
Abstract
This essay discusses a potential method for predicting the behavior of various physical processes and uses the COVID-19 outbreak to demonstrate its applicability. This study assumes that the current data set reflects the output of a dynamic system that is governed by a nonlinear ordinary differential equation. This dynamic system may be described by a Differential Neural Network (DNN) with time-varying weights matrix parameters. A new hybrid learning scheme based on the decomposition of the signal to be predicted. The decomposition considers the slow and fast components of the signal which is more natural to signals such as the ones corresponding to the number of infected and deceased patients who suffered of COVID 2019 sickness. The paper results demonstrate the recommended method offers competitive performance (70 days of COVID prediction) in comparison to similar studies.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
1.1 Predictions Based on Neural Networks
This section reviews how neural networks may predict the evolution of signal temporal evolution.
1.1.1 Prediction by Static (Feed-Forward) NN
A set of input values are considered by each neuron. Each one is associated with a weight, which is a varying value that may be determined by supervised or unsupervised training techniques like data clustering, and a bias. The network selects a neuron’s output depending on its weight and bias. All such activities in the context of Classification require labeled datasets. You thus require guided learning. In supervised learning, people verify that the neural network’s predictions are accurate. This aids the neural network in comprehending how labels and data related. Face identification, picture recognition and labeling, voice detection, and speech transcription are a few examples of this. Deep learning can link pixels in a picture and a person’s name via categorization. The act of grouping or clustering is the identification of commonalities. Understand that labels are not always necessary for the deep learning model to detect commonalities. Unsupervised learning is when a system utilizes machine learning to learn on its own when there are no helping human labels from which to draw. This keeps the possibility of creating extremely precise models. Customer churn is a type of clustering.
As we are all aware, predictive analytic uses methods like predictive modeling and machine learning to examine historical data and forecast future patterns [7]. Contrary to conventional forecasting techniques, neural networks are unique. In contrast to a neural network, the most popular model, linear regression, is actually a pretty straightforward approach to problem-solving. Because of their hidden layers, neural networks do predictive analytic more effectively. Only input and output nodes are used in linear regression models to generate predictions. The hidden layer is also used by the neural network to improve prediction accuracy. That’s because it learns similarly to how people do. So why isn’t neural network prediction used by everyone? They are prohibitively expensive due to their high computer power requirements. In addition, massive data sets are required to train neural networks, which your company might not have. But as IT technology becomes more affordable, the first obstacle could soon vanish. Soon, there won’t be any more "unpleasant shocks" because to technologies like Artificial Neural Networks (ANNs).
1.1.2 Prediction by Dynamic (with Feedback) NN
ANNs are often regarded as effective instruments for modeling intricate, nonlinear systems using hazy dynamic models. ANNs were first utilized as reliable predictors of various processes with static reliance on input–output data. The time effect should be included in the ANN when it must be used to describe a rough model of time-dependent input–output interactions, which necessitates the creation of a dynamic ANN or DNN [11]. In continuous time modelling we will be refereed to DNN as Differential Neural Networks. The review [13] lays forth the different recurrent and differential forms of Dynamic Neural Networks (DNN), their mathematical construction, and techniques for adjusting the network weights. The characteristics of DNNs motivate their use to represent the dynamics of decontamination processes. This review details recent findings on the DNN application for the modelling and controlling of treatment systems based on either biological or chemical processes. The modeling application of DNN for common methods used in the treatment of wastewater, contaminated soil, and the atmosphere is described. The major benefits of using the approximate DNN-based model instead of designing the complex mathematical description for each treatment are analyzed to enhance the efficiency of the decontamination treatment. In this paper, we also highlight the remarkable efficiency of DNNs as a keystone tool for modelling of epidemics. [15, 18].
1.2 On Mathematical Predictions of Epidemics
In the last few years, researchers and government officials have used computer-based models to try to forecast the course of the coronavirus pandemic (see, for example, [2, 8, 10, 19]). To predict the future of the coronavirus disease 2019 (COVID-19) outbreaks globally, several mathematical models have been developed. These forecasts have a significant impact on how soon and forcefully, governments respond to an outbreak. However, rather than producing accurate quantitative predictions regarding the magnitude or duration of illness burdens, the primary and most efficient application of epidemiological models to evaluate the relative efficacy of different treatments in lowering disease burden.
There are several studies remarking that models are hardly crystal balls when it comes to making predictions, and according to science journalist Miles O’Brien (PBS News Hour), "all of them require human assumptions" [1]. The creation of these models and their eventual goal are more sophisticated than many of us think, according to specific research periodicals. Our world is complex and has more data than knowledge. The Global Epidemic and Mobility Model, or GLEAM, is curated by a group of bio-statisticians at Seattle’s Fred Hutchinson Cancer Research Center [3]. They create mathematical models that explain how infections spread chaotically and exponentially. According to the projection from last month, 17,000 to 29,300 additional fatalities would likely be reported in the US solely for the week ending February 13, 2021, totaling 465,000 to 508,000 COVID-19 deaths by this time. The accuracy of mathematical forecasts in battling epidemics is still being worked on. Nevertheless, creating such illness prediction models is a crucial issue for scientific societies worldwide. It necessitates prompt and comprehensive answers, including a potential application for defining new politics and prevention schemes.
1.3 Main Concepts of This Paper
The results presented here are based on three principle concepts:
-
Although we have hundreds of years of theoretical knowledge on how to create mathematical models of infectious diseases, have any of these models ever been put to the test using all of the data sources at our disposal in real-time? No. As we create this automobile and learn more about these models, it is hurtling down the highway. For a more accurate model design, it is really difficult to take into consideration all human aspects (social, informational, climatic, and others) acting during sickness.
-
Any recommended model must include the inherent uncertainties associated with the most recent data. Thus, for instance, we lack sufficient statistical data to accept all of the conditions that should be satisfied to use any stochastic prediction models that are accessible (such as the Kalman filter or any of its modifications such as a requirement for noises to have Gaussian distributions with known covariation matrices, local linearity of the model, exact knowledge all participating parameters and so on). We only have one data trajectory (realization), making it complicated to apply statistical concepts like mathematical expectation (mean value), variance, and confidence interval. We can also not repeat the experiment to get at least one other data curve. This indicates that a statistical method for this kind of problem is not applicable!
-
Given the previous items, we suppose that the current data-set represents the output of some dynamic system governed by a nonlinear ordinary differential equation and may be modeled by a Differential Neural Network with time-varying weights matrix parameters whose dynamics is governed by special Learning laws containing slow and fast components.
All results reported below justify nice performances of the suggested approach.
2 DNN Model with Slow and Fast Learning
2.1 Ideas of a Prediction Algorithm for Models with Complete Information
2.1.1 Non-causal Model
Consider initially an ideal scenario where we know that the following mathematical model produces the scalar output \(x\left( t\right) \in {\mathbb {R}}\) of any dynamic plant.
where the nonlinear function \(f:{\mathbb {R}}_{+}\times {\mathbb {R}} ^{n}\rightarrow {\mathbb {R}}\) and initial condition \(x_{0}\) supposed to be known exactly. Defining vector \({\textbf{x}}\left( t\right) \in R^{n}\) with components
we can represent (1) as
In the corresponding integral form the differential model (3) can be rewritten as
where the variable \({\textbf{r}}\left( t,T\right) \) represents the "averaged rate" of changing the considered output variable \({\textbf{x}}\left( t\right) \) on the time-interval \(\left[ t,t+T\right] \). Considering the data set \( \left\{ {\textbf{x}}\left( \tau \right) \right\} _{\tau \in \left[ 0,t\right] } \) as the information on the process available up to the moment t we may conclude that \({\textbf{r}}\left( t,T\right) \) (4) contains the information on nearest future \(\left\{ {\textbf{x}}\left( \tau \right) \right\} _{\tau \in \left[ t,t+T\right] }\) with the horizon T and hence may be considered as “non-causal”.
2.1.2 Causal Approximation
Introduce standard operators of delay \(e^{-sT}\) and differentiation s acting as
and using the local approximation
for the "forecasting operator" \(e^{sT}\), we can obtain the following approximate relation:
where
depends on available information \(\left\{ {\textbf{x}}\left( \tau \right) \right\} _{\tau \in \left[ t-T,t\right] }\). Given that the new variable \({\textbf{r}}_{caus}\left( t,T\right) \) (5) can be treated as the "causal approximation" of variable \({\textbf{r}}\left( t,T\right) \) and the integral representation (4) of the considered dynamics (1) can be locally approximated as
Remark 1
Since the right-hand side of (7) contains only information
\(\left\{ x\left( \tau \right) \right\} _{\tau \in \left[ t-T,t \right] }\), available up to time t, we can consider the value \(x\left( t+T\right) \) as the " prediction (or forecasting)" of the process \( \left\{ {\textbf{x}}\left( \tau \right) \right\} _{\tau \in \left[ 0,t\right] } \) ahead on horizon T.
3 Prediction Algorithm for Models with Incomplete Information: DNN Approach
When the original dynamics \({\textbf{F}}\left( t,{\textbf{x}}\left( t\right) \right) \) in (3) is completely or partially unknown, we suggest applying the DNN approach [11] which showed nice results being applied to various problems in bio-engineering and the environment science [12, 13].
3.1 DNN Identification Model
Artificial neural networks (ANNs) are thought to be effective modeling tools for non-linear, complicated systems with ambiguous dynamic models. ANNs were first utilized as reliable predictors of various processes with static reliance on input–output data. The time effect must be included in the ANN when it is used to characterize a rough model of time-dependent input–output relationships, which necessitates the reconstruction of a dynamic ANN or the use of Recurrent Neural Networks (RNNs) in discrete time or Differential Neural Networks (DNNs) in continuous time. DNNs sometimes referred to as Auto Associative or Feedback Networks, are a subclass of ANNs in which the connections between the input and the output are organized into a directed cycle. As a result, the network develops an internal state that displays dynamic, temporally dependent behavior. DNN allows the signal to go both forward and backward by including loops in the network design or topology. To achieve the required behavior of this DNN, a particular tuning for the time-dependent weight matrix parameters is realized as a result of such a suggestion. In our scenario, define the single layer DNN model following [11], where the measurable output x(t) is a vector, as
where
-
\(\sigma ^{\top }\left( {\hat{\textbf{x}}}\right) =\left( \sigma _{1}\left( {\hat{\textbf{x}}}\right) ,\sigma _{2}\left( {\hat{\textbf{x}}} \right) ,\ldots ,\sigma _{p}\left( {\hat{\textbf{x}}}\right) \right) \) is the vector with sigmoidal components
$$\begin{aligned} \sigma _{j}\left( {\hat{\textbf{x}}}\right) =\frac{\alpha _{j}}{1+\beta _{j}e^{-\gamma _{j}^{\top }{\hat{\textbf{x}}}}}+\delta _{j}, j=1,\ldots ,p \end{aligned}$$(\(\alpha _{j},\) \(\beta _{j}\) and \(\delta _{j}\) are positive scalars and \( \gamma _{j}\in {\mathbb {R}} ^{n}\) is a weighting vector for the component of \({\hat{\textbf{x}}}\));
-
\(\hat{W}\left( t\right) \) is the weight matrix, changing in time according to the Learning Procedure (LP)
$$\begin{aligned} \left. \begin{array}{c} \dfrac{d}{dt}\hat{W}\left( t\right) =K^{-1}P\left[ \mathbf {x(}t{)- \hat{\textbf{x}}(}t\mathbf {)}\right] \sigma ^{\top }\left( {\hat{\textbf{x}}} \left( t\right) \right) \\ \\ 0<K=K^{\top }\in {\mathbb {R}}^{n\times n},0<P=P^{\top }\in {\mathbb {R}}^{n\times n} \end{array} \right\} \end{aligned}$$(9) -
The vector L \(\in {\mathbb {R}} ^{n}\) must be selected in such a way that
$$\begin{aligned} \begin{array}{c} L\in {\mathbb {R}}^{n\times 1}:A^{0}(L)=A-LC^{\top }\text { is Hurwitz,} \\ \textrm{spectrum}\left( A^{0}(L)\right) \in {\mathbb {C}} ^{-}\text {.} \end{array} \end{aligned}$$
As it is mentioned in ( [11]), a special selection of matrix P we may guarantee a good DNN-approximation (identification) \( {\hat{\textbf{x}}}\left( t\right) \simeq {\textbf{x}}\left( t\right) \) practically for all \(t\ge 0\). The next subsection explains how the algorithms ( 8) and (9) should be modified to be able to generate a good prediction trajectory \({\hat{\textbf{x}}}\left( t+T\right) \) using only available information \(\left\{ {\hat{\textbf{x}}} \left( \tau \right) ,\right\} _{\tau \in \left[ t-T,t\right] }\).
3.2 DNN Prediction Model
The DNN dynamics (8) in the integral causal format (7) may be represented as
where
-
the signal \({\hat{\textbf{x}}}\left( t\right) \) is generated by (8),
-
the auxiliary vector \({\hat{\textbf{r}}}_{caus}\left( t,T\right) \) is defined as
$$\begin{aligned} \begin{array}{c} {\hat{\textbf{r}}}_{caus}\left( t,T\right) \text {:=}{\hat{\textbf{r}}}\left( t-T,T\right) +T\dfrac{d}{dt}{\hat{\textbf{r}}}\left( t-T,T\right) \\ + \dfrac{T^{2}}{2}\dfrac{d^{2}}{dt^{2}}{\hat{\textbf{r}}}\left( t-T,T\right) + \dfrac{T^{2}}{2}\dfrac{d^{3}}{dt^{3}}{\hat{\textbf{r}}}\left( t-T,T\right) \end{array} \end{aligned}$$(11)with
$$\begin{aligned} \left. \begin{array}{c} {\hat{\textbf{r}}}\left( t-T,T\right) :=\dfrac{1}{T}\displaystyle \int \limits _{\tau =t-T}^{t}{\hat{\textbf{F}}}\left( \tau ,{\textbf{x}}\left( \tau \right) \right) d\tau , \\ \\ {\hat{\textbf{F}}}\left( \tau ,{\textbf{x}}\left( \tau \right) \right) :={ A\hat{\textbf{x}}}\left( \tau \right) \mathbf {+b}x_{1}^{\left( n\right) }\left( \tau \right) + \hat{W}\left( \tau \right) \sigma \left( {\hat{\textbf{x}}}\left( \tau \right) \right) +{L}\left[ x_{1}(\tau )-C^{\top }{\hat{\textbf{x}}}\left( \tau \right) \right] , \end{array} \right\} \nonumber \\ \end{aligned}$$(12) -
the derivatives \(x_{1}^{\left( m\right) }\left( t\right) ,\) \(\left( m=1,\ldots ,n\right) \) and \(\dfrac{d^{k}}{dt^{k}}{\hat{\textbf{r}}}\left( t-T,T\right) ,\) \(\left( k=1,2,3\right) \) are calculated recurrently based on "super-twist algorithm" ( [9]), [16]. To differentiate time function \(f\left( t\right) \), the super-twisting controller is designed to reduce the error s(t) (\(s=x-f\)) between its input \(f\left( t\right) \) and output x(t) to zero:
$$\begin{aligned} \left. \begin{array}{c} {\dot{x}}(t)=-\alpha \sqrt{|s(t)|}\textrm{sign}(s(t))+y(t), \\ {\dot{y}}(t)=-M\,\textrm{sign}(s(t)) \\ \left| \ddot{f}\right| <F_{0},M>F_{0} \end{array} \right\} \end{aligned}$$(13)The error s(t) is reduced to zero after a finite time interval \(t_{0}\) and state component y(t) is equal to the first-time derivative of a function \(f\left( t\right) ,\) namely, \(y(t)=\frac{d}{dt}f\left( t\right) \) for all \( t\ge t_{0}\). If \(f\left( t\right) \) is corrupted by bounded noise \( \left| s(t)\right| \le \Delta =\textrm{const}\), then an upper bound of the differentiation, the error is estimated by inequality
$$\begin{aligned} \left| y(t)-\frac{d}{dt}f\left( t\right) \right| \le \alpha _{1}\Delta +\alpha _{2}\sqrt{\Delta },\alpha _{1},\alpha _{2}\text { {- positive constants.}} \end{aligned}$$
3.3 DNN Predictor with Slow and Fast Components
There are several systems whose trajectories can be understood as the overlapping of signals formed with the combination of slow and fast components. Such systems are also known as multi-rate system that appears naturally in mobile robotics [4], chemical [17] and biochemical [6] reactions, evolution of medical sicknesses [14], evolution of ecosystems animal populations [5] and many others. The same type of combined dynamics is valid for describing the evolution of both infected and deceased persons suffering of the Covid-19 sickness.
The developed DNN structure with mixed (slow and fast) learning scheme could be useful to represent the dynamics of COVID-19. Such a fact can be justified considering that the evolution of infected and deceased persons can be represented as the combination of a slow dynamics defined by the seasonal variations and a fast evolution which corresponds to the daily evolution. One may notice that such multi-rate dynamics has not been considered before in the design of non-parametric identifiers based on differential neural networks, which is indeed a contribution of this study.
3.3.1 Slow Predictive Component
Based on available data \(\left\{ x\left( \tau \right) \right\} _{\tau \in \left[ 0,t\right] }\) let us reconstruct a "slow" trajectory \(\left\{ x_{slow}\left( \tau \right) \right\} _{\tau \in \left[ 0,t\right] }\) defined as the best least squares polynomial approximation of a given order N, that is,
The behavior of trajectory \({{\textbf{x}}}_{slow}\left( t\right) \) is shown in Fig. 1 for COVID-19 case.

Comparative evolution of the slow part of the infected cases over time using the corresponding DNN with its state \({\textbf{x}}_{slow}\left( t\right) \)
Then, as in (10), (11) and (12), define \( {\hat{\textbf{x}}}_{slow}\left( t+T\right) \) as
where
-
\({\hat{\textbf{x}}}_{slow}\left( t\right) \) is generated by the following DNN model:
$$\begin{aligned} \left. \begin{array}{c} \dfrac{d}{dt}{\hat{\textbf{x}}}_{slow}\left( t\right) {=A\hat{\textbf{x}}} _{slow}\left( t\right) \mathbf {+b}x_{1,slow}^{\left( n\right) }\left( t\right) + \\ \hat{W}_{slow}\left( t\right) \sigma \left( {\hat{\textbf{x}}} _{slow}\left( t\right) \right) +L\left[ x_{1,slow}(t)-C^{\top } {\hat{\textbf{x}}}_{slow}\left( t\right) \right] , \\ \dfrac{d}{dt}\hat{W}_{slow}\left( t\right) =K^{-1}P\left( {\textbf{x}} _{slow}\mathbf {(t)}-\hat{\textbf{x}}_{slow}\mathbf {(}t\mathbf {)} \right) \sigma ^{\top }\left( {\hat{\textbf{x}}}_{slow}\left( t\right) \right) \\ {\hat{\textbf{x}}}_{slow}\left( 0\right) ={\textbf{x}}\left( 0\right) \in {\mathbb {R}}^{n},C^{\top }=\left( 1,0,\ldots ,0\right) \in {\mathbb {R}} ^{n}, \\ \hat{W}_{slow}\left( t\right) \in {\mathbb {R}}^{n\times p},\sigma : {\mathbb {R}}^{n}\rightarrow {\mathbb {R}}^{p}, \end{array} \right\} \end{aligned}$$(16) -
the auxiliary vector \({\hat{\textbf{r}}}_{caus}^{slow}\left( t,T\right) \) is defined as
$$\begin{aligned} \left. \begin{array}{c} {\hat{\textbf{r}}}_{caus}^{slow}\left( t,T\right) :={\hat{\textbf{r}}} ^{slow}\left( t-T,T\right) +T\dfrac{d}{dt}{\hat{\textbf{r}}}^{slow}\left( t-T,T\right) + \\ \dfrac{T^{2}}{2}\dfrac{d^{2}}{dt^{2}}{\hat{\textbf{r}}}^{slow}\left( t-T,T\right) +\dfrac{T^{2}}{2}\dfrac{d^{3}}{dt^{3}}{\hat{\textbf{r}}} ^{slow}\left( t-T,T\right) , \end{array} \right\} \end{aligned}$$(17)with
$$\begin{aligned} \left. \begin{array}{c} {\hat{\textbf{r}}}^{slow}\left( t-T,T\right) :=\dfrac{1}{T} \displaystyle \int \limits _{\tau =t-T}^{t}{\hat{\textbf{F}}}^{slow}\left( \tau ,{\textbf{x}} _{slow}\left( \tau \right) \right) d\tau , \\ \\ {\hat{\textbf{F}}}^{slow}\left( \tau ,{\textbf{x}}_{slow}\left( \tau \right) \right) :={A\hat{\textbf{x}}}_{slow}\left( \tau \right) \mathbf {+b} x_{1,slow}^{\left( n\right) }\left( \tau \right) + \\ \hat{W}\left( \tau \right) \sigma \left( {\hat{\textbf{x}}}_{slow}\left( \tau \right) \right) +{L}\left[ x_{1,slow}(\tau )-C^{\top } {\hat{\textbf{x}}}_{slow}\left( \tau \right) \right] , \end{array} \right\} \end{aligned}$$(18)
3.3.2 Fast Predictive Component
Define \(x_{fast}\left( t\right) \) as
The behavior of trajectory \({\textbf{x}}_{fast}\left( t\right) \) is shown in Fig. 2 for COVID-19 case.

Comparative evolution of the faster part of the infected cases over time using the corresponding DNN with its state \({\textbf{x}}_{fast}\left( t\right) \)
Then, as in (16), (17) and (18), define \({\hat{\textbf{x}}}_{fast}\left( t+T\right) \) as
where
-
\({\hat{\textbf{x}}}_{fast}\left( t\right) \) is generated by the following DNN model:
$$\begin{aligned} \left. \begin{array}{c} \dfrac{d}{dt}{\hat{\textbf{x}}}_{fast}\left( t\right) {=A\hat{\textbf{x}}} _{fast}\left( t\right) \mathbf {+b}x_{1,fast}^{\left( n\right) }\left( t\right) + \\ \hat{W}_{fast}\left( t\right) \sigma \left( {\hat{\textbf{x}}}_{fast}\left( t\right) \right) +L\left[ x_{1,fast}(t)-C^{\top }{\hat{\textbf{x}}} _{fast}\left( t\right) \right] , \\ \\ \dfrac{d}{dt}\hat{W}_{fast}\left( t\right) =K^{-1}P\left( {\textbf{x}}_{fast} \mathbf {(}t)-{\hat{\textbf{x}}}_{fast}\mathbf {(}t\mathbf {)}\right) \sigma ^{\top }\left( {\hat{\textbf{x}}}_{fast}\left( t\right) \right) \\ \\ {\hat{\textbf{x}}}_{fast}\left( 0\right) ={\textbf{x}}\left( 0\right) \in {\mathbb {R}}^{n},C^{\top }=\left( 1,0,\ldots ,0\right) \in {\mathbb {R}} ^{n}, \\ \hat{W}_{fast}\left( t\right) \in {\mathbb {R}}^{n\times p}, \sigma : {\mathbb {R}}^{n}\rightarrow {\mathbb {R}}^{p}, \end{array} \right\} \end{aligned}$$(21) -
the auxiliary vector \({\hat{\textbf{r}}}_{caus}^{fast}\left( t,T\right) \) is defined as
$$\begin{aligned} \left. \begin{array}{c} {\hat{\textbf{r}}}_{caus}^{fast}\left( t,T\right) :={\hat{\textbf{r}}} ^{fast}\left( t-T,T\right) +T\dfrac{d}{dt}{\hat{\textbf{r}}}^{fast}\left( t-T,T\right) + \\ \dfrac{T^{2}}{2}\dfrac{d^{2}}{dt^{2}}{\hat{\textbf{r}}}^{fast}\left( t-T,T\right) +\dfrac{T^{2}}{2}\dfrac{d^{3}}{dt^{3}}{\hat{\textbf{r}}} ^{fast}\left( t-T,T\right) , \end{array} \right\} \end{aligned}$$(22)with
$$\begin{aligned} \left. \begin{array}{c} {\hat{\textbf{r}}}^{fast}\left( t-T,T\right) :=\dfrac{1}{T}\displaystyle \int \limits _{\tau =t-T}^{t}{\hat{\textbf{F}}}^{fast}\left( \tau ,{\textbf{x}}_{fast}\left( \tau \right) \right) d\tau , \\ {\hat{\textbf{F}}}^{fast}\left( \tau ,{\textbf{x}}_{fast}\left( \tau \right) \right) :={A\hat{\textbf{x}}}_{fast}\left( \tau \right) \mathbf {+b} x_{1,fast}^{\left( n\right) }\left( \tau \right) + \\ \hat{W}\left( \tau \right) \sigma \left( {\hat{\textbf{x}}}_{fast}\left( \tau \right) \right) +L\left[ x_{1,fast}(\tau )-C^{\top }{\hat{\textbf{x}}} _{fast}\left( \tau \right) \right] . \end{array} \right\} \end{aligned}$$(23)
3.4 Joint Slow and Fast Predictor
In this paper, we use more advance predictor, consisting in two components: slow \({\hat{\textbf{x}}}_{slow}\left( t+T\right) \) and fast \( {\hat{\textbf{x}}}_{fast}\left( t+T\right) ,\) namely,
4 Structure of Numerical Procedure
The suggested predictive numerical structure consists of the following steps:
-
1.
Based on given discrete-time data \(\left\{ x\left( k\right) \right\} _{k\in \left[ 0,1,\ldots {\mathcal {K}}\right] }\), where \(x\left( k\right) \) corresponds to the data value at day k, and applying a spline approximation (herein examples, we use the spline of 15-th order) we construct the continuous-time curve \(\left\{ x\left( \tau \right) \right\} _{\tau \in \left[ 0,t\right] }\) where \(t={\mathcal {K}}\Delta \) (\(\Delta \) is time interval between discrete data).
-
2.
Then using (14) and (19), based on the obtained curve \(\left\{ x\left( \tau \right) \right\} _{\tau \in \left[ 0,t \right] }\) we need to construct the slow \(x_{slow}\left( t\right) \) and fast \(x_{fast}\left( t\right) \) trajectories.
-
3.
Applying the procedures (16), (17) and (18) we obtain the slow predictive curve \({\hat{\textbf{x}}}_{slow}\left( t+T\right) \) (15).
-
4.
Then applying the procedures (20), (22 ) and (23) we obtain the fast predictive curve \( {\hat{\textbf{x}}}_{fast}\left( t+T\right) \) (15).
-
5.
The last step is to construct the final predictive curve \({\hat{ \textbf{x}}}\left( t+T\right) \) (24) for desired T (for example, taking \(T=60,90,120\) days on the COVID-19 prediction).
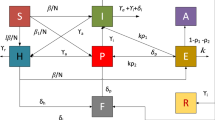
The corresponding block scheme is shown in Fig. 3.

Flow diagram describing how the proposed forecasting evolution is derived using the tools included in the toolbox
The developed algorithm was implemented accordingly to the following pseudocode.
-
1.
Load information corresponding to infected or deceased patients suffered from COVID-19 sickness
-
2.
Interpolate the loaded information using a third order spline strategy
-
3.
Implement a p-th order low-pass filter with a finite-impulse response strategy using a cut-off frequency of 0.5 Hz. This frequency was determined using the collected information. The value of p-th order is fixed to 7 considering the evolution of Covid information.
-
4.
Filter the loaded information separating the slow and fast components of the infected or deceased datasets, according to the selected cut-off frequency.
-
5.
Develop the slow learning algorithm in the first differential neural network implemented as an non-parametric identifier.
-
6.
Develop the fast learning algorithm in the first differential neural network implemented as an non-parametric identifier.
-
7.
Divide the information considering the training period and the complementary validation period.
-
8.
Evaluate both the slow and fast identifiers to reproduce the information corresponding to the information considered in the training period.
-
9.
Repeat the identification task until the least mean square error of the identification error for both the slow and the fast learning is smaller than a given threshold value \(\varepsilon \).
-
10.
Once the expected quality of training is expected, recover the values of the weights produced during this part of the process for both the slow and fast evaluations.
-
11.
Develop the numerical simulation of the differential neural network working as the predictor using two models using the recovered weights from the slow and the fast evolution of the training algorithms.
-
12.
Add the results of the slow and fast predictors to reconstruct the information during the prediction period.
-
13.
Compare if possible, the information obtained from the Covid statistics during the prediction period with respect to the obtained data during the evaluation of the added identifier.
-
14.
Determine the Least Mean Square Error and the Maximum Error for the predicted period, if possible to characterize the quality of the prediction task.
5 Seventy Days Prediction of Infections and Deaths for Different Countries
This research uses a publicly available dataset “2019 Novel Coronavirus Data Repository-published by Johns Hopkins University Center for Systems Science and Engineering (JHU CSSE) available at: https://github.com/CSSEGISandData/COVID-19. Models achieved and the code used in their generation are available in a repository located at: https://github.com/RitehAIandRobot/COVID-19-MLP. This information is proposed in COVID-19 MLP, Riteh AI and Robotics Group, 2020, https://github.com/RitehAIandRobot/COVID-19-MLP.
The presented set of numerical simulations considered a temporal horizon of 70 days. All the selected parameters were obtained using the Hurwitz conditions for \(A-{\textbf {L}}C^{\top }\). The values for the parameters considered in the activation functions were obtained with a uniform distribution for the exponential term, unitary gain with a fixed offset to 0.5. Hence, the parameters used for solving the numerical simulation for this the study was the following:
The number of sigmoidal functions (artificial neurons in the DNN) used for the identification process was 9600. The parameters in the sigmoidal functions were \(\alpha _{j} = 1\) for all \( j=1,\ldots ,9600\). The parameter in the denominator are \(\beta _{j} = 0.05\) and \(\beta _{j} = 0.08\) for all \(j=1,\ldots ,9600\). The period T was fixed to 10 days. All the initial conditions were fixed as random values between 0 and 1. These selections were obtained using a trial and testing method that effectively estimated the number of infected and deceased persons with Sars-Cov2 virus. These estimations were evaluated using the collected information reported by the World Health Organization.
The values of matrices K, P, and L are as follows:
5.1 Turkey
Figure 4 shows the comparison of estimated data evolution for infected people in Turkey. The comparison of trajectories confirms at first glance the effectiveness of the proposed DNN-based forecasting considering a period of estimation of 70 days. Moreover, it shows the effective estimation of the forecast information.

Prediction results with future estimation for the infected people detected in Turkey using the proposed DNN-based predictor
Figure 5 depicts the evolution of the predicted data for deceased people in Turkey using the proposed multi-rate identifier. In this case, there is a comparison considering the estimated data and the one corresponding to the actual data.

Prediction results with future estimation for the deceased people detected in Turkey using the proposed DNN-based predictor
5.2 USA
Figure 6 shows the comparison of estimated data evolution for infected people in the United States of America. The comparison of trajectories confirms at first glance the effectiveness of the proposed DNN-based forecasting considering a period of 70 days.

Prediction results with future estimation for the infected people detected in the United States of America using the proposed DNN-based predictor
Figure 5 depicts the evolution of the predicted data for deceased people in the United States of America using the proposed multi-rate identifier. In this case, there is a comparison considering the estimated data and the one corresponding to the actual data.
All the previous results confirm that the proposed forecaster is based on the dual configuration of DNN. Moreover, the proposed technique can be easily implemented in different forecast problems taking advantage of the generalized formulation presented here.
For both studied cases, we included here some methods used for comparison including a traditional recurrent neural network (RNN), a Long-Short term memory (LSTM), and a gated network unit (GNU). These networks were considered for comparison taking into account the significant outcomes shown before as potential predictors of complex time dependent information. We have presented two tables (one per infected and one per deceased persons) comparing some quality measurements, including the least mean square evaluation for the signals corresponding to the evolution of infected and deceased persons during the COVID outbreak (Tables 1 and 2). With the aim of introducing a fair comparison, the number of flops used for each of the prediction tasks was also estimated. These results confirm the advances generated by applying the proposed predictor based on the combined learning method introduced in this study.

Prediction results with future estimation for the deceased people detected in the United States of America using the proposed DNN-based predictor
The proposed outcomes shown in the previous tables confirm the benefits of the proposed methodology, including the prediction quality, as well as the convergence conditions (noticing the maximum error value). However, the augmented number of flops required by the methodology considered in this study still requires some work to improve the prediction abilities. Moreover, showing the better least mean square errors obtained with the proposed methodology highlights the benefit of introducing the mixed learning with slow and fast dynamics.
6 Conclusions
-
In this paper, it is shown that time-series data may be effectively modeled by a Differential Neural Network (DNN) with time-varying weights matrix parameters whose dynamics are governed by special Learning laws containing slow and fast components;
-
This study also demonstrates one of the possible applications of the suggested technique to COVID-19 epidemic prediction, where we suppose that the current data set represents the output of some dynamic system, governed by a nonlinear ordinary differential equation; this method has been evaluated for two nations’ databases (Turkey and the USA) and has demonstrated great performances (70 days of forecast).
Data availibility
The datasets generated during and/or analyzed during the current study are available from the corresponding author upon reasonable request.
References
Adam D (2020) Special report: the simulations driving the world’s response to COVID-19. Nature 580(7803):316–318
Anirudh A (2020) Mathematical modeling and the transmission dynamics in predicting the Covid-19 - What next in combating the pandemic. Infect Disease Model 5:366–374
Balcan D et al (2010) Modeling the spatial spread of infectious diseases: the global epidemic and mobility computational model. J Comput Sci 1(3):132–145
da Costa Barros R, Nascimento TP (2021) Robotic mobile fulfillment systems: a survey on recent developments and research opportunities. Robot Auton Syst 137:103729
Deangelis DL, Mooij WM (2005) Individual-based modeling of ecological and evolutionary processes. Ann Rev Ecol Evol Syst 147–168
Goutsias John (2007) Classical versus stochastic kinetics modeling of biochemical reaction systems. Biophys J 92(7):2350–2365
Haykin S (2008) Neural networks and learning machines, 3rd edn. Prentice Hall, Upper Saddle River
Jewell NP, Lewnard JA, Jewell BL (2020) Predictive mathematical models of the COVID-19 pandemic: underlying principles and value of projections. JAMA 323(19):1893–1894. https://doi.org/10.1001/jama.2020.6585
Levant A (2003) Higher-order sliding modes, differentiation and output-feedback control. Int J Control 76(9):924–941
Priyanka R, Kumari A, Sood M (2021) Implementation of simple RNN and LSTMs based prediction model for coronavirus disease (Covid-19). In: IOP Conf. Ser.: Mater. Sci. Eng., 1022 012015
Poznyak A, Sanchez E, Yu W (2001) Differential neural networks for robust nonlinear control: identification, state estimation, and trajectory tracking. World Scientific, Singapore
Poznyak T, Chairez I, Poznyak A (2019) Ozonation and biodegradation in environmental engineering: dynamic neural network approach. Elsevier, Ansterdam-NY
Poznyak A, Chairez I, Poznyak T (2019) A survey on artificial neural networks application for identification and control in environmental engineering: biological and chemical systems with uncertain models. Annu Rev Control 48:250–272
Reason JT (1978) Motion sickness adaptation: a neural mismatch model. J R Soc Med 71(11):819–829
Santosh KC (2020) COVID-19 prediction models and unexploited data. J Med Syst 44(9):1–4
Utkin V, Poznyak A, Orlov YV, Polyakov A (2020) Road map for sliding mode control design, SpringerBriefs in mathematics. Springer, Berlin. https://doi.org/10.1007/978-3-030-41709-3
Vora Nishith, Daoutidis Prodromos (2001) Nonlinear model reduction of chemical reaction systems. AIChE J 47(10):2320–2332
Wynants L, Van Calster B, Collins GS, Riley RD, Heinze G, Schuit E, van Smeden M (2020) Prediction models for diagnosis and prognosis of covid-19: a systematic review and critical appraisal. BMJ 369
Zeb A, Alzahrani E, Suat Erturk V, Zaman G (2020) Mathematical model for coronavirus disease 2019 (COVID-19) containing isolation class. Hindawi BioMed Rese Int. https://doi.org/10.1155/2020/3452402
Acknowledgements
The paper was prepared under the financial support of the Automatic Control Department at CINVESTAV-IPN, Mexico.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
All the authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Poznyak, A., Chairez, I. & Anyutin, A. Differential Neural Networks Prediction Using Slow and Fast Hybrid Learning: Application to Prognosis of Infectionsand Deaths of COVID-19 Dynamics. Neural Process Lett 55, 9597–9613 (2023). https://doi.org/10.1007/s11063-023-11216-1
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11063-023-11216-1