
Hierarchical semantic interaction-based deep hashing network for cross-modal retrieval
- Published
- Accepted
- Received
- Academic Editor
- Thippa Reddy Gadekallu
- Subject Areas
- Artificial Intelligence, Computer Vision, Data Mining and Machine Learning, Multimedia, Visual Analytics
- Keywords
- Bidirectional Bi-linear Interaction, Dual-Similarity Measurement, Cross-Modal Hashing, Deep Neural Network
- Copyright
- © 2021 Chen et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2021. Hierarchical semantic interaction-based deep hashing network for cross-modal retrieval. PeerJ Computer Science 7:e552 https://doi.org/10.7717/peerj-cs.552
Abstract
Due to the high efficiency of hashing technology and the high abstraction of deep networks, deep hashing has achieved appealing effectiveness and efficiency for large-scale cross-modal retrieval. However, how to efficiently measure the similarity of fine-grained multi-labels for multi-modal data and thoroughly explore the intermediate layers specific information of networks are still two challenges for high-performance cross-modal hashing retrieval. Thus, in this paper, we propose a novel Hierarchical Semantic Interaction-based Deep Hashing Network (HSIDHN) for large-scale cross-modal retrieval. In the proposed HSIDHN, the multi-scale and fusion operations are first applied to each layer of the network. A Bidirectional Bi-linear Interaction (BBI) policy is then designed to achieve the hierarchical semantic interaction among different layers, such that the capability of hash representations can be enhanced. Moreover, a dual-similarity measurement (“hard” similarity and “soft” similarity) is designed to calculate the semantic similarity of different modality data, aiming to better preserve the semantic correlation of multi-labels. Extensive experiment results on two large-scale public datasets have shown that the performance of our HSIDHN is competitive to state-of-the-art deep cross-modal hashing methods.
Introduction
The recent exponential growth of multimedia data (e.g., images, videos, audios, and texts) increases the interest in these different modality data. These different modality data, also named multi-modal data, may share similar semantic content or topics. Therefore, cross-modal retrieval, which uses a query from one modality to retrieve all semantically relevant data from another modality, has attracted increasing attention. Because of the existing potential heterogeneous gaps among these multi-modal data, which may be inconsistent in different spaces, it posed a challenge to efficiently and effectively retrieve the related data among these multi-modal data.
Specifically, cross-modal retrieval aims to learn common latent representations for different modalities data so that the embedding of different modalities could be evaluated in the trained latent space (Kaur, Pannu & Malhi, 2021). Many cross-modal retrieval methods are based on real-valued latent representations for modality-irrelevance data, such as Wang et al. (2014), Jia, Salzmann & Darrell (2011), Mao et al. (2013), Gong et al. (2014), Karpathy, Joulin & Fei-Fei (2014), and Wang et al. (2015). However, the measure of real-valued latent representations suffers from the low efficiency of searching and high complexity of computing. To reduce the search time and the storage cost of cross-modal retrieval, hashing-based cross-modal (CMH) retrieval methods are proposed to map the data into compact and modality-specific hash codes in a Hamming space, which have shown their superiority in cross-modal retrieval task such as Ling et al. (2019); Qin (2020).
So far, plentiful CMH algorithms including unsupervised, supervised, and semi-supervised learning manners have been proposed to learn robust hash functions as well as high-quality hash representations. Unsupervised CMH algorithms explore underlying correlation and model the inter and intra-modality similarity among the unlabeled data. In contrast, both semi-supervised and supervised methods employ supervised information, e.g., labels/tags, to learn hash function and hash binary codes, which have better performance than unsupervised manner. However, these CMH algorithms heavily depend on the shallow framework, where the features extraction and hash code projection are two separate steps. Thus, it may limit the robustness of the final learned hash functions and hash representations.
With the remarkable development in the field of artificial neural networks (ANN), deep neural networks (DNN) has shown their high performance at various multimedia tasks, such as Han, Laga & Bennamoun (2019), Girshick (2015), Wu et al. (2017b, 2017a), Guo et al. (2016a, 2016b), Mohammad, Muhammad & Shaikh (2019), Swarna et al. (2020), Muhammad et al. (2021), and Sarkar et al. (2021). Because of the significant capability of DNN in fitting non-linear correlations, it has been widely utilized for the task of cross-modal hashing retrieval, which simultaneously learns robust hash functions and hash representations in an end-to-end deep architecture. Moreover, DNN based models have illustrated great advantages over other hand-crafted shallow models. To name a few, Deep Cross-Modal Hashing (DCMH) (Jiang & Li, 2017), Self-Super Adversarial Hashing (SSAH) Li et al. (2018), Correlation Hashing Network (CHN) (Cao et al., 2016), Self-Constraint and Attention-based Hashing Network (SCAHN) (Wang et al., 2020a), Triplet-based Deep Hashing (TDH) (Deng et al., 2018), Self-Constraining and Attention-based Hashing Network (SCAHN) (Wang et al., 2020b), Pairwise Relationship Guided Deep Hashing (PRDH) (Yang et al., 2017) and Multi-Label Semantics Preserving Hashing (MLSPH) (Zou et al., 2021). However, these DNN based models still suffer from the following disadvantages. Firstly, the single-class label-based supervised information is adopted to measure the semantic similarity between inter and intra-modality instances. However, this oversimple measurement cannot fully exploit the fine-grained relevance, as the pairwise data from inter and intra-modality may share more than one label. Secondly, the abstract semantic features produced by the top layer of DNN are adopted to represent the semantic information of different modalities. However, the representations from the intermediate layer, which has specific information, are neglected. Moreover, this manner cannot fully make use of the multi-scale local and global representations, resulting in suboptimal hash representations.
In this paper, we propose a novel Hierarchical Semantic Interaction-based Deep Hashing Network (HSIDHN) to address the above-mentioned problems. As demonstrated in Fig. 1, the proposed HSIDHN consists of two essential components. One component is the backbone network used to extract the hierarchical hash representations from different modality data (e.g., images and text). The other one is the Bidirectional Bi-linear Interaction (BBI) module used to capture the hierarchical semantic correlation of each modality data from a different level. In the bidirectional bi-linear interaction module, a multi-scale and fusion process is first operated on each layer of the backbone network. The bidirectional interaction policy consisting of a bottom-top interaction and a top-bottom interaction is then designed to exploit the specific semantic information from different layers. And finally, each interaction is aggregated by a bi-linear pooling operation, and the interactions between bottom-up and up-bottom are concatenated together to enhance the capability of hash representations. Moreover, a dual-similarity measurement (“hard” similarity and “soft” similarity) is designed to calculate the semantic similarity of different modality data, aiming to better preserve the semantic correlation of multi-labels. The “hard” similarity means the instances share at least one label, while the “soft” similarity means the distribution difference between two label vectors measured by Maximum Mean Discrepancy (MMD).
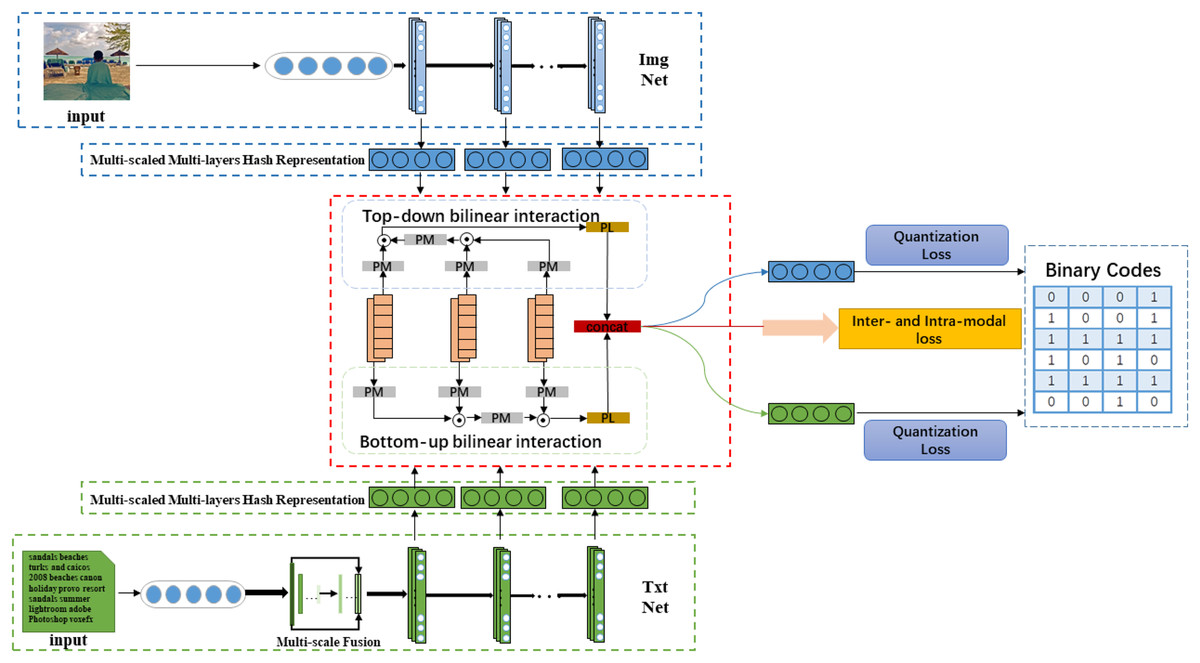
Figure 1: The architecture of our proposed HSIDHN which consists of two parts.
One component is the backbone network used to extract hash representations. The other one is the Bidirectional Bi-linear Interaction (BBI) module used to capture the hierarchical semantic correlation of each modality data from different levels.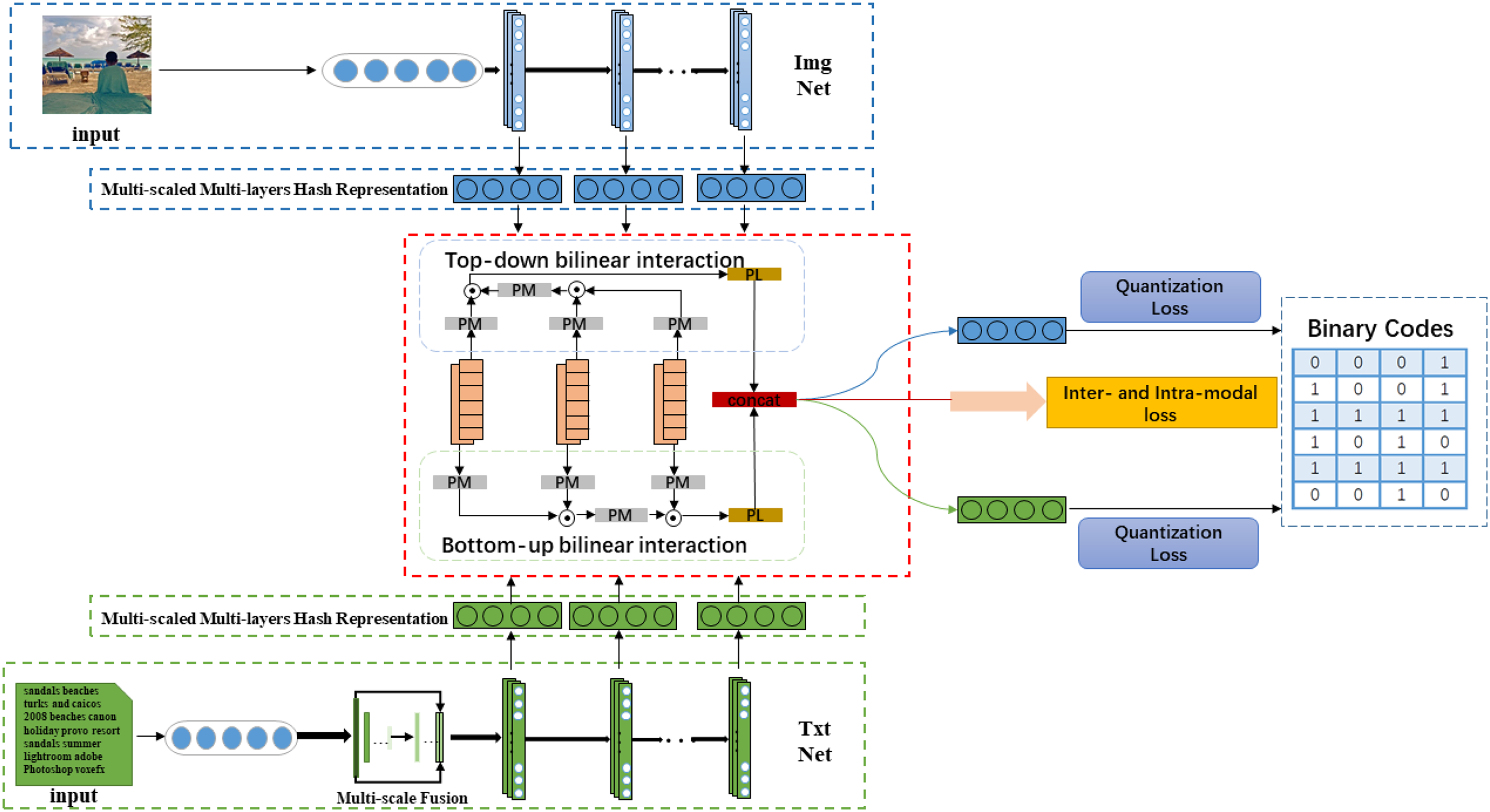{kind=link}
The main contributions of HSIDHN are summarized as follows:
-
Firstly, a novel bidirectional bi-linear interaction module is designed to achieve hierarchical semantic interaction for different modality data. The bidirectional bi-linear interaction policy could effectively aggregate the hash representations from multiple layers and explore pairwise semantic correlation, promoting significant parts from different layers in a macro view. Therefore, it could enhance the discrimination of final hash representations.
-
Secondly, a dual-similarity measurement using both a single class label constraint and Maximum Mean Discrepancy is proposed to map label vectors into the Reproducing Kernel Hilbert Space (RKHS). Thus, the semantic relationship of different modalities, especially instances with multi-labels, can be thoroughly explored.
-
Thirdly, we apply the HSIDHN model on two large-scale benchmark datasets with images and text modalities. The experiment results illustrated the HSIDHN surpasses other baseline models on the task of hashing-based cross-modal retrieval.
The rest of this paper is organized as follows. The related work is summarized in “Related Work”. The detailed description of HSIDHN for cross-modal retrieval is presented in “Proposed HSIDHN”. The experimental results and evaluations are illustrated in “Experiment”. Finally, we conclude this paper in “Conclusion”.
Related Work
Deep cross-modal hashing
In these years, deep learning has been widely used in cross-modal retrieval tasks due to its appealing performance in various computer vision applications such as Vasan et al. (2020), Dwivedi et al. (2021), Bhattacharya et al. (2020), Gadekallu et al. (2020), Jalil Piran et al. (2020), Jalil Piran, Islam & Suh (2018), and Joshi et al. (2018). It obtains hash representations and hash function learning in an optimal end-to-end framework which also demonstrates the robustness. One of the most typical is deep cross-modal hashing (DCMH) (Jiang & Li, 2017), which firstly applies the deep learning architecture to cross-modal hashing retrieval. The self-constraint and attention-based hashing network (SCAHN) (Wang et al., 2020a) explores the hash representations of intermediate layers in an adaptive attention matrix. The correlation hashing network (CHN) (Cao et al., 2016) adopts the triplet loss measured by cosine distance to reveal the semantic relationship between instances and acquires high-ranking hash codes. Pairwise relationship guided deep hashing (PRDH) (Yang et al., 2017) leverages pairwise instances as input for each modality where supervised information is fully explored to measure the distance of intra- and inter-modality, respectively. Cross-modal hamming hashing (CMHH) (Cao et al., 2018) learns high-quality hash representations and hash codes with a well-designed focal loss and a quantization loss. Although these algorithms mentioned above have obtained high performance in CMH tasks, they ignore the rich spatial information from intermediate layers, which is essential to the modality-invariant hash representations learning procedure.
Multi-label similarity learning
In the real-world scenario or benchmark datasets, instances are always related to multiple labels. Thus multi-label learning has attracted more and more attention in various applications. However, most existing CMH methods adopt single label constraints to measure the similarity among intra- and inter-modality instances. Self-supervised adversarial hashing (SSAH) (Li et al., 2018), which uses an independent network to learn multi-label representations, and thus the semantic correlations are preserved. However, it only takes the multi-label information to supervise the label network training, and the original images or text are still measured by single-label. Improved deep hashing network (IDHN) (Zhang et al., 2019) introduces pairwise similarity metrics to fit the multi-label instances applications. In contrast, this method concentrates on the single modality hashing retrieval. Different from these methods that apply multi-label information, our HSIDHN employs both single-label and multi-label constraint to learn more robust hash representations. Significantly, the Maximum Mean Discrepancy (MMD) is adopted as the multi-label calculation criterion. To our knowledge, the HSIDHN is the first method using MMD in the deep CMH framework.
Proposed HSIDHN
In this section, the problem definition, the details of Hierarchical Semantic Interaction-based Deep Hashing Network (HSIDHN), including feature extraction architecture, are presented one by one. Without losing generality, we assume each instance has both image-modality and text-modality. However, it can be easily extended to other modalities such as videos, audios and graphics.
Problem definition
We use uppercase letters to represent matrices, such as X, and lowercase letters representing vectors, such as y. The transpose of G are denoted as GT, and sign function sign(·) is defined as:
(1)
We assume the training dataset with N instances, which all of them have label information and image-text modality feature vectors. The ith training instance is denoted as , where vi ∈ and ti ∈ denote the dv and dt dimensional feature vectors of image and text respectively. Moreover, the label based semantic similarity matrix is defined as , where and denote the intra-modality similarity matrix of image and text, denotes the inter-modality similarity matrix between image and text. S* means the “hard” similarity and “soft” similarity when * = h or * = r.
Given the training datasets O and S, the main objective of our proposed HSIDHN is to learn two modality discriminative hash functions h(v)(v) and h(t)(t) for image and text modalities, which can map features vectors into a compact binary space and preserve relationship and correlation among instances. The learning framework can be roughly divided into two parts, hash representations learning section and hash function learning section. Therefore, and are used to denote the learned hash representations of image-modality and text-modality. Besides, is the projection of the final hash codes from F and G by simply using a sign function B = sign(F + G).
The architecture of our proposed HSIDHN which consists of two parts. One component is the backbone network used to extract hash representations. The other one is the Bidirectional Bi-linear Interaction (BBI) module used to capture the hierarchical semantic correlation of each modality data from different levels.
Network framework of HSIDHN
For most cross-modal hashing retrieval methods, the multi-level and multi-scale information cannot be fully explored. Thus, it may limit the invariance and discrimination of the final learned hash representations. In this paper, we propose a novel Hierarchical Semantic Interaction-based Deep Hashing Network (HSIDHN) for large-scale cross-modal retrieval, where a multi-level and multi-scale interaction based network and bidirectional bi-linear interaction module are used to explicitly specifics spatial and semantic information. The general architecture of our proposed HSIDHN is shown in Fig. 1.
In terms of the multi-level and multi-scale hash representations generation, HSIDHN contains double end-to-end network to learn hash functions and hash representations from text and image modality. The deep feature extraction procedure is conducted on Resnet (He et al., 2016), and pair-wise pairs of images and text are applied as input for the Image Network and Text Network. For the Text Network, the bag-of-words (BoW) vector policy has been widely adopted to extract features from Text Networks since Jiang & Li (2017). However, it is inappropriate to learn rich features demanded by the hash functions learning procedure because of BoW vectors’ sparsity. To solve this issue, a multi-scale operation is leveraged by multiple pooling layers, and the vectors are resized by bi-linear-interpolation. Finally, these vectors are concatenated together and fed to the text network, which consequently is helpful to construct semantic correlation for the text. Both image and text networks generate multi-level feature information from mid-layers by exploring an adaptive average pooling. Motivated by SPPNet (Purkait, Zhao & Zach, 2017), the multi-scale fusion structure is also applied to hash representations from each layer to obtain rich spatial information. Therefore, the semantic relevance and correlation from different layers can be fully explored to enhance the invariance of hash representations for both image and text modality. The whole architecture is shown in Fig. 2.

Figure 2: The generation of multi-scale and multi-level hash representations.
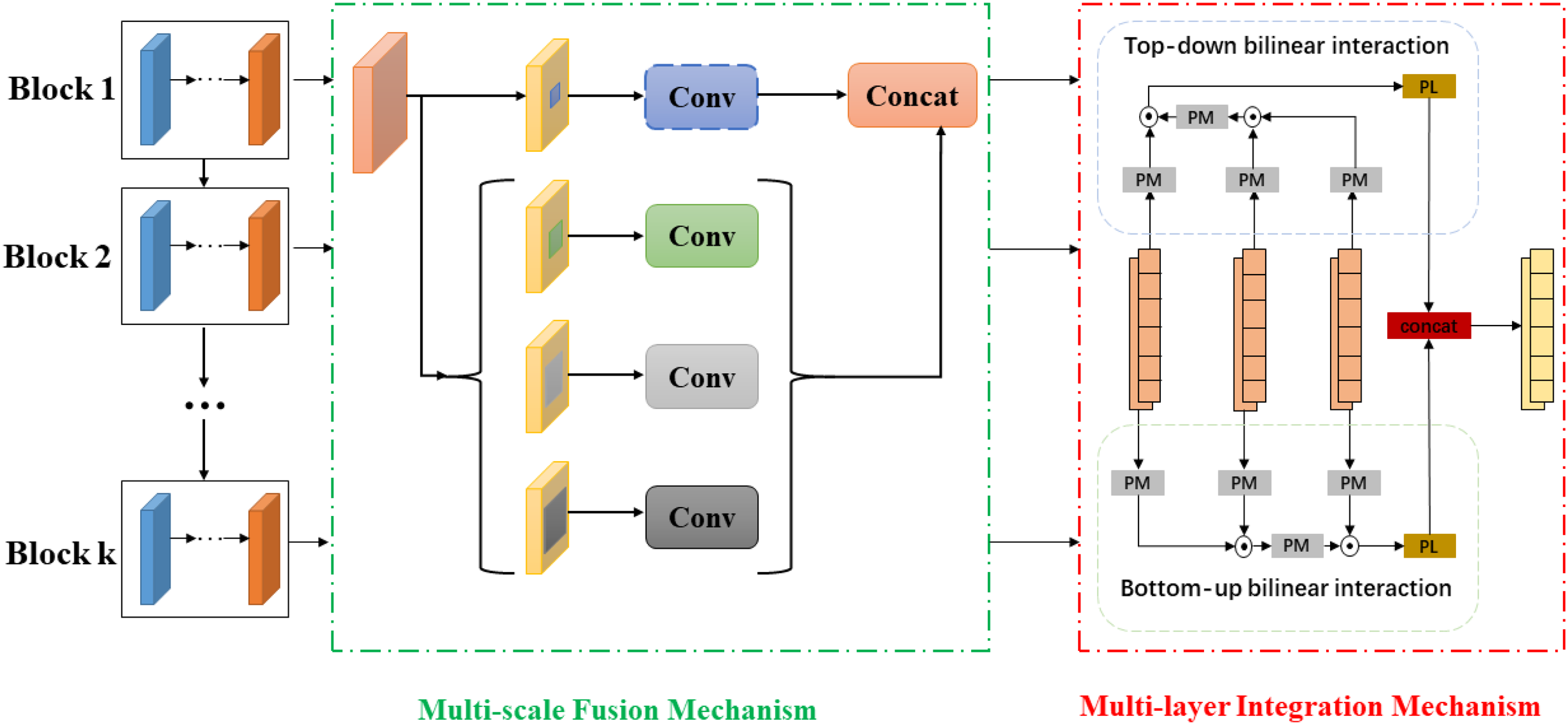{kind=link}
As different layers of the network have complementary hash representations. Thus the interaction among different layers may help to learn discriminative hash representations. A bidirectional bi-linear integration module integrates the multi-scaled multi-level hash representations from intermediate layers to learn more robust hash representations. The bidirectional bi-linear integration policy has two main procedures, the bottom-up and top-down progress. The bottom-up procedure allows shadow activation, which always being covered by the top layers to accumulate slowly. The top-down operation can take advantage of contextual and spatial information. Therefore, the combination of bottom-up and top-down interaction policy could generate better hash representations. We assume there are K multi-scaled and multi-levels hash representations generated from Resnet (He et al., 2016), and the f(k) and g(k) are output from Kth block.
Feeding an instance to the network, the output feature map is X ∈ Rc, where c is the dimension of X, and Z ∈ Ro is the bi-linear representation with dimension o. For Zi in , the bi-linear pooling interaction can be defined as:
(2) where Wi is the weighted projection matrix need to be learned, I(x, x) is the interaction function. According to Rendle (2010), the weighted projection matrix in Eq. (2) can be rewritten by factorizing as:
(3) where Ui ∈ Rc and Vi ∈ Rc. And consequently, the output features z is calculated as:
(4) where U, V and P are projection matrices.
The proposed bidirectional bi-linear integration policy aims to explore the interaction between intermediate layers. Taking the image modality as an example, we firstly select two layers fi and fj from multi-scaled multi-level hash representations. Hence, inspired by Yu et al. (2018), the Eq. (4) can be rewritten as:
(5) where P,U,V are projection matrices. To reduce number of parameters, the bi-linear pooling is divided into two stages, which can be formulated as:
(6)
(7)
Thus, the interaction between two layers can be defined as:
(8)
(9)
In this paper, the interaction is applied on multi-layer and the representation of each layers is defined as:
(10)
(11) where f1, f2, f3 and g1, g2, g3 are hash representations from different layers of image and text modality, and concat denotes the concatenation operation. However, the bi-linear pooling operation from one direction may lead to a vanishing gradient problem. This is because parameters from intermediate layers update faster than the end. Thus, the bidirectional bi-linear integration policy can be written as:
(12)
(13) where f1, f2, f3 and g1, g2, g3 are hash representations from different layers of image and text modality and concat denotes the concatenation operation. And Z1 and Z2 are the multi-layer interaction from bottom-up and top-down procedure.
Dual-similarity measurement
For most cross-modal retrieval benchmark datasets, it is common for an image or text to have multiple labels. Thus, the traditional methods, which only explore if labels are shared among instances, are not suitable for this situation. Therefore, to enhance the quality of similarity measurement, we propose a Dual-similarity evaluation strategy.
“Hard” similarity based hamming distance loss
We use to represent the “hard” similarity matrix. In this scenario, the similarity definition follows the identical way which is similar to the previous methods. Given the training instances oi and oj, the element of similarity matrix means the instances share at least one label, and thus the inner product of these two instance should be large, and otherwise. In the ImgNet and TxtNet, there are k parts of features, the k − th parts of the hash representations from networks are denotes as and . The likelihood function of image and text inter- and intra-instances are calculated as:
(14) where .
(15) where .
(16) where . α is a control hyper-parameter to self-adapt in different length of binary codes, which the value is set to and . The Hamming distance intra-loss of image and text and inter-loss can be defined as:
(17)
(18)
(19)
The overall “hard” similarity based hamming distance loss can be written as:
(20)
“Soft” similarity based mean square error loss
We use to represent the “Soft” Similarity matrix. In this scenario, we use the Maximum Mean Discrepancy (MMD) (Borgwardt et al., 2006) to measure the distance between two label vectors by projecting the original vector into a Reproducing Kernel Hilbert Space (RKHS). The “Soft” Similarity is defined as:
(21) where lv and lt denotes label vectors of image and text instances.
It is hard to find a suitable projection function ϕ(.) in cross-modal retrieval tasks. Thus, the formula of “Soft” is expanded as:
(22)
We can easily calculate the above formula by the kernel function k(*). The final definition of “Soft” Similarity is shown as:
(23) where lv is the label information of image modality and lt is the label information of text modality. denotes the number of instances.
Thus, according to Eq. (23), we apply this metric to define pairwise intra-modality similarity for image-modality and text-modality as:
(24)
(25) where k(*) is the Gaussian kernel since it can map the original label information to an infinite dimension.
As the similarity is continuous, the Mean Square Error (MSE) loss function is adopted to adapt the “Soft” Similarity. Besides, we apply both inter-and intra-modality constraint loss to bridge the heterogeneous gap and preserve the semantic relevance. Thus, the MSE loss is calculated as:
(26)
(27)
(28) where fi represents the hash representation of ith image instance, gj represents the hash representation of jth text instance and c is the length of binary codes. Since the inner product , the value range of will be the same as .
The overall “Soft” Similarity based MSE loss can be written as:
(29)
Quantization loss
The purpose of the dual-similarity based loss function is to guarantee the hash representations F, and G can preserve similarity. While the similarity of hash codes B(v) = sign(F) and B(t) = sign(g) has been neglected. Therefore, we also need to make sure that the binary codes B(v) and B(t) preserve the similarity, which is also the goal of cross-modal retrieval. As both B(v) and B(t) share the same label information in a mini-batch, the hash codes is set to B(v) = B(t) = B. Accordingly, the quantization loss is defined as:
(30)
Optimization
By aggregating the Eqs. (20), (29) and (30), we get the general objective function as:
(31) where θx and θy are network parameters of image and text, and B is the learned binary codes. γ and β are hyper-parameters to control each part’s weights in the general objective function. We adopt an alternating optimization algorithm, and some parameters are fixed while other parameters are optimized.
Fix B, optimize θx and θy
The back propagation (BP) algorithm is adopted to update parameters θDx, θDy by descending gradients:
(32)
Fix θx and θy, optimize B
As the θx and θy is fixed, the optimization of binary codes B can be defined as:
(33)
which can be formulated as:
(34)
Experiment
To evaluate the algorithm we proposed, two large-scale public datasets MIRFlickr-25k (Huiskes & Lew, 2008) and NUS-WIDE (Chua et al., 2009) are employed as our training data to compare with other sate-of-the-art cross-modal hashing methods.
Datasets
MIRFlickr-25K (Huiskes & Lew, 2008): There are 25,000 instances images in the MIRFlickr-25K collected from Flickr with several textual descriptions. Following the standard experimental settings proposed in DCMH (Jiang & Li, 2017), 20,015 data are samples are leveraged with less than 24 distinct labels. A 1,386-dimensional BoW vector is generated for each text description.
NUS-WIDE (Chua et al., 2009): There are 269,468 image-text instances pair belonging to 81 categories collected from real-world web datasets. Each textual description for image instance is represented by a 1,000-dimensional binary vector. In this paper, 21 of the most frequently used categories are chosen with 190,421 images and related text.
We randomly select 10,000 and 10,500 instances from MIRFlickr-25K and NUS-WIDE as the training set to reduce the computational cost. Meanwhile, we randomly choose 2,000 and 2,100 samples as the query set for MIRFlickr-25k and NUS-WIDE, respectively. The remained data are leveraged as a retrieval set after the query set is selected. Images are normalized before inputting to the network. The details of dataset division are summarized in Table 1.
| Dataset name | Total number | Training set/test set |
|---|---|---|
| MIRFLlickr-25K | 20,015 | 10,000/2,000 |
| NUS-WIDE | 190,421 | 10,500/2,100 |
Implementation details
Our HSIDHN is implemented using the Pytorch (Paszke et al., 2019) framework and performed on one TITAN Xp GPU server. In the end-to-end framework, Resnet-34 is applied as the backbone network. For the bidirectional bi-linear interaction module, the last three parts of hash representations are integrated to enhance the capability hash representations, respectively. Moreover, the multi-scale fusion of text is applied on pooling sizes of 1, 5, 10, 15, 30. The image network parameters initialization is pre-trained on the ImageNet (Russakovsky et al., 2015) dataset, and the network for text-modality is initialized by Normal distribution with μ = 0 and σ = 0.1. Learning rate is initialized in 10−1.1 and gradually decays to 10−6.1, and the mini-batch size is 128. Besides, we use the SGD as our optimization for image and text networks.
Evaluation and baselines
To measure CMH methods’ performance, we adopt hamming ranking as the retrieval protocol, which sorting instances by hamming distance. In this paper, the PR Curves and Mean Average Precision (MAP) (Liu et al., 2014) are leveraged as the evaluation criteria for HSIDHN.
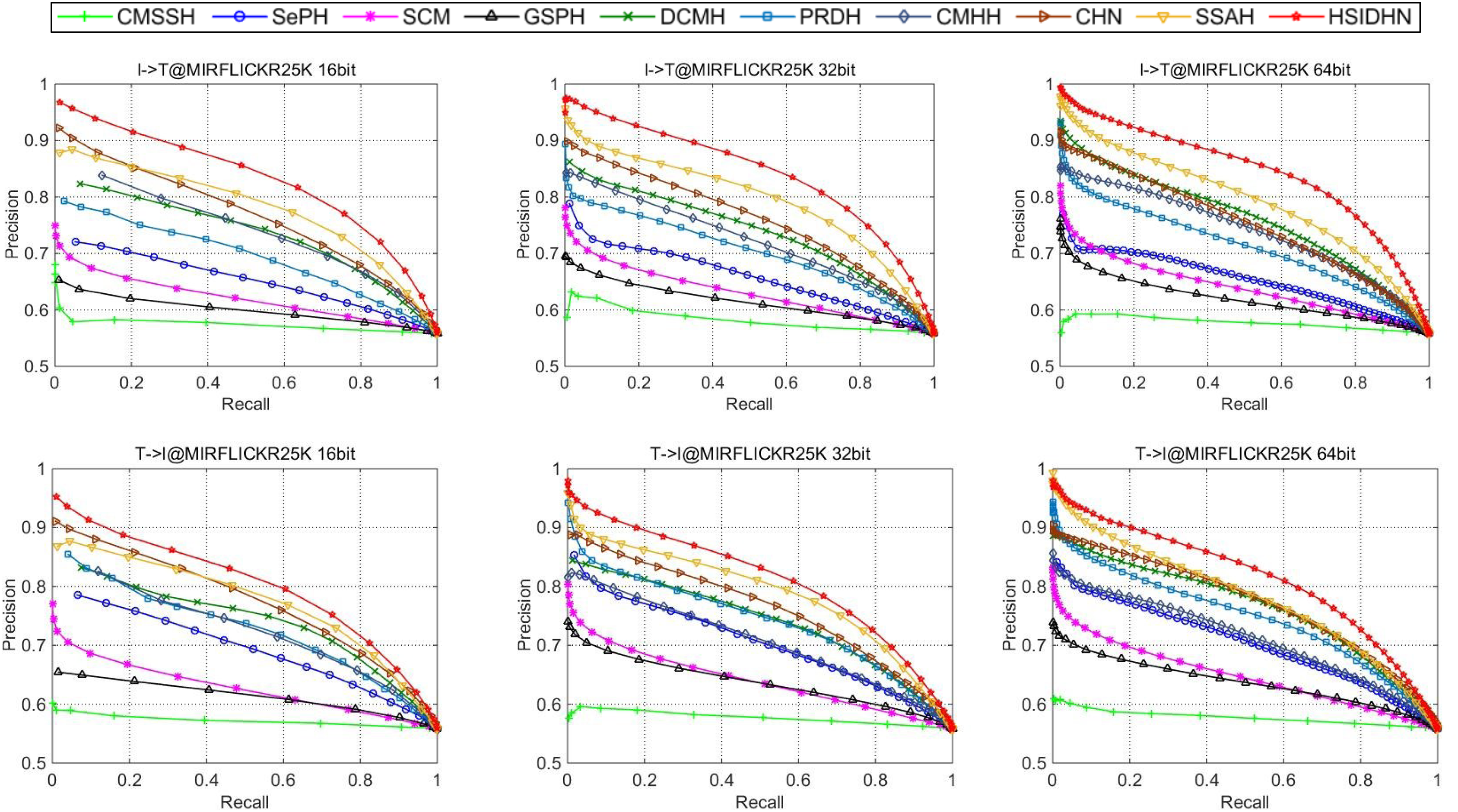
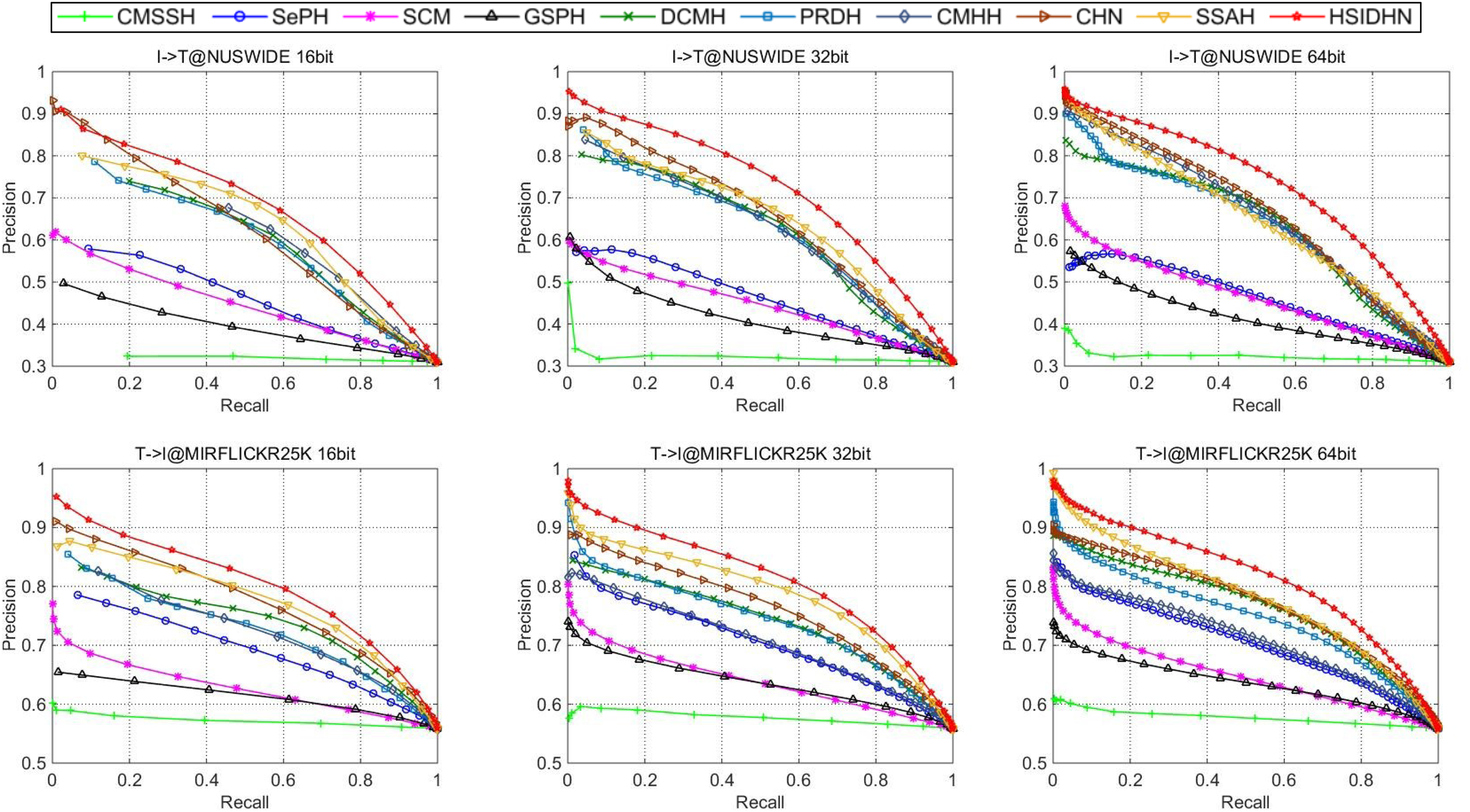
The HSIDHN is compared with several baseline methods including SCM (Zhang & Li, 2014), DCMH (Jiang & Li, 2017), CMHH (Cao et al., 2018), PRDH (Yang et al., 2017), CHN (Cao et al., 2016), SepH (Lin et al., 2015) and SSAH (Li et al., 2018). Table 2 and Table 3 illustrates the MAP results of HSIDHN and other methods in different lengths of hash codes. Fig. 3 and Fig. 4 demonstrate the PR curves of different length of hash codes conducted on MIRFlickr-25K and NUS-WIDE. From the result, we can get the following observations and analysis.
-
HSIDHN dramatically exceeds other methods on different lengths of hash codes in consideration of the MAP, which reveals the advantages of the multi-scale and multi-level interaction module. It is worth nothing that HSIDHN outperform DCMH by 9.8–3.9% and 17.77–12.93% in terms of MAP for Image-query-Text and Text-query-Image tasks on MIRFLICKR-25K and NUS-WIDE. This is mainly because that the multi-scale process could explore different receptive field of input data, where information with different size could be fully used. Additionally, the hierarchical feature interaction could explore the useful specific feature from different layer and integrated them to enhance the capability of final hash representations.
-
The high performance of HSIDHN is partly because the semantic relation and correlation from different intermediate layers are explored by bidirectional bi-linear interaction module. Besides, the multi-scale fusion could further make full use of leverage spatial information.
-
There is a kind of imbalance between the performance of image-query-text and text-query-image in almost all the other baselines. However, this phenomenon could be effectively avoided in HSIDHN. This is mainly due to the dual-similarity measurement, which can be sufficient to unify the image-modality and text-modality in the latent common space.
-
All deep CMH methods, including DCMH, CHN, PRDH, CMHHH, and SSAH obtain higher performance than other shadow hashing methods such as SePH and SCM. This demonstrates the effectiveness and efficiency of deep neural networks in hash representations and hash function learning, which is more robust than the non-deep neural network methods. Thus, deep neural network based deep hashing methods could obtain better performance.
| MIRFLICKR-25K | ||||||
|---|---|---|---|---|---|---|
| Method | Image-query-text | Text-query-image | ||||
| 16 bits | 32 bits | 64 bits | 16 bits | 32 bits | 64 bits | |
| SCM Zhang & Li (2014) | 0.6354 | 0.5618 | 0.5634 | 0.6340 | 0.6458 | 0.6541 |
| SePH Lin et al. (2015) | 0.6740 | 0.6813 | 0.6830 | 0.7139 | 0.7258 | 0.7294 |
| DCMH Jiang & Li (2017) | 0.7316 | 0.7343 | 0.7446 | 0.7607 | 0.7737 | 0.7805 |
| CHN Cao et al. (2016) | 0.7504 | 0.7495 | 0.7461 | 0.7776 | 0.7775 | 0.7798 |
| PRDH Yang et al. (2017) | 0.6952 | 0.7072 | 0.7108 | 0.7626 | 0.7718 | 0.7755 |
| SSAH Li et al. (2018) | 0.7745 | 0.7882 | 0.7990 | 0.7860 | 0.7974 | 0.7910 |
| CMHH Cao et al. (2018) | 0.7334 | 0.7281 | 0.7444 | 0.7320 | 0.7183 | 0.7279 |
| HSIDHN | 0.7978 | 0.8097 | 0.8179 | 0.7802 | 0.7946 | 0.8115 |
| NUS-WIDE | ||||||
|---|---|---|---|---|---|---|
| Method | Image-query-text | Text-query-image | ||||
| 16 bits | 32 bits | 64 bits | 16 bits | 32 bits | 64 bits | |
| SCM Zhang & Li (2014) | 0.3121 | 0.3111 | 0.3121 | 0.4261 | 0.4372 | 0.4478 |
| SePH Lin et al. (2015) | 0.4797 | 0.4859 | 0.4906 | 0.6072 | 0.6280 | 0.6291 |
| DCMH Jiang & Li (2017) | 0.5445 | 0.5597 | 0.5803 | 0.5793 | 0.5922 | 0.6014 |
| CHN Cao et al. (2016) | 0.5754 | 0.5966 | 0.6015 | 0.5816 | 0.5967 | 0.5992 |
| PRDH Yang et al. (2017) | 0.5919 | 0.6059 | 0.6116 | 0.6155 | 0.6286 | 0.6349 |
| SSAH Li et al. (2018) | 0.6163 | 0.6278 | 0.6140 | 0.6204 | 0.6251 | 0.6215 |
| CMHH Cao et al. (2018) | 0.5530 | 0.5698 | 0.5924 | 0.5739 | 0.5786 | 0.5889 |
| HSIDHN | 0.6498 | 0.6787 | 0.6834 | 0.6396 | 0.6529 | 0.6792 |

Figure 3: Performance on MIRFlickr-25K evaluated by PR curves.
{kind=link}

Figure 4: Performance on NUS-WIDE evaluated by PR curves.
{kind=link}
Ablation study
In this section, the importance of each component of HSIDHN is validated. To evaluate the effect of the different modules, the settings of experimental are defined as:
-
HSIDHN-SIM is designed by replacing the dual-similarity by single hamming distance measurement.
-
HSIDHN-BBI is designed by removing the interaction between layers, and the final hash representations are generated from the final layer of the network.
The results of the ablation study are shown in Table 4. Firstly, there is no doubt that the dual-similarity measurement is better than the hamming-based distance. This is mainly due to that the fine-grained dual-similarity could better preserve the semantic relationship. Moreover, the performance experiences a significant drop when the BBI policy is removed. This may partly because the BBI policy can explore the more robust hash representations from intermediate layers of networks.
| Method | MIRFLICKR-25K | NUS-WIDE | ||
|---|---|---|---|---|
| Image-query-text | Text-query-image | Image-query-text | Text-query-image | |
| HSIDHN-SIM | 0.8140 | 0.8097 | 0.6432 | 0.6401 |
| HSIDHN-BBI | 0.8034 | 0.8004 | 0.6316 | 0.6275 |
| HSIDHN | 0.8179 | 0.8115 | 0.6834 | 0.6792 |
Time complexity
The Eq. (31) is taken as the final loss function to train. Each term of the Eq. (31) is MSE loss or max log-likelihood loss which are general in cross-modal retrieval applications. A server with a Titan Xp card is leveraged to train. For the whole HSIDHN, the training and validation procedure need around 28 h for MIRFLICKR-25K and 53 h for NUS-WIDE. The proposed HSIDHN have a fast convergence rate than other deep hashing methods, as the introduction of bidirectional bi-linear interaction and dual-similarity measurement.
Limitation of HSIDHN and future work
Although the appealing performance has been obtained in the HSIDHN framework, there are still some limitations. Firstly, the network architecture, especially the multi-scale and multi-level features extraction process, requires huge GPU memory to train. The model compression might be the possible solution to solve it. Secondly, the performance of text-query-image is not as significant as image-query-text. This is partly because of the sparsity of features learning from text modality. Some pretraining model is the possible way to learn higher quality features from the original text.
Conclusion
In this paper, an efficient and effective framework called HSIDHN is proposed for cross-modal hashing retrieval tasks. HSIDHN has three main benefits over the existing methods in CMH community. Firstly, a multi-scale fusion and a Bidirectional Bi-linear Interaction (BBI) module are designed in our framework, with the goal of learning modal-specific hash representations and discriminative hashing codes. Additionally, a dual-similarity measurement strategy is proposed to calculate the fine-grained semantic similarity for both intra and inter-modality pairwise labels. Finally, but certainly not least, experimental results on two large scale benchmark datasets illustrate the superiority of HSIDHN compared with other baseline methods.