
Abstract
Aiming to optimize the shape of closed embedded curves within prescribed isotopy classes, we use a gradient-based approach to approximate stationary points of the Möbius energy. The gradients are computed with respect to Sobolev inner products similar to the \(W^{3/2,2}\)-inner product. This leads to optimization methods that are significantly more efficient and robust than standard techniques based on \(L^2\)-gradients.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Let \(\gamma :{\mathbb {T}}\rightarrow {{\mathbb {R}}^{m}}\) be a sufficiently smooth embeddingFootnote 1 of the circle \({\mathbb {T}}\) into Euclidean space. Its Möbius energy [27, 61] is defined as
where \(\varrho _\gamma (x,y)\) denotes the length of the shortest arc of \(\gamma \) connecting \(\gamma (x)\) and \(\gamma (y)\).
The original motivation [28] was to define an energy that measures complexity or “entangledness” of a given curve. One may expect that minimization will unravel the initial configuration to a state of less complexity. Ideally, this should also preserve topological properties, in particular the isotopy class. By definition, an isotopy class is a path component in the space of embedded curves. The Möbius energy was designed to erect infinite energy barriers that separate isotopy classes within the space of curves. The term \(|{\gamma (x)-\gamma (y)}|^{-2}\) blows up whenever a self-contact emerges, lending itself as contact barrier for modeling impermeability of curves and rods. Moreover, this term promotes the spreading of the geometry, which indeed leads to the desired unfurling. Subtracting the second term \(\varrho _\gamma ^{-2}(x,y)\) guarantees that the energy is finite for sufficiently smooth embeddings. This way, any time-continuous descent method like, e.g., a gradient flow, will necessarily preserve the isotopy class.Footnote 2 Another pleasant feature of the Möbius energy is that its critical points enjoy higher smoothness.

Discrete Sobolev gradient descent subject to edge length constraint and barycenter constraint. The isotopy class is maintained along the iteration which is the crucial feature of a knot energy. As initial condition, we use a “difficult” configuration proposed in [27] (1648 edges; numbers in parentheses indicate the iteration steps). The global minimizer (the round circle) is reached after about 200 iterations. The curves have perceived constant thickness in the plots while a coordinate cross serves as a reference for the respective scaling factor. See also Fig. 3 for a comparison to further optimization methods; the present one is “\(W^{3/2,2}\) projected gradient, explicit”
In this paper we propose a new concept of numerical optimization techniques for the large family of self-repulsive energies by discussing the prototypical case of the Möbius energy. Due to the nonlocal point-point interactions (which manifest themselves in the occurrence of a double integral), any evaluation of the energy or its gradient is rather expensive; this renders the numerical optimization a challenging task. The key idea of our approach is to introduce a special geometric variant of the metric of the Sobolev space \(W^{{3/2},2}\) that discourages movement of an embedded curve in regions of near self-contact. Contrary to black-box approaches, our method allows us to minimize the Möbius energy of even quite complicated starting configuration within only a few hundred iterations (see Figs. 1, 6). As illustrated in Fig. 2, computing gradients with respect to this metric allows for choosing significantly larger step sizes compared to the \(L^{2}\)- or even the \(W^{{3/2},2}\)-metric. This is in agreement with the interpretation of \(W^{{3/2},2}\)-gradient descent as a coarse discretization of an ordinary differential equation. In contrast to full discretization (i.e., in space and time) of a general (transient) partial differential equation, an ordinary differential equation does not require any mesh-dependent bound on the time step size for stability. Consequently, our gradient descent scheme requires only few iteration steps, even for fine spatial resolution. This makes it, besides from being robust, particularly efficient. This is demonstrated by the performance comparison in Fig. 3.
Potential applications for self-repulsive energies are manifold as they can be employed as barriers for shape optimization problems and physical simulation with self-contact: They arise, for instance, in mechanics [21, 29, 47, 80, 81, 93] and in molecular biology [22, 23, 34, 35, 52, 53]. The Möbius energy can also be considered as differentiable relaxation of curve thickness. For example, as reported in [82], the speed of migration of knotted DNA molecules undergoing gel electrophoresis seems to be proportional to the average crossing number of the corresponding maximizers of curve thickness. Software tools for the maximization of thickness or equivalently, for the minimization of ropelength, have been developed in [65] (SONO) and [2] (ridgerunner). Further potential fields of applications for repulsive energies include computer graphics [10, 79], packing problems [30, 31], the modeling of coiling and kinking of submarine communications cables [24, 100], and even solar coronal structures [70].

We visualize different gradients as vector fields along a given curve. The \(L^2\)-gradient is pathologically concentrated on regions of near self-contact. Consequently, one has to pick tiny step sizes to prevent self-collision. The pure \(W^{{3/2},2}\)-gradient behaves much better in the sense that it is more uniformly distributed along the curve. However, this can still be improved considerably by adding a lower order term to the inner product that discourages movement in regions of near self-contact, cf. Theorem 4.1
1.1 Previous work
Since its invention by O’Hara [61,62,63] and the very influential paper by Freedman, He, and Wang [27], the Möbius energy has been studied by many authors. Detailed investigations on its derivatives have been performed in [17, 37, 42]. Existence of minimizers in prime knot classes has been established in [27]. Invariance of the energy under conformal transformations of \({{\mathbb {R}}^{m}}\) has been studied in [3, 27, 49, 56]. Smoothness of minimizers has been established in [27, 37], while smoothness and even analyticity of all critical points has finally been shown in [17] and [18]. Except for the global minimizer [27] and first results on critical points in nontrivial prime knot classes [14, 44], almost nothing is known on the geometry of the energy space. In light of the Smale conjecture (proven by Hatcher [36]), it would be of great interest to know whether some gradient flow of the Möbius energy actually defines a retract of the unknots to the round circles. The \(L^2\)-gradient flow of the Möbius energy has been studied in [12, 13, 37].

Exemplary performance comparison between several feasible (top) and infeasible (bottom) optimization methods and with respect to various Sobolev metrics, applied to the initial configuration from Fig. 1 (1648 edges). “Feasible” means that the constraints were respected in each iteration step (up to a certain tolerance, of course). “Infeasible” means that a penalty formulation was used in place of hard constraints. Each dataset corresponds to a combination of an optimization method (encoded by line dashing) and a Sobolev-metric (encoded by color; e.g., green corresponds to our Sobolev metric) that have been employed to compute gradients. We see that apart from the implicit projected gradient descent (which generally does not work well in this context), all optimization methods perform best in conjuction with our \(W^{{3/2},2}\)-metric. All experiments were implemented in Mathematica® and ran single-threaded for 60 min on an Intel® Xeon® E5-2690 v3. Further details will be provided in Sect. 6.4
Various numerical methods have been devised for discretizing and minimizing the Möbius energy [44, 48, 49, 78], partially with error analysis [67, 68, 73]. A recently proposed scheme also preserves conformal invariance [5, 15].
The Möbius energy has also inspired the development of similar so-called knot energies [19, 33, 83, 86, 87] and higher-dimensional generalizations [43, 46, 49, 64, 84, 85, 88].

As a matter of fact, the statistics in Fig. 3 highly rely on the hardware. To provide a more independent comparison, we here plot the number of iteration steps versus the values of the Möbius energy attained after that time. Of course, as the effort involved for performing a single iteration step differs among the methods discussed here, it is debatable whether this is a meaningful unit after all
Both theoretical and numerical results have been obtained on linear combinations of the bending energy and the Möbius energy [51, 61, 95]. More generally, in order to find minimizers of an elastic energy within an isotopy class, each knot energy can be employed in two ways: either as regularizer as it was done, e.g., in [4,5,6, 29, 32, 40, 94, 97], or by using it to encode a hard bound into the domain, which was done with the knot thickness in [39, 76, 96].
The applicability of self-avoiding energies is heavily limited by their immense cost: Typical discretizations replace the double integrals by double sums which leads to a computational complexity of at least \(\varOmega ((N \cdot m)^2)\) for evaluating the discrete Möbius energy and its derivative, where \(N \cdot m\) is the number of degrees of freedom of the discretized geometry (e.g., the number of vertices of a polygonal line times the dimension of the ambient space). This issue can be mended by sophisticated kernel compression techniques, see [99]. In this article, however, we focus on another issue that is more related to mathematical optimization, namely the fact that, for \(N \rightarrow \infty \), the discretized optimization problems become increasingly ill-conditioned. It is well-known that the convergence rate of many gradient-based optimization methods (method of steepest descent, nonlinear conjugate gradient method, and also more sophisticated quasi-Newton methods like L-BFGS) is very sensitive to the condition number of the Hessian of the energy (at a minimum) on the one hand, and the inner product that is used to compute the gradients on the other hand. The Hessian of the Möbius energy is deeply related to the fractional Laplacian \((-\varDelta )^{3/2}\) which is a differential operator of order three, cf. [37]. Thus the condition number of the discrete problem grows like \(O(h^{-3})\) where h denotes the typical length of an edge in the discretization. In practice, this results in a rapid increase of the number of optimization iterations to “reach the minimizer” when the discretization is refined (i.e., for \(h \rightarrow 0\)). Combined with the immense cost of evaluating \({\mathcal {E}}\) and \(D{\mathcal {E}}\), this leads to a prohibitively high cost of minimizing \({\mathcal {E}}\) with black-box optimization routines (see Figs. 3, 4).
In particular, this issue applies to the explicit Euler time discretization scheme for the \(L^2\)-gradient flow of the Möbius energy. Denoting the discretized energy by \({\mathcal {E}}_h\), the next time iterate \(\gamma _{(t + \varDelta t)}\) is computed from the current iterate \(\gamma _t\) by solving
where \(\left\langle u,v \right\rangle _{L^2_{\gamma _t}}=\int _{{\mathbb {T}}}\left\langle u(x),v(x) \right\rangle |{\gamma '(x)}|{{\text {d}}}x\). This can also be reinterpreted as method of steepest descent with respect to the (discretized) \(L^2\)-gradient and with step size \(\varDelta t>0\). Here the ill-conditioning manifests itself in the Courant–Friedrichs–Lewy condition: As the \(L^2\)-gradient flow is a system of third order parabolic partial differential equations, the step size has to be truncated to \(\varDelta t = {{\,\mathrm{O}\,}}(h^3)\) in order to make this scheme stable. This is also why a line search that enforces the Armijo condition (also referred to as first Wolfe condition), cf. [59], Chapter 3, will typically lead to tiny step sizes, rendering the method impractical for optimization (see Fig. 3). It is well-known that the Courant–Friedrichs–Lewy condition can be circumvented by implicit time integration schemes. For example, in the implicit Euler or backward Euler scheme, one determines the next iterate \(\gamma _{(t + \varDelta t)}\) by solving the equation
Standard techniques for solving this nonlinear equation, e.g., Newton’s method, require solving multiple linearizations of the above equation and thus involve the Hessian \(DD{\mathcal {E}}_h\) in each time iteration. Moreover, the linearization has to be recomputed whenever the step size \(\varDelta t\) changes, which makes it nontrivial to set up an adaptive time stepping scheme. This explains why implicit time integrators turn out to be rather inefficient optimization schemes (see Fig. 3). If one allows oneself to employ second derivatives of \({\mathcal {E}}_h\), applying Newton’s method (and its damped or regularized derivates) for solving \(D{\mathcal {E}}_h(\gamma _{(t+\varDelta t)}) = 0\) in the first place would lend itself as a more efficient optimization algorithm. However, it is well-known that Newton’s method does not necessarily perform well when applied far away from critical points.
1.2 Sobolev gradients
These problems can be overcome by optimization methods based on Sobolev gradients which are defined in terms of a Sobolev metric G that is “natural” for the Möbius energy. Blatt [11] characterized the energy space of the Möbius energy \({\mathcal {E}}\) as \(W^{1,\infty }({\mathbb {T}};{\mathbb {R}}^m)\cap W^{{3/2},2}({\mathbb {T}};{\mathbb {R}}^m)\), cf. Theorem 2.1. Here and in the following, \(W^{s,p}\) denotes the Sobolev–Slobodeckiĭ space of functions with “s fractional derivatives in \(L^{p}\)” if \(s \not \in {\mathbb {Z}}\) and a conventional Sobolev space for \(s \in {\mathbb {Z}}\). This result points to the fact that \(D {\mathcal {E}}\) is a nonlinear differential operator of order \(2 \cdot \frac{3}{2} = 3\), which has already been observed by He [37]. So morally, a suitable inner product G should be of the form
Then the G-gradient \({{\,\mathrm{grad}\,}}({\mathcal {E}}) |_\gamma \) at \(\gamma \) can be defined by the following weak formulation:
Thus, at least formally, the G-gradient satisfies the equation
By a somewhat naive counting of fractional derivatives, the right hand side is a nonlinear differential operator of order zero. Hence there is a chance that \({{\,\mathrm{grad}\,}}({\mathcal {E}}) |_\gamma \) resides in the same Banach space as \(\gamma \) so that \({{\,\mathrm{grad}\,}}({\mathcal {E}})\) would be a vector field. Then the evolution equation
would actually be an ordinary differential equation. Indeed, this turns out to be true and is part of our main result (see Theorem 1.2). This seems to imply that no Courant–Friedrichs–Lewy condition applies to the discretized problem, so that the number of gradient descent iterations “to reach the minimum” is quite insensitive to the mesh resolution. At least, this is what we observed in our experiments.
Since the inner product G involves a choice of a Riemannian metric on the parametrization domain (line element and Laplacian), it is even more natural to define a \(\gamma \)-dependent family \(\gamma \mapsto G_\gamma \) of inner products. With the Riesz operator  , the G-gradient can then be expressed by
, the G-gradient can then be expressed by

There are plenty of possible choices for  . Most important is that
. Most important is that  is an elliptic pseudo-differential operator of order three. All compact perturbations of
is an elliptic pseudo-differential operator of order three. All compact perturbations of  that are positive-definite will lead to the operator with the same qualitative properties. In particular, we are not limited to the exact fractional Laplacian; this gives us the freedom to pick an
that are positive-definite will lead to the operator with the same qualitative properties. In particular, we are not limited to the exact fractional Laplacian; this gives us the freedom to pick an  that is computationally more amenable. Up to lower order terms, we design G such that it resembles the \(W^{{3/2},2}\)-Gagliardo inner product, replacing intrinsic distances by (the easier computable) secant distances (see Theorem 4.1). For a curve parametrized by arc length (i.e., \(|{\gamma '}| = 1\)) and up to lower order terms, it reads as
that is computationally more amenable. Up to lower order terms, we design G such that it resembles the \(W^{{3/2},2}\)-Gagliardo inner product, replacing intrinsic distances by (the easier computable) secant distances (see Theorem 4.1). For a curve parametrized by arc length (i.e., \(|{\gamma '}| = 1\)) and up to lower order terms, it reads as
where in case of a curve \(\gamma \) parameterized by arc length the lower-order terms are given by
and \(\varrho _{\gamma }\) denotes the geodesic distance introduced in (6) below. Here the first summand is essentially the \(W^{1/2,2}\)-Gagliardo inner product with the energy density as additional weight.
Indeed, even if \(\gamma \) is not parametrized by arc length, a more detailed analysis reveals that  has (up to a constant) the same principal symbol as \((-\varDelta _\gamma )^{3/2}\) where \(\varDelta _\gamma \) is the Laplace-Beltrami operator with respect to the Riemannian metric on \({\mathbb {T}}\) induced by the embedding \(\gamma \) (see the proof of Theorem 4.1).
has (up to a constant) the same principal symbol as \((-\varDelta _\gamma )^{3/2}\) where \(\varDelta _\gamma \) is the Laplace-Beltrami operator with respect to the Riemannian metric on \({\mathbb {T}}\) induced by the embedding \(\gamma \) (see the proof of Theorem 4.1).

Discrete Sobolev gradient descent as in Fig. 1 starting at another difficult configuration (1940 edges)
1.3 As Riemannian as you can get
The overarching idea behind all this is to consider \((\mathcal {C},G)\) as a Riemannian manifold and \({\mathcal {E}}:\mathcal {C}\rightarrow {\mathbb {R}}\) as a smooth function. Here \(\mathcal {C}\) denotes a Banach manifold of immersed embedded curves which will be defined in (5) below. If \({{\,\mathrm{grad}\,}}({\mathcal {E}})\) is a well-behaved vector field on \(\mathcal {C}\), various optimization techniques that work on Riemannian manifolds can be utilized to minimize \({\mathcal {E}}\). This is actually a long standing dream of differential geometers: to apply Riemannian geometry to an infinite-dimensional space of shapes. Such Sobolev inner products and their geodesics have been studied from a geometrical point of view, e.g., in [7, 8, 55]. It has been observed that \(W^{1,2}\)-inner products work well in the numerical treatment of full dimensional elasticity and of membrane energies such as the area functional for surfaces or the length functional for curves [58, 66, 75]. Moreover, it is known that \(W^{2,2}\)-inner products provide good preconditioning for bending energies such as Bernoulli’s elastic energy of curves, Kirchhoff’s thin shell energy, the Willmore energy and Helfrich-type energies [26, 38, 74, 75]. Various standard optimization schemes (e.g, nonlinear conjugate gradient, Nesterov’s accelerated gradient, L-BFGS, trust region) can be sped up significantly by using the “right” notion of gradient (see Figs. 3 and 4). This is because these methods exploit that the gradient field is (locally) Lipschitz continuous with respect to the employed metric.
Alas, the story here is not that simple, because there is no Morrey embedding from the energy space \(W^{3/2,2}({\mathbb {T}};{\mathbb {R}}^m)\) to \(W^{1,\infty }({\mathbb {T}};{\mathbb {R}}^m)\) and any open \(W^{{3/2},2}\)-neighborhood of an embedded arc-length parametrized \(W^{{3/2},2}\)-curve may contain non-embedded curves or curves with vanishing or infinite derivative. Therefore, Fréchet differentiability of the Möbius energy could only be established with respect to the somewhat artificial \(W^{3/2,2}\cap W^{1,\infty }\)-topology [17]. This problem can be resolved by working in the slightly smaller Banach space  with suitable \({\nu }>0\) and \(p \ge 2 \). Then
with suitable \({\nu }>0\) and \(p \ge 2 \). Then  embeds into \(C^{1}\) and the configuration space
embeds into \(C^{1}\) and the configuration space
is an open subset of \(C^{1}\).

We construct the Riesz isomorphism  as an elliptic pseudo-differential operator of order three, and we show in Theorem 4.1 that it gives rise to a generalized Riesz isomorphism
as an elliptic pseudo-differential operator of order three, and we show in Theorem 4.1 that it gives rise to a generalized Riesz isomorphism  where
where  , with the Hölder conjugate \(q \;{:}{=}\; (1-1/p)^{-1}\) of p. Notice that
, with the Hölder conjugate \(q \;{:}{=}\; (1-1/p)^{-1}\) of p. Notice that  does no longer identify
does no longer identify  with its dual space as
with its dual space as  , thus
, thus  . So one of our major tasks (see Theorem 3.1) will be to establish that
. So one of our major tasks (see Theorem 3.1) will be to establish that  whenever \(\gamma \in \mathcal {C}\). Moreover, we show that \(D{\mathcal {E}}\) is locally Lipschitz continuous as a mapping
whenever \(\gamma \in \mathcal {C}\). Moreover, we show that \(D{\mathcal {E}}\) is locally Lipschitz continuous as a mapping  , leading to our first main result.
, leading to our first main result.
Theorem 1.1
The gradient \({{\,\mathrm{grad}\,}}({\mathcal {E}})\) of \({\mathcal {E}}\) defined by (3) is a well-defined, locally Lipschitz continuous vector field on the configuration space \(\mathcal {C}\) (with respect to the norm on  ). Moreover, it satisfies \( D{\mathcal {E}}(\gamma ) \, {{\,\mathrm{grad}\,}}({\mathcal {E}}) |_\gamma \ge 0 \) with equality if and only if \(D{\mathcal {E}}(\gamma ) = 0\).
). Moreover, it satisfies \( D{\mathcal {E}}(\gamma ) \, {{\,\mathrm{grad}\,}}({\mathcal {E}}) |_\gamma \ge 0 \) with equality if and only if \(D{\mathcal {E}}(\gamma ) = 0\).
Combined with the Picard–Lindelöff theorem, this statement guarantees the short-time existence of the gradient flow, both for the downward and the upward direction.
In Sect. 5, we deal also with equality constraints, i.e., with Banach submanifolds of the form \({\mathcal {M}}\;{:}{=}\; \{\gamma \in \mathcal {C}| \varPhi (\gamma ) = 0\}\), where \(\varPhi :\mathcal {C}\rightarrow \mathcal {N}\) is a suitable submersion, namely the constraint of constant speed and vanishing barycenter, cf. (33), into a further Banach space \(\mathcal {N}{}=W^{\sigma +\nu , p}({\mathbb {T}};{\mathbb {R}})\oplus {\mathbb {R}^m}\). We formulate a linear saddle point system for determining the projected gradient \({{\,\mathrm{grad}\,}}_{{\mathcal {M}}} ({\mathcal {E}}|_{\mathcal {M}})|_\gamma \) and analyze when the system is solvable. We perform the analysis for a concrete set of constraints (fixed barycenter and parametrization by arc length), but we also try to outline which steps have to be taken for more general constraints. Finally, Theorem 5.1 will establish our second main result.
Theorem 1.2
(Projected gradient) The projected gradient \({{\,\mathrm{grad}\,}}_{\mathcal {M}}({\mathcal {E}}|_{\mathcal {M}})\) of \({\mathcal {E}}|_{\mathcal {M}}\) defined by
is a well-defined, locally Lipschitz continuous vector field on \({\mathcal {M}}\). The gradient satisfies \( D({\mathcal {E}}|_{\mathcal {M}})(\gamma ) \; {{\,\mathrm{grad}\,}}_{\mathcal {M}}({\mathcal {E}}|_{\mathcal {M}}) |_\gamma \ge 0 \) with equality if and only if \(D({\mathcal {E}}|_{\mathcal {M}})(\gamma ) = 0\).
Invoking the Picard–Lindelöff theorem again, we conclude that both the downward and the upward gradient flows of \({\mathcal {E}}|_{\mathcal {M}}\) exist for short times.
The question of long-time existence is much more involved. Following the way paved by Knappmann et al. [45] for a subfamily of integral Menger curvature functionals, one may derive this property in the case of subcritical Hilbert spaces. These correspond to the functionals obtained by replacing the squares in (1) by powers \(\alpha \in (2,3)\). Due to the fact that the general case where \(p\ne 2\) seems to be “degenerate” analogously to the p-Laplacian it seems unclear whether long-time existence can be established also for the setting discussed in this article.
1.4 Future Directions
The present study demonstrates the design of a minimization scheme being both robust and efficient which is based on a metric that is tailored to the structure of a geometric nonlocal functional modeling self-avoidance.
The general strategy outlined in this paper applies to a large range of functionals on curves and surfaces of arbitrary dimension and codimension. We stress the fact that the arguments given below mainly rely on analytical features of a functional defined on fractional Sobolev spaces rather than on geometric peculiarities, except for the metric itself which has to be chosen carefully depending on the respective problem.
Although the definition of the Möbius energy has been motivated by the electrostatic energy [62], it is admittedly not a physical quantity in the first place. However, it seems to be an appropriate candidate to demonstrate the general approach while avoiding too much technicalities as, from an analyst’s perspective, it is the most elementary smooth knot energy.
Even more importantly, one may find minimizers of physical functionals such as, e.g., the bending energy or the Helfrich energy within prescribed isotopy classes by a regularization approach, cf. [29]. In this context one may choose the regularizer to be a smooth repulsive functional which approximates the (reciprocal) thickness such as the tangent-point potential which has been employed e.g. in [4]. In combination with the technique described in the present paper, one may greatly improve not only the performance but also the complexity of the objects (i.e., isotopy types) that can be dealt with.
The higher-dimensional case as well as the adaption of this technique to other functionals is work in progress [98].
2 Preliminaries
2.1 General notation
Throughout, we let \({\mathbb {T}}\;{:}{=}\; \{x \in {\mathbb {R}}^2 | |{x}| = (2\,{\uppi })^{-1}\}\) be the round circle with a fixed orientation and normalized to have total length \(|{{\mathbb {T}}}| = 1\). We will make use of the identification \({\mathbb {T}}\cong {\mathbb {R}}/{\mathbb {Z}}\) whenever convenient. Moreover, we write \({{\mathbb {T}}^2}= {\mathbb {T}}\times {\mathbb {T}}\) for the Cartesian product of the circle with itself and denote by \(\pi _1:{{\mathbb {T}}^2}\rightarrow {\mathbb {T}}\) and \(\pi _2:{{\mathbb {T}}^2}\rightarrow {\mathbb {T}}\) the Cartesian projections onto the first and second factor, respectively. We denote the canonical intrinsic distance function on \({\mathbb {T}}\) by
and the canonical line measure by \({{\text {d}}}x\) or \({{\text {d}}}y\). Each sufficiently smooth immersed embedding \(\gamma :{\mathbb {T}}\rightarrow {{\mathbb {R}}^{m}}\) induces a line element \({\omega _{\gamma }}{(x)}\) and a unit tangent field \(\tau _\gamma \) via
Moreover \(\gamma \) induces two further distance functions that we have to distinguish: The secant distance \(|{\triangle \gamma }|(x,y) \;{:}{=}\; |{\gamma (x) - \gamma (y)}|\) and the geodesic distance \(\varrho _\gamma \); more precisely,
where \(I_\gamma (x,y)\) denotes the shortest arc that connects x and y. Since \(\gamma \) is immersed, \(d_{\mathbb {T}}\) and \(\varrho _\gamma \) are equivalent. We point out that this equivalence extends to \(|{\triangle \gamma }|\) if the embedding \(\gamma \) is sufficiently smooth, e.g., of class \(C^{1,\alpha }\) with \(\alpha \in \left]0,1\right[\) or \(W^{1+\sigma ,r}\) with \(\sigma - 1/r \ge 0\), cf. [11, Lemma 2.1]. In this case \(\gamma \) is bi-Lipschitz continuous and the measures \({{\text {d}}}x\) and \(\omega _{\gamma }\) are equivalent as well, i.e., there are \(c_1\), \(c_2 >0\) such that \(c_1 \, {{\text {d}}}x \le \omega _{\gamma }(x) \le c_2 \, {{\text {d}}}x\) holds for all \(x \in {\mathbb {T}}\). This implies that also the Lebesgue norms
for \(1\le p < \infty \) and any measurable function \(u :{\mathbb {T}}\rightarrow {{\mathbb {R}}^{m}}\) are equivalent. We also employ this notation for bivariate measurable functions \(U:{\mathbb {T}}^{2}\rightarrow {{\mathbb {R}}^{m}}\), letting
Likewise, for \( 0< \sigma <1\) and \(1\le p < \infty \), the Sobolev–Slobodeckiĭ seminorms
and the induced norms \(\Vert {u}\Vert _{W^{\sigma ,p}} \;{:}{=}\; [{u}]_{W^{\sigma ,p}} + \Vert {u}\Vert _{L_{p}}\) and \(\Vert {u}\Vert _{W^{\sigma ,p}_{\gamma }} \;{:}{=}\; [{u}]_{W^{\sigma ,p}_{\gamma }} + \Vert {u}\Vert _{L_{\gamma }^{p}}\) are equivalent, respectively. In all what follows, we will frequently make use of the following \(\gamma \)-dependent measures and operators:
For example, the \(\gamma \)-dependent Sobolev–Slobodeckiĭ seminorm can be written much more economically as \( \left[ u\right] _{W^{\sigma ,p}_{\gamma }} =\Vert { \delta ^{\sigma +1/p}_{\gamma } u}\Vert _{L^{p}_{\gamma }} = \Vert { \delta ^{\sigma }_{\gamma } u}\Vert _{L^{p}_{\mu _\gamma }}, \) where \(L^{p}_{\mu _\gamma }({\mathbb {T}}^2;{\mathbb {R}}^m)\) denotes the Lebesgue space with respect to \(\mu _\gamma \) and \(\Vert {\cdot }\Vert _{L^{p}_{\mu _\gamma }}\) its associated norm. We define \(W^{s,p}\)-seminorms for \(1<s<2\) by concatenating the \(W^{s-1,p}_{\gamma }\)-seminorms with suitable differential operators of first order:
Here, the differential operator \({\mathcal {D}}_\gamma \) can be interpreted as derivative with respect to arc length. Provided that \(\gamma \) is a sufficiently smooth immersed embedding, \(\Vert {u}\Vert _{W^{s,p}} \;{:}{=}\; [{u}]_{W^{s,p}} + \Vert {u}\Vert _{L^p}\) and \(\Vert {u}\Vert _{W_{\gamma }^{s,p}} \;{:}{=}\; [{u}]_{W_{\gamma }^{s,p}} + \Vert {u}\Vert _{L_{\gamma }^{p}}\) are equivalent and both topologize the Sobolev–Slobodeckiĭ space
More precisely, the norm \(\Vert {\cdot }\Vert _{W_{\gamma }^{s,p}}\) is well-defined and equivalent to \(\Vert {\cdot }\Vert _{W^{s,p}}\) if \(\gamma \) is an immersed embedding of class \(W^{S,P}({\mathbb {T}};{\mathbb {R}}^m)\) provided that one of the conditions for the “product rule” Theorem A.4 are met for \(\sigma _1 = S-1\), \(p_1 = P\), \(\sigma _2 = s-1\), \(p_2 = p\).
2.2 Spaces
Our initial motivation to consider \(W^{{3/2},2}\)-inner products for optimization is the following characterization of the energy space of the Möbius energy, i.e., of the smallest space that contains all finite-energy configurations:
Theorem 2.1
(Blatt [11]) Let \(\gamma \in W^{1, \infty }({\mathbb {T}};{\mathbb {R}}^m)\) be an embedded immersed curve parametrized by arc length, i.e., \(|{\gamma '(x)}| =1\) for a.e. x. Then one has \( {\mathcal {E}}(\gamma ) < \infty \) if and only if \(\gamma \in W^{3/2,2}({\mathbb {T}};{\mathbb {R}}^m)\).
Moreover, provided that \(\gamma \) has a certain minimal regularity, the differential of \({\mathcal {E}}\) has been characterized as a nonlinear, nonlocal “differential operator“ of order 3 in the sense that \(D{\mathcal {E}}(\gamma )\) is a distribution with three derivatives less than \(\gamma \) (see [37]). We will see this also in Theorem 3.1 below. As indicated in the introduction, instead of working with the energy space \(W^{3/2,2}({\mathbb {T}};{\mathbb {R}}^m) \cap W^{1,\infty }({\mathbb {T}};{\mathbb {R}}^m)\), we prefer spaces of curves with slightly higher regularity. In the first place, we avoid some technicalities effected by the critical scaling of \(W^{1/2,2}({\mathbb {T}};{\mathbb {R}}^m)\) (see [54]) related to discontinuous tangents, in particular with respect to product rules. Here and in the following, we fix parameters \({s}\), \(\nu \), and \(p\) satisfying

In fact, we will soon focus on the case \({s}= \frac{3}{2}\) only. Moreover, we think of \({\nu }\) being close to 0 and of \(p\) being close to 2. By the Morrey embedding theorem [25, Therorem 6.5], the space \(W^{s+\nu ,p}({\mathbb {T}};{\mathbb {R}}^m)\) embeds continuously into \(C^{1,\alpha }({\mathbb {T}};{\mathbb {R}}^m)\) where \(\alpha \;{:}{=}\; s+\nu - 1 - 1/p\in \left]0,1\right[\). Thus, the configuration space \(\mathcal {C}\) defined in (5) is well-defined and an open subset of \(W^{s+\nu ,p}({\mathbb {T}};{\mathbb {R}}^m)\). We consider the Banach spaces
where \(q \;{:}{=}\; (1- 1/p)^{-1}\) denotes the Hölder conjugate of p. For \(\gamma \in \mathcal {C}\), we will equip these spaces with the norms
Their continuous dual spaces will be denoted by \({\mathcal {X}}'{^{\!}}\), \({\mathcal {H}}'{^{\!}}\), and \({\mathcal {Y}}'{^{\!}}\). Since \(\mathcal {C}\subset {\mathcal {X}}\) is an open set, its tangent space \(T_\gamma \mathcal {C}\) is identical to \({\mathcal {X}}\) for each \(\gamma \in \mathcal {C}\). By the Sobolev embedding theorem, the canonical embeddings
are well-defined and continuous with dense images. We point out that \({\mathcal {H}}\) is a Hilbert space; suitable scalar products on this space will play a pivotal role in defining the Sobolev gradients of the Möbius energy (see Sect. 4).
There are several reasons for picking the parameters \({\nu }\) and \(p\) as in (9): So far, it is only clear that \(p\ge 2\) and \({\nu }\ge 0\) are necessary for the existence of the continuous embeddings \(i_{\mathcal {C}}\) and \(j_{\mathcal {C}}\) while \({{s}+{\nu }}- 1/p>1\) is necessary for the Morrey embedding \(\mathcal {C}\hookrightarrow W^{1,\infty }(\mathbb {T};{\mathbb {R}}^m)\). In addition to that, we require \({\nu }> 0\) in order to be able to use certain product rules for bilinear maps of the form \(B :W^{{{s}+{\nu }},p} \times W^{{{s}-{\nu }},q} \rightarrow W^{{{s}-{\nu }},q}\) and \(B :W^{{{s}+{\nu }},p} \times W^{{s},2} \rightarrow W^{{s},2}\) as discussed in Theorem A.4. Indeed, the requirements \({{s}+{\nu }}- 1/p>1\) and \({\nu }>0\) allow us to treat all occurring nonlinearities in a satisfactory way. The condition \(p< \infty \) guarantees that all involved Banach spaces are reflexive and separable.
3 Energy
From now on, if not stated otherwise, we fix \({s}= \frac{3}{2}\) and suppose that \({\nu }>0\) and \(p\ge 2\). Our principal aim in this section is to investigate the Möbius energy
along with its first two derivatives. The first two variations of the Möbius energy have been discussed under various regularity assumptions before, cf. [17, 37, 42]. The first variation is typically given in terms of principal-value integrals. Here, by keeping everything in weak (or variational) formulation, we can work with very low regularity assumptions and avoid principal-value integrals altogether.
Theorem 3.1
The following statements hold true:
-
1.
The Möbius energy \({\mathcal {E}}:\mathcal {C}\rightarrow {\mathbb {R}}\) is Fréchet differentiable.
-
2.
The linear functional
 can be continuously extended to a functional
can be continuously extended to a functional 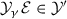 . In particular, this shows that
. In particular, this shows that  ,
,  is a (nonlinear) differential operator of order at most \(({{s}+{\nu }}) + ({{s}-{\nu }}) = 3\).
is a (nonlinear) differential operator of order at most \(({{s}+{\nu }}) + ({{s}-{\nu }}) = 3\). -
3.
The mapping
 is locally Lipschitz continuous.
is locally Lipschitz continuous.
 can be continuously extended to a functional
can be continuously extended to a functional 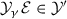 . In particular, this shows that
. In particular, this shows that  ,
,  is a (nonlinear) differential operator of order at most
is a (nonlinear) differential operator of order at most  is locally Lipschitz continuous.
is locally Lipschitz continuous.Proof
We are going to show that the energy density \(E :\mathcal {C}\rightarrow L^{1}_{\gamma }{(\mathbb {T}^2;\mathbb {R}})\) is Fréchet differentiable. This will also imply that \({\mathcal {E}}\) is Fréchet differentiable with derivative identical to the linear form  defined by
defined by

We do so by following a “shoot first ask questions later” approach. To this end, we first investigate pointwise derivatives of \(E(\gamma )\). For \(k \in \mathbb {N}_0\) and \(u_1, \dotsc ,u_k \in {\mathcal {X}}\), we abbreviate
Recall that the \(W^{s+{\nu },p}\)-norm dominates the \(C^{1}\)-norm. Thus, due to the definition of the geodesic distance in (6), for each point (x, y) in the open set
there is an open neighborhood \({\mathcal {U}}(x,y)\) of \(\mathcal {C}\) such that \(\gamma \mapsto I_\gamma \) is constant on \({\mathcal {U}}(x,y)\). Consequently, sufficiently small perturbations of \(\gamma \) do not affect the integration domain of \(G_k(\gamma ;\cdots )\). Utilizing the formulas
we obtain
By pointwise differentiation at \((x,y) \in \varSigma \) and by observing that \(\varSigma \) has full measure, we are lead to the following identities which hold almost everywhere on \({{\mathbb {T}}^2}\):
Claim 1 below will imply that \(F_1(\gamma ;u_1)\) is indeed a candidate for \(DE(\gamma ) \, u_1\). Moreover, it guarantees that the right hand side of (13) makes sense even if one replaces \(u \in {\mathcal {X}}\) by \(w \in {\mathcal {Y}}\) so that  has a unique continuous extension to an element
has a unique continuous extension to an element  .
.
Claim 1
There exists a \(\gamma \)-dependent \(C\ge 0\) such that \(\Vert {F_1(\gamma ;u_1)}\Vert _{L^{1}_{\gamma }}\le C \, \Vert {u_1}\Vert _{W^{s-{\nu },q}_{\gamma }}\) holds for all \(u_1 \in {\mathcal {X}}\).
We split \(F_1\) as follows:
The desired bound for the first summand is derived in Theorem 3.4. The second summand can be treated with Theorem 3.3 because it has the form \(2\, {\mathcal {B}}^{\alpha ,\beta }_\gamma (\gamma ,u)\) with \(\alpha = 0\) and \(\beta = 2\).
We would like to use the \(L^{1}\)-norm of \(F_2\) to bound remainder terms of Taylor expansions. This will make use of the following claim.
Claim 2
There exists a number \(\varXi (\gamma ) {}>{} 0\), continuous in \(\gamma \), such that for all \(u_1\), \(u_2 \in {\mathcal {X}}\), we have \(\Vert {F_2(\gamma ;u_1,u_2)}\Vert _{L^{1}_{\gamma }} \le \varXi (\gamma ) \, \Vert {u_1}\Vert _{{\mathcal {X}},\gamma } \, \Vert {u_2}\Vert _{{\mathcal {Y}},\gamma }\).
We may split \(F_2(\gamma ;u_1,u_2)\) into the following four summands:
Here, (15) and (16) are again of the type discussed in Theorem 3.3, namely with \(\alpha = 0\), \(\beta = 4\) and \(\alpha = 0\), \(\beta = 2\), respectively. We may factorize (17) as
to discover that we have discussed its second factor already. Up to a \(\gamma \)-dependent constant, its first factor is bounded by \(2 \, \Vert {{\mathcal {D}}_\gamma u_1}\Vert _{L^{\infty }}\), thus dominated by \(\Vert {u_1}\Vert _{{\mathcal {X}},\gamma }\). With \(H \;{:}{=}\; \int _{I_\gamma }\!\langle {\mathcal {D}}_\gamma u_1 , {\mathcal {D}}_\gamma u_2 \rangle \, \omega _{\gamma }\), we can split (18) into the following two summands:
The first summand of (19) can be treated with Theorem 3.4. With \(\varphi _i \;{:}{=}\; \langle {\mathcal {D}}_\gamma \gamma , {\mathcal {D}}_\gamma u_i \rangle \) and the identities \(\varrho _\gamma = \int _{I_\gamma } \omega _{\gamma }(s)\) and \(H-G_2(\gamma ;u_1,u_2) = \int _{I_\gamma } \varphi _1(t) \, \varphi _2(t)\, \omega _{\gamma }(t)\) the second summand of (19) simplifies to
Now the same techniques as in Theorem 3.4 and the product rule Theorem A.4 imply
which proves the claim.
Claim 3
E is Fréchet differentiable with \(DE(\gamma ) \,u = F_1(\gamma ;u)\).
It suffices to show that there is a \(C \ge 0\) such that \( \Vert { E(\gamma + u)-E(\gamma )-F_1(\gamma ;u) }\Vert _{L^{1}_{\gamma }} \le C \, \Vert {u}\Vert _{{\mathcal {X}},\eta }^2 \) holds for all sufficiently small \(u \in {\mathcal {X}}\). Because \(\mathcal {C}\subset {\mathcal {X}}\) is open and \(\varXi \) is continuous, we may find an \(\varepsilon >0\) such that for all \(\Vert {u}\Vert _{{\mathcal {X}},\gamma } < \varepsilon \) we have \(\eta \;{:}{=}\; \gamma +u \in \mathcal {C}\) and \(\varXi (\eta ) \le 2 \, \varXi (\gamma )\). By shrinking \(\varepsilon \) if necessary, we may achieve that all the densities \(\varOmega _{\eta }\) and the norms \(\Vert {\cdot }\Vert _{{\mathcal {X}},\eta }\) are equivalent for all such u, i.e., there are \(c>0\) and \(\varLambda >1\) such that
For the remainder of the proof, we let \(u \in {\mathcal {X}}\) be of length \(\Vert {u}\Vert _{{\mathcal {X}},\gamma } < \varepsilon \) and abbreviate \(\eta \;{:}{=}\; \gamma + u\) and \(\gamma _t \;{:}{=}\; \gamma + t\, u\).

Illustration why handling \(\gamma \mapsto \varrho _\gamma \) correctly is so difficult. a Two points \(\gamma (x)\) and \(\gamma (y)\) on a circular curve and the geodesic arc \(\gamma (I_\gamma (x,y))\) connecting them. b A displacement vector field u along \(\gamma \). c The geodesic arc \(\eta (I_\eta (x,y))\) connecting \(\eta (x)\) and \(\eta (y)\) on the displaced curve \(\eta = \gamma + u\). Observe that \(I_\gamma (x,y) \ne I_\eta (x,y)\), so (x, y) belongs to the “bad” set V(u). d The points (x, y), (y, x) and the “bad” set V(u), plotted over the relief of \(\varrho _\gamma \) in the parameterization domain \({{\mathbb {T}}^2}\)
Now we split the integration domain \({{\mathbb {T}}^2}= U(u) \cup V(u)\cup \{(x,x) | x \in {\mathbb {T}}\} \) into a “good” part U(u), a “bad” part V(u), and an “ugly“ part, the diagonal of \({{\mathbb {T}}^2}\) (cf. Fig. 7). Since the latter is a null set, it may be neglected. The other two parts are defined as follows:

On the “good” part, we may apply Taylor’s theorem along with Claim 2 and (21) to obtain
Here the first estimate is only admissible on the “good” set U(u) as the intrinsic distance (6) is differentiable. However, we cannot argue this way on the “bad” set V(u). Instead, we observe that V(u) has positive distance from the diagonal. Thus, by Claim 4 below, \(\gamma \mapsto E(\gamma )|_{V(u)}\) is Lipschitz continuous as a map into \(L^{\infty }(V(u);\mathbb {{\mathbb {R}}})\). Together with Claim 5 below, which states that V(u) is a small set, the triangle inequality \( |{E(\eta ) - E(\gamma ) - F_1(\gamma ; u)}| \le |{E(\eta ) - E(\gamma )}| + |{F_1(\gamma ; u)}| \) leads us to
which proves the claim.
Claim 4
\(\gamma \mapsto \varrho _\gamma \) is locally Lipschitz continuous as a mapping into \(L^{\infty }\).
As \({{\mathbb {T}}^2}\setminus \varSigma \) is a set of measure zero, we may restrict our attention to \((x,y) \in \varSigma \). For \(\eta \;{:}{=}\; \gamma + u\) and \((x,y) \in \varSigma \) there are two cases: The first case is \(I_{\eta }(x,y) = I_{\gamma }(x,y)\). Then the bound \(|{\varrho _{\eta }(x,y)-\varrho _\gamma (x,y)}| \le C \,\Vert {{\mathcal {D}}_\gamma u}\Vert _{L^{\infty }}\) follows from the differentiability of \(\omega _{\gamma }\). The second case \(I_{\eta }(x,y) \ne I_{\gamma }(x,y)\) is a bit more elaborate. We abbreviate \(I \;{:}{=}\; I_\gamma (x,y)\) and denote its complement by \(J \;{:}{=}\; {\mathbb {T}}\setminus I\). With (20), we obtain
Here we used (20) for the first and the third inequality. This shows \( |{ \int _{J} \omega _{\gamma } \! - \! \int _{I} \omega _{\gamma } }| = \int _{J} \omega _{\gamma } - \int _{I} \omega _{\gamma } \le 2 \, c \, \ell \, \Vert {{\mathcal {D}}_\gamma u}\Vert _{L^{\infty }} \). By (20), we obtain \( |{ \int _{J} \omega _{\eta } \! - \! \int _{J} \omega _{\gamma } }| \le 2 \, c \, \ell \Vert {{\mathcal {D}}_\gamma u}\Vert _{L^{\infty }} \). Combining these latter two inequalities proves Claim 4:
Claim 5
\(\int _{V(u)} \, \varOmega _\gamma \le C \, \Vert {{\mathcal {D}}_\gamma u}\Vert _{L^{\infty }}\) for \(\Vert {u}\Vert _{{\mathcal {X}},\gamma } < \varepsilon \).
A Taylor expansion of the integrand leads to
Now let \((x,y) \in V(u)\). Then there is a \(t \in \left[ 0,1\right] \) such that \(I_{\gamma + t \, u}(x,y) = J\) and we have

Together with Claim 4 this implies that V(u) is contained in a narrow band around the set \(\{(x,y) | \varrho _\gamma (x,y) = \ell \}\) whose area is proportional to \(\Vert {{\mathcal {D}}_\gamma u}\Vert _{L^{\infty }}\) (cf. Fig. 7d).
Claim 6
There is a \(C \ge 0\) such that  holds for all \(w \in {\mathcal {Y}}\) and all \(u \in {\mathcal {X}}\) with \(\Vert {u}\Vert _{{\mathcal {X}},\gamma }< \varepsilon \).
holds for all \(w \in {\mathcal {Y}}\) and all \(u \in {\mathcal {X}}\) with \(\Vert {u}\Vert _{{\mathcal {X}},\gamma }< \varepsilon \).
With the operator \(\varPsi _\gamma w \;{:}{=}\; \big ( \langle {\mathcal {D}}_\gamma \gamma , {\mathcal {D}}_\gamma w \rangle \circ \pi _1+ \langle {\mathcal {D}}_\gamma \gamma , {\mathcal {D}}_\gamma w \rangle \circ \pi _2\big )\), we may write  . By the triangle inequality and the fundamental theorem of calculus, we may bound
. By the triangle inequality and the fundamental theorem of calculus, we may bound  from above by
from above by
Recall that on the “good” set U(u) we may interchange differentiation and integration. Hence, we have
Now it follows from the other claims above that (22) is bounded by a multiple of \(\Vert {u}\Vert _{{\mathcal {X}},\gamma } \, \Vert {w}\Vert _{{\mathcal {Y}},\gamma }\). For (23), we exploit that V(u) has finite, positive distance to the diagonal of \({{\mathbb {T}}^2}\): This implies that the quantities \(|{\triangle \gamma (x,y)}|\) and \(\varrho _\gamma (x,y)\) are uniformly bounded away from zero and that this remains true for sufficiently small perturbations \(\eta = \gamma + u\) of \(\gamma \). This is why we can express the term \(\big [\big ( F_1(\gamma ;w) + E(\gamma ) \, (\varPsi _\gamma w)\big ) \, \varOmega _\gamma \big ](x,y)\) by
for \((x,y) \in V(u)\) with Lipschitz continuous functions \(Z_1\) and \(Z_2\). So the same applies to \(\eta \), and Claim 5 shows that (23) is bounded by
which finally proves the claim. \(\square \)
Remark 3.2
In fact, a bit more is true: The mapping  is even continuously Fréchet differentiable and what we have shown in Claim 6 above is that
is even continuously Fréchet differentiable and what we have shown in Claim 6 above is that  is a continuous bilinear form. Now we may conclude that its second derivative must satisfy
is a continuous bilinear form. Now we may conclude that its second derivative must satisfy  for \(u_1\), \(u_2 \in {\mathcal {X}}\) where \(i_{\mathcal {C}}\) and \(j_{\mathcal {C}}\) denote the canonical embeddings defined in (11). Although this might be relevant for optimization methods based on Newton’s method and also for the implicit integration of the \(L^2\)-gradient flow, we do not dive into details here.
for \(u_1\), \(u_2 \in {\mathcal {X}}\) where \(i_{\mathcal {C}}\) and \(j_{\mathcal {C}}\) denote the canonical embeddings defined in (11). Although this might be relevant for optimization methods based on Newton’s method and also for the implicit integration of the \(L^2\)-gradient flow, we do not dive into details here.
3.1 Details
Here we state and prove the lemmas used in the proof of Theorem 3.1 above. The following is our main tool for dealing with the lower order terms that occur in  .
.
Lemma 3.3
Suppose \(s = \frac{3}{2}\) and (9) with \(\frac{1}{p}+\frac{1}{q}=1\). Fix \(k \in \mathbb {N}\cup \{0\}\), \(\alpha \), \(\beta \in {\mathbb {R}}\). Let \(\gamma \in \mathcal {C}\) be an embedded curve and let \(b :(\prod _{i=1}^k {\mathbb {R}}^{m_i}) \times {\mathbb {R}}^d \rightarrow {\mathbb {R}}\) be a \((k+1)\)-multilinear form. For operators \(L_i\), \(K \in \{ \triangle / \varrho _\gamma , \varphi \mapsto {\mathcal {D}}_\gamma \varphi \circ \pi _1, \varphi \mapsto {\mathcal {D}}_\gamma \varphi \circ \pi _2\}\), \(i \in {1,\dotsc ,k}\) consider the following multilinear form \( {\mathcal {B}}^{\alpha ,\beta }_\gamma :(\prod _{i=1}^k {\mathcal {X}}'{^{\!}}) \times {\mathcal {Y}}'{^{\!}}\rightarrow {\mathbb {R}}\):
Then \({\mathcal {B}}^{\alpha ,\beta }_\gamma \) is well-defined and there is a continuous function  such that
such that
Here the expression \(\Vert {b}\Vert \) denotes the operator norm of the multilinear form b. If \(k=0\), we use the convention \((\prod _{i=1}^0 {\mathbb {R}}^{m_i}) \times {\mathbb {R}}^d={\mathbb {R}}^{d}\) and \((\prod _{i=1}^0 {\mathcal {X}}'{^{\!}}) \times {\mathcal {Y}}'{^{\!}}= {\mathcal {Y}}'{^{\!}}\). In this case, \({\mathcal {B}}^{\alpha ,\beta }_\gamma \) only depends on \(\psi \).
Proof
We heavily rely on the techniques developed in the proof of Theorem 1.1 in [11]. With the function \(\zeta :\left]0,\infty \right[ \rightarrow {\mathbb {R}}\), \( \zeta (r) \;{:}{=}\; r^{2+\alpha } \, \frac{r^{2+\beta } - 1}{r^{2} - 1} \), we write
Denoting the shorter arc between x, \(y \in {\mathbb {T}}\) by \(I_\gamma \), we observe
Since \(\zeta \) is continuous and \(\gamma \) is bi-Lipschitz, the factor \(\zeta (\tfrac{\varrho _\gamma }{|{\triangle \gamma }|})\) is bounded. Moreover, the functions \(L_i \varphi _i\) are uniformly bounded. So it suffices to bound the \(L^{1}_\gamma \)-norm of
We abbreviate half the length of \(\gamma \) by \(\ell \) and denote by \(\eta _x \;{:}{=}\; \exp _x^\gamma :\left]-\ell ,\ell \right[ \rightarrow {\mathbb {T}}\) the Riemannian exponential map induced by \(\varrho _\gamma \). With X such that \(y = \eta _x(X)\), we may write \(\varrho _\gamma (x,y) = |{X}|\) and \(K \,\psi (x,y) = \int _0^1 {\mathcal {D}}_\gamma \psi (\xi _{x}(\theta _1 , X))\, {{\text {d}}}\theta _1\), where \(\xi _{x}(\theta _1 , X)\) is either \(\eta _{x}(\theta _1 \, X)\), x, or \(\eta _{x}(X) = y\). Thus, we may rewrite (24) as follows:
By Fubini’s theorem, the \(L^{1}_\gamma \)-norm of (24) is bounded by
We employ the Hölder inequality to obtain an upper bound for this integral: For \(s=\frac{3}{2}\) we define \(\tilde{q}\) by \({\tilde{q}} \;{:}{=}\; 2\, p \, (p -2 + 2 \, p \, {\nu })^{-1} \ge 1\). Then we have a Sobolev embedding \(W^{{s}-1 - {\nu },q} \hookrightarrow L^{{\tilde{q}}}\) due to (9), see Theorem A.3, thus \(\Vert {{\mathcal {D}}_\gamma \psi }\Vert _{L_{\gamma }^{\tilde{q}}} \le C(\gamma ) \, \Vert {\psi }\Vert _{W_{\gamma }^{s-{\nu },q}}\) with \(C(\gamma )\) depending continuously on \(\gamma \). The Hölder conjugate of \({\tilde{q}}\) is \({\tilde{p}} \;{:}{=}\; 2 \, p \, (p + 2 - 2 \, p \, {\nu })^{-1}\). Thus, we obtain the following upper bound:
Exploiting that \(\eta _{(\cdot )}(\theta _i \, X) :{\mathbb {T}}\rightarrow {\mathbb {T}}\) are isometries with respect to \(\varrho _\gamma \), and utilizing the substitution \(Y \;{:}{=}\; (\theta _2-\theta _3) \, X\), we may compute as follows:

Here \(\Vert {\cdot }\Vert _{B,\gamma }\) is a natural, \(\gamma \)-dependent norm on the Besov space \(B^{s-1}_{2 {\tilde{p}},2}({\mathbb {T}};{{\mathbb {R}}^{m}})\). This shows that \(\varXi (\gamma ) = \frac{1}{2} \, \Vert {\zeta (\varrho _\gamma /|{\triangle \gamma }|)}\Vert _{L^{\infty }} \, C(\gamma ) \, \Vert {\tau _\gamma }\Vert _{B,\gamma }^2\). Because of \(s - 1 +{\nu }- 1/p > s - 1 - 1/ (2 {\tilde{p}})\) with \(s=\tfrac{3}{2}\) and (9), we have a continuous Sobolev embedding \(W^{s - 1 +{\nu },p} ({\mathbb {T}};{\mathbb {R}}^m)\hookrightarrow B^{s-1}_{2 {\tilde{p}},2}({\mathbb {T}};{{\mathbb {R}}^{m}})\) (see [92, Theorem 3.3.1] or [72, Theorem 2.4.4/1]), showing that \(\varXi \) is continuous. \(\square \)
The next statement allows us to handle the principal order terms of  .
.
Lemma 3.4
Suppose \(s = \frac{3}{2}\) and (9) with \(\frac{1}{p}+\frac{1}{q}=1\). Let \(I_\gamma (x,y) \subset {\mathbb {T}}\) denote a shortest arc with respect to \(\varrho _\gamma \) that connects x and y. Then the bilinear form \({\mathcal {B}}_\gamma :{\mathcal {X}}'{^{\!}}\times {\mathcal {Y}}'{^{\!}}\rightarrow {\mathbb {R}}\) given by
is well-defined and bounded. More precisely, we have \( |{{\mathcal {B}}_\gamma (u,w)}| \le [{u}]_{{\mathcal {X}},\gamma }\,[{w}]_{{\mathcal {Y}},\gamma } \).
Proof
Using the following two identities
we obtain
Now we apply the same technique as in (25): Utilizing the notation of Theorem 3.3 and the substitutions \(y = \eta _x(X)\), \(s = \eta _x(\theta _1 \, X)\), \(t = \eta _x(\theta _2 \, X)\), and \(Y = (\theta _1 -\;\theta _2) \, X\), we arrive at:
Thus, we can bound \(|{{\mathcal {B}}_\gamma (u,w)}|\) from above by
\(\square \)
4 Metrics and Riesz isomorphisms
Next to the differential of the energy, the second ingredient that one requires for defining a gradient is a Riemannian metric on the configuration space \(\mathcal {C}\) that has been introduced in (5). Below, we pick a suitable inner product on \({\mathcal {H}}\) which is essentially a geometric version of the \(W^{{s},2}\)-Gagliardo inner product G from the introduction (see (4)). Throughout, we represent this inner product at the point \(\gamma \in \mathcal {C}\) only by its Riesz isomorphism  .
.
If  identified the tangent space \(T_\gamma \mathcal {C}\) of \(\mathcal {C}\) at \(\gamma \) with the cotangent space, i.e., its dual \(T_\gamma '{^{\!}}\mathcal {C}\), we could define the gradient of \({\mathcal {E}}\) by
identified the tangent space \(T_\gamma \mathcal {C}\) of \(\mathcal {C}\) at \(\gamma \) with the cotangent space, i.e., its dual \(T_\gamma '{^{\!}}\mathcal {C}\), we could define the gradient of \({\mathcal {E}}\) by

Alas, \(T_\gamma \mathcal {C}= {\mathcal {X}}\) is not a Hilbert space for its Hilbert space completion (with respect to  ) is \({\mathcal {H}}\ne {\mathcal {X}}\), so that there cannot be any linear isomorphism \(T_\gamma \mathcal {C}\rightarrow T_\gamma '{^{\!}}\mathcal {C}= {\mathcal {X}}'{^{\!}}\) induced by a positive-definite bilinear form. However, we have already seen in Theorem 3.1 that \(D {\mathcal {E}}(\gamma )\) can be interpreted as an element
) is \({\mathcal {H}}\ne {\mathcal {X}}\), so that there cannot be any linear isomorphism \(T_\gamma \mathcal {C}\rightarrow T_\gamma '{^{\!}}\mathcal {C}= {\mathcal {X}}'{^{\!}}\) induced by a positive-definite bilinear form. However, we have already seen in Theorem 3.1 that \(D {\mathcal {E}}(\gamma )\) can be interpreted as an element  in the smaller space \({\mathcal {Y}}'{^{\!}}\subset {\mathcal {X}}'{^{\!}}\), and that
in the smaller space \({\mathcal {Y}}'{^{\!}}\subset {\mathcal {X}}'{^{\!}}\), and that  is locally Lipschitz continuous. Thus, Theorem 1.1 is proven as soon as we show that
is locally Lipschitz continuous. Thus, Theorem 1.1 is proven as soon as we show that  induces an isomorphism
induces an isomorphism  which depends locally Lipschitz continuously on \(\gamma \). This is our goal in this section.
which depends locally Lipschitz continuously on \(\gamma \). This is our goal in this section.
Depending on context, we use \(\langle \cdot , \cdot \rangle \) for the dual pairing of a Banach space with its dual, e.g., \(\langle \cdot , \cdot \rangle :{\mathcal {H}}'{^{\!}}\times {\mathcal {H}}\rightarrow {\mathbb {R}}\) and \(\langle \cdot , \cdot \rangle :{\mathcal {Y}}'{^{\!}}\times {\mathcal {Y}}\rightarrow {\mathbb {R}}\), as well as the Euclidean inner product on \({{\mathbb {R}}^{m}}\). Note that the canonical embeddings \(i_{\mathcal {C}} :{\mathcal {X}}\hookrightarrow {\mathcal {H}}\) and \(j_{\mathcal {C}} :{\mathcal {H}}\hookrightarrow {\mathcal {Y}}\) introduced in (11) give rise to dual maps \(i_{\mathcal {C}}'{^{\!}}:{\mathcal {H}}'{^{\!}}\hookrightarrow {\mathcal {X}}'{^{\!}}\) and \(j_{\mathcal {C}}'{^{\!}}:{\mathcal {Y}}'{^{\!}}\hookrightarrow {\mathcal {H}}'{^{\!}}\).
Proposition 4.1
For each \(\gamma \in \mathcal {C}\), with \(\sigma \;{:}{=}\; s - 1=\tfrac{1}{2}\) and the notation from (7), (8), and (9), we define  and
and  as follows:
as follows:

for \(v_1\), \(v_2 \in {\mathcal {H}}\), \(u \in {\mathcal {X}}\), and \(w \in {\mathcal {Y}}\). These operators are well-defined, continuously invertible, and they make the following diagram commutative:

Moreover, the mappings  ,
,  , and
, and  ,
,  , are of class \(C^1\) and hence locally Lipschitz continuous.
, are of class \(C^1\) and hence locally Lipschitz continuous.
Here and in what followers, a doubly headed arrow in the diagram (27) above indicates a linear operator with dense image.
Proof
Well-definedness: It follows from the bi-Lipschitz continuity of \(\gamma \) and from Hölder’s inequality that the integrals
are well-defined and finite. Indeed, we have by Hölder’s inequality that
and, analogously, \( |{ \textstyle \int _{{\mathbb {T}}^2}\langle \delta ^{\sigma }_{\gamma } {\mathcal {D}}_\gamma v_1 , \delta ^{\sigma }_{\gamma } {\mathcal {D}}_\gamma v_2 \rangle \, \mu _\gamma }| \le \left[ v_1\right] _{{\mathcal {H}},\gamma } \left[ v_2\right] _{{\mathcal {H}},\gamma }\). Moreover, the existence of the integrals
follows from Theorem 3.3 with \(k=1\), \(\alpha = 2\), \(\beta =0\), and \(L_1 = K = \triangle /\varrho _\gamma \). (Here we use \(\sigma =\tfrac{1}{2}\).) The commutativity of (27) follows from the pointwise identity
which holds for arbitrary functions \(\varphi \), \(\psi :{\mathbb {T}}\rightarrow {{\mathbb {R}}^{m}}\).
Invertibility: We show this only for  , as the argument for
, as the argument for  is analogous. First we observe that
is analogous. First we observe that  is injective. Indeed, let
is injective. Indeed, let  . Then
. Then

implies that \({\mathcal {D}}_{\gamma } u\) must be constant and that the mean value of u vanishes. But the first condition can only hold if u is already constant and the second one forces this constant to be zero. So it suffices to show that  is a Fredholm operator of index 0. To this end, we define the operator \(A_\gamma :{\mathcal {X}}\rightarrow {\mathcal {Y}}'{^{\!}}\) by
is a Fredholm operator of index 0. To this end, we define the operator \(A_\gamma :{\mathcal {X}}\rightarrow {\mathcal {Y}}'{^{\!}}\) by
Now we observe that \(\langle A_\gamma \, u, w \rangle = \int _{{\mathbb {T}}^2}\big \langle D^{{{\sigma }+{\nu }}}_{\gamma } {\mathcal {D}}_\gamma u, D^{{{\sigma }-{\nu }}}_{\gamma } {\mathcal {D}}_\gamma u \big \rangle \, {{\text {d}}}\mu _\gamma \) and that

From Theorem 3.3 we may conclude that \(A_\gamma \) is a compact perturbation of  . So it suffices to show that \(A_\gamma \) is a Fredholm operator of index 0. As this is a bit more involved, we defer this to Theorem 4.2 below.
. So it suffices to show that \(A_\gamma \) is a Fredholm operator of index 0. As this is a bit more involved, we defer this to Theorem 4.2 below.
Fréchet differentiability: This can be shown by utilizing basically the same technique as in the proof of the Fréchet differentiability of the energy: first order Taylor expansion of the integrand around the point \(\gamma \) and bounding the integral of the second order remainder term (see Claim 3 in Theorem 3.1). In fact, the analysis here is bit easier for the geodesic distance \(\varrho _\gamma \) does not appear in the definitions of  and
and  . For the sake of brevity, we omit the details. \(\square \)
. For the sake of brevity, we omit the details. \(\square \)
4.1 Details
The remainder of this section is devoted to proving the following lemma. The employed techniques are fairly standard in the area of pseudo-differential operators; only the fact that the differential operators involved here are nonlocal introduces a couple of further technicalities. Throughout, we will suppose that \(\gamma \in \mathcal {C}\). Moreover, we will denote by \(K :{\mathcal {X}}\rightarrow {\mathcal {Z}}\) a generic compact operator that—pretty much like the ever-expanding “constant” C—may change from line to line.
Lemma 4.2
The operator \(A_\gamma :{\mathcal {X}}\rightarrow {\mathcal {Y}}'{^{\!}}\) defined in (28) is a Fredholm operator of index 0.
Proof
As the Fredholm property and the index are invariant under compact perturbations, it suffices to show that \(A_\gamma + M_\gamma \) is continuously invertible, where we define the compact operator \(M_\gamma :{\mathcal {X}}\rightarrow {\mathcal {Y}}'{^{\!}}\) by  The operator \(A_\gamma + M_\gamma \) is injective because of
The operator \(A_\gamma + M_\gamma \) is injective because of  . Since the operator \(j_{\mathcal {C}} \, i_{\mathcal {C}} :{\mathcal {X}}\hookrightarrow {\mathcal {Y}}\) is injective and has dense image, this also implies that \(A_\gamma + M_\gamma \) has dense image. By virtue of the Schauder lemma (see Theorem A.5), it suffices to establish an elliptic estimate of the form \( \Vert {u}\Vert _{{\mathcal {X}}} \le C\, \big ( \Vert {(A_\gamma + M_\gamma )\, u}\Vert _{{\mathcal {Y}}'{^{\!}}} + \Vert {K \, u}\Vert _{{\mathcal {Z}}} \big )\) for all \(u \in {\mathcal {X}}\) with suitable norms \(\Vert {\cdot }\Vert _{{\mathcal {X}}}\) and \(\Vert {\cdot }\Vert _{{\mathcal {Y}}}\) that will be defined soon. Indeed, we will show in Theorem 4.6 that
. Since the operator \(j_{\mathcal {C}} \, i_{\mathcal {C}} :{\mathcal {X}}\hookrightarrow {\mathcal {Y}}\) is injective and has dense image, this also implies that \(A_\gamma + M_\gamma \) has dense image. By virtue of the Schauder lemma (see Theorem A.5), it suffices to establish an elliptic estimate of the form \( \Vert {u}\Vert _{{\mathcal {X}}} \le C\, \big ( \Vert {(A_\gamma + M_\gamma )\, u}\Vert _{{\mathcal {Y}}'{^{\!}}} + \Vert {K \, u}\Vert _{{\mathcal {Z}}} \big )\) for all \(u \in {\mathcal {X}}\) with suitable norms \(\Vert {\cdot }\Vert _{{\mathcal {X}}}\) and \(\Vert {\cdot }\Vert _{{\mathcal {Y}}}\) that will be defined soon. Indeed, we will show in Theorem 4.6 that
Since \(M_\gamma \) is compact, this implies the previous inequality (for different C, K and \({\mathcal {Z}}\)). \(\square \)
In order to prove (29), it is convenient to introduce some additional notation. The operator \(A_\gamma \) is defined in terms of \(D^{{{\sigma }+{\nu }}}_{\gamma } = \frac{\triangle }{\varrho _\gamma ^{{\sigma }+{\nu }}}\) and \(D^{{{\sigma }-{\nu }}}_{\gamma } = \frac{\triangle }{\varrho _\gamma ^{{\sigma }-{\nu }}}\), see (28), so it is natural to consider the following local semi-norms: For an open set \(U \subset {\mathbb {T}}\), \(0<\alpha <1\), and \(1 \le r < \infty \) and a measurable \(v :{\mathbb {T}}\rightarrow {{\mathbb {R}}^{m}}\), we define

For convenience, we fix \(\gamma \) and define

We point out that \(\gamma \in \mathcal {C}\) has always finite energy, thus \(\gamma \) is bi-Lipschitz continuous, see [62, Thm. 2.3]); hence the norms \(\Vert {\cdot }\Vert _{{\mathcal {X}}}\), \(\Vert {\cdot }\Vert _{{\mathcal {Y}}}\) are equivalent to \(\Vert {\cdot }\Vert _{{\mathcal {X}},\gamma }\), \(\Vert {\cdot }\Vert _{{\mathcal {Y}},\gamma }\), respectively, cf. (10). For a measurable function \({\tilde{v}} :{\mathbb {R}}\rightarrow {{\mathbb {R}}^{m}}\) and an open set \({\tilde{U}} \subset {{\mathbb {R}}^{m}}\), we define
as well as the following semi-norms:

Moreover, we use following abbreviations for the global Sobolev spaces and their norms:
Via localization techniques, we will compare \(A_\gamma \) to \(L :{\tilde{{\mathcal {X}}}} \rightarrow {\tilde{{\mathcal {Y}}}}'{^{\!}}\) given by
Compare this to the weak formulation of the fractional Laplacian
which is given by
for some \(C_{\sigma } > 0\) (see e.g., [50, Theorem 1.1]). So up to a constant, we have \(L = {\mathcal {D}}'{^{\!}}(-\varDelta )^\sigma {\mathcal {D}}\), hence L is a pseudo-differential operator of order \(2 \, \sigma +2=2s=3\) and its principal symbol \(P(L) :T'{^{\!}}\, {\mathbb {R}}\cong {\mathbb {R}}\times {\mathbb {R}}\rightarrow {{\,\mathrm{End}\,}}({{\mathbb {R}}^{m}})\) is (up to a constant) given by \(P(L)(x,\xi ) = |{\xi }|^{2s}\, {{\,\mathrm{id}\,}}_{{\mathbb {R}}^{m}} = P(({{\,\mathrm{id}\,}}-\varDelta )^{s})(x,\xi )\). By [92, 2.3.8], the operator L is continuously invertible.Footnote 3
The following two lemmas will help us in localizing Sobolev norms.
Lemma 4.3
(Norm localization) Let \(0<\alpha <1\), \(1 \le r < \infty \) and let \(U \subset \subset V \subset \subset {\mathbb {T}}\) be relatively compact, open sets. Then there is a \(C = C(\gamma ,\alpha ,r,U,V)>0\) such that
Lemma 4.4
(Norm localization) Let \(0<\alpha <1\), \(1 \le r < \infty \) and let \({\tilde{V}} \subset \subset {\tilde{U}} \subset \subset {\mathbb {R}}\) be relatively compact, open sets. Then there is a \(C = C(\alpha ,r,{\tilde{U}}, {\tilde{V}})>0\) such that
Their proofs are quite similar, so we show only the proof of the latter for it contains an additional difficulty.
Proof of Theorem 4.4
Since \({{\,\mathrm{supp}\,}}({\tilde{v}}) \subset {\tilde{V}} \subset {\tilde{U}}\), we obviously have

The following identity is caused by the nonlocality of \(D^{\alpha }_{}\) and it is easily overlooked:

Notice that we used here that \({{\,\mathrm{supp}\,}}({\mathcal {D}}\, {\tilde{v}}) \subset {\tilde{V}}\). We assumed that \({\tilde{V}} \subset \subset {\tilde{U}}\) is relatively compact, so there is an \(R>0\) such that \(|{x-y}| \ge R\) for all \(x \in {\mathbb {R}}\setminus {\tilde{U}}\) and \(y \in {\tilde{V}}\). Because of \(1+\alpha \, r>1\), we have \( \textstyle \sup _{y \in {\tilde{V}}} \int _{{\mathbb {R}}\setminus {\tilde{U}}} \, \frac{{{\text {d}}}x}{|{x-y}|^{1+\alpha \, r}} \le \int _R^\infty \frac{{{\text {d}}}t}{t^{1+\alpha \, r}} < \infty \), leading us to

which concludes the proof. \(\square \)
Now we can start to show (29), at least for functions u with small support.
Lemma 4.5
(Local elliptic estimate) For each point \(a \in {\mathbb {T}}\), there are open neighborhoods \(W \subset \subset U \subset {\mathbb {T}}\) and a compact operator \(K :{\mathcal {X}}\rightarrow {\mathcal {Z}}\) into some Banach space \({\mathcal {Z}}\) such that
Proof
We start by picking an isometric coordinate system around the point \(a\in {\mathbb {T}}\). With \(L \;{:}{=}\; \int _{\mathbb {T}}\omega _{\gamma }\) denoting the curve length, we choose \(U \;{:}{=}\; B_{L/4}(a)\), \(V \;{:}{=}\; B_{L/8}(a)\), and \(W \;{:}{=}\; B_{L/16}(a)\), where these balls are meant with respect to the intrinsic distance \(\varrho _\gamma \). We point out that U is geodesically convex, i.e., each shortest arc between two points in U is contained in U. Likewise we define the following open balls \({\tilde{U}} \;{:}{=}\; B_{L/4}(0)\), \({\tilde{V}} \;{:}{=}\; B_{L/8}(0)\), and \({\tilde{W}} \;{:}{=}\; B_{L/16}(0)\) in \({\mathbb {R}}\), this time with respect to the standard distance on \({\mathbb {R}}\). Now we define the isometric chart \( f:U \rightarrow {\tilde{U}} \) by \(f(x) = \pm \varrho _\gamma (a,x)\), where the sign depends on whether the shortest curve from a to x is oriented positively (\(+\)) or negatively (−) with respect to the standard orientation of \({\mathbb {T}}\). Let \(u \in {\mathcal {X}}\) be a function with \({{\,\mathrm{supp}\,}}(u) \subset W\). Then we can find a unique function \({\tilde{u}} \in {\tilde{{\mathcal {X}}}}\) with \({{\,\mathrm{supp}\,}}({\tilde{u}}) \subset {\tilde{W}}\) and \(u = {\tilde{u}} \circ f\).Footnote 4 Because f is an isometry, we have \(\Vert {u}\Vert _{{W^{s+\nu ,p}_{\varrho ,\gamma }}{(U)}} = \Vert {{\tilde{u}}}\Vert _{W^{{{s}+{\nu }},p}{({\tilde{U}})}}\). From Theorem 4.3 and from the continuous invertibility of \(L :{\tilde{{\mathcal {X}}}} \rightarrow {\tilde{{\mathcal {Y}}}}\), we deduce that there is a \(C \ge 0\) (depending only on \(\gamma \), \({{s}+{\nu }}\), \(p\), U, and W) such that
Our next goal is to control \(\Vert {L \, {\tilde{u}}}\Vert _{{\tilde{{\mathcal {Y}}}}'{^{\!}}}\) by \(\Vert {A_\gamma \, u}\Vert _{{\mathcal {Y}}}\) modulo a compact operator. To this end, we choose a bump function \(\eta \in W^{{{s}+{\nu }},p}({\mathbb {T}};{\mathbb {R}})\) with values in \(\left[ 0,1\right] \) that satisfies \(\eta (x) = 1\) for all \(x \in {\bar{W}}\) and \({{\,\mathrm{supp}\,}}(\eta ) \subset V\). We denote by \({\tilde{\eta }} \in W^{{{s}+{\nu }},p}({\mathbb {R}};{\mathbb {R}})\) the unique function \({\tilde{\eta }} \circ f= \eta \) and \({{\,\mathrm{supp}\,}}({\tilde{\eta }}) \subset {\tilde{V}}\). These functions induce the following multiplication operators:
Because of \(H\, u = u\) and \({\tilde{H}} \, {\tilde{u}} = {\tilde{u}}\), we may split \(A_\gamma \, u \) and \(L {\tilde{u}}\) into
Claim
The operators \(Q \;{:}{=}\; A_\gamma \, H- H'{^{\!}}\, A_\gamma \) and \({\tilde{Q}} \;{:}{=}\; L \, {\tilde{H}} - {\tilde{H}}'{^{\!}}\, L\) are compact.
For \(0<\alpha <1\) and \(v :{\mathbb {T}}\rightarrow {{\mathbb {R}}^{m}}\), the Leibniz rule implies
where \(\pi _1\), \(\pi _2:{{\mathbb {T}}^2}\rightarrow {\mathbb {T}}\) are the projections given by \(\pi _1(x,y) = x\) and \(\pi _2(x,y) = y\). This allows us to write
with compact operators \(K_1 :{\mathcal {X}}\rightarrow (L^{q}_{\mu _\gamma }({\mathbb {T}}^2;{\mathbb {R}}^{m}))'{^{\!}}\) and \(K_2 :{\mathcal {Y}}\rightarrow L^{q}_{\mu _\gamma }({\mathbb {T}}^2;{\mathbb {R}}^{m})\). Now we have
thus \(A_\gamma \, H- H'{^{\!}}\, A_\gamma = (D^{{{\sigma }-{\nu }}}_{\gamma } {\mathcal {D}}_\gamma )'{^{\!}}\, K_1 - K_2'{^{\!}}\, D^{{{\sigma }+{\nu }}}_{\gamma } {\mathcal {D}}_\gamma \) is compact. This shows the first statement. The second statement is proven analogously.
From this claim it follows that the “leading term” of \(L {\tilde{u}}\) is \({\tilde{H}}'{^{\!}}\, L \, {\tilde{u}}\). Next we are going to bound \(\Vert {{\tilde{H}}'{^{\!}}\, L \, {\tilde{u}}}\Vert _{{\tilde{{\mathcal {Y}}}}'{^{\!}}}\). For this it suffices to test \({\tilde{H}}'{^{\!}}\, L \, {\tilde{u}}\) against only such \({\tilde{w}} \in {\tilde{Y}}\) with \({{\,\mathrm{supp}\,}}({\tilde{w}}) \subset V\). More precisely, we have
For every such \({\tilde{w}}\) there is a \(w \in {\mathcal {Y}}\) with \({{\,\mathrm{supp}\,}}(w) \subset V\) such that \(w = {\tilde{w}} \circ f\). Since also \({\tilde{u}}\) and \({\tilde{\eta }}\) are constructed in this way from u and \(\eta \), we have
By Theorem 4.3 and Theorem 4.4, there is a \(C \ge 0\) (depending only on \(\gamma \), \({{s}-{\nu }}\), \(q\), U, W, \({\tilde{U}}\), and \({\tilde{W}}\) such that \( \Vert {w}\Vert _{{\mathcal {Y}}} \le C \, \Vert {w}\Vert _{W^{{{s}-{\nu }},q}_{\varrho ,\gamma }(U)} = C \, \Vert {{\tilde{w}}}\Vert _{W^{{{s}-{\nu }},q}({\tilde{U}})} \le C^2 \, \Vert {{\tilde{w}}}\Vert _{{\tilde{{\mathcal {Y}}}}} . \) Thus we obtain
Combined with (32), this leads to
Again by Theorem 4.3 and Theorem 4.4, the mapping \(u \mapsto u = H u \mapsto {\tilde{u}}\) is continuous. Since \({\tilde{Q}}\) is compact, the mapping \(u \mapsto {\tilde{Q}} \, {\tilde{u}}\) is compact as well. This concludes the proof. \(\square \)
Finally, we piece together the local estimates from above.
Lemma 4.6
(Global elliptic estimate) Let \(\gamma \in \mathcal {C}\). Then there are \(C >0\) and a compact, linear operator \(K :{\mathcal {X}}\rightarrow {\mathcal {Z}}\) into some Banach space \({\mathcal {Z}}\) such that
Proof
We start by covering \({\mathbb {T}}\) by finitely many open sets \(W_i \subset \subset U_i \subset {\mathbb {T}}\), \(i = 1, \dotsc ,k\), as in Theorem 4.5 such that there are local elliptic estimates of the form
with suitable constants \(C_i \ge 0\) and suitable compact operators \(K_i :{\mathcal {X}}\rightarrow {\mathcal {Z}}_i\) into Banach spaces \({\mathcal {Z}}_i\). Now we pick a smooth partition of unity \(\{\varphi _1,\dotsc ,\varphi _k\} \subset C^{\infty }(\mathbb {T};\left[ 0,1\right] )\) subordinate to \(\{W_1,\dotsc ,W_k\}\). We denote the corresponding multiplication operators by \(\varPhi _i :{\mathcal {X}}\rightarrow {\mathcal {X}}\), \(\varPhi _i \, u \;{:}{=}\; \varphi _i \, u\) and \(\varPhi _i :{\mathcal {Y}}\rightarrow {\mathcal {Y}}\), \(\varPhi _i \, w \;{:}{=}\; \varphi _i \, w\). Now we observe
With the triangle inequality, we obtain
The separate claim in the proof of Theorem 4.5 shows that \(A_\gamma \, \varPhi _i - \varPhi _i'{^{\!}}\, A_\gamma \) is a compact operator. So setting \(C \;{:}{=}\; \sum _{i=1}^k C_i \, \Vert {\varPhi _i}\Vert + \max (C_1, \dotsc , C_k)\), \({\mathcal {Z}}\;{:}{=}\; ({\mathcal {Y}}'{^{\!}}\oplus {\mathcal {Z}}_1) \oplus \cdots \oplus ({\mathcal {Y}}'{^{\!}}\oplus {\mathcal {Z}}_k)\), \(\Vert {(\eta _1,z_1,\dotsc ,\eta _k,z_k)}\Vert _{{\mathcal {Z}}} \;{:}{=}\; \Vert {\eta _1}\Vert _{{\mathcal {Y}}'{^{\!}}} + \Vert {z_1}\Vert _{{\mathcal {Z}}_1} + \cdots + \Vert {\eta _k}\Vert _{{\mathcal {Y}}'{^{\!}}} + \Vert {z_k}\Vert _{{\mathcal {Z}}_k}\), and
concludes the proof. \(\square \)
5 Constraints
Our aim in this section is to set up constraints on the barycenter and on the parametrization of curves and to show Theorem 1.2, i.e., well-definedness of the associated projected gradient and its flow.
Here, as before, we abbreviated \({\sigma }\;{:}{=}\; {s}-1=\tfrac{1}{2}\). By the choice of \({\nu }\) and \(p\) (see (9)), we have \(\mathcal {C}\subset W^{1+{{\sigma }+{\nu }},p}({\mathbb {T}};{\mathbb {R}}^m) \subset W^{1,\infty }({\mathbb {T}};{\mathbb {R}}^m)\). Hence for each \(\gamma \in \mathcal {C}\), the functions \(x \mapsto |{\gamma '(x)}|\) and \(x \mapsto |{\gamma '(x)}|^{-1}\) are both members of \(W^{{{\sigma }+{\nu }},p}({\mathbb {T}};{\mathbb {R}})\hookrightarrow L^{\infty }({\mathbb {T}};{\mathbb {R}})\). By the chain rule Theorem A.1, the following mapping is well-defined:
A curve \(\gamma \in \mathcal {C}\) is parametrized by constant speed L and has 0 as barycenter if and only if \(\varPhi (\gamma ) = (0,0)\). Our main task is to prove Theorem 5.1 below; it states that the feasible set
equipped with a generalized Riesz isomorphism inherited from  is almost a Riemannian manifold, at least in view of the projected or intrinsic gradients. Theorem 1.2 will follow from this immediately.
is almost a Riemannian manifold, at least in view of the projected or intrinsic gradients. Theorem 1.2 will follow from this immediately.
To this end (and in analogy to the space triple \({\mathcal {X}}\), \({\mathcal {H}}\), and \({\mathcal {Y}}\)), we introduce the Banach space triple
and the continuous dense injections \( i_{\mathcal {N}} :{\mathcal {X}}\mathcal {N}\hookrightarrow {\mathcal {H}}\mathcal {N}\) and \( j_{\mathcal {N}} :{\mathcal {H}}\mathcal {N}\hookrightarrow {\mathcal {Y}}\mathcal {N}\). A straight-forward computation shows that \(\varPhi \) is differentiable and that its derivative \(D\varPhi (\gamma ) :{\mathcal {X}}\rightarrow {\mathcal {X}}\mathcal {N}\) is given by
Theorem A.4 implies that \(u \mapsto \langle {\mathcal {D}}_\gamma \gamma ,{\mathcal {D}}_\gamma u \rangle \) induces well-defined and continuous linear operators \({\mathcal {X}}\rightarrow {\mathcal {X}}\mathcal {N}\), \({\mathcal {H}}\rightarrow {\mathcal {H}}\mathcal {N}\), and \({\mathcal {Y}}\rightarrow {\mathcal {Y}}\mathcal {N}\), provided that \({\nu }> 0\), and \(p\ge 2\). With the usual convention \(\mathcal {X}_{\gamma }{\varPhi } \;{:}{=}\; D\varPhi (\gamma )\) etc. we generate a triple \((\mathcal {X}_{\gamma }{\varPhi },\mathcal {H}_{\gamma }{\varPhi }, \mathcal {Y}_{\gamma }{\varPhi })\) of continuous, linear operators that makes the following diagram commutative:

By Theorem 5.2, the mapping \(\varPhi \) is a submersion. Thus the implicit function theorem implies that the set \({\mathcal {M}}\) is a Banach submanifold of \(\mathcal {C}\). For \(\gamma \in {\mathcal {M}}\) and \(\mathcal {Z} \in \{\mathcal {X},\mathcal {H},\mathcal {Y}\}\), define \( \mathcal {Z}_{\gamma }{{\mathcal {M}}} \;{:}{=}\; \ker ( \mathcal {Z}_{\gamma }{\varPhi }) \).The set \(\mathcal {Z}{{\mathcal {M}}} \;{:}{=}\; \coprod _{\gamma \in {\mathcal {M}}} \{\gamma \} \times \mathcal {Z}_{\gamma }{{\mathcal {M}}}\) together with the footpoint map \(\pi _{\mathcal {Z}{\mathcal {M}}} :\mathcal {Z}{{\mathcal {M}}} \rightarrow {\mathcal {M}}\) constitutes a smooth Banach vector bundle over \({\mathcal {M}}\) and we have  . The Banach spaces \(\mathcal {H}_{\gamma }{{\mathcal {M}}}\) and \(\mathcal {Y}_{\gamma }{{\mathcal {M}}}\) are the completions of \(T_\gamma {\mathcal {M}}= \ker ( D \varPhi (\gamma ))\) with respect to the topologies of \({\mathcal {H}}\) and \({\mathcal {Y}}\), respectively. Via Galerkin subspace projection, we may define linear operators \(I_{{\mathcal {M}}}|_\gamma :\mathcal {H}_{\gamma }{{\mathcal {M}}} \rightarrow \mathcal {H}{'{^{\!}}}_{\gamma }{{\mathcal {M}}}\) and \(\mathcal {J}_{{\mathcal {M}}}|_\gamma :\mathcal {X}_{\gamma }{{\mathcal {M}}} \rightarrow \mathcal {Y}{'{^{\!}}}_{\gamma }{{\mathcal {M}}}\) by
. The Banach spaces \(\mathcal {H}_{\gamma }{{\mathcal {M}}}\) and \(\mathcal {Y}_{\gamma }{{\mathcal {M}}}\) are the completions of \(T_\gamma {\mathcal {M}}= \ker ( D \varPhi (\gamma ))\) with respect to the topologies of \({\mathcal {H}}\) and \({\mathcal {Y}}\), respectively. Via Galerkin subspace projection, we may define linear operators \(I_{{\mathcal {M}}}|_\gamma :\mathcal {H}_{\gamma }{{\mathcal {M}}} \rightarrow \mathcal {H}{'{^{\!}}}_{\gamma }{{\mathcal {M}}}\) and \(\mathcal {J}_{{\mathcal {M}}}|_\gamma :\mathcal {X}_{\gamma }{{\mathcal {M}}} \rightarrow \mathcal {Y}{'{^{\!}}}_{\gamma }{{\mathcal {M}}}\) by
for \(v_1\), \(v_2 \in \mathcal {H}_{\gamma }{{\mathcal {M}}}\), \(u \in \mathcal {X}_{\gamma }{{\mathcal {M}}}\), and \(w \in \mathcal {Y}_{\gamma }{{\mathcal {M}}}\). The mappings \(i_{c}\) and \(j_{c}\) induce continuous injections \({i}_{{\mathcal {M}}}|_\gamma :\mathcal {X}_{\gamma }{{\mathcal {M}}} \hookrightarrow \mathcal {H}_{\gamma }{{\mathcal {M}}}\) and \({ j}_{{\mathcal {M}}}|_\gamma :\mathcal {H}_{\gamma }{{\mathcal {M}}} \hookrightarrow \mathcal {Y}_{\gamma }{{\mathcal {M}}}\). By (27), we have \(j'{^{\!}}_{{\mathcal {M}}} \, \mathcal {J}_{{\mathcal {M}}} = \mathcal {I}_{{\mathcal {M}}} \, i_{{\mathcal {M}}}\).
We define the intrinsic gradient \({{\,\mathrm{grad}\,}}_{\mathcal {M}}({\mathcal {E}}|_{\mathcal {M}})|_{\gamma } \in {\mathcal {X}}_{\gamma }{\mathcal {M}}\) by
or simply by \({{\,\mathrm{grad}\,}}_{\mathcal {M}}({\mathcal {E}}|_{\mathcal {M}})|_\gamma \;{:}{=}\; (\mathcal {J}_{{\mathcal {M}}}|_\gamma )^{-1} D({\mathcal {E}}|_{\mathcal {M}})(\gamma )\). Its well-definedness is established by the following theorem which states that \({\mathcal {M}}\) has a “nearly Riemannian structure”. Note that \({\mathcal {M}}\) cannot support a Riemannian structure because the tangent space \(T_\gamma {\mathcal {M}}\) is not Hilbertable in the sense that there is no positive-definite bilinear form whose norm topologizes \(T_\gamma {\mathcal {M}}\).
Theorem 5.1
The operators \(\mathcal {I}_{{\mathcal {M}}}|_\gamma \) and\(\mathcal {J}_{{\mathcal {M}}}|_\gamma \) define a family of continuous and continuously invertible operators.
Proof
Denote by \(F:{\mathcal {M}}\hookrightarrow \mathcal {C}\) and by

the canonical injections which give rise to dual maps

Observe that  and
and  .
.
The Galerkin projection of a Hilbert space’s Riesz isomorphism onto a closed subspace equals the Riesz isomorphism of the restricted scalar product. So the invertibility of  is straight-forward. The nontrivial part here is to show that
is straight-forward. The nontrivial part here is to show that  is continuously invertible. By the open mapping theorem, it suffices to show that
is continuously invertible. By the open mapping theorem, it suffices to show that  is both injective and surjective. Injectivity can be deduced from the injectivity of
is both injective and surjective. Injectivity can be deduced from the injectivity of  ,
,  , and
, and  as follows: Let
as follows: Let  and put
and put  . Now the following shows that \(u=0\):
. Now the following shows that \(u=0\):

In order to establish surjectivity of  , we fix an arbitrary \(\eta \in \mathcal {Y}'_{\gamma }{{\mathcal {M}}} \). By the Hahn-Banach theorem, the mapping
, we fix an arbitrary \(\eta \in \mathcal {Y}'_{\gamma }{{\mathcal {M}}} \). By the Hahn-Banach theorem, the mapping  is surjective. Thus there is an \(\eta _0 \in {\mathcal {Y}}'{^{\!}}\) with
is surjective. Thus there is an \(\eta _0 \in {\mathcal {Y}}'{^{\!}}\) with  . By Theorem 5.4 below, the saddle point problem
. By Theorem 5.4 below, the saddle point problem

has a unique solution with \(u_0 \in {\mathcal {X}}\) and \(\lambda _0 \in {\mathcal {Y}}'{^{\!}}\mathcal {N}\). In particular, we have  , hence we may write
, hence we may write  with
with  . Thus, we have
. Thus, we have

where we used the fact that  in the last step which follows by \(\varPhi \circ F=0\) due to \({\mathcal {M}}=\varPhi ^{-1}(0)\). \(\square \)
in the last step which follows by \(\varPhi \circ F=0\) due to \({\mathcal {M}}=\varPhi ^{-1}(0)\). \(\square \)
This leads us immediately to the proof of our main result Theorem 1.2:
Proof
The proof of Theorem 5.1 shows that we the gradient \(u_0 \;{:}{=}\; {{\,\mathrm{grad}\,}}_{\mathcal {M}}({\mathcal {E}}|_{\mathcal {M}})|_\gamma \) can be computed by solving (36) with \(\eta _0 = D{\mathcal {E}}(\gamma )\). Theorem 5.6 below shows that it is also the projected gradient, i.e., \({{\,\mathrm{grad}\,}}_{\mathcal {M}}({\mathcal {E}}|_{\mathcal {M}})|_\gamma \) coincides with the \(\mathcal {I}_{{\mathcal {M}}}|_\gamma \)-orthogonal projection of \({{\,\mathrm{grad}\,}}({\mathcal {E}})|_\gamma \) onto \(T_\gamma {\mathcal {M}}= \ker (D \varPhi (\gamma ))\). Because \(D{\mathcal {E}}(\gamma )\) and the saddle point matrix from (36) depend locally Lipschitz continuously on \(\gamma \), the gradient \({{\,\mathrm{grad}\,}}_{\mathcal {M}}({\mathcal {E}}|_{\mathcal {M}})\) is a locally Lipschitz continuous vector field on \({\mathcal {M}}\). \(\square \)
5.1 Details
Now, statements and proofs of the auxiliary results are in order.
Lemma 5.2
(Right inverse) The triple  induced by the derivative \(D\varPhi (\gamma )\) allows a triple
induced by the derivative \(D\varPhi (\gamma )\) allows a triple  of continuous right inverses such that the following diagram commutes:
of continuous right inverses such that the following diagram commutes:

Moreover  depend smoothly on \(\gamma \) and in particular, they are locally Lipschitz continuous.
depend smoothly on \(\gamma \) and in particular, they are locally Lipschitz continuous.
Proof
Denote by \({{\,\mathrm{pr}\,}}_\gamma ^\perp (x) \;{:}{=}\; {{\,\mathrm{id}\,}}_{{{\mathbb {R}}^{m}}} - \tau _\gamma (x) \otimes \langle \tau _\gamma (x),\cdot \rangle \) the orthogonal projector onto the orthogonal complement of \(\tau _\gamma (x)\). Fix a  and a \((\xi ,U) \in {\mathcal {Z}}\mathcal {N}\). Denote the length of \(\gamma \) by
and a \((\xi ,U) \in {\mathcal {Z}}\mathcal {N}\). Denote the length of \(\gamma \) by  . Fix a given point \(y_0 \in {\mathbb {T}}\) and define
. Fix a given point \(y_0 \in {\mathbb {T}}\) and define

with a vector \({\tilde{U}} \in {{\mathbb {R}}^{m}}\) to be determined later. This way, the components of \(D\varPhi (\gamma ) \, u\) stated in (34) amount to
Using the product rule Theorem A.4 (for which \(p\ge 2\) is crucial here), we see that u is a member of \({\mathcal {Z}}\), provided that we can find a \({\tilde{U}} \in {{\mathbb {R}}^{m}}\) such that u becomes continuous at \(y = y_0\). For this, it is necessary and sufficient that  Define the vector \(b_\gamma (\xi ) \in {{\mathbb {R}}^{m}}\) and the symmetric matrix \(\varTheta _\gamma \in {{\,\mathrm{End}\,}}({{\mathbb {R}}^{m}})\) by
Define the vector \(b_\gamma (\xi ) \in {{\mathbb {R}}^{m}}\) and the symmetric matrix \(\varTheta _\gamma \in {{\,\mathrm{End}\,}}({{\mathbb {R}}^{m}})\) by  and
and  Assume \(\varTheta _\gamma \) is not invertible. Then there is a unit vector \(V \in {{\mathbb {R}}^{m}}\) in its kernel and we have that \( 0 = \langle V,\varTheta _\gamma \, V \rangle = \textstyle \int _{\mathbb {T}}\big ( |{V}|^2 - \langle \tau _\gamma ,V \rangle ^2\big ) \, \omega _{\gamma } \). But that means that \(\tau _\gamma (x) = \pm V\) has to hold for almost every \(x\in {\mathbb {T}}\). Since \(\tau _\gamma \) is continuous, this implies that \(\gamma \) is a straight line, which is impossible due to \(\gamma \) being closed. This contradicts our assumption and thus \(\varTheta _\gamma \) must be invertible. So we may choose \({\tilde{U}} \;{:}{=}\; - \varTheta _\gamma ^{-1} \, b_\gamma (\xi )\) and put
Assume \(\varTheta _\gamma \) is not invertible. Then there is a unit vector \(V \in {{\mathbb {R}}^{m}}\) in its kernel and we have that \( 0 = \langle V,\varTheta _\gamma \, V \rangle = \textstyle \int _{\mathbb {T}}\big ( |{V}|^2 - \langle \tau _\gamma ,V \rangle ^2\big ) \, \omega _{\gamma } \). But that means that \(\tau _\gamma (x) = \pm V\) has to hold for almost every \(x\in {\mathbb {T}}\). Since \(\tau _\gamma \) is continuous, this implies that \(\gamma \) is a straight line, which is impossible due to \(\gamma \) being closed. This contradicts our assumption and thus \(\varTheta _\gamma \) must be invertible. So we may choose \({\tilde{U}} \;{:}{=}\; - \varTheta _\gamma ^{-1} \, b_\gamma (\xi )\) and put  By (38),
By (38),  is indeed a right inverse of
is indeed a right inverse of  . Finally, it is only a matter of some elementary calculus to show that
. Finally, it is only a matter of some elementary calculus to show that  and
and  depend smoothly on \(\gamma \). \(\square \)
depend smoothly on \(\gamma \). \(\square \)
In analogy to Theorem 4.1, we may equip the target space  with the following Riesz isomorphisms. This will help us to generalize the concept of adjoint operators between Hilbert spaces.
with the following Riesz isomorphisms. This will help us to generalize the concept of adjoint operators between Hilbert spaces.
Proposition 5.3
Analogously to Theorem 4.1, we define the \(\gamma \)-dependent, linear operators  and
and  as follows:
as follows:

for \((\eta _1,V_1)\), \((\eta _2,V_2) \in {\mathcal {H}}\mathcal {N}\), \((\xi ,U) \in {\mathcal {X}}\mathcal {N}\), and \((\psi ,W) \in {\mathcal {Y}}\mathcal {N}\). These operators are well-defined, continuous, and continuously invertible, and they satisfy  . Moreover,
. Moreover,  and
and  are of class
are of class  .
.
The proof is entirely along the lines of the proof of Theorem 4.1.
Lemma 5.4
(Saddle point matrix) For each \(\gamma \in \mathcal {C}\), the saddle point matrix

is continuously invertible.
Proof
Let B be as in Theorem 5.2 above. As  is invertible, the saddle point matrix \(\mathcal {A}|_\gamma \) is invertible if and only if its Schur complement
is invertible, the saddle point matrix \(\mathcal {A}|_\gamma \) is invertible if and only if its Schur complement  is invertible. In analogy to the adjoint operators
is invertible. In analogy to the adjoint operators  and
and  , we introduce the generalized adjoint operators
, we introduce the generalized adjoint operators

Observe that we may express the Schur complement as  , hence it suffices to show that
, hence it suffices to show that  is continuously invertible. Since
is continuously invertible. Since  is surjective,
is surjective,  is invertible. Utilizing the identities
is invertible. Utilizing the identities  and
and  as well as the diagram (35), one verifies that
as well as the diagram (35), one verifies that  . This shows that
. This shows that  is injective. By Theorem 5.5 below; the operator
is injective. By Theorem 5.5 below; the operator  is invertible. This allows us to define the projector
is invertible. This allows us to define the projector  . With
. With  ,
,  , and
, and  , we can verify that
, we can verify that  is surjective:
is surjective:

Finally, the open mapping theorem implies that  is continuously invertible. \(\square \)
is continuously invertible. \(\square \)
Lemma 5.5
(Invertibility of \(B^*B\)) For each \(\gamma \in \mathcal {C}\), the linear operator  is continuously invertible.
is continuously invertible.
Proof
We have  with
with  . Thus it suffices to show that T is invertible. Let \({\bar{\xi }} \;{:}{=}\; (\xi ,U) \in {\mathcal {X}}\mathcal {N}\) and \({\bar{\psi }} \;{:}{=}\; (\psi ,W) \in {\mathcal {Y}}\mathcal {N}\). Put
. Thus it suffices to show that T is invertible. Let \({\bar{\xi }} \;{:}{=}\; (\xi ,U) \in {\mathcal {X}}\mathcal {N}\) and \({\bar{\psi }} \;{:}{=}\; (\psi ,W) \in {\mathcal {Y}}\mathcal {N}\). Put  and
and  . By construction, we have
. By construction, we have

With the notation from the proof of Theorem 5.2, we put \({\tilde{U}} \;{:}{=}\; - \varTheta _\gamma ^{-1} \, b_\gamma (\xi )\) and \({\tilde{W}} \;{:}{=}\; - \varTheta _\gamma ^{-1} \, b_\gamma (\psi )\). Now we observe that
Writing only the terms of highest order in \(\xi \) and \(\psi \), we obtain
The latter pairing is identical to  up to the term \(\int _{{\mathbb {T}}} \xi \, \psi \, \omega _\gamma + \langle U,W \rangle \), which is a combination of lower order and finite rank, thus represents a compact operator \({\mathcal {X}}\mathcal {N}\rightarrow {\mathcal {Y}}'{^{\!}}\mathcal {N}\). This means that T is a compact perturbation of
up to the term \(\int _{{\mathbb {T}}} \xi \, \psi \, \omega _\gamma + \langle U,W \rangle \), which is a combination of lower order and finite rank, thus represents a compact operator \({\mathcal {X}}\mathcal {N}\rightarrow {\mathcal {Y}}'{^{\!}}\mathcal {N}\). This means that T is a compact perturbation of  and thus a Fredholm operator of index 0. Hence it suffices to show that T is injective. Let \({\bar{\xi }} \in \ker (T)\) and put
and thus a Fredholm operator of index 0. Hence it suffices to show that T is injective. Let \({\bar{\xi }} \in \ker (T)\) and put  . A diagram chase in (37) and (27) yields
. A diagram chase in (37) and (27) yields

Since  is injective and since
is injective and since  is a scalar product on \({\mathcal {H}}\), this implies
is a scalar product on \({\mathcal {H}}\), this implies  . The injectivity of
. The injectivity of  and we see that T is injective. So as an injective Fredholm operator with index zero, T must also be surjective, hence continuously invertible by the open mapping theorem. \(\square \)
and we see that T is injective. So as an injective Fredholm operator with index zero, T must also be surjective, hence continuously invertible by the open mapping theorem. \(\square \)
The invertibility of the saddle point matrix leads to the following generalizations of (i) the Moore-Penrose pseudoinverse of a surjective operator between Hilbert spaces and (ii) the orthoprojector onto the orthogonal complement of the operator’s null space. Being able to reduce the action of these operators to solving a linear saddle point system will be crucial for applications (see Sect. 6).
Corollary 5.6
The Moore-Penrose pseudoinverse  of
of  and the orthoprojector
and the orthoprojector  with kernel
with kernel  can be completed to a continuous right inverse
can be completed to a continuous right inverse  of
of  and a continuous projector
and a continuous projector  . For \(\xi \in {\mathcal {X}}\mathcal {N}\) and \({\tilde{u}} \in {\mathcal {X}}\), the operators can be evaluated by solving the following saddle point systems
. For \(\xi \in {\mathcal {X}}\mathcal {N}\) and \({\tilde{u}} \in {\mathcal {X}}\), the operators can be evaluated by solving the following saddle point systems

where \(\lambda \), \(\mu \in {\mathcal {Y}}'{^{\!}}\mathcal {N}\) act as Lagrange multipliers.
6 Computational treatment
For the ease of use, we discretize curves by polygonal lines and approximate the Möbius energy and the Riesz isomorphisms from Theorem 4.1 by simple quadrature rules. In the language of finite element analysis, we employ a nonconforming Ritz–Galerkin scheme because the discrete ansatz space is not a subset of the smooth configuration space. We try to outline a discrete setting that can be applied also to more general self-avoiding energies; therefore, we do not care about Möbius-invariance of the energy, although Möbius-invariant discretizations have already been proposed (see e.g., [49] and [15, 16]).
6.1 Spatial discretization
Let \({\mathcal {T}}\) denote a partition of \({\mathbb {T}}\) with vertex set \(V({\mathcal {T}}) \subset {\mathbb {T}}\) and edge set \(E({\mathcal {T}}) \subset V({\mathcal {T}}) \times V({\mathcal {T}})\). Denote the number of edges by N. If the partition is sufficiently fine, i.e., \(h({\mathcal {T}}) \;{:}{=}\; \max _{I\in E({\mathcal {T}})} |{I}|\) is sufficiently small, then we may identify each edge with the closed, oriented interval connecting its end vertices. For an edge \(I\in E({\mathcal {T}})\), we denote by \(I^\downarrow \in V({\mathcal {T}})\) and \(I^\uparrow \in V({\mathcal {T}})\) its backward and forward boundary vertex, respectively.
Let \(P:V({\mathcal {T}}) \rightarrow {{\mathbb {R}}^{m}}\) be an embedded polygon in \({{\mathbb {R}}^{m}}\), i.e., there is a piecewise linear embedding \(\gamma :{\mathbb {T}}\rightarrow {{\mathbb {R}}^{m}}\) such that \(\gamma |_{V({\mathcal {T}})} = P\) and such that \(\gamma \) maps \(I\) affinely onto the line segment connecting \(P(I^\downarrow )\) to \(P(I^\uparrow )\). We denote by \(\mathcal {C}_{{\mathcal {T}}}\) the set of such embedded polygons which is an open set in the space of all closed polygons with N edges. Since the latter is finite dimensional and isomorphic to \(({{\mathbb {R}}^{m}})^N\), we have \({\mathcal {X}}_{{\mathcal {T}}}= {\mathcal {H}}_{{\mathcal {T}}}= {\mathcal {Y}}_{{\mathcal {T}}}\cong ({{\mathbb {R}}^{m}})^N\). Likewise, we discretize the target spaces by \({\mathcal {X}}\mathcal {N}_{{\mathcal {T}}}= {\mathcal {H}}\mathcal {N}_{{\mathcal {T}}}= {\mathcal {Y}}\mathcal {N}_{{\mathcal {T}}}= \{\lambda :E({\mathcal {T}}) \rightarrow {\mathbb {R}}\} \times {{\mathbb {R}}^{m}}\cong {\mathbb {R}}^N \times {{\mathbb {R}}^{m}}\). By \(\ell _P(I) \;{:}{=}\; |{P(I^\downarrow ) - P(I^\uparrow )}|\), we denote the edge length of edge I.
6.1.1 Discrete energy
There are several possibilities to discretize the Möbius energy \({\mathcal {E}}\). A very general approach employs simple quadrature rules and works for reparametrization-invariant energies \({\mathcal {F}}\) of the form \( \textstyle {\mathcal {F}}(\gamma ) = \int _{{\mathbb {T}}^2}F(\gamma ) \, \varOmega _\gamma \) with some energy density \(F(\gamma ) :{{\mathbb {T}}^2}\rightarrow {\mathbb {R}}\). If, for a sufficiently smooth curve \(\gamma \), the integrand \(F(\gamma )\) is not too singular around the diagonal of the integration domain \({{\mathbb {T}}^2}\), we have
Typically, the right hand side makes sense also if \(\gamma \) is a polygonal line. Indeed, cutting out the diagonal is somewhat necessary: An elegant scaling argument in [89, Figure 2.2] shows that the Möbius energy of a polygonal line with at least one nontrivial turning angle is infinite.
We may exploit parametrization invariance and pull back \(F(\gamma )\) along the the local parameterization \(\gamma _I:\left[ 0,1\right] \rightarrow {{\mathbb {R}}^{m}}\), \(\gamma _I(s) \;{:}{=}\; P(I^\downarrow ) \, (1 - s) + s\, P(I^\uparrow )\) and \(\gamma _J:\left[ 0,1\right] \rightarrow {{\mathbb {R}}^{m}}\), \(\gamma _J(t) \;{:}{=}\; P(J^\downarrow ) \, (1 - t) + t \, P(J^\uparrow )\) to the unit square. Denoting the pullback by \(F_{IJ}(P) :\left[ 0,1\right] ^2 \rightarrow {\mathbb {R}}\), we have
So with a k-point quadrature rule \(t_1, \dotsc , t_k \in \left[ 0,1\right] \), \(\omega _1,\dotsc ,\omega _k \in {\mathbb {R}}\), we may discretize \({\mathcal {F}}\) by \( {\mathcal {F}}_{{\mathcal {T}}}(P) \;{:}{=}\; \textstyle \sum _{{\bar{I}} \cap {\bar{J}} = \emptyset } W_{IJ}(P) \) with the local contributions
Applying this with \(k =1\) to \(F=E\) from (12), one is naturally lead to the vertex energy (\(t_1 = 0\), \(\omega _1 = 1\)) and to the edge energy (\(t_1 = 1/2\), \(\omega _1 = 1\)) as proposed by Kusner and Sullivan in [48]. Scholtes proved in [73] that the vertex energy for equilateral polygons \(\varGamma \)-converges towards \({\mathcal {E}}\) under refinement of partitions, i.e., for \(h({\mathcal {T}}) \rightarrow 0\), with respect to the \(W^{k,q}\)-topology, \(k\in \{0,1\}\), \(q\in [1,\infty ]\). Roughly speaking, \(\varGamma \)-convergence implies that cluster points of minimizers of the discrete energies are minimizers of \({\mathcal {E}}\). This result justifies the quite harsh variational crimes that one commits by choosing polygonal lines as discrete configurations. Although it is restricted to equilateral polygons (which was one of the reasons for us to include the edge length constraint), we deem it likely that it can be extended to non-equilateral polygons with a uniform bound on  as \(h\rightarrow 0\). At least our experiments indicate that the precise distributions of edge lengths does not matter.
as \(h\rightarrow 0\). At least our experiments indicate that the precise distributions of edge lengths does not matter.
We require also the derivative of the discrete energy. In a Similar as to Sect. 3, the explicit dependence of E on the geodesic distance \(\varrho _\gamma \) causes problems: Without taking further measures, this would lead to the very high complexity of \(\varOmega (N^3)\) to assemble the derivative \(D{\mathcal {E}}_{{{\mathcal {T}}}}(P)\) for the vertex energy and edge energy.Footnote 5 This can be circumvented by utilizing the identity \({\mathcal {E}}(\gamma ) = \textstyle 4 \!+\! \int _{{\mathbb {T}}^2}F(\gamma ) \, \varOmega _\gamma \) with the integrand
which was derived by Ishizeki and Nagasawa in [41]. For the sake of efficiency, we discretize with the midpoint rule, i.e., with \(k =1\), \(t_1 = 1/2\), and \(\omega _1 = 1\). For this F, the local contributions \(W_{IJ}(P)\) depend only on the coordinates of the four points \(P(I^\downarrow )\), \(P(I^\uparrow )\), \(P(J^\downarrow )\), and \(P(J^\uparrow )\). So the expression of the first and second derivative of \(W_{IJ}\) with respect to these four points can once be computed symbolically and compiled into runtime-efficient libraries. The first and second derivative of \({\mathcal {F}}_{{\mathcal {T}}}\) can then be assembled from \(DW_{IJ}(P)\) and \(D^2W_{IJ}(P)\) as a vector and a matrix of size \(m\, N\) and \((m\, N) \times (m\, N)\), respectively. Due to the nonlocal nature of the energy, the matrix \(D^2{\mathcal {F}}(P)\) is dense.
6.1.2 Discrete inner product
Next we discretize the inner product  from Theorem 4.1. Let \(U :V({\mathcal {T}}) \rightarrow {{\mathbb {R}}^{m}}\) and denote by \(u :{\mathbb {T}}\rightarrow {{\mathbb {R}}^{m}}\) piecewise linear interpolation. For the computation of the local contribution of the edge pair \((I,J)\) to the Gram matrix, we put
from Theorem 4.1. Let \(U :V({\mathcal {T}}) \rightarrow {{\mathbb {R}}^{m}}\) and denote by \(u :{\mathbb {T}}\rightarrow {{\mathbb {R}}^{m}}\) piecewise linear interpolation. For the computation of the local contribution of the edge pair \((I,J)\) to the Gram matrix, we put
The first two terms of  can now be discretized as follows:
can now be discretized as follows:
where we employ the same quadrature rule as for the discrete Möbius energy. In the presence of a barycenter constraint, we may simply omit the term  without loosing definiteness of the inner product on \(\ker (D \varPhi _{{\mathcal {T}}}(P))\). By virtue of the polarization formula, this defines the Gram matrix uniquely, leading to discrete bilinear forms
without loosing definiteness of the inner product on \(\ker (D \varPhi _{{\mathcal {T}}}(P))\). By virtue of the polarization formula, this defines the Gram matrix uniquely, leading to discrete bilinear forms  . The local matrices are of size \((4 \,m) \times (4 \,m)\) (\(m\) coordinates for each of the four vertices belonging to the edge pair \((I,J)\)). They can be computed in parallel and added into the global matrix afterwards. The resulting global Gram matrix is a dense matrix of size \((m\, N) \times (m\, N)\).Footnote 6
. The local matrices are of size \((4 \,m) \times (4 \,m)\) (\(m\) coordinates for each of the four vertices belonging to the edge pair \((I,J)\)). They can be computed in parallel and added into the global matrix afterwards. The resulting global Gram matrix is a dense matrix of size \((m\, N) \times (m\, N)\).Footnote 6
6.1.3 Discrete constraints
As for the constraints, we discretize \(\varPhi \) by
where \(\ell _0 :E({\mathcal {T}}) \rightarrow \left]0,\infty \right[\) is a prescribed distribution of desired edge lengths, for example \(\ell _0(I) = L \, |{I}|\). Although restoring feasibility for the edge length constraint comes at a certain cost, it prevents edges from collapsing to points and from being overstretched in the course of optimization. The latter is crucial since the discrete energy is not exactly self-avoiding; it becomes singular only if quadrature points approach each other. So overstretched edges make it more likely that the curve tries to form a self-intersection.
Some care should be given to the choice of the target edge lengths \(\ell _0\). A coarse mesh may not be sufficient to preclude self-intersections, a very fine mesh is expensive as the computational effort grows quadratically in the number of nodes. As a rule of thumb, the distance between two neighboring vertices of a polygon should be strictly smaller than the distance between any other pairs of vertices. In principle, it is also possible to drop the edge length constraints; instead one could introduce a global length constraint and one could handle short and long edges by adaptive edge split and edge collapse strategies. We refrained from opting for this route here for the sake of simplicity.
6.2 Projected gradient
Once we have assembled the vector  , and the matrices
, and the matrices  and
and  , the projected gradient \(u \;{:}{=}\; {{\,\mathrm{grad}\,}}_{{\mathcal {M}}_{{\mathcal {T}}}}({\mathcal {E}}_{{\mathcal {T}}}|_{{\mathcal {M}}_{{\mathcal {T}}}})|_P\) can be obtained by solving the following discrete analogue of the linear saddle point system (36):
, the projected gradient \(u \;{:}{=}\; {{\,\mathrm{grad}\,}}_{{\mathcal {M}}_{{\mathcal {T}}}}({\mathcal {E}}_{{\mathcal {T}}}|_{{\mathcal {M}}_{{\mathcal {T}}}})|_P\) can be obtained by solving the following discrete analogue of the linear saddle point system (36):

We assemble the saddle point matrix as a dense, symmetric matrix with \((N \,m+ N + m)\) rows, and solve it via a dense LU-factorization. Hence it costs roughly \({{\,\mathrm{O}\,}}(N^2 m^2)\) for the assembly and a further \({{\,\mathrm{O}\,}}(N^3 m^3)\) for the factorization. It is not surprising that this is the most expensive part in the overall optimization process. We would like to point out that this can be sped up considerably by more sophisticated methods: The assembly of the saddle point matrix can be avoided by assembling \(D\varPhi _{{\mathcal {T}}}(P)\) as a sparse matrix and by compressing  in a hierarchical matrix data structure that is efficient for fast matrix-vector multiplication. Similar techniques can be employed to approximate \({\mathcal {E}}_{\mathcal {T}}(P)\) and \(D{\mathcal {E}}_{\mathcal {T}}(P)\) in subquadratic time, but all this is beyond the scope of the present work.
in a hierarchical matrix data structure that is efficient for fast matrix-vector multiplication. Similar techniques can be employed to approximate \({\mathcal {E}}_{\mathcal {T}}(P)\) and \(D{\mathcal {E}}_{\mathcal {T}}(P)\) in subquadratic time, but all this is beyond the scope of the present work.
6.3 Restoring feasibility and time step size rules
Suppose that \(\varPhi _{{\mathcal {T}}}(P) = 0\) and that u is a feasible search direction, i.e., \(D\varPhi _{{\mathcal {T}}}(P) u = 0\). The constraint mapping \(\varPhi _{{\mathcal {T}}}\) is Lipschitz continuously differentiable. Hence provided that the step size \(\tau > 0\) is sufficiently small, the modified Newton method
converges quickly to a point \(Q_\infty \) that satisfies \(\varPhi _{{\mathcal {T}}}(Q_\infty ) = 0\). Here \(D\varPhi _{{\mathcal {T}}}(P)^{\dagger \!}\) denotes the Moore-Penrose pseudoinverse with respect to the inner product \(G_P\) and we utilize Theorem 5.6 to evaluate it.Footnote 7 For a given descending direction u, we may apply backtracking line search to find a suitable step size \(\tau > 0\): If the residual \(\varPhi _{{\mathcal {T}}}(Q_i)\) is smaller than a prescribed tolerance after a small, prescribed number of iterations, then the point \(Q_i\) may serve as the next iterate of the optimization method. Otherwise we shrink \(\tau \) and restart the modified Newton method. By shrinking \(\tau \) even further, if necessary, we can also achieve that \(Q_i\) satisfies the Armijo condition \({\mathcal {E}}_{{\mathcal {T}}}(Q_i) \le {\mathcal {E}}_{{\mathcal {T}}}(P) + (\tau /2) \, D{\mathcal {E}}_{{\mathcal {T}}}(P) \, u\). An initial guess for \(\tau \) can be obtained, e.g., by collision detection (see, e.g., [69]): One determines the smallest step size \(\tau _*\) such that \(P+ \tau _* \, u\) has a self-intersection and starts the backtracking procedure with, e.g., \(\tau = \tfrac{2}{3} \tau _*\). By utilizing suitable space partitioning data structures, this collision detection can be performed in subquadratic time. However, we simply cycled over all \(O(N^2)\) edge pairs because its runtime is proportional to the runtime of \(D{\mathcal {E}}_{{\mathcal {T}}}(P)\).
6.4 Optimization methods employed in Fig. 3
Feasible methods Projected \(L^2\)-, \(W^{1,2}\)-, \(W^{3/2,2}\)-, and \(W^{2,2}\)-flows were simulated both with explicit and implicit time integration schemes. We followed the approach above, only replacing  by the Riesz operator corresponding to the particular choice of metric. Armijo backtracking line search automatically determines a stable step size. For the implicit integration of the \(L^2\)-gradient flow, we employ the backward Euler method. Since it is not unconditionally stable, Armijo backtracking has to be employed also here. Because backtracking requires the implicit equations to be solved again, this is particularly expensive.
by the Riesz operator corresponding to the particular choice of metric. Armijo backtracking line search automatically determines a stable step size. For the implicit integration of the \(L^2\)-gradient flow, we employ the backward Euler method. Since it is not unconditionally stable, Armijo backtracking has to be employed also here. Because backtracking requires the implicit equations to be solved again, this is particularly expensive.
The employed trust region method is a blend of the method from [20] with the two-dimensional subspace method from [77] (without computing the lowest eigenvalues): The next iterate is found by minimizing a quadratic model in a trust region within a low-dimensional subspace spanned by the current projected gradient, the projection of the previous gradient onto the current tangent space, and the Newton search direction – provided the current projected gradient is shorter than a given threshold. This means that the optimization is mostly driven by gradient and momentum; and the Hessian is utilized only in the end phase of optimization. Shrinkage and expansion of the trust region is handled as usual, but the radius is of course to be interpreted with respect to the employed inner product.
Infeasible methods In order to compare also to unconstrained optimization methods, we applied them to an analogous discretization of the penalized energy
whose penalty can be interpreted as Hencky’s stretch energy. The optimization methods were made aware of this penalty by using the metric  to compute gradients, where
to compute gradients, where  denotes the Riesz operator of
denotes the Riesz operator of  .Footnote 8 As nonlinear conjugate gradient method, we employed the Polak-Ribière method “with automatic reset” (method \(\mathrm {PR}_+\) in [59, Section 5.2]). L-BFGS was implemented with history length 30 and as described in [59, Section 7.2]. The only difference is that we replace the initial guess for the inverse Hessian by the inverse of the current metric (because using a single initial guess turned out to be less efficient).Footnote 9 As for Nesterov’s accelerated gradient method (acc. grad.), we followed [57], but added collision detection to truncate the step sizes (in both steps of the method). Moreover, as suggested in [60], we reset the momentum to 0 whenever an increase of the objective was observed.Footnote 10 All these methods were complemented with a line search that tries to find a weak Wolfe-Powell step size.
.Footnote 8 As nonlinear conjugate gradient method, we employed the Polak-Ribière method “with automatic reset” (method \(\mathrm {PR}_+\) in [59, Section 5.2]). L-BFGS was implemented with history length 30 and as described in [59, Section 7.2]. The only difference is that we replace the initial guess for the inverse Hessian by the inverse of the current metric (because using a single initial guess turned out to be less efficient).Footnote 9 As for Nesterov’s accelerated gradient method (acc. grad.), we followed [57], but added collision detection to truncate the step sizes (in both steps of the method). Moreover, as suggested in [60], we reset the momentum to 0 whenever an increase of the objective was observed.Footnote 10 All these methods were complemented with a line search that tries to find a weak Wolfe-Powell step size.
Notes
In many cases we consider curves \(\gamma \) being differentiable a.e. but not necessarily \(C^{1}\). Therefore we will always assume an embedding to be a \(C^{0}\)-embedding. Furthermore, \(\gamma \) is immersed (or regular) if \({{\,\mathrm{ess\,inf}\,}}\left|\gamma '\right|>0\).
Strictly speaking, this is not the full picture: Being scaling-invariant, the Möbius energy does not penalize pull-tight of small knotted arcs (see [62], Thm. 3.1), which is in fact a change of topology.
In the source it is shown that the operator \(({{\,\mathrm{id}\,}}-\varDelta )^{\sigma } :B^{t}_{p,q}\rightarrow B^{t-2\sigma }_{p,q}\) is continuously invertible for general Besov spaces \(B^{t}_{p,q}\). Note that \(W^{t,p}=B^{t}_{p,p}\) for \(t\in {\mathbb {R}}_{+}\setminus {\mathbb {Z}}\) and \(p\in [1,\infty )\). Moreover, \((-\varDelta )^{\sigma }\) is a compact perturbation of \(({{\,\mathrm{id}\,}}-\varDelta )^{\sigma }\), so \((-\varDelta )^{\sigma }\) is a Fredholm operator of index zero; being also positive-definite, it must be continuously invertible.
We point out that \(f\) is of class \(W^{{{s}+{\nu }},p} \subset C^{1}\). So indeed, both pullback and pushforward along it preserve the regularity of functions in the classes \(W^{{{s}+{\nu }},p}\) and \(W^{{{s}-{\nu }},q}\), a consequence of the chain rule Theorem A.1.
For an optimization method that requires only the projected gradients and that enforces the edge length constraints in each iteration, the contribution of \(D \varrho (\gamma )\) to \(D {\mathcal {E}}(\gamma )\) can be ignored.
In fact, the assembly can be sped up by first assembling the \(N \times N\)-matrix
 for the case \(m=1\). This way, the local matrices have only size \(4 \times 4\). Afterwards, the \((m\, N) \times (m\, N)\) matrix can be obtained as block-diagonal matrix with \(m\) identical blocks of size \(N \times N\).
for the case \(m=1\). This way, the local matrices have only size \(4 \times 4\). Afterwards, the \((m\, N) \times (m\, N)\) matrix can be obtained as block-diagonal matrix with \(m\) identical blocks of size \(N \times N\).We employ the modified Newton method (instead of Newton’s method) because the saddle point matrix from (41) is already factorized, so that evaluating \(D\varPhi _{{\mathcal {T}}}(P)^{\dagger \!}\, {\tilde{u}}\) on a given vector \({\tilde{u}}\) can be performed quite inexpensively with Theorem 5.6. Alternatively, also every other scheme for solving \(\varPhi _{{\mathcal {T}}}(Q) = 0\) can be employed.
This had a negative effect on methods based on the \(L^2\)-metric, so we omitted this extension in that case.
We are well-aware that this ad-hoc modification might not be superlinearly convergent.
We are also aware that Nesterov’s method was designed for convex optimization problems; as a heavy ball method it still serves its purpose to push the optimization through shallow regions of the energy landscape.
 for the case
for the case References
Arendt, W., Kreuter, M.: Mapping theorems for Sobolev spaces of vector-valued functions. Studia Math. 240(3), 275–299 (2018). https://doi.org/10.4064/sm8757-4-2017.
Ashton, T., Cantarella, J., Piatek, M., Rawdon, E.J.: Knot tightening by constrained gradient descent. Exp. Math. 20(1), 57–90 (2011). https://doi.org/10.1080/10586458.2011.544581.
Auckly, D., Sadun, L.: A family of Möbius invariant \(2\)-knot energies. In Geometric topology (Athens, GA, 1993), volume 2 of AMS/IP Stud. Adv. Math., 235–258. Amer. Math. Soc., Providence, RI, (1997).
Bartels, S., Reiter, Ph.: Stability of a simple scheme for the approximation of elastic knots and self-avoiding inextensible curves. Math. Comp. 90, 1499–1526 (2021). https://doi.org/10.1090/mcom/3633
Bartels, S., Reiter, Ph: Numerical solution of a bending-torsion model for elastic rods. Numer. Math.146(4), 661–697 (2020). https://doi.org/10.1007/s00211-020-01156-6
Bartels, S., Reiter, Ph., Riege, J.: A simple scheme for the approximation of self-avoiding inextensible curves. IMA J. Numer. Anal. 38(2), 543–565 (2018). https://doi.org/10.1093/imanum/drx021
Bauer, M., Harms, Ph., Michor, P.W.: Sobolev metrics on shape space of surfaces. J. Geom. Mech. 3(4), 389–438 (2011).
Bauer, M., Harms, Ph., Michor, P. W.: Fractional Sobolev metrics on spaces of immersions. Calc. Var. Partial Differ. Equ. 59(2):Paper No. 62, 27 (2020). https://doi.org/10.1007/s00526-020-1719-5
Behzadan, A., Holst, M.: Multiplication in Sobolev Spaces, Revisited. ArXiv e-prints, (2015). arXiv: 1512.07379
Bergou, M., Wardetzky, M., Robinson, S., Audoly, B., Grinspun, E.: Discrete elastic rods. ACM Trans. Graph. 27(3):63:1–63:12 (2008). https://doi.org/10.1145/1360612.1360662
Blatt, S.: Boundedness and regularizing effects of O’Hara’s knot energies. J. Knot Theory Ramificat. 21(1):1250010, 9 (2012). https://doi.org/10.1142/S0218216511009704
Blatt, S.: The gradient flow of the Möbius energy near local minimizers. Calc. Var. Partial Differ. Equ. 43(3–4), 403–439 (2012). https://doi.org/10.1007/s00526-011-0416-9.
Blatt, S.: The gradient flow of the Möbius energy: \(\varepsilon \)-regularity and consequences. Anal. PDE. 13(3), 901–941 (2020). https://doi.org/10.2140/apde.2020.13.901.
Blatt, S., Gilsbach, A., Reiter, Ph., von der Mosel, H.: Symmetric critial knots for the Möbius energy. In preparation.
Blatt, S., Ishizeki, A., Nagasawa, T.: A Möbius invariant discretization of O’Hara’s Möbius energy. arXiv e-prints, (2018). arXiv: 1809.07984
Blatt, S., Ishizeki, A., Nagasawa, T.: A Möbius invariant discretization and decomposition of the Möbius energy. arXiv e-prints, (2019). arXiv: 1904.06818
Blatt, S., Reiter, Ph., Schikorra, A.: Harmonic analysis meets critical knots. Critical points of the Möbius energy are smooth. Trans. Amer. Math. Soc. 368(9):6391–6438 (2016) https://doi.org/10.1090/tran/6603.
Blatt, S., Vorderobermeier, N.: On the analyticity of critical points of the Möbius energy. Cal. Variat. Partial Differ. Equ. 58(1):16 (2018) https://doi.org/10.1007/s00526-018-1443-6.
Buckm, G., Orloff, J.: A simple energy function for knots. Topol. Appl. 61(3), 205–214 (1995). https://doi.org/10.1016/0166-8641(94)00024-W.
Byrd, R. H., Schnabel, R. B., Shultz, G.A.: A trust region algorithm for nonlinearly constrained optimization. SIAM J. Numer. Anal. 24(5), 1152–1170 (1987). https://doi.org/10.1137/0724076.
Clauvelin, N., Audoly, B., Neukirch, S.: Matched asymptotic expansions for twisted elastic knots: a self-contact problem with non-trivial contact topology. J. Mech. Phys. Solids. 57(9), 1623–1656 (2009) https://doi.org/10.1016/j.jmps.2009.05.004.
Coleman, B.D. , Swigon, D.: Theory of supercoiled elastic rings with self-contact and its application to DNA plasmids. J. Elasticity 60(3):173–221 (2000). https://doi.org/10.1023/A:1010911113919
Coleman, B. D., Swigon, D.: Theory of self-contact in Kirchhoff rods with applications to supercoiling of knotted and unknotted DNA plasmids. Philos. Trans. R. Soc. Lond. Ser. A Math. Phys. Eng. Sci. 362(1820):1281–1299 (2004). https://doi.org/10.1098/rsta.2004.1393
Coyne, J.: Analysis of the formation and elimination of loops in twisted cable. IEEE J. Oceanic Eng. 15(2), 72–83 (1990). https://doi.org/10.1109/48.50692.
Di Nezza, E., Palatucci, G., Valdinoci, E.: Hitchhiker’s guide to the fractional Sobolev spaces. Bull. Sci. Math. 136(5), 521–573 (2012). https://doi.org/10.1016/j.bulsci.2011.12.004.
Eckstein, I., Pons, J.-P., Tong, Y., Kuo, C.-C. J.: Desbrun, M. : Generalized surface flows for mesh processing. In Proceedings of the Fifth Eurographics Symposium on Geometry Processing, SGP ’07, pages 183–192. Eurographics Association, (2007).
Freedman, M. H., He, Z.-X., Wang, Z.: Möbius energy of knots and unknots. Ann. Math. 139(1):1–50 (1994). https://doi.org/10.2307/2946626
Fukuhara, S.: Energy of a knot. In A fête of topology, pages 443–451. Academic Press, Boston, MA, (1988).
Gerlach, H., Reiter, Ph., von der Mosel, H.: The elastic trefoil is the doubly covered circle. Arch. Ration. Mech. Anal. 225(1), 89–139 (2017). https://doi.org/10.1007/s00205-017-1100-9.
Gerlach, H., von der Mosel, H.: On sphere-filling ropes. Amer. Math. Monthly 118(10), 863–876 (2011). https://doi.org/10.4169/amer.math.monthly.118.10.863.
Gerlach, H., von der Mosel, H.: What are the longest ropes on the unit sphere? Arch. Ration. Mech. Anal. 201(1), 303–342 (2011). https://doi.org/10.1007/s00205-010-0390-y.
Gilsbach, A., Reiter, Ph., von der Mosel, H.: Symmetric elastic knots. arXiv e-prints, (2021). arXiv:2105.08558.
Gonzalez, O., Maddocks, J.H.: Global curvature, thickness, and the ideal shapes of knots. Proc. Natl. Acad. Sci. USA 96(9), 4769–4773 (1999). https://doi.org/10.1073/pnas.96.9.4769.
Goyal, S., Perkins, N., Lee, C.: Non-linear dynamic intertwining of rods with self-contact. Int. J. Non-Linear Mech. 43(1), 65–73 (2008). https://doi.org/10.1016/j.ijnonlinmec.2007.10.004.
Goyal, S., Perkins, N. C., Lee, C. L.: Nonlinear dynamics and loop formation in Kirchhoff rods with implications to the mechanics of DNA and cables. J. Comput. Phys. 209(1), 371–389 (2005). https://doi.org/10.1016/j.jcp.2005.03.027.
Hatcher, A.E.: A proof of the Smale conjecture, \(\text{Diff}(S^{3})\simeq \text{ O }(4)\). Ann. Math. 117(3):553–607 (1983)
He, Z.-X.: The Euler-Lagrange equation and heat flow for the Möbius energy. Commun. Pure Appl. Math. 53(4):399–431 (2000).
Heeren,B., Rumpf, M., Schröder, P., Wardetzky, M., Wirth, B.: Exploring the geometry of the space of shells. Comput Graph Forum, 33(5):247–256 (2014).
Hoffman, K.A., Seidman, T.I.: A variational characterization of a hyperelastic rod with hard self-contact. Nonlinear Anal. 74(16), 5388–5401 (2011). https://doi.org/10.1016/j.na.2011.05.022.
Hoffman, K.A., Seidman, T.I.: A variational rod model with a singular nonlocal potential. Arch. Ration. Mech. Anal. 200(1), 255–284 (2011). https://doi.org/10.1007/s00205-010-0368-9.
Ishizeki, A., Nagasawa, T.: A decomposition theorem of the Möbius energy I: Decomposition and Möbius invariance. Kodai Math. J. 37(3), 737–754 (2014). https://doi.org/10.2996/kmj/1414674619.
Ishizeki, A., Nagasawa, T.: A decomposition theorem of the Möbius energy II: variational formulae and estimates. Math. Ann. 363(1–2), 617–635 (2015). https://doi.org/10.1007/s00208-015-1175-2.
Käfer, B., von der Mosel, H.: Möbius-invariant self-avoidance energies for non-smooth sets in arbitrary dimensions. arXiv e-prints, (2020). arXiv: 2010.03906
Kim, D., Kusner, R.: Torus knots extremizing the Möbius energy. Exp. Math. 2(1), 1–9 (1993).
Knappmann, J. , Schumacher, H., Steenebrügge, D., von der Mosel, H.: A speed preserving Hilbert gradient flow for generalized integral Menger curvature. arXiv e-prints, (2021). arXiv: 2103.10408
Kolasiński, S., Strzelecki, P., von der Mosel, H.: Compactness and isotopy finiteness for submanifolds with uniformly bounded geometric curvature energies. Commun. Anal. Geom. 26(6), 1251–1316 (2018). https://doi.org/10.4310/CAG.2018.v26.n6.a2.
Krömer, S., Valdman, J.: Global injectivity in second-gradient nonlinear elasticity and its approximation with penalty terms. Math. Mech. Solids 24(11), 3644–3673 (2019). https://doi.org/10.1177/1081286519851554.
Kusner, R. B., Sullivan, J. M. : Möbius energies for knots and links, surfaces and submanifolds. In Geometric topology (Athens, GA, 1993), volume 2 of AMS/IP Stud. Adv. Math., pages 570–604. Amer. Math. Soc., Providence, RI, (1997).
Kusner, R.B.,Sullivan, J.M.: Möbius-invariant knot energies. In: Ideal knots, pp. 315–352. volume 19 of Series on Knots and Everything. World Sci. Publ, River Edge, NJ (1998) https://doi.org/10.1142/9789812796073_0017
Kwaśnicki, M.: Ten equivalent definitions of the fractional Laplace operator. Fract. Calc. Appl. Anal. 20(1), 7–51 (2017). https://doi.org/10.1515/fca-2017-0002.
Lin, C.-C., Schwetlick, H. R.: On a flow to untangle elastic knots. Calc. Var. Partial Differ. Equ. 39(3–4), 621–647 (2010). https://doi.org/10.1007/s00526-010-0328-0.
Maddocks, J. H.: Bifurcation theory, symmetry breaking and homogenization in continuum mechanics descriptions of DNA. Mathematical modelling of the physics of the double helix. In A celebration of mathematical modeling, pages 113–136. Kluwer Acad. Publ., Dordrecht, (2004).
Manning, R. S., Rogers, K. A., Maddocks, J. H.:Isoperimetric conjugate points with application to the stability of DNA minicircles. R. Soc. Lond. Proc. Ser. A Math. Phys. Eng. Sci, 454(1980):3047–3074, (1998). https://doi.org/10.1098/rspa.1998.0291
Mazowiecka, K., Schikorra, A.: Fractional div-curl quantities and applications to nonlocal geometric equations. J. Funct. Anal. 275(1), 1–44, (2018). https://doi.org/10.1016/j.jfa.2018.03.016.
Michor, P. W., Mumford, D.: Riemannian geometries on spaces of plane curves. J. Eur. Math. Soc. (JEMS) 8(1):1–48, (2006). https://doi.org/10.4171/JEMS/37.
Nagasawa, T.: On Möbius invariant decomposition of the Möbius energy. In S. Blatt, Ph. Reiter, and A. Schikorra, editors, New directions in geometric and applied knot theory, Partial Differ. Equ. Meas. Theory, pages 36–76. De Gruyter, Berlin, (2018).https://doi.org/10.1515/9783110571493
Nesterov, Y.E.,: A method for solving the convex programming problem with convergence rate \(O(1/k^{2})\). Dokl. Akad. Nauk SSSR 269(3), 543–547 (1983).
Neuberger, J. W.:Sobolev gradients and differential equations, volume 1670 of Lecture Notes in Mathematics. Springer, Berlin, (1997). https://doi.org/10.1007/BFb0092831
Nocedal, J., Wright, S.J.: Numerical optimization, 2nd edn. Springer Series in Operations Research and Financial Engineering. Springer, New York (2006).
O’Donoghue B., Candès, E.: Adaptive restart for accelerated gradient schemes. Found. Comput. Math. 15(3), 715–732 (2015). https://doi.org/10.1007/s10208-013-9150-3.
O’Hara, J.: Energy of a knot. Topology 30(2), 241–247 (1991). https://doi.org/10.1016/0040-9383(91)90010-2.
O’Hara, J.: Family of energy functionals of knots. Topol. Appl. 48(2), 147–161, 1992. https://doi.org/10.1016/0166-8641(92)90023-S.
O’Hara, J.: Energy of knots and conformal geometry, volume 33 of Series on Knots and Everything. World Scientific Publishing Co., Inc., River Edge, NJ, (2003). https://doi.org/10.1142/9789812795304
O’Hara, J.: Self-repulsiveness of energies for closed submanifolds. arXiv e-prints, (2020)
Pierański, P.:In search of ideal knots. In: Ideal knots, volume 19 of Ser, pp. 20–41. Knots Everything. World Sci. Publ, River Edge, NJ (1998) https://doi.org/10.1142/9789812796073_0002
Pinkall, U., Polthier, K.: Computing discrete minimal surfaces and their conjugates. Exp. Math. 2(1), 15–36 (1993).
Rawdon, E. J., Simon, J. K.: Polygonal approximation and energy of smooth knots. J. Knot Theory Ramificat. 15(4), 429–451 (2006). https://doi.org/10.1142/S0218216506004543.
Rawdon, E.J., Worthington, J.: Error analysis of the minimum distance energy of a polygonal knot and the Möbius energy of an approximating curve. J. Knot Theory Ramificat. 19(8), 975–1000 (2010). https://doi.org/10.1142/S0218216510008303.
Redon, S., Kheddar, A., Coquillart, S.: Fast continuous collision detection between rigid bodies. Comput. Graph. Forum 21(3), 279–287 (2002). https://doi.org/10.1111/1467-8659.t01-1-00587.
Ricca, R. L.: New energy and helicity bounds for knotted and braided magnetic fields. Geophys. Astrophys. Fluid Dyn. 107(4), 385–402 (2013). https://doi.org/10.1080/03091929.2012.681782.
Scharein / Hypnagogic Software R.: Knotplot 1.0 for macOS, April 5, (2021).
Runst, T., Sickel, W.: Sobolev spaces of fractional order, Nemytskij operators, and nonlinear partial differential equations, volume 3 of De Gruyter Series in Nonlinear Analysis and Applications. Walter de Gruyter & Co., Berlin, (1996).https://doi.org/10.1515/9783110812411
Scholtes, S.: Discrete Möbius energy. J. Knot Theory Ramifications, 23(9):1450045–1–16, (2014).https://doi.org/10.1142/S021821651450045X
Schumacher, H.: On \({H}^2\)-gradient flows for the Willmore energy. arXiv e-prints, (2017) . arXiv: 1703.06469
Schumacher, H.: Pseudogradient flows of geometric energies. In S. Blatt, Ph. Reiter, and A. Schikorra, editors, New directions in geometric and applied knot theory, Partial Differ. Equ. Meas. Theory, pages 77–108. De Gruyter, Berlin, (2018).
Schuricht, F., von der Mosel, H.: Euler-Lagrange equations for nonlinearly elastic rods with self-contact. Arch. Ration. Mech. Anal. 168(1), 35–82 (2003). https://doi.org/10.1007/s00205-003-0253-x.
Shultz, G.A., Schnabel, R.B., Byrd, R.H.: A family of trust-region-based algorithms for unconstrained minimization with strong global convergence properties. SIAM J. Numer. Anal. 22(1), 47–67, (1985). https://doi.org/10.1137/0722003.
Simon, J.: Energy functions for polygonal knots. J Knot Theory Ramificat. 3:09 (1996) https://doi.org/10.1142/S021821659400023X.
Spillmann, J., Teschner, M. : An adaptive contact model for the robust simulation of knots. Comput. Graph. Forum 27(2), 497–506 (2008). https://doi.org/10.1111/j.1467-8659.2008.01147.x.
Starostin, E. L., van der Heijden, G. H. M.: Theory of equilibria of elastic 2-braids with interstrand interaction. J. Mech. Phys. Solids 64:83–132 (2014) https://doi.org/10.1016/j.jmps.2013.10.014.
Starostin, E.L., van der Heijden, G.H.M.: Equilibria of elastic cable knots and links. In S. Blatt, Ph. Reiter, and A. Schikorra, editors, New directions in geometric and applied knot theory, pages258–275. De Gruyter, Berlin (2018).
Stasiak, A., Katritch,V., Bednar,J., Michoud, D., Dubochet, J.: Electrophoretic mobility of DNA knots. Nature, 384(6605): 122 (1996) https://doi.org/10.1038/384122a0.
Strzelecki, P., Szumańska, M., von der Mosel, H.: Regularizing and self-avoidance effects of integral Menger curvature. Ann. Sc. Norm. Super. Pisa Cl. Sci. (5), 9(1):145–187 (2010).
Strzelecki, P., von der Mosel, H.: On a mathematical model for thick surfaces. In: Physical and numerical models in knot theory, volume 36 of Ser, pp. 547–564. Knots Everything. World Sci. Publ, Singapore (2005) https://doi.org/10.1142/9789812703460_0027
Strzelecki, P., von der Mosel H.: Integral Menger curvature for surfaces. Adv. Math.226(3), 2233–2304 (2011). https://doi.org/10.1016/j.aim.2010.09.016.
Strzelecki, P., von der Mosel, H.: Tangent-point self-avoidance energies for curves. J. Knot Theory Ramificat. 21(5), 1250044, 28 (2012). https://doi.org/10.1142/S0218216511009960
Strzelecki, P., von der Mosel, H.: Menger curvature as a knot energy. Phys. Rep. 530(3), 257–290 (2013). https://doi.org/10.1016/j.physrep.2013.05.003.
Strzelecki, P., von der Mosel,H.: Tangent-point repulsive potentials for a class of non-smooth \(m\)-dimensional sets in \(\mathbb{R}^n\). Part I: Smoothing and self-avoidance effects. J. Geom. Anal. 23(3):1085–1139 (2013).https://doi.org/10.1007/s12220-011-9275-z
Strzelecki, P., von der Mosel, H.:Geometric curvature energies: facts, trends, and open problems. In S. Blatt, Ph. Reiter, and A. Schikorra, editors, New directions in geometric and applied knot theory, pages 8–35. De Gruyter, Berlin, (2018). https://doi.org/10.1515/9783110571493-002
Taylor, M. E.: Partial differential equations I. Basic theory, volume 115 of Applied Mathematical Sciences. Springer, New York, second edition, (2011).https://doi.org/10.1007/978-1-4419-7055-8
Triebel, H.: Interpolation theory, function spaces, differential operators, vol. 18. North-Holland Mathematical Library. North-Holland Publishing Co., Amsterdam-New York (1978).
Triebel, H.: Theory of function spaces, volume 78 of Monographs in Mathematics. Birkhäuser Verlag, Basel, (1983),https://doi.org/10.1007/978-3-0346-0416-1.
van der Heijden, G., Neukirch, S., Goss, V., Thompson, J.: Instability and self-contact phenomena in the writhing of clamped rods. Int. J. Mech. Sci. 45(1):161–196, (2003).
von Brecht, J.H., Blair, R.: Dynamics of embedded curves by doubly-nonlocal reaction-diffusion systems. J. Phys. A, 50(47):475203, 57 (2017). https://doi.org/10.1088/1751-8121/aa9109
von der Mosel, H.: Minimizing the elastic energy of knots. Asymptot. Anal. 18(1–2), 49–65 (1998).
von der Mosel, H.: Elastic knots in Euclidean \(3\)-space. Ann. Inst. H. Poincaré Anal. Non Linéaire. 16(2):137–166, (1999).https://doi.org/10.1016/S0294-1449(99)80010-9
Walker, S.W. : Shape optimization of self-avoiding curves. J. Comput. Phys. 311:275–298 (2016). https://doi.org/10.1016/j.jcp.2016.02.011.
Yu, C., Brakensiek, C., Schumacher, H., Crane, K.: Repulsive surfaces, (2021). arXiv:2107.01664
Yu, C., Schumacher, H., Crane, K.: https://doi.org/10.1145/3439429 Repulsive curves. ACM Trans. Graph. 40(2) (2021).
Zajac, E.E. : Stability of two planar loop elasticas. Trans. ASME Ser. E. J. Appl. Mech. 29:136–142 (1962)
Zolesio, J.L.: Multiplication dans les espaces de Besov. Proc. Roy. Soc. Edinburgh Sect. A 78(1-2):113–117, 1977/78. https://doi.org/10.1017/S0308210500009872
Acknowledgements
Both authors wish to thank Armin Schikorra and Thorsten Hohage for fruitful discussions.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by M. Ortiz.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work was partially funded by a postdoc fellowship of the German Academic Exchange Service (H. S.), by DFG-Grant RE 3930/1–1 (Ph. R.), and by DFG-Project 282535003: Geometric curvature functionals: energy landscape and discrete methods (both authors).
Auxiliaries
Auxiliaries
We require some technical results for Sobolev–Slobodeckiĭ spaces on the circle \({\mathbb {T}}\). Typically, such statements are formulated on \({\mathbb {R}}^n\) or for sufficiently smooth domains \(\varOmega \subset {\mathbb {R}}^n\), but standard techniques allow one to port them also to smooth manifolds such as \({\mathbb {T}}\). Proofs for the following two results can be found, e.g., in [72, Theorem 5.3.6/1 (ii)] and [91, 2.8.2, Eq. (19)].
Lemma A.1
(Chain rule) Let \(\varOmega \subset {\mathbb {R}}^{n}\) be a bounded \(C^{\infty }\)-domain,  ,
,  . If \(\psi :{\mathbb {R}}\rightarrow {\mathbb {R}}\) is Lipschitz continuous with Lipschitz constant \(\varLambda \ge 0\) and
. If \(\psi :{\mathbb {R}}\rightarrow {\mathbb {R}}\) is Lipschitz continuous with Lipschitz constant \(\varLambda \ge 0\) and  then
then  and we have
and we have 
Lemma A.2
(Sobolev embedding) Let \(\varOmega \subset {\mathbb {R}}^{n}\) be a bounded \(C^{\infty }\)-domain. If \(s_{0},s_{1}\in {\mathbb {R}}\), \(p_{0},p_{1}\in \left]1,\infty \right[\) satisfy \(s_{0} \ge s_{1}\) and \(s_{0}-\frac{n}{p_0} \ge s_{1}-\frac{n}{p_1}\) then the embedding \( W^{s_{0},p_{0}}(\varOmega ;{\mathbb {R}}) \hookrightarrow W^{s_{1},p_{1}}(\varOmega ;{\mathbb {R}}) \) is well-defined and continuous.
Lemma A.3
(Vector-valued Sobolev embedding) Let \(\varOmega \subset {\mathbb {R}}^{n}\) be a bounded \(C^{\infty }\)-domain. If  ,
,  with \(s-\frac{n}{p} = - \frac{n}{q} <0\) then, for any Banach space X, there is a continuous Sobolev embedding
with \(s-\frac{n}{p} = - \frac{n}{q} <0\) then, for any Banach space X, there is a continuous Sobolev embedding 
Proof
We follow the argumentation in Theorem 5.1 from [1]: The norm \(\psi \;{:}{=}\; \Vert {\cdot }\Vert _{X}\) is Lipschitz with Lipschitz constant 1. Utilizing the Sobolev embedding for scalar functions (Theorem A.2) and for  along with the chain rule (Theorem A.1), we obtain
along with the chain rule (Theorem A.1), we obtain  where \(C>0\) is the Sobolev constant of the embedding for scalar functions. \(\square \)
where \(C>0\) is the Sobolev constant of the embedding for scalar functions. \(\square \)
The following is essentially a fractional Leibniz rule. The first proof seems to be due to Zolesio [101] who even considers the more general concept of Besov spaces. For Sobolev–Slobodeckiĭ spaces stronger requirements apply compared to the case of Triebel–Lizorkin spaces, see Runst and Sickel [72, Theorem 4.3.1/1 (i), Equation (11)]. We refer to the survey of Behzadan and Holst [9] for further information.
Lemma A.4
(Product rule) Let \(\varOmega \subset {\mathbb {R}}^{n}\) be a bounded \(C^{\infty }\)-domain, \(\sigma _i \in \left]0,1\right[\), \(p_i \in \left[ 1,\infty \right] \), for \(i \in \{1,2\}\). Let \(b :{\mathbb {R}}^{m_{1}} \times {\mathbb {R}}^{m_{2}} \rightarrow {\mathbb {R}}^{m}\) be a bounded bilinear mapping. Then the bilinear mapping  , given by
, given by  is well-defined and continuous if at least one of the following two conditions is satisfied:
is well-defined and continuous if at least one of the following two conditions is satisfied:
-
(i)
\(\big (\sigma _{1}- \tfrac{n}{p_{1}}\big )>0\), \(\big (\sigma _{2}- \tfrac{n}{p_{2}}\big )>0\), \(\sigma _1 \ge \sigma _2\), and \(\big (\sigma _{1}- \tfrac{n}{p_{1}}\big ) \ge \big (\sigma _{2}- \tfrac{n}{p_{2}}\big )\),
-
(ii)
\(\big (\sigma _{1}- \tfrac{n}{p_{1}}\big )>0\), \(\sigma _1 > \sigma _2\), and \(\big (\sigma _{1}- \tfrac{n}{p_{1}}\big ) > \big (\sigma _{2}- \tfrac{n}{p_{2}}\big )\).
The following “Schauder lemma”, communicated to us by Thorsten Hohage, helps us in Sect. 4 to show that the Riesz isomorphism of the metric is invertible. It does so by allowing us to play invertibility back to an “elliptic estimate”; see, e.g., [90, Appendix A, Proposition 6.7] for a proof.
Lemma A.5
(Schauder lemma) Let X be a Banach space, let Y and Z be normed spaces, and let \(A :X \rightarrow Y\) be a continuous, injective, linear operator. Suppose that there exists a \({\tilde{C}} \ge 0\) and a compact, linear operator \(K :X \rightarrow Z\) into a further Banach space Z such that \(\Vert {u}\Vert _X \le {\tilde{C}} \,\left( \Vert {A \, u}\Vert _Y + \Vert {K \, u}\Vert _Z\right) \) holds for all \(u \in X\). Then A has closed image and there is a further constant \(C \ge 0\) such that
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Reiter, P., Schumacher, H. Sobolev Gradients for the Möbius Energy. Arch Rational Mech Anal 242, 701–746 (2021). https://doi.org/10.1007/s00205-021-01680-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00205-021-01680-1