
Abstract
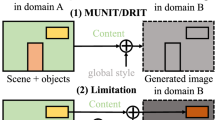
We present a novel Transformer-based network architecture for instance-aware image-to-image translation, dubbed InstaFormer, to effectively integrate global- and instance-level information. By considering extracted content features from an image as visual tokens, our model discovers global consensus of content features by considering context information through self-attention module of Transformers. By augmenting such tokens with an instance-level feature extracted from the content feature with respect to bounding box information, our framework is capable of learning an interaction between object instances and the global image, thus boosting the instance-awareness. We replace layer normalization (LayerNorm) in standard Transformers with adaptive instance normalization (AdaIN) to enable a multi-modal translation with style codes. In addition, to improve the instance-awareness and translation quality at object regions, we present an instance-level content contrastive loss defined between input and translated image. Although competitive performance can be attained by InstaFormer, it may face some limitations, i.e., limited scalability in handling multiple domains, and reliance on domain annotations. To overcome this, we propose InstaFormer++ as an extension of Instaformer, which enables multi-domain translation in instance-aware image translation for the first time. We propose to obtain pseudo domain label by leveraging a list of candidate domain labels in a text format and pretrained vision-language model. We conduct experiments to demonstrate the effectiveness of our methods over the latest methods and provide extensive ablation studies.





















Similar content being viewed by others


Data availability
The data that support the findings of this study are openly available online; (1)INIT (Shen et al., 2019) at https://zhiqiangshen.com/projects/INIT/index.html, (2)Kitti (Geiger et al., 2012) at http://www.cvlibs.net/datasets/kitti/, and (3)CityScapes (Cordts et al., 2016) at https://www.cityscapes-dataset.com/dataset-overview/.
References
Abdal, R., Zhu, P., Femiani, J., Mitra, N. J., & Wonka, P. (2021). Clip2stylegan: Unsupervised extraction of stylegan edit directions. arXiv preprint arXiv:2112.05219.
Ba, J. L., Kiros, J. R., & Hinton, G. E. (2016). Layer normalization. arXiv preprint arXiv:1607.06450.
Baek, K., Choi, Y., Uh, Y., Yoo, J., & Shim, H. (2021). Rethinking the truly unsupervised image-to-image translation. In ICCV, pp. 14154–14163.
Bau, D., Andonian, A., Cui, A., Park, Y., Jahanian, A., Oliva, A., & Torralba, A. (2021). Paint by word. arXiv preprint arXiv:2103.10951.
Bhattacharjee, D., Kim, S., Vizier, G., & Salzmann, M. (2020). Dunit: Detection-based unsupervised image-to-image translation. In CVPR, pp. 4787–4796.
Borji, A. (2019). Pros and cons of gan evaluation measures. Computer Vision and Image Understanding, 179, 41–65.
Brooks, T., Holynski, A., & Efros, A. A. (2023). Instructpix2pix: Learning to follow image editing instructions. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 18392–18402.
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., & Zagoruyko, S. (2020). End-to-end object detection with transformers. In ECCV, Springer, pp. 213–229.
Chen, H., Wang, Y., Guo, T., Xu, C., Deng, Y., Liu, Z., Ma, S., Xu, C., Xu, C., & Gao, W. (2021). Pre-trained image processing transformer. In CVPR, pp. 12299–12310.
Choi, Y., Choi, M., Kim, M., Ha, J. W., Kim, S., & Choo, J. (2018). Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In CVPR, pp. 8789–8797.
Choi, Y., Uh, Y., Yoo, J., & Ha, J. W. (2020a). Stargan v2: Diverse image synthesis for multiple domains. In Proceedings of the IEEE conference on computer vision and pattern recognition.
Choi, Y., Uh, Y., Yoo, J., & Ha, J. W. (2020b). Stargan v2: Diverse image synthesis for multiple domains. In CVPR, pp. 8188–8197.
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., & Schiele, B. (2016). The cityscapes dataset for semantic urban scene understanding. In CVPR, pp. 3213–3223.
Couairon, G., Grechka, A., Verbeek, J., Schwenk, H., & Cord, M. (2022). Flexit: Towards flexible semantic image translation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 18270–18279.
Dai, Z., Cai, B., Lin, Y., & Chen, J. (2021a). Up-detr: Unsupervised pre-training for object detection with transformers. In CVPR, pp. 1601–1610.
Dai, Z., Liu, H., Le ,Q. V., & Tan. M. (2021b). Coatnet: Marrying convolution and attention for all data sizes. arXiv preprint arXiv:2106.04803.
Dhariwal, P., & Nichol, A. (2021). Diffusion models beat gans on image synthesis. Advances in Neural Information Processing Systems, 34, 8780–8794.
Dong, C., Loy, C. C., He, K., & Tang, X. (2015). Image super-resolution using deep convolutional networks. TPAMI, 38(2), 295–307.
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
Gabbay, A., & Hoshen, Y. (2021). Scaling-up disentanglement for image translation. arXiv preprint arXiv:2103.14017.
Gal, R., Patashnik, O., Maron, H., Chechik, G., & Cohen-Or, D. (2021). Stylegan-nada: Clip-guided domain adaptation of image generators. arXiv preprint arXiv:2108.00946.
Gatys, L. A., Ecker, A. S., & Bethge, M. (2016) Image style transfer using convolutional neural networks. In CVPR, pp. 2414–2423.
Geiger, A., Lenz, P., & Urtasun, R. (2012). Are we ready for autonomous driving? The Kitti vision benchmark suite. In CVPR, IEEE, pp. 3354–3361.
Gonzalez-Garcia, A., Van De Weijer, J., & Bengio, Y. (2018). Image-to-image translation for cross-domain disentanglement. arXiv preprint arXiv:1805.09730.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative adversarial nets. In NeurIPS, pp. 2672–2680.
Graham, B., El-Nouby, A., Touvron, H., Stock, P., Joulin, A., Jégou, H., & Douze, M. (2021). Levit: A vision transformer in convnet’s clothing for faster inference. In Proceedings of the IEEE/CVF international conference on computer vision, pp. 12259–12269.
He, K., Gkioxari, G., Dollár, P., & Girshick, R. (2017). Mask r-cnn. In ICCV, pp. 2961–2969.
Hertz, A., Mokady, R., Tenenbaum, J., Aberman, K., Pritch, Y., & Cohen-Or, D. (2022). Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626.
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., & Hochreiter, S. (2017). Gans trained by a two time-scale update rule converge to a local nash equilibrium. In NeurIPS, pp. 6626–6637.
Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33, 6840–6851.
Hoffman, J., Tzeng, E., Park, T., Zhu, J. Y., Isola, P., Saenko, K., Efros, A., & Darrell, T. (2018). Cycada: Cycle-consistent adversarial domain adaptation. In ICML, pp. 1989–1998.
Huang, X., & Belongie, S. (2017). Arbitrary style transfer in real-time with adaptive instance normalization. In ICCV, pp. 1501–1510.
Huang, X., Liu, M. Y., Belongie, S., & Kautz, J. (2018). Multimodal unsupervised image-to-image translation. In ECCV, pp. 172–189.
Hudson, D. A., & Zitnick, C. L. (2021). Generative adversarial transformers. arXiv preprint arXiv:2103.01209.
Iizuka, S., Simo-Serra, E., & Ishikawa, H. (2017). Globally and locally consistent image completion. ACM Transactions on Graphics (ToG), 36(4), 1–14.
Inoue, N., Furuta, R., Yamasaki, T., & Aizawa, K. (2018). Cross-domain weakly-supervised object detection through progressive domain adaptation. In CVPR, pp. 5001–5009.
Isola, P., Zhu, J. Y., Zhou, T., & Efros, A. A. (2017). Image-to-image translation with conditional adversarial networks. In CVPR, pp. 1125–1134.
Jeong, S., Kim, Y., Lee, E., & Sohn, K. (2021). Memory-guided unsupervised image-to-image translation. In CVPR, pp. 6558–6567.
Jiang, L., Zhang, C., Huang, M., Liu, C., Shi, J., Loy, C. C. (2020). Tsit: A simple and versatile framework for image-to-image translation. In European conference on computer vision, Springer, pp. 206–222.
Jiang, Y., Chang, S., & Wang, Z. (2021). Transgan: Two transformers can make one strong gan. arXiv preprint arXiv:2102.07074.
Katharopoulos, A., Vyas, A., Pappas, N., & Fleuret, F. (2020). Transformers are rnns: Fast autoregressive transformers with linear attention. In ICML, pp. 5156–5165.
Kim, J., Kwon Lee, J., & Mu Lee, K. (2016). Accurate image super-resolution using very deep convolutional networks. In CVPR, pp. 1646–1654.
Kim, S., Baek, J., Park, J., Kim, G., & Kim, S. (2020). Instaformer: Instance-aware image-to-image translation with transformer. In CVPR.
Kim, T., Cha, M., Kim, H., Lee, J. K., & Kim, J. (2017). Learning to discover cross-domain relations with generative adversarial networks. arXiv preprint arXiv:1703.05192.
Kim, T., Jeong, M., Kim, S., Choi, S., & Kim, C. (2019). Diversify and match: A domain adaptive representation learning paradigm for object detection. In CVPR, pp. 12456–12465.
Kwon, G., & Ye, J. C. (2021). Clipstyler: Image style transfer with a single text condition. arXiv preprint arXiv:2112.00374.
Lee, H. Y., Tseng, H. Y., Huang, J. B., Singh, M., & Yang, M. H. (2018). Diverse image-to-image translation via disentangled representations. In ECCV, pp. 35–51.
Lee, H. Y., Tseng, H. Y., Mao, Q., Huang, J. B., Lu, Y. D., Singh, M., & Yang, M. H. (2020). Drit++: Diverse image-to-image translation via disentangled representations. International Journal of Computer Vision, 128(10), 2402–2417.
Lee, K., Chang, H., Jiang, L., Zhang, H., Tu, Z., & Liu, C. (2021). Vitgan: Training gans with vision transformers. arXiv preprint arXiv:2107.04589.
Li, W., Wang, X., Xia, X., Wu, J., Xiao, X., Zheng, M., & Wen, S. (2022). Sepvit: Separable vision transformer. arXiv preprint arXiv:2203.15380.
Li, Y., Liu, H., Wu, Q., Mu, F., Yang, J., Gao, J., Li, C., & Lee, Y. J. (2023). Gligen: Open-set grounded text-to-image generation. arXiv preprint arXiv:2301.07093.
Liu, H., Dai, Z., So, D. R., & Le, Q. V. (2021a). Pay attention to mlps. arXiv preprint arXiv:2105.08050.
Liu, M. Y., Breuel, T., & Kautz, J. (2017) Unsupervised image-to-image translation networks. In NeurIPS, pp. 700–708.
Liu, M. Y., Huang, X., Mallya, A., Karras, T., Aila, T., Lehtinen, J., & Kautz, J. (2019). Few-shot unsueprvised image-to-image translation. In arxiv.
Liu, X., Gong, C., Wu, L., Zhang, S., Su, H., & Liu, Q. (2021b). Fusedream: Training-free text-to-image generation with improved clip+ gan space optimization. arXiv preprint arXiv:2112.01573.
Liu Y, Sangineto E, Chen, Y., Bao, L., Zhang, H., Sebe, N., Lepri, B., Wang, W., & De Nadai, M. (2021c). Smoothing the disentangled latent style space for unsupervised image-to-image translation. In CVPR, pp. 10785–10794.
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., & Guo, B. (2021d). Swin transformer: Hierarchical vision transformer using shifted windows. arXiv preprint arXiv:2103.14030.
Melas-Kyriazi, L. (2021). Do you even need attention? A stack of feed-forward layers does surprisingly well on imagenet. arXiv preprint arXiv:2105.02723.
Mirza, M., & Osindero, S. (2014). Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784.
Mo, S., Cho, M., & Shin, J. (2018). Instagan: Instance-aware image-to-image translation. arXiv preprint arXiv:1812.10889.
Oord, A., Li, Y., & Vinyals, O. (2018). Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748.
Park, J., Kim, S., Kim, S., Cho, S., Yoo, J., Uh, Y., & Kim, S. (2023). Lanit: Language-driven image-to-image translation for unlabeled data. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 23401–23411.
Park, T., Liu, M. Y., Wang, T. C., & Zhu, J. Y. (2019). Semantic image synthesis with spatially-adaptive normalization. In CVPR, pp. 2337–2346.
Park, T., Efros, A. A., Zhang, R., & Zhu J. Y. (2020). Contrastive learning for unpaired image-to-image translation. arXiv preprint arXiv:2007.15651.
Patashnik, O., Wu, Z., Shechtman, E., Cohen-Or, D., & Lischinski, D. (2021). Styleclip: Text-driven manipulation of stylegan imagery. In Proceedings of the IEEE/CVF international conference on computer vision, pp. 2085–2094.
Pathak, D., Krahenbuhl, P., Donahue, J., Darrell, T., & Efros, A. A. (2016). Context encoders: Feature learning by inpainting. In CVPR, pp. 2536–2544.
Peebles, W., & Xie, S. (2022). Scalable diffusion models with transformers. arXiv preprint arXiv:2212.09748.
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al. (2021). Learning transferable visual models from natural language supervision. In International conference on machine learning, pp. 8748–8763.
Rahaman, N., Baratin, A., Arpit, D., Draxler, F., Lin, M., Hamprecht, F., Bengio, Y., & Courville, A. (2019) On the spectral bias of neural networks. In ICML, pp. 5301–5310.
Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., Chen, M., & Sutskever, I. (2021). Zero-shot text-to-image generation. In International conference on machine learning, pp. 8821–8831.
Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster r-cnn: Towards real-time object detection with region proposal networks. NeurIPS, 28, 91–99.
Rodriguez, A. L., & Mikolajczyk, K. (2019). Domain adaptation for object detection via style consistency. arXiv preprint arXiv:1911.10033.
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. (2021). arXiv:2112.10752.
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10684–10695.
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E., Ghasemipour, S. K. S., Ayan, B. K., Mahdavi, S. S., Lopes, R. G., Salimans, T., Salimans, T., Ho, J., Fleet, D. J., & Norouzi, M. (2022). Photorealistic text-to-image diffusion models with deep language understanding. arXiv preprint arXiv:2205.11487.
Saito, K., Saenko, K., & Liu, M. Y. (2020). Coco-funit: Few-shot unsupervised image translation with a content conditioned style encoder. In European conference on computer vision, Springer, pp. 382–398.
Sakaridis, C., Dai, D., & Gool, L. V. (2019). Guided curriculum model adaptation and uncertainty-aware evaluation for semantic nighttime image segmentation. In Proceedings of the IEEE/CVF international conference on computer vision, pp. 7374–7383.
Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., & Chen, X. (2016). Improved techniques for training gans. NeurIPS, 29, 2234–2242.
Shen, Z., Huang, M., Shi, J., Xue, X., & Huang, T. S. (2019). Towards instance-level image-to-image translation. In CVPR, pp. 3683–3692.
Tolstikhin, I., Houlsby, N., Kolesnikov, A., Beyer, L., Zhai, X., Unterthiner, T., Yung, J., Steiner, A., Keysers, D., Uszkoreit, J., et al. (2021). Mlp-mixer: An all-mlp architecture for vision. arXiv preprint arXiv:2105.01601.
Touvron, H., Bojanowski, P., Caron, M., Cord, M., El-Nouby, A., Grave, E., Izacard, G., Joulin, A., Synnaeve, G., Verbeek, J., et al. (2021a). Resmlp: Feedforward networks for image classification with data-efficient training. arXiv preprint arXiv:2105.03404.
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., & Jégou, H. (2021b). Training data-efficient image transformers and distillation through attention. In: ICML, pp. 10347–10357.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. In NeurIPS, pp. 5998–6008.
Wang, T. C., Liu, M. Y., Zhu, J. Y., Tao, A., Kautz, J., & Catanzaro, B. (2018). High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 8798–8807.
Wang, W., Xie, E., Li, X., Fan, D. P., Song, K., Liang, D., Lu, T., Luo, P., & Shao, L. (2021a). Pvtv2: Improved baselines with pyramid vision transformer. arXiv preprint arXiv:2106.13797.
Wang, W., Xie, E., Li, X., Fan, D. P., Song, K., Liang, D., Lu, T., Luo, P., & Shao, L. (2021b). Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. arXiv preprint arXiv:2102.12122.
Wang, Y., Khan, S., Gonzalez-Garcia, A., Weijer, Jvd., & Khan, F. S. (2020). Semi-supervised learning for few-shot image-to-image translation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 4453–4462.
Wang, Z., Bovik, A. C., Sheikh, H. R., & Simoncelli, E. P. (2004). Image quality assessment: From error visibility to structural similarity. TIP, 13(4), 600–612.
Wang, Z., Lu, Y., Li, Q., Tao, X., Guo, Y., Gong, M., & Liu, T. (2022). Cris: Clip-driven referring image segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 11686–11695.
Wei, T., Chen, D., Zhou, W., Liao, J., Tan, Z., Yuan, L., Zhang, W., & Yu, N. (2021). Hairclip: Design your hair by text and reference image. arXiv preprint arXiv:2112.05142.
Wu, P. W., Lin, Y. J., Chang, C. H., Chang, E. Y., & Liao, S. W. (2019). Relgan: Multi-domain image-to-image translation via relative attributes. In Proceedings of the IEEE/CVF international conference on computer vision, pp. 5914–5922.
Xia, Z., Pan, X., Song, S., Li, L. E., & Huang, G. (2022). Vision transformer with deformable attention. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp. 4794–4803.
Xiao, T., Singh, M., Mintun, E., Darrell, T., Dollár, P., & Girshick, R. (2021). Early convolutions help transformers see better. arXiv preprint arXiv:2106.14881.
Xie, E., Wang, W., Yu, Z., Anandkumar, A., Alvarez, J. M., & Luo, P. (2021). Segformer: Simple and efficient design for semantic segmentation with transformers. arXiv preprint arXiv:2105.15203.
Yi, Z., Zhang, H., Tan, P., & Gong, M. (2017). Dualgan: Unsupervised dual learning for image-to-image translation. In ICCV, pp. 2849–2857.
Yu, X., Chen, Y., Liu, S., Li, T., & Li, G. (2019). Multi-mapping image-to-image translation via learning disentanglement. In Advances in neural information processing systems 32.
Zhang, D., Zhang, H., Tang, J., Wang, M., Hua, X., & Sun, Q. (2020a). Feature pyramid transformer. In ECCV, Springer, pp. 323–339.
Zhang, L., & Agrawala, M. (2023). Adding conditional control to text-to-image diffusion models. arXiv preprint arXiv:2302.05543.
Zhang, P., Zhang, B., Chen, D., Yuan, L., & Wen, F. (2020b). Cross-domain correspondence learning for exemplar-based image translation. In CVPR, pp. 5143–5153.
Zhang, R., Isola, P., & Efros, A. A. (2016). Colorful image colorization. In ECCV, Springer, pp. 649–666.
Zhang, R., Zhu, J. Y., Isola, P., Geng, X., Lin, A. S., Yu, T., & Efros, A. A. (2017). Real-time user-guided image colorization with learned deep priors. arXiv preprint arXiv:1705.02999.
Zhao, L., Zhang, Z., Chen, T., Metaxas, D. N., & Zhang, H. (2021). Improved transformer for high-resolution gans. arXiv preprint arXiv:2106.07631.
Zheng, C., Cham, T. J., & Cai, J. (2021a). The spatially-correlative loss for various image translation tasks. In CVPR, pp. 16407–16417.
Zheng, S., Lu, J., Zhao, H., Zhu, X., Luo, Z., Wang, Y., Fu, Y., Feng, J., Xiang, T., Torr, P. H., et al. (2021b). Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In CVPR, pp. 6881–6890.
Zhong, Y., Yang, J., Zhang, P., Li, C., Codella, N., Li, L. H., Zhou, L., Dai, X., Yuan, L., Li, Y., et al. (2022). Regionclip: Region-based language-image pretraining. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 16793–16803.
Zhou, X., Zhang, B., Zhang, T., Zhang, P., Bao, J., Chen, D., Zhang, Z., & Wen, F. (2021). Cocosnet v2: Full-resolution correspondence learning for image translation. In CVPR, pp. 11465–11475.
Zhu, J. Y., Park, T., Isola, P., & Efros, A. A. (2017a). Unpaired image-to-image translation using cycle-consistent adversarial networks. In ICCV, pp. 2223–2232.
Zhu, J. Y., Zhang, R., Pathak, D., Darrell, T., Efros, A. A., Wang, O., & Shechtman, E. (2017b). Toward multimodal image-to-image translation. In Advances in neural information processing systems, 30.
Zhu, X., Su, W., Lu, L., Li, B., Wang, X., & Dai, J. (2020). Deformable detr: Deformable transformers for end-to-end object detection. arXiv preprint arXiv:2010.04159.
Acknowledgements
This research was supported by the MSIT, Korea (IITP-2022-2020-0-01819, ICT Creative Consilience program, No. 2020-0-00368, A NeuralSymbolic Model for Knowledge Acquisition and Inference Techniques), and National Research Foundation of Korea (NRF-2021R1C1C1006897). This research was partially supported by Culture, Sports, and Tourism R &D Program through the Korea Creative Content Agency grant funded by the Ministry of Culture, Sports and Tourism in 2023 (4D Content Generation and Copyright Protection with Artificial Intelligence, R2022020068)
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Boxin Shi.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Kim, S., Baek, J., Park, J. et al. InstaFormer++: Multi-Domain Instance-Aware Image-to-Image Translation with Transformer. Int J Comput Vis 132, 1167–1186 (2024). https://doi.org/10.1007/s11263-023-01866-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11263-023-01866-y