29] that describes first-pass screening subgroup analysis for a variety of risk factors, to a large AE dataset. To test this methodology, FAERS data were selected because they include more than 13 × 106 reports, are public domain, are widely used for method testing and contain a diverse set of medications, albeit not vaccines. In the absence of any gold-standard reference set for the subgroup analyses, the PRAC subgroup examples were selected as a reference set. They were chosen because they are externally recognised, are in the public domain and are not reliant on spontaneous reporting. They constitute a valuable independent reference set of safety concerns that warrant discussion by a regulatory body, regardless of future labelling status. To our knowledge, this is the first study to evaluate the Sandberg subgroup method [29] and report on its ability to detect subgroups of potential increased risk across a large, diverse dataset. Our analysis demonstrated that the subgroup methodology detected PRAC subgroup examples in FAERS with a low sensitivity (7% at subgroup example level and 0.1% at subgroup DEC level).
Removing the requirement of the Sandberg methodology for signals to not be disproportionately reported overall, not only improved the sensitivity (from 7 to 52% at the subgroup example level and from 0.1 to 10% at the subgroup DEC level) but also generated more subgroup signals from FAERS data. It resulted in improved sensitivity for age and sex (detection of 45% and 83% at the subgroup example level and 7% and 25% at the subgroup DEC level, respectively). However, it should be noted that those signals would have been identified as DECs by routine disproportionality analysis and subsequently used by safety reviewers to identify subgroups disproportionately reported and potentially responsible for the overall disproportionality. Eighty-one percent of the DECs detected by this adapted subgroup methodology would have been detected by routine overall disproportionality analysis. Conversely, 57% of DECs detected by routine disproportionality analysis would also be detected by the adapted subgroup methodology. We also assessed the sensitivity after excluding PRAC examples with combinations of covariates or where only one subgroup had the ability to be exposed to the drug or to experience the event in a post hoc analysis. PRAC examples for age were mainly included and the sensitivity at the subgroup example level was reduced to 20% for age and 18% overall. After reviewing the outputs of the post hoc analysis, the low sensitivity observed was mostly attributed to the small sample size of observed cases in FAERS and the resulting broad credibility intervals.
Candore et al. [20] assessed several overall disproportionality methods using various spontaneous reporting systems and showed a sensitivity ranging from 19 to 46% and a positive predictive value from 10 to 21%. In this study, the sensitivity ranged from 0.1 to 52%, therefore sensitivities were similar to overall disproportionality analyses. Positive predictive value could not be calculated because our reference set did not include the exhaustive list of positive controls but is likely very low. It should be noted that the reference set of positive controls used by Candore et al. [20] and the one used in this study are very different.
The decision of how to group or split covariates into subgroups may affect the analysis. For example, age subgroups defined by Sandberg et al. [29] did not always match with the age subgroups mentioned in PRAC examples, potentially diluting the disproportionality. In addition, not combining covariates, when combinations were present in 59% of PRAC examples, ignores the fact that the modifying effect of one covariate may differ by subgroups of the other covariate. A scan test (or more advanced machine learning techniques) could be used to handle these limitations by assessing all meaningful combinations while controlling for multiple testing and not having to define the subgroups a priori.
There are several limitations to our study that should be considered when interpreting concordance. First, the PRAC minutes may not use product active moieties and event MedDRA® PTs to represent drug exposure and adverse events. Translating these to standardised dictionaries with a different granularity, such as MedDRA®, may allow for variability in results. After the mapping, the majority of PRAC subgroup examples concerned a range of active moieties, subgroups and MedDRA® PTs. These multiple entries for drug, event and subgroup may reduce the detection power by resulting in more subgroup DECs with fewer data, or diluting the effect by mixing subgroups with high exposure effect with subgroups with low exposure effect. This might explain the observed discrepancy between sensitivity at the subgroup example level versus the subgroup DEC level. Furthermore, the PRAC subgroup examples included in this study represent a sample of only 5 years, therefore the reference set used is not comprehensive and specificity could not be assessed. Moreover, any mention of subgroups that might be at greater risk of developing a particular AE after exposure to a given drug was included in our reference set regardless of whether it was validated. Sensitivity to validated subgroup signals may differ from sensitivity to the reference set we used in our experiment. To some extent, the overall low concordance observed might also be explained by the fact that subgroups discussed by PRAC are based on various data and methods, whereas the method used in this analysis is purely quantitative and does not account for qualitative aspects that are not readily available in structured databases. Additional work would be needed to understand whether traditional methods as used by PRAC could be complemented by quantitative subgroup disproportionality analyses. Additionally, the number of our PRAC examples was small and weighted towards specific subgroups tested (age and underlying condition). On the other hand, the use of FAERS data, which mainly cover the US population (whereas PRAC is a European committee that likely uses European data), may have impacted concordance. However, none of the products from the PRAC subgroup examples are exclusively marketed in the European Union, and although healthcare provision and usage might differ, this is unlikely to result in highly different subgroup categorisation in the two geographical regions.
Another limitation resides in the use of spontaneous data. Non-random reporting patterns at the case level, and also at the case attribute level, impact what data are listed or missing on a case report and the way they are recorded. This non-random recording of data in spontaneous AE reports may make it particularly challenging to conduct quantitative analysis of spontaneous data. Subgroups such as underlying condition and pregnancy are captured sporadically and unsystematically in spontaneous AE data, therefore imposing limitations on subgroup analyses. In our study, when the data were considered regardless of disproportionately reported in the entire database, the sensitivity for underlying condition was low (10% at subgroup example level and 6% at the subgroup DEC level). The sensitivity for pregnancy was 100% but accounted for only one subgroup example/DEC, for an event that only pregnant women can experience (gestational diabetes). Consequently, this example was excluded from the post hoc analysis. Although it was attempted to minimise missing data (e.g. by using indications of drugs to determine underlying condition), the alternative information required was also frequently missing or could introduce bias into the analysis (e.g. due to certain indications of concomitant drugs being more frequently reported than others). In addition, identification of the subgroup of pregnant cases relied on an algorithm based on structured fields and coded events because we could not access free-text fields in FAERS. This limited our capacity to identify pregnant cases and resulted in a low number of such cases. Sandberg et al. [29] did not consider concomitant medication or exposure in pregnancy with the risk in offspring, therefore we excluded 4 and 12 such examples, respectively. Nevertheless, these data might also pertain to this category of covariates, i.e. sporadically and unsystematically reported, and are therefore difficult to assess in spontaneous data because of reporting biases and missing mother–child linkage. Electronic health care records data in these situations could provide additional insights. A logical next step could be to assess whether performance is improved for these covariates when enriching spontaneous data with these relevant observational data [36].
In light of these limitations, we would recommend to not consider subgroups meeting one of the following criteria for subgroup analyses in spontaneous reports data.
-
Timebound subgroups (e.g. definitive overlap of exposures for a specific period of time, such as with drug–drug interactions, exposure to a concomitant drug within 60 days of occurrence of an event following another drug exposure, exposure to a drug for at least 1 year). The dates and times are not reliable and are often missing in spontaneous reports data, rendering temporal relationships between subgroup elements difficult to establish.
-
Conditional subgroups (e.g. patients with a history of a particular event or patients who take a particular concomitant drug). The rationale for exclusion is that reporting of medical or medication history and concomitant drugs in spontaneous reports data is very sporadic and heavily biased.
-
Combination subgroups (e.g. a female under the age of 20 years). Although certain characteristics (e.g. age and sex) are more commonly reported in spontaneous reports data, combining these would potentiate the variability of the results based on the sporadic and non-random reporting of these data elements.
-
Subgroups normally missing from spontaneous reports data (e.g. genetic risk factors). The rationale for exclusion is that if the data element is not populated on the database, then it cannot be used to determine allocation to subgroups.
-
Subgroups requiring linkage to other records (e.g. in utero exposure and fetal adverse events). There are very few reports of linkage of mother–child records with robust data in spontaneous safety databases.
Alternative approaches have been proposed in the literature. Giangreco and Tatonetti proposed a subgroup method within the paediatric population [37] using a generalised additive model (GAM) approach, more technical than simple proportional reporting ratios. Nonetheless, their results do not convincingly suggest that the GAM approach performed significantly better than proportional reporting ratios. In another study, Chandak and Tatonetti created matched cohorts for sex, which could be used to identify differential effects in sex subgroups [38]. They generated propensity scores (PSs) for women then used them to create PS-matched cohorts of men and women, and subsequently evaluated all drug AEs in both cohorts. While an independent PS model could be created for sex regardless of the drug/AE investigated, it may be driven by factors that are good predictors of sex but have no effect on the risk of the ADR or on the probability of being exposed to the drug, preventing a good adjustment for confounding factors.
5 Conclusions
Overall, we noted apparent low concordance between the Sandberg method applied in a large ADR database and a reference set of PRAC meeting subgroup examples, especially when used as first-pass screening. The performance was improved for variables that are better captured in spontaneous report data, namely age and sex, but covariates such as underlying condition and pregnancy likely require enrichment with alternative data sources. While we have offered some suggestions for future approaches to improve subgroup analyses, further research is needed to assess the optimal combination of data sources, individual characteristics, reference set and statistical methods and thresholds needed to screen subgroups that might be at high risk of ADRs. Ultimately, the nature of spontaneous reports and the application of quantitative approaches, rather than the specific use of subgroup analyses, seemed to limit the ability to identify issues discussed in a regulatory context. Thus, progress to an increasingly personalised view of predictive safety will require a multimodal data approach.
References
Sacristán JA, Avendaño-Solá C. On heterogeneity of treatment effects and clinical freedom. Int J Clin Pract. 2015;69:6–8. https://doi.org/10.1111/ijcp.12537.
Pirrone I, Farruggia P, Cacciatore F, Giambona A, Guarina A, Marcello AP, et al. Rasburicase-induced methemoglobinemia: a case report and literature review. J Pediatr Hematol Oncol. 2021;43:e886–90. https://doi.org/10.1097/mph.0000000000001979.
Relling MV, McDonagh EM, Chang T, Caudle KE, McLeod HL, Haidar CE, et al. Clinical Pharmacogenetics Implementation Consortium (CPIC) guidelines for rasburicase therapy in the context of G6PD deficiency genotype. Clin Pharmacol Ther. 2014;96:169–74. https://doi.org/10.1038/clpt.2014.97.
Mevorach D, Anis E, Cedar N, Bromberg M, Haas EJ, Nadir E, et al. Myocarditis after BNT162b2 mRNA vaccine against Covid-19 in Israel. N Engl J Med. 2021;385:2140–9. https://doi.org/10.1056/NEJMoa2109730.
Witberg G, Barda N, Hoss S, Richter I, Wiessman M, Aviv Y, et al. Myocarditis after Covid-19 vaccination in a large health care organization. N Engl J Med. 2021;385:2132–9. https://doi.org/10.1056/NEJMoa2110737.
Karlstad Ø, Hovi P, Husby A, Härkänen T, Selmer RM, Pihlström N, et al. SARS-CoV-2 vaccination and myocarditis in a Nordic cohort study of 23 million residents. JAMA Cardiol. 2022;7:600–12. https://doi.org/10.1001/jamacardio.2022.0583.
Makkar RR, Fromm BS, Steinman RT, Meissner MD, Lehmann MH. Female gender as a risk factor for torsades de pointes associated with cardiovascular drugs. JAMA. 1993;270:2590–7. https://doi.org/10.1001/jama.270.21.2590.
Lehmann MH, Hardy S, Archibald D, Quart B, MacNeil DJ. Sex difference in risk of torsade de pointes with d, l-sotalol. Circulation. 1996;94:2535–41. https://doi.org/10.1161/01.cir.94.10.2535.
Drici MD, Clément N. Is gender a risk factor for adverse drug reactions? The example of drug-induced long QT syndrome. Drug Saf. 2001;24:575–85. https://doi.org/10.2165/00002018-200124080-00002.
Locati EH, Zareba W, Moss AJ, Schwartz PJ, Vincent GM, Lehmann MH, et al. Age- and sex-related differences in clinical manifestations in patients with congenital long-QT syndrome: findings from the International LQTS Registry. Circulation. 1998;97:2237–44. https://doi.org/10.1161/01.cir.97.22.2237.
Zolpidem containing products: drug safety communication—FDA requires lower recommended dose. US Department of Health and Human Services. http://wayback.archive-it.org/7993/20170112032721/http://www.fda.gov/Safety/MedWatch/SafetyInformation/SafetyAlertsforHumanMedicalProducts/ucm334738.htm. Accessed 28 Sep 2022.
Lewis DJ, Lythgoe MP. Application of “systems vaccinology” to evaluate inflammation and reactogenicity of adjuvanted preventative vaccines. J Immunol Res. 2015;2015: 909406. https://doi.org/10.1155/2015/909406.
Mennecozzi M, Landesmann B, Palosaari T, Harris G, Whelan M. Sex differences in liver toxicity - do female and male human primary hepatocytes react differently to toxicants in vitro? PLoS ONE. 2015;10: e0122786. https://doi.org/10.1371/journal.pone.0122786.
Hartmanshenn C, Scherholz M, Androulakis IP. Physiologically-based pharmacokinetic models: approaches for enabling personalized medicine. J Pharmacokinet Pharmacodyn. 2016;43:481–504. https://doi.org/10.1007/s10928-016-9492-y.
Brose MS, Worden FP, Newbold KL, Guo M, Hurria A. Effect of age on the efficacy and safety of lenvatinib in radioiodine-refractory differentiated thyroid cancer in the phase III SELECT trial. J Clin Oncol. 2017;35:2692–9. https://doi.org/10.1200/jco.2016.71.6472.
Lacy BE, Harris LA, Chang L, Lucak S, Gutman C, Dove LS, et al. Impact of patient and disease characteristics on the efficacy and safety of eluxadoline for IBS-D: a subgroup analysis of phase III trials. Therap Adv Gastroenterol. 2019;12:1–12. https://doi.org/10.1177/1756284819841290.
Onakpoya IJ, Heneghan CJ, Aronson JK. Post-marketing withdrawal of 462 medicinal products because of adverse drug reactions: a systematic review of the world literature. BMC Med. 2016;14:10. https://doi.org/10.1186/s12916-016-0553-2.
Izem R, Sanchez-Kam M, Ma H, Zink R, Zhao Y. Sources of safety data and statistical strategies for design and analysis: postmarket surveillance. Ther Innov Regul Sci. 2018;52:159–69. https://doi.org/10.1177/2168479017741112.
Moore N, Berdaï D, Blin P, Droz C. Pharmacovigilance—the next chapter. Therapie. 2019;74:557–67. https://doi.org/10.1016/j.therap.2019.09.004.
Candore G, Juhlin K, Manlik K, Thakrar B, Quarcoo N, Seabroke S, et al. Comparison of statistical signal detection methods within and across spontaneous reporting databases. Drug Saf. 2015;38:577–87. https://doi.org/10.1007/s40264-015-0289-5.
Wisniewski AF, Bate A, Bousquet C, Brueckner A, Candore G, Juhlin K, et al. Good signal detection practices: evidence from IMI PROTECT. Drug Saf. 2016;39:469–90. https://doi.org/10.1007/s40264-016-0405-1.
Orre R, Lansner A, Bate A, Lindquist M. Bayesian neural networks with confidence estimations applied to data mining. CSDA. 2000;34:473–93. https://doi.org/10.1016/S0167-9473(99)00114-0.
Seabroke S, Candore G, Juhlin K, Quarcoo N, Wisniewski A, Arani R, et al. Performance of stratified and subgrouped disproportionality analyses in spontaneous databases. Drug Saf. 2016;39:355–64. https://doi.org/10.1007/s40264-015-0388-3.
Hopstadius J, Norén GN, Bate A, Edwards IR. Impact of stratification on adverse drug reaction surveillance. Drug Saf. 2008;31:1035–48. https://doi.org/10.2165/00002018-200831110-00008.
Lilienfeld D, Nicholas S, Macneil D, Kurjatkin O, Gelardin T. Violation of homogeneity: a methodologic issue in the use of data mining tools. Drug Saf. 2003;26:363–4. https://doi.org/10.2165/00002018-200326050-00005. (author reply 4–6).
Yu Y, Chen J, Li D, Wang L, Wang W, Liu H. Systematic analysis of adverse event reports for sex differences in adverse drug events. Sci Rep. 2016;6:24955. https://doi.org/10.1038/srep24955.
Star K, Sandberg L, Bergvall T, Choonara I, Caduff-Janosa P, Edwards IR. Paediatric safety signals identified in VigiBase: methods and results from Uppsala Monitoring Centre. Pharmacoepidemiol Drug Saf. 2019;28:680–9. https://doi.org/10.1002/pds.4734.
Noseda R, Bonaldo G, Motola D, Stathis A, Ceschi A. Adverse event reporting with immune checkpoint inhibitors in older patients: age subgroup disproportionality analysis in VigiBase. Cancers (Basel). 2021;13:1131. https://doi.org/10.3390/cancers13051131.
Sandberg L, Taavola H, Aoki Y, Chandler R, Norén GN. Risk factor considerations in statistical signal detection: using subgroup disproportionality to uncover risk groups for adverse drug reactions in VigiBase. Drug Saf. 2020;43:999–1009. https://doi.org/10.1007/s40264-020-00957-w.
21 CFR 316.3. Definitions. In: The Code of Federal Regulations. European Council on Foreign Relations. https://www.ecfr.gov/current/title-21/chapter-I/subchapter-D/part-316/subpart-A/section-316.3. Accessed 28 Sep 2022.
Norén GN, Orre R, Bate A, Edwards IR. Duplicate detection in adverse drug reaction surveillance. Data Min Knowl Disc. 2007;14:305–28. https://doi.org/10.1007/s10618-006-0052-8.
Arlett P, Portier G, de Lisa R, Blake K, Wathion N, Dogne JM, et al. Proactively managing the risk of marketed drugs: experience with the EMA Pharmacovigilance Risk Assessment Committee. Nat Rev Drug Discov. 2014;13:395–7. https://doi.org/10.1038/nrd3713-c1.
Norén GN, Bate A, Orre R, Edwards IR. Extending the methods used to screen the WHO drug safety database towards analysis of complex associations and improved accuracy for rare events. Stat Med. 2006;25:3740–57. https://doi.org/10.1002/sim.2473.
Hopstadius J, Norén GN. Robust discovery of local patterns: subsets and stratification in adverse drug reaction surveillance. In: Proceedings of the 2nd ACM sighit international health informatics symposium, Miami. 2012. p. 265–74.
Norén GN, Caster O, Juhlin K, Lindquist M. Zoo or savannah? Choice of training ground for evidence-based pharmacovigilance. Drug Saf. 2014;37:655–9. https://doi.org/10.1007/s40264-014-0198-z.
Li R, Chen Y, Ritchie MD, Moore JH. Electronic health records and polygenic risk scores for predicting disease risk. Nat Rev Genet. 2020;2020(21):493–502. https://doi.org/10.1038/s41576-020-0224-1.
Giangreco NP, Tatonetti NP. Evaluating risk detection methods to uncover ontogenic-mediated adverse drug effect mechanisms in children. BioData Min. 2021;14:34. https://doi.org/10.1186/s13040-021-00264-9.
Chandak P, Tatonetti NP. Using machine learning to identify adverse drug effects posing increased risk to women. Patterns (N Y). 2020;1: 100108. https://doi.org/10.1016/j.patter.2020.100108.
Acknowledgements
Jeffery Painter reviewed the code written to run the analyses and made suggestions for improvement. Vijay Kara reviewed the sample of PRAC examples, and retrieved and participated in discussions regarding their inclusion or exclusion from the analyses. Editorial/medical writing assistance in the preparation of this article was provided by Stavroula Bitsi and Nick Rusbridge of Apollo, OPEN Health Communications, funded by GSK.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Funding
This study was funded by GSK.
Conflict of interest
Olivia Mahaux, Greg Powell, François Haguinet, Paulina Sobczak, Namrata Saini and Andrew Bate are employees of GSK and may hold stock or stock options or GSK restricted shares. Allen Barry and Amira Mustafa declare that they have no conflicts of interest.
Availability of data
The datasets generated or analysed during the current study are available from the corresponding author on reasonable request.
Ethical approval
Not applicable.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Code availability
Not applicable .
Author contributions
All authors contributed to study conceptualisation, methodology, data curation, and formal analysis, and writing and review of the manuscript. All authors read and approved the final version of the manuscript.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License, which permits any non-commercial use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc/4.0/.
About this article

Cite this article
Mahaux, O., Powell, G., Haguinet, F. et al. Identifying Safety Subgroups at Risk: Assessing the Agreement Between Statistical Alerting and Patient Subgroup Risk. Drug Saf 46, 601–614 (2023). https://doi.org/10.1007/s40264-023-01306-3
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40264-023-01306-3