4.1. Datasets
In our experiments, we use four public datasets: Sim10k [
51], BDD100K [
52], Cityscapes [
53] and Kitti [
54] to evaluate our proposed method.
Sim10k [
51] is an synthetic dataset rendered directly by the GTA5 game engine, consisting of 10,000 images and 58,701 corresponding car annotations.
Kitti [
54] is a real-world dataset collected in various road scenes, which comprises 7481 training images. The annotations of this dataset mainly consist of eight classes related to road targets. In this paper, we only use the “car” category to evaluate the performance of the model in cross-camera adaptation.
BDD100K [
52], a large-scale autonomous driving dataset with various time periods, diverse weather conditions (including sunny, cloudy, and rainy, as well as different times of day such as daytime and evening), and driving scenes. In our experiment, we select and obtain images captured under sunny weather conditions to validate the adaptability of our model to scene variations.
Cityscapes [
53] is a dataset captured in urban autonomous driving scenarios, including 2975 images for training and 500 images for validation.
Based on the aforementioned four datasets, we can obtain two cross-domain scenarios under autonomous driving conditions: (1) synthetic to real adaptation (Sim10k → Cityscapes), where the images in the source domain and target domain are captured from the synthetic and real-world scenarios; (2) across-cameras adaptation (Cityscapes → BDD100k and KITTI → Cityscapes), where all the three datasets are taken from various cities using different cameras. The combination of all datasets and cross-domain scenarios is presented in
Table 1.
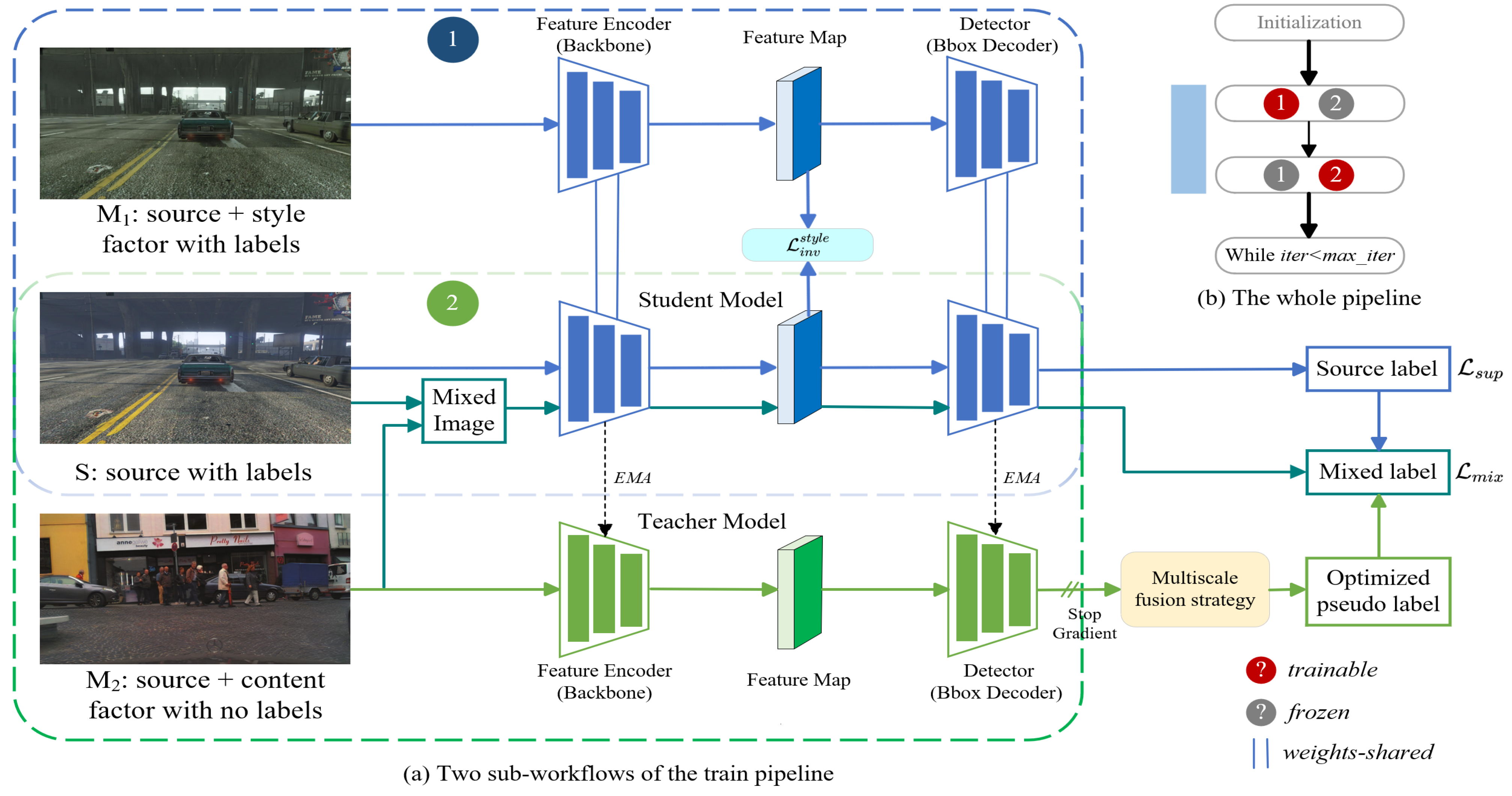
4.2. Implementation Details
In this paper, RetinaNet [
38] serves as the benchmark detector, and the original ResNet is replaced with Swin-T as the new backbone. During training, the student model is trained by the SGD [
55] with a learning rate of 0.00125 and a batch size of 2. Moreover, in order to make model training more stable, we implement a linear learning rate warmup in the first 0.5k iteration. Regarding the image size, We followed [
18] to adjust the shorter side of all images to 600 and keep the image aspect ratio constant. For the hyperparameters in the mean teacher self-training framework, we set the score threshold
for pseudo-label filtering to 0.7, and the smoothing coefficient
for EMA to 0.999. The total number of iterations is set to 80k. The default value
of the weights in Equation (
5) is set to 10 for synthetic-to-real adaptation, and 5 for across-cameras adaptation. All experiments were conducted using the mmdetection framework [
56] and PyTorch [
57].
4.3. Performance Comparison
Synthetic-to-Real Adaptation. In previous research, we have typically collected data manually and annotated it artificially. However, this approach is time-consuming, labor-intensive, and costly. With the advancement of data synthesis engines, it is now possible to automatically generate synthetic datasets and corresponding labels based on actual needs. Therefore, it is highly worthwhile to investigate how models trained on synthetic datasets can be adapted to real-world scenarios. In this setting, we utilize the Sim10k dataset as the source domain and Cityscapes as the target domain to evaluate the cross-domain performance of our proposed method in the synthetic-to-real adaptation. We compare several state-of-the-art methods, and the experimental results are shown in
Table 2. From the experimental results, we can observe that our proposed method achieve an improvement of +1.1 compared to the state-of-the-art method OADA [
58] in the car category.
Across Cameras Adaptation. On the other hand, due to the thriving development of autonomous driving, numerous scholars have proposed different road object detection datasets. These datasets are obtained from various cities using different cameras, resulting in significant variations in terms of style, resolution, and other aspects of the captured images. Such variations can negatively affect the performance of trained detectors in practical applications, so we need to make sure that our proposed approach is able to mitigate the domain shift in different datasets so as to ensure robust performance and generalization. And in order to compare it with existing state-of-the-art methods, we have chosen three public datasets: Cityscapes, KITTI, and BDD100k. We conduct two experiments in across-cameras adaptation: KITTI → Cityscapes and Cityscapes → BDD100k. The results of these two experiments are shown in
Table 3 and
Table 4, respectively. For KITTI → Cityscapes, our model receives +0.6 improvement in the “car” category. Moreover, a performance improvement of +1.7 is achieved in Cityscapes → BDD100k.
4.4. Discussion
The optimal value of the hyperparameter and . First, we discuss the optimal value of
. During the training process, there are differences in the quality of pseudo-labels obtained from different images. Based on this, we apply a dynamically changing hyperparameter
to
, which is proportional to the quality of pseudo-labels. To validate the effectiveness of
, we conducted comparative experiments by setting
to different constant values of 0.2, 0.4, 0.6, 0.8, and 1. The experimental results are shown in
Table 5. We found that utilizing
achieves the best detection performance, with a performance improvement of 0.7 compared to when the weight is set to a constant value 0.6. This well demonstrates that dynamically adjusting the proportion of
based on the quality of pseudo-labels can allow the model to achieve the optimal performance. Now, we compare the the default value 10 of
with five other values. As depicted in
Table 6, when
= 10, the model has the best performance. However, we also observed that when
changes, the car AP fluctuates within a small range, indicating a weak correlation between the optimal performance that the model can achieve and
. Based on the experimental process, it is highly likely due to the sufficiently large total number of iterations, which allows the model to fully learn relevant knowledge about the style factor, resulting in minimal fluctuations in model performance.
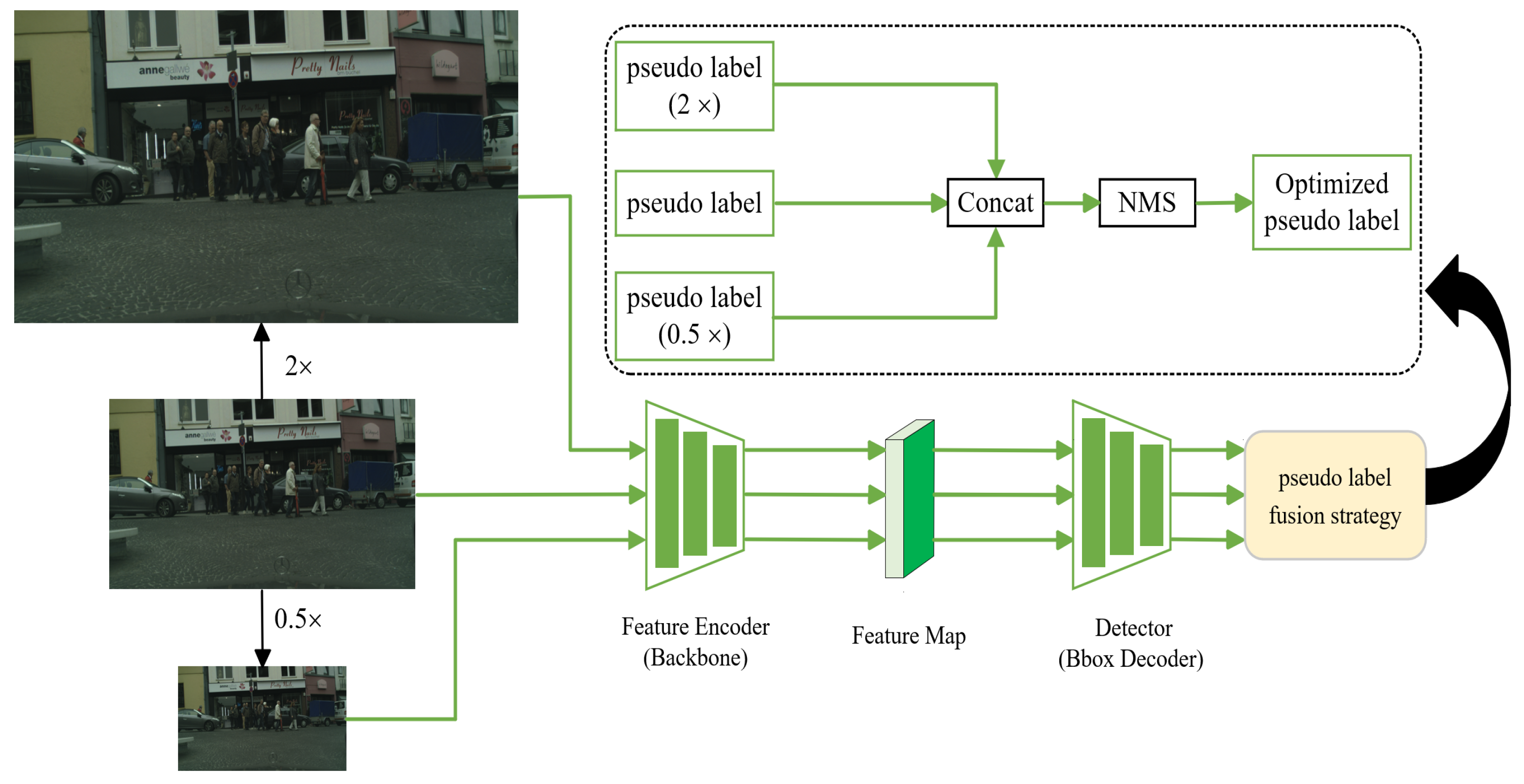
Effectiveness of the multiscale fusion strategy. As mentioned above, in the mean teacher self-training framework, improving the quality of pseudo-labels is the most effective method to enhance cross-domain knowledge transfer. Typically, we only obtain corresponding pseudo-labels using single-resolution images. Therefore, we propose a multiscale fusion strategy. To validate the effectiveness of our proposed module, we conducted a series of ablation experiments on the Cityscapes dataset. The experimental results are shown in
Table 7. With the addition of low-resolution images, there is a significant improvement of +1.5 in car AP for large objects compared to the absence of such images. Moreover, by solely incorporating high-resolution images, there is a notable enhancement of +2.2 in car AP for small objects. These findings further reinforce the positive impact of integrating high-resolution or low-resolution images on performance enhancement while ensuring that the detection performance of objects of other sizes is either maintained or even slightly improved. Finally, by simultaneously combining pseudo-labels obtained from high-resolution and low-resolution images, we achieve a “1 + 1 > 2” effect, whereby the detection performance of objects of different sizes has been further improved compared to solely adding a single resolution image. This validates the effectiveness of the multiscale fusion strategy in enhancing the detection performance of large and small objects.
Comparison of methods for dealing with the domain gap.
Table 8 illustrates the results of different methods for dealing with the domain gap. Due to our decoupling of the domain gap into the style gap and content gap, we conducted a series of ablation experiments to validate the superiority of our proposed method. Currently, we primarily encounter the style gap, content gap, and the genuine domain gap that arises from the combination of both in the source and target domains. Therefore, we first conducted experiments on the style gap, content gap, and domain gap between
and
,
and
,
and
. Based on the experimental results shown in
Table 2, we observed that among the three methods,
achieved the best performance, followed by
. This can be attributed to two main factors: (1) Compared to
,
reduces the domain gap, resulting in improved quality of the pseudo-label obtained by the teacher model in the mean teacher self-training framework, thereby enhancing cross-domain detection performance. (2) Compared to
, although the style gap handled between
and
have significantly reduced compared to the original gap between
and
in actual domains, we also discovered that this will result in quite small gap between
and
. At this moment, when we utilize style-invariant loss for style knowledge learning, even if we can fully learn the relevant knowledge, the cross-domain performance achieved cannot reach the level of directly using
. In summary, we find that both the style gap and the content gap play a significant role in improving the cross-domain performance of the model. From the last two rows of
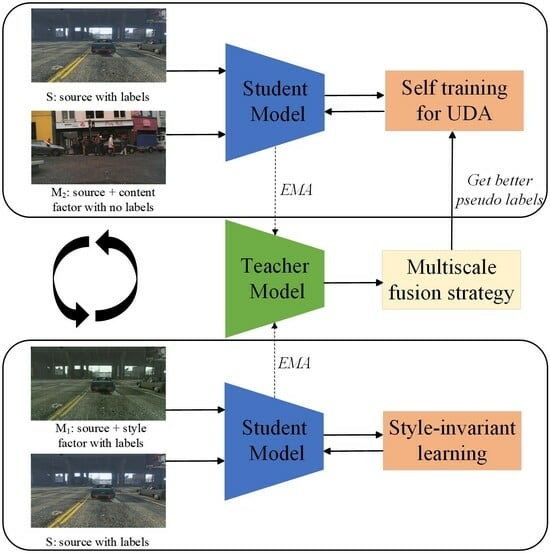
Table 8, we find that dealing with both of the two gaps can effectively promote the performance improvement of cross-domain detectors. In particular, the use of alternate learning to deal with the style and content gap separately can achieve the optimal performance. This is because when dealing with two domain gaps at the same time, the relevant knowledge transferred can interfere with each other. Therefore, in this paper, we use the alternating training strategy to deal with style and content gaps, respectively. The specific details of the performance enhancement achievable through this training strategy will be further elucidated in the subsequent section, where visualized results will provide a more comprehensive explanation.
Qualitative results. Based on the various quantitative analyses provided above, in order to provide a more intuitive visualization and facilitate discussion, we visualized and compared the model’s predicted results. The intuitive results are shown in
Figure 4 and
Figure 5.
As shown in
Figure 4, we compared the results of four model training approaches: source, +
, +
and our proposed IDI-SCD, against the ground truth labels. We observe that without cross-domain model training, there are significant instances of duplicate detections, missed detections, and false detections in the predicted results. However, with the inclusion of either
or
(e.g., dealing with the style gap or the content gap). there was a substantial reduction in duplicate detections and false detections within the model. Furthermore, by combining both approaches and effectively addressing the both the style and content gap, there is further improvement in detection performance for overlapping or small objects. For more detailed information about these results, please refer to
Figure 5.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}