
Abstract
Dent, Humphreys, and Braithwaite (2011) showed substantial costs to search when a moving target shared its color with a group of ignored static distractors. The present study further explored the conditions under which such costs to performance occur. Experiment 1 tested whether the negative color-sharing effect was specific to cases in which search showed a highly serial pattern. The results showed that the negative color-sharing effect persisted in the case of a target defined as a conjunction of movement and form, even when search was highly efficient. In Experiment 2, the ease with which participants could find an odd-colored target amongst a moving group was examined. Participants searched for a moving target amongst moving and stationary distractors. In Experiment 2A, participants performed a highly serial search through a group of similarly shaped moving letters. Performance was much slower when the target shared its color with a set of ignored static distractors. The exact same displays were used in Experiment 2B; however, participants now responded “present” for targets that shared the color of the static distractors. The same targets that had previously been difficult to find were now found efficiently. The results are interpreted in a flexible framework for attentional control. Targets that are linked with irrelevant distractors by color tend to be ignored. However, this cost can be overridden by top-down control settings.
Similar content being viewed by others

Human behavior takes place in a complex, cluttered, dynamic environment. The human visual system can not simultaneously process all of this information (see, e.g., Broadbent 1958; Tsotos, 1990). Mechanisms of selection are required in order to prioritize relevant and to deprioritize irrelevant stimuli for further processing and action. The visual search task (see Chan & Hayward, 2013; Wolfe, 1998; Wolfe & Horowitz, 2004, for reviews), in which an observer is required to find a target amongst a set of spatially distributed distractors, has been used extensively to characterize these mechanisms of selection. In the visual search task, the slope of the function relating the number of potential targets to RT (search slope) is the primary measure of the efficiency of a given search. Certain targets may be detected highly efficiently, with little increase of RT as the number of items increases. In the extreme, when the search slope is close to zero, all of the items in a display may be processed in parallel. For example, the visual system is highly sensitive to differences in the gross features of objects; a single red item amongst green items may “pop out” effortlessly from a display, and may be very difficult to ignore (e.g., Theeuwes, 1992; see Theeuwes, 2010, for a review). According to Treisman’s feature integration theory (FIT; Treisman & Gelade, 1980; Treisman, 2006) and its derivatives (e.g., Guided Search [GS], Wolfe, 1994, 2007; dimension weighting [DW], Müller, Heller, & Ziegler, 1995; Krummenacher & Müller, 2012), these basic features are represented in distinct feature maps within dimensional modules that code the gross distribution of a particular feature in the environment; thus, these feature maps alone may signal the presence of unique features. In contrast, recovering more detailed information, including how multiple features are conjoined, requires spatial selection, producing search slopes greater than zero, as single items or small groups of items are inspected in turn.
Revisions to this basic FIT architecture allow the feature maps to guide selection even for complex conjunctively defined targets, such as a red X amongst green Xs and red Os (e.g., Treisman & Sato, 1990; Wolfe, 1994; Wolfe, Cave, & Franzel, 1989). Instead of spatial selective attention being deployed at random, selection may be guided toward locations that contain relevant features and away from locations that contain irrelevant features. According to the GS model (Wolfe et al., 1989; see also Wolfe, 1994, 2007), feature maps activate locations in an activation map, the level of which determines the likelihood that an item will be selected. By increasing the weighting on inputs from target feature maps, search can be biased toward likely target locations, increasing the speed of search. In some cases, in which the target is defined as a conjunction of two highly discriminable features (e.g., a red X amongst green Xs and red Os [Wolfe et al., 1989] or a moving X amongst static Xs and moving Os [McLeod, Driver, & Crisp, 1988]), parallel search may result, in which there is little or no cost as more items are added to the display. A similar architecture was also suggested by Treisman and Sato (1990); however, they proposed the inhibition of locations containing nontarget features rather than the activation of locations containing target features. Other authors, although they accepted the basic architecture of FIT, have emphasized the role of different feature dimensions (e.g., color vs. orientation) rather than specific feature values (e.g., red vs. horizontal) as targets for attentional modulation (e.g., Krummenacher & Müller, 2012; Müller et al., 1995). Thus, according to the DW model, the feature contrasts within different feature dimensions may be differentially weighted, according to top-down goals. Appropriate weights across multiple dimensions can lead to efficient conjunction search (see Weidner & Müller, 2009; Weidner, Pollmann, Müller, & von Cramon, 2002).
Exactly how the different features of objects compete and cooperate to guide selection is not fully understood. One important issue regards the independence of guidance by multiple features. According to FIT and related models, it is possible to independently control guidance by distinct features, since no direct mechanism determines the interactions between distinct feature maps from different dimensions (aside from common projections to a master activation map). More recent explicit computational models of how feature maps drive activity in a master activation or saliency map also assume independent summation across dimensions (e.g., Itti & Koch, 2000). This independence of guidance by the multiple features of objects is an important point of contrast between FIT and the attentional engagement theory (AET), proposed by Duncan and Humphreys (1989, 1992). According to AET, stimuli gain or lose attentional weight to the extent that they match a target template held in working memory. Importantly, the attentional weights of different stimuli that share features are not independent but linked, so that items that are grouped together tend to gain or lose weight together. Importantly, this “weight linkage” exists even if the linkage is based on a feature that is not explicitly relevant.
The specific notion of weight linkage is clearly related to the subsequent, broader articulation of the integrated competition hypothesis (ICH; e.g., Duncan, Humphreys, & Ward, 1997). ICH states that objects compete for representation in multiple brain systems coding specific features, but that this competition is integrated such that as objects gain or lose dominance in one system, their representation in other systems follows suit. ICH has gained support from behavioral studies demonstrating that it is easier to encode two properties of one object than two properties of two objects (e.g., Duncan, 1984; see Scholl, 2001, for a review). More recent neuroimaging experiments have also supported the notion of integrated competition at the level of multiple properties of single objects. O’Craven, Downing, and Kanwisher (1999) measured brain responses to superimposed images of faces and houses, one of which could be in motion. The results showed that even though all three attributes occupied the same location, attention to movement also led to an enhanced response in the category-specific area representing the moving object (face or house). Specifically, in the context of visual search over multiple items, several failures of independent feature-based control of search guidance have been demonstrated in the literature. Found (1998; see also Takeda, Phillips, & Kumada, 2006) showed that task-irrelevant size differences that correlated with task-relevant color and form differences improved search performance, consistent with nonindependence.
Braithwaite and colleagues (e.g., Andrews, Watson, Humphreys, & Braithwaite, 2011; Braithwaite, Humphreys, & Hodsoll, 2003; Braithwaite, Humphreys, Hulleman, & Watson, 2007) have investigated the issue of the independence of guidance extensively in the context of temporal selection. When the cue for selection is temporal (e.g., one set of stimuli appears 1 s before the remaining distractors and the target), the early-appearing distractors can be effectively excluded from search (see Watson, Humphreys, & Olivers, 2003). However, this preview benefit is associated with costs under some conditions—for example, targets that share color with the early-appearing distractors are difficult to find—consistent with the nonindependence of selection by temporal and color cues. Braithwaite et al. (2003) explained this negative color carryover effect in terms of inhibition of the color of the distractors, contingent on active inhibitory processes applied to the locations of the early-appearing distractors, in the time window prior to the appearance of the target.
Recently, Dent, Humphreys, and Braithwaite (2011) extended this phenomena of negative color carryover to a nontemporal selection cue: segmentation by motion. Participants searched for a moving target letter amongst static and moving distractors. When the target shared its color with the static distractors, it was very difficult to find. This negative color effect occurred despite clear evidence that participants could use movement to restrict search to a moving group. The results of Dent et al. (2011) challenged the proposal of FIT, GS, and DW that search may be guided by motion independently of color, but are consistent with the proposal of ICH and AET that the attentional weights of items that share features change together (weight linkage). Thus, one interpretation of the results reported by Dent et al. (2011) is that when the target shares the color of the static distractors, it inherits a loss of attentional weight or priority due to weight linkage with the rejected static distractors, making it difficult to find.
Search efficiency and the independence of guidance cues
However, one issue for the study of Dent et al. (2011) is that search through the moving heterogeneous letters was difficult, showing an extremely serial letter-by-letter pattern of performance (the search slope in the baseline condition was around 80 ms per item). Half of the letters moved, and half were stationary, so guidance of search by motion was possible. However, the target letter Z or N could not be distinguished from the distractors (H, I, V, and X) by a single form feature, but only by the spatial configuration of its parts, rendering guidance by form inert. It is possible that the nonindependence of control exhibited by participants in this study was specific to a situation in which selection through a subset is driven by a systematic serial search.
Models in the GS family were initially developed to account for cases of highly efficient conjunction search (e.g., conjunctions of color and form, form and motion, etc.). In these situations, a single location in the master activation map will have substantially higher activation than other locations (on target-present trials) and will be selected with one of the very first deployments of spatial attention. Although this first deployment of spatial attention may be made on the basis of computations that treat multiple features independently, subsequent shifts of attention may not. In Dent et al.’s (2011) task, shifts of attention through the moving group will not be effectively guided by an activation map, since all potential moving targets will have similar activation values. When spatial attention shifts through a target group without strong guidance to any particular location from the activation map, the system is likely to fall back on other principles to direct search. One such heuristic could be deliberate strategic avoidance of items sharing color with static distractors. Initial selection of a static distractor may also automatically and involuntarily lead to priming of same colored distractors, leading to a disadvantage for targets colored differently. Thus, in this regard the study of Dent et al. (2011), whilst providing an important demonstration of nonindependence, does not rule out that independence as predicted by GS may be observed, so long as GS mechanisms are effectively operating to drive efficient search.
Segmentation and second-order parallel processing
Models like GS, which attempt to explain search and selection using a map that sums signals across different feature dimensions, may be contrasted with other models that use segmentation and grouping processes to select targets. For example, McLeod, Driver, and Crisp (1988) introduced the idea of a motion filter, in order to explain their finding of efficient search for targets defined by a conjunction of movement and shape (e.g., a moving X amongst moving Os and static Xs). The motion filter is a dedicated functional motion-processing system, realized by neural hardware in the brain (e.g., hMT/V5+). The motion filter preferentially represents moving items and is sensitive to their gross form. Essentially, the motion filter allows form-processing operations to be restricted to a moving group of objects, allowing detection of an odd shaped item amongst a moving group. Although some of the predictions made by the motion filter account have been disconfirmed (e.g., von Mühlenen & Müller, 2000, 2001), Ellison, Lane, and Schenk (2007) reinvigorated this hypothesis by demonstrating using transcranial magnetic stimulation that even when searches were of similar efficiency, when search was guided by motion rather than color, it recruited parietal regions to a smaller extent, depending primarily on intact sensory hMT/V5.
The general idea that the parallel computation of differences along a secondary dimension may be restricted to a subset of elements sharing features along a different primary dimension is referred to as second-order parallel processing (e.g., Friedman-Hill & Wolfe, 1995). In addition to the idea of a motion filter, the idea of second-order parallel processing forms an important component of some general models of search and selection (e.g., Grossberg, Mingolla, & Ross, 1994; Huang & Pashler, 2007) in which segmentation is not restricted to movement, but can operate for many other dimensions. Friedman-Hill and Wolfe experimentally explored the possibility of second-order parallel processing of orientation driven by color, by asking participants to search for a conjunctive target of known color but unknown orientation. Importantly, no single orientation or set of orientations always characterized the target; the target orientation on one trial could be the target-colored distractor orientation on another. Here, the logic was that if the orientation was unknown, search could not be guided toward a specific orientation. If form processing could be restricted to items in the target color, a target of unknown but unique orientation should pop out nonetheless. Friedman-Hill and Wolfe concluded that whilst such color-driven second-order processing was possible, it was time consuming to implement; thus, second-order parallel processing might be of secondary importance relative to feature-based guidance, at least when it comes to explaining efficient conjunction search.
Studies in the DW framework have further examined second-order parallel processing. Weidner and colleagues (Weidner & Müller 2009, 2013; Weidner et al., 2002) have explored the second-order processing of color and motion driven by primary segmentation by size. Participants searched for a large target, ignoring a set of small distractors that were heterogeneous in color and motion direction. The large nontargets were homogeneous and had fixed values of color and motion direction. Under these conditions, so long as participants knew the target-defining dimension (color or motion), there was no cost to performance from uncertainty regarding the specific color (red or blue) or motion (+45 or –45 deg) value. In contrast, substantial costs to performance arose when there was uncertainty regarding the dimension within which the target would be defined. In contrast to Friedman-Hill and Wolfe’s (1995) results, it appears that for some stimulus configurations, dimension-based guidance is more important than guidance to a specific feature. Thus, according to DW, second-order parallel processing can be achieved by feature-based filtering along a primary dimension coupled with a high dimensional weight being assigned to the secondary, target-defining dimension. When it is not possible to weight the secondary dimension optimally, costs arise, because the contribution of the appropriate dimension to saliency computations will not always be maximized.
Weidner and Müller (2009, 2013) argued that, rather than a sequence of operations—for instance, segmentation by size and then by motion or form, as has been supposed in certain models (e.g., Grossberg et al., 1994; Huang & Pashler, 2007)—all of the dimensions feed information into an activation map in parallel, as in GS. Support for this assertion has come from the finding that a temporal preview of the small distractors (e.g., Watson & Humphreys, 1997) can greatly reduce the cost associated with not knowing the target dimension. If the cost for dimensional uncertainty arises because participants must check through both secondary dimensions on some trials, then these costs should continue to be present under these preview conditions (Weidner & Müller, 2013). Additionally, when a target is dimensionally uncertain but happens to be defined redundantly on both dimensions, performance is facilitated in a way that is consistent with coactivation from both secondary dimensions (Weidner & Müller, 2009). These results are consistent with limitations on the amount of dimensional weight that may be assigned. The majority of dimensional weight is assigned to the primary dimension, and the remaining weight is assigned to the secondary dimensions. Large costs occur as a result of dimensional uncertainty, since under these conditions the limited remaining dimensional weight cannot be reliably directed to the target-defining dimension. The important point for the present work is that, if participants can increase the weight assigned to the form dimension to reliably detect targets, they may be able to operate in a color-independent fashion.
Clearly, in the study of Dent et al. (2011) second-order parallel processing would be ineffective, because the target shared form features with the moving distractors. If second-order parallel processing of form driven by motion is possible—or even obligatory, as is suggested by the idea of a motion filter—then when such second-order form processing is possible, irrelevant color differences may be immaterial. Likewise, when participants are able to assign high dimensional weight to the target-defining form dimension, they may be immune to the effects of motion. Alternatively, once participants begin to search for an odd-shaped item amongst the moving group, they may also become sensitive to odd-colored items, essentially operating in a singleton detection mode (e.g., Bacon & Egeth, 1994) amongst the moving items. Dent et al. (2011) argued that their results were difficult to account for by a motion filter or by other second-order parallel-processing accounts. However, the nature of the search task used in the Dent et al. (2011) study was not really an optimal test of the motion filter and related second-order parallel accounts. Thus, it may be that the weight linkage of color and motion was observed in the study of Dent et al. (2011) not because search was serial per se, but because second-order cues were absent.
The present study
In summary, it is certainly not clear that the motion segmentation used to drive a serial search through a relevant subset (as in Dent et al., 2011) operates according to the same mechanisms as when motion segmentation is used to efficiently detect a form singleton amongst a relevant subset (as in McLeod et al., 1988). In efficient conjunction search, the target location is specified more clearly in the activation map. When participants rely to a greater extent on these guiding representations, movement may be treated independently of color. One aim of the present study was to examine whether the negative effect of sharing color with a set of static distractors would generalize to situations in which search was more efficient. In cases of efficient search, in which the contribution of a guiding activation map is maximized, principles of independence may in fact hold. The present study tested this view by examining negative color effects in the case of efficiently detected movement–form conjunction targets. If participants continued to show negative color effects—even when the target was highly discriminable in form amongst the moving group and participants had every incentive to use either an activation map or second-order parallel processing—the importance of weight linkage as a general principle in search would be ratified. Furthermore, fundamental problems with representing conjunctions of color and form (see, e.g., McLeod et al. 1988) were ruled out by showing that targets that shared a color with static distractors could be relatively efficiently detected when color was explicitly relevant.
Experiment 1
In Experiment 1, participants searched for a target letter (H or I) amongst distractor letters (see Fig. 1). In the critical motion segmentation case, the target was presented amongst moving O and static H and I distractors. Thus, the target always possessed different features from the other moving items, but shared form features with the static items; that is, the target was only distinguished from the distractors by a conjunction of movement and form. Although the exact form of the target (H or I) was unpredictable, the horizontal and vertical features common to the targets were never present elsewhere amongst the moving distractors, and thus guidance based on form feature maps was possible. Importantly, the moving and static distractors were always colored differently. On half of the trials, the target shared its color with the static distractors and was thus differently colored from the other moving items, constituting a color singleton within the moving group. On the other half, the target was the same color as the other moving items and different in color from the static distractors. Would the negative color carryover effect generalize to this situation, in which a feature-unique target was sought amongst a motion-defined subset? The motion segmentation condition was contrasted with a half-set condition, in which only the moving items were presented, in order to demonstrate that when the moving subset was presented in isolation, performance was efficient.

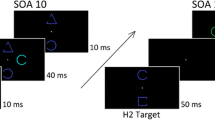
Example stimulus display for a color singleton trial in the motion segmentation condition of Experiment 1. Arrows indicate motion, and gray levels indicate color
In the experiment of Dent et al. (2011), the moving and static distractors consistently appeared in the same color throughout the experiment. For one group, the static distractors were red and the moving distractors green, and for the other group this mapping was reversed. In the present experiments, in order to rule out the possibility that any negative color effects were driven by the consistent pairing of a particular color with the static distractors, a set of six possible colors were mapped onto the moving and stationary distractors at random.
Method
Participants
Twelve students (four males, eight females; one left-handed) from the University of Essex, between 19 and 28 years of age (M = 22.6), took part for course credit.
Equipment
The stimuli were generated by a Macintosh PowerPC Dual G5 computer, using routines programmed with the Psychophysics Toolbox extensions for MATLAB (Brainard, 1997), and presented on a Mitsubishi 23sb 17-in screen.
Stimuli
The search displays were composed from the uppercase letters H, I, and O (see Fig. 1 for an illustration). The viewing distance was approximately 40 cm. The letters measured 0.6 × 0.6 cm (0.86º × 0.86º) and were composed of lines 0.06 cm (0.086º) wide. The H was composed of one horizontal and two vertical lines, and the I was two horizontal lines and one vertical line. The H and I were 90º rotations of each other, and the O was a closed circle. The letters were positioned randomly within the cells of an 11 × 11 grid of 121 cells (excluding the center cell, which contained the fixation cross). The stimuli were bounded by an outline frame 0.3 mm (0.043º) wide, measuring 16 × 16 cm (22.6º × 22.6º), and the display center was marked by a fixation cross, 0.6 × 0.6 cm (0.86º × 0.86º), with each component line being 0.3 mm (0.043º) wide. Static letters appeared centered within a cell, and moving letters were initially offset to the end point of the path that they would move through. Motion took the form of a linear up/down oscillation (2.6 cm/s, 3.72º/s) centered on the relevant cell (magnitude of oscillation = 0.36 cm, 0.56º). The initial motion direction (up or down) was random across trials.
Design and procedure
The design consisted of three factors: Condition (motion segmentation, half-set) × Target Color (target color singleton, target color nonsingleton) × Number of Moving Letters (six, 12). The critical condition was the motion segmentation condition (see Fig. 1 for an illustration). Here, either 12 or 24 letters were presented; half of the letters were static, and the other half, including the target, moved. The static distractors were uniformly colored Hs and Is (presented in equal numbers), and the moving distractors were uniformly colored Os of a different color from the static distractors. Target color was manipulated, so that on half of the trials, the target was a color singleton in the moving group (sharing its color with the static items; target singleton case). On the remaining trials, the target was the same color as the moving items, differing in color from the static group (target color nonsingleton case). A single baseline condition was also included; in the half-set baseline condition, only the moving items from the motion segmentation condition were presented; thus, the displays contained only six or 12 moving items. On half of the trials, the target was a color singleton, and on the other trials, it was identical in color to the moving distractors (color singleton and nonsingleton trials, respectively). In both conditions a single moving target was always present, and the task was to identify the target form (H or I) by pressing the Z or N key on the keyboard. Six colors (red, green, blue, yellow, cyan, and pink) were possible, formed from all possible combinations of the values of 255 or 0 on the red, green, and blue channels of the monitor (excluding black and white). Which two colors would be present was determined at random, with the constraint that no two colors were permitted to repeat on successive trials. Thus, it was never the case that a target on trial n would take on the color of the static distractors on trial n – 1.
The different conditions were presented to participants in separate blocks of trials, within which the other factors varied. Participants first completed one block of 24 practice trials for each of the two conditions; the data from these practice blocks were discarded. Participants then completed two further blocks of each of the conditions (the 120 trials of the first two blocks were prefaced by 24 practice trials, and the second two blocks were prefaced by eight practice trials). Thus, 60 trials were in each cell of the experimental design. The two conditions alternated, with the order of presentation being counterbalanced over participants (ABAB or BABA).
Each trial commenced with a keypress from the participant. Each trial started with a blank screen for 100 ms, followed by the outline square and fixation cross for 500 ms. The search stimuli then appeared and began to move immediately. The display was cleared when the participant responded, and the next trial began.
Results
Accuracy
Accuracy was overall extremely high (98 % correct; see Table 1 for a breakdown)—too high to permit a meaningful analysis.
RT
Incorrect trials (2.3 %) and trials with RTs <100 ms or >10s (0.04 %) were excluded. RTs can be seen illustrated in Fig. 2. First, an analysis of variance (ANOVA) with the factors Target Color (singleton or nonsingleton), Condition (motion segmentation or half-set), and Number of Moving Items (six or 12) was conducted. Of critical importance, the interaction between all three factors was significant, F(1, 11) = 21.72, p < .001, consistent with negative effects on search slopes of the target sharing its color with the static distractors in the motion segmentation condition.

Search response times (RTs) in Experiment 1 as a function of condition (separate lines), number of moving items (horizontal axis), and target color (left vs. right graph). The target color nonsingleton cases are shown on the left, and target singleton cases are on the right. Error bars show standard errors of the means
In order to further explore the three-way interaction, the performance in each condition was analyzed separately using an ANOVA with two factors: Target Color and Number of Moving Items. In the motion segmentation condition, performance on target color singleton trials was overall slower [F(1, 11) = 8.04, p < .005, for the main effect of target color] and less efficient [slope of 30 vs. 14.5 ms/item for the color singleton and nonsingleton targets, respectively; F(1, 11) = 21.95, p < .001, for the interaction between set size and condition]. In contrast, in the half-set condition, performance was neither faster [F(1, 11) < 1, for the condition main effect] nor more efficient [F(1, 11) = 1.22, p = .292, for the interaction between set size and condition] as a function of target color. The highly efficient performance was indistinguishable for the color singleton and nonsingleton cases (search slopes of 0.7 and 1.5 ms/item), although a significant main effect of number of moving items was apparent [F(1, 11) = 9.75, p < .01].
In the motion segmentation condition for color nonsingleton trials, although performance was relatively efficient in the group as a whole (14.5 ms/item), it was not as efficient as many conjunction searches (5–10 ms/item) that Wolfe (1998) designated as “quite efficient.” However, there was substantial variation in efficiency; Fig. 3 shows the scatterplot of the relationship between conjunction search efficiency in the motion segmentation condition for nonsingleton targets and the cost in efficiency resulting from the target sharing its color with the static distractors (motion segmentation color singleton – nonsingleton efficiency). It is clear to see that every participant showed some numerical cost in the color singleton case; although a significant correlation is apparent, this was driven by a single inefficient participant. In order to ensure that the negative carryover effect did not disproportionately reflect the performance of the least efficient participants, the data from the motion segmentation condition were median split, and the six most efficient participants were examined separately. Here, the mean efficiency was 9.4 ms/item (see Fig. 2 for an illustration). The interaction between number of moving items and color in the motion segmentation condition continued to be present for these highly efficient participants, F(1, 5) = 70.444, p < .0001.

Scatterplot of the relationship between conjunction search efficiency and the efficiency cost related to the presence of a color singleton in the moving group. The solid line shows the linear regression line
Discussion
Experiment 1 showed that even when the target is defined as a conjunction of movement and form, there is a cost when the target shares its color with the static items. Importantly, this cost occurred when participants were tuned to detect a salient featural difference amongst the moving group. Thus, the negative color effect is not limited to situations in which the target is similar in form to the other moving items. Furthermore, the performance of the group was relatively efficient, and response times were fast (around 1 s), as compared to those in the previous report by Dent et al. (2011). Additionally, all participants, including those who exhibited highly efficient performance, showed the color effect. Thus, the effect is not a characteristic of a search mode in which selection operates in a serial, item-by-item fashion.
In terms of general theoretical principles of search and selection, these results demonstrate a scenario in which selection by motion and selection by color are not independent. Thus, GS and related models will require modification to incorporate this correlation between guidance from different features. The integration between different features in the control of search is a core principle of the ICH framework, and elements of this framework will need to be incorporated into any comprehensive account of search. But exactly how in detail should the negative color effect reported here be explained? AET, as a more specific version of the general ICH framework, provides a natural explanation in terms of weight linkage and spreading suppression, but should the data be explained in terms of weight linkage between the target and the moving items or weight linkage between the target and the static items?
It is tempting to try to explain the effect by appealing to processes operating on the moving items. This explanation might appeal to improved target selection when it can be linked by color to the other moving items. However, it is important to note that interactions exclusively within the moving group cannot explain the data; if that were the case, a cost should also be observed when only the moving items were presented in the half-set condition. Clearly, at least the presence of a group of static distractors is necessary for the effect to occur. Still, one might contend that the contribution of the static items is to abolish any advantage associated with a first-order color singleton, and that over and above this, the cost should be explained in terms of interactions between the moving items. Firstly, although weight linkage between the target and moving distractors might help to distribute increased weight to the target on the basis of motion, since the target is always moving and will receive increased weight directly, it is difficult to see how such sharing could further increase the weight. Secondly, such an explanation is untenable, since it misses the point that the moving items are distractors, and these distractors are efficiently rejected from search, as is shown by the relatively efficient performance here. In contrast to the experiment of Dent et al. (2011), in which form was not a reliable guidance cue, in the present experiment the participants were much more efficient at rejecting the moving distractors, as is evidenced by the search efficiency (14 ms/item, for nonsingleton targets in the motion segmentation condition of the present experiment vs. 35 ms/item in Dent et al., 2011). Essentially, the target must have a stronger attentional weight than the moving distractors. Linking the target with these distractors by common color would make it more difficult to individuate the target, undermining the benefit from form guidance, leading to a cost, rather than the benefit that is in fact observed. Thus, the most likely explanation is that when observers act rapidly to ignore a set of static distractors, which happen to have a particular color, by default other items that share color with these items tend also to get ignored. According to AET, this is due to the attentional weight of the target being reduced due to weight linkage with the static distractors, resulting in spreading suppression.
The difficulty with finding a target that shares color with a group of static distractors, even though it is color unique amongst the moving group, and even when individuals are set to detect salient featural differences amongst that group, is somewhat paradoxical. As was outlined above, one hypothesis here recruits the idea of second-order parallel processing of the moving subset. According to this notion, feature processing is constrained to apply separately to the moving group. Thus, if participants are searching for a form-unique item, it might be expected that since the locations of the target and the color singleton are perfectly correlated, an advantage would occur when the target was defined redundantly by a color difference, rather than the cost that is observed. At least two accounts can explain why second-order color singletons fail to aid performance. One possibility is that these second-order signals are difficult or impossible to generate as a result of the visual feature-processing architecture (e.g., the idea that motion and form are paradigmatic examples of separable features). Indeed, in the motion filter hypothesis of McLeod et al. (1988), the motion filter is “color blind.” Thus, it is possible that weight linkage occurs, and redundancy gains are absent only when dynamic signals combine with color. A second possibility is that although it is in principle possible to generate such signals if color is explicitly task-relevant, they are not generated automatically, and by default weight linkage is dominant.
More recent studies conducted within the framework of DW have contrasted the relative impacts of uncertainty regarding the specific secondary feature or dimension defining the target. Weidner and Müller (2013, 2009; see also Weidner et al., 2002) demonstrated that when participants knew the primary basis for selection (e.g., size) the cost of uncertainty regarding the secondary target dimension (color or motion) was greater than the cost of uncertainty regarding the target feature (red or green). These dimensional costs could be partially overridden by a semantic precue, consistent with the idea that participants can alter the weights assigned to differences originating in a particular dimension top-down, leading to enhanced performance. However, whether efficient detection of second-order color targets would be possible with the present stimuli, for which movement was the primary segmentation cue, is unknown. In order to test whether, in principle, second-order color singleton targets can be detected efficiently if that is explicitly required, Experiment 2 was conducted.
Experiment 2
In Experiment 2, participants viewed displays similar to those used by Dent et al. (2011), but with random assignments of color to the different distractor types. In Experiment 2A, participants searched for a Z or N target amongst moving and stationary H–I–V–X distractors. In Experiment 2B, participants searched exactly the same displays, but this time they were asked to detect the presence of an oddly colored item in the moving group. These specific stimuli were used in order to eliminate guidance by form, in order to isolate processing of color–motion conjunctions. Would color singletons in the moving group remain difficult to detect even when they were explicitly relevant?
Method
Participants
A total of 24 students from the University of Essex took part in return for course credit. Experiment 2A included 12 participants (three males, nine females; one left-handed) between 19 and 29 years of age (M = 21), and Experiment 2B included a different 12 participants (five males, seven mfemales; three left-handed) between 19 and 31 years of age (M = 20.8).
Equipment
This was as in Experiment 1.
Stimuli
The stimuli were displays of letters, as in Experiment 1. However, the specific letters used were different. All but one of the letters were selected from among the letters H, I, V, and X; one, the target, was either a Z or an N (see Fig. 4).

Example stimulus display for a color singleton trial in the motion segmentation condition of Experiment 2. Arrows indicate motion, and gray levels indicate color
Design and procedure
The design of Experiment 2A consisted of three factors: Condition (motion segmentation, full-set, half-set)×Target Color (target singleton, target nonsingleton) × Display Size (12, 24; motion segmentation condition only). The two baseline conditions (full-set and half-set) were constructed with reference to the critical motion segmentation condition. In the motion segmentation condition (illustrated in Fig. 4), either 12 or 24 items were presented, with half of them static and half moving (six or 12 items). As in the motion segmentation condition in Experiment 1, the static items shared a uniform color selected from one of six possibilities. The moving distractors were assigned a different uniform color from one of the remaining possibilities. Target color was varied as in Experiment 1, with 50 % of the targets sharing color with the static letters (target color singleton) and 50 % sharing color with the other moving items (target color nonsingleton). The full-set baseline condition was like the motion segmentation condition, except that here all the items moved. Thus, in the full-set condition, the target color manipulation was merely that targets that would have been color singletons in the motion segmentation condition appeared in a slight color majority (7 vs. 5 or 13 vs. 11). The half-set condition was like the motion segmentation condition, except that here the static items were not presented (and thus the true set size was six or 12 items). In Experiment 2A, the task was to identify the target form (Z or N) by pressing Z or N on the keyboard.
Participants completed each of the three conditions in a separate block of 144 trials (the first 24 trials were treated as practice and discarded). The order of presentation of the three blocks was counterbalanced over participants, such that each condition appeared equally often in each serial position. Thus, 30 trials were in each cell of the design. In addition, participants completed a short block of 24 practice trials of each of the conditions (in the same order as in the experimental blocks) prior to beginning the main experiment.
Experiment 2B was based on Experiment 2A, with two major modifications: (1) Here, the task was simply to detect whether or not a target color singleton was present. (2) Since this task was not possible in the full-set condition, when all items moved (since here there was no true color singleton amongst the moving group), only the motion segmentation condition and the half-set baseline conditions were included. Participants pressed “Z” to indicate present and “N” to indicate absent. In Experiment 2B, participants completed two blocks of experimental trials per condition, as in Experiment 1. Thus, 60 trials were in each cell of the design. In addition, participants also completed one short block of 24 trials in each condition prior to commencing the experiment proper.
Experiment 2A results
Accuracy
The overall accuracy was extremely high: 98 % correct (see Table 2 for a breakdown), too high to permit a meaningful analysis.
RT
Incorrect trials (1.97 %) and trials with RTs <100 ms or >10 s (0.53 %) were excluded. RTs can be seen illustrated in Fig. 5. Of critical importance, the three-way interaction of all factors was significant, F(2, 22) = 10.21, p < .001. In order to further understand the pattern of results in the three-way interaction, separate analyses were carried out comparing the motion segmentation condition against both the full-set and half-set conditions.

Search response times (RTs) in Experiment 2A as a function of condition (separate lines), set size in the motion segmentation condition (horizontal axis), and target color (left vs. right graph). Note that the set size in the half-set condition is half of the value indicated. The target color nonsingleton cases are shown on the left, and target singleton cases are on the right. Error bars show standard errors of the means
Motion segmentation versus full-set
An ANOVA with the factors Target Color (singleton nonsingleton), Condition (full-set, half-set, motion-segmentation), and Set Size (12 or 24 items; motion segmentation condition only) revealed a significant three-way interaction, F(1, 11) = 7.87, p < .05, consistent with large costs to search efficiency for target color singleton trials only in the motion segmentation condition. The three-way interaction was further decomposed by means of separate analyses of each condition and separate analyses of color singleton and color nonsingleton targets.
Considering the full-set condition, no main effect of target color emerged, F(1, 11) < 1, nor any difference in efficiency, F(1, 11) = 1.22, p = .294, as a function of target color. In contrast in the motion segmentation condition, the slope was much higher (78 vs. 50 ms/item) [F(1, 11) = 7.53, p < .05, for the Condition × Set Size interaction] when the target shared its color with the static distractors in the color singleton case than in the nonsingleton case.
For target color nonsingleton trials, performance was faster [F(1, 11) = 50.89, p < .0001, for the condition main effect] and more efficient (87 vs. 50 ms/item) [F(1, 11) = 8.5, p < .05, for the Set Size × Condition interaction] in the motion segmentation than in the full-set condition. In contrast, when the target was a color singleton in the moving group that shared its color with the static distractors (when present), performance was faster [F(1, 11) = 5.64, p < .05, for the condition main effect] but no more efficient (73 vs. 78 ms item) [F(1, 11) < 1 for the Set Size × Condition interaction] in the motion segmentation than in the full-set condition. Importantly, the benefit obtained from motion segmentation (in terms of efficiency) was completely eliminated when the target shared its color with the static distractors.
Motion segmentation versus half-set
An ANOVA with the factors Target Color (singleton, nonsingleton), Condition (full-set, half-set, motion segmentation), and Number of Moving Items (six or 12 items) showed a significant three-way interaction, F(1, 11) = 26.5, p < .05. The three-way interaction was decomposed by conducting separate analysis for each target color, singleton versus nonsingleton, and each condition.
In contrast to impaired performance in the color singleton case documented above for the motion segmentation condition, in the half-set baseline condition, performance was actually more efficient if the target was a color singleton (35 vs. 9 ms/item) [F(1, 11) = 21.27, p < .001, for the interaction between the number of moving items and target color]. In the half-set condition, the effect of the number of moving items was significant for color nonsingleton trials, F(1, 11) = 48.79, p < .0001, but only just significant if a color singleton was present, F(1, 11) = 5.88, p < .05.
The separate analysis of the color nonsingleton trials showed that when the target was a color nonsingleton, performance was slower in the motion segmentation condition [F(1, 11) = 12.9, p < .005, for the condition main effect], but the increase in RTs as a function of the number of moving items did not differ between conditions [F(1, 11) = 2.33, p = .155, for the interaction between the number of moving items and condition]. Thus, in the color nonsingleton case, motion segmentation was highly effective, with performance in the motion segmentation condition being as efficient as when the static items were not present. When the target was a color singleton in the moving group, performance was slower [F(1, 11) = 64.09, p < .0001, for the condition main effect] and showed a larger increase in RTs as a function of the number of moving items (78 vs. 9 ms/item) [F(1, 11) = 50.82, p < .0001, for the Number of Moving Items × Display Size interaction] in the motion segmentation than in the half-set condition. Thus, in the color singleton case, motion segmentation was now ineffective, with performance being much poorer when the static items were present (motion segmentation) than when they were absent (half-set).
Experiment 2B results
Accuracy
The overall accuracy was high (96 %; see Table 3 for a breakdown). Error rates were 5 % or less in all conditions, except when 12 moving items were in the motion segmentation condition, in which case 10 % of the targets were missed. Given the overall high accuracy, a further ANOVA was not conducted.
RT
Incorrect trials (4.2 %) and trials with RTs <100 ms or >10 s (0.14 %) were excluded. RTs can be seen illustrated in Fig. 6. An ANOVA with the factors Target Color (singleton, nonsingleton), Condition (half-set, motion segmentation), and Number of Moving Items (six or 12) was performed. Critically, the three-way interaction of all factors was significant, F(1, 11) = 13.37, p < .005. In order to further understand the three-way interaction, separate analyses of each condition were conducted. In the half-set condition, although performance was slightly faster in the target-present case, F(1, 11) = 8.75, p < .05, no effect of set size was apparent, F(1, 11) = 2.09, p = .176, and no trace of an interaction between the two, F < 1. In the motion segmentation condition, performance was faster overall, F(1, 11) = 14.17, p < .005, and more efficient on color singleton trials (30 vs. 15 ms/item) [F(1, 11) = 15.4, p < .005, for the interaction between number of moving items and condition]. Importantly, participants detected oddly colored items amongst a moving group relatively efficiently, and approximately as efficiently as they had found form-unique targets in a moving group in Experiment 1.

Search response times (RTs) in Experiment 2B as a function of condition (separate lines), number of moving items (horizontal axis), and target color (left vs. right graph). The target color nonsingleton cases are shown on the left, and target singleton cases are on the right. Error bars show standard errors of the means
Discussion
In Experiment 2, participants viewed displays similar to those used by Dent et al. (2011), but with random assignments of colors to the targets and distractors. In Experiment 2A, when search was explicitly based on shape performance, it was generally less efficient than in Experiment 1, since the target was now defined by the spatial configuration of the constituent lines rather than by any one simple form feature. Despite this difference, the qualitative pattern of results was very similar to that in the previous experiment; moving targets that shared their color with the static distractors were extremely difficult to find, resulting in performance equivalent to when no segmentation cue was present. In contrast, when participants viewed exactly the same displays, but with the task now to respond “present” to a color singleton, the task was vastly easier, with RTs being reduced by about 1,200 ms at the higher set size. Strikingly, participants were able to detect the presence of a color singleton amongst the moving group at least as efficiently as they had responded to the form singleton of Experiment 1. It should be acknowledged that the relatively efficient RT performance in Experiment 2B did come at the cost of a small increase in miss errors as display size increased (6 %). However, even if a conservative approach were taken and RT values corrected according to Townsend and Ashby’s (1983) suggestion (RT/accuracy), the resulting search slope would remain a respectable 20 ms/item, and remain more efficient than the 30 ms/item slopes seen for a color singleton target in Experiment 1. Thus, this does not indicate a general problem in processing conjunctions of movement and color; conjunctions both of color and motion and of form and motion appear to be processed with similar levels of efficiency. However, in order for these displays to yield efficient performance, color differences had to be an explicit part of the task set or target template.
Treisman and Sato (1990) also concluded that conjunctions of movement and form were not special and that conjunctions of color and form could also be detected relatively efficiently. However, in this earlier study all of the distractors moved, but in different directions; since all items would thus be represented in a motion filter, it is difficult to properly assess this hypothesis. In the present experiment, the contrast was between moving and static items. Additionally, in the study of Treisman and Sato, participants knew in advance the specific color value that would characterize the target, whereas in the present experiment, the specific target color was unknown. In the present experiment (see also Friedman-Hill & Wolfe, 1995), no color or set of colors could reliably differentiate the target from the distractors over the experiment; the target color on one trial could become the color of the moving distractors on another. The present experiment thus goes beyond a demonstration of relatively efficient search for Color×Motion conjunctions; it shows that Color×Motion conjunctions can be detected relatively efficiently even when feature-based guidance cannot operate on the basis of color. Thus, second-order processing of color driven by motion is possible and can be achieved relatively efficiently.
General discussion
The present three experiments explored the conditions under which items that are color unique in a motion-defined subset, but that share their color with a group of static distractors, result in efficient search performance. Experiment 1 showed that if observers are set to search for a target defined by a conjunction of motion and shape, they may do so relatively efficiently. Even though search is relatively efficient and participants are set to detect feature differences in the moving group, color singletons in the moving group do not aid performance. In fact, performance is worse, not better, when the target is both form and color unique. Experiment 2 explored whether the failure of color-unique targets to speed search was linked to a fundamental problem with second-order color processing within a moving group. The results showed that targets that were exceedingly difficult to detect when color was not an explicit part of the task set became easy to detect when color differences defined the target.
Similar negative color carryover effects have been demonstrated in the context of preview search, when an early-appearing set of distractors are rejected from search (see, e.g., Braithwaite, Humphreys, & Hodsoll, 2003). Whether similar effects would occur for segmentation based on all dimensions (e.g., color, depth, orientation, etc.), or whether they are specific to segmentation driven by dynamic features remains to be fully explored. However, Andrews, Watson, Humphreys, and Braithwaite (2011) explored negative color carryover effects in preview search when both the old and the new items were moving. Here, both the old and the new items were dynamic, so being dynamic did not reliably distinguish the old and new items. Under these dynamic conditions, negative color carry-over effects were larger than when all items were static, suggesting that a simple dynamic-versus-static distinction is not critical.
The results of Experiments 1 and 2A are easily accommodated within the broad framework of integrated competition (e.g., Duncan et al., 1997; see also Duncan, 1995). More specifically, the results may be explained by recruiting the idea of weight linkage discussed by Duncan and Humphreys (1989); when the target shares its color with static distractors, the attentional weight of the target is linked to the low attentional weight of the static, known-to-be-irrelevant distractors, and the target is suppressed. An explanation in terms of suppression gains independent support from other studies. Firstly, Driver, McLeod, and Dienes (1992) showed that manipulating the heterogeneity of the motion trajectories of a set of distractors that did not share the target motion direction was more disruptive than a similar manipulation of those distractors that shared the target motion direction. The authors interpreted this finding in terms of disrupted inhibition of distractors with nontarget motion as a consequence of increased heterogeneity. That the disruption is greater for distractors without target motion than for those with target motion suggests that inhibition of these distractors is primary. Secondly, Dent, Allen, Braithwaite, and Humphreys (2012), using a probe dot detection paradigm, demonstrated costs for probes appearing on static distractors, consistent with the suppression of static distractors in motion–form conjunction search. Thus, far from being a peculiarity of a certain kind of difficult search task, in which the target is similar in form to other task-relevant moving items, weight linkage seems to be a far more pervasive phenomenon. That weight linkage occurs even for rapid and efficient conjunction search, a situation for which GS and second-order parallel accounts were specifically developed, provides a special difficulty for these accounts.
Nor is it the case that combinations of color and motion pose special problems for the visual system. When they were explicitly task-relevant in Experiment 2B, targets defined as odd colors in the moving group could be detected relatively efficiently. Indeed, odd colors were detected faster and more efficiently than were targets that shared their color with the static items in Experiment 1. Differences on multiple dimensions cannot therefore be extracted simultaneously and combined automatically in this task; otherwise, redundancy gains (similar to those observed by Weidner & Müller, 2009) would have been observed in Experiment 1. Recent studies in the framework of DW have demonstrated the importance of trial history in conjunction search (e.g., Weidner & Müller, 2009, 2013). Thus, when the target-defining dimension changes, there is a cost relative to when it repeats. The explanation given by DW for this finding is that once the target is detected, a high dimensional weight is applied to the dimension that defined it; when the dimension subsequently changes, the weight settings are suboptimal, and a cost occurs. The present experiments place clear limits on this reconfiguration of dimension weights consequent on target detection. The dimensional weight assigned to color when it is task-irrelevant but happens to define the target does not increase. Had the weight increased in this way, a benefit rather than a cost would be seen for singleton targets. Thus, the reconfiguration of dimension weights consequent on target detection that has been proposed by DW must be limited by explicit task relevance, changing only for dimensions that are marked as relevant. It appears that weight linkage for color and motion is dominant, and the visual system tends to make the assumption that elements that share features with ignored distractors are unlikely to be targets. However, there is sufficient flexibility that these links can be broken by an explicit task set to detect color differences.
Although the results of Experiment 1 demonstrate that form similarity amongst the moving items is not critical for the negative color effect to occur, the role of similarity in form between the target and the static distractors remains to be investigated. It may be that the attentional weight assigned to the static distractors on the basis of movement must be reduced in order to compensate for the high weight assigned on the basis of form. Future experiments will explore whether the negative color effect holds when the target does not share its form with the static distractors.
The whole set of results is best accounted for within a framework that incorporates aspects of both the DW variant of GS and AET. Such a framework would allow for flexible selection mechanisms, including both negative biases against irrelevant (and associated) items, and positive biases toward relevant items, including biases toward second-order differences in feature values, in addition to feature values per se, as is proposed by DW (e.g., Weidner & Müller, 2013). From AET comes the principle of weight linkage, such that when a feature—in this case, color—is not explicitly task-relevant, the default assumption is that items appearing in the color of the static distractors are also likely to be distractors. From the DW variant of GS comes the principle that top-down biases toward differences in a particular dimension that is known to be task-relevant can override these default linkages. Weight linkage for color and motion dominates when the dimensional weight assigned to color is low, but increasing the dimensional weight assigned to the color dimension can override this linkage. Determining which other principles must accompany these core mechanisms in order to provide a full account of search and selection will require further research.
References
Andrews, L. S., Watson, D. G., Humphreys, G. W., & Braithwaite, J. J. (2011). Flexible feature-based inhibition in visual search mediates magnified impairments of selection: Evidence from carry-over effects under dynamic preview-search conditions. Journal of Experimental Psychology: Human Perception and Performance, 37, 1007–1016. doi:10.1037/a0023505
Bacon, W. F., & Egeth, H. E. (1994). Overriding stimulus-driven attentional capture. Perception & Psychophysics, 55, 485–496. doi:10.3758/BF03205306
Brainard, D. H. (1997). The Psychophysics Toolbox. Spatial Vision, 10, 433–436. doi:10.1163/156856897X00357
Braithwaite, J. J., Humphreys, G. W., & Hodsoll, J. (2003). Color grouping in space and time: Evidence from negative color-based carryover effects in preview search. Journal of Experimental Psychology: Human Perception and Performance, 29, 758–778. doi:10.1037/0096-1523.29.4.758
Braithwaite, J. J., Humphreys, G. W., Hulleman, J., & Watson, D. G. (2007). Fast color grouping and late color inhibition: Evidence for distinct temporal windows for separate processes in preview search. Journal of Experimental Psychology: Human Perception and Performance, 33, 503–517. doi:10.1037/0096-1523.33.3.503
Broadbent, D. A. (1958). Perception and communication. London: Pergamon Press.
Chan, L. K. H., & Hayward, W. G. (2013). Visual search. Wiley Interdisciplinary Reviews: Cognitive Science, 4, 415–429.
Dent, K., Allen, H. A., Braithwaite, J. J., & Humphreys, G. W. (2012). Inhibitory guidance in visual search: The case of movement–form conjunctions. Attention, Perception, & Psychophysics, 74, 269–284.
Dent, K., Humphreys, G. W., & Braithwaite, J. J. (2011). Spreading suppression and the guidance of search by movement: Evidence from negative carry-over effects. Psychonomic Bulletin & Review, 18, 690–696.
Driver, J., McLeod, P., & Dienes, Z. (1992). Motion coherence and conjunction search: Implications for guided search theory. Perception & Psychophysics, 51, 79–85. doi:10.3758/BF03205076
Duncan, J. (1984). Selective attention and the organization of visual information. Journal of Experimental Psychology: General, 113, 501–517. doi:10.1037/0096-3445.113.4.501
Duncan, J. (1995). Target and nontarget grouping in visual search. Perception & Psychophysics, 57, 117–120. doi:10.3758/BF03211854
Duncan, J., & Humphreys, G. W. (1989). Visual search and stimulus similarity. Psychological Review, 96, 433–458. doi:10.1037/0033-295X.96.3.433
Duncan, J., & Humphreys, G. (1992). Beyond the search surface: Visual search and attentional engagement. Journal of Experimental Psychology: Human Perception and Performance, 18, 578–588. doi:10.1037/0096-1523.18.2.578
Duncan, J., Humphreys, G., & Ward, R. (1997). Competitive brain activity in visual attention. Current Opinion in Neurobiology, 7, 255–261.
Ellison, A., Lane, A. R., & Schenk, T. (2007). The interaction of brain regions during visual search processing as revealed by transcranial magnetic stimulation. Cerebral Cortex, 17, 2579–2584.
Found, A. (1998). Parallel coding of conjunctions in visual search. Perception & Psychophysics, 60, 1117–1127.
Friedman-Hill, S., & Wolfe, J. M. (1995). Second-order parallel processing: Visual search for the odd item in a subset. Journal of Experimental Psychology: Human Perception and Performance, 21, 531–551. doi:10.1037/0096-1523.21.3.531
Grossberg, S., Mingolla, E., & Ross, W. D. (1994). A neural theory of attentive visual search: Interactions of boundary, surface, spatial, and object representations. Psychological Review, 101, 470–489. doi:10.1037/0033-295X.101.3.470
Huang, L., & Pashler, H. (2007). A Boolean map theory of visual attention. Psychological Review, 414, 599–631. doi:10.1037/0033-295X.114.3.599
Itti, L., & Koch, C. (2000). A saliency-based search mechanism for overt and covert shifts of visual attention. Vision Research, 40, 1489–1506. doi:10.1016/S0042-6989(99)00163-7
Krummenacher, J., & Müller, H. J. (2012). Dynamic weighting of feature dimensions in visual search: Behavioral and psychophysiological evidence. Frontiers in Psychology, 3, 221. doi:10.3389/fpsyg.2012.00221
McLeod, P., Driver, J., & Crisp, J. (1988). Visual search for a conjunction of movement and form is parallel. Nature, 332, 154–155.
Müller, H. J., Heller, D., & Ziegler, J. (1995). Visual search for singleton feature targets within and across feature dimensions. Perception & Psychophysics, 57, 1–17. doi:10.3758/BF03211845
O’Craven, K. M., Downing, P. E., & Kanwisher, N. (1999). fMRI evidence for objects as the units of attentional selection. Nature, 401, 584–587. doi:10.1038/44134
Scholl, B. J. (2001). Objects and attention: The state of the art. Cognition, 80, 1–46. doi:10.1016/S0010-0277(00)00152-9
Takeda, Y., Phillips, S., & Kumada, T. (2006). A conjunctive feature similarity effect for visual search. Quarterly Journal of Experimental Psychology, 60, 186–190.
Theeuwes, J. (1992). Perceptual selectivity for color and form. Perception & Psychophysics, 51, 599–606. doi:10.3758/BF03211656
Theeuwes, J. (2010). Top-down and bottom-up control of visual selection. Acta Psychologica, 135, 77–99. doi:10.1016/j.actpsy.2010.02.006
Townsend, J. T., & Ashby, F. G. (1983). Stochastic modeling of elementary psychological processes. Cambridge: Cambridge University Press.
Treisman, A. (2006). How the deployment of attention determines what we see. Visual Cognition, 14, 411–443. doi:10.1080/13506280500195250
Treisman, A. M., & Gelade, G. (1980). A feature integration theory of attention. Cognitive Psychology, 12, 97–136. doi:10.1016/0010-0285(80)90005-5
Treisman, A., & Sato, S. (1990). Conjunction search revisited. Journal of Experimental Psychology: Human Perception and Performance, 16, 459–478. doi:10.1037/0096-1523.16.3.459
Tsotsos, J. K. (1990). Analyzing vision at the complexity level. Behavioural and Brain Sciences, 13, 423–445.
von Mühlenen, A., & Müller, H. J. (2000). Perceptual integration of motion and form information: Evidence of parallel-continuous processing. Perception & Psychophysics, 62, 517–531.
von Mühlenen, A., & Müller, H. J. (2001). Visual search for motion–form conjunctions: Is form discriminated within the motion system? Journal of Experimental Psychology: Human Perception and Performance, 27, 707–718. doi:10.1037/0096-1523.27.3.707
Watson, D. G., & Humphreys, G. W. (1997). Visual marking: Prioritizing selection for new objects by top-down attentional inhibition of old objects. Psychological Review, 104, 90–122. doi:10.1037/0033-295X.104.1.90
Watson, D. G., Humphreys, G. W., & Olivers, C. N. L. (2003). Visual marking: Using time in visual selection. Trends in Cognitive Sciences, 7, 180–186. doi:10.1016/S1364-6613(03)00033-0
Weidner, R., & Müller, H. J. (2009). Dimensional weighting of primary and secondary target-defining dimensions in visual search for singleton conjunction targets. Psychological Research, 73, 198–211.
Weidner, R., & Müller, H. J. (2013). Dimension weighting in cross-dimensional singleton conjunction search. Journal of Vision, 13(3), 25. doi:10.1167/13.3.25
Weidner, R., Pollmann, S., Müller, H. J., & von Cramon, D. Y. (2002). Top-down controlled visual dimension weighting: An event-related fMRI study. Cerebral Cortex, 12, 318–328.
Wolfe, J. M. (1994). Guided Search 2.0: A revised model of visual search. Psychonomic Bulletin & Review, 1, 202–238. doi:10.3758/BF03200774
Wolfe, J. M. (1998). Visual search. In H. Pashler (Ed.), Attention (pp. 13–73). Hove: Psychology Press.
Wolfe, J. M. (2007). Guided Search 4.0: Current progress with a model of visual search. In W. D. Gray (Ed.), Integrated models of cognitive systems (pp. 99–119). New York: Oxford University Press.
Wolfe, J. M., Cave, K. R., & Franzel, S. L. (1989). Guided search: An alternative to the feature integration model for visual search. Journal of Experimental Psychology: Human Perception & Performance, 15, 419–433. doi:10.1037/0096-1523.15.3.419
Wolfe, J. M., & Horowitz, T. S. (2004). What attributes guide the deployment of visual attention and how do they do it? Nature Reviews Neuroscience, 5, 495–501. doi:10.1038/nrn1411
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Dent, K. Explaining efficient search for conjunctions of motion and form: Evidence from negative color effects. Atten Percept Psychophys 76, 931–944 (2014). https://doi.org/10.3758/s13414-014-0640-4
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-014-0640-4