
Abstract
Observers can adopt attentional control settings that regulate how their attention is drawn to salient stimuli in the environment. Do observers choose their attentional control settings voluntarily, or are they primed in a bottom-up manner based on the stimuli that the observer has recently attended and responded to (i.e., target-selection history)? In the present experiment, we tested these two accounts using a long-term memory attentional control settings paradigm, in which participants memorized images of 18 common visual objects, and then searched for those objects in a spatial blink task. Unbeknownst to participants, we manipulated priming by dividing the set of target objects into two subsets: nine objects appeared frequently as targets in the spatial blink task (frequently primed objects), and nine infrequently (infrequently primed objects). We assessed attentional capture by presenting these objects as distractors in the spatial blink task and measuring their effect on task accuracy. We found that both subsets of objects captured attention more than non-studied objects, and frequently primed objects did not capture attention more than infrequently primed objects. Moreover, a follow-up analysis revealed that all studied objects captured attention, even before those objects had appeared as targets in the spatial blink task. These findings suggest that priming through target-selection history plays little-to-no role in long-term memory attentional control settings. Rather, these findings align with a growing body of evidence that attentional control settings are primarily implemented through voluntary control.
Similar content being viewed by others

One of the enduring debates in cognition surrounds the automaticity of attentional capture: Do salient stimulus events, like the flashing lights on an ambulance, always automatically draw our attention to their spatial location, or only when we want them to? The evidence that capture is under our control comes from the attentional control setting literature (Burnham, 2007; Büsel, Voracek, & Ansorge, 2020; Folk, Remington, & Johnston, 1992; Lamy, Leber, & Egeth, 2012). Depending on our goals, we adopt attentional control settings that prioritize processing of the relevant portions of our environment, and capture is contingent on these control settings. For example, red stimuli will capture our attention when we are searching for something red, but not when searching for something green (Folk & Remington, 1998).
Demonstrations that capture is contingent on attentional control settings, however, have been challenged in numerous ways. While some measures reveal contingent capture, such as the Posner cueing (Folk et al., 1992) and spatial blink (Folk, Leber, & Egeth, 2002) paradigms, the additional singleton paradigm does not (Theeuwes, 1991, 1992), although this discrepancy can likely be explained by the confound of filtering costs in the latter paradigm (Al-Aidroos, Harrison, & Pratt, 2010; Folk & Remington, 1998). As well, what appears to be control over capture may instead be control over the speed of disengaging attention (Theeuwes, 2010; although see Al-Aidroos et al., 2010; Büsel et al., 2020; Chen & Mordkoff, 2007) or latent attentional capture (Gaspelin, Ruthruff, & Lien, 2016; Lamy, Darnell, Levi, & Bublil, 2018; Ruthruff, Faulks, Maxwell, & Gaspelin, 2020). In the present study, we looked at another challenge: The role of target-selection history (Awh, Belopolsky, & Theeuwes, 2012). Attentional capture is greater for stimuli that have recently been attended to as targets (Maljkovic & Nakayama, 1994), leading some researchers to propose that past evidence of control over capture does not stem from voluntary control, rather it is a spontaneous by-product from priming based on target-selection history (Awh et al., 2012; Belopolsky, Schreij, & Theeuwes, 2010; Theeuwes, 2013). Here, we examined this target-selection account in relation to the recent demonstration that attentional control settings can be formed based on episodic long-term memory representations (Giammarco, Paoletti, Guild, & Al-Aidroos, 2016; Nickel, Hopkins, Minor, & Hannula, 2020; Plater, Giammarco, Fiacconi, & Al-Aidroos, 2020). Can priming based on target-selection history explain long-term memory control settings, or do long-term memory control settings provide a clear demonstration of voluntary control over attentional capture unrelated to priming?
The strongest evidence for attentional control settings comes from the Posner cueing task (Folk & Remington, 1998; Folk et al., 1992) and spatial blink task (Folk et al., 2002; Folk, Leber, & Egeth, 2008). In cueing tasks (Posner, 1980; Posner & Cohen, 1984), participants are told to detect the appearance of a visual target, such as a red stimulus, color singleton, or new object onset. Task-irrelevant pre-cues only capture attention and alter target detection if they possess features related to detecting the target: For example, color singleton pre-cues, but not onset pre-cues, capture attention when participants are looking for color singleton targets, and vice versa when they are looking for onset targets (Folk et al., 1992). Thus, attentional capture by pre-cues is contingent on the attentional control settings that participants have adopted for their specific task. In spatial blink tasks, participants are told to monitor for the appearance of a visual target in a rapid serial visual presentation stream. For example, they might have to detect the single red letter in a stream of 15 rapidly presented gray letters that appear one after the other in a single location, and to report the identity of the red letter once the stream has finished (Folk et al., 2002). In this task, task-irrelevant distractors presented adjacent to the stream that capture attention produce a spatial blink: reduced target identification accuracy if the distractor appeared just before the target (e.g., within about 2-to-5 letters before the target; a.k.a., lags 2-to-5), but not well before the target since there is sufficient time to resolve capture. As with pre-cues, the types of distractors that capture attention in spatial blink tasks depend on what participants are looking for, demonstrating again that observers have voluntary control over attentional capture.
There is, however, an alternative account of these findings that does not require voluntary control. As pointed out by Belopolsky et al. (2010), in most studies examining attentional control settings, participants are asked to look for the same target for the duration of the study. Accordingly, attentional control settings may not be voluntarily chosen, but may instead be a consequence of bottom-up priming from the repeated selection of the same target. For example, when participants are looking for red targets, a red pre-cue might only capture attention because a red target had been selected and responded to on the previous trail. To differentiate between these two interpretations, Belopolsky et al. (2010) had participants alternate from trial-to-trial between looking for a color singleton or an object-onset target, and found that what captured attention was more related to what the participants had responded to on the previous trial (i.e., priming) than what they were supposed to be looking for on the current trial (i.e., voluntary control). Although this finding led to some early proposals that attentional control settings may only ever be generated though bottom-up priming (Theeuwes, 2013), findings have also emerged suggesting control settings are sometimes determined voluntarily (Belopolsky & Awh, 2016; Lamy & Kristjánsson, 2013; Lien, Ruthruff, & Johnston, 2010; Lien, Ruthruff, & Naylor, 2014). Nevertheless, it is clear that modulations of attentional capture effects do not only result from voluntary control of attentional control settings, but can also be driven by bottom-up priming (Awh et al., 2012; Belopolsky & Awh, 2016; Belopolsky et al., 2010; Silvis, Belopolsky, Murris, & Donk, 2015).
Recently, we examined what memory systems store the properties that define an observer’s attentional control settings and found that episodic long-term memory can serve this role (Giammarco et al., 2016; Plater et al., 2020). Although we interpreted our findings as voluntary control settings, we did not directly test for a potential role of bottom-up priming. Interestingly, the design of our tasks is amenable to testing for the contribution of priming, and can provide a strong test of voluntary control, and, more generally, potential limits on implementing attentional control settings.
Giammarco et al. (2016) demonstrated that observers can adopt attentional control settings based on episodic long-term memory representations by having participants memorize a set of common visual objects—pictures of an umbrella, soccer ball, hedgehog, etc.—and then search for these objects in either a Posner cueing task or spatial blink task. In both tasks, attentional capture was contingent. Task-irrelevant objects (pre-cues and spatial blink distractors) only captured attention if they were from the set of searched-for objects. As argued by Giammarco et al. (2016), while conducive to episodic long-term memory, such a set of target objects (as many as 30 visual objects) cannot be remembered using semantic memory or working memory. Moreover, when they had participants memorize two separate sets of objects and then only search for one set, once again only the searched-for objects captured attention. Memorized, but ignored, objects did not capture attention, suggesting that long-term memory attentional control settings are driven by episodic memory, rather than feelings of familiarity.
Can the effects of long-term memory attentional control settings be explained by bottom-up priming based on target-selection history, or do they reflect voluntary control over attentional capture? On the one hand, it seems unlikely that priming could explain the effects observed by Giammarco et al. (2016), especially since Plater et al. (2020) recently demonstrated that the long-term memory representations that are part of an attentional control set are not more actively represented than those that are not (Oberauer, 2001), as might be expected following priming (Maljkovic & Nakayama, 2000). Moreover, in the experiments by Giammarco et al. (2016). and Plater et al. (2020), participants searched for as many as 30 target objects. Consequently, the distractor object on one trial was almost never the same as the target on the previous trial, and usually had not appeared as a target for many trials. As a result, priming can only explain long-term memory attentional control settings if some form of long-lasting priming is considered, where priming accrues and persists across multiple trials (Brascamp, Pels, & Kristjánsson, 2011; Kristjánsson & Ásgeirsson, 2019); yet priming effects are typically short lived (Belopolsky et al., 2010; Kruijne, Brascamp, Kristjánsson, & Meeter, 2015; Maljkovic & Nakayama, 2000).
On the other hand, it is surprising to think that long-term memory attentional control settings could reflect a voluntary process. Retrieving information from episodic long-term memory is typically characterized as a slow, effortful process (Jacoby, 1991; although see Giammarco et al., 2016; Moscovitch, 2008) that is hard to reconcile with the rapid evaluation required to control attentional capture. As well, if observers can voluntarily choose to have attention captured by only specific visual objects, then why is visual search ever difficult? Observers should be able to choose to adopt a control setting for a conjunction of features, yet conjunction searches are usually difficult (Treisman & Sato, 1990). While these aspects of Giammarco et al.'s (2016) findings seem puzzling from the perspective of voluntary long-term memory attentional control settings, it is easier to explain them using bottom-up priming effects, which can unfold quickly (Maljkovic & Nakayama, 2000), and are regulated automatically by external factors rather than voluntarily through internal choices.
In the present study, we tested whether long-term memory attentional control settings can be implemented through voluntary control by assessing the contribution of priming from target-selection history. As most studies of attentional control settings have had participants search for only one, or a small number of, targets throughout the duration of the experiment (Büsel et al., 2020), it is often difficult to disentangle priming from volitional control: The distractors that capture attention often match both what participants are looking for, and what they responded to on recent trials (Belopolsky et al., 2010; Theeuwes, 2013). Conversely, because participants search for many targets in long-term memory control setting tasks (Giammarco et al., 2016; Plater et al., 2020), it is easy to manipulate priming by presenting some stimuli as targets more often than others. Moreover, many target stimuli will naturally appear as distractors before they have ever appeared as a target, allowing us to test for contingent capture in the absence of any history of target selection.
In the present experiment, participants memorized a set of 18 common objects and then searched for these objects in a spatial blink task. As discussed in Giammarco et al. (2016), we chose to use the spatial blink task because it avoids potential masking effects in cueing tasks when the cue and target appear at the same location. Unbeknownst to participants, the set of target objects was divided into two subsets: frequently primed and infrequently primed. The objects in the frequently primed subset appeared as targets on 75% of trials (i.e., each object was a target, on average, once every 12 trials), and those in the infrequently primed subset on 25% of trials (i.e., on average, once every 36 trials). To measure attentional capture, three types of distractors were presented in the spatial blink task (frequently primed, infrequently primed, and—to serve as a baseline—a set of non-studied objects) at three different lags (2, 5, or 8). If the effects previously described as long-term memory attentional control settings (Giammarco et al., 2016; Plater et al., 2020) are generated by the long-lasting accrual of priming from target selection, we should expect to see a greater spatial blink at lag 2 for frequently primed distractors relative to non-studied distractors, than for infrequently primed distractors. Alternatively, if long-term memory attentional control settings are voluntary, we may see evidence of contingent capture even for objects that have yet to appear as targets.
Methods
Participants
Twenty-eight undergraduate students (mean age of 18.4 years) at the University of Guelph completed the experiment and they received partial course credit as compensation for their participation. All participants provided informed consent and reported having normal color vision and normal or corrected-to-normal visual acuity.
Apparatus and stimuli
The experiment was conducted on an 18-inch ViewSonic CRT monitor with a 1280 × 1024 resolution and a refresh rate of 75 Hz, and responses were made on a standard keyboard. The experiment was programed using PsychoPy (Peirce et al., 2019). Object images were selected from Brady et al. (2008). Target images for the training and cueing tasks included images from many categories, including animals, food, toys, vehicles, clothing, appliances, and tools.
Memory training task
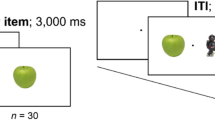
The experimental session began with a memory training task during which participants studied, and were then tested on, a set of 18 images of objects, randomly selected from a pool of 130 images (see Fig. 1). During the study phase, participants passively viewed each of the 18 centrally presented 3.44 × 3.44° images for 3000 ms with an interstimulus interval of 950 ms. Participants were instructed to memorize these images, as they would subsequently be tested on all objects. Following the study phase of the training task participants completed the recognition phase: Participants were shown all 18 studied images serially in random order, each paired with a non-studied image, and were required to locate the studied image. The 18 non-studied images were selected without replacement from a separate pool of 2100 images. All images subtended 3.44 × 3.44°, the studied image was presented at random either 7° to the right or left of center with the non-studied image in the opposite position, and both images remained on screen until participants provided a response. Together, the study and recognition phases comprised one block of the training task. To ensure that participants could confidently recognize studied images, a 90% accuracy threshold was required for two consecutive blocks (i.e., two rounds of the study and recognition phases) before participants were able to advance to the spatial blink task.

Example study phase (left) and recognition phase (right) of the memory training task. Both phases were repeated until participants achieved 90% accuracy on two consecutive recognition phases
Spatial blink task
Following memory training, participants completed a spatial blink task (see Fig. 2). They were instructed to monitor the center of the display for the appearance of any of the 18 objects from their target set. Unbeknownst to participants, the target set was divided into two subsets of nine images: frequently primed and infrequently primed. The target was randomly selected from the frequently primed subset on 75% of trials, and from the infrequently primed subset on 25% of trials.

Example trial sequence of the spatial blink task
The trial sequence began with the presentation of a black fixation point with a diameter of 2°, presented for 500 ms. This was followed by a blank screen for 200 ms, then a stream of 20 centrally located images subtending 3.44 × 3.44°. Images appeared one after the other, each for 100 ms, with a 50-ms blank inter-stimulus interval (ISI). One of the images between the 11th and 16th in the stream (randomly selected) was the target image, which participants had to report at the end of the stream. Either 2, 5, or 8 images (i.e., lags) before the target, the central image was flanked by two distractor images subtending 4.58 × 4.58°, one 4.24° below and the other 4.24° above the central image. One of these distractors was always a non-studied image selected randomly without replacement from the pool of 2100 images, while the other critical distractor image was either a frequently primed or infrequently primed image (other than the target image for that trial), or another non-studied item. The three distractor types (frequently primed, infrequently primed, non-studied) were equally likely to occur.
Upon completion of the spatial blink stream, a probe screen appeared containing 8 images subtending 3 × 3° on an imaginary 10 × 10° square centered on a 2 × 2° black fixation cross. The image choices on the probe screen included the target for that trial, four new non-studied objects from the pool of 2100 images, and three additional objects from the target set. To equate participants’ exposure to frequently primed and infrequently primed target set items (other than from target selection), two images on the probe screen were always frequently primed, and two images were always infrequently primed. The critical distractor and target were never the same image; as well, the distractor on a given trial was never present as a response option on the probe screen. The probe screen remained visible until participants responded by selecting the number on the keyboard number pad that corresponded to the target’s spatial location. Participants were encouraged to be as accurate as possible in their responses. For incorrect responses, a 500-Hz tone was generated for 50 ms.
Participants completed a total of 288 spatial blink trials. All levels of distractor type (frequently primed, infrequently primed, or non-studied) and distractor lag (2, 5, or 8) were fully crossed within-subjects, and each unique combination of lag and distractor type occurred in combination with an infrequently primed target image on 25% of trials, and a frequently primed target image on 75% of trials. The location of each image within the probe screen was randomly determined on each trial.
Analysis
Results were analyzed using both null hypothesis significance tests and Bayesian analyses in JASP 0.13.1 (JASP Team, 2020). Effects sizes for t tests are reported using Cohen’s d. Given that we had no strong predictions about the outcomes of the critical statistical tests, we used the default JASP priors for calculating Bayes factors (Wagenmakers et al., 2018). For each statistical test, we report the results of the null hypothesis significance test along with Bayes factors, where BF10 > 3 provides evidence in favor of the alternative model, and BF10 < 1/3 provides evidence in favor of the null. Bayes factors for the main effects and interactions of ANOVAs are reported against the null model.
Accuracy
The main analysis of interest was accuracy on the spatial blink task. Primed distractors that capture attention should interfere with target identification at lag 2 relative to non-studied distractors, with little-to-no interference at later lags. Consequently, paired samples t tests were planned to compare accuracies across distractor conditions at lag 2.
Target repetition count
In addition to this main analysis, we also examined the effect of priming on attentional capture by computing distractor effects as a function of how many times that distractor object had appeared as a target during the spatial blink task. For this analysis, we collapsed across the frequently and infrequently primed conditions since we were calculating the extent of priming based on the actual presentation history of each stimulus. We also only included lag 2 trials, because there should be little to no evidence of capture at lags 5 and 8. Every time a target object appeared as a distractor, we calculated a ‘target repetition count’ by counting the number of times that object had appeared as a target during the spatial blink task. For each of these target distractor trials we also found the trial with a non-studied distractor that had occurred closest in time, and used accuracy on these trials as a baseline measure of accuracy when attention was not captured. Across target repetition counts 0-to-5, we had an average of at least 4.8 trials per count across participants, with only one participant having a repetition count with no trials: That participant had no trials for target repetition count 3. For analyses below, excluding the participant with missing data did not alter the pattern of statistically significant results. Given the reasonable sample size (28 participants), we chose to report parametric null-hypothesis statistical tests despite the small numbers of trials per participant. Follow-up non-parametric one-way ANOVAs (Friedman’s test) and t tests (Wilcoxon signed-rank) revealed the same pattern of statistically significant results.
Results
Memory training task
All participants completed memory training in two blocks, except for one who completed training in three blocks, indicating that the majority of participants reached the accuracy threshold by the minimum number of testing rounds. Average accuracy was 95.8% for the first blocks, 99.6% for the second blocks, and 97.2% for the third, suggesting participants were able to effectively commit the required images to memory.
Spatial blink task
Accuracy
Visual inspection of the accuracy results (see Fig. 3), suggest that a spatial blink (i.e., reduced task accuracy at lag 2 relative to non-studied distractors) was present for both frequently and infrequently primed distractors. To assess the statistical reliability of these differences, accuracies were subjected to a 3 (Distractor Type: frequently primed, infrequently primed, or non-studied distractor) × 3 (Lag: 2, 5, or 8) within-subjects ANOVA. The sphericity assumption was violated for the main effect of lag, however, corrections did not alter the pattern of statistically significant results. This analysis revealed statistically significant main effects of distractor type, F(2, 54) = 8.79, p < .001, η2 = .056, BF10 = 13.7, and lag, F(2, 54) = 23.7, p < .001, η2 = .224, BF10 = 1.37 × 1010. Moreover, there was a significant 2-way interaction between distractor type and lag, F(4, 108) = 3.69, p = .007, η2 = .035, BF10 = 1.46, likely reflecting the larger spatial blink for both types of primed distractors relative to non-studied distractors. Of primary interest was the evidence of attentional capture at lag 2, which was examined using planned t tests. Relative to the non-studied distractor baseline, both frequently primed distractors, t(27) = 3.70, p < .001, d = 0.70, BF10 = 34.5, and infrequently primed distractors, t(27) = 3.12, p = .004, d = 0.59, BF10 = 9.56, produced greater attentional capture. However, the evidence favored no difference in capture (i.e., Bayes factor less than one third) between frequently and infrequently primed distractors, t(27) = 0.48, p = .635, d = 0.09, BF10 = 0.22. These findings suggest that the manipulation of priming has little-to-no effect on attentional capture: Both frequently and infrequently primed distractors equivalently captured attention.

Spatial blink accuracy results. There were little-to-no differences in accuracy between the frequently and infrequently primed distractor trials, and both produced comparable attentional capture (i.e., spatial blinks) relative to non-studied distractors, as shown by the equivalent drops in accuracy at lag 2. Error bars on all figures are corrected (Morey, 2008) within-subject standard errors (Cousineau, 2005)
Target repetition count
In addition to the experimental manipulation of priming analyzed above, we also examined priming by computing task accuracy as a function of target repetition count: the actual number of times a studied distractor (i.e., both frequently and infrequently primed distractors) had appeared as a target in the spatial blink task. For example, the target repetition count 0 condition conveys spatial blink accuracy on trials with studied distractors that had yet to appear as a target, and, as a control condition, accuracy from an equal number of trials with non-studied distractors from the same time in the experiment. The target repetition count data are plotted in Figure 4, and once again reveal greater attentional capture by studied than non-studied distractors. This assertion was supported by a 2 (Distractor Type: studied or non-studied) × 6 (Target Repetition Count: 0-to-5) within-subjects ANOVA, which revealed a statistically significant main effect of distractor type, F(1, 26) = 14.4, p < .001, η2 = .096, BF10 = 2.57 × 105. In contrast, the evidence favored the null model (i.e., Bayes factor less than one third) over both the main effect of repetition count, F(5, 130) = 0.87, p = .504, η2 = .015, BF10 = 0.03, and over the two-way interaction, F(5, 130) = 1.17, p = .326, η2 = .011, BF10 = 0.04. Interestingly, even at target repetition count 0, studied distractors produced statistically significantly more attentional capture than non-studied distractors, t(27) = 3.13, p = .004, d = 0.59, BF10 = 9.80. Thus, participants had adopted an attentional control setting for studied distractors that modulated attentional capture before those distractors had ever been selected as targets in the spatial blink task, and, there is no change in the magnitude of this capture across the first through fifth instances of priming.

Spatial blink accuracy on lag 2 trials as a function of target repetition count. For studied distractors, target repetition count is the number of times the distractor object had previously appeared as a spatial blink target. For each studied distractor trial we also found the trial closest in time with a non-studied distractor and used accuracy these trials as a baseline for comparison. Studied distractors (i.e., frequently and infrequently primed objects) captured attention more than non-studied distractors across all levels of repetition. Moreover, studied distractors captured attention before they appeared as targets in the spatial blink task (i.e., target repetition count 0), consistent with the conclusion that long-term memory attentional control settings capture attention via volitional control, not via bottom-up priming
General discussion
In the present study, we asked whether priming based on target-selection history could explain some of the surprising properties of long-term memory attentional control settings, or whether long-term memory-based control would provide a clear demonstration of voluntary control settings. Our findings favor the latter. In both the present and past long-term memory control setting studies, control over capture cannot be explained by short-lived priming, since large sets of targets were used, and the distractor on a given trial was rarely the same as the target on any recent trials (Giammarco et al., 2016; Plater et al., 2020). Here, we also show that long-term memory control settings cannot be explained by the accrual of long-lasting priming effects. The magnitude of attentional capture was unaffected by whether stimuli appeared as targets frequently (about once every 12 trials) or infrequently (about once every 36 trials). Moreover, we also observed that target objects preferentially captured attention relative to non-studied objects, even before they had appeared as targets, and that there were no changes in capture across the first five instances of priming. Thus, participants had a stable attentional control set for their target objects prior to any history of target selection in the spatial blink task. Combined with the lack of effect of our experimental manipulation of priming frequency, the present findings support the conclusion that bottom-up priming from target-selection history has no role in the establishment of long-term memory attentional control settings; rather, these control settings reflect the voluntary control of attentional capture.
Priming accounts of ACSs
We interpret the present findings, in particular those from the target repetition count 0 condition, as a clear demonstration that attentional control settings can be adopted voluntarily. These objects had yet to appear as targets, yet, despite no history of target selection, they preferentially captured attention. There is, however, a potential alternative explanation. Although distractors in the target repetition count 0 condition had never been primed as targets in the spatial blink task, they had been seen, attended to, and memorized during the initial memory training task. Could this bottom-up exposure have been sufficient to induce the observed modulations of attentional capture? The findings of Giammarco et al. (2016) make this account unlikely. In particular, they found that when participants memorized two lists of objects before being told that one would serve as the targets in a spatial blink task and the other was now task irrelevant, only the target objects captured attention. Thus, we know from Giammarco et al. (2016) that exposure to objects during the memory training task is insufficient for those objects to comprise an attentional control set. And from the present study we know that priming during the spatial blink task is unnecessary. Together, these findings suggest that voluntary control—not target-selection history—is the main determinant of long-term memory attentional control settings.
That said, the question remains: Does bottom-up priming ever play a role in attentional control settings? Looking back over the last 15 years, the findings surrounding priming are mixed. Some studies have found that priming plays a prominent role in attentional control (Belopolsky & Awh, 2016; Belopolsky et al., 2010; Theeuwes, 2013), and other have argued it plays little-to-no role (Ansorge, Kiss, & Eimer, 2009; Lien et al., 2010, 2014). Given the mixed literature on this topic, Büsel et al. (2020) were able to provide a clearer picture on the role of priming through their recent meta-analysis of contingent capture effects. They assessed the effect of priming by comparing the magnitude of contingent capture on blocks of trials with a single target type against those with multiple target types; the former should elicit greater priming effects since the target-matching distractors always matched the target from the previous trial. Although they were only able to include 12 studies in this component of the meta-analysis, they found no clear evidence of a role for priming. Our findings are consistent with this conclusion. We tested for, but found no evidence of, effects of priming on attentional control.
Conclusions
Together, the present findings suggest that the control of attentional capture is largely a voluntary process that can be instantiated without bottom-up priming from target-selection history. Not only did target objects produce greater attentional capture than non-studied objects from the outset of the experiment (i.e., prior to any selection of those targets in the spatial blink task), we found no evidence of increased capture with increased priming. Whether it was across the first five repetitions of a target stimulus, or between stimuli primed on average every 12 trials versus 36, there were no differences in the magnitude of attentional capture by those stimuli. The present findings also advance our understanding of long-term memory attentional control settings. While bottom-up priming might seem like a viable explanation for how observers can rapidly distinguish whether a stimulus matches any of a large set of objects in time to regulate attentional capture, it does not seem to play a role. Long-term memory attentional control settings are established voluntarily based on an observer’s top-down attentional goals.
References
Al-Aidroos, N., Harrison, S., & Pratt, J. (2010). Attentional control settings prevent abrupt onsets from capturing visual spatial attention. Quarterly Journal of Experimental Psychology, 63(1), 31–41. https://doi.org/10.1080/17470210903150738
Ansorge, U., Kiss, M., & Eimer, M. (2009). Goal-driven attentional capture by invisible colors: Evidence from event-related potentials. Psychonomic Bulletin and Review, 16(4), 648–653. https://doi.org/10.3758/PBR.16.4.648
Awh, E., Belopolsky, A. V., & Theeuwes, J. (2012). Top-down versus bottom-up attentional control: A failed theoretical dichotomy. Trends in Cognitive Sciences, 16(8), 437–443. https://doi.org/10.1016/j.tics.2012.06.010
Belopolsky, A. V., & Awh, E. (2016). The role of context in volitional control of feature-based attention. Journal of Experimental Psychology: Human Perception and Performance, 42(2), 213–224. https://doi.org/10.1037/xhp0000135
Belopolsky, A. V., Schreij, D., & Theeuwes, J. (2010). What is top-down about contingent capture? Attention, Perception, & Psychophysics, 72(2), 326–341. https://doi.org/10.3758/APP
Brady, T. F., Konkle, T., Alvarez, G. A., & Oliva, A. (2008). Visual long-term memory has a massive storage capacity for object details. Proceedings of the National Academy of Sciences of the United States of America, 105(38), 14325–14329. https://doi.org/10.1073/pnas.0803390105
Brascamp, J. W., Pels, E., & Kristjánsson, Á. (2011). Priming of pop-out on multiple time scales during visual search. Vision Research, 51(17), 1972–1978. https://doi.org/10.1016/j.visres.2011.07.007
Burnham, B. R. (2007). Displaywide visual features associated with a search display’s appearance can mediate attentional capture. Psychonomic Bulletin & Review, 14(3), 392. https://doi.org/10.3758/BF03194082
Büsel, C., Voracek, M., & Ansorge, U. (2020). A meta-analysis of contingent-capture effects. Psychological Research, 84(3), 784–809. https://doi.org/10.1007/s00426-018-1087-3
Chen, P., & Mordkoff, J. T. (2007). Contingent capture at a very short SOA: Evidence against rapid disengagement. Visual Cognition, 15(8), 637–646. https://doi.org/10.1080/13506280701317968
Cousineau, D. (2005). Confidence intervals in within-subject designs: A simpler solution to Loftus and Masson’s method. Tutorials in Quantitative Methods for Psychology, 1(1), 42–45. https://doi.org/10.20982/tqmp.01.1.p042
Folk, C. L., Leber, A. B., & Egeth, H. E. (2002). Made you blink! Contingent attentional capture produces a spatial blink. Perception & Psychophysics, 64(5), 741–753. https://doi.org/10.3758/BF03194741
Folk, C. L., Leber, A. B., & Egeth, H. E. (2008). Top-down control settings and the attentional blink: Evidence for nonspatial contingent capture. Visual Cognition, 16(5), 616–642. https://doi.org/10.1080/13506280601134018
Folk, C. L., & Remington, R. (1998). Selectivity in distraction by irrelevant featural singletons: Evidence for two forms of attentional capture. Journal of Experimental Psychology: Human Perception and Performance, 24(3), 847–858. https://doi.org/10.1037/0096-1523.24.3.847
Folk, C. L., Remington, R. W., & Johnston, J. C. (1992). Involuntary covert orienting is contingent on attentional control settings. Journal of Experimental Psychology: Human Perception and Performance, 18(4), 1030–1044. https://doi.org/10.1037/0096-1523.18.4.1030
Gaspelin, N., Ruthruff, E., & Lien, M. C. (2016). The problem of latent attentional capture: Easy visual search conceals capture by task-irrelevant abrupt onsets. Journal of Experimental Psychology: Human Perception and Performance, 42(8), 1104–1120. https://doi.org/10.1037/xhp0000214
Giammarco, M., Paoletti, A., Guild, E. B., & Al-Aidroos, N. (2016). Attentional capture by items that match episodic long-term memory representations. Visual Cognition, 24(1), 78–101. https://doi.org/10.1080/13506285.2016.1195470
Jacoby, L. L. (1991). A process dissociation framework: Separating automatic from intentional uses of memory. Journal of Memory and Language, 30(5), 513–541. https://doi.org/10.1016/0749-596X(91)90025-F
JASP Team (2020). JASP (Version 0.13.1) [Computer software]. https://jasp-stats.org/faq/how-do-i-cite-jasp/#:~:text=To%20cite%20JASP%20in%20publications,Version%200.14)%5BComputer%20software%5D
Kristjánsson, Á., & Ásgeirsson, Á. G. (2019). Attentional priming: Recent insights and current controversies. Current Opinion in Psychology, 29, 71–75. https://doi.org/10.1016/j.copsyc.2018.11.013
Kruijne, W., Brascamp, J. W., Kristjánsson, Á., & Meeter, M. (2015). Can a single short-term mechanism account for priming of pop-out? Vision Research, 115, 17–22. https://doi.org/10.1016/j.visres.2015.03.011
Lamy, D. F., Darnell, M., Levi, A., & Bublil, C. (2018). Testing the attentional dwelling hypothesis of attentional capture. Journal of Cognition, 1(1), 1–16. https://doi.org/10.5334/joc.48
Lamy, D. F., & Kristjánsson, A. (2013). Is goal-directed attentional guidance just intertrial priming? A review. Journal of Vision, 13(3), 14. https://doi.org/10.1167/13.3.14
Lamy, D. F., Leber, A. B., & Egeth, H. E. (2012). Selective attention. In Handbook of Attention, Second Edition, 4.
Lien, M.-C., Ruthruff, E., & Johnston, J. C. (2010). Attentional capture with rapidly changing attentional control settings. Journal of Experimental Psychology: Human Perception and Performance, 36(1), 1–16. https://doi.org/10.1037/a0015875
Lien, M.-C., Ruthruff, E., & Naylor, J. (2014). Attention capture while switching search strategies: Evidence for a breakdown in top-down attentional control. Visual Cognition, 22(8), 1105–1133. https://doi.org/10.1080/13506285.2014.962649
Maljkovic, V., & Nakayama, K. (1994). Priming of pop-out: I. Role of features. Memory & Cognition, 22(6), 657. https://doi.org/10.3758/BF03209251
Maljkovic, V., & Nakayama, K. (2000). Priming of popout: III. A short-term implicit memory system beneficial for rapid target selection. Visual Cognition, 7(5), 571–595. https://doi.org/10.1080/135062800407202
Morey, R. D. (2008). Confidence intervals from normalized data: A correction to Cousineau (2005). Tutorials in Quantitative Methods for Psychology, 4(2), 61–64. https://doi.org/10.20982/tqmp.04.2.p061
Moscovitch, M. (2008). The hippocampus as a “stupid,” domain-specific module: Implications for theories of recent and remote memory, and of imagination. Canadian Journal of Experimental Psychology, 62(1), 62. https://doi.org/10.1037/1196-1961.62.1.62
Nickel, A. E., Hopkins, L. S., Minor, G. N., & Hannula, D. E. (2020). Attention capture by episodic long-term memory. Cognition, 201, 104312. https://doi.org/10.1016/j.cognition.2020.104312
Oberauer, K. (2001). Removing irrelevant information from working memory: A cognitive aging study with the modified Sternberg task. Journal of Experimental Psychology: Learning, Memory, and Cognition, 27(4), 948–957. https://doi.org/10.1037/0278-7393.27.4.948
Peirce, J., Gray, J. R., Simpson, S., MacAskill, M., Höchenberger, R., Sogo, H., … Lindeløv, J. K. (2019). PsychoPy2: Experiments in behavior made easy. Behavior Research Methods, 51(1), 195–203. https://doi.org/10.3758/s13428-018-01193-y
Plater, L., Giammarco, M., Fiacconi, C., & Al-Aidroos, N. (2020). No role for activated long-term memory in attentional control settings. Journal of Experimental Psychology: General, 149(2), 209–221. https://doi.org/10.1037/xge0000642
Posner, M. I. (1980). Orienting of attention. Quarterly Journal of Experimental Psychology, 32(1), 3–25. https://doi.org/10.1080/00335558008248231
Posner, M. I., & Cohen, Y. (1984). Components of visual orienting. Attention and Performance: Control of Language Processes, 32, 531–556. https://doi.org/10.1162/jocn.1991.3.4.335
Ruthruff, E., Faulks, M., Maxwell, J. W., & Gaspelin, N. (2020). Attentional dwelling and capture by color singletons. Attention, Perception, and Psychophysics, 82, 3048–3064. https://doi.org/10.3758/s13414-020-02054-7
Silvis, J. D., Belopolsky, A. V., Murris, J. W. I., & Donk, M. (2015). The effects of feature-based priming and visual working memory on oculomotor capture. PLoS One, 10(11), e0142696. https://doi.org/10.1371/journal.pone.0142696
Theeuwes, J. (1991). Cross-dimensional perceptual selectivity. Perception & Psychophysics, 50(2), 184–193. https://doi.org/10.3758/BF03212219
Theeuwes, J. (1992). Perceptual selectivity for color and form. Perception & Psychophysics, 51(6), 599–606. https://doi.org/10.3758/BF03211656
Theeuwes, J. (2010). Top-down and bottom-up control of visual selection. Acta Psychologica, 135(2), 77–99. https://doi.org/10.1016/j.actpsy.2010.02.006
Theeuwes, J. (2013). Feature-based attention: It is all bottom-up priming. Philosophical Transactions of the Royal Society B, 368, 20130055. https://doi.org/10.1098/rstb.2013.0055
Treisman, A., & Sato, S. (1990). Conjunction search revisited. Journal of Experimental Psychology: Human Perception and Performance, 16(3), 459–478. https://doi.org/10.1037/0096-1523.16.3.459
Wagenmakers, E. J., Love, J., Marsman, M., Jamil, T., Ly, A., Verhagen, J., … Morey, R. D. (2018). Bayesian inference for psychology. Part II: Example applications with JASP. Psychonomic Bulletin and Review, 25(1), 58–76. https://doi.org/10.3758/s13423-017-1323-7
Open Practices Statement
At the time of data collection (pre-2016), our consent forms explicitly stated that data would only be viewed by the research group. While our practices have since changed, the data for the experiment reported are not publicly available. The experiment materials, however, are available here: https://osf.io/5gzve/.
Funding
This research was supported in part by an Ontario Graduate Scholarship to M.G. and an NSERC Discovery Grant (418507-2012) and CFI Grant (30374) to N.A.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Giammarco, M., Plater, L., Hryciw, J. et al. Getting it right from the start: Attentional control settings without a history of target selection. Atten Percept Psychophys 83, 133–141 (2021). https://doi.org/10.3758/s13414-020-02193-x
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-020-02193-x