1. Introduction
A process network is a collection of time series variables that interact at different time scales [
1]. Each time series variable is a node in the network, and nodes are linked through time dependencies. Synapses in the human brain, industrial processes in a factory, or climate-vegetation-soil relationships can all be studied as process networks [
2,
3,
4]. In each of these examples, a time dependent relationship between the history of a source node and current state of a target node defines a network link that has some strength, time scale, and directionality. A whole-network property such as average node degree, average link strength, or dominant time scale can define a “system state”. It is important to correctly detect and interpret these links to reveal aspects of a network such as forcing structure, feedback, and shifts or breakdowns of links over time. Breakdowns or shifts in links could indicate changes in network response due to perturbations or gradual changes in the environment. With this framework, questions relating to threshold responses and overall health of a system can be readily addressed, and the system as a whole can be better understood. Process network construction requires accurate detection of time dependent links and evaluation of their importance and strength in terms of network behavior.
Studies on networks composed of oscillators and coupled chaotic logistic equations have shown that interacting nodes exhibit a wide range of dynamics depending on node coupling strengths, imposed time dependencies, and forcing [
5,
6,
7,
8,
9,
10]. Time series nodes can range from being unconnected to exhibiting various types of synchronization such as complete, lagged, general, or phase synchronization. Complete and lagged synchronized nodes have coincident states either simultaneously or at a time delay, phase synchronized nodes are locked in phase but vary in amplitude, and generally synchronized nodes have some functional relationship [
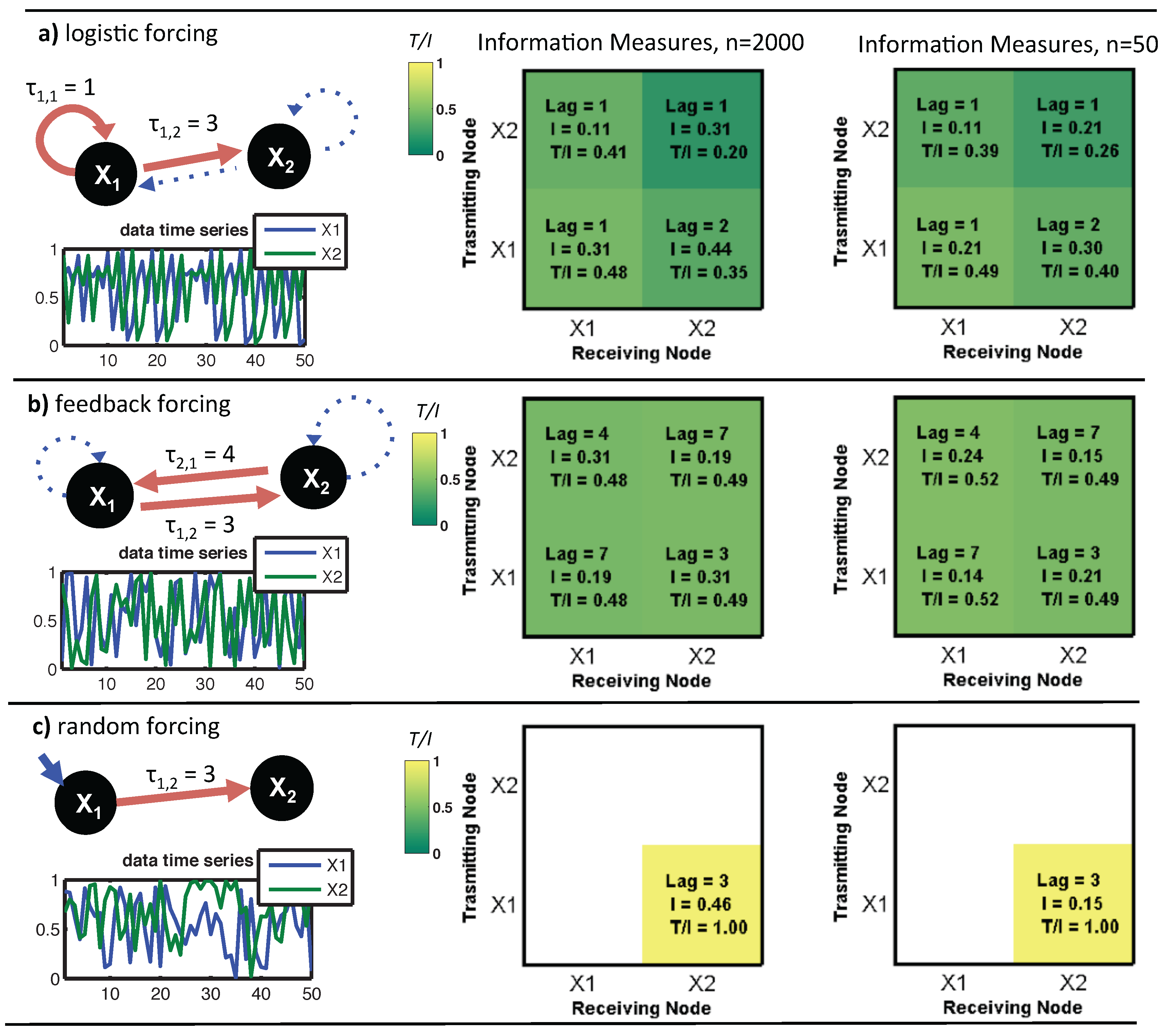
8]. In chaotic logistic networks, the potential for these dynamics depends on delay (
τ) distribution, coupling strength (
ϵ) and connectivity (
) [
5,
6,
9]. For strongly connected networks, synchronization is largely independent of the connection topology (Δ). As a result, networks with different connection topologies, such as random, scale free, and small-world, all achieve complete synchronization at a threshold connectivity as measured by average node degree multiplied by node coupling strength
ϵ [
6]. When delays (
τ) between nodes are uniform, the network synchronizes to a chaotic trajectory [
6]. When delays are distributed over multiple
τ values, the network synchronizes to a steady state, or fixed point value [
6]. At lower connectivities, the network displays a range of dynamics. The complexity of network behavior increases with the incorporation of stochastic forcing or noise.
In observed or measured process networks, nodes are likely to exhibit a combination of deterministic behavior due to functional dependencies and stochastic behavior due to random influences. In this study, we aim to identify time dependencies within networks of various structures, in addition to classifying networks in terms of their forcing-feedback mechanisms. Shifts in time dependencies or driving nodes in process networks could identify behavioral shifts in response to perturbations. These shifts could indicate alterations in important structural or functional components of the system.
Identification of coupling in real networks relies on statistical measures designed to capture the diversity of time dependent interactions. Metrics used to detect synchronization and time dependencies between nodes include variance and correlation measures [
5,
6,
9], information theory measures [
2,
3], convergent cross mapping [
11], coupling spectrums [
12], graphical models [
13,
14], and various others [
4]. Variance (
) measures between nodes and over time estimate relative levels of synchronization between nodes and identify the existence of complete synchronization to a single trajectory or fixed point [
5,
6,
9]. Information theory measures such as entropy
, mutual information
, transfer entropy
[
15], and partial mutual information [
16,
17] quantify uncertainty of node states and reductions in uncertainty given other node states. Information theory measures have been applied in ecohydrology [
1,
2,
18], neuroscience [
19,
20], and industrial engineering [
3], among others, to identify transmitters and receivers of information in addition to feedback within a network. When contributions from multiple “source” nodes to a “target” node are considered, shared information can be decomposed into redundant, unique and synergistic components [
21]. Redundant information is the information shared between every source node and the target node, and unique information is that which only a single source shares with the target. In some cases, the knowledge of two source nodes may provide information to a target node that is greater than the union of the information provided by both sources individually, thus providing synergistic information.
The objective of this article is to determine the additional knowledge that information theory measures can provide over variance measures concerning process network behavior, such as distinguishing between types of drivers, locating feedback, and identifying redundant
versus unique sources of information. How well do information theory measures capture imposed network dynamics? When a time dependent link is identified, is it critical in terms of network function, or redundant with other interactions? Time dependencies identified in real process networks could be either important aspects of system health or functioning, or redundant due to induced feedback. Although the existence of feedback within process networks can obscure what is a “cause”
versus an “effect” and prevent detection of causality, the estimation of redundancy can identify groups of redundant links [
22] which can then be further evaluated in terms of their contributions to system behavior.
This study uses a method to compute information theory measures that does not assume time series variables to follow a Gaussian distribution, and performs well given limited datasets with as few as 200 data points. This minimization of the data requirement is valuable because data used to form real world process networks are often sparse, fragmented, or noisy [
19]. There are several proposed methods to directly evaluate redundancy, synergy, and unique information [
20,
21,
23,
24] that each have advantages and disadvantages in their interpretation [
24,
25,
26]. Here we instead use combinations of established information theory measures that reveal multiple aspects of information transfers.
We create chaotic-logistic networks with a range of τ-distributions, coupling strengths ϵ, topologies Δ, and levels of noise, and compare information theory and variance measures to the imposed network structures. We evaluate our methods in terms of correctly identified links, or statistically significant detections of information measures that correspond to imposed time dependencies. In a network of observed time series data, structural properties such as driving nodes, node degrees, and coupling strengths are generally unknown and may change over time. However, process network construction can reveal some of this structure, and temporal changes in detected links indicate shifts in properties. In addition, comparisons of process networks can detect differences between inputs and outputs of a model or between measured and simulated variables. Through this analysis of generated network dynamics, we improve our ability to identify and interpret real-world process networks that range from uncoupled to completely synchronized.
2. Methods: Definition of Metrics
We evaluate network behavior with several measures that capture variability and time-dependent interactions. The standard deviation between node values,
, indicates synchronization between nodes [
5]. In a network composed of
nodes and
time steps per node,
For complete synchronization,
. The standard deviation between time steps averaged over the
N nodes,
, indicates the temporal variation of nodes [
5].
In these metrics,
is the mean node value at time
t, and
is the mean temporal value of node
i. If both
and
, all the nodes in the network are at the same fixed point value for all time steps. If
and
, nodes are at different fixed point values. Finally, if
and
, nodes are completely synchronized to each other but vary with time [
5]. These measures can also be applied to any pair of nodes or subsystems within a larger network, and are useful when comparing networks to a reference or baseline condition. Since
and
depend on the range of values (
) taken by nodes in the network, the significance of any
is difficult to evaluate without further knowledge of the range of possible network behaviors.
Information theory measures involve comparing probability density functions (
pdfs) of nodes rather than their magnitudes. Shannon entropy
quantifies the uncertainty or variability of a node.
can be computed and normalized to between 0 and 1 by dividing by the upper bound
, where
is the chosen number of bins into which the
pdf is discretized.
Mutual information
is the reduction in uncertainty of node
given knowledge of the state of another variable
, and is computed from the joint
pdf.
Lagged mutual information
quantifies the information shared between a target node
and the
-lagged history of a source node
. Although
I is a symmetric quantity,
introduces a directionality if we assume that past node states inform future states, and not vice versa. In other words, we consider past node states to be “sources” and a future state to be a “target”. In a network of interacting nodes, multiple sources in the form of different nodes or a single node at different time scales can provide information to a single “target” node. The total lagged
shared by two sources (
and
) to a target (
) is the mutual information between one source and the target added to the conditional mutual information as follows:
Using the partial information decomposition approach [
21,
27], we see that this shared information between two sources and the target can be partitioned into elements as follows:
In Equations (
6)–(
8),
and
represent the unique information that only
and
, respectively, share with
,
is the synergistic information that arises only from the knowledge of both
and
together, and
is the redundant information that is provided by either source node separately.
We see from substituting Equations (
8) and (
6) into Equation (
5) that the conditional information term
is equivalent to
, or the unique information component of one source node and the synergistic information due to the knowledge of both sources. The same result can be obtained by observing that conditional mutual information is equal to the interaction information or co-information [
21,
28,
29] (
) added to the mutual information (
). A positive interaction information (
) indicates that synergy dominates over redundancy in the partitioning of shared information [
21]. An
indicates dominant redundancy, or that the knowledge of any one variable “explains” correlation between the other two [
29]. Conditional
(
i.e.,
) is also referred to as partial information, since it represents the part of the total mutual information that is not contained in the second source node (
) [
17]. The conditional
is computed between two sources and a target node as follows:
In Equations (
5) and (
9), if we consider the special case where one of the source nodes
is the lagged history of the target node
itself (
i.e.,
), the conditional mutual information term is equivalent to the transfer entropy
. Transfer entropy [
15] is the reduction in uncertainty of a node
due to the knowledge of the
history of another node
that is not already accounted for in the
history of
[
2,
18].
is often interpreted as the amount of predictive information transferred between two processes [
30]. Some formulations of
involve consideration of block lengths
l and
k of the histories of the transmitting node
and receiving node
, respectively. However, the values of
l and
k are generally set equal to 1 so as to not impose additional data requirements for the computation of a higher dimensional
pdf [
7,
15,
31]. In this study, we relax the usual assumption in transfer entropy computations that predictive information from a source node is only conditioned on the target node’s history.
provides a generalization of
that conditions the predictive information of the time dependency of any source, including the history of the target node itself.
In this paper, we establish network links by computing lagged mutual information
using Equation (
4) between each potential source and target node for a range of time delays. To test for statistical significance of the detected value, we randomly shuffle the target node
to destroy time correlations while retaining other properties of the time series data [
2,
32,
33]. We compute 100 values of
, and perform a hypothesis test at a 99% confidence level. If the detected value is less than
, we dismiss the detected link as not significant.
After establishing time dependent links in the network, we compute the total and conditional
provided by each pair of sources to every target node using Equations (
9) and (
5). We define
as an index to measure the non-redundant component of each link as a function of conditional and total shared information as follows:
where
Computation of
requires a pairwise evaluation of sources for each detected target node in the network. For a link between
and a source
, minimization across each each alternate source
provides a conservative measure of the unique and synergistic components of the link. In the absence of synergistic relationships, if a source
is completely redundant due to another source (
i.e.,
and
), then
. If
is the only source or is much stronger than all other sources (
i.e.,
), then
approaches 1. Therefore,
characterizes the relative amount of unique or synergistic information provided by a link as originally determined based on statistically significant
. While
detects a single time dependent link, conditioning on other dependencies allows for detection of unique and redundant linkages [
16,
34]. High
values can also result from synergistic relationships, where much more information is shared by two sources together than either shares separately. Other methods of detecting or eliminating redundant sources include direct transfer entropy [
3] or causation entropy [
35], which involve 4D
pdf estimation to condition on multiple source nodes.
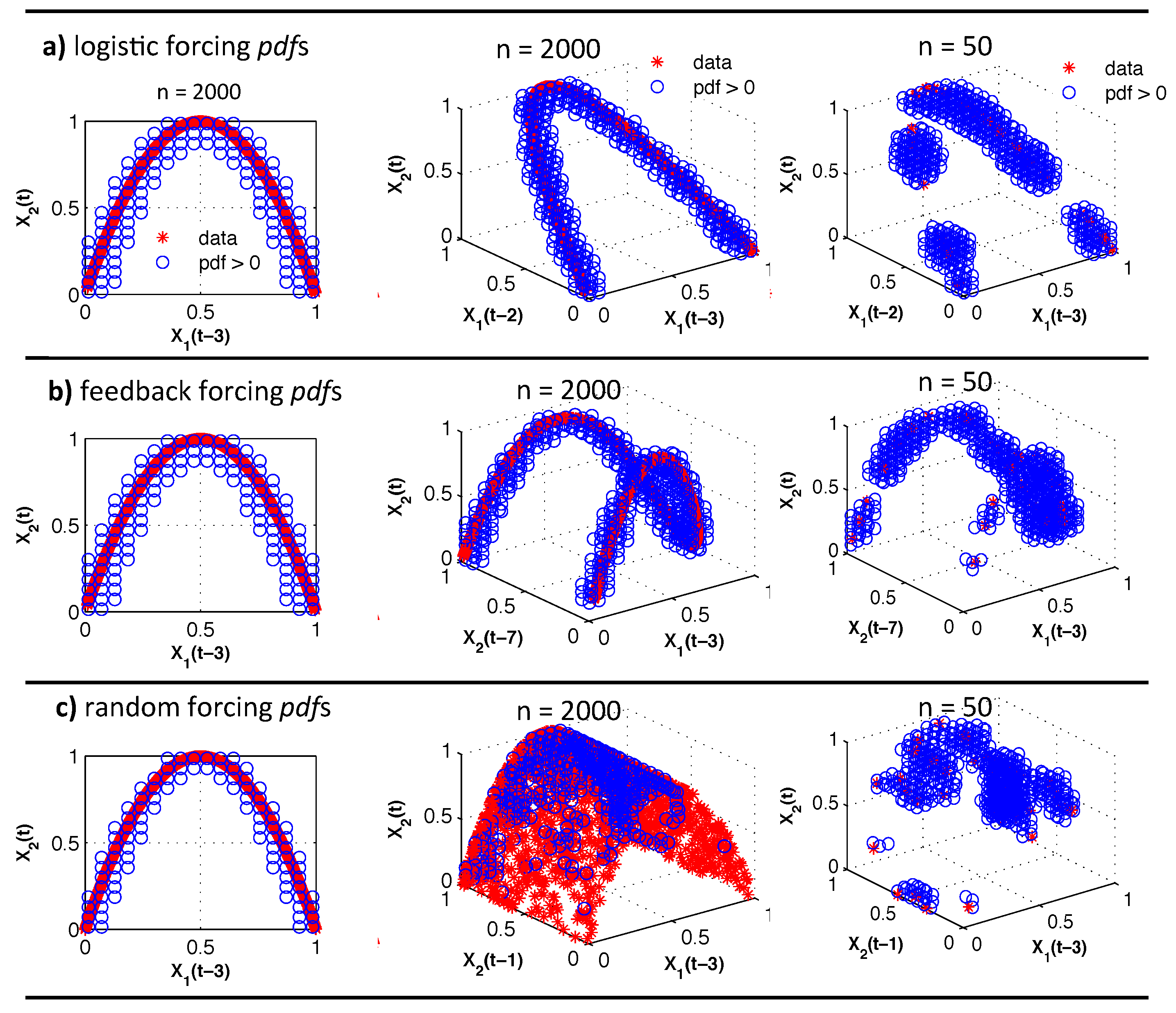
We use the Kernel Density Estimation (KDE) [
19,
22,
36] method to estimate the 3D
pdf (
) required to compute conditional
and the 2D and 1d
pdfs needed for
and
H after testing several techniques [
2,
7,
12,
19] on two-node networks of
data points and varying noise levels. The kernel estimator at a grid point or location
y given
observations is defined as [
36]:
The multivariate Epanechnikov kernel
[
36] is as follows:
in which
d is the dimension of the
,
is the volume of a
d-dimensional unit sphere, and
n is the number of observations. The optimal window width
h for the kernel is chosen to vary with
n and
d based on [
36] as follows:
in which
σ is the standard deviation of the data. We evaluate the kernel at
evenly spaced grid points (
y) in each dimension. The KDE method performed similarly to fixed-binning [
2,
19] and partitioning methods [
19] for large data sets, but the smoothing of the
pdf due to the kernel improved performance for small data sets with
.
4. Results: Coupled Chaotic Logistic Networks
Previous studies have determined that chaotic logistic network synchronization capacity in terms of
σ measures (
and
) depends more on the delay (
τ) distribution than network topology Δ [
5,
6,
9]. For a range of Δ including small-world, scale-free, and random networks, increasing connectivity (increasing coupling strength or number of links) leads to synchronization of all connected nodes. The dynamics of the resulting synchronized trajectory depend on the
τ-distribution [
6]. Networks with uniform delays (e.g.,
for all linked nodes) synchronize to a single chaotic logistic trajectory. In contrast, networks with heterogenous delays (e.g., random
for linked nodes) synchronize to the fixed point (
) of the logistic equation. This type of synchronization occurs when nodes that receive from enough neighbors at different lags converge toward the fixed point
and all nodes approach zero amplitude [
38]. In terms of information theory measures, it has been found that information transfer can be used to predict synchronization and distinguish between origins of interaction fields, or types of forcing, in different types of generated networks [
7].
In this section, we extend the forcing mechanisms introduced in the two-node examples to larger 10-node networks. A 10 node network is small enough for computation efficiency and to represent many systems of interest, and large enough to capture the complexity and synchronization that larger networks exhibit. We generated networks of between 5 and 50 nodes and observed that larger networks synchronize at lower connectivities, but display otherwise similar behavior. The networks are generated over a range of connectivities, with different proportions of chaotic logistic and uniform random noise forcing. We introduce randomness into the network through randomly generated “driving nodes” that act as controls, or through the addition of uniform random noise to each node in equal proportion. We compute information and variance measures for the generated networks, and use whole-network measures to summarize each individual case. In chaotic logistic networks with no random component, we observe the expected delay-dependent synchronization.
4.1. Network Formation
We generate networks using Equation (
18), each with
nodes of
time series points per node, using the framework given as:
In Equation (
18),
i and
j are node indices,
,
t is time step,
is the in-degree of node
i,
w is the adjacency matrix (
if
is a function of
,
otherwise),
τ is the delay matrix associated with
w, and
z is a uniform random noise between 0 and 1. As in the two-node example, we set
so that each individual
is in the chaotic regime.
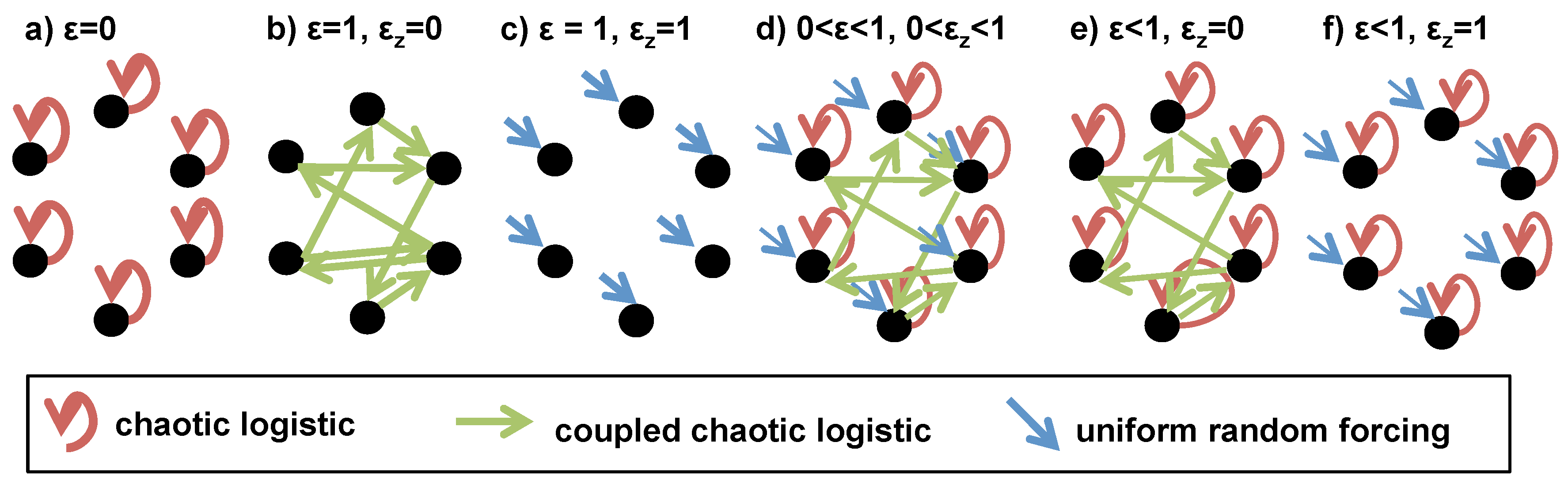
4.1.1. Network Forcing
The formulation of Equation (
18) defines a node
to be forced by (
1) its own lagged history; (
2) the lagged histories of connected nodes; and (
3) random noise. The extents to which these components influence
are defined by the coupling strengths
ϵ and
. For example, for
and
,
is solely a function of the histories of all
for which
(
Figure 3b). If
, each node is an independent chaotic logistic time series, since
is only dependent on its own history (
Figure 3a). If
and
, the network is entirely composed of uniform random noise (
Figure 3c). For values of
and
, the network responds to all three types of forcing (
Figure 3d).
In Equation (
18), the imposed adjacency matrix
w determines the interaction “field”, or set of nodes to which each node responds. The field is homogenous over time, but is different for each node. To explore the effect of external forcing, we introduce cases in which some of the 10 nodes are randomly generated time series (
). The remaining nodes are generated from Equation (
18), and can be functions of both chaotic logistic and randomly generated nodes, depending on the adjacency matrix
w. The noise component
represents a different type of random forcing in that it affects each node in the network in equal proportion.
Figure 3.
Illustration of network cases based on variations of Equation (
18). (
a) unconnected network driven by individual chaotic logistic equations; (
b) network driven by chaotic logistic couplings; (
c) unconnected network driven by random forcing; (
d) network driven by combination of forcings according to
and
; (
e) network driven by combination of individual and coupled chaotic logistic equations; (
f) unconnected network driven by random forcing and chaotic logistic equation.
Figure 3.
Illustration of network cases based on variations of Equation (
18). (
a) unconnected network driven by individual chaotic logistic equations; (
b) network driven by chaotic logistic couplings; (
c) unconnected network driven by random forcing; (
d) network driven by combination of forcings according to
and
; (
e) network driven by combination of individual and coupled chaotic logistic equations; (
f) unconnected network driven by random forcing and chaotic logistic equation.
4.1.2. Network Topologies and Delays
Network topologies used to generate the adjacency matrix
w include random and small world. Random networks are generated based only on a link probability
p, while small world topologies [
39] are bi-directional cyclic networks of degree 2 (each node transmits to and receives from
neighbor on each side), and links are added randomly with probability
p. A “theoretical weighted degree”
K for each network type is the average number of incoming links per node multiplied by the coupling strength term
. A fractional weighted degree
is a measure of connectivity that ranges between 0 (unconnected nodes) and 1. At
, nodes are completely connected at maximum coupling strength,
i.e.,
and
.
Four specific classes of networks were tested, combining network topologies and delay distributions (
Table 1). Cases 1 and 2 are random networks, while Cases 3 and 4 have small world topologies. Cases 1 and 3 have uniform delay distributions (
for
), and Cases 2 and 4 have random delay distributions (
for
). As expected, we find that both topologies Δ behave similarly as network connectivity
increases in terms of both standard deviation and information measures. As found in previous studies, we see that network behavior is most dependent on the
τ-distribution and the connectivity
rather than Δ. Cases 1 and 3 synchronize to a single chaotic logistic trajectory as
is increased (Case 1 shown in
Figure 4a), while Cases 2 and 4 synchronize to a fixed-point value as
is increased (Case 2 shown in
Figure 4b). Other network configurations tested include scale-free networks and higher degree (
) small world networks, all of which synchronized similarly according to their
τ-distribution. Due to the similarities between network topologies, we show results for only Cases 1 and 2, the random network cases. Networks of various sizes from 5 to 50 nodes and observed similar results in terms of synchronization and detected information measures.
We canvas a range of parameters to form the adjacency matrices
w and forcing structures and generate the subsequent process networks (
Table 2). For each network,
ϵ and
are constants (
i.e., all nodes transmit and receive with equal coupling strengths), except for cases where
. In these cases,
of the
N total nodes are randomly generated nodes that only transmit information according to
. Over 40,000 distinct networks are generated (
Table 2), and we compare several categories.
Table 1.
Synchronization characteristics of four network cases composed of different topologies and delay (τ) distributions.
Table 1.
Synchronization characteristics of four network cases composed of different topologies and delay (τ) distributions.
| Case | Structure | τ-Distribution | | Synchronization Type |
|---|
| 1 | random | uniform, | | chaotic trajectory |
| 2 | random | random, | | fixed point |
| 3 | small world | uniform, | | chaotic trajectory |
| 4 | small world | random, | | fixed point |
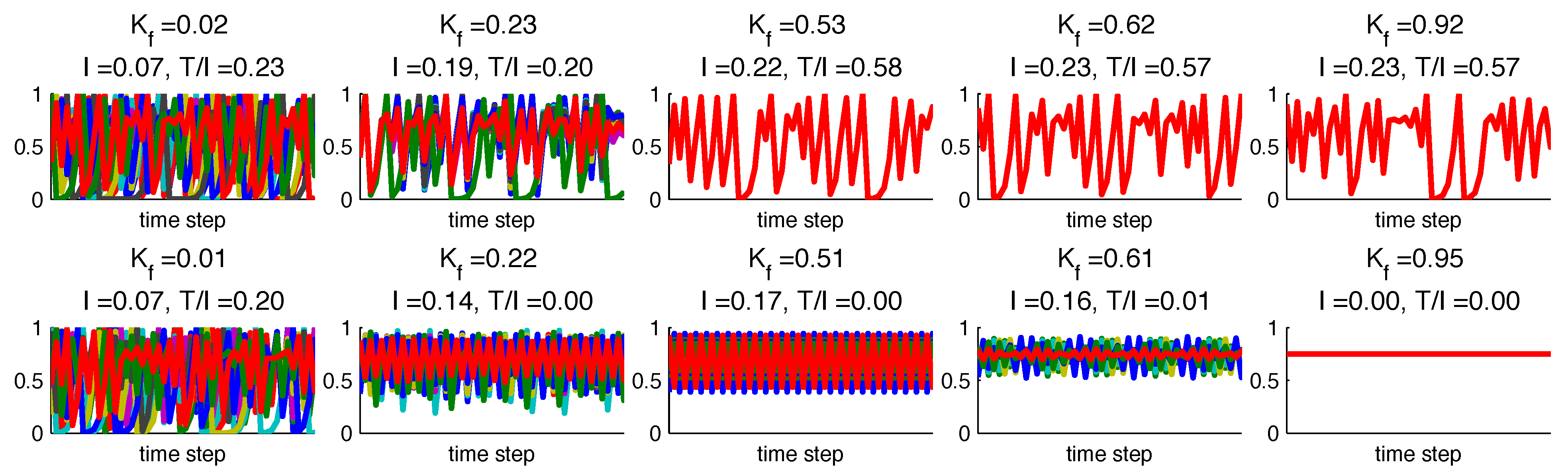
Figure 4.
Time series (50 time steps shown) for several generated networks for (a) Case 1 with uniform () delay distribution and (b) Case 2 with random delay distribution. Both cases approach synchronization as increases.
Figure 4.
Time series (50 time steps shown) for several generated networks for (a) Case 1 with uniform () delay distribution and (b) Case 2 with random delay distribution. Both cases approach synchronization as increases.
Table 2.
10 node network parameter range (42,336 total networks generated).
Table 2.
10 node network parameter range (42,336 total networks generated).
| Parameter | Range of Values | Number of Cases |
|---|
| p | [0,0.05 1] | 21 |
| ϵ | [0,0.05 1] | 21 |
| [0, 0.01, 0.1, 0.5] | 4 |
| [0, 1 5] | 6 |
| topology Δ | [random, small world ] | 2 |
| τ-distributions | [random, uniform] | 2 |
| total number of networks | 42,336 |
| cases with random Δ, , | 882 |
4.2. Synchronization and Information in Noise Free Networks
We first set
in Equation (
18) to obtain a noise free network, and consider the range of coupling strengths
and link probability values
(illustrations in
Figure 3a,b,e). We see from the generated time-series data that nodes completely synchronize for high values of
according to their
τ-distributions (
Figure 4). Observation of
(
Figure 5a) leads to the same conclusion that both network cases synchronize to a single trajectory as
increases, but at different rates. For Case 1 (uniform
τ), complete synchronization to a time-varying trajectory is reached at
(
Figure 5a,d). Case 2 (random
τ-distribution) synchronizes more gradually as
increases, and is completely synchronized to a fixed-point trajectory for
(
Figure 5a,d).
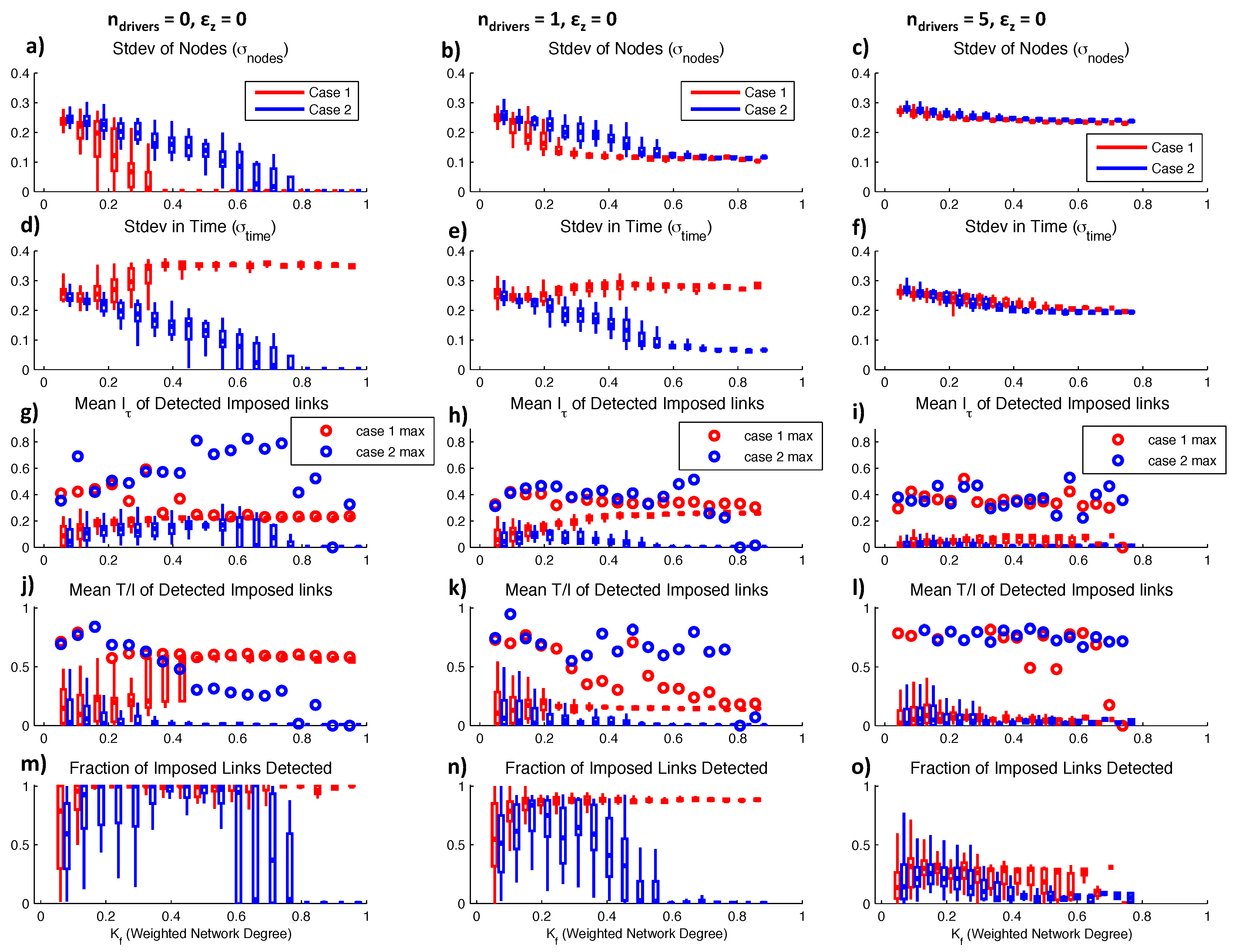
Figure 5.
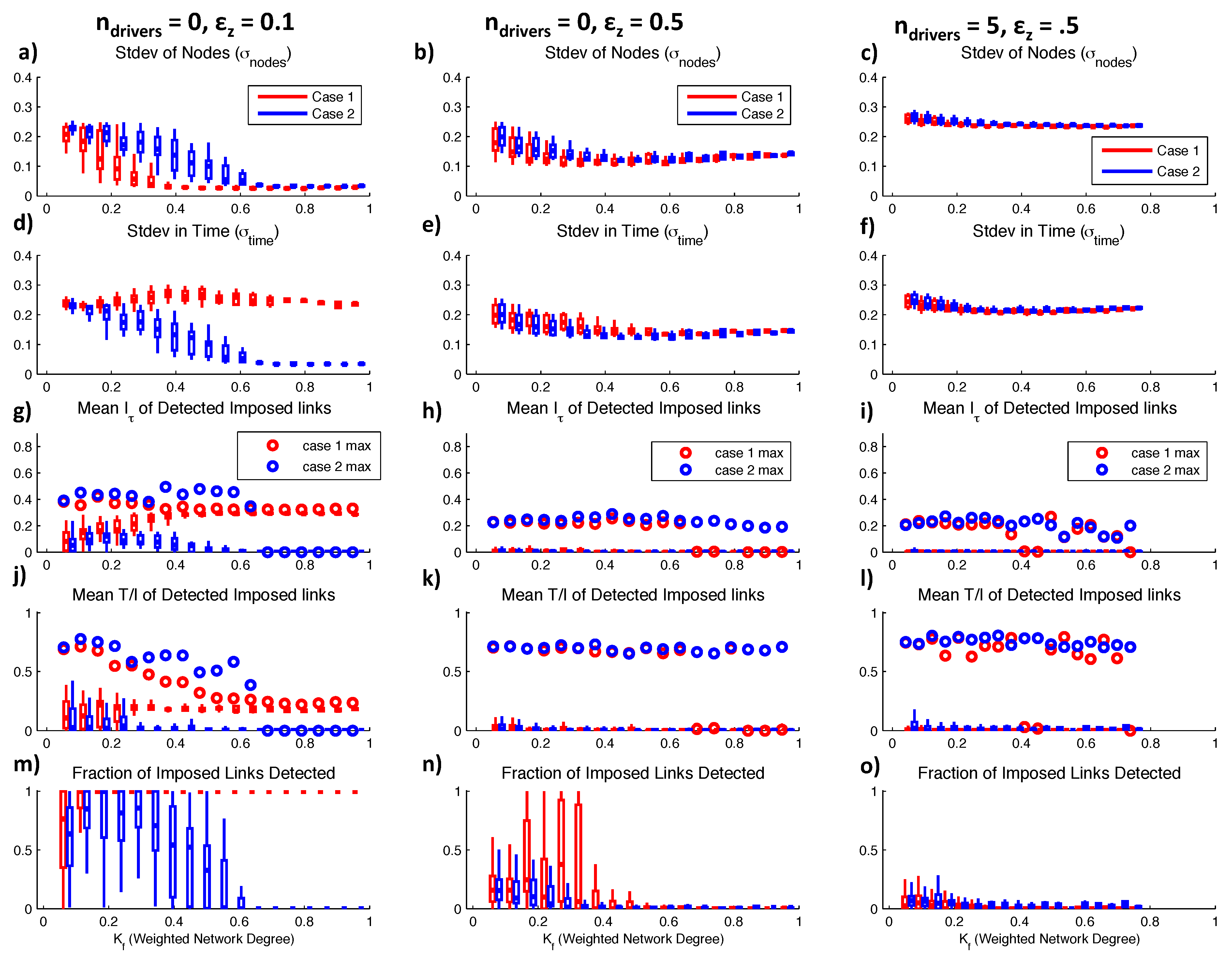
Behaviors of 882 network configurations with range of connectivities for (left) the case with no randomly generated driving nodes, (middle) , and (right) . (a–c) Standard deviation across nodes ; (d–f) Standard deviation across time ; (g–i) Box plots show mean detected for all imposed linkages for all networks in each range, and open circles are maximum detected of any imposed link; (j–l) mean over all networks and maximum detected as in (g–i); (m–o) Fraction of all imposed links that were correctly identified as time dependencies through detected .
Figure 5.
Behaviors of 882 network configurations with range of connectivities for (left) the case with no randomly generated driving nodes, (middle) , and (right) . (a–c) Standard deviation across nodes ; (d–f) Standard deviation across time ; (g–i) Box plots show mean detected for all imposed linkages for all networks in each range, and open circles are maximum detected of any imposed link; (j–l) mean over all networks and maximum detected as in (g–i); (m–o) Fraction of all imposed links that were correctly identified as time dependencies through detected .
The mean values of
and
displayed in the bar plots of
Figure 5g,j represent the mean statistics for imposed links over all networks in each
interval, while the maximum
and
values displayed in the open circles represent the maximum individual values detected within any of the networks in each
range. In other words, mean values represent average detections for imposed links, while the maximum represents overall maximum detected values. For Case 1, mean
for imposed links approaches a constant and statistically significant value of approximately
(
Figure 5g) as the network synchronizes, indicating that the synchronized trajectory retains the imposed uniform
time dependency.
also reaches a constant non-zero value when the network synchronizes, indicating that multiple sources are detected, but the imposed lag is dominant compared to others. For unsynchronized networks (
), the low value of mean
indicates that most target nodes have multiple sources that lead to redundancies. These redundant sources may not be imposed links from the adjacency matrix, but arise due to induced feedback as illustrated in the two-node example cases. However, for low
in Case 1, we see high maximum individual values of
(open red circles in
Figure 5j). These high maximum values result from cases in which a target node receives from one source (its own history in the unconnected chaotic logistic case) very strongly, and other sources very weakly, so that
is close to 1. Maximum values of
and
that are much higher than average values indicate that most imposed links become redundant, but there is at least one less connected node that receives more unique information. For Case 1,
links are weaker on average for less synchronized networks, and more redundant. However, maximum individual
and
values are highest for less synchronized networks, representing cases of high coupling strength but low link probability (
and
) in which a single node is a dominant influence on a target.
For Case 2, slightly lower
values are detected for the range of connectivities (
Figure 5g). However, we observe very high maximum individual
values over the non-synchronized high connectivity range (
). From the time series (
Figure 4b), we see that this is because nodes are generally phase-locked at a time lag of 2 in this range of
values, so they are completely predictable based on their own histories. As expected, these high
values are associated with lower
(
Figure 5j) because of many redundant sources. At complete synchronization (
) for Case 2 networks, we see that no
or
are detected on average. Case 1 and Case 2 networks show similar behavior at low connectivities, but information measures diverge for the different types of synchronization.
decreases as Case 2 networks synchronize, indicating the increase in redundant links. In contrast,
increases as Case 1 networks synchronize due to the dominant
“self”-dependency that arises on the path to synchronization.
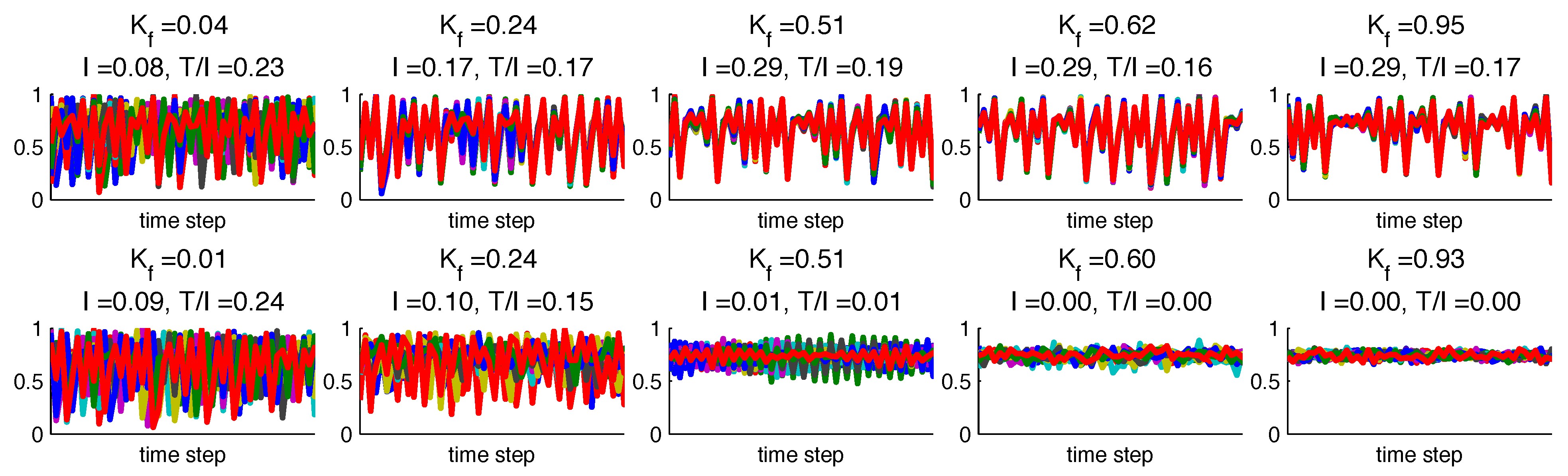
We define a correctly detected link as a statistically significant value of
detected for a node pair
at the imposed lag time
. For unsynchronized networks with mid-range connectivities (
), we correctly identify nearly all imposed links according to
for both network cases (
Figure 5m). Even for very low-connectivity networks, over half of imposed links are detected. When Case 1 networks are synchronized, a link is detected between every node pair due to the common trajectory, regardless of the imposed
w. This leads to a 100% correct link detection rate, but also a 100% “false” detection [
37] rate of unimposed links. As discussed in the two-node examples, these detections are all due to induced feedback, thus we do not show their increasing number as networks synchronize. For Case 2, as networks synchronize to a very low amplitude phase-locked state, we cease to detect any of the imposed links.
4.3. Influence and Detection of External Drivers
When nodes in a process network contain complete predictive information, as in the previously discussed noiseless case, complete synchronization occurs at high connectivities. However, real process networks are likely to involve some proportion of nodes that are unpredictable due to influences from outside of the network. These unpredictable nodes may act only as drivers and do not respond to the network dynamics. To simulate these conditions, we generate networks in which one or more nodes (
of
N total nodes) have independent dynamics, and act only as sources. While chaotic logistic nodes approach synchronization with increasing
, the random driving nodes remain independent of this behavior. However, even chaotic logistic nodes do not entirely synchronize due to their varying dependencies on the drivers (
Figure 6). From observation of
and
for the
case (
Figure 5b,e), we see similar trends as in the
case, but no complete synchronization.
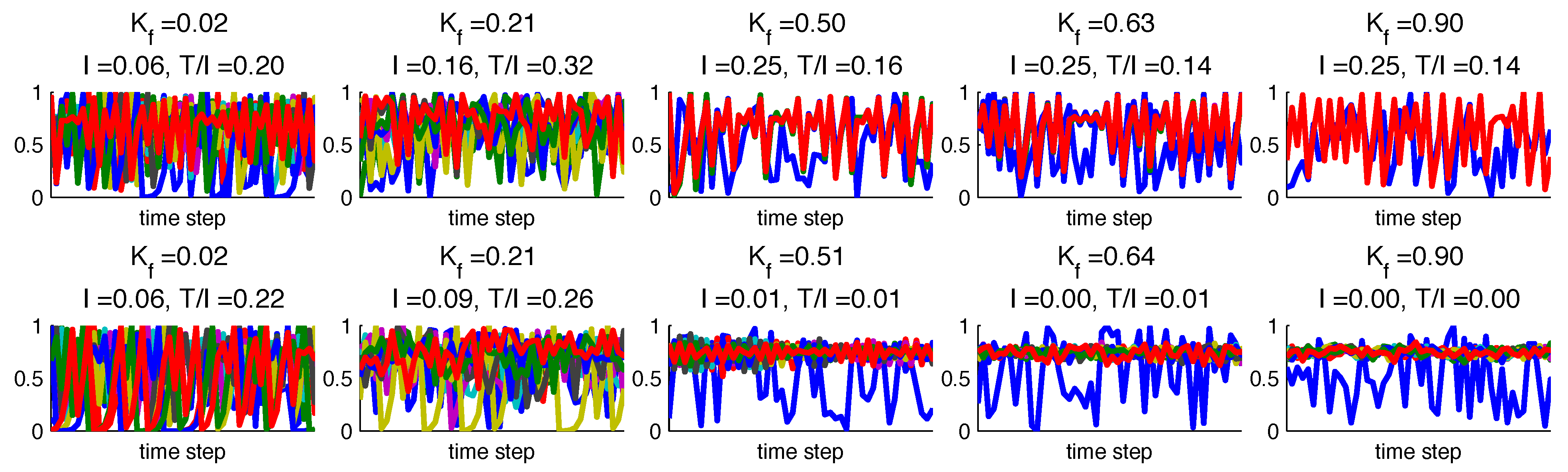
Figure 6.
Time series (50 time steps shown) for several generated networks with for (a) Case 1 (b) Case 2.
Figure 6.
Time series (50 time steps shown) for several generated networks with for (a) Case 1 (b) Case 2.
For Case 1, we detect similar mean and maximum
values for imposed links over the
range (
Figure 5h), but maximum
values decrease as
increases (
Figure 5k). This indicates that imposed sources become increasingly redundant with other sources as connectivity increases, and that imposed sources are weaker than induced feedback that arises as the non-driving nodes partially synchronize. The decreasing maximum
behavior for Case 1 networks with
is very similar to the Case 2 networks with
. When Case 1 networks are prevented from completely synchronizing due to a random driver, no single source becomes dominant as in the case where
. Case 2 networks with
have lower detected mean and maximum
(
Figure 5h) than the
case, and lower mean
(
Figure 5k). However, the maximum individual
values are higher at higher
values for Case 2, reflecting the influence of the random driving node. If a random driver forces a target node, the shared information is not redundant with any other source, except in the case where induced feedback exists to form an indirect link. For example, if the random node forces an intermediate node that in turn forces the target node, some of the information shared between the the random and target node is also encoded in the intermediate node history, resulting in some redundancy. However, random sources do not propagate feedback as do time-dependent drivers, leading to more unique transfers of information.
When
, we observe a continuing trend of decreased synchronization capacity (
Figure 5c,f), decreased shared information
(
Figure 5i), decreased average
, and increased maximum individual
(
Figure 5l). We also see that the fraction of correctly detected imposed links decreases with increased randomness in the network (
Figure 5m,n,o). For the set of
networks, uniform and random
τ-distribution cases are nearly indistinguishable, and only slight synchronization is observable from
σ measures (
Figure 5c,f). Although target nodes receive from a similar number of source nodes as in previous cases, the randomness of some of the sources results in high values of
, reflecting unique contributions of information. Essentially, any given source node may only share a small amount of information with a target node, but this information is more likely to be unique if the source is random. On average however, linkages are increasingly redundant (low
) as connectivity increases and feedback is created.
4.4. Influence of Noise in Network
In real networks, variability cannot always be attributed to the behavior of other nodes, but may be caused by noise. In this section, we set
in Equation (
18) to represent sources of variability such as measurement noise. While randomly generated driving nodes force other network components according to connectivity as determined by adjacency matrix
w, a noise component represents random variability
z applied to each node. Similar to cases where
, randomness due to
prevents complete synchronization. The introduction of noise as 10% of the coupling strength (
) to the case with no random drivers (
Figure 7 Left) results in similar synchronization behavior as the initial noiseless scenario (
Figure 5 Left), except that nodes do not completely synchronize. In contrast to the
cases, all nodes contain time dependencies in addition to the noise components, and we observe that nodes tend to synchronize to an equal degree (
Figure 8) as
increases. When the noise component is increased to
, the network further loses capacity to synchronize (
Figure 7b,e), and Cases 1 and 2 are nearly indistinguishable.
The shared information
for the
case (
Figure 7g) is similar to the initial noiseless case (
Figure 5g) for Case 1 networks, but lower for Case 2 networks. While mean detected
increases with
for Case 1 networks up to a constant value, we observe an opposite trend in
, in which the maximum detected
decreases with increased
until it reaches a constant low value at
. As the nodes partially synchronize, the noise components cause scatter in the
s that results in similar strengths of information measures between sources. The detected
is similar to the case with 1 external driver (
Figure 7k). At low
, a node may receive a large amount of unique information from a source, but feedback results in redundancy at high
.
Figure 7.
Behaviors of 882 network configurations with range of connectivities for (left) and , (middle) and , and (right) and (a–c) Standard deviation of nodes; (d–f) Standard deviation in time; (g–i) Box plots indicate mean , and open circles are maximum detected ; (j–l) mean and maximum detected values as in (g–i); (m–o) Fraction of all imposed links that were correctly identified as peak time dependencies through detected .
Figure 7.
Behaviors of 882 network configurations with range of connectivities for (left) and , (middle) and , and (right) and (a–c) Standard deviation of nodes; (d–f) Standard deviation in time; (g–i) Box plots indicate mean , and open circles are maximum detected ; (j–l) mean and maximum detected values as in (g–i); (m–o) Fraction of all imposed links that were correctly identified as peak time dependencies through detected .
Figure 8.
Time series (50 time steps shown) for several generated networks with and no random driving nodes for (a) Case 1 (b) Case 2.
Figure 8.
Time series (50 time steps shown) for several generated networks with and no random driving nodes for (a) Case 1 (b) Case 2.
Increasing the noise component to
(
Figure 7b,e) results in similar
and
as the
case, in which the two cases are not distinguishable. However, the mean
and
(
Figure 7h,k) are very small compared to the case with random driving nodes. For Case 1, there is a threshold connectivity value around
at which no
is detected for any imposed link. This is due to the high noise in addition to many source nodes. Nodes would synchronize to a chaotic trajectory if not for the noise, and the spread of the resulting
does not allow for significant detection of any sources. For Case 2, maximum detected
is statistically significant even at high
values, because nodes tend toward synchronization to a phase-locked trajectory in which
. Although
is very low on average for
networks (
Figure 7k), the maximum detected
is high over the range of connectivities. Similar to the case of multiple random drivers, when a target node receives from a single source that is partially random, the information due to the random component is more likely to be unique, resulting in a high
.
A final case in which
and
combines the influences of random driving nodes and noise. In this case, little synchronization is detected based on
σ measures (
Figure 7c,f) for either Cases 1 or 2. Shared information
is statistically significant over the range of
, but very small (
Figure 7i). However, the maximum individual
values tend to be large over the entire
range, similar to the previous cases with high noise levels in the form of either random drivers or noise.
As noise and randomness are introduced in the networks, fewer imposed links are correctly identified (
Figure 7m,n,o). However, for high
, a higher fraction of imposed links is detected in the case with random drivers and noise (
Figure 7o) than the case with only noise (
Figure 7n). This is because the random drivers transmit information more strongly than source nodes composed of both noise and chaotic logistic components, so are more likely to be detected at higher
values. Detection of links improves with longer time series datasets, but we consider only networks of
data points to reflect realistic data availability. For all of the network cases generated, some links are not detected at low
values because they are very weak. At high
, links other than those imposed are detected due to feedback induced by the high connectivity.
4.5. Summary of Structure and Synchronization of Networks
The addition of randomness or noise to a connected network prevents complete synchronization. This random component could be in the form of driving nodes that do not directly participate in feedback, or in the form of noise inherent to each individual node. Driving nodes remain independent of the synchronization of the rest of the network, while nodes in a noisy but feedback-connected network synchronize to an equal degree. Measures of and are useful to gage the relative level of synchronization, and particularly distinguish between uniform and random delay τ-distributions in noiseless network cases through their detection of synchronization and amplitude death. However, they do not convey information about time dependencies and redundancies within the network, and do not distinguish between high and low connectivities when there is a high level of randomness.
Information measures such as lagged mutual information (), conditional information given other sources (), and total shared information between multiple sources () detect time dependencies between node pairs in a process network, and enable detection of dominant drivers, and unique and redundant sources of information. Even for completely synchronized nodes, detects time dependencies within a single trajectory, as in the noiseless Case 1 (uniform τ-distribution) networks. For unsynchronized networks with detected time dependencies (significant ), further conditions on other source nodes and time scales to reveal redundancies and unique links. A indicates that the detected link is not completely redundant given the history of another source node, which could be the target’s own history, as is detected with transfer entropy. In the case of a network forced only by feedback, there may be high between node pairs, but low due to redundancies in the synchronizing nodes. In contrast, for a network forced randomly or by a node with no time dependencies, target nodes may share information with only one source, or completely unique sources. In these cases, we detect both significant and , indicating a high level of unique information transfer.
We define a correctly detected link as statistically significant value of lagged mutual information detected between two nodes () that corresponds to an imposed link according to and . In a weakly connected network with little noise, we identify nearly all imposed links. As connectivity increases, if nodes tend to synchronize to a time-dependent trajectory, we increasingly detect “false” links between nodes that are not defined to be connected, or are connected at a different time scale. These false links are actually feedback induced by the imposed time dependencies. When a network begins to synchronize, it is not possible to distinguish links due to imposed network structure from those due to induced feedback. In cases where nodes synchronize to a fixed point trajectory, we cease to detect any links. In networks with noise, some imposed links are correctly detected at high levels of connectivity since the random components provide unique information that prevents complete synchronization.
5. Discussion
The two-node and 10-node network scenarios presented here represent a small fraction of potential network dynamics that could be observed in real-world networks. The two-node networks help us understand induced feedback and types of forcing, and the resulting interpretation from analysis of the data. The 10-node networks capture general features of a larger network dynamic arising from multiple pieces of feedback. Process networks based on measured or simulated nodes of time series exhibit a wide range of connectivities and time-varying interactions. Coupling strengths and timescales vary between nodes and shift over time, and thresholds may exist for which certain couplings break down while others become dominant. Additionally, shared information between two or more variables could be synergistic, if the knowledge of two nodes together provides more information than their union separately. Although we present relatively simple cases in this study, the metrics used for analysis allow for the detection of a range of behaviors such as complete or partial synchronization, weak or strong time dependencies, and redundancy or uniqueness of shared information. The information theoretic measures used in this study may be compared with efficient statistical learning methods applied to graphical models, such as the graphical lasso [
13] or methods that combine graphical models with conditional dependencies [
14], particularly in cases with many time series nodes.
In real-world process networks in which noise and other drivers prevent complete synchronization, some detected time dependencies are likely to correspond to causality (i.e., “correctly detected links”), while others represent induced feedback. When nodes in the network are highly connected with feedback present, detected links are identified as redundant, and it is difficult to distinguish critical interactions from induced feedback. This feature of process networks indicates a future challenge in terms of connecting network time dependencies to system functionality.
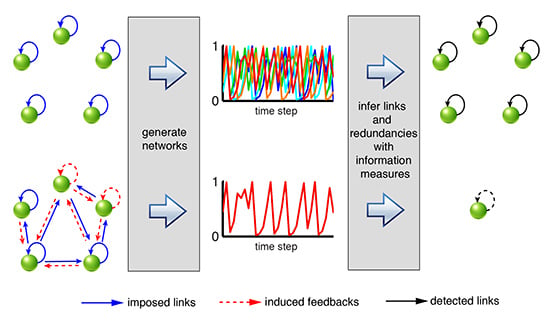
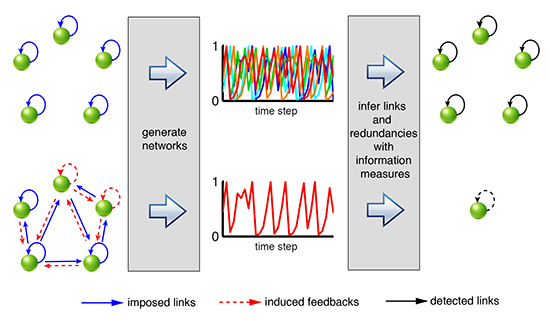
Figure 9 categorizes the range of possible whole-network or subsystem behaviors that can be extended to an observed process network. If a network is not completely synchronized, nodes could be lag-synchronized, or transferring and receiving information at different time scales and strengths. Real-world process networks consist of measured time-series data for which the underlying mechanisms are partially or completely unknown. There may be unmeasured or hidden driving and receiving nodes, and network connectivity can shift over time. The weakening of a single link may result in decreased redundancy in the form of induced feedback throughout an entire network. For real process network analysis, the measures presented in this study can aid in comparing observations to simulation results, evaluating system states, or assessing the influence of noise or bias on time dependencies.
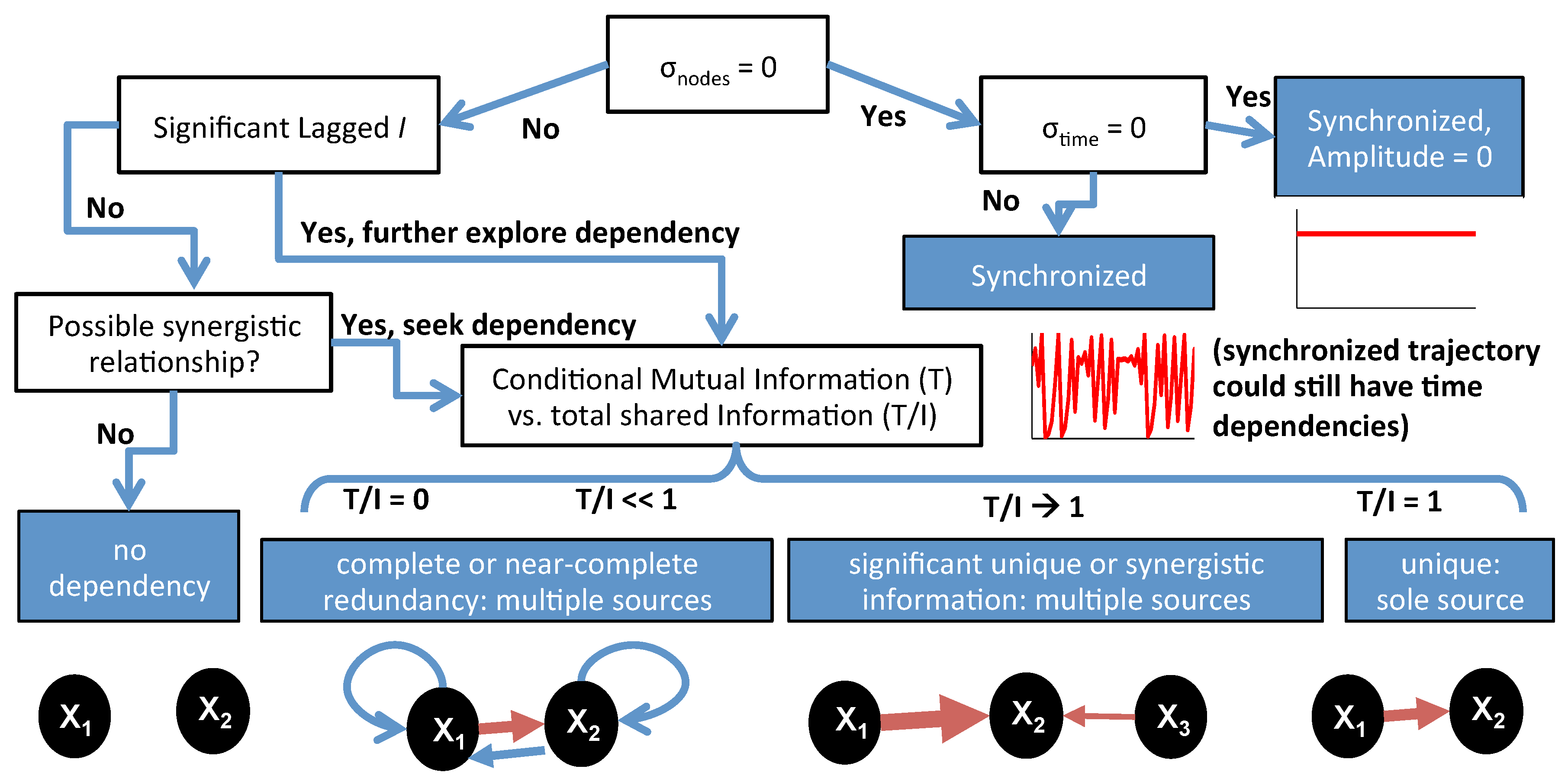
Figure 9.
Illustration of a range of network dynamics that can be identified using information theoretical measures. Nodes are synchronized if and synchronized to zero-amplitude trajectories if . In asynchronous cases, the absence of statistically significant indicates a disconnected network in the case of no synergistic shared information. Otherwise, the dependencies between nodes can be further explored with conditional and total information measures (). If , multiple sources are completely redundant with each other. If , there is only 1 unique source providing information to the target node. In between, sources can be partially redundant, synergistic or unique.
Figure 9.
Illustration of a range of network dynamics that can be identified using information theoretical measures. Nodes are synchronized if and synchronized to zero-amplitude trajectories if . In asynchronous cases, the absence of statistically significant indicates a disconnected network in the case of no synergistic shared information. Otherwise, the dependencies between nodes can be further explored with conditional and total information measures (). If , multiple sources are completely redundant with each other. If , there is only 1 unique source providing information to the target node. In between, sources can be partially redundant, synergistic or unique.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





