3.1. Image Retrieval Architecture
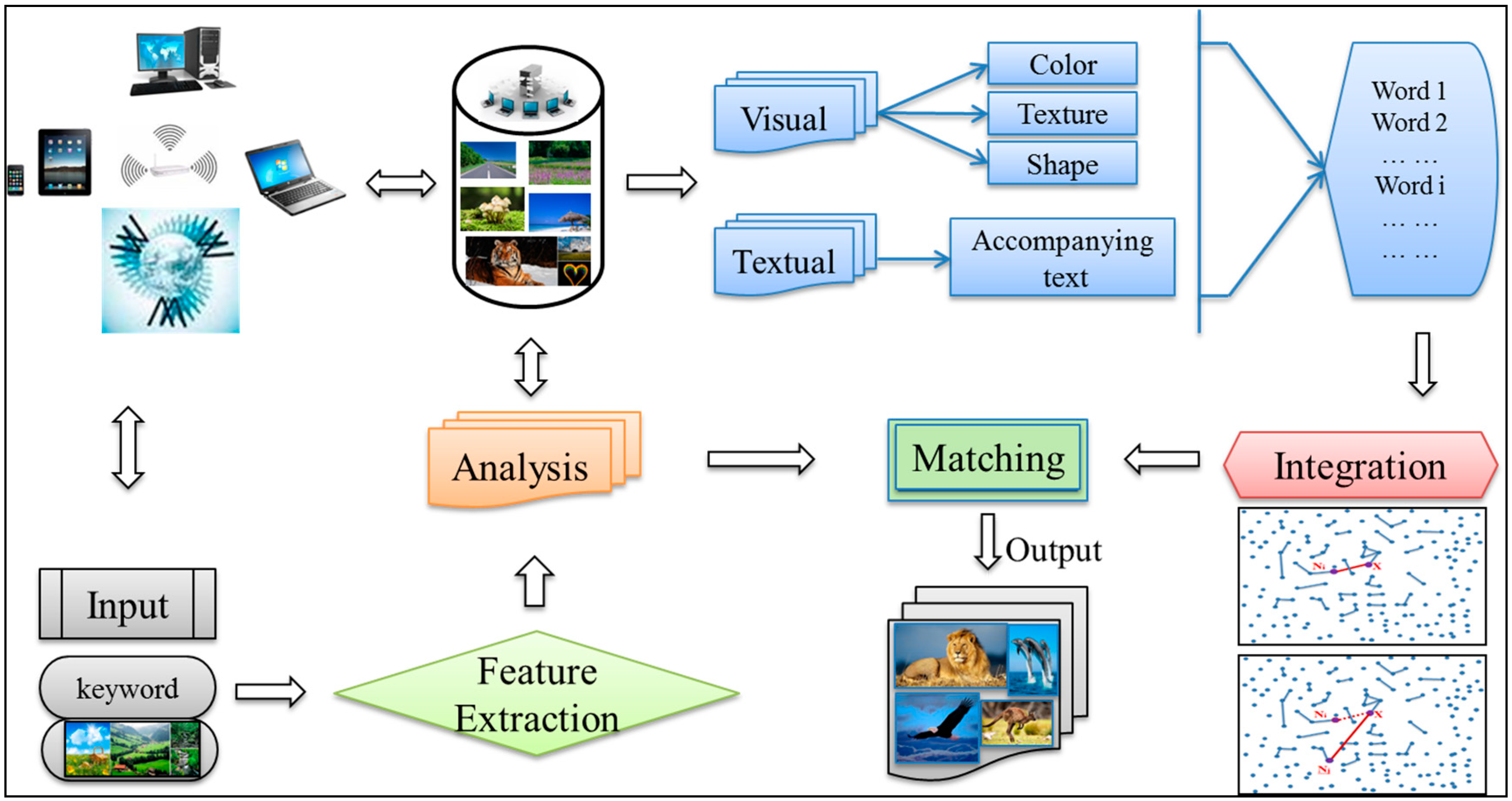
CBIR has attracted more studies in the field of informatics. CBIR facilitates techniques for effective indexing and retrieval of images by features, such as color, texture, shape, movement, and contours. We propose a content-based image retrieval framework, as shown in
Figure 2.
Figure 2.
Proposed content-based image retrieval framework.
Figure 2.
Proposed content-based image retrieval framework.
Figure 2 shows a typical prototype of the content-based image retrieval architecture. In this scenario, users interact with the system to retrieve images that meet their queries. In the indexing phase, the image database is organized and managed. In the retrieval phase, a way for interaction between user and system is provided. This scenario combines the text-based and content-based approaches that consist of two major aspects, visual feature extraction and multi-label indexing engine. The user interface supplies a basic textbox for textual image query, and typically provides an image browser interface for non-textual image query (image). This system builds a text or visual index to search among image collections. Each image in the database can be represented by the association with visual features and semantic annotations in a multi-modal label. First, feature extraction uses principal component analysis to select the most appropriate visual features for prediction and removes the irrelevant and redundant features. Then, each image will be assigned with one or multiple annotations from a predefined label set.
Annotations play an important role in search engines, information extraction, and for the auto-production of linked data. More relevant annotations would allow users to further exploit the indexing and retrieval architecture of image search-engines to improve image search. Therefore, one of the next research challenges deals with the annotation integration. It requires a great deal of intelligent processing of this data because high quality data is mixed up with low quality noisy text. However, the main problem of annotation is users’ subjective preferences, which means that a different user may have different perceptions of the same image. Therefore, to effectively and correctly find user desired images from large-scale image collections is not an easy task. The major problem is that the images are usually not annotated using semantic descriptors. Because image data is typically associated with multi-labels, each image could contain various objects and, therefore, could be associated with a set of labels. By exploiting a large collection of image annotations, the basic idea is to identify annotations which are frequently detected together and to derive their type(s) of relationship based on the semantic correlation. The verification step includes machine learning techniques to compute the type of relationship between two annotations.
3.2. Problem
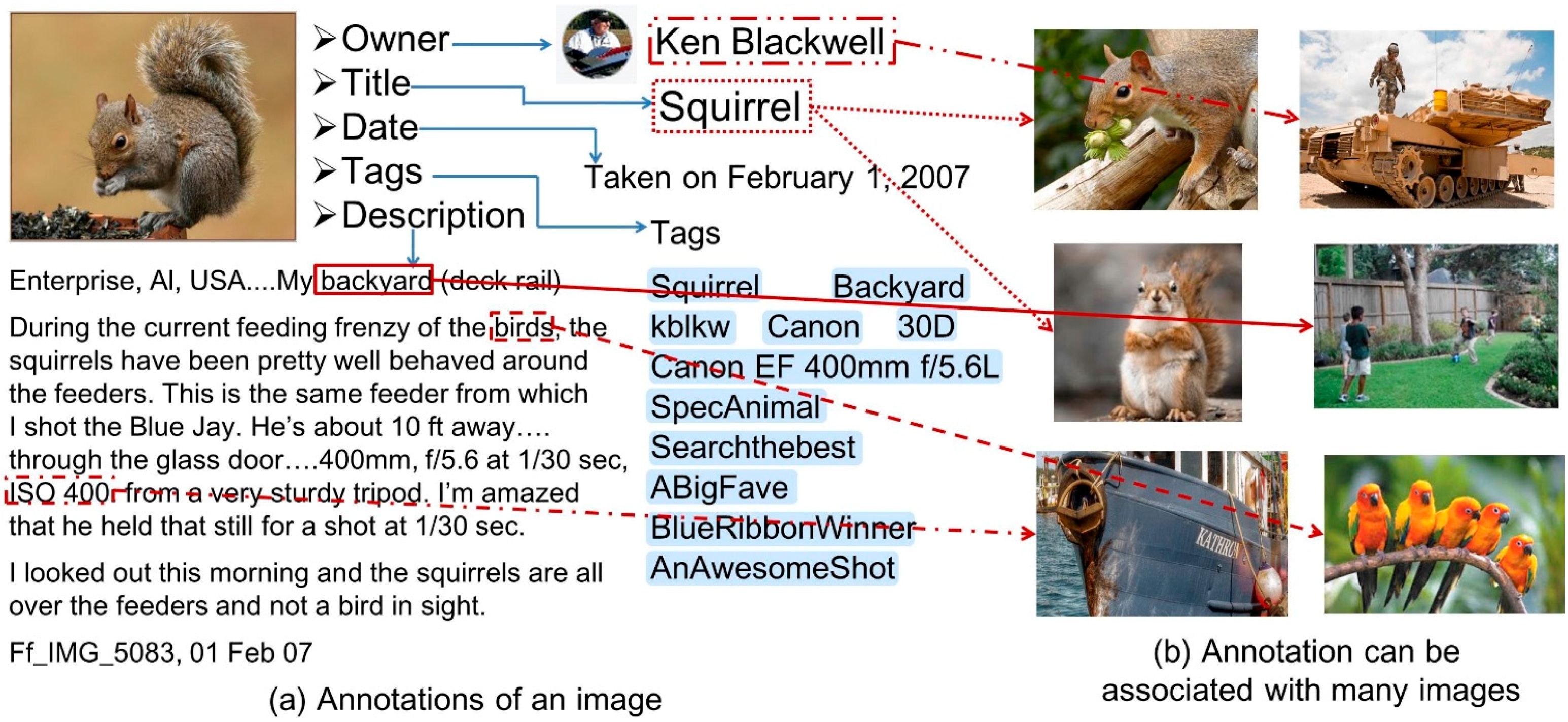
The problem of image annotation has gained interest more recently. Realistically, more and more words have been annotated to images, and irrelevant images have been connected to each other.
Figure 3 clearly shows the image-to-image and word-to-word correlation model in the real-world dataset Flickr. Images were connected to each other via to the interrelated and diverse annotations (the leftmost figure). The rightmost figure shows an example of annotations; the nearest annotations can be found in the learned embedding space. Indeed, an image belonging to the category “nature” is more likely annotated with words “sky” and “trees” than words “car” and “vehicle”. Subsets labels are correlated, as many annotations are semantically close to each other. Therefore, this correlation among subsets can help predict the keywords of query examples. The main problems of multi-label indexing consist of two components. First, it is not clear how much annotation is sufficient for describing the image. Second, it is not clear what the best subset of objects to annotate is. Unlike spoken language and text documents, the semantic annotations of images are usually unavailable. Thus, we focus on how to integrate annotation in order to specify the meaning of each image annotation, thus leading to the most representative annotations of the intent of a keyword search. The goal of our approach is to translate a user-defined keyword query into refined annotations. Indeed, an annotation must capture not only the objects contained in an image, but it also must express how these images relate to each other as well as the annotations they are involved in (
Figure 3). This task is significantly harder, for example, than the well-studied image classification or image objects recognition tasks, which have been a main focus in the computer vision community [
24]. Annotations embed into a dense word representation, the semantically relevant annotations can be found by calculating the Euclidean distance between two dense words in metric space.
Figure 3.
Example of correlative images.
Figure 3.
Example of correlative images.
In this paper, we propose an integration of probabilistic model to refine annotation
A*R from images. Recent advances in statistical machine translation have shown that, given a powerful sequence model, it is possible to achieve high-quality results by directly maximizing the probability of the correct translation given an input keyword in an “end-to-end” fashion. We propose to directly maximize the probability of the correct annotation given the image by using the following formulation:
where
k is the parameters of our model,
g is an image, and
As is the existing annotations.
3.3. Probabilistic Model
DEFINITION 1. Image database are collected as a directed form D(G, C, As). Each image g is assigned to image category C = {c1, c2, … , cn} according to its characteristics. Given a set of images G = {g1, g2, … , gn} and the relations Ω between them, each image g in G is characterized by its annotations As. For ∀g, let As = {a1, a2, … , an} denote a collection of annotations mentions in g. For each ci, the order of the frequency annotations for As to be defined as AF = {f0, f1,…, fm}. Each image query q is characterized by its annotation Q. The objective of our probabilistic model is to determine the referent images in G of the annotations in As.
To capture the relationships in the annotation, we will make use of
Ω which states the relationships between categories of images. The most common constraints supported for concepts are:
- ✧
Jointness constraints cm ∧ cn ⊆ ⊕, stating that g is an image of category cm and also an image of category cn.
- ✧
Disjointness constraints cm ∧ cn ⊆ ⊘, stating that category cm and cn have an empty intersection.
The above constraints are supported by the relationships of annotations. We exploit the statistics of the extracted probabilistic model groundings. Based on that, we define the probability
P(a|c) that category
c in
G refers to image annotation
a
where
countcorrelation(a, c) denote the number of correlation using
c as primary unit pointing to
a as destination and
c is the set of images that have the correlative images.
In addition, we define the probability
P(ai∈A) that the annotation
ai in an image is an annotation name as
where
countcorrelation(ai) denotes the number of annotations that is assigned to
c and
counttotal(ai) denotes the number of annotations where appears in
G.
Subsequently, we map
As into the metric space to harvest expressive words from existing image annotations. We would like to present model that start from the keyword
Q of image as a input query, and is trained to maximize the likelihood of producing a target sequence of annotations
A*R = {a*0,…, a*m}, where denote by
a*0 a special start annotation (the most frequently word) and by
a*m a special stop annotation, and each annotation
a*i come from a given dictionary, that describes the image adequately. We model the relevance of an annotation
a which serves as a keyword with conditional probability
P(ci|
a) and
P(fi|
a), which can be interpreted as the probability of that keyword search by the user after we observe the user's query
q. With Bayes rule, we have:
The functions only depend on two component probabilities. The first is P(ci), which is the likelihood that we would observe query q if g is indeed relevant. The second is P(fi), which denotes the probability density of annotation. This conditional probability can capture how well image g matches the keyword in query q that if user desires image g, the user would likely search a query matching the annotations of image g. P(fi|a) is the probability that the user who desires image g would include a preference for the keyword query. In the proposed model, relevance is primarily based on the probability that the user interested in an image will search using the query. The model attempts to simulate the query formulation process of a user and recognize annotations for the keyword of a query.
We set these two probabilities as abscissa and ordinate, each
a ∈ As can be mapped into a point p(
P(ci|a), P(fi|a)) in metric space. Then, we present the Query-Frequency Pair (QF-P) algorithm to integrate the annotations. Notice that in the acronym, “
Q” is the keyword of query, “
F” is the most frequently annotation
FA in
ci which “
Q” occurred most frequently. The distance
d between
Q and
FA is used to detect the relevant subset
S for integrating annotation. For
∀ai,
We can give a certain threshold value (as the number of points) of parameter k to limit the number of object (point) in S. If the number of subset k’ is smaller than k, selecting the f0’ in S as the new FA to further detect relevant subset. When the k’ ≥ k, S = {f0*, f1*,…fk*}. There is a special subset SS in which the annotations ai satisfied d(ai, Q) ≤ d and d(ai, FA) ≤ d. Finally, we can use relevant subset to integrate annotation for image retrieval.
For a new test instance, the pre-processing first using query to find
FA and then makes the QF-P algorithm to detect relevant subsets for integrating annotation. For the retrieval task, the index only depends on integrated annotation
A*R. In testing, the general trend is that the most relevant annotations exist in
Ss. Assume that
k is big enough for a large scale database: we propose a hierarchical design for integrated annotation index structure (
Figure 4).
Figure 4.
Hierarchical design for integration.
Figure 4.
Hierarchical design for integration.
3.4. Query-Frequency Pair Algorithm
The detailed QF-P algorithm is shown in
Figure 5. QF-P algorithm is derived via the traditional k-nearest neighbor algorithm. The input to the procedure is A
s = {a
1, a
2, … , a
n}. Also, Q∈A
s, F
A∈A
s. The pair (Q, F
A) provides distance to limit detection range of relevant subset S. The given threshold k is used to limit the maximum number of words in S. In fact, our proposed algorithm implied two major meanings; “hierarchical” means use of hierarchical model to classify the original features in order to express different degrees of correlations. If the number of words in S is k’<k, then we chose the most frequent word f
0’ (f
0’ ≠ F
A) as new F
A to construct a new pair (Q, f
0’), and then, repeated the detection procedure. Otherwise, the relevant subset S = {f
0*, f
1*,…f
k*}is a set sorted by frequency. This algorithm can find the best combination between the visual and textual features, as the annotations, and it exploits the high-quality representative correlation between annotations and the image.
Figure 5.
Query-Frequency Pair algorithm.
Figure 5.
Query-Frequency Pair algorithm.
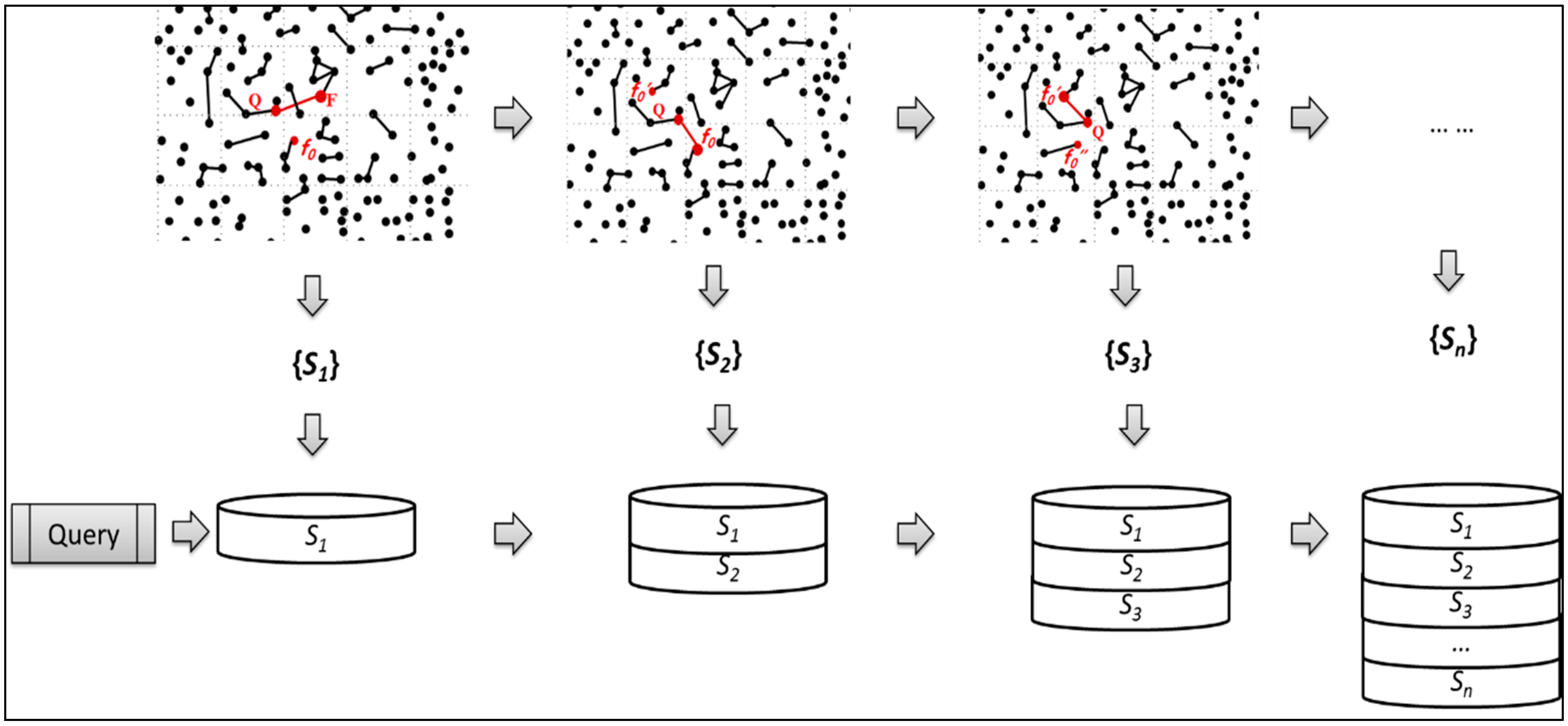
Actually, the QF-P algorithm is also a greedy algorithm that is derived via the traditional
k-nearest neighbors’ algorithm. We use a tree structure to present this method, and the tree would continue to grow until a threshold
k is satisfied (see
Figure 6). The more correlative annotations will have higher probabilities detected in the
S. According to different degrees of a relevant subset, we establish hierarchical levels to classify the subset for retrieving the information from the database. In reference to the relevant subset
S1, for the matching annotations, we index the matching images. Otherwise, go to the next
S2,
S3 continuously. It is an efficient way to improve the retrieval speed and ensure the accuracy of the results. For the retrieval task (as the algorithm shown in
Figure 7), we rank the images based on prioritized recall with the query keyword and output the top ranked ones.
Figure 6.
The tree-growth of QF-P algorithm.
Figure 6.
The tree-growth of QF-P algorithm.
Figure 7.
The prioritized retrieval algorithm.
Figure 7.
The prioritized retrieval algorithm.
3.5. Geometric-Center Approach
Generally, if you try to use multiple hot keywords as a text entry to find related images, it is possible to refine using keyword annotations. Therefore, we propose another method of automatically assigning relevant multi-keywords to a user specified image which could greatly improve the retrieval accuracy, and fast response is also required. “Multi-keywords” in a text search involves some information by uploaders being manually supported and, in visual searches, some hidden image information under the conditions of invisibility is also considered as a multi-keywords problem. So, the multi-keywords problem is common to both text and visual searches.
Semantic is a “feeling” expression of images. Sometimes, it is not sufficient to explain an image, but rather, users express the affective semantics of the images using some manual words. Some background information is equally important to express the images, which always contain many hidden relationships. Unlike QF-P which is proposed for integrating annotations, research on multi-keywords’ retrieval based on multiple relations information retrieval, as far as possible, allows relevant keywords to converge to a user specified image, in order to get a probable minimum subset which contains the major and the most correlative annotations. Then, based on these selected and classified annotations, we retrieved the relevant images in the metric space. We called this approach the Geometric-Center algorithm.
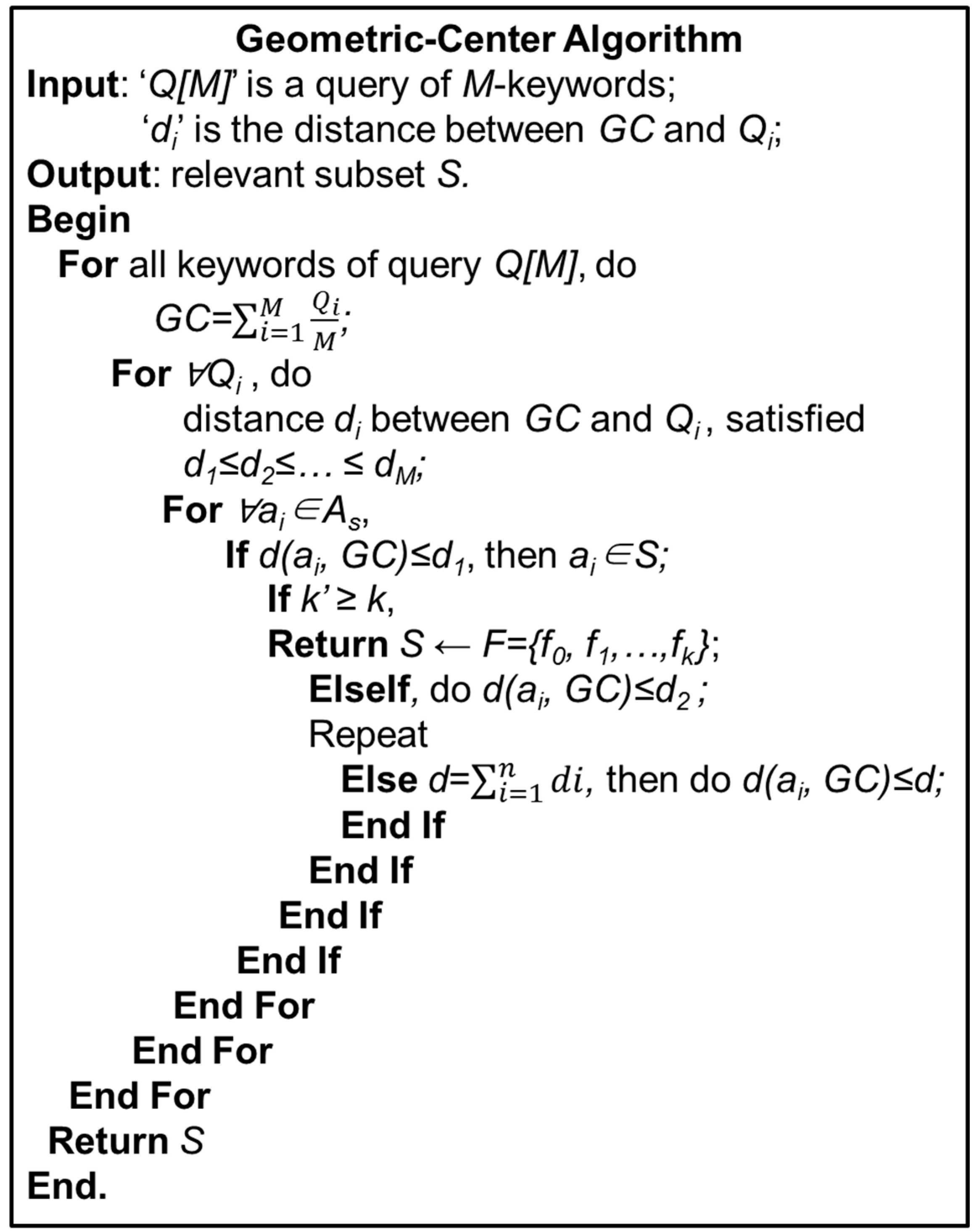
For instance, in the
2-keyword query situation,
Q1 and
Q2 are the keywords for query. It is easy to search the Geometric Center (GC) between these two keywords
GC = (Q1, Q2)/2. In the
3-keywords query situation, the GC =
(Q1, Q2, Q3)/3. By this way, the GC of
M-keywords query is GC = (
Q1, …,
QM)/
M. all major keywords and the most related objects in this relevant subset should be combined and the images that can be indexed and retrieved should be discussed. The detailed algorithm is shown in
Figure 8.
THEOREM 1. Suppose a certain M-keywords query Q[M] = {Q
1, Q
2, Q
3……Q
M}, we construct a M-level relevant subset S
M is consistent with the distance d(GC, Q
i) from a proximal end to a distal end. The GC of Q[M] is defined as:
THEOREM 2. Consider the distance d
i(GC, Q
i) from GC to Q
i according to d
1 ≤ d
2 ≤ … ≤ d
M. For i-level S, S
i = {a
i| a
i∈A
s, d(GC, a
i) ≤ d
i}. If k’ < k, then proceed to the next level. If the k is big enough, the (M + j)-level detecting distance is
Figure 8.
The Geometric-Center algorithm.
Figure 8.
The Geometric-Center algorithm.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











