
Abstract
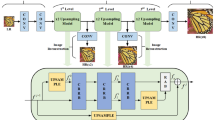
The ready accessibility of high-resolution image sensors has stimulated interest in increasing depth resolution by leveraging paired color information as guidance. Nevertheless, how to effectively exploit the depth and color features to achieve a desired depth super-resolution effect remains challenging. In this paper, we propose a novel depth super-resolution method called CODON, which orchestrates cross-domain attentive features to address this problem. Specifically, we devise two essential modules: the recursive multi-scale convolutional module (RMC) and the cross-domain attention conciliation module (CAC). RMC discovers detailed color and depth features by sequentially stacking weight-shared multi-scale convolutional layers, in order to deepen and widen the network at low-complexity. CAC calculates conciliated attention from both domains and uses it as shared guidance to enhance the edges in depth feature while suppressing textures in color feature. Then, the jointly conciliated attentive features are combined and fed into a RMC prediction branch to reconstruct the high-resolution depth image. Extensive experiments on several popular benchmark datasets including Middlebury, New Tsukuba, Sintel, and NYU-V2, demonstrate the superiority of our proposed CODON over representative state-of-the-art methods.















Similar content being viewed by others


References
Buades, A., Duran, J., & Navarro, J. (2019). Motion-compensated spatio-temporal filtering for multi-image and multimodal super-resolution. International Journal of Computer Vision, 127(10), 1474–1500.
Butler, D. J., Wulff, J., Stanley, G. B., & Black, M. J. (2012). A naturalistic open source movie for optical flow evaluation. In European conference on computer vision (pp. 611–625).
Diebel, J., & Thrun, S. (2006). An application of Markov random fields to range sensing. In Proceedings of the international conference on neural information processing systems (pp. 291–298).
Dong, C., Loy, C. C., He, K., & Tang, X. (2015). Image super-resolution using deep convolutional networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(2), 295–307.
Ferstl, D., Reinbacher, C., Ranftl, R., Rüther, M., & Bischof, H. (2013). Image guided depth upsampling using anisotropic total generalized variation. In Proceedings of the IEEE international conference on computer vision (pp. 993–1000).
Ham, B., Cho, M., & Ponce, J. (2015). Robust image filtering using joint static and dynamic guidance. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4823–4831).
He, K., Sun, J., & Tang, X. (2012). Guided image filtering. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(6), 1397–1409.
Hirschmuller, H., & Scharstein, D. (2007). Evaluation of cost functions for stereo matching. In 2007 IEEE conference on computer vision and pattern recognition (pp. 1–8).
Hu, J., Shen, L., & Sun, G. (2018). Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7132–7141).
Hui, T. W., Loy, C. C., & Tang, X. (2016). Depth map super-resolution by deep multi-scale guidance. In European conference on computer vision (pp. 353–369).
Kiechle, M., Hawe, S., & Kleinsteuber, M. (2013). A joint intensity and depth co-sparse analysis model for depth map super-resolution. In Proceedings of the IEEE international conference on computer vision (pp. 1545–1552).
Kim, J., Kwon Lee, J., & Mu Lee, K. (2016a). Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1646–1654).
Kim, J., Kwon Lee, J., & Mu Lee, K. (2016b). Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1637–1645).
Kwon, H., Tai, Y. W., & Lin, S. (2015). Data-driven depth map refinement via multi-scale sparse representation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 159–167).
LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 2278–2324.
Li, J., Fang, F., Mei, K., & Zhang, G. (2018). Multi-scale residual network for image super-resolution. In Proceedings of the European conference on computer vision (ECCV) (pp. 517–532).
Li, Y., Huang, J. B., Ahuja, N., & Yang, M. H. (2016). Deep joint image filtering. In European conference on computer vision (pp. 154–169).
Li, Y., Xue, T., Sun, L., & Liu, J. (2012). Joint example-based depth map super-resolution. In 2012 IEEE international conference on multimedia and expo (pp. 152–157).
Lu, J., & Forsyth, D. (2015). Sparse depth super resolution. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2245–2253).
Lutio, R. D., D’Aronco, S., Wegner, J. D., & Schindler, K. (2019). Guided super-resolution as pixel-to-pixel transformation. In Proceedings of the IEEE international conference on computer vision (pp. 8829–8837).
Martull, S., Peris, M., & Fukui, K. (2012). Realistic CG stereo image dataset with ground truth disparity maps. In ICPR workshop TrakMark2012 (Vol. 111, pp. 117–118).
Mustafa, H. T., Yang, J., & Zareapoor, M. (2019). Multi-scale convolutional neural network for multi-focus image fusion. Image and Vision Computing, 85, 26–35.
Nair, V., & Hinton, G. E. (2010). Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th international conference on machine learning (ICML-10) (pp. 807–814).
Pei, Z., Cao, Z., Long, M., & Wang, J. (2018). Multi-adversarial domain adaptation. In Proceedings of the AAAI conference on artificial intelligence (pp. 3934–3941).
Qi, C. R., Liu, W., Wu, C., Su, H., & Guibas, L. J. (2018). Frustum pointnets for 3D object detection from RGB-D data. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 918–927).
Scharstein, D., Hirschmüller, H., Kitajima, Y., Krathwohl, G., Nešić, N., Wang, X., & Westling, P. (2014). High-resolution stereo datasets with subpixel-accurate ground truth. In German conference on pattern recognition (pp. 31–42).
Scharstein, D., & Pal, C. (2007). Learning conditional random fields for stereo. In 2007 IEEE conference on computer vision and pattern recognition (pp. 1–8).
Scharstein, D., & Szeliski, R. (2002). A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. International Journal of Computer Vision, 47(1–3), 7–42.
Scharstein, D., & Szeliski, R. (2003). High-accuracy stereo depth maps using structured light. In 2003 IEEE computer society conference on computer vision and pattern recognition, 2003. Proceedings (Vol. 1, p. I).
Shen, X., Zhou, C., Xu, L., & Jia, J. (2015). Mutual-structure for joint filtering. In Proceedings of the IEEE international conference on computer vision (pp. 3406–3414).
Silberman, N., Hoiem, D., Kohli, P., & Fergus, R. (2012). Indoor segmentation and support inference from RGBD images. In European conference on computer vision (pp. 746–760). Springer.
Supančič, J. S., Rogez, G., Yang, Y., Shotton, J., & Ramanan, D. (2018). Depth-based hand pose estimation: Methods, data, and challenges. International Journal of Computer Vision, 126(11), 1180–1198.
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., & Wojna, Z. (2016). Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2818–2826).
Tai, Y., Yang, J., & Liu, X. (2017). Image super-resolution via deep recursive residual network. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3147–3155).
Tzeng, E., Hoffman, J., Saenko, K., & Darrell, T. (2017). Adversarial discriminative domain adaptation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7167–7176).
Wang, C., Xu, D., Zhu, Y., Martín-Martín, R., Lu, C., Fei-Fei, L., & Savarese, S. (2019). Densefusion: 6D object pose estimation by iterative dense fusion. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3343–3352).
Wang, F., Jiang, M., Qian, C., Yang, S., Li, C., Zhang, H., Wang, X., & Tang, X. (2017). Residual attention network for image classification. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3156–3164).
Wei, M., Kang, Y., Song, W., & Cao, Y. (2018). Crowd distribution estimation with multi-scale recursive convolutional neural network. In International conference on multimedia modeling (pp. 142–153). Springer.
Wen, Y., Sheng, B., Li, P., Lin, W., & Feng, D. D. (2019). Deep color guided coarse-to-fine convolutional network cascade for depth image super-resolution. IEEE Transactions on Image Processing, 28(2), 994–1006.
Woo, S., Park, J., Lee, J. Y., & So Kweon, I. (2018). Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (pp. 3–19).
Yue, K., Sun, M., Yuan,Y., Zhou, F., Ding, E., & Xu, F. (2018). Compact generalized non-local network. In Proceedings of the 32nd international conference on neural information processing systems (pp. 6511–6520).
Zhang, K., Zuo, W., & Zhang, L. (2018a). Learning a single convolutional super-resolution network for multiple degradations. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3262–3271).
Zhang, L., Wang, P., Shen, C., Liu, L., Wei, W., Zhang, Y., & van den Hengel, A. (2019). Adaptive importance learning for improving lightweight image super-resolution network. International Journal of Computer Vision, 128, 1–21.
Zhang, X., Dong, H., Hu, Z., Lai, W. S., Wang, F., & Yang, M. H. (2020). Gated fusion network for degraded image super resolution. International Journal of Computer Vision, 128, 1–23.
Zhang, Y., Li, K., Li, K., Wang, L., Zhong, B., & Fu, Y. (2018b). Image super-resolution using very deep residual channel attention networks. In Proceedings of the European conference on computer vision (ECCV) (pp. 286–301).
Zhang, Y., Tian, Y., Kong, Y., Zhong, B., & Fu, Y. (2018c). Residual dense network for image super-resolution. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2472–2481).
Zhou, H., Ummenhofer, B., & Brox, T. (2019). Deeptam: Deep tracking and mapping with convolutional neural networks. International Journal of Computer Vision, 128, 1–14.
Zhou, W., Li, X., & Reynolds, D. (2017). Guided deep network for depth map super-resolution: How much can color help? In 2017 IEEE International conference on acoustics, speech and signal processing (ICASSP) (pp. 1457–1461).
Zhu, J., Zhang, J., Cao, Y., & Wang, Z. (2017). Image guided depth enhancement via deep fusion and local linear regularizaron. In Proceedings of the IEEE international conference on image processing (pp. 4068–4072). IEEE.
Zou, C., Guo, R., Li, Z., & Hoiem, D. (2019). Complete 3D scene parsing from an RGBD image. International Journal of Computer Vision, 127(2), 143–162.
Acknowledgements
This work was supported by the National Natural Science Foundation of China (61873077, 61806062). This work was supported by the Zhejiang Provincial Key Lab of Equipment Electronics.
Author information
Authors and Affiliations
Corresponding authors
Additional information
Communicated by Yasushi Yagi.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
We also present the implementation details of CODON in Table 9.
Rights and permissions
About this article

Cite this article
Yang, Y., Cao, Q., Zhang, J. et al. CODON: On Orchestrating Cross-Domain Attentions for Depth Super-Resolution. Int J Comput Vis 130, 267–284 (2022). https://doi.org/10.1007/s11263-021-01545-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11263-021-01545-w