1. Introduction
Air pollution has worsened over the past few decades; therefore, it has received significant attention from scholars and policymakers. An air quality index (AQI), which is composed of six pollutants, including particulate matter 10 (PM
10), particulate matter 2.5 (PM
2.5), sulfur dioxide (SO
2), nitrogen dioxide (NO
2), carbon monoxide (CO), and ozone (O
3), is an overall index that can more objectively depict the levels of air pollution than an index that includes a single air contaminant [
1,
2]. Pakistan has invariably encountered severe air pollution issues caused by industrial sources and automobile exhausts, particularly in Karachi City, located in southern Pakistan [
3]. Consequently, air pollution poses a severe threat to health, and prompt monitoring of air quality is vital to control pollution and immensely useful for protecting human health. Air pollution has a variety of adverse effects, both physiological and psychological, on people’s health. It is a contributor to the development of infectious illnesses. In 2012, infectious diseases were responsible for the deaths of 9,500,000 people all over the world. Air pollution is a clear warning sign of potential danger to one’s health [
4]. Additionally, when breathing polluted air, people should consider the possibility that they could catch an illness. Long-term exposure to extremely high PM2.5 concentrations has been linked to the onset of cardiovascular disease and other major health problems, as well as negative effects on the liver and lungs [
5,
6,
7].
Currently, air quality data collection is mostly micro-station based. Though, because of the expensive material and set-up costs of advanced sensors, such in-situ monitoring is less possible in the majority of regions of concern, and this represents a significant financial burden for developing and emerging nations in the long term [
8]. It is possible to use image-based systems for air quality monitoring as a backup when gauges are unavailable or when they are not operating effectively. Recently, there have been several initiatives to build low-cost air pollution monitoring equipment [
9,
10,
11,
12]. Predictions of air pollution are primarily based on deterministic [
13,
14,
15,
16,
17] and statistical models. The deterministic approach makes use of a theoretical meteorological emission and a chemical model to simulate the creation and diffusion process of contaminants. However, because of the ideal theory used to determine the model structure and estimate parameters, it falls short of explaining the nonlinearity and heterogeneity of many factors connected to pollution generation. When compared to the deterministic approach, the statistical method’s use of a data-driven statistical modeling strategy allows it to sidestep the complexity and hassle of modeling while still delivering impressive results.
Machine learning (ML) has recently achieved substantial advancements in numerous areas, including speech and image recognition, with improved eminent excellence. The convolutional neural network, abbreviated as CNN, has seen extensive use in research in the fields of computer vision and image processing, with credible performance in attempting various inspiring tasks on classification and estimation [
18,
19,
20,
21,
22,
23,
24,
25,
26]. The use of machine learning and deep learning methods in analyzing air quality has grown in popularity in recent years [
27,
28,
29]. Air pollution has been classified or estimated using image processing in many studies [
12,
30,
31,
32]. Additionally, an image-based air pollution estimate provides a promising future; however, few such studies have been conducted in this context. Therefore, more investigation into image-based air quality estimates is needed to boost accuracy and reliability. Due to the rapid growth of machine learning algorithms and computer vision technology, recently, many automatic algorithms have been offered as potent tools to address the crack detection difficulties in practice [
33]. With the use of deep convolutional neural networks (DCNNs) and an improved chicken swarm algorithm, the authors of [
34] created a visual method for diagnosing cracks (ECSA). To better forecast and analyze the air pollution generated by Combined Cycle Power Plants, a novel hybrid intelligence model based on long short-term memory (LSTM) and multi-verse optimization algorithm (MVO) has been created [
35,
36]. This developed a deep learning model to predict PM2.5 atmospheric air pollution using meteorological data, ground-based observations, and big data from remote-sensing satellites. To forecast the concentration of air pollutants in various areas inside a city, using spatial-temporal correlations, a convolutional neural network with a long short-term memory deep neural network (CNN-LSTM) model was developed [
37]. Using a recurrent neural network deep learning model, the presence of SO2 and PM10 in the air of Sakarya city was demonstrated [
38]. In order to forecast the quality of the air, [
39] a spatio-temporal deep learning model called Conv1D-LSTM, which integrates a deep convolutional neural network (1D CNN) with a long short-term memory (LSTM) to extract spatial and temporal correlation data, was presented [
40]. The model presented the application of an attention-based convolutional BiLSTM autoencoder model for air quality forecasting.
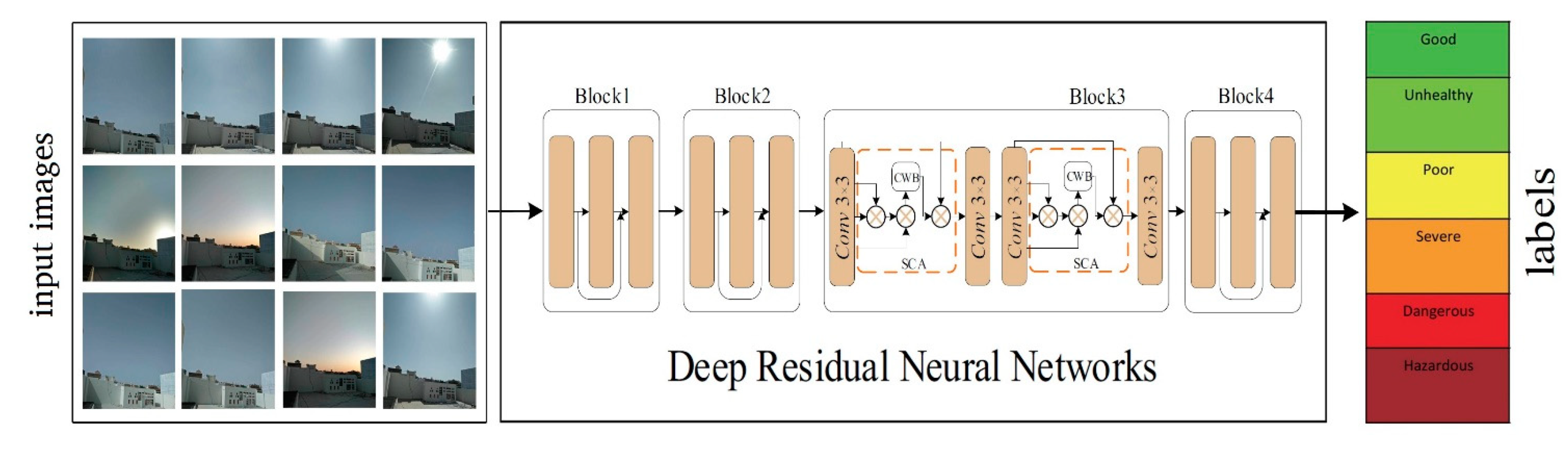
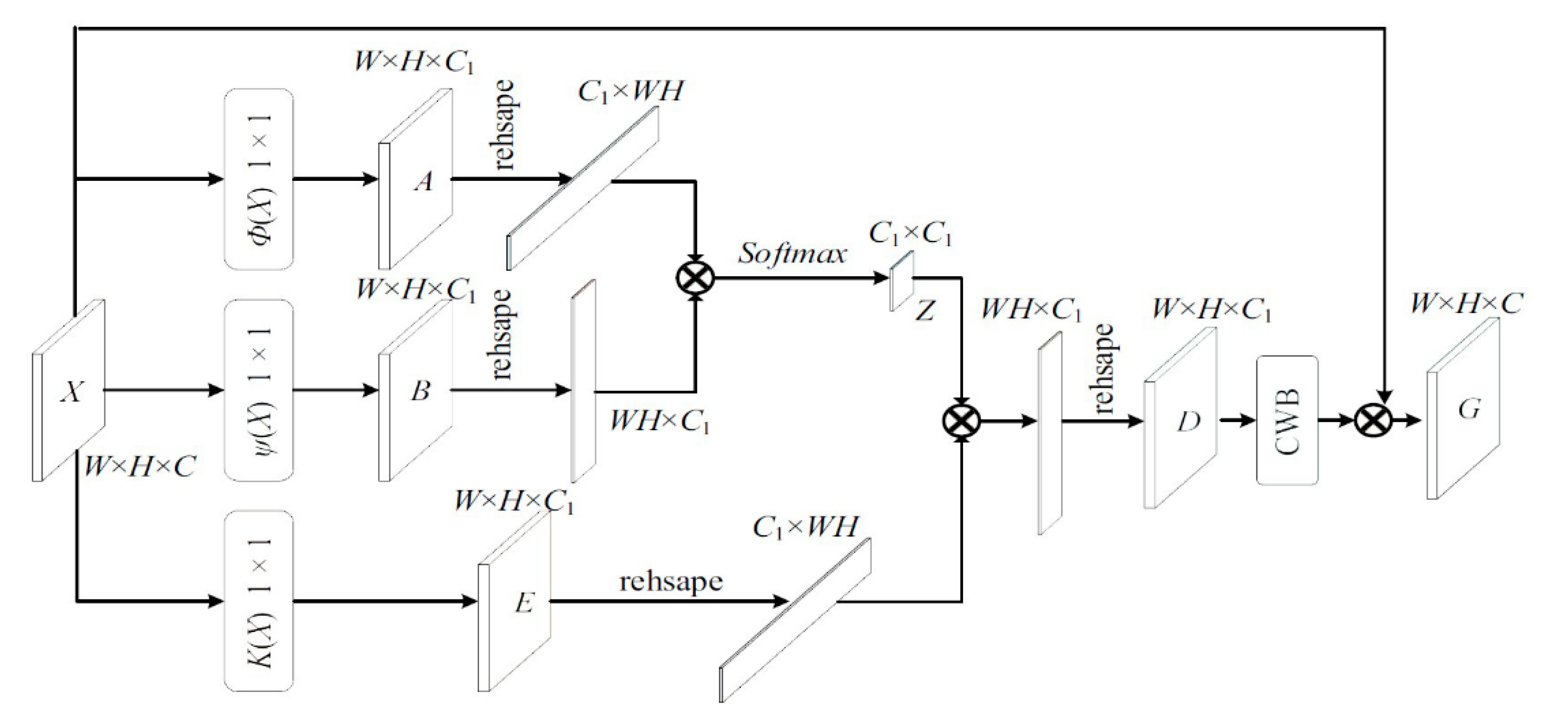
This study proposes a deep CNN model (AQE-Net) based on ResNet to classify photos per air quality level. Previous approaches based on CNN networks concentrate almost solely on PM2.5, despite the fact that PM2.5 is just a small component of air pollution and does not accurately reflect overall air quality information. Additionally, the existing studies have estimated air quality in different aspects. Among them, much research focuses on particular pollutants. However, this study contributes theoretically and practically and takes AQI as an outcome variable to estimate air quality. Moreover, many studies use satellite images for air quality estimations. In contrast, this study uses mobile images. Therefore, more investigations into image-based air quality estimates are needed to boost accuracy and reliability. Our proposed model can measure the AQI directly, more accurately estimating the environment’s air quality. In this context, this study investigates the connection between air quality and image characteristics using air quality analysis of many fixed-site photographs, builds a prediction model, and calculates air quality everywhere. People can collect pictures easily and quickly using portable terminals such as mobile phones, tablets, and other smart devices and can use this method to estimate the AQI in real-time.
3. Results
In this study, the standard machine learning technique SVM and the deep learning methods VGG16, InceptionV3, and AQE-Net were contrasted and examined on the KHI-AQI dataset. Furthermore, the accuracy, sensitivity, F1 score, and error rate metrics have been employed for evaluating the performance of deep learning models for classification problems.
The SVM classifier’s basic premise is to turn image classification problems into high-dimensional feature classification spaces, with difficult-to-classify problems becoming linearly separable due to the transformation. A kernel is utilized to construct a hyperplane in the high-dimensional feature classification space, which is then used to discriminate between different air quality levels. An RBF radial basis kernel is employed because the picture classification issue exhibits linear inseparability. SVM achieved 56.2% accuracy after training on the KHI dataset, but for predicting a single image for classification, the process typically takes 0.0532 s. For the SVM model, the sensitivity, the F1 score, and the error rate were all determined (0.77, 0.87, 0.16). Following the application of the SVM model to the KHI dataset, we then utilized the VGG16 model on the same dataset in order to compare the outcomes. By increasing the depth of the network and making use of tiny convolution kernels rather than large convolution kernels, VGG improves the accuracy of the model, which in turn provides good performance for image classification. The VGG16 algorithm obtained an accuracy of 59.2% when predicting the air quality index based on photographs, which is 3% higher than the SVM model’s performance. It was found that the VGG16 model had an error rate of 0.14%, a sensitivity of 0.79, and an F1 score of 0.88, and the error rate was calculated as 0.14. With this model, we see a decrease in errors of 0.02% of points compared to the SVM model. On the KHI dataset, the InceptionV3 model was used for testing after the VGG16 model. The accuracy of InceptionV3 was measured at 64.6%, which is 5.4% better than VGG16’s performance. The calculated sensitivity for InceptionV3 was 0.85, while the F1 score and error rate for InceptionV3 were 0.96 and 0.05, respectively. These values are significantly lower than those for VGG16. Following the use of the three earlier models, SVM, VGG16, and InceptionV3, we then applied our newly proposed model, AQE-Net, on the same dataset in order to test it and compare the results. When compared to VGG16, the accuracy of identifying air quality levels from photos using the AQE-Net model increased by 5.5%. The AQE-Net model that we have proposed has an accuracy of 70.1%. The values for sensitivity, F1 score, and error rate were calculated to be 0.92, 0.96, and 0.03, respectively. Following the application of the SVM, VGG16, and InceptionV3 models to the KHI dataset, it was observed that the AQE-Net model achieved the greatest accuracy compared to the other models in terms of classifying images.
Table 3 demonstrates the prediction time, accuracy, sensitivity, F1 score, and error rate values for all of the models that have been utilized in this research.
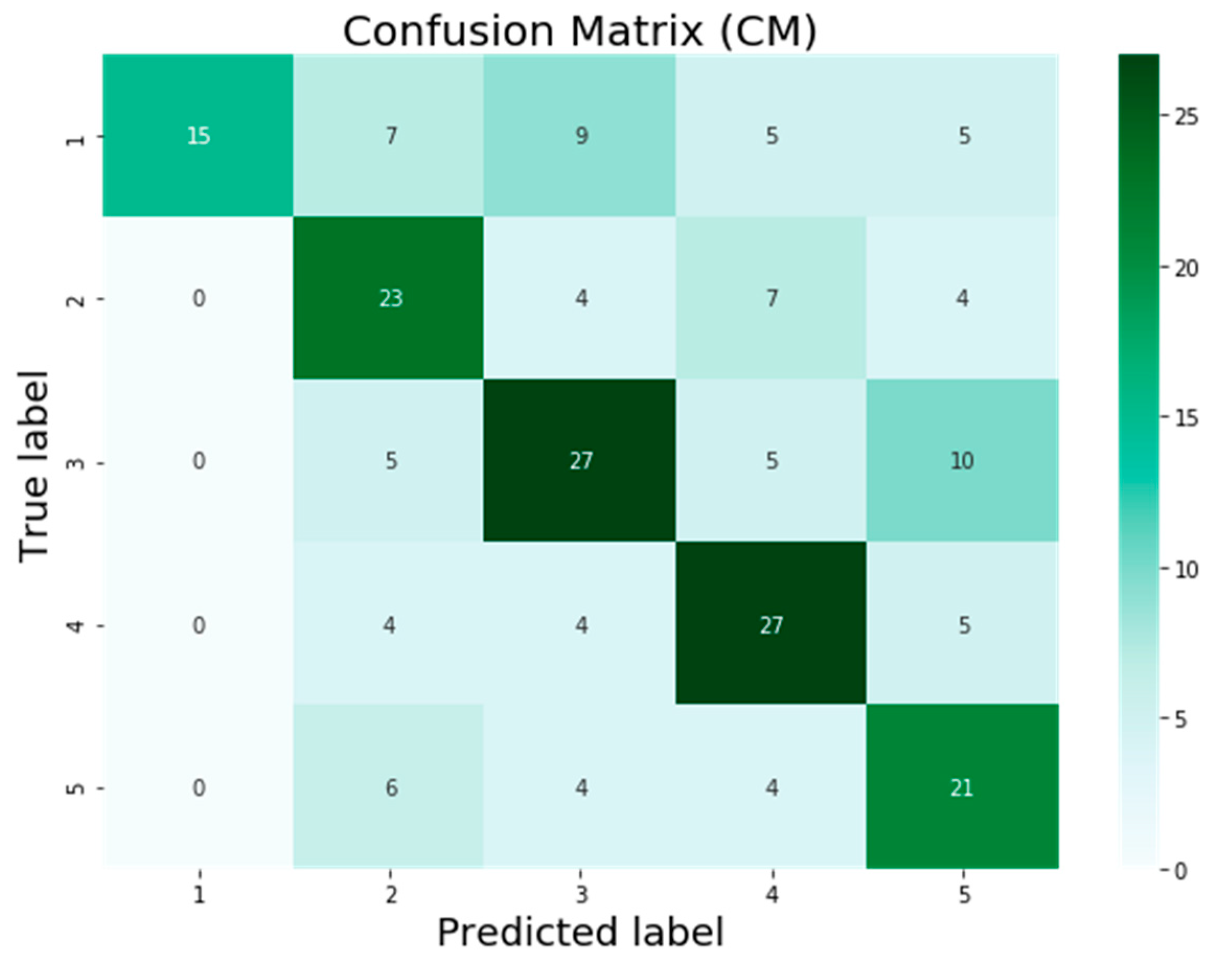
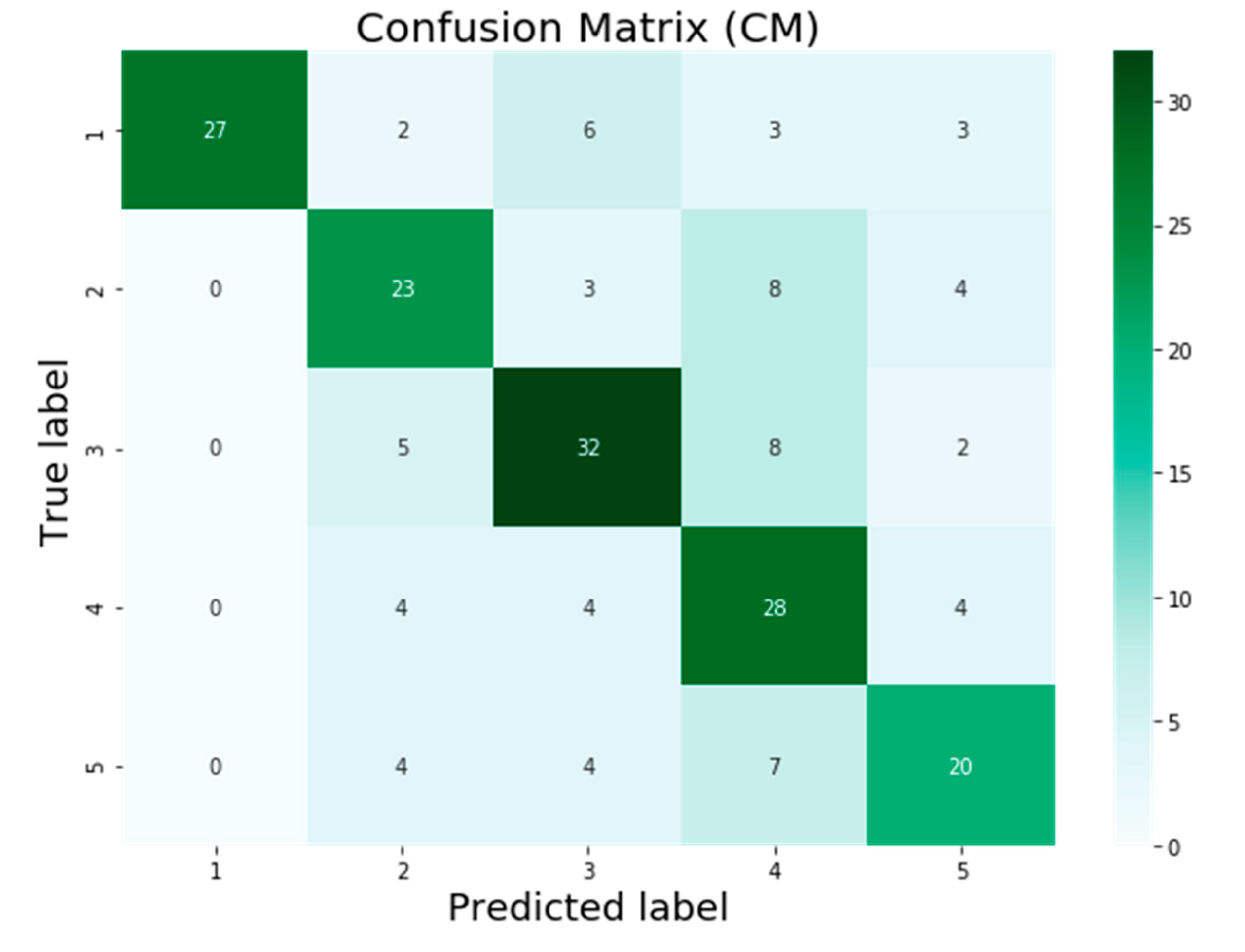
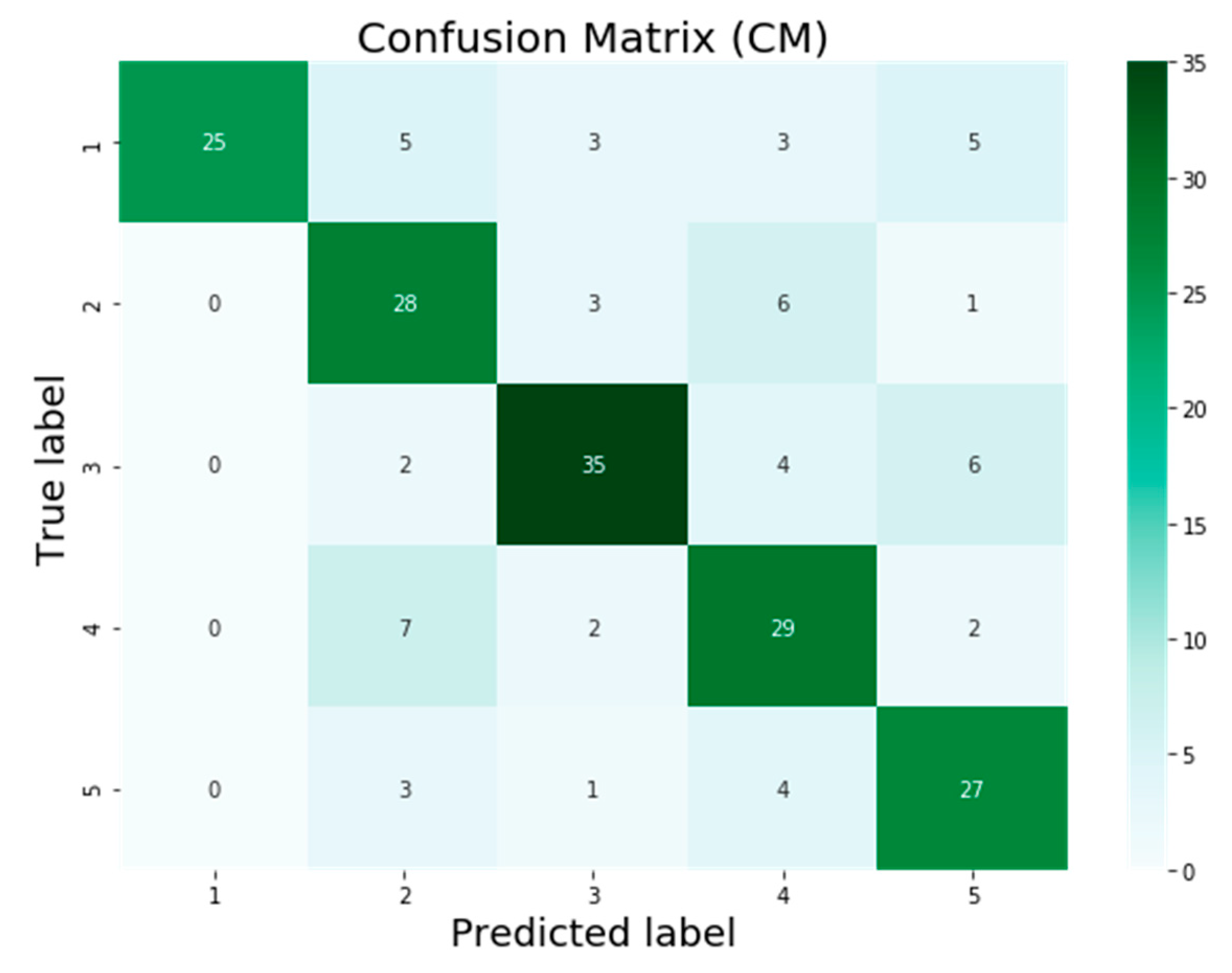
The testing dataset contains a total of 201 photos relating to the first five air pollution level classes such as good, unhealthy, poor, severe, and dangerous. These levels are represented in the classification problem by the numbers 1, 2, 3, 4, and 5. On the basis of the classification results provided by models, a confusion matrix was computed, which is also known as a summary of the results of the predictions made on a classification task or model classification accuracy.
The confusion matrix is presented in
Figure 7,
Figure 8,
Figure 9 and
Figure 10 for the four machine learning models SVM, VGG16, InceptionV3, and AQE-net that have been deployed in this study. The numbers 1 to 5 on the horizontal axis reflect the values that were predicted for the test samples, and the values 1 to 5 on the vertical axis represent the actual values of the test samples, respectively. In
Figure 7,
Figure 8,
Figure 9 and
Figure 10, the values that are on-diagonal show the number of correctly classified photos, whereas the values that are off-diagonal reflect the number of images with incorrect classifications that vary from the diagonal. After applying the SVM model to the KHI-AQI testing dataset, the confusion matrix is displayed in
Figure 7 below. In accordance with the findings, the SVM model successfully classified 113 out of 201 samples, whereas it mistakenly classified 88 samples. In total, there were 201 samples included in the study. The confusion matrix for the KHI-AQI testing dataset using VGG16 is depicted in
Figure 8. It was found that 119 of the samples were correctly categorized across all classes, whereas 82 of the samples were misclassified. When compared to the SVM model, the VGG16 algorithm provided six more results that were correctly categorized. After running VGG16 on the same testing dataset, the InceptionV3 algorithm was then applied; the confusion matrix for the InceptionV3 model can be seen in
Figure 9. The findings show that out of 201 samples, only 130 were correctly identified using the InceptionV3 model, while 71 samples were incorrectly classified. InceptionV3 had 11 more correctly classified results than VGG16. After first attempting to use the SVM, VGG16, and InceptionV3 models, we finally attempted to validate our proposed model, AQE-Net, by applying it to a testing dataset.
Figure 10 presents the classification results using the confusion matrix generated by the AQE-Net model after it was applied to the testing dataset. Out of 201 possible classifications, there were a total of 144 accurate classifications, while there were 57 wrong classifications. AQE-Net was found to have delivered 14 more correct classifications than InceptionV3, according to the findings. When it comes to the categorization of images with AQI levels, the overall confusion matrices on classification results obtained by models indicate that AQE-Net is more superior than other models.
In addition, we evaluated the predictive performance of the SVM, VGG16, InceptionV3, and AQE-Net models with the help of three statistical error metrics known as mean squared error (MSE), mean absolute error (MAE), and mean absolute percentage error (MAPE).
Table 4 shows the MSE, MAE, and MAPE values. When applied to the testing dataset, the SVM model achieved values of 1.915 MSE, 0.830 MAE, and 0.473 MAPE, respectively. The MSE was found to be 1.910, the MAE was 0.796, and the MAPE was found to be 0.465 using the VGG16 model. When compared to the SVM model, the VGG16 model produced fewer errors than the SMV model. Following the application of the VGG16 model, we next applied the InceptionV3 model, and the results of MSE, MAE, and MAPE were 1.373, 0.626, 0.326, respectively, which also reflects fewer errors than were produced by the earlier models, SVM and VGG16. In overall, the AQE-Net model that we proposed had a lower error rate than the other models that were employed in this research. AQE-Net generated estimates of 1.278 MSE, 0.542 MAE, and 0.310 MAPE, respectively, which is quite less than all other models. This shows that the AQE-Net model that we proposed is superior than other models.
4. Discussion
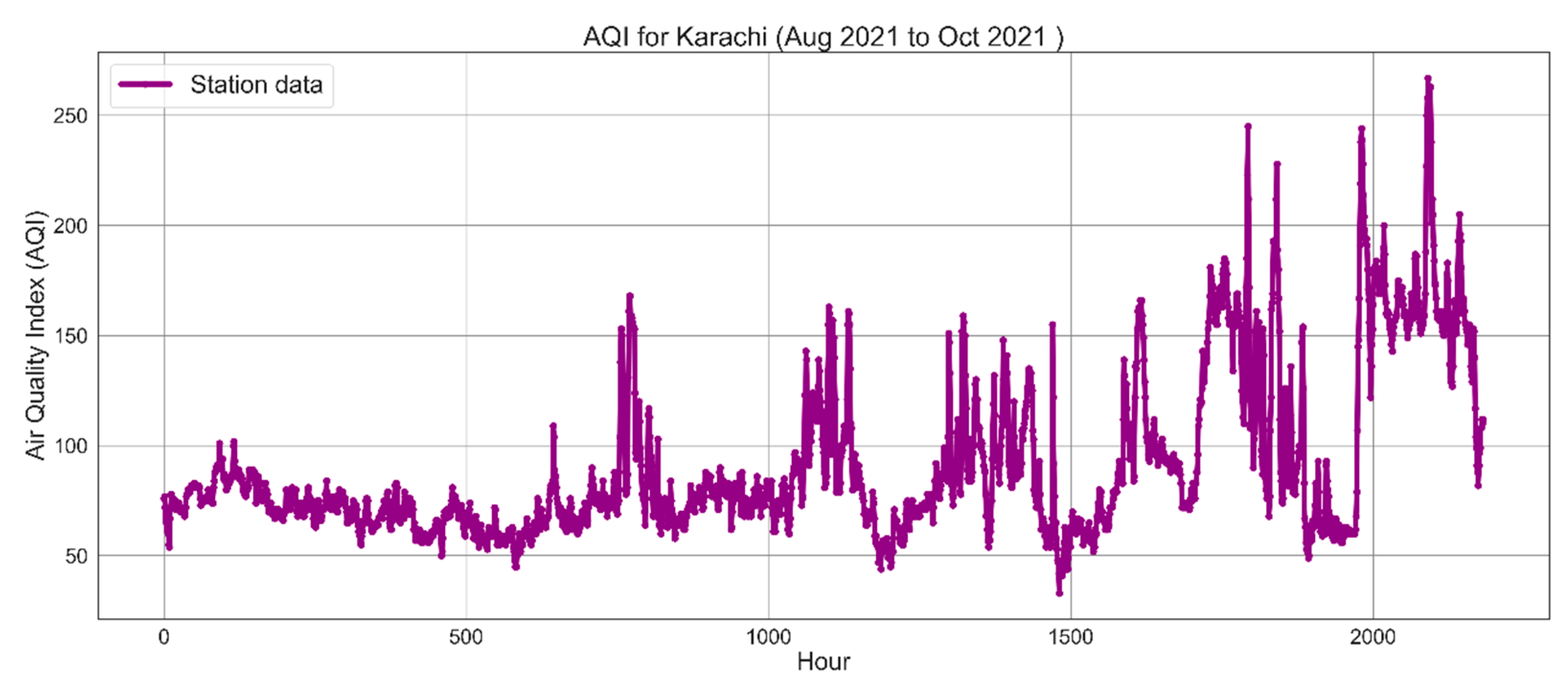
In this study, all of the sample images were taken from fixed-point images, which means the image is acquired at an angle to the sky and that about one-third of the image is taken up by land shared with a building. The goal is to emulate a more frequent and simpler shooting perspective. For monitoring purposes, at least 50% of the frames taken are of the sky. The photographs in this experiment depict scenarios that occur throughout the day (between 7:00 and 19:00). In the evenings, vision is quite poor due to the poor imaging quality. This experimental model is only appropriate for daytime air quality monitoring and is not suitable for nighttime monitoring. Because the model training data is gathered in Karachi, the model’s controllability, dependability, and efficiency are all pretty good in the local region, and the model’s prediction speed and accuracy are all relatively consistent. However, owing to regional climatic and atmospheric variances, the model may not be able to attain the requisite precision in other areas. Our model must be trained and tweaked again with local picture data before it can be used elsewhere. Due to various restrictions, this model will not be able to match the precision of air quality monitoring stations, but it can serve as a complementing tool. The model’s benefit is that individuals can utilize portable image acquisition equipment to get real-time air quality metrics, especially in rural and suburban regions, where the monitoring stations are located far from population centers. Future studies should focus on several areas that can be improved. Different weather conditions significantly impact the brightness or blackness of air quality photographs. The model can be used to directly extract the brightness properties of the picture from the data. Humidity, however, has no discernible influence on photos of air pollution, even though it may impact air quality. Future studies can take into account these considerations to increase model accuracy. Finally, we concentrated our investigation on the AQI, a complete indication of air quality. Future studies could focus on PM2.5 if they wanted to do so.
The dataset size, the initial learning rate, and the number of layers are three training network characteristics that have an impact on the results. This section discusses the impact of the MiniBatchsize training parameter. MiniBatchsize or Batch training involves backpropagating the error of classification via groups of pictures [
66]. We propose training the model for various MiniBatchsize values in order to see how this parameter affects the model.
Table 5 and
Table 6 give the findings for the values of 60 and 10.
Classification rates during a major training period that ranged between 0.4866 and 0.6541 were obtained by training for various numbers of epochs and a big MiniBatchsize of 60. When compared to the results from
Table 5, the decline in rate helps to explain the memorization issue depicted in
Figure 11, where unhealthy has been misclassified to the poor category. Images (a), (b), (c), and (d) in
Figure 11 are all unhealthy which were mislabeled.
The training for various numbers of epochs results in significant values of the classification rate, as shown in
Table 6. These values, which range from 0.5866 to 0.7014, are computed over a training period of 25,934.44 s. Precision in performing the categorization operation is made possible by MiniBatchsize’s low value.
5. Conclusions
In recent decades, air pollution has posed major hazards to human health, prompting widespread public concern. However, ambient pollution measures are expensive, so the geographic coverage of air quality monitoring stations is limited. A low-cost, high-efficiency air quality sensor system benefits human health and air pollution prevention. The AQE-Net air quality assessment model, which is based on deep learning, is proposed in this article. Specifically, deep convolutional neural networks are used to extract feature representational information relating to air quality from scene photos, with the information used to identify air quality levels. A comparative examination of our developed model with traditional and deep learning models, such as SVM, VGG16, and InceptionV3, was also carried out on the KHI-AQI dataset. The experimental findings indicated that the AQE-Net model is superior to other models in classifying photos with AQI levels.
This study has certain limitations. The study used a small sample size and focused only on the Karachi region. Future research should add more datasets and multiple regions to compare the findings with our study. Future studies should take in to account different pollutants, such as PM2.5, PM10, and carbon monoxide (CO2). Additionally, it is also important to examine seasonal weather conditions and estimate air quality, particularly when visibility is affected due to a foggy environment.



 and
and 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}