
Abstract
This work leverages an original dependency analysis to parallelize loops regardless of their form in imperative programs. Our algorithm distributes a loop into multiple parallelizable loops, resulting in gains in execution time comparable to state-of-the-art automatic source-to-source code transformers when both are applicable. Our graph-based algorithm is intuitive, language-agnostic, proven correct, and applicable to all types of loops. Importantly, it can be applied even if the loop iteration space is unknown statically or at compile time, or more generally if the loop is not in canonical form or contains loop-carried dependency. As contributions we deliver the computational technique, proof of its preservation of semantic correctness, and experimental results to quantify the expected performance gains. We also show that many comparable tools cannot distribute the loops we optimize, and that our technique can be seamlessly integrated into compiler passes or other automatic parallelization suites.
This research is supported by the Transatlantic Research Partnership of the Embassy of France in the United States and the FACE Foundation. Th. Rubiano and Th. Seiller are also supported by the Île-de-France region through the DIM RFSI project “CoHOp”. N. Rusch is supported in part by the Augusta University Provost’s office, and the Translational Research Program of the Department of Medicine, Medical College of Georgia at Augusta University.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Notes
- 1.
In practice, private copies of
 are automatically created by e.g., the standard parallel programming API for C, OpenMP. Its
are automatically created by e.g., the standard parallel programming API for C, OpenMP. Its
 directives are illustrated in Fig. 5.
directives are illustrated in Fig. 5. - 2.
We focus on
 loops, but other kinds of loops (
loops, but other kinds of loops (
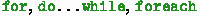 ) can always be translated into
) can always be translated into
 and general applicability follows.
and general applicability follows. - 3.
OpenMP’s
 directive is illustrated in Sect. 5.
directive is illustrated in Sect. 5. - 4.
The use command represents any command which does not modify its variables but use them and should not be moved around carelessly (e.g., a
 ). In practice, we currently treat all function calls as use, even if the function is pure.
). In practice, we currently treat all function calls as use, even if the function is pure. - 5.
We will use the order in which the variables occur in the program as their implicit order most of the time.
- 6.
Identifying the dfg with its embeddings, it is hence the identity matrix of any size.
- 7.
This is different from our previous treatment of
 loop [33, Definition 6], that required to compute the transitive closure of \(\mathbb {M}(\texttt{C})\): for the transformation we present in Sect. 3, this is not needed, as all the relevant dependencies are obtained immediately—this also guarantees that our analysis can distribute loop-carried dependencies.
loop [33, Definition 6], that required to compute the transitive closure of \(\mathbb {M}(\texttt{C})\): for the transformation we present in Sect. 3, this is not needed, as all the relevant dependencies are obtained immediately—this also guarantees that our analysis can distribute loop-carried dependencies. - 8.
- 9.
This example is inspired by benchmark bicg from PolyBench/C and presented in our artifact.
 are automatically created by e.g., the standard parallel programming API for
are automatically created by e.g., the standard parallel programming API for  directives are illustrated in Fig.
directives are illustrated in Fig.  loops, but other kinds of loops (
loops, but other kinds of loops (
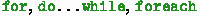 ) can always be translated into
) can always be translated into
 and general applicability follows.
and general applicability follows. directive is illustrated in Sect.
directive is illustrated in Sect.  ). In practice, we currently treat all function calls as
). In practice, we currently treat all function calls as  loop [
loop [References
Abel, A., Altenkirch, T.: A predicative analysis of structural recursion. J. Funct. Program. 12(1), 1–41 (2002). https://doi.org/10.1017/S0956796801004191
Abu-Sufah, W., Kuck, D.J., Lawrie, D.H.: On the performance enhancement of paging systems through program analysis and transformations. IEE Trans. Comput. 30(5), 341–356 (1981). https://doi.org/10.1109/TC.1981.1675792
Aho, A.V., Lam, M.S., Sethi, R., Ullman, J.D.: Compilers: Principles, Techniques, and Tools, 2nd edn. Addison Wesley, Boston (2006)
Amini, M.: Source-to-source automatic program transformations for GPU-like hardware accelerators. Theses, Ecole Nationale Supérieure des Mines de Paris, December 2012. https://pastel.archives-ouvertes.fr/pastel-00958033
Amini, M., et al.: Par4All: from convex array regions to heterogeneous computing. In: IMPACT 2012 : Second International Workshop on Polyhedral Compilation Techniques HiPEAC 2012. Paris, France, January 2012. https://hal-mines-paristech.archives-ouvertes.fr/hal- 00744733
Arabnejad, H., Bispo, J., Cardoso, J.M.P., Barbosa, J.G.: Source-to-source compilation targeting OpenMP-based automatic parallelization of C applications. J. Supercomput. 76(9), 6753–6785 (2019). https://doi.org/10.1007/s11227-019-03109-9
Aubert, C., Rubiano, T., Rusch, N., Seiller, T.: A novel loop fission technique inspired by implicit computational complexity, May 2022. https://hal.archives-ouvertes.fr/hal-03669387v1. draft
Aubert, C., Rubiano, T., Rusch, N., Seiller, T.: Loop fission benchmarks (2022). https://doi.org/10.5281/zenodo.7080145. https://github.com/statycc/loop-fission
Aubert, C., Rubiano, T., Rusch, N., Seiller, T.: MWP-analysis improvement and implementation: realizing implicit computational complexity. In: Felty, A.P. (ed.) 7th International Conference on Formal Structures for Computation and Deduction (FSCD 2022). Leibniz International Proceedings in Informatics, vol. 228, pp. 26:1–26:23. Schloss Dagstuhl-Leibniz-Zentrum für Informatik (2022). https://doi.org/10.4230/LIPIcs.FSCD.2022.26
Aubert, C., Rubiano, T., Rusch, N., Seiller, T.: pymwp: MWP analysis in Python, September 2022. https://github.com/statycc/pymwp/
Bae, H., et al.: The Cetus source-to-source compiler infrastructure: overview and evaluation. Int. J. Parallel Program. 41(6), 753–767 (2013). https://doi.org/10.1007/s10766-012-0211-z
Baier, C., Katoen, J., Larsen, K.: Principles of Model Checking. MIT Press, Cambridge (2008)
Benabderrahmane, M.-W., Pouchet, L.-N., Cohen, A., Bastoul, C.: The polyhedral model is more widely applicable than you think. In: Gupta, R. (ed.) CC 2010. LNCS, vol. 6011, pp. 283–303. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-642-11970-5_16
Bertolacci, I., Strout, M.M., de Supinski, B.R., Scogland, T.R.W., Davis, E.C., Olschanowsky, C.: Extending OpenMP to facilitate loop optimization. In: de Supinski, B.R., Valero-Lara, P., Martorell, X., Mateo Bellido, S., Labarta, J. (eds.) IWOMP 2018. LNCS, vol. 11128, pp. 53–65. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-98521-3_4
Bondhugula, U., Hartono, A., Ramanujam, J., Sadayappan, P.: A practical automatic polyhedral Parallelizer and locality optimizer. SIGPLAN Not. 43(6), 101–113 (2008). https://doi.org/10.1145/1379022.1375595
Chung, F.R.K.: On the coverings of graphs. Discret. Math. 30(2), 89–93 (1980). https://doi.org/10.1016/0012-365X(80)90109-0
Dave, C., Bae, H., Min, S., Lee, S., Eigenmann, R., Midkiff, S.P.: Cetus: a source-to-source compiler infrastructure for multicores. Computer 42(11), 36–42 (2009). https://doi.org/10.1109/MC.2009.385
Ferrante, J., Ottenstein, K.J., Warren, J.D.: The program dependence graph and its use in optimization. ACM Trans. Programm. Lang. Syst. 9(3), 319–349 (1987). https://doi.org/10.1145/24039.24041
gcc.gnu.org git - gcc.git/blob - gcc/tree-loop-distribution.c. https://gcc.gnu.org/git/?p=gcc.git;a=blob;f=gcc/tree-loop- distribution.c;h=65aa1df4abae2c6acf40299f710bc62ee6bacc07;hb=HEAD#l39
Grosser, T.: Enabling Polyhedral Optimizations in LLVM. Master’s thesis, Universität Passau, April 2011. https://polly.llvm.org/publications/grosser-diploma- thesis.pdf
Holewinski, J., et al.: Dynamic trace-based analysis of vectorization potential of applications. In: Proceedings of the 33rd ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI 2012, pp. 371–382. Association for Computing Machinery, New York (2012). https://doi.org/10.1145/2254064.2254108
Intel: oneTBB documentation (2022). https://oneapi-src.github.io/oneTBB/
Intel Corporation: Intel C++ Compiler Classic Developer Guide and Reference. https://www.intel.com/content/dam/develop/external/us/en/ documents/cpp_compiler_classic.pdf
Karp, R.M., Miller, R.E., Winograd, S.: The organization of computations for uniform recurrence equations. J. ACM 14(3), 563–590 (1967). https://doi.org/10.1145/321406.321418
Klemm, M., de Supinski, B.R. (eds.): OpenMP application programming interface specification version 5.2. OpenMP Architecture Review Board, November 2021. https://www.openmp.org/wp-content/uploads/OpenMP-API- Specification-5-2.pdf
Kristiansen, L., Jones, N.D.: The flow of data and the complexity of algorithms. In: Cooper, S.B., Löwe, B., Torenvliet, L. (eds.) CiE 2005. LNCS, vol. 3526, pp. 263–274. Springer, Heidelberg (2005). https://doi.org/10.1007/11494645_33
Laird, J., Manzonetto, G., McCusker, G., Pagani, M.: Weighted relational models of typed lambda-calculi. In: LICS, pp. 301–310. IEEE Computer Society (2013). https://doi.org/10.1109/LICS.2013.36
Lattner, C., Adve, V.S.: LLVM: a compilation framework for lifelong program analysis & transformation. In: 2nd IEEE / ACM International Symposium on Code Generation and Optimization (CGO 2004), 20–24 March 2004, San Jose, CA, USA, pp. 75–88. IEEE Computer Society (2004). https://doi.org/10.1109/CGO.2004.1281665, https://ieeexplore.ieee.org/xpl/conhome/9012/proceeding
Lee, C.S., Jones, N.D., Ben-Amram, A.M.: The size-change principle for program termination. In: Hankin, C., Schmidt, D. (eds.) Conference Record of POPL 2001: The 28th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, London, UK, 17–19 January 2001, pp. 81–92. ACM (2001). https://doi.org/10.1145/360204.360210
[loopfission]: Loop fission interference graph (fig). https://reviews.llvm.org/D73801
Mehta, S., Lin, P., Yew, P.: Revisiting loop fusion in the polyhedral framework. In: Moreira, J.E., Larus, J.R. (eds.) ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, PPoPP 2014, Orlando, FL, USA, 15–19 February 2014, pp. 233–246. ACM (2014). https://doi.org/10.1145/2555243.2555250
Microsoft: Parallel patterns library (PPL) (2021). https://docs.microsoft.com/en-us/cpp/parallel/concrt/ parallel-patterns-library-ppl?view=msvc-170
Moyen, J.-Y., Rubiano, T., Seiller, T.: Loop quasi-invariant chunk detection. In: D’Souza, D., Narayan Kumar, K. (eds.) ATVA 2017. LNCS, vol. 10482, pp. 91–108. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-68167-2_7
Palkowski, M., Klimek, T., Bielecki, W.: TRACO: an automatic loop nest parallelizer for numerical applications. In: Ganzha, M., Maciaszek, L.A., Paprzycki, M. (eds.) 2015 Federated Conference on Computer Science and Information Systems, FedCSIS 2015, Lódz, Poland, 13–16 September 2015. Annals of Computer Science and Information Systems, vol. 5, pp. 681–686. IEEE (2015). https://doi.org/10.15439/2015F34
Prema, S., Nasre, R., Jehadeesan, R., Panigrahi, B.: A study on popular auto-parallelization frameworks. Concurr. Comput. Pract. Exp. 31(17), e5168 (2019). https://doi.org/10.1002/cpe.5168
Quinlan, D., et al.: Rose user manual: a tool for building source-to-source translators draft user manual (version 0.9.11.115). https://rosecompiler.org/uploads/ROSE-UserManual.pdf
Rauchwerger, L., Padua, D.A.: Parallelizing while loops for multiprocessor systems. In: Proceedings of the 9th International Symposium on Parallel Processing, IPPS 1995, pp. 347–356. IEEE Computer Society (1995)
Seiller, T.: Interaction graphs: full linear logic. In: Grohe, M., Koskinen, E., Shankar, N. (eds.) Proceedings of the 31st Annual ACM/IEEE Symposium on Logic in Computer Science, LICS 2016, New York, NY, USA, 5–8 July 2016, pp. 427–436. ACM (2016). https://doi.org/10.1145/2933575.2934568
Vitorović, A., Tomašević, M.V., Milutinović, V.M.: Manual parallelization versus state-of-the-art parallelization techniques. In: Hurson, A. (ed.) Advances in Computers, vol. 92, pp. 203–251. Elsevier (2014). https://doi.org/10.1016/B978-0-12-420232-0.00005-2
Acknowledgments
The authors wish to express their gratitude to João Bispo for explaining how to integrate AutoPar-Clava in the first version of their benchmark, to Assya Sellak for her contribution to the first steps of this work, and to the reviewers for their insightful comments.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Aubert, C., Rubiano, T., Rusch, N., Seiller, T. (2023). Distributing and Parallelizing Non-canonical Loops. In: Dragoi, C., Emmi, M., Wang, J. (eds) Verification, Model Checking, and Abstract Interpretation. VMCAI 2023. Lecture Notes in Computer Science, vol 13881. Springer, Cham. https://doi.org/10.1007/978-3-031-24950-1_1
Download citation
DOI: https://doi.org/10.1007/978-3-031-24950-1_1
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-24949-5
Online ISBN: 978-3-031-24950-1
eBook Packages: Computer ScienceComputer Science (R0)