
Abstract
Microlandform classification of grid digital elevation models (DEMs) is the foundation of digital landform refinement applications. To solve the shortcomings of the traditional regular grid DEM microlandform classification method, including low automation and incomplete classification results, a support vector machine (SVM) classifier was designed for grid DEM microlandform classification, and an automatic grid-based DEM microlandform classification method based on the SVM method was created. The experiment applies the SVM-based grid DEM microlandform classification method to identify different hill positions, namely, the summit, shoulder, back-slope, foot-slope, toe-slope, and alluvium. The results show that this method is most efficient in identifying the toe-slope, with an accuracy rate of 99.60%, and least efficient in identifying the foot-slope, with an accuracy rate of 98.18%. The kappa coefficient and model evaluation index F1-score verify that the method and model are reliable when applied to grid DEM microlandform classification problems.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Terrain is an active element in the human living environment and has an important influence on other elements and overall environmental characteristics; the identification and classification of terrain features are of great significance to the ecological environment, hydrological research, geological structure analysis, and other geological research (Liu et al. 2015). In recent years, with the continuous improvement in the accuracy of digital elevation model (DEM) data, especially grid DEM data, and the continuous in-depth mining and analysis of terrain factors, many scholars and experts have used digital terrain analysis technology to gradually push DEM-based terrain classification to small scales. The development direction of semiautomatic or automatic development at the microscale level, such as microlandform classification, as a continuation and deepening of macrolandform morphological classification (Zhou 2006), is important for land ecology research, geomorphological mapping, and natural disasters.
Hammond first proposed the idea of dividing geomorphic types by slope and relative relief within a unit (Hammond 1964), and it was then realized and developed by (Dikau et al. 1991) and Brabyn Morgan and Lesh (2005). In terms of microlandform classification, Ruhe used the slope, length and width of the longitudinal slope to divide hill positions into the summit, shoulder, back-slope, foot-slope, toe-slope and alluvium, creating a microlandform classification system for the hill position. On this basis, (Dragut and Dornik 2016; Dornik et al. 2016) classifies and merges mountain parts and slope types into the same system by slope, plane curvature and profile curvature and develops a more detailed classification scheme. Based on the theoretical framework of digital terrain analysis and considering the spatial structure characteristics of landform types, Zhou and Liu (2008a, b) improved Dragut’s classification decision-making plan and realized the automatic classification of microlandforms through overlay analysis with grid DEM data of the Loess Plateau Zhou and Liu (2008a, b). However, this traditional microlandform classification method based on regularized knowledge grid DEM data has problems, such as a low degree of automation and incomplete classification.
In recent years, the phenomena of massive amounts of data, an explosion of information, and increasing difficulty in finding knowledge have become more prominent. It is imperative to move from geographic data information services to knowledge services, and knowledge mining or extraction has become more automated and intelligent (Chen et al. 2019). Artificial intelligence (AI) has attracted much attention in the field of surveying and mapping and has become a research hotspot. Academician Jinsheng (Ning 2019) believes that the current scientific and technological methods and applications of surveying and mapping can be closely integrated with high technology, such as mobile Internet, cloud computing, big data Internet of Things, and AI. The effects of the intelligent revolution triggered by AI are spreading to various industries, and the related methods, technologies, industrial forms and business models of surveying and mapping science and technology are facing considerable challenges and opportunities. Academician Deren (Li 2017) believes that traditional surveying and mapping in the era of big data will surely integrate communications, navigation, remote sensing, AI, virtual reality, and brain cognitive sciences into geospatial information intelligent service science. Academician Jiayao (Wang 2017) believes that various emerging information technologies can be integrated into the whole process of spatiotemporal perception and cognition in the era of spatiotemporal big data, especially deep learning and deep reinforcement learning, and deep integration of human natural intelligence and computer AI. (Liu et al. 2019) analyzed and discussed the new requirements, development directions, and key technologies of geographic information dynamic monitoring in the intelligent era, which provided a reference for the transformation and upgrading of digital and information-based surveying and mapping to intelligent surveying and mapping. In terms of terrain and landform classification, Qin et al. proposed a similarity-based fuzzy slope position classification method from the perspective of geography and comprehensively analyzed the existing automatic classification methods of landforms (Qin et al. 2009a, b; 2012; Wang and Qin 2017). Xiao et al. 2003a, b introduced the support vector machine (SVM) method in the recognition of hills and mountains. Zhang (Zhang et al. 2006) proposed the high spatial resolution RS image classification based on SVM method with the multi-source data. (Zhou et al. 2019; Zhang et al. 2019) introduced the back-propagation (BP) neural network method and random forest method in the division of mountain parts. Cao (Cao et al. 2020) proposed a landform classification method based on the random forest method in the study of landform classification of typical loess regions in the Loess Plateau. Wang (Wang et al. 2018) used the random forest algorithm to achieve fuzzy slope position classification. A novel model with improved prediction accuracy based on SVM is proposed, protection of urban ecosystems and alleviates discrepancies in urban development, resource utilization, and environmental protection Liu and Lei (2018). Deals with the high spatial resolution image (IKONOS) classification based on the SVM method integrating the information of spectral, texture and structure Li et al. (2018). Combining SVM and Certainty Factor (CF), CF-SVM model is established to evaluate the geological susceptibility of the region (Li et al. 2018). The performance quality of LR, SVM, and RF for earthquake-induced landslides susceptibility mapping incorporating remote sensing imagery (Liu et al. 2021).These studies provide new ideas for the application of AI technology to the automatic classification of topography and landforms (Shen et al. 2006). Furthermore, the SVM method has been widely used in the fields of predictive warning (Babak and Zahra 2020; Yazid et al. 2019) and classification recognition (Elahe et al. 2017; Hamidreza et al. 2017) because of its great advantages in solving small-sample, nonlinear and high-dimensional pattern recognition problems. This study attempts to take the SVM algorithm into microtopography grid DEM automatic classification, use existing classification schemes and decision-making prior knowledge to extract a representative point-to-point sample as a training set for the SVM classifier, construct an SVM classifier suitable for the automatic classification of grid DEM microlandforms, realize the automatic classification of grid DEM microlandforms by SVM, and solve the incomplete classification problem of the traditional microlandform classification method based on regularized knowledge of the grid DEM. Furthermore, this study attempts to avoid tedious data overlay analysis process in the microlandform classification process and to improve the generalization ability of the SVM method of grid DEM microlandform.
Design of classifier based on SVM
SVM
SVM is a machine learning method based on statistical learning theory. It is based on VC dimension theory and the structured risk minimization principle (Ding et al. 2011). It takes the minimization of the confidence range as the optimization goal and the training error as the constraint condition, which has good generalization. It has great advantages in solving small-sample, nonlinear, high-dimensional pattern recognition problems, as well as other problems (Shen et al. 2006). The SVM mechanism involves finding an optimal classification hyperplane that meets the classification requirements so that the hyperplane can maximize the blank area on both sides of the hyperplane while ensuring the classification accuracy. Given training sample{xi, yi}, i = 1, 2, ⋯, l, xi ∈ R, yi ∈ {−1, 1}, the SVM classifier is constructed, and the optimal linear hyperplane is set as (w ⋅ x) + b = 0. The classification interval is 1/2‖w‖2. The SVM optimization problem can be described as:
C is the error penalty factor, and ξi ≥ 0, i = 1, 2, ⋯, l is the relaxation factor. For the case where the sample data are nonlinear, a kernel function needs to be selected, and the problem of inseparable linearity in the original space is solved by mapping the data to a high-dimensional space. According to different data, different kernel functions are used to obtain different nonlinear SVMs. There are four types of commonly used kernel functions:
Linear kernel:
Polynomial kernel:
Radial basis kernel function:
After nonlinear mapping, the optimized dual form is obtained from the Lagrange function, and the original problem is transformed into:
αi, αj is the Lagrange coefficient, and φ(xi) ⋅ φ(yi) is the inner product of the high-dimensional space H. That is, the search for the optimal linear hyperplane is transformed into solving a quadratic programming problem. Based on Mercer’s theorem, a nonlinear problem in low-dimensional space is mapped to the high-dimensional space H, and the linear method is used for classification in the high-dimensional feature space. The form of the SVM classification function is similar to a neural network, and its mapping structure is shown in Fig. 1.

Decision functions of a support vector machine
SVM classifier parameter selection
There are two main parameters in the kernel function, namely, the penalty parameter c and the gamma parameter g in the kernel function. The error penalty parameter c represents the penalty coefficient for the deviation associated with a wrong sample, which can adjust the ratio of the experience risk and the confidence range of the learning machine, making the promotion performance of the learning machine the best. Setting reasonable parameters c and g has an important impact on the performance of the classifier. For specific sample data, only when the parameters c and g are set to reasonable values can the classification accuracy and generalization ability of the SVM classifier be effectively improved. This study uses cross validation to divide the sample data set into 3 parts, two-thirds of which are used as the training set and the remainder as the test set to evaluate the performance of the classifier. At the same time, the grid search method is used to train the model for each pair of parameters (c, g), and the group of parameters (c, g) with the highest classification accuracy is selected as the optimal group of parameters.
SVM method for classification of microterrain
Classification decision plan
The classification decision plan is the explicit expression and quantitative regularization of landform classification knowledge. It is also the basis and core of terrain classification. The completeness and scientificity of the classification decision plan directly affect the quality of the classification results. Due to different researchers in different disciplines and different application purposes, different classification standards, systems and methods have formed. There are mainly classification systems based on physical geography, hydrology, soil landscape, and geomorphology to study topographic features. In the subject of physical geography, the division of terrain is mainly based on slope. Commonly, slopes are divided into gentle slopes, medium slopes, steep slopes and vertical planes in the geographical sense according to the steepness of their slopes. Hydrological research on terrain classification mainly considers the hydrological process to be a highly nonlinear and spatially varying process. As a typical example, Ruhe uses the slope, length and width of the longitudinal slope to divide the landform slope into the summit, shoulder, back-slope, foot-slope, toe-slope and alluvium; at the same time, it is further divided into source slope, hillside slope and side slope according to the curvature of the slope surface plane to express the characteristics of water flow dispersion and confluence. The classification of microtopography based on geomorphology mainly starts from the perspective of morphology, taking certain topographic morphological characteristics as the focus of research and obtaining characteristic landforms through the spatial combination and comparative analysis of the elements describing the topographic morphological characteristics. This study uses the mountain body classification decision-making scheme in the literature. As shown in Table 1, the scheme takes the most widely used and classic Ruhe landform classification system in grid DEM microlandform classification as the prototype. Referring to Dragut’s expression form and using slope, plane curvature and section curvature as classification indicators improves the shortcomings of the original mountain part classification decision scheme. Microlandform factors such as slope, aspect, plane curvature, profile curvature, etc. from the DEM are selected as classification indicators, and the classification indicators are combined to form a classification decision scheme that scientifically and reasonably expresses the characteristics of microlandforms.
SVM-based microlandform classification process
Utilizing the advantages of SVM in solving small-sample, nonlinear recognition problems and the research results of microlandform classification, this research builds an automatic microlandform classification model based on SVM and uses grid DEM data as the source data to achieve SVM microlandform classification. First, the plane curvature, section curvature, slope and elevation of the grid DEM in the experimental area are extracted as a data set. According to the decision table and prior knowledge, the mountain terrain of the sample data set is divided into 6 categories. Moreover, 2/3 of the sample data set is used as the training set, and 1/3 is used as the test set. Second, the SVM classifier is trained on the training set from the sample data set to automatically learn the data characteristics of the training set and construct the training model, and the test set is used to evaluate the accuracy of the model. After the model meets the accuracy requirements, the new microlandform factor is input again to generalize the model, and the results of terrain classification are output. That is, the model is used to automatically identify more mountain parts in the grid DEM data in the test area based on the sample area classification. Finally, the classification results are analyzed. The process of the method is shown in Fig. 2.

Flow of grid DEM microlandform classification based on a support vector machine
Experiment and analysis
Selection of sample data set
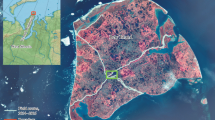
To verify the SVM method’s ability to perform the automatic classification of grid DEM microtopography proposed in this research, a mountainous region is classified as the experimental research object, a 1:10,000 grid DEM is the source data, and a certain area is selected as the experimental research area, as shown in Fig. 3(a). As shown on the left, the sample data are obtained by arbitrarily selecting a certain area in the study area, and the DEM shading map of the sample area is shown to the right of Fig. 3(a). The elevation of the highest point in this area is 1070.9 m, the elevation of the lowest point is 927.3 m, and the relative elevation difference is 143.6 m. The pixel size of the sample area is 5 × 5 m, and there are 40,000 pixels in total. According to the mountain body part classification decision scheme and the assumption that the mountain body part distribution has a certain continuity, the sample is screened; some very discrete feature points are deleted in all categories, and the balance of the number of sample categories is considered. Subsequently, 9879 typical samples were finally selected, with the summit having 879, the shoulder having 1800, the back-slope having 916, the foot-slope having 2299, the toe-slope having 2631 and the alluvium having 1,354 sample points. The determined sample data distribution is shown in Fig. 2(b). Then, a total of 6586 points, representing 2/3 of the samples, are used as the training set, and the remaining 3293 sample points are used as the test set. The determined training set and test set sample data distribution are shown in Table 2.

Spatial distribution of the sample: (a) DEM shading map of the sample area and (b) distribution of the sample data
Kernel function selection and model establishment
This study uses MATLAB and the LIBSVM library to build the SVM model. The input factors, i.e., plane curvature, slope curvature, slope and elevation, are 4-dimensional factors, and the output result is the predicted slope position type. To select the appropriate kernel function, this study tested the training accuracy of three commonly used kernel functions for mountain slopes. The test results are shown in Table 3. Table 3 shows that the RBF kernel function has the highest training accuracy, so this study chooses the RBF kernel function when constructing the SVM classification model.
Model evaluation
To verify and evaluate the SVM classification model, this study uses the kappa coefficient and F1-score to describe the model performance. The calculation formulas of the accuracy rate P, recall rate R and F1-score are:
TP: number of samples correctly classified into this category
FN: number of samples misclassified into other categories
FP: number of samples misclassified into this category
TN: number of samples correctly classified into other categories
This study uses the typical sample points selected in the study area to train the SVM classifier, builds an SVM model for grid DEM microlandform classification, uses the test set to test the model accuracy, and performs an automatic classification experiment in a mountainous area. The confusion matrix of the test set in the experiment is shown in Table 4. The overall accuracy of the model test set established with typical sample points reached 99.51%, and the kappa coefficient was 0.9939, indicating that the classification accuracy of the constructed SVM model is reliable and that the application of the SVM method for hill position classification at the study site is feasible. The classification statistical results of the test set are shown in Table 5. From Table 5, it can be seen that the SVM algorithm has inconsistent performance for the 6 types of microlandforms. The accuracy rate of the summit reaches 100%, and the accuracy rate of the foot-slope is 98.08%. The highest F1-score index is 99.83% for the summit, and the lowest is 99.41% for the shoulder, which verifies the applicability of the SVM algorithm in microlandform classification. The SVM method has a strong dependence on the terrain category knowledge contained in the representative sample points. Incomplete the terrain category feature knowledge will directly affect the ability of the SVM to mine implicit knowledge, resulting in inconsistent adaptability to the six types of microlandforms.
Overall Accuracy=0.9951 Kappa=0.9939
Experimental comparative analysis
To verify the effectiveness of the automatic classification method proposed in this research, the experimental area is expanded to the entire study area based on the sample data area. The pixel size of the study area is 5 × 5 m, with a total of 160,000 pixels. The classification result of the superposition analysis method based on rule knowledge is shown in Fig. 4(a). The SVM model established in this study is generalized to realize automatic classification of mountain parts, and the classification results are shown in Fig. 4(b). In the experimental area, the rule-based overlay analysis method and the SVM-based method are used to classify the mountain parts at each grid point, and the incomplete statistics are shown in Table 6. It can be clearly seen that the area of the SVM classification results in each category are higher than the comparative rule method; for example, the proportion of slopes has increased by up to 16.79%, and the proportion of hilltops has increased by at least 0.95%. The SVM-based method ensures the completeness of the classification results, and there is no incomplete classification. The fundamental reason is that the superposition analysis method is a multifactor system classification method for each grid point. For different areas, the complexity of the terrain is inconsistent, and the degree range is uncertain. The SVM method uses the kernel function to obtain the optimal separation hyperplane, and there is a unique global optimal solution, which solves the problem of incomplete classification.

Test area classification results: (a) classification result of superposition analysis and (b) classification results of SVM
Taking the grid DEM of 5 × 5m pixels in the experimental area as the original data, the grid DEM data of 2.5 × 2.5m and 10 × 10m pixels are interpolated and extracted, respectively. The typical sample points are re-extracted from grid DEM with 2.5 m and 10 m pixels for training, and the classifiers with 2.5 m and 10 m resolutions are obtained respectively, and the grid DEM with 2.5 m and 10 m pixels is classified. The experimental results show that the classification accuracy of SVM method for microlandform classification of grid DEM data with different pixel sizes is different, which is over 95% on the whole, and the average classification accuracy of pixel size 5m is the highest, which is 99.51%; The classification accuracy of pixel size 10m is the lowest, reaching 98.19%. Grid DEM with a pixel size of 5m has the smallest dispersion of classification accuracy among the six types of hill-position, which shows strong adaptability to all types of landform.
Conclusion
With the continuous improvement in DEM data accuracy and the rapid development of digital terrain analysis technology, terrain classification based on DEMs is gradually being pushed in the direction of semiautomatic or automated development at the small-scale and microscale levels. As the research foundation of the fine application of digital terrain, microlandform classification has broad application prospects in soil research, agricultural production, urban planning, natural disasters, and civil engineering. In this study, the traditional microlandform classification method based on regularized knowledge of the grid DEM is low in automation and results in incomplete classification. Using the advantages of the SVM algorithm, the SVM algorithm is introduced into grid DEM microlandform classification. Using the existing classification decision scheme and prior knowledge to extract typical sample points, these typical sample points are used as the training set to train an SVM classifier, and an SVM model suitable for automatic classification of grid DEM microlandforms is constructed. The kappa coefficient and the model evaluation index F1-score verify that the method and model have reliable accuracy when applied to grid DEM microlandform classification problems. The experimental results show that the incorporation of the SVM method into grid DEM microlandform classification is effective in practice. Compared with the classification method based on overlay analysis, this method not only reduces the tedious data overlay analysis process and ensures the integrity of the classification results but also improves classification accuracy. The successful application of the SVM algorithm in grid DEM microlandform classification provides an effective method for automatic microterrain classification.
References
Babak M, Zahra A (2020) Estimation of solar radiation using neighboring stations through hybrid support vector regression boosted by Krill Herd algorithm. Arab J Geosci 13(3-4):423–435. https://doi.org/10.1007/s12517-020-05355-1
Cao ZT, Fang ZD, Yao J et al (2020) Loess landform classification based on random forest. J Geo Info Sci 22(03):452–463
Chen J, Liu WZ, Wu H et al (2019) Basic issues and research agenda of geospatial knowledge service. Geom Info Sci Wuhan University 44(01):38–47
Dikau R, Brabb EE, Mark RM (1991) Landform classification of New Mexico by computer. US Department of the Interior, US Geological Survey
Ding SF, Qi BJ, Tan YH (2011) An overview on theory and algorithm of support vector machines. J Univ Elect Sci Technol China 40(01):2–10
Dornik A, Dragut L, Urdea P (2016) Knowledge-based soil type classification using terrain segmentation. Soil Res 54(07):809–823
Dragut L, Dornik A (2016) Land-surface segmentation as a method to create strata for spatial sampling and its potential for digital soil mapping. Int J Geogr Inf Sci 30(07):1359–1376
Elahe T, Hamid E, Abbas K (2017) Evaluation of different metaheuristic optimization algorithms in feature selection and parameter determination in SVM classification. Arab J Geosci 10(22):478. https://doi.org/10.1007/s12517-017-3254-z
Hamidreza K, Winfried V, Esmaeil A (2017) Land-cover classification and analysis of change using machine-learning classifiers and multi-temporal remote sensing imagery. Arab J Geosci 10(6):1–15. https://doi.org/10.1007/s12517-017-2899-y
Hammond EH (1964) Analysis of properties in land form geography: an application to broad-scale land form mapping. Ann Assoc Am Geogr 54(1):11–19
Li DR (2017) From geomatics to geospatial intelligent service science. Acta Geodaetica et Cartographica Sinica 46(10):1207–1212
Li YY, Mei HB, Ren XJ et al (2018) Geological disaster susceptibility evaluation based on certainty factor and support vector machine. J Geo Info Sci 20(12):1699–1709
Liu LN, Lei YL (2018) An accurate ecological footprint analysis and prediction for Beijing based on SVM model. Ecological Info 44(1):33–42. https://doi.org/10.1016/j.ecoinf.2018.01.003
Liu SL, Li FY, Jiang RQ, Chang RX, Liu W (2015) A method of loess landform automatic recognition based on slope spectrum. J Geo Info Sci 17(10):1234–1242
Liu JJ, Chen J, Zhang J et al (2019) Geographic information dynamic monitoring in intelligent era. Geom Info Sci Wuhan University 44(01):92–96
Liu R, Li LY, Saied P et al (2021) The performance quality of LR, SVM, and RF for earthquake-induced landslides susceptibility mapping incorporating remote sensing imagery. Arab J Geosci 14:259. https://doi.org/10.1007/s12517-021-06573-x
Morgan JM, Lesh AM (2005) Developing landform maps using Esri's model-builder. Towson University-Center for Geographic Information Sciences, Towson, MD
Ning JS (2019) Research on the development strategy of surveying and mapping science and technology transformation and upgrading. Geom Info Sci Wuhan University 44(01):1–9
Qin CZ, Lu YJ, Bao LL et al (2009a) Simple digital terrain analysis software (SimDTA 1.0) and its application in fuzzy classification of slope positions. J Geo Info Sci 11(06):737–743
Qin CZ, Zhu AX, Shi X, Li BL, Pei T, Zhou CH (2009b) Quantification of spatial gradation of slope positions. Geomorphology 110(03):152–161
Qin CZ, Zhu AX, Qiu WL et al (2012) Mapping soil organic matter in small low-relief catchments using fuzzy slope position information. Geoderma 171(02):64–74
Shen MH, Xiao L, Wang FX (2006) Application of support vector machine (SVM) in pattern recognition. Telecom Eng 4(04):9–12
Wang JY (2017) Cartography in the age of spatio-temporal big data. Acta Geodaetica et Cartographica Sinica 46(10):1226–1237
Wang YW, Qin CZ (2017) Review of method for landform automatic classification. Geography and Geo Information Science 33(04):16–21
Wang L, Ma FH, Wu W et al (2018) Fuzzy slope position segmentation based on random forest. Journal of Southwest China Normal University (Natural Science Edition) 43(01):10–17
Xiao J, Wu F, Zhuang YT et al (2003a) 3D terrain recognition and retrieval based on support vector machine and level of detail. Journal of Computer-Aided Design & Computer Graphics 4:410–415
Xiao J, Zhuang YT, Wu F (2003b) Recognition and retrieval of 3d terrain based on level of detail and minimum spanning tree. Journal of Software 11:1955–1963
Yazid T, Doudja S-G, Ozgur K (2019) A new intelligent method for monthly streamflow prediction: hybrid wavelet support vector regression based on grey wolf optimizer (WSVR–GWO). Arab J Geosci 12(17):1–20. https://doi.org/10.1007/s12517-019-4697-1
Zhang JS, He CY, Pan YZ et al (2006) The high spatial resolution RS image classification based on SVM method with the multi-source data. Journal of remote sensing 10(1):49–57
Zhang XJ, Guo YK, Zhou FB et al (2019) Micro landform classification method of grid DEM based on random forest. Geomatics & Spatial Information Technology 42(10):107–109 115
Zhou FB (2006) Automated classification of micro landform based on grid digital elevation model. Changsha University of Science & Technology
Zhou FB, Liu XJ (2008a) Improved hill-position classification decision and experiment of micro landform classification based on DTA. Acta Agriculturae Boreali-occidentalis Sinica 17(03):343–346
Zhou FB, Liu XJ (2008b) Research on the automated classification of micro landform based on grid DEM. Journal of WUT(Information & Management Engineering) 30(02):172–175
Zhou FB, Zou LH, Zhang XJ et al (2019) Micro landform classification method of grid DEM based on BP neural network. Bulletin of Surveying and Mapping 10(101-104):132
Zhou FB, Zou LH, Liu XJ et al (2020) Micro landform classification method of the grid DEM-based on convolutional neural network. Geomatics and Information Science of Wuhan University:1–9. https://doi.org/10.13203/j.whugis20190311
Funding
This research was funded by the National Natural Science Foundation of China, with grant numbers 41671446 and 41971421, the Open Fund of Key Laboratory of Special Environment Road Engineering of Hunan Province (Changsha University of Science & Technology), with grant number kfj140502, and the Scientific Research and Innovation project by Graduate Students of Academic Degree in Changsha University of Science & Technology, with grant number CX2020SS17.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there are no conflicts of interest regarding the publication of this paper.
Additional information
Responsible Editor: Stefan Grab
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhou, F., Zou, L., Liu, X. et al. Microlandform classification method for grid DEMs based on support vector machine. Arab J Geosci 14, 1269 (2021). https://doi.org/10.1007/s12517-021-07596-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12517-021-07596-0