
Abstract
Recyclable waste sorting has become a key step for promoting the development of a circular economy with the gradual realization of carbon neutrality around the world. This study aims to develop an intelligent and efficient method for recyclable waste sorting by the method of deep learning. Thus, RWNet models, which refers to various ResNet structures (ResNet-18, ResNet-34, ResNet-50, ResNet-101, and ResNet-152) based on transfer learning, were proposed to classify different types of recyclable waste. Cyclical learning rate and data augmentation were taken to improve the performance of RWNet models. In addition, accuracy, precision, recall, F1 score, and ROC were taken to evaluate the performance of RWNet models. Results showed that the accuracy of various RWNet models is almost at 88%, and the best accuracy is 88.8% in RWNet-152. The highest precision, recall, and F1 score in terms of weighted average value appeared in RWNet-101 (89.9%), RWNet-152 (88.8%), and RWNet-152 (88.9%), respectively. The area under the ROC curve (AUC) is higher than 0.9, except for the AUC value of plastic (0.85), which indicated that most of the recyclable waste can be well sorted by RWNet models. This study demonstrates the good performance of RWNet models that can be used to automatically sort most of the recyclable waste, which paves the way for better recyclable waste management.
Similar content being viewed by others
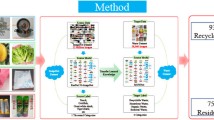


Introduction
The rapid development of industrialization and urbanization has brought considerable quantities of municipal solid waste (MSW). The amount of global MSW generation already reached about 2.01 billion tons in 2020, and it is expected to reach 2.59 billion tons in 2030 and 3.40 billion tons in 2050 (Ram et al. 2021). In developed countries, 16% of the total population generates about 34% of the global MSW, and the MSW per capita is close to 2.1 kg/day, which is higher than the average of the world (0.74 kg/day) (Jaunich et al. 2019). Even for low- and middle-income countries, such as Africa and parts of Asia, it will also grow fast and account for about 35% of the global MSW (Kaza and Bhada-Tata 2018). However, the current MSW treatment capacity is insufficient. United Nations Environment Programme (UNEP) pointed out that this has become a significant problem affecting economic development, human settlements, and public health (Harris et al. 2021). To improve the level of global governance, UNEP and the International Solid Waste Association (ISWA) jointly released the “Global Waste Management Outlook,” trying to propose global solutions for solid waste management. Moreover, the United Nations released the 2030 Global Agenda for Sustainable Development, which proposed 17 Sustainable Development Goals (SDGs) and 169 specific goals (Schmidt-Traub et al. 2017). Especially, MSW management is the key goal target of SDG11, and waste reduction and recycling were also pointed out in SDG12 (Brunner and Rechberger 2015). MSW management would have directly impact on human life, economic, and business communication (Abbas et al. 2019a; Aman et al. 2021; Hussain et al. 2021; Yu et al. 2022). Therefore, it is urgent to enhance the level of MSW management.
It is worth noting that about 43–59% of MSW in developed countries and 26–47% of MSW in developing countries is relatively high-value components (so-called recyclable waste). Recyclable waste management is also emphasized by the circular economy, which is low consumption and low emissions and is also in line with the SDGs (Schmidt-Traub et al. 2017). The US Environmental Protection Agency (USEPA) already released the “National Recycling Strategy,” which pointed out that recyclable waste sorting should be rapidly improved (Regan 2021). Thus, recyclable waste sorting has become a key step for promoting the development of the circular economy with the gradual realization of carbon neutrality around the world.
In the “National Recycling Strategy” of USEPA, it indicated that efficiencies of recyclable waste sorting should be enhanced, including reducing the cost of sorting, decreasing the number of residual waste, and improving the quality and quantity of recyclables (Regan 2021). The classification of recyclable waste is related to the social responsibility, the propagation of social media and internet, especially technology innovation (Abbas et al. 2021; Hussain et al. 2019; Li et al. 2021b; Mubeen et al. 2021a). Recently, great attention has been caught on smart classification with the development of the Internet of Things, electronic technology, and control technology. Image recognition plays a crucial role in intelligent classification and automation. The method of traditional machine learning like support vector machine (SVM) (Wang et al. 2019), laser-induced breakdown spectroscopy and stoichiometric tools (Costa et al. 2017), and Fourier transform infrared spectroscopy coupled with principal component analysis (PCA) (Chophi et al. 2021) to realize image/data process. However, these methods are needed to extract hand-designed features, which show poor discrimination ability and weak generalization for high-level features (Zhang et al. 2021a).
Recently, deep learning has emerged as a powerful method for high-level features, which is being widely used in image classification, object detection, and semantic segmentation (Alom et al. 2019). In comparison to the traditional image classification method (Alom et al. 2019), by automating the extraction of representations, deep learning algorithms have strong robustness to stand up against noise, which is more robust, scalable, and generalized (Yan et al. 2021). Deep learning like a convolutional neural network (CNN) has already been applied in recyclable waste sorting (Adedeji and Wang 2019) and food waste sorting (Frost et al. 2019). Although the deep residual network (ResNet) is being widely used in image classification in other fields (Cheng et al. 2021, Ghosh and Ghosh 2022), with the capacity to address the problem of gradient degradation in network performance by identity mapping (He et al. 2016), limited literature has reported applying the residual network (ResNet) model to waste classification. Notably, the ResNet model is a data-driving model, which required a large number of data. Fortunately, transfer learning can be applied to solve this bottleneck (Pan and Yang 2009). In addition, the selection of hyper-parameters like learning rate is challenging and cumbersome work, as small or large learning rates will cause slow convergence or divergence in training algorithms (Bengio 2012). This problem could be overcome by the method of cyclical learning rate (Smith 2017). Deep learning is considered the block box, but integrating the t-distributed stochastic neighbor embedding (t-SNE) (Retsinas et al. 2017) and PCA (Serranti et al. 2012) could make the deep learning model visible.
Few studies used the method of transfer learning and cyclical learning rate with deep learning model to realize the finely classified the recyclable waste. This study aims to develop an intelligent and efficient method for recyclable waste sorting through deep learning. Thus, RWNet models, various ResNet structures (ResNet-18, ResNet-34, ResNet-50, ResNet-101, and ResNet-152) based on transfer learning, combined with the technology of data augmentation and cyclical learning rate, was proposed to classify different types of recyclable waste images in this paper. Considering the shortcomings of the accuracy assessment method due to the unbalanced data, precision, and recall, F1 score and receiver operating characteristic (ROC) also were applied to evaluate the performance of RWNet models. Algorithms of t-SNE and PCA were adopted to extract the representations of recyclable waste from high dimension to low dimension. The main contributions of this article are summarized as follows: A recyclable waste image dataset with the 45,486 images was collected by the method of data augmentation. The experimental results indicated that the method of cyclical learning rate and transfer learning to improve the performance of RWNet is practical and feasible.
Materials and methods
Data collection
The datasets were collected from open source (https://github.com/garythung/trashnet), which contained cardboard, glass, metal, paper, plastic, and trash. The number of these categories was 403, 501, 410, 594, 482, and 137, respectively (Fig. 1).

Gallery of recyclable waste: cardboard, glass, metal, paper, plastic, and trash
Data augmentation
Considering recyclable waste in the environment is random and irregular, measures of color space transformation, rotation, flipping, and noise injection have been taken to augment the image sample (Abbas et al. 2019b; Abbasi et al. 2021; Mubeen et al. 2021b; Zhang et al. 2022), as shown in Fig. S1. After data augmentation, the numbers for cardboard, glass, metal, paper, plastic, and trash were enlarged to 7254, 9018, 7380, 10,692, 8676, and 2466, respectively. The pixel size of images was reshaped as 224 × 224 [(height) × (width)] for efficient training of the deep learning neural network. In addition, the number of the training dataset, validation dataset, and test dataset was 32,747, 3639, and 9100, respectively.
The experimental platform is given in SI (Table S1).
Convolutional neural network (CNN)
Process of convolution layer and pooling layer
The CNN is a kind of feedforward neural network, and it automatically extracts representations or abstractions from data by using its convolutional layer and pooling layer (Li et al. 2021a). The convolutional layer can be computed as in Eq. (2–1):
where \({{conv}}_{{i}}^{{f}}\left[{{j}}\right]\) is the output of the jth neuron at layer l; F is a nonlinear function; \({{w}}_{{ki}}^{{f}}{ and }{{b}}_{{ki}}^{{f}}\) are the scaler weight and bias of the jth neuron at layer l, respectively; Sj represents the selection of the input maps.
For the pooling layer calculation, it can be obtained according to Eq. (2–2):
where the \({{Max}}\left({{conv}}_{{i}}^{{f}}\right)\) and \({{Average}}\left({{conv}}_{{i}}^{{f}}\right)\) dependent on the pooling layer type.
Residual network (ResNet)
ResNet won the 1st place in ImageNet classification, which was first introduced by He et al. (2016). ResNet is a network-in-network architecture that relies on many stacked residual units (Garcia-Garcia et al. 2018). The structure of ResNet was shown in Fig. 2, which was consisted of two deep building blocks: bottleneck 1 and bottleneck 2. ResNet-18 and ResNet-34 were stacked by bottleneck 1, while bottleneck 2 was used to stack the structure of ResNet-50, ResNet-101, and ResNet-152. The number of ResNet like 18 and 152 was represented the 18 and 152 layers, respectively. Compared with bottleneck 1, the three layers 1 × 1, 3 × 3, and 1 × 1 convolutions in bottleneck 2, where the function of 1 × 1 layer is reducing and increasing the dimension of input, making the 3 × 3 layer a bottleneck with small input/output dimensions (He et al. 2016). Identity mapping is a key measure for addressing the degradation problem, how it works introduce in below:

The structure of the ResNet: ResNet-18, ResNet-34, ResNet-50, ResNet-101, and ResNet-152
As shown in bottleneck 1 in Fig. 2, x, y, and \({F(x}{,}\left\{{{w}}_{{i}}\right\}{)}\) was represented the input, output vectors, and residual mapping for learning, respectively. The operation \({F(x}{,}\left\{{{w}}_{{i}}\right\}{)}\) + x is conducted by a shortcut connection (Fulkerson 1996) and element-wise addition, which could effectively avoid the degradation problem.
It is worth noting that average pooling was introduced and linked to the fully connected layer in Conv5_x, where the activation function of the rectified linear unit (ReLu) was used to predict classes based on the highest probability given the input data, which can be expressed in the mathematics form as follows (2–4):
where elements of w and b denote the weights and bias, respectively. Index j was used to normalize the posterior distribution.
The model prediction is the class with the highest probability:
The elements of weights and bias in deep ResNet structure are also optimized by the error backpropagation algorithm, which uses an error metric to calculate the distance between true class labels and the predicted class labels. Cross-entropy function (2–6) was chosen as the loss function to be minimized for dataset V.
where L denotes the loss function; here, \({V} = \left\{{{v}}^{\left({1}\right)}{,}{{v}}^{\left({2}\right)}{,}{{v}}^{\left({3}\right)}{,...,}{{v}}^{\left({{n}}\right)}\right\}\) is the set of input samples in the training dataset; \({Y} = \left\{{{y}}^{\left({1}\right)}{,}{{y}}^{\left({2}\right)}{,}{...}{,}{{y}}^{\left({6}\right)}\right\}\) is the corresponding labels: cardboard, glass, metal, paper, plastic, and trash; the a(v) represents the output of the ResNet given input v.
Transfer learning
Transfer learning is a machine learning technique to migrate knowledge between different physical scenarios, involving the concepts of domain and task. Given a source domain, ImageNet (Xs), and a corresponding source task, Image label (Ys), there is a marginal probability distribution Px(x,y) between Xs and Ys. For the task of recyclable waste classification, there is also a target domain, trash dataset (XT) as well as a target task, corresponding label (YT). The objective of transfer learning is to learn the target probability distribution PT(x,y) in XT with the knowledge gained from Xs and Ys. Noticeably, ImageNet consists of 12 million images and 1000 categories. Therefore, Xx ≠ Ys or Xt ≠ YT.
The measure of fine-tuning was taken to adjust the final learnable layers of the pretrained ResNet models, changing neurons in the output layer from 1000 to 6. This method can share the pre-trained parameters and handle the task of recyclable waste classification.
Model evaluation metrics
As for the definition of true positive (TP), true negative (TN), false positive (FP), and false negative (FN), taking the cardboard as example. The recyclable wastes which are cardboard and detected are represented as TP; the recyclable waste that are not cardboard and actually predicted not-cardboard are denoted as TN; while, if recyclable waste that were actually cardboard but not misjudged as other types of recyclable waste, which denoted as FN; as for FP, it can be defined that if recyclable waste were classified as cardboard in non-cardboard waste.
Confusion matrix, recall, precision, F1 score, accuracy, ROC, and area under the curve (AUC) were used to evaluate the performance of RWNet models. Recall, precision, F1 score, and accuracy were defined as follows:
in which, TP, TN, FN, and FP are the numbers of true positives, true negatives, false negatives, and false positives, respectively.
Visualization
PCA
PCA was employed to create low-dimensional data representing and interpreting waste sorting (Thomaz and Giraldi 2010). First, the matrix X of m × n training was set to include m input samples and n pixels (or variables). Secondly, the covariance matrix C of the data matrix was obtained according to Eq. (2–12):
Thirdly, the eigenvector P and eigenvalue Ʌ of this covariance matrix C were calculated according to Eq. (2–13):
Therefore, such a set of eigenvectors P for the training set matrix X was regarded as the principal component.
t-SNE
The t-SNE is capable of reducing dimensionality tasks via minimizing the divergence between the pairwise similarity distribution of input points and low-dimensional embedding points (Maaten and Hinton 2008, Retsinas et al. 2017). The input points were set as \(\left\{{{x}}_{1}{,}{{x}}_{2}{,}{{x}}_{3}{,...,}{{x}}_{{n}}\right\}\) and their corresponding embedding points were \(\left\{{{y}}_{1}{,}{{y}}_{2}{,}{{y}}_{3}{,...,}{{y}}_{{n}}\right\}\). The pairwise similarity between points xi and xj can be measured using the joint probability, pi,j, as given by Eqs. (2–14) and (2–15):
where \(\mathrm{d}\left({{x}}_{\mathrm{i}}{,}{\mathrm{x}}_{{j}}\right)\) represented distance function that is considered to be Euclidean.
A similar method was applied to calculate the pairwise similarity between points yi and yj in the embedding space, that is:
The Kullback–Leibler divergence was minimized to calculate the embedding Y that consider the pairwise similarity distribution for both initial and the embedding spaces as follows:
The gradient descent method was applied to find an embedding Y to minimize the divergence. The divergence gradient for each point of the embedding space was calculated according to Eq. (2–18):
The overall framework for the algorithmic of ResNet based on transfer learning applied in recyclable waste sorting (RWNet) is provided as follows.
Algorithm RWNet
-
1.
Training phase: Input: Xtrain1, Ytrain1: X: RGB ImagNet image, y: class labels.
-
2.
Setting up ResNet architecture and selecting hyper-parameters like batch size, epoch number, and work numbers.
-
3.
Learning parameters of ResNet-ImageNet model with cyclical learning rate using Xtrain1, Ytrain1.
-
4.
Using transfer learning and fine-tuning trained ResNet-ImageNet
-
5.
Input: Xtrain, Ytrain, Xvalid, Yvalid: X: RGB waste image, y: class labels.
-
6.
Learning parameters of RWNet model using (Xtrain, Ytrain) and (Xvalid,Yvalid)
-
7.
Testing phase: Input RWNet model, Xtest
-
8.
Compute RWNet inference for testing data \(\to\) recyclable waste classification
-
9.
Explanation phase: Generating output features via PCA and t-SNE, respectively.
Results and discussion
Learning rate
Figure S2 shows the relationship between the learning rate and loss in various RWNet models based on the ImageNet dataset processed with cyclical learning rate. Instead of a fixed or exponentially decreasing value, the value of learning rate in the method of cyclical learning rate is varied between bounds. The optimum learning rate will be between the bounds and the near-optimum learning rate can be found throughout the training. The gradient between loss and learn rate reach maximum in RWNet-18, RWNet-34, RWNet-50, RWNet-101, and RWNet-152 when the value of the learning rate is 1.8 × 10−4, 5.0 × 10−4, 4.8 × 10−4, 3.2 × 10−4, and 2.1 × 10−4, respectively. These points are the optimum learning rate for various ResNet architectures. Therefore, 1.8 × 10−4, 5.0 × 10−4, 4.8 × 10−4, 3.2 × 10−4, and 2.1 × 10−4 of the learning rate from ImageNet dataset training were separately applied in RWNet-18, RWNet-34, RWNet-50, RWNet-101, and RWNet-152 to train the recyclable waste training and validation dataset.
Effect of the transfer learning on RWNet-18 performance for recyclable waste classification
Figure 3 shows the effect of transfer learning on ResNet-18 performance in terms of loss, accuracy and training time. Figure 3a and b separately plot train loss and valid loss with various epoch applied ResNet-18 without/with transfer learning (TL) to sort the recyclable waste. The tendency of loss from ResNet-18 without TL and ResNet-18 with TL was decreased with the increase of the epoch number in both the training dataset and validation dataset. At the 10th epoch, the loss in the training dataset from ResNet-18 without/with TL was 0.043 and 0.006, respectively.

Comparison of the performance of waste sorting by ResNet-18 without/with transfer learning (TL): a training and valid loss in ResNet-18 without TL; b training and valid loss in RWNet-18; c training and valid accuracy in ResNet-18 without TL; d training and valid accuracy in RWNet; e training time in ResNet-18 without TL; f training time in RWNet-18 with TL. Note: TL was represented to transfer learning
As for accuracy, its tendency showed an upward trend with the increase of the epoch number both ResNet-18 without/with TL (Fig. 3c and d), and reached 98.59% and 99.78% in the training dataset at the 10th epoch. The accuracy from ResNet-18 with TL in the training dataset and validation dataset reached approximately maximum (98.18% and 98.18%, respectively) at the 5th epoch. Transfer learning could promote ResNet-18 to reach a better accuracy of recyclable waste sorting. As shown in Fig. 3e and f, the average training time in ResNet-18 without TL and ResNet-18 with TL was approximately 277.1 s and 231.3 s, respectively.
Performance of various RWNet models in training and validation dataset
Figure S3 shows various RWNet model performance on recyclable waste sorting in terms of training time, loss, and accuracy. The average training time was increased generally with the increase of the layer of ResNet architecture. It can be ascribed to much more parameters needed to be trained with the layer increased (Table S2). Specifically, the average training time was 231.3 s in RWNet-18, 242.9 s in RWNet-34, 272.8 s in RWNet-50, 350.3 s in RWNet-101, and 738.4 s in RWNet-152 (Fig. S1).
As shown in Fig. S3, the loss in various RWNet architectures showed a similar trend. The loss decreased with the epoch number increase in both the training dataset and the validation dataset. On the contrary, the trend of accuracy in various RWNet architectures increased with the iteration of the epoch.
Model performance in the test datasets
Confusion matrix
As shown in Fig. 4, confusion matrices of the assessment in model performance for RWNet models ran on the recyclable waste testing dataset. The number of the recyclable waste image on the diagonal line means correct classifications. And the values outside the diagonal line represent unpaired labels and images (Aliper et al. 2016). As for cardboard in RWNet-18, 1382 cardboard images were accurately sorted, in comparison to 0 images of glass, 4 images of metal, 4 images of paper, 3 images of plastic, and 0 images of trash were wrongly identified as the cardboard (Fig. 4b). It is noted that much more correct classifications in RWNet-18 compared with that in ResNet-18-without TL (Fig. 4a), indicating that RWNet models provided a better performance on the TrashNet test on the testing dataset.

Confusion matrices from RWNet runs on the TrashNet test dataset: a ResNet-18-without transfer learning; b RWNet-18; c RWNet-34; d RWNet-50; e RWNet-101; f RWNet-152; Note: TL was represented to transfer learning
In addition, most recyclable wastes like cardboard (1382), glass (1727), metal (1363), paper (1960), plastic (1194), and trash (418) were found on the diagonal line in Fig. 6b, and almost at the same level with other RWNet models. It indicated that each RWNet model can perform well on recyclable waste classification.
Accuracy, precision, recall, and F1 score
The meaning of accuracy, precision, recall, and F1-score was the proportion of the waste classification model correctly classified, the ratio of real correctly predicted positive items to all samples predicted to be positive, the ratio of correctly identified positive items to all real positive samples, and harmonic mean of recall and precision, respectively (Munir et al. 2019). The accuracy, precision, recall, and F1-score were adopted to quantitatively evaluate the performance of different RWNet models for recyclable waste sorting. The details of model evaluation metrics were shown in Fig. 5 and Table S3. The accuracy of various RWNet models is almost at 88%, and the best accuracy is 88.8% in RWNet-152 in Fig. 6a, which is much higher than the accuracy for recyclable waste in previous studies, 22% (Thung and Yang 2016), 63% (Thung and Yang 2016), and 87% (Adedeji and Wang 2019). However, due to the unbalanced data, there are shortcomings of the accuracy assessment method (Dhillon and Verma 2019).

Comparison of different RWNet models performance in terms of accuracy, precision, recall, and F1 score

ROC curves from RWNet models: a RWNet-18-without TL; b RWNet-18; c RWNet-34; d RWNet-50; e RWNet-101; f RWNet-152. Note: TL was represented to transfer learning. The class 0, class 1, class 2, class 3, class 4, and class 5 represent the cardboard, glass, metal, paper, plastic, and trash, respectively
For the precision value, as shown in Fig. 5b and Table S3, RWNet-101 shows better performance than other RWNet models in terms of a weighted average (89.9%). There is an excellent performance in all categories of recyclable waste except glass. The precision value of glass in various RWNet models followed this order: RWNet-50 (88.4%) > RWNet-18 (88.0%) > RWNet-152 (87.1%) > RWNet-101 (85.9%) > RWNet-34 (84.7%). Certainly, RWNet-101 still has room for enhancing the performance, especially for trash (55.6%).
For the recall value, as shown in Fig. 5c and Table S3, RWNet-152 shows a little better performance than other RWNet models in terms of weighted average (88.8%). Specifically, the recall value of RWNet-152 for 9100 images classified into cardboard, glass, metal, paper, plastic, and trash was 95.2%, 93.3%, 94.9%, 90.3%, 72.1%, and 87.4%, respectively. As given in Table S3, cardboard (97.5%), glass (95.7%), metal (94.9%), paper (91.6%), plastic (72.1%), brick (79.3%), and trash (87.4%) can be well separated by RWNet-34, RWNet-18, RWNet-152, RWNet-101, RWNet-152, and RWNet-152, respectively.
As shown in Fig. 5d and Table S3, the weighted average of F1-score follows this order: RWNet-152 (88.9%) > RWNet-50 (88.7%) = RWNet-101 (88.7%) > RWNet-18 (88.5%) > RWNet-34 (88.3%). This suggested that most of recyclable waste can be well sorted by RWNet models. In addition, the sorting performance for plastic and trash has great potential to improve.
ROC
The area under the ROC curve (AUC) can be used to assess the classification performance (Ahmad et al. 2020; Zhang et al. 2021b). It means a better classification effect along with a larger AUC value. All the macro average AUC of RWNet models was 0.93 (Fig. 6). Class 0, class 1, class 2, class 3, class 4, and class 5 represent cardboard, glass, metal, paper, plastic, and trash, respectively.
As presented in Fig. 6, all the RWNet models show similar performance. All the AUC value is higher than 0.9, except for the AUC value of plastic, which indicated that most recyclable waste can be well sorted by the RWNet models. The maximum AUC value of the cardboard is 0.98, followed by metal (0.97), glass (0.96), paper (0.94), trash (0.92), and plastic (0.85). It means that the classification effect of cardboard is the best, in contrast, the classification effect of plastic is the lowest. This is because of the plastic waste images, which often were wrongly identified as glass or trash (Fig. S4). In short, RWNet models show excellent performance in recyclable waste. The performance of RWNet models in terms of accuracy, precision, F1 score, and AUC is different from the conclusion of the ImagetNet application, which indicates that the deeper ResNet structures, the better performance. This phenomenon can be ascribed to the dataset of TrashNet that are not as complex as those from the ImageNet (Yang et al. 2021). Those results suggested that the structure and depth choice should be appropriate for the practical application in recyclable waste sorting.
Visual explanation by using PCA and t-SNE
PCA and t-SNE were adopted to present the distribution of the TrashNet test dataset in RWNet models. Figure 7a shows 2-dimension representations extracted from the last layer of the RWNet-152 model by the method of PCA algorithm. The features from RWNet-152 models demonstrate a relatively clear semantic clustering. However, all the features of recyclable waste overlapped a little bit, which indicates there exists confusion.

A 2-D feature visualization of an image representation of waste images by the method of PCA and t-SNE for the last layer of RWNet-152 with transfer learning: a PCA; b t-SNE. Each color illustrates a different class in the dataset
Figure 7b shows that the features of cardboard, glass, metal, paper, plastic, and trash were clearly separated, indicating that representations of recyclable waste were better separated by t-SNE from high dimension to low dimension compared to PCA. Therefore, combined with its advantages, the t-SNE method can be used to accurately describe the classification features of recyclable waste (Gisbrecht et al. 2015).
RWNet model limitations
Developing an intelligent and efficient method for recyclable waste classification and recycling is imperative due to the continuous increase of global MSW, especially during the period time of the global COVID-19 pandemic (Ge et al. 2022; Liu et al. 2021; Mamirkulova et al. 2022; Raza Abbasi et al. 2021; Zhou et al. 2021). RWNet model has some limitations, which can be improved in the future work. The training time of RWNet-152 is slower (average time for one epoch was approximately 700 s) due to millions of parameters need to be trained, it can be adjusted the structure of ResNet model to reduce the number of parameters. In addition, the images used in this study are not sufficiently realistic, and the real image of waste can be considered to test the robustness of RWNet.
Conclusion
The optimized learning rate for RWNet-18, RWNet-34, RWNet-50, RWNet-101, and RWNet-152 to train the trash dataset is 1.8 × 10−4, 5.0 × 10−4, 4.8 × 10−4, 3.2 × 10−4, and 2.1 × 10−4, respectively. Transfer learning can help RWNet models reach a better accuracy of recyclable waste sorting. The average training time increased with the increase of the layer of ResNet architecture from RWNet-18 (231.3 s) to RWNet-152 (738.4 s). The accuracy of various RWNet models is almost at 88% and the best accuracy is 88.8% in RWNet-152. The highest precision, recall, and F1 score in terms of weighted average value appeared in RWNet-101 (89.9%), RWNet-152 (88.8%), and RWNet-152 (88.9%), respectively. This suggested that most recyclable waste can be well sorted by RWNet-152 models. Specifically, the recall value of RWNet-152 for 9100 images classified into cardboard, glass, metal, paper, plastic, and trash was 95.2%, 93.3%, 94.9%, 90.3%, 72.1%, and 87.4%, respectively. Moreover, all the AUC value is higher than 0.9, except for the AUC value of plastic (0.85), which indicates that most recyclable waste can be well sorted by RWNet models. The classification effect of cardboard (AUC value = 0.98) is the best, in contrast, the plastic is the lowest. In addition, representations of recyclable waste were better separated by t-SNE from high dimension to low dimension compared to PCA.
Policy recommendations
This study demonstrates the good performance of RWNet models that can be used to sort most of the recyclable waste automatically, although the sorting performance for plastic has the potential to improve. Based on these findings, market-based environmental regulations should be introduced, which would encourage economic development as well as technology innovation.
Data availability
Enquiries about availability should be directed to the authors.
Abbreviations
- AUC:
-
Area under the curve
- CNN:
-
Convolutional neural network
- FN:
-
False negative
- FP:
-
False positive
- ISWA:
-
International Solid Waste Association
- MSW:
-
Municipal solid waste
- PCA:
-
Principal component analysis
- ResNet:
-
Residual network
- ROC:
-
Receiver operating characteristic
- RWNet:
-
ResNet based on transfer learning for recyclable waste sorting
- SDG:
-
Sustainable development goals
- SVM:
-
Support vector machine
- TN:
-
True negative
- TP:
-
True positive
- TL:
-
Transfer learning
- t-SNE:
-
T-Distributed stochastic neighbor embedding
- UNEP:
-
United Nations Environment Programme
- USEPA:
-
US Environmental Protection Agency
References
Abbas J, Mahmood S, Ali H, Raza M, Ali G, Aman J, Bano S, Nurunnabi M (2019a) The effects of corporate social responsibility practices and environmental factors through a moderating role of social media marketing on sustainable performance of firms’ operating in Multan, Pakistan. Sustainability 11https://doi.org/10.3390/su11123434
Abbas J, Raza S, Nurunnabi M, Minai MS, Bano S (2019b) The impact of entrepreneurial business networks on firms’ performance through a mediating role of dynamic capabilities. Sustainability 11https://doi.org/10.3390/su11113006
Abbas J, Mubeen R, Iorember PT, Raza S, Mamirkulova G (2021) Exploring the impact of COVID-19 on tourism: transformational potential and implications for a sustainable recovery of the travel and leisure industry. Curr Res Behav Sci 2https://doi.org/10.1016/j.crbeha.2021.100033
Abbasi KR, Adedoyin FF, Abbas J, Hussain K (2021) The impact of energy depletion and renewable energy on CO2 emissions in Thailand: fresh evidence from the novel dynamic ARDL simulation. Renew Energ 180:1439–1450. https://doi.org/10.1016/j.renene.2021.08.078
Adedeji O, Wang Z (2019) Intelligent waste classification system using deep learning convolutional neural network. Procedia Manufactruring 35:607–612. https://doi.org/10.1016/j.promfg.2019.05.086
Ahmad K, Khan K, Al-Fuqaha A (2020) Intelligent fusion of deep features for improved waste classification. IEEE Access 8:96495–96504. https://doi.org/10.1109/ACCESS.2020.2995681
Aliper A, Plis S, Artemov A, Ulloa A, Mamoshina P, Zhavoronkov A (2016) Deep learning applications for predicting pharmacological properties of drugs and drug repurposing using transcriptomic data. Mol Pharmaceut 13:2524–2530. https://doi.org/10.1021/acs.molpharmaceut.6b00248
Alom MZ, Taha TM, Yakopcic C, Westberg S, Sidike P, Nasrin MS, Hasan M, Van Essen BC, Awwal AAS, Asari VK (2019) A state-of-the-art survey on deep learning theory and architectures. Electronics 8https://doi.org/10.3390/electronics8030292
Aman J, Abbas J, Shi G, Ain NU, Gu L (2021) Community wellbeing under China-Pakistan economic corridor: role of social, economic, cultural, and educational factors in improving residents’ quality of life. Front Psychol 12:816592. https://doi.org/10.3389/fpsyg.2021.816592
Bengio Y (2012) Neural networks: tricks of the trade, chapter practical recommendations for gradient-based training of deep architectures. Springer, Berlin Heidelberg
Brunner PH, Rechberger H (2015) Waste to energy-key element for sustainable waste management. Waste Manage 37:3–12. https://doi.org/10.1016/j.wasman.2014.02.003
Cheng J, Tian S, Yu L, Gao C, Kang X, Ma X, Wu W, Liu S, Lu H (2021) ResGANet: Residual group attention network for medical image classification and segmentation. Med Image Anal 76:102313. https://doi.org/10.1016/j.media.2021.102313
Chophi R, Sharma S, Singh R (2021) Discrimination of vermilion (sindoor) using attenuated total reflectance fourier transform infrared spectroscopy in combination with PCA and PCA-LDA. J Forensic Sci 66:594–607. https://doi.org/10.1111/1556-4029.14609
Costa VC, Aquino FWB, Paranhos CM, Pereira-Filho ER (2017) Identification and classification of polymer e-waste using laser-induced breakdown spectroscopy (LIBS) and chemometric tools. Polym Test 59:390–395. https://doi.org/10.1016/j.polymertesting.2017.02.017
Dhillon A, Verma GK (2019) Convolutional neural network: a review of models, methodologies and applications to object detection. Progress Artif Intell 9:85–112. https://doi.org/10.1007/s13748-019-00203-0
Frost S, Tor B, Agrawal R, G.Forbes A (2019) CompostNet: an image classifier for meal waste, IEEE Global Humanitarian Technology Conference (GHTC), pp. 1–4. https://doi.org/10.1109/GHTC46095.2019.9033130
Fulkerson B (1996) Pattern recognition and neural networks. Cambridge University Press
Garcia-Garcia A, Orts-Escolano S, Oprea S, Villena-Martinez V, Martinez-Gonzalez P, Garcia-Rodriguez J (2018) A survey on deep learning techniques for image and video semantic segmentation. Appl Soft Comput 70:41–65. https://doi.org/10.1016/j.asoc.2018.05.018
Ge T, Abbas J, Ullah R, Abbas A, Sadiq I, Zhang R (2022) Women’s entrepreneurial contribution to family income: innovative technologies promote females’ entrepreneurship amid COVID-19 crisis. Front Psychol 13:828040. https://doi.org/10.3389/fpsyg.2022.828040
Ghosh SK, Ghosh A (2022) ENResNet: a novel residual neural network for chest X-ray enhancement based COVID-19 detection. Biomed Signal Process Control 72:103286. https://doi.org/10.1016/j.bspc.2021.103286
Gisbrecht A, Schulz A, Hammer B (2015) Parametric nonlinear dimensionality reduction using kernel t-SNE. Neurocomputing 147:71–82. https://doi.org/10.1016/j.neucom.2013.11.045
Harris NL, Gibbs DA, Baccini A, Birdsey RA, De Bruin S, Farina M, Fatoyinbo L, Hansen MC, Herold M, Houghton RA (2021) Global maps of twenty-first century forest carbon fluxes. Nat Clim Change 11:234–240. https://doi.org/10.1038/s41558-020-00976-6
He K, Zhang X, Ren S, Sun J (2016): Deep residual learning for image recognition, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA pp. 770–778. https://doi.org/10.1109/CVPR.2016.90
Hussain T, Abbas J, Wei Z, Nurunnabi M (2019) The effect of sustainable urban planning and slum disamenity on the value of neighboring residential property: application of the hedonic pricing model in rent price appraisal. Sustainability 11https://doi.org/10.3390/su11041144
Hussain T, Abbas J, Wei Z, Ahmad S, Xuehao B, Gaoli Z (2021) Impact of urban village disamenity on neighboring residential properties: empirical evidence from Nanjing through hedonic pricing model appraisal. J Urban Plan Dev 147https://doi.org/10.1061/(ASCE)UP.1943-5444.0000645
Jaunich MK, Levis JW, F.DeCarolis J, Barlaz MA, Ranjithan SR (2019) Solid waste management policy implications on waste process choices and systemwide cost and greenhouse gas performance. Environ Sci Technol 53:1766-1775https://doi.org/10.1021/acs.est.8b04589
Kaza S, Bhada-Tata P (2018) Decision maker’s guides for solid waste management technologies. https://doi.org/10.1596/31694
Li Z, Liu F, Yang W, Peng S, Zhou J (2021a) A survey of convolutional neural networks: analysis, applications, and prospects. IEEE Trans Neural Netw Learn Syst 2162–2388https://doi.org/10.1109/TNNLS.2021a.3084827
Li Z, Wang D, Abbas J, Hassan S, Mubeen R (2021b) Tourists’ health risk threats amid COVID-19 era: role of technology innovation, transformation, and recovery implications for sustainable tourism. Front Psychol 12:769175. https://doi.org/10.3389/fpsyg.2021.769175
Liu Q, Qu X, Wang D, Abbas J, Mubeen R (2021) Product market competition and firm performance: business survival through innovation and entrepreneurial orientation amid COVID-19 financial crisis. Front Psychol 12:790923. https://doi.org/10.3389/fpsyg.2021.790923
Maaten L, Hinton G (2008) Visualizing data using t-SNE. J Mach Learn Res 9:2579–2605
Mamirkulova G, Mi J, Abbas J (2022): Economic corridor and tourism sustainability amid unpredictable COVID-19 challenges: assessing community well-being in the World Heritage Sites. Front Psychol 12
Mubeen R, Han D, Abbas J, Alvarez-Otero S, Sial MS (2021a) The relationship between CEO duality and business firms’ performance: the moderating role of firm size and corporate social responsibility. Front Psychol 12:669715. https://doi.org/10.3389/fpsyg.2021.669715
Mubeen R, Han D, Abbas J, Raza S, Bodian W (2021b) Examining the relationship between product market competition and Chinese firms performance: the mediating impact of capital structure and moderating influence of firm size. Front Psychol 12:709678. https://doi.org/10.3389/fpsyg.2021.709678
Munir K, Elahi H, Ayub A, Frezza F, Rizzi A (2019) Cancer diagnosis using deep learning: a bibliographic review Cancers 11https://doi.org/10.3390/cancers11091235
Smith LN (2017) Cyclical learning rates for training neural networks, IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, Santa Rosa, CA, USA. https://doi.org/10.1109/WACV.2017.58
Pan SJ, Yang Q (2009) A survey on transfer learning. IEEE T Knowl Data En 22:1345–1359. https://doi.org/10.1109/TKDE.2009.191
Ram C, Kumar A, Rain P (2021) Municipal solid waste management: a review of waste to energy (WtE) approaches. Bioresources 16:4275–4320. https://doi.org/10.15376/biores.16.2.Ram
Raza Abbasi K, Hussain K, Abbas J, Fatai Adedoyin F, Ahmed Shaikh P, Yousaf H, Muhammad F (2021) Analyzing the role of industrial sector’s electricity consumption, prices, and GDP: a modified empirical evidence from Pakistan. AIMS Energy 9:29–49. https://doi.org/10.3934/energy.2021003
Regan MS (2021) National recycling strategy. In: Agency USEP (Hrsg.)
Retsinas G, Stamatopoulos N, Louloudis G, Sfikas G, Gatos B (2017) Nonlinear manifold embedding on keyword spotting using t-SNE, International Conference on Document Analysis and Recognition (ICDAR), pp. 487–492. https://doi.org/10.1109/ICDAR.2017.86
Schmidt-Traub G, Kroll C, Teksoz K, Durand-Delacre D, Sachs JD (2017) National baselines for the sustainable development goals assessed in the SDG index and dashboards. Nat Geosci 10:547–555. https://doi.org/10.1038/NGEO2985
Serranti S, Gargiulo A, Bonifazi G (2012) Classification of polyolefins from building and construction waste using NIR hyperspectral imaging system. Resour Conserv Recy 61:52–58. https://doi.org/10.1016/j.resconrec.2012.01.007
Thomaz CE, Giraldi GA (2010) A new ranking method for principal components analysis and its application to face image analysis. Image Vision Comput 28:902–913. https://doi.org/10.1016/j.imavis.2009.11.005
Thung G, Yang M (2016) Classification of trash for recyclability status, Computer Science, pp. 940–945
Wang Z, Peng B, Huang Y, Sun G (2019) Classification for plastic bottles recycling based on image recognition. Waste Manag 88:170–181. https://doi.org/10.1016/j.wasman.2019.03.032
Yan B, Liang R, Li B, Tao J, Chen G, Cheng Z, Zhu Z, Li X (2021) Fast identification and characterization of residual wastes via laser-induced breakdown spectroscopy and machine learning. Resour Conserv Recy 174https://doi.org/10.1016/j.resconrec.2021.105851
Yang K, Yang T, Yao Y, Fan S-d (2021) A transfer learning-based convolutional neural network and its novel application in ship spare-parts classification. Ocean Coast Manage 215https://doi.org/10.1016/j.ocecoaman.2021.105971
Yu S, Abbas J, Draghici A, Negulescu OH, Ain NU (2022) Social media application as a new paradigm for business communication: the role of COVID-19 knowledge, social distancing, and preventive attitudes. Front Psychol 13:903082. https://doi.org/10.3389/fpsyg.2022.903082
Zhang Q, Yang Q, Zhang X, Bao Q, Su J, Liu X (2021a) Waste image classification based on transfer learning and convolutional neural network. Waste Manag 135:150–157. https://doi.org/10.1016/j.wasman.2021.08.038
Zhang Q, Zhang X, Mu X, Wang Z, Tian R, Wang X, Liu X (2021b)Recyclable waste image recognition based on deep learning. Resour Conserv Recy 171https://doi.org/10.1016/j.resconrec.2021b.105636
Zhang X, Husnain M, Yang H, Ullah S, Abbas J, Zhang R (2022) Corporate business strategy and tax avoidance culture: moderating role of gender diversity in an emerging economy. Front Psychol 13:827553. https://doi.org/10.3389/fpsyg.2022.827553
Zhou Y, Draghici A, Abbas J, Mubeen R, Boatca ME, Salam MA (2021) Social media efficacy in crisis management: effectiveness of non-pharmaceutical interventions to manage COVID-19 challenges. Front Psychiatry 12:626134. https://doi.org/10.3389/fpsyt.2021.626134
Funding
This work was financially supported by the National Natural Science Foundation of China (no. 51878470; no. 52000143), the National Key R&D Program of China (no. 2018YFC1901400), and the International Postdoctoral Exchange Fellowship Program (YJ20200280).
Author information
Authors and Affiliations
Contributions
Kunsen Lin designed the research, performed the calculation and analysis, and drafted the manuscript. Meilan Zhang, Chunlong Zhao, Lu Peng, and Qian Zhang gave comments and revisions. Xiaofeng Gao, Tao Zhou, and Youcai Zhao carried out the main revisions of contents and figures.
Corresponding author
Ethics declarations
Ethics approval
Not applicable.
Consent to participate
All the authors (Kunsen Lin, Youcai Zhao, Xiaofeng Gao, Meilan Zhang, Chunlong Zhao, Lu Peng, Qian Zhang, Tao Zhou) consent to participate.
Consent for publication
All the authors (Kunsen Lin, Youcai Zhao, Xiaofeng Gao, Meilan Zhang, Chunlong Zhao, Lu Peng, Qian Zhang, Tao Zhou) approved the version to be published.
Competing interests
The authors declare no competing interests.
Additional information
Responsible editor: Guilherme L. Dotto
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Lin, K., Zhao, Y., Gao, X. et al. Applying a deep residual network coupling with transfer learning for recyclable waste sorting. Environ Sci Pollut Res 29, 91081–91095 (2022). https://doi.org/10.1007/s11356-022-22167-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11356-022-22167-w