
Abstract
Sesame (Sesamum indicum L.) is an ancient oilseed crop known for its nutty seeds and high-quality edible oil. It is an unexplored crop with a great economic potential. The present study deals with assessment of genetic diversity in the crop. Twenty two RAPD and 18 SSR primers were used for analysis of the 47 different sesame accessions grown in different agroclimatic zones of India. A total of 256 bands were obtained with RAPD primers, of which 191 were polymorphic. SSR primers gave 64 DNA bands, of which all of were polymorphic. The Jaccardʼs similarity coefficient of RAPD, SSR, and pooled RAPD and SSR data ranged from 0.510 to 0.885, 0.167 to 0.867, and 0.505 to 0.853, respectively. Maximum polymorphic information content was reported with SSRs (0.194) compared to RAPDs (0.186). Higher marker index was observed with RAPDs (1.426) than with SSRs (0.621). Similarly, maximum resolving power was found with RAPD (4.012) primers than with SSRs (0.884). The RAPD primer RPI-B11 and SSR primer S16 were the most informative in terms of describing genetic variability among the varieties under study. At a molecular level, the seed coat colour was distinguishable by the presence and absence of a group of marker amplicon/s. White and brown seeded varieties clustered close to each other, while black seeded varieties remained distanced from the cluster. In the present study, we found higher variability in Sesamum indicum L. using RAPD and SSR markers and these could assist in DNA finger printing, conservation of germplasm, and crop improvement.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Sesamum indicum L. (Pedaliaceae), commonly known as sesame or Gingelly, is an ancient oilseed crop cultivated in almost all continents. It is a source of high-quality edible oil that contains, in addition, medicinally important antioxidant lignans, namely, sesamin, sesamolin, and sesamol (Anilakumar et al. 2010; Dar et al. 2014). Lignans impart resistance to rancidity of the oil and enhance tumor inhibiting properties of certain drugs (Sacco et al. 2007; Dar and Arumugam 2013; Dar et al. 2015). India, Sudan, and China are the major sesame producing countries. However, the global per unit area production of sesame seed, especially in developing countries, is far less (FAO STAT 2014). The low yield has been attributed to indeterminate growth, uneven ripening of capsules, absence of non-shattering types, and biotic and abiotic stresses (Ashri 1998). Importance of crop genetic diversity in the era of post green revolution and threat by change cannot be over emphasized (Abberton et al. 2015). A focused research on genetic diversity and breeding of sesame is needed to improve its worldwide productivity.
Morpho-agronomic traits have been the prime variables used for studying genetic diversity (Liu 1997; Bisht et al. 1998). Selection of plant varieties based on these traits alone has proved to be ineffective due to problems of low heritability, strong influence of the environment, and genetic complexity. Fortunately, advances in molecular technologies have enabled proper identification, selection, and use of germplasm in crop improvement programmes (Spandana et al. 2012). DNA markers in particular are useful and reliable as they remain stable under different environmental conditions (Ferdinandez et al. 2001). Random amplified polymorphic DNA (RAPD) is the simplest of all molecular techniques enabling quick detection of polymorphisms at a number of loci with only small amounts (nanogram) of genomic DNA required (Bhat et al. 1999; Salazar et al. 2006; Pham et al. 2011). RAPD technique first reported by Welsh and McClelland (1990) and Williams et al. (1990) has been routinely used for genetic analysis in a vast array of crops, including foxtail millet, sunflower, birch, soybean, and oilseed rape (Schontz and Rether 1999; Popov et al. 2002; Xu and Gai 2003; Zeng et al. 2003; Yu et al. 2005). Simple sequence repeat (SSR) is yet another popular DNA marker used in the assessment of the genetic diversity, phylogenetic relationships, and population structures in crops. SSR markers are tandem repeats of short nucleotide sequences of about one-to-six bases that have revealed a high polymorphism in several crops, including barley (Malysheva-Otto et al. 2006), perilla (Park et al. 2008), and rice (Cui et al. 2010). The polymorphism with this marker arise either due to polymerase slippage during DNA replication or unequal crossing over (Levinson and Gutman 1987). The SSR has advantage of identifying many alleles at a single locus, extensive genome coverage, co-dominance, and repeatability, can be carried out with just a small quantity of DNA (ng), and avoids radioactivity (Abdelkrim et al. 2009; Allentoft et al. 2009). The SSR markers have also proved useful in the preparation of genetic map by linking it with other markers (Nimmakayala et al. 2005).
As compared to many crop plants, information on molecular characterization of genetic diversity in sesame has been very meagre. The molecular techniques of RAPD (Bhat et al. 1999; Ercan et al. 2004; Kumar and Sharma 2009; Pham et al. 2011; Akbar et al. 2011; Mahdizadeh et al. 2012), AFLP (amplified fragment length polymorphism) (Laurentin and Karlovsky 2006, 2007), ISSR (inter-simple sequence repeats) (Kim et al. 2002; Parsaeian et al. 2011; Kumar and Sharma 2011; Nyongesa et al. 2013; Woldesenbet et al. 2015), SSR (Spandana et al. 2012; Dixit et al. 2005; Cho et al. 2011; Wang et al. 2012; Yepuri et al. 2013; Wei et al. 2014; Surapaneni et al. 2014; Uncu et al. 2015; Dossa et al. 2016; Sehr et al. 2016), and SRAP (sequence-related amplified polymorphism) (Li and Quiros 2001; Li et al. 2007; Zhang et al. 2010) have been used to evaluate the genetic diversity in sesame of different origins. Morphologically, Indian collection of sesame is characterized by variable forms being cultivated in different agroclimatic zones. The molecular data on the diversity of Indian germplasm are very limited. In this paper, we describe comparative evaluation of molecular genetic diversity of the sesame varieties of Indian origin using RAPD and SSR markers. The results are discussed in the light of developing strategy for breeding and conservation of the crop.
Materials and methods
Plant material
The 47 improved varieties of sesame germplasm used in the study are presented in Table 1. The seeds of the germplasm were procured from the National Bureau of Plant Genetic Resources (NBPGR), New Delhi, and the crop was raised and maintained by growing in the experimental garden of our department. The members of the germplasm differed in their seed colour and the region of their cultivation.
DNA isolation and quantification
Fresh leaves from healthy plants were used for DNA isolation. Approximately 1 g of leaf tissue taken in a pestle and mortor and ground into a fine powder in liquid nitrogen and total genomic DNA was isolated following CTAB method (Murray and Thompson 1980), and the DNA isolated was dissolved in TE buffer (10 mM Tris, 1 mM EDTA, pH 8.0) and stored at −20 °C until use. DNA concentration was determined using Nanodrop (Thermo Scientific Nanodrop 2000 Spectrophotometer), and the purity was confirmed by electrophoresis on 0.8% nuclease-free and protease-free agarose gel run with a power pack set at 80 V for 1 h in 1× TAE buffer consisting of 0.04 M Tris base, 17.4 M Glacial acetic acid, 0.001 M EDTA.
RAPD/SSR primers and PCR conditions
For RAPD analysis, 22 random primers of RPI-B series procured from GeNei™, Bangalore were used (Table 2). The primers were 10 bp in length with partial specificity to detect polymorphism in plants in detection of polymorphisms. Some preliminary experiments were carried out to arrive at the optimal condition for the RAPD-PCR. The results showed that a 25 µL reaction mix containing of 2.5 µL of 10× PCR buffer, 1 µL of 10 mM dNTP mix, 100 ng of RAPD primer, 0.5 µL Taq DNA polymerase (3U/µl), and 5 µL of template DNA (10 ng/µl) was optimal. PCR was done in an Eppendorf Mastercycler gradient (Germany) with an initial extended denaturation step at 94 °C for 5 min followed by 8 cycles of denaturation (94 °C for 45 s), primer annealing (35 °C for 1 min), and elongation (72 °C for 1.5 min), followed again by 35 cycles of 94 °C for 45 s, 38 °C for 1 min, and 72 °C for 1 min with final extended elongation step at 72 °C for 10 min.
Eighteen pairs of SSR primers selected from previous reports (Dixit et al. 2005; Wei et al. 2011) and procured by synthesis from Sigma Aldrich (India). The sequences of the primers are given in Table 3. PCR was carried out in a reaction volume of 20 µl containing 1× PCR buffer (100 mM Tris–HCl, pH 8.3, 500 mM KCl, 15 mM MgCl2, and 0.01% gelatin), 0.2 mM dNTP mix, 1 µM of each of forward and reverse primer, 1U Taq Polymerase, and 200 ng of template DNA. Reaction mixture was diluted to final volume by nuclease-free water. The amplification was carried out using the PCR programme: 94 °C for 3 min, then 30 cycles each of 94 °C for 30 s, 55 °C for 45 s, and 72 °C for 1 min followed by 10 cycles of 94 °C for 30 s, 53 °C for 45 s, and 72 °C for 1 min and a final extension of 72 °C for 10 min.
Gel electrophoresis
Amplified PCR samples were subjected to electrophoresis on 1.5% (for RAPD) or 3% (for SSR), agarose gel prepared in 1× TAE buffer. GeNei™ Low Range DNA Ruler plus (Cat No. 118668, 100–3000 bp) was used for RAPD, and 100 bp marker from either Promega (Cat No. G2101) or Merck Bioscience (Cat No. 61265267050173) was used for SSR, as molecular weight marker. Electrophoresis was run using 80–100 V. The gel was stained with ethidium bromide and viewed under a Gel Doc (BIO RAD Universal Hood II 2 ChemiDoc XRS, USA). The images were photographed and stored in computers. Reproducibility of the amplification products was ascertained by running at least two independent PCRs for each primer (RAPD) or primer pairs (SSR). Only consistent bands were taken for analysis.
Statistical analysis
Each amplification product was considered as a dominant locus for RAPD and codominant locus for SSR markers. They were manually scored across all samples and recorded in the form of a binary in an excel sheet with ‘1’ for the presence of a band and ‘0’ for the absence of it. Percentage of polymorphism for each primer was derived as the proportion of polymorphic bands over the total number of different molecular weight bands observed. Marker attributes, namely, allele frequency (FA), gene diversity (GD), polymorphic information content (PIC), effective multiplex ratio (EMR), marker index (MI), and resolving power (RP), were estimated using the 3.25 version of the Power Marker statistics software (Liu and Muse 2005). Allele frequency was calculated as \(\frac{{n_{u} }}{N}\), where n u is the number of alleles and N is total number of individuals sampled. Gene diversity at the lth locus was estimated as \((1 - \sum_{i = 1}^{n} p_{{i^{2} }} )/(1 - \tfrac{1 + f}{N})\), where f is breeding incoefficient, and pi is the frequency of the ith allele. EMR was obtained by multiplying the proportion of polymorphic markers (β) and the total number of polymorphic fragments (n) obtained (Powell et al. 1996). The PIC refers to the value assigned to a marker in detecting an allelic variability. It is estimated as \(\sum_{i = 1}^{n} p_{{i^{2} }} - 2[\sum_{i = 1}^{n - 1} \sum_{j = i + 1}^{n} p_{{i^{2} }} p_{{j^{2} }} ]\), where pi is the frequency of the ith allele (Botstein et al. 1980). The MI, signifying the overall utility of the marker system for the diversity study, was obtained as the product of PIC and EMR (Anderson et al. 1993; Varshney et al. 2007). MI together with PIC value was used to assess the informative property of the markers. Band informativeness (Ib) is given by 1 − (2 × |0.5 − p|), where p is the proportion of the total genotypes containing a particular band. It is useful in calculating the resolving power (RP), which in turn enabled us to know that the ability of a primer to distinguish various genotypes is presented as ∑Ib (Prevost and Wilkinson 1999).
The binary data thus recorded were analyzed to obtain Jaccardʼs similarity coefficient (S) and Jaccardʼs distance (D). Subsequently, ‘S’ was used for construction of the dendrogram following UPGMA (Unweighted Pair Group Method with Arithmetic Mean) method. Principal coordinate analysis (PCoA) was done using the software PAST, version 2.15 (Hammer et al. 2001). The results were converted to a biplot to reveal the distribution pattern of the varieties in the two-dimensional space. To estimate the extent of the genetic diversity among the varieties belonging to different classes based on seed colour, the RAPD and SSR matrix data were realigned on the basis of seed coat colour and analyzed (Table 1). A dendrogram was constructed using the statistical package POPGENE 1.31, as described in Yeh et al. (1997). The binary data of RAPD and SSR were pooled to infer their combinatorial potential in revealing the genetic diversity. Pearson correlation of the variables was computed using SPSS statistical package version 16.0.2.
Results
DNA profile and marker attributes
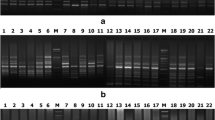
Summary of binary data and estimates of the marker attributes for different RAPD primers is presented in Table 2. A representative picture of electrophoresis gel showing RAPD profile of some sesame accessions used in the study is presented in Fig. S1A. The RAPD analysis revealed a total of 256 bands of which 191 were polymorphic. The molecular weights of the amplicons ranged from 100 to 3000 bp in molecular weight. On average, 11.6 bands per primer were seen. Cent percent of polymorphic bands were obtained with primers RPI-B11 and RPI-B13, while least of the polymorphism (38.5%) was observed for RPI-B24 (Table 2). Seven of the RAPD primers amplified unique DNA fragments (Table S1). RPI-B18, RPI-B21, RPI-B22, and RPI-B23, respectively, have characterized the varieties AMRIT, YLM17, KALLIKA, and FFAT-08-22, respectively, by amplifying a unique band with each of the primers. Varieties RT46 showed amplification of three unique bands with RPI-B18 and RPI-B19, and UMA showed two unique bands with RPI-B5 and RPI-B13 (Table S1). Estimates of the marker attributes from RAPD showed a substantial difference in the potential of primers to reveal polymorphism (Table 2). Estimates of marker attributes showed that RPI-B11 primer was characterized by the highest values for GD, PIC, MI, and RP and the lowest value for FA was the most potential of the random primers in revealing polymorphism among the accessions studied. RPI-B8 was characterized by the lowest values for GD, PIC, MI, and RP but with highest value for FA. The GD that indicates the proportion of heterozygosity (He) was found negative correlated with FA (r = −0.987, p = 0.01). PIC, however, showed a positive correlation of 0.998 (p = 0.01) with GD. MI, which was maximum for the primer RPI-B11 and minimum for RPI-B8 and showed a positive correlation with PIC (0.874; p = 0.01).
DNA profile of the accessions using some SSR primers is shown in Fig. S1B. A total number of 64 amplicons were obtained with SSR with all of them being polymorphic (Table 3). The maximum number of nine alleles was obtained with primer S9 with molecular weights in the range of 150–1500 bp. Mean number of bands/primer obtained was 3.55. Some of the SSR primers revealed amplification of bands specific to a variety (Table S1). JLT7 and JLT26 varieties showed amplification of a unique band (allele) each with primer S1 and for RAJESWARI with the primer S10. While S13, S9, and S10 amplified two unique bands each, respectively, for CHANDANA, PRACHI, and VRI1. S11 amplified four unique bands in VINAYAK. The estimates of marker attributes for SSR primers varied widely. GD and PIC were the highest for primer S12 and least for S13 (Table 3). As observed earlier in RAPD, data here again GD showed a negative correlation of −0.971 (p = 0.01) with FA. PIC showed a positive correlation with GD (0.996, p = 0.01). The values for MI and RP were maximal for primer S16 and minimal for S14 and S15. The RP and MI one again showed a positive correlation of 0.856 with MI (p = 0.01).
Cluster analysis
Matrix analysis of RAPD data showed a Jaccardʼs similarity coefficient in the range of 0.510–0.885. This reflected the presence of a high genetic variability among the accessions under study. Similarity was the highest between the accessions T13 and TKG55 and least between N32 and GT10. Clustering and PCoA confirmed this observation. UPGMA grouping reveals that the sesame germplasm under study can be divided into two distinct clusters (Fig. S2A). Cluster A was smaller and comprised of 11 accessions. Cluster B was larger which diverged further into two subclusters, namely, B1 and B2. Cluster B1 further subdivided into B1a comprising of 24 accessions and B1b comprising of 11 varieties. Cluster B2 was represented by solitary TC289.
Jaccards similarity coefficient obtained from SSR data ranged from 0.167 to 0.867, indicating a high genetic variability among the accessions. In contrast to RAPD, SSR reveals that RT127 and JT7 were the closest and PRACHI and YLM17 were highly dissimilar. The UPGMA of SSR data grouped the accession into two clusters (Fig. S2B). There was complete realignment of the varieties observed. Cluster A was represented by the solitary PRAGHTI. Remaining 46 accessions together formed cluster B, which further got split into B1 and B2 subclusters. Cluster B1 was the largest with 40 accessions, and cluster B2 consisted of six cultivars. The cophenetic correlation was 0.8 for both RAPD and SSR clusters which was considered as a good fit for the data matrix and the resultant clusters (Romesburg 1990).
Dendrogram obtained after pooling of the RAPD and SSR binary data is presented in Fig. 1. The polymorphism now observed was 79.7% which was little higher as compared to polymorphism obtained with RAPD. Jaccardʼs similarity coefficient ranged from 0.505 to 0.853. The most diverse varieties, however, were N32 and JLT7, and the closest were AKT64 and RT127. The gross structure of dendrogram and grouping of the accessions into clusters showed a similarity with the distribution obtained with that of RAPD data. The accessions were observed to realign into two major clusters. Cluster A consisted of 11 genotypes. Cluster B subdivided into B1 comprising of 36 genotypes and TC289 remaining as solitary under cluster B2 as in RAPD.

UPGMA based dendrogram of the germplasm of Sesamum indicum L. based on pooled data of RAPD and SSR markers
Principal coordinate analysis
The PCoA of RAPD data grouped the accession in a two-dimensional space with a clustering pattern synonymous with the dendrogram obtained with RAPD (Fig. S3A). Analysis revealed that the first two principal coordinates accounted for about 30% of the total variance. PCoA divided the cultivars into three groups. Group A included 24 varieties (T12, RT125, XLM19, T13, TKG55, N32, JT7, PRAGHTI, TMV3, TMV4, TMV5, TMV6, PRACHI, VINAYAK, PBTIL, JTS8, FFAT0822, KRISHNA, GT2, JLT26, JLT1, PHULETIL, TC289, and DS1). Group B consisted of 11 varieties (RAJESWARI, JLT7, TC25, RT46, TKG22, UMA, T78, TARUN, GT10, AMRIT, and VRI1). Group C consisted of 12 varieties (YLM17, E8, N8, RT103, AKT64, RT127, SHEKHAR, SVPR1, NIRMALA, GT1, CHANDANA, and KALLIKA).
For SSR data, the PCoA showed that the first two principal coordinates accounted for about 25% of the total variance. However, there observed a complete realignment of the accessions leading to clustering of accessions into three groups (Fig. S3B). Group A consisted of 34 varieties (NIRMALA, JLT1, RT103, PRAGHTI, SVPR1, RT46, TMV4, TMV6, TMV3, SHEKHAR, T13, PHULETIL, GT2, AMRIT, KALLIKA, TC289, TKG55, AKT64, GT1, GT10, CHANDANA, TARUN, T78, UMA, PBTIL, VINAYAK, E8, N8, N32, TC25, RT125, XLM19, DS1, and JLT7). Group B consisted of seven varieties (RAJESWARI, T12, JLT26, PRACHI, VRI1, KRISHNA, and TMV5). In addition, Group C included six varieties (FFAT0822, RT127, JTS8, TKG22, YLM17, and JT7).
PCoA of pooled data (RAPD and SSR) gave a grouping pattern that resembled the one obtained with RAPD data as seen earlier with dendrogram plots. There were two distinct major groups observed. Group A had 11 varieties, and Group B consisted of 36 accessions, including TC289 that remained solitary in dendrogram (Fig. 2).

Principal coordinate analysis of S.indicum accessions in two-dimensional space based on pooled data of RAPD and SSR markers
Genetic diversity among and within the population on the basis of seed colour
There were 29 white, 13 brown, and 5 black seeded varieties recognized in the population (Table 1). Analysis of the molecular data for the seed coat colour revealed that of a set of markers could be recognized that correlate with seed colour. The trend was applicable for both RAPD and SSR markers. Black varieties were characterized by complete absence of specific amplicons in 35 out of 45 instances for RAPD and in 25 out of 35 instances in SSR profiles (Tables S2, S3). The proportion of genetic diversity (Gst) observed between seed colour populations was 9% in the case of RAPD and 7% in the case of SSR. POPGENE analysis and tree construction revealed that white and brown seeded populations were close to each other as compared to the black seeded population (Fig. S4).
Discussion
Sesame is an unexplored crop which needs a focused research for its genetic improvement in several fronts. Major sesame traits that require attention to achieve higher yields are harvest index, seed retention, uniform maturity, and resistance to abiotic and biotic stresses. Foremost requirement for this is the assessment of genetic diversity available in the crop. RAPD and SSR markers have been effectively used for the assessment of molecular diversity, and the data were integrated with the other markers for construction of genetic map in several crop plants (Nimmakayala et al. 2005). In the present study, with the use of two markers, we demonstrate the presence of a considerable genetic variability in the germplasm of sesame grown in different agroclimatic zones of India.
The extent of polymorphism and diversity reported herein is comparable to genetic diversity reported for certain varieties of sesame grown in India as well as for germplasm from other countries, such as Turkey (Ercan et al. 2004; Frary et al. 2015; Uncu et al. 2015) and Cambodia and Vietnam (Pham et al. 2009). Up to 73% polymorphism was reported for core collection of sesame from China (Zhang et al. 2010) and for Indian genotypes (Kumar and Sharma 2011). Three of the primers viz., RPI-B5, RPI-B17, and RPI-B19 that were common to some of the previous studies gave similar results (Bhat et al. 1999; Pham et al. 2009). Normally, SSR markers are codominant in nature and help in identification of heterozygotes in the population. In the present study, however, the SSR gave a higher mean value for alleles per locus indicating the presence of multiple loci for certain alleles in some of the varieties.
Variability in marker attributes resulted from the differences in primers used and their priming sites. The RAPD primer RPI-B11 and the SSR primer S16 were found to be the most informative primers to discriminate the sesame genotypes. A higher value for the marker attributes is critical for considering use of the dominant (RAPD and AFLP) and codominant markers (SSR and RFLP) for classification, fingerprinting, genetic diversity analysis, gene mapping, molecular breeding, and germplasm evaluation (Sathyanarayana et al. 2011). On comparative basis, we found that GD was almost similar for both RAPD (0.229) and SSR (0.230). Mean values of MI and RP were larger in case of for RAPD as compared to SSR. Mean PIC value, however, was found to be larger for SSR (0.194) than RAPD (0.186). The higher PIC value for SSR has been reported earlier in common bean (Zargar et al. 2016) and walnut (Ahmed et al. 2012). The PIC values ranging from 0.03 to 0.96 were reported in the previous studies also (Li-Bin et al. 2008; Cho et al. 2011; Spandana et al. 2012; Park et al. 2013).
The genetic similarity coefficient observed in our study (0.510–0.885 in case of RAPD; 0.167–0.867 in case of SSR; and 0.503–0.853 in case of pooled data of RAPD and SSR) was comparable with earlier reports (Bhat et al. 1999; Kumar and Sharma 2009; Yepuri et al. 2013). It is a general practice to use a dominant (RAPD) and a codominant (SSR) markers for diversity studies. The clustering pattern obtained with the pooled RAPD and SSR binary data reassembled the one based on RAPD data alone as has been reported recently in bamboo (Desai et al. 2015). The impact of RAPD data may be attributed due to a higher number of markers involved in analysis as compared to that of the SSR. This led us to conclude that high resolution of crop genotypes into a phylogeny can be achieved considerably with higher number of polymorphic marker. The unique bands amplified by RAPD and SSR primers are important as they could be developed into PCR-based SCAR and sequence-tagged CAPS markers, respectively, for use in fingerprinting, identification of interspecific hybrids, marker-assisted selection for crop improvement, and genetic resource management (Fernadez et al. 2002; Xu 2003; Bandyopadhyay 2011).
Seed coat colour is an important trait that is associated with properties, such as antioxidant activity and disease resistance exhibited by sesame seed. The seed coat trait also finds application in estimating sesame evolution (Zhang et al. 2013a). In this study, we reported that white and brown population was phylogenetically close as compared to black one. We also found that at molecular level, the black varieties had the absence of specific DNA bands rather than its presence in white and brown varieties. Occurrence of three different seed colours indicates that this trait may be controlled by more than one gene as has been recently reported in sesame by Zhang et al. (2013a) and in other crops (Padmaja et al. 2005). Genetic diversity among the three populations was estimated to be lesser as compared to within population variability and such variability could be of use in genetic improvement by selection within groups and without having to compromise on seed coat colour.
We conclude that the polymorphism and fine marker attribute reported herein can be reliably used for the selection and evaluation of parents in sesame breeding programs, maintenance of germplasm, DNA fingerprinting, and analyzing the evolutionary path of sesame cultivars. Further the data would be useful in identifying parents for heterosis breeding, conservation, and genetic improvement for yield and other desirable traits in sesame. The sesame genome sequence recently studied by Zhang et al. (2013b) has provided and opened up new challenges for the present scientists to improve the crop efficiently at each and every level.
References
Abberton M, Batley J, Bentley A et al (2015) Global agriculature intentification during climate change: a role of genomics. P Biotechnol. doi:10.1111/pbi12467
Abdelkrim J, Robertson BC, Stanton JAL, Gemmell NJ (2009) Fast, cost effective development of species-specific microsatellite markers by genomic sequencing. Biotechniques 46:185–192
Ahmed N, Mir JI, Mir RR, Rather NA, Rashid R, Wani SH, Shafi W, Mir H, Sheikh MA (2012) SSR and RAPD analysis of genetic diversity in walnut (Juglans regia L.) genotypes from Jammu and Kashmir. India Physiol Mol Biol Plants 18:149–160
Akbar F, Rabbani MA, Masood MS, Shinwari ZK (2011) Genetic diversity of sesame (Sesamum indicum L.) germplasm from Pakistan using RAPD markers. Pak J Bot 43:2153–2160
Allentoft ME, Schuster S, Holdaway RN, Hale ML, McLay E (2009) Identification of microsatellites from an extinct moa species using high throughput (454) sequence data. Biotechniques 46:195–200
Anderson JA, Churchill JE, Autrique SD, Tanksley S, Sorrells ME (1993) Optimizing parental selection for genetic linkage maps. Genome 36:181–188
Anilakumar KR, Pal A, Khanum F, Bawa AS (2010) Nutritional, medicinal and industrial uses of sesame (Sesamum indicum L.) seeds—an overview. Agric Conspec Sci 75:159–168
Ashri A (1998) Sesame breeding. Plant Breed Rev 16:179–228
Bandyopadhyay T (2011) Molecular marker technology in genetic improvement of tea. Int J Plant Breed Genet 5:23–33
Bhat KV, Babrekar PP, Lakhanpaul S (1999) Study of genetic diversity in Indian and exotics sesame (Sesamum indicum L) germplasm using random amplified polymorphic DNA (RAPD) markers. Euphytica 110:21–33
Bisht IS, Mahajan RK, Loknathan TR, Agrawal RC (1998) Diversity in Indian sesame collection and stratification of germplasm accessions in different diversity groups. Genet Resour Crop Evol 45:325–335
Botstein D, White RL, Skolnick M, Davis RW (1980) Construction of a genetic linkage map in man using restriction fragment length polymorphisms. Am J Hum Genet 32:314–331
Cho YI, Park JH, Lee CW, Ra WH, Chung JW, Lee JR, Ma KH, Lee SY, Lee KS, Lee MC, Park YJ (2011) Evaluation of the genetic diversity and population structure of sesame (Sesamum indicum L.) using microsatellite markers. Genes Genom 33:187–195
Cui H, Moe KT, Chung JW, Cho YI, Lee GA, Park YJ (2010) Genetic diversity and population structure of rice accessions from South Asia using SSR markers. Korean J Breed Sci 42:11–22
Dar AA, Arumugam N (2013) Lignans of sesame: purification methods, biological activities and biosynthesis—a review. Bioorg Chem 50:1–10
Dar AA, Choudhury AR, Arumugam N (2014) A study on seed protein profile of Indian cultivars of Sesamum indicum L. Int J Curr Biotechnol 2:10–17
Dar AA, Verma NK, Arumugam N (2015) An updated method for isolation, purification and characterization of clinically important antioxidant lignans—sesamin and sesamolin, from sesame oil. Ind Crops Prod 64:201–208
Desai P, Gajera B, Mankad M, Shah S, Patel A, Patil G, Narayanan S, Kumar N (2015) Comparative assessment of genetic diversity among Indian bamboo genotypes using RAPD and ISSR markers. Mol Biol Rep 42:1265–1273
Dixit A, Jin MH, Chung JW, Yu JW, Chung HK, Ma KH, Park YJ, Cho EG (2005) Development of polymorphic microsatellite markers in sesame (Sesamum indicum L.). Mol Ecol Notes 5:736–738
Dossa K, Wei X, Zhang Y, Fonceka D, Yang W, Diouf D, Liao B, Cisse N, Zhang X (2016) Analysis of genetic diversity and population structure of sesame accessions from Africa and Asia as major centers of its cultivation. Genes 7:14. doi:10.3390/genes7040014
Ercan AG, Taskin M, Turgut K (2004) Analysis of genetic diversity in Turkish sesame (Sesamum indicum L.) populations using RAPD markers. Genet Resour Crop Evol 51:599–607
FAO Statistical database (2014) http://faostat.fao.org/beta/en/#data/QC. Accessed 30 Oct 2016
Ferdinandez YSN, Somers DJ, Coulman BE (2001) Estimation the genetic relationship of hybrid bromegrass to smooth bromegrass and meadow bromegrass using RAPD markers. Plant Breed 120:149–153
Fernadez M, Figueiras A, Benito C (2002) The use of ISSR and RAPD markers for detecting DNA polymorphism, genotype identification and genetic diversity among barley cultivars with known origin. Theor Appl Genet 104:845–851
Frary A, Tekin P, Celik I, Furat S, Uzun B, Doganlar S (2015) Morphological and molecular diversity in Turkish sesame germplasm and core set selection. Crop Sci 55:702–711
Hammer O, David AT, Harper Paul D, Ryan P (2001) Paleontological Statistics Software Package for education and data analysis (PAST). Palaeontol Electron 4:1–9
Kim D, Zur G, Danin-Poleg Y, Lee S, Shim K, Kang C, Kashi Y (2002) Genetic relationships of sesame germplasm collection as revealed by inter-simple sequence repeats. Plant Breed 121:259–262
Kumar V, Sharma SN (2009) Assessment of genetic diversity of sesame (Sesamum indicum L.) genotypes using morphological and RAPD markers. Ind J Genet 69:209–218
Kumar V, Sharma SN (2011) Comparative potential of phenotypic, ISSR and SSR Markers for characterization of sesame (Sesamum indicum L.) varieties from India. J Crop Sci Biotech 14:163–171
Laurentin H, Karlovsky P (2006) Genetic relationship and diversity in sesame (Sesamum indicum L) germplasm collection using amplified fragment length polymorphism (AFLP). BMC Genet 7:1–10
Laurentin H, Karlovsky P (2007) AFLP fingerprinting of sesame (Sesamum indicum L.) cultivars: identification, genetic relationship and comparison of AFLP informativeness parameters. Genet Resour Crop Evol 54:1437–1446
Levinson G, Gutman GA (1987) Slipped-strand mispairing: a major mechanism for DNA sequence evolution. Mol Biol Evol 4:203–221
Li G, Quiros CF (2001) Sequence-related amplified polymorphism (SRAP), a new marker system based on a simple PCR reaction: its application to mapping and gene tagging in Brassica. Theor Appl Genet 103:455–461
Li YY, Shen JX, Wang TH, Fu TD, Ma CZ (2007) Construction of a linkage map using SRAP, SSR and AFLP markers in Brassica napus L. Sci Agric Sinica 40:1118–1126
Li-Bin W, Zhang HY, Zheng YZ, Guo WZ, Zhang TZ (2008) Developing EST-Derived microsatellites in sesame (Sesamum indicum L.). Acta Agron Sin 34:2077–2084
Liu CJ (1997) Geographical distribution of genetic variation in Stylosanthes scabra revealed by RAPD analysis. Euphytica 98:21–27
Liu K, Muse SV (2005) Power marker. Integrated analysis environment for genetic marker data. Bioinformatics 21:2129–2198
Mahdizadeh V, Safaie N, Goltapeh EM (2012) Genetic diversity of sesame isolates of Macrophomina phaseolina using RAPD and ISSR markers. Trakia J Sci 2:65–74
Malysheva-Otto LV, Ganal MW, Roder MS (2006) Analysis of molecular diversity, population structure and linkage disequilibrium in a worldwide survey of cultivated barley germplasm (Hordeum vulgare L.). BMC Genet 7:6
Murray MG, Thompson WF (1980) Rapid isolation of high molecular weight plant DNA. Nucl Acids Res 8:4321–4326
Nimmakayala P, Kaur P, Bashet AZ, Bates GT, Langham R, Reddy OUK (2005) Molecular characterization of Sesamum using SSRs and AFLPs. Plant and animal genomes XIII conference. San Diego, CA, pp 15–19
Nyongesa BO, Were BA, Gudu S, Dangasuk OG, Onkware AO (2013) Genetic diversity in cultivated sesame (Sesamum indicum L.) and related wild species in East Africa. J Crop Sci Biotechnol 16:9. doi:10.1007/s12892-012-0114-y
Padmaja KL, Arumugam N, Gupta V, Mukhopadhyay A, Sodhi YS, Pental D, Pradhan AK (2005) Mapping and tagging of seed coat colour and the identification of microsatellite markers for marker-assisted manipulation of the trait in Brassica juncea. Theor Appl Genet 111:8–14
Park YJ, Dixit A, Ma KH, Lee JK, Lee MH, Chung CS, Nitta M, Okuno K, Kim TS, Cho EG et al (2008) Evaluation of genetic diversity and relationships within an on-farm collection of Perilla frutescens (L.) Britt. using microsatellite markers. Genet Resour Crop Evol 55:523–535
Park JH, Suresh S, Cho GT, Choi NG, Baek HJ, Lee CW, Chung JW (2013) Assessment of molecular genetic diversity and population structure of sesame (Sesamum indicum L.) core collection accessions using simple sequence repeat markers. Plant Genet Resour C 12:112–119
Parsaeian M, Mirlohi A, Saeidi G (2011) Study of genetic variation in sesame (Sesamum indicum L.) using agromorphological traits and ISSR Markers. Russ J Genet 47:314–321
Pham TD, Tri MB, Gun W, Tuyen CB, Arnulf MA, Carlsson S (2009) A study of genetic diversity of sesame (Sesamum indicum L.) in Vietnam and Cambodia estimated by RAPD markers. Genet Resour Crop Evol 56:679–690
Pham TD, Mulatu G, Tri MB, Tuyen CB, Arnulf M, Anders SC (2011) Comparative analysis of genetic diversity of sesame (Sesamum indicum L) from Vietnam and Cambodia using agro-morphological and molecular markers. Hereditas 148:28–35
Popov VN, Urbanovich OIU, Kiricenko VV (2002) Studying genetic diversity in inbred sunflower lines by RAPD and isoenzyme analysis. Genetika 38:937–943
Powell W, Margenta M, Andre C, Hanfrey M, Vogel J, Tingey S, Rafalsky A (1996) The utility of RFLP, RAPD, AFLP and SSR (microsatellite) markers for germplasm analysis. Mol Breed 2:225–238
Prevost A, Wilkinson MJ (1999) A new system of comparing PCR primers applied to ISSR fingerprinting of potato cultivars. Theor Appl Genet 98:107–112
Romesburg HC (1990) Cluster analysis for researchers. Krieger Publishing, Malabar
Sacco SM, Power KA, Chen J, Ward WE, Thompson LU (2007) Interaction of sesame seed and tamoxifen on tumor growth and bone health in athymic mice. Exp Biol Med 232:754–761
Salazar B, Laurentin H, Davila M, Castillo MA (2006) Reliability of the RAPD technique for germplasm analysis of Sesame (Sesamum indicum L.) from Venezuela. Interciencia 31:456–460
Sathyanarayana N, Leelambika M, Mahesh S, Jaheer M (2011) AFLP assessment of genetic diversity among Indian Mucuna accessions. Physiol Mol Biol Plants 17:171–180
Schontz D, Rether B (1999) Genetic variability in foxtail millet, Setaria italica (L.) P. Beauv. identification and classification of lines with RAPD markers. Plant Breed 118:190–192
Sehr EM, Okello-Anyanga W, Hasel-Hohl K, Burg A, Gaubitzer S, Rubaihayo PR, Okori P, Vollmann J, Gibson P, Fluch SJ (2016) Assessment of genetic diversity amongst Ugandan sesame (Sesamum indicum L.) landraces based on agromorphological traits and genetic markers. Crop Sci Biotechnol 19:117. doi:10.1007/s12892-015-0105-x
Spandana B, Reddy VP, Prasanna GJ, Anuradha G, Sivaramakrishnan S (2012) Development and characterization of microsatellite markers (SSR) in Sesamum (Sesamum indicum L) species. Appl Biochem Biotechnol 168:1594–1607
Surapaneni M, Yepuri V, Vemireddy LR, Ghanta A, Siddiq EA (2014) Development and characterization of microsatellite markers in Indian sesame (Sesamum indicum L.). Mol Breeding 34:1185–1200
Uncu AO, Gultekin V, Allmer J, Frary A, Doganlar S (2015) Genomic simple sequence repeat markers reveal patterns of genetic relatedness and diversity in sesame. Plant Genome. doi:10.3835/plantgenome2014.11.0087
Varshney RK, Chabane K, Hendre PS, Aggarwal RK, Graner A (2007) Comparative assessment of EST-SSR, EST-SNP and AFLP markers for evaluation of genetic diversity and conservation of genetic resources using wild, cultivated and elite barleys. Plant Sci 173:638–649
Wang L, Zhang Y, Xiaoqiong Q, Gao Y, Zhang X (2012) Development and characterization of 59 polymorphic cDNA-SSR markers for the edible oil crop Sesamum indicum (Pedaliaceae). Am J Bot 99:394–398
Wei W, Qi X, Wang L, Zhang Y, Hua W, Li D, Lv H, Zhang X (2011) Characterization of the sesame (Sesamum indicum L.) global transcriptome using Illumina paired-end sequencing and development of EST–SSR markers. BMC Genom 12:451
Wei X, Wang L, Zhang Y, Qi X, Wang X, Ding X, Zhang J, Zhang X (2014) Development of simple sequence repeat (SSR) markers of sesame (Sesamum indicum) from a genome survey. Molecules 19:5150–5162
Welsh J, McClelland M (1990) Fingerprinting genomes using PCR with arbitrary primers. Nucleic Acids Res 18:7213–7218
Williams JGK, Kubelik AR, Livak KJ, Rafalski JA, Tingey SV (1990) DNA polymorphisms amplified by arbitrary primers are useful as genetic markers. Nucleic Acids Res 18:6531–6535
Woldesenbet DT, Tesfaye K, Bekele E (2015) Genetic diversity of sesame germplasm collection (Sesamum indicum L.): implication for conservation, improvement and use. Int J Biotechnol Mol Biol Res 6:7–18
Xu Y (2003) Developing marker-assisted selection strategies for breeding hybrid rice. Plant Breed Rev 23:73–174
Xu DH, Gai JY (2003) Genetic diversity of wild and cultivated soybeans growing in China revealed by RAPD analysis. Plant Breed 122:503–506
Yeh FC, Yang RC, Boyle TB, Ye ZH, Mao JX (1997) POPGENE, the user-friendly shareware for population genetic analysis Molecular Biology and Biotechnology Centre. University of Alberta, Canada
Yepuri V, Surapaneni M, Kola VSR, Vemireddy LR, Jyothi B, Dineshkumar V, Anuradha G, Siddiq EA (2013) Assessment of genetic diversity in sesame (Sesamum indicum L.) genotypes, using EST-derived SSR markers. J Crop Sci Biotech 16:93–103
Yu CY, Hu SW, Zhao HX, Guo AG, Sun GL (2005) Genetic distances revealed by morphological characters, isozymes, proteins and RAPD markers and their relationships with hybrid performance in oilseed rape (Brassica napus L.). Theor Appl Genet 110:511–518
Zargar SM, Farhat S, Mahajan Bhakhri A, Sharma A (2016) Unraveling the efficiency of RAPD and SSR markers in diversity analysis and population structure estimation in common bean. Saudi J Biol Sci 23:139–149
Zeng J, Zou Y, Bai J, Zheng H (2003) RAPD analysis of genetic variation in natural populations of Betula alnoides from Guangxi, China. Euphytica 134:33–41
Zhang Y, Zhang X, Hua W, Wang L, Che Z (2010) Analysis of genetic diversity among indigenous landraces from sesame (Sesamum indicum L.) core collection in China as revealed by SRAP and SSR markers. Genes Genom 32:207–215
Zhang H, Miao H, Wei L, Li C, Zhao R, Wang C (2013a) Genetic analysis and QTL mapping of seed coat color in sesame (Sesamum indicum L.). PLoS One 8(5):e63898
Zhang H, Mia H, Wan L, Qu L, Liu H, Wang Q, Yue M (2013b) Genome sequencing of the important oilseed crop Sesamum indicum L. Genome Biol 14:401
Acknowledgements
We acknowledge the National Bureau of Plant Genetic Resources (NBPGR), New Delhi for providing the germplasm used in this study. We also acknowledge DBT-BUILDER Project No. BT/PR14554/INF/22/125/2010 and University Grants Commission-Special Assistance Programme (UGC-SAP) New Delhi for financial assistance.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no competing interests.
Ethical standard
The authors declare that this manuscript has been prepared according to the ethical standards as advised.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Dar, A.A., Mudigunda, S., Mittal, P.K. et al. Comparative assessment of genetic diversity in Sesamum indicum L. using RAPD and SSR markers. 3 Biotech 7, 10 (2017). https://doi.org/10.1007/s13205-016-0578-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13205-016-0578-4