
Abstract
The present work addresses the question how sampling algorithms for commonly applied copula models can be adapted to account for quasi-random numbers. Besides sampling methods such as the conditional distribution method (based on a one-to-one transformation), it is also shown that typically faster sampling methods (based on stochastic representations) can be used to improve upon classical Monte Carlo methods when pseudo-random number generators are replaced by quasi-random number generators. This opens the door to quasi-random numbers for models well beyond independent margins or the multivariate normal distribution. Detailed examples (in the context of finance and insurance), illustrations and simulations are given and software has been developed and provided in the R packages copula and qrng.
Similar content being viewed by others


1 Introduction
In many applications, in particular in finance and insurance, the quantities of interest can be written as \(\mathbb {E}[\varPsi _0(\varvec{X})]\), where \(\varvec{X}=(X_1,\ldots ,X_d):\varOmega \rightarrow \mathbb {R}^d\) is a random vector with distribution function H on a probability space \((\varOmega ,\mathscr {F},\mathbb {P})\) and \(\varPsi _0:\mathbb {R}^d\rightarrow \mathbb {R}\) is a measurable function. The components of \(\varvec{X}\) are typically dependent. To account for this dependence, the distribution of \(\varvec{X}\) can be modeled by
where \(F_j(x)=\mathbb {P}(X_j\le x), j\in \{1,\ldots ,d\}\), are the marginal distribution functions of H and C:\([0,1]^d\rightarrow [0,1]\) is a copula, i.e., a distribution function with standard uniform univariate margins; for an introduction to copulas, see McNeil et al. (2005, Chap. 5), Nelsen (2006) or Joe (2014). A copula model such as (1) allows one to separate the dependence structure from the marginal distributions. This is especially useful in the context of model building and sampling in the case where \(\mathbb {E}[\varPsi _0(\varvec{X})]\) mainly depends on the dependence between the components of \(\varvec{X}\), so on C; for examples of this type, see Sect. 5.
In terms of copula model (1), we may then write
where \(\varvec{U}=(U_1,\ldots ,U_d):\varOmega \rightarrow \mathbb {R}^d\) is a random vector with distribution function \(C, \varPsi :[0,1]^d\rightarrow \mathbb {R}\) is defined as
and \(F_j^-(p)=\inf \{x\in \mathbb {R}: F_j(x)\ge p\}, j\in \{1,\ldots ,d\}\), are the marginal quantile functions. If C and the margins \(F_j, j\in \{1,\ldots ,d\}\), are known, we can use Monte Carlo simulation to estimate \(\mathbb {E}[\varPsi (\varvec{U})]\). For a (pseudo-)random sample \(\{\varvec{U}_i:i=1,\ldots ,n\}\) from C, the (classical) Monte Carlo estimator of \(\mathbb {E}[\varPsi (\varvec{U})]\) is given by
The main challenge of a Monte Carlo simulation is thus the sampling of the copula. This challenge also holds for quasi-Monte Carlo (QMC) methods, and is actually amplified by the fact that these methods are more sensitive to certain properties of the function \(\varPsi \). Thus the choice of the construction method of a stochastic representation for C can have complex effects on the performance of QMC methods, a feature that does not show up when using Monte Carlo methods. The present work includes a careful analysis of these effects, as they must be thoroughly understood in order to successfully replace pseudorandom numbers by quasi-random numbers into different copula sampling algorithms.
Let us briefly summarize the idea behind QMC methods and how they can be used for copula models; more precise definitions on some of the concepts used here will be given later. The idea is to start with a so-called low-discrepancy point set \(P_n =\{\varvec{v}_1,\ldots ,\varvec{v}_n\} \subseteq [0,1)^{k}\), with \(k \ge d\), which is designed so that its empirical distribution over \([0,1)^k\) is closer (in a sense to be defined later) to the uniform distribution \({\text {U}}[0,1)^k\) than a set of independent and identically (i.i.d.) random points is. Assuming that for \(\varvec{U}' \sim {\text {U}}[0,1]^k\) we have a transformation \(\phi _C\) such that \(\phi _C(\varvec{U}')\sim C\), we can then construct the approximation
Figure 1 shows the points \(\phi _C(\varvec{v}_i)\) obtained using either pseudo-random or quasi-random numbers, for a transformation \(\phi _C\) designed for the Clayton copula.

1000 realizations of a bivariate Clayton copula with \(\theta =2\) (Kendall’s tau equals 0.5), generated by a pseudo-random number generator (top) and by a quasi-random number generator (bottom)
QMC methods are typically used to approximate integrals of functions over the unit cube via
A widely used upper bound for the integration error \(|I(f)-Q_n|\) is the Koksma–Hlawka inequality (see, e.g., Niederreiter (1992)), which is of the form \(V(f)D^*(P_n)\), where V(f) measures the variation of f in the sense of Hardy and Krause, while \(D^*(P_n)\) measures the discrepancy of \(P_n\), i.e., how far \(P_n\) is from \({\text {U}}[0,1)^k\).
To analyze the properties of the QMC approximation (2) for \(\mathbb {E}[\varPsi (\varvec{U})]\), there are two possible approaches. The first one is to define \(f = \varPsi \circ \phi _C\) and work within the traditional framework given by (3), the Koksma–Hlawka inequality with this composed function and the low-discrepancy point set \(P_n\). The second one is to think of (2) as approximating
and work with generalizations of the Koskma–Hlawka inequality that apply to measures other than the Lebesgue measure; see Hlawka and Mück (1972) or Aistleitner and Dick (2015). In the latter case, we work with the function \(\varPsi \) and view the transformation \(\phi _C\) as one that is applied to the low-discrepancy point set \(P_n\) rather than to \(\varPsi \). That is, here we work with the transformed point set \(\tilde{P}_n = \{\phi _C(\varvec{v}_1),\ldots ,\phi _C(\varvec{v}_n)\}\) and analyze its quality via measures of discrepancy that quantify its distance to C rather than comparing \(P_n\) to \({\text {U}}[0,1)^k\).
QMC methods have been used in a variety of applications, but so far most of the problems considered have been such that the stochastic models used can be formulated using independent random variables (e.g., a vector of dependent normal variates can be written as a linear transformation of independent normal variates). In such cases, the transformation of the uniform vector \(\varvec{v}\) into observations from the desired stochastic model can be easily obtained by transforming each component \(v_j\) of \(\varvec{v}\) using the inverse transform method, which is deemed to work well with QMC in part because of its monotonicity, and also because it corresponds to an overall one-to-one transformation from \([0,1)^d\) to \(\mathbb {R}^d\).
In the more general copula setting considered in this paper, at first sight the so-called conditional distribution method (CDM) (which is the inverse of the copula-based version of the Rosenblatt transform) appears to be a good choice to use with quasi-random numbers, as it is the direct multivariate extension of the inverse transform mentioned in the previous paragraph. Namely, it is a one-to-one transformation that maps \([0,1)^d\) to \([0,1)^d\) and it is monotone in each variable. A transformation with \(k=d\) is certainly desirable (and preferable to a many-to-one transformation with \(k>d\)) when used in conjunction with QMC methods, since these methods do better on problems of lower dimension. Also, intuitively the monotonicity should be helpful to preserve the smoothness of \(\varPsi \) (for the first approach) and the low-discrepancy of \(P_n\) (for the second approach). An additional advantage of the CDM is that it is applicable to any copula C (and the only known algorithm such general). However, the involved (inverses of the) conditional copulas are often challenging to evaluate which has led to other sampling algorithms being more frequently used. An example is the Marshall–Olkin algorithm for sampling Archimedean copulas, which we also address in this work.
The paper is organized as follows. Section 2 provides a short introduction to quasi-random numbers. Section 3 shows how quasi-random samples from various copulas (and thus multivariate models with these dependence structures) can be obtained using different sampling algorithms. Detailed examples are given. In Sect. 4 we discuss the theoretical background supporting each of the two approaches mentioned earlier to analyze the use of low-discrepancy sequences for copula sampling. Numerical results are provided in Sect. 5. Finally, Sect. 6 includes concluding remarks and a discussion of future work. Note that most results and figures presented in this paper (as well as additional experiments conducted) can be found in the R packages copula (see the vignette qrng) and qrng (see demo(basket_options) and demo(test_functions)).
2 Quasi-random numbers
Here we assume that a random sample \(\{\varvec{U}_i:i=1,\ldots ,n\}\) from a copula C can be generated by transforming a random sample \(\{\varvec{U}_i':i=1,\ldots ,n\}\) from \({\text {U}}[0,1]^k\) with \(k\ge d\); several algorithms for copula models fall under this setup. Due to the independence of the vectors \(\varvec{U}_i'\), realizations of the sample \(\{\varvec{U}_i':i=1,\ldots ,n\}\) (obtained by so-called pseudo-random number generators (PRNGs)) will inevitably show regions of \([0,1]^k\) which are lacking points and other areas of \([0,1]^k\) which contain more samples than expected by the uniform distribution. To reduce this problem of an inhomogeneous concentration of samples, quasi-random number generators (QRNGs) do not aim at mimicking i.i.d. samples but instead at producing a homogeneous coverage of \([0,1]^k\). The homogeneity of a sequence of points over the unit hypercube can be measured by its discrepancy, which relates to the error incurred by representing the (Lebesgue-)measure of subsets of the unit hypercube by the fraction of points in these subsets. Quasi-random sequences aim at achieving smaller discrepancy than pseudo-random number sequences and are thus also called low-discrepancy sequences. The rest of this section reviews concepts related to QRNG that are used in this paper. The reader is referred to Niederreiter (1992), Morokoff (1998), Glasserman (2004, Chap. 5), and Dick and Pillichshammer (2010) for more details.
2.1 Discrepancy
The notion of discrepancy applies to sequences of points \(X=\{\varvec{v}_1,\varvec{v}_2,\ldots \}\) in the unit hypercube \([0,1)^k\). Denote by \(P_n =\{\varvec{v}_1,\ldots ,\varvec{v}_n\}\subseteq [0,1)^k\) the first n points of the sequence. Let \(\mathscr {J^*}\) be the set of intervals of \([0,1)^k\) of the form \([\varvec{0},\varvec{z})=\prod _{j=1}^k [0,z_j)\), where \(0 <z_j \le 1, j=1,\ldots ,k\). Then the discrepancy function of \(P_n\) on an interval \([\varvec{0},\varvec{z})\) is the difference
where \(A([\varvec{0},\varvec{z});P_n)=\#\{i;\ 1\le i \le n,\varvec{v}_i \in [\varvec{0},\varvec{z})\}\) is the number of points from \(P_n\) that fall in \([\varvec{0},\varvec{z})\) and \(\lambda ([\varvec{0},\varvec{z})) = \prod _{j=1}^k z_j\) is the Lebesgue measure of \([\varvec{0},\varvec{z})\).
The star discrepancy \(D^*\) of \(P_n\) is defined by
An infinite sequence X satisfying \(D^*(P_n)\in O(n^{-1}\log ^k n)\) is said to be a low-discrepancy sequence.
For a function \(\varPsi :[0,1)^k \rightarrow \mathbb {R}\), we have the well-known Koksma–Hlawka error bound given by
where \(\varvec{U}'\sim {\text {U}}[0,1]^k\) and \(V(\varPsi )\) denotes the variation of the function \(\varPsi \) in the sense of Hardy and Krause. See Owen (2005) for a detailed account of the notion of variation and its applicability in practice. We also refer the interested reader to Hartinger et al. (2004) and Sobol’ (1973) for results handling unbounded functions (and thus of unbounded variation).
2.2 Low-discrepancy sequences
There are two main approaches for constructing low-discrepancy sequences: integration lattices and digital sequences. Only the latter are used in this paper, so our discussion will focus on those.
Digital sequences contain the well-known constructions of Sobol’ (1967), Faure (1982), and Niederreiter (1987), and are also closely related to the sequence proposed in Halton (1960). The basic building block for this construction is the van der Corput sequence in base \(b \ge 2\), defined as
where \(a_r(i)\) is the rth digit of the b-adic expansion of \(i-1=\sum _{r=0}^\infty a_r(i)\ b^r\). To construct a sequence of points in \([0,1)^k\) from this one-dimensional sequence, one approach is the one proposed by Halton (1960), which consists of choosing k pairwise relatively prime integers \(b_1,\ldots ,b_k\) and defining the ith point of the sequence as
Another possibility is to fix the base b, and choose k linear transformations that are then applied to the digits \(a_r(i)\) from the expansion of \(i-1\) before being used in (5) to define a real number between 0 and 1. More precisely, let \(M_1,\ldots ,M_k\) be (unbounded) “\(\infty \times \infty \)” matrices with entries in \(\mathbb {Z}_b\) and let
where \(m_{r,l}\) is the element in the rth row and lth column of \(M_j\). Here we assume for simplicity that b is prime and all operations in (6) are performed in the finite field \(\mathbb {F}_b\). One can then define a sequence of points in \([0,1)^k\) by taking
as its ith point. Sobol’ was the first to propose such a construction, working in base 2 and defining the matrices \(M_1,\ldots ,M_k\) so that he was able to prove that the obtained sequence has \(D^*(P_n) \in O(n^{-1} \log ^k n)\); see Sobol’ (1967).
We also point out that Halton sequences can be generalized using the same idea as in (7). That is, one can choose matrices \(M_1,\ldots ,M_k\) with the elements of \(M_j\) in \(\mathbb {Z}_{b_j}\), and “scramble” the digits of the expansion of \(i-1\) before reverting them via (5) to produce a number between 0 and 1. A very simple way to achieve this is via diagonal matrices \(M_j\), each containing a well-chosen element (or factor) of \(\mathbb {Z}_{b_j}\). In our numerical experiments, we use such an approach, with the factors provided in Faure and Lemieux (2009); see the R package qrng for an implementation.
2.3 Randomized quasi-Monte Carlo
In contrast to the error rate \(O(n^{-1/2})\) for Monte Carlo methods based on PRNGs, approximations based on QRNGs have the advantage of having an error in \(O(n^{-1}\log ^kn)\) when the function of interest \(\varPsi \) is of bounded variation. However, in practice it is also important to be able to estimate the corresponding error. While bounds such as the Koksma–Hlawka inequality are useful to understand the behaviour of approximations based on quasi-random sequences, they do not provide a practical way to estimate the error. To circumvent this problem, an approach that is often used is to randomize a low-discrepancy point set in such a way that its high uniformity (or low discrepancy) is preserved, but at the same time unbiased estimators can be constructed (and sampled) from it. Another advantage of this approach is that variance expressions can be derived and compared with Monte Carlo sampling for wider classes of functions, i.e., not necessarily of bounded variation (see Owen (1997a), Lemieux (2009) and the references therein). This approach gives rise to randomized quasi-Monte Carlo (RQMC) methods.
To apply this approach, we need a randomization function r:\([0,1)^s \times [0,1)^k \rightarrow [0,1)^k\) with \(s \ge k\) such that for any fixed \(\varvec{v} \in [0,1)^k\), we have that if \(\varvec{U}' \sim {\text {U}}[0,1]^s\), then \(r(\varvec{U}',\varvec{v}) \sim {\text {U}}[0,1]^k\). Hence the individual RQMC samples have the same properties as those from a random sample; the difference lies in the fact that the RQMC samples are dependent.
An early randomization scheme originally proposed by Cranley and Patterson (1976) is to take
A randomized point set is then obtained by generating a uniform vector \(\varvec{U}'\) and letting \(\tilde{P}_n(\varvec{U}') = \{\tilde{\varvec{v}}_1,\ldots ,\tilde{\varvec{v}}_n\}\), where \(\tilde{\varvec{v}}_i = r(\varvec{U}',\varvec{v}_i),\quad i\in \{1,\ldots ,n\}.\) Hence the same shift \(\varvec{U}'\) is applied to all points in \(P_n\). If we let \(\varvec{U}'_1,\ldots ,\varvec{U}'_B\) be independent \({\text {U}}[0,1]^s\) vectors, we can construct B i.i.d. unbiased estimators
for \(\mathbb {E}[\varPsi (\varvec{U})]\), whose variances can be estimated via the sample variance of \(\hat{\mu }^1_n,\ldots ,\hat{\mu }^B_n\).
In addition to the simple random shift described in (8), several other randomization schemes have been proposed and studied. A popular randomization method for digital nets is to “scramble” them, an idea originally proposed by Owen (1995) and subsequently studied by Owen (1997a, (1997b), Owen (2003), Matousěk (1998) and Hong and Hickernell (2003), among others.
A simpler randomization for digital nets is to use the digital counterpart of (8), where instead of adding two real numbers modulo 1, we add (in \(\mathbb {Z}_b\)) the digits of their base b expansion. That is, for \(u=\sum _{r=0}^{\infty } u_r b^{-r-1}\) and \(v =\sum _{r=0}^{\infty } v_r b^{-r-1}\), we let
and define \(r(\varvec{u},\varvec{v}) = \varvec{u} \oplus _b \varvec{v},\) where the \(\oplus _b\) operation is applied component-wise to the k coordinates of \(\varvec{u}\) and \(\varvec{v}\). The same idea can be applied to randomize Halton sequences [as shown, e.g., in Lemieux (2009)], but where a different base b is used in each of the k coordinates. Digital shifts for the Sobol’ and generalized Halton sequences are available in our R package qrng.
3 Quasi-random copula samples
Sampling procedures for a d-dimensional copula C can be viewed as transformations \(\phi _C:[0,1]^k\rightarrow [0,1]^d\) for some \(k\ge d\), such that, for \(\varvec{U}'\sim {\text {U}}[0,1]^k, \varvec{U}:=\phi _C(\varvec{U}')\sim C\); that is, \(\phi _C\) transforms independent \({\text {U}}[0,1]\) random variables to d dependent random variables with distribution function C.
The case \(k=d\) is mostly known and applied as conditional distribution method (CDM) and involves the inversion method for sampling univariate conditional copulas [although, for example, for Archimedean copulas another transformations \(\phi _C\) with \(k=d\) is known; see Wu et al. (2006)]. This approach thus naturally uses d independent \({\text {U}}[0,1]\) random variables as input. The case \(k\ge d\) (often: \(k>d\)) is typically known as stochastic representation and is usually based on sampling k univariate random variables from elementary probability distributions, as we will see in Sect. 3.2.
In what follows we consider the above two approaches and show how they can be adapted to quasi-random number generation.
3.1 Conditional distribution method and other one-to-one transformations (\(k = d\))
3.1.1 Theoretical background
The only known general sampling approach which works for any copula is the CDM. For \(j\in \{2,\ldots ,d\}\), let
denote the conditional copula of \(U_j\) at \(u_j\) given \(U_1=u_1,\ldots , U_{j-1}=u_{j-1}\). If
denotes the corresponding quantile function, the CDM is given as follows; see Embrechts et al. (2003) or Hofert (2010, p. 45).
Theorem 1
(Conditional distribution method) Let C be a d-dimensional copula, \(\varvec{U}'\sim {\text {U}}[0,1]^d\), and \(\phi _C^{\text {CDM}}\) be given by
Then \(\varvec{U}=(U_1,\ldots ,U_d)=\phi _C^{\text {CDM}}(\varvec{U}')\sim C\).
To find the conditional copulas \(C_{j|1\ldots j-1}\), for \(j\in \{2,\ldots ,d\}\), for a specific copula C, the following result (which holds under mild assumptions) is often applied. A rigorous proof can be found in (Schmitz 2003, p. 20), an implementation is provided by the function cCopula() in the R package copula. The corollary that follows is an immediate consequence of Sklar’s theorem, for example.
Theorem 2
(Computing conditional copulas) Let C be a d-dimensional copula, which, for \(d\ge 3\), admits continuous partial derivatives with respect to the first \(d-1\) arguments. For \(j\in \{2,\ldots ,d\}\) and \(u_l\in [0,1], l\in \{1,\ldots ,j\}\),
where \({\text {D}}_{j-1\ldots 1}\) denotes the derivative with respect to the first \(j-1\) arguments, \(C_{1\ldots j}\) denotes the marginal copula corresponding to the first j components and \(c_{1\ldots j-1}\) denotes the density of \(C_{1\ldots j-1}\). If C admits a density, then (9) equals
Corollary 1
(Conditional copulas for general multivariate distributions) Let H be a d-dimensional absolutely continuous distribution function with density h, margins \(F_1,\ldots ,F_d\) and copula C. For \(j\in \{2,\ldots ,d\}\) and \(u_l\in [0,1], l\in \{1,\ldots ,j\}\),
3.1.2 Examples
We now present several copula families and show how the corresponding conditional copulas and their inverses can be computed.
3.1.3 Elliptical copulas
An elliptical copula describes the dependence structure of an elliptical distribution; for the latter, see Cambanis et al. (1981), Embrechts et al. (2002), Embrechts et al. (2003), or McNeil et al. (2005, Sect. 3.3, 5). The most prominent two families in the class of elliptical copulas are the Gauss and the t copulas.
Gauss copulas. Gauss copulas are given by
where \(\varPhi _P\) denotes the d-variate normal distribution function with location vector \(\varvec{0}\) and scale matrix P (a correlation matrix) and \(\varPhi ^{-1}\) is the standard normal quantile function. Consider the dimension to be j and let \(\varvec{X}\sim \varPhi _P\) with \(\varvec{X}=(\varvec{X}_{1:(j-1)},X_j)\). Furthermore, assume
to be positive definite. It follows from (Fang et al. 1990, p. 45 and 78) that
where
so \(H_{j|1\ldots j-1}\) is again normal. With \(\varPhi ^{-1}(\varvec{u}_{1:(j-1)})=(\varPhi ^{-1}(u_1),\) \(\ldots ,\varPhi ^{-1}(u_{j-1}))\), it follows from (11) that
and thus that
An implementation of this inverse is provided via cCopula(, inverse=TRUE) in the R package copula.
t copulas. t copulas are given by
where \(t_{\nu ,P}\) denotes the d-variate \(t_\nu \) distribution function with location vector \(\varvec{0}\) and scale matrix P (a correlation matrix) and \(t_\nu ^{-1}\) is the standard \(t_\nu \) quantile function. The following proposition provides formulas for the conditional copulas and their inverses; see (Fang et al. 1990, Sect. 2.5) and (Joe 2014, Sect. 2.7) for more details.
Proposition 1
(Conditional t copulas and inverses) With the notation as in the Gauss case and
the conditional t copula at \(u_j\), given \(u_1,\ldots ,u_{j-1}\), and its inverse are given by
where \(s_1=s_1(\varvec{x}_{1:(j-1)})\) and \(s_2=s_2(\varvec{x}_{1:(j-1)})\) for \(\varvec{x}_{1:(j-1)}=(t_\nu ^{-1}(u_1),\ldots ,t_\nu ^{-1}(u_{j-1}))\) and
Figure 2 displays 1000 samples from a t copula with three degrees of freedom and correlation parameter \(\rho =P_{1,2}=1/\sqrt{2}\) (Kendall’s tau equals 0.5), once drawn with a PRNG (top) and once with a QRNG (bottom). We can visually confirm in this case that the low discrepancy of the latter is preserved. How this seemingly good feature translates into better estimators of the form (2) will be studied further through the theoretical results of Sect. 4 and the numerical experiments of Sect. 5.

1000 realizations of a t copula with three degrees of freedom and correlation parameter \(\rho =1/\sqrt{2}\) (Kendall’s tau equals 0.5), generated by a PRNG (top) and by a QRNG (bottom)
3.1.4 Archimedean copulas
An (Archimedean) generator is a continuous, decreasing function \(\psi \):\([0,\infty ]\rightarrow [0,1]\) which satisfies \(\psi (0)=1, \psi (\infty )=\lim _{t\rightarrow \infty }\psi (t)=0\), and which is strictly decreasing on \([0,\inf \{t:\psi (t)=0\}]\). A d-dimensional copula C is called Archimedean if it permits the representation
where \(\varvec{u}=(u_1,\ldots ,u_d)\in [0,1]^d\), and for some generator \(\psi \) with inverse \({\psi ^{-1}}:[0,1]\rightarrow [0,\infty ]\), where \({\psi ^{-1}}(0)=\inf \{t:\psi (t)=0\}\). For applications and the importance of Archimedean copulas in the realm of finance and insurance, see, e.g., Hofert et al. (2013).
McNeil and Nešlehová (2009) show that a generator defines an Archimedean copula if and only if \(\psi \) is d -monotone, meaning that \(\psi \) is continuous on \([0,\infty ]\), admits derivatives \(\psi ^{(l)}\) up to the order \(l=d-2\) satisfying \((-1)^l\psi ^{(l)}(t)\ge 0\) for all \(l\in \{0,\ldots ,d-2\}, t\in (0,\infty )\), and \((-1)^{d-2}\psi ^{(d-2)}(t)\) is decreasing and convex on \((0,\infty )\).
Assuming \(\psi \) to be sufficiently often differentiable, conditional Archimedean copulas follow from Theorem 2 and are given by
where \(u_l\in [0,1],\ l\in \{1,\ldots ,j\}\), and thus
The generator derivatives \(\psi ^{(j-1)}\) and their inverses \({\psi ^{(j-1)}}^{-1}\) can be challenging to compute. The former are known explicitly for several Archimedean families and certain generator transformations; see Hofert et al. (2012) for more details. To compute the inverses, one can use numerical root-finding on [0, 1]; see cCopula(..., inverse=TRUE) in the R package copula. This can be applied, e.g., in the case of Gumbel copulas.
The following example shows the case of a Clayton copula family, for which (15) can be given explicitly and thus where the CDM is tractable; this explicit formula is also utilized by cCopula(, inverse=TRUE).
Example 1
(Clayton copulas) If \(\psi (t)=(1+t)^{-1/\theta }, t\ge 0, \theta >0\), denotes a generator of the Archimedean Clayton copula, then \(\psi ^{(j)}(t)=(-1)^j(1+t)^{-(j+1/\theta )}\prod _{l=0}^{j-1}(l+1/\theta )\). Therefore, (14) equals
and (15) equals
Figure 1 displays 1000 samples from a Clayton copula with \(\theta =2\) (Kendall’s tau equals 0.5), once drawn with a PRNG (top) and once with a QRNG (bottom).
3.1.5 Marshall–Olkin copulas
A class of bivariate copulas for which \(C^-_{2|1}\) is explicit is the class of Marshall–Olkin copulas \(C(u_1,u_2)=\min \{u_1^{1-\alpha _1}u_2\), \(u_1u_2^{1-\alpha _2}\}, \alpha _1,\alpha _2\in (0,1)\), where one can show that
Figure 3 shows 1000 samples, once drawn from a PRNG (top) and once from a QRNG (bottom). Here again we can visually confirm the low discrepancy.

1000 realizations of a Marshall–Olkin copula with \(\alpha _1=0.25\) and \(\alpha _2=0.75\) (Kendall’s tau equals roughly 0.23), generated by a PRNG (top) and by a QRNG (bottom)
Another class of copulas not discussed in this section which is naturally sampled with the CDM and thus can easily be adapted to construct corresponding quasi-random numbers is the class of pair copula constructions; see, e.g., Kurowicka and Cooke (2007). For this purpose, we modified the function RVineSim() in the R package VineCopula (version \(\ge \) 1.3). It now allows to pass a matrix of quasi-random numbers to be transformed to the corresponding samples from a pair copula construction; see the vignette qrng in the R package copula for examples. Note that if sampling of the R-vine involves numerical root-finding (required for certain copula families), the corresponding numerical inaccuracy may have an effect on the low discrepancy of the generated samples.
3.2 Stochastic representations (\(k\ge d\), typically \(k>d\))
3.2.1 Theoretical background
As mentioned above, pair-copula constructions are one of the rare copula classes for which the CDM is applied in practice. For most other copula classes and families, faster sampling algorithms derived from stochastic representations of \(\varvec{U}\sim C\) are known, especially for \(d\gg 2\). They are mostly class- and family-specific, as can be seen in the examples below.
3.2.2 Examples
3.2.3 Elliptical copulas
Gauss and t copulas are typically sampled via their stochastic representations.
3.2.4 Gauss copulas
A random vector \(\varvec{X}\sim \varPhi _P\) admits the stochastic representation \(\varvec{X}=A\varvec{Z}\) where A denotes the lower triangular matrix from the Cholesky decomposition \(P=AA^{\top }\) and \(\varvec{Z}\) is a vector of d independent standard normal random variables. A random vector \(\varvec{U}\sim C_P^{\text {Ga}}\) thus admits the stochastic representation \(\varPhi (\varvec{X})=\varPhi (A\varvec{Z})\) for \(\varvec{Z}=\big (\varPhi ^{-1}(U_1'),\ldots ,\) \(\varPhi ^{-1}(U_d')\big )\) and \(\varvec{U}'\sim {\text {U}}[0,1]^d\); here \(\varPhi \) is assumed to act on \(A\varvec{Z}\) component-wise. Note that for Gauss copulas, this sampling approach is equivalent to the CDM.
t copulas. A random vector \(\varvec{X}\sim t_{\nu ,P}\) admits the stochastic representation \(\varvec{X}=\sqrt{W}A\varvec{Z}\) where A and \(\varvec{Z}\) are as above and \(W=1/\varGamma \) for \(\varGamma \) following a Gamma distribution with shape and rate equal to \(\nu /2\). A random vector \(\varvec{U}\sim C_{\nu ,P}^{t}\) thus admits the stochastic representation \(t_\nu (\varvec{X})=t_{\nu }(\sqrt{W}A\varvec{Z})\); as before, \(t_{\nu }\) is assumed to act on \(\sqrt{W}A\varvec{Z}\) component-wise. Note that for t copulas with finite \(\nu \), this sampling approach is different from the CDM.
3.2.5 Archimedean copulas
The conditional independence approach behind the Marshall–Olkin algorithm for sampling Archimedean copulas is one example for transformations \(\phi _C\) for \(k>d\); see Marshall and Olkin (1988). For this algorithm, \(k=d+1\) and one uses the fact that for an Archimedean copula C with completely monotone generator \(\psi \),
where \(V\sim F=\mathscr {LS}^{-1}[\psi ]\), independent of \(E_1,\ldots ,E_d\sim {\text {Exp}}(1)\); here, \(F=\mathscr {LS}^{-1}[\psi ]\) denotes the distribution function corresponding to \(\psi \) by Bernstein’s Theorem (\(\mathscr {LS}^{-1}[\cdot ]\) denotes the inverse Laplace–Stieltjes transform). To give an explicit expression for the transformation \(\phi _C=\phi _C^{\text {MO}}\) in this case, we assume that \(v_1\) is used to generate V via the inversion method, and \(v_{j+1}\) is used to generate \(E_j\), for \(j\in \{1,\ldots ,d\}\). Then we have that \(\phi _C^{\text {MO}} = (\phi ^{\text {MO}}_{C,1},\ldots ,\phi ^{\text {MO}}_{C,d})\), where
We can use a low-discrepancy sequence in \(k=d+1\) dimensions to produce a sample based on this method. Having \(k=d+1\) instead of \(k=d\) is a slight disadvantage, since it is well known that the performance of QMC methods tends to deteriorate with increasing dimensions.

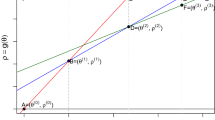
1000 realizations of the first two components of a three-dimensional Halton sequence with marked points (\(\triangle \) and \(+\)) in the respective regions \([0,\sqrt{1/8}]^2\) and \([1-\sqrt{1/8},1]^2\) (top): corresponding \(\phi _C^{\text {CDM}}\)-transformed points (bottom) to a Clayton copula with \(\theta =2\) (Kendall’s tau equals 0.5)
To explore the effect of the transformation \(\phi _C\) on \(P_n\), we generated 1000 realizations of a three-dimensional Halton sequence; see the top of Fig. 4 where we used different markers for points falling in two non-overlapping regions in \([0,1)^2\). The first two of the three dimensions are then mapped via \(\phi _C^{\text {CDM}}\) (see the bottom of Fig. 4) to a Clayton copula with parameter \(\theta =2\) (such that Kendall’s tau equals 0.5). As we can see, the non-overlapping marked regions remain non-overlapping after the one-to-one transformations have been applied. To study the effect of the Marshall–Olkin algorithm, we look at when the first dimension of the Halton sequence is mapped to a Gamma \(\varGamma (1/\theta ,1)\) distribution by inversion of \(v_1\)(the distribution of V in (16) for a Clayton copula) and the last two to unit exponential distributions (by inversion of \(1-v_j\) for \(j=2,3\), so that the obtained \(u_j\) is increasing in each of \(v_1\) and \(v_{j+1}\) for \(j=1,2\)). The top of Fig. 5 shows the second and third coordinates of the Halton sequence, and marks the points belonging to two different three-dimensional intervals (this is why not all two-dimensional points are marked in the two-dimensional projected regions). We see on the bottom of Fig. 5 that here again, the marked regions remain non-overlapping. However, it should also be clear that two points in a given interval defined over the second and third dimension could end up in very different locations after this transform, if the corresponding first coordinates are far apart. Hence, the fact that the Marshall–Olkin transform uses \(k=d+1\) uniforms (and thus is not one-to-one) makes it more challenging to understand its effect when used with quasi-random numbers. On the other hand, because it is designed so that the first uniform \(v_1\) is very important, it may work quite well with QMC since these methods are known to perform better when a small number of variables are important (i.e., see Dick and Pillichshammer (2010); Lemieux (2009)). This combination (QRNG with the Marshall–Olkin approach) is studied further in Sect. 4, with numerical results provided in Sect. 5.

1000 realizations of the second and third components of a three-dimensional Halton sequence with marked points (\(\triangle \) and \(+\)) corresponding to the respective regions \([0,0.5]^3\) and \([0.5,1]^3\) (top): corresponding \(\phi _C^{\text {MO}}\)-transformed points (bottom) to a Clayton copula with \(\theta =2\) (Kendall’s tau equals 0.5)

Samples obtained from Clayton copula with \(\theta =2\) with the CDM method based on coordinates 20 and 21 of the Halton sequence (top) and the generalized Halton sequence (bottom)
3.2.6 Marshall–Olkin copulas
Bivariate (\(d=2\)) Marshall–Olkin copulas C also allow for a stochastic representation in our framework \(\phi _C\) for \(k>d\). For example, it is easy to check that for \((U_1',U_2',U_3')\sim {\text {U}}[0,1]^3\),
This construction can be generalized to \(d>2\) (but we omit further details about Marshall–Olkin copulas in the remaining part of this paper).
3.3 Words of caution
The plots showing copula samples obtained from QRNGs that we have seen so far have been promising, in that the additional uniformity (or low discrepancy) compared to pseudo-sampling was visible. Here we want to add a word of caution to the effect that it is crucial to work with high quality quasi-random numbers, as defects that exist with respect to their uniformity on the unit cube will translate into poor copula samples. Figure 6 illustrates this by showing two-dimensional copula samples obtained from quasi-random numbers of poor quality, corresponding to the projection on coordinates (20,21) of the first 1000 points of the Halton sequence (top) and a similar sample obtained from a generalized Halton sequence (bottom), which was designed to address defects of this type in the Halton sequence. More precisely, here the problem is that this particular projection is based on the twin prime numbers 71 and 73 for the base. Defects of this type are discussed further, e.g., in Morokoff and Caflisch (1994).
4 Analyzing the performance of copula sampling with quasi-random numbers
In this section, we discuss the two approaches outlined in the introduction to analyze the validity of sampling algorithms for copulas that are based on low-discrepancy sequences.
4.1 Composing the sampling method with the function of interest \(\varPsi \)
Our goal here is to assess the quality of a quasi-random sampling method for copula models by viewing the transformation \(\phi _C\) as being composed with the function \(\varPsi \) of interest, so that we can work in the usual Koksma–Hlawka setting based on uniform discrepancy measures.
Given that a copula transform \(\phi _C=(\phi _{C,1},\ldots ,\phi _{C,d})\) is regular enough, denote its Jacobian by
and write
In the case of \(\phi _C=\phi _C^{\text {CDM}}\), one can easily show that \(|J_{\phi _C}(\phi _C(\varvec{v}))|=c(\phi _C(\varvec{v}))^{-1}\), and thus
While the properties of the CDM approach allow one to directly show (18) in its integral form as done above, this equality holds more generally for any transformation \(\phi _C:[0,1]^k\rightarrow [0,1]^d\) such that \(\phi _C(\varvec{U}) \sim C\) whenever \(\varvec{U} \sim {\text {U}}[0,1]^k\); see also Caflisch (1998); Pillards and Cools (2006).
In the case where (18) holds, one can apply the Koksma–Hlawka error bound (4) to transformed samples.
Proposition 2
(Koksma–Hlawka bound for a change of variables) Let \(\varvec{U}\sim C, \phi _C\) such that (18) holds, and \(\varvec{u}_i=\phi _C(\varvec{v}_i)\) for \(P_n = \{\varvec{v}_i,i=1,\ldots ,n\}\) in \([0,1]^d\). Then
Note that \(V(\varPsi )<\infty \) does not imply \(V(\varPsi \circ \phi _C)<\infty \) in general. To get further insight into the conditions required to have a finite bound on the integration error, we work with a slight variation of the above bound that is given in (Niederreiter 1992, pp. 19–20) (see also (Hlawka and Mück 1972, (4’)) and (Hlawka 1961, (4))), where the term \(V(\varPsi \circ \phi _C)\) is replaced by an expression given in terms of the partial derivatives of \(\varPsi \circ \phi _C\) assuming the latter exist and are continuous. It is given by
where
and the second sum is taken over all nonempty subsets \(\varvec{\alpha } = \{\alpha _1,\ldots ,\alpha _l\} \subseteq \{1,\ldots ,d\}\). Furthermore, the notation \(\varvec{1}\) in \(\varPsi \circ \phi _C (v_{\alpha _1},\ldots ,v_{\alpha _l},\varvec{1})\) means that each variable \(v_j\) with \(j \notin \{\alpha _1,\ldots ,\alpha _l\}\) is set to 1.
The following proposition provides sufficient conditions on the functional \(\varPsi \) and on the copula C to ensure that \(\Vert \varPsi \circ \phi _C \Vert _{d,1} < \infty \) when \(\phi _C=\phi _C^{\text {CDM}}\).
Proposition 3
(Conditions to have bounded variation with variable change in the CDM) Assume that \(\varPsi \) has continuous mixed partial derivatives up to total order d and there exist \(m,M,K>0\) such that for all \(\varvec{u}\in (0,1)^d, c(\varvec{u})\ge m>0, C_{i|1\ldots i-1}=C(u_i\,|\,u_1,\ldots ,u_{i-1})\) and
for each \(1\le k\le i\le d\). Furthermore, assume that for all \(1\le k \le l\le d\) and \(\{\alpha _1,\ldots ,\) \(\alpha _l\}\) \(\subseteq \{1,\ldots ,d\}\), we have
Then there exists a constant \(C^{(d)}\) (independent of n but dependent on \(\varPsi \)) such that for the choice \(\phi _C = \phi _C^{\text {CDM}}\), we have
where \(\varvec{u}_i = \phi _C^{\text {CDM}}(\varvec{v}_i), \quad i=1,\ldots ,n\).
Proof
See (Hlawka and Mück 1972, (11) and the remark thereafter). \(\square \)
Remark 1
-
(1)
As we will see in the discussion preceding the next proposition, in general, to ensure that \(\Vert \varPsi \circ \phi _C \Vert _{d,1} < \infty \) holds, a possible approach is to bound the mixed partial derivatives involving \(\varPsi \) and then to verify that the mixed partial derivatives involving \(\phi _C\) are integrable. As explained in Hlawka and Mück (1972), Condition (19) ensures that the latter condition is verified in the case of the CDM (or Rosenblatt) transform, and avoids having to deal with the function \(\phi _C\) and its partial derivatives. Unfortunately (and while it may seem easier to work with the conditional copulas \(C_{j|1\ldots j-1}\) than with \(\phi _C\)), in many cases the copulas involved do not have bounded mixed partial derivatives everywhere, with singularities appearing near the boundaries when one or more arguments are 0 or 1. A non-trivial case where we were able to verify (19) is for the Eyraud-Farlie-Gumbel-Morgenstern copula (see Jaworski et al. (2010)), assuming the parameters are chosen so that the density \(c(\varvec{u})\) and thus the denominator of \(C_{j|1\ldots j-1}\) is bounded away from 0 for all \(\varvec{u} \in [0,1)^d\).
-
(2)
We note that the conditions given in (20) are not the same as those required to prove that
$$\begin{aligned}&\Vert \varPsi \Vert _{d,1} \\&\quad =\sum _{l=1}^d\sum _{\varvec{\alpha }} \int \limits _{[0,1)^l} \left| \frac{\partial ^l \varPsi (u_{\alpha _1},\ldots ,u_{\alpha _l},\varvec{1})}{\partial u_{\alpha _1} \ldots \partial u_{\alpha _l}}\right| du_{\alpha _1}\ldots du_{\alpha _l} \end{aligned}$$is bounded; in the latter case, we only need to consider mixed partial derivatives of order at most one in each variable (since the \(\alpha _j\)’s are distinct). However, in (20), the \(\beta _j\)’s are not necessarily distinct. In particular, this means that we need to consider the partial derivative of \(\varPsi \) of order d with respect to each variable and make sure it is bounded.
Let us now move away from the CDM method and consider a general transformation \(\phi _C\). In order to study \(\Vert \varPsi \circ \phi _C \Vert _{d,1}\), we first need to decompose mixed partial derivatives of the form
in terms of \(\varPsi \) and \(\phi _C\) separately. To do so, we follow Hlawka and Mück (1972), as well as Constantine and Savits (1996, Theorem 2.1), and obtain an expression for the mixed partial derivative of a composition of functions via the representation
where \(\varvec{\beta } \in \mathbb {N}_0^d\) and \(|\varvec{\beta }| = \sum _{j=1}^d \beta _j\). Here we do not specify over which values of \(\gamma _j\) and \(k_j\) the inner sum in the above expression is taken: details can be found in the proof of Proposition 4. But let us point out that in the product over j, each index \(\alpha _1,\ldots ,\alpha _l\) appears exactly once. On the other hand—and as noted in item 2) of Remark 1 above—in the mixed partial derivative of \(\varPsi \), a given variable can appear with order larger than 1.
From (21), we see that a sufficient condition to show that \( \Vert \varPsi \circ \varPhi _C \Vert _{d,1} < \infty \) is to establish that all products of the form
are in \(L_1\).
We note that for the MO algorithm (assuming as we did in (17) that \(v_1\) is used to generate V and \(v_{j+1}\) is used to generate \(E_{j}\)), \(\phi _{C,j}\) is a function of \(v_1\) and \(v_{j+1}\) only, for \(j\in \{1,\ldots ,d\}\). Hence the only partial derivatives of \(\phi _{C,j}\) that are nonzero are those with respect to variables in \(\{v_1,v_{j+1}\}\). This observation is helpful to prove the following result, which shows that the error bound obtained when using the MO algorithm has the desired behavior induced by the low-discrepancy point set used to generate the copula samples; note that it does not show that \(\varPsi \circ \varPhi _C\) has bounded variation. Its proof can be found in the appendix.
Proposition 4
(Error behaviour for MO for continuous V) Let \(\phi _C^{\text {MO}}\) be the transformation associated with the Marshall–Olkin algorithm, as given in (17), and that \(V\sim F\) is continuously distributed. Let \(P_n=\{\varvec{v}_i,i=1,\ldots ,n\}\) be the point set in \([0,1)^{d+1}\) used to produce copula samples via the transformation \(\phi _C^{\text {MO}}\) and let \(\varvec{u}_i = \phi _C^{\text {MO}}(\varvec{v}_i)\). If
-
(1)
the point set \(P_n\) excludes the origin and there exists some \(p \ge 1\) such that \(\min _{1 \le i \le n} v_{i,1} \ge 1/pn\);
-
(2)
the function \(\varPsi \) satisfies \(|\varPsi (\varvec{u})| < \infty \) for all \(\varvec{u} \in [0,1)^{d+1}\) and
$$\begin{aligned} \frac{\partial ^{|\varvec{\beta }|} \varPsi }{\partial ^{\beta _1} u_{1} \ldots \partial ^{\beta _d} u_{d}} < \infty \text{ for } \text{ all } \varvec{\beta }=(\beta _1,\ldots ,\beta _d), \end{aligned}$$(23)with \(\beta _l \in \{0,\ldots ,d\}\) and \(|\varvec{\beta }| \le d\);
-
(3)
and the generator \(\psi (\cdot )\) of the Archimedean copula C is such that
-
(a)
\(\psi '(t)+t\psi ''(t)\) has at most one zero \(t^*\) in \((0,\infty )\) and it satisfies \(-t^*\psi '(t^*)<\infty \); and
-
(b)
\(F^{-1}(1-1/pn)\) is in \(O(n^{a})\) for some constant \(a>0\);
-
(a)
then there exists a constant \(C^{(d)}\) (independent of n but dependent on \(\varPsi \) and \(\phi _C^{\text {MO}}\)) such that
Remark 2
We note that if \(\mathbb {E}[V]<\infty \), as is the case for Clayton’s copula family, Condition (3)b can be easily checked via Markov’s inequality. In the case of the Gumbel copula, V has an \(\alpha \)-stable distribution and it can be shown that \(P(V>x) \le c x^{-\alpha }\) for \(x \ge x_0\) and for some constant c, where c and \(x_0\) depend both on the parameters of the distribution; see (Nolan 2014, Theorem 1.12). Therefore \(F^{-1}(1-1/pn)\) can be bounded by a constant time \(n^{a}\) in this case (namely by \(\max \{x_0,(cpn)^{1/\alpha }\}\)). As for Condition (3)a, one can show that \(t^* = \theta \) and \(t^*=1\) are the only zeros for the Clayton and Gumbel copulas, respectively.
When F is discrete, we can split the problem into subproblems based on the value taken by V. Then, in each case, the bounded variation condition is much easier to verify, because the transformation \(\phi _C\) given V is essentially one-dimensional as it is mapping each \(v_j\) to an exponential \(E_{j-1}\) for \(j\in \{2,\ldots ,d+1\}\). Its proof can be found in the appendix.
Proposition 5
(Error behaviour for the Marshall–Olkin algorithm for discrete V) Let \(\phi _C^{\text {MO}}\) be the transformation associated with the Marshall–Olkin algorithm, as given in (17) and assume C is an Archimedean copula whose distribution function F of V is discrete. Let \(P_n=\{\varvec{v}_i,i=1,\ldots ,n\}\) be the point set in \([0,1)^{d+1}\) used to produce copula samples via the transformation \(\phi _C^{\text {MO}}\) and let \(\varvec{u}_i = \phi _C^{\text {MO}}(\varvec{v}_i)\). If (23) holds and
-
(1)
there exists some \(p \ge 1\) such that the point set \(P_n\) satisfies \(\max _{1 \le i \le n} v_{i,1} \le 1-1/pn\);
-
(2)
there exist constants \(c>0\) and \(q \in (0,1)\) such that \(1-F(l) \le cq^l\) for \(l \ge 1\);
then there exists a constant \(C^{(d)}\) (independent of n but dependent on \(\varPsi \) and \(\phi _C^{\text {MO}}\)) such that
Remark 3
We note that the Frank, Joe and Ali-Mikhail-Haq copulas are such that F is discrete. The condition on the tail of F stated in the proposition can be shown to hold for the Frank and Ali-Mikhail-Haq copulas, but not for the Joe copula (the distribution of V in this case has a Sibuya distribution, for which no moments exists, i.e., it has a very fat tail).
Let us now move on to RQMC methods. We already mentioned that an advantage they have over their deterministic counterparts is that expressions for their variance can be obtained under weaker conditions than what is required to get error expressions and bounds for deterministic sampling schemes. The following result shows that similar variance expressions also hold after composing \(\varPsi \) with \(\phi _C\).
Proposition 6
(Variance expression with a change of variables) If \(\tilde{P}_n = \{\widetilde{\varvec{v}}_1,\ldots ,\widetilde{\varvec{v}}_n\}\) is a randomly digitally shifted net with corresponding RQMC estimator \(\widehat{\mu }_n=\frac{1}{n}\sum _{i=1}^n \varPsi (\phi _C(\widetilde{\varvec{v}}_i))\) and if \(\mathrm{Var}(\varPsi (\varvec{U})) < \infty \) with \(\varvec{U}\sim C\), then we have that
where \(\mathscr {L}_d^*\) is the dual net of the deterministic net that has been shifted to get \(\tilde{P}_n\), and \(\hat{f}(\varvec{h})\) is the Walsh coefficient of f at \(\varvec{h}\), while
Proof
It is clear from Theorem 3 in the appendix and using Representation (18) that (24) holds and the condition \(\mathrm{Var}(\varPsi (\varvec{U})) < \infty \) with \(\varvec{U}\sim C\) ensures it is finite. So what remains to be shown is the expression for the Walsh coefficient of the composed function \(\varPsi \circ \phi _C\). It is obtained as follows:
where the third equality holds thanks to Fubini’s theorem. \(\square \)
By adding assumptions on the smoothness of \(\varPsi \) and thus on the behavior of its Walsh coefficients, one could obtain improved convergence rates for the variance given in (24) compared to the O(1 / n) we get with MC, something we plan to study in future work.
4.2 Transforming the low-discrepancy samples
As mentioned in the introduction, we can think of \(\phi _C\) as transforming the point set \(P_n\) instead of being composed with \(\varPsi \). The integration error can then be analyzed via a generalized version of the Koksma–Hlawka inequality such as the one studied in Aistleitner and Dick (2015), which we now explain.
Similarly to the Lebesgue case we define the copula-discrepancy function with respect to a copula-induced measure \(P_C\) on an interval B (i.e., \(P_C(B)=\mathbb {P}(\varvec{U}\in B)\) for \(\varvec{U}\sim C\)) as
Let \(\mathscr {J}\) be the set of intervals of \([0,1)^d\) of the form \([\varvec{a},\varvec{b})=\prod _{j=1}^d [a_j,b_j)\), where \(0\le a_j\le b_j\le 1\). The copula-discrepancy \(D_C\) of \(P_n\) is then defined as
and similarly for \(D_C^*(P_n)\), the star-copula-discrepancy function when the \(\sup \) in (25) is taken over \(\mathscr {J}^*\) instead.
The generalization of the Koksma–Hlawka inequality studied in (Aistleitner and Dick 2015, Theorem 1) then provides
where we assume \(\varvec{u}_i=\phi _C(\varvec{v}_i), i\in \{1,\ldots ,n\}\). To get some insight on this upper bound, we need to know how \(D^*_C(\varvec{u}_1,\ldots , \varvec{u}_n)\) behaves as a function of n. Unfortunately, in general we cannot prove that \(D^*(\varvec{v}_1,\ldots ,\varvec{v}_n) {\in } O(n^{-1} \log ^d n)\) implies that \(D^*_C(\varvec{u}_1,\ldots ,\varvec{u}_n) {\in } O(n^{-1} \log ^d n)\). Here are a few things we can say, though.
First, an obvious case for which discrepancy is preserved is when \(\phi _C\) maps rectangles to rectangles, because then \(\phi _C(B)\in \mathscr {J}\) for all \(B\in \mathscr {J}\), and thus
where \(\widetilde{P}_n=\{\varvec{u}_1,\ldots ,\varvec{u}_n\}\). However, this only happens when C is the independence copula, and in this case the equality holds. This is not a very interesting case since our focus here is on dependence modelling.
For the more realistic setting where \(\phi _C\) does not map rectangles to rectangles, the following result from Hlawka and Mück (1972) holds and gives a much slower convergence rate for \(D^*_C(\widetilde{P}_n)\).
Proposition 7
Let C be such that the Rosenblatt transform \(\phi _C^{-1}\) is Lipschitz continuous on \([0,1]^d\) w.r.t. the sup-norm \(\Vert \cdot \Vert _{\infty }\), and \(\{\varvec{u}_i=\phi _C(\varvec{v}_i)\}\) for some sequence of points \(\{\varvec{v}_i\}\) in \([0,1]^d\). Then
for some function c(d), constant in n.
Note that the above results fully depend on the properties of \(\phi _C\). The aim would then be to choose \(\phi _C\) such that a low-discrepancy sequence \(\{\phi _C(\varvec{v}_i)\}\) w.r.t. the copula measure \(P_C\) results whenever applied to a low-(Lebesgue-)discrepancy sequence \(\{\varvec{v}_i\}\). A more fundamental approach would be to directly produce a low-discrepancy sequence \(\{\varvec{u}_i\}\) where the discrepancy is measured w.r.t. the copula measure C. This is something we intend to study in future work.
Now, computing \(D_C\) or \(D^*_C\) is usually not feasible in practice. If we replace the sup-norm by the \(L_2\)-norm, we obtain \(L_2\)-discrepancies which are usually more practical to compute. Let \(L_2\)-discrepancies \(T_C(\varvec{u}_1,\ldots ,\varvec{u}_n)\) and \(T^*_C(\varvec{u}_1,\ldots ,\varvec{u}_n)\) be defined by
and
respectively. Proceeding similarly to Morokoff and Caflisch (1994), \(T^*_C\) can be computed as
If we consider a convex combination \(C(u_1,\ldots ,u_d)=\lambda \prod _{i=1}^d u_i+(1-\lambda )\min (u_1,\ldots ,u_d), \lambda \in (0,1)\), of the independence copula and the upper Fréchet–Hoeffding bound, then one can compute \(T^*_C\) explicitly via
5 Numerical results
Through typical examples from the realm of finance and insurance and a few test functions, we now illustrate in this section the efficiency of QRNG in comparison to standard (P)RNG for copula sampling. More precisely, we compare Monte Carlo sampling approaches with two types of QRNGs based on randomized low-discrepancy sequences: The Sobol’ sequence and the generalized Halton sequence, both randomized with a digital shift. Variance/error estimates are obtained by using \(B=25\) i.i.d. copies of the randomized sequence and comparisons are made with MC sampling based on the same total number of replications. Each plot includes lines showing \(n^{-0.5},n^{-1}\) and/or \(n^{-1.5}\) convergence rates. In addition, on top of each plot and for each QRNG method, we provide the regression estimate of \(\alpha \) such that the variance/error is in \(O(n^{\alpha })\). For PRNG, we only show the results with the CDM sampling algorithm, since the choice of method does not affect the error or variance very much. On the other hand, for QRNG we show the results both with CDM and MO (when applicable), as this seems to sometimes make a difference. Understanding better why it is so and under what circumstances a sampling algorithm perform better when used in conjunction with QRNG will be a subject of further research.
While the examples given in the next section illustrates the use of our proposed method in typical contexts where they might be used, the test functions results in the section that follows are meant to focus on assessing the performance of QRNG compared to PRNG on the sole basis of generating copula samples \(\varvec{U}\)—without including the effect of the marginal distributions—and also to see if the sampling algorithm (CDM or MO) has an effect on the performance of QRNG. Finally, we note that QRNG based on Sobol’ point sets is typically slightly faster than PRNG, while the generalized Halton sequence runs slower than PRNG.
5.1 Examples from the realm of finance and insurance
Consider a random vector \(\varvec{X}=(X_1,\ldots ,X_d)\) modeling d risks in a portfolio of stocks or insurance losses. We assume that the jth marginal distribution is either log-normal with \(X_j\sim {\text {LN}}(\log (100)+\mu -\sigma ^2/2,\sigma ^2), j\in \{1,\ldots ,d\}\), where \(\mu =0.0001\) and \(\sigma =0.2\), or Pareto distributed with the same mean and variance as in the log-normal case. The copula C of \(\varvec{X}\) throughout this numerical study is either a Clayton or an exchangeable t copula with three degrees of freedom. To allow a comparable degree of dependence, we will use the same Kendall’s tau for both models. This easily translates to the parameter \(\theta \) of a Clayton copula via the relationship \(\theta =2\tau (1-\tau )^{-1}\) and to the correlation parameter \(\rho \) of an exchangeable t copula via \(\rho =\sin (\pi \tau /2)\). We denote \(S=\sum _{j=1}^d X_j\) and consider the estimation of the following functionals \(\varPsi (\varvec{X})\):
-
the Best-Of Call option payoff \((\max X_i - K)^+\);
-
the Basket Call option payoff \((d^{-1}S - K)^+\);
-
the Value-at-Risk at level 0.99 on the aggregated risks
$$\begin{aligned} {\text {VaR}}_{0.99}\left( S\right) =F_S^{-1}(0.99)=\inf \left\{ x\in \mathbb {R}:F_S(x)\ge 0.99\right\} , \end{aligned}$$ -
the expected shortfall at level 0.99 on the aggregated risks
$$\begin{aligned} {\text {ES}}_{0.99}\left( S\right) =\frac{1}{1-0.99}\int _{0.99}^1 F_S^{-1}(u)\text {d}u; \end{aligned}$$ -
the contribution of a given margin (without loss of generality, the first margin was chosen) to \({\text {ES}}_{0.99}\) of the sum under the Euler principle, see Tasche (2008)
$$\begin{aligned} \mathbb {E}\left[ X_1\,|\,S>F^{-1}_S(\alpha )\right] ; \end{aligned}$$we refer to this functional as Allocation First.
Figures 7, 8, 9, and 10 (as well as Figs. 13, 14 in the online supplement) display selected variance estimates for Clayton and t copulas with Kendall’s tau parameter equal to 0.2 and 0.5, using either lognormal or Pareto margins, in dimensions \(d=5,10,20\) (displayed in different rows) and sample sizes \(n\in \{10{,}000,15{,}000,\ldots ,200{,}000\}\). In the Clayton case, the experiment uses both the MO and CDM sampling methods. For the t copulas, while there is a sampling approach based on a stochastic representation (as seen in Sect. 3.2.2), there is no version of the MO algorithm available, so we only use the CDM method. In addition, both the Sobol’ and generalized Halton QRNGs are used. In all cases, we see that the variances associated with the Sobol’ and generalized Halton quasi-random sequences are smaller and converge faster than the Monte Carlo variance. It is not clearly determined whether one sampling method is performing considerably better than the other. But we note that in some cases, such as the estimate of the Basket Call with \(\tau =0.2\) in \(d=20\) dimensions (Fig. 7, bottom) the MO sampling seems to perform better than CDM.

Variance estimates for the functional Basket Call with lognormal margins based on \(B = 25\) repetitions for a Clayton copula with parameter such that Kendall’s tau equals 0.2 for \(d = 5\) (top), \(d = 10\) (middle) and \(d = 20\) (bottom)

Variance estimates for the functional Best-of Call with Pareto margins based on \(B = 25\) repetitions for an exchangeable t copula with three degrees of freedom such that Kendall’s tau equals 0.5 for \(d = 5\) (top), \(d = 10\) (middle) and \(d = 20\) (bottom)

Variance estimates for the functional \({\text {VaR}}_{0.99}\) with lognormal margins for an exchangeable t copula with three degrees of freedom such that Kendall’s tau equals 0.2 based on \(B = 25\) repetitions for \(d=5\) (top), \(d=10\) (middle) and \(d=20\) (bottom)

Variance estimates for the functional \({\text {ES}}_{0.99}\) with Pareto margins for a Clayton copula with parameter such that Kendall’s tau equals 0.5 based on \(B = 25\) repetitions for \(d=5\) (top), \(d=10\) (middle) and \(d=20\) (bottom)
5.2 Test functions
We now consider integration results on two different test functions. The results are shown in Figs. 11, 12, Supplementary Fig. 15 (the latter is in the online supplement), and 16 (the latter is in the online supplement), which are based on a Clayton (or t) copula with \(\tau =0.2\) and \(\tau =0.5\), respectively. The first test function is given by
where the vector \(\varvec{u}\) is obtained after transforming the uniform points \(\varvec{v}\) using either the CDM transform or the MO algorithm. Recall that the former requires d-dimensional points (using either a PRNG or a QRNG), whereas the latter requires \((d+1)\)-dimensional points. Note that \(\varPsi _1\) integrates exactly to 1 with respect to the copula-induced measure, since \(U_j\sim {\text {U}}[0,1], j\in \{1,\ldots ,d\}\). While we know the exact value of the integral in this case, we still compare estimators based on B i.i.d. copies of either MC or RQMC, but we plot the average absolute error rather than the estimated variance.
The second test function is given by
where
which is often used as a test function in the QMC literature; see, e.g., Faure and Lemieux (2009) and the references therein. So here we first apply the inverse of the CDM transform to the copula-transformed points obtained either using the CDM approach or MO, and then apply the d-dimensional function \(g_1\). While this has the effect of simply applying the standard test function \(g_1\) to the original sample points \(\varvec{v}_i\) in the case of the CDM, in the case of the MO algorithm, we are not falling back on the original points \(\varvec{v}_i\). The hope is that if MO does not preserve so well the low discrepancy of the original points, this function would be able to detect this problem.
While the second test function is mostly interesting for Archimedean copulas, the first one can be used more generally. This is why in the results reported in Figs. 11 and 12, we also consider an exchangeable t copula with three degrees of freedom and Kendall’s \(\tau \) equal to 0.2. For both test functions, we see that the Sobol’ and generalized Halton sequences always clearly outperform Monte Carlo, with an error often converging in \(O(n^{-1})\) rather than the \(O(n^{-0.5})\) corresponding to Monte Carlo. For the first function \(\varPsi _1\), both the CDM and MO methods perform about the same. We believe this might be due to the simplicity of \(\varPsi _1\)—a sum of univariate powers of the \(u_j\)’s—and the fact that both methods perform equally well in the univariate case when combined with RQMC. Looking at the results for \(\varPsi _2\), we see that with RQMC the CDM method performs better than MO, as there is no copula transformation performed in the case of CDM. However, RQMC with MO is still better than Monte Carlo, which suggests that the MO algorithm manages to preserve the low discrepancy of the original point set.

Average absolute errors for the test functions \(\varPsi _1(\varvec{u})=3(u_1^2 + \cdots + u_d^2)/d\) (top) and \(\varPsi _2(\varvec{u})=g_1((\phi ^{\text {CDM}})^{-1}(\varvec{u}))\) (bottom) for a Clayton copula with parameter such that Kendall’s tau equals 0.2 based on \(B=25\) repetitions for \(d=5\); the middle plot shows results for \(\varPsi _1(\varvec{u})\) and an exchangeable t copula with 3 degrees of freedom and Kendall’s tau of 0.2

Average absolute errors for the test functions \(\varPsi _1(\varvec{u})=3(u_1^2 + \cdots + u_d^2)/d\) (top), \(\varPsi _2(\varvec{u}) = K_C(C(\varvec{u}))+1/2\) (middle), and \(\varPsi _3(\varvec{u})=g_1((\phi ^{\text {CDM}})^{-1}(\varvec{u}))\) (bottom) for a Clayton copula with parameter such that Kendall’s tau equals 0.2 based on \(B=25\) repetitions for \(d=15\); the middle plot shows results for \(\varPsi _1(\varvec{u})\) and an exchangeable t copula with 3 degrees of freedom and Kendall’s tau of 0.2
Overall, the numerical results presented in this section suggest that replacing PRNG by QRNG within algorithms that sample from copulas reduces the variance of the obtained estimators and typically also improve the convergence rate of the variance. The improvement was seen across the range of dimensions from 5 to 20 that were tested, and the different functions considered. In small dimensions, different copula sampling algorithms (CDM and MO) tend to perform similarly, but when the dimension increases we sometimes see differences in their performance, with so far neither of the two algorithms clearly dominating the other.
6 Conclusion and discussion
The main goal of this paper was to show how copula samples can be generated using quasi-random numbers. This is of interest when replacing PRNGs by QRNGs in applications involving dependent samples, possibly in higher dimensions. We have seen that different sampling approaches can be used, with a focus on the CDM approach and, additionally for Archimedean copulas, on the Marshall–Olkin algorithm. We have studied the error behaviour for both methods and have seen that in order to prove that the composed function \(\varPsi \circ \phi _C\) is smooth enough to satisfy the Koksma–Hlawka bound for the error, sufficient conditions on the function \(\varPsi \) are that it must have smooth higher order mixed partial derivatives. For the Marshall–Olkin algorithm, we have shown that for several Archimedean copula families, the corresponding transformation \(\phi _C\) is smooth enough to guarantee the good behaviour of the error bound. The superiority of QRNG over PRNG for copula sampling was illustrated on several examples, including a simulation addressing an application in the realm of finance and insurance. Most of the results in this paper are reproducible using the R packages copula and qrng.
Some ideas for future work would be to follow-up on Proposition 6 and to analyze the speed of decay of the Walsh coefficients of the composed function \(\varPsi \circ \phi _C\), based on assumptions on the speed of decay of the Walsh coefficients of \(\varPsi \) and the properties of the sampling method \(\phi _C\).
Concerning the copula-induced discrepancy studied in Sect. 4.2, a possible avenue for future research would be to construct point sets that directly minimize this discrepancy, without first transforming a (uniform-based) low-discrepancy sample. In addition, proving error bounds based on the \(L_2\)-discrepancy would be useful, as this discrepancy measure is easier to compute. Finally, numerically computing the copula-induced discrepancy for samples transformed either using the CDM or the MO algorithm would give us some insight as to how conservative the bound given in Proposition 7 is.
References
Aistleitner, C., Dick, J.: Functions of bounded variation, signed measures, and a general Koksma-Hlawka inequality. Acta Arith. 167, 143–171 (2015)
Caflisch, R.: Monte Carlo and quasi-Monte Carlo methods. Acta Numer. 7, 1–49 (1998)
Cambanis, S., Huang, S., Simons, G.: On the theory of elliptically contoured distributions. J. Multivar. Anal. 11(3), 368–385 (1981)
Constantine, G., Savits, T.: A multivariate Faa Di Bruno formula with applications. Trans. Am. Math. Soc. 348(2), 503–520 (1996)
Cranley, R., Patterson, T.N.L.: Randomization of number theoretic methods for multiple integration. SIAM J. Numer. Anal. 13(6), 904–914 (1976)
Dick, J., Pillichshammer, F.: Digital Nets and Sequences: Discrepancy Theory and Quasi-Monte Carlo Integration. Cambridge University Press, Cambridge (2010)
Embrechts, P., McNeil, A.J., Straumann, D.: Correlation and dependence in risk management: properties and pitfalls. Risk Management: Value at Risk and Beyond. Cambridge University Press, Cambridge (2002)
Embrechts, P., Lindskog, F., McNeil, A.J.: Modelling dependence with copulas and applications to risk management. In: Rachev, S. (ed.) Handbook of Heavy Tailed Distributions in Finance, pp. 329–384. Elsevier, Boston (2003)
Fang, K.T., Kotz, S., Ng, K.W.: Symmetric Multivariate and Related Distributions. Chapman & Hall, Boca Raton (1990)
Faure, H.: Discrépance des suites associées à un système de numération (en dimension \(s\)). Acta Arith. 41, 337–351 (1982)
Faure, H., Lemieux, C.: Generalized Halton sequence in 2008: a comparative study. ACM Trans. Model. Comput. Simul. 19, 15 (2009)
Glasserman, P.: Monte Carlo Methods in Financial Engineering. Springer, New York (2004)
Halton, J.H.: On the efficiency of certain quasi-random sequences of points in evaluating multi-dimensional integrals. Numer. Math. 2, 84–90 (1960)
Hartinger, J., Kainhofer, R., Tichy, R.: Quasi-Monce Carlo algorithms for unbounded, weighted integration problems. J. Complex. 20, 654–668 (2004)
Hlawka, E.: Über die diskrepanz mehrdimensionaler folgen mod 1. Math. Z. 77, 273–284 (1961)
Hlawka, E., Mück, R.: Über eine transformation von gleichverteilten folgen II. Computing 9(2), 127–138 (1972)
Hofert, M.: Sampling nested Archimedean copulas with applications to CDO pricing. PhD thesis, University of Ulm (2010)
Hofert, M., Mächler, M., McNeil, A.J.: Likelihood inference for Archimedean copulas in high dimensions under known margins. J. Multivar. Anal. 110, 133–150 (2012)
Hofert, M., Mächler, M., McNeil, A.J.: Archimedean copulas in high dimensions: estimators and numerical challenges motivated by financial applications. Journal de la Société Française de Statistique 154(1), 25–63 (2013)
Hong, H.S., Hickernell, F.J.: Algorithm 823: implementing scrambled digital sequences. ACM Trans. Math. Softw. 29, 95–109 (2003)
Jaworski, P., Durante, F., Härdle, W.K., Rychlik, T.: Copula Theory and Its Applications. Lecture Notes in Statistics—Proceedings. Springer, Heidelberg (2010)
Joe, H.: Dependence Modeling with Copulas. Chapman & Hall, Boca Raton (2014)
Kurowicka, D., Cooke, R.M.: Sampling algorithms for generating joint uniform distributions using the vine-copula method. Comput. Stat. Data Anal. 51, 2889–2906 (2007)
Lemieux, C.: Monte Carlo and Quasi-Monte Carlo Sampling. Springer Series in Statistics. Springer, New York (2009)
Marshall, A.W., Olkin, I.: Families of multivariate distributions. J. Am. Stat. Assoc. 83(403), 834–841 (1988)
Matousěk, J.: On the \({L_2}\)-discrepancy for anchored boxes. J. Complex. 14, 527–556 (1998)
McNeil, A., Frey, R., Embrechts, P.: Quantitative Risk Management: Concepts, Techniques, Tools. Princeton University Press, Princeton (2005)
McNeil, A.J., Nešlehová, J.: Multivariate Archimedean copulas, \(d\)-monotone functions and \(l_{1}\)-norm symmetric distributions. Ann. Stat. 37(5b), 3059–3097 (2009)
Morokoff, W.: Generating quasi-random paths for stochastic processes. SIAM Rev. 40(4), 765–788 (1998)
Morokoff, W., Caflisch, R.: Quasi-random sequences and their discrepancies. SIAM J. Sci. Comput. 15(6), 1251–1279 (1994)
Nelsen, R.: An Introduction to Copulas, 2nd edn. Springer, New York (2006)
Niederreiter, H.: Point sets and sequences with small discrepancy. Monatshefte für Mathematik 104, 273–337 (1987)
Niederreiter, H.: Random number generation and quasi-Monte Carlo methods. Society for Industrial and Applied Mathematics, Philadelphia (1992)
Nolan, J.: Stable distributions—models for heavy tailed data. http://academic2.american.edu/jpnolan/stable/chap1 (2014)
Owen, A.B.: Randomly permuted \((t, m, s)\)-nets and \((t, s)\)-sequences. In: Niederreiter, H., Shiue, P.J.S. (eds.) Monte Carlo and Quasi-Monte Carlo Methods in Scientific Computing. Lecture Notes in Statistics, vol. 106, pp. 299–317. Springer, New York (1995)
Owen, A.B.: Monte Carlo variance of scrambled equidistribution quadrature. SIAM J. Numer. Anal. 34(5), 1884–1910 (1997a)
Owen, A.B.: Scrambled net variance for integrals of smooth functions. Ann. Stat. 25(4), 1541–1562 (1997b)
Owen, A.B.: Variance and discrepancy with alternative scramblings. ACM Trans. Model. Comput. Simul. 13, 363–378 (2003)
Owen, A.B.: Multidimensional variation for quasi-Monte Carlo. In: Fan, J., Li, G. (eds.) International Conference on Statistics in honour of Professor Kai-Tai Fang’s 65th birthday, pp. 49–74. World Scientific Publications, Hackensack, NJ (2005)
Pillards, T., Cools, R.: Using box-muller with low discrepancy points. In: ICCSA 2006, Lecture Notes in Computer Science, vol. 3984, pp 780–788. Springer, Berlin (2006)
Schmitz, V.: Copulas and stochastic processes. PhD thesis, Institute of Statistics, Aachen University (2003)
Sobol’, I.M.: On the distribution of points in a cube and the approximate evaluation of integrals. USSR Comput. Math. Math. Phys. 7, 86–112 (1967)
Sobol’, I.M.: Calculation of improper integrals using uniformly distributed sequences. Sov. Math. Dokl. 14, 734–738 (1973)
Tasche, D.: Capital allocation to business units and sub-portfolios: the Euler principle. In: Resti, A. (ed.) Pillar II in the New Basel Accord: The Challenge of Economic Capital, pp. 423–453. Risk Books, London (2008)
Wu, F., Valdez, E.A., Sheris, M.: Simulating exchangeable multivariate archimedean copulas and its applications. Commun. Stat. 36(5), 1019–1034 (2006)
Acknowledgments
We thank the Associate Editor and the two anonymous reviewers for their helpful comments, which helped us improve this paper. The first author wishes to thank SCOR for their financial support. The second and third authors acknowledge the support of NSERC through grants #5010 and #238959, respectively.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Appendix
Appendix
For all the randomization schemes mentioned in Sect. 2, in addition to having a simple method to estimate the variance of the corresponding RQMC estimator, results giving exact expressions for this variance are also known and typically rely on using a well-chosen series expansion of the function \(\varPsi \) of interest. The following result recalls this variance expression in the case of randomly digitally shifted net; see Lemieux (2009) for a detailed proof. This result is used in the proof of Proposition 6 in Sect. 4.1.
Theorem 3
(Variance for randomly digitally shifted nets) Let \(\tilde{P}_n = \{\tilde{\varvec{v}}_1,\ldots ,\tilde{\varvec{v}}_n\}\) be a randomly digitally shifted net in base b with corresponding RQMC estimator \(\widehat{\mu }_n\) given by
and assume \(\mathrm{Var}(\varPsi (\varvec{U})) < \infty \) for \(\varvec{U} \sim U[0,1)^d\). Then we have that
where \(\widehat{\varPsi }(\varvec{h})\) is the Walsh coefficient of \(\varPsi \) at \(\varvec{h}\), given by
where \(\langle \varvec{h}, \varvec{u} \rangle _b = \frac{1}{b} \sum _{j=1}^d \sum _{l=0}^{\infty } h_{j,l}u_{j,l+1}\) with \(h_{j,l}\) and \(u_{j,l}\) obtained from the base b expansion of \(h_j\) and \(u_j\), respectively, and \(\mathscr {L}_d^*=\{\varvec{h} \in \mathbb {Z}^d: \langle \varvec{h}, \varvec{v}_i \rangle _b \in \mathbb {Z}, \forall i=1,\ldots ,n \}\) is the dual net of the deterministic net \(P_n = \{\varvec{v}_i,i=1,\ldots ,n\}\) that has been shifted to get \(\tilde{P}_n\).
1.1 Proofs
Proof (Proof of Proposition 4)
We start by providing more details on the expression (21), which is given by:
where \(\varvec{\beta } \in \mathbb {N}_0^d, |\varvec{\beta }| = \sum _{j=1}^d \beta _j\), and the set \( p_s(\varvec{\beta },\varvec{\alpha })\) includes pairs \((\varvec{k},\varvec{\gamma })\) such that \(\varvec{k}\) is an s-dimensional vector \(\varvec{k}=(k_1,\ldots ,k_s)\) where each \(k_j\in \{1,\ldots ,d\}\), and \(\varvec{\gamma }\) is an sl-dimensional vector \(\varvec{\gamma }=(\varvec{\gamma }_1,\ldots ,\varvec{\gamma }_s)\) where each \(\varvec{\gamma }_j\) is an l-dimensional vector whose entries are either 0 or 1, and \(\sum _{j=1}^s {\gamma }_{j,i} = 1\) for \(i\in \{1,\ldots ,l\}\). Finally, the \(c_{\varvec{\gamma }}\) are constants, which are defined in detail in Constantine and Savits (1996), along with further information on the precise definition of \(p_s(\varvec{k},\varvec{\gamma })\). As mentioned in Sect. 4.1, a sufficient condition to show that \( \Vert \varPsi \circ \varPhi _C \Vert _{d,1} < \infty \) is to establish that all products of the form (22) are in \(L_1\), which we recall is given by
for \(s\in \{1,\ldots ,l\}\) and \((\varvec{k},\varvec{\gamma }) \in p_s(\varvec{\beta },\varvec{\alpha })\).
Recall also that for the MO algorithm, \(\phi _{C,l}\) is a function of \(v_1\) and \(v_{l+1}\) only, for \(l=1,\ldots ,d\). Hence the only partial derivatives of \(\phi _{C,l}\) that are nonzero are those with respect to variables in \(\{v_1,v_{l+1}\}\).
Now, since we assume that (23) holds, then it means we just need to show that the product found in (22) is in \(L_1\), under the conditions stated in the proposition. In turn, we first show that this holds if the following bounds hold for the mixed partial derivatives of \(\phi _C\):
for all \(l \le d+1\),
We have three cases to consider.
Case 1 \(1 \notin I\). Then the product in (22) is given by
where we assumed w.l.o.g. that \(I = \{2,\ldots ,l+1\}, s=l\) and \(k_j=j+1\) for \(j\in \{1,\ldots ,s\}\). Since each term in the product depends on a distinct variable, the product is in \(L_1\) if (26) holds.
Case 2 \(1\in I\) and j such that \(\gamma _{j,1}=1\) has \(k_j+1 \notin I\). This case can be analyzed w.l.o.g. by assuming I is of the form \(I=\{1,\ldots ,r,r+2,\ldots ,l+1\}\) for some \(r\ge 1\). In that case, the products in (22) are of the form
and is thus in \(L_1\) as long as (28) holds.
Case 3 \(1\in I\) and j such that \(\gamma _{j,1}=1\) has \(k_j+1 \in I\). In this case, we can assume w.l.o.g. that \(I=\{1,\ldots ,l\}\) and therefore the products in (22) are of the form
and is thus in \(L_1\) as long as (27) holds.
The last part of the proof is to show that (26), (27), and (28) hold. First we study the partial derivatives involved in these expressions and find they are given by:
where \(x_1 = F^{-1}(v_1)\) and \(\frac{\partial x_1}{\partial v_1}= 1/f(x_1)\), where f is the pdf corresponding to F, which exists since we assumed F was continuous. Now, the partial derivatives with respect to either \(v_1\) or \(v_2\) are clearly non-negative for all \(v_1\) and \(v_2\). Hence it is easy to see that (26) and (28) hold, because we can remove the absolute value inside the integrals and therefore, these integrals amount to take differences/sums of \(\phi _{C,r}(\cdot ,\cdot )\) at different values over its domain, which obviously yields a finite value since \(\phi _{C,r}(\cdot ,\cdot )\) always takes values in [0, 1].
As for the mixed partial derivative with respect to \(v_1\) and \(v_2\), our assumption on \(\psi '(t)+t\psi ''(t)\) implies we have at most one sign change over the domain of the integral. If there is no sign change, the argument used in the previous paragraph to handle (26) and (28) can be used to show (27) is bounded. If there is one sign change, then we let \(t^*\) be such that
Then let q(v) be a function such that \(-\log q(v)/F^{-1}(v) = t^*\). For instance, one can verify that for the Clayton copula, \(q(v)=e^{-\theta F^{-1}(v)}\). When integrating the absolute value of the mixed partial derivative \(\partial ^2 \phi _{C,1}(v_1,v_2)/\partial v_1 \partial v_2\), we get
Now, in most cases \(F^{-1}(1)\) is not bounded, and thus we cannot prove that \(\varPsi \circ \phi _C\) has bounded variation. However, from there we can still get the upper bound on the error given in the result, by using a technique initially developed by Sobol’ (1973) to handle improper integrals, and later by Hartinger et al. (2004) to deal with unbounded integration problems taken w.r.t. to a measure that is not necessarily uniform (as studied in Sect. 4.2). Note that to apply their approach more easily, we need to make a small change and assume that rather than generating V as \(F^{-1}(v_1)\), we use \(F^{-1}(1-v_1)\), so that in our study of the variation above (via the integral of the absolute value of the mixed partial derivatives), the boundedness condition fails at \(v_1=0\) instead of \(v_1=1\). Following the approach in Hartinger et al. (2004) (see their Equation (24)) and taking \(\varvec{c}=(1/pn,0,\ldots ,0)\), the integration error satisfies
where \(V_{[\varvec{c},\varvec{1}]}(\varPsi \circ \phi _C)\) denotes the variation of \(\varPsi \circ \phi _C\) over \([\varvec{c},\varvec{1}]\) and
since we assumed \(|\psi (\varvec{u})|\) was bounded. As for \(V_{[\varvec{c},\varvec{1}]}(\varPsi \circ \phi _C)\), we can infer from the steps that led to (29) that it is bounded by a constant times \(\log F^{-1}(1-1/pn) \le a \log n + \log c\) by assumption. Therefore there exists a constant \(K^{(d)}\) such that \(V_{[\varvec{c},\varvec{1}]}(\varPsi \circ \phi _C) \le K^{(d)} \log n\). \(\square \)
Proof (Proof of Proposition 5)
Let \(p_l\) be such that \(P(V=l)=p_l\), for \(l \ge 1\). Let \(P_l = \sum _{k=1}^l p_k\) for \(l \ge 1\) and \(P_0=0\). We also let \(\phi _C^l(v_2,\ldots ,v_{d+1})\) \(= \phi _C(P_{l-1},v_2,\ldots ,v_{d+1})\) for \(l \ge 1\) (transformation \(\phi _C\) when \(v_1\) generates the value l for V). Consider a given value of n and low-discrepancy point set \(P_n\). If we use inversion to generate V, then we have that the subset \(P_n^l = \{\varvec{v}_i: P_{l-1} < v_{i,1} \le P_l\}\) will be used to produce copula samples with \(V=l\). Let \(\tilde{n}_l = |P_n^l|\) and \(n_l = np_l\). It is clear that if l becomes too large, then \(\tilde{n}_l\) will eventually be 0. Let L(n) be the largest value of l such that \(\tilde{n}_{l} >0\), and let \(\tilde{p}_l = \tilde{n}_l/n\). Then we can write
where A(n, d), B(n, d), and C(n, d) are bounds such that
First, by definition of \(D^*(P_n)\) we have \(|\tilde{n}_l - n_l| \le 2nD^*(P_n)\) and thus \(|\tilde{p}_l-p_l| \le 2D^*(P_n)\). Hence we can take \(C(n,d) = 2{\text {E}}(|\varPsi (\varvec{U})|)D^*(P_n)\). Similarly, we can show that \(\sum _{l=L(n)+1}^{\infty } p_l \le D^*(P_n)\) and can therefore take \(B(n,d) = {\text {E}}(|\varPsi (\varvec{U})|) D^*(P_n)\). The analysis of the expression to be bounded by A(n, d) is more complicated. First, we note that under the assumption we have on \(\varPsi \) and its partial derivatives, we need to show that the product in (22) is in \(L_1\), but where each \(\phi _{C,k_j}\) is replaced by \(\phi _{C,k_j}^l\) for a given l. Since \(\phi _{C,k_j}^l\) is solely a function of \(v_{k_j+1}\), then it means that the only relevant products to consider are of the form
in which each term is of the form \( -\psi ^{'} \left( \frac{-\log v_{k_j+1}}{l}\right) \frac{1}{l v_{k_j+1}} \) which is non-negative for any \(v_{k_j+1}\). Using a similar reasoning to the one used in the proof of Proposition 4 (to conclude that (26) and (28) hold), it is easy to see that (30) is in \(L_1\).
What remains to be done is to analyze the discrepancy of \(P_n^l\). That is, here we are looking for a bound on \(\sup _{\varvec{z} \in \mathscr {J}^*} |E(\varvec{z};P_n^l)|\), where we recall that \( \mathscr {J}^*\) is the set of intervals of \([0,1)^d\) of the form \(\varvec{z} = \prod _{j=1}^d [0,z_j)\), where \(0 < z_j \le 1\). So consider a given \(\varvec{z} \in [0,1)^d\). Then \(E(\varvec{z};P_n^l) = A(\varvec{z};P_n^l)/\tilde{n}_l - \lambda (\varvec{z})\). Let \(\varvec{z}_1 = (P_l,\varvec{z})\) and \(\varvec{z}_2 = (P_{l-1},\varvec{z})\), which are both in \([0,1)^{d+1}\). Note that \(A(\varvec{z}_1;P_n) - A(\varvec{z}_2;P_n) = A(\varvec{z};P_n^l)\). By definition of \(D^*(P_n)\), it is not hard to see that
and therefore
Using the fact that \(|\tilde{n}_l-n_l| \le 2nD^*(P_n)\), after some further simplifications we get that
Hence we can take \(A(n,d) = 4D^*(P_n)\frac{n}{\tilde{n}_l}\) and then get \(\sum _{l=1}^{L(n)} \tilde{p}_l A(n,d) \le 4 L(n)D^*(P_n)\). To show that the overall bound for the integration error is of the form \((\log n)D^*(P_n)\) times a constant, we simply need to show that \(L(n) \in O(\log n)\). But this follows from our assumptions on \(P_n\) and F, since by definition, L(n) is the largest integer such that \(1-F(L(n)) > 1/pn\) but we also have \(1-F(L(n)) \le cq^{L(n)}\), hence
and thus \(L(n) \le (\log n + \log p + \log c)/\log (1/q)\), as required. \(\square \)
Rights and permissions
About this article

Cite this article
Cambou, M., Hofert, M. & Lemieux, C. Quasi-random numbers for copula models. Stat Comput 27, 1307–1329 (2017). https://doi.org/10.1007/s11222-016-9688-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11222-016-9688-4
Keywords
- Quasi-random numbers
- Copulas
- Conditional distribution method
- Marshall–Olkin algorithm
- Tail events
- Risk measures