
Abstract
In the present work, we analyze the hp version of virtual element methods for the 2D Poisson problem. We prove exponential convergence of the energy error employing sequences of polygonal meshes geometrically refined, thus extending the classical choices for the decomposition in the hp finite element framework to very general decomposition of the domain. A new stabilization for the discrete bilinear form with explicit bounds in h and \(p\) is introduced. Numerical experiments validate the theoretical results. We also exhibit a numerical comparison between hp virtual elements and hp finite elements.
Similar content being viewed by others
1 Introduction
The virtual element method (VEM) is a very recent generalization of the finite element method (FEM), see [10]. VEM utilizes polygonal/polyhedral meshes in lieu of the classical triangular/tetrahedral and quadrilateral/hexaedral meshes. This automatically includes nonconvex elements, hanging nodes (enabling natural handling of interface problems with nonmatching grids), easy construction of adaptive meshes and efficient approximations of geometric data features.
Among the properties of VEM, in addition to the employment of polytopal meshes, we recall the possibility of handling approximation spaces of arbitrary \({\mathcal {C}}^k\) global regularity [19, 25] and approximation spaces that satisfy exactly the divergence-free constraint [3, 18].
The main idea of VEM consists in enriching the classical polynomial space with other functions, whose explicit knowledge is not needed for the construction of the method (this explains the name virtual).
We point out that the literature concerning methods based on polytopal meshes is not restricted to the VEM. A (very short and incomplete) list of other polytopal-based methods follows: hybrid high order methods [31], mimetic finite difference [16, 24], hybrid discontinuous Galerkin methods [30], polygonal finite element method [36, 43, 48], polygonal discontinuous Galerkin methods [27], BEM-based finite element methods [46].
Although VEM is a very recent technology, the associated bibliography is widespread. We here limit ourselves in citing [3, 10, 12, 13, 18,19,20,21, 25, 26, 28, 33, 34, 44, 45, 51] and refer to [15] for a more complete overview of the literature.
In all these works, the convergence of VEM approximations has been achieved by increasing the number of mesh elements while keeping the degree of local approximation fixed. In other words and according to the existing terminology, these methods utilize the h -version of VEM. An alternative avenue to construct convergent approximations is the \(p\) -version of VEM which is based on increasing the degree of local approximations while keeping the underlying mesh fixed. A combination of both methodologies is termed the hp -version of VEM.
The recent work [14] provides a mathematical ground for the \(p\)-version of VEM for the two-dimensional Poisson problem. In particular, it includes the a priori convergence theory for the \(p\)- and hp-version of VEM on quasiuniform polygonal meshes and for uniform distributions of local degrees of approximation. An exponential convergence has been established for analytic solutions, see [14, Theorem 5.2], and convergence at algebraic rates for solutions having finite Sobolev regularity, see [14, Theorems 4.1, 5.1].
The objectives of the present paper are the following. First, we generalize the results in [14] and in particular the definition of \(H^1\) conforming VEM to the case with varying local degree of accuracy from element to element. Such construction fits very naturally in the framework of VEM without additional complications. Furthermore, we extend the hp-VEM approach to nonquasiuniform approximations and prove their exponential convergence for nonsmooth solutions having typical corner singularities, see [5, 6].
Similarly to the hp-version of FEM (see [47] and the references therein) the approximation is based on geometrically refined meshes with appropriate (linearly varying) local degree of accuracy. In order to derive the proofs, we introduce a new stabilization for the method, which turns out to be more suitable for the \(p\) and hp version of VEM. Importantly, explicit bounds of the new stabilizing term with respect to the \(H^1\) seminorm in terms of the local degree of accuracy are shown. This proof requires a particular inverse estimate on polynomials, presented in the “Appendix”. To the best of the authors knowledge, such an inverse estimate has been never published before.
We highlight that new tools for the approximation by means of functions in the VE space are presented. Such tools permits to avoid additional assumptions on the polygonal decomposition of the computational domain.
The structure of the paper is the following. After presenting the model problem and the VEM in Sects. 2 and 3 respectively, we deal with explicit bounds in terms of the degree of accuracy of a new stabilization term in Sect. 4. In Sect. 5 we show the approximation results and the main theorem of the paper, namely the exponential convergence of the energy error in terms of the dimension of the virtual space, while in Sect. 6 we validate the theoretical results with numerical tests, including a set of experiments on the comparison between hp FEM and hp VEM. Finally, in the “Appendix”, we discuss a hp polynomial inverse estimates on polygons needed for proving the stability bounds of Sect. 4.
2 Model problem
In this section, we discuss the functional space setting and the model problem under consideration.
Firstly, we introduce the functional spaces that will be used throughout the paper. Let \(\ell \in {\mathbb {N}}\) and let \(D \subseteq {\mathbb {R}}^2\) be a given domain whose closure contains the origin, i.e. \({\mathbf {0}} \in {\overline{D}}\). We denote with \(L^\ell (D)\) the Lebesgue space of \(\ell \)-summable functions and we denote with \(H^\ell (D)\) the Sobolev space of order \(\ell \) on the domain D, respectively; let \(\Vert \cdot \Vert _{\ell ,D}\) and \(| \cdot |_{\ell ,D}\) be the Sobolev norm and seminorm, see [1]. Let \(H^1_0(D)=\{u\in H^1(D): u|_{\partial D}=0\}\).
Let now \(\beta \in (0,1)\), \({\varPhi } _{\beta } ({\mathbf {x}})=|{\mathbf {x}}|^{\beta }\), where \(|\cdot |\) represents the Euclidean norm in \({\mathbb {R}} ^2\). Given \(u: D \rightarrow {\mathbb {R}}\), \(m,\,l \in {\mathbb {N}}\), \(m\ge \ell \), we set
where:
We define the weighted Sobolev spaces
where the corresponding weighted Sobolev norm reads
Having this, we recall the countably normed spaces (also known as Babuška spaces), see [47] and the references therein:
where \(c\ge 0\) and \(d\ge 1\) are two constants depending on u and D. We point out that space (4) is not empty since it contains functions of the form \(u=|{\mathbf {x}}|^{\alpha }\), for some \(\alpha >0\).
Definition (4) can be generalized to the case of functions with “multiple” singularities at the vertices of a polygonal domain i.e. adding in definition (1) weights of the form \(|{\mathbf {x}} -{\mathbf {x}}_{0}|\), \(\mathbf {x_0}\) being a vertex of the polygon different from \({\mathbf {0}}\); see [47]. In particular, defining \(N_V(D)\) and \(\{{\mathbf {A}}_i(D)\}_{i=1}^{N_V(D)}\) the number and set of vertices of D respectively, we denote the general space with \(H^{m,\varvec{\ell }}_{\varvec{\beta }}(D)\), where \(\varvec{\beta }=(\beta _1,\dots ,\beta _{N_V(D)})\) and \(\varvec{\ell }=(\ell _1(\beta _1),\dots , \ell _{N_V(\omega )}(\beta _{N_V(D)}))\) are the vectors associated with the singularities at the vertices of \(\omega \). The associated weight function reads:
Secondly, we introduce the model problem. Let \({\varOmega }\) be a open simply connected polygonal domain. Let \(f\in L^2({\varOmega })\) be given. We consider the two dimensional Poisson problem:
and its weak formulation:
where \((\cdot , \cdot )_{0,{\varOmega }}\) is the \(L^2\) scalar product on \({\varOmega }\) and \(a(\cdot , \cdot ) = (\nabla \cdot , \nabla \cdot )_{0,{\varOmega }}\). The Lax–Milgram lemma guarantees the existence of a unique weak solution \(u\in V\).
We recall a regularity result for the solution of problem (6). Let \(N_V\) and \(\{{\mathbf {A}}_i\}_{i=1}^{N_V}\) be the number and the set of vertices of \({\varOmega }\) respectively; let \(\omega _i\) be the (internal) angle associated with vertex \({\mathbf {A}}_i\), \(i=1,\dots , N_V\). To each \({\mathbf {A}}_i\), we associate the set of the so-called singular exponents for Poisson problem with Dirichlet condition (see also [47, formula (4.2.2)]):
Then, the following holds:
Theorem 1
Following the notation of problem (6), let \(f\in H^{0,0}_{\varvec{\beta }}({\varOmega })\), \(\beta \in [0,1)\); assume that the singular exponents \(\alpha _{i}\) defined in (7) satisfy:
Then the solution of (6)belongs to \(H^{2,2}_{\varvec{\beta }}({\varOmega })\) and the a propri estimate:
holds. Moreover, if \(f \in {\mathcal {B}}^0_{\varvec{\beta }}({\varOmega })\), then \(u\in {\mathcal {B}}^2_{\varvec{\beta }} ({\varOmega })\).
Proof
For the sake of simplicity, we assume in the rest of the paper that:
Finally, we point out that throughout the paper we write \(a \approx b\) and \(a \lesssim b\) meaning that there exist \(c_1\), \(c_2\) and \(c_3\) positive constants independent of the discretization parameters, such that \(c_1 \, a \le b \le c_2 \, a\) and \( a \le c_3 \, b\) respectively; we also denote by \({\mathbb {P}} _\ell (K)\) and \({\mathbb {P}} _\ell (E)\) the spaces of polynomials of degree \(\ell \) over a polygon \(K\) and an edge \(E\) respectively.
3 Virtual element spaces with non uniformly distributed degree of accuracy
In this section, we introduce a VEM for problem (6) with nonuniform local degree of accuracy.
Let \(\{{\mathcal {T}} _n\}\) be a sequence of polygonal decompositions of the domain \({\varOmega }\). The approximation have a “geometric layer” structure; hence, in the sequel, the integer n represents the number of layers used for the corner singularity refinement as in [47]; see Sect. 5.1 for the precise definition of layers.
Let \( {\mathcal {V}} _n\) be the set of vertices of \({\mathcal {T}} _n\), \( {\mathcal {V}} _n^{b} = \{\nu \in {\mathcal {V}} _n \mid \nu \in \partial {\varOmega }\}\) be the subset of boundary vertices, \({\mathcal {E}} _n\) be the set of edges \(E\) of \({\mathcal {T}} _n\), \({\mathcal {E}} _n ^b = \{e\in {\mathcal {E}}_n \mid e\subseteq \partial {\varOmega }\}\) be the subset of boundary edges. To each \(K\in {\mathcal {T}} _n\), we associate \(h_{K}=\text {diam}(K)\), \( {\mathcal {V}} ^{K}=\{\nu \in {\mathcal {V}} _n \mid \nu \in \partial K\}\) and \({\mathcal {E}} ^{K}=\{e\in {\mathcal {E}}_n \mid e\subseteq \partial K\}\). We require the two following basic assumptions on the regularity of the decomposition:
- \((\mathbf {D1})\) :
-
\(\forall K\in {\mathcal {T}} _n\), \(K\) is star-shaped with respect to a ball of radius greater than or equal to \(h_{K} \, \gamma \), where \(\gamma \) is a positive constant independent of the decompositions; see [23] for the definition of star-shapedness. We note that this condition can be satisfied by possibly many balls. Henceforth, we fix for each \(K\in {\mathcal {T}} _n\) a unique ball \(B(K)\).
- \((\mathbf {D2})\) :
-
\(\forall K\in {\mathcal {T}} _n\), \(\forall E\in {\mathcal {E}} ^{K}\), \(|E|\ge h_K\, {\widetilde{\gamma }}\), where \({\widetilde{\gamma }}\) is a positive constant independent of the decompositions. Moreover, \(\forall K\in {\mathcal {T}} _n\), \(\text {card}({\mathcal {E}}^K)\) is uniformly bounded.
More technical assumptions on the mesh will be introduced in Sect. 5 for the construction of proper geometric meshes.
Remark 1
Assuming that (D1) and (D2) hold true, then the following is also valid. The subtriangulation \(\widetilde{{\mathcal {T}}} _n(K)\) of \(K\) obtained by joining the vertices of \(K\) to the center of the ball \(B(K)\) introduced in assumption (D1) is made of triangles that are star-shaped with respect to a ball of radius greater than or equal to \(\gamma _1 \, h_T\), \(h_T\) being the diameter of \(T\), \(\forall T\in \widetilde{{\mathcal {T}}} _n(K)\), and \(\gamma _1\) being a positive constant independent of the decompositions.
Given \(K\in {\mathcal {T}} _n\), let \(i_{K}\) be the position of polygon \(K\) in the ordered sequence \({\mathcal {T}} _n\). Let \({\mathbf {p}} \in {\mathbb {N}}^{\text {card}({\mathcal {T}} _n)}\). We associate to each \(K\in {\mathcal {T}} _n\) the local degree of accuracy \(p_{i_{K}}=(\mathbf p)_{i_{K}}\). In order to simplify the notation, we write \(p_{K}:= p_{i_{K}}\).
Henceforth, we assume that \({\mathcal {T}} _n\) is a conforming decomposition into polygons of \({\varOmega }\), i.e. for all edges \(E\in {\mathcal {E}}\), either \(E\) belongs to two polygons if it is an internal edge or it belongs to a single polygon if it is a boundary edge.
In the former case, it must hold that there exist \(K_1\), \(K_2\in {\mathcal {T}} _n\) such that \(E\in {\mathcal {E}}^{K_1} \cap {\mathcal {E}}^{K_2}\); we associate to \(E\) the degree \(p_{E}=\max \{p_{K_1}, p_{K_2}\}\), that is we adopt the so-called maximum rule; see Remark 2 for further comments. In the latter case, let \(K\in {\mathcal {T}} _n\) be the unique polygon in the decomposition such that \(E\in {\mathcal {E}}^{K}\); we associate to \(E\) the degree \(p_{E}=p_{K}\).
Let \(K\in {\mathcal {T}} _n\). We firstly define the space of piecewise continuous polynomials on the boundary of \(K\):
The local virtual space on \(K\) reads:
with the convention \({\mathbb {P}}_{-1} (K) = 0\) and where \({\mathbb {B}}(\partial K)\) is defined in (9).
Definition (10) and the maximum rule immediately imply that \({\mathbb {P}} _{p_{K}} (K)\subseteq V(K)\).
We associate with the local space the following set of degrees of freedom:
-
the values at the vertices of \(K\);
-
the values at \(p_{E}-1\) internal nodes (e.g. Gauß–Lobatto nodes) for all \(E\in {\mathcal {E}}^{K}\);
-
the scaled internal moments of the form:
$$\begin{aligned} \frac{1}{\vert K\vert } \int _{K} q_{\varvec{\alpha }} v_{n}, \end{aligned}$$(11)where \(\{q_{\varvec{\alpha }}\}_{|\varvec{\alpha }|=0}^{p_{K}- 2}\) is a properly chosen basis of \({\mathbb {P}}_{p_{K}-2}(K)\); see Remark 5 for possible explicit choices of the polynomial basis.
This is in fact a set of degrees of freedom for the local space (10); see [10]. If we set \(\text {dof}_i\) the i-th degree of freedom, \(i=1,\dots ,\dim (V(K))\), then we can define the local virtual canonical basis \(\{\varphi _j,\, j=1,\dots , \dim (V(K))\}\) by:
The global virtual space is obtained by matching the boundary degrees of freedom on each edge, i.e.:
We note that we can split the global continuous bilinear form \(a(\cdot , \cdot )\), introduced with the continuous problem (6), into a sum of local contributions as follows:
We observe that we cannot compute the bilinear form \(a(\cdot , \cdot )\) applied on virtual functions since it is not possible in principle to know the values of such functions at any internal points of each polygon. The same argument applies to the computation of the right-hand side. For this reason, we must approximate both the stiffness matrix and the right-hand side.
Thus, the structure of VEM approximation is based on the two following ingredients which are defined in what follows:
-
a symmetric bilinear form \( a _{n} : V_n\times V_n\rightarrow {\mathbb {R}}\), which we decompose into a sum of local symmetric bilinear forms \( a _{n} ^{K}: V(K)\times V(K)\rightarrow {\mathbb {R}}\) as follows:
$$\begin{aligned} a _{n} (v_{n}, w_n) = \sum _{K\in {\mathcal {T}} _n} a _{n} ^{K} (v_{n}, w_n)\quad \forall \, v_{n}, w_n \in V_n; \end{aligned}$$(15) -
a piecewise discontinuous polynomial \( f _{n} \),which is piecewise of degree \(p_{K}\), and the associated linear functional \(( f _{n} ,\cdot )_{0,{\varOmega }}\).
The discrete bilinear form \(a_n(\cdot , \cdot )\) and the discrete right-hand side \( f _{n} \) are chosen in such a way that the discrete counterpart of (6)
is well-posed and it is possible to recover local hp-estimates analogous to those proved in [14].
We start by discussing the construction of the discrete bilinear form. We require that \( a _{n}^{K} \) in (15) satisfy the two following assumptions:
- (\(\mathbf {A1}\)):
-
polynomial consistency: \(\forall K\in {\mathcal {T}} _n\), it must hold:
$$\begin{aligned} a^{K} (q, v_{n}) = a _{n} ^{K} (q,v_{n}) \quad \forall \,q\in {\mathbb {P}}_{p_{K}}(K),\; \forall \,v_{n}\in V(K); \end{aligned}$$(17) - (\(\mathbf {A2}\)):
-
local stability: \(\forall K\in {\mathcal {T}} _n\), it must hold
$$\begin{aligned} \alpha _* (p_{K}) \vert v_{n}\vert ^2_{1,K} \le a _{n} ^{K} (v_{n},v_{n}) \le \alpha ^* (p_{K}) \vert v_{n}\vert _{1,K}^2 \quad \forall \, v_{n}\in V(K), \end{aligned}$$(18)where \(0<\alpha _*(p_{K})\le \alpha ^*(p_{K})< +\infty \) are two constants which may depend only on the local degree of accuracy \(p_{K}\).
On each \(K\in {\mathcal {T}} _n\), we can introduce a local energy projector \({\varPi }^{\nabla ,K}_{p_{K}}: V(K)\rightarrow {\mathbb {P}}_{p_{K}}(K)\) via

When no confusion occurs, we write \({\varPi }^{\nabla }_{p_{K}}\) in lieu of \({\varPi }^{\nabla ,K}_{p_{K}}\).
Note that condition (19b) only fixes an additive constant of the projection and can be modified if necessary, see [2, 10]. Importantly, this local energy projector can be computed by means of the degrees of freedom of space (10), see [10, 12], without the need of knowing explicitly functions in the virtual space.
In [10, 12], it was also shown that a computable candidate for \( a _{n} ^{K_i}\) may have the following form:
where \(S^{K}\) is any computable symmetric bilinear form on \(V(K)\) such that:
where \(0<c_*(p_{K})\le c^*(p_{K})< +\infty \) are two constants, which may depend on the local degree of accuracy \(p\). In [10] it was shown that (21) implies (18) with:
Now, we introduce a computable discrete loading term \( f _{n} \). Let \(S^{{\mathbf {p}}, -1}({\varOmega }, {\mathcal {T}} _n)\) be the set of piecewise discontinuous polynomials over the decomposition \({\mathcal {T}} _n\) of degree \(p_{K}\) on each \(K\in {\mathcal {T}} _n\). For \(\ell \in {\mathbb {N}}\), let \({\varPi }^{0,K}_{\ell } := {\varPi }^{0}_{\ell }\) be the \(L^2(K)\) projector from the local space (10) to \({\mathbb {P}}_{\ell } (K)\), the space of polynomials of degree \(\ell \) over \(K\); such a projector can easily be computed whenever \(\ell \le p_{K}-2\) by means of the internal degrees of freedom of the space (10), see [12].
We define the discrete loading term as follows: \( f _{n} \in S^{{\mathbf {p}}, -1}({\varOmega }, {\mathcal {T}} _n)\) is such that
A deeper analysis on the discrete loading term can be found in [2] and [11].
We remark that in this paper we do not consider the case of approximation with \(p_{K}=1\) in order to avoid technical discussions on the right-hand side.
Remark 2
We point out that in the definition of the local virtual space (10), we fixed the degree of the edge to be the maximum of the degree of the two adjacent polygons (maximum-rule). One could also fix such an edge degree to be the minimum of the degree of the neighbouring polygons (minimum-rule). The first choice leads to \({\mathbb {P}}_{p_{K}}(K) \subseteq V(K)\); therefore, it is possible to recover local (i.e. on each polygon) classical hp-estimates, see [14]. On the other hand, in view of Sect. 5 also the choice of the minimum would yield the same convergence result.
Let \( {\mathcal {F}} _n^K\), \(K\in {\mathcal {T}} _n\), be the smallest positive constants such that:
and let
where \(\alpha _*(p_{K})\) and \(\alpha ^*(p_{K})\) are introduced in (18).
We show how the energy error \(\vert u-u_{n}\vert _{1,K}\) can be bounded, \(u\) and \(u_{n}\) being respectively the solutions of (6) and (16). We carry out, in particular, an abstract error analysis which is similar to the one presented in [10]; nevertheless, we decide to show the details, since assumption (A2) is here weaker than its h counterpart in [10], where the stability constants \(\alpha _*(p_{K})\) and \(\alpha ^*(p_{K})\) are assumed to be independent of the local degree of accuracy.
Lemma 1
Assume that (A1) and (A2) hold. Let \(u\) and \(u_{n}\) be the solutions of problems (6) and (16) respectively. Then, for all \(u_{I}\in V_n\) and for all \(u_{\pi }\in S^{{\mathbf {p}}, -1}({\varOmega }, {\mathcal {T}} _n)\), it holds that
where \( {\mathcal {F}} _n^K\) and \(\alpha (K)\) are defined in (24) and (25) respectively.
Proof
Given any \(u_{\pi }\in S^{{\mathbf {p}}, -1}({\varOmega }, {\mathcal {T}} _n)\) and \(u_{I}\in V_n\):
where the Cauchy–Schwarz inequality has been used in the last step. Applying a triangular inequality, we get:
This finishes the proof. \(\square \)
4 Stability
In this section, we present an explicit choice for the stabilizing bilinear form \(S^K\) introduced in (21) and we discuss the associated stability bounds (21) in terms of the local degree of accuracy. Our choice for the stabilization is the following:
We note that this local stabilization term is explicitly computable by means of the local degrees of freedom, since on the boundary virtual functions are known polynomials and the \(L^2\) projections are computable using only the internal degrees of freedom, see [12].
Following the guidelines of [47, formula (4.5.61)], that is the \(p\)-version of the Aubin–Nitsche duality argument, it holds for a convex \(K\):
Note that, in order to apply the Aubin–Nitsche argument, we use the fact that \(v_{n}- {\varPi }^{\nabla }_{p_{K}}v_{n}\in \ker ({\varPi }^{\nabla }_{p_{K}})\), which guarantees that \(v_{n}- {\varPi }^{\nabla }_{p_{K}}v_{n}\) has zero average on \(K\); for a detailed proof see [29, Lemma 3.2].
Assume now that \(K\) is nonconvex. Let \(\pi< \omega _K< 2\pi \) the largest angle of \(K\). Then, the Aubin–Nitsche analysis in addition to interpolation theory [49, 50] and regularity of solutions of elliptic problems on polygonal domains [5, 6] can be refined giving:
for all \(\varepsilon > 0\).
We now prove the following result.
Theorem 2
Assume that \(p_{K}\), the degree of accuracy of the method on the element \(K\), coincides with the polynomial degrees \(p_{E}\), for all edges \(E\in {\mathcal {E}}^K\) of polygon \(K\). Then, using definition (27), the bounds in (21) hold with:
for all \(\varepsilon > 0 \), where \(\omega _K\) denotes the largest angle of \(K\).
Proof
We assume without loss of generality that the size of polygon \(K\) is 1. The general result follows from a scaling argument.
We start by proving the estimate on \(c_*(p_{K})\). Integrating by parts, we obtain for \(v_{n}\in \ker ({\varPi }^{\nabla }_{p_{K}})\):
We split our analysis into two parts. We firstly investigate the integral over \(K\) in (31). For this purpose, we need a technical result, namely the following hp polynomial inverse estimate in two dimensions, see Theorem 5 (which can be applied thanks to Remark 1):
where we denote with \(\Vert \cdot \Vert _{-1,K}\) the dual norm associated with \(H^1_0(K)\), i.e.
Subsequently, we note that, owing to (32), we have:
As a consequence:
Next, we turn our attention to the integral over \(\partial K\) in (31). Applying a Neumann trace inequality (see e.g. [47, Theorem A33]):
Then, we use (33) on the second term in the first factor and a one dimensional hp inverse estimate in addition to interpolation theory on the second factor (see [49, 50]), thus obtaining:
Plugging (34) and (35) in (36), we deduce:
whence
Next, we estimate \(c^*(p_{K})\). Let \(v_{n}\in \ker ({\varPi }^{\nabla }_{p_{K}})\), then:
We estimate the three terms separately. We begin with the first one. Applying the multiplicative trace inequality (see e.g. [23]), the \(p\) version of the Aubin–Nitsche duality argument (28) for convex \(K\) and (29) for nonconvex \(K\):
where we recall \(\omega _K\) is the largest angle in \(K\) for all \(\varepsilon \).
We now deal with the second term; using [14, Lemma 4.1]:
where in the last inequality we used that \(v_{n}- {\varPi }^{\nabla }_{p_{K}}v_{n}\) has zero average on \(\partial K\).
Finally, we treat the third term; using Aubin–Nitsche argument (28) and its modified version for nonconvex polygon (29):
Collecting the three bounds, we obtain the claim. \(\square \)
Remark 3
In order to keep the notation simpler, we proved Theorem 2 assuming that the polynomial degrees \(p_{E}\) on each edge \(E\in {\mathcal {E}} ^K\) coincide with the degree of accuracy \(p_{K}\) of the local space \(V(K)\); the same result remains valid if \(p_{K}\approx p_{E}\), for all \(E\in {\mathcal {E}} ^K\). In view of the forthcoming definition (59), the case of interest in the following satisfies such condition and therefore, for the proof of the main result of this work, namely Theorem 3, we do not use directly Theorem 2, but its nonuniform degree version.
As a consequence of Theorem 2, the quantity \(\alpha (K)\), defined in (25), can be bounded in terms of \(p_{K}\) as follows:
Remark 4
Owing to [22, formula (2.14)], we could replace the boundary term of \(S^K\), defined in (27), with a spectrally equivalent algebraic expression employing Gauß–Lobatto nodes. In particular, let \({\widehat{I}}=[-1,1]\) and let \(\{\rho _j^{p_{{\widehat{I}}}+1}\}_{j=0}^{p_{{\widehat{I}}}}\) and \(\{\xi _j^{p_{{\widehat{I}}}+1}\}_{j=0}^{p_{{\widehat{I}}}}\) be the Gauß–Lobatto nodes and weights on \({\widehat{I}}\) respectively. Then:
where \(c\) is a positive universal constant. We could replace in (27) the \(L^2\) integral on the boundary with a piecewise Gauß–Lobatto combination, mapping each edge on the reference interval \({\widehat{I}}\) and using (40); the advantage of such a choice is that we can automatically use the nodal degrees of freedom on the skeleton, assuming that they have a Gauß–Lobatto distribution on each edge.
The boundary term of the new stabilization is now very close to the classical stabilization choice (see e.g. [10] and [14]) and its implementation is much easier than the implementation of (27), where one should reconstruct polynomials on each edge; in fact, it suffices to take instead of the Euclidean inner product of all the degrees of freedom only the boundary one with some Gauß–Lobatto weights.
For additional issues concerning the stabilization (only for the h version of VEM) see [17], while for more details concerning the implementation of the method we refer to [12].
It is worth to mention that stabilization (27) is not the only one available in the context of hp VEM, but it has the merit of having explicit bounds in terms of \(p\) in the stability constants \(c_*(p_{K})\) and \(c^*(p_{K})\) introduced in (21). Such dependence is algebraic in \(p_{K}\) and this will allow us to prove the exponential convergence of the energy error in Theorem 3.
As a consequence, every stabilization satisfying stability bounds of the form:
where \(r_1\) and \(r_2\) are two positive universal constants, works fine for proving exponential convergence of the method.
Finally, we note that at the practical level, as investigated in [41], choosing different stabilizing forms has little effect on the results.
4.1 Numerical tests for the stability bounds
In Theorem 2, we proved the stability bounds (21) for a possible choice of \(S^K\). Such bounds, which also reflect on \(\alpha _*(p_{K})\) and \(\alpha ^*(p_{K})\) introduced in (18), are rigorously proven but have a quite stray dependence on \(p\). In the following, we check numerically whether the dependence on \(p\) of the above-mentioned constants is sharp.
In order to do that, we note that finding \(\alpha _*(p_{K})\) and \(\alpha ^*(p_{K})\) in (18) is equivalent to find the minimum and maximum eigenvalues \(\lambda _{min}\) and \(\lambda _{max}\) of the generalized eigenvalue problem:
Here, \({\mathbf {A}}^K_n\) and \({\mathbf {A}}^K\in {\mathbb {R}}^{\dim (V(K)) \times \dim (V(K))}\) are defined as
where \(\{\varphi _i\}_{i=1}^{\dim (V(K))}\) denotes the virtual canonical basis of \(V(K)\), see (12). We are adopting the usual notation, by calling \(\mathbf {v_{n}} \in {\mathbb {R}}^{\dim (V(K))}\) the vector of the degrees of freedom associated with \(v_{n}\in V(K)\).
We note that we restrict our analysis on functions having zero average on \(K\), since both \({\mathbf {A}}_n^K\) and \({\mathbf {A}}^K\) have constant functions in their kernel; this strategy allows to avoid the problems related to solving the generalized eigenvalue problem for singular matrices. Moreover, the entries of matrix \({\mathbf {A}}^K\) are not computable exactly, since virtual functions are not known explicitly; therefore, we approximate them by solving numerically the associated diffusion problem, by means of a fine and high-order finite element approximation.
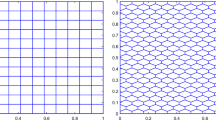
In Table 1, we present the results on three different types of polygon (namely, those which we employ for the tests in the forthcoming Sect. 6): a square, a nonconvex decagon (like any of the polygons in the outer layer of Fig. 1, right), a nonconvex hexagon (like any of the polygons in the outer layer of Fig. 1, center).
The maximum generalized eigenvalue always scales like 1. On the contrary, the minimum eigenvalue behaves in all the three cases like \(p^{-1}\). This means that in fact the bounds of Theorem 2 are abundant, whereas the actual behaviour of the stability bounds may be much milder. Unfortunately, currently we are not able to improve the stability bounds of Theorem 2. It is worth mentioning that this has no impact on the asymptotic exponential convergence results in the next section.
The nonmonotonicity of the eigenvalues in Table 1 is due to the fact that the matrices \({\mathbf {A}}^K_n\) are associated with bilinear forms which vary in n, see (20), since their definition also depend on the choice of the stabilization.
We also observe that a similar numerical investigation was also performed in [14, Section 6.4] for the hp version of VEM on quasi-uniform meshes, giving analogous results; moreover, always in [14], numerical evidence shows that the actual effect of the stabilization on the error slopes of the \(p\) version of VEM when approximating finite Sobolev regularity solutions is extremely mild.
5 Exponential convergence for corner singularity on geometric meshes
In this section, we want to show that exponential convergence is achieved if geometric mesh refinement and degree of accuracy distribution are chosen appropriately.

In order to achieve such a convergence we employ geometrically graded polygonal meshes, which are discussed in Sect. 5.1. Then, we show in Sect. 5.2 estimates for the first and the second terms in the error decomposition (26), in particular proving bounds for the local right-hand side approximation and for the local best approximation by means of polynomials. In Sect. 5.3, we obtain estimates for the third term in (26), in particular illustrating bounds for the best approximation by means of functions belonging to the virtual space defined in (13). Finally, in Sect. 5.4, under a proper choice for the polynomial degree vector p introduced in Sect. 3 and the sequence \(\{{\mathcal {T}} _n\}_n\) of polygonal decompositions, we combine together the above error bounds; as a consequence, we guarantee exponential convergence for the error in the energy norm in terms of the number of degrees of freedom of the global virtual space \(V_n\) defined in (13).
5.1 Geometric meshes
Here, we describe a class of sequences of nested geometric meshes which we employ in order to show error convergence. We recall we are assuming that the only “singular” corner is the origin \({\mathbf {0}} \in \partial {\varOmega }\), see (8). Let \(\sigma \in (0,1)\) be the grading parameter of the mesh.
The decomposition \({\mathcal {T}} _n\) consists of \(n+1\) layers defined as follows. We set \(L_0\) the 0-th layer as the set of all polygons \(K\) in decomposition \({\mathcal {T}} _n\) such that \({\mathbf {0}} \in {\mathcal {V}} ^K_n\); next, we define by induction:
We set \({\mathcal {T}}_0 = \{{\varOmega }\}\). Given \({\mathcal {T}} _n\), the decomposition \({\mathcal {T}}_{n+1}\) is obtained by refining \({\mathcal {T}} _n\) only in the layer around the singularity (i.e. \(L_0\)). We require that at level n the decomposition satisfies the following grading condition.
- (D3):
-
The diameter \(h_K\) of \(K\) satisfies:
$$\begin{aligned} h_{K}\approx {\left\{ \begin{array}{ll} \displaystyle {\frac{1-\sigma }{\sigma }}\text {dist}({\mathbf {0}}, K)&{} \text {if } K\notin L_0\\ \sigma ^{n}&{} \text {otherwise}\\ \end{array}\right. }. \end{aligned}$$(43)Furthermore, the number of elements in each layer is uniformly bounded with respect to the discretization parameters. We also assume that \(p_{K}\ge 2\). A more precise choice is discussed in the forthcoming definition (59).
Assumption (D3) justifies the name geometric for the sequence; more specifically, the closer a polygon is to 0 the smaller its diameter is. Moreover, it is possible to check that the ratio between the size of two neighbouring layers is proportional to \(\frac{1-\sigma }{\sigma }\). As a consequence of assumption (D3), we also have, for \(K\in L_j\), \(h_K\approx \sigma ^{n-j}\).
Example 1
A possible sequence satisfying (D1)–(D3) is the graded mesh of squares elements with hanging nodes on the L-shaped domain, that is used in [47, Definition 4.30], see Fig. 1 (left). We note that in the VEM context, this mesh contains pentagons and squares, whereas in the finite element counterpart the very same mesh is “afflicted” by the presence of squares with hanging nodes.
Example 2
As a second example, see Fig. 1 (center), we consider a mesh which is obtained by merging all the elements that correspond to one layer in the mesh from Example 1 in a single large element and by adding an oblique cut on the “central” diagonal. This mesh still cannot be used for conforming FEM approximations. Moreover, it satisfies assumptions (D1) and (D4).
Example 3
Another choice is depicted in Fig. 1 (right). This mesh is obtained by merging all the elements that correspond to one layer in the mesh from Example 1 in a single large element. We observe that this mesh is made of n decagons and one hexagon around 0. Moreover, we want to stress the fact that this mesh, that cannot be used in the conforming FEM environment, needs many less degrees of freedom than the meshes in Examples 1 and 2. Finally, we point out that such a mesh does not satify the star-shapedness assumption (D1).
We require the following additional assumption on the geometry of the decomposition, which we need in order to state the approximation results in Sects. 5.2 and 5.3.
- (D4):
-
Let \({\mathcal {T}} _n\) be a geometric polygonal decomposition; write \({\mathcal {T}} _n= {\mathcal {T}} _n^0 \cup {\mathcal {T}} _n^1\), where \({\mathcal {T}} _n^0 = L_0\) and \({\mathcal {T}} _n^1=\cup _{j=1}^n L_j\). Then, there exists a collection \(C_n^1\) of squares, with edges not necessarily aligned with the coordinate axes, such that:
-
\(\text {card}(C_n^1)=\text {card}({\mathcal {T}} _n^1)\); for each \(K\in {\mathcal {T}} _n^1\), there exists \(Q=Q(K)\in C_n^1\) such that \(Q\supseteq K\) and \(h_{K}\approx h_{Q}\); in addition, it must hold dist(\({\mathbf {0}},Q(K\)))\(\approx h_{K}\);
-
every \({\mathbf {x}} \in {\varOmega }\) belong at most to a fixed number of squares \(Q\), independently on all the discretization parameters;
-
\(\forall K\in {\mathcal {T}} _n^0\), \(K\) is star-shaped with respect to \({\mathbf {0}}\); moreover, the subtriangulation of \(K\) obtained by joining \({\mathbf {0}}\) with the other vertices is uniformly shape regular (\(\gamma \) being the shape-regularity constant).
We set \({\varOmega }^{\text {ext}}_{n} = (\cup _{Q\in C_n^1} Q) \cup (\cup _{K\in {\mathcal {T}} _n^0} K)\).
We point out that (D4) is a (rather) technical requirement, which has the scope to import some tools of \(hp\) FEM into \(hp\) VEM. Indeed, we will numerically prove in Sect. 6 that also meshes not satisfying (D4) may produce the expected convergence behaviour shown in Theorem 3, hinting that a potential improvement upon (D4) would immediately generalize the presented theory.
Assumption (D4) is in the spirit of the strategy of the overlapping square technique used in [14, 27]. We here additionally require that squares covering polygons far from the singularity cannot cover also such a singularity (since in this case \(p\) approximation results would not hold, thus invalidating Theorem 3). We also stress that the decomposition in Example 3 does not satisfy neither (D1) nor (D4). Finally, we point out that instead of considering a decomposition of squares \(C_n\), it is possible to consider in (D4) a decomposition in sufficiently regular quadrilaterals (e.g. parallelograms), since the same analysis by means of Legendre polynomials that follows (for instance in Lemmas 2 and 4) could be performed.
5.2 Local approximation by polynomials
Here, we deal with the approximation of the first and the second term in the right-hand side (26). What we are going to prove are hp approximation properties by means of local polynomials on polygons. In hp-FEM literature, classical approximation of this type is not effectuated on general polygons but only on squares and triangles, see [7, 8, 37, 40, 47] and the references therein.
The basic tool behind this approach is the employment of orthogonal bases, namely tensor product of Legendre polynomials on the square, see [47], and Koornwinder polynomials (that is collapsed tensor product of Jacobi polynomials) on triangles, see [32, 39]; with such basis, explicit computations can be performed, owing to properties of Legendre and Jacobi polynomials. On a generic polygon an explicit basis with good approximation properties is not available.
The error analysis follows the lines of [14, 47] and is summarized below. Let \({\mathbf {p}}\) be the vector of the local degree of accuracy on each polygon. We recall that we denote with \(S^{{\mathbf {p}},-1}({\mathcal {T}} _n, {\varOmega })\) the space of piecewise discontinuous polynomials over the decomposition \({\mathcal {T}} _n\) of degree \(p_{K}\) on each polygon \(p_{K}\).
The first result is a polynomial approximation estimate regarding regular functions on polygons far from the singularity. This result is used for the approximation of the local second term in (26) for the elements \(K\) separated from the singularity.
Lemma 2
Under assumptions (D1)–(D4), let \(K\in L_j\), \(j = 1, \dots , n\). Let \(Q(K)\) be defined in (D4) and let \(u\in H_{\beta }^{s_K+3,2}(Q(K))\), \(\beta \in [0,1)\), \(1\le s_{K}\le p_{K}\). Then, there exists \({\varPhi }\in {\mathbb {P}}_{p_{K}}(Q(K))\) such that:
where \(m=0,1,2\); \(1\le j\le n\); \(\rho =\max (1,\frac{1-\sigma }{\sigma })\), \(\sigma \) is the grading parameter of the mesh and \({\varGamma }\) is the Gamma function.
Proof
The result follows from classical scaling arguments and [47, Lemma 4.53]. Here, we only give the idea of the proof. Firstly one encapsulates polygon \(K\) into the corresponding square \(Q(K)\). It is possible to bound the left hand side of inequality (44) with the same (semi)norm on the square. After that, the square is mapped into the reference square \({\widehat{Q}} = [-1,1]^2\) and a \(p\) analysis by means of tensor product of Legendre polynomials is developed (see [47, Theorem 4.46]). Subsequently, the reference square is pushed forward to square \(Q\). Using the property of the geometric mesh stated in assumption (D3) and [47, Lemma 4.50], the result follows. \(\square \)
Estimate on polygons around the singularity are discussed in the following lemma. We point out that for the error control in layer \(L_0\) we can work directly on the element without the need of employing covering squares, as effectuated for the analysis on the polygons of the other layers, see Lemma 2. The proof is an extension to polygonal domains of that in Theorem [47, Lemma 4.16].
Lemma 3
Under assumptions (D1)–(D4), let \(K\in L_0\). Let \(u\in H_{\beta }^{2,2}(K)\), \(\beta \in [0,1)\). Then, there exists \({\varPhi }\in {\mathbb {P}}_{1}(K)\) such that:
where \(\sigma \) is the grading factor from assumption (D3).
Proof
We start by proving the following Hardy inequality on polygons with a vertex at \({\mathbf {0}}\). Let \(\alpha >0\), let be given a function u such that \(\int _K\vert {\mathbf {x}} \vert ^\alpha \vert D^1 u \vert ^2 < +\infty \) and \(u \in {\mathcal {C}}^0({\overline{K}})\). Then:
We consider the regular subtriangulation by joining \({\mathbf {0}}\) with the other vertices of \(K\); the existence of such a decomposition is guaranteed by assumption (D4). Thanks to [47, Lemma 4.18], the “triangular” counterpart of (46) holds:
It suffices then to split the integral over \(K\) into a sum of integrals over the triangles of the subtriangulation, apply (47) and collect all the terms.
Using (46) and applying the argument of [47, Lemma 4.19] to the polygon \(K\), we observe that \(H^{2,2}_\beta (K)\) is compactly embedded in \(H^1(K)\). Using such a compact embedding and proceeding as in [47, Lemma 4.16], the following inequality holds true for a polygon \(K\) star-shaped with respect to \({\mathbf {0}}\):
where \(\{ {\mathbf {A}}_i \}_{i=1}^3\) is a set of three arbitrary nonaligned vertices of \(K\).
Let \({\varPhi }\) be the linear interpolant of \(u\) at \({\mathbf {A}}_i\), \(i=1,\dots , 3\). Then, plugging \(U = u- {\varPhi }\) in (48), noting that \(U({\mathbf {A}}_i)=0\), \(i=1,2,3\), and using the geometric assumption (D3), we get the claim. \(\square \)
We note that (45) does not rely on \(p\) approximation results, but only on scaling argument. This is enough in order to prove the main result of this work, that is Theorem 3, and it is in accordance with the choice of the vector of local degrees of accuracy that is effectuated in the forthcoming definition (59). We emphasize that this is in the spirit of classical hp refinement, see [47].
We now turn our attention to the approximation of the first local term in (26), i.e. to the local approximation of the loading term. Since we are approximating it with piecewise polynomials of local degree \(p_{K}-2\), we set \(\overline{{\mathbf {p}}} = {\mathbf {p}}-2\), i.e. \(\forall K\in {\mathcal {T}} _n\), \({\overline{p}}_{K}= p_{K}-2\). We have, for all \(v_{n}\in V_n\):
where we recall we are assuming for the sake of simplicity \(p_{K}\ge 2\) for all \(K\in {\mathcal {T}} _n\), see Sect. 3.
As above, we develop a different analysis for polygons near and far from the singularity. We start with the “far” case.
Lemma 4
Under assumptions (D1)–(D4), let \(K\in L_j\), \(j = 1,\dots , n\). Let \(Q(K)\) be defined in (D4). Let \(f \in H_{\beta }^{{\overline{s}}_{K}+3,2}(Q(K))\), \(\beta \in [0,1)\), \(0\le {\overline{s}}_{K}\le {\overline{p}}_K\), with \({\overline{p}}_K= p_{K}-2\). Then, for all \(v_{n}\in V(K)\),
with the same notation of Lemma 2.
Proof
It suffices to use a Cauchy–Schwarz inequality in (49), standard bounds for the projection errors and analogous estimate to those in Lemma 2. \(\square \)
Assume now that \(K\) is an element in the finest level \(L_0\). We work here a bit differently from what we did in Lemma 3. In particular we get the following.
Lemma 5
Under assumptions (D1)–(D3), let \(K\in L_0\). Assume \(f \in L^2(K)\). Let \(\beta \in [0,1)\). Then:
where \(\sigma \) is the grading factor from assumption (D3).
Proof
Using a Cauchy–Schwarz inequality and Bramble Hilbert lemma (see [23]), we obtain:
\(\square \)
We point out that for the proof of Lemmas 3 and 5 we work directly on the polygon without the need of using the covering squares technique of assumption (D4), like in Lemmas 2 and 4. This justifies the fact that in assumption (D4) we did not require the existence of a collection of squares \({\mathcal {C}}_n^0\) associated with the finest layer \(L_0\) but only the existence of collection \({\mathcal {C}}_1^n\) associated with all the other layers.
5.3 Approximation by functions in the virtual space
Here, we treat the approximation of the third term in the right-hand side of (26). We observe that this term has two main differences with respect to the other two. The first difference is that we need an approximant \(u_{I}\) which is globally continuous; the second one is that \(u_{I}\) is not a piecewise polynomial but a function belonging to the virtual space \(V_n\).
As done in Sect. 5.2, we split the analysis into two parts. Firstly, we work on polygons not abutting the singularity, see Lemma 6; secondly, we work on elements \(K\) in the first layer \(L_0\), see Lemma 7.
Lemma 6
Let assumptions (D1)–(D4) hold. Let \(K\in L_j\), \(j=1,\dots , n\). Let \(\beta \in [0,1)\). Let f, the right-hand side of (6), belong to space \({\mathcal {B}} _{\beta }^0 ({\varOmega })\); consequently, \(u\), the solution of problem (6), belongs to space \({\mathcal {B}} _{\beta }^2 ({\varOmega })\), see Theorem 1 and definition (4). Assume that \(p_{E}\approx p_{K}\) if \(E\in \partial K\). Assume moreover that if \(K\in L_1\), then \(p_{K}\approx 2\). Then, for all \(1\le s_{K}\le p_{K}\), there exists \(u_{I}\in V(K)\) such that:
where we recall that \({\varPi }^0_{p_{K}-2}\) is the \(L^2(K)\) orthogonal projection from \(V(K)\) into \({\mathbb {P}}_{p_{K}-2}(K)\), \(\sigma \) is the grading factor from assumption (D3) and \(\rho = \max \left( 1, \frac{1-\sigma }{\sigma } \right) \).
Proof
Before starting the proof, we observe that the boundary norm in the right-hand side of (50) exists, since \(u\in {\mathcal {B}}^2_{\beta }({\varOmega })\) implies that \(u\in H^t(K)\) for all \(t \in {\mathbb {N}}\) and polygons \(K\notin L_0\).
We define \(u_{I}\) as the weak solution of the following problem:
where \(\pi u\in {\mathbb {B}}(\partial K)\), see (9), is defined in the following way. Assume for the time being that \(K\notin L_1\). Let \({\widehat{I}}= [-1,1]\). Given an edge \(E\subseteq \partial K\), \(\pi u\) is defined as the push-forward of a function \(\widehat{\pi u}\in {\mathbb {P}}_{p_{E}}({\widehat{I}})\) which we fix as follows. Let \({\widehat{u}}\) be the pull-back of \(u|_E\) on \({\widehat{I}}\). Then, \(\widehat{\pi u}^{\prime }\) is the Legendre expansion of \({\widehat{u}}^{\prime }\) up to order \(p_{E}- 1\). In particular, we write:
Here \(\{L_i(\xi )\}_{i=0}^{\infty }\) is the \(L^2({\widehat{I}})\) orthogonal basis of Legendre polynomials, with \(L_i(-1)=(-1)^i\) and \(L_i(1)=1\). Next, we define \(\widehat{\pi u}\) as:
It is possible to prove that \(\widehat{\pi u}\) interpolates \({\widehat{u}}\) at the endpoints of \({\widehat{I}}\) using the definition of \(\widehat{\pi u}\) and the fundamental theorem of calculus. Recalling [47, Theorem 3.14] and using simple algebra, the following holds true:
Applying a scaling argument, interpolation theory (see [49, 50]) and summing on all the edges, we get:
If now \(K\in L_1\), we define \(\pi u|_E\) as above if \(E\) does not belong to the interface between \(L_0\) and \(L_1\), otherwise \(u_{I}\) is defined as the linear interpolant of \(u\) at the two endpoints of \(E\). We point out that (54) remains valid also if \(K\in L_1\) paying an additional constant \(c^{2s_{K}+1}\), since \(p_{K}\approx 2\) whenever \(K\in L_1\). We also note that (54) implies, recalling that \(p_{E}\approx p_{K}\) if \(E\subseteq \partial K\) and following the ideas in [47, Lemma 3.39]:
where we recall that j denotes the number of the layer to which \(K\) belongs.
We are now ready to prove the error estimate. For arbitrary constants \(c_1\) and \(c_2\), there holds (also recalling that \((f- {\varPi }^0_{p_{K}-2}f)\) is \(L^2\)-orthogonal to constants):
Applying the trace inequalities on Neumann and Dirichlet traces, choosing \(c_2\) to be the average of \(u- \pi u\) on \(K\) and applying a Poincaré inequality, we get:
We deduce, picking \(c_1\) to be the average of \(u-u_{I}\) on \(\partial K\) and applying a Poincaré inequality:
In order to conclude, it suffices to apply (55). \(\square \)
We turn now our attention to the approximation on the polygons abutting the singularity.
Lemma 7
Let assumptions (D1)–(D4) hold. Let \(\beta \in [0,1)\). Let f, the right-hand side of (6), belong to space \({\mathcal {B}} _{\beta }^0 ({\varOmega })\); consequently, \(u\), the solution of problem (6), belongs to space \({\mathcal {B}} _{\beta }^2 ({\varOmega })\), see Theorem 1 and definition (4). Assume that \(p_{K}=2\) if \(K\in L_0\) and \(p_{K}\approx 2\) if \(K\in L_1\). Then there exists \(u_{I}\in V(K)\) such that:
where we recall that \({\varPi }^0_{p_{K}-2}\) is the \(L^2(K)\) orthogonal projection from \(V(K)\) into \({\mathbb {P}}_{p_{K}-2}(K)\), \(\sigma \) is the grading factor discussed in assumption (D3) and \(n+1\) is the number of layers.
Proof
We consider \(u_{I}\) defined as in (51); in particular, we fix \(\pi u\), the trace of \(u_{I}\) on \(\partial K\) to be the piecewise affine interpolant of \(u\) at the vertices of \(K\). From Lemma 6, we have:
where \(c_1\) is the average of \(u-u_{I}\) on \(\partial K\).
In order to get the claim, it suffices to bound the second term. As in Lemma 3, we consider the subtriangulation \(\widetilde{{\mathcal {T}}} _n= \widetilde{{\mathcal {T}}} _n(K)\) of \(K\) obtained by connecting all the vertices of \(K\) to \({\mathbf {0}}\), see assumption (D4). In particular, every triangle \(T\in \widetilde{{\mathcal {T}}} _n\) is star-shaped with respect to a ball of radius \(\ge {\widetilde{\gamma }} h_T\), where \({\widetilde{\gamma }}\) is a positive universal constant. We define \({\widetilde{u}}_K\) as the piecewise linear interpolant polynomials over the triangular subtriangulation, interpolating \(u\) at the vertices of \(T\), for every \(T\in \widetilde{{\mathcal {T}}} _n\). Using [47, Lemma 4.16] and applying a Poincaré inequality, yield to:
We stress that the third inequality in (57) holds since \({\widetilde{u}}_K|_{T}\) is a linear polynomial and therefore \(D^2 {\widetilde{u}}_K=0\) on all \(T\in \widetilde{{\mathcal {T}}} _n\). \(\square \)
We note that in Lemmas 6 and 7 the error between f and its \(L^2\) projection can be bounded using Lemmas 4 and 5. We also point out that the hypothesis concerning the distribution of the local degrees of accuracy, i.e. the fact that \(p_{K}=2\) if \(K\in L_0\), \(p_{K}\approx 2\) if \(K\in L_1\), \(p_{E}\approx p_{K}\) if \(E\subseteq \partial K\), are in accordance with the forthcoming definition (59) that we introduce for the proof of Theorem 3. Finally, we point out in Lemmas 6 and 7 we introduced a function \(u_{I}\) which is locally in \(V(K)\) and globally continuous; thus, \(u_{I}\) is a function in the global VE space \(V_n\) introduced in (13).
5.4 Exponential convergence
We set \({\varOmega }^{\text {ext}}=\cup _{n\in {\mathbb {N}}} {\varOmega }^{\text {ext}}_{n} = {\varOmega }^{\text {ext}}_{1}\), where the \({\varOmega }^{\text {ext}}_{n}\) are introduced in (D4). We recall that we are assuming that \({\mathbf {0}} \in \partial {{\varOmega }^{\text {ext}}}\).
We observe that our error analysis needs regularity on f and subsequently on \(u\), the right-hand side and the solution of problem (6), respectively. In particular, we require:
With a little abuse of notation we call this two functions f and \(u\). Assuming \(f \in {\mathcal {B}}^0_\beta \left( {\varOmega } \right) \) automatically implies that \(u\) is in \({\mathcal {B}}^2_\beta \left( {\varOmega } \right) \); this follows from classical elliptic regularity theory, see Theorem 1. In the classical hp finite element method, this regularity leads to exponential convergence of the energy error, see [47]. In order to prove the same exponential convergence with hp VEM, we need (58) since the approximation by means of polynomials on the polygons not abutting the singularity needs regularity of the target function on a square containing the polygon, see Lemmas 2 and 4.
We recall the inflated domain \({\varOmega }^{\text {ext}}\) has been built in such a way that the singularity is never at the interior of \({\varOmega }^{\text {ext}}\), see assumption (D4). We highlight also the fact that (58) can be easily generalized to the case of multiple singularities, see e.g. [47].
In order to obtain exponential convergence of the energy error in terms of the number of degrees of freedom, we henceforth assume that the vector \({\mathbf {p}}\) of the degrees of accuracy associated with \({\mathcal {T}} _n\) is given by:
where \(\mu \) is a positive constant which to be determined in the proof of Theorem 3 and where \(\lceil \cdot \rceil \) is the ceiling function. Note that choice (59) could be modified asking for \(p_{K}=1\) if \(K\in L_0\); under this requirement in fact Lemmas 3, 5 and 7 are still valid. Nonetheless, we prefer to use (59) in order to avoid technical discussions on the construction of the right-hand side of the method and keep the simple representation (23).
It is clear from (59) that if \(K_1\) and \(K_2\) belong to the j-th and the \((j+1)\)-th layers respectively, for some \(j=1,\dots ,n-1\), then \(p_{K_1} \approx p_{K_2}\), independently on all the other discretization parameters. Thus, owing to Sect. 4, we also have \(\alpha (K_1)\approx \alpha ({K_2})\), independently on all the other discretization parameters. Besides, \(p_{E}\approx p_{K}\) whenever \(E\subseteq \partial K\).
Theorem 3
Let \(\{{\mathcal {T}} _n\}_n\) be a sequence of polygonal decomposition satisfying (D1)–(D4). Let \(u\) and \(u_{n}\) be the solutions of problems (6) and (16) respectively; let f be the right-hand side of problem (6). Let \(N=N(n)=\dim (V_n)\). Assume that \(u\) and f satisfy (58). Then, there exists \(\mu >0\) such that \({\mathbf {p}}\), defined in (59), guarantees the following exponential convergence of the \(H^1\) error in terms of the number of degrees of freedom:
with b a constant independent of the discretization parameters.
Proof
It suffices to combine Lemma 1, the results of Sect. 4, Lemmas from 2 to 7 and to use the same arguments of [47, Theorem 4.51], properly choosing the parameter \(\mu \).
The basic idea behind the proof is that around the singularity, geometric mesh refinement are employed, since \(p\) approximation leads only to an algebraic decay of the error; on the other hand, on polygons far from the singularity, it suffices to increase the degree of accuracy, since on such polygons both the loading term and the exact solution of (6) are assumed to belong to the Babuska space \({\mathcal {B}}_\beta ^2({\varOmega }^{\text {ext}})\) defined in (4) and therefore \(p\) approximation leads to exponential convergence of the local errors (see [14, Theorem 5.6]).
Following [47, Theorem 4.51] and using Lemma 1 yield:
where \(c\) is a constant independent of both the discretization parameters and the number of layers. Applying (39), we obtain:
where we recall \(n+1\) denotes the number of layers. Plugging (62) in (61), we get:
We infer:
Now, we prove that \(N \lesssim (n+1)^3\). In order to see this, we proceed as follows. In each layer there exists a fixed maximum number of elements; this follows from the geometric assumptions (D1) and (D3), applying for instance the arguments in [38, Section 4]. Using geometric assumption (D2) (which guarantees a maximum number of edges per each element), the definition of the local virtual space (10) and the distribution of the local degrees of accuracy (59), it is straightforward to note that for all \(K\in {\mathcal {T}} _n\) the dimension of each local space \(V(K)\) is proportional to \(p_{K}^2\), with \(p_{K}^2 \approx \ell ^2\) for \(K\in L_{\ell }\).
Recalling again (59), we can now compute a bound for the dimension of the local space, viz. the number of the degrees of freedom:
where we stress that we are using that in each layer there is a fixed maximum number of elements. The result follows from Poincaré inequality. \(\square \)
5.5 Extension to more general problems
The very same analysis performed in the foregoing sections can be generalized and applied to general elliptic problems. The VE approximation of such problems was firstly introduced in [13] and it bases on the existence of local \(L^2\) projectors \({\varPi }^0_{p_{K}}\) on spaces of polynomials of degree \(p_{K}\) and not \(p_{K}-2\) as required in our framework.
A straightforward way for enabling the computation of these projectors consists in replacing the definition of local spaces \(V(K)\) in (10) with the following:
where we recall that the space \({\mathbb {B}}(\partial K)\) is defined in (9).
Doing so, the present theoretical analysis would extend easily, but the dimension of the local and global spaces would increase without implying any gain in the rate of convergence of the method. A possible way to overcome this increase of the dimension is to follow the approach in [13] and, more precisely, using the so-called enhancing technique introduced in [2] which allows to remove the additional degrees of freedom introduced in definition (63) and keeping the computability of projectors \({\varPi }^{\nabla }_{p_{K}}\) on each \(K\in {\mathcal {T}} _n\). The resulting VE spaces go under the name of enhanced spaces.
We highlight that we performed some numerical tests employing such enhanced spaces and computing the local discrete right-hand sides as:
The numerical results obtained using (64) are comparable to those presented in Sect. 6 where we considered the standard definition (23). Nonetheless, we stress that a theoretical analysis of VEM when employing enhanced spaces has not been investigated yet.
6 Numerical results
We show here numerical experiments validating Theorem 3. Let u, the solution of (6), given by the classical benchmark
on the L-shaped domain:
6.1 Tests on different meshes
We consider sequences of the meshes depicted in Fig. 1 and we consider two different choices for the degree of accuracy distribution \({\mathbf {p}}\). As a first selection, we pick on all the elements a constant local degree of accuracy which is equal to the number of layers, i.e. \({\mathbf {p}} = (n+1,n+1,\dots ,n+1)\). As a second selection, we pick \({\mathbf {p}}_{K}\) as in (59), with \(\mu =1\), \(\mu \) being the parameter introduced for the construction of the vector of the degrees of accuracy. In Figs. 2, 3 and 4, the numerical results are shown.

Error \(\vert u- {\varPi } ^{\nabla }_{{\mathbf {p}}} u_{n}\vert _{1,{\mathcal {T}} _n}\) employing the meshes in Fig. 1, \(\sigma =\frac{1}{2}\). Left: the degree of accuracy is uniform and equal to the number of layers. Right: the degree of accuracy is varying over the mesh layers, \(\mu =1\) in (59)

Error \(\vert u- {\varPi } ^{\nabla }_{{\mathbf {p}}} u_{n}\vert _{1,{\mathcal {T}} _n}\) employing the meshes in Fig. 1, \(\sigma =\sqrt{2} -1\). Left: the degree of accuracy is uniform and equal to the number of layers. Right: the degree of accuracy is varying over the mesh layers, \(\mu =1\) in (59)

Error \(\vert u- {\varPi } ^{\nabla }_{{\mathbf {p}}} u_{n}\vert _{1,{\mathcal {T}} _n}\) employing the meshes in Fig. 1, \(\sigma =(\sqrt{2} -1)^2\). Left: the degree of accuracy is uniform and equal to the number of layers. Right: the degree of accuracy is varying over the mesh layers, \(\mu =1\) in (59)
On the y-axis, we plot a log scale of the relative energy error between u, defined in (65), and the energy projection \({\varPi } ^{\nabla }_{p_{K}}\), defined in (19a), (19b), of the solution \(u_{n}\) of the discrete problem (16), i.e.
where we recall that \({\varPi } ^{\nabla }_{p_{K}}\) is defined in (19a) and (19b).
On the other hand, in the x-axis we plot the cubic root of the number of the degrees of freedom of the relative virtual space. The reason for choice (67) is that it is not possible to compute the true energy error since virtual functions are not known explicitly.
We consider the behaviour of the error with three different \(\sigma \), grading parameter, namely \(\sigma =\frac{1}{2}\), \(\sqrt{2} -1\), \((\sqrt{2} -1)^2\) and we compare the three types of meshes. In particular, we denote by mesh a), mesh b) and mesh c) the meshes depicted in Fig. 1 (left), (center) and (right) respectively.
As mentioned previously, the sequence of meshes in Fig. 1 (right) does not satisfy assumptions (D1) and (D4). Nevertheless, the expected exponential convergence rate is attained in all cases and for all geometric parameters \(\sigma \).
6.2 A comparison between hp FEM and hp VEM
We want now to show a comparison between the performances of hp (quadrilateral) FEM and hp VEM. We stress that an analogous of Theorem 3 holds for hp FEM, see e.g. [47]. We consider again the benchmark with known solution (65) and we consider the quadrilateral mesh in Fig. 5. In the following we denote such mesh with d) whereas we recall that we denote by (a), (b) and (c) the meshes depicted in Fig. 1 (left), (center) and (right) respectively.

Mesh used for the hp FEM
In particular, we pick in both cases \({\mathbf {p}}_{K}\) as in (59) for all \(K\in {\mathcal {T}} _n\), with \(\mu =1\). We discuss the case of sequences of meshes with grading parameter \(\sigma \) equal to \(\frac{1}{2}\), \(\sqrt{2} -1\) and \((\sqrt{2} -1)^2\).
Since we cannot compute the true energy error with the VEM (it is not computable since functions in the virtual space are not known explicitly), in order to compare the two methods, we investigate the \(L^2\) error on the skeleton \({\mathcal {E}}_n\) (it is computable in all cases a),\(\dots \),d), since also the virtual functions are polynomials on \({\mathcal {E}}_n\)), i.e.
and we postpone the comparison between \(H^1\) errors later.
The results are shown in Fig. 6, where the hp version of VEM is applied to meshes (a), (b) and (c), while the hp version of FEM is applied to mesh (d).

hp FEM versus hp FEM. \(L^2\) error on the skeleton \(\Vert u- u_{n}\Vert _{0,{\mathcal {E}} _n}\) employing different sequence of meshes and different parameters \(\sigma \). Left: \(\sigma =\frac{1}{2}\), middle: \(\sigma =\sqrt{2}-1\), right: \(\sigma =(\sqrt{2}-1)^2\), linearly varying over the mesh layers degrees of accuracy \(\mu =1\) defined in (59)
It is possible to see that there is not a preferential choice; for instance, hp VEM performs better than hp FEM when \(\sigma = \frac{1}{2}\), they perform almost the same when \(\sigma = \sqrt{2}-1\), performs much worse when \(\sigma = (\sqrt{2} -1)^2\).
In this sense, we can say that the two methods are comparable; nonetheless, the VEM leads to a huge flexibility in the choice of the domain meshing which is not available in standard \(H^1\) conforming FEM.
We believe that, in order to really see a marked advantage of hp-VEM over hp-FEM, more complex situations need to be addressed. This may involve, for instance, complex geometries (where polyhedral meshes can do a better job), hp-adaptivity (where again there is more refinement freedom) or more involved problems (Discrete Fracture Network, crack propagation, Fluid Structure Interaction, etc.). At the present stage, on the Laplace problem on academic examples, what we can display is the flexibility in refining near corners. Note that hp-adaptivity is currently under investigation.
Next, in Fig. 7, we compare the \(H^1\) error of VEM defined in (67) with the standard \(H^1\) error of hp FEM employing the same meshes and discretization parameters discussed for the comparison of \(L^2\) errors on the skeleton.

Error \(\vert u- {\varPi } ^{\nabla }_{\mathbf p} u_{n}\vert _{1,{\mathcal {T}} _n}\) for hp VEM and error \(\vert u- u_{n}\vert _{1,{\varOmega }}\) for hp FEM, employing different sequence of meshes and different parameters \(\sigma \). Left: \(\sigma =\frac{1}{2}\), middle: \(\sigma =\sqrt{2}-1\), right: \(\sigma =(\sqrt{2}-1)^2\), linearly varying over the mesh layers degrees of accuracy \(\mu =1\) defined in (59)
The results are comparable to those related to the \(L^2\) error on the skeleton and more precisely the two method display similar behaviours.
Remark 5
We have not discussed yet the choice that we perform for the polynomial basis \(\{q_{\varvec{\alpha }}\}_{|\varvec{\alpha }|=0}^{p_{K}- 2}\) which is dual to the definition of the internal degrees of freedom defined in (11). In all the numerical experiments so far we employed the monomial basis:
Such a choice is typical in VEM literature and was in fact introduced in the pioneering works [10, 12] since the implementation of the method under (68) turns out to be simple.
Nonetheless, as firstly observed in [4], employing (68) entails a bad effect on the condition number of the VEM stiffness matrix for high values of \(p\). In order to avoid such a ill-conditioning one may define local polynomial bases which are orthonormal in \(L^2\) on each element, for instance obtained by employing a stable Gram–Schimdt algorithm, e.g. as that presented in [9]. A deep investigation of this aspect can be found in [41].
References
Adams, R.A., Fournier, J.J.F.: Sobolev Spaces, vol. 140. Academic Press, London (2003)
Ahmad, B., Alsaedi, A., Brezzi, F., Marini, L., Russo, A.: Equivalent projectors for virtual element method. Comput. Math. Appl. 66(3), 376–391 (2013)
Antonietti, P.F., Beirão da Veiga, L., Mora, D., Verani, M.: A stream virtual element formulation of the Stokes problem on polygonal meshes. SIAM J. Numer. Anal. 52(1), 386–404 (2014)
Antonietti, P.F., Mascotto, L., Verani, M.: A multigrid algorithm for the \(p\)-version of the virtual element method. https://arxiv.org/abs/1703.02285 (2017)
Babuška, I., Guo, B.Q.: Regularity of the solution of elliptic problems with piecewise analytic data. Part I. Boundary value problems for linear elliptic equation of second order. SIAM J. Math. Anal. 19(1), 172–203 (1988)
Babuška, I., Guo, B.Q.: Regularity of the solution of elliptic problems with piecewise analytic data. Part II: the trace spaces and application to the boundary value problems with nonhomogeneous boundary conditions. SIAM J. Math. Anal. 20(4), 763–781 (1989)
Babuška, I., Suri, M.: The \(hp\) version of the finite element method with quasiuniform meshes. ESAIM Math. Model. Numer. Anal. 21(2), 199–238 (1987)
Babuška, I., Suri, M.: The optimal convergence rate of the \(p\)-version of the finite element method. SIAM J. Numer. Anal. 24(4), 750–776 (1987)
Bassi, F., Botti, L., Colombo, A., Di Pietro, D.A., Tesini, P.: On the flexibility of agglomeration based physical space discontinuous Galerkin discretizations. J. Comput. Phys. 231(1), 45–65 (2012)
Beirão da Veiga, L., Brezzi, F., Cangiani, A., Manzini, G., Marini, L., Russo, A.: Basic principles of virtual element methods. Math. Models Methods Appl. Sci. 23(01), 199–214 (2013)
Beirão da Veiga, L., Brezzi, F., Marini, L.: Virtual elements for linear elasticity problems. SIAM J. Numer. Anal. 51, 794–812 (2013)
Beirão da Veiga, L., Brezzi, F., Marini, L.D., Russo, A.: The Hitchhiker’s guide to the virtual element method. Math. Models Methods Appl. Sci. 24(8), 1541–1573 (2014)
Beirão da Veiga, L., Brezzi, F., Marini, L.D., Russo, A.: Virtual element method for general second-order elliptic problems on polygonal meshes. Math. Models Methods Appl. Sci. 26(4), 729–750 (2016)
Beirão da Veiga, L., Chernov, A., Mascotto, L., Russo, A.: Basic principles of \(hp\) virtual elements on quasiuniform meshes. Math. Models Methods Appl. Sci. 26(8), 1567–1598 (2016)
Beirão da Veiga, L., Chernov, A., Mascotto, L., Russo, A.: Exponential convergence of the \(hp\) virtual element method with corner singularity. http://arxiv.org/abs/1611.10165 (2016)
Beirão da Veiga, L., Lipnikov, K., Manzini, G.: The Mimetic Finite Difference Method for Elliptic Problems, vol. 11. Springer, Berlin (2014)
Beirão da Veiga, L., Lovadina, C., Russo, A.: Stability analysis for the virtual element method. Math. Models Methods Appl. Sci. (2017). doi:10.1142/S021820251750052X
Beirão da Veiga, L., Lovadina, C., Vacca, G.: Divergence free virtual elements for the Stokes problem on polygonal meshes. ESAIM Math. Model. Numer. Anal. 51(2), 509–535 (2017)
Beirão da Veiga, L., Manzini, G.: A virtual element method with arbitrary regularity. IMA J. Numer. Anal. 34(2), 759–781 (2014)
Benedetto, M., Berrone, S., Pieraccini, S., Scialò, S.: The virtual element method for discrete fracture network simulations. Comput. Methods Appl. Mech. Eng. 280, 135–156 (2014)
Benedetto, M.F., Berrone, S., Borio, A., Pieraccini, S., Scialò, S.: A hybrid mortar virtual element method for discrete fracture network simulations. J. Comput. Phys. 306, 148–166 (2016)
Bernardi, C., Maday, Y.: Polynomial interpolation results in Sobolev spaces. J. Comput. Appl. Math. 43(1), 53–80 (1992)
Brenner, S.C., Scott, L.R.: The Mathematical Theory of Finite Element Methods. Texts in Applied Mathematics, vol. 15, 3rd edn. Springer, New York (2008)
Brezzi, F., Lipnikov, K., Shashkov, M.: Convergence of the mimetic finite difference method for diffusion problems on polyhedral meshes. SIAM J. Numer. Anal. 43(5), 1872–1896 (2005)
Brezzi, F., Marini, L.: Virtual element method for plate bending problems. Comput. Methods Appl. Mech. Eng. 253, 455–462 (2013)
Cáceres, E., Gatica, G.N.: A mixed virtual element method for the pseudostress–velocity formulation of the Stokes problem. IMA J. Numer. Anal. 37(1), 296–331 (2017)
Cangiani, A., Georgoulis, E.H., Houston, P.: \(hp\)-version discontinuous Galerkin methods on polygonal and polyhedral meshes. Math. Models Methods Appl. Sci. 24(10), 2009–2041 (2014)
Cangiani, A., Manzini, G., Sutton, O.J.: Conforming and nonconforming virtual element methods for elliptic problems. IMA J. Numer. Anal. 37(3), 1317–1354 (2016)
Chernov, A., Mascotto, L.: The harmonic virtual element method: stabilization and exponential convergence for the Laplace problem on polygonal domains. https://arxiv.org/abs/1705.10049 (2017)
Cockburn, B., Gopalakrishnan, J., Lazarov, R.: Unified hybridization of discontinuous Galerkin, mixed and continuous Galerkin methods for second order elliptic problems. SIAM J. Numer. Anal. 47(2), 1319–1365 (2009)
Di Pietro, D.A., Ern, A.: Hybrid high-order methods for variable-diffusion problems on general meshes. C. R. Math. Acad. Sci. Paris 353(1), 31–34 (2015)
Dubiner, M.: Spectral methods on triangles and other domains. J. Sci. Comput. 6(4), 345–390 (1991)
Frittelli, M., Sgura, I.: Virtual element method for the Laplace Beltrami equation on surfaces. ESAIM Math. Model. Numer. Anal. (2017). doi:10.1051/m2an/2017040
Gain, A., Talischi, C., Paulino, G.: On the virtual element method for three-dimensional elasticity problems on arbitrary polyhedral meshes. Comput. Methods Appl. Mech. Eng. 282, 132–160 (2014)
Georgoulis, E.: Inverse-type estimates on \(hp\) finite element spaces and applications. Math. Comput. 77(261), 201–219 (2008)
Gillette, A., Rand, A., Bajaj, C.: Error estimates for generalized barycentric interpolation. Adv. Comput. Math. 37(3), 417–439 (2012)
Guo, B., Wang, L.: Jacobi approximations in non-uniformly Jacobi-weighted Sobolev spaces. J. Approx. Theory 128(1), 1–41 (2004)
Hiptmair, R., Moiola, A., Perugia, I., Schwab, C.: Approximation by harmonic polynomials in star-shaped domains and exponential convergence of Trefftz \(hp\)-dgFEM. ESAIM Math. Model. Numer. Anal. 48(3), 727–752 (2014)
Koornwinder, T.: Two-variable analogues of the classical orthogonal polynomials. In: Askey, R.A. (ed.) Theory and Applications of Special Functions, Proceedings of an Advanced Seminar Sponsored by the Mathematics Research Center, the University of Wisconsin-Madison, March 31-April 2, 1975 pp. 435–495 (1975)
Li, H., Shen, J.: Optimal error estimates in Jacobi-weighted Sobolev spaces for polynomial approximations on the triangle. Math. Comput. 79(271), 1621–1646 (2010)
Mascotto, L.: Ill-conditioning in the Virtual Element Method: stabilizations and bases. https://arxiv.org/abs/1705.10581 (2017)
Melenk, J.M.: \(hp\)-interpolation of non-smooth functions. SIAM J. Numer. Anal. 43, 127–155 (2005)
Menezes, I.F.M., Paulino, G.H., Pereira, A., Talischi, C.: Polygonal finite elements for topology optimization: a unifying paradigm. Int. J. Numer. Methods Eng. 82(6), 671–698 (2010)
Mora, D., Rivera, G., Rodríguez, R.: A virtual element method for the Steklov eigenvalue problem. Math. Models Methods Appl. Sci. 25(08), 1421–1445 (2015)
Perugia, I., Pietra, P., Russo, A.: A plane wave virtual element method for the Helmholtz problem. ESAIM Math. Model. Numer. Anal. 50(3), 783–808 (2016)
Rjasanow, S., Weißer, S.: Higher order BEM-based FEM on polygonal meshes. SIAM J. Numer. Anal. 50(5), 2357–2378 (2012)
Schwab, C.: \(p\)-and \(hp\)-Finite Element Methods: Theory and Applications in Solid and Fluid Mechanics. Clarendon Press, Oxford (1998)
Sukumar, N., Tabarraei, A.: Conforming polygonal finite elements. Int. J. Numer. Methods Eng. 61, 2045–2066 (2004)
Tartar, L.: An Introduction to Sobolev Spaces and Interpolation Spaces, vol. 3. Springer, Berlin (2007)
Triebel, H.: Interpolation Theory, Function Spaces, Differential Operators. North-Holland, Amsterdam (1978)
Wriggers, P., Rust, W.T., Reddy, B.D.: A virtual element method for contact. Comput. Mech. 58(6), 1039–1050 (2016)
Acknowledgements
The authors are grateful to the anonymous referees for their valuable and constructive comments, which have greatly contributed to the improvement of the paper. The first author has received funding from the European Research Council (ERC) under the European Unions Horizon 2020 research and innovation programme (Grant Agreement No. 681162). The third author thanks the departments of mathematics of Università degli Studi di Milano Statale and Carl von Ossietzky Universitat Oldenburg, where he mostly worked on this paper.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
The aim of this first appendix is addressing the polynomial hp inverse estimate (32).
Theorem 4
Let \({\widehat{T}}\) be the reference triangle of vertices (0, 0), (1, 0) and (0, 1). Let \(b_{{\widehat{T}}}\) be the cubic bubble function associated with \({\widehat{T}}\). Let \(q\in {\mathbb {P}}_p({\widehat{T}})\), \(p\in {\mathbb {N}}\). Then:
where \(c\) is a positive constant independent on p.
Proof
The proof is a modification of that in [42, Theorem D2]. For a complete proof in the case \(\alpha \ge 0\), see [15, Theorem A.3]. \(\square \)
Lemma 8
Let \(T\) be a triangle and let \(b_{T}\) be the associated cubic bubble function. Let \(q\in {\mathbb {P}}_{p}(T)\), \(p\in {\mathbb {N}}\). Then:
where c is a positive constant independent on \(h_T\) and \(p\), \(h_T=\text {diam}(T)\).
Proof
The idea of the proof is presented in [42, Theorem D2]. For a complete proof, see [15, Lemma A.4]. \(\square \)
We are now ready for the inverse estimate involving the \(H^{-1}\) norm of polynomials.
We highlight that such result, namely Theorem 5, has been firstly proven in [35, Theorem 3.9]. It is worth to mention that the work [35] is devoted to prove hp polynomial inverse estimates on (possibly) bad-shaped domains; this keeps the topic at a very general level. On the other hand, this work provides rather technical proofs that can be in fact eased when employing regular triangles/polygons. In particular, the proof of Theorem 5 provided here turns out to be simpler than the one in [35, Theorem 3.9].
Theorem 5
Let \(K\subseteq {\mathbb {R}}^2\) be a polygon. Assume that there exists \({\mathcal {T}} _n(K)\) subtriangulation of \(K\) such that \(h_K\approx h_T\) for all \(T\in {\mathcal {T}} _n(K)\), where \(h_\omega =\text {diam}(\omega )\), \(\omega \subseteq {\mathbb {R}}^2\). Let \(q\in {\mathbb {P}}_p(K)\) with \(p\in {\mathbb {N}} \cup \{0\}\). Then:
where \(\Vert q \Vert _{-1,K}:=\Vert q \Vert _{(H_0^1(K))^*}\).
Proof
Let \(b_{K}\) be the piecewise bubble function, defined on each \(T\in {\mathcal {T}} _n(K)\) as the local cubic bubble function \(b_{T}\) introduced in Lemma 8. Then:
Using now Lemma 8, (70) and the hypothesis that \(h_K\approx h_T\) for all \(T\) in the subtriangulation of \(K\), we obtain:
Finally, we apply Theorem 4 with \(\alpha =0\) and \(\beta =1\) and we get:
\(\square \)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
da Veiga, L.B., Chernov, A., Mascotto, L. et al. Exponential convergence of the hp virtual element method in presence of corner singularities. Numer. Math. 138, 581–613 (2018). https://doi.org/10.1007/s00211-017-0921-7
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00211-017-0921-7