An Entropy Regularization k-Means Algorithm with a New Measure of between-Cluster Distance in Subspace Clustering

School of Information Engineering Department, East China Jiaotong University, R.d 808, East Shuanggang Avenue, Nanchang 330013, China
*
Author to whom correspondence should be addressed.
Entropy 2019, 21(7), 683; https://doi.org/10.3390/e21070683
Submission received: 15 April 2019
/
Revised: 6 July 2019
/
Accepted: 10 July 2019
/
Published: 12 July 2019
Abstract
:Although within-cluster information is commonly used in most clustering approaches, other important information such as between-cluster information is rarely considered in some cases. Hence, in this study, we propose a new novel measure of between-cluster distance in subspace, which is to maximize the distance between the center of a cluster and the points that do not belong to this cluster. Based on this idea, we firstly design an optimization objective function integrating the between-cluster distance and entropy regularization in this paper. Then, updating rules are given by theoretical analysis. In the following, the properties of our proposed algorithm are investigated, and the performance is evaluated experimentally using two synthetic and seven real-life datasets. Finally, the experimental studies demonstrate that the results of the proposed algorithm (ERKM) outperform most existing state-of-the-art k-means-type clustering algorithms in most cases.
1. Introduction
Clustering is a process of dividing a set of points into multiple clusters. In this process, the similarity among points in a cluster is higher than that among points from different clusters. Due to high efficiency, k-means-type clustering algorithms have been widely used in various fields of real life [1,2], such as marketing [3] and bioinformatics [4].
In the past few decades, the research of clustering techniques has been extended to many fields [5] such as gene analysis [6] and community detection [7]. The idea of most clustering algorithms aims at making the similarity among points in a cluster higher than those from different clusters, namely to minimize the within-cluster distance [8]. However, the traditional clustering methods seem to be weak when dealing with high-dimensional data under many cases [9]. For example, for points in the same cluster, the distance between each dimension should be small, but the true results after clustering by traditional clustering algorithms are that the distance between some dimensions may be very large.
The classic k-means-type algorithms cannot automatically determine the importance of a dimension, i.e., which are important dimensions and which are noise dimensions, because they treat all dimensions equally in the clustering process [10]. At the same time, it is also worth noting that the valid dimensions are often a part of the dimensions rather than all in the process of high-dimensional data clustering. Fortunately, in recent years, some subspace clustering algorithms [11,12,13,14,15,16] have largely alleviated this problem. For example, the work in [16] considered that different dimensions make different contributions, by introducing entropy weighting to the identification of objects in clusters.
To date, many subspace clustering algorithms have been proposed and well applied in various fields; however, most of them overlooked the within-cluster distance in the clustering process. Namely, the between-cluster information is not fully utilized [17] for improving the clustering performance. The between-cluster information is utilized in some algorithms [5,18,19]. However, in some cases, e.g., clusters with a blurred decision boundary, the existing methods cannot conquer this effectively.
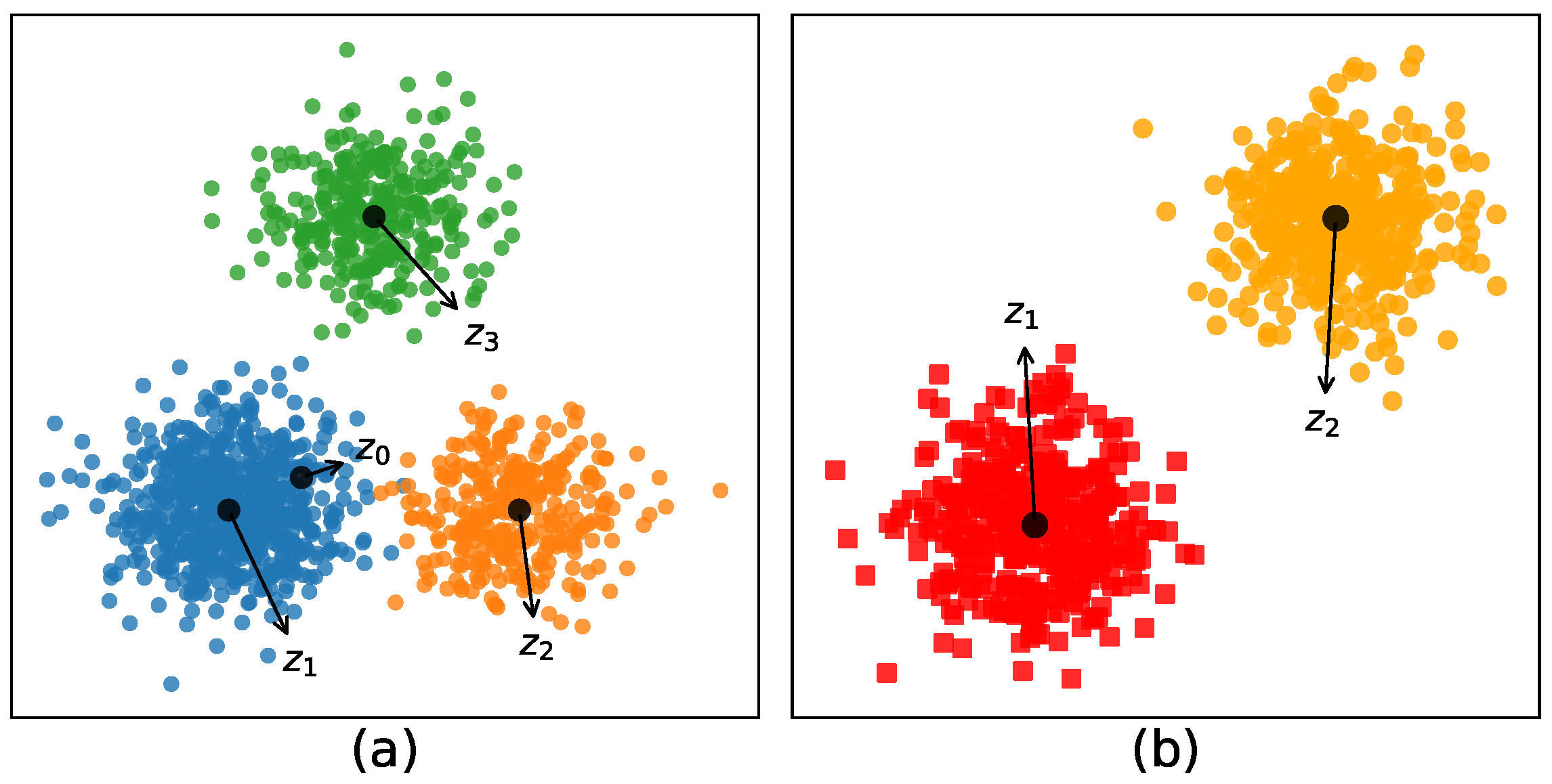
In traditional ways, many algorithms utilize the between-cluster information by introducing the global center [5,18]. The main idea of these methods is to maximize the distance between the center of each cluster and the global center. Under these circumstances, if the number of points in each cluster differs greatly, then the global center will be heavily biased toward the cluster with a large number of points (e.g., in Figure 1a, the global center is heavily biased toward Cluster 1). Subsequently, in order to maximize the distance between and , the latent center of Cluster 1 will greatly deviate from its true cluster center , resulting in the decrease of the performance in convergence.
Motivated by this, we propose a new measure of between-cluster distance based on entropy regularization in this paper, which is totally different from these existing methods (see, for instance, [5,18,19,20,21,22]). The key idea is to maximize the distance between the points in the subspace that do not belong to the cluster and the center point of the cluster. As shown in Figure 1b, ERKM maximizes the distance between and circle-points (square-points) in subspace. In order to award more dimensions to make contributions to the identification of each cluster, avoiding few sparse dimensions, we also introduce the entropy regularization term in the objective function.
Moreover, the measure of between-cluster distance proposed in this paper can also be applied to other clustering algorithms, not only limited to k-means-type algorithms. The main contributions of this paper are as follows:
- The study on subspace clustering mentioned in previous papers is summarized.
- By optimization, the update rules of ERKM algorithm are obtained, and the convergence and robustness analysis of the algorithm are given.
- The hyperparameters are studied on synthetic and real-life datasets. Finally, through experimental comparison, the results show that the ERKM algorithm outperforms most existing state-of-the-art k-means-type clustering algorithms.
The rest of this paper is organized as follows: Section 2 is an overview of related works about subspace clustering algorithms. Section 3 presents a new k-means-type subspace clustering algorithm, and update rules are given. Experiments and results are analyzed in Section 4. In Section 5, conclusions and future work are presented.
2. Related Work
The research on subspace clustering [24] has always been an important direction in clustering algorithms. In order to achieve high performance, many methods, such as sparse clustering-based methods [25,26,27], weight entropy-based methods [16,28], between-cluster information-based methods [29,30,31], and so on, have been proposed. Furthermore, different ways in different cases will have a different impact on the results of clustering algorithms. In this section, we will give a brief summary of the ways in different fields proposed in recent years.
For a clear statement of related work, we first introduce the most common notations. Let denote a dataset in the matrix form with n points and m dimensions. denotes a partition matrix, where indicates that point i is assigned to cluster l; otherwise, it is not assigned to cluster l. is a set of k vectors representing the centers of k clusters. W is a weighting matrix or vector depending on specific algorithms.
2.1. Sparseness-Based Methods
In order to cluster high-dimensional objects in subspace, Witten et al. [26] proposed a novel framework for sparse clustering, which clusters the points using an adaptively-chosen subset of the dimensions. The main idea it to use a lasso-type penalty to select the features. This framework can be used for sparse k-means clustering and also sparse hierarchical clustering. Taking sparse k-means as an example, its objective function can be reformulated as follows:
subject to:
The weights in this algorithm will be sparse for an appropriate choice of the tuning parameter s, which should satisfy . If , the objective function (1) simply reduces to the criterion standard k-means clustering.
Combining the penalized likelihood approach with an penalty function and model-based clustering [32], Pan et al. [27] presented a penalized model-based clustering algorithm, automatically selecting features and delivering a sparse solution. This can be used for high-dimensional data. Its objective function can be expressed as follows:
where is a penalty function with penalization parameter . The choice of depends on the goal of the analysis.
2.2. Entropy-Based Methods
For the sake of stimulating dimensions in subspace, Jing et al. [16] extended the k-means algorithm to calculate a weight for each dimension in each cluster, achieved by including the weight entropy in the objective function, and used it to identify the subsets of important dimensions. The weights of all dimensions can be automatically computed only by adding an additional step to the k-means clustering process. The objective function of this algorithm (EWKM) can be written as follows:
subject to:
where the weight is to measure the contribution (or importance) of the j-th dimension in cluster l. The more , the higher contribution of dimension j in partitioning cluster l. The positive parameter controls the strength of the incentive for clustering on more dimensions. The first term in (3) is the sum of the within-cluster distance and the second term the negative weight entropy, which is to stimulate more dimensions to contribute to the identification of clusters, avoiding the problem of identifying clusters by a few dimensions.
To achieve the same goal, Zhou et al. [28] proposed a novel fuzzy c-means algorithm, by using a weighted dissimilarity measure and adding a weight entropy regularization term to the objective function. It only adds a fuzzy index to the algorithm EWKM, and its objective function can be re-written as follows:
where the exponent is to control the extent of membership sharing between the fuzzy clusters. When , then the objective function (4) simply reduces to the EWKM algorithm.
2.3. Between-Cluster Measure-Based Methods
2.3.1. Liang Bai’s Methods
The k-modes algorithms and its modified versions for categorical data have always been a hot topic in clustering algorithms. Like the clustering algorithm for real number data, the use of between-cluster information is also particularly vital for the categorical data. A good between-cluster measure approach can often achieve better results.
Based on the fuzzy k-modes algorithm [1], Bai et al. [21] presented a new algorithm by adding the between-cluster information term so that one can simultaneously minimize the within-cluster dispersion and enhance the between-cluster separation. The objective function can be written as follows:
where the second term in (5) is a definition of the between-cluster information, which is a similarity measure between cluster and point and defined as:
where the parameter is used to maintain a balance between the effect of the within-cluster information and the between-cluster information on the minimization process of the objective function (5).
Similar to (5), Bai et al. [22] defined another between-cluster similarity term to evaluate the between-cluster separation. The between-cluster similarity term is defined as:
where is a similarity measure between and . At the same time, this term with different forms can be added in different k-means-types algorithm in different cases, such as in (7).
where is to maintain a balance between the effect of the within-cluster information and the between-cluster information on the minimization process. is defined as:
where is the distance between cluster and point .
2.3.2. Huang’s Methods
k-means-type clustering aims at partitioning a dataset into clusters such that the objects in a cluster are compact and in different clusters are well separated. By integrating within-cluster compactness and between-cluster separation, Huang et al. [18] also designed a new method to utilize the between-cluster information. Based on this basic idea, many traditional algorithms without considering between-cluster separation can be modified, such as basic k-means and wk-means [10] algorithms.
An example of a modified objective function of k-means algorithm can be re-written as follows:
where is the j-th feature of the global center of a dataset. Its main idea is to minimize the distances between objects and the center of the cluster that the objects belong to, while maximizing the distances between centers of clusters and the global center. From (8), we can find that it considers the distance between cluster center and global center , indicating that the greater the distance, the higher the probability of cluster center being confirmed.
Based on a similar motivation, Huang et al. [19] proposed another new discriminative subspace k-means-type clustering algorithm, which integrates the within-cluster compactness and the between-cluster separation simultaneously. Its main idea is to use a three-order tensor weighting method to discriminate the weights of features when comparing every pair of clusters. The objective function can be represented as:
where the weight w is a three-order tensor and each value in denotes the importance of the feature j in cluster p when comparing cluster p to cluster q, where . is a parameter that controls the distribution of the weight, and parameter is used for balancing the effect of within-cluster compactness and between-cluster separation. In the objective function (9), the first term includes two parts: one is the sum of within-cluster compactness; the other is the sum of the distances between centers of different clusters, which involves maximizing the inter-cluster separation.
2.4. Others
While between-cluster information and weight entropy are commonly used in most subspace clustering algorithms, their performance can be further enhanced. A major weakness of entropy-based clustering algorithms is that they do not consider the between-cluster information. Motivated by this, Deng et al. [5] proposed an Enhanced Soft Subspace Clustering (ESSC) algorithm, combining the EWKM and a new measure between-cluster distance, which is to maximize the distance between cluster centers and global center in subspace.
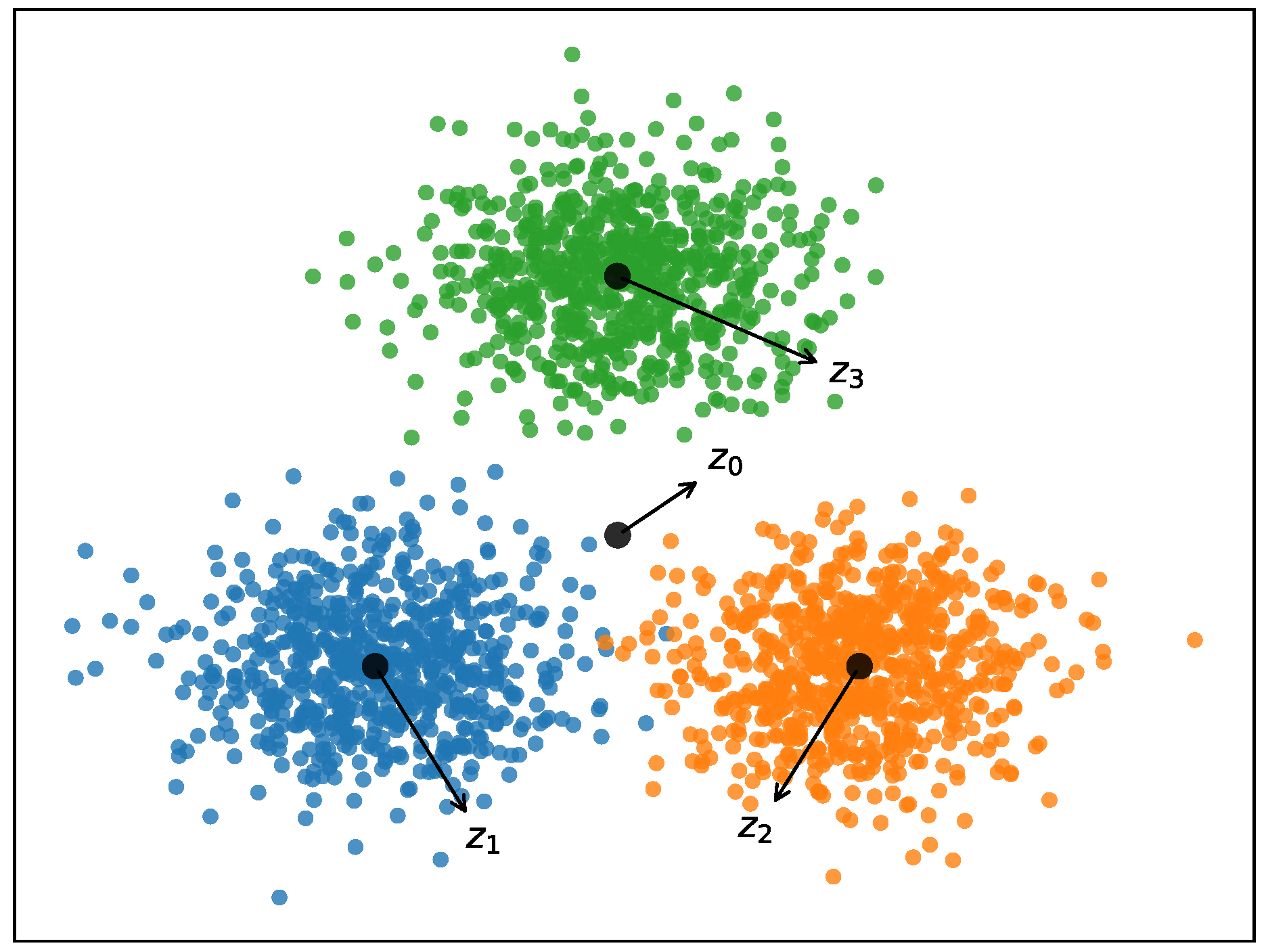
An intuitive explanation of the between-cluster separation is given below. As illustrated in Figure 2, the main idea of ESSC is to both minimize the with-cluster distance and maximize between-cluster distance (e.g., ) simultaneously in subspace, which can make the three clusters’ centers as far apart as possible from each other.
The objective function of ESSC can be expressed as:
where and are the fuzzy index and weighting matrix, respectively, and , is the weight of the j-th feature in the p-th cluster. are two parameters. is the global center of all points. The total weighted distance in the subspace between the global center and each cluster center is calculated by the third term in (10), which is used to maximize the between-cluster distance as much as possible in clustering.
Enlightened by the regularization, Chang et al. [33] proposed a novel Fuzzy c-Means (FCM) model with sparse regularization, by reformulating the FCM objective function into the weighted between-cluster sum of squares form and imposing the spare regularization on the weights. Its objective function can be rewritten as follows:
subject to:
where , , and is the sparse regularization constraint conditions, which is to make the weight of some dimensions near zero so that the relevant features can be found.
3. Entropy Regularization Clustering
The ERKM algorithm proposed in this paper mainly extends the EWKM algorithm [16]. On this basis, a new method of measuring between-cluster distance is introduced. The idea of the new method is to maximize the between-cluster distance by maximizing the distance between the center of a cluster and the points that do not belong to the cluster in subspace. The new algorithm uses vector-weighting to find the best subspace and adjusts the weight of each dimension through the entropy regularization term. Based on this idea, we firstly develop an objective function for the algorithm. Then, the update rules of each variable are obtained by minimizing the objective function, and the convergence is proven.
3.1. ERKM Algorithm
Let be the weights of features that represent the contribution of each dimension in the clustering process.
The new objective function is written as follows:
subject to:
There are three terms in the objective function: the weighted within-cluster distance term, the entropy regularization term, and the weighted between-cluster distance term. The first and second terms are directly extended from EWKM. The first term is to make the within-cluster distance as small as possible in subspace, and the second term is to allow more dimensions to participate in the clustering process. The parameter controls the distribution of w in each dimension. The last term is a new between-cluster distance measure method proposed in this paper, which is to maximize the between-cluster distance. is a hyperparameter used to control the influence of between-cluster distance on the objective function, degenerating into the EWKM algorithm when .
It is established based on the three basic theorems below.
Theorem 1.
Given U and Z are fixed, P is minimized only if:
where:
Proof.
We use the Lagrangian multiplier technique to obtain the following unconstrained minimization problem:
where is the Lagrange multiplier. By setting the gradient of the function Equation (16) with respect to and to zero, we obtain the equations:
where includes the information of the within-cluster distance and the between-cluster distance of all the points on the dimension.
From (17), we obtain:
From (20), we obtain:
Theorem 2.
Given U and W are fixed, P is minimized only if:
Proof.
By setting the gradient of the function (24) with respect to to zero, we obtain the equations:
From (25), we have:
From (26), we derive:
Theorem 3.
Similarly to the k-means algorithm, given Z and W are fixed, u is updated as:
The ERKM algorithm that minimizes Equation (12), using (14), (23), and (29), is summarized as follows (Algorithm 1):
| Algorithm 1 ERKM. |
| Input: The number of clusters k and parameters ; Randomly choose k cluster centers, and set all initial weights with a normalized uniform distribution; repeat Fixed , update the partition matrix U by (29) Fixed , update the cluster centers Z by (23) Fixed , update the dimension weights W by (14) until Convergence return |
The hyperparameter is used to balance the within-cluster distance and the between-cluster distance. It has the following features in the control of the clustering process:
- For others, according to (14) and (15), is proportional to . The larger , the larger . This violates the basic idea that the more important the corresponding dimension, the smaller the sum of the distance on this dimension. Under this circumstance, it will cause the value of , so that the objective function diverges.
3.2. Convergency and Complexity Analysis
For the ERKM algorithm, when the parameter satisfies this condition (33), global or local optimal values will be obtained after a finite number of iterations. Obviously, there are only a finite number of possible partitions U, because the number of points is not infinite, and each of the possible partitions will appear only once in the clustering process. Similar to [16], assume that we have , where and represents the number of iterations. Then, based on , we can obtain by minimizing according to (24). Subsequently, and are obtained respectively, and furthermore, because . Finally, according to (14), we can compute the minimizer and by using and , and and respectively. Naturally, again. Therefore, we obtain . However, the sequence is strictly decreasing, which is broken by the analysis result, that is to say, the ERKM algorithm converges in a finite number of iterations.
Similar to the basic k-means algorithm, the proposed one is also iterative. The computational complexity of the basic k-means is , where t is the iterative times; , and k are the number of dimensions, points, and clusters, respectively. As shown in Section 3.1, ERKM has three computational steps including updating the weights, updating the cluster centers, and updating the partition matrix [16]. The complexity of updating the weights is . The complexities of updating the cluster centers and partition matrix are and , respectively. Hence, the overall computational complexity of ERKM is also . Compared with the basic k-means algorithm, its only needs extra computational time to calculate the weights and to calculate the distance of each point i in dimension j. Fortunately, it does not change the total computational complexity of ERKM.
4. Experiments and Discussion
4.1. Experimental Setup
In the experiments, the performance of the proposed algorithm was extensively evaluated on two synthetic and seven real-life datasets tabulated in Table 1, which can be downloaded at the UCI website. We compared the clustering results produced by ERKM with the benchmark clustering algorithms including basic k-means (KMEA), WKME, EWKM, ESSC, and the last three years’ clustering algorithms, AFKM [36] Sampling-Clustering (SC) [37], and SSC-MP [38].
As we all know, most of k-means-type clustering algorithms produce local optimal solution, and the final results depend on the initial cluster centers. For the weighting k-means algorithms: WKME and EWKM (also including ours), the initial weights also affect the final results. For the sake of fairly comparing the clustering results, all the cluster centers and weights of each algorithm were randomly initialized. Finally, we compared the average value and standard deviation of each metric produced by the algorithms after 100 runs. in order to speed up the convergence time of the algorithms, all datasets were normalized.
4.2. Evaluation Method
In this paper, four metrics, Accuracy (Acc), Adjusted Rand Index (ARI), F-score (Fsc), and Normal Mutual Information (NMI), were used for evaluating the proposed ERKM algorithm. Acc was used to measure the accuracy of clustering results, and its value range was [0, 1]. Fsc is a weighted harmonic average of precision and recall, and its value range was also [0, 1]. Both ARI and NMI were used to measure the degree of agreement between the two data distributions, which ranged from [−1, 1] and [0, 1], respectively. For the above four evaluation metrics, the larger the value, the better the clustering results. More detail can be found in [19].
4.3. Parameter Setting
Form the objective function (12), the proposed algorithm had only two hyperparameters and . Hence, we will first choose proper parameters for and produced by the results on the datasets.
- Parameter :Hyperparameter appears in the EWKM, ESSC, and ERKM algorithms. ESSC and ERKM algorithms were directly extended from the EWKM algorithm, and only a between-cluster distance constraint was added to the objective function of the EWKM algorithm. At the same time, since the EWKM only contained one parameter , the value of can be studied by the performance of EWKM on two synthetic and seven real-life datasets, respectively. We fixed the range of in [1, 50] and set the step to 1.
- Parameter :In the algorithm ERKM, has a similar effect as in the ESSC algorithm. However, since the two algorithms adopted different feature weighting methods and between-cluster distance measures, a reasonable value will be selected by the results of the ERKM algorithm on two synthetic and seven real-life datasets, respectively. Since the within-cluster distance and the between-cluster distance have different contributions to the whole clustering process, the value of should satisfy the condition (33), so as to avoid the divergence of the objective function. In the section below, we fixed the range of in [0.002, 0.2] and set the step to 0.002 in [0, 0.05] and 0.02 in (0.05, 0.2] to search for a proper value.
In summary, we will first choose parameter by the results of EWKM and parameter by the results of ERKM both on two synthetic and seven real-life datasets. For the rest of the comparative algorithms, the default configuration was done (as tabulated in Table 2).
4.4. Experiment on Synthetic Data
In this section, we first use two synthetic datasets as described in [27] to verify the performance of the proposed algorithm ERKM. In each synthetic dataset, there were three clusters.
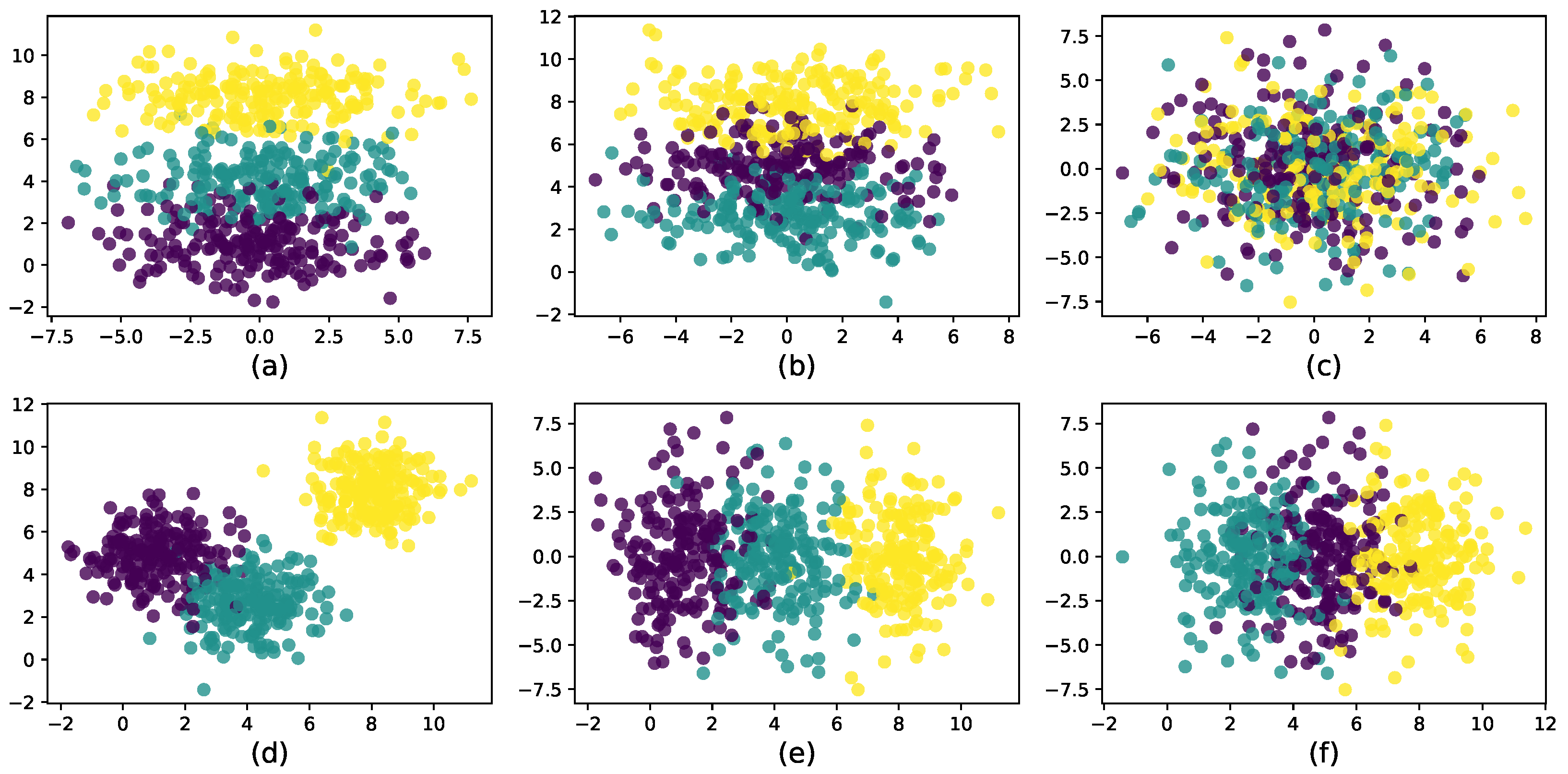
For the first synthetic dataset: there was a total of 4 variables with 2 effective, while the other 2 were noise variables. There were 500 points scattered in three clusters with 200 in the first cluster, 100 in the second cluster, and 200 in the last one. As plotted in Figure 3, each dimension was independent and identically distributed (iid) from a normal distribution with the 2 effective features iid from and , respectively, for Cluster 1, and , respectively, for Cluster 2, and for Cluster 3; the remaining 2 features were all iid from for all clusters.
For the second synthetic dataset: there was a total of 1000 variables with 150 effective, while the other 850 were noise. Specifically, there were 250 points with 100 in Cluster 1, 50 in Cluster 2, and 100 in the other. The 150 effective features were all iid from for the first cluster, for the second cluster, and for the third cluster; the remaining 850 features were all iid from for the three clusters.
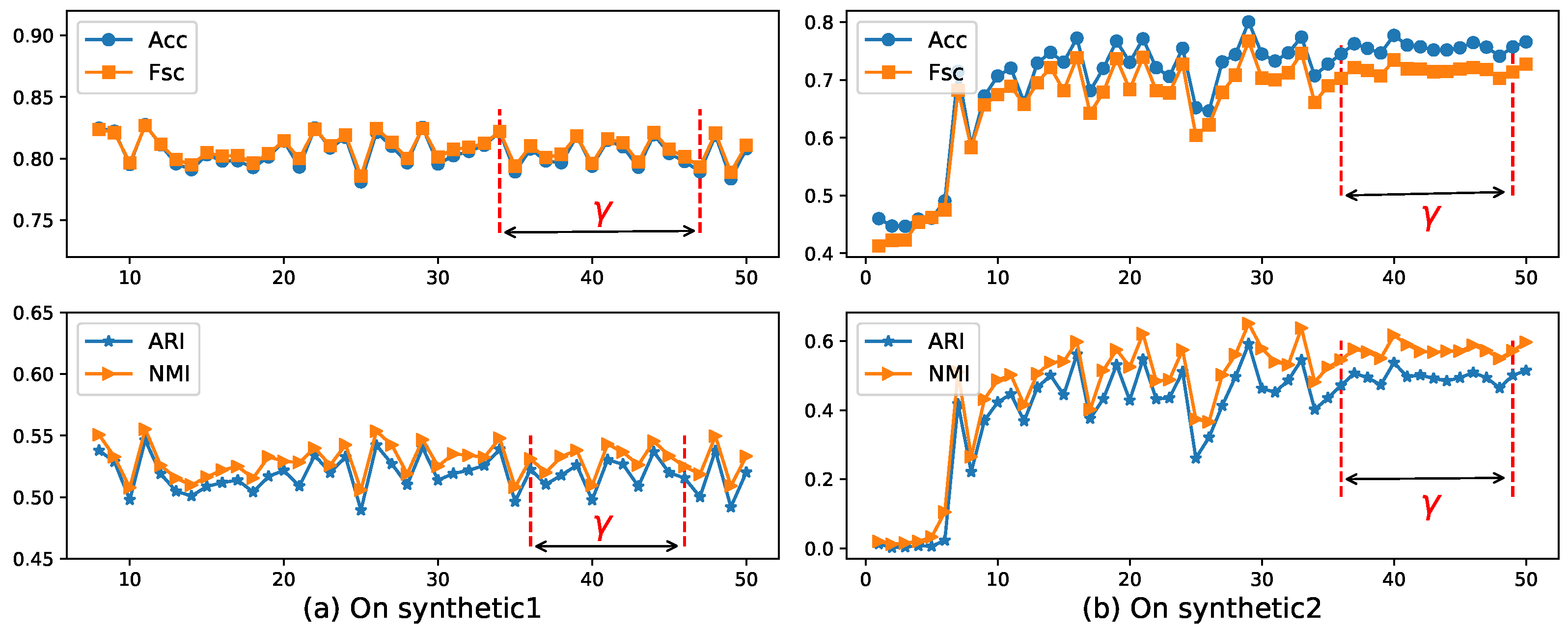
Now, we use the EWKM algorithm on two synthetic datasets to select a reasonable value of parameter using the four metrics selected in Section 4.2. Figure 4 shows the change of Acc, Fsc, ARI, and NMI for EWKM on synthetic datasets.
4.4.1. Parameter Study
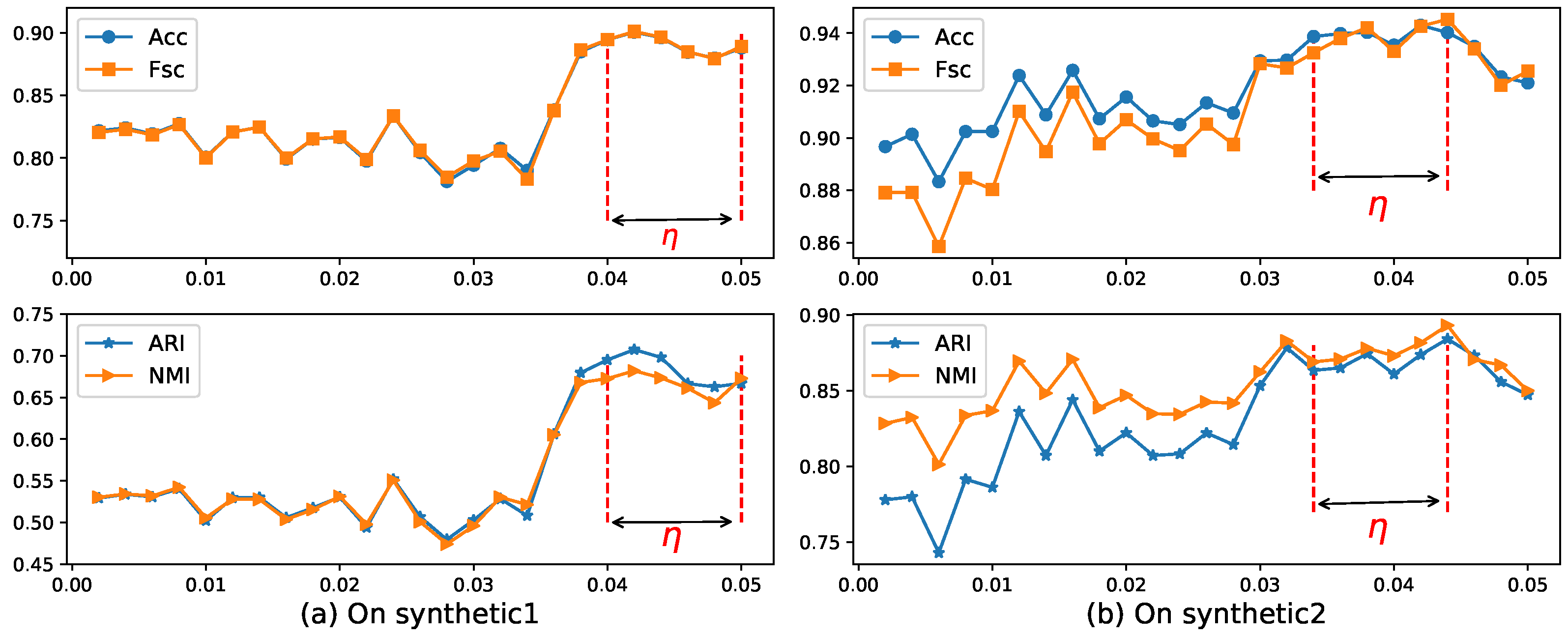
As can be seen from Figure 4, when the value of was located in the range of 36–49 on Synthetic 1 and 36–45 on Synthetic 2, the algorithm EWKM was generally stable, where the changes in the four metrics were within 2%. However, in the other range, the performance of EWKM was greatly affected by , either greater than about 4% or no convergence. from Figure 5, we can see that when the range of was about 0.04–0.05 on Synthetic 1 and 0.034–0.044 on Synthetic 2, the results of ERKM with a higher performance did not change much. Therefore, on these two synthetic datasets, we chose the two hyperparameters .
4.4.2. Results and Analysis
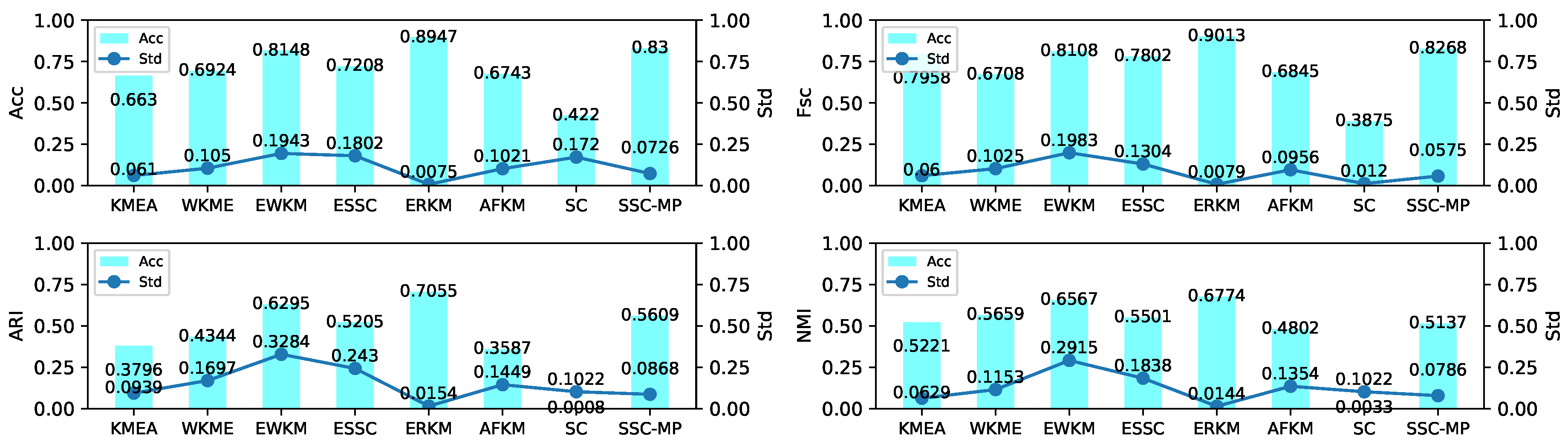
The experiment results shown in Figure 6 and Figure 7 on two synthetic datasets indicated that: (1) the Acc, Fsc, ARI, and NMI of the ERKM algorithm were higher than v other algorithms; ERKM achieved the highest score on the four metrics on both datasets. In Acc and Fsc, the results of ERKM were at least 6% higher than that of the second-best algorithm on Synthetic 1 and at least 13% on Synthetic 2. In ARI and NMI, it also was 2% higher than that of the second on Synthetic 1. Compared with the other algorithms, ERKM obtained significant achievement on Synthetic 2, where each of metric was 13% higher than that of the second-best, especially in ARI and NMI by more than 17%. (2) From the perspective of stability, ERKM, achieved the best one of all eight algorithms. From the standard deviation, ERKM achieved the minimum value among the four metrics on Synthetic 1 and good results on Synthetic 2.
4.5. Experiment on Real-Life Data
4.5.1. Parameter Study
In this section, we will also use the EWKM algorithm on seven real-life datasets to select a reasonable parameter with the four metrics selected in Section 4.2. Figure 8 shows the change of four metrics of EWKM on seven real-life datasets.
It can be seen from Figure 8 that among the four metrics, EWKM had a large fluctuation mainly concentrating on the two datasets of iris and wine, and also a little fluctuation on knowledge. However, there was almost no significant change on the remaining four datasets. Therefore, this paper only determines the value of from the results of EWKM on the three datasets of iris, wine, and knowledge.
In Figure 8, the results of EWKM on the dataset wine changed by more than 30% for all four metrics and more than 40% for ARI and NMI. At the same time, with the increase of , the results of EWKM on the dataset wine was increasing and generally tended to be stable near , with a change of less than 2%. On the iris dataset, the results of EWKM on all four metrics showed a downward trend with a change of more than 10% and generally stabilized after . Finally, for the dataset knowledge, the EWKM algorithm had a small change for the four metrics, mainly within 10%, and with the increase of , the results of EWKM slightly increased, while when was around 40, it tended to be stable overall. In summary, through the above comparison and analysis, we found that for the two algorithms EWKM and ESSC, when was equal to 40, it was a reasonable value.
In order to obtain a robust range of eta, which should enable ERKM to have reasonable results for most unknown datasets, we can identify it by analyzing the results of ERKM on seven known real-life datasets. Figure 9 is a plot of the results of ERKM on seven real-life datasets. Then, we will determine a reasonable value by analyzing the results in Figure 9. From the three metrics of Acc, ARI, and NMI, with the increase of , the results of the ERKM algorithm showed a significant change only for the three datasets wine, iris, and knowledge. For the dataset wine, with the increase of , the results of ERKM started to decrease slightly around and tended to be stable in the vicinity of . For the dataset iris, the results of ERKM, from , started to rise and were stable at around . For the dataset knowledge, when , the results of ERKM were generally in a stable state.
For Fsc, when , the results of ERKM on the datasets wine, iris, knowledge, and chess had a declining trend and on the dataset car had an increasing trend, while they were almost unchanged on tictactoe and messidor. When , the results had large fluctuations only on knowledge; and when , the results on the seven datasets were generally stable.
In summary, through the above analysis of the ERKM algorithm on the four metrics, it had a reasonable value for .
4.5.2. Results and Analysis
In this section, we will compare ERKM (with and obtained in Section 4.5.1) with all the algorithms on seven real-life datasets and analyze the results. The final test results are tabulated in Table 3.
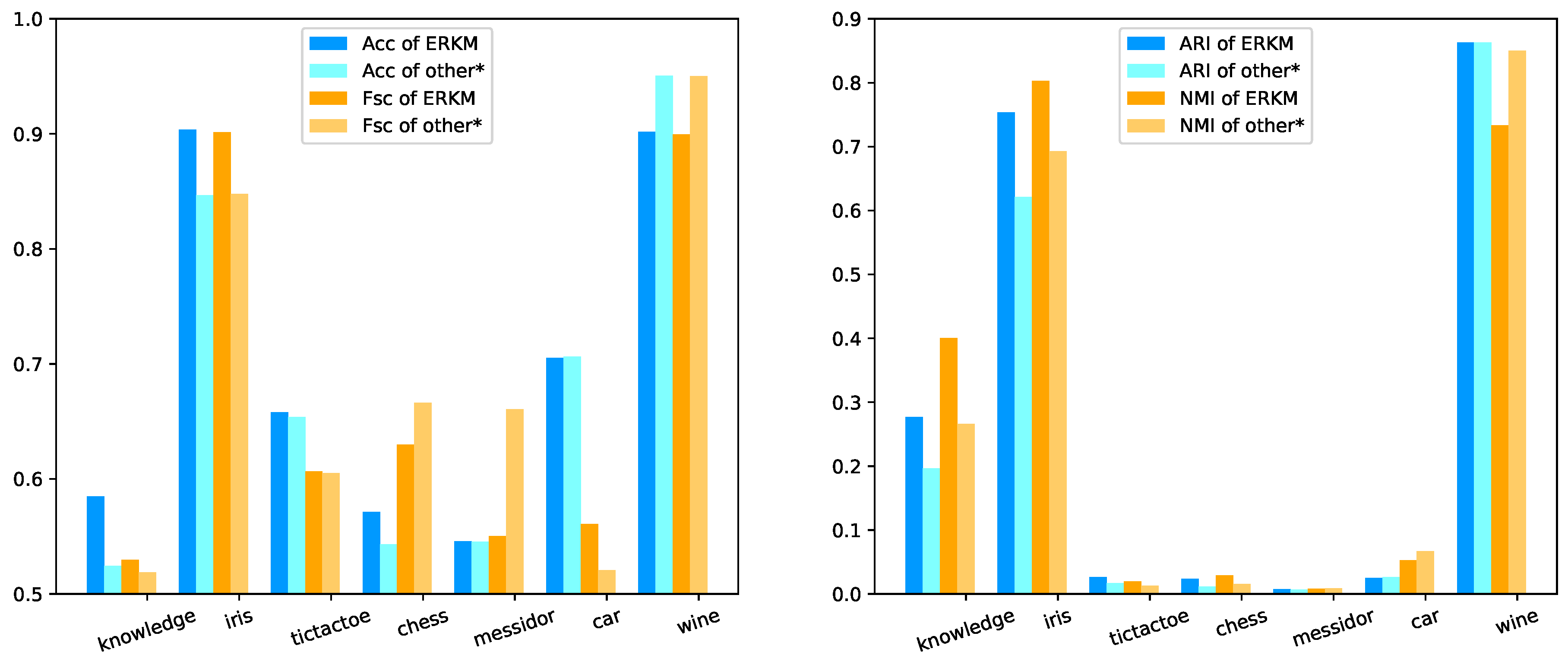
As can be seen from Table 3, for Acc, the results of ERKM for the five datasets were higher than the other seven algorithms. Among them, the results on knowledge and iris were the best, which was 6% higher than the second-best algorithm ESSC. On datasets tictactoe, chess, and messidor, it was also higher than the second-best algorithm by 0.41%, 2.8%, and 0.4%, respectively. For Fsc, ERKM performed better than the other seven algorithms on the four datasets: 1.44% higher than the second-best algorithm for the dataset knowledge, 5.38% higher for iris, 0.14% higher for tictactoe, and 4% higher for car. For ARI, the results of the ERKM algorithm on the six datasets were higher than the other seven algorithms: for the datasets knowledge, iris, tictactoe, chess, messidor, and wine, it was higher than the second-best algorithm by 8.05%, 13.2%, 1.23%, 1.21%, 0.2%, and 1.12%, respectively. For NMI, the results of the ERKM algorithm were higher than the other seven algorithms on the four datasets: 13.3% higher than the second-best algorithm for the dataset iris, 13.4% higher for knowledge, 0.93% higher for tictactoe, and 0.14% higher for chess.
From Figure 10 left, it is clear that ERKM obtained in general better results than the other second-best cluster algorithms on most datasets. Just as clearly, for the metrics of Acc and Fsc, the results of ERKM were higher than the second-best algorithms on the datasets knowledge, iris, and tictactoe; and nearest to the best algorithms on the datasets chess, messidor, and car. On the right, it shows that the results of ERKM were much better than the others on the datasets knowledge and iris. On the rest of the datasets, the results of ERKM were slightly better than others.
Based on the two-part analysis above, the ERKM algorithm could be better than the other seven clustering algorithms in most cases. That is to say, through the experimental results, the new between-cluster distance measure can effectively improve the clustering results.
4.6. Convergence Speed
Figure 11 shows the convergence time of the eight algorithms on the two synthetic and seven real-life datasets. The method of recording convergence time was to record the total time spent by each algorithm run on each dataset 100 times with randomly initializing the cluster center and weights. It can be seen from Figure 11 that in addition to AFKM, on the six datasets of knowledge, iris, chess, car, wine, and Synthetic 2, the convergence speed of the ERKM algorithm was significantly faster than that of the other five algorithms. It was also relatively moderate on the other three datasets, tictactoe, messidor, and Synthetic 1. Compared with the algorithm KMEA, WKME, EWKM, ESSC, SC, and SSC-MP, the convergence speed of the algorithm ERKM was the best one on the datasets knowledge, iris, car, and wine. The reason may be that the KMEA, WKKM, and EWKM algorithms did not utilize the between-cluster distance, and WKME and EWKM used complex matrix feature weighting. Although the ESSC algorithm incorporated the between-cluster information, its measure was improper. for the algorithm SC, before clustering, it needed to generate a KNN-graph. In general, ERKM had a good and competitive convergence speed.
4.7. Robustness Analysis
The two hyperparameters and of the algorithm ERKM will affect the performance of the algorithm. At the same time, the ERKM is directly extended from the EWKM where is used to control the effect of weights on the objective function. From Figure 4 and Figure 8, it is clear that when was around 40, the results of the algorithm ERKM were relatively stable on both synthetic data and real-life data. Then, we fixed to analyze the effect of on ERKM. In ERKM, plays the role of adjusting the influence between within-cluster distance and between-cluster distance. Therefore, the robustness of the algorithm ERKM can be analyzed by its sensitivity to hyperparameters . From Figure 5 and Figure 9, when was around 0.03, the algorithm ERKM was relatively stable on both synthetic and real-life datasets.
5. Conclusions
In this paper, a new soft subspace clustering algorithm based on between-cluster distance and entropy regularization was proposed. Different from the traditional algorithms that utilize the between-cluster information by maximizing the distance between each cluster center and the global center (e.g., ESSC), ERKM effectively uses the between-cluster information by maximizing the distance between the points in the subspace that do not belong to the cluster and the center point of the cluster. Based on this assumption, this paper first designed an objective function for the algorithm and then derived the update formula by the Lagrange multiplier method. Finally, we compared several traditional subspace clustering algorithms on seven real datasets and concluded that the ERKM algorithm can achieve better clustering results in most cases.
In real-world applications, many high-dimensional data have various cluster structure features. In future research work, we plan to expand the application scope of the algorithm by modifying the objective function to adapt the case of including various complex cluster structures.
Author Contributions
L.X. and X.H. contributed equally to this work; Conceptualization, L.X. and X.H.; formal analysis, C.W. and X.H.; software, C.W. and H.Z.; validation, C.W. and H.Z.; writing, original draft preparation, L.X. and C.W.; writing, review and editing, C.W. and X.H.; visualization, H.Z.
Funding
This research was funded by the NSFC under Grant No. 61562027, the Natural Science Foundation of Jiangxi Province under Grant No. 20181BAB202024, and the Education Department of Jiangxi Province under Grant Nos. GJJ170413, GJJ180321, and GJJ170379.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ERKM | Entropy Regularization k-means |
| KMEA | k-Means |
| WKME | Weighted k-Means |
| EWKM | Entropy Weighted k-Means |
| ESSC | Enhanced Soft-Subspace Clustering |
| AFKM | Assumption-Free k-Means |
| SC | Sampling-Clustering |
| SSC-MP | Subspace Sparse Clustering by the greedy orthogonal Matching Pursuit |
| Acc | Accuracy |
| ARI | Adjusted Rand Index |
| Fsc | F-score |
| NMI | Normal Mutual Information |
References
- Huang, Z. Extensions to the k-means algorithm for clustering large datasets with categorical values. Data Min. Knowl. Discov. 1998, 2, 283–304. [Google Scholar] [CrossRef]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA, 21 June–18 July 1967; Volume 1, pp. 281–297. [Google Scholar]
- Green, P.E.; Kim, J.; Carmone, F.J. A preliminary study of optimal variable weighting in k-means clustering. J. Classif. 1990, 7, 271–285. [Google Scholar] [CrossRef]
- ElSherbiny, A.; Moreno-Hagelsieb, G.; Walsh, S.; Wang, Z. Phylogenomic clustering for selecting non-redundant genomes for comparative genomics. Bioinformatics 2013, 29, 947–949. [Google Scholar] [Green Version]
- Deng, Z.; Choi, K.S.; Chung, F.L.; Wang, S. Enhanced soft subspace clustering integrating within-cluster and between-cluster information. Pattern Recognit. 2010, 43, 767–781. [Google Scholar] [CrossRef]
- Sardana, M.; Agrawal, R. A comparative study of clustering methods for relevant gene selection in microarray data. In Advances in Computer Science, Engineering & Applications; Springer: Berlin/Heidelberg, Germany, 2012; pp. 789–797. [Google Scholar]
- Tang, L.; Liu, H.; Zhang, J. Identifying evolving groups in dynamic multimode networks. IEEE Trans. Knowl. Data Eng. 2012, 24, 72–85. [Google Scholar] [CrossRef]
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data clustering: A review. ACM Comput. Surv. 1999, 31, 264–323. [Google Scholar] [CrossRef]
- Cao, Y.; Wu, J. Projective ART for clustering datasets in high dimensional spaces. Neural Netw. 2002, 15, 105–120. [Google Scholar] [CrossRef]
- Huang, J.Z.; Ng, M.K.; Rong, H.; Li, Z. Automated variable weighting in k-means type clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 657–668. [Google Scholar] [CrossRef]
- DeSarbo, W.S.; Carroll, J.D.; Clark, L.A.; Green, P.E. Synthesized clustering: A method for amalgamating alternative clustering bases with differential weighting of variables. Psychometrika 1984, 49, 57–78. [Google Scholar] [CrossRef]
- De Soete, G. Optimal variable weighting for ultrametric and additive tree clustering. Qual. Quant. 1986, 20, 169–180. [Google Scholar] [CrossRef]
- De Soete, G. OVWTRE: A program for optimal variable weighting for ultrametric and additive tree fitting. J. Classif. 1988, 5, 101–104. [Google Scholar] [CrossRef]
- Makarenkov, V.; Legendre, P. Optimal variable weighting for ultrametric and additive trees and k-means partitioning: Methods and software. J. Classif. 2001, 18, 245–271. [Google Scholar]
- Wang, Y.X.; Xu, H. Noisy sparse subspace clustering. J. Mach. Learn. Res. 2016, 17, 320–360. [Google Scholar]
- Jing, L.; Ng, M.K.; Huang, J.Z. An entropy weighting k-means algorithm for subspace clustering of high-dimensional sparse data. IEEE Trans. Knowl. Data Eng. 2007, 19, 1026–1041. [Google Scholar] [CrossRef]
- Wu, K.L.; Yu, J.; Yang, M.S. A novel fuzzy clustering algorithm based on a fuzzy scatter matrix with optimality tests. Pattern Recognit. Lett. 2005, 26, 639–652. [Google Scholar] [CrossRef]
- Huang, X.; Ye, Y.; Zhang, H. Extensions of kmeans-type algorithms: A new clustering framework by integrating intracluster compactness and intercluster separation. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 1433–1446. [Google Scholar] [CrossRef] [PubMed]
- Huang, X.; Ye, Y.; Guo, H.; Cai, Y.; Zhang, H.; Li, Y. DSKmeans: A new kmeans-type approach to discriminative subspace clustering. Knowl.-Based Syst. 2014, 70, 293–300. [Google Scholar] [CrossRef]
- Han, K.J.; Narayanan, S.S. Novel inter-cluster distance measure combining GLR and ICR for improved agglomerative hierarchical speaker clustering. In Proceedings of the 2008 IEEE International Conference on Acoustics, Speech and Signal Processing, Las Vegas, NV, USA, 31 March–4 April 2008; pp. 4373–4376. [Google Scholar]
- Bai, L.; Liang, J.; Dang, C.; Cao, F. A novel fuzzy clustering algorithm with between-cluster information for categorical data. Fuzzy Sets Syst. 2013, 215, 55–73. [Google Scholar] [CrossRef]
- Bai, L.; Liang, J. The k-modes type clustering plus between-cluster information for categorical data. Neurocomputing 2014, 133, 111–121. [Google Scholar] [CrossRef]
- Zhou, J.; Chen, L.; Chen, C.P.; Zhang, Y.; Li, H.X. Fuzzy clustering with the entropy of attribute weights. Neurocomputing 2016, 198, 125–134. [Google Scholar] [CrossRef]
- Deng, Z.; Choi, K.S.; Jiang, Y.; Wang, J.; Wang, S. A survey on soft subspace clustering. Inf. Sci. 2016, 348, 84–106. [Google Scholar] [CrossRef] [Green Version]
- Chang, X.; Wang, Y.; Li, R.; Xu, Z. Sparse k-means with ℓ∞/ℓ0 penalty for high-dimensional data clustering. Stat. Sin. 2018, 28, 1265–1284. [Google Scholar]
- Witten, D.M.; Tibshirani, R. A framework for feature selection in clustering. J. Am. Stat. Assoc. 2010, 105, 713–726. [Google Scholar] [CrossRef] [PubMed]
- Pan, W.; Shen, X. Penalized model-based clustering with application to variable selection. J. Mach. Learn. Res. 2007, 8, 1145–1164. [Google Scholar]
- Zhou, J.; Chen, C.P. Attribute weight entropy regularization in fuzzy c-means algorithm for feature selection. In Proceedings of the 2011 International Conference on System Science and Engineering, Macao, China, 8–10 June 2011; pp. 59–64. [Google Scholar]
- Sri Lalitha, Y.; Govardhan, A. Improved Text Clustering with Neighbours. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 23–37. [Google Scholar]
- Forghani, Y. Comment on “Enhanced soft subspace clustering integrating within-cluster and between-cluster information” by Z. Deng et al. (Pattern Recognition, vol. 43, pp. 767–781, 2010). Pattern Recognit. 2018, 77, 456–457. [Google Scholar] [CrossRef]
- Das, S.; Abraham, A.; Konar, A. Automatic clustering using an improved differential evolution algorithm. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2008, 38, 218–237. [Google Scholar] [CrossRef]
- McLachlan, G.J.; Peel, D.; Bean, R. Modelling high-dimensional data by mixtures of factor analyzers. Comput. Stat. Data Anal. 2003, 41, 379–388. [Google Scholar] [CrossRef]
- Chang, X.; Wang, Q.; Liu, Y.; Wang, Y. Sparse Regularization in Fuzzy c-Means for High-Dimensional Data Clustering. IEEE Trans. Cybern. 2017, 47, 2616–2627. [Google Scholar] [CrossRef]
- Bezdek, J.C. A convergence theorem for the fuzzy ISODATA clustering algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 1980, PAMI-2, 1–8. [Google Scholar] [CrossRef]
- Selim, S.Z.; Ismail, M.A. K-means-type algorithms: A generalized convergence theorem and characterization of local optimality. IEEE Trans. Pattern Anal. Mach. Intell. 1984, PAMI-6, 81–87. [Google Scholar] [CrossRef]
- Bachem, O.; Lucic, M.; Hassani, H.; Krause, A. Fast and provably good seedings for k-means. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 55–63. [Google Scholar]
- Tarn, C.; Zhang, Y.; Feng, Y. Sampling Clustering. arXiv 2018, arXiv:1806.08245. [Google Scholar]
- Tschannen, M.; Bölcskei, H. Noisy subspace clustering via matching pursuits. IEEE Trans. Inf. Theory 2018, 64, 4081–4104. [Google Scholar] [CrossRef]
Figure 1.
(a) The idea with the global center; (b) the idea without the global center.

Figure 2.
Main idea of ESSC ( are the cluster centers, and is the global center). ESSC: Enhanced Soft Subspace Clustering.
Figure 2.
Main idea of ESSC ( are the cluster centers, and is the global center). ESSC: Enhanced Soft Subspace Clustering.

Figure 3.
Synthetic dataset with three clusters in the two-dimensional subspace of and two noise dimensions . (a) Subspace of . (b) Subspace of . (c) Subspace of . (d) Subspace of . (e) Subspace of . (f) Subspace of .
Figure 3.
Synthetic dataset with three clusters in the two-dimensional subspace of and two noise dimensions . (a) Subspace of . (b) Subspace of . (c) Subspace of . (d) Subspace of . (e) Subspace of . (f) Subspace of .

Figure 4.
Four metrics’ change with EWKM for different on two synthetic datasets. Acc: accuracy; Fsc: F-score; ARI: adjusted rand index; NMI: normal mutual information.
Figure 4.
Four metrics’ change with EWKM for different on two synthetic datasets. Acc: accuracy; Fsc: F-score; ARI: adjusted rand index; NMI: normal mutual information.

Figure 5.
Four metrics’ change with ERKM for different on two synthetic datasets.

Figure 6.
Results of the eight algorithms on the Synthetic 1 dataset.

Figure 7.
Results of the eight algorithms on the Synthetic 2 dataset.

Figure 8.
Four metrics’ change with EWKM for different on real-life datasets.

Figure 9.
Four metrics’ change with ERKM for different on real-life datasets.

Figure 10.
The results of ERKM and others* on real-life datasets. other* means the second-best algorithm, if ours is the best; or the best, if ours is not the best.
Figure 10.
The results of ERKM and others* on real-life datasets. other* means the second-best algorithm, if ours is the best; or the best, if ours is not the best.

Figure 11.
Convergence time.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
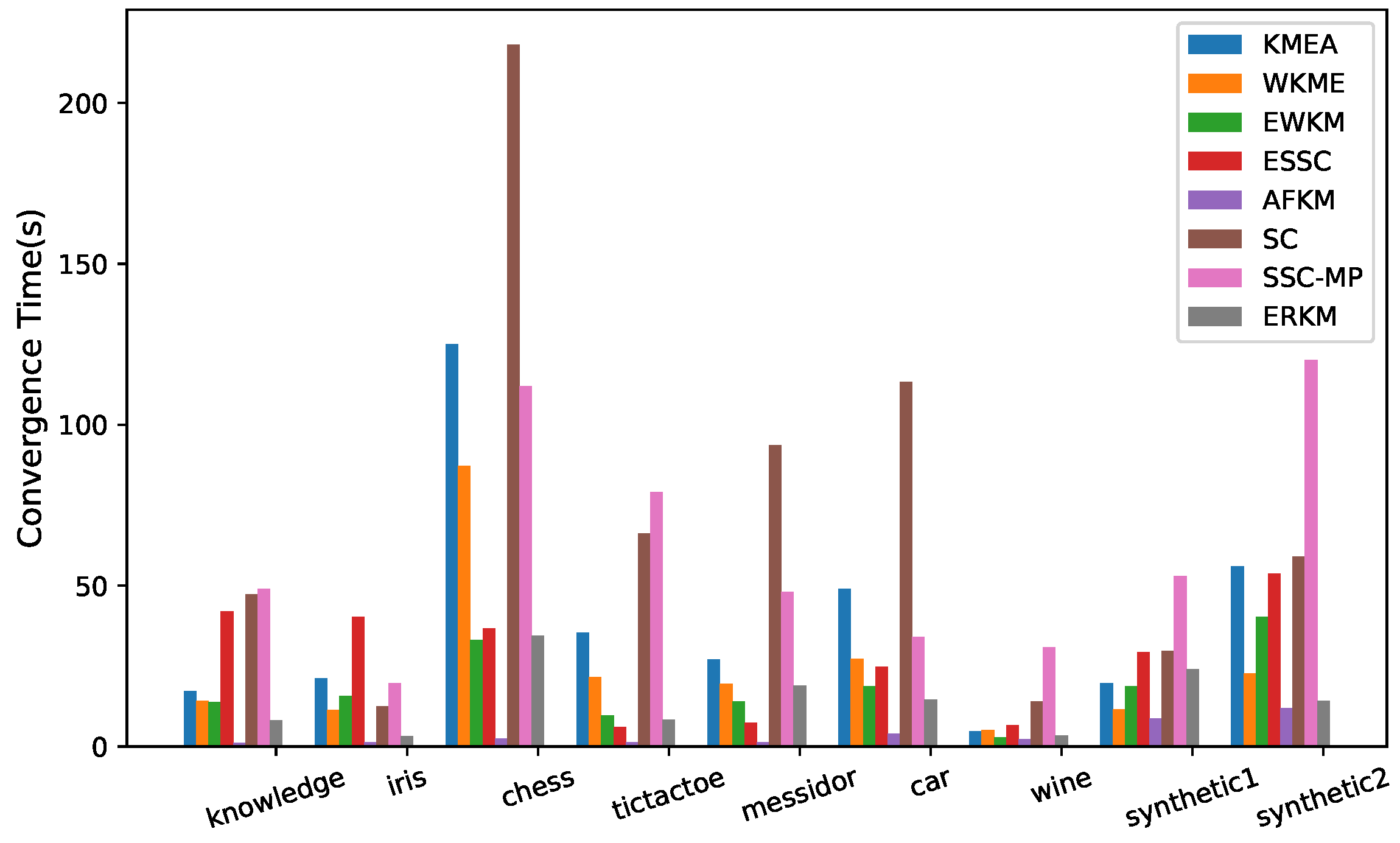{kind=link}
Table 1.
Information of the datasets.
| Datasets | Points | Dimensions | Clusters |
|---|---|---|---|
| Synthetic1 | 500 | 4 | 3 |
| Synthetic2 | 250 | 1000 | 3 |
| Knowledge | 403 | 5 | 4 |
| Iris | 150 | 4 | 3 |
| Chess | 3196 | 36 | 2 |
| Tictactoe | 958 | 9 | 2 |
| Messidor | 1151 | 19 | 2 |
| Car | 1728 | 6 | 4 |
| Wine | 178 | 13 | 3 |
Table 2.
Default parameters of comparative algorithms. * We will study this parameter of the corresponding algorithms.
Table 2.
Default parameters of comparative algorithms. * We will study this parameter of the corresponding algorithms.
| Algorithms | Parameters |
|---|---|
| KMEA | - |
| WKME [10] | |
| EWKM [16] | |
| ESSC [5] | = 0.01 |
| AFKM [36] | - |
| SC [37] | r = 0.2, size = 16 |
| SSC-MP [38] |
Table 3.
Results on real-life datasets (standard deviation in brackets).
| Metric | Model | Knowledge | Iris | Tictactoe | Chess | Messidor | Car | Wine |
|---|---|---|---|---|---|---|---|---|
| KMEA | 0.4600(0.02) | 0.8054(0.06) | 0.6535(0.01) | 0.5359(0.02) | 0.5452(0.01) | 0.7057(0.02) | 0.9443(0.07) | |
| WKME | 0.4897(0.06) | 0.7847(0.08) | 0.6534(0.00) | 0.5432(0.03) | 0.5382(0.01) | 0.7063(0.016) | 0.9471(0.07) | |
| EWKM | 0.4789(0.09) | 0.8209(0.06) | 0.6534(0.00) | 0.5334(0.02) | 0.5329(0.00) | 0.7011(0.01) | 0.9024(0.08) | |
| Acc | ESSC | 0.5244(0.02) | 0.8466(0.00) | 0.6539(0.00) | 0.5288(0.00) | 0.5308(0.00) | 0.7004(0.00) | 0.9506(0.00) |
| AFKM | 0.4780(0.04) | 0.8127(0.06) | 0.6534(0.00) | 0.5354(0.00) | 0.5416(0.01) | 0.7002(0.00) | 0.9399(0.08) | |
| SC | 0.4987(0.00) | 0.8066(0.00) | 0.6535(0.00) | 0.5222(0.00) | 0.5308(0.00) | 0.7002(0.01 | 0.8707(0.00) | |
| SSC-MP | 0.5012(0.00) | 0.7120(0.01) | 0.6513(0.00) | 0.5222(0.00) | 0.5311(0.00) | 0.7002(0.00) | 0.5865(0.00) | |
| ERKM | 0.5848(0.08) | 0.9036(0.01) | 0.6580(0.01) | 0.5714(0.03) | 0.5456(0.01) | 0.7051(0.02) | 0.9016(0.04) | |
| KMEA | 0.1945(0.02) | 0.8115(0.04) | 0.5672(0.03) | 0.5270(0.02) | 0.5533(0.03) | 0.4613(0.06) | 0.9469(0.06) | |
| WKME | 0.4769(0.05) | 0.7979(0.07) | 0.5643(0.03) | 0.5350(0.03) | 0.6029(0.06) | 0.4551(0.05) | 0.9482(0.06) | |
| EWKM | 0.4652(0.09) | 0.8264(0.05) | 0.6051(0.03) | 0.6210(0.05) | 0.6601(0.01) | 0.5206(0.06) | 0.9046(0.07) | |
| Fsc | ESSC | 0.5151(0.03) | 0.8477(0.00) | 0.6004(0.04) | 0.6642(0.00) | 0.6604(0.01) | 0.5156(0.05) | 0.9503(0.00) |
| AFKM | 0.4689(0.03) | 0.8158(0.05) | 0.5699(0.03) | 0.5895(0.00) | 0.5814(0.05) | 0.3864(0.04) | 0.9431(0.06) | |
| SC | 0.4355(0.21) | 0.4719(0.00) | 0.5709(0.01) | 0.543(0.00) | 0.5349(0.00) | 0.3818(0.04) | 0.8694(0.00) | |
| SSC-MP | 0.5189(0.01) | 0.7672(0.00) | 0.5207(0.00) | 0.6662(0.00) | 0.5629(0.00) | 0.5176(0.00) | 0.5842(0.00) | |
| ERKM | 0.5295(0.08) | 0.9015(0.01) | 0.6065(0.04) | 0.6297(0.02) | 0.5503(0.02) | 0.5606(0.06) | 0.8997(0.04) | |
| KMEA | 0.1318(0.02) | 0.5890(0.06) | 0.0140(0.02) | 0.0068(0.01) | 0.0070(0.00) | 0.0526(0.05) | 0.8580(0.11) | |
| WKME | 0.1588(0.06) | 0.5719(0.10) | 0.0128(0.02) | 0.0113(0.01) | 0.0024(0.00) | 0.0474(0.04) | 0.8632(0.11) | |
| EWKM | 0.1425(0.14) | 0.6144(0.07) | −0.0028(0.02) | 0.0047(0.01) | 0.0000(0.00) | 0.0152(0.05) | 0.7545(0.12) | |
| ARI | ESSC | 0.1965(0.03) | 0.6210(0.00) | 0.0023(0.02) | 0.0015(0.00) | −0.0008(0.00) | 0.0259(0.05) | 0.8520(0.00) |
| AFKM | 0.1412(0.04) | 0.5987(0.07) | 0.0171(0.02) | 0.0053(0.00) | 0.0046(0.00) | 0.0162(0.02) | 0.8496(0.12) | |
| SC | 0.1062(0.00) | 0.1851(0.00) | 0.0123(0.00) | 0.0004(0.00) | 0.0013(0.00) | −0.0070(0.02) | 0.6458(0.00) | |
| SSC-MP | 0.1453(0.00) | 0.5520(0.00) | 0.0055(0.00) | 0.0013(0.00) | 0.0020(0.00) | 0.0266(0.00) | 0.2135(0.00) | |
| ERKM | 0.277(0.10) | 0.7535(0.01) | 0.0263(0.05) | 0.0234(0.02) | 0.0072(0.00) | 0.0247(0.01) | 0.8632(0.11) | |
| KMEA | 0.1945(0.02) | 0.6472(0.02) | 0.0100(0.01) | 0.0054(0.01) | 0.0088(0.01) | 0.1187(0.06) | 0.8474(0.08) | |
| WKME | 0.2323(0.08) | 0.6511(0.04) | 0.0084(0.01) | 0.0091(0.01) | 0.0184(0.01) | 0.0962(0.06) | 0.8503(0.08) | |
| EWKM | 0.2197(0.15) | 0.6691(0.02) | 0.0038(0.00) | 0.0074(0.01) | 0.0261(0.01) | 0.0396(0.03) | 0.7620(0.09) | |
| NMI | ESSC | 0.2662(0.03) | 0.6321(0.00) | 0.0060(0.011) | 0.0153(0.01) | 0.0089(0.01) | 0.0458(0.04) | 0.8197(0.00) |
| AFKM | 0.2102(0.05) | 0.6560(0.03) | 0.0127(0.01) | 0.0125(0.00) | 0.0164(0.01) | 0.0431(0.03) | 0.8414(0.09) | |
| SC | 0.1819(0.00) | 0.4667(0.00) | 0.0045(0.01) | 0.0003(0.00) | 0.0011(0.00) | 0.0159(0.04) | 0.649(0.00) | |
| SSC-MP | 0.1684(0.00) | 0.6930(0.01) | 0.0032(0.00) | 0.0006(0.00) | 0.0087(0.00) | 0.0671(0.00) | 0.2289(0.00) | |
| ERKM | 0.4003(0.14) | 0.8026(0.01) | 0.0193(0.03) | 0.0291(0.03) | 0.0079(0.00) | 0.0526(0.06) | 0.7333(0.05) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Xiong, L.; Wang, C.; Huang, X.; Zeng, H. An Entropy Regularization k-Means Algorithm with a New Measure of between-Cluster Distance in Subspace Clustering. Entropy 2019, 21, 683. https://doi.org/10.3390/e21070683
AMA Style
Xiong L, Wang C, Huang X, Zeng H. An Entropy Regularization k-Means Algorithm with a New Measure of between-Cluster Distance in Subspace Clustering. Entropy. 2019; 21(7):683. https://doi.org/10.3390/e21070683
Chicago/Turabian StyleXiong, Liyan, Cheng Wang, Xiaohui Huang, and Hui Zeng. 2019. "An Entropy Regularization k-Means Algorithm with a New Measure of between-Cluster Distance in Subspace Clustering" Entropy 21, no. 7: 683. https://doi.org/10.3390/e21070683
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.