On the Properties of the Reaction Counts Chemical Master Equation


1
Computational Medicine, Zuse Institute Berlin, 14195 Berlin, Germany
2
Department of Mathematics and Computer Science, Freie Universität Berlin, 14195 Berlin, Germany
Entropy 2019, 21(6), 607; https://doi.org/10.3390/e21060607
Submission received: 28 February 2019
/
Revised: 10 June 2019
/
Accepted: 13 June 2019
/
Published: 19 June 2019
(This article belongs to the Special Issue Probability Distributions and Maximum Entropy in Stochastic Chemical Reaction Networks)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:The reaction counts chemical master equation (CME) is a high-dimensional variant of the classical population counts CME. In the reaction counts CME setting, we count the reactions which have fired over time rather than monitoring the population state over time. Since a reaction either fires or not, the reaction counts CME transitions are only forward stepping. Typically there are more reactions in a system than species, this results in the reaction counts CME being higher in dimension, but simpler in dynamics. In this work, we revisit the reaction counts CME framework and its key theoretical results. Then we will extend the theory by exploiting the reactions counts’ forward stepping feature, by decomposing the state space into independent continuous-time Markov chains (CTMC). We extend the reaction counts CME theory to derive analytical forms and estimates for the CTMC decomposition of the CME. This new theory gives new insights into solving hitting times-, rare events-, and a priori domain construction problems.
1. Introduction
Continuous-time Markov chains (CTMC) accurately capture the dynamics of a broad range of biochemical reaction systems. The CTMCs come in two flavours: The discrete state space, the chain transitions from one state to another, or the continuous state space, the state transitions are smooth yet non-differentiable. Each type has an intuitive interpretation. Discrete state spaces describe the population or counts of chemicals in a system, while continuous states spaces describe concentrations of chemicals in a system [1,2]. It is tempting to generalise concentrations to be simply scaled populations, which would mean that all systems could be mapped into the continuous setting and solved there. However, this is not the case mathematically. It was shown that for large populations, the discrete CTMC and continuous CTMC were equivalent [3,4]. If the large population assumption is not satisfied, mathematically, the discrete state space system has to be studied in its own right.
The probability distribution of a CTMC over the discrete state space in the biochemical context is found by solving the chemical master equation (CME). We first present the CME and then describe its components. The formula of the CME is written as follows,
In the equation above, is a CTMC over the state space Each state is a vector of non-negative integers describing the population of the species at time Starting from the left-hand side, the equation states that the change in probability of being in a state at time t is given by the sum of two terms. The first term describes the probability flowing into the state and the second term describes the probability flowing out of the state There are reactions perturbing the population; the terms are referred to as stoichiometric vectors, they capture the net change in population if the nth reaction fires. Hence, subtracting the stoichiometric vectors from gives us the set of all previous states which might transition into and “contribute” probability. The last piece of information in the equation are the rates at which reactions fire, these are encapsulated in the propensity functions In summary, the CME describes the change in probability of observing a CTMC in a certain state, which is equal to the sum of probability transitioning into the state, minus the sum of probability leaving the state.
Even though the dynamics of the derivative are fairly simple, solving the CME is a hard problem [5,6,7,8,9,10,11,12]. A special case of the CME which is truly unyielding to approximation is when a system is close to its population boundary (for example, close to zero). In this scenario, none of the state transitions around a state near the boundary can be summarised by the average transitions out of the state. This impedes most approximation methods, and even if a method was successful, its computational effort would be equivalent to that of solving the Finite State Projection for the same error. An approach which was proposed in various different contexts to simplify dynamics, was to study the number of reactions fired rather than the population counts [6,13,14,15,16,17]. Because reactions cannot “un-fire”, the state transitions are only moving forward. Furthermore, given that the system’s starting population is known, the species count in any state can be reconstructed from the reaction counts.
In this work, we will reintroduce the reaction counts variant of the CME. We will then explore the theoretical and structural results which emerge from its forward stepping process. Then, we will show how the reaction counts CME can be used to construct solutions to the classical CME. Lastly, we decompose the state space of the CME into independent CTMCs and give analytical forms and estimates to calculate their probabilities. The purpose of this work is to gain intuition and explore structural properties of the CME, hence, the motivation is more theory rather than the application of the CME. In light of that, we omit a discussion of numerical methods in this paper and envisage this aspect in future research.
2. Reaction Counts CME
2.1. Formulation
We denote the state space of the reaction counts CME by Each state is a vector of non-negative integers of length Each element of the vector represents the number of times its corresponding reaction has fired. In the CME setting, the change in state after a reaction fires is given by the stoichiometric vector, which we denoted earlier by for This vector quantifies the net change in populations after the reaction has fired. Analogously, in the reaction counts CME setting, a change in state indicates that a reaction has fired, and its corresponding reaction count is incremented by one. Therefore, the stoichiometric vector for the nth reaction is simply the identity vector the vector is zero in all but the nth position, where it is one.
We bridge the species counts CME and the reaction counts CME with the mapping that is, for
The mapping above links the reaction counts CME to the species counts CME by stating that, given the starting state and the reactions which have fired are known, then the current state in the species counts is the starting species state plus the sum of stochiometries of all the reactions which have fired. It is important to note that the map is injective into the species state space In most cases, is of higher dimension than hence, is seldom bijective. For our purpose, we only need the pull back map of We denote the pull back map as where for
With the mapping between and established, we can now inherit the propensity function from the species counts over to the reaction counts. For the reaction counts propensity of the nth reaction is given by,
With the state space, stoichiometry, and the propensities established in the reaction counts setting, we are ready to formulate the reaction counts based Kurtz process. For let be the reaction counts Kurtz process,
The corresponding reaction counts CME for the process above is given by,
for all The initial condition for the reaction counts CME is a points mass on the origin,
Upon first glance, the CME of the reaction counts is simpler in its complexity compared to its species counter part. In the reaction case, the processes only move forward, which gives rise to simple forward propagating dynamics. Furthermore, given solutions to the reaction counts CME exist, with the simple application of the push forward measure, we would obtain:
The relationship given above is the critical motivation for studying the reaction counts CME. In principle, if structures and results could be attained in the reaction counts setting, then by using these results can be mapped into species setting. The simplest example of this is the proof for the existence of solutions of the CME for finite time. We now show that the reaction counts CME has analytical solutions, then using the push forward measure in Equation (8), we prove that the solutions of the CME exist for a broad range of propensity functions.
2.2. Analytical Solutions of the Reaction Counts CME
Firstly, we will establish the notations and assumptions needed to present the results. For brevity, we denote the sum of all propensities as:
The reaction counts CME in Equation (6) is a difference differential equation, hence, by arranging the probability states in a vector we reduce solving the reaction counts CME to solving the ODE,
For the matrix has the properties: with We will prove that is a generator of a one-parameter semigroup. Before this, let us consider a simple two reaction system to gain some intuition into the different components of the reaction counts setting.
Example 1.
Let us consider the birth-death process in the context of the reaction counts CME. The birth-death process in the species count is given by,
where is the starting population, and the birth and death rates are denoted by and respectively. We can translate this process into the reaction counts setting using the mapping,
We restrict the reaction counts state space to only contain states which yield non-negative values by applying Substituting the mapping and the process into Equations (2) to (5) leads to the reaction counts birth-death process formulation:
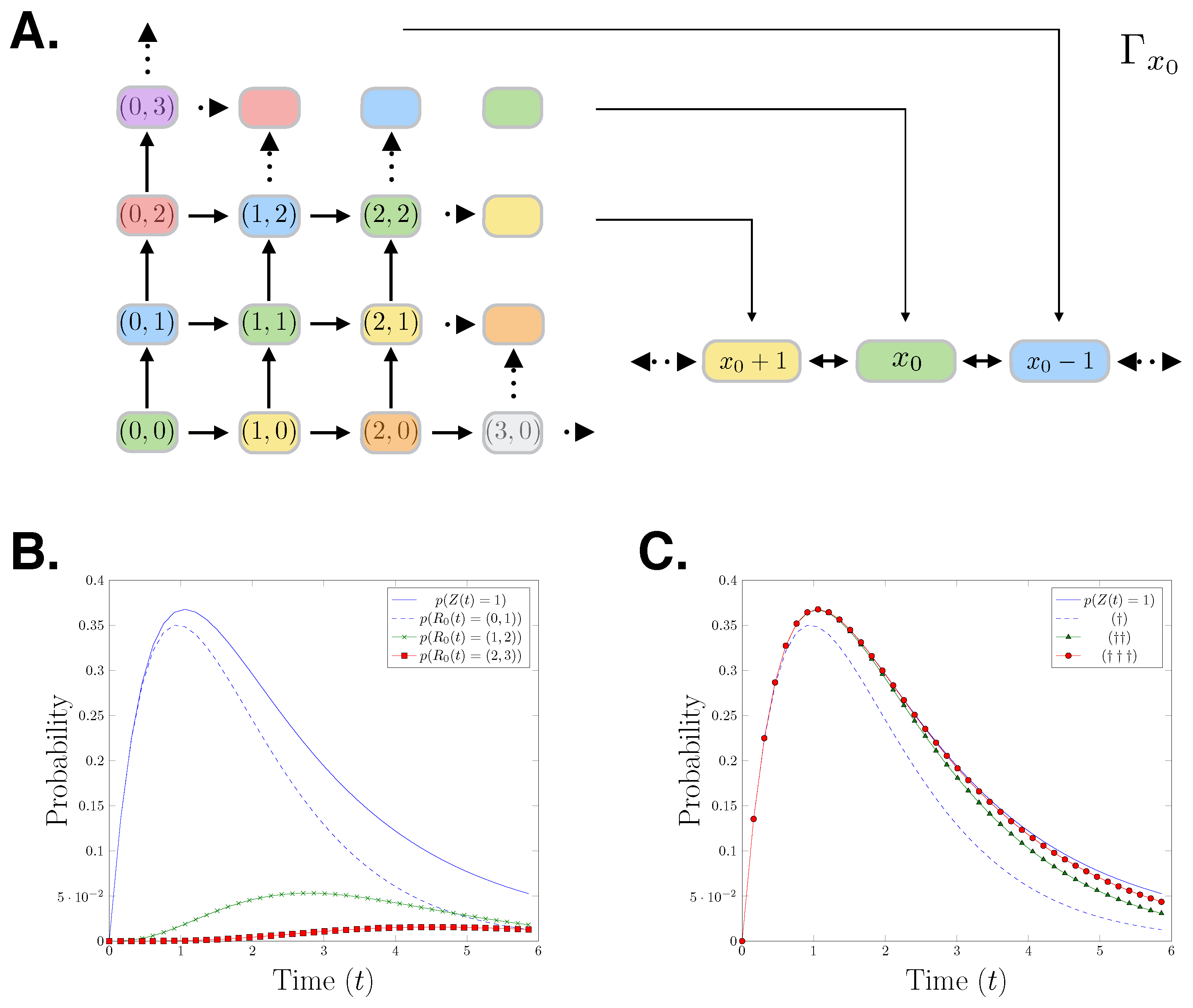
The relationship between the reaction count state space and the species count state space is visualised in Figure 1A. The colours in the figure show how the species count state space partitions the reaction count state space. To demonstrate the forward moving structure of the reaction counts CME, we derive the generator for the first nine states of its state space:
where,
The initial condition is the identity vector with the total probability mass on state We can observe that due to the forward moving nature of the reaction counts setting, is a lower diagonal matrix. In Figure 1B,C, we present a birth-death process with initial state birth rate and death rate Specifically, we show the probability distributions of the first three states of that process which correspond to state 1 in the species count setting. In Figure 1B, it is shown that the probability distribution of being in state 1 in the species count CME setting bounds the corresponding reaction counts CME distributions. In Figure 1C, we progressively add the first three reaction counts states corresponding to the state 1, showing that the reaction counts CME approximates the species counts CME from below.
Theorem 1.
(Sunkara 09 ([15])) Given a system with species and reactions at a starting state If is the generator for the reaction counts CME (6), then:
- 1.
- There exists a permutation matrix P such that is lower triangular;
- 2.
- The spectrum of is the set:
The property of the reaction counts setting, that the process only moves forward, aids in showing that the generator could be rewritten as a lower triangular matrix. We know that the spectrum of a lower triangular matrix are the diagonal elements of the matrix. In our case, the diagonal elements are simply the negative sum of the outgoing propensities. This then reveals that the spectrum of the generator is in the negative real numbers. Then by the spectral mapping theorem, solutions to the reaction counts CME exist. We can further exploit this “forward stepping” structure to write the analytical solutions for the probability at each state in
Proposition 1.
Combining Proposition 1 with the push forward measure in Equation (8), we see that at finite time t the solutions to the CME (1) exist. Unfortunately, since the reaction counts CME cannot reach a stationary state (in cases where the state space is not finite), the proof for the existence of stationary solutions for a generalised CME is still an open problem. Now that the solutions of the reaction counts CME have been established, we can probe further into its properties. Firstly, we explore how the state space of the reaction count CME has a naturally hierarchical partitioning, and how this partitioning can be used to build a sequence of approximate sub-processes.
3. Partitioning the State Space
Definition 1.
For we define,
to be the set of all states which are reachable by m steps from the origin The state space Λ naturally partitions into non-intersecting subsets,
If we consider truncating the state space progressively, we find that this is equivalent to the Finite State Projection with an N-step domain expander [9,18].
Lemma 1.
For let be the reaction counts Kurtz process (5). Then for any ,
Proof.
Fix Let be the same process as but with the restriction that all propensities of states are zero. Since in the reaction counts case, states only transition forward, we have that,
That is, the probability of both processes are the same for states leading up to the states in However, since the process does not evolve past , by the conservation of probability we have that,
Substituting in Equation (15) for states which appear before reduces the above expression to,
By the conservation of probability,
hence, substituting this into the right-hand side of Equation (17) and subtracting the like terms gives,
☐
Lemma 1 is an alternative formulation of the principle behind the Finite State Projection method. We extend on this result and can show that for a desired error , there exists a subset of the state space which will produce an approximation with the desired error.
Theorem 2.
For let be the reaction counts Kurtz process (5). For there exists such that,
Proof.
The proof is an extension of Lemma 1. We define,
and,
the left- and right-hand terms of Equation (14). Then for Lemma 1 can be reformulated to state,
separating the states from gives us,
Combining the last and first term in the equalities gives us,
Rearranging the equality reduces to, We have shown that is monotonically decreasing. By definition, has the properties that and Hence, there exists an m such that ☐
Theorem 2 is an alternative proof for the fact that, when studying transient dynamics (finite time) of the CME for an arbitrary precision, one can always find a finite state space to project the CME onto. The key structure that we used to prove this is that the state space of reaction counts has a natural partitioning and that the probability only flows forward. This gave us the monotonicity needed to prove that state space truncation of the CME is well-posed. In the next section, we further decompose each state in the reaction counts state space into paths over the state space.
4. Paths
Definition 2.
For , a vector is said to be an admissible path if for every index there exists an such that where is the identity vector with one in the nth position.
Definition 3.
For we denote the set of all admissible paths of length m by,
Definition 4.
For a point we denote the set of all admissible paths of length which start at the origin and end at the state r by,
4.1. Path Chains
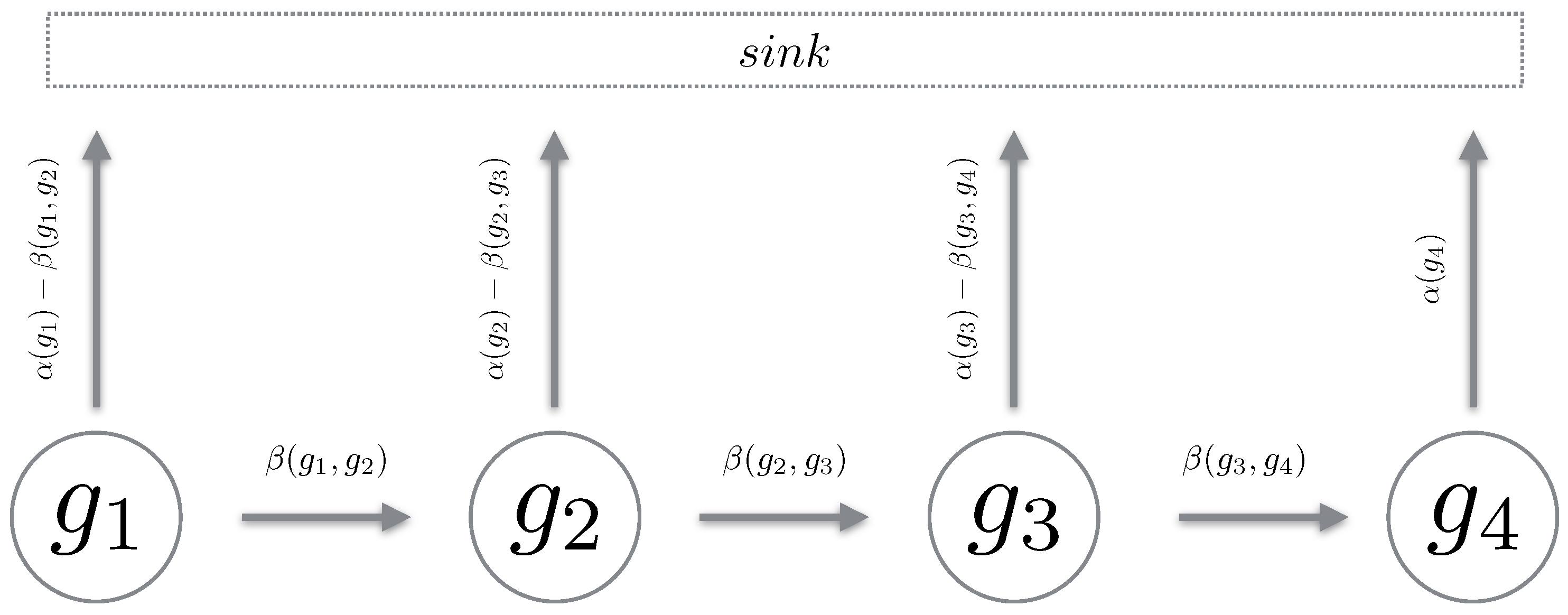
We define a Markov chain over a path in the reaction counts state space. The chain must be such that it mimics a “realisation” over the reaction state space. Using Proposition 1, we define a path chain over an admissible path in the reaction state space. It is important to note that a path chain is a continuous-time Markov chain (CTMC) [19], where all reactions which transition the state off the path of the chain are accrued into a sink state. For brevity, we simply remove this component and only describe the states of interest (see Figure 2). Also, given all chains are from the same reaction counts setting, we omit explicitly stating in the propensity functions. We now define a path chain.
Definition 5.
For and we define a path chain to be the stochastic process with state space and the probability distribution given by,
for Then to conserve probability,
The propensity function α is inherited from Equation (9) and where n is the reaction index which transitions the state to
Before stating the new proposition, let us recall the decompositions performed so far. Firstly, we showed that every state in the species state space can be decomposed into multiple reaction states in the reaction count setting. That is, a population state can be decomposed into all the different ways in which it can be visited. We then ventured further and showed that a path on the species counts state space corresponds to a path with only forward stepping transitions in the reaction counts state space. Now, we extend this further by showing that any state in the reaction counts state space can be decomposed into the sum of all independent path chains which start at the origin and end in that state.
Proposition 2.
For let be the Reaction counts Kurtz process (5).
For let
be the set of all admissible paths of length which start at and ending at r (Definition 4).
Then,
Proof.
The Proposition will be proved using mathematical induction. Firstly, we show the base case; that every state which is reachable by one step from the origin satisfies Equation (20). Let with Applying Proposition 1 we know that,
Now we consider the path chains leading to The state can only be reached in one way, hence, we have that Now calculating the probability of the evolution of a path chain (Definition 5) over gives us,
Given the two equations above match, we can conclude that for
Now we perform the inductive step. Fix . Assume that for
Then for Proposition 1 states that,
using the inductive assumption Equation (23) on the right-hand side inside the integral,
Rewriting the propensities in the path propensity notation gives,
Since all paths in are paths from the set with r as the last state, the two summations reduce to give,
By Definition 5, the term above captures all the paths in , therefore,
We have shown that given Equation (23) holds on then Equation (23) also holds for Hence, by mathematical induction, for any
☐
We have shown that each state in the reaction counts CME can be decomposed into the framework of “path chains” that we have defined. In essence, we have shown that the path chains are trajectories of the reaction counts Kurtz process. Even though at first glance the result is not a startling revelation, the real novelty lies in how we derived the probability distributions for these trajectories. By carefully decomposing the state space and concurrently deriving the corresponding probability distributions, we were able to give an analytical form for the probability of individual trajectories of the Kurtz process. Using the probability distribution given over the path chains in Definition 5, we can derive the classical stochastic simulation algorithm [20]. Using the path chains framework we have introduced so far, we can build realisations for applications such as: Hitting time problems, rare event problems, observable problems, etc. In the following section, we further build on the properties of path chains by proposing a method for estimating the path probabilities of trajectories.
4.2. Gated- and Un-Gated Path Chains
Given a path or trajectory, we define the path probability to be the probability distribution of the last state in the chain. We can use Definition 5 to analytically compute the probability of any path. However, we can exploit the properties of the path chains further and derive some simple estimates for the path probability. We borrow the notion of gating and un-gating introduced by Sunkara (2013) [21], and show how these can be used to calculate estimates for the path probabilities.
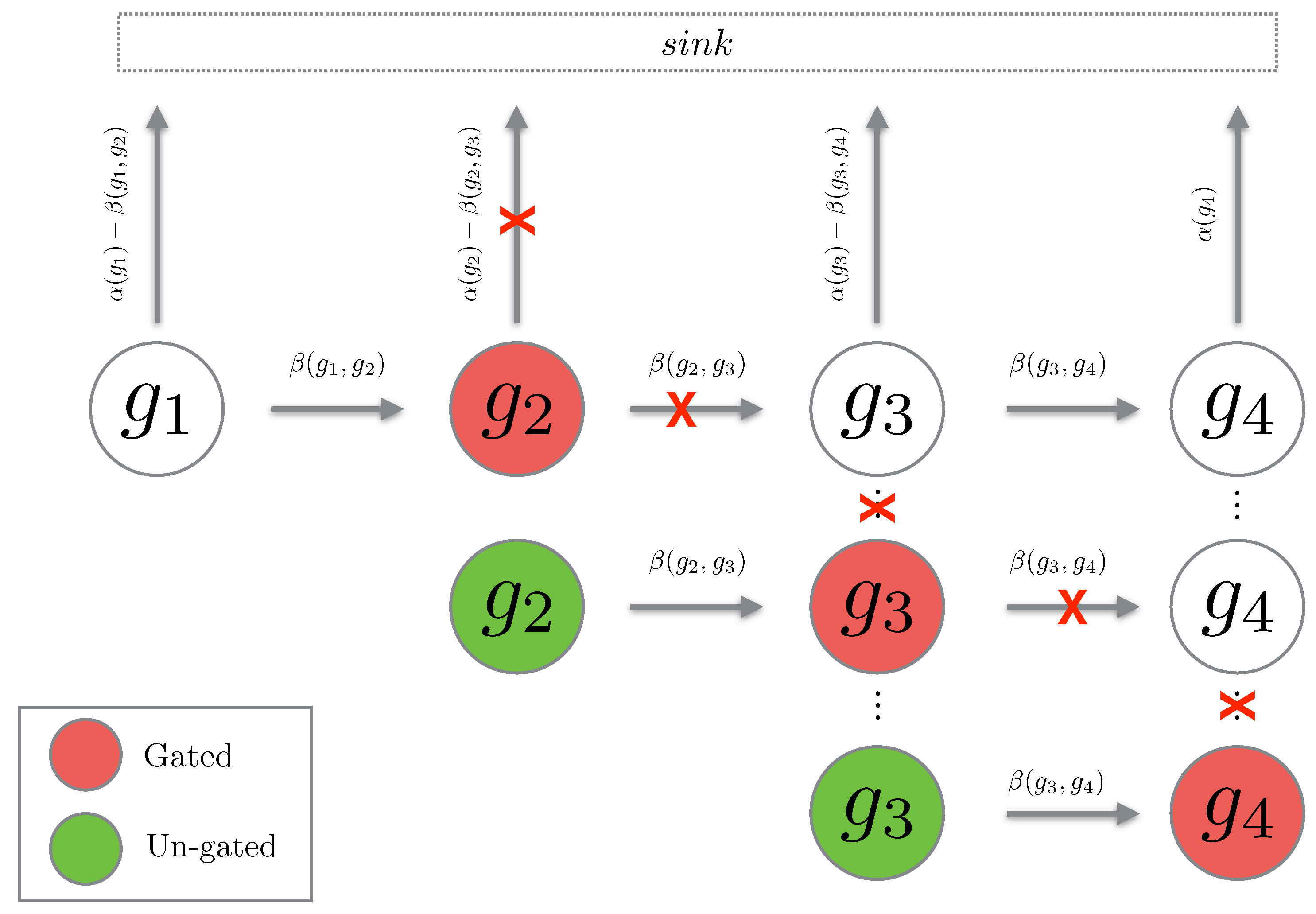
The concept of gating is mathematically tedious to prove, however, the concept is fairly simple. Given a chain g of length gating this chain at position means that we set the propensity of leaving state to zero. Hence, the probability will simply flow into state and remain there (hence, the term “gating”). Then we can “un-gate” the state which means that we reset the time to zero, set the initial probability at state to the accumulated probability from the gating, and then allow the process to continue. The reason we are interested in this notion of gating and un-gating is that for path chains, it happens so that gating and un-gating the chains gives an upper bound for the original path probability. We will now prove that this is indeed the case.
Definition 6.
For an admissible path we define a truncated path where the first terms of the path are ignored.
Definition 7.
Fix and Let be a path of length We define to be a path chain over g in the time interval Then for we define an un-gated path chain over to be given by:
for and,
where,
To conserve probability,
We see that the un-gated path chain is a normal path chain with the initial probability reset to the total probability which has flown into the gated state (see Figure 3). We now show that gating and un-gating over a path gives an upper bound for the path probability. First we consider the case of a single gating and un-gating at the position
Lemma 2.
Fix and Given two path chains and it follows that for all
and for
Proof.
We break down the proof into two steps. First we investigate the bounds formed by gating at the second step, and then we prove the bound over the remaining states in the chain. We begin by showing that for ],
From the definition of the path chain (Definition 5), the solution for the probability of being in state at time t is given by,
Using the solution above, we can calculate the probability which would accumulate in if the chain was gated at
Substituting the above terms into the definition of the probability of being is state at time t in the un-gated path chain gives us,
Taking the integral of Equations (26) and (28) over the interval gives us,
To simplify notation, let us define,
Then the difference between and reduces to,
Since for all we attain the lower bound,
We show that the right-hand side of the equation above is always positive. We define the right hand-side of Equation (32) as a function,
We notice that the function has the property,
Firstly, if we consider the case we can see that Using the symmetry of we only need to consider the case Then it follows that,
replacing with gives us,
Hence, the right-hand side of Equation (33) is positive. So it follows that for
We have shown that the outflow of probability in the un-gated chain is more than in the original path chain. We now show that this phenomenon continues all the way down the chain. We prove this using mathematical induction. First, let us consider the base case By the definition of path chains,
applying condition (25) gives us that,
Hence, for
We now build the inductive step. Fix assume that, for all
Then by the definition of path chains,
applying the inductive assumption Equation (34) gives us that,
Hence, by mathematical induction, for and the probabilities of the un-gated chain bound the probability on the original path chain, that is,
☐
The intuition behind Lemma 2 is that once we gate and un-gate a state, the un-gated chain has more probability in it than the regular path chain beyond the gated state. Since the dynamics of the path chain beyond the gated state are not changed, we would expect that the un-gated chain (having more probability) would be an upper bound for the original path chain. The proof, as seen above, is sadly tedious. We now consider a cascade of gating and un-gating, that is, we gate and un-gate as we transition through the path chain. We prove that this gives an upper bound for the path probabilities.
4.3. Cascade of Gating and Un-Gating
We now set up a cascade of gating and un-gating at ever state of the path chain. We achieve this by defining the starting probability of the un-gating. Previously, an un-gated path chain at position j had a initial probability of,
We now introduce a recurrent initial probability,
for Using this new recursive initial probability, we will build a sequence of path chains and using the idea of gating and un-gating at each transition of the path chain, we can construct an upper bound for the path probability.
Theorem 3.
Fix and Let be a path chain over We recursively define a set of un-gated chains, Then for
Proof.
We prove this result by repeatedly applying Lemma 2. Fix then by the first clause of Lemma 2 we have that,
since is the third state of the chain we can apply the second clause of Lemma 2 to get,
stepping backward in the chain using Lemma 2, we reduce down to,
☐
In summary, by gating and un-gating along a path chain we can easily construct estimates for the probability of the trajectories of interest. We now consider an example where we build a path chain of the birth-death process introduced in Example 1, to show how to compute the gating and un-gating steps.
Example 2.
Let us consider the birth-death process introduced in Example 1, with the parameters and We will now construct the path probability of the chain:
The generator for this path chain is given by,
We can solve for by simply taking the matrix exponential at time t and applying it to the respective initial probability. Now we will construct the gating and un-gating approximation. This approximation is calculated using the following recursive equation: Let m be the number of states in the chain then,
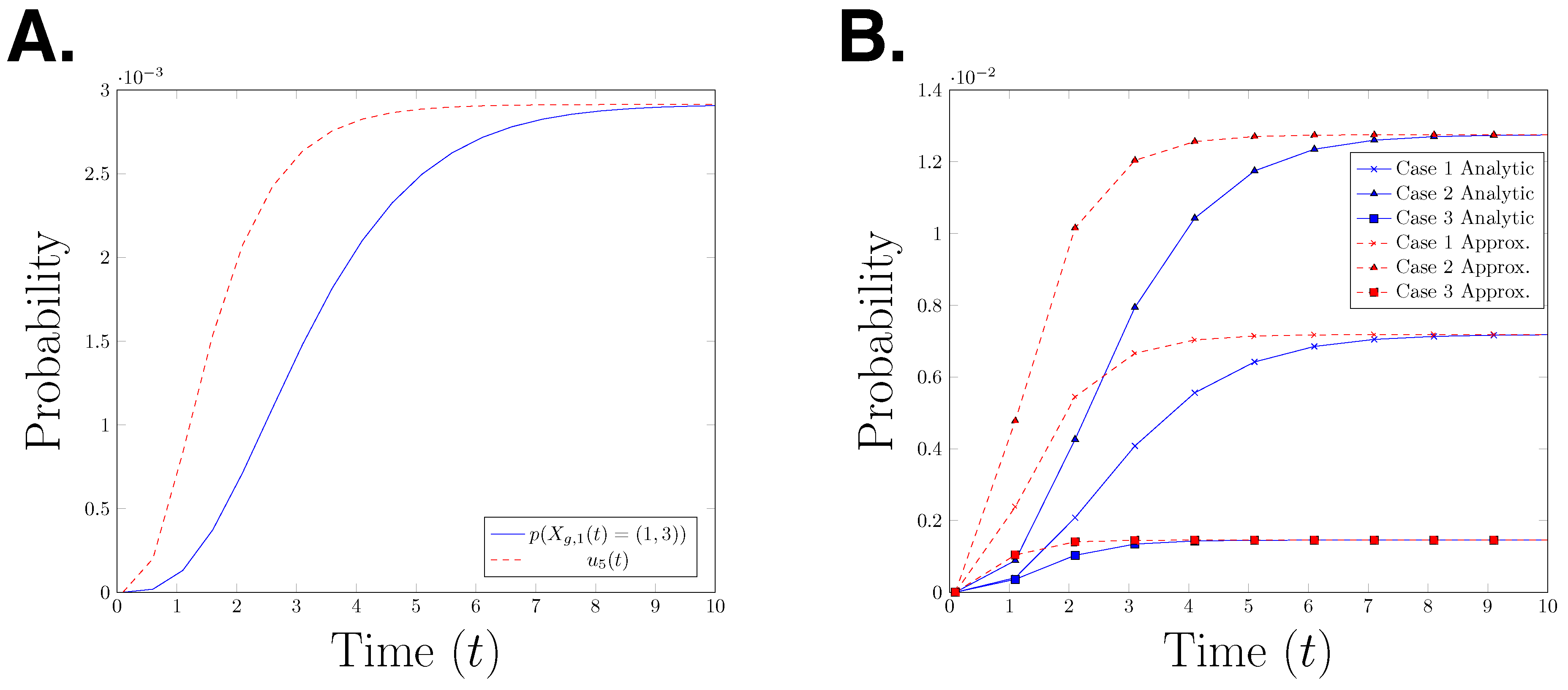
for with The functions α and β are as given in Definition 5. Hence, is the gated and un-gated estimate for the probability In Figure 4A, we plot the true path probability, and the upper bound for the path probability, for time interval seconds. The graph shows that is an upper bound for at any time point. It is interesting to observe that the error between the two functions decreases over time, however it is not clear whether the difference will converge to zero as time goes to infinity. To test whether this behaviour can be observed in other parameter settings, we plot the analytical path probability and its upper bound for three different parameter settings in Figure 4B. We observe the same effect in all three presented cases. This raises the question whether this observation is a structural property or only an artefact of the specific model which is considered here.
5. Conclusions
We began by formulating the reaction counts CME and showing that its forward stepping characteristic yields analytical solutions. Then, with a simple application of the push forward measure, we could prove the existence of solutions of the CME for finite time. We further decomposed the reaction counts state space into independent CTMCs and gave analytical forms and estimates for their path probabilities. Hence, we have derived analytical theory for trajectories which arise from the solutions of the CME. This theory can be used for computing observable estimates of the underlying CTMCs. We can also use the paths to estimate the hitting times and rare event probabilities. A natural future direction would be to investigate if the current framework of the time independent propensities can be translated to the time dependent propensities. An even more challenging task would be, in the context of parameter inference, to reverse time on the trajectories and to cascade probability backwards.
Funding
V. Sunkara was supported by the BMBF (Germany) project PrevOp-OVERLOAD, grant number 01EC1408H, and the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy—The Berlin Mathematics Research Center MATH+ (EXC-2046/1, project ID: 390685689). The publication cost were funded by the German Research Foundation and the OpenAccess Publication Fund of Freie Universität Berlin.
Acknowledgments
The author would like to thank the Biocomputing group at FU Berlin for all their stimulating discussions and constant encouragement.
Conflicts of Interest
The author declares no conflict of interest.
References
- Wilkinson, D.J. Mathematical and Computational Biology Series. In Stochastic Modelling for Systems Biology; Chapman & Hall/CRC: Boca Raton, FL, USA, 2006. [Google Scholar]
- Van Kampen, N.G. Stochastic Processes in Physics and Chemistry, 3rd ed.; North Holland: Amsterdam, The Netherlands, 2007. [Google Scholar]
- Kurtz, T.G. Strong approximation theorems for density dependent Markov chains. Stoch. Process. Their Appl. 1978, 6, 223–240. [Google Scholar] [CrossRef] [Green Version]
- Grima, R.; Thomas, P.; Straube, A.V. How accurate are the nonlinear chemical Fokker-Planck and chemical Langevin equations? J. Chem. Phys. 2011, 135, 084103. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Higham, D.J. Modeling and Simulating Chemical Reactions. SIAM Rev. 2008, 50, 347–368. [Google Scholar] [CrossRef] [Green Version]
- Hegland, M.; Hellander, A.; Lötstedt, P. Sparse grids and hybrid methods for the chemical master equation. BIT Numer. Math. 2008, 48, 265–283. [Google Scholar] [CrossRef]
- Engblom, S. Spectral approximation of solutions to the chemical master equation. J. Comput. Appl. Math. 2009, 229, 208–221. [Google Scholar] [CrossRef] [Green Version]
- Jahnke, T.; Udrescu, T. Solving chemical master equations by adaptive wavelet compression. J. Comput. Phys. 2010, 229, 5724–5741. [Google Scholar] [CrossRef] [Green Version]
- Sunkara, V.; Hegland, M. An Optimal Finite State Projection Method. Procedia Comput. Sci. 2010, 1, 1579–1586. [Google Scholar] [CrossRef]
- Kazeev, V.; Khammash, M.; Nip, M.; Schwab, C. Direct Solution of the chemical master equation Using Quantized Tensor Trains. PLoS Comput. Biol. 2014, 10, e1003359. [Google Scholar] [CrossRef] [PubMed]
- Schnoerr, D.; Sanguinetti, G.; Grima, R. Approximation and inference methods for stochastic biochemical kinetics—A tutorial review. J. Phys. A Math. Theor. 2017, 50, 093001. [Google Scholar] [CrossRef]
- Vlysidis, M.; Kaznessis, Y. Solving Stochastic Reaction Networks with Maximum Entropy Lagrange Multipliers. Entropy 2018, 20, 700. [Google Scholar] [CrossRef]
- Haseltine, E.L.; Rawlings, J.B. Approximate simulation of coupled fast and slow reactions for stochastic chemical kinetics. J. Chem. Phys. 2002, 117, 6959–6969. [Google Scholar] [CrossRef] [Green Version]
- Goutsias, J. Quasiequilibrium approximation of fast reaction kinetics in stochastic biochemical systems. J. Chem. Phys. 2005, 122, 184102. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sunkara, V. The chemical master equation with respect to reaction counts. In Proceedings of the 18th World IMACS Congress and (MODSIM09) International Congress on Modelling and Simulation, Cairns, Australia, 13–17 July 2009; Volume 1, pp. 2377–2383. [Google Scholar]
- Menz, S.; Latorre, J.; Schütte, C.; Huisinga, W. Hybrid Stochastic–Deterministic Solution of the Chemical Master Equation. Multiscale Model. Simul. 2012, 10, 1232–1262. [Google Scholar] [CrossRef]
- Black, A.J.; Ross, J.V. Computation of epidemic final size distributions. J. Theor. Biol. 2015, 367, 159–165. [Google Scholar] [CrossRef] [PubMed]
- Khammash, M.; Munsky, B. The finite state projection algorithm for the solution of the chemical master equation. J. Chem. Phys. 2006, 124, 1–12. [Google Scholar] [CrossRef]
- Norris, J.R. Markov Chains; Cambridge University Press: Cambridge, UK, 1997. [Google Scholar]
- Gillespie, D.T. Exact stochastic simulation of coupled chemical reactions. J. Phys. Chem. 1977, 81, 2340–2361. [Google Scholar] [CrossRef]
- Sunkara, V. Analysis and Numerics of the Chemical Master Equation. Ph.D. Thesis, The Australian National University, Canberra, Australia, 2013. [Google Scholar]
Figure 1.
(A) Cartoon showing the mapping of the reactions counts birth-death process to the species count birth-death process. (B) An evaluation of the birth-death process for parameters The plot shows: The distribution of the species having population one over time and the distributions of reaction and firing at time in the reaction counts setting. (C) , , The distribution of the species count chemical master equation (CME) in state 1 at t is approached from below by the sum of the probabilities of the reactions firing which result in being in state .
Figure 1.
(A) Cartoon showing the mapping of the reactions counts birth-death process to the species count birth-death process. (B) An evaluation of the birth-death process for parameters The plot shows: The distribution of the species having population one over time and the distributions of reaction and firing at time in the reaction counts setting. (C) , , The distribution of the species count chemical master equation (CME) in state 1 at t is approached from below by the sum of the probabilities of the reactions firing which result in being in state .

Figure 2.
The cartoon above depicts the generator of a path chain. With being the total outward propensity and the propensity to transition to the next state in the chain. All reactions leading away from the chain are directed into the sink state.
Figure 2.
The cartoon above depicts the generator of a path chain. With being the total outward propensity and the propensity to transition to the next state in the chain. All reactions leading away from the chain are directed into the sink state.

Figure 3.
The cartoon above depicts the cascade of gating being performed on a path chain. When a state is gated, the propensities leaving the state are set to zero (depicted with a red cross). When the state is un-gated, the propensities are reintroduced.
Figure 3.
The cartoon above depicts the cascade of gating being performed on a path chain. When a state is gated, the propensities leaving the state are set to zero (depicted with a red cross). When the state is un-gated, the propensities are reintroduced.

Figure 4.
(A) Graph of the path probability and the upper bound of the path probability for the time interval (B) Case 1: Case 2: Case 3: “analytical” refers to the path probability and “approximation” refers to the upper bound of the path probability.
Figure 4.
(A) Graph of the path probability and the upper bound of the path probability for the time interval (B) Case 1: Case 2: Case 3: “analytical” refers to the path probability and “approximation” refers to the upper bound of the path probability.

© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Sunkara, V. On the Properties of the Reaction Counts Chemical Master Equation. Entropy 2019, 21, 607. https://doi.org/10.3390/e21060607
AMA Style
Sunkara V. On the Properties of the Reaction Counts Chemical Master Equation. Entropy. 2019; 21(6):607. https://doi.org/10.3390/e21060607
Chicago/Turabian StyleSunkara, Vikram. 2019. "On the Properties of the Reaction Counts Chemical Master Equation" Entropy 21, no. 6: 607. https://doi.org/10.3390/e21060607
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.