
Abstract
Studying a social whole such as a city, an economy, or a society, requires the construction of ‘group data sets’ where the group is made up of a number of individual data series, each one in turn made up of a string of individual data points or datums. This group set forms the most important context for considering the travels of any single numerical datum. The purpose of this paper is to explore and explain how it is that different kinds of group data sets, where the data are collected and aligned according to different measuring principles and to represent different subject matters, affect the travels of any datum point in the group. Using examples from social science, the paper examines how the relations of the data points within the whole set determine the possibilities for any single individual datum to travel within and out of its set, and how the integrity and fruitfulness of data or datum journeys will be dependent on those bit-whole relations that characterize the group data set.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others


1 Introduction
The natural world is full of examples of clouds of individuals travelling in groups, groups significant enough that we have given them special labels that suggest their different group behaviour in terms of individuals: swarms of midges, murmurings of starlings, armies of ants, packs of wolves. To the amateur naturalist: ants line up, wolves practice hierarchy and strategy, starlings free-wheel according to some unaccountable design, while midges just swarm. The specialist animal behaviour expert will have more exact descriptions than these folk terms, but the point to focus on is how the whole is understood as a large set of small elements which cohere in very different forms and behave in different ways to make up the whole.
We can see a similar variety in the bit-whole relations of data that are taken to represent complex group behaviour in the social world. Studying a social whole such as a city, an economy, or a society, requires the construction of ‘group data sets’ where the group is made up of a number of individual data series, each one in turn made up of a string of individual data points or datums.Footnote 1 Any individual datum (or bit) has relations not just with the other data points in their series, but also with those of the group (or whole) data set. For example, the data on population growth of a society consist of individuals, who can be counted in a simple aggregate whole, but for social science purposes will more likely be found in data series divided by occupational classes, or age cohorts, or regional spaces. The bit-whole relations will depend upon the kind of group data involved, for there is variety in bit-whole relations just as in those naturalists’ examples suggested above. No doubt these varied kind of datum-to-‘group data set’ relations can be found in other fields of science with complex wholes such as ecology, physiology, and so forth; it is not necessarily a special feature of social science data. What is important is that different kinds of data sets in the sciences have different bit-whole properties, and that these turn out to be very important for the possibilities and fruitfulness of individual datum journeys. So, while the datum and its travels take centre stage in this paper, it does so always in relation to its ‘companions’ not just in the individual data set, but in the group data set, which should be conceived as its primary context. This focus on the datum-group data relations sits in contrast to many other studies in this volume, and to earlier studies of travelling data, which focus on other kinds of ‘companions’ and other background and foreground contexts which affect the journeys of data.Footnote 2
The purpose of this paper is to explore and explain – for quantitative data – how it is that different ‘kinds’ of numerical data form an important context for a single numerical datum. I take kinds of numerical data to indicate numerical data collected and aligned according to different principles into group data sets. The most important principles that I consider are those that stem from the kinds of measuring systems involved in the construction of the group data set. The subject matter of the data set is also important of course, but this is not the primary focus of my discussion here.
For an example, consider the measuring system based on statistical thinking. This involves the notion of an underlying statistical population, and modes of sampling in collecting data (random, systematic, representative, stratified, etc). The relations between individual data points within each statistical data series will depend primarily on what kind of population is involved and whether the datums come from, for example: a sample from a controlled trial in medicine, a time series in economics, a survey in sociology, or the demographic census of population. They will each have different bit-whole relations that depend on the statistical framework and the subject matter. For example, the data points in a rain-fall data series are clearly related in the time sequence and cannot be randomly re-ordered in the data array without losing some really important information from the data set, whereas data taken from a controlled field trial can likely be ordered and re-ordered in the array without breaking any internal relationships between the data points. Broader subject matters hold further power. Ted Porter (1986) and Ian Hacking (1990), in their writing about the history of statistical thinking, have exemplified how such subject matters meant that astronomers’ personal errors of measurement were first formulated according to a ‘law of error’, and then show how such law-like distributions were reformulated as human social character deviations, and thence reinterpreted into natural biological variation in what became known as the ‘normal’ curve. Meanwhile, the behaviour of populations of human individuals became the analogy for the kinetic theory of gases and evolutionary theorizing using biometrics. The data from all these domains share notions of statistical populations and distributions, but their subject interpretations and usage differ.
Following further the original example, the data of a national population when measured by a census of population are both statistically ‘governed’ (by the nature of such population distributions, and principles of taking good samples) and ‘governed’ by the socio-economic characteristics of the nation (such as occupational class, or age aspect, or regional characteristics) that are to be measured. So, we can understand whole (or group) data sets as involving the following elements: individual datums (or bits) that are assembled into data series, which are then packed into subject category boxes, which taken together form parts of a whole data set. The category boxes depend on the purpose and framing of the whole data set, so the same data series may appear in many different whole data sets. But how those boxes or parts fit together depends on the principles of measurement of the whole that are being followed. There is rarely a simple aggregation at any point. In the population example, a simple aggregation (from samples to population, and over time and space) will tell us the total number of individuals at a given date, but this has little use. Most analysis will want to know the categories and how they fit together in the whole. Then, what can be extracted from the whole to travel with validity depends on both the base principles of measuring the bits, the categories and how they divide the world, and the conceptual nature of the whole.Footnote 3
This point may be clarified by contrast with another data set dependent on the statistical notions of population. The data of sampled biological populations in worldwide genetics or genomics data sets depend on the hereditary properties of specimens and evolved relationships of sample subjects as well as on theoretical assumptions and empirical practices of sampling and specimen collection.Footnote 4 These two different fields of science both use the term ‘population’ and rely on statistical principles of collection and ordering. The data journeys that occur in these fields have multiple valences, and their data journeys surely differ. Even so, the datums from these different fields may well share similar characteristics of detachability, and so their journeys might have more in common with each other than with the journeys of data from sets in the same subject field but constructed according to very different principles of observation and measurement.
Both principles of measurement and subject field relations have considerable impact on the way that data are conceived and used, and so on their possibilities for travel as empirical objects, as ‘theoretical’ stand ins, as stand-alone values, and the like. Whether, and under what conditions, an individual datum point can travel within the data set, or independently beyond it, and whether such data travels are associated with integrity and fruitfulnessFootnote 5 in travelling will depend in part on the nature of those internal relations of measurement principles and subject matter that characterise the data set. This creates a presumption that data journeys will be affected by the characteristics of the whole, as much as of the parts and of the relations between those parts.
The importance of this framing, and emphasis, on the principles that lie behind whole data set measurement is demonstrated in this paper in a comparison of two sets of numbers that economists and social scientists use when they aim to get a grip on a national socio-economy. These two data sets are assembled according to two very different kinds of measuring and aggregating principles. One set uses accounting principles: everything must be counted once and nothing twice, columns must add, and bottom lines must balance. Using these accounting principles produces a group (or whole) data set that includes many individual data series, each of which has a place in the accounting system: – a system set up to measure national economic activity both within certain categories and as a whole. The other group data consists of a set of ‘indicators’: numbers that are not conceived as direct measurements of the concepts they relate to (such as the business cycle, or the health status, of a country), but are understood to be indicators for characteristics relevant for those concepts (such as, respectively, industrial production or infant mortality). These two kinds of group data sets were first developed in the mid twentieth century to draw together many different data series in attempts to count, measure, or capture the whole economic activity of the nation state: they were the social scientists’ ‘big data’ projects of their time. They were, and are, produced according to very different principles – accounting vs indicators – and so exhibit very different bit-whole relations within the group data set. Both provide aggregates in some sense, but according to different principles. My analysis will show how their bit-whole relations are critical for determining the very different possibilities for using individual datum points within the data set, and will explore the kinds of reasoning and analysis that goes on when data are taken out of the whole for use.
2 Data Sets and Their Kinds
Scientific discussions typically refer to data not to a datum, because scientists rarely deal with an individual datum which is not also part of a bigger set. Often, the term ‘set’ refers to a data series (a string of data collected under the relevant same conditions) but here the arguments relate to a group of such series – referred to here as a ‘group, or whole, data set’. Typically (as suggested above) the data points – the datums (see note 2 again) – within such a group set are held together by two sorts of relationship. One comes with the theoretical and interpretative constraints of the scientific subject field in which they live. The other – more important for the argument of this paper – comes with the means and principles of measurement that underlie their collection and their colligation into the group set. At the level of the group, these measuring principles generate different kinds of relations between the individual datums and between the series in the group. Conceived as measurements, numerical data are not all the same kind of thing.
I use the term kind of data to point to the facts that there are different kinds of ‘measuring instruments’ involved in producing numerical data, a term of usage in this context due to Marcel Boumans.Footnote 6 The measuring instruments used in social sciences look rather different from the thermometers, Geiger counters, and so forth, that might be first thought of when considering scientific measuring instruments. In the social field, they are mostly various kinds of counting systems that rely on observation posts spread out across the country in government offices, banks, companies and families who all report aspects of their lives (usually for completely other purposes). The raw data collected from these observation points are numerical, and combined in different ways, according to the frameworks or principles and techniques of the measuring instruments (consisting, as Boumans argues, of models, formulae, rules, conventions, etc) used to turn such raw numbers into measurements of the economy and society.
The following analogy may communicate the point. One can think of there being families of measuring instruments rather like there are families of musical instruments in an orchestra: woodwind, percussion, brass, strings etc. Each family of instruments produces sounds according to a common principle or recipe and set of techniques; but within each family, individual instruments occur with slightly different characteristics: violins and cellos use one principle (using taught strings) for making music, but do so with different objects and range; the percussion family has their own different strategy (of hitting objects), with individual instruments of more variety of range. Within an orchestra, all play together, but still, the family voices can be separately recognised as characterised by the principles of the instrument of the relevant group. The analogy here is that in socio-economics we have different families or kinds of measuring instruments, all producing numbers as measurements. Some of these numbers are produced using principles of statistical thinking (populations and samples); some use accounting principles (of aggregating and balancing); some use principles of tracking (indicators that track characteristics of the phenomena); and some use principles of splicing with weights to make aggregates (in the form of index numbers).Footnote 7 Thus, for the social scientists, statistical processes produce data of a different kind than those produced by accounting principles, which are in turn of a different kind than those producing indicator data, and another kind than those producing index numbers. These different kinds of data come from using four different kinds of ‘measuring instruments’, each using different principles and strategies to recognise, collect, code, assemble, and organise the information from raw observations into numbers (see Morgan 2001, 2007). Just as the instruments in the different orchestral sections produce sounds according to different principles, these different measuring instruments produce numbers of different kinds using four different principles of measurement. So when I refer to kinds of measurements in this account, I am pointing back to these principled-based measuring instruments that produce such kinds of data at the group level.
That specificity of the kind of data in question has implications for the possibilities for data travels, not just because of the different nature of those data kinds, but also because the internal relations between data points that are carried within any data series or group data set derive from their principles of construction and usage. These four different kinds of measuring instruments will produce data sets where the relationships of individual data points to their group data sets, that is of bits to wholes, have different formats. Any one datum will come from a group data set which is collected, and aligned, according to the principles of a specific kind of measuring instrument, and that datum has to be used and interpreted with that relevant set of background principles of the measuring system always in mind. This family sharing in the principles of a measurement instrument used in constructing a data set may matter as much, possibly more, than the scientific subject field for the nature of any data journeys. Thus, for socio-economic data that come from different measuring instruments, and so produce different kinds of group data sets, the very different internal relations will be critical for understanding the different possibilities for data journeys, and what happens to datums when they travel.
Conceived as measurements, the group data set produced using any one of these four socio-economic measuring instruments is expected to have some kind of a representing relation to the phenomena of interest that scientists want to investigate. These are likely to differ according to the kind of data involved. The formal ‘representational theory of measurement’ investigated this question seriously for a number of characteristic measuring systems (see Suppes 1998). That approach can be contrasted with the pragmatic approach of Finkelstein (1982) for whom ‘measurement’ always involves some form of observation. The materials here suggest that both notions are more valuable when they can be taken together. First, socio-economic numbers are often not direct measures of such phenomena by active scientists, but more often ‘observations’ taken for other purposes and abstracted from their original economic contexts in life. Second, for data to capture complex socio-economic phenomena, just as for complex environmental processes (such as in ecology), a single datum will rarely do so, which is why the nature of the group data set and its construction is so important. While at the level of the individual data series, social scientists habitually use different kinds of data sets produced by different measuring instruments to represent the things in their world, that does not immediately tell us what matters about the differences in these forms of representation for their group data set, nor for their data journeys (either as a set or individually). So, I use the term representing here in a pragmatic way, generic but informal, and will explore in what follows, how – for a kind of data (ie from a kind of measuring instrument) – datum and data journeys will be affected by the characteristics of the whole, as much as of the parts, and of the relations between them.
3 Economic Data: Perspectives on the World
There are two very expansive sets of data used by economists and social scientists to look at, and into, the economy/society as a whole unit. They both operate by assembling data at the national level, and they do so in standardised forms to enable comparisons across nations. They both provide a numerical account of the economy or society showing not just the whole, but also the bits of the economy/society in relation to the whole. They do so by using two (of the above four) different kinds of measuring instruments which offer very different kinds of perspectives and so create different kinds of data. One kind offers a broad view and one a deep view, and so parallel in numerical form the kinds of visual perspectival accounts that Svetlana Alpers (1984) examined in her contrast between the broad cityscapes of the Dutch painters and the deep distant landscape view provided by the Italian painters of the early modern period. Both groups of artists provided pictures of the whole, and both enabled you to see the elements in the landscapes as bits in the whole in relation to each other. These are paralleled in these social science measurement systems in that one kind looks broadly to pick up the full range and diversity of phenomena, the other looks more deeply to reveal the interrelations between a smaller range of phenomena that are taken the characterise the economy as a whole.
These two different kinds of data set examined in the rest of this paper provide the materials to consider the dependency of datum travels on the measuring structures or instruments they come from. One kind of data set, the one that looks deeply, is the national income accounts (NIA). It announces the nature of it its internal relations in its name:- an individual datum is tightly ordered in the whole by the accounting principles of the measuring instrument. The other kind, socio-economic indicators, are much less individually constrained and together they look across a wide range of the phenomena of the whole, capturing all the individual elements separately that make up a picture of socio-economic development.
I need to be careful here: for we are really talking about two master data sets – whole or group data sets – one assembled according to accounting rules, the other according to the indicator format. But inside each group data set, there are many series of data, each one consisting of data that have been collected, coded, assembled and manipulated to represent a particular element of the economy or society. These data series are not raw but highly wrought and polished. Any one set of numbers in the NIA data set, or any one indicator series in the overall database of indicators, may be constructed according to any of the measuring instruments: some may come from accounting processes, others by statistical methods from surveys or censuses, others are simple numerical counts. Regardless of the numerical provenance of the individual series, it is the relation of each of these individual and separate series to each other and to the whole that are formulated according to those group-level (accounting or indicator) measurement frameworks.
Both kinds of measuring instruments are generative, in the sense that they generate whole data sets designed to represent in some direct or indirect way some conceptualised phenomena. The middle level stuff of the social sciences represented in the separate data series is not stuff that can be found raw (with whatever practical difficulties); it is stuff that must be fashioned to fit, more or less indirectly, their conceptualised phenomena. Thus ‘national income’ and socio-economic development’ are both highly abstract: no one can ‘see’ national income, or socio-economic development in any direct way through a microscope. But social scientists do ‘see’ (ie generate) with their microscopes, data on something they conceptualise as development, or national income. We could even label the NIA a ‘national-level analytical-accounting macroscope’. The point here is not to subvert Ian Hacking’s (1983) seminal point about seeing with rather than through our measuring instruments, but rather to extend it for thinking about measurement at the macro scale and in the social sciences where measuring instruments are not physical but organisational and technical.
3.1 Accounting
National Income Accounting (NIA) began in the late 1930s as a project to count all economic activity of the national economy for each year. It was developed into a usable system by the end of the 1940s, its development hastened by the needs of various national governments to organise the ‘war economy’, a period which stretched the limits of productive capacity and in which governments needed to plan the economy. Such accounting became equally important in peace times as the new post-war international economic arrangements and agencies required such measurements as part of their regulatory agendas. In such an accounting, a national income data set, constructed for each country (or possibly sub-region) separately, provides an accounting picture of the whole national economy and its salient parts, where all the parts are related to each other in an accounting framework. That framework provides the rules of what to count, how to count, how to check that everything is counted, and uses balance checks between the wholes to ensure that everything (within its framework) is taken into account.
It is a three-dimensional account – the aggregate economy is measured according to all incomes (Column I), all things produced (Column II), and all expenditures (Column III). It appears in one of its earliest and simplest forms in Table 1 showing the three columns or dimensions each with its associated categories (adapted from Deane 1948, and see Morgan 2011b). Everything that has to be counted has to be placed in the right place (column and row), so every individual data series has to be categorised, that is, national accounting operates under a system of categorization rules for the individual series. (And these accounts can be broken down into finer sub-categories and equivalent numbers.) The bottom line categories for each column: 6, 13, and 16 form an identity based on the principles of the accounting. When the table is filled in with the relevant numbers, the three numbers for these categories should be equal because they constitute three different ways to count what economists consider to be equivalent in monetary terms. If the different columns of the system do not balance, the implication is that there is something missing somewhere. That is, ‘the bottom line’ of accounting must balance as a matter of principle.
The national income accounts operate not only to measure aspects of the aggregate economy as depicted in the data set, but as a standardised set of measurements that can be reasoned with and are essential in helping governments make policy. Those reasonings are primarily driven by the functional or behavioural economic connections between the elements in the accounts, but any reasoning will have to be reflected in the accounting numbers and consistent with the accounting principles. This is just the same as using accounting for a firm or company. A firm’s accounts are both a representation of the company’s health, and a functional space for thinking about changing the performance of the company. So, if a company invests more, it expects to grow in overall product in successive years as a functional relationship; such changes will of course be reflected in the accounting relations. But less obviously, they are also constrained by the accounting relations: if there is no profit, there is no money to invest and so it must come from other change in the company’s activities. These relationships and constraints are all revealed in the accounting numbers. Similarly for the aggregate numbers of the NIA: the numbers represent the economic situation for the national state for a year (the usual accounting period) and so function in two different, but coherent, ways: as subject categories with accounting rules, and as subject categories with economic relations. So, again, if a nation invests more, it expects to grow in overall product in successive years. Fruitful uses of the data can be found even when the individual datum elements are mutable, and surprisingly this is precisely because of these strong internal relations.
This may all seem obscure, so an example that demonstrates these characteristics of a travelling datum in this context may clarify. The example comes from Wolfgang’s Stolper’s attempt to make a plan for the Nigerian economy in the early 1960s at a time when it had just gained independence (see Morgan 2008). His planning asked each individual region to submit their specific plans for investment to the federal government so that all their plans could be put together. Each datum point supplied by the regions had to be found a place in the national aggregate plan, but the construction of the measurement system meant that to do so, it had to fit with all the other current and future pieces of information in the NIA system that represented the Nigerian economy of the day. So, for example, a region that wanted to build more schools could come along with their costed project to do so. Such a project would require more trained teachers (and so more college places in the education system), and more construction (entailing the building industry, with labour and resources), all requiring changes in Column II, row 12 (see Table 1). Both more teachers and more school buildings would necessitate more government expenditure in Column III, row 14 or 15. If this part of the plan went ahead, those activities would generate more incomes in Column I, row 4 or 5, and so consumption in the system as a whole: Column III, row 14. This last reaction is described by the economic relation, known as the ‘multiplier effect’, that can be traced through the categories and data set of the NIA. The individual datum elements for each numbered category can be ‘taken out’ of the accounts by the government planner, altered to show this change, travel and be re-situated in other contexts (such as in a local budget for a school building), and be replaced in the national accounts by a new number. But the usefulness and fruitfulness of such datum journeys are most evident when each travels as a member of the national (NIA) data set into a context where both the internal accounting principles, and the subject matter economic relations of that NIA data set are made use of.
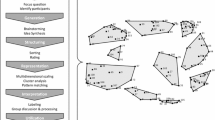
As an accounting system, there are very strong requirements of consistency, but the processes for re-balancing the bottom lines are driven by the economic relations within and between the columns. If, for example – as a result of the new school bid – some other government funded activity (asked for by some other region perhaps) would have to be curtailed to make this schools investment possible, this in turn would reduce the multiplier effects – that is, there would be balancing effects across the accounting columns and rows. Any planning number that is taken out and replaced with another such is likely to alter the whole table, as depicted in Fig. 1. These numbers are expressed in, and represent, monetary amounts, but in turn those monetary amounts represent real things in the economy: people earn incomes by educating children in school buildings. Time consistency matters too – more investment in schools this year would not only imply less of something else now, but might also produce more returns in the future from an educated workforce, so there was also a process of making the present and future numbers consistent. As Deane remarked, the economic policy maker

Accounting kind: NIA whole data set
wants to be able to see each of the constituent items in the network of national economic activity not only as a separate feature of the national accounts, but also as a factor influencing and influenced by other activities… (Deane 1953, p 3)
Even without going into more details, it is possible to see that, in reasoning about one datum point (the numbers for investment in new schools) – it is not possible to pull the accounting principles and economic reasoning away from each other. But it is equally easy (I hope) to see that the accounting principles operate not only as a reasoning space, but also as a constraint on that reasoning about the future of that society, a specific society in time and place taking into account all the other datum points that involves. An individual datum can be transported in or out, and be mutable within the planning system, and create mutability in the represented economic system – provided only that all the consistencies hold. In other words, there are strong requirements in the accounting principles that constrain the numbers and determine the reasoning with them (see Morgan 2008).
3.2 Indicating
The second kind of data base involves so-called ‘indicators’, typically made up of a set of data series, each one indicating something of relevance for understanding the many dimensions of socio-economic aspects of life. An indicator series is one that aims to track or indicate one aspect of a complex phenomena – each characteristic of that phenomenon will have a separate data series. Sometimes these can be charted or sited in tables together, but they are not so easily combined for both technical and subject matter reasons.Footnote 8
There are two examples which are close to the NIA in aiming to capture, in numbers, characteristics of the aggregate economy or socio-economy. The first example, business cycle indicators, were developed in the 1920s and 1930s in literature which crossed over between academic and public domains (and are still evident in the financial press nowadays). They were numbers that were held to capture or represent characteristics of the business cycle at the level of the nation state, a phenomenon that was difficult to define beyond the idea that it was cycles in the economic activity of an economy. While the causes and mechanisms were not so evident (and are still argued over), the community of economists had more agreement over the general characteristics of the phenomenon, yet also believed that these characteristics (and the timing of such cycles) were to some extent specific to a national economy. While all national economies would have some indicators in common (eg interest rates, exchange rates, bank deposits, exports and imports, etc), a highly industrialised economy might additionally be characterised by a set of industry indicators, while a more agricultural economy might be best represented by an additional set of primary sector indicators. A relatively small set of such indicators (perhaps up to a dozen) were taken to characterise economic activity as well as offering some insight into the timing of cycles evident in the time relations between each indicator series and thus in each characteristic element. Both the overall set, and the time relations between them were taken to indicate the nature and path of economic activity for the national economy. None of them could serve as ‘proxy’ for the whole economy, because they did not represent the whole economy directly or indirectly but only aspects of it. And there were technical difficulties in making combinations: they did not each follow the same pattern in the same time frame. More pertinantly, they could not easily be combined into one single indicator because, although they exhibited correlations, there was no principled way that they could be related as far as subject matter was concerned. Business cycles on the one hand operated as a rather vague concept, and on the other hand as a phenomenon of many characteristics which could not easily be patterned or drawn together into a causal network, nor measured in any direct way.Footnote 9 Indeed it was partly this problem that lead economists to prefer the greater insight offered by the joined-up system of national income accounts which became available in the 1940s and 1950s and so made business cycle indicators less important.
A similar kind of data structure, but with a much higher dimension of characteristic elements and with much broader reach of subject area, are the indicator set now being developed for the UN’s Sustainable Development Goals. These replaced the Millenium Development Goals (2000–2015), and are substantially more ambitious (see Morgan and Bach 2018). This set of 230 data series is designed to offer a numerical picture of every nation’s socio-economic health, including now their environmental health. They consist of a bundle of separate data series, each one having an ‘indicator’ relationship to one of 169 ‘targets’, each of which itself has an indirect relationship to the 17 ‘goals’. By indirect, I mean that the indicators don’t offer measurements of, or for, one of the targets but only numbers related to one characteristic of each target; in most cases there are several indicators per target and several targets per goal. That is, both goals and targets are multidimensional and goals in particular are defined verbally and conceptually rather than in any measurable way (unlike the aggregate gross national income in the NIA accounts). For example, Goal 3 of the SDGs is aimed at increasing health and well being. It is accompanied by a set of targets concerned with maternal and infant healthiness, reducing preventable diseases, providing access to health care, and so forth. Some of these are easier to associate with numerical evidence than others. Each of the 9 targets for Goal 3 is accompanied by a set of indicators which can offer numerical evidence associated with the current situation of that target in different countries over time. These indicators – such as ‘malaria incidence per 1000 population’ or ‘road traffic deaths’ – indicate: they offer numerical information about some aspect of one target in relation to the goal, but they are far from measuring or representing the target let alone the overall goal that needs to be represented. This example is rather straightforward for there are lots of health-related data series that can be turned into numerical indicators. But suppose we take a more opaque Goal 16: ‘promoting peaceful and inclusive societies’ and ask for ‘legal identity’ as a target for inclusivity: we are immediately faced with difficulties in finding ways to indicate this concept. For example, how should one rank-order the various forms of legal identity, let alone find numbers for them? Registered birth and citizenship are relatively straightforward and likely have relatively good numbers collected by the state. But what about the host of in-between status such as ‘the right to remain and work but not have your children have the right to school or health care’? Even assuming we had numbers that would fit those categories of people, we have no principled way to rank-ordering the categories, nor to value them in some commensurable way.
Because of the three-level ‘goals-targets-indicators’ system of the SDGs, these indicators have a double degree of detachment from their goals, and so distance in representing power, for those goals and targets to which they are attached (see Morgan and Bach 2018). The indicators are taken to represent the characteristics of the targets (in some form), and the targets are taken to represent the characteristics of the goals (in some form). This is a downside for the representing power of any data set. At the same time, the various indicator series remain largely independent of each other, having no formal or informal relations between them. They are not part of an interrelated causal account, although individual series might capture individual symptoms, causes or consequences of underdevelopment. (For example, high infant mortality is thought to be a consequence of low levels of development whereas low levels of education are thought to be a cause of low levels of development.) They cannot be aggregated according to any usable or principled rules as works for the NIA, nor provide matter for functional or behavioural theorizing about socioeconomic development as we saw for the NIA. And unlike the ‘index numbers’ by which economists regularly measure multiply-component concepts (for example inflation, or industrial output), social scientists cannot easily turn these sustainable development indications into a single overall data series that would make sense according to measurement principles. Why not – because they are not measured in comparable units (eg money) nor is there any principled ways of deciding how to weight the various elements in the whole (eg is legal identity worth 10% of total sustainable development or 1%). They cannot be turned in any principled way in an aggregate measure like the national income, nor combined in a principled way consistent with ideas about development into one meta-data series for each country and so be available for international comparison.Footnote 10 While these data certainly contain information indicating characteristics of development, they should not be considered measurements of development.
As individual indicators, these data series and individual datum points can and do travel fruitfully from the statisticians to many users including into social scientists’ research labs and are used for many varied topics not just those of development even though their status as measurements in relation to development theory is not generally easy to determine They also travel from UN usages to a variety of other users for any other purpose they choose for them: they are public numbers for public use and their usage depends in considerable part on their UN provenance that makes them trustworthy (Porter 1995). As a set of 230 different data series indicating levels of development for each country member of the UN, they provide a whole data set. As such, they most frequently appear for use in comparison purposes in social scientific work, and for certain action purposes at national level.Footnote 11 But they remain a set of data series, not an integrated whole measurement system, as depicted in Fig. 2. Consider the problem situation parallel to our NIA example: suppose a government wanted to use the SDG structure of goals and targets to create a more sustainable development path. They cannot be reasoned with for planning a development programme in a nation state because they have no internal socio-economic relations generated either by association with the kind of measuring instrument involved, nor by any behavioural or theoretical relations from their subject matter. But, the very fact that the indicator numbers are not held tightly together by internal relations between different indicators (as in the NIA), and that they might be indicating a cause or effect or symptom, means that individually they can be (and are easily) taken out of their group set, to be used separately for prompting action in all sorts of circles: academic and scientific in the professional sphere; and in public and international circles where the indicator data can be used for lobbying, asking for development aid, held up as exemplary for encouragement, or pronounced as dire in order to shame the government concerned. The lack of internal principles to hold the individual indicator series together makes for different characteristics of usage than individual numbers in the NIA.Footnote 12 Indicators can be used with considerable freedom without worrying about the constraints of measurement principles or where they fit in the overall subject contexts, and this is most evident when they travel from domain to domain of usage. Unlike the NIA, where every datum travelling in and out has the potential to change all the other numbers (if only to correct them), travels of the SDG’s indicators cause no ripples within the rest of the indicator system of data, as indicated in Fig. 2 in comparison with Fig. 1.

Indicator kind: SDGs whole data set
4 Conclusions
Economists have developed two kinds of data to capture social-economic well-being. They are based on two different frameworks of measurement The national income accounts are designed to measure the complete set of income, expenditure and products at the level of the nation. They do so by building up from the subcategories of all these three activities which are understood to be – in the bottom line – equivalent (in economic and monetary terms). In contrast, the indicator series may look just as ordered because they are arrayed in connection with bigger targets, but they are in fact held together by no such constraints.
From these different measuring frameworks, come differences in usage. For the bundle of indicators, each of which can be used for action but not reasoning – any travelling datum has no effect on the whole. In contrast, the other kind is the highly constrained NIA which can be used for measuring the current health of the economy, and for reasoning and action in that realm, but in which any travelling datum can upset – and then must reset – the whole system. Perhaps counter-intuitively, datums from both travel easily and fruitfully into new contexts.
Not all indicator systems have this degree of bit-whole freedom. Datums from the business cycle indicators for example, tend to travel together because they indicate time-related characteristics of the same phenomena. Each datum and indicator can be taken out separately, but they gain from travelling together in a pattern, perhaps like a murmuring of starlings. In contrast, the indicators of the SDGs are more like a swarm of midges, with no recognisable pattern and no obvious relationships between the bits. Both of these indicator sets are very different in their relations to each other and to the whole compared to the national income accounts (NIA). Whereas both individual datums and series from the indicators have bit-whole relations, those for the NIA depend on their part-whole relations. The NIA parts might look like the ant-line, because if one element travels off the path for some reason (eg, for correction or updating), the rest have to fall in to make up the line. But they have more part-whole relations than just lining up, since they rely on multiple relations for their effectiveness in reasoning and analytical usage, and this relies on a well ordered hierarchy of rows and columns; thus the relation of parts within the whole is more like the hierarchy and co-ordination of the wolf-pack. Or perhaps – as Jim Griesemer suggested,Footnote 13 to bring the analogy into line with our socio-economic world: a bundle of indicators is like a flashmob of independent agents – taking a datum out or bringing one in does not upset the whole; in contrast, the national income accounts are tightly joined together so that taking out a datum would be equivalent of taking a section of piping out of a chemical plant: the whole process would need to be reassembled.
When we think of individual datum travels, one has to think first of the rest of the data set as their most intimate of travelling companions. Datums rarely travel on their own without their companions in the data series or set, but when they do, that set of interrelations – or indeed lack of such relations – within the whole data set is critical to their independence of travel and how they fit into their new contexts. That set of interrelations in turn depends on the measuring structures or instruments that were used to generate and organise the individual data series and individual datums within them.
Notes
- 1.
It is important in this paper to signal the collection of individual data points in a way that maintains their individuality: as ‘datums’, a jarring term that enables me to insist on this important distinction to the collective plural ‘data’ where individual distinctions are not relevant.
- 2.
See the notion of ‘travelling companions’ for the successful journeys of data (to use the language of the How Well Do Facts Travel? project – see Morgan 2011a, and the other essays in Howlett and Morgan 2011). Sabina Leonelli’s (2011) contribution to that project volume, and her subsequent book (2016), on the curation of plant research, provides an important parallel for the ideas of this paper. In her case, the information on both background and labelling are essential elements that travel with the data. Here the focus is on the other data points in the data set as companions.
- 3.
And given this, it is no surprise that any data that travel have to be carefully resituated in a way that protects their integrity in any new site, as other papers in this volume make clear (see Leonelli’s introduction).
- 4.
I thank Jim Griesemer for this parallel example from his field (see his chapter in this volume that exemplifies the point).
- 5.
See Morgan 2011a for the importance of ‘integrity’ and ‘fruitfulness’ in data journeys.
- 6.
- 7.
- 8.
- 9.
See Boumans and Leonelli (this volume) who discuss the rather ‘inflexible’ characteristics of data clustering associated with business cycle indicators; they argue that these practices, in this context, are an interpretative move which has not encouraged the re-use, or aggregation, of these data for other purposes.
- 10.
Several data series might be ‘mashed up’ (see again Leonelli and Tempini 2018) into a single series for each country or region, but the informative quality of the resulting numbers would likely be low, and the country comparisons largely meaningless, for the grain of analysis is not nearly fine enough across the geographical space to be helpful. This is in contrast to the Multidimensional Poverty Index which was carefully designed to be a combined number that was informative at a finer grain than previous poverty indices (see Bach and Morgan Forthcoming).
- 11.
It would be a false separation to think that there are scientific uses and policy or practical uses for these indicator number or for the NIA: all these numbers are hard to come by; gathering them generally requires public resources; they are used by professional communities of practice in and out of academic institutions; and for a wide range of purposes.
- 12.
It is possible that these independent data series in the indicators could be analysed and combined with correlated analysis within the national unit, or between/across national units. The latter possibility is not dealt with in this paper (but see also FN10).
- 13.
Thanks to James Griesemer for this incisive analogy – provided at the Exeter meeting in 2017 that spawned this volume.
References
Alpers, Svetlana. 1984. The Art of Describing. Chicago: University of Chicago Press.
Bach, Maria, and Mary S. Morgan (Forthcoming). Measuring Difference? The United Nations’ Shift from Progress to Poverty. History of Political Economy.
Boumans, Marcel. 2001. Fisher’s Instrumental Approach to Index Numbers. History of Political Economy 33 (supplement): 313–344.
———. 2005a. How Economists Model the World to Numbers. London: Routledge.
———. 2005b. Measurement Outside the Laboratory. Philosophy of Science 72 (5): 850–863.
Boumans, Marcel, and Sabina Leonelli. this volume. From Dirty Data to Tidy Facts: Clustering Practices in Plant Phenomics and Business Cycle Analysis. In Data Journeys in the Sciences, ed. Sabina Leonelli and Niccolò Tempini. Cham: Springer.
Deane, Phyllis. 1948. The Measurement of Colonial National Incomes: An Experiment. National Institute of Economic and Social Research, Occasional Papers XII. Cambridge: Cambridge University Press.
———. 1953. Colonial Social Accounting. Cambridge: Cambridge University Press.
Finkelstein, L. 1982. Theory and Philosophy of Measurement. In Handbook of Measurement Science, Vol 1: Theoretical Fundamentals, ed. P.H. Sydenham. New York: Wiley.
Griesemer, James. this volume. A Data Journey Through Dataset-Centric Population Genomics. In Data Journeys in the Sciences, ed. Sabina Leonelli and Niccolò Tempini. Cham: Springer.
Hacking, Ian. 1983. Representing and Intervening. Cambridge: Cambridge University Press.
———. 1990. The Taming of Chance. Cambridge: Cambridge University Press.
Howlett, W.P., and Mary S. Morgan, eds. 2011. How Well Do Facts Travel? Cambridge: Cambridge University Press.
Leonelli, Sabina. 2011. Packaging Small Facts for Reuse: Databases in Model Organism Biology. In How Well Do Facts Travel? The Dissemination of Reliable Knowledge, ed. P. Howlett and M. Morgan, 325–348. Cambridge: Cambridge University Press.
———. 2016. Data-Centric Biology: A Philosophical Study. Chicago: Chicago University Press.
———. this volume. Learning from Data Journeys. In Data Journeys in the Sciences, ed. Sabina Leonelli and Niccolò Tempini. Cham: Springer.
Leonelli, Sabina, and Niccolò Tempini. 2018. Where Health and Environment Meet: The Use of Invariant Parameters in Big Data Analysis. Synthese (online, June 8, 2018), https://doi.org/10.1007/s11229-018-1844-2.
Morgan, Mary S. 2001. Making Measuring Instruments. In The Age of Economic Measurement (edited with Judy Klein) History of Political Economy, Annual Supplement to Volume 33, 235–251. Duke University Press.
———. 2007. An Analytical History of Measuring Practices: The Case of Velocities of Money. In Measurement in Economics: A Handbook, ed. M. Boumans, 105–132. Amsterdam: Academic Press.
———. 2008. ‘On a Mission’ with Mutable Mobiles. Working Paper 34, The Nature of Evidence: How Well Do ‘Facts’ Travel? project, Department of Economic History, LSE.
———. 2011a. Travelling Facts. In How Well Do Facts Travel? The Dissemination of Reliable Knowledge, ed. Peter Howlett and Mary S. Morgan, 3–39. Cambridge: Cambridge University Press.
———. 2011b. Seeking Parts, Looking for Wholes. In Histories of Scientific Observation, ed. L.J. Daston and E. Lunbeck, 303–325. Chicago: University of Chicago Press.
Morgan, Mary S., and Maria Bach. 2018. Measuring Development – from the UN’s Perspective. In The Political Economy of Development Economics: A History Perspective, ed. Michele Alacevich and Mauro Boianovsky. History of Political Economy 50, (supplement): 193-210.
Porter, Theodore. 1986. The Rise of Statistical Thinking. Princeton: Princeton University Press.
———. 1995. Trust in Numbers: The Pursuit of Objectivity in Science and Public Life. Princeton: Princeton University Press.
Suppes. P. 1998 [2000]. Measurement, theory of. In Routledge Encylopedia of Philosophy, ed. E. Craig ed. London: Routledge. https://doi.org/10.4324/9780415249126.
Acknowledgments
I thank Sabina Leonelli, Niccolò Tempini, participants at the Exeter conference and especially Jim Griesemer for an interesting collaborative writing experience which prompted this paper. I thank Marcel Boumans for many illuminating discussions about measurements in science and economics which have influenced the content of this paper; Michel Durinx for help with the illustrations; and Maria Bach for allowing me to draw on our two recent papers (Morgan and Bach 2018, and Bach and Morgan Forthcoming).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2020 The Author(s)
About this chapter

Cite this chapter
Morgan, M.S. (2020). The Datum in Context: Measuring Frameworks, Data Series and the Journeys of Individual Datums. In: Leonelli, S., Tempini, N. (eds) Data Journeys in the Sciences. Springer, Cham. https://doi.org/10.1007/978-3-030-37177-7_6
Download citation
DOI: https://doi.org/10.1007/978-3-030-37177-7_6
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-37176-0
Online ISBN: 978-3-030-37177-7
eBook Packages: Religion and PhilosophyPhilosophy and Religion (R0)