
Abstract
Sui and colleagues (Journal of Experimental Psychology: Human Perception and Performance, 38, 1105–1117, 2012) introduced a matching paradigm to investigate prioritized processing of instructed self-relevance. They arbitrarily assigned simple geometric shapes to the participant and two other persons. Subsequently, the task was to judge whether label-shape pairings matched or not. The authors found a remarkable self-prioritization effect, that is, for matching self-related trials verification was very fast and accurate in comparison to the non-matching conditions. We analyzed whether single features or feature conjunctions are tagged to the self. In particular, we assigned colored shapes to the labels and included partial-matching trials (i.e., trials in which only one feature matched the label, whereas the other feature did not match the label). If single features are tagged to the self, partial matches would result in interference, whereas they should elicit the same data pattern as non-matching trials if only feature conjunctions are tagged to the self. Our data suggest the latter; only feature conjunctions are tagged to the self and are processed in a prioritized manner. This result emphasizes the functionality of self-relevance as a selection mechanism.
Similar content being viewed by others


Multiple information simultaneously reach our brain in everyday life and appropriate selection is indispensable to distinguish between significant and less significant information. A dimension to identify important information is self-relevance. Consequently, self-relevant content allocates attention automatically (Alexopoulos, Muller, Ric, & Marendaz, 2012) and is prioritized against non-self-relevant stimuli (Bargh, 1982; Gray, Ambady, & Lowent, 2004).
An important question concerns how stimuli become self-relevant. Recent evidence suggests that this process is much faster than previously assumed and that formerly neutral stimuli can be associated arbitrarily with the self after a simple instruction to do so (Sui, He, & Humphreys, 2012). In particular, Sui and colleagues introduced a paradigm in which participants learned associations of simple geometric forms with themselves, a familiar person, or a neutral instance. In a subsequent matching task, form-label pairings were presented and participants had to judge whether the pairings fitted to the previously learned associations. In several experiments, a prioritization of self-relevant trials was found in that correct self-relevant pairings were verified faster and more accurate than correct non-self-relevant pairings. This self-prioritization in the matching task has been replicated several times (Sui, Rotshtein, & Humphreys, 2013; Schäfer, Wentura, & Frings, 2015), its neuronal correlates have been investigated (Sui, Rotshtein, & Humphreys, 2013), and it has been extended from perception to action (Frings & Wentura, 2014).
The present paper is concerned with the cognitive representation of this new kind of instructed self-relevance. In all published experiments using the matching task, participants were instructed to tag an arbitrary shape (which was not shown but only instructed by a verbal description) to a particular label (the word “you”, “mother”, or “stranger”, for example). Then participants had to evaluate whether label-shape pairings matched the learned associations. For example, participants might have been instructed to tag a triangle to their self. After a few matching trials they knew how the particular triangle looked like (i.e., its color, specific shape, and size). Yet, are the single features of the triangle tagged to the self or is it the object in its specific feature configuration that becomes associated with the self?
Looking at the literature, both alternatives seem possible. On the one hand, one could presume that individual features of the matched stimulus are bound to the self. Such independent bindings between single features have been shown in the literature on stimulus-response binding. In particular, it has been argued that several features of one stimulus are connected to a response via separate binary bindings resulting in a number of binary bindings loosly connected and integrated in a so-called event file (Hommel & Colzato, 2004). Another important aspect of binding is that the perception of one of the integrated features induces the retrieval of the complete event file including the response (Hommel, 1998, 2004). Moreover, bindings might include perceptual as well as abstract information (Henson, Eckstein, Waszak, Frings, & Horner, 2014) and the mere planning of a response on a specific stimulus elicits a binding between the stimulus and the response, without executing the response (Wenke, Robert, & Nattkemper, 2007). By analogue, it can be hypothesized that after a few trials in the matching paradigm binary bindings between the features (color, shape, etc.) of the particular stimulus and the self have been generated. We will refer to this model as the binary model.
On the other hand, one might hypothesize that a holistic configuration of all features is bound to the self. This assumption can be backed up by findings from research on face processing, suggesting that the holistic composite of features is automatically extracted and effortlessly processed upon face presentation (Allison, Puce, Spencer, & McCarthy, 1999; cf. Rossion, 2014). Holistic processing can be found in more basic research as well: Using feature conjunctions in interference tasks suggests that only the complete repetition of the conjunction leads to interference (Khurana, Smith, & Baker, 2000, for evidence from a negative priming paradigm). Accordingly, one could presume that the complete feature conjunction of the matched stimulus is bound to the self. We will refer to this model as the conjunction model.
To distinguish between these possibilities, we modified the matching paradigm in that the self, a familiar person, and a neutral instance were associated with two particular features (color and shape). Participants learned, for example, the sentences “I am the red triangle. My mother is the blue circle. The chair is the green square.” In the subsequent matching task, pairings of the labels and colored shapes were shown which were either matching according to the learned associations (e.g., “I” with a red triangle), partially matching (e.g., “I” with a red square), or non-matching (e.g., “I” with a blue square).
Both models actually predict a benefit in matching trials compared with non-matching trials, because self-prioritization is expected in matching but not in non-matching trials. Moreover, the binary model suggests highest reaction times (RTs) in partial-matching trials, because one feature retrieves a matching label while the other feature retrieves a non-matching label. Dissolving this conflict will result in partial-matching costs, that is, increased RTs and/or error rates (comparable to stimulus-response binding where the perception of each feature introduces the retrieval of the corresponding response; Hommel, 2004). Above that, prioritized processing of self-related features will increase the conflict for self-relevant partial-matching trials, resulting in even higher costs in self-relevant partial matches (compared with non-self-relevant partial matches). In contrast, the conjunction model suggests that partial matches should elicit the same performance as non-matches, because only the complete configuration retrieves the corresponding label (Khurana, Smith, & Baker, 2000). Accordingly, response times should be comparable to those in non-matching trials. Figure 1 depicts the two competing models and the particular predictions.

Two models and the particular predicted outcomes. Note that the assumption of slightly decreased RTs for “mother”-matching trials compared to “chair”-matching trials is based on prior research (Sui et al., 2012)
Method
Participants
Sixty students from the University of Trier (43 females) took part in the experiment receiving course credit. Mean age was 23.5 (range 19-37) years, and all participants had normal or corrected-to-normal vision. Four participants were excluded, because they were outliers (i.e., far-out values according to Tukey, 1977) either according to the number of errors or the mean RT over all conditions, resulting in a sample size of 56 participants.
Design
The experiment comprised a 3 (matching condition: matching vs. partial matching vs. non-matching) × 3 (label: I vs. mother vs. chair) within-participant design. The assignment of label and stimulus was balanced across participants following a Latin square.
With regard to power considerations, we focused on two effects. One difference between the two hypotheses concerns the main effect of matching condition (i.e., different RTs in matching, partial-, and non-matching trials due to different effects of the label within each matching condition). The other difference concerns the contrast between self-relevant and non-self-relevant partial-matching trials. Because an acceptance of the null hypothesis would be interpreted in favor of the conjunction model, we set β = α = 0.05. The self-prioritization effect (as the difference between the mean RT in self-relevant matching trials and the mean RT in non-self-relevant matching trails) was rather large in previous studies (dz > 0.81 in Sui et al., 2012). Thus, the assumption of dz = 0.50 (i.e., a “medium” effect as defined by Cohen, 1988) for the effects described above seems to be quite conservative. To detect an effect of this magnitude with a probability of 1 - β = 0.95 and α-value of 0.05, a sample size of 54 participants was required (G*Power 3.1.3, Faul, Erdfelder, Lang, & Buchner, 2007).
Material and apparatus
The experiment was conducted using standard PCs with TFT monitors that had display resolutions of 1680 x 1050 pixels, standard German QWERTZ keyboards, and E-Prime 2.0 software. Stimuli were the German words Ich [I], Mutter [mother], and Stuhl [chair] presented in white on black background. The geometric forms were square, circle, and triangle. Words were presented in Courier New, with a viewing distance of 60 cm resulting in a visual angle of approximately 0.57°. All stimuli were presented at the screen center, stimuli at a visual angle of 8.26° from the upper border of the screen, a fixation cross at 10.32°, and the label at 12.37°. The geometric forms were presented subtending each about 3.15° × 3.15° visual angle.
Procedure
Participants were tested individually in soundproof chambers. Task instructions were given on the screen and summarized by the experimenter. The experiment consisted of a learning phase and an experimental phase. In the learning phase, the three label-stimulus assignments (one assignment for each label) were shown on the display for 60 seconds. For a particular participant this instruction might read: “I am the red triangle. My mother is the green square. The chair is the blue circle.” Participants were instructed to place the index finger of the left hand on the S-key (non-matching response) and the index finger of the right hand on the L-key (matching response).
In the experimental phase, each trial started with a 500-ms presentation of a black screen, followed by a fixation cross for 500 ms, the label-stimulus assignment for 100 ms, and another black screen until the participant responded or 1500 ms had elapsed. Participants’ task was to judge whether the displayed label-stimulus pairing corresponded to the initially learned assignment or not. They were explicitly instructed that only assignments with the correct stimulus and the correct color should be classified as matching assignments. Assignments with only one correct feature, that is, when either the color or the shape of the stimulus corresponds to the learned assignment, should be classified as non-matching assignments.
One experimental session consisted of a practice block with 36 trials and an experimental block with 216 trials. In the experimental block, each label was presented in 72 trials, one third with matching assignments, one third with partial-matching assignments (to be classified as non-matching assignments), and one third with non-matching assignments. The same proportions were realized in the practice trials. Trials were presented in random order.
Results
Only correct responses with RTs above 100 ms and below 3 interquartile ranges above the third quartile of the overall RT distribution (far-out values according to Tukey, 1977) were used for the RT analysis. Averaged across participants, 92.2 % of the trials were selected for RT analysis; 7.1 % of the trials were excluded because of erroneous responses and 0.7 % due to the RT outlier criteria. Mean RTs and error rates are shown in Table 1.
Reaction times
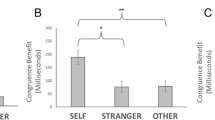
In a 3 (matching condition: matching vs. partial matching vs. non-matching) × 3 (label: I vs. mother vs. chair) repeated-measures MANOVA (see O'Brien & Kaiser, 1985, for the use of MANOVA analyzing repeated - measures designs) with mean RTs as the dependent variable, the main effect of label missed the conventional criterion of significance, F(2,54) = 2.87, p = .065, ηp 2 = 0.10, whereas the main effect of matching condition was significant (we will consider this effect below). We expected the interaction of label and matching condition to be significant; this was indeed the case with F(4,52) = 5.34, p = 0.001, ηp 2 = 0.29, indicating that the effect of the label differs according to the matching condition. Following this interaction and according to Sui et al. (2012), each matching condition was analyzed separately. In the matching condition, a one-factorial MANOVA with the within-participant factor label revealed a significant main effect of the label, F(2,54) = 8.73, p = 0.001, ηp 2 = 0.24; that is, mean RTs varied significantly in dependence of the label. Helmert contrasts revealed a self-prioritization effect, indicating faster RTs in self-relevant matching trials (with the label “I”) compared with the average mean RT in non-self-relevant matching trials (with the label “mother” or the label “chair”), F(1,55) = 9.29, p = 0.004, ηp 2 = 0.15. The second Helmert contrast (“mother” vs. “chair”) was significant as well, F(1,55) = 8.64, p = 0.005, ηp 2 = 0.14, RTs in matching trials with the label “mother” were faster than matching trials with the label “chair” (Fig. 2).Footnote 1 Comparable to Sui and colleagues’ findings, in the non-matching trials, the label did not affect performance at all, F(2,54) = 2.43, p = 0.097, ηp 2 = 0.08. In the partial-matching condition, a one-factorial MANOVA with the within-participant factor label yielded a non-significant main effect, F < 1, indicating that even in partial-matching trials mean RTs did not vary in dependence of the label.

Mean RTs as a function of label and matching condition. Error bars depict confidence intervals (95 %) for a repeated-measures design according to Jarmasz & Hollands, 2009
More relevant for testing the predictions of the binary versus conjunction model was the significant main effect of matching condition in the 3 × 3 MANOVA, F(2,54) = 13.24, p < 0.001, ηp 2 = 0.33, indicating that RTs differed according to the matching of the label-stimulus pairing (averaged across all labels). Simple contrasts revealed significantly faster mean RTs in matching trials compared to mean RTs in partial-matching trials, F(1,55) = 15.31, p < 0.001, ηp 2 = 0.22, but no significant difference between mean RTs in partial- and non-matching trials, F(1,55) = 2.08, p = 0.155. That is, participants responded faster in matching trials than in partial- and non-matching trials, but partial- and non-matching trials did not differ significantly (Fig. 2). Thus, no partial-matching costs emerged.
To test our second prediction of the binary model, we checked whether partial-matching costs in self-relevant trials were covered by certain effects in non-self-relevant trials. A one-factorial MANOVA on self-relevant trials with the within-participant factor matching condition revealed a significant main effect, F(2,54) = 30.48, p < 0.001, ηp 2 = 0.53, yet a comparison of partial-matching and non-matching trials showed that participants did not respond more slowly in partial-matching trials (actually, they responded even faster in partial-matching trials, F(1,55) = 4.54, p = 0.038, ηp 2 = 0.08).
Error rates
A 3 (matching condition: matching vs. partial-matching vs. non-matching) × 3 (label: I vs. mother vs. chair) repeated-measures MANOVA with error rates revealed no significant main effect of label, F < 1, but a significant main effect of matching condition, F(2,54) = 28.98, p < 0.001, ηp 2 = 0.52, and a significant interaction of both, F(4,52) = 4.14, p = 0.006, ηp 2 = 0.24.
The interaction indicated a modulation of the effect of the label due to the matching condition. Thus, one-factorial MANOVAs with the within-participant factor label in each matching condition were computed but revealed no significant effects. In matching trials, neither the main effect of label, F(2,54) = 2.22, p = 0.119, nor the Helmert contrast, indicating the difference between self- and non-self-relevant trials, F(1,55) = 1.76, p = 0.191, was significant. Furthermore, neither in partial-matching (F(2,54) = 3.11, p = 0.053, for the main effect, F(1,55) = 2.03, p = 0.160, for the Helmert contrast) nor in non-matching trials (F(2,54) = 1.52, p = 0.227, for the main effect, F(1,55) = 1.62, p = 0.208, for the Helmert contrast) the label affected error rates significantly.
The main effect of matching condition in the 3 × 3 MANOVA showed that error rates differed according to the matching of the label-stimulus pairing. Simple contrasts revealed a significant difference between error rates in matching and partial-matching trials, F(1,55) = 48.90, p < 0.001, ηp 2 = 0.47, but no significant difference between error rates in partial- and non-matching trials, F < 1. That is, participants made more errors in matching trials but did not make more errors in partial-matching than in non-matching trials, indicating no partial-matching costs in error rates.
A one-factorial MANOVA on self-relevant trials with the within-participant factor matching condition showed a significant main effect, F(2,54) = 6.51, p = 0.003, ηp 2 = 0.19, but simple contrast comparing partial- and non-matching trials indicated that participants did not make more errors in partial-matching trials, F < 1.
Discussion
We replicated the self-prioritization effect in that RTs were significantly faster for verifications of self-relevant matching trials than for verifications of non-self-relevant matching trials. Second, we replicated that this pattern of means was exclusively for the matching trials, that is, in the non-matching trials no effect of label was observed. These parts of the data pattern are in line with all the published evidence from the matching paradigm (Sui et al., 2012).
Most importantly for our research question was the performance in partial-matching trials, in detail, whether partial repetitions of self-associated features result in interference or not. In fact, the observed data pattern was in line with the conjunction model in all aspects. In particular, RTs in matching trials were faster compared to RTs in non-matching trials, due to a self-prioritization effect working only in matching trials. In addition, partial matches did not result in interference (regardless of the particular label) and performance was comparable to non-matches. Furthermore, the different label conditions were comparable within the partial-matching trials; hence, the self-relevant label did not affect performance in partial matches. As a consequence, the binary model cannot explain the observed data pattern. The cognitive representation of instructed self-relevance comprises feature conjunctions.
Our argument in deciding whether instructed self-relevance is holistic or binary was whether single features or conjunctions are tagged to the self. One might argue that we have played it unfair. In actual fact, we instructed conjunctions (“You are the red triangle.”) and we reinforced conjunctions (only if both features matched, a matching response had to be given). However, binding models would still predict partial-matching costs, because the idea would be that one particular feature (say the shape) becomes bound to another particular feature (say the matching label); accordingly in partial-matching trials the two stimulus features each retrieve possibly different labels (e.g., the shape might be tagged to the label “mother” while the color might be tagged to the label “I”) thereby causing interference, which should lead to higher RTs. This was not the case in our data.
Note that, according to visual attention theories, stimulus conjunctions (i.e., objects) are supposed to be processed at a quite late stage of processing, whereas single features are processed in a preattentive stage (Treisman & Gelade, 1980; Wolfe, 1994). Our results indicate that the SPE occurs at rather late stages of visual processing. Hence, one implication would be that the number of features tagged to the self is irrelevant, because only the whole object is associated with the self and profits from prioritization.
Whereas in previous studies dealing with self-relevant content the self-relevant material (e.g., participant’s own name, autobiographical information) was highly overlearned, this confound is eliminated in the matching paradigm. Consequently, the results gathered with the matching paradigm in general speak in favor of the attention allocating potential of self-relevant information independent of the learning history. Our results suggest as well how easily self-relevance can be acquired. Most importantly, it suggests that objects comprising several features immediately acquire the status of a self-relevant item. The assumption of a fast and general tendency to tag complex contents to the self, whenever it appears to be appropriate, is sustained by the variety of stimuli that can be used in the matching task. The prioritization of self-related pairings after the assignment of movements with the self (Frings & Wentura, 2014) indicates the SPE’s independence of the associated stimulus material. Above that, not only associations with the label “I” but even with other self-related stimuli reveal prioritization. That was shown by a study in which four geometric forms were associated with four badges either of a favorite, a rival, or two neutral football teams, and later responses to favorite-associated pairings were faster and more accurate than responses to rival-associated pairings (Moradi, Sui, Hewstone, & Humphreys, 2015).
The observed effects in the matching paradigm use direct instructions to create self-relevance and a task in which participants are required to evaluate these instructions (as a result the instruction is task-relevant). It is clear that self-relevance in real life is usually not acquired this way. So one challenge for research with the matching task will be to analyze the relationship of instructed self-relevance with previous research on self-relevance. In this regard, one might link instructed self-prioritization to research on self-relevance and extension of the self. Recent research on the mere ownership effect in memory (Cunningham, Turk, Macdonald, & Macrae, 2008) shows that objects (i.e., meaningful feature configurations) that are randomly assigned to the self are better remembered than objects assigned to someone else. This effect seems to be a mere effect of extending the self to objects (Kim & Johnson, 2010, for neurocognitive evidence). Thus, the self-prioritization of feature conjunctions (i.e., objects) resembles the mere ownership effect and complements research on the extended self in general and supports the pivotal role of the me/mine—not me/not mine border in our psychic life (Belk, 1988).
Self-prioritization is characterized by an automatic attention allocation through self-relevant stimuli and therefore allows for fast processing of highly relevant information in everyday life. However, such prioritized processing of information appears useful only if the boundaries of self-relevance are fairly strict, as loose boundaries would possibly increase the number of potentially relevant stimuli and false alarm rates, thereby invalidating the function of self-relevance as a selection mechanism. Thus, prioritization of stimuli that share only simple features with a self-relevant stimulus would reduce our sensitivity for important information and redirect our attention to potentially less important information. Summarized, it is very adaptive and functional that self-prioritization affects only conjunctions and is unaffected by partial matches.
Notes
In fact, a follow-up test comparing RTs in self-relevant matching trials with RTs in matching trials with the label “mother” missed the conventional criterion of significance, t(55) = 1.50, p = .07 (one-tailed). Given prior research using this paradigm (e.g., Sui et al., 2012), however, it is within the range of expectations that “mother” shows a prioritization effect compared to neutral labels, though extenuated with regard to the self.
References
Alexopoulos, T., Muller, D., Ric, F., & Marendaz, C. (2012). I, me, mine: Automatic attentional capture by self‐related stimuli. European Journal of Social Psychology, 42, 770–779. doi:10.1002/ejsp.1882
Allison, T., Puce, A., Spencer, D. D., & McCarthy, G. (1999). Electrophysiological studies of human face perception. I: Potentials generated in occipitotemporal cortex by face and non-face stimuli. Cerebral Cortex, 9, 415–430.
Bargh, J. A. (1982). Attention and automaticity in the processing of self-relevant information. Journal of Personality and Social Psychology, 43, 425–436. doi:10.1037/0022-3514.43.3.425
Belk, R. W. (1988). Possessions and the extended self. The Journal of Consumer Research, 15, 139–168.
Cohen, J. (1988). Statistical power analysis for the behavioral sciences. Hillsdale: Lawrence Erlbaum.
Cunningham, S. J., Turk, D. J., Macdonald, L. M., & Macrae, C. N. (2008). Yours or mine? Ownership and memory. Consciousness and Cognition, 17, 312–318. doi:10.1016/j.concog.2007.04.003
Faul, F., Erdfelder, E., Lang, A., & Buchner, A. (2007). GPower 3: A flexible statistical power analysis program for the social, behavioral and biomedical sciences. Behavior Research Methods, 39, 175–191.
Frings, C., & Wentura, D. (2014). Self-priorization processes in action and perception. Journal of Experimental Psychology: Human Perception and Performance, 40, 1737–1740. doi:10.1037/a0037376
Gray, H. M., Ambady, N., & Lowent, W. T. (2004). P300 as an index of attention to self-relevant stimuli. Journal of Experimental Social Psychology, 40, 216–224. doi:10.1016/S0022-1031(03)00092-1
Henson, R. N., Eckstein, D., Waszak, F., Frings, C., & Horner, A. J. (2014). Stimulus–response bindings in priming. Trends in Cognitive Sciences, 18, 376–384. doi:10.3758/s13421-011-0118-8
Hommel, B. (1998). Event files: Evidence for automatic integration of stimulus-response episodes. Visual Cognition, 5, 183–216. doi:10.1080/713756773
Hommel, B. (2004). Event files: Feature binding in and across perception and action. Trends in Cognitive Sciences, 8, 494–500. doi:10.1016/j.tics.2004.08.007
Hommel, B., & Colzato, L. (2004). Visual attention and the temporal dynamics of feature integration. Visual Cognition, 11, 483–521. doi:10.1080/13506280344000400
Jarmasz, J., & Hollands, J. G. (2009). Confidence intervals in repeated-measures designs: The number of observations principle. Canadian Journal of Experimental Psychology, 63, 124–138. doi:10.3758/PBR.17.1.135
Khurana, B., Smith, W. C., & Baker, M. T. (2000). Not to be and then to be: Visual representation of ignored unfamiliar faces. Journal of Experimental Psychology: Human Perception and Performance, 26, 246–263. doi:10.1037//0096-1523.26.1.246
Kim, K., & Johnson, M. K. (2010). Extended self: medial prefrontal activity during transient association of self and objects. Social Cognitive and Affective Neuroscience, 7, 199–207. doi:10.1093/scan/nsq096.
Moradi, Z., Sui, J., Hewstone, M., & Humphreys, G. W. (2015). In-group modulation of perceptual matching. Psychonomic Bulletin & Review, 22, 1255–1277. doi:10.3758/s13423-014-0798-8.
O'Brien, R., & Kaiser, M. K. (1985). MANOVA method for analyzing repeated measures designs: an extensive primer. Psychological Bulletin, 97, 316–333. doi:10.1037/0033-2909.97.2.316
Rossion, B. (2014). Understanding individual face discrimination by means of fast periodic visual stimulation. Experimental Brain Research, 232, 1599–1621. doi:10.1007/s00221-014-3934-9
Schäfer, S., Wentura, D., & Frings, C. (2015). Self-prioritization beyond perception. Experimental Psychology. doi:10.1027/1618-3169/a000307
Sui, J., He, X., & Humphreys, G. W. (2012). Perceptual effects of social salience: Evidence from self-prioritization effects on perceptual matching. Journal of Experimental Psychology: Human Perception and Performance, 38, 1105–1117. doi:10.1037/a0029792
Sui, J., Rotshtein, P., & Humphreys, G. W. (2013). Coupling social attention to the self forms a network for personal significance. Proceedings of the National Academy of Sciences, 19, 7607–7612. doi:10.1073/pnas.1221862110
Treisman, A. M., & Gelade, G. (1980). A feature-integration theory of attention. Cognitive Psychology, 12, 97–136.
Tukey, J. W. (1977). Exploratory data analysis. Reading: Addison-Wesley.
Wenke, D., Robert, G., & Nattkemper, D. (2007). Instruction-induced feature binding. Psychological Research, 71, 92–106. doi:10.1007/s00426-005-0038-y
Wolfe, J. M. (1994). Guided search 2.0 a revised model of visual search. Psychonomic Bulletin & Review, 1, 202–238. doi:10.3758/BF03200774
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Schäfer, S., Frings, C. & Wentura, D. About the composition of self-relevance: Conjunctions not features are bound to the self. Psychon Bull Rev 23, 887–892 (2016). https://doi.org/10.3758/s13423-015-0953-x
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-015-0953-x