
Using Crowdsourced Trajectories for Automated OSM Data Entry Approach

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Why Is an Automated Data Entry Process Required?
- Spatial quality assurance measures: due to the free and open nature of OSM there is a need to check the quality of OSM data on an ongoing basis. As reviewed by [22] there are three main categories of OSM quality control: (a) comparing OSM data against authoritative spatial data; (b) user and rule-based checking; and (c) crowdsourced rule and pattern extraction for rule-based checking.
- Easily interactive and user-friendly mapping interfaces: When the majority of OSM contributors are not part of the ‘active mappers’ group, levels of enthusiasm can vary dramatically and some may get bored and unengaged faster. In this regard, the online user-interface, where the underlying map can be viewed and edited, can both help or confuse these contributors. In addition to this, the introduction of more easily interactive and less complicated approaches for data entry and editing can help users to spend more time on mapping which can potentially result in better quality and completeness of OSM data.
- Easy to follow procedures for data entry: mapping procedures which require a minimum of experience, skills, human-interaction and overall dedicated time, can help non-experts to contribute more frequently.
3. Methodology
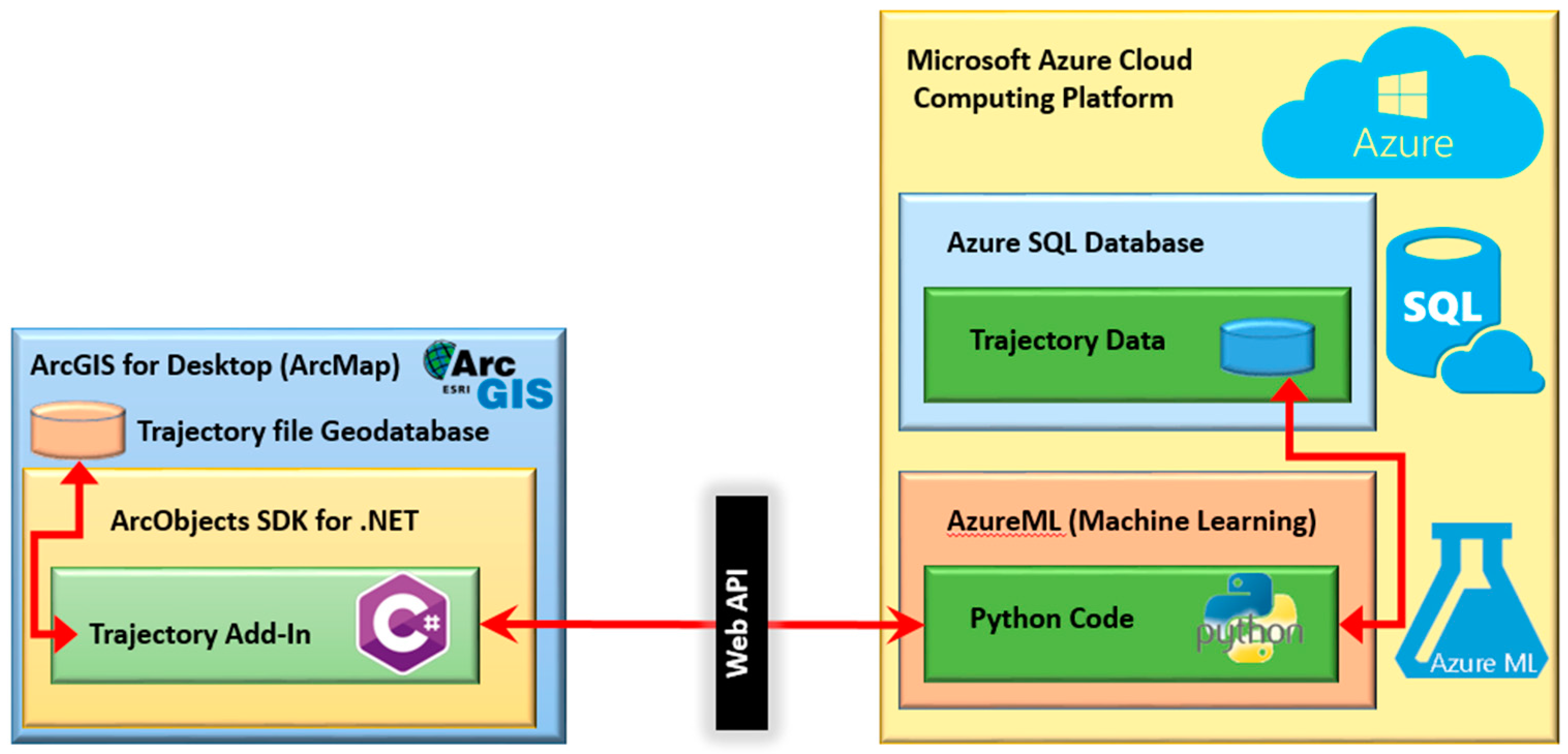
3.1. Input Data Preparation and Storage
3.2. Pattern Recognition and Rule Extraction
- Spatio-Temporal Associations. These are similar in concept to their static counterparts as described by [52]. Association Rules are in the form X → Y (c%, s%) where the occurrence of X is accompanied by the occurrence of Y in c% of cases (while X and Y occur together in a transaction in s% of cases).
- Spatio-Temporal Generalisation. This is a process whereby concept hierarchies are used to aggregate data, thus allowing stronger rules to be developed at the expense of specificity. Two types are discussed in the literature: spatial-data-dominant generalisation proceeds by first ascending spatial hierarchies and then generalising attribute data by region. Non-spatial-data-dominant generalisation proceeds by first ascending the spatial attribute hierarchies. For each of these types, different rules may result.
- Spatio-Temporal Clustering. While the complexity is far higher than its static non-spatial counterpart the ideas behind spatio-temporal clustering are similar. In this case, either characteristic features of objects in a spatio-temporal region or the spatio-temporal characteristics of a set of objects are sought.
- Evolution Rules. This form of rule has an explicit temporal and spatial context and describes the manner in which spatial entities change over time. Due to the exponential number of rules that can be generated, it requires the explicit adoption of sets of predicates that are usable and understandable. Example predicates include Follows, Coincides, Parallels and Mutates [53,54].
- Meta-Rules. These are created when rule sets rather than datasets are inspected for trends and coincidental behaviour. They describe observations discovered amongst sets of rules. For example, the support for the suggestion that X is increasing. This form of rule is particularly useful for temporal and spatio-temporal knowledge discovery.
4. Implementation and Results
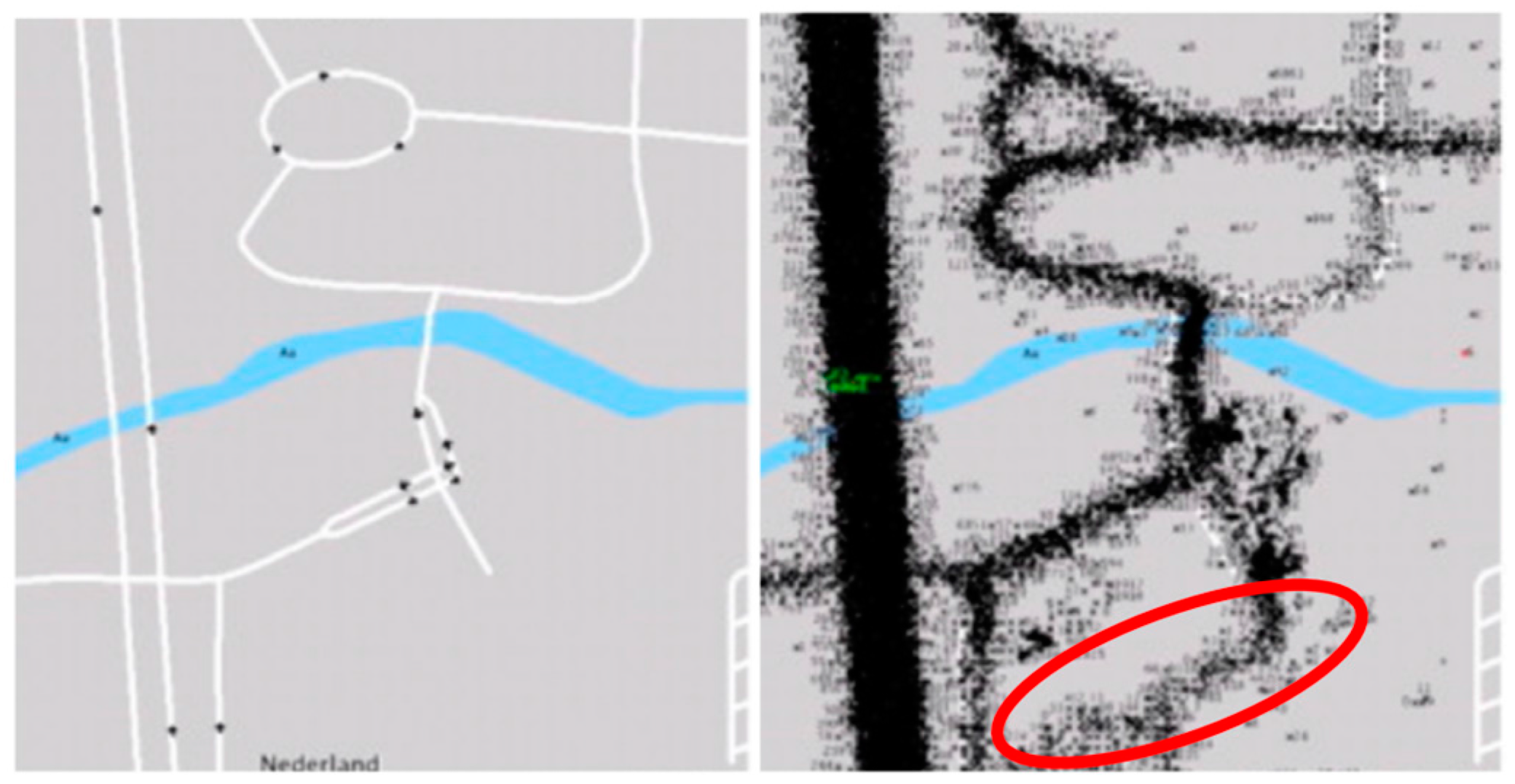
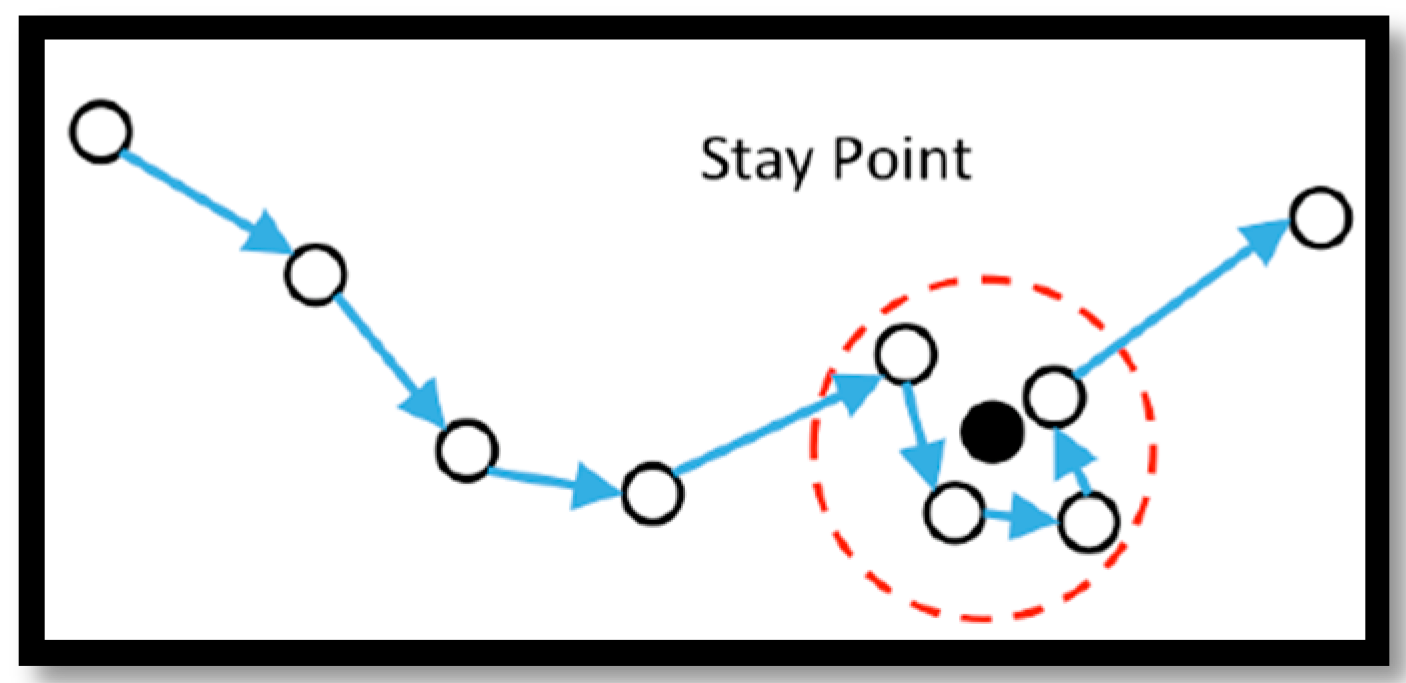
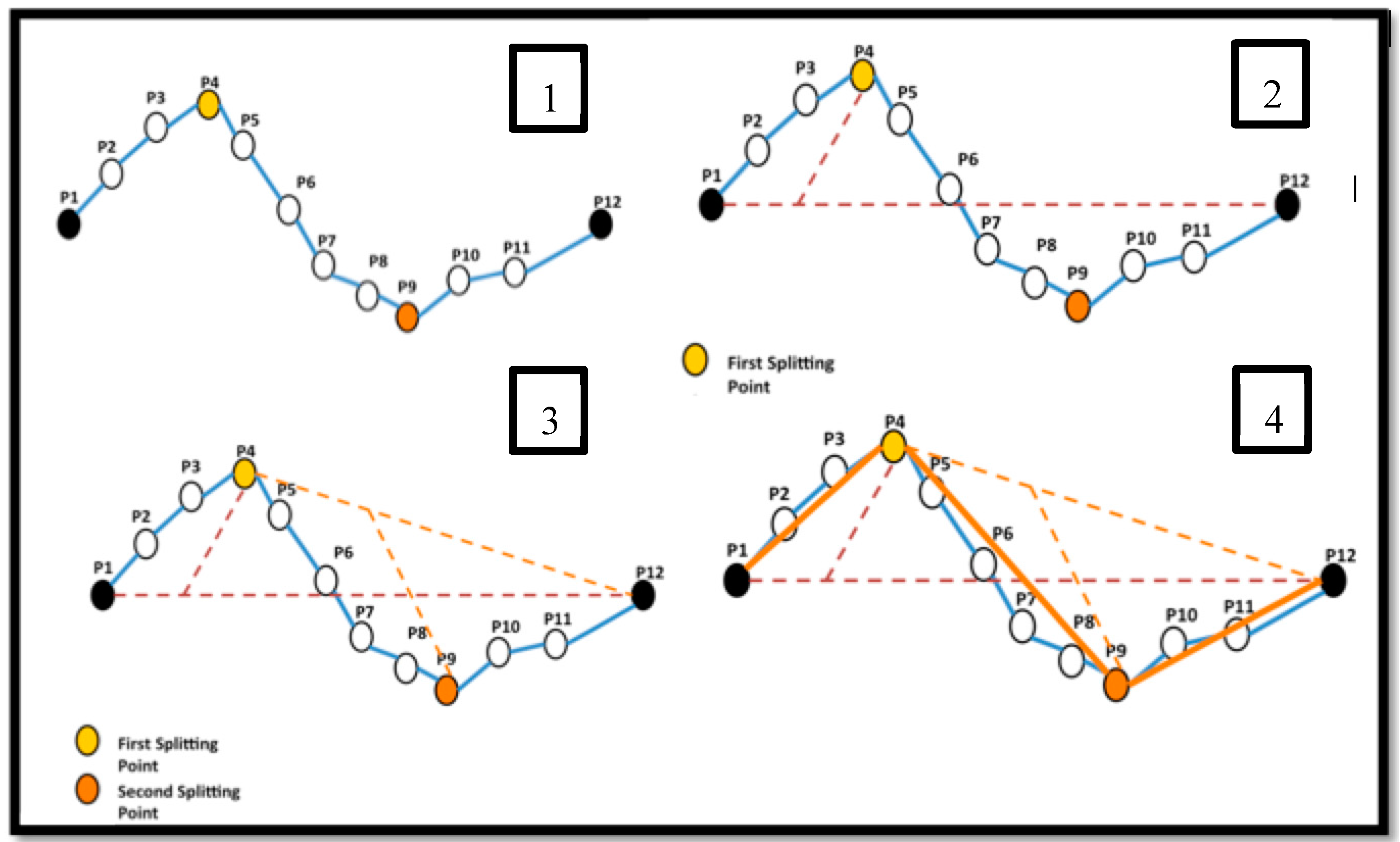
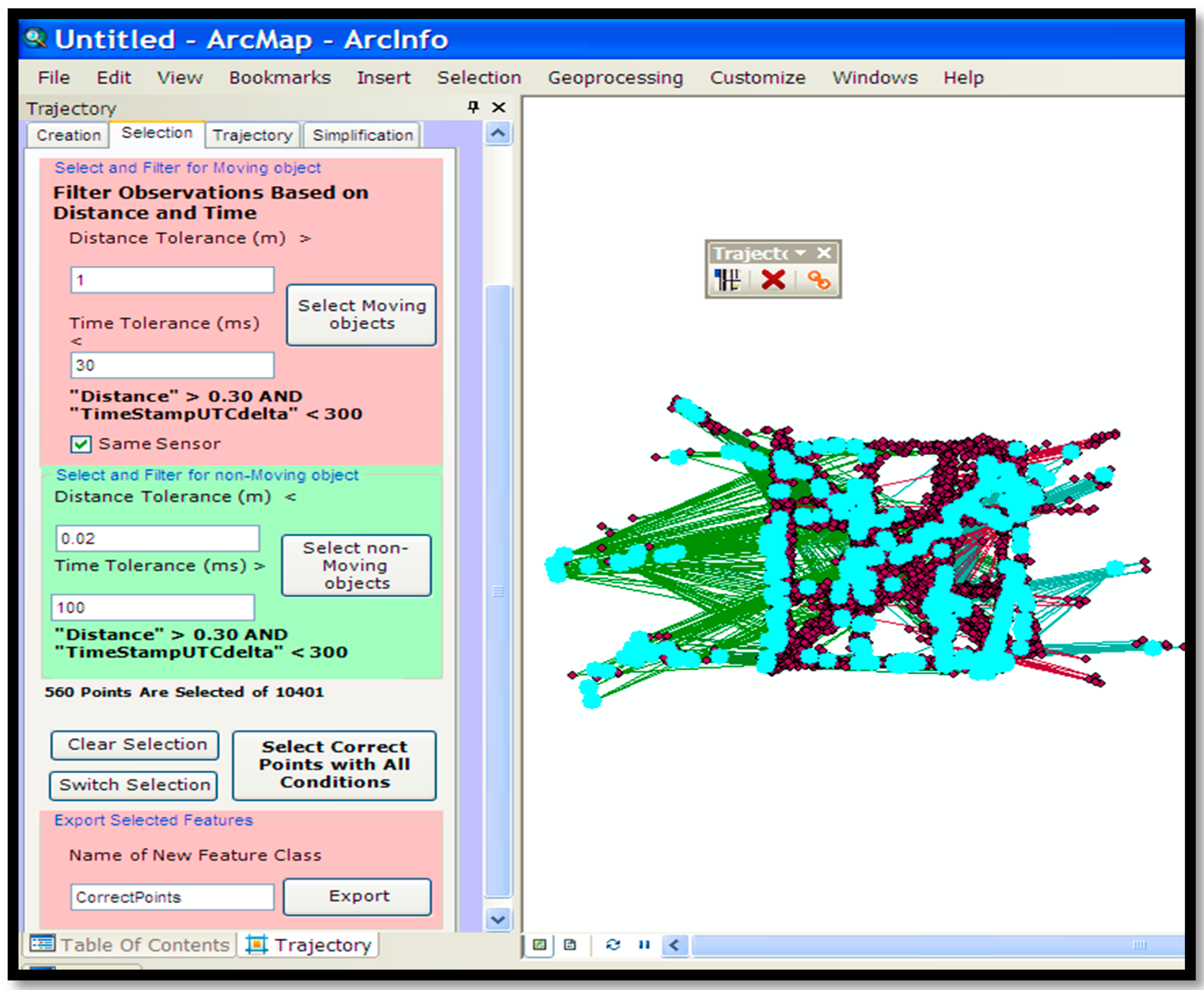
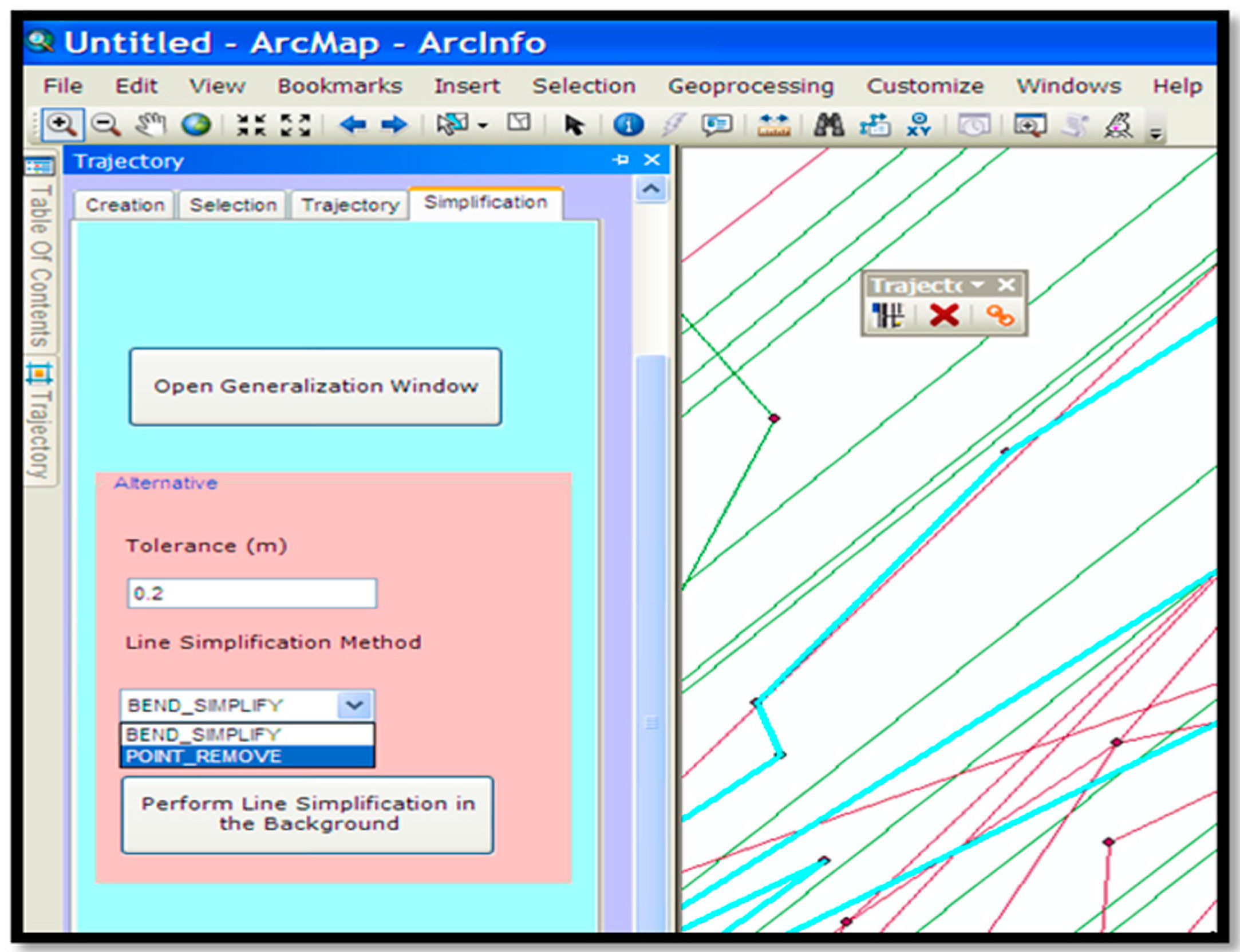
Trajectory Pre-Processing
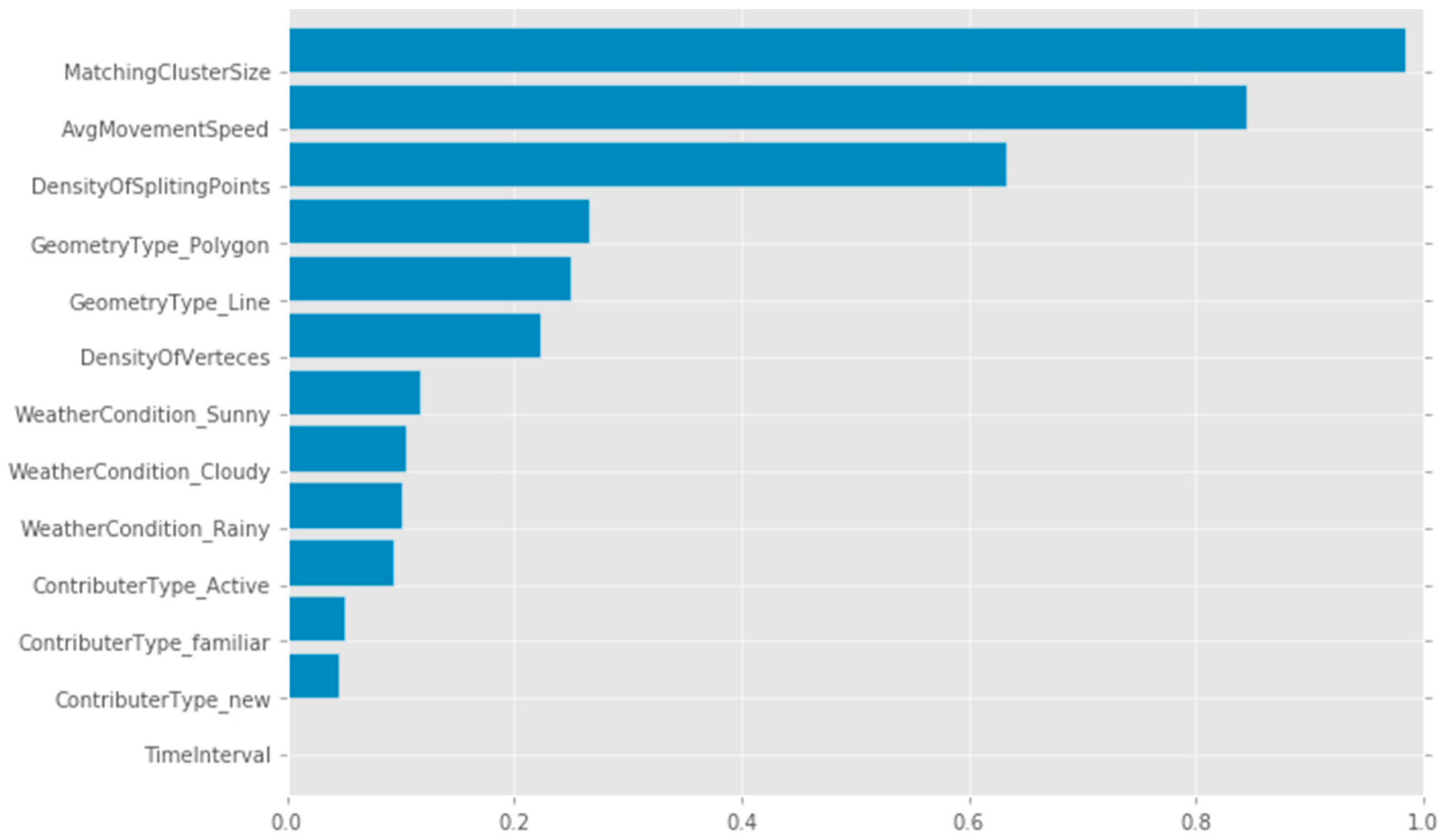
- If the average speed of the movement is more than 50 km/h and the number of splitting points is less than 6 then the feature is polyline with the tag or attribute, ‘road’.
- If the average speed of the movement is more than 15 km/h, the number of splitting points is less than 10 and the cluster of trajectories include less than 10 trajectories gathering in the area smaller than 500 m2 on a nightly basis then the geometry type is polygon and the tag or attribute represents a residential building.
5. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Koukoletsos, T.; Haklay, M.; Ellul, C. Assessing data completeness of VGI through an automated matching procedure for linear data. Trans. GIS 2012, 16, 477–498. [Google Scholar] [CrossRef]
- Arsanjani, J.J.; Mooney, P.; Zipf, A.; Schauss, A. Quality assessment of the contributed land use information from openstreetmap versus authoritative datasets. In OpenStreetMap in GIScience, Experiences, Research, and Applications (LNCS); Jokar Arsanjani, J., Zipf, A., Mooney, P., Helbich, M., Eds.; Springer: Berlin, Germany, 2015; pp. 37–58. [Google Scholar]
- Fan, H.; Zipf, A.; Fu, Q.; Neis, P. Quality assessment for building footprints data on OpenStreetMap. Int. J. Geogr. Inf. Sci. 2014, 28, 700–719. [Google Scholar] [CrossRef]
- Zielstra, D.; Hochmair, H.H.; Neis, P. Assessing the effect of data imports on the completeness of OpenStreetMap—A United States case study. Trans. GIS 2013, 17, 315–334. [Google Scholar] [CrossRef]
- Girres, J.F.; Touya, G. Quality assessment of the French OpenStreetMap dataset. Trans. GIS 2010, 14, 435–459. [Google Scholar] [CrossRef]
- Hecht, R.; Kunze, C.; Hahmann, S. Measuring completeness of building footprints in OpenStreetMap over space and time. ISPRS Int. J. Geo-Inf. 2013, 2, 1066–1091. [Google Scholar] [CrossRef]
- Helbich, M.; Amelunxen, C.; Neis, P.; Zipf, A. Comparative spatial analysis of positional accuracy of OpenStreetMap and proprietary geodata. In Proceedings of the GI_Forum 2012, Salzburg, Austria, 5–8 July 2012; pp. 24–33.
- Heipke, C. Crowdsourcing geospatial data. ISPRS J. Photogramm. Remote Sens. 2010, 65, 550–557. [Google Scholar] [CrossRef]
- Salk, C.F.; Sturn, T.; See, L.; Fritz, S.; Perger, C. Assessing quality of volunteer crowdsourcing contributions: Lessons from the cropland capture game. Int. J. Digit. Earth 2015. [Google Scholar] [CrossRef] [Green Version]
- Hashemi, P.; Abbaspour, R.A. Assessment of logical consistency in OpenStreetMap based on the spatial similarity concept. In OpenStreetMap in GIScience, Experiences, Research, and Applications (LNCS); Jokar Arsanjani, J., Zipf, A., Mooney, P., Helbich, M., Eds.; Springer: Berlin, Germany, 2015; pp. 19–36. [Google Scholar]
- Yang, A.; Fan, H.; Jing, N. Amateur or professional: Assessing the expertise of major contributors in OpenStreetMap based on contributing behaviors. ISPRS Int. J. Geo-Inf. 2016, 5, 21. [Google Scholar] [CrossRef]
- Van Exel, M.; Dias, E.; Fruijtier, S. The impact of crowdsourcing on spatial data quality indicators. In Proceedings of the GiScience 2011, Zurich, Switzerland, 14–17 September 2010.
- Mooney, P.; Corcoran, P. The annotation process in OpenStreetMap. Trans. GIS 2012, 16, 561–579. [Google Scholar] [CrossRef]
- Jilani, M.; Corcoran, P.; Bertolotto, M. Automated highway tag assessment of openstreetmap road networks. In Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Dallas, TX, USA, 4–7 November 2014; pp. 449–452.
- Mooney, P.; Corcoran, P. Characteristics of heavily edited objects in OpenStreetMap. Future Internet 2012, 4, 285–305. [Google Scholar] [CrossRef]
- Ballatore, A.; Bertolotto, M. Semantically enriching VGI in support of implicit feedback analysis. In Web and Wireless Geographical Information Systems; Springer: Berlin, Germany, 2011; pp. 78–93. [Google Scholar]
- Mooney, P.; Morganb, L. How much do we know about the contributors to volunteered geographic information and citizen science projects? ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015. [Google Scholar] [CrossRef]
- Neis, P.; Zipf, A. Analyzing the contributor activity of a volunteered geographic information project—The case of OpenStreetMap. ISPRS Int. J. Geo-Inf. 2012, 1, 146–165. [Google Scholar] [CrossRef]
- Newman, G.; Zimmerman, D.; Crall, A.; Laituri, M.; Graham, J.; Stapel, L. User-friendly web mapping: Lessons from a citizen science website. Int. J. Geogr. Inf. Sci. 2010, 24, 1851–1869. [Google Scholar] [CrossRef]
- Feldkamp, N.; Strassburger, S. Automatic generation of route networks for microscopic traffic simulations. In Proceedings of the 2014 Winter Simulation Conference, Savanah, GA, USA, 7–10 December 2014; pp. 2848–2859.
- Haklay, M.; Basiouka, S.; Antoniou, V.; Ather, A. How many volunteers does it take to map an area well? The validity of linus’ law to volunteered geographic information. Cartogr. J. 2010, 47, 315–322. [Google Scholar] [CrossRef]
- Basiri, A.; Jackson, M.; Amirian, P.; Pourabdollah, A.; Sester, M.; Winstanley, A.; Moore, T.; Zhang, L. Quality assessment of OpenStreetMap data using trajectory mining. Geo Spat. Inf. Sci. 2016, 19, 56–68. [Google Scholar] [CrossRef]
- Kuntzsch, C.; Sester, M.; Brenner, C. Generative models for road network reconstruction. Int. J. Geogr. Inf. Sci. 2015, 5, 1–28. [Google Scholar] [CrossRef]
- Yang, B.; Fantini, N.; Jensen, C.S. iPark: Identifying parking spaces from trajectories. In Proceedings of the 16th International Conference on Extending Database Technology, Genoa, Italy, 18–22 March 2013; pp. 705–708.
- Jordan, K.; Sheptykin, I.; Gruter, B.; Vatterrott, H.R. Identification of structural landmarks in a park using movement data collected in a location-based game. In Proceedings of the First ACM SIGSPATIAL International Workshop on Computational Models of Place, Orlando, FL, USA, 5–8 November 2013; pp. 1–8.
- Sila-Nowicka, K.; Vandrol, J.; Oshan, T.; Long, J.A.; Demsar, U.; Fotheringham, A.S. Analysis of human mobility patterns from GPS trajectories and contextual information. Int. J. Geogr. Inf. Sci. 2015, 5, 881–906. [Google Scholar] [CrossRef]
- Hasan, S.; Schneider, C.M.; Ukkusuri, S.V.; Gonzalez, M.C. Spatiotemporal patterns of urban human mobility. J. Stat. Phys. 2013, 151, 304–318. [Google Scholar] [CrossRef]
- Yan, Z.; Chakraborty, D.; Parent, C.; Spaccapietra, S.; Aberer, K. SeMiTri: A framework for semantic annotation of heterogeneous trajectories. In Proceedings of the 14th International Conference on Extending Database Technology, Uppsala, Sweden, 21–24 March 2011; pp. 259–270.
- Lee, J.G.; Han, J.; Li, X.; Cheng, H. Mining discriminative patterns for classifying trajectories on road networks. IEEE Trans. Knowl. Data Eng. 2011, 23, 713–726. [Google Scholar] [CrossRef]
- Endo, Y.; Toda, H.; Nishida, K.; Kawanobe, A. Deep feature extraction from trajectories for transportation mode estimation. In Advances in Knowledge Discovery and Data Mining; Springer International Publishing: Berlin, Germany, 2016; pp. 54–66. [Google Scholar]
- Johnson, N.; Hogg, D. Learning the distribution of object trajectories for event recognition. Image Vis. Comput. 1996, 14, 609–615. [Google Scholar] [CrossRef]
- Goodchild, M.F. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- Goodchild, M.F.; Glennona, J.A. Crowdsourcing geographic information for disaster response: A research frontier. Int. J. Digit. Earth 2010, 3, 231–241. [Google Scholar] [CrossRef]
- Haklay, M.; Weber, P. Openstreetmap: User-generated street maps. IEEE Pervasive Comput. 2008, 7, 12–18. [Google Scholar] [CrossRef]
- Neis, P.; Zielstra, D.; Zipf, A. Comparison of volunteered geographic information data contributions and community development for selected world regions. Futur. Internet 2014, 5, 282–300. [Google Scholar] [CrossRef]
- OpenStreetMap Project Wiki. Available online: http://www.wiki.openstreetmap.org/wiki/ (accessed on 1 May 2016).
- Thompson, S. Battling ebola: Anna tate fights the outbreak with open source maps. Hum. Ecol. 2015, 43, 44. [Google Scholar]
- Basiri, A.; Petolta, P.; Silva, P.F.; Lohan, E.S.; Moore, T.; Hill, C. Indoor positioning technology assessment using analytic hierarchy process for pedestrian navigation services. In Proceedings of the International Conference on Localization GNSS, Gothenburg, Sweden, 22–24 June 2015.
- Kalnis, P.; Ghinita, G.; Mouratidis, K.; Papadias, D. Preventing location-based identity inference in anonymous spatial queries. IEEE Trans. Knowl. Data Eng. 2007, 19, 1719–1733. [Google Scholar] [CrossRef]
- Lee, W.C.; Krumm, J. Trajectory processing. In Computing with Spatial Trajectories; Zheng, Y., Zhou, X., Eds.; Springer: Berlin, Germany, 2011; pp. 1–31. [Google Scholar]
- Zhang, L.; Dalyot, S.; Sester, M. Travel-mode classification for optimizing vehicular travel route planning. In Progress in Location-Based Services; Springer: Berlin, Germany, 2013; pp. 277–295. [Google Scholar]
- Dietterich, T.G. Ensemble methods in machine learning. In International Workshop on Multiple Classifier Systems; Springer: Berlin, Germany, 2000; pp. 1–15. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: Berlin, Germany, 2013. [Google Scholar]
- Davidson-Pilon, C. Bayesian Methods for Hackers: Probabilistic Programming and Bayesian Inference; Addison-Wesley: Boston, MA, USA, 2015. [Google Scholar]
- Zheng, Y. Trajectory data mining: An overview. ACM Trans. Intell. Syst. Technol. 2015, 6, 29. [Google Scholar] [CrossRef]
- Amirian, P.; Basiri, A.; Gales, G.; Winstanley, A.; McDonald, J. The next generation of navigational services using OpenStreetMap data: The integration of augmented reality and graph databases. In OpenStreetMap in GIScience—Experiences, Research, and Applications; Jokar Arsanjani, J., Zipf, A., Mooney, P., Helbich, M., Eds.; Springer: Berlin, Germany, 2015; pp. 211–228. [Google Scholar]
- Li, Q.; Zheng, Y.; Xie, X.; Chen, Y.; Liu, W.; Ma, M. Mining user similarity based on location history. In Proceedings of the 16th Annual ACM International Conference on Advances in Geographic Information Systems, Irvine, CA, USA, 5–7 November 2008.
- Yuan, N.J.; Zheng, Y.; Xie, X.; Wang, Y.; Zheng, K.; Xiong, H. Discovering urban functional zones using latent activity trajectories. IEEE Trans. Knowl. Data Eng. 2015, 27, 712–725. [Google Scholar] [CrossRef]
- Hershberger, J.E.; Snoeyink, J. Speeding Up the Douglas-Peucker Line-Simplification Algorithm; University of British Columbia, Department of Computer Science: Vancouver, BC, Canada, 1992; pp. 134–143. [Google Scholar]
- Mokbel, M.F.; Ghanem, T.M.; Aref, W.G. Spatio-temporal access methods. IEEE Data Eng. Bull. 2003, 26, 40–49. [Google Scholar]
- Abraham, T.; Roddick, J.F. Opportunities for knowledge discovery in spatio-temporal information systems. Australas. J. Inf. Syst. 1998, 5, 3–12. [Google Scholar] [CrossRef]
- Agrawal, R.; Imielinski, T.; Swami, A.N. A Mining association rules between sets of items in large databases. In Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data, Washington, DC, USA, 25–28 May 1993; pp. 207–216.
- Allen, J.F. Maintaining knowledge about temporal intervals. CACM 1983, 26, 832–843. [Google Scholar] [CrossRef]
- Hornsby, K.; Egenhofer, M. Identity-based change operations for composite objects. In Proceedings of the Eighth International Symposium on Spatial Data Handling, Vancouver, BC, Canada, 11–15 July 1998; pp. 202–213.
- Lee, J.G.; Han, J.; Whang, K.Y. Trajectory clustering: A partition-and-group framework. In Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data, Beijing, China, 11–14 June 2007; pp. 593–604.
- Dodge, S.; Weibel, R.; Lautenschutz, A.-K. Towards a taxonomy of movement patterns. Inf. Vis. 2008, 7, 240–252. [Google Scholar] [CrossRef] [Green Version]
- Tejada, Z. Mastering Azure Analytics: Architecting in the Cloud with Azure Data Lak; O’Reilly Media: Sebastopol, CA, USA, 2016. [Google Scholar]
- Amirian, P. Beginning ArcGIS for Desktop Development Using NET; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Gromping, U. Variable Importance Assessment in Regression: Linear Regression versus Random Forest. Am. Stat. 2009, 63, 308–319. [Google Scholar] [CrossRef]
- Andrieu, C. An introduction to MCMC for machine learning. Mach. Learn. 2003, 50, 5–43. [Google Scholar] [CrossRef]










© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Basiri, A.; Amirian, P.; Mooney, P. Using Crowdsourced Trajectories for Automated OSM Data Entry Approach. Sensors 2016, 16, 1510. https://doi.org/10.3390/s16091510
Basiri A, Amirian P, Mooney P. Using Crowdsourced Trajectories for Automated OSM Data Entry Approach. Sensors. 2016; 16(9):1510. https://doi.org/10.3390/s16091510
Chicago/Turabian StyleBasiri, Anahid, Pouria Amirian, and Peter Mooney. 2016. "Using Crowdsourced Trajectories for Automated OSM Data Entry Approach" Sensors 16, no. 9: 1510. https://doi.org/10.3390/s16091510