
Abstract
In the emerging domain of quantum algorithms, Grover’s quantum search is certainly one of the most significant. It is relatively simple, performs a useful task and more importantly, does it in an optimal way. However, due to the success of quantum walks in the field, it is logical to study quantum search variants over several kinds of walks. In this paper, we propose an in-depth study of the quantum search over a hypercube layout. First, through the analysis of elementary walk operators restricted to suitable eigenspaces, we show that the acting component of the search algorithm takes place in a small subspace of the Hilbert workspace that grows linearly with the problem size. Subsequently, we exploit this property to predict the exact evolution of the probability of success of the quantum search in polynomial time.
Similar content being viewed by others

1 Introduction
Many computational problems can be reduced to the search of one or more items in a set that meet a predefined criterion. For instance in a digital communications context, with channel coding using block codes, the receiver has to find the binary word which best explains the received data. If there are 50 bits per data word, this means finding the best solution among \(2^{50}\) (approximately \(10^{15}\)) possibilities.
This is the kind of problem Grover’s algorithm, introduced in [4], can resolve with a high probability in \(\mathcal {O}(\sqrt{N})\) steps, N being the number of possibilities. This implies that quantum computing could significantly speed up some problems too complex to be simulated with a classical computer.
Quantum walks over graphs are a great tool in the design of quantum algorithms. It has been shown in [1] that quantum walks can be faster than their classical counterparts up to a polynomial factor. Further reading about quantum walks can be found in [9].
The choice of the hypercube structure over other walks is motivated by its direct connection with information science, where it is often used to represent binary values. Indeed, every n-bit value can be placed on the n-dimensional hypercube, where the number of edges separating the two values is equal to the number of bits that differ from one value to the other. Additionally, a displacement along the d-th dimension on the hypercube is equivalent to a flip (0 becomes 1 and conversely) of the value of the d-th bit, as illustrated in Fig. . It has been shown in [5] that quantum walks on hypercube are faster to mix than a classical random walk.

The 4-dimensional hypercube structure, with vertices labeled and direction arrowed
While Grover’s algorithm is simple to build, one is also required to determine the optimal number of iterations to get the maximal probability of success, since if there are too many iterations, the probability decreases. The optimal number of iterations for the standard Grover’s algorithm R is bounded by:

where M is the number of solutions. Note that even if the number of solutions is unknown, it is possible to use an incremental procedure as shown in [8] or to compute an approximation of this number using the quantum counting technique. However, this formula is invalid for its quantum walk counterparts. Asymptotic results have been obtained by Shenvi et al. in [7] for a search by quantum walks on the hypercube for which there is a unique solution. They prove that when the hypercube dimension n becomes large, after \(\frac{\pi }{2}\sqrt{2^n-1}\) iterations, the probability of success is \(\frac{1}{2}-\mathcal {O}(\frac{1}{n})\). In this paper, we describe a method that allows us to compute the exact probability of success of a walk on the hypercube for any number of solutions, in order to find the optimal number of iterations required to maximize this probability.
The main idea behind the quantum walks is to split the Hilbert space \(\mathcal {H}\) into two distinct parts: the position space \(\mathcal {H^S}\), which corresponds to the vertices on the graph (in our case, a hypercube), and the coin space \(\mathcal {H^C}\), which corresponds to the possible directions of displacement from the vertices. Thus, \(\mathcal {H}= \mathcal {H^S}\otimes \mathcal {H^C}\), where \(\otimes \) is the Kronecker tensor product. On an n-dimensional hypercube, there are \(N = 2^n\) vertices and n possible directions. In this representation, we chose as basis states the distinct positions in \(\mathcal {H^S}\) and the distinct directions in \(\mathcal {H^C}\). Therefore, a basis state in \(\mathcal {H}\) can be written \(| \psi \rangle = | p \rangle | d \rangle \), where \(| p \rangle \) is the position state and \(| d \rangle \) the direction of movement, often referred as the "quantum coin". In the n-dimension hypercube, p and d are integers with \(p\in [0, N-1]\) and \(d\in [1, n]\). On a hypercube, it is often easier to use binary words to index position. For example, the state located on vertex 4 will be displaced along direction 1 that is \(| \psi \rangle = | 4 \rangle | 1 \rangle \). For each value of p, we associate a binary word \(\rho \). Our last example can be written as \(| \psi \rangle = | 0010 \rangle | 1 \rangle \). Note that the most significant bit of \(\rho \) is on the right and that moving along the i-th dimension will therefore flip the i-th bit of \(\rho \).
The discrete-time quantum walk search algorithm consists in the repeated application of two unitary operators, the oracle O followed by the uniform walk operator U. The global iteration operator is \(Q = UO\). The oracle’s role is to mark the solutions, while walk operator disperses the states on the hypercube. The uniform walk operator U is itself the product of two operators: the shift operator S and the coin operator C, so that \(U = SC\) and \(Q = SCO\). These operators are defined and studied in Sect. 2.
Let \(| \psi _0 \rangle \) be the initial state and t the number of iterations until the system is measured. At each iteration, the operator Q is applied. This operator is constant along the process and is defined once according to the problem. Therefore, the final state will be:
The algorithm is a success if the measurement of \(| \psi _t \rangle \) returns one of the M solutions. As for all quantum algorithms, the outcome is probabilistic. Let \(| s \rangle \) be the uniform superposition of all solutions. The probability of success after t iterations is:
Note that this expression, as well as many other fundamental results about quantum information, can be found in [6].
The goal of this paper is to maximize \(p_t\). As Q depends only on the size of the problem and its solutions, the probability of success depends only on t. In order to maximize \(p_t\), we study a special subspace of \(\mathcal {H}\), which is the complement of the joint eigenspace of the operators U and O. Let us denote this joint eigenspace \(\mathcal {\overline{E}}\) and its complement \(\mathcal {E}\). Let \(U_\mathcal {\overline{E}}\), \(O_\mathcal {\overline{E}}\) and \(Q_\mathcal {\overline{E}}\) be the components of U, O and Q inside \(\mathcal {\overline{E}}\). In their joint eigenspace, operators always commute, and as we will see in Sect. 2.3, O is always self-inverse. Therefore, we have
This means that in \(\mathcal {\overline{E}}\), to apply the global operator twice is to apply the uniform walk twice, without the search component brought by the oracle. Therefore, it has no reason to converge to a solution, and the algorithm effectively takes place in \(\mathcal {E}\).
We proceed as follows:
-
We show that the dimension of \(\mathcal {E}\) is approximately 2Mn, and its exact value will be given in Sect. 6. That means that \(\mathcal {E}\) grows linearly in n, while \(\mathcal {H}\) grows exponentially. We also prove that the uniform state \(| u \rangle \) and the superposition of solutions \(| s \rangle \) are both in \(\mathcal {E}\).
-
We determine the eigenvalues associated with Q in \(\mathcal {E}\) and their multiplicities. The number of eigenvalues to determine is lesser than or equal to 2Mn. We also have developed a method which can be easily programmed and executed on a classical computer, which uses a minima search over a specifically designed criterion.
-
Finally, we propose a method to compute the components in \(\mathcal {E}\) of the initial state and of the uniform superposition of the solutions \(| s \rangle \). With these components and the eigenvalues, it is then possible to compute the probability of success with respect to the number of iterations in polynomial time.
2 Notations and mathematical background
2.1 Notations
Throughout this paper, some notations will frequently be used in different contexts:
-
n is the dimension of the hypercube and the dimension of the coin space \(\mathcal {H^C}\).
-
\(N = 2^n\) is the number of positions on the hypercube and the dimension of the position space \(\mathcal {H^S}\).
-
\(N_e = nN\) is the dimension of the global space \(\mathcal {H}= \mathcal {H^S}\otimes \mathcal {H^C}\).
-
M is the number of solutions for a given problem.
-
\(A^{\text{ T }}\) is the transpose of the matrix A and \(A^\dagger \) is the conjugate transpose of the matrix A.
-
\(| u_k \rangle \) is the \(k\times 1\) uniform column vector. We have
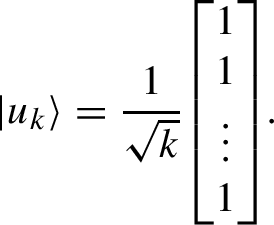 (1.1)
(1.1)When there is no ambiguity, we may omit the index and simply write \(| u \rangle \). We also define the \(n\times (n-1)\) \(\Lambda \) matrix, characterized by \(\langle u |\Lambda = 0\) and \(\Lambda ^{\text{ T }}\Lambda = 0\).
-
\(| 1_p \rangle \) is a length N vector which contains 1 at the position p and 0 elsewhere.
-
I is the \(2\times 2\) identity matrix, while \(I_n\) is the \(n\times n\) identity matrix.
-
X is the Pauli-X matrix, also known as the quantum NOT:
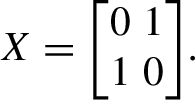 (1.2)
(1.2) -
H is the normalized Hadamard matrix:
 (1.3)
(1.3)We denote the tensor power \(H^{\otimes n}\) by \(H_N\), as it is frequently used.
We will also use the unnormalized Hadamard \(\bar{H}_N\), given by
$$\begin{aligned} \bar{H}_N = \sqrt{N}H_N. \end{aligned}$$(1.4) -
\(E^A_\alpha \) is the eigenspace of the operator A associated with the eigenvalue \(\alpha \). We denote the intersection of two eigenspaces \(E^A_{\alpha }\cap E^B_{\beta }\) by \(E^{A, B}_{\alpha , \beta }\). As almost every eigenvalue we will encounter is \({\pm } 1\), we will simply denote them by their signs, such as in \(E^{A, B}_{+, -}\).
-
\(P_{a, b}\) is a permutation matrix obtained by reading column per column elements organized row per row. For example, if \(a = 2\) and \(b = 3\), we write all integers from 1 to \(a\times b =6\) row per row in a \(a\times b = 2 \times 3\) matrix. We obtain:
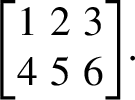 (1.5)
(1.5)By reading column per column, we get the order 1, 4, 2, 5, 3, 6. The permutation-associated matrix \(P_{2, 3}\) is obtained by moving the rows of a \(6\times 6\) identity matrix according to this order. The first row remains the first, the second row is moved to the fourth, etc. We obtain
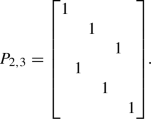 (1.6)
(1.6) -
The default space we are using is \(\mathcal {H}= \mathcal {H^S}\otimes \mathcal {H^C}\), but we will also need the \(\mathcal {H^C}\otimes \mathcal {H^S}\) space. If A is an \(N_e\times N_e\) operator in \(\mathcal {H^S}\otimes \mathcal {H^C}\), we denote its \(\mathcal {H^C}\otimes \mathcal {H^S}\) counterpart by \(A^{\mathcal{C}\mathcal{S}}\).
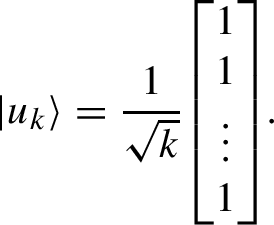
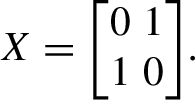

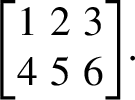

2.2 The Kronecker product
The Kronecker product is a bilinear operation on two matrices. Let A and B be two matrices of dimension \(m_A\times n_A\) and \(m_B\times n_B\). Let \(a_{jk}\) be the A element of the j-th row and k-th column. The tensor product of A and B is:

We will also use the Kronecker matrix power, the Kronecker product of a matrix with itself a given number of times. The k-th Kronecker power of a matrix A is denoted \(A^{\otimes k}\).
The inverse of a tensor product \(A\otimes B\) is:
The interactions between the matrix product and the Kronecker product follow the property known as mixed product:
The Kronecker product is associative but not commutative. However, the structure of the permutation matrices defined in Sect. 1.1, inspired from [2], leads to this interesting property:
Note that \(P_{a, b}^{\text{ T }}= P_{b, a}\), so
The permutation matrices allow us to switch between the workspaces \(\mathcal {H^S}\otimes \mathcal {H^C}\) and \(\mathcal {H^C}\otimes \mathcal {H^S}\).
2.3 The discrete Fourier transform
One important use of the discrete Fourier transform (DFT) is to diagonalize certain operators. In its general form, the coefficients of the \(N\times N\) DFT operator are given by:
where \(\omega = \textrm{e}^{-2\pi \textrm{i}/N}\) and \(\text {DFT}_{j,k}\) is the value on the j-th row and k-th column.
In our case, we will use the DFT in \(\mathcal {H^S}\), where each component belongs to \(\{0, 1\}\). When \(N = 2\), the DFT matrix is equal to the Hadamard matrix H. Therefore, applying the DFT over each of the n dimensions of the hypercube in \(\mathcal {H^S}\) is equivalent to applying \(H_N\) to the state vector. We also define F to be the \(N_e\times N_e\) matrix that applies the DFT in \(\mathcal {H^S}\) while leaving \(\mathcal {H^C}\) unchanged:
In this paper, we will say that we switch between the Fourier and the original domains whenever we multiply by F. Note that since H is self-inverse, F is too, and we will therefore invert a Fourier transform with another one. Note that the use of the term "Fourier transform" in this paper implies different calculations: in \(\mathcal {H}\), it is a multiplication by F, while in \(\mathcal {H^S}\) it is the transform produced by \(H_N\). Furthermore, the Fourier transform of an operator A in \(\mathcal {H}\) is FAF, while the one of a vector \(| v \rangle \) (or a matrix which is a collection of vectors) if \(F| v \rangle \). The same goes for \(H_N\) in \(\mathcal {H^S}\).
We will denote the Fourier transform of a matrix A by \(\hat{A}\).
2.4 The singular value decomposition
The singular value decomposition, or SVD, is a matrix factorization that generalizes the eigendecomposition. The SVD of a given complex \(M\times N\) matrix A is of the form
where U is a \(M\times M\) unitary matrix, S a \(M\times N\) rectangular diagonal matrix and V an \(N\times N\) unitary matrix. The diagonal elements of S are non-negative real values known as the singular values.
The SVD can always be computed in polynomial time. According to Golub and Van Loan in [3], the complexity of the R-SVD algorithm is \(\mathcal {O}(N^3+NM^2)\). It is even possible to compute only the singular values in \(\mathcal {O}(MN^2)\). We will not discuss further the complexity of the SVD as it can already be considered as efficient.
In this paper, we only use a reduced version of this decomposition, namely the thin SVD. Let us define \(K = \min (M, N)\). In this variant of the SVD, we keep only the first K columns of U and S and the first K rows of S and V. This allows for a significant economy in computation time and memory, while the \(A = USV^\dagger \) relation remains true.
2.5 Notes on unitary matrix
Unitary matrices are omnipresent in the quantum domain. As a reminder, an \(n\times n\) matrix A is said to be "unitary" when
If a matrix is unitary, all its eigenvalues lie on the unit circle and all its eigenspaces are orthogonal. Those eigenvalues and eigenvectors are either real or come in conjugate pairs of complex numbers.
If A is a unitary matrix such as \(A^2 = I_n\), then all its eigenvalues are \({\pm } 1\). The dimensions of its eigenspaces are:
where \(E_+^A\) is the eigenspace associated with \(+1\) and \(E_-^A\) to \(-1\). Furthermore, if \(A^2 = I_n\), we can express the projector onto \(E_{\pm }^A\) as
2.6 Indexation and signatures
In this paper, we will often use the binary word associated with an index. We always use a Latin character to denote the index and a Greek one to denote its binary equivalent. For instance, if \(p=3\), then \(\rho =110\). Sometimes, we will use those binary indices as vectors. In such cases, we will use a ket to denote them, such as \(| \rho \rangle \).
In order to simplify several proofs, we will also label elements (rows, columns, diagonal values) with the Hamming weight w of their binary indices. For example, if \(N = 8\), the indices are 000, 100, 010, 110, 001, 101, 011, 111, and their respective weights are 0, 1, 1, 2, 1, 2, 2, 3.
When working with \(N_e\times N_e\) matrices, we will attribute a \({\pm } 1\) signature \(\sigma \) to each row or column. We split the \(N_e\) elements in N intervals of size n. The n signatures in the p-th interval are defined from the n-bit binary representation of p, where bits 0 are mapped to \(\sigma = +1\), and 1 to \(\sigma = -1\). For example, with \(n = 3\), an \(N_e\times N_e\) matrix has \(N = 8\) blocks of 3 elements. In the case of the first block, \(p=0\) and its binary representation is 000. Therefore, the three first rows or columns have a signature \(\sigma = +1\). In the second block, the position binary representation is 100 and the fourth element has a signature \(\sigma = -1\), while the fifth and the sixth have a signature \(\sigma = +1\). This apparently arbitrary definition will naturally emerge in Sect. 2.1.
2.7 Useful submatrices
Throughout this paper, we will use submatrices of \(H_N\):
-
\(H_N^s\) is the \(N\times M\) matrix obtained by keeping only the column of \(H_N\) associated with the solutions.
-
\(H_N^{s, w}\) is the \(\left( {\begin{array}{c}n\\ w\end{array}}\right) \times M\) matrix obtained by keeping only the rows of \(H_N^s\) whose indices have a Hamming weight of w.
-
We define \(I_N^s\) and \(I_N^{s, w}\) in the same manner from the \(N\times N\) identity matrix.
-
We define the \(N\times (N-M)\) matrix \(I_N^{\bar{s}}\) in a similar way to \(I_N^s\), but by keeping only the columns of \(I_N\) associated to the non-solutions.
-
\(\bar{H}_N^w\) is the \(\left( {\begin{array}{c}n\\ w\end{array}}\right) \times N\) matrix obtained by keeping only the rows of \(\bar{H}_N\) whose indices have a Hamming weight of w
3 Operators and their eigenspaces
3.1 The shift operator
The shift operator S represents a position shift controlled by the quantum coin. Along the d-th dimension, the shift operator permutes the values associated with adjacent vertices. It follows that along direction d it is simply the operator X. For each of the n dimensions, we can create an \(N\times N\) operator \(S_d\) that only affects the d-th dimension in \(\mathcal {H^S}\):
From this, we can find the shift operator in the \(\mathcal {H^C}\otimes \mathcal {H^S}\): it is a block diagonal matrix we denote \(S^{\mathcal{C}\mathcal{S}}\), where each of its blocks is a \(S_d\). We can identify the n \(S_d\) blocks in Fig. .

The shift operator \(S^{\mathcal{C}\mathcal{S}}\) in \(\mathcal {H^C}\otimes \mathcal {H^S}\) for \(n=3\). The \(S_d\) blocks are delimited by the dashed lines
We can show that the \(S_d\) are diagonalized by \(H_N\). If we define \(\hat{S}_d = H_NS_dH_N\), we have
\(\hat{S}_d\) is therefore diagonal because \(H^2 = I\) and HXH is diagonal (HXH is the Pauli Z matrix):

As a consequence, the diagonalized operator in \(\mathcal {H^C}\otimes \mathcal {H^S}\), denoted \(\hat{S}^{\mathcal{C}\mathcal{S}}\), is composed of n diagonal submatrices \(\hat{S}_d\). We note that each \(\hat{S}_d\) matrix is made up of \(2^{n-d}\) repetitions of a block made of \(2^{d-1}\) ’+1’ followed by \(2^{d-1}\) ’-1’, as seen in Fig. . The relation between the shift operator and its diagonalized version in \(\mathcal {H^C}\otimes \mathcal {H^S}\) is

The diagonalized shift operator \(\hat{S}^{\mathcal{C}\mathcal{S}}\) in \(\mathcal {H^C}\otimes \mathcal {H^S}\) for \(n=3\). The \(\hat{S}_d\) blocks are delimited by the dashed lines
The shift operator has a simple block diagonal structure in \(\mathcal {H^C}\otimes \mathcal {H^S}\), but we need to get its representation in \(\mathcal {H^S}\otimes \mathcal {H^C}\), that we denote S. We will use the permutation matrices seen in Sect. 1.2 to obtain S. Let us note \(P = P_{N, n}\). We have

The shift operator S in \(\mathcal {H^S}\otimes \mathcal {H^C}\) for \(n=3\)
As we can see in Fig. , the shift operator is more complex in \(\mathcal {H^S}\otimes \mathcal {H^C}\). However, it is the opposite for the coin operator, which is block diagonal in \(\mathcal {H^S}\otimes \mathcal {H^C}\) but not in \(\mathcal {H^C}\otimes \mathcal {H^S}\). We arbitrarily choose to study the operators in \(\mathcal {H^S}\otimes \mathcal {H^C}\), as this space is the most commonly used in quantum walk studies.
In order to study the eigendecomposition of S, we need to diagonalize it. Note that \(P^{\text{ T }}P = I_{N_e}\). We have
As \(\hat{S}^{\mathcal{C}\mathcal{S}}\) is diagonal, \(P\hat{S}^{\mathcal{C}\mathcal{S}}P^{\text{ T }}\) is diagonal too (that is true for any permutation matrix). Therefore, F diagonalizes S and we can denote \(P\hat{S}^{\mathcal{C}\mathcal{S}}P^{\text{ T }}\) by \(\hat{S}\).

The diagonalized shift operator \(\hat{S}\) in \(\mathcal {H^S}\otimes \mathcal {H^C}\) for \(n=3\). The \(\hat{S}(p)\) blocks are delimited by the dashed lines
The structure of \(\hat{S}\) is remarkable: if we map the \(+1\) to 0 and the \(-1\) to 1, we find along its diagonal all the possible n-bit words in ascending order, as seen in Fig. . We also observe that those values are equivalent to the signatures \(\sigma \) defined in Sect. 1.6. We deduce that the eigenvectors of S are the columns of F and that they are associated with \(\lambda _S = {\pm } 1\) eigenvalues. Using Equation (1.16), we can determine that the eigenspaces associated with both eigenvalues have the same dimension:
We set \(\hat{S}(p)\) to be the \(n\times n\) block indexed by p. A quick way to find \(\hat{S}(p)\) is to map the binary elements of \(\rho \), the binary representation of p, to \(+1/-1\) as noted before, then to place those elements on the diagonal.
3.2 The coin operator
The coin operator C is a uniform diffusion operator in \(\mathcal {H^C}\). Its structure is based on the \(n\times n\) Grover diffusion operator G defined by
The coin operator only affects \(\mathcal {H^C}\). Therefore, its representation in \(\mathcal {H^S}\otimes \mathcal {H^C}\) is \(C = I_N\otimes G\), which gives a block diagonal matrix as seen in Fig. .

The coin operator in \(\mathcal {H^S}\otimes \mathcal {H^C}\) for \(n=3\)
The eigendecompositions of G and C are easily linked. Let us denote those decompositions \(G = V_GD_GV_G^\dagger \) and \(C = V_CD_CV_C^\dagger \). Then,
and so \(V_C = I_N\otimes V_G\) and \(D_C = I_N\otimes D_G\).
Observe that \(G| u \rangle = | u \rangle \), therefore \(| u \rangle \) is an eigenvector of G associated with the eigenvalue \(+1\). Also, \(G\Lambda = -\Lambda \) (the \(n\times (n-1)\) matrix \(\Lambda \) is defined in Sect. 1.1 as the kernel of \(\langle u |\)); therefore, the \(n-1\) columns of \(\Lambda \) are all eigenvectors associated with the eigenvalue \(-1\). The dimensions of the eigenspaces of G are \(\hbox {dim}\,E^G_{+1} = 1\) and \(\hbox {dim}\,E^G_{-1} = n-1\), and so the dimensions of the eigenspaces of C are:
A useful observation is that C is invariant under the Fourier transform. We have
3.3 The oracle
The oracle O is the core of the quantum search algorithm. Its structure varies according to the number of solutions and their positions on the hypercube. The easiest way to design the oracle operator is to create a diagonal matrix with \(-1\) at the solution positions and \(+1\) elsewhere, but we use another structure which gives a smaller eigenspace \(E^O_-\). As the problem is to find the correct positions on the hypercube, all directions associated with a same vertex are equally valid. Therefore, the solutions always come in groups of n in \(\mathcal {H^S}\otimes \mathcal {H^C}\) if we work with a block diagonal oracle. If an \(n\times n\) block corresponds to a group of solutions, it is set to \(-G\), where G is the Grover diffusion operator defined in Sect. 2.2. Else, the block is set to \(I_n\). An example of oracle for a \(n = 3\) qubit problem with solutions at position \(p = 3\) and \(p = 6\) is given in Fig. . In this example, the Grover diffusion operator is

We can see that the \(M = 2\) blocks corresponding to the solutions in position \(p=3\) and \(p=6\) are set to \(-G\), and that the \(N-M = 6\) others are set to I.

The oracle for \(n=3\) with solutions at positions 3 and 6. The blocks corresponding to the \(N = 8\) outputs are delimited by the dashed lines
As we already know the eigendecomposition of G, we can immediately deduce the dimensions of the oracle eigenspaces and their eigenvalues:
The eigenvectors associated with \(-1\) are \(| 1_p \rangle \otimes | u_n \rangle \), where p is the position of a solution. It is interesting to note that \(E^O_{-}\) is the subspace of the solution space \(E^s\) corresponding to the solutions uniformly spread out in all directions and that \(E^O_{+}\) is, therefore, the union of the non-solution space \(E^{\bar{s}}\) and the non-uniformly spread out solutions. Note that O and C commute, as they are both block diagonal with only I and \({\pm } G\) as possible blocks. Also, \(G^2 = I_n\) so \(O^2 = I_{N_E}\).
4 Generators
In this section, we will build "generators", matrices which will be useful in what follows. We define the first three generators as:
where \(I_N^s\) and \(I_N^{\bar{s}}\) are submatrices defined in Sect. 1.7.
These matrices have orthonormal columns and taken globally; they constitute an orthonormal basis of \(\mathcal {H}\). We will see in the next section that they generate subspaces which are closely related to the eigenspaces of the quantum walk operators. Their sizes are, respectively, \(N_e\times M\), \(N_e\times (N-M)\) and \(N_e\times (N_e - N)\). Their horizontal concatenation forms a unitary \(N_e\times N_e \) matrix \(L_{1,2,3}\) shown in Fig. . We will also use \(L_{1, 2}\) the horizontal concatenation of \(L_1\) and \(L_2\).

The generators concatenation \(L_{1, 2, 3}\) for \(n=3\) with solutions at positions 2 and 5. The generators are delimited by the dashed lines
We can show that \(L_{1, 2}\) and \(L_3\) span the same subspaces in the Fourier domain as in the original domain: we have \(FL_3 = H_N\otimes \Lambda \). Since we can multiply on the right by any non-singular matrix without changing the spanned subspace, we can multiply by \(H_N\otimes I_n\) and recover \(L_3\) once more. Therefore,
The proof for \(L_{1, 2}\) is done the same way by replacing \(\Lambda \) by \(| u \rangle \).
It is possible to create a variation of \(L_3\) with most of its columns eigenvectors of \(\hat{S}\). This variation will be denoted \(L_3'\). To do so, we will replace each block individually by a custom block \(\Lambda _p\). Those blocks all span the same subspace as \(\Lambda \), as all their columns are orthogonal to \(| u_n \rangle \). That means \(L_3'\) spans the same subspace as \(L_3\). Each \(\Lambda _p\) is itself the concatenation of three matrices, \(\Lambda _p^+\), \(\Lambda _p^-\) and \(\Lambda _p^{\circ }\), whose sizes depends on the Hamming weight w of the binary representation of the p indices:
-
\(\Lambda _p^-\) is an \(n\times (w-1)\) matrix (or an empty matrix if \(w\le 1\)). It has nonzero elements only at the w rows with signature \(\sigma = -1\). Therefore, its columns are eigenvectors of \(\hat{S}\) associated with the eigenvalue \(-1\). Those elements form \(w-1\) vectors of length w all orthogonal to \(| u_{w} \rangle \) and to each other.
-
\(\Lambda _p^+\) is an \(n\times (n-w-1)\) matrix (or an empty matrix if \(n-w\le 1\)). It has nonzero elements only at the \(n-w\) rows with signature \(\sigma = +1\). Therefore, its columns are eigenvectors of \(\hat{S}\) associated with the eigenvalue \(+1\). Those elements form \(n-w-1\) vectors of length \(n-w\) all orthogonal to \(| u_{n-w} \rangle \) and to each other.
-
\(\Lambda _p^{\circ }\) is a column vector if \(w\ne 0\) and \(w\ne n\), and otherwise is empty. Its elements are
$$\begin{aligned} \sqrt{(n-w)/(nw)}&\text { where } \sigma = -1,\end{aligned}$$(3.5)$$\begin{aligned} -\sqrt{k/(n(n-w))}&\text { where } \sigma = +1. \end{aligned}$$(3.6)This column is not an eigenvector of \(\hat{S}\), which is to be expected considering all of them are either in \(\Lambda _p^-\) or \(\Lambda _p^+\).
The resulting matrix \(L_3'\) is shown in Fig. .

Generator \(L_3'\) for \(n=3\)
We define \(L_3'^-\), \(L_3'^+\) and \(L_3'^\circ \) as the submatrices of \(L_3'\) that are made up of the columns corresponding, respectively, to the \(\Lambda _p^-\), \(\Lambda _p^+\) and \(\Lambda _p^\circ \). The size of \(L_3'^-\) and \(L_3'^+\) is \(N_e\times (N_e/2 - N + 1)\), and the size of \(L_3'^\circ \) is \(N_e\times (N-2)\).
We also define the two generators \(F^+\) and \(F^-\) as the submatrices of F that correspond, respectively, to the columns with signature \(\sigma = +1\) and \(\sigma = -1\). Both have size \(N_e\times N_e/2\).
Finally, we define \(| l_- \rangle \) as the Fourier transform of the column of \(L_{1, 2}\), which has all of its nonzero elements having a signature \(\sigma = -1\), that is \(| 1_{N-1} \rangle \otimes | u_n \rangle \). Therefore,
where \(| 1_{N-1} \rangle \) is a vector having a 1 at the position \(N-1\) and 0 elsewhere, as defined in Sect. 1.1.
5 Eigenspaces junctions
In this section, we propose an exhaustive analysis of the joint eigenspaces of the quantum walk operators S, C and O in order to study the eigendecompositions of U and Q. All these results can be found in Table . While some proofs are trivial, others are quite tedious and the reader may skip these and proceed without difficulty from the results in the table.
We already determined the dimension of the eigenspaces of the three elementary operators, and we can easily find that they are all spanned by one of the generators defined in Sect. 3. For instance, \(E^O_- = \text {span}\left\{ L_1\right\} \) and \(E^C_+ = \text {span}\left\{ L_{1,2}\right\} \).
In the study of the joint eigenspaces, some cases are easily resolved. For instance, we have
Some of the joint eigenspaces do not appear in the table because they are empty:
A useful step for what follows is to work with the operator CO. It is straightforward because C and O commute, which means they share the same eigenspaces. Therefore, we have
and
because \(E^{C, O}_{-,-}=\emptyset \).
We begin the analysis of the joint eigenspaces of S and C with the observation that C is invariant under the Fourier transform, as seen in Sect. 2.2, which means we can search for \(E^{\hat{S}, C}_{{\pm },{\pm }}\) then switch back to the original domain. We have also seen that a vector is in \(E_{\pm }^{\hat{S}}\) if it has nonzero elements only in positions with signature \({\pm }1\). Since \(E^C_- = \text {span}\left\{ L_3\right\} = \text {span}\left\{ L_3'\right\} \), we have
and so,
Therefore, the dimension of \(E^{S,C}_{{\pm }-}\) is:
The next step is to note that \(E^C_+ = \text {span}\left\{ L_{1, 2}\right\} \) and that \(\text {span}\left\{ L_{1, 2}\right\} = F\text {span}\left\{ L_{1, 2}\right\} \). There is only one column of \(L_{1, 2}\) in \(E_-^{\hat{S}}\), the one that has all its elements with signature \(-1\). We defined its Fourier transform as \(| l_- \rangle \) above. Similarly the only column of \(L_{1, 2}\) in \(E_+^{\hat{S}}\) is the one that has nonzero elements only in positions with signature \(+1\). The Fourier transform of such a column is always the uniform vector \(| u \rangle \).
Obviously, they both have dimension 1.
The only eigenspace that C and O share together that intersects \(E^S_{\pm }\) is \(\text {span}\left\{ L_3\right\} \). We have
Therefore, \(E^{S,C,O}_{{\pm },-,+}\) is equal to \(E^{S,C}_{{\pm }-}\), while all other joint eigenspaces of S, C and O are empty.
We note that \(E^{S,CO}_{+,-}\) includes \(E^{S,C,O}_{+,-,+} = E^{S,C}_{+,-}\), which is spanned by \(FL_3'^+\). We will create eigenvectors that span the complement of \(E^{S,C}_{+,-}\) in \(E^{S,CO}_{+,-}\). In the Fourier domain, \(L_3'^+\) spans \(E^{S,C}_{+,-}\) and \(L_3'^-\) is orthogonal to \(E^{S}_+\). Then, we will build those eigenvectors \(| \varepsilon \rangle \) as linear combinations of the columns of \(FL_1\) and \(F_3'^\circ \). We have
where \(| \varepsilon _1 \rangle \) and \(| \varepsilon _3 \rangle \) are vectors of length M and \(N-2\). We also observe that the first and last rows of \(F_3'^\circ \) are zero because there is no \(\Lambda _p^\circ \) for \(p = 0\) and \(p = N-1\) and because
In order to obtain \(| \varepsilon \rangle \) in \(E^{\hat{S}}_+\), we must cancel the elements with signature \(-1\). All possible \(| \varepsilon \rangle \) have to cancel the last block because all its elements always have signature \(-1\). Since, as already noted, \(L_3'^\circ \) is already zero in this block, we only have to cancel the \(| \varepsilon _1 \rangle \) component. Let us define \(\langle h |\) as the last row of \(H^s_N\). We have
where \(w_k\) is the weight of the binary index of the k-th solution. We must have \(\langle h|\varepsilon _1\rangle = 0\). Since \(\langle h |\) is a M length vector, we can find \(M-1\) orthogonal \(| \varepsilon _1 \rangle \). We also can show that if \(| \varepsilon _1 \rangle \) is known, then we can determine a unique \(| \varepsilon _3 \rangle \). Let us consider any column \(\Lambda _p^\circ \) of \(L_3'^\circ \). Inside each block p, the positions with signature \(-1\) contain \(\sqrt{(n-w)/(nw)}\) and \(FL_1| \varepsilon _1 \rangle \) contains a value indexed by p of \((H_N^s| \varepsilon _1 \rangle )/\sqrt{n}\), denoted \((H_N^s| \varepsilon _1 \rangle )_p/\sqrt{n}\). Then, the part of \(| \varepsilon _3 \rangle \) associated with block p guarantees:
Therefore,
We can deduce that the dimension of the complement of \(E^{S,C}_{-,-}\) in \(E^{S,CO}_{-,-}\) is \(M-1\), and since \(\hbox {dim}\, E^{S,C}_{-,-} = N_e/2 - N + 1\), we have
The proof is similar for \(E^{S,CO}_{+,-}\). In that case, we define \(\langle h |\) as the first row of \(H_N^s\), that is \(\langle u |\).
We can also see that \(E^{S,CO}_{+,-}\) includes \(E^{S,C,O}_{+,-,+} = E^{S,C}_{+,-}\), which is spanned by \(FL_3'^+\)
6 Eigendecomposition of the uniform walk operator
In this section, we will determine the total eigendecomposition of the uniform walk operator U. As in the last section, the reader can refer to Table for a summary of the results.
The uniform walk operator is \(U = SC\); therefore, we have
which implies:
As illustrated in Fig. , the structure of U is complicated and turns out to be much simple in the Fourier domain:

The uniform walk operator for \(n=3\)
We can see that \(\hat{U}\) is a block diagonal matrix containing N blocks \(\hat{U}_p\) such as
where \(\hat{S}(p)\) is the block of \(\hat{S}\) associated with p defined in Sect. 2.1, and G the Grover diffusion operator defined in Sect. 2.2. The diagonal of each \(\hat{S}(p)\) accounts for \(n-w\) times ’\(+1\)’ and w times ’\(-1\)’.
The only coefficient of the diagonal of G is \(-1+2/n\); therefore, the trace of each \(\hat{U}_p\) is
For any matrix, the sum of its eigenvalues is equal to the trace, and we already know that when \(p\ne 0\) and \(p\ne N-1\), there are \((n-w-1)\) ’\(-1\)’ eigenvalues and \((w-1)\) ’\(+1\)’ eigenvalues. The sum of these \(n-2\) eigenvalues is therefore \(-n+2w\), and there are still two eigenvalues left to determine, which we will denote by \(\lambda _{w}\) and \(\lambda ^*_{w}\). Their sum must be \(2(1-2(w/n))\), which means:
Since U is unitary, so are the \(\hat{U}_p\) and \(| \lambda _{w} |=1\). Thus,
Note that \(\lambda _{w}\) and \(\lambda _{w}^*\) are complex conjugate eigenvalues. The choice of which one is \(\lambda _{w}\) is arbitrary.
We define the vector \(| v_{w} \rangle \) by:
where \(| \rho \rangle \) and \(| \bar{\rho } \rangle \) are the vectors containing the binary representation of the block index and its negation. We will prove that \(| v_{w} \rangle \) is an eigenvector of \(\hat{U}_p\) associated with the eigenvalue \(\lambda _{w}\). Note that
since it is the sum of all terms in \(| v_{w} \rangle \) divided by \(\sqrt{n}\). We also have
and
We deduce that
Thus, \(| v_{w} \rangle \) and \(| v_{w} \rangle ^*\) constitute \(2(N-2)\) eigenvectors. Taking into consideration the \(2(N_e/2 - N + 2)\) already known from \(E^{S,C}_{{\pm },{\pm }}\), this accounts for all of them. Since none of the \(2(N-2)\) new eigenvectors are associated with an eigenvalue \({\pm } 1\), we have
which implies
We can also determine the size of each \(E^U_{\lambda _{w}}\), as there are \(\left( {\begin{array}{c}n\\ w\end{array}}\right) \) positions whose binary index weight is w. We have
To summarize, we can list the eigenvectors of U in the Fourier domain, i.e., the eigenvectors of \(\hat{U}\):
-
The orthonormal basis of \(E^{\hat{U}}_-\) is composed of:
-
The \(N_e/2 - N + 1\) columns \(L_3'^+\).
-
The column of \(L_{1, 2}\) \(| 1_{N-1} \rangle \otimes | u_n \rangle \).
-
-
The orthonormal basis of \(E^{\hat{U}}_+\) is composed of:
-
The \(N_e/2 - N + 1\) columns \(L_3'^-\).
-
The column of \(L_{1, 2}\) \(| 1_{0} \rangle \otimes | u_n \rangle \).
-
-
The orthonormal basis of \(E^{\hat{U}}_{\lambda _{w}}\) is composed of the \(\left( {\begin{array}{c}n\\ w\end{array}}\right) \) vectors \(| 1_p \rangle \otimes | v_{w} \rangle \).
-
The orthonormal basis of \(E^{\hat{U}}_{\lambda _{w}^*}\) is composed of the \(\left( {\begin{array}{c}n\\ w\end{array}}\right) \) vectors \(| 1_p \rangle \otimes | v_{w} \rangle ^*\) for all p whose binary representation Hamming weight is w.
If needed, the eigenvectors of U can easily be deduced from those of \(\hat{U}\) using a multiplication by F to switch back to the original domain. We define two new conjugate generators \(V_{w}\) and \(V_{w}^*\) that span, respectively, \(E^{\hat{U}}_{\lambda _{w}}\) and \(E^{\hat{U}}_{\lambda _{w}^*}\). Their respective columns are \(F| 1_p \rangle \otimes | v_{w} \rangle \) and \(F| 1_p \rangle \otimes | v_{w} \rangle ^*\).
7 Dimension of the complement space
As explained in the introduction, the purpose of the eigenspaces study is to determine the dimension of \(\mathcal {E}\) and the eigenvalues of the effective quantum walk operator Q associated with it. Since \(Q = UO\), it has a complicated structure in both original and Fourier domains, and we will need to use results from previous sections. Its structure in the original domain is shown in Fig. . Once again, we will summarize the results in Table at the end of this section.

The effective walk operator for \(n=3\) with solutions at positions 3 and 6
Let us start by demonstrating that \(E^{U,O}_{\lambda ,-} = \emptyset \) for any \(\lambda \). We know that \(E^O_-\subset E^C_+\), so
Furthermore, since \(U = SC\), \(E^{U,C}_{\lambda ,+} = E^{S,C}_{\lambda ,+}\), and
which means that \(\lambda = {\pm } 1\), since S does not have other eigenvalue. Therefore,
and so
Since both \(| l_- \rangle \) and \(| u \rangle \) contain only nonzero elements, they are not in \(\text {span}\left\{ L_1\right\} = E^O_-\) and finally
Let us now consider \(E^{U,O}_{{\pm },+}\). We saw that
and
We can show that \(| u \rangle \) and \(| l_- \rangle \) are not in \(E^O_+\) for the same reason as they are not in \(E^O_-\). Furthermore, \(\text {span}\left\{ FL_3'^+\right\} \subset \text {span}\left\{ L_3\right\} \), and since \(E^O_+ = \text {span}\left\{ L_{2,3}\right\} \),
and
A secondary but important result is that both \(E^{S,C}_{-,+}\) and \(E^{S,C}_{-,+}\) are in \(\mathcal {E}\), as they have no intersection with any eigenspace of O. That means \(| u_{N_e} \rangle \) is in \(\mathcal {E}\), and any quantum walk initialized in this state will remain in \(\mathcal {E}\).
Note that \(E^O_+ = \text {span}\left\{ L_{2,3}\right\} = \ker \left\{ L_1^{\text{ T }}\right\} \). Denote by \(\hat{O}\) the Fourier transform of O. Then,
and
where \(H_N^s\) is the submatrix defined in Sect. 1.7. It now follows that
In the Fourier domain, \(E^{\hat{U}}_{\lambda _w} = \text {span}\left\{ V_w\right\} \), where \(V_w\) is the generator defined in Sect. 5. We have
Since \(V_w\) is an \(N_e\times \left( {\begin{array}{c}n\\ w\end{array}}\right) \) matrix, each unit vector of \(\text {span}\{V_w\}\) can be expressed as \(V_w| \nu \rangle \), where \(| \nu \rangle \) is a unit vector of length \(\left( {\begin{array}{c}n\\ w\end{array}}\right) \). If in addition
such a vector also belongs to \(E^{\hat{O}}_+\), which means \(| \nu \rangle \) must be orthogonal with all of the \(\left( {H_N^s}^{\text{ T }}\otimes \langle u_n | \right) V_w\) columns. These columns are:
We identify here \({H_N^s}^{\text{ T }}| 1_p \rangle \) as the column of \({H_N^s}^{\text{ T }}\) indexed by p and \(\langle u_n|v_w\rangle \) as a scalar value that we will denote by \(\alpha _w\). We have
which means
Since \(\alpha _w \ne 0\) for any w, we have
that is
and finally
In the following, we will denote \({{\,\textrm{rank}\,}}\left\{ H_N^{s,w}\right\} \) by \(r_w\). The same proof applies to \(V_w^*\), so
We now have everything we need to determine the dimension of \(\mathcal {\overline{E}}\) and \(\mathcal {E}\). We recall that
where \(\lambda _u\) and \(\lambda _o\) are the eigenvalues of U and O. Therefore,
Since \(\sum _{w=0}^n\left( {\begin{array}{c}n\\ w\end{array}}\right) = 2^n\), we have:
and finally
We also know that \(\mathcal {\overline{E}}\subseteq E^O_+\), so
Then, because \(1\le r_w\le \min (M, \left( {\begin{array}{c}n\\ w\end{array}}\right) )\), we have:
We have shown that even if the dimension of the total space \(\mathcal {H}\) increases exponentially with n, the dimension of \(\mathcal {E}\) only grows linearly. For instance, for \(n=50\) and \(M=4\), \(\hbox {dim}\,\mathcal {H}\approx 5.6\times 10^{16}\) while \(\hbox {dim}\, \mathcal {E}\le 394\). This result does not imply that the quantum search algorithm can be run on a classical computer, but it allows us to compute efficiently the evolution of the probability of success.
8 Computation of the probability of success
8.1 Eigenvalues of the eigenspace of interest
Recall that \(| u \rangle \) is the uniform state (\(N_e\) dimensional in this case), \(| s \rangle \) is the uniform superposition of all solutions and \(| \bar{s} \rangle \) is the uniform superposition of all non-solutions. In the last section, we have established an upper bound on the dimension of \(\mathcal {E}\) and shown that it includes \(| u \rangle \) and \(| l_- \rangle \). Since \(E^O_-\subset \mathcal {E}\) and \(E^O_- = \text {span}\left\{ L_1\right\} \), we know that \(| s \rangle \subset \mathcal {E}\). Then,
so \(| \bar{s} \rangle \) is a linear combination of \(| u \rangle \) and \(| s \rangle \) and is in \(\mathcal {E}\) too. We also noted that if the initial state is in \(\mathcal {E}\), then it will remain in \(\mathcal {E}\) during the algorithm. We will therefore initiate with \(| u \rangle \).
The goal of this section is to determine the eigenvalues of Q associated with \(\mathcal {E}\), as well as the components of \(| u \rangle \) and \(| s \rangle \) in this subspace. Then, we will see that it is easy to compute the probability of success for any number of iterations t.
If we use an orthonormal basis of eigenvectors of Q, we can represent the component of Q in \(\mathcal {E}\) as a \(\hbox {dim}\,\mathcal {E}\times \hbox {dim}\,\mathcal {E}\) diagonal operator \(Q_\mathcal {E}\), whose diagonal elements are its eigenvalues. If we denote those eigenvalues by \(\textrm{e}^{\textrm{i}\varphi _k}\), the components of the state after t iterations are:
and the probability of success
where the terms \(\psi _t(k,l)\), u(k, l) and s(k, l) are the respective components of \(| \psi _t \rangle \), \(| u \rangle \) and \(| s \rangle \) in the eigenspace associated with \(\textrm{e}^{\textrm{i}\varphi _k}\), and the parameter l allows us to distinguish the components of a given eigenspace whose dimension is greater than 1. We also define \(| u(k) \rangle \) and \(| s(k) \rangle \) the vectors made of all u(k, l) and s(k, l) for a given k. The length of those vectors is the multiplicity of the \(\textrm{e}^{\textrm{i}\varphi _k}\) eigenvalue.
Since \(E^{CO}_- \cup E^{CO}_+ = \mathcal {H}\), any eigenvector \(| \varepsilon \rangle \) in \(\mathcal {E}\) can be represented as the sum of two vectors belonging to \(E^{CO}_-\) and \(E^{CO}_+\):
Let us denote \(\lambda = \textrm{e}^{\textrm{i}\varphi }\) an eigenvalue of Q. We have
and
Therefore,
Since \(S^2 = I\), we have
Let us denote \(P_{\pm }^S\) the projectors onto \(E_{\pm }^S\). As seen in Sect. 1.5, if \(S^2 = I\), then \(P_{\pm }^S = (I{\pm } S)/2\). From the two last equations, we have
that is
Suppose \(\lambda \ne {\pm } 1\), the particular cases will be treated later. Since \(\lambda = \textrm{e}^{\textrm{i}\varphi }\), we have
Then,
Because \(P^S_+ + P^S_- = I\), we can sum these two equations to obtain
and conversely
Let us denote by \(\hat{P}^S_+\) the Fourier transform of \(P^S_+\). From the study of the eigenspaces of S in Sect. 2.1, we know that \(\hat{P}^S_+\) is a diagonal matrix which contains 1 at the positions with signature \(+1\) and 0 elsewhere. In the same way, we define \(\hat{P}^S_-\) the diagonal matrix which contains 1 at the positions with signature \(-1\) and 0 elsewhere. Define
so that
where \(| {\hat{\varepsilon }_+} \rangle \) and \(| {\hat{\varepsilon }_-} \rangle \) are the Fourier transforms of \(| {\varepsilon _+} \rangle \) and \(| {\varepsilon _-} \rangle \).
We have
but since \(FL_3'^{\pm }\) span eigenspaces orthogonal to \(\mathcal {E}\), we can restrict ourselves to \(FL_3'^\circ \) instead of \(L_3\). Then,
Using the definitions of the generators in Eqs. (3.1) and (3.2), we have
Define the vectors
Note that \(FL_3'^\circ | \varepsilon _3 \rangle \) is a vector whose per block average value is zero, therefore
We can decompose \(\hat{\Gamma }_\varphi ^{-1}\) as
where \(\hat{D}_\varphi ^{-1}\) is a diagonal matrix whose diagonal elements are the per block average values of the diagonal of \(\Gamma _\varphi ^{-1}\)
\(w_p\) is the Hamming weight of the binary representation of p and \(\Upsilon _\varphi \) is another diagonal matrix whose per block average is zero. Let \(| \hat{e}_{\pm } \rangle \) be the Fourier transform of \(| e_{\pm } \rangle \). By using Equation (7.22), we have
because \(\Upsilon _\varphi \left( | \hat{e}_+ \rangle \otimes | u_n \rangle \right) = 0\). Notice that
If the diagonal of \(\hat{D}_\varphi ^{-1}\) has no zero element (this case will be treated later), we have
were \(\hat{D}_\varphi \) is a diagonal matrix whose elements are
Since they only depend on \(w_p\), the elements of \(\hat{D}_\varphi \) and its inverse can be indexed by the Hamming weight of their binary indices only. We will denote those elements \(\hat{D}_\varphi (w_p)\).
Back to the original domain, we have
so
Define \(D_\varphi ^s\) to be the \(M\times M\) submatrix of \(D_\varphi \) that contains only the rows and columns associated with a solution. Then,
It is always the case that
which implies
This inequality can easily be tested using the singular value decomposition of \(D_\varphi ^s\): at least one of its singular values must be zero. Eigenvalues \(\varphi _k\) come in conjugate pairs where one of each pair has its argument in \([0, \pi [\). As a consequence, we can decompose \(D_\theta ^s\) for multiple values of \(\theta \) between 0 and \(\pi \) until we find all the eigenvalues of Q associated with eigenvectors in \(\mathcal {E}\), provided that \(D_\theta ^s\) computation is not too complex. The dimension of the kernel gives us the multiplicity of the eigenvalue \(\textrm{e}^{\textrm{i}\varphi _k}\). It is possible to halve the duration of the eigenvalue search by noticing that
and that
Therefore, it is possible to restrain the search to the \([0, \pi /2]\) span.
8.2 Efficient computation of the criterion
The direct computation of \(D_\theta ^s\) becomes impossible on a classical computer if n is big, as it involves a \(2^n\times 2^n\) matrix. However, we have
Let us define \(\Xi _{w_p}\) as the matrix product \({H_N^{s,{w_p}}}^{\text{ T }}H_N^{s,{w_p}}\). We have
We will see that \(\Xi _{w_p}\) can be efficiently computed without the need of \(H_N^s\). Let us note a the position of a given solution, \(\alpha \) its binary representation, and \(| h_{a} \rangle \) the corresponding column in \(\bar{H}_N^{w_p}\), the unnormalized Hadamard matrix restricted to the rows whose indices have a Hamming weight of \(w_p\) defined in Sect. 1.7. The elements of \(\Xi _w\) are
The unnormalized Hadamard matrix has an interesting property about its values:
where \(\alpha \) and \(\beta \) are the binary representation of a and b. Therefore,
where \(a\oplus b\) is the position whose binary index is \(\alpha \oplus \beta \). Thus,
Denote by \(\eta _m(w_p)\) the sum of all elements of \(h_m\) whose weight is \(w_p\).
The elements of the sum are \(+1\) when \(\langle \rho |\mu \rangle \) is even, which happens when \(\rho \) contains an even number of 1 inside the \(w_m\) positions corresponding to 1 in \(\mu \) (the Hamming weight of \(\mu \) is \(w_m\)). Denote this number by 2l. There are \(\left( {\begin{array}{c}w_m\\ 2l\end{array}}\right) \) possible placements for these 1, and \(\left( {\begin{array}{c}n-w_m\\ w_p-2l\end{array}}\right) \) for the \(w_p-2l\) remaining 1. The total number of \(+1\) in the previous sum is then
for all values of l for which the binomial coefficient exists, that is
Since the number of indices associated with \(w_p\) is \(\left( {\begin{array}{c}n\\ w_p\end{array}}\right) \), we have \(\left( {\begin{array}{c}n\\ w_p\end{array}}\right) - \zeta _m(w_p)\) times \(-1\) in the sum and
so
If \(m=0\), we have \(\left( {\begin{array}{c}0\\ 0\end{array}}\right) = 1\) and \(\eta _0(w_p) = \left( {\begin{array}{c}n\\ w_p\end{array}}\right) \).
Note that \(\eta _m(w_p)\) does not depend on m but on \(w_m\), which allows us to compute it for several solutions at the same time. Therefore, we can denote it by \(\eta (w_p, w_m)\). Finally
Thanks to this result, it is possible to compute \(D_\theta ^s\), and therefore the criterion, in a polynomial time with a classical computer.
8.3 Components of the key vectors in the eigenspace of interest
8.3.1 Regular cases
In order to compute the probability of success, we need to compute the components of \(| u \rangle \) and \(| s \rangle \) in \(\mathcal {E}\). Once the eigenvalues \(\lambda _k = \textrm{e}^{\textrm{i}\varphi _k}\) are determined, we can compute the vectors \(| \varepsilon _1 \rangle \) in the eigenspace associated with each \(\lambda _k\) with Equation (7.42). For a given eigenvalue \(\lambda = \textrm{e}^{\textrm{i}\varphi }\)
We also have
so


and


where
Recall that \(\langle e_+|u_N\rangle \) is equal to the average value of \(\langle e_+ |\) and that the first term of a Fourier transform is the average value of the transformed vector, therefore,
and then
We now have the components of \(| s \rangle \) and \(| u \rangle \) in \(\mathcal {E}\) for each \(| \varepsilon _1 \rangle \) associated with each eigenvalue \(\lambda _k\):
Note that we use the notations \(s^\prime (k, l)\) and \(u^\prime (k, l)\) instead of s(k, l) and u(k, l). This is because the vectors \(| \varepsilon \rangle \) are not necessarily orthogonal nor unit vectors, so these equations do not directly provide the projections of \(| u \rangle \) and \(| s \rangle \) in the eigenspace associated with \(\textrm{e}^{\textrm{i}\varphi }\). A correction is required. First, we define the transformation f, identical to the one seen in Sect. 7.2 by
where \(A(w_p)\) is a diagonal matrix whose elements are functions of \(w_p\) only.
Due to the orthogonality of \(| {\hat{\varepsilon }_-} \rangle \) and \(| {\hat{\varepsilon }_+} \rangle \), for two given vectors \(| {\hat{\varepsilon }} \rangle \) and \(| {\hat{\varepsilon }'} \rangle \), we have
and so, for each \(| \varepsilon _1 \rangle \), we have





and






where \(T_\varphi \) is a diagonal matrix such that the \(T_\varphi (p)\) contains the average value of the diagonal of \(\hat{\Gamma }_\varphi ^{-2}\) over block p, that is
Finally, we have

Let \(E_1\) be a matrix whose columns are the \(| \varepsilon _1 \rangle \) in the eigenspace associated with \(\lambda _k\). Then,
where each column of E is an eigenvector \(| \hat{\varepsilon } \rangle \) in the same eigenspace and \(E^\dagger E\) is a correlation matrix from which we will deduce the correction. We can diagonalize \(E^\dagger E\) via
where \(S_E^2\) is a diagonal matrix containing the eigenvalues of \(E^\dagger E\) and \(V_E\) a matrix whose columns are its eigenvectors. We can deduce the singular value decomposition of E. Since
where \(U_E\) is an \(N\times M\) matrix and \(S_E\) and \(V_E\) are \(M\times M\) matrices. Therefore
where \(| E(l) \rangle \) is the l-th column of E. Because the columns of \(U_E\) are orthogonal unit vectors, we can use it to compute the correct projection of \(| s \rangle \) in \(\mathcal {E}\), that is
Note that \(U_E\) has \(N_e\) rows and as many columns as there are eigenvectors associated to \(\lambda \), so it may be too big for a classical computer to handle. However, its computation can be avoided since
where \(S_E\) and \(V_E\) are square matrices whose size is \(\hbox {dim}\,\ker \left\{ D_\varphi ^s\right\} \).
Finally
8.3.2 Real eigenvalues case
We will now consider the case \(\lambda = +1\). This eigenvalue implies that \(P^S_+| \varepsilon _- \rangle = 0\) and \(P^S_-| \varepsilon _+ \rangle = 0\). Then, \(| \varepsilon _- \rangle \in E^{S,CO}_{-,-}\) and \(| \varepsilon _+ \rangle \in E^{S,CO}_{+,+}\), but we have shown that \(\hbox {dim}\, E^{S,CO}_{+,+} = 0\), so \(| \varepsilon \rangle \in E^{S,CO}_{-,-}\). The intersection of \(E^{S,CO}_{-,-}\) with \(\mathcal {E}\) has a dimension of \(M-1\). Similarly, if \(\lambda = -1\), we have \(P^S_-| \varepsilon _- \rangle = 0\) and \(P^S_+| \varepsilon _+ \rangle = 0\). Then, \(| \varepsilon _- \rangle \in E^{S,CO}_{+,-}\) and \(| \varepsilon _+ \rangle \in E^{S,CO}_{-,+}\), but \(\hbox {dim}\, E^{S,CO}_{-,+} = 0\), so \(| \varepsilon \rangle \in E^{S,CO}_{+,-}\), whose dimension in the complement is also \(M-1\). In the following, we will only consider \(\lambda = -1\), as the discussion related to \(\lambda = +1\) is similar, but of less interest since both \(| u \rangle \) and \(| s \rangle \) have null projections over this eigenspace. We have shown in Sect. 4 that the subspace of \(E^{S,CO}_{-,-}\) in the complement of \(E^{S,C}_{-,-}\), that is in \(\mathcal {E}\), has a dimension of \(M-1\). Furthermore, we established a parametric form of the corresponding eigenvectors:
with a constraint on \(| \varepsilon _1 \rangle \) that is \(\langle \varepsilon _1|h\rangle =0\), \(\langle h |\) being the last row of \(H^s_N\). It also follows that
Since \(| u \rangle \) and \(| s \rangle \) are both orthogonal to \(L_3'^\circ \), we have


and



As for the previous case, the generated \(| \varepsilon \rangle \) are not orthogonal and must be corrected in a similar way.
Due to the orthogonality of \(L_1\) and \(L_3'^\circ \), we have
Let W be the diagonal matrix whose elements are \(W(p) = w_p/(n-w_p)\). Then


The corresponding correlation matrix can be computed via
From this point, the correction method is the same as in the previous case.
8.3.3 Singular \(\hat{D}_\varphi ^{-1}\) case
The last case to cover is the one where \(\hat{D}_\varphi ^{-1}\) is not invertible because it contains at least one zero value on its diagonal. According to Equation (7.33), this happens when
that is
so
which corresponds to the complex eigenvalues of U, \(\lambda = \lambda _{w_p}\). In this case, \(\hat{D}_\varphi ^{-1}(p) = 0\), and Eq. (7.36) implies that \(| \hat{e}_-(p) \rangle = 0\). Since
we have a new constraint on \(| \varepsilon _1 \rangle \), so
As \(H_N^{s,w_p}\) is a large matrix, its kernel can be complex to compute, but since for any operator
we have
where \(\Xi _{w_p} = {H_N^{s,w_p}}^{\text{ T }}H_N^{s,w_p}\). We showed in Sect. 7.2 that \(\Xi _{w_p}\) can be computed easily.
Equation (7.37) is only valid over the positions \(\bar{p}\) whose binary representation Hamming weight is not \(w_p\). We have
We define \(| \hat{e}_+^{\bar{p}} \rangle \) as the vector whose elements at positions p are zero and others are determined by the equation above. It can be obtained by using a modified \(\hat{D}_\varphi \) whose elements at positions p are zero. Let us denote this modified matrix \(\hat{D}^{\bar{p}}_\varphi \). Let us note \(| x \rangle \) the length \(\left( {\begin{array}{c}n\\ w_p\end{array}}\right) \) vector containing the elements of \(| \hat{e}_+ \rangle \) at positions p. We have
Since \(| \hat{e}_+ \rangle \in \text {span}\{H_N^{\bar{s}}\}\), its M components corresponding to solutions must be zero. Therefore,
and
which we denote
We have

In order to deal with this constraint and the one from Eq. (7.123), we introduce a matrix Y whose columns are an orthonormal basis of \(\ker \left\{ \Xi _{w_p}\right\} \). We have
The matrix \({H^{s,w_p}_N}^{\text{ T }}\) can be huge, so computing its kernel may be difficult. However, this can be avoided using the properties of the singular value decomposition. Let the SVD of \(H^{s,w_p}_N\) be
We have
Any vector \(| a \rangle \) in \(\text {span}\left\{ {H^{s,w_p}_N}^{\text{ T }}\right\} \) can be written:
where \(| b_\parallel \rangle = U_{w_p}^\dagger | b \rangle \). Conversely
where \(| b_\perp \rangle \) is the component of \(| b \rangle \) orthogonal to \(\text {span}\left\{ U_{w_p}\right\} \). Since \(| b_\perp \rangle \) has no impact on \(| a \rangle \), it can be considered null. Then,
and, therefore,
Also, note that for two vectors \(| b \rangle \) and \(| b' \rangle \)




since \(| b_\perp \rangle \) can be forced to zero.
\(V_{w_p}\) and \(S_{w_p}\) can easily be computed from the SVD of \(\Xi _{w_p}\), an \(M\times M\) matrix. Then,
Then, Eq. (7.129) becomes

where \(| \tilde{x} \rangle = U_{w_p}^\dagger | x \rangle \) is a length \({{\,\textrm{rank}\,}}\left\{ \Xi _{w_p}\right\} \) vector. We now have




and



Since \(\cos \varphi = 1-2w_p/n\),
Then, at positions p
and we have


If we denote by X the matrix whose columns are the vectors \(| \tilde{x} \rangle \), the correlation matrix \(E^\dagger E\) is given by
The computation of the components of \(| u \rangle \) and \(| s \rangle \) in \(\mathcal {E}\) is done in the same way as the previous cases: The computation of \(\langle \varepsilon |s\rangle \) only involves \(L_1\), which is orthogonal to \(| x \rangle \), and the computation of \(\langle \varepsilon |u\rangle \) involves \(\langle \varepsilon _+|u\rangle \) which depends on \(L_2\). This could lead to the appearance of \(| x \rangle \). However, we see that \(\langle \varepsilon _+|u\rangle = | \hat{e}_+(0) \rangle \), which is never affected by \(| x \rangle \). Indeed, \(| x \rangle \) only affects the positions whose weight is \(w_p\), and in the case we are currently studying, \(w_p \in [1, n-1]\). Therefore, \(| x \rangle \) does not appear in the computation of \(\langle \varepsilon |u\rangle \).
9 Simulation and results
9.1 Procedure
As a consequence of the results obtained in Sect. 7, it is possible to design a simple procedure to compute \(p_t\) as a function of t:
-
1.
Compute the dimension of \(\mathcal {E}\) according to Eq. 6.36 and create with an arbitrary chosen step a linearly spaced set of angle \(\theta \) from 0 to \(\pi /2\).
-
2.
Compute the \(D^s_\theta \) according to the method seen in Sect. 7.2 and their least singular values.
-
3.
Find all local minima of the criterion, which is the lowest singular value of each \(D^s_\theta \) as a function of \(\theta \). Those local minima are found where \(\theta \) equals one of the \(\varphi \).
-
4.
Compute the S and V matrices from the SVD of each \(D^s_\varphi \). The number of singular values equal to zero is the multiplicity m of the eigenvalue \(\textrm{e}^{\textrm{i}\varphi }\). Discard eigenvalues with a multiplicity of \(m = 0\). Add the symmetric eigenvalues from the \(]\pi /2, \pi ]\) span to the found eigenvalues.
-
5.
For each \(\varphi \), extract the m last columns of V as the vectors \(| \varepsilon _1 \rangle \). Then for each vector \(| \varepsilon _1 \rangle \) of each eigenvalue, compute \(s'(k, l)\) according to 7.81. Correct the \(| s(k) \rangle \) according to Eq. 7.103 and compute the \(| u(k) \rangle \) according to Eq. 7.104. Then, compute the \(| u \rangle \) and \(| s \rangle \) components associated with the conjugate eigenvalues, that is the conjugates of all u(k, l) and s(k, l) computed above.
-
6.
Compute the \(M - 1\) \(| \varepsilon _1 \rangle \) vectors associated with the \(-1\) eigenvalue as the kernel of \(\langle h |\), the last row of \(H^s_N\). Compute the \(s^\prime (k, l)\) according to Eq. 7.108 and correct the \(| s(k) \rangle \) in the same manner as before with the correlation matrix obtained in Eq. 7.115. Deduce the corresponding \(| u(k) \rangle \). If the total number of s(k, l) found is equal to \(\hbox {dim}\, \mathcal {E}\), go to step 9.
-
7.
Compute all \(\varphi \) that respect Eq. 7.119 and their \(D^{\bar{p}}_\varphi \) as described in Sect. 7.3.3. Compute the SVD of the \(D^{s,\bar{p}}_\varphi \) and keep those whose least singular value is 0. Then, compute the \(s^\prime (k, l)\) in the same manner as before, using \(D^{s,\bar{p}}_\varphi \) instead of \(D^{s}_\varphi \). Correct the \(| s(k) \rangle \) in the same manner as before with the correlation matrix obtained in Eq. 7.159. Finally, compute the corresponding \(| u(k) \rangle \).
-
8.
If the number of s(k, l) found is still lesser than \(\hbox {dim}\, \mathcal {E}\), one can choose to start the procedure again with a smaller step on \(\theta \) or continue with a less precise simulation.
-
9.
Compute the probability of success \(p_t\) for all values of t between 0 and a chosen number of iterations according to Eq. 7.3.
9.2 Example
In this section, we will show an overview of the proposed procedure for a 6-dimension hypercube. The results are summarized in Figs. and . Note that here, the eigenvalues search is done in the \([0, \pi ]\) span. The results plotted in Fig. 13 are compared to those obtained by direct simulation using the walk operator Q. The probability of success obtained by this method is computed according to Eq. 0.2, implying the computation of \(Q^t\), which becomes exponentially long as n increases. The results of both simulation methods match closely as predicted.

Search for the eigenvalues phases with \(n = 6\), \(M = 2\) solutions at position 3 and 6 and a step \(\Delta \theta = \pi /10\,000\). Found eigenvalues are circled
First, we compute \(\hbox {dim}\,\mathcal {E}\). It is not required for the simulation itself, but it allows us to check if we find enough eigenvalues. In this example, we find \(\hbox {dim}\,\mathcal {E}= 22\).
We chose a step of \(\Delta \theta = \pi /10\,000\), but \(\pi /500\) would be precise enough to obtain a good approximation. Over the \(10\,000\) angle values tested, we find 15 local minima in the \([0, \pi ]\) span. After computing the SVD of the corresponding \(D^s_\theta \) matrices, we can find that 4 of them do not have any singular value equal to zero. These correspond to the 4 highest local minima seen in Fig. 12. Additionally, the \(D^s_\theta \) matrix for \(\theta = \pi /2\) is undefined, as \(\hat{D}_{\pi /2}^{-1}\) is singular. In this case, we apply Sect. 7.3.3.
Then, we add the symmetric eigenvalues over \(]\pi , 2\pi [\) and the eigenvalue \(-1\) with a multiplicity of \(M-1 = 1\).
As in any numerical computation, deciding under which threshold a very small singular value is considered zero is always somewhat arbitrary. In some cases, depending on this threshold, the procedure can produce more eigenvalues than expected. These excess values are not an issue, as they correspond to vectors outside \(\mathcal {E}\). Therefore, they give zero components to \(| s \rangle \) and \(| u \rangle \) and do not affect the computation.
Then, we can compute the corresponding components of \(| s \rangle \) and \(| u \rangle \) in \(\mathcal {E}\). Note that in this example, among the 22 components of \(| s \rangle \) and \(| u \rangle \), only 12 are nonzero. These are displayed in Table .

Evolution of the probability of success in function of the number of iterations. The circles correspond to our method results while the crosses are the exact values obtained by direct simulation. Simulation with \(n = 6\), \(M = 2\) solutions at position 3 and 6
9.3 Upper bound for the probability of success
From the values of \(\varphi _k\) and s(k, l), it is possible to compute an upper bound for the probability of success. Indeed, we have
Using the triangle inequality, we obtain
From Eq. 7.104, we have
and finally
In the example shown in Sect. 8.2, we obtain \(p_t\le 0.5509\). We checked the validity of this upper bound: after \(10{\,}000\) iterations, the maximum value reached by the probability of success is 0.4279, which is, as expected, under the upper bound (here it is 28% under the bound). While the upper bound is not a close one in this example, such a theoretical bound is always interesting to have a fast estimate of the best possible performance that the quantum walk search could reach.
10 Conclusion
Quantum random walk search is a promising algorithm. However its theoretical study can be extremely complex and possibly intractable, especially when there is more than one solution. In this paper, we have proposed a method which allows us to compute the probability of success of the algorithm as a function of the number of iterations, without simulating the search itself. It is therefore possible to compute that probability on a classical computer even for search whose state space dimension is very large.
Knowledge of the probability of success allows us to determine the optimal time of measurement (the time which maximizes this probability), provided that we know the number of solutions and their relative positions. For instance, we may know that the acceptable solutions are the interior of a hypersphere of a given radius, whose absolute position is unknown.
It is also a powerful tool for in-depth study and better understanding of quantum random walk search properties. For instance, in our future work we plan to study how the number of solutions and their relative positions impact the probability of success. This may highlight a phenomenon of interference between solutions which does not exist in a classical search.
The study of the subspace \(\mathcal {E}\) could also be transposed over different walks patterns, such as planar quantum walks, possibly leading to interesting results. A further study could be considered in order to find the exact complexity of the method, or the required precision on \(\theta \) during the eigenvalues search.
Data Availability
Data sharing was not applicable to this article as no datasets were generated or analyzed during the current study.
References
Aharonov, D., Ambainis, A., Kempe, J., Vazirani, U.: Quantum Walks On Graphs. arXiv:quant-ph/0012090 (2002)
D’Angeli, D., Donno, A.: Shuffling matrices, kronecker product and discrete Fourier Transform. Discrete Appl. Math. 233, 1–18 (2017)
Golub, G.H., Van Loan, C.F.: Matrix computations. In: Johns Hopkins Studies in the Mathematical Sciences, 4th edn. The Johns Hopkins University Press, Baltimore (2013)
Grover, L.K.: A fast quantum mechanical algorithm for database search. In: Proceedings of the Twenty-Eighth Annual ACM Symposium on Theory of Computing-STOC ’96, pp. 212–219. ACM Press, Philadelphia (1996)
Moore, C., Russell, A.: Quantum Walks on the Hypercube. arXiv:quant-ph/0104137 (2001)
Nielsen, M.A., Chuang, I.L.: Quantum Computation and Quantum Information: 10th Anniversary Edition (2010). ISBN: 9780511976667 Publisher: Cambridge University Press
Shenvi, N., Kempe, J., Birgitta Whaley, K.: A quantum random walk search algorithm. Phys. Rev. A 67(5), 052307 (2003)
Song, F.: Early days following Grover’s quantum search algorithm. arXiv:1709.01236 [quant-ph] (2017)
Venegas-Andraca, S.E.: Quantum walks: a comprehensive review. Quantum Inf. Process. 11(5), 1015–1106 (2012). arXiv: 1201.4780
Acknowledgements
The authors thank the Brest Institute of Computer Science and Mathematics (IBNM) CyberIoT Chair of Excellence at the University of Brest for its support.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no conflicts of interest to declare that are relevant to the content of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Pillin, H., Burel, G., Baird, P. et al. Hypercube quantum search: exact computation of the probability of success in polynomial time. Quantum Inf Process 22, 149 (2023). https://doi.org/10.1007/s11128-023-03883-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11128-023-03883-9