1. Introduction
Rapid growth of the population and economy, acceleration of urbanization, and unreasonable land use lead to a serious waste of land resources and ecological and environmental impacts in China. Bare soil land (BSL) is a significant source of air pollution. Large-area BSL leads to low land utilization rates, as well as ecological and environmental problems, such as dust pollution and soil erosion [
1]. In recent years, the accurate monitoring of BSL is an urgent need for the refined management of urban environments and the improvement of land resources utilization.
Compared with traditional methods, remote sensing technology has obvious advantages in large-scale and dynamic automatic monitoring for BSL. The commonly used classification systems for land use/land cover (LULC) were proposed by the United States Geological Survey (USGS) [
2], the Food and Agriculture Organization of the United Nations (FAO) [
3], and the Chinese Academy of Sciences (CAS) [
4]. For these systems, there are some differences in the number and definition of the classes. BSL is not defined in the USGS’s and the CAS’s classification systems. In the FAO’s land cover classification system (LCCS), “bare areas” is defined, which includes bare soil and loose/shifting sands. For current research on the classification of LULC, BSL is mostly overlooked, and the granularity of the classification involving bare land is usually coarse. According to the Chinese National Standard for Classification of Land Use Status (GB/T 2010–2017) [
5], “BSL” is defined as “soil covered land in surface layer, basically without vegetation cover”, and it is classified as “other land categories”, including bare rock and gravel land and sandy land.
In terms of the classification and mapping of BSL based on remote sensing technology, there are mainly two types of studies. The first is based on traditional methods. For example, Tateishi [
6] and Friedl [
7] used supervised classification based on MODIS data to produce land cover products. The land cover type containing bare land is mostly defined as mixing exposed rock, saline–alkali land, sand and other lands. For these products, the renewal frequency, spatial resolution and the class granularity cannot meet the requirements for BSL monitoring. The second uses the bare soil index (BSI). Xu [
1] constructed a BSI using 30 m resolution data from Landsat TM5. Nguyen [
8] proposed a modified BSI using 15 m resolution data from Landsat 8. The calculation of the BSI depends on the shortwave infrared and midinfrared bands. With the development of remote sensors with high spatial resolution, sensors increasingly retain only four bands, including red, green, blue, and near-infrared, as well as a panchromatic band [
9]. As a result, it is difficult to establish the BSI. In addition, BSL is mostly shapeless and has different sizes and broken boundaries. Therefore, it is still a challenge to extract BSL from other land cover classes using high-resolution remote sensing images.
Deep learning methods have been widely used in recent years. Compared with the classical machine learning method based on supervised classification, they have the advantages of a strong ability to extract adaptive features, high computational and reasoning speed, high transferability and end-to-end learning. Therefore, they are more suitable for the classification of large volumes of high-resolution images. There are many studies on semantic segmentation for the extraction of buildings [
10], roads [
11], water bodies [
12], etc., using deep learning. In addition, Karra [
13] applied a deep learning method using 10 m resolution Sentinel-2 data to produce a global LULC map. However, semantic segmentation requires a significant amount of annotated data, which limits the use of deep learning models. To address this challenge, transfer learning is proposed. Transfer learning can be divided into instance-based transfer learning, feature-based transfer learning, model-based transfer learning and relation-based transfer learning [
14]. Domain adaptation is another term commonly used in transfer learning, and many studies address this challenge of limited annotated data [
15,
16,
17,
18]. For cases where the dataset types of the source and target domains are homogeneous (for example, photos of roads in different countries), domain adaptation can transfer their domain invariant features. If the data types of the source and target domains are heterogeneous (for example, photos taken by a phone and remote sensing images), model-based transfer learning is more feasible.
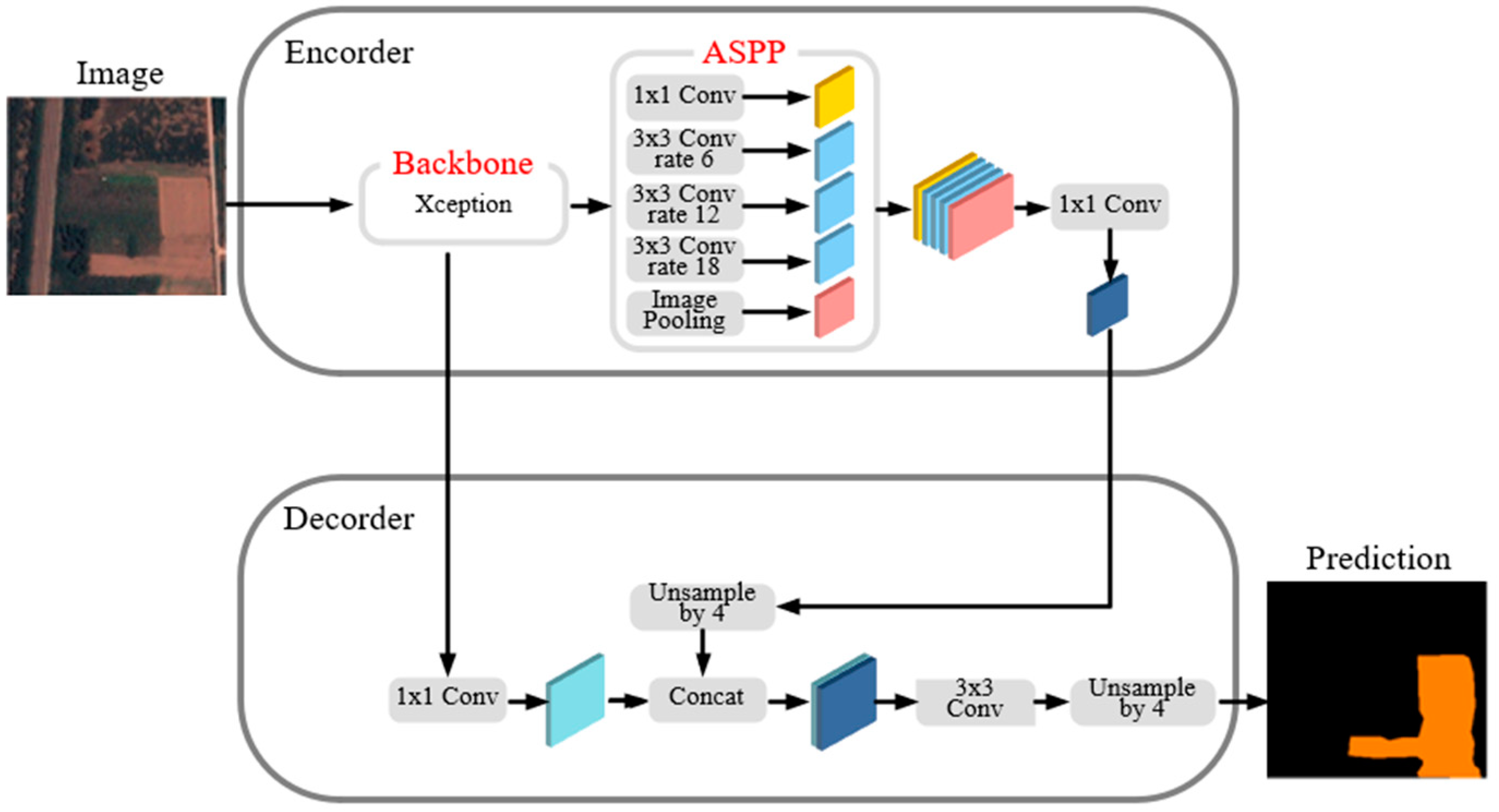
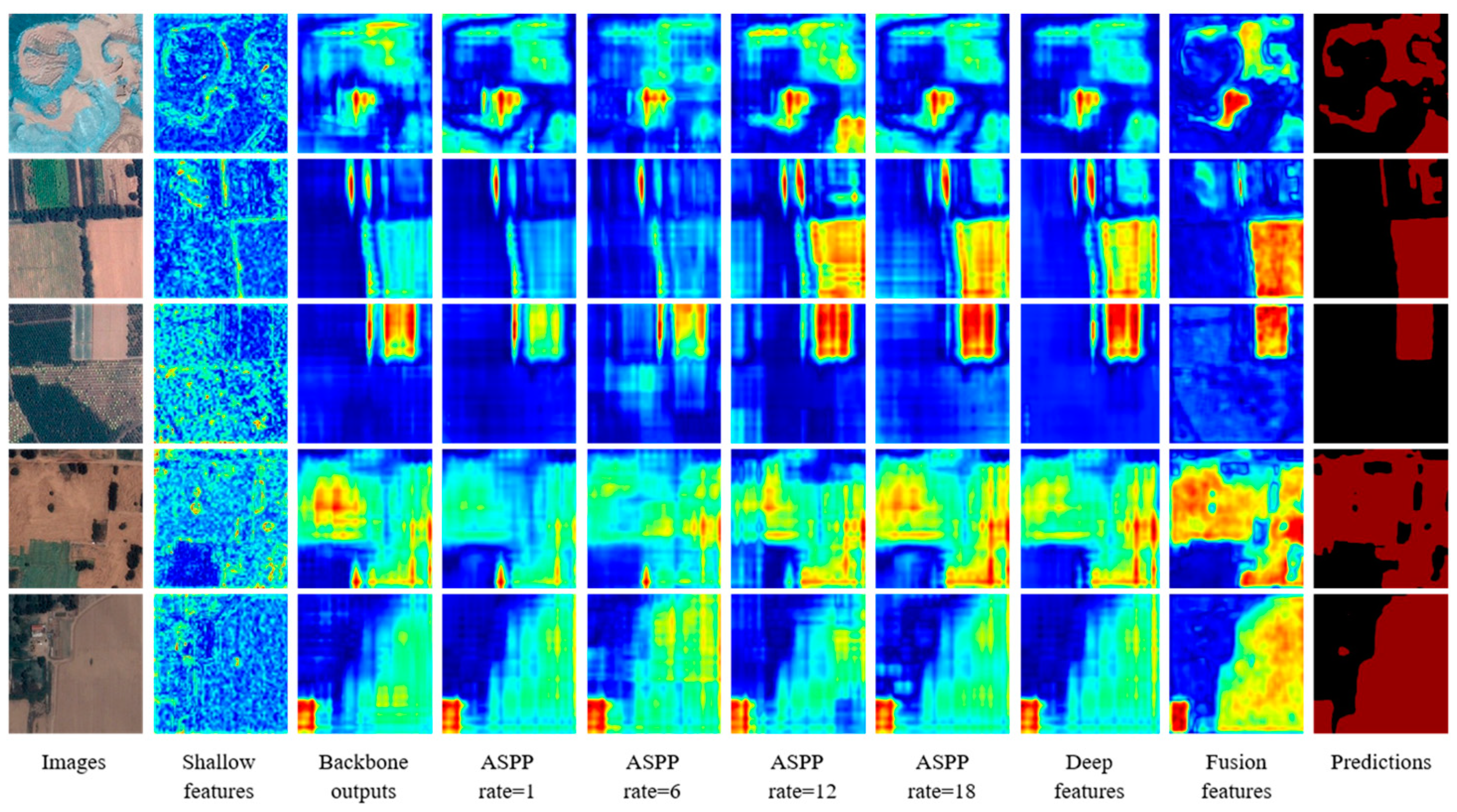
As a typical deep learning model for semantic segmentation, DeepLab was developed in four versions, V1, V2, V3 and V3+, from 2015 to 2018. For DeepLab V1 [
19], convolution in full convolutional networks (FCNs) is replaced with atrous convolution to expand the receptive field. For DeepLab V2 [
20], atrous spatial pyramid pooling (ASPP) is introduced. It allows for the input image at arbitrary scales to be performed by feature maps. For DeepLab V3 [
21], several atrous convolution modules with different expansion rates are used to capture the multiscale context. Simultaneously, the model removes the full connection condition random field (CRF), which has a lesser effect on the model. Deeplabv3+ [
22] was released in 2018, which uses ASPP to fuse the multiscale information in its encoder, and its concise decoder can efficiently recover the precision edge. There are some successful applications in semantic segmentation for high-resolution remote sensing images. Lin [
23] integrated the attention mechanism module squeeze-and-excitation (SE) for channels into DeepLab V3 to alleviate the multiscale problems due to the different length–width ratios of roads so that the weights could be applied to different channels. The intersection over union (IoU) of the two classifications of road/nonroad was 84.62%. To solve the imbalanced distribution problem of samples, Ren [
24] combined the Dice loss functions and the binary cross entropy (BCE) loss functions with Deeplabv3+ so that the mean intersection over union (mIoU) for desert, road, water and other categories reached 87.74%. However, Deeplabv3+ has not been used for BSL extraction so far.
To reduce the impact of BSL on the environment, common governance measures include covering with dust-proof nets, hardening with cement and planting trees or grass. The areas where these measures are taken mainly have no dust pollution risk, so they were not treated as BSL in this study. They were regarded as the background objects. However, even if these areas have been treated, there will probably be some bare soil exposed. We named the BSL areas by the governance measure of planting trees, for short, BSL-PT. For the areas where bare soil is often, again, exposed due to the seasonal withering of grass, we named them, for short, BSL-PG. As a temporary treatment measure, coverings with dust-proof nets easily lead to the repeated exposure of BSL. Meanwhile, the spectral characteristics of BSL on high-resolution images are similar to those of buildings [
25]. The distinction between them has still been a difficulty for the research of urban impervious surface extraction. Therefore, together with the BSL-PT, BSL-PG, dust-proof nets and buildings, they form a complex background that affects the extraction of BSL.
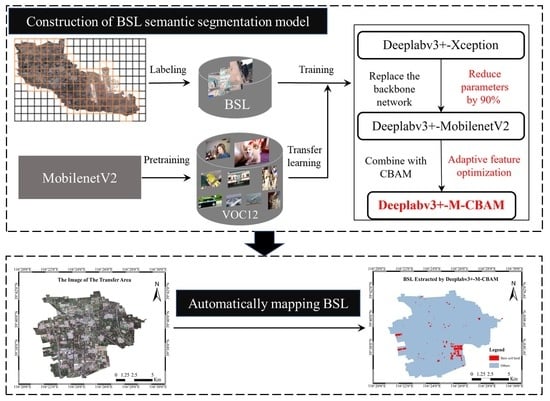
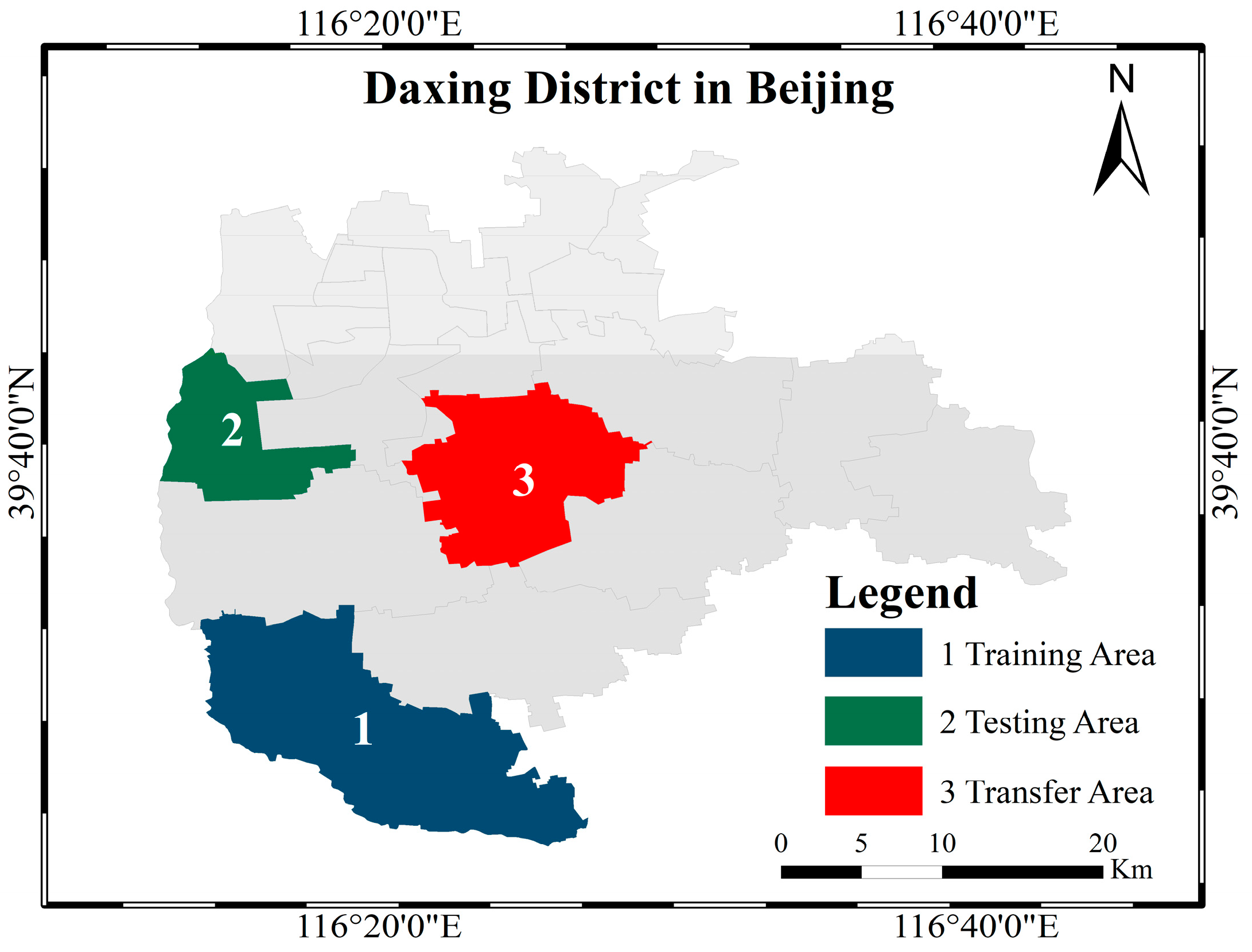
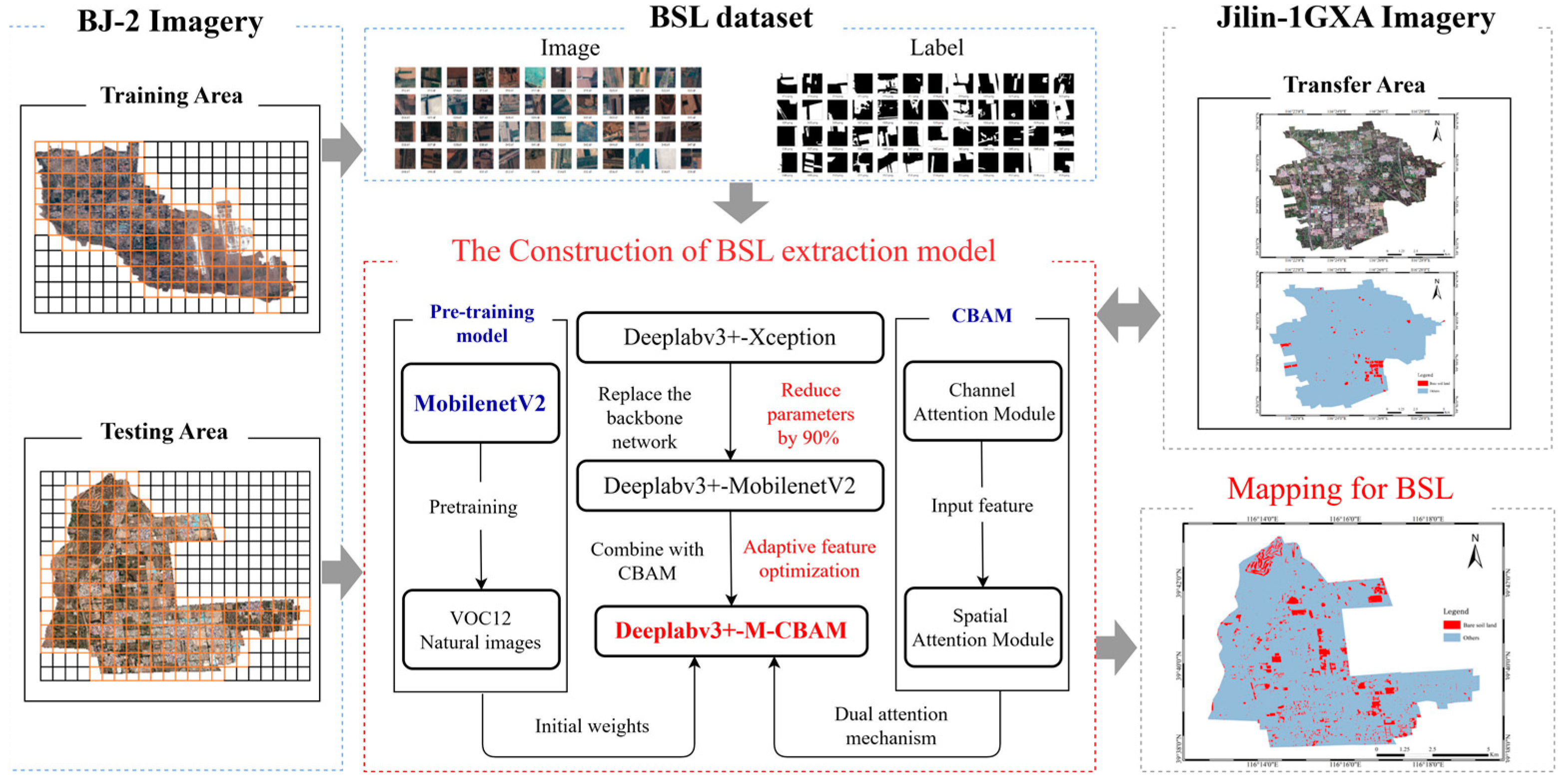
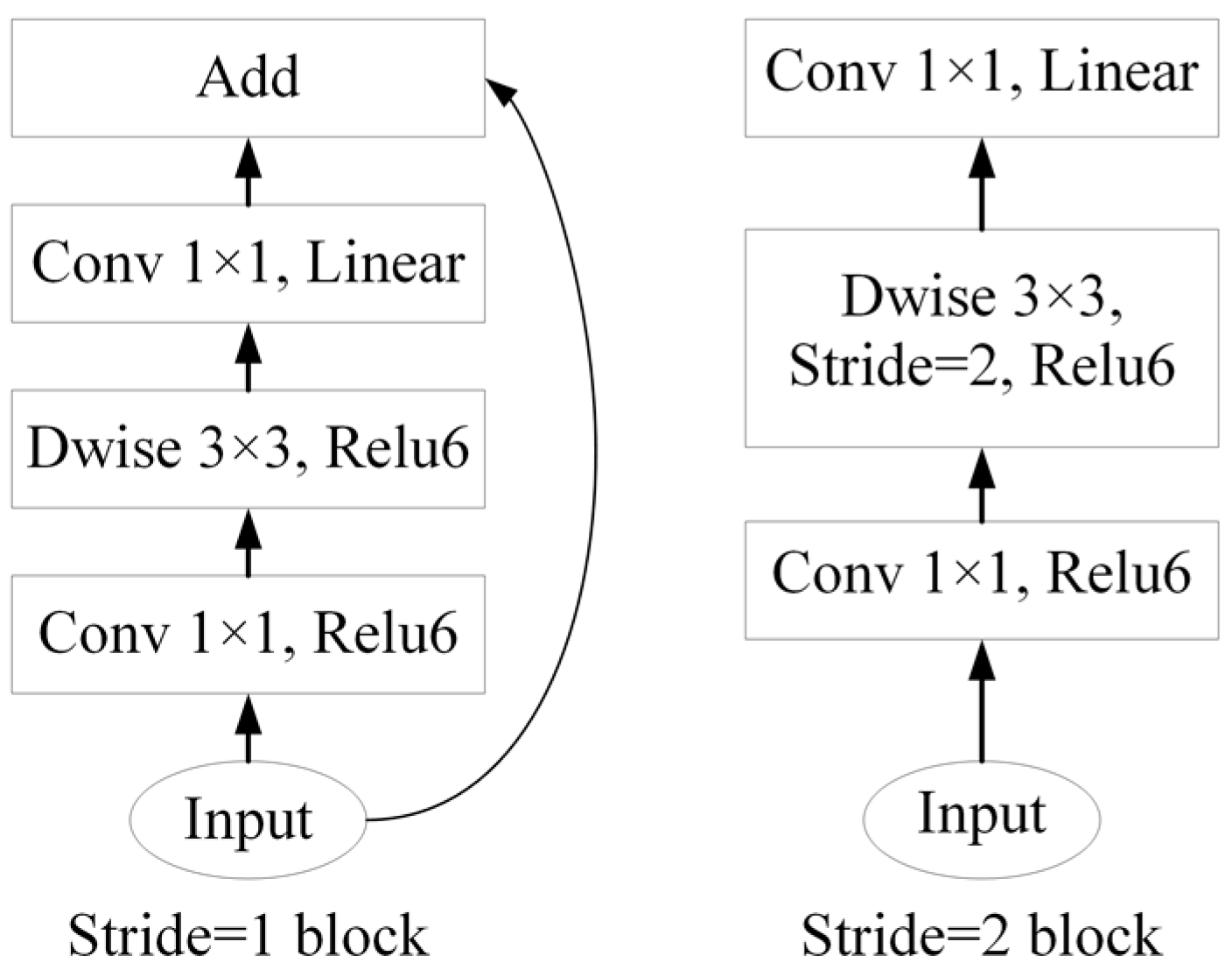
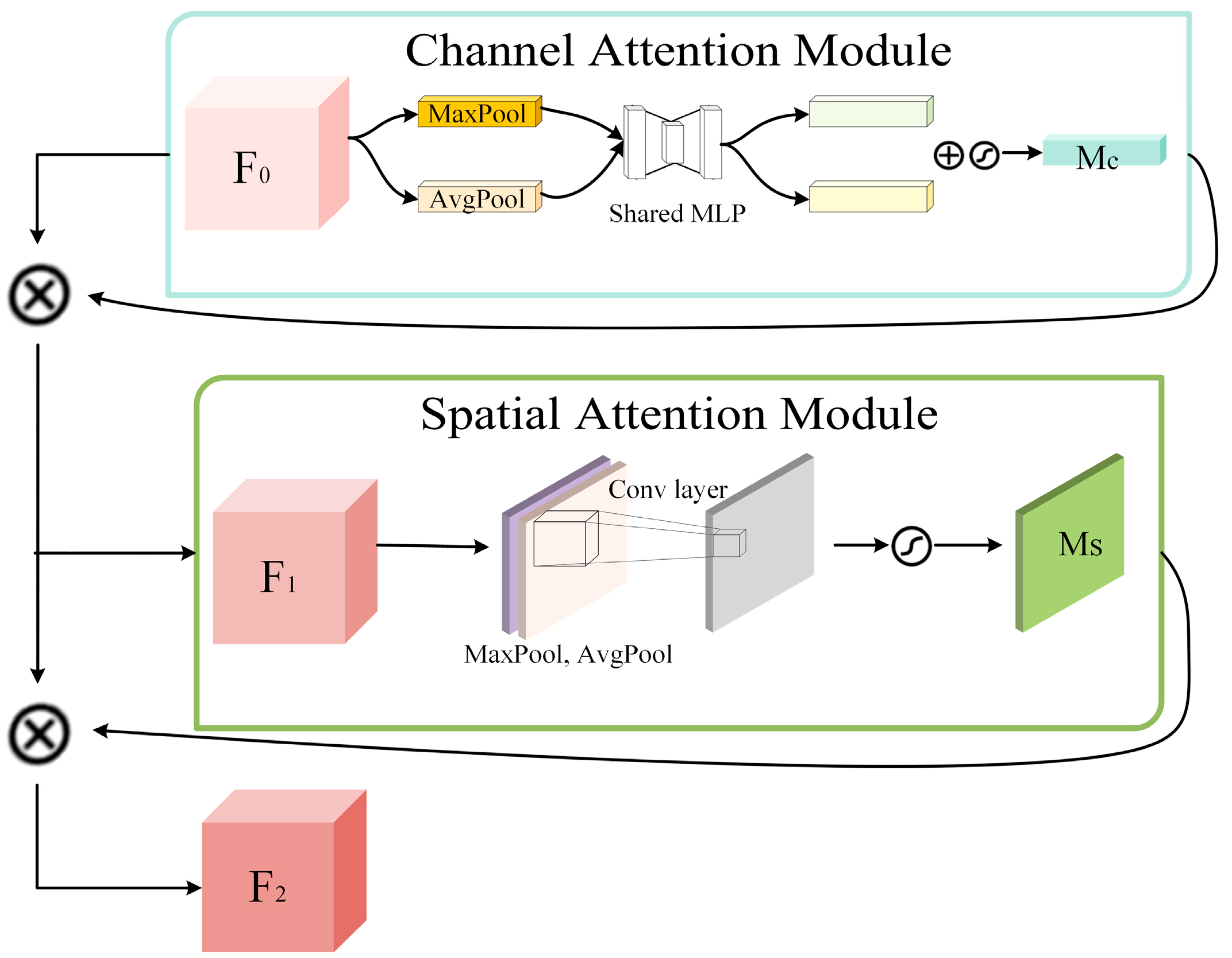
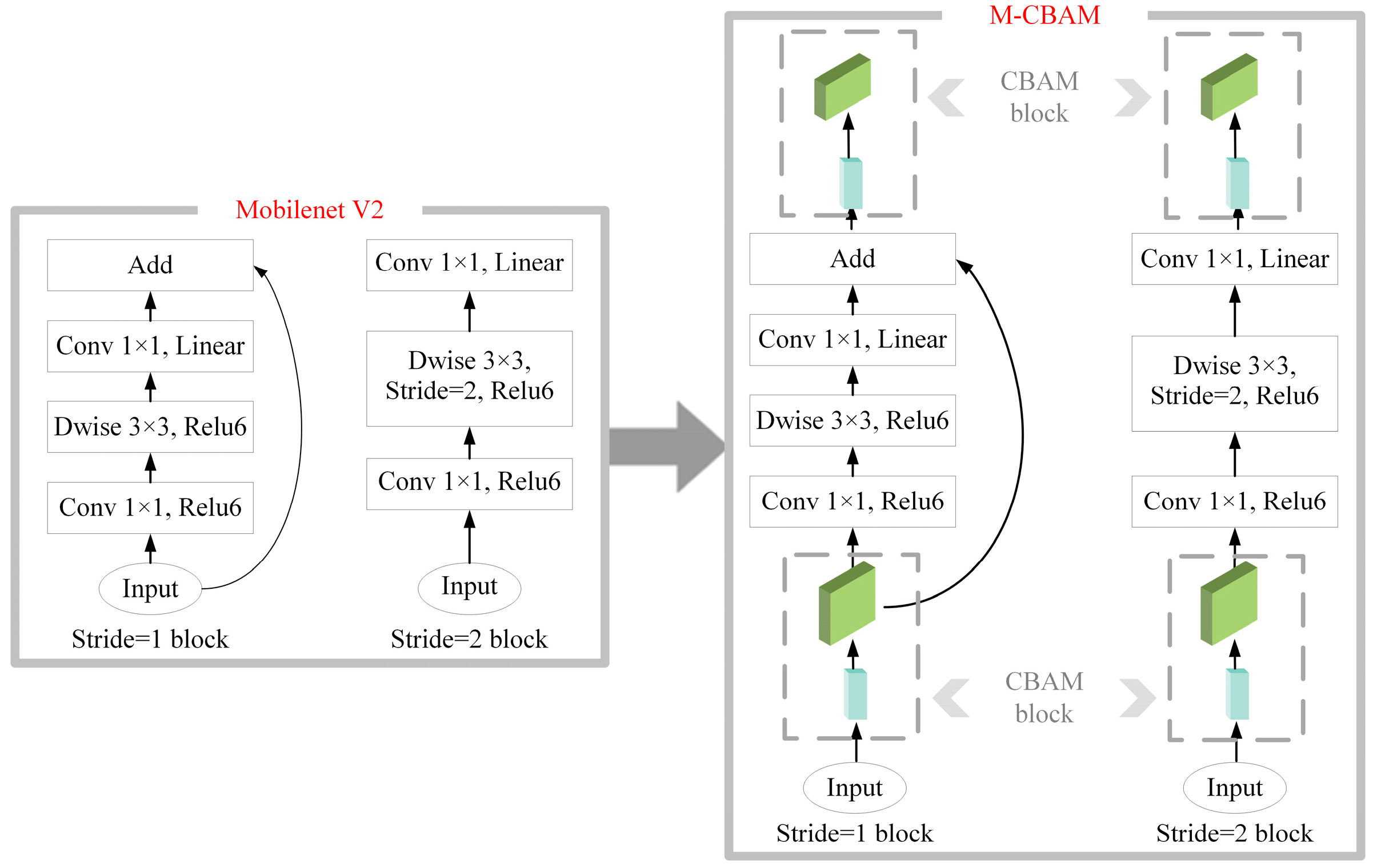
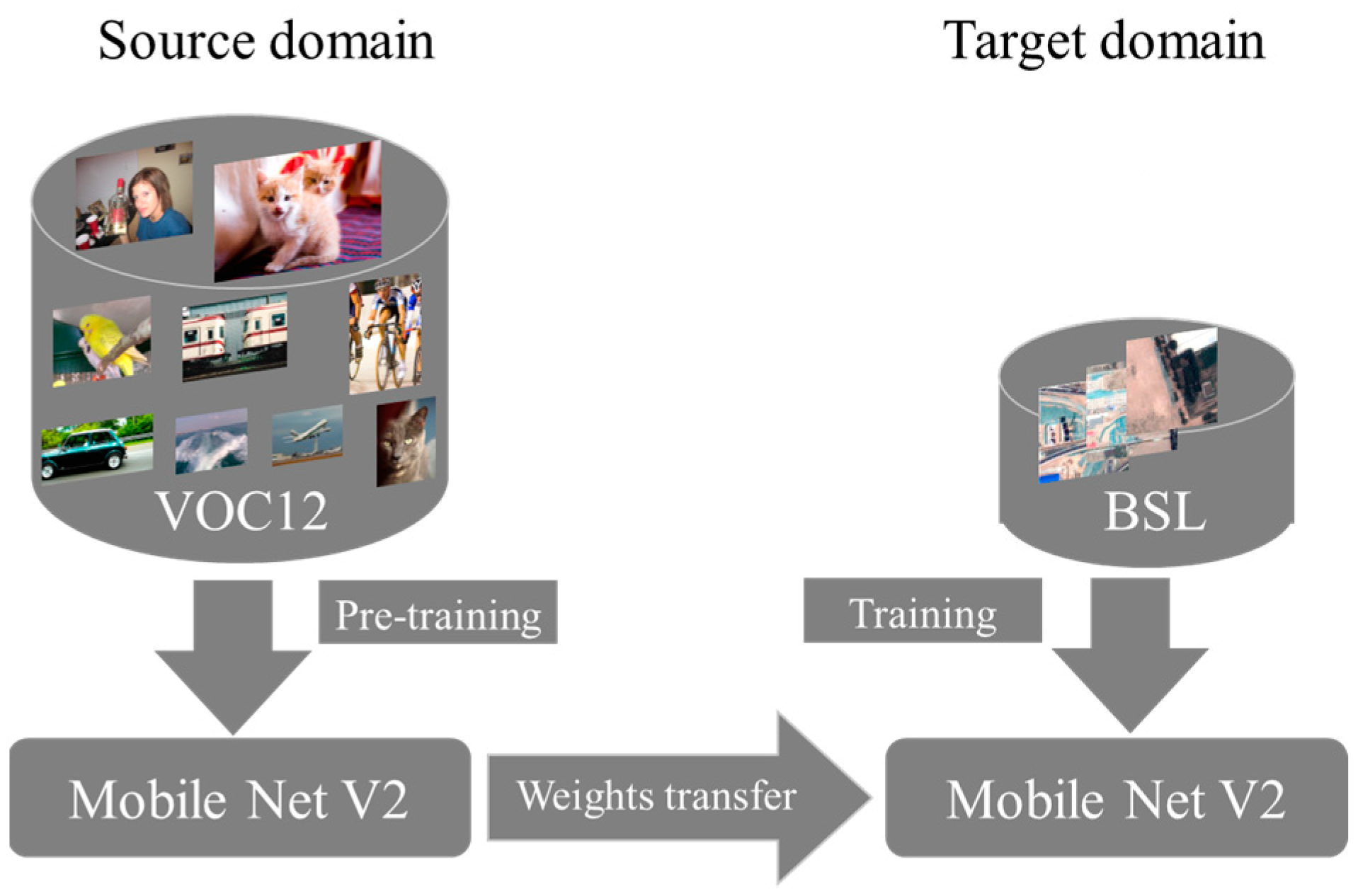
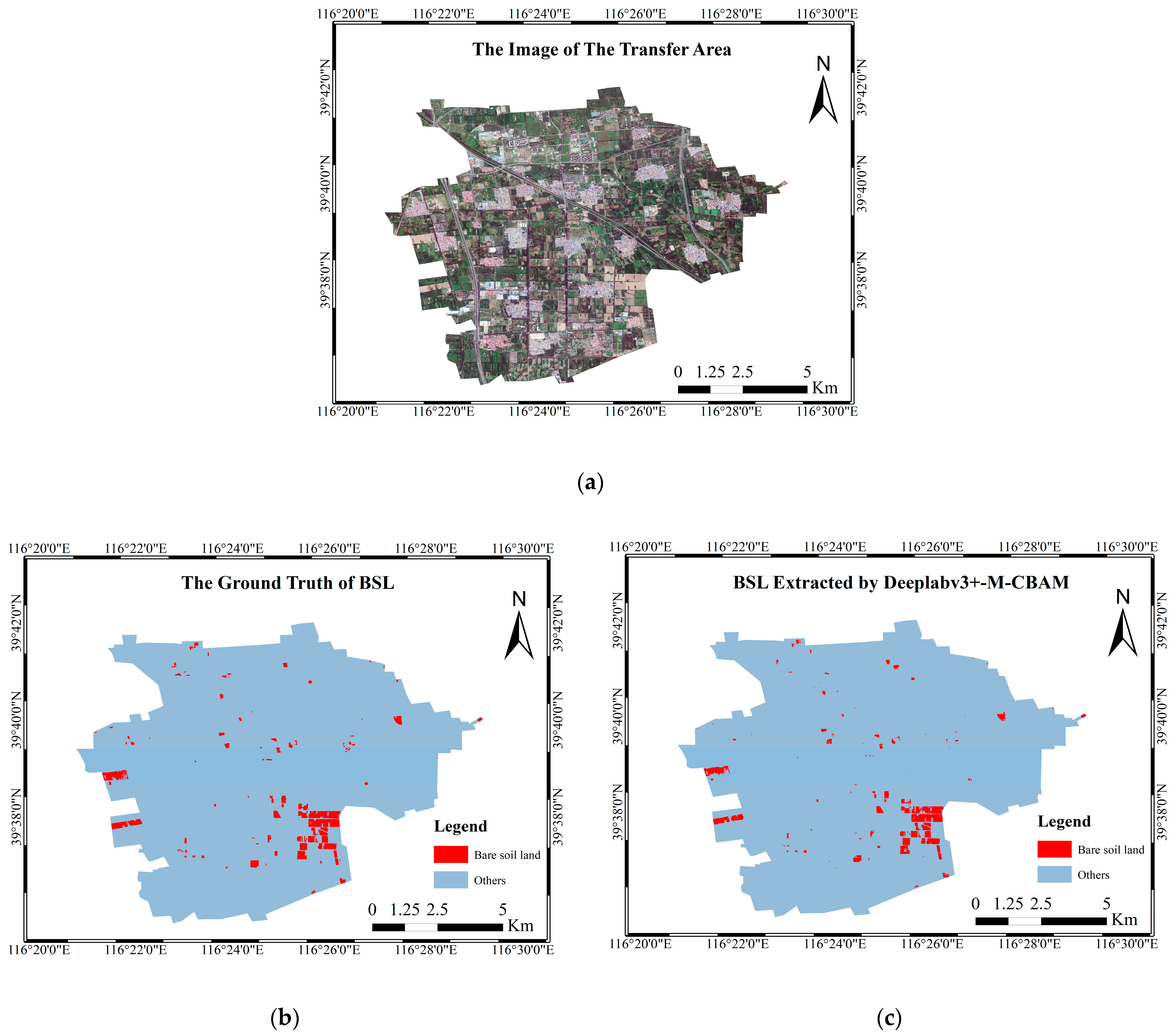
In this study, we adopted the definition of BSL in the Chinese National Standard for Classification of Land Use Status. In order to reduce the impacts on BSL extraction caused by complex backgrounds, buildings, BSL-PT and BSL-PG were regarded as the background in the process of the BSL dataset construction based on high-resolution remote sensing images. Then we constructed the Deeplabv3+–MobileNetV2–convolutional block attention module (Deeplabv3+-M-CBAM) based on Deeplabv3+ for the real-time semantic segmentation of BSL. Finally, it was tested on two different sources of data to verify its transferability.
5. Conclusions
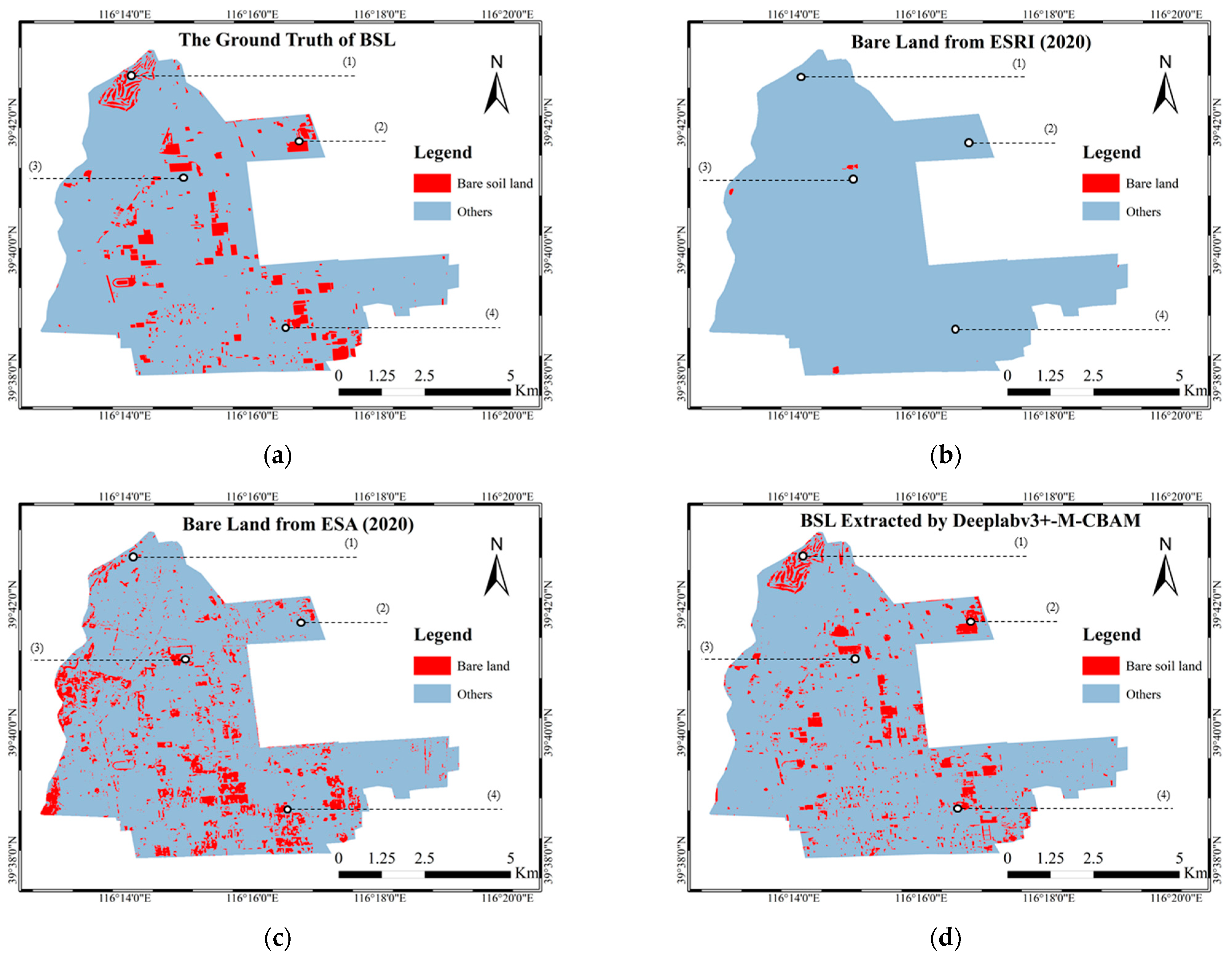
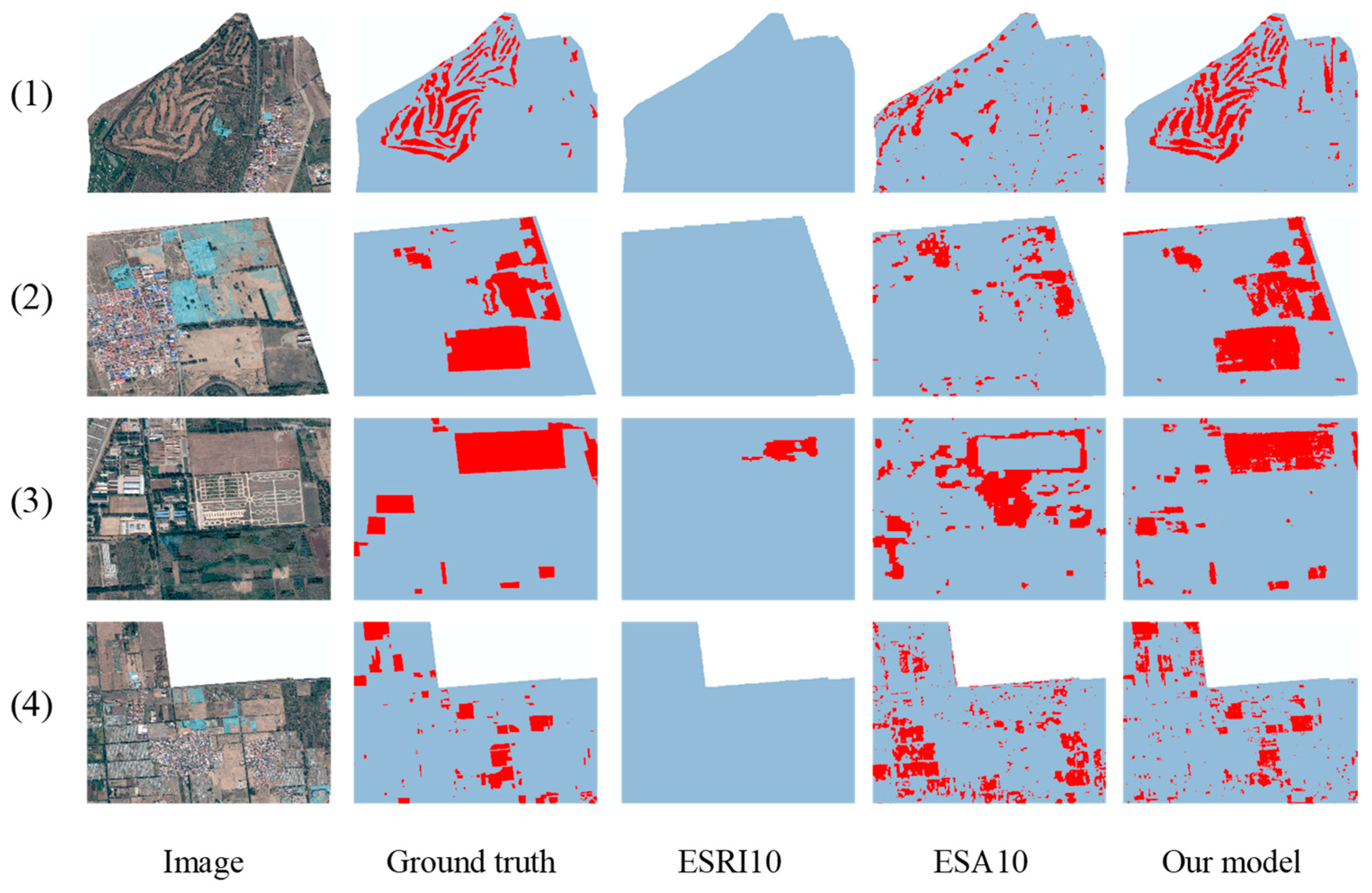
The precise detection of BSL is of great significance to improve the utilization rate of land resources and ecological environmental governance. Current land cover products are mostly produced based on medium- or low-resolution images, such as MODIS, Landsat and Sentinel, and the granularity and accuracy of the classes cannot meet the requirements of regional BSL extraction and monitoring. High-resolution images can provide more detailed information on objects, but its limited number of spectral bands results in some difficulties in separating BSL and buildings with similar spectral characteristics. Moreover, complex backgrounds with rich semantic information pose challenges to traditional methods. In the process of the fine management of BSL, BSL-PT and BSL-PG are formed due to the planting of grass and trees, which makes the background more complicated and interferes with the extraction of BSL.
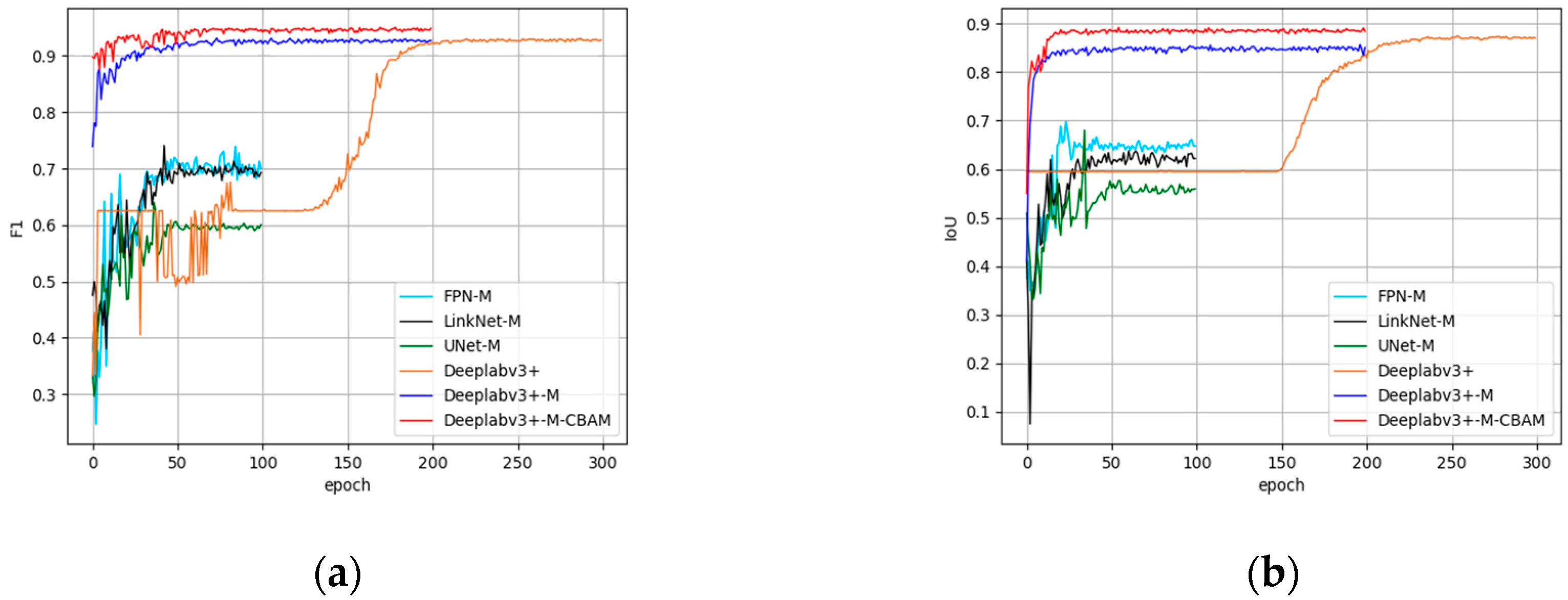
In summary, this study proposes a lighter semantic segmentation model combined with the CBAM. The improved Deeplabv3+ model (Deeplabv3+-M-CBAM) extracts BSL from complex backgrounds and performs well in test accuracy. Compared with mainstream models, Deeplabv3+-M-CBAM had the highest ability to distinguish BSL from BSL-PG, BSL-PT and buildings. Due to the 90% reduction in the parameters, Deeplabv3+-M-CBAM can be deployed to run on machines with more limited resources. This study provides technical support for the governance of BSL by artificial intelligence technology. Meanwhile, it will enrich the classification granularity of traditional LULC classification and promote the fine classification of LULC in the near future.
Certainly, there are still two further studies on the datasets and postprocessing for the results that can be considered. In regard to the data, the cloud coverage of the image data we used was 0%. However, in most cases, the acquired images often have cloud coverage. Therefore, in order to enhance the robustness of the model, cloud samples can be added into the BSL dataset for the training of the model. In regard to the postprocessing of the results of the model, since the BSL extraction results were pixel-based raster data, it should be processed according to the different minimum statistic units, for example, 3 × 3 pixels, to remove the pixels smaller than this size and to satisfy the different demands for BSL governance. These improvements will provide better technical support for perennial BSL monitoring and more detailed demands.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}