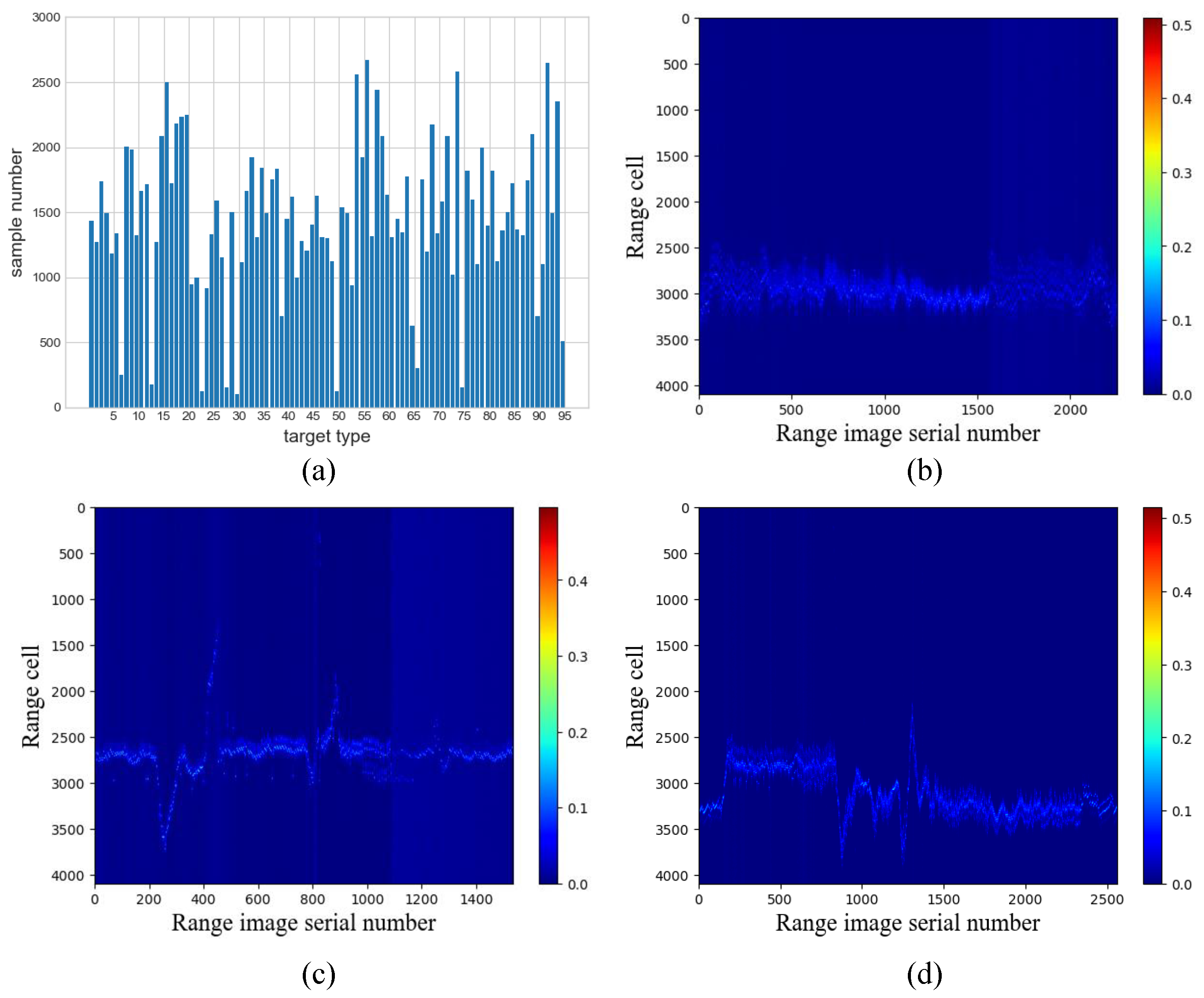
Acquiring a large number of labeled samples of non-cooperative targets for HRRPs is a challenging task. Additionally, the scattering structures of different classes of ships are similar, and environmental factors significantly affect the HRRP samples of the same class, resulting in a considerable challenge for few-shot HRRP target recognition. Therefore, in this paper, a twofold objective is pursued by the proposed few-shot HRRP target recognition method: firstly, to fully extract the available information from the HRRPs of cooperative ship targets and employ appropriate transfer strategies for non-cooperative target recognition; and secondly, to enhance recognition accuracy by highlighting commonalities among samples of the same class and differences among samples of different classes to mitigate strong confusability during HRRP classification. To achieve this, transfer learning and meta-learning are employed to construct a suitable embedding space using cooperative target data with a large number of labeled samples.
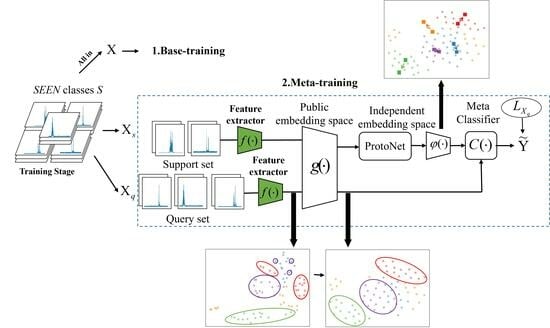
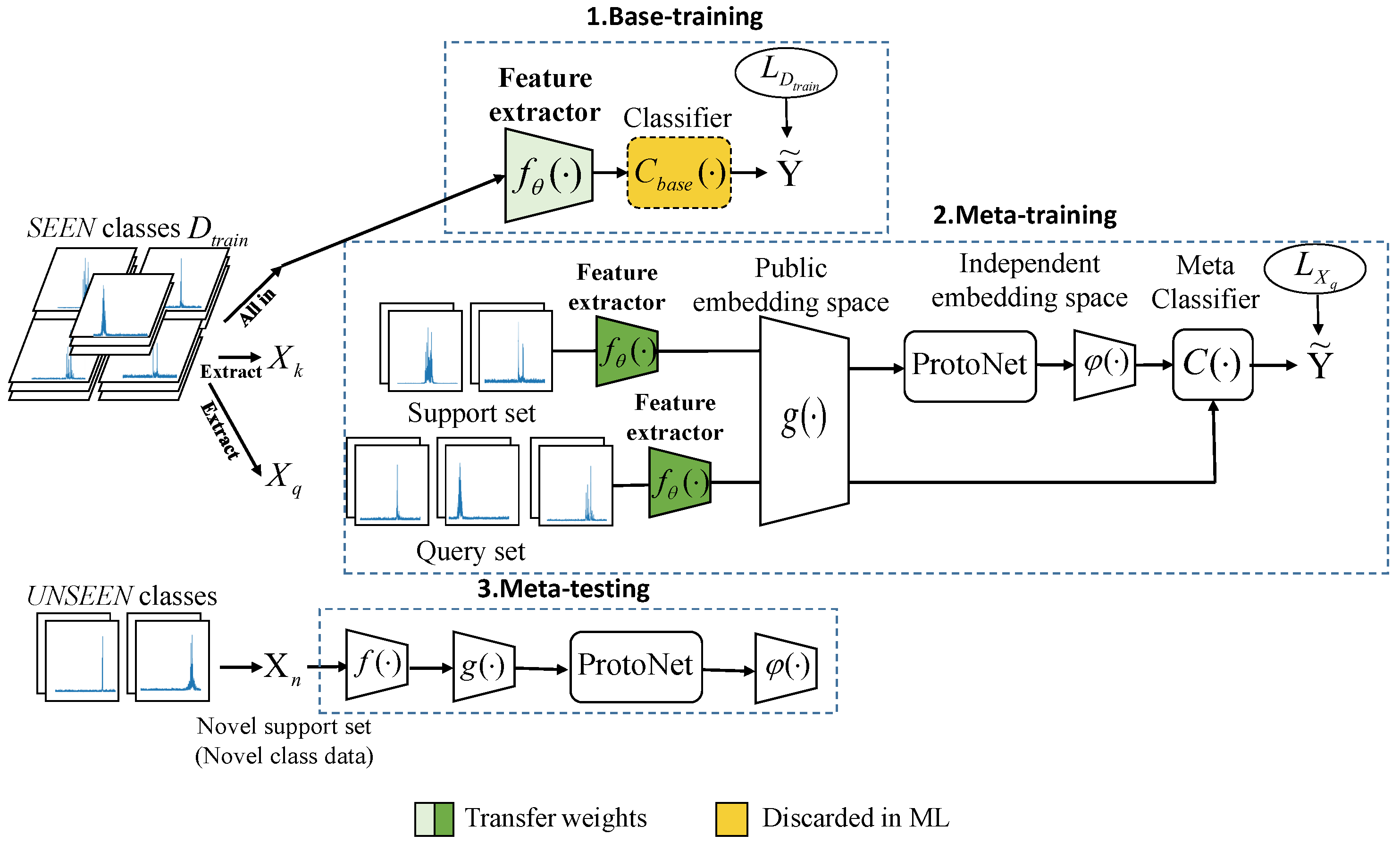
As depicted in
Figure 2, the method in this paper can be delineated into three primary stages: the base-training, meta-training, and meta-testing phases. The first stage, termed base-training, defines the task as HRRP target recognition on a closed dataset. In this stage, the feature extractor
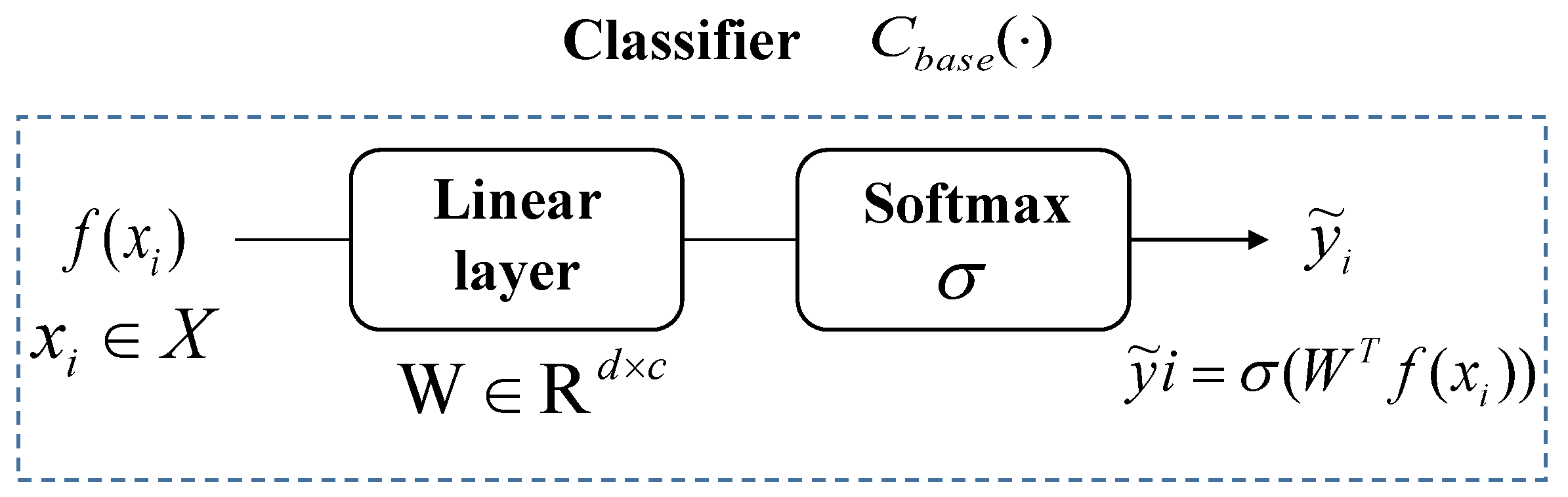
and classifier
are trained using the complete dataset of cooperative HRRP targets. Subsequently, the weights of the feature extractor with superior classification performance are selected as the initial weights for the feature extractor in the meta-training phase. The second stage is designed to tackle the open-set recognition problem, specifically the challenge of dealing with few-shot HRRP target recognition. In this phase, a substantial number of tasks are sampled from the cooperative HRRP dataset to train and adapt the parameters
, the embedding space function
, and
. Each task includes a support set
for network training and a query set
for evaluating network performance. Firstly, the feature extractor
and the embedding space function
transform the samples from the support set
into feature representations conducive to classification, facilitating the closer proximity of samples from the same class in the metric space. Secondly, the prototype network creates class prototypes by calculating the mean embedding vectors for each class. Finally,
accentuates the inter-class differences, enabling better differentiation of class prototypes in the embedding space. An in-depth explanation of the transfer strategy for the parameter
during the training phase and the embedding space functions will be provided in
Section 3.2. The third stage is the meta-testing phase. Based on the well-trained feature extractor
, and the embedding space functions
and
, a small number of samples is employed to establish prototype representations in the metric space for new classes. The class of a given sample can then be ascertained by calculating the distance between the embedding vector of the sample and the prototype representation. It is noteworthy that our research is based on Resent12, a widely used convolutional neural network.
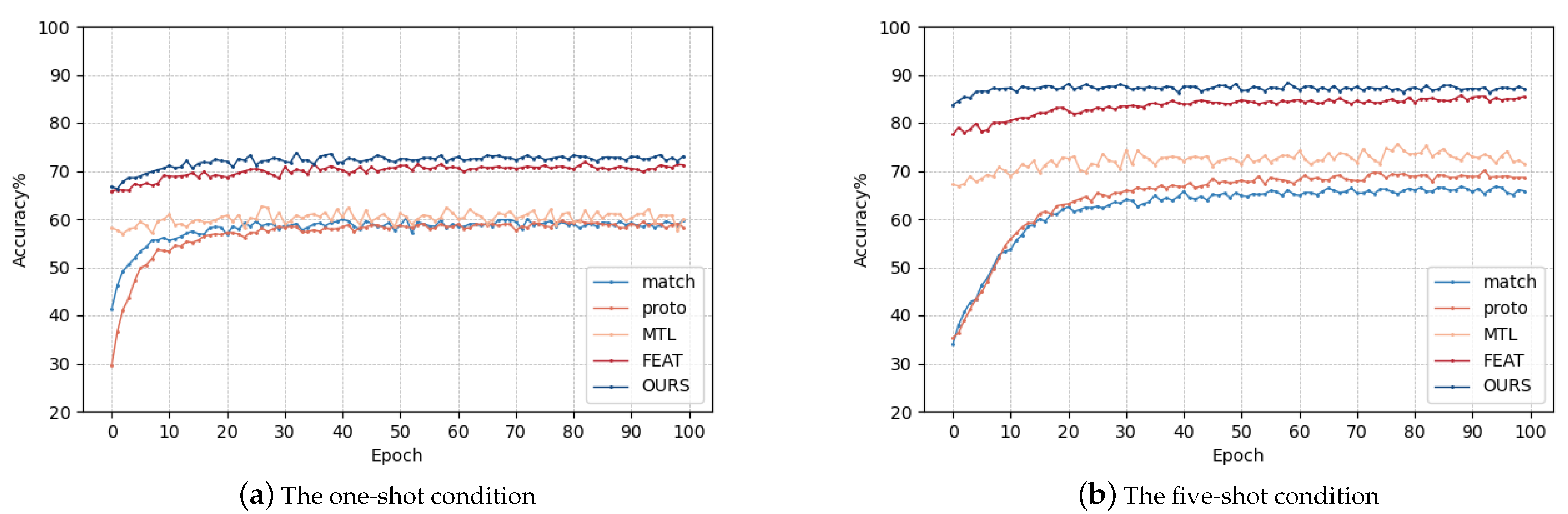
3.2. Task-Specific Meta-Training
The problem of a limited number of labeled instances and high confusion in HRRP ship classification can be addressed through meta-learning. In the initial stage, the learning of each class of cooperative ship is completed by the feature extractor, and improved feature extraction weights are obtained. However, the features extracted by the current feature extractor may be insufficient or redundant for the new task. Therefore, the meta-training phase involves not only learning how to classify N-way K-shot tasks across a large number of similar tasks, but also accurately and efficiently transferring the trained feature weights to the new task and adapting them to the new task.
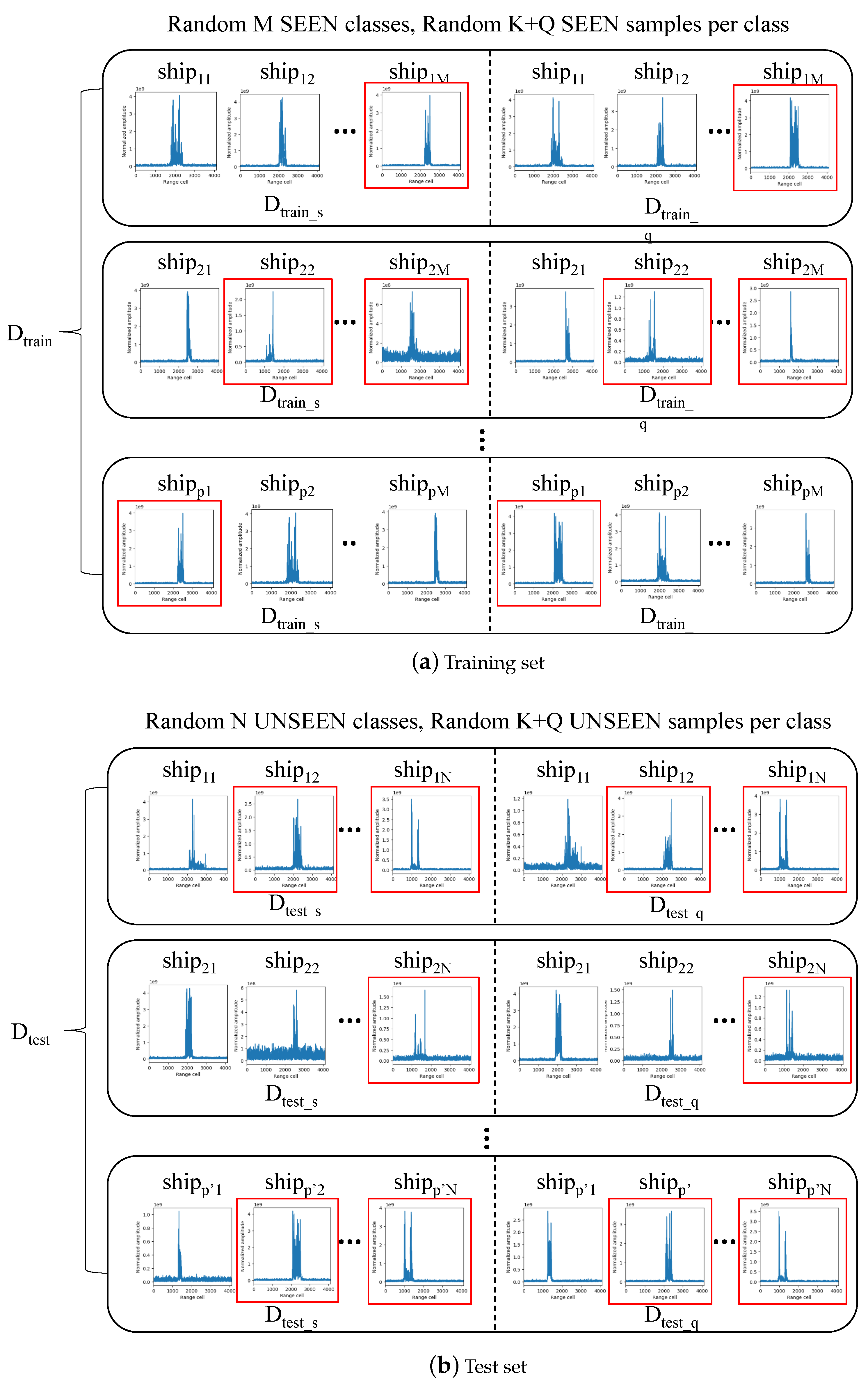
There are a series of episodes in the meta-training set. Each episode in this study is randomly sampled from dataset , and comprises two subsets: a support set and a query set. The support set is similar to a traditional training set in machine learning, and includes N classes, each with K training samples. The query set, on the other hand, resembles a test set and comprises Q samples of the same classes as the support set, but without any overlapping samples. Additionally, the meta-learning process is divided into two phases: the meta-training and the meta-testing. For a task within the meta-training phase, its dataset can be represented as = {(, ), (, )}, where (, ) constitutes the support set, and (, ) forms the query set. The number of classes contained in and is denoted as N. Let represent the subset of classes in for n = 1, 2, 3…N, with corresponding labels .
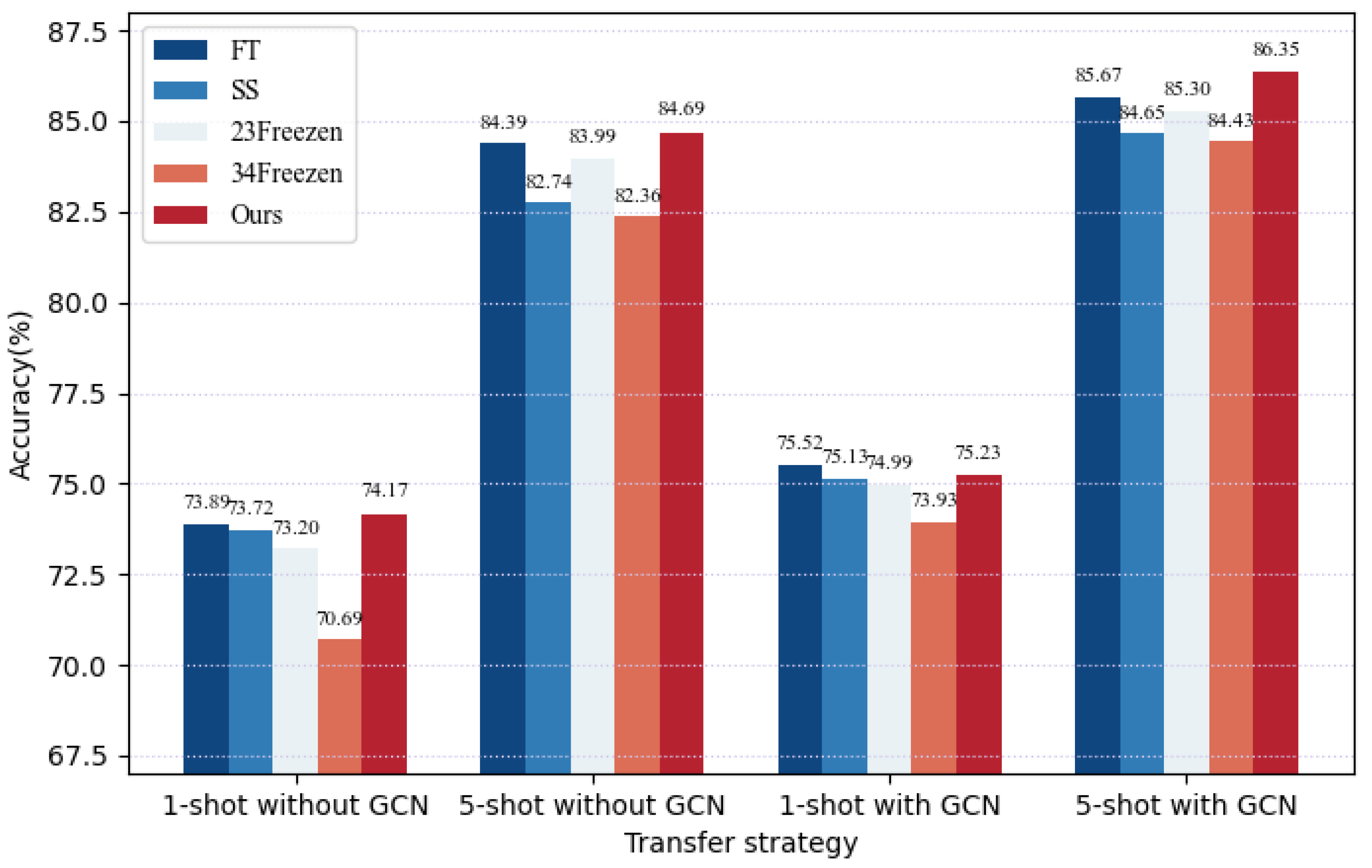
(1) Task-Adaptive Mixed Transfer.
The training objectives diverge between the base-training phase and the meta-training phase. Consequently, freezing all the weights of the feature extractor would render the network unable to adapt to new tasks. Nonetheless, whether dealing with SEEN or UNSEEN classes, the structural differences among ships are marginal, and the discriminative feature types necessary for ship HRRP data classification remain consistent. Completely relearning all the initial weights could potentially introduce redundancy and squander computational resources. To address these challenges, a Task-Adaptive Mixed Transfer (TAMT) method is proposed, which fine-tunes the parameters in different ways based on the distinct roles of various network blocks in feature extraction. Specifically, the shallow blocks are frozen to preserve the memory of the pre-trained model in extracting ship data envelope features and local physical structure features, while adjusting the deep blocks to adapt to the new few-shot tasks.
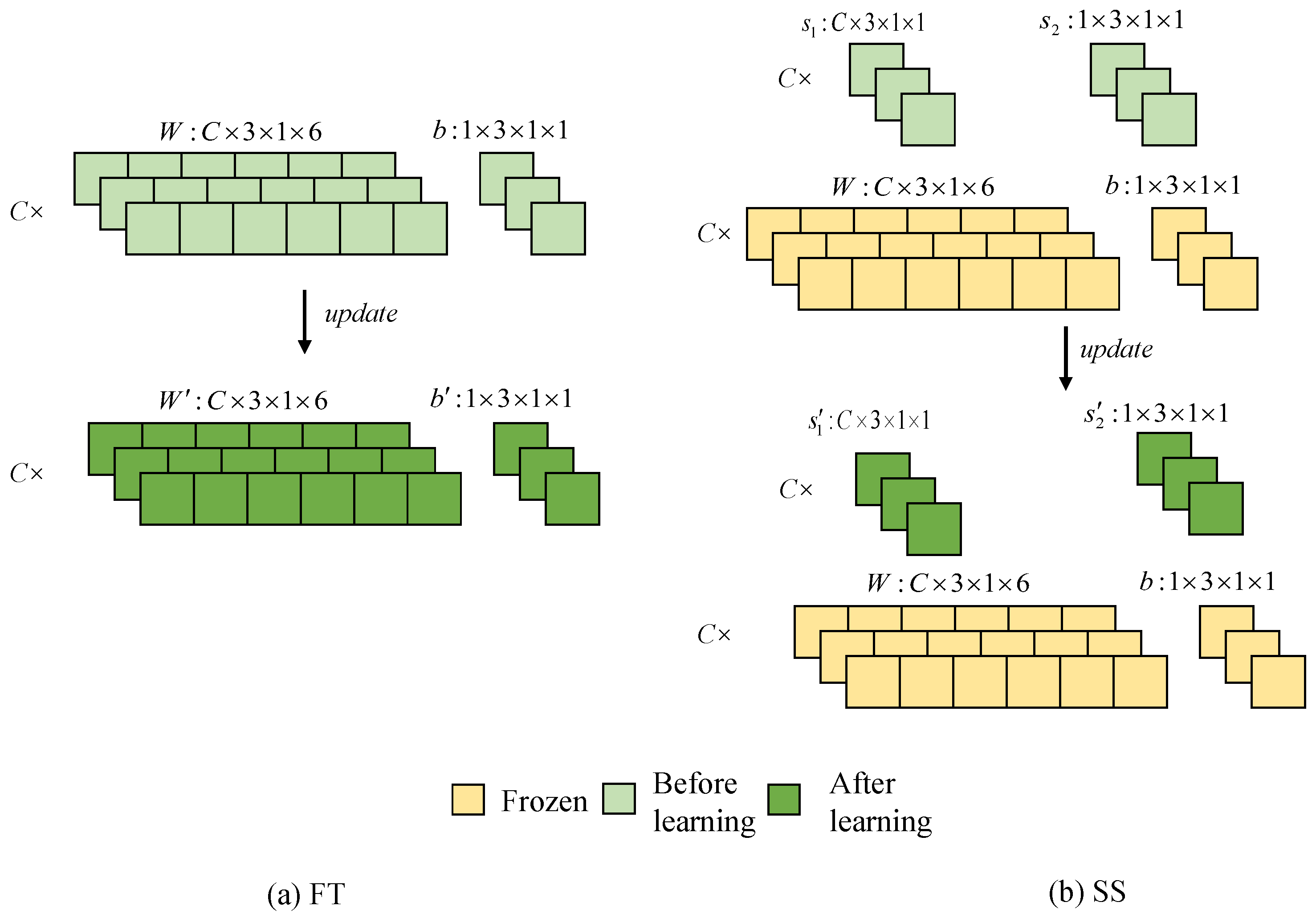
The fine-tuning process involves two methods: Neuron-level Scaling and Shifting (SS), and Parameter-level Fine-Tuning (FT). SS involves freezing neurons and then performing scaling and shifting based on their original weights and biases, as shown in
Figure 4b. Given the trained
, for its
l-th layer containing
M neurons, there are
M pairs of parameters, respectively, as weight and bias, denoted as {(
,
)}. Note that the neuron location
l,
m will be omitted for readability. Based on the methods in this paper, we learn
M pairs of scalars. Assuming
is input, we apply
to (
W,
b) as
where ⊙ denotes the element-wise multiplication. Taking
Figure 4b as an example of a single 1 × 6 filter, after SS operations, this filter is scaled by
then the feature maps after convolutions are shifted by
in addition to the original bias b.
Figure 4b illustrates FT, which involves making small adjustments to all the neural network weight parameters of the model to make it better suited to specific tasks or data. It is evident that FT updates the entire values of W and b, encompassing a large number of parameters, making it susceptible to overfitting when the sample size is limited. Furthermore, performing FT on the entire network may result in the complete forgetting of pre-training memory, known as “catastrophic forgetting”. By contrast, as seen in the examples in the
Figure 4, SS reduces the number of training parameters, significantly reducing the computational and memory overhead. However, when SS is applied to all neurons, the adaptation of the network to few-shot tasks may be somewhat lacking.
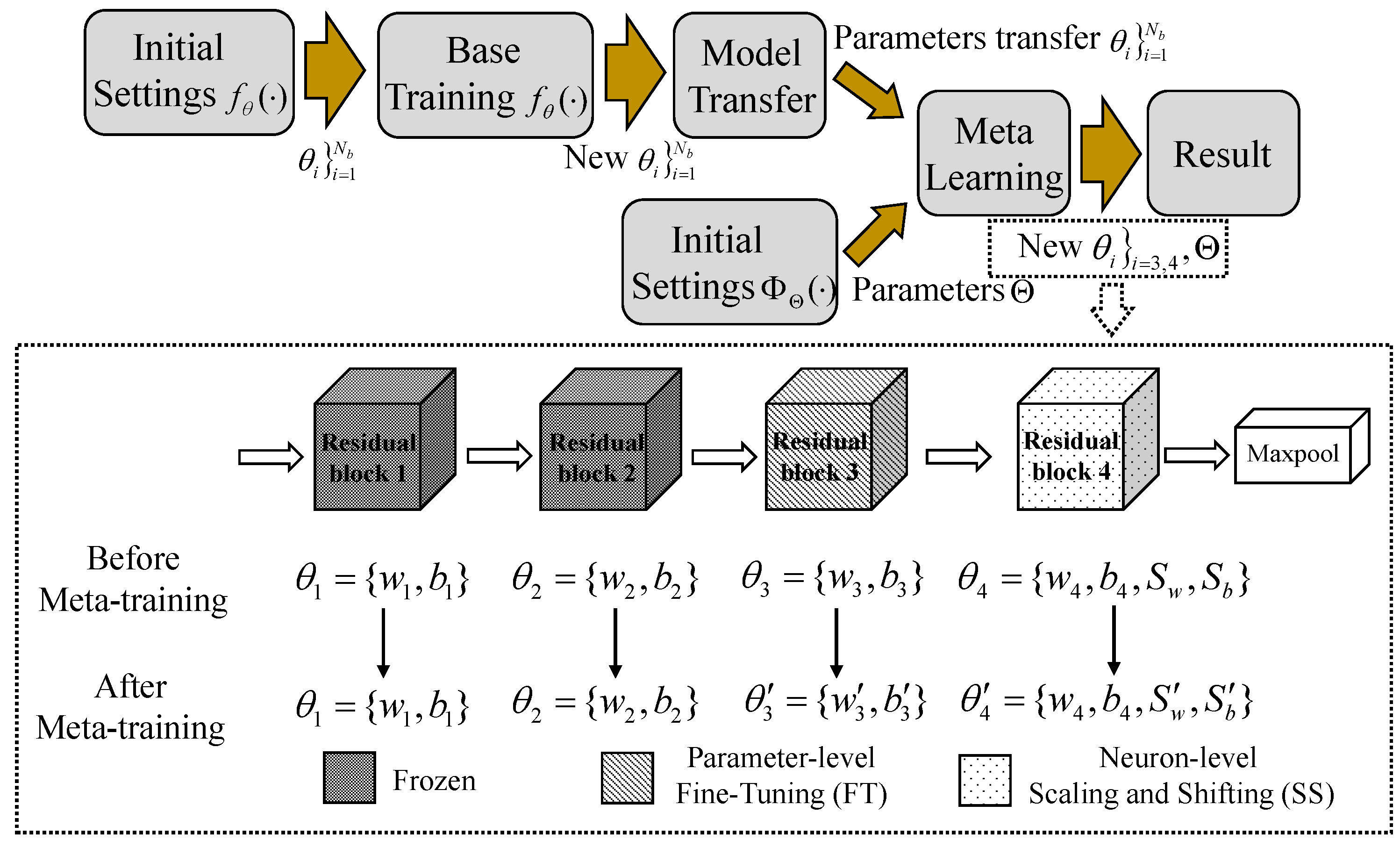
Assume that the feature extractor
, initialized with weights, acquires new network weights denoted as
}
after the base-training, and considering that the number of network blocks
is 4 due to our use of ResNet12 for feature extraction. During the meta-training phase, in addition to learning the parameters for the introduced meta embedding, there is a need to fine-tune the existing feature extractor network weights
}
to adapt to the changing recognition task. Based on FT and SS, the transfer strategy designed in this paper is depicted in
Figure 5, which includes the mapping of network parameters before and after meta-training.
The frozen blocks are referred to as shallow static blocks, while the ones that need adjustment to adapt to the new task are referred to as deep dynamic blocks. Initially, the neurons in shallow blocks, including block 1 and block 2, are frozen to preserve their capability to extract HRRP sample envelope features and initial separability features. Thus, the network parameters } remain unchanged before and after training. Subsequently, to adapt to new few-shot tasks and extract relevant features based on task characteristics, block 3 and block 4 are fine-tuned using different fine-tuning methods. Block 3, serving as the deep dynamic block that bridges the two training modes, adopts FT, meaning that the neuron weights of the entire block can be learned. Its main task is to flexibly transform feature vectors from the shallow static module, thoroughly sift, and further extract relevant information to obtain useful features for the new task, initiating the initial adaptation learning for the new task. Block 4 undergoes scaling and shifting based on the initialized weights. Given that its channel count is eight times that of block 1, FT would significantly increase the number of parameters to be learned. In this paper, SS is employed to fine-tune Block 4, a method that substantially reduces the computational and memory overhead while allowing for further adaptation to new classification tasks built on the foundation of Block 3.
This transfer strategy accomplishes several key objectives. Firstly, it preserves the feature extraction capabilities of the feature extractor during the base-training phase for effective HRRP sample extraction, thereby preventing the occurrence of “catastrophic forgetting” that may arise when fine-tuning the entire network. Secondly, it ensures network flexibility and adaptability to new tasks. Finally, by freezing certain neurons and applying SS to others, the number of training parameters in the meta-training phase is reduced, thereby preventing overfitting when dealing with a limited number of labeled ship HRRP samples.
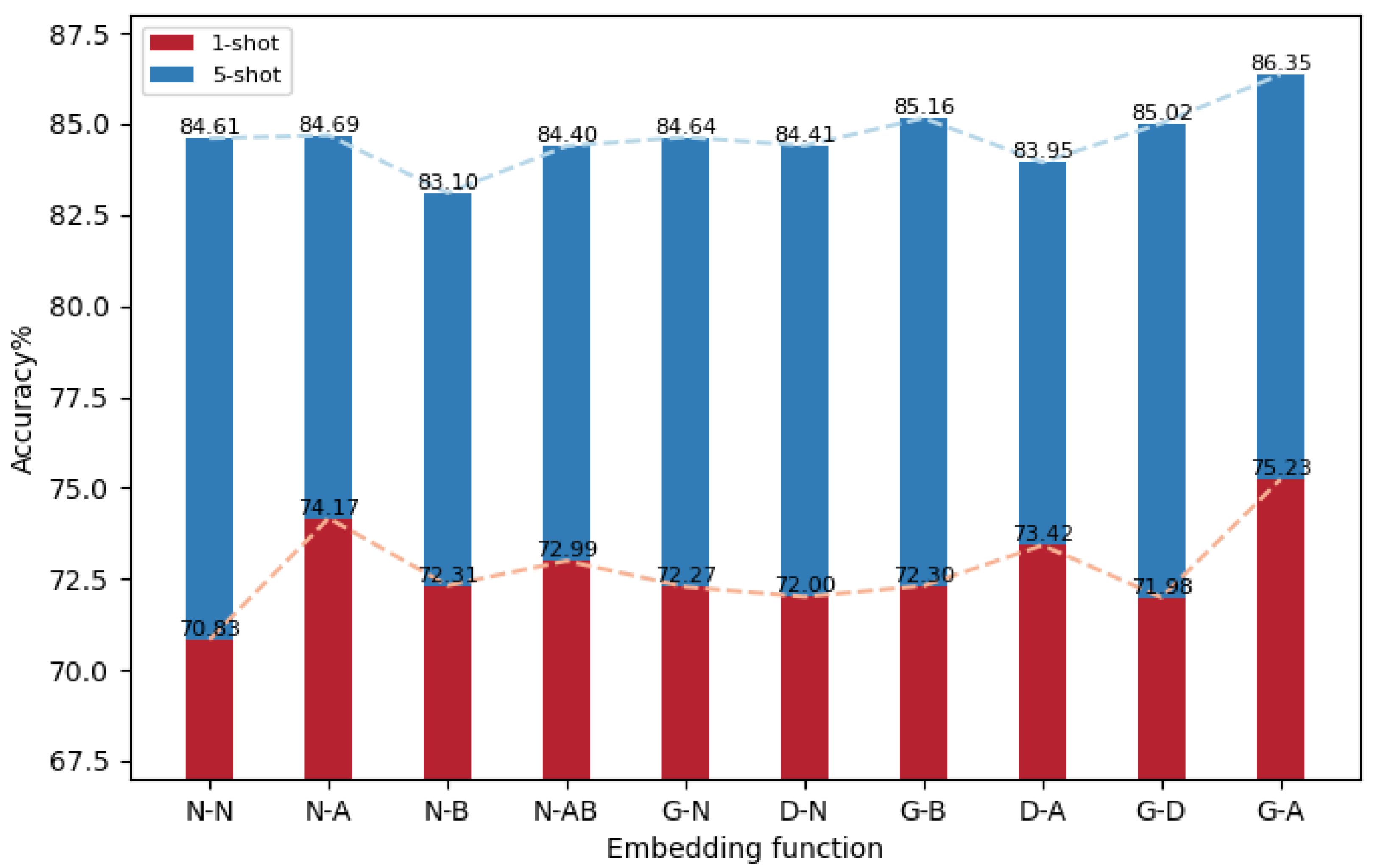
(2) Space-Adjusted Meta Embedding based on GCN and Multi-head Attention.
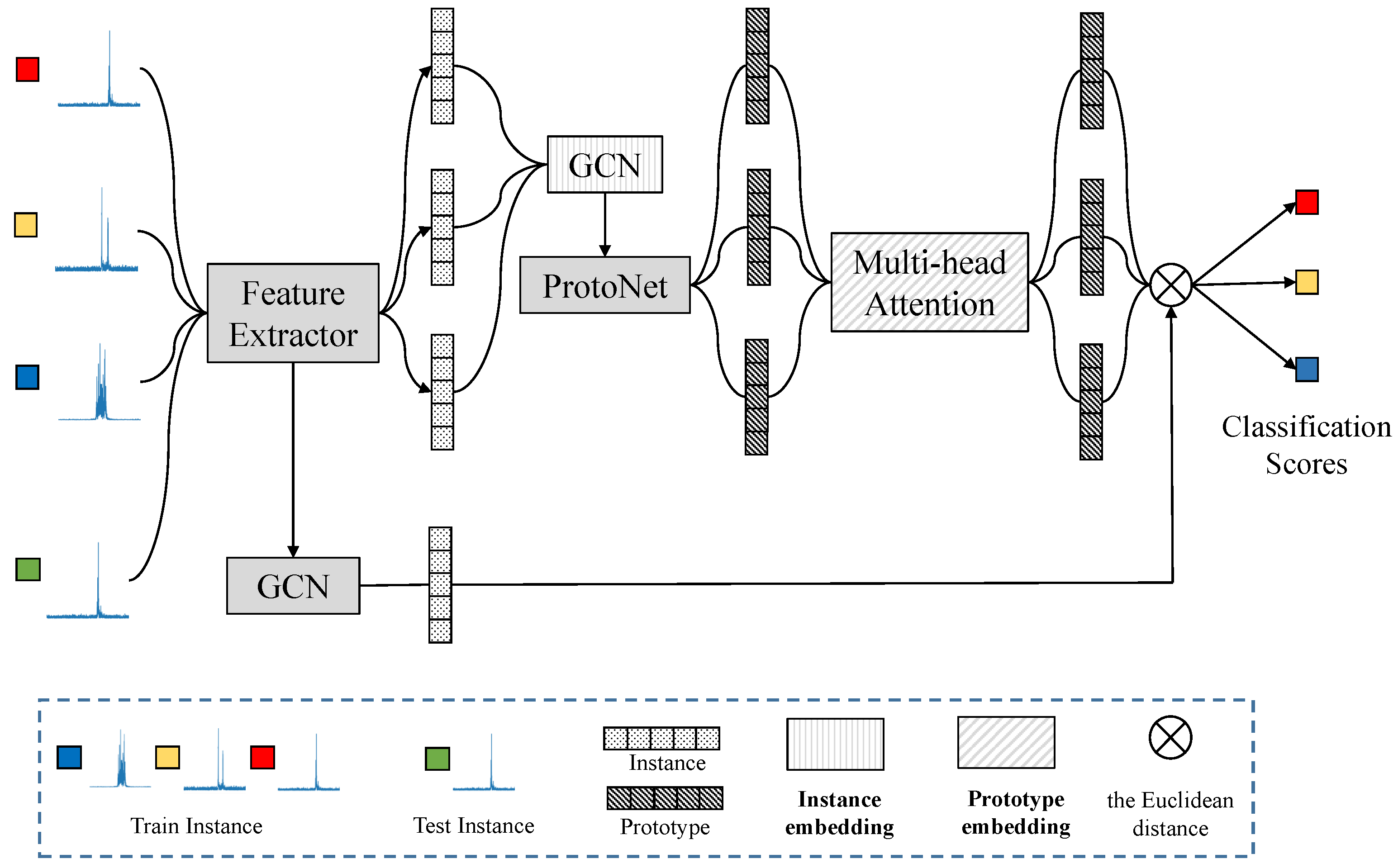
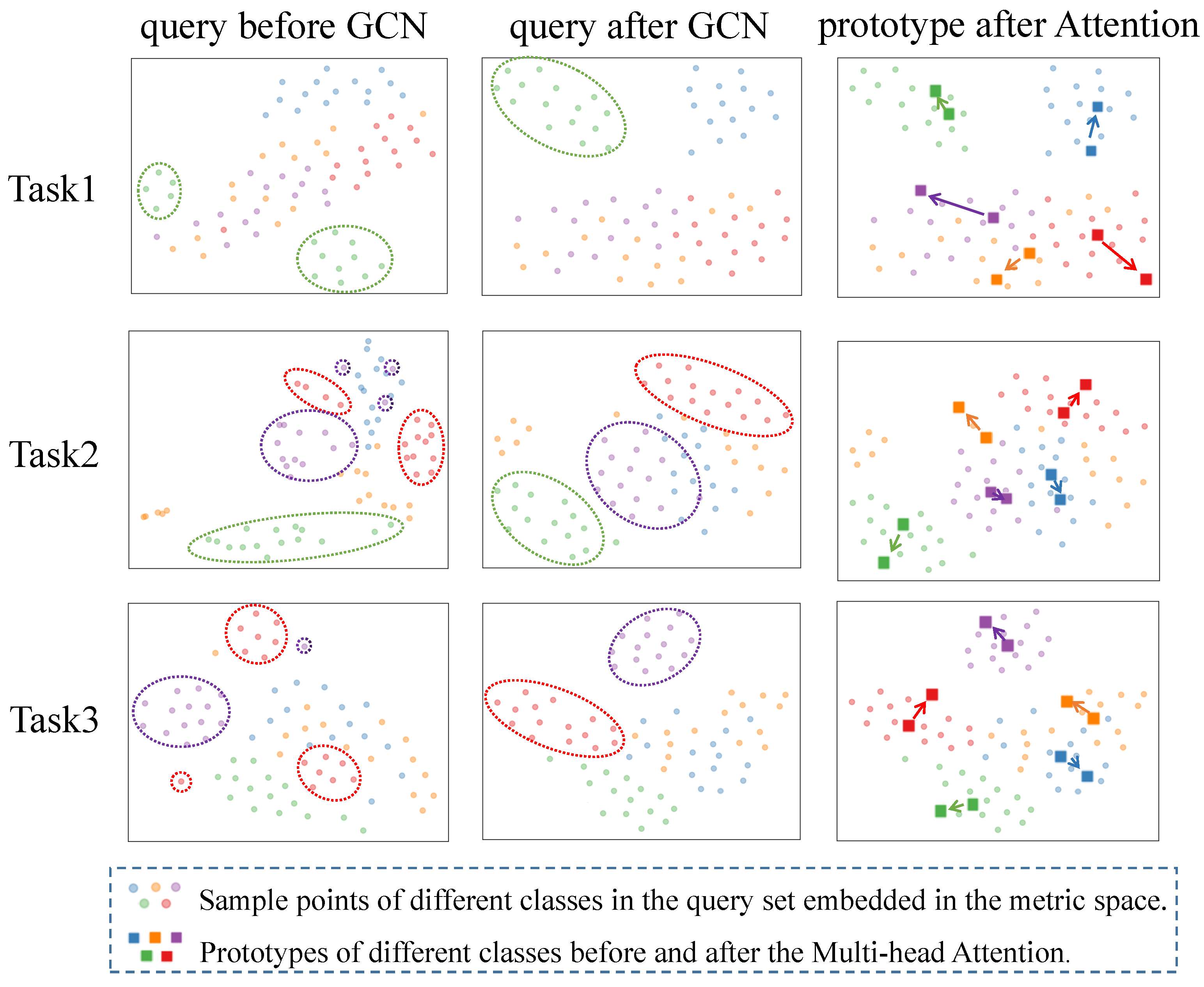
Achieving the goal of reducing the diversity within the same ships while increasing the differences between different classes is a challenging task when using only a uniform feature extraction network. To address the problem of high confusion about ship HRRP targets in the classification process, this paper introduces a task adaptation step that employs an embedding function focusing on instances and relationships between classes. The embedding function, based on the GCN with a good clustering effect and Multi-head Attention that can emphasize critical classification features, involves all instances entering a new embedding space. This space comprises a sample-based public embedding space and an independent embedding space based on prototypes, as illustrated in
Figure 6, designed to perform opposite and complementary functions. The “public” embedding space aims to resolve the problem of significant sample differences within the same type of ships in HRRP, while the “independent” embedding space addresses the issue of slight variations between different ship classes.
Fully connected layers, such as classifier during base-training, are less flexible, since they cannot adapt to changes in the number of classifications. To enhance model flexibility and avoid learning complex recognition models from a limited number of labeled examples of HRRP ships, this study proposes using a prototype network to dynamically construct prototypes and perform the nearest prototype classification. In TAMT, initial adaptation to the new task from a feature extraction perspective is performed by adjusting the weights of the deep blocks. In contrast, the proposed embedding function facilitates further adaptation to the new task from the perspective of class classification and optimal prototype acquisition. The support set samples are processed through the feature extractor to obtain , which represents the features of the input samples. Correspondingly, within , the subset for categories where is denoted as , with their respective class labels .
The GCN, initially utilized for irregular data structures, particularly graph structures, focuses on the relationships between nodes and exhibits a good clustering effect on the embedded data points. To address the relatively large differences between HRRP samples of the same ship target, GCN serves as a public embedding space based on samples to decrease the distance between samples of the same ships.
Each HRRP instance is considered a data point. For each data point, the GCN can consider both the adjacent data points and the feature information contained in itself. The input to the GCN is denoted as
, where feature representation vector of each sample is considered as a separate data point. The similarity between each instance is represented by an adjacency matrix
A. Specifically, if two ship instances belong to the same class, the corresponding element in
A is set to 1, otherwise to 0.
and
A are fed as inputs to the GCN. The adjacency matrix
A is symmetrized and normalized to obtain the matrix:
where
I is the identity matrix and
D is the diagonal matrix whose elements are equal to the sum of the elements in the corresponding rows of
. The relationship between instances could be propagated based on S:
where
W is a projection matrix for feature transformation.
is the input feature matrix of each layer, and
is the output of the feature extractor
. In GCN, the embedding in the set is transformed based on Equation (
7) multiple times, which eventually produces the embedding result. The output result of GCN is denoted by
:
After the instances are embedded into the public embedding space using GCN, the data points belonging to the same ship are more tightly aggregated, exhibiting less variability. This reduces the probability of misclassifying instances that belong to the same ship but with large differences to different classes.
Prototype
is obtained by calculating the average of all vectors belonging to a class of ships in
:
Therefore, the prototypes for the task are recorded as =}.
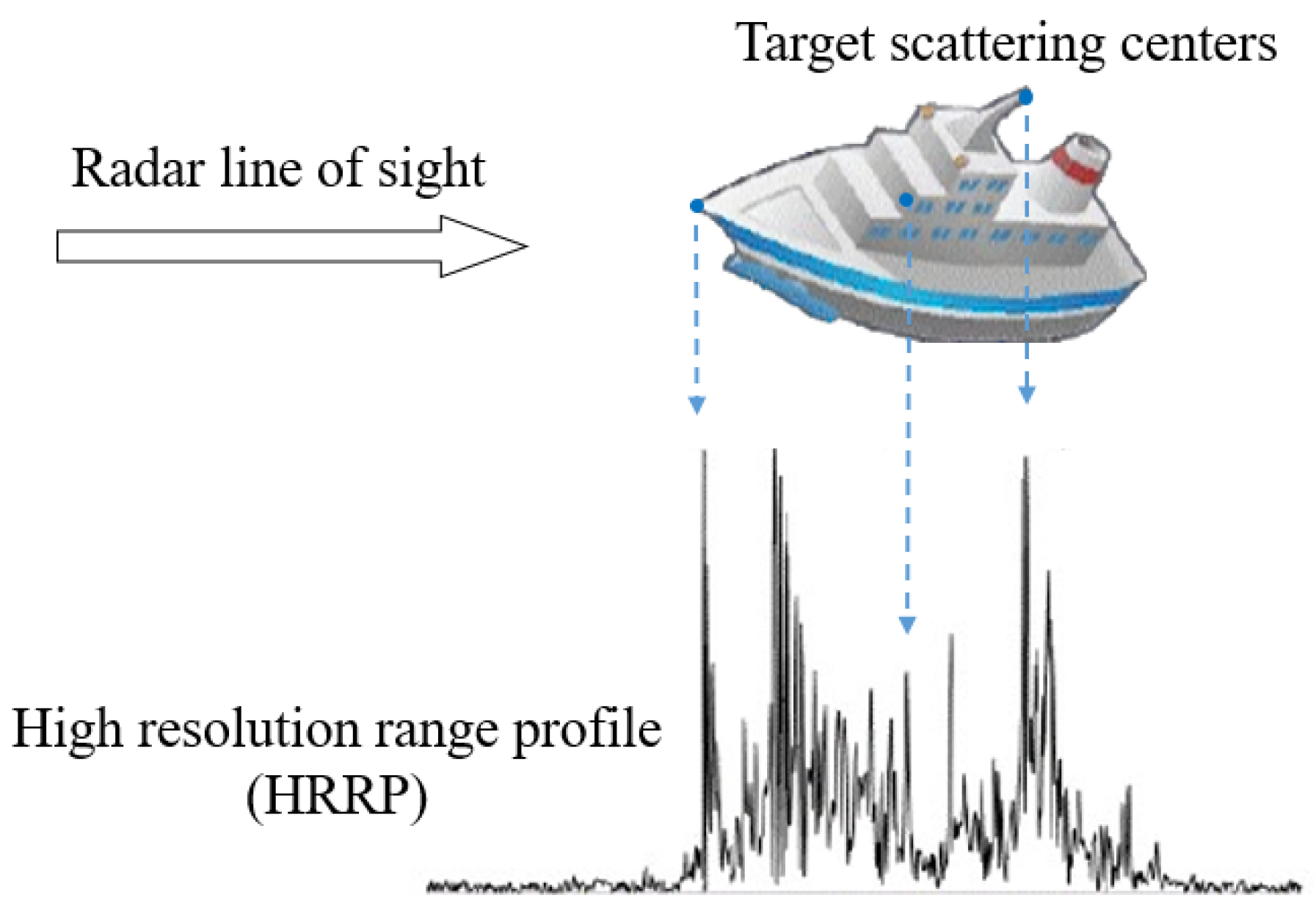
As ships are the only classification objects considered in this paper, their target structures exhibit a significant degree of similarity. Furthermore, the HRRP reflects the projection of the target scatterer in the direction of the LOS, causing the HRRP data returned by ships with similar structures to be highly similar as well. As a result, treating the prototype as a data point means that the distance between prototypes of different ships would be relatively small. To overcome this issue, an independent embedding space is required for the prototype to accentuate the distinguishable differences between different ship classes.
The Multi-head Attention has the ability to focus on context, extracting important information from an extensive amount of data and highlighting it, while disregarding the rest of the information which is mostly irrelevant. By employing this mechanism in the embedding of the prototype, the Multi-head Attention highlights the vital information from the prototype set. For the classification task, this means enhancing the discernible information between prototypes of different ship classes by assigning weights to them and reducing their commonality. This process increases the distance between different class prototypes and reduces the probability of classifying different classes of ships into the same class. To accomplish this, we first apply the self-attention mechanism to the matrix
=
}
:
where
represents the vector length.
Then, the output matrix of each self-attention operation is concatenated along the feature dimension to form a new matrix, which is subsequently fed into a fully connected layer to generate the final output:
where
W is a projection matrix for feature transformation, and
=
}
is the result of prototype processed by the Multi-head Attention.
For all the embedding points
, the Euclidean distance d to a certain class prototype
can be represented as:
where
.
Normalizing the distances from embedded samples to all prototypes using the Softmax can transform the distances into probabilities for the corresponding classes:
So, the loss function for this network on a single training sample is the negative natural logarithm of the true class probability:
The presented process describes one task in the meta-training procedure. And the overarching objective is to learn the meta-function , which comprises the functions , and .



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}