
Abstract
A large body of work has established an influence of other people’s actions on our own actions. For example, actors entrain to the movements of others, in studies that typically employ continuous movements. Likewise, studies on co-representation have shown that people automatically co-represent a co-actor’s task, in studies that typically employ discrete actions. Here we examined entrainment and co-representation within a single task paradigm. Participants sat next to a confederate while simultaneously moving their right hand back and forth between two targets. We crossed whether or not the participant and the confederate moved over an obstacle and manipulated whether participants generated discrete or continuous movement sequences, while varying the space between the actors and whether the actors could see each other’s movements. Participants moved higher when the confederate cleared an obstacle than when he did not. For continuous movements, this effect depended on the availability of visual information, as would be expected on the basis of entrainment. In contrast, the co-actor’s task modulated the height of discrete movements, regardless of the availability of visual information, which is consistent with co-representation. Space did not have an effect. These results provide new insights into the interplay between co-representation and entrainment for discrete- and continuous-action tasks.
Similar content being viewed by others


In the past two decades, research on embodied cognition has surged. The field of joint action research provides one example that signifies this development. Because minds do not operate in a vacuum, it is important to study action planning and execution in interpersonal contexts. Much recent research has focused on how joint actions are planned and how they are coordinated.
Interestingly, studies on joint action planning and joint action coordination relate to divergent theoretical frameworks. Joint action planning studies often take a representational approach, whereas joint coordination studies tend to rely on dynamical-systems principles (see Knoblich, Butterfill, & Sebanz, 2011; van der Wel, Sebanz, & Knoblich, 2015). Whereas the representational approach focuses more heavily on the role of goals and intentions that may be represented symbolically, the dynamical-systems approach focuses on the emergence of behavior from the self-organization of the components of a complex nonlinear system. These two theoretical accounts are not fully reconcilable with one another, making it important to determine possible boundary conditions for each of these theoretical approaches.
Joint action planning and joint action coordination studies also differ with respect to the research paradigms they employ. The study of joint action planning mostly concerns discrete action tasks, such as pressing a button in response to a stimulus, in the presence of a co-actor (e.g., Sebanz, Knoblich, & Prinz, 2005). In contrast, joint coordination studies mostly employ continuous-action tasks, such as two people swinging pendulums alongside one another (e.g., Schmidt, Carello, & Turvey, 1990; Schmidt & O’Brien, 1997). The distinction between using discrete- versus continuous-action tasks is important, because such actions may rely on different movement primitives. Discrete movements are typically goal-directed and relatively intentional, whereas continuous movements may be less goal-directed and more automatic. To demonstrate this, the discrete action of getting on a bicycle requires elaborate motor planning, whereas continuing to peddle after one has started cycling does not. Continuous movements are not just strings of discrete movements, but may involve different brain regions (e.g., Schaal, Sternad, Osu, & Kawato, 2004). They may also involve different kinematic signatures (e.g., Hogan & Sternad, 2007; Howard, Ingram, & Wolpert, 2011) and may employ the spinal cord to different degrees, as well (Goto et al., 2014).
With this in mind, it is important to determine the extent to which divergence between representational and dynamical-systems approaches arises not just due to theoretical differences, but also to the use of different action types. This issue is difficult to address on the basis of the extant literature, because the literature supporting each account relies on paradigms that differ in terms of the broad tasks and the action types employed. Here, we sought to determine whether one could find evidence for one process central to the representational account and one process central to the dynamical-systems account within a single task, by changing just the required action type.
In joint action-planning studies, a core finding has been the notion of task co-representation (Sebanz, Knoblich, & Prinz, 2003, 2005). In particular, people appear to automatically co-represent aspects of a co-actor’s task. Although a wide range of paradigms have provided converging evidence for co-representation (Knoblich, Butterfill, & Sebanz, 2011), there is still debate about the underlying mechanisms (Dolk, Hommel, Prinz, & Liepelt, 2013; Wenke et al., 2011) and their boundary conditions. For example, it is unclear whether just the belief that one is interacting with another human agent (who is in a different room) is sufficient to induce task co-representation, or whether the co-actor needs to be visible (see Tsai, Kuo, Jing, Hung, & Tzeng, 2006; Welsh, Higgins, Ray, & Weeks, 2007). Evidence is also conflicting on the effect of the space between actors. Some findings have suggested that task co-representation may only happen when actors are within each other’s peripersonal space (Guagnano, Rusconi, & Umiltà, 2010), whereas other findings are inconsistent with this interpretation (Welsh et al., 2013).
In joint emergent-coordination studies, a core finding is that co-actors’ movements entrain each other while the actors perform continuous movement sequences. For example, when two people rock in rocking chairs alongside each other, they unintentionally tend to adopt similar movement frequencies (Richardson, Marsh, Isenhower, Goodman, & Schmidt, 2007). Such entrainment even occurs when the eigenfrequencies of the chairs differ. The tendency to entrain has been shown to depend on the availability of visual information (Richardson, Marsh, & Schmidt, 2005). Findings such as these speak to the close link between action perception and action production (see van der Wel, Sebanz, & Knoblich, 2013). They also suggest that perception–action coupling may reflect a largely bottom-up, emergent phenomenon. Nonetheless, perception–action coupling has been shown to be influenced by social factors, as well. For example, Kilner, Paulignan, and Blakemore (2003) found that participants’ movements were influenced by the observation of incongruent movements made by another human actor, but not by those made by a robot. Other studies (see Marsh, Richardson, & Schmidt, 2009) have shown an influence of the social relationship between actors on unintentional coordination as well. Thus, it is possible that top-down effects may modulate emergent coordination. Similarly, it is possible that bottom-up factors influence joint task representations.
Altogether, the differences in the research paradigms used to study joint task representations and emergent joint coordination raise the question of whether task co-representation is limited to discrete actions, and whether entrainment is limited to continuous actions. Here, we examined task co-representation and entrainment within one paradigm while we manipulated the types of sequences that participants performed and the information that they had available about their co-actor’s actions. We did so by using a modified version of a hand-path priming task (see Jax & Rosenbaum, 2007; van der Wel, Fleckenstein, Jax, & Rosenbaum, 2007) that has been shown to induce interpersonal priming effects in a turn-taking setting (Griffiths & Tipper, 2009). In our paradigm, actors performed movement sequences in parallel while we manipulated action type (discrete vs. continuous), the visual information about a co-actor’s movements, and the space between co-actors.
In keeping with previous research, we hypothesized that entrainment should depend on visual information, whereas task co-representation should not. Along with this reasoning, we predicted that visual information would influence actors’ movements during continuous sequences, because such information would support entrainment. We also predicted that the presence of visual information should not influence performance for discrete action sequences, because such sequences should invoke task co-representation instead. We did not have unequivocal predictions about the effect of space, because the previous literature has been inconsistent with respect to this factor.
Method
Participants
A total of 18 students (ten females and eight males between the ages of 18 and 29) from Rutgers University–Camden participated in the experiment in exchange for $10. All of the participants were right-handed (Oldfield, 1971), and none reported any neurological deficits. We planned to test 16 participants in order to obtain sufficient power (informed by Griffiths & Tipper, 2009) while fully counterbalancing the order of conditions. Due to miscommunication, two additional participants were tested before the data were analyzed. We decided to include all tested participants and all recorded data in the data analyses.
Experimental procedure and setup
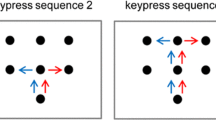
The general task was to move a dowel rod back and forth in time with an auditory metronome between two circular targets (5 cm in diameter) on the table (see Fig. 1). The center of the farther target was 40 cm away from the starting position of the participant’s reaching hand (after Griffiths & Tipper, 2009). The closer target was placed at a distance of 5 cm from the edge of the table closest to the participant. The participant and confederate sat side by side, each holding one dowel rod (20 cm in height and 2.4 cm in diameter) in their right hand with a power grip. We fully crossed the presence of an obstacle (20 cm in height) halfway between the targets for the participant and the confederate, creating blocks of four trials in which either both did not clear an obstacle, both did clear an obstacle, or one of the actors cleared an obstacle while the other did not. These four trials were administered in a random order within each block.

Overview of the experimental conditions. Panel A shows the main comparison between participants’ movements while the confederate moved over an obstacle (left side) versus when he did not (right side). Panel B shows the manipulations of visual information (left side) and space (right side)
Participants completed eight blocks (resulting in 32 total trials) while we manipulated our factors across blocks: Action Type (discrete movement vs. continuous movement), Vision (of the confederate’s movements: available vs. occluded), and Space (within vs. outside of peripersonal space). The order of the blocks was randomized across participants. Participants were instructed to follow the pace of the metronome and to move over rather than around the obstacle. Before the start of the experiment, participants had the opportunity to perform a practice trial to ensure their understanding of the instructions.
To create discrete and continuous action sequences, we manipulated the characteristics of the auditory metronome. For the discrete sequences, the metronome played two 10-ms pure tones separated by 850 ms, to indicate the timing of one back-and-forth movement, followed by a 2-s pause during which the actors rested their hands on the closer target. Continuous sequences consisted of a continuous looping of the 10-ms tones every 850 ms. We chose this metronome rate because previous research had suggested that movements at this rate are close to the preferred rate for continuous movements over the distance that we used (van der Wel, Rosenbaum, & Sternad, 2010). Participants and the confederate completed 20 back-and-forth movements in each trial. We discarded the first and last back-and-forth movements for the analyses in order to avoid startup and stopping effects (see Smits-Engelsman, Van Galen, & Duysens, 2002).
The wooden occluder that was placed between the participant and confederate to manipulate visual information was 50 cm in height and protruded 60 cm from the edge of the table closest to the participant (Fig. 1, left side of panel B). In the occluded-vision trials, the actors always saw whether or not their co-actor cleared an obstacle before the start of the trial. To manipulate space, the lateral distance between the participant and the confederate was set at 40 cm in the “within peripersonal space” conditions and at 110 cm in the “outside of peripersonal space” conditions.
Three OPTOTRAK markers were attached to the top of each dowel rod. As participants moved the dowel rod with their hands, the movements of the markers represented the movements of the participants’ and the confederate’s hands. We processed the data with a custom-built MATLAB script and analyzed the data in SPSS.
Results
Peak height differences
Our first analysis focused on whether the movements of the confederate had an influence on the participants’ movements in general. For this analysis, we calculated the mean difference scores of the peak heights when the confederate moved over an obstacle versus when he did not. In terms of absolute movement heights, participants had to move higher to clear an obstacle than when they did not, but this was not an effect of interest. The critical measure instead was whether participants changed their movement heights on the basis of the confederate’s task. Difference scores greater than zero would indicate an effect of the confederate’s movements on the participants’ movements. For these mean difference values, we collapsed over cases in which the participant had an obstacle and in which (s)he did not, because preliminary analyses indicated no significant effect of this factor on difference scores. We then tested these mean difference scores against zero. The results revealed an effect of the confederate’s movements, t(17) = 4.31, p < .01, such that participants moved higher when the confederate cleared an obstacle than when he did not (M = 3.24 cm, SE = 0.75, CI = 1.65–4.82).
Next, we tested the effect of our manipulations on the differences in peak heights. Figure 2 shows the results. We conducted a 2 (Action Type: discrete/continuous) × 2 (Vision: available/occluded) × 2 (Space: within/outside peripersonal) repeated measures analysis of variance (ANOVA). The results revealed a two-way interaction between vision and action type [F(1, 17) = 5.83, p < .05, η 2 = .26]. Whereas the availability of visual information mattered for continuous action sequences (M = 0.04 cm, SE = 1.54, for vision occluded; M = 5.51 cm, SE = 1.55, for vision available), this was not the case for discrete action sequences (M = 3.54 cm, SE = 1.33, for vision occluded; M = 3.26 cm, SE = 1.28, for vision available). We found no other significant main effects or interactions.

Difference values in the mean peak heights that participants achieved when the confederate moved over an obstacle versus when he did not, as a function of experimental condition. The error bars reflect the standard errors of the means
To further infer the presence of task co-representation and entrainment effects, we conducted several planned t tests. Table 1 shows the results. First, we tested each of the data points for the Vision × Action Type interaction against 0. This analysis indicated significant effects for all conditions except when participants performed continuous sequences with vision occluded. Thus, neither entrainment nor task co-representation occurred in that condition. Second, to distinguish between task co-representation and entrainment effects, we tested for the effect of vision within each type of action sequence. Consistent with previous research suggesting that entrainment ought to depend on vision (Richardson et al., 2005; Schmidt & O’Brien, 1997), the results indicated a significant difference between the continuous sequences when vision was occluded versus available, t(17) = 2.32, p < .05. Consistent with a task co-representation effect, seeing the confederate’s actions did not exert a significant influence on discrete sequences, p = .87.
To ensure that the difference between the two continuous conditions reflected differences in entrainment, we calculated the amounts of group synchrony for these conditions. To do so, we used the cluster-phase method (Frank & Richardson, 2010; Richardson, Garcia, Frank, Gergor, & Marsh, 2012). This method quantifies rho (a measure of group synchrony in two or more continuous signals; it takes on values between 0 and 1). We then ran a paired t test to compare group synchrony for the continuous conditions and confirmed that participants were more entrained in the vision-available (M = 0.82, SE = 0.02)than in the vision-occluded condition (M = 0.73, SE = 0.02), t(17) = 3.13, p < .01.
Dwell time results
To ensure that participants followed the patterns of the metronome equally in each condition, we calculated the dwell times on the targets for each trial by using a spatial onset and offset criterion of 1 cm above the target regions. For the discrete trials, we only used the dwell times on the closer target, because that target corresponded to the discretization of the action sequence (the target on which the participants dwelled for approximately 2 s). We then conducted a 2 (Obstacle Presence Participant) × 2 (Obstacle Presence Confederate) × 2 (Action Type) × 2 (Vision) × 2 (Space) repeated measures ANOVA on the mean dwell times for each condition. Unsurprisingly, the results indicated a main effect of action type [F(1, 16) = 1228.93, p < .01, η 2 = .99] in which participants were instructed to pause much longer between movements for the discrete sequences than for the continuous sequences. The results also indicated a main effect of obstacle presence participant [F(1, 16) = 27.12, p < .01, η 2 = .63]. These main effects were qualified by an interaction between these two factors [F(1, 16) = 9.53, p < .01, η 2 = .37]. Participants shortened their dwell times when they cleared an obstacle, and this effect was stronger when they performed discrete sequences (M = 1,856 ms, SE 0.04, for obstacle absent; M = 1,685 ms, SE = 0.06, for obstacle present) than when they completed continuous sequences (M = 269 ms, SE = 0.01, for obstacle absent; M = 229 ms, SE = 0.01, for obstacle present). Importantly, the dwell times for the continuous sequences correspond to the lower boundary of dwell times that people produce when they move their forearms at their preferred rates (van der Wel, Rosenbaum, & Sternad, 2010). The results did not show other main effects or interactions.
Discussion
Whereas much of the previous literature on joint action planning had relied on representational approaches, much of the literature on joint coordination has taken a dynamical-systems approach. These theoretical differences have been accompanied by differences in the kinds of paradigms used to study joint action. Here, we sought to investigate the extent to which two core findings from the joint action-planning and joint action-coordination literatures actually influence behavior during a discrete versus a continuous sequential action task. In particular, by manipulating the characteristics of an auditory metronome, we examined task co-representation and entrainment within a single paradigm.
Our findings suggest that a part of the theoretical divergence between the representational and dynamical-systems approaches may stem from differences in the types of actions used to study joint action. For continuous action sequences, our findings are consistent with previous findings on entrainment: People entrain quite strongly when they can see a co-actor’s actions, and do not entrain in the absence of informational coupling. This finding is also compatible with previous work on automatic imitation (e.g., Heyes, 2011; Kilner et al., 2003), according to which seeing others’ actions may modulate people’s own actions through the mirror neuron system. For discrete action sequences, our results are most easily accounted for on the basis of task co-representation: People are influenced by a co-actor’s task, even when they do not actually see the co-actor perform that task. Thus, our results support a dual-process interpretation. Statistical differences between particular data points further support this interpretation. For discrete sequences, the difference values in peak movement heights were significantly greater than zero and did not significantly depend on visual information. For continuous sequences, the difference values in peak movement heights only differed from zero when visual information from the co-actor’s task was available.
Although our task paradigm did not involve intentional joint actions (but, rather, intentional parallel actions), task co-representation and entrainment form two processes that may be employed to support successful joint actions. Indeed, Vesper and colleagues (Vesper, Butterfill, Knoblich, & Sebanz, 2010) proposed a model for joint action in which people may achieve successful joint performance based on prediction and monitoring of a co-actor’s task contributions. Whereas task co-representation may contribute to successful performance based on prediction of a co-actor’s behavior (see Vesper, van der Wel, Knoblich, & Sebanz, 2013), entrainment may feed into monitoring mechanisms to support joint coordination. Such monitoring may rely on visual information, but may be driven by haptic information available through physical coupling, as well (see Harrison & Richardson, 2009; van der Wel, Knoblich, & Sebanz, 2011). In addition, people may employ signaling (Vesper & Richardson, 2014) and speeding (Vesper, van der Wel, Knoblich, & Sebanz, 2011) as strategies to accomplish joint goals.
Although the model by Vesper et al. (2010) provides a useful framework for joint actions, it is unclear from the model whether discrete and continuous action sequences might differentially tap into prediction and monitoring mechanisms. One way to address this was by assuming that more time is available for predictive mechanisms during discrete than during continuous sequences, and that continuous sequences would in general rely more heavily on lower-level monitoring mechanisms. Such a proposal is consistent with the motor control literature on discrete versus continuous actions but will require further testing within joint contexts. The present results suggest that a general framework for intentional joint action should specify how different types of actions may employ different supporting mechanisms to different degrees.
The present findings relate to previous work on the hand-path priming effect (Jax & Rosenbaum, 2007; van der Wel, Fleckenstein, Jax, & Rosenbaum, 2007). In particular, Griffiths and Tipper (2009) found that people moved higher between two targets after they had watched another actor move over an obstacle than when they had watched a movement not involving the clearance of an obstacle. In their study, Griffiths and Tipper found that such a priming effect only occurred when the actors sat within each other’s peripersonal space. In our results, we did not find a modulation of entrainment or task co-representation based on the space between actors. It should be noted, as well, that the effects of space have been unclear within the task co-representation literature (see Guagnano, Rusconi, & Umiltà, 2010; Welsh et al., 2013). More research will be needed to elucidate the influence of this factor. An important difference between the priming effect found by Griffiths and Tipper and the results of our study is that our study involved parallel action execution rather than a turn-taking sequence. Previous work (Jax & Rosenbaum, 2009) has also suggested that hand-path priming effects rely on dorsal stream processing and wane after intervals exceeding 1 s. In our study, it is therefore possible that priming contributed to entrainment effects, but it is very unlikely that it drove the task co-representation effects for discrete sequences in the absence of visual information.
Moving forward, we suggest that more research is needed on the interactions between planning processes and emergent processes in the context of joint actions. Our findings suggest that the engagement of such processes may reflect particulars of the action tasks employed in previous paradigms. We hope that further research will ultimately lead to the integration of task co-representation, entrainment, and related processes into an overarching theory of joint action.
References
Dolk, T., Hommel, B., Prinz, W., & Liepelt, R. (2013). The (not so) social Simon effect: A referential coding account. Journal of Experimental Psychology: Human Perception and Performance, 39, 1248–1260. doi:10.1037/a0031031
Frank, T. D., & Richardson, M. J. (2010). On a test statistic for the Kuramoto order parameter of synchronization: with an illustration for group synchronization during rocking chairs. Physica D, 239, 2084–2092.
Goto, Y., Jono, Y., Hatanaka, R., Nomura, Y., Tani, K., Chujo, Y., & Hiraoka, K. (2014). Different corticospinal control between discrete and rhythmic movement of the ankle. Frontiers in Human Neuroscience, 8, 578. doi:10.3389/fnhum.2014.00578
Griffiths, D., & Tipper, S. P. (2009). Priming of reach trajectory when observing actions: Hand-centred effects. Quarterly Journal of Experimental Psychology, 62, 2450–2470. doi:10.1080/17470210903103059
Guagnano, D., Rusconi, E., & Umiltà, C. A. (2010). Sharing a task or sharing space? On the effect of the confederate in action coding in a detection task. Cognition, 114, 348–355. doi:10.1016/j.cognition.2009.10.008
Harrison, S. J., & Richardson, M. J. (2009). Horsing around: Spontaneous four-legged coordination. Journal of Motor Behavior, 41, 519–524.
Heyes, C. (2011). Automatic imitation. Psychological Bulletin, 137, 463–483. doi:10.1037/a0022288
Hogan, N., & Sternad, D. (2007). On rhythmic and discrete movements: Reflections, definitions and implications for motor control. Experimental Brain Research, 181, 13–30. doi:10.1007/s00221-007-0899-y
Howard, I. S., Ingram, J. N., & Wolpert, D. M. (2011). Separate representations of dynamics in rhythmic and discrete movements: Evidence from motor learning. Journal of Neurophysiology, 105, 1722–1731. doi:10.1152/jn.00780.2010
Jax, S. A., & Rosenbaum, D. A. (2007). Hand path priming in manual obstacle avoidance: Evidence that the dorsal stream does not only control visually guided actions in real time. Journal of Experimental Psychology: Human Perception and Performance, 33, 425–441. doi:10.1037/0278-7393.33.2.425
Jax, S. A., & Rosenbaum, D. A. (2009). Hand path priming in manual obstacle avoidance: Rapid decay of dorsal stream information. Neuropsychologia, 47, 1573–1577. doi:10.1016/j.neuropsychologia.2008.05.019
Kilner, J. M., Paulignan, Y., & Blakemore, S. J. (2003). An interference effect of observed biological movement on action. Current Biology, 13, 522–525.
Knoblich, G., Butterfill, S., & Sebanz, N. (2011). Psychological research on joint action: Theory and data. In B. H. Ross (Ed.), The psychology of learning and motivation (Vol. 54, pp. 59–101). Burlington, VT: Academic Press.
Marsh, K. L., Richardson, M. J., & Schmidt, R. C. (2009). Social connection through joint action and interpersonal coordination. Topics in Cognitive Science, 1, 320–339. doi:10.1111/j.1756-8765.2009.01022.x
Oldfield, R. C. (1971). The assessment and analysis of handedness: The Edinburgh inventory. Neuropsychologia, 9, 97–113. doi:10.1016/0028-3932(71)90067-4
Richardson, M. J., Garcia, R. L., Frank, T. D., Gergor, M., & Marsh, K. L. (2012). Measuring group synchrony: A cluster-phase method for analyzing multivariate movement time-series. Frontiers in Physiology, 3, 405. doi:10.3389/fphys.2012.00405
Richardson, M. J., Marsh, K. L., Isenhower, R. W., Goodman, J. R., & Schmidt, R. C. (2007). Rocking together: Dynamics of intentional and unintentional interpersonal coordination. Human Movement Science, 26, 867–891. doi:10.1016/j.humov.2007.07.002
Richardson, M. J., Marsh, K. L., & Schmidt, R. C. (2005). Effects of visual and verbal interaction on unintentional interpersonal coordination. Journal of Experimental Psychology: Human Perception and Performance, 31, 62–79. doi:10.1037/0096-1523.31.1.62
Schaal, S., Sternad, D., Osu, R., & Kawato, M. (2004). Rhythmic arm movement is not discrete. Nature Neuroscience, 7, 1136–1143. doi:10.1038/nn1322
Schmidt, R. C., Carello, C., & Turvey, M. T. (1990). Phase transitions and critical fluctuations in the visual coordination of rhythmic movements between people. Journal of Experimental Psychology: Human Perception and Performance, 16, 227–247. doi:10.1037/0096-1523.16.2.227
Schmidt, R. C., & O’Brien, B. (1997). Evaluating the dynamics of unintended interpersonal coordination. Ecological Psychology, 9, 189–206.
Sebanz, N., Knoblich, G., & Prinz, W. (2003). Representing others’ actions: Just like one’s own? Cognition, 88, B11–B21.
Sebanz, N., Knoblich, G., & Prinz, W. (2005). How two share a task: Corepresenting stimulus–response mappings. Journal of Experimental Psychology: Human Perception and Performance, 31, 1234–1246. doi:10.1037/0096-1523.31.6.1234
Smits-Engelsman, B. C., Van Galen, G. P., & Duysens, J. (2002). The breakdown of Fitts’ Law in rapid, reciprocal aiming movements. Experimental Brain Research, 145, 222–230.
Tsai, C.-C., Kuo, W.-J., Jing, J.-T., Hung, D. L., & Tzeng, O. J.-L. (2006). A common coding framework in self–other interaction: Evidence from joint action task. Experimental Brain Research, 175, 353–362. doi:10.1007/s00221-006-0557-9
van der Wel, R. P. R. D., Fleckenstein, R. M., Jax, S. A., & Rosenbaum, D. A. (2007). Hand path priming in manual obstacle avoidance: Evidence for abstract spatio-temporal forms in human motor control. Journal of Experimental Psychology: Human Perception and Performance, 33, 1117–1126. doi:10.1037/0096-1523.33.5.1117
van der Wel, R. P. R. D., Knoblich, G., & Sebanz, N. (2011). Let the force be with us: Dyads exploit haptic coupling for coordination. Journal of Experimental Psychology: Human Perception and Performance, 37, 1420–1431. doi:10.1037/a0022337
van der Wel, R. P. R. D., Rosenbaum, D. A., & Sternad, D. (2010). Moving the arm at different rates: Slow movements are avoided. Journal of Motor Behavior, 42, 29–36.
van der Wel, R. P. R. D., Sebanz, N., & Knoblich, G. (2013). Action perception from a common coding perspective. In K. Johnson & M. Schiffrar (Eds.), People watching: Social, perceptual, and neurophysiological studies of body perception (pp. 101–119). New York, NY: Oxford University Press.
van der Wel, R. P. R. D., Sebanz, N., & Knoblich, G. (2015). A joint action perspective on embodiment. In M. H. Fischer & Y. Coello (Eds.), Foundations of embodied cognition: Vol. 2. Conceptual and interactive embodiment. Oxford, UK: Taylor & Francis.
Vesper, C., Butterfill, S., Knoblich, G., & Sebanz, N. (2010). A minimal architecture for joint action. Neural Networks, 23, 998–1003. doi:10.1016/j.neunet.2010.06.002
Vesper, C., & Richardson, M. J. (2014). Strategic communication and behavioral coupling in asymmetric joint action. Experimental Brain Research, 232, 2945–2956. doi:10.1007/s00221-014-3982-1
Vesper, C., van der Wel, R. P. R. D., Knoblich, G., & Sebanz, N. (2011). Making oneself predictable: Reduced temporal variability facilitates joint action coordination. Experimental Brain Research, 211, 517–530. doi:10.1007/s00221-011-2706-z
Vesper, C., van der Wel, R. P. R. D., Knoblich, G., & Sebanz, N. (2013). Are you ready to jump? Predictive mechanisms in interpersonal coordination. Journal of Experimental Psychology: Human Perception and Performance, 39, 48–61. doi:10.1037/a0028066
Welsh, T. N., Higgins, L., Ray, M., & Weeks, D. J. (2007). Seeing vs. believing: Is believing sufficient to activate the processes of response co-representation? Human Movement Science, 26, 853–866. doi:10.1016/j.humov.2007.06.003
Welsh, T. N., Kiernan, D., Neyedli, H. F., Ray, M., Pratt, J., Potruff, A., & Weeks, D. J. (2013). Joint Simon effects in extrapersonal space. Journal of Motor Behavior, 45, 1–5.
Wenke, D., Atmaca, S., Holländer, A., Liepelt, R., Baess, P., & Prinz, W. (2011). What is shared in joint action? Issues of co-representation, response conflict, and agent identification. Review of Philosophy and Psychology, 2, 147–172.
Author note
We thank Nisan Novack for his help as a confederate.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
van der Wel, R.P.R.D., Fu, E. Entrainment and task co-representation effects for discrete and continuous action sequences. Psychon Bull Rev 22, 1685–1691 (2015). https://doi.org/10.3758/s13423-015-0831-6
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-015-0831-6