
Abstract
Information can be conveyed to the user by means of a narrative, modeled according to the user’s context. A case in point is the weather, which can be perceived differently and with distinct levels of importance according to the user’s context. For example, for a blind person, the weather is an important element to plan and move between locations. In fact, weather can make it very difficult or even impossible for a blind person to successfully negotiate a path and navigate from one place to another. To provide proper information, narrated and delivered according to the person’s context, this paper proposes a project for the creation of weather narratives, targeted at specific types of users and contexts. The proposal’s main objective is to add value to the data, acquired through the observation of weather systems, by interpreting that data, in order to identify relevant information and automatically create narratives, in a conversational way or with machine metadata language. These narratives should communicate specific aspects of the evolution of the weather systems in an efficient way, providing knowledge and insight in specific contexts and for specific purposes. Currently, there are several language generator’ systems, which automatically create weather forecast reports, based on previously processed and synthesized information. This paper, proposes a wider and more comprehensive approach to the weather systems phenomena, proposing a full process, from the raw data to a contextualized narration, thus providing a methodology and a tool that might be used for various contexts and weather systems.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


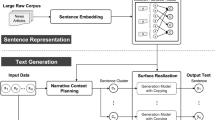
1 Introduction
Weather narration for the blind is an extremely challenging objective as the blind can’t visually check or confirm the information. Methodologically and technically there are other contexts for which this project proposal can be of great interest as well. The automatic construction of weather narratives will be developed with a strong focus on previously studied techniques for the narration to blind users of scenes and real-world dynamics in real time, as well as those techniques used in other projects,. Most of the time, computer interfaces for the visually impaired are based on narratives of the information to be transmitted to the user. A simple example is Microsoft Narrator, which narrates the computer screen content, allowing visually impaired users to access Microsoft Windows. In other more complex systems dedicated to blind users narration play a very important role, as it defines how information is presented and communicated to the user. In the systems BLAVIGATOR [1] and C4BLIND [2] an electronic white cane was developed, in collaboration with the University of Texas (UT) (the project C4BLIND UTAPEXPL/EEISII/0043/2014). This cane uses several sensors, characteristic scene elements, and numerical models to detect the surrounding environment and to position the user in a specific context of the scene, as well as to identify the elements of the scene. With this knowledge, it is possible to assist the blind user in specific actions, e.g., navigate to a location, identify an object, etc. In order to effectively assist the user, it is necessary to extract meaningful information out of this knowledge, according to the user’s intention and current context, which is communicated to the user as a narrative. This use case of a narrative to inform a blind user is particularly important, as it attributes to the narration the role of replacing the sense of sight.
In a broader sense, and including other types of information, namely big data from scientific activities, there has been a great progress in the data acquisition, processing, and visualization technologies, making large amounts of data available to the general public, e.g. data from: atmospheric activity, financial markets, consumer marketing, sports analysis, genome, etc. These data and technologies are very useful for science, providing rich and detailed information, though a simple and eloquent narrative is desirable in some contexts and for some purposes.
The observation and recording of weather phenomena generate large amounts of data, covering long periods of time and geographic areas. This data is used to build numerical models, which together with advanced computation techniques, provide forecasts of the evolution of weather systems. This activity is essential to understand our planet, as well as to plan human activities with greater predictability.
2 Literature Review
2.1 Natural Language Narration
The narration approach draws on the experience that the team at INESC TEC acquired with the development of the previous projects funded by FCT, SmartVision (PTDC/EIA/73633/2006) and Blavigator (RIPD/ADA/109690/2009) [1], and C4Blind (UTAPEXPL/EEISII/0043/2014) [2], funded by the UT Austin Portugal Program. Considering the visually impaired and the dynamics of the environments, the static description (narratives) of urban environments are not good enough, so the project developed a mobile digital platform, using noninvasive natural interfaces, well suited to meet user needs. A user-centric design methodology was used, in partnership with the ACAPO (Association of Blind and Partially Sighted Portugal) to conduct extensive tests [3, 4].
The Natural Language Generation (NGL) is included in the artificial intelligence (IA) research field, as a computational linguistics subfield, with the main objective of producing understandable texts in human language, by using computer systems algorithms. These algorithms will input some form of nonlinguistic information and use knowledge about language and application domain in order to automatically produce a text message. This field is characterized by a variety of theoretical approaches, which has the effects of fragmenting the community and reducing communication and cooperative research efforts. Still, several reference architectures have been proposed for NGL systems and the technology is mature enough to be introduced in commercial products [5, 6]. Some NGL systems have been created to produce textual weather reports, from simulation forecast models and human annotated forecast data. An excellent example is the system used by the Canadian Weather Services since 1993, which produces text reports from numerical weather simulation data, annotated by a human forecaster [7,8,9]. An automated narrator system can be based on a NGL architecture, as proposed by Reiter and Dale [6].
Currently, the Apache OpenNLP library is a machine-learning based toolkit for the processing of natural language text that supports the most common NLP simple and advanced tasks [10]. The OpenNLP CCG Library is an open source natural language processing library written in Java, which provides parsing and realization services based on Mark Steedman’s Combinatory Categorial Grammar (CCG) formalism [11]. The library makes use of multimodal extensions to CCG developed by Jason Baldridge [12].
2.2 Advanced Computing and E-Science
Weather systems data analysis, information extraction and visualization are resource-demanding activities regarding data and computation management. The Texas University (TU), Texas Advanced Computer Center (TACC), provides a high-performance computing (HPC) cyberinfrastructure, designed to cope with the most demanding research projects. To do so, it has developed the Agave Platform, which provides an ecosystem of APIs, software development kits and tools to power cyberinfrastructure at the national research level and provide the foundation for the next generation of science gateways. Agave aims to reduce the development burden on science gateway engineers, as well as individual scientists making use of computational resources, by providing a set of flexible, scalable software components that solve common problems across hybrid cloud and high-performance computing. At the heart of the platform is a set of APIs for managing the systems, applications, jobs and metadata involved in any computational experiment. The primary goal of Agave is to accelerate the development of web-enabled science projects and, thereby, drastically reduce the time of discovery [13,14,15].
2.3 Weather Systems Phenomena
Extratropical cyclones, atmospheric fronts and frontal systems are central components of weather (and hence climate) over much of the world. These frequent phenomena (every few days over many extratropical regions) are associated with the day-to-day weather conditions, including among others, precipitation, dramatic changes in temperature and wind (direction and speed) and extreme events [16]. In fact, wind extremes and heavy precipitation events occurring in the winter over land in the midlatitudes are almost always associated with extratropical cyclones (e.g. [17,18,19]). It is well known that the Azores Archipelago, due to its location, is prone to the occurrence of these extreme phenomena and associated hazards [19, 20].
With the development of computer technology and its rapid adoption by the atmospheric and climate sciences, it became clear that comprehensive cyclonic and frontal analysis would benefit greatly from automatic, computer analysis [16, 21,22,23]. Algorithms on data provided on a four-dimensional structured grid for the efficient detection and tracking of features in spatiotemporal atmospheric data have and continue to be developed at an increasing level of complexity. These may include the precise localization of the occurring genesis, lysis, merging and splitting events, and may allow access to their natural and socioeconomic impacts. However, given the difficulties of arriving at an accepted definition of these weather systems, clearly designing a numerical scheme from 3D analyses to identify cyclones, fronts and frontal zones or atmospheric rivers is a task of even greater difficulty and is still an important research theme [24].
Long-term climate datasets are critical both for understanding climate variations and evaluating their simulation in climate models. Since the 1990s, major national and international efforts have led to the creation of climate datasets, with reconstructions of meteorological and oceanographic fields (see, e.g. [25,26,27,28,29,30]), called retrospective analyses or ‘re-analyses’, which may span extended periods of time. Examples are re-analyses covering the whole 20th century (The Twentieth Century Reanalysis Project; 20CR or the ECMWF EU-funded ERACLIM project; ERA20C reanalysis) or the Last Millennium climate Reanalysis (LMR) project.
3 Plan and Methods
3.1 The Plan
To develop the project, we intent to execute 3 tasks, where task 1 and task 2 have a high degree of overlapping, as represented in the Timeline figure.
In a first phase, and as part of tasks 1 and 2, the weather system’s related information will be researched, including the following:
Identification of the weather phenomena to narrate and to work on, including fronts, atmospheric rivers, and extratropical cyclones; identification of the available data sources and their parameters; identification of the information extraction methodologies for the selected phenomena. At the same time, some narrative format mockups will be studied and tested, in order to design the narrative styles to be developed later. These mockups will be tested with an audience, as defined by the target audiences for the proof-of-concept demonstrators. Also, in this first phase, and in parallel with the previously described work, an operation model will be designed to retrieve and process data, considering the data sources and the data characteristics.
On a second phase, overlapping task 2, the work will be focused on designing the pipeline model and designing the specific components to be developed later.
On a third phase, overlapping task 2, the focus will be on software development, including the development of the necessary components the development of the NLG, and the individual test of these elements.
On a fourth phase, overlapping task3 and a part of task 2, the elements will be combined and tested, as a full featured system pipeline and probably some adjustments and software refactoring will also be executed.
A fifth, and final phase, overlapping task3 and a part of task 2, will focus on assembling the system in specific configurations and data sources, in order to produce the proof-of-concept narratives demonstrators.
3.2 The Methods
Supporting the Full Narration Process
The system to support the process will be designed as a pipeline, constituted of several functional components, properly arranged for each specific narrative type. This approach was chosen in order to have functional independence and isolation of the several components, as well as to keep the system as flexible as possible. This solution provides a framework on which different developers can add components to the systems, as well as use the existing ones in combinations that might suite their specific needs: type of narrative, raw data, weather phenomena, etc. In other previous work, this narration paradigm has been useful to design interactions with users [31,32,33].
The system’s components will be developed as software parts that can be independently designed, implements and tested. This degree of flexibility and the exploratory character of the project are well suited to justify an agile approach, regarding the software development methodology, which will be our main choice.
The final system assembly will be tested in the Agave system [8] at the UT TACC. The weather systems data is particularly demanding in terms of storage, bandwidth and processors. TACC and Agave are the perfect matches to deal with these big data science requirements.
Natural Language Narrative Construction
The narratives of weather phenomena, in natural language, will be produced by a system component of the type “Narration composition”, as described in task 2. This component will be implemented as a simple Natural Language Generator (NLG), to be developed, using the OpenNLP CCG Library. The NGL will have a classic pipeline design, for which a set of document plans will be designed, according to a communicative goal for each specific context. These plans will define the information to be included in the text narrative, as well as provide a structure for a coherent text message. They will be further processed on a microplanning stage, where the plans for the individual sentences will be defined. A final stage of linguistic realization will render a text document, thus producing a text narrative meaningful for a specific context, as previously defined.
Weather Systems Phenomena Data Extraction and Classification
The IDL team has extensive experience in developing and using such objective algorithms, namely for detecting and tracking extratropical cyclones [18, 22] and atmospheric rivers [23]. Thus, extratropical cyclones (ECs), associated frontal systems and atmospheric rivers (ARs) will be the weather systems used for this exploratory project. These algorithms are mostly applied to large gridded data sets that are produced by climate models (e.g. multidecadal period of atmospheric and ocean reanalysis data at different resolutions from several data centres [25]).
Extratropical Cyclones (ECs)
The structure and evolution of ECs, as viewed from the surface, has been described throughout the 20th century by the development of refined conceptual models (namely, the Norwegian, Shapiro and Keyser, cyclone models). Today three-dimensional conceptual models of extratropical cyclones provide a framework for understanding their dynamical evolution (see the annex for details). Detailed analysis of the structure and evolution of individual extratropical cyclones suggest that although there is no universal lifecycle of extratropical cyclones, some general cyclone characteristics can be identified [28, 30].
Atmospheric Rivers (ARs)
ARs are relatively narrow and elongated filaments of high-water vapor transport, with their occurrence generally interpreted as large atmospheric water vapor transport events in the extra-tropics [26]. This phenomenon is associated with tropical moisture exports and occurs often in combination with the passage of extratropical cyclones [19]. The warm, moist air in the cyclones’ warm sector is swept up by the advancing cold front, leading to a filament of high specific moisture content, which is transported northward at the basis of the warm conveyor belt ([19], Fig. 5). As the cyclones travel poleward, such bands of high humidity may trace back over large distances, extending from regions of high sea surface temperature in the subtropics into the midlatitudes, leading to strong precipitation along its path (e.g., storm “Xynthia”) [18]. Such structures transport more than 90% of the total midlatitude vertically-integrated water vapor [26] and can lead to intense precipitation over different continental regions due to its interaction with the topography [28]. Recently, an international agreement has been reached regarding the relationships between ARs, warm conveyor belts, and tropical moisture exports [26]. The term warm conveyor belt refers to the zone of dynamically uplifted heat and vapor transport close to a midlatitude cyclone. This vapor is often transported to the warm conveyor belt by an AR and was earlier brought poleward to the extra-tropics by tropical moisture exports ([26], Fig. 1). The uplift associated with the warm conveyor belt typically leads to heavy rainfall. This generally marks the downwind end of an AR, unless the AR has experienced orographic uplift earlier on, causing rainout over mountain areas.
The impacts of ARs have been analyzed in detail in Western Europe and revealed the importance of ARs in extreme weather events, both for case studies and from a climatological perspective [23].
An objective identification of ARs has been developed by the IDL team by means of the IVT computed with both the NCEP–NCAR and ERA Interim datasets [23].
Weather Fronts
Another important feature associated with cyclones and heavy precipitation events and its impacts are weather fronts. An objective method, the Thermal Method [29] is used to detect and depict weather fronts over a gridded map. The method is based on the choice of a Thermal Frontal Parameter (θe), directly related with the location and intensity of the frontal zone. The link between frontal precipitation and extreme weather events will also be addressed by objectively evaluating the proportion of precipitation collocated to the fronts.
Conceptual Models
All these conceptual models are widely used in educational meteorology courses and textbooks throughout the world to illustrate the basic structure and evolution of weather systems, such as extratropical cyclones and atmospheric rivers. These conceptual models have been the basis for objective detection and tracking methods developed by IDL researchers [21,22,23], which will be used here in this exploratory project.
To describe the structural evolution of ECs or ARs, a combination of surface observations, satellite imagery, radar data and model output are needed. These allow meteorologists to identify and describe the evolution of cyclonic flows such as the warm and cold conveyor belt flows and the dry intrusion. Atmospheric parameters such as horizontal wind (u, v), pressure velocity (ω), temperature and geopotential may be obtained with a 0.125° longitude × 0.125° latitude grid resolution available at 37 isobaric levels from 1000 to 1 hPa, at time intervals of 6 h or more.
The Project Proposal
This exploratory project will be based mainly on reconstructions of meteorological and oceanographic fields, meaning different available reanalysis datasets (e.g. 6hourly ERA-Interim 19792017 reanalysis over the Northern Hemisphere with a 0.75 degree of horizontal resolution; [25] and references therein). However, the methodology will be developed for any gridded data, so that it will also be tested for atmospheric and ocean reanalysis data at different resolutions from several data centres – ECMWF, National Centers for Environmental Prediction–National Center for Atmospheric Research (NCEP–NCAR), or the Japan Meteorological Agency (JMA) as well as for simulations from six Coupled Model Intercomparison Project Phase 5 (CMIP5) global climate models (GCMs) to quantify possible changes during the current century, with emphasis on the Atlantic Ocean.
This project will be aimed at building a general tool which will include future developments expected as reanalysis datasets become more diverse (atmosphere, ocean and land components), more complete (moving towards Earth-system coupled reanalysis), more detailed, and of longer timespans.
4 Tasks
The project is divided into 3 straightforward tasks.
4.1 Task 1 - Identification and Definition of Contexts and Phenomena
In this task we will identify and define the phenomena for which the narratives will be created, including atmospheric rivers, fronts, and extratropical cyclones, as well as the contexts for those narratives. A narrative provides insight and meaning to data in a specific context. Three user scenarios (contexts) will be adopted to develop the narration process. This set represents three very different types of narration, regarding the target audience and the message format:
-
Weather phenomena description, in a natural and conversational language, targeted at the general public. This narrative will provide a description or explanation of a phenomena as it is represented by the data at an exact moment and location.
-
Weather system’s data description, as a metadata classification of the phenomena data, targeted at machine systems. The main goal is to use the narration process as a method to classify and index the original data, thus creating the metadata to be used by other machine systems, e.g., indexing and search engines systems, machine leaning systems, image analysis, etc.
-
Weather phenomena progression, in a natural and scientific language, targeted at climate science students. This narrative describes the progression of a phenomena during its occurrence, as it develops over time and location. It provides a didactic storyline that can be used in teaching or science dissemination, as a solo message or as part of a multimedia message, including video and computer-generated graphics.
According to the previously described contexts, a set of weather phenomena will be chosen for narration. The phenomena will be characterized regarding the detailed methods, including algorithms and criteria that might be used to identify their occurrence and development in the original climate and weather data. These methods will later be used to extract information from the data, which will be rendered and formatted according to the context and target usage, creating a meaningful message.
4.2 Task 2 - Development of the Narration Process
In this task the narration process will be developed, which will be applied to three demonstration scenarios, according to the previously described contexts.
The process will be designed as a pipeline process, in which several components will be combined in order to have a full functional process, starting with the raw data and concluding with a narrative. The types of components will be:
-
Data biding, to connect and bind to a raw data source;
-
Data processing, to process raw data from several sources and create usable datasets;
-
Information extraction, to search and extract information from data;
-
Narration composition, to create a narrative from the extracted information, giving it meaning according to a context.
In this task several components of the previously defined types will be developed, which will then be assembled in distinct configurations, in order to create three narratives with different characteristics, which will act as proofs of concept for this project of weather system’s narration.
The narratives will be created according to the phenomena and context previously defined in task 1.
The pipeline design approach provides flexibility and segregation in the different phases of the process by providing a framework for the independent development and lifecycle management of components regarding the following: distinct data sources, raw data formats, usable data sets, weather systems phenomena, and narration type.
4.3 Task 3 – Integration, Tests and Evaluation
In this task, the previously developed components will be integrated, by assembling them into several pipeline configurations, in order to evaluate the complete narration process, regarding its functionality as a fully automatic narrative creation system. First, the components will be individually tested, as independent functional units, after which they will be assembled and tested as a full functional system. To produce the final narratives, the system will be assembled in distinct pipeline configurations, using the necessary components, according to the desired outcome.
The ultimate evaluation of the system will be carried out by assessing the narratives produced, according to the three contexts defined in task 1 and later implemented in task2. In fact, the quality of these narratives will be an indicator of the overall quality and validity of the project’s proof-of-concept.
The final narratives deliverables to assess are the following: a weather phenomenon description, in a natural and conversational language; a weather system’s raw data metadata classification; and a weather phenomenon progression, in natural and scientific language.
Besides the evaluation of the final outcomes, other aspects of the project will also be evaluated regarding the functionality, sustainability and reproducibility of the automatic weather systems narration process. In fact, the process is heavily based on data and processing capacity, which can be provided by science infrastructures, but after having validated the automatic weather systems narration process, the next step should be to tailor and streamline the process for some marketwise application segments, in order to have the same positive outcomes, but consuming a reasonable amount of resources, accordingly to each application segment.
5 Conclusion
This exploratory project follows up the work started by CE4Blind project, extending the experience of the team to the domain of climate change. The proposal extends to supercomputing, the Big Data analytics domain and climate and atmospheric sciences.
The final goal is to combine and study the areas of weather systems, data computation, narrative creation, and human computer interface for the blind. A major milestone is the development of a working prototype, which may be tested and demonstrated outside the lab.
References
Fernandes, H., Sousa, A., Paredes, H., Filipe, V., Barroso, J.: Feature detection applied to context-aware blind guidance support. In: Antona, M., Stephanidis, C. (eds.) UAHCI 2015. LNCS, vol. 9178, pp. 129–138. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-20687-5_13
Fernandes, H., Costa, P., Paredes, H., Filipe, V., Barroso, J.: Integrating computer vision object recognition with location based services for the blind. In: Stephanidis, C., Antona, M. (eds.) UAHCI 2014. LNCS, vol. 8515, pp. 493–500. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-07446-7_48
Costa, P., Barroso, J., Fernandes, H., Hadjileontiadis, L.J.: Using Peano–Hilbert space filling curves for fast bidimensional ensemble EMD realization. J. Adv. Sig. Process. 1 (2011). https://doi.org/10.1186/168761802012181
Fernandes, H., Conceição, N., Paredes, H., Pereira, A., Araújo, P., Barroso, J.: Providing accessibility to blind people using GIS. Univers. Access Inf. Soc. 11(4), 19 (2011). https://doi.org/10.1007/s1020901102557
Mellish, C., Scott, D., Cahill, L., Paiva, D., Evans, R., Reape, M.: A reference architecture for natural language generation systems. Nat. Lang. Eng. 12(1), 1–34 (2006)
Reiter, E., Dale, R., Feng, Z.: Building Natural Language Generation Systems, vol. 33. Cambridge University Press, Cambridge (2000)
Goldberg, E., Kittredge, R., Driedger, N.: FoG: a new approach to the synthesis of weather forecast text. IEEE Expert (Special Track on NLP) (1994)
Goldberg, E., Driedger, N., Kittredge, R.I.: Using natural language processing to produce weather forecasts. IEEE Expert 9(2), 4553 (1994)
Ramos Soto, A., Bugarín, A.J., Barro, S., Taboada, J.: Linguistic descriptions for automatic generation of textual short term weather forecasts on real prediction data. IEEE Trans. Fuzzy Syst. 23, 4457 (2015). ISSN 10636706
Apache OpenNLP (2017). https://opennlp.apache.org
Open CCG (2017). http://openccg.sourceforge.net/
Baldridge (2017). http://www.jasonbaldridge.com/
Dooley, R., Hanlon, M.R.: Recipes 2.0: building for today and tomorrow. Concurr. Comput.: Pract. Exp. 27(2), 258–270 (2015)
Wang, L., Buren, P.V., Ware, D.: Architecting a Distributed Bioinformatics Platform with iRODS and iPlant Agave API. In: 2015 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, pp. 420–423 (2015). https://doi.org/10.1109/csci.2015.121
Gesing, S.: et al.: Gathering requirements for advancing simulations in HPC infrastructures via science gateways. Futur. Gener. Comput. Syst. http://doi.org/10.1016/j.future.2017.02.042. Accessed 14 Mar 2017, ISSN 0167739X
Simmonds, I., Keay, K., Bye, J.A.T.: Identification and climatology of southern hemisphere mobile fronts in a modern reanalysis. J. Clim. (2012). https://doi.org/10.1175/jclid1100100.1
Liberato, M.R.L., Pinto, J.G., Trigo, I.F., Trigo, R.M.: Klaus an exceptional winter storm over Northern Iberia and Southern France. Weather 66, 330334 (2011). https://doi.org/10.1002/wea.755
Liberato, M.L.R., et al.: Explosive development of winter storm Xynthia over the subtropical North Atlantic Ocean. Nat. Hazards Earth Syst. Sci. 13, 22392251 (2013). https://doi.org/10.5194/nhess1322392013
Dacre, H.F., Clark, P.A., Martinez Alvarado, O., Stringer, M.A., Lavers, D.A.: How do atmospheric rivers form? Bull. Amer. Meteor. Soc. 96(8), 12431255 (2015). https://doi.org/10.1175/BAMSD1400031.1
Liberato, M.L.R.: The 19 January 2013 windstorm over the north Atlantic: largescale dynamics and impacts on Iberia. Weather Clim. Extrem. 56, 16–28 (2014)
Trigo, I.F.: Climatology and interannual variability of storm tracks in the EuroAtlantic sector: a comparison between ERA40 and NCEP/NCAR reanalyses. Clim. Dyn. 26, 127–143 (2006)
Neu, U., et al.: IMILAST—a community effort to intercompare extratropical cyclone detection and tracking algorithms. Bull. Am. Meteor. Soc. 94(4), 529–547 (2013). https://doi.org/10.1175/BAMSD1100154.1
Ramos, A.M., Trigo, R.M., Liberato, M.L.R., Tome, R.: Daily precipitation extreme events in the Iberian Peninsula and its association with atmospheric rivers. J. Hydrometeorol. 16, 579–597 (2015)
Limbach, S.: Software tools and efficient algorithms for the feature detection, feature tracking, event localization, and visualization of large sets of atmospheric data. PhD thesis, University of Mainz, 256 p. (2013)
Dee, D.P., Balmaseda, M., Balsamo, G., Engelen, R., Simmons, A.J., Thépaut, J.N.: Toward a consistent reanalysis of the climate system. Amer. Meteorol. Soc., Bull (2014). https://doi.org/10.1175/BAMSD1300043.1
Dettinger, M., Ralph, F.M., Lavers, D.: Setting the stage for a global science of atmospheric rivers. Eos Trans. AGU 96 (2015), https://doi.org/10.1029/2015eo038675
Ramos, A.M., Tomé, R., Trigo, R.M., Liberato, M.L.R., Pinto, J.G.: Projected changes in atmospheric rivers affecting Europe in CMIP5 models. Geophys. Res. Lett. 43, 9315–9323 (2016). https://doi.org/10.1002/2016GL070634
Ramos, A.M., et al.: Atmospheric rivers moisture sources from a Lagrangian perspective. Earth Syst. Dynam. 7, 371384 (2016). https://doi.org/10.5194/esd73712016
Shemm, S., Rudeva, I., Simmonds, I.: Extratropical fronts in the lower troposphere global perspectives obtained from two automated methods. Q. J. R. Meteorol. Soc. 141(690), 1686–1698 (2015). https://doi.org/10.1002/qj.2471
Ulbrich, U., Leckebusch, G.C., Pinto, J.G.: Extratropical cyclones in the present and future climate: a review. Theor. Appl. Climatol. 96, 117131 (2009). https://doi.org/10.1007/s0070400800838
Rocha, T., Fernandes, H., Reis, A., Paredes, H., Barroso, J.: Assistive platforms for the visual impaired: bridging the gap with the general public. In: Rocha, Á., Correia, A.M., Adeli, H., Reis, L.P., Costanzo, S. (eds.) WorldCIST 2017. AISC, vol. 570, pp. 602–608. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-56538-5_61
Reis, A., Barroso, I., Monteiro, M.J., Khanal, S., Rodrigues, V., Filipe, V., Paredes, H., Barroso, J.: Designing autonomous systems interactions with elderly people. In: Antona, M., Stephanidis, C. (eds.) UAHCI 2017. LNCS, vol. 10279, pp. 603–611. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-58700-4_49
Gonçalves, C., Rocha, T., Reis, A., Barroso, J.: AppVox: an application to assist people with speech impairments in their speech therapy sessions. In: Rocha, Á., Correia, A.M., Adeli, H., Reis, L.P., Costanzo, S. (eds.) WorldCIST 2017. AISC, vol. 570, pp. 581–591. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-56538-5_59
Acknowledgements
This work was supported by the project “WEx-Atlantic - Weather Extremes in the Euro Atlantic Region: Assessment and Impacts” (PTDC/CTA-MET/29233/2017) funded by Fundação para a Ciência e a Tecnologia, Portugal (FCT) and Portugal Horizon2020.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Reis, A., Liberato, M., Paredes, H., Martins, P., Barroso, J. (2019). Creating Weather Narratives. In: Antona, M., Stephanidis, C. (eds) Universal Access in Human-Computer Interaction. Multimodality and Assistive Environments. HCII 2019. Lecture Notes in Computer Science(), vol 11573. Springer, Cham. https://doi.org/10.1007/978-3-030-23563-5_25
Download citation
DOI: https://doi.org/10.1007/978-3-030-23563-5_25
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-23562-8
Online ISBN: 978-3-030-23563-5
eBook Packages: Computer ScienceComputer Science (R0)