
Insights into the Evolution of a Snake Venom Multi-Gene Family from the Genomic Organization of Echis ocellatus SVMP Genes


Abstract
:1. Introduction
2. Results and Discussion
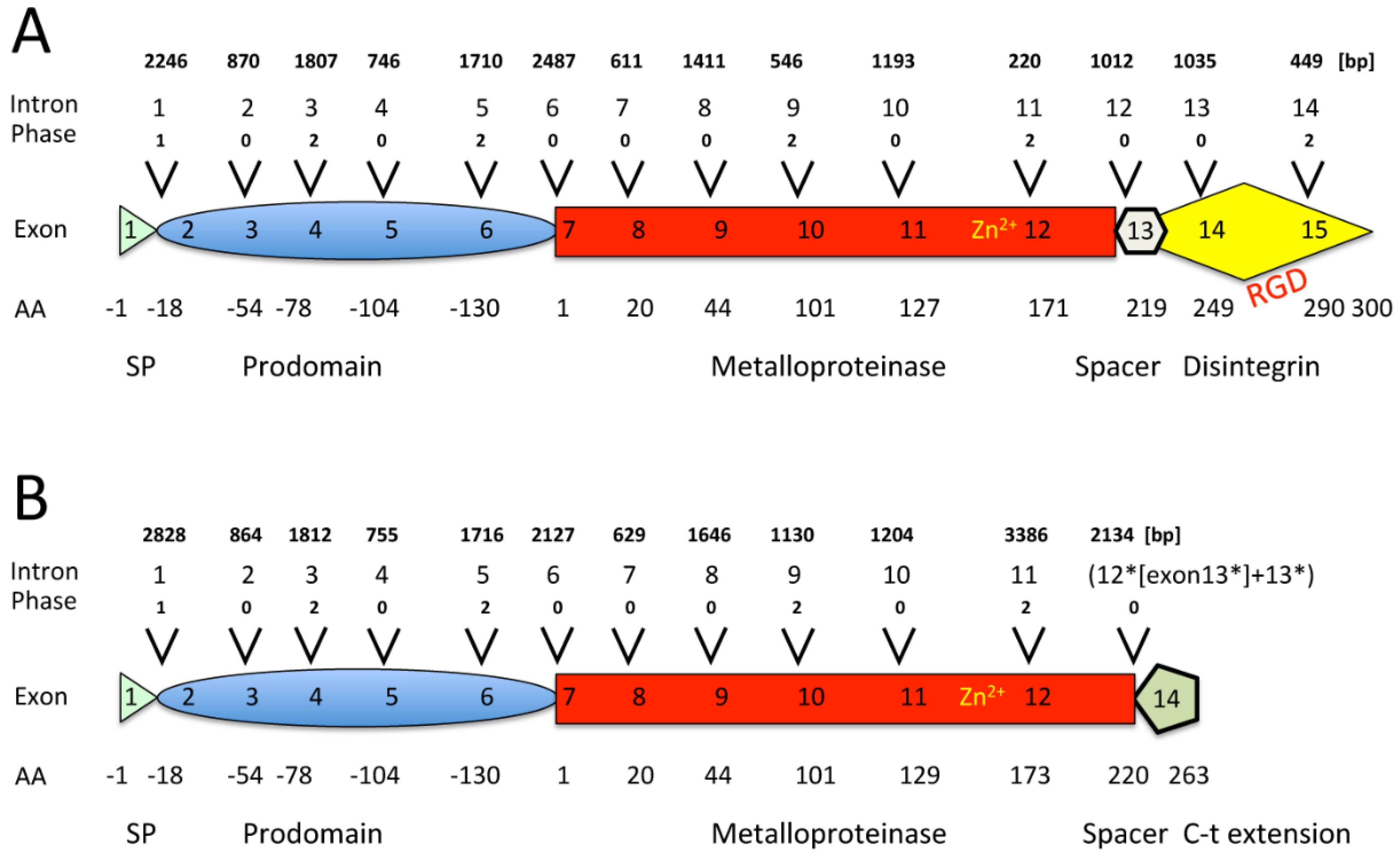
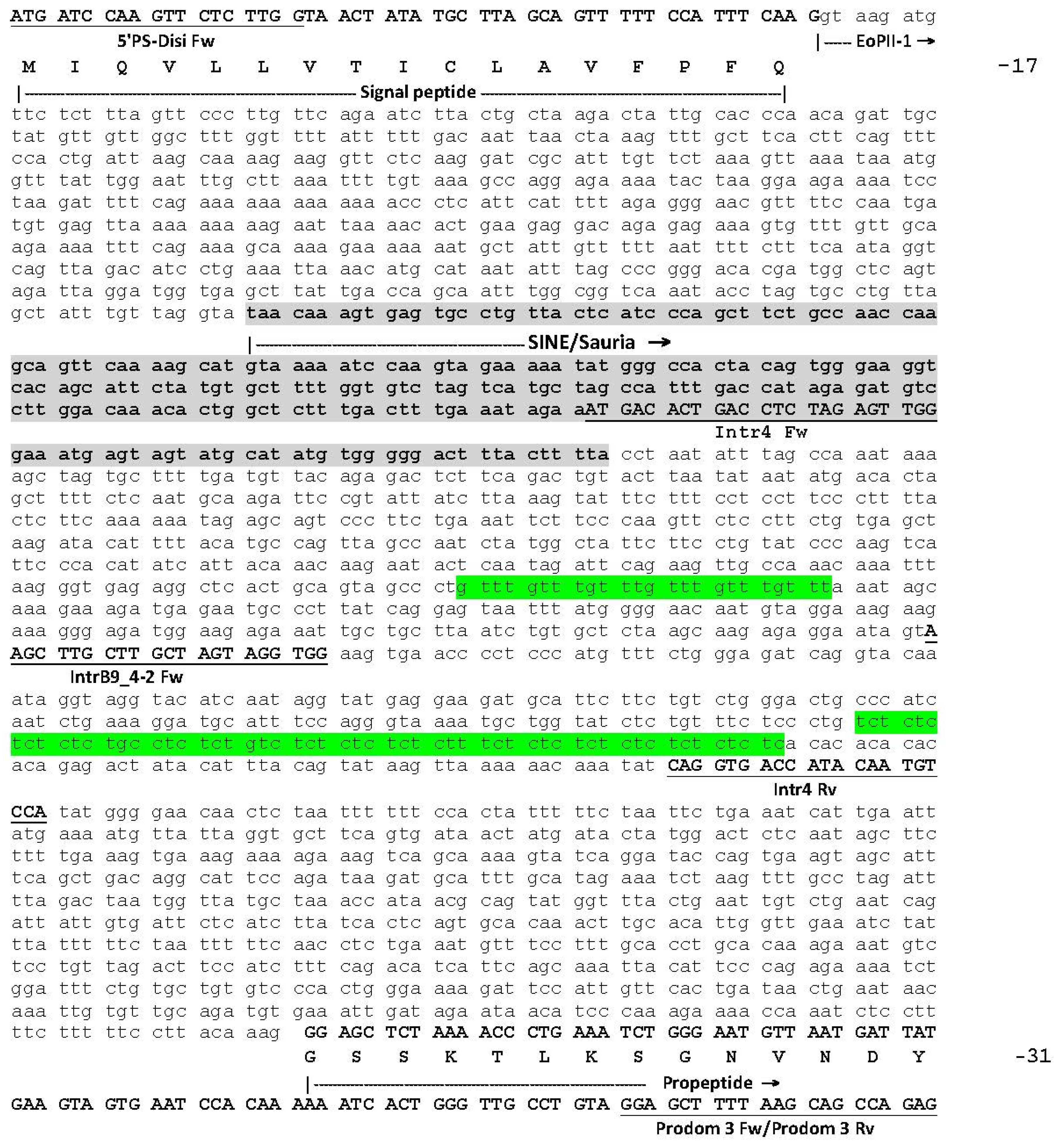
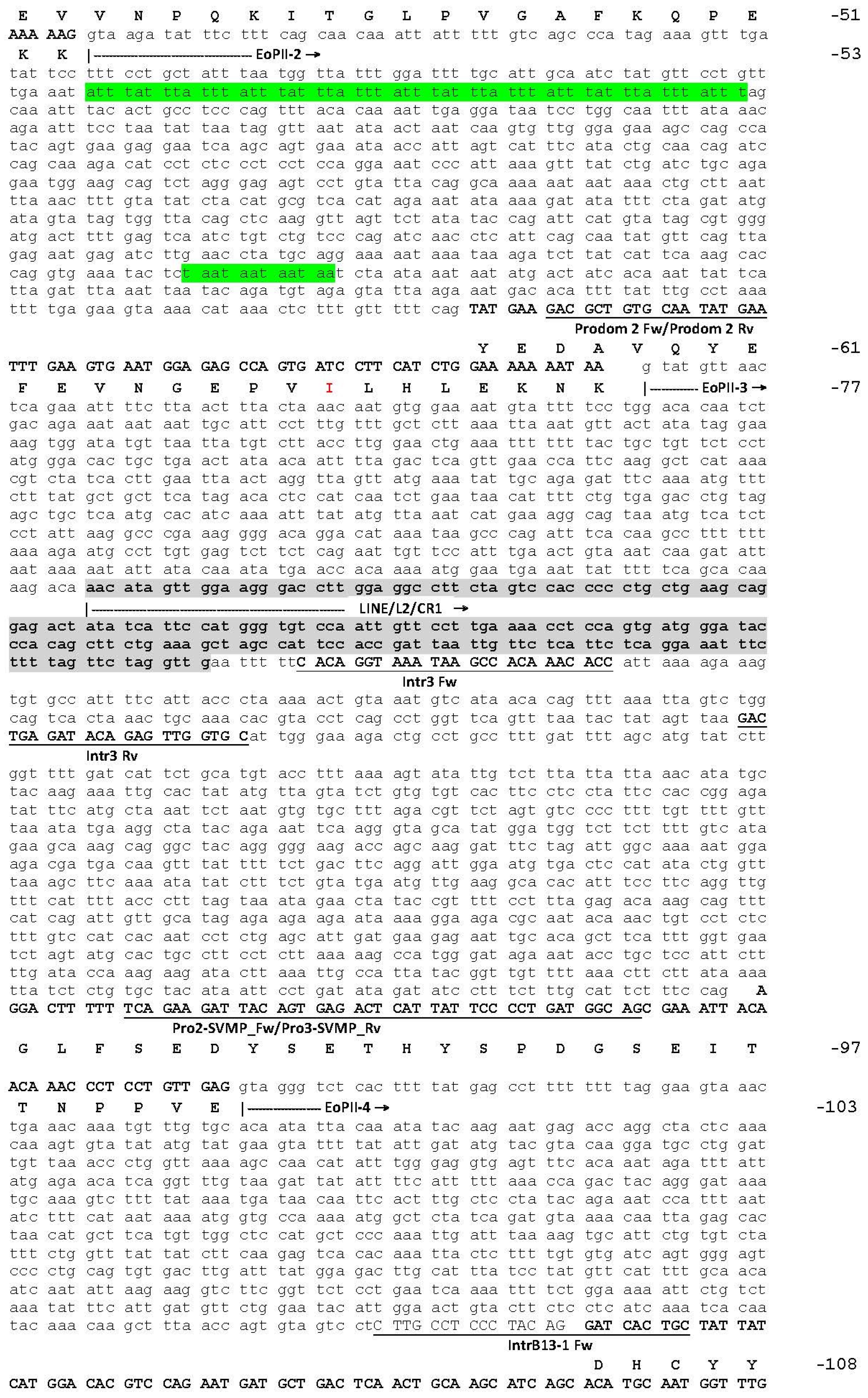
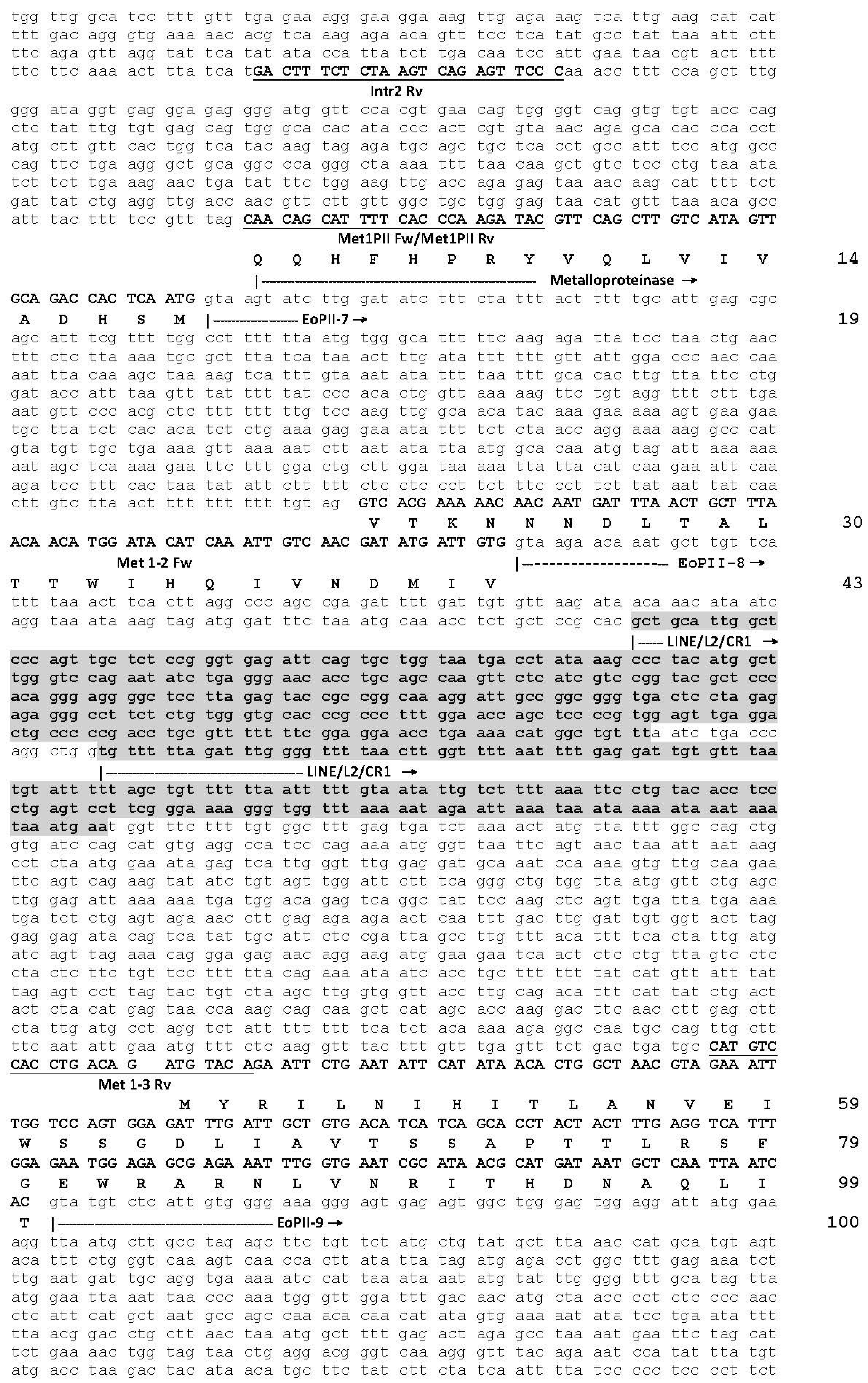
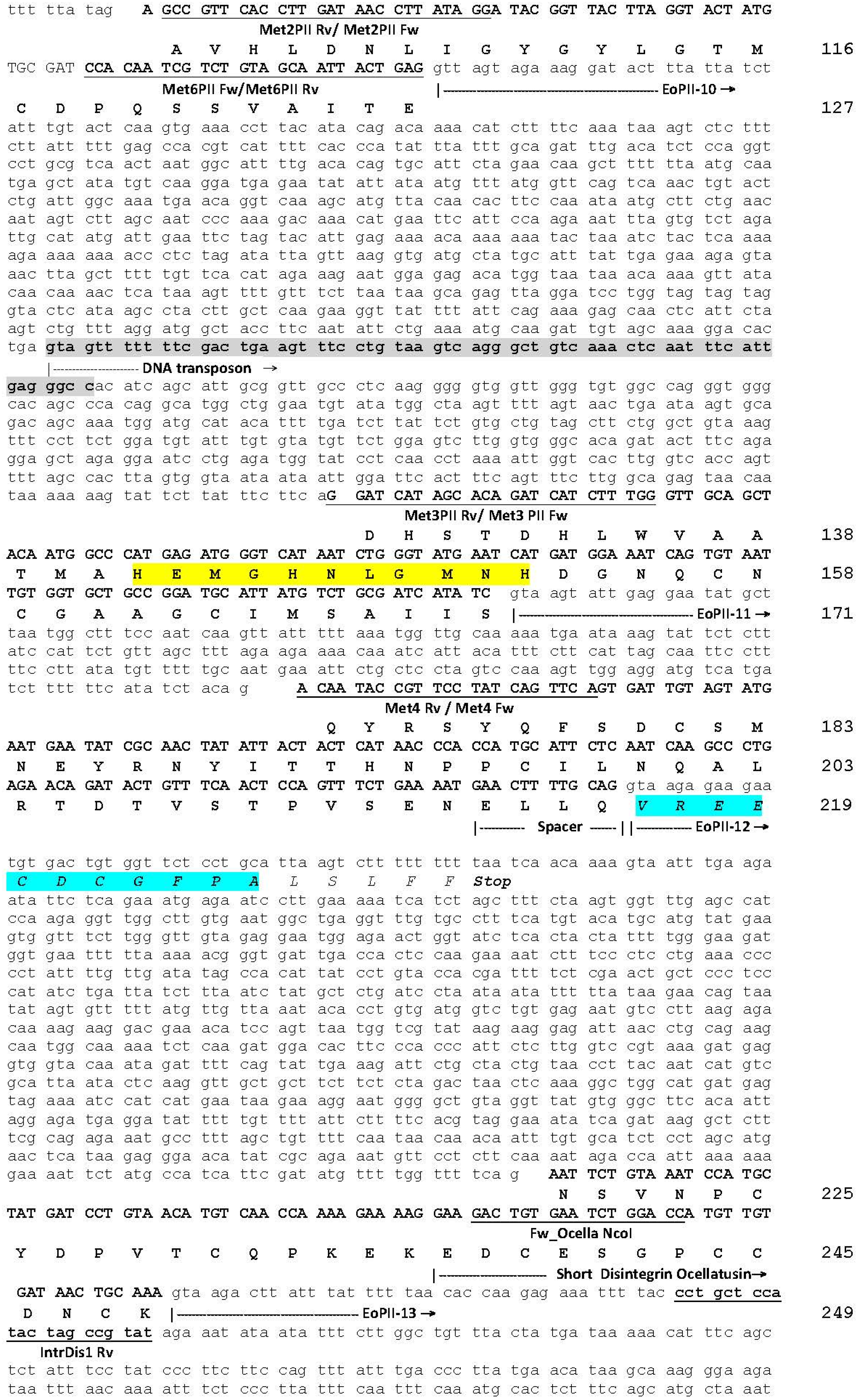
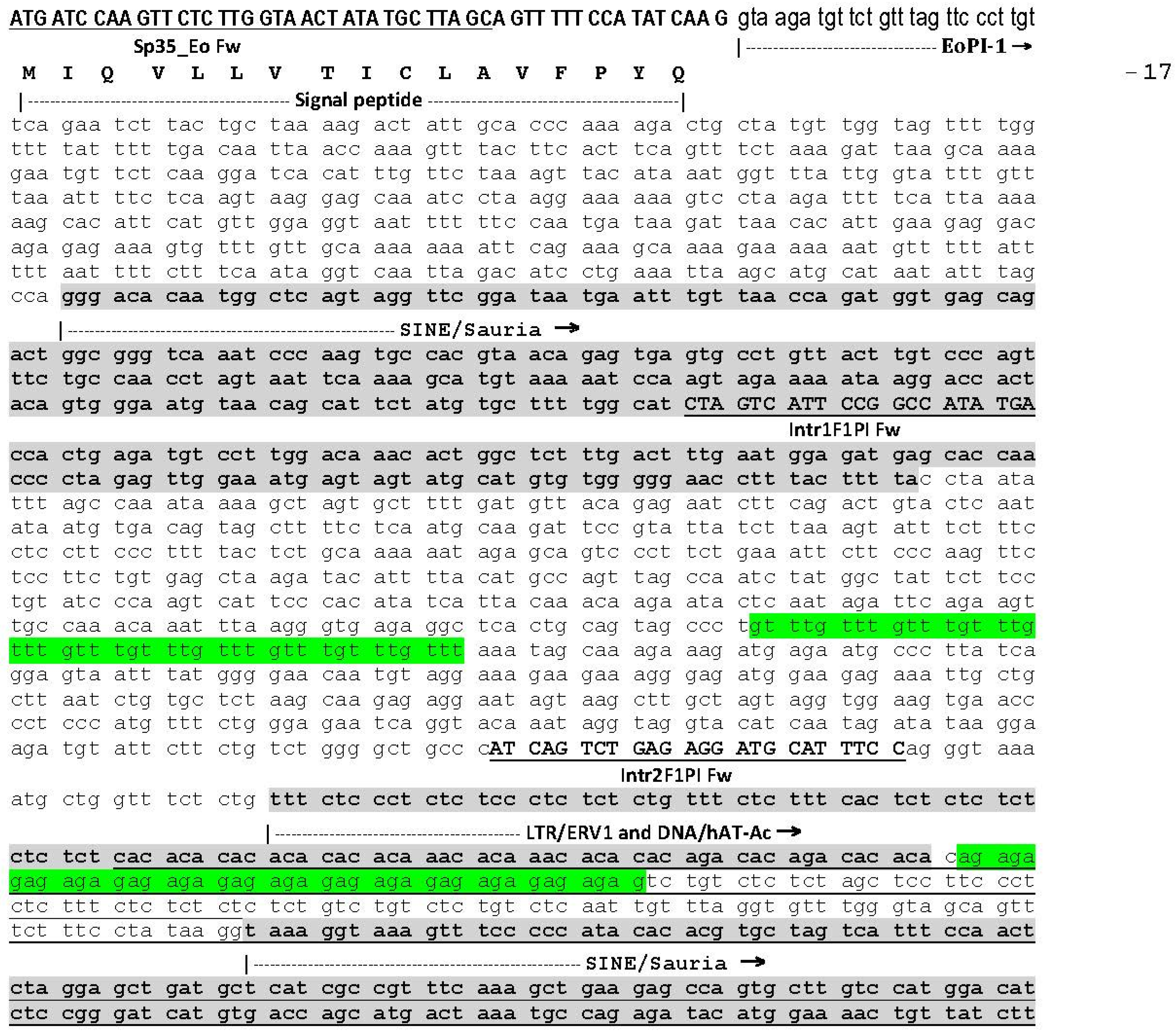
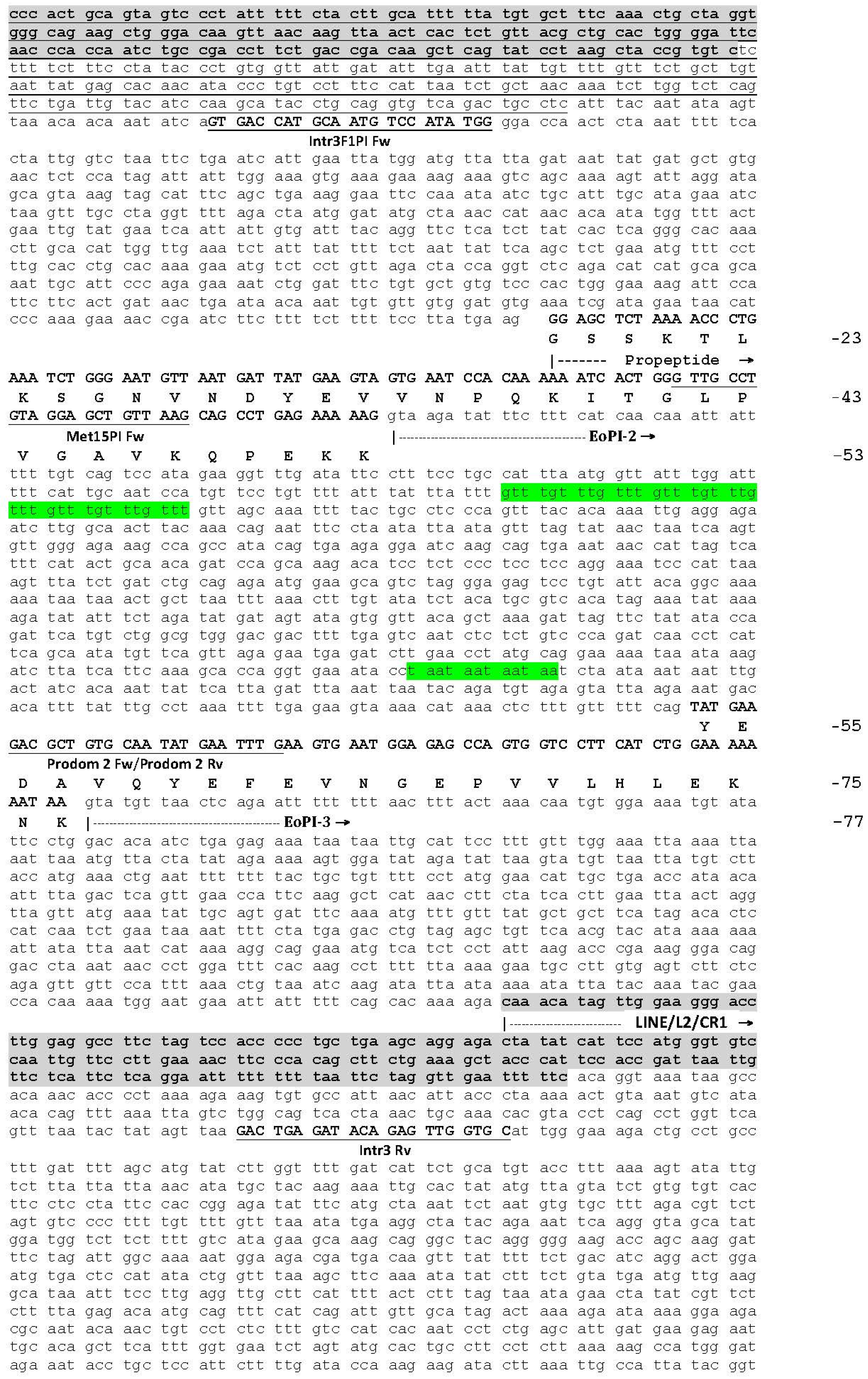
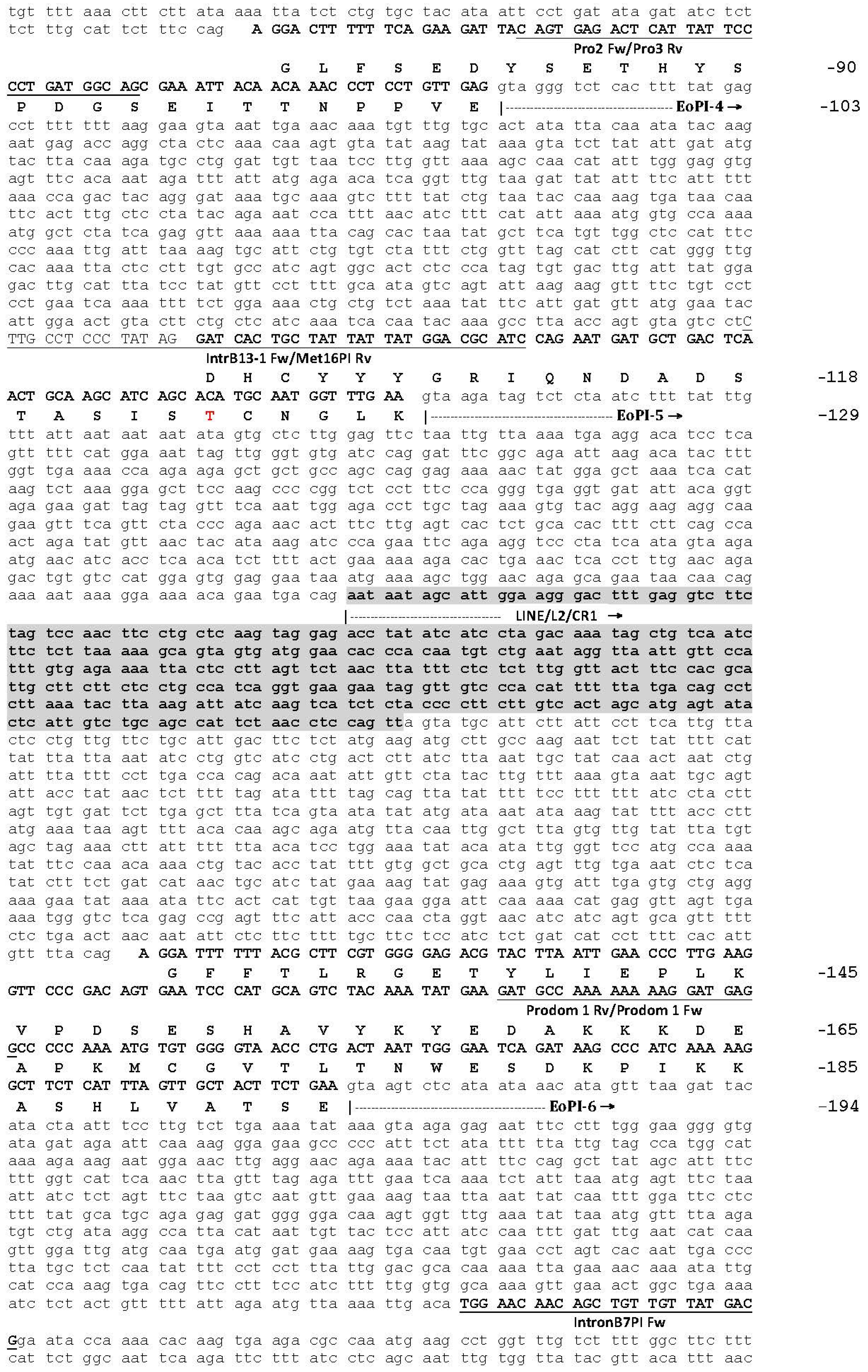
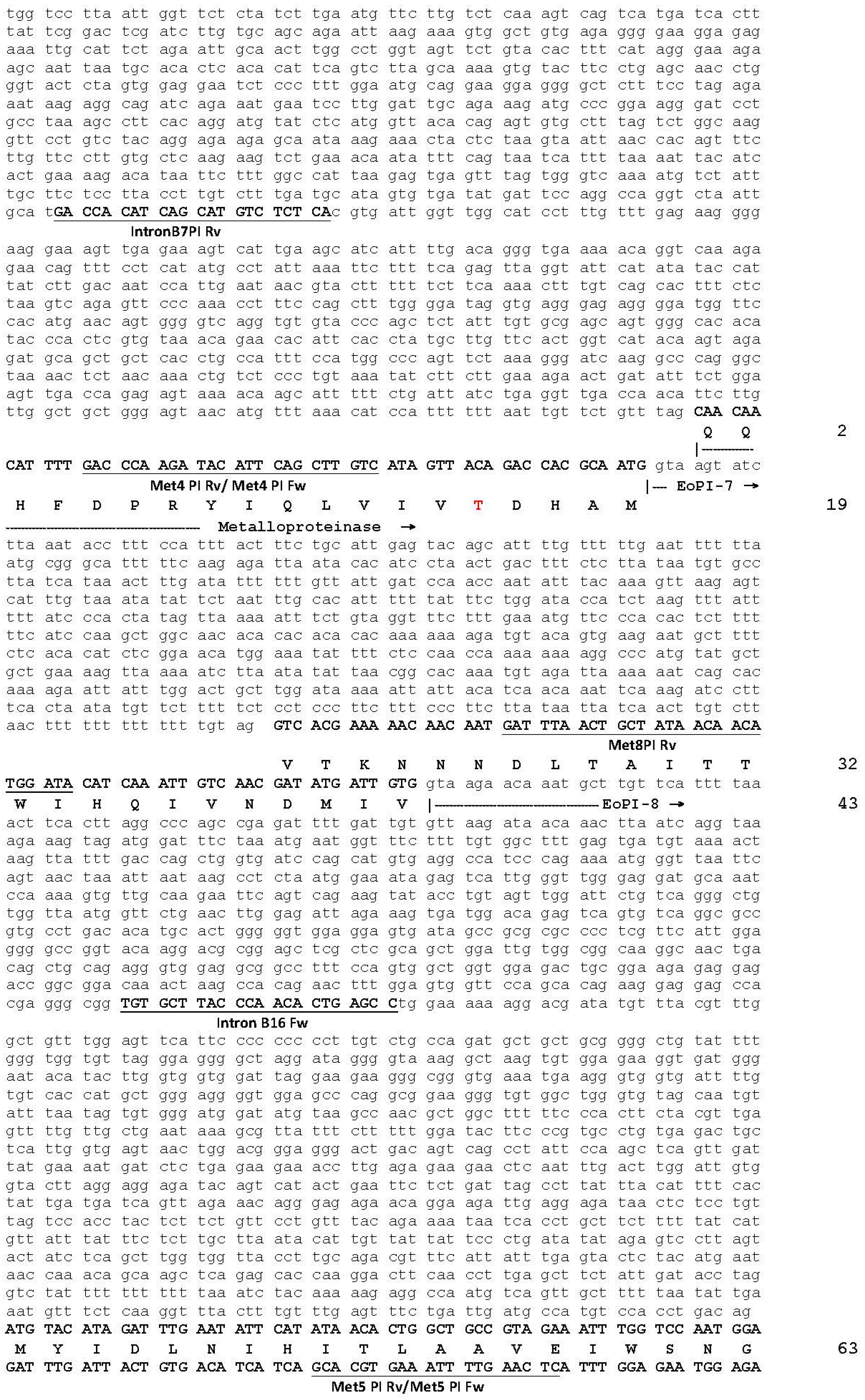
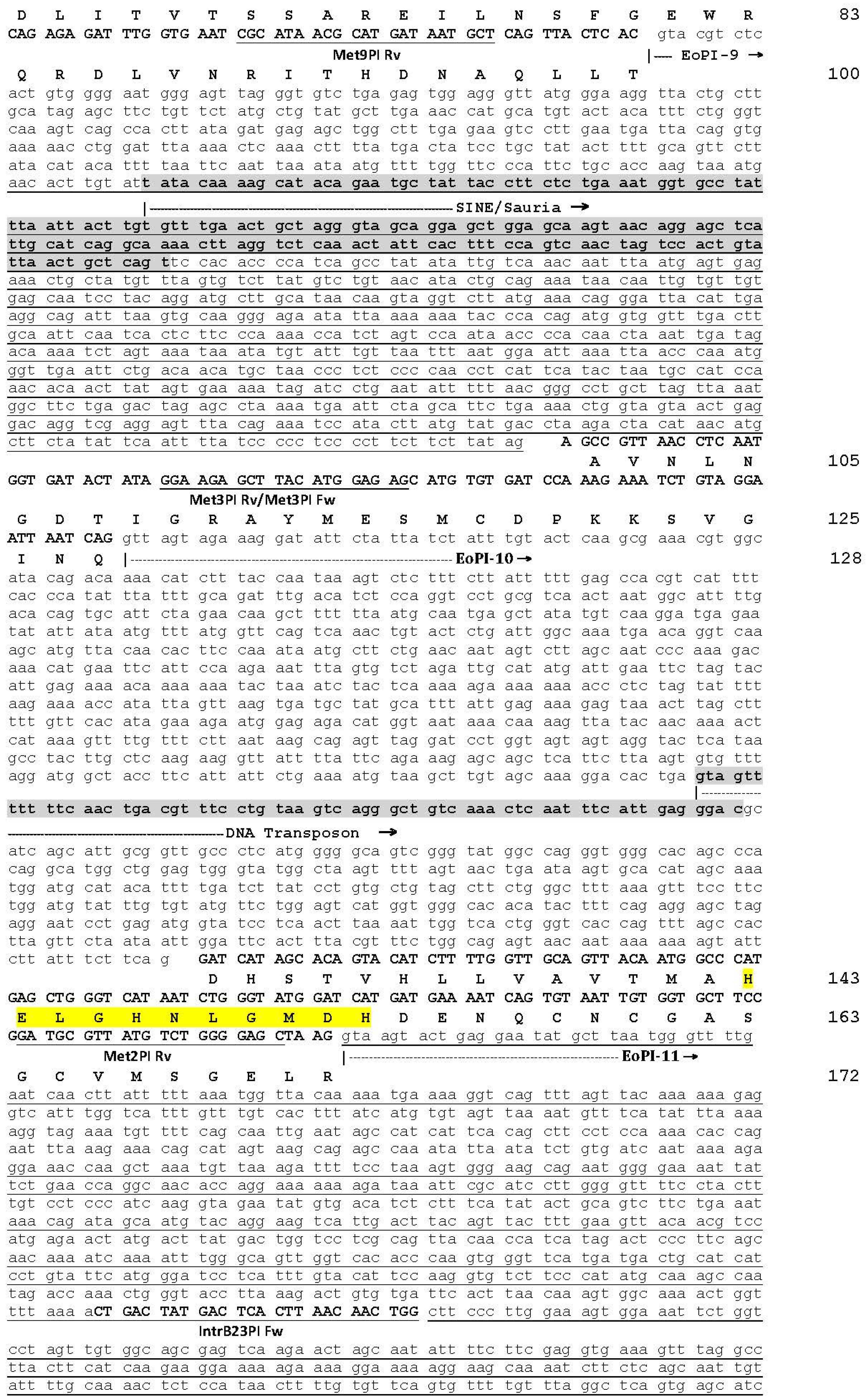
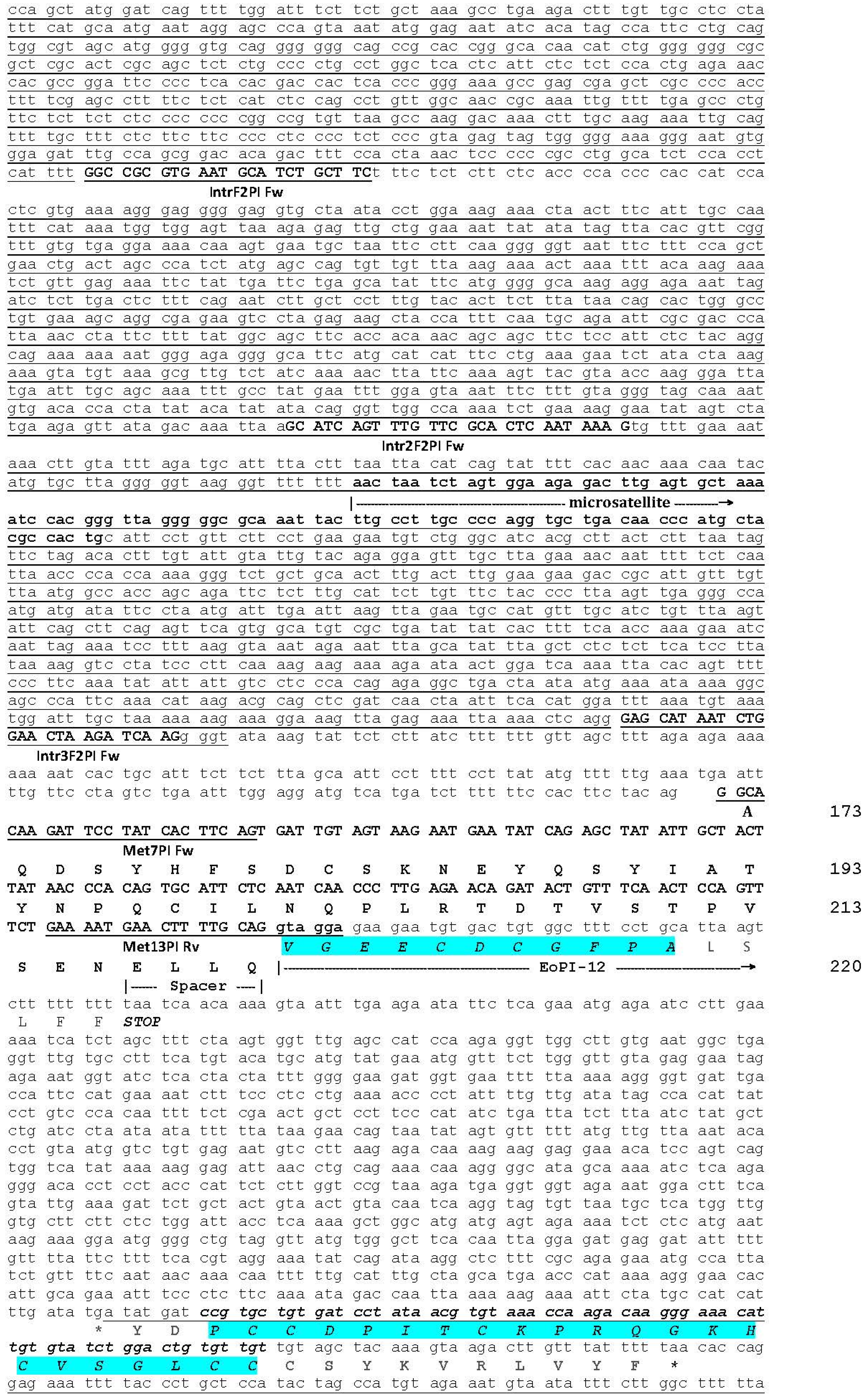
2.1. The Genomic Structure of Pre-Pro EOC00006-Like PII-SVMP and Pre-Pro EOC00028-Like Genes
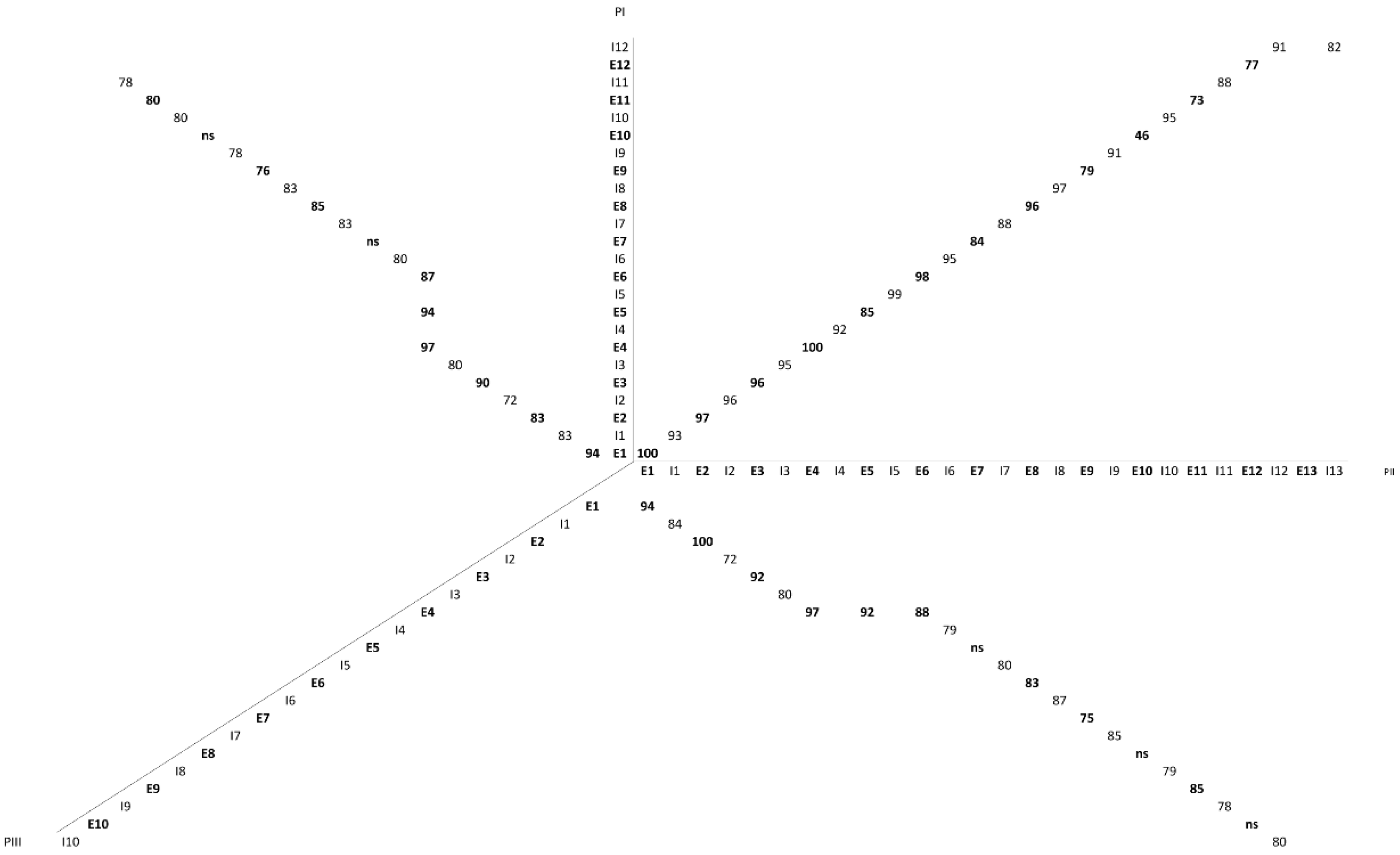
2.2. Role of Introns in the Evolution of the SVMP Multi-Gene Family
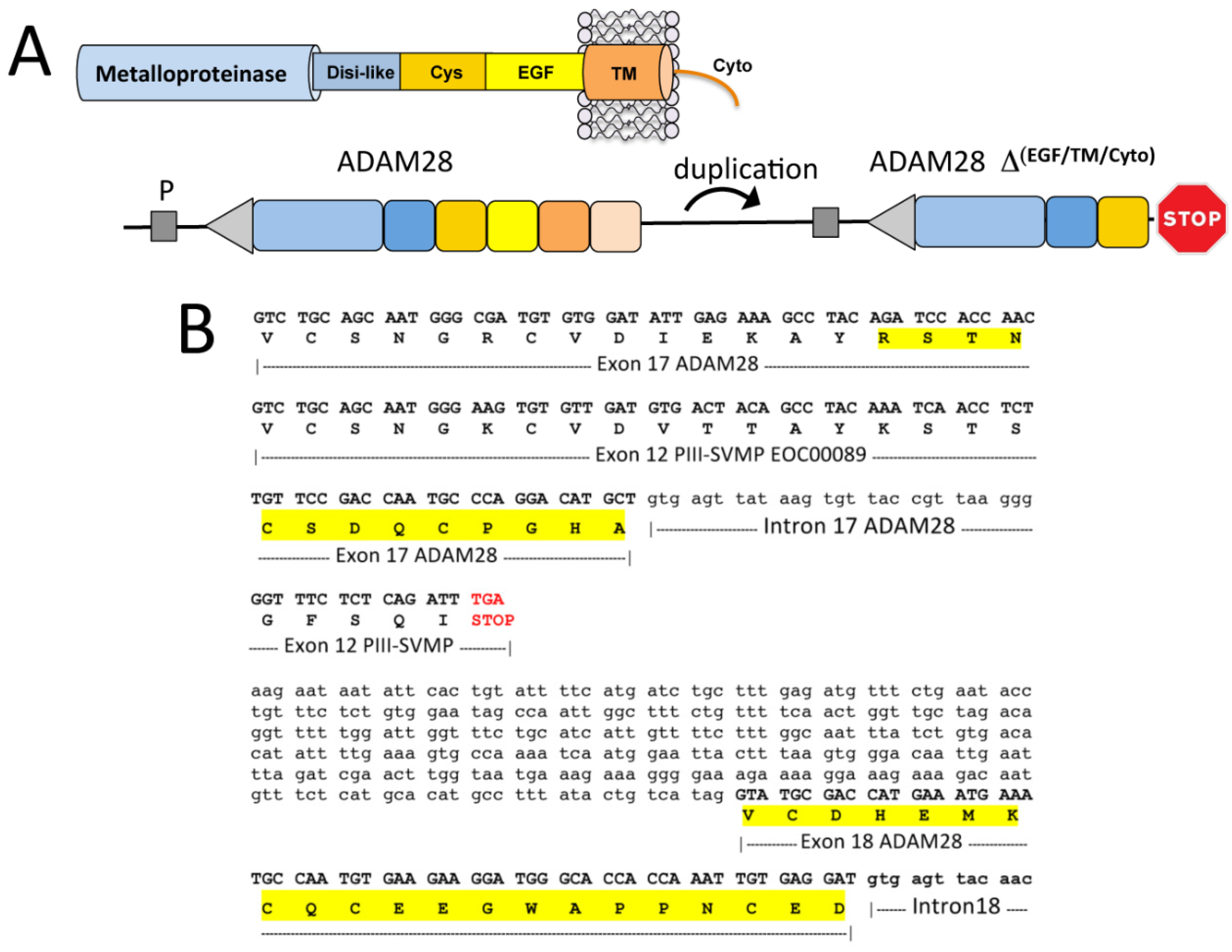
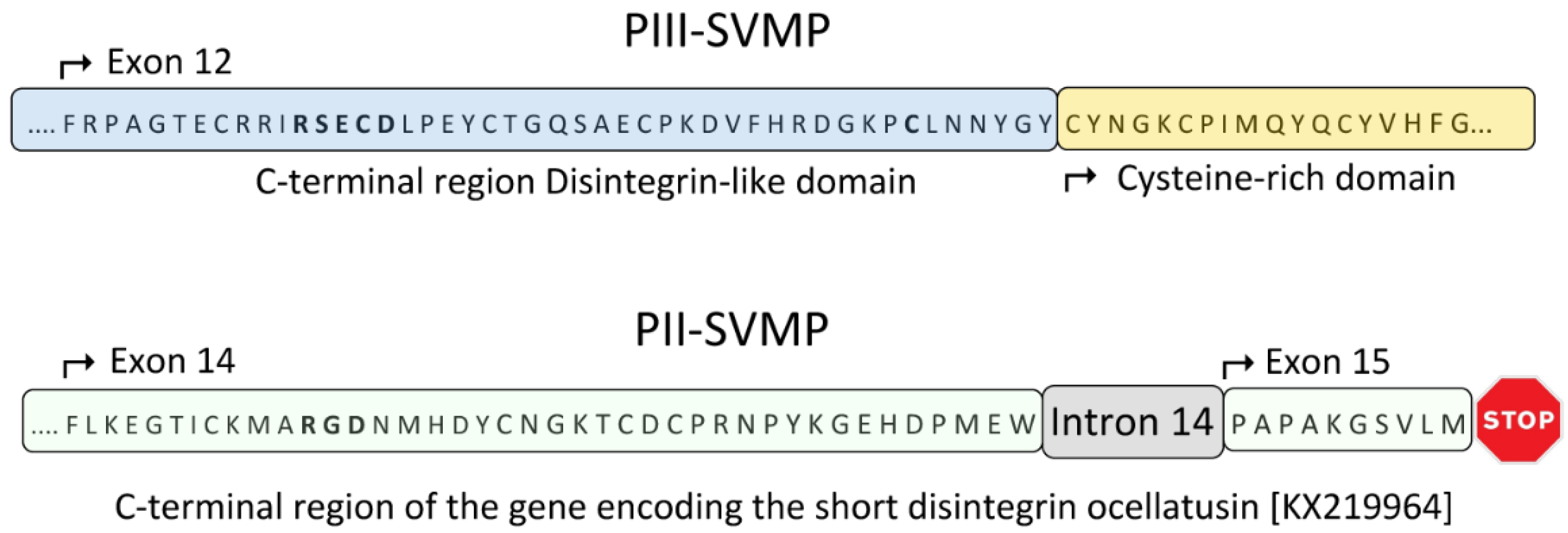
2.3. A Fusion Event Led to the Conversion of a PII(e/d)-Type SVMP into EOC00028-like PI-SVMP
3. Concluding Remarks and Perspectives
4. Materials and Methods
4.1. Genomic DNA
4.2. Strategy for PCR Amplification of Overlapping Genomic DNA Fragments
4.3. Purification and Cloning of PCR Products
4.4. Sequence Analysis
4.5. Sequence Availability
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A













References
- MEROPS- the Peptidase Database: Family M72. Available online: https://merops.sanger.ac.uk/cgi-bin/famsum?family=M12 (accessed on 8 May 2016).
- PFAM Family: REprolysin. Available online: http://pfam.xfam.org/family/PF01421 (accessed on 8 May 2016).
- Seals, D.F.; Courtneidge, S.A. The ADAMs family of metalloproteases: Multidomain proteins with multiple functions. Genes Dev. 2003, 17, 7–30. [Google Scholar] [CrossRef] [PubMed]
- Giebeler, N.; Zigrino, P. A disintegrin and metalloprotease (ADAM): Historical overview of their functions. Toxins 2016, 8. [Google Scholar] [CrossRef] [PubMed]
- Arendt, D.; Technau, U.; Wittbrodt, J. Evolution of the bilaterian larval foregut. Nature 2001, 409, 81–85. [Google Scholar] [CrossRef] [PubMed]
- Tucker, R.P.; Adams, J.C. Adhesion Networks of Cnidarians: A Postgenomic View. Int. Rev. Cell Mol. Biol. 2014, 308, 323–377. [Google Scholar] [PubMed]
- Bahudhanapati, H.; Bhattacharya, S.; Wei, S. Evolution of Vertebrate Adam Genes; Duplication of Testicular Adams from Ancient Adam9/9-like Loci. PLoS ONE 2015, 10, e0136281. [Google Scholar] [CrossRef] [PubMed]
- Cho, C. Testicular and epididymal ADAMs: Expression and function during fertilization. Nat. Rev. Urol. 2012, 9, 550–560. [Google Scholar] [CrossRef] [PubMed]
- Bates, E.E.; Fridman, W.H.; Mueller, C.G. The ADAMDEC1 (decysin) gene structure: Evolution by duplication in a metalloprotease gene cluster on chromosome 8p12. Immunogenetics 2002, 54, 96–105. [Google Scholar] [CrossRef] [PubMed]
- Wei, S.; Whittaker, C.A.; Xu, G.; Bridges, L.C.; Shah, A.; White, J.M.; Desimone, D.W. Conservation and divergence of ADAM family proteins in the Xenopus genome. BMC Evol. Biol. 2010, 10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Taylor, J.S.; Raes, J. Duplication and divergence: The evolution of new genes and old ideas. Annu. Rev. Genet. 2004, 38, 615–643. [Google Scholar] [CrossRef] [PubMed]
- Ohno, S. Evolution by Gene Duplication; Springer-Verlag: Berlin-Heidelberg, Germany, 1970. [Google Scholar]
- Zhang, J. Evolution by gene duplication: An update. Trends Ecol. Evol. 2003, 18, 292–298. [Google Scholar] [CrossRef]
- True, J.R.; Carroll, S.B. Gene co-option in physiological and morphological evolution. Annu. Rev. Cell Dev. Biol. 2002, 18, 53–80. [Google Scholar] [CrossRef] [PubMed]
- Kaessmann, H.; Vinckenbosch, N.; Long, M. RNA-based gene duplication: Mechanistic and evolutionary insights. Nat. Rev. Genet. 2009, 10, 19–31. [Google Scholar] [CrossRef] [PubMed]
- Vinckenbosch, N.; Dupanloup, I.; Kaessmann, H. Evolutionary fate of retroposed gene copies in the human genome. Proc. Natl. Acad. Sci. USA 2006, 103, 3220–3225. [Google Scholar] [CrossRef] [PubMed]
- Fry, B.; Wüster, W. Assembling an Arsenal: Origin and evolution of the snake venom proteome inferred from phylogenetic analysis of toxin sequences. Mol. Biol. Evol. 2004, 21, 870–883. [Google Scholar] [CrossRef] [PubMed]
- Fry, B.G.; Vidal, N.; Norman, J.A.; Vonk, F.J.; Scheib, H.; Ramjan, S.F.; Kuruppu, S.; Fung, K.; Hedges, S.B.; Richardson, M.K.; et al. Early evolution of the venom system in lizards and snakes. Nature 2006, 439, 584–588. [Google Scholar] [CrossRef] [PubMed]
- Fry, B.G.; Casewell, N.R.; Wüster, W.; Vidal, N.; Young, B.; Jackson, N. The structural and functional diversification of the Toxicofera reptile venom system. Toxicon 2012, 60, 434–448. [Google Scholar] [CrossRef] [PubMed]
- Casewell, N.R.; Wüster, W.; Vonk, F.J.; Harrison, R.A.; Fry, B.G. Complex cocktails: The evolutionary novelty of venoms. Trends Ecol. Evol. 2013, 28, 219–229. [Google Scholar] [CrossRef] [PubMed]
- Haney, R.A.; Clarke, T.H.; Gadgil, R.; Fitzpatrick, R.; Hayashi, C.Y.; Ayoub, N.A.; Garb, J.E. Effects of gene duplication, positive selection, and shifts in gene expression on the evolution of the venom gland transcriptome in widow spiders. Genome Biol. Evol. 2016, 8, 228–242. [Google Scholar] [CrossRef] [PubMed]
- Wong, E.S.; Belov, K. Venom evolution through gene duplications. Gene 2012, 496, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Vonk, F.J.; Casewell, N.R.; Henkel, C.V.; Heimberg, A.M.; Jansen, H.J.; McCleary, R.J.; Kerkkamp, H.M.; Vos, R.A.; Guerreiro, I.; Calvete, J.J.; et al. The king cobra genome reveals dynamic gene evolution and adaptation in the snake venom system. Proc. Natl. Acad. Sci. USA 2013, 110, 20651–20656. [Google Scholar] [CrossRef] [PubMed]
- Hedges, S.B.; Vidal, N. Lizards, snakes, and amphisbaenians (Squamata). In The Timetree of Life; Hedges, S.B., Kumar, S., Eds.; Oxford University Press: Oxford, UK, 2009; pp. 383–389. [Google Scholar]
- Jones, M.E.; Anderson, C.L.; Hipsley, C.A.; Müller, J.; Evans, S.E.; Schoch, R.R. Integration of molecules and new fossils supports a Triassic origin for Lepidosauria (lizards, snakes, and tuatara). BMC Evol. Biol. 2013, 13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pyron, R.A.; Burbrink, F.T.; Wiens, J.J. A phylogeny and revised classification of Squamata, including 4161 species of lizards and snakes. BMC Evol. Biol. 2013, 13. [Google Scholar] [CrossRef] [PubMed]
- Reeder, T.W.; Townsend, T.M.; Mulcahy, D.G.; Noonan, B.P.; Wood, P.L., Jr.; Sites, J.W., Jr.; Wiens, J.J. Integrated analyses resolve conflicts over squamate reptile phylogeny and reveal unexpected placements for fossil. PLoS ONE 2015, 10, e0118199. [Google Scholar] [CrossRef] [PubMed]
- Hsiang, A.Y.; Field, D.J.; Webster, T.H.; Behlke, A.D.; Davis, M.B.; Racicot, R.A.; Gauthier, J.A. The origin of snakes: Revealing the ecology, behavior, and evolutionary history of early snakes using genomics, phenomics, and the fossil record. BMC Evol. Biol. 2015, 15. [Google Scholar] [CrossRef] [PubMed]
- Reeks, T.A.; Fry, B.G.; Alewood, P.F. Privileged frameworks from snake venom. Cell. Mol. Life Sci. 2015, 72, 1939–1958. [Google Scholar] [CrossRef] [PubMed]
- Hite, L.A.; Jia, L.G.; Bjarnason, J.B.; Fox, J.W. cDNA sequences for four snake venom metalloproteinases: Structure, classification, and their relationship to mammalian reproductive proteins. Arch. Biochem. Biophys. 1994, 308, 182–191. [Google Scholar] [CrossRef] [PubMed]
- Moura-da-Silva, A.M.; Theakston, R.D.; Crampton, J.M. Evolution of disintegrin cysteine-rich and mammalian matrix-degrading metalloproteinases: Gene duplication and divergence of a common ancestor rather than convergent evolution. J. Mol. Evol. 1996, 43, 263–269. [Google Scholar] [CrossRef] [PubMed]
- Casewell, N.R. On the ancestral recruitment of metalloproteinases into the venom of snakes. Toxicon 2012, 60, 449–454. [Google Scholar] [CrossRef] [PubMed]
- Escalante, T.; Rucavado, A.; Fox, J.W.; Gutiérrez, J.M. Key events in microvascular damage induced by snake venom hemorrhagic metalloproteinases. J. Proteomics 2011, 74, 1781–1794. [Google Scholar] [CrossRef] [PubMed]
- Markland, F.S., Jr.; Swenson, S. Snake venom metalloproteinases. Toxicon 2013, 62, 3–18. [Google Scholar] [CrossRef] [PubMed]
- Herrera, C.; Escalante, T.; Voisin, M.B.; Rucavado, A.; Morazán, D.; Macêdo, J.K.; Calvete, J.J.; Sanz, L.; Nourshargh, S.; Gutiérrez, J.M.; et al. Tissue localization and extracellular matrix degradation by PI, PII and PIII snake venom metalloproteinases: Clues on the mechanisms of venom-induced hemorrhage. PLoS Negl. Trop. Dis. 2015, 9, e0003731. [Google Scholar] [CrossRef] [PubMed]
- Gutiérrez, J.M.; Escalante, T.; Rucavado, A.; Herrera, C. Hemorrhage Caused by Snake Venom Metalloproteinases: A Journey of Discovery and Understanding. Toxins 2016, 8. [Google Scholar] [CrossRef] [PubMed]
- Jia, L.G.; Shimokawa, K.; Bjarnason, J.B.; Fox, J.W. Snake venom metalloproteinases: Structure, function and relationship to the ADAMs family of proteins. Toxicon 1996, 34, 1269–1276. [Google Scholar] [CrossRef]
- Pyron, R.A.; Burnbrink, F.T. Extinction ecological opportunity and the origins of global snake diversity. Evolution 2012, 66, 163–178. [Google Scholar] [CrossRef] [PubMed]
- Fox, J.W.; Serrano, S.M. Structural considerations of the snake venom metalloproteinases, key members of the M12 reprolysin family of metalloproteinases. Toxicon 2005, 45, 969–985. [Google Scholar] [CrossRef] [PubMed]
- Fox, J.W.; Serrano, S.M. Insights into and speculations about snake venom metalloproteinase (SVMP) synthesis, folding and disulfide bond formation and their contribution to venom complexity. FEBS J. 2008, 275, 3016–3030. [Google Scholar] [CrossRef] [PubMed]
- Casewell, N.R.; Sunagar, K.; Takacs, Z.; Calvete, J.J.; Jackson, T.N.W.; Fry, B.G. Snake venom metalloprotease enzymes. In Venomous Reptiles and Their Toxins: Evolution, Pathophysiology and Biodiscovery; ISBN 978-0-19-930939-9. Fry, B.G., Ed.; Oxford University Press: Oxford, UK, 2015; Chapter 23; pp. 347–363. [Google Scholar]
- Juárez, P.; Comas, I.; González-Candelas, F.; Calvete, J.J. Evolution of snake venom disintegrins by positive Darwinian selection. Mol. Biol. Evol. 2008, 25, 2391–2407. [Google Scholar] [CrossRef] [PubMed]
- Carbajo, R.J.; Sanz, L.; Pérez, A.; Calvete, J.J. NMR structure of bitistatin—A missing piece in the evolutionary pathway of snake venom disintegrins. FEBS J. 2015, 282, 341–360. [Google Scholar] [CrossRef] [PubMed]
- Calvete, J.J. Brief History and Molecular Determinants of Snake Venom Disintegrin Evolution. In Toxins and Hemostasis. From Bench to Bedside; Kini, R.M., Markland, F., McLane, M.A., Morita, T., Eds.; Springer Science+Business Media B.V.: Amsterdam, The Netherlands, 2010; pp. 285–300. [Google Scholar]
- Casewell, N.R.; Wagstaff, S.C.; Harrison, R.A.; Renjifo, C.; Wüster, W. Domain loss facilitates accelerated evolution and neofunctionalization of duplicate snake venom metalloproteinase toxin genes. Mol. Biol. Evol. 2011, 28, 2637–2649. [Google Scholar] [CrossRef] [PubMed]
- Sanz-Soler, R.; Sanz, L.; Calvete, J.J. Distribution of RPTLN genes across Reptilia. Hypothesized role for RPTLN in the evolution of SVMPs. Integr. Compar. Biol. 2016. [Google Scholar] [CrossRef] [PubMed]
- Sanz, L.; Harrison, R.A.; Calvete, J.J. First draft of the genomic organization of a PIII-SVMP gene. Toxicon 2012, 60, 455–469. [Google Scholar] [CrossRef] [PubMed]
- Endo, T.; Fedorov, A.; de Souza, S.J.; Gilbert, W. Do Introns Favor or Avoid Regions of Amino Acid Conservation? Mol. Biol. Evol. 2002, 19, 521–525. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Q.; Wang, W. On the origin and evolution of new genes-a genomic and experimental perspective. J. Genet. Genomics 2008, 35, 639–648. [Google Scholar] [CrossRef]
- Kordis, D.; Gubensek, F. Adaptive evolution of animal toxin multigene families. Gene 2000, 261, 43–52. [Google Scholar] [CrossRef]
- Cao, Z.; Yu, Y.; Wu, Y.; Hao, P.; Di, Z.; He, Y.; Chen, Z.; Yang, W.; Shen, Z.; He, X.; et al. The genome of Mesobuthus martensii reveals a unique adaptation model of arthropods. Nat. Commun. 2013, 4. [Google Scholar] [CrossRef] [PubMed]
- Fry, B.G.; Wüster, W.; Kini, R.M.; Brusic, V.; Khan, A.; Venkataraman, D.; Rooney, A.P. Molecular evolution and phylogeny of elapid snake venom three-finger toxins. J. Mol. Evol. 2003, 57, 110–129. [Google Scholar] [CrossRef] [PubMed]
- Reyes-Velasco, J.; Card, D.C.; Andrew, A.L.; Shaney, K.J.; Adams, R.H.; Schield, D.R.; Casewell, N.R.; Mackessy, S.P.; Castoe, T.A. Expression of venom gene homologs in diverse python tissues suggests a new model for the evolution of snake venom. Mol. Biol. Evol. 2015, 32, 173–183. [Google Scholar] [CrossRef] [PubMed]
- Hargreaves, A.D.; Swain, M.T.; Logan, D.W.; Mulley, J.F. Testing the Toxicofera: Comparative transcriptomics casts doubt on the single, early evolution of the reptile venom system. Toxicon 2014, 92, 140–156. [Google Scholar] [CrossRef] [PubMed]
- Sunagar, K.; Jackson, T.N.; Undheim, E.A.; Ali, S.A.; Antunes, A.; Fry, B.G. Three-fingered RAVERs: Rapid Accumulation of Variations in Exposed Residues of snake venom toxins. Toxins 2013, 5, 2172–2208. [Google Scholar] [CrossRef] [PubMed]
- Chang, D.; Duda, T.F. Extensive and continuous duplication facilitates rapid evolution and diversification of gene families. Mol. Biol. Evol. 2012, 29, 2019–2029. [Google Scholar] [CrossRef] [PubMed]
- Chow, L.T.; Gelinas, R.E.; Broker, T.R.; Roberts, R.J. An amazing sequence arrangement at the 5′ ends of adenovirus 2 messenger RNA. Cell 1977, 12, 1–8. [Google Scholar] [CrossRef]
- Berget, S.M.; Moore, C.; Sharp, P.A. Spliced segments at the 5′ terminus of adenovirus 2 late mRNA. Proc. Natl. Acad. Sci. USA 1977, 74, 3171–3175. [Google Scholar] [CrossRef] [PubMed]
- Bicknell, A.A.; Cenik, C.; Chua, H.N.; Roth, F.P.; Moore, M.J. Introns in UTRs: Why we should stop ignoring them. BioEssays 2012, 34, 1025–1034. [Google Scholar] [CrossRef] [PubMed]
- Cenik, C.; Chua, H.N.; Zhang, H.; Tarnawsky, S.P.; Akef, A.; Derti, A.; Tasan, M.; Moore, M.J.; Palazzo, A.F.; Roth, F.P. Genome analysis reveals interplay between 5′-UTR introns and nuclear mRNA export for secretory and mitochondrial genes. PLoS Genet. 2011, 7, e1001366. [Google Scholar] [CrossRef] [PubMed]
- Comeron, J.M.; Kreitman, M. The correlation between intron length and recombination in Drosophila: Dynamic equilibrium between mutational and selective forces. Genetics 2000, 156, 1175–1190. [Google Scholar] [PubMed]
- De Souza, S.J.; Long, M.; Gilbert, W. Introns and gene evolution. Genes Cells 1996, 1, 493–505. [Google Scholar] [CrossRef] [PubMed]
- Patthy, L. Exon shuffling and other ways of module exchange. Matrix Biol. 1996, 15, 301–310. [Google Scholar] [CrossRef]
- Hughes, A.L.; Hughes, M.K. Small genomes for better flyers. Nature 1995, 377, 391. [Google Scholar] [CrossRef] [PubMed]
- Lynch, M. Intron evolution as a population-genetic process. Proc. Natl. Acad. Sci. USA 2002, 99, 6118–6123. [Google Scholar] [CrossRef] [PubMed]
- Haddrill, P.R.; Charlesworth, B.; Halligan, D.L.; Andolfatto, P. Patterns of intron sequence evolution in Drosophila are dependent upon length and GC content. Genome Biol. 2005, 6, R67. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, M.; He, L.; Gu, Y.; Wang, Y.; Chen, Q.; He, C. Genome-wide analyses of a plant-specific LIM-domain gene family implicate its evolutionary role in plant diversification. Genome Biol. Evol. 2014, 6, 1000–1012. [Google Scholar] [CrossRef] [PubMed]
- Tordai, H.; Patthy, L. Insertion of spliceosomal introns in proto-splice sites: The case of secretory signal peptides. FEBS Lett. 2004, 575, 109–111. [Google Scholar] [CrossRef] [PubMed]
- Tomita, M.; Shimizu, N.; Brutlag, D.L. Introns and reading frames: Correlation between splicing sites and their codon positions. Mol. Biol. Evol. 1996, 13, 1219–1223. [Google Scholar] [CrossRef] [PubMed]
- Long, M.; de Souza, S.J.; Rosenberg, C.; Gilbert, W. Relationship between proto-splice sites and intron phases: Evidence from dicodon analysis. Proc. Natl. Acad. Sci. USA 1998, 95, 219–223. [Google Scholar] [CrossRef] [PubMed]
- Von Heijne, G. Patterns of amino acids near signal-sequence cleavage sites. Eur. J. Biochem. 1983, 133, 17–21. [Google Scholar] [CrossRef] [PubMed]
- Pinho, C.; Rocha, S.; Carvalho, B.M.; Lopes, S.; Mourão, S.; Vallinoto, M.; Brunes, T.O.; Haddad, C.F.B.; Gonçalves, H.; Sequeira, F.; et al. New primers for the amplification and sequencing of nuclear loci in a taxonomically wide set of reptiles and amphibians. Conserv. Genet. Resour. 2010, 2, 181–185. [Google Scholar] [CrossRef]
- Ellegren, H. Microsatellites: Simple sequences with complex evolution. Nat. Rev. Genet. 2004, 5, 435–445. [Google Scholar] [CrossRef] [PubMed]
- Adams, R.H.; Blackmon, H.; Reyes-Velasco, J.; Schield, D.R.; Card, D.C.; Andrew, A.L.; Waynewood, N.; Castoe, T.A. Microsatellite landscape evolutionary dynamics across 450 million years of vertebrate genome evolution. Genome 2016, 59, 295–310. [Google Scholar] [CrossRef] [PubMed]
- Liang, K.C.; Tseng, J.T.; Tsai, S.J.; Sun, H.S. Characterization and distribution of repetitive elements in association with genes in the human genome. Comput. Biol. Chem. 2015, 57, 29–38. [Google Scholar] [CrossRef] [PubMed]
- Schlötterer, C.; Tautz, D. Slippage synthesis of simple sequence DNA. Nucleic Acids Res. 1992, 20, 211–215. [Google Scholar] [CrossRef] [PubMed]
- Charlesworth, B.; Sniegowski, P.; Stephan, W. The evolutionary dynamics of repetitive DNA in eukaryotes. Nature 1994, 371, 215–220. [Google Scholar] [CrossRef] [PubMed]
- Martin, P.; Makepeace, K.; Hill, S.A.; Hood, D.W.; Moxon, E.R. Microsatellite instability regulates transcription factor binding and gene expression. Proc. Natl. Acad. Sci. USA 2005, 102, 3800–3804. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.C.; Korol, A.B.; Fahima, T.; Beiles, A.; Nevo, E. Microsatellites: Genomic distribution, putative functions and mutational mechanisms: A review. Mol. Ecol. 2002, 11, 2453–2465. [Google Scholar] [CrossRef] [PubMed]
- Shaney, K.J.; Schield, D.R.; Card, D.C.; Ruggiero, R.P.; Pollock, D.D.; Mackessy, S.P.; Castoe, T.A. Squamate reptile genomics and evolution. In Handbook. of Toxinology: Venom Genomics and Proteomics; Gopalakrishnakone, P., Calvete, J.J., Eds.; Springer Science+Business Media: Dordrecht, The Netherlands, 2016; pp. 29–49. [Google Scholar]
- Balaresque, P.; King, T.E.; Parkin, E.J.; Heyer, E.; Carvalho-Silva, D.; Kraaijenbrink, T.; de Knijff, P.; Tyler-Smith, C.; Jobling, M.A. Gene conversion violates the stepwise mutation model for microsatellites in Y-chromosomal palindromic repeats. Hum. Mutat. 2014, 35, 609–617. [Google Scholar] [CrossRef] [PubMed]
- Eller, C.D.; Regelson, M.; Merriman, B.; Nelson, S.; Horvath, S.; Marahrens, Y. Repetitive sequence environment distinguishes housekeeping genes. Gene 2007, 390, 153–165. [Google Scholar] [CrossRef] [PubMed]
- Sverdlov, E.D. Perpetually mobile footprints of ancient infections in human genome. FEBS Lett. 1998, 428, 1–6. [Google Scholar] [CrossRef]
- Makalowski, W. Genomic scrap yard: How genomes utilize all that junk. Gene 2000, 259, 61–67. [Google Scholar] [CrossRef]
- Bourque, G.; Leong, B.; Vega, V.B.; Chen, X.; Lee, Y.L.; Srinivasan, K.G.; Chew, J.L.; Ruan, Y.; Wei, C.L.; Ng, H.H.; et al. Evolution of the mammalian transcription factor binding repertoire via transposable elements. Genome. Res. 2008, 18, 1752–1762. [Google Scholar] [CrossRef] [PubMed]
- Irimía, M.; Rukov, J.L.; Penny, D.; Vinther, J.; García-Fernández, J.; Roy, S.W. Origin of introns by ‘intronization’ of exonic sequences. Trends Genet. 2008, 24, 378–381. [Google Scholar] [CrossRef] [PubMed]
- Bazaa, A.; Juarez, P.; Marrakchi, N.; Bel Lasfer, Z.; El Ayeb, M.; Harrison, R.A.; Calvete, J.J.; Sanz, L. Loss of introns along the evolutionary diversification pathway of snake venom disintegrins evidenced by sequence analysis of genomic DNA from Macrovipera lebetina transmediterranea and Echis ocellatus. J. Mol. Evol. 2007, 64, 261–271. [Google Scholar] [CrossRef] [PubMed]
- Bonen, L.; Vogel, J. The ins and outs of group II introns. Trends Genet. 2001, 17, 322–331. [Google Scholar] [CrossRef]
- Dibb, N.J.; Newman, A.J. Evidence that introns arose at proto-splice sites. EMBO J. 1989, 8, 2015–2021. [Google Scholar] [PubMed]
- Logsdon, J.M., Jr. The recent origins of spliceosomal introns revisited. Curr. Opin. Genet. Dev. 1998, 8, 637–648. [Google Scholar] [CrossRef]
- Lynch, M.; Richardson, A.O. The evolution of spliceosomal introns. Curr. Opin. Genet. Dev. 2002, 12, 701–710. [Google Scholar] [CrossRef]
- Patel, A.A.; Steitz, J.A. Splicing double: Insights from the second spliceosome. Nat. Rev. Mol. Cell Biol. 2003, 4, 960–970. [Google Scholar] [CrossRef] [PubMed]
- Rodríguez-Trelles, F.; Tarrío, R.; Ayala, F.J. Origins and evolution of spliceosomal introns. Annu. Rev. Genet. 2006, 40, 47–76. [Google Scholar] [CrossRef] [PubMed]
- Luo, Y.; Li, C.; Gong, X.; Wang, Y.; Zhang, K.; Cui, Y.; Sun, Y.E.; Li, S. Splicing-related features of introns serve to propel evolution. PLoS ONE 2013, 8, e58547. [Google Scholar] [CrossRef] [PubMed]
- Nakashima, K.; Ogawa, T.; Oda, N.; Hattori, M.; Sakaki, Y.; Kihara, H.; Ohno, M. Accelerated evolution of Trimeresurus. flavoviridis venom gland phospholipase A2 isozymes. Proc. Natl. Acad. Sci. USA 1993, 90, 5964–5968. [Google Scholar] [CrossRef] [PubMed]
- Nakashima, K.; Nobuhisa, I.; Deshimaru, M.; Nakai, M.; Ogawa, T.; Shimohigashi, Y.; Fukumaki, Y.; Hattori, M.; Sakaki, Y.; Hattori, S.; et al. Accelerated evolution in the protein-coding regions is universal in crotalinae snake venom gland phospholipase A2 isozyme genes. Proc. Natl. Acad. Sci. USA 1995, 92, 5605–5609. [Google Scholar] [CrossRef] [PubMed]
- Ikeda, N.; Chijiwa, T.; Matsubara, K.; Oda-Ueda, N.; Hattori, S.; Matsuda, Y.; Ohno, M. Unique structural characteristics and evolution of a cluster of venom phospholipase A2 isozyme genes of Protobothrops flavoviridis snake. Gene 2010, 461, 15–25. [Google Scholar] [CrossRef] [PubMed]
- Chijiwa, T.; Ikeda, N.; Masuda, H.; Hara, H.; Oda-Ueda, N.; Hattori, S.; Ohno, M. Structural characteristics and evolution of a novel venom phospholipase A2 gene from Protobothrops flavoviridis. Biosci. Biotechnol. Biochem. 2012, 76, 551–558. [Google Scholar] [CrossRef] [PubMed]
- Chijiwa, T.; Nakasone, H.; Irie, S.; Ikeda, N.; Tomoda, K.; Oda-Ueda, N.; Hattori, S.; Ohno, M. Structural characteristics and evolution of the Protobothrops elegans pancreatic phospholipase A2 gene in contrast with those of Protobothrops genus venom phospholipase A2 genes. Biosci. Biotechnol. Biochem. 2013, 77, 97–102. [Google Scholar] [CrossRef] [PubMed]
- Koszul, R.; Fischer, G. A prominent role for segmental duplications in modeling eukaryotic genomes. C. R. Biol. 2009, 332, 254–266. [Google Scholar] [CrossRef] [PubMed]
- Ohta, T. Simple model for treating evolution of multigene families. Nature 1976, 263, 74–76. [Google Scholar] [CrossRef] [PubMed]
- Smith, G.P. Evolution of repeated DNA sequences by unequal crossover. Science 1976, 191, 528–535. [Google Scholar] [CrossRef] [PubMed]
- Juárez, P.; Wagstaff, S.C.; Sanz, L.; Harrison, R.A.; Calvete, J.J. Molecular cloning of Echis ocellatus disintegrins reveals non-venom-secreted proteins and a pathway for the evolution of ocellatusin. J. Mol. Evol. 2006, 63, 183–193. [Google Scholar] [CrossRef] [PubMed]
- GeneWise. Available online: http://www.ebi.ac.uk/Tools/Wise2/index.html (accessed on 31 May 2016).
- Basic Local Alignment Search Tool (BLAST). Available online: http://blast.ncbi.nlm.nih.gov/Blast.cgi (accessed on 5 June 2016).
- ClustalW2-Multiple Sequence Alignment. Available online: http://www.ebi.ac.uk/Tools/msa/clustalw2 (accessed on 5 June 2016).
- RepeatMasker. Available on: http://www.repeatmasker.org (accessed on 30 December 2015).
- Genetic Information Research Institute. Available on: http://www.girinst.org (accessed on 7 January 2016).
- National Center for Biotechnology Information (NCBI) Database. Available on: http://www.ncbi.nlm.nih.gov (accessed on 10 January 2016).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Intron | PII-SVMP | PI-SVMP |
|---|---|---|
| Inserted Retroelement | ||
| 1 | SINE/Sauria | 2 SINE/Sauria, LTR/ERV1, DNA/hAT-Ac |
| 3 | LINE/L2/CR1 | LINE/L2/CR1 |
| 5 | LINE/L2/CR1 | LINE/L2/CR1 |
| 6 | SINE/Sauria | - |
| 8 | LINE/L2/CR1 | - |
| 9 | - | SINE/Sauria |
| 10 | DNA transposon | DNA transposon |
| Primer | DNA sequence | Primer | DNA sequence |
|---|---|---|---|
| Sp35_Eo Fw | ATGATCCAAGTTCTCTTGGTAACTATATGCTTAGC | 5’ PS-Disi Fw | ATGATCCAAGTTCTCTTGG |
| Met14PI Fw | CTATATGCTTAGCAGTTTTTCCATATC | Intr4 Fw | ATGACACTGACCTCTAGAGTTGG |
| Intr1F1PI Fw | CTAGTCATTCCGGCCATATGAC | IntrB9_4-2 Fw | AAGCTTGCTTGCTAGTAGGTGG |
| Intr2F1PI Fw | ATCAGTCTGAGAGGATGCATTTCC | Intr4 Rv | TGGACATTGTATGGTCACCTG |
| Intr3F1PI Fw | GTGACCATGCAATGTCCATATG | Prodom 3 Fw | GGAGCTTTTAAGCAGCCAGAG |
| Met15PI Fw | GTTGCCTGTAGGAGCTGTTAAG | Prodom 3 Rv | CTCTGGCTGCTTAAAAGCTCC |
| Prodom 2 Fw | GACGCTGTGCAATATGAATTTG | Prodom 2 Fw | GACGCTGTGCAATATGAATTTG |
| Prodom 2 Rv | CAAATTCATATTGCACAGCGTC | Prodom 2 Rv | CAAATTCATATTGCACAGCGTC |
| Intr3 Rv | GCACCAACTCTGTATCTCAGTC | Intr3 Fw | CACAGGTAAATAAGCCACAAACACC |
| Pro2 Fw | CAGTGAGACTCATTATTCCCCTGATGGCAG | Intr3 Rv | GCACCAACTCTGTATCTCAGTC |
| Pro3 Rv | CTGCCATCAGGGGAATAATGAGTCTCACTG | Pro2-SVMP_Fw | CAGAAGATTACAGTGAGACTCATTATTCCCWGATGG |
| IntrB13-1 Fw | CTTGCCTCCCTATAGGATCACTGC | Pro3-SVMP_Rv | CTGCCATCAGGGGAATAATGAGTCTCACT |
| Met16PI Rv | GATGCGTCCATAATAATAGCAGTG | IntrB13-1 Fw | CTTGCCTCCCTATAGGATCACTGC |
| Prodom 1 Fw | GATGCCAAAAAAAAGGATGAGG | Prodom 1 Fw | GATGCCAAAAAAAAGGATGAGG |
| Prodom 1 Rv | CCTCATCCTTTTTTTTGGCATC | Prodom 1 Rv | CCTCATCCTTTTTTTTGGCATC |
| IntronB7PI Fw | TGGAACAACAGCTGTTGTTATGACG | Intr2 Fw | ACAATGGGAAACTGAGGAACAG |
| IntronB7PI Rv | TGAGAGACATGCTGATGTGGTC | Intr2 Rv | GGGAACTCTGACTTAGAGAAAGTC |
| Met4 PI Fw | GACCCAAGATACATTCAGCTTGTC | Met1PII Fw | CAACAGCATTTTCACCCAAGATAC |
| Met4 PI Rv | GACAAGCTGAATGTATCTTGGGTC | Met1PII Rv | GTATCTTGGGTGAAAATGCTGTTG |
| Met8PI Rv | TATCCATGTTGTTATAGCAGTTAAATC | Met 1-2 Fw | CATGGATACATCAAATTGTCAACG |
| Intron B16 Fw | TGTGCTTACCCAACACTGAGCC | Met 1-3 Rv | TGTACATCTGTCAGGTGGACATG |
| Met5 PI Fw | GCACGTGAAATTTTGAACTCA | Met2PII Fw | GCCGTTCACCTTGATAACCTTATAGG |
| Met5PI Rv | GAGTTCAAAATTTCACGTGCTG | Met2PII Rv | CCTATAAGGTTATcAAGGTGAACGGC |
| Met9PI Rv | AGCATTATCATGCGTTATGCG | Met 6 PII Fw | CCACAATCGTCTGTAGCAATTACTGA |
| Met3 PI Fw | GGAAGAGCTTACATGGAGAG | Met 6 PII Rv | TCAGTAATTGCTACAGACGATTGTGG |
| Met3PI Rv | CTCTCCATGTAAGCTCTTCC | Met3 PII Fw | GATCATAGCACAGATCATCTTTGG |
| Met2PI Rv | GCTCCCCAGACATAACGCATC | Met3PII Rv | CCAAAGATGATCTGTGCTATGATCc |
| IntrB23PI Fw | CTGACTATGACTCACTTAACAACTGG | Met 4 Fw | ATGATCCAGGTTCTCTTGGTAACTATATG |
| IntrF2PI Fw | GGCCGCGTGAATGCATCTGCTTC | Met 4 Rv | TGAACTGATAGGAACGGTATTGTG |
| Intr2F2PI Fw | GCATCAGTTTGTTCGCACTCAATAAAG | Fw_Ocella NcoI | ATCCATGGTAGACTGTGAATCTGGACC |
| Intr3F2PI Fw | GAGCATAATCTGGAACTAAGATCAAG | IntrDis1 Rv | ATACGGCTAGTATGGAGCAGG |
| Met7PI Fw | GCACAAGATTCCTATCACTTCAG | Dis PII Rv | TCACATCAACACACTGCCTTTTGC |
| Met13PI Rv | TCCTACCTGCAAAAGTTCATTTTC | - | - |
| Intron B10PI Rv | CTGACTCAGGGCACCAATCTC | - | - |
| Met1PI Rv | CTACTGCAGATCGTTCCATCTCTG | - | - |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sanz, L.; Calvete, J.J. Insights into the Evolution of a Snake Venom Multi-Gene Family from the Genomic Organization of Echis ocellatus SVMP Genes. Toxins 2016, 8, 216. https://doi.org/10.3390/toxins8070216
Sanz L, Calvete JJ. Insights into the Evolution of a Snake Venom Multi-Gene Family from the Genomic Organization of Echis ocellatus SVMP Genes. Toxins. 2016; 8(7):216. https://doi.org/10.3390/toxins8070216
Chicago/Turabian StyleSanz, Libia, and Juan J. Calvete. 2016. "Insights into the Evolution of a Snake Venom Multi-Gene Family from the Genomic Organization of Echis ocellatus SVMP Genes" Toxins 8, no. 7: 216. https://doi.org/10.3390/toxins8070216