Comparison of Five Spatio-Temporal Satellite Image Fusion Models over Landscapes with Various Spatial Heterogeneity and Temporal Variation


Abstract
:
1. Introduction
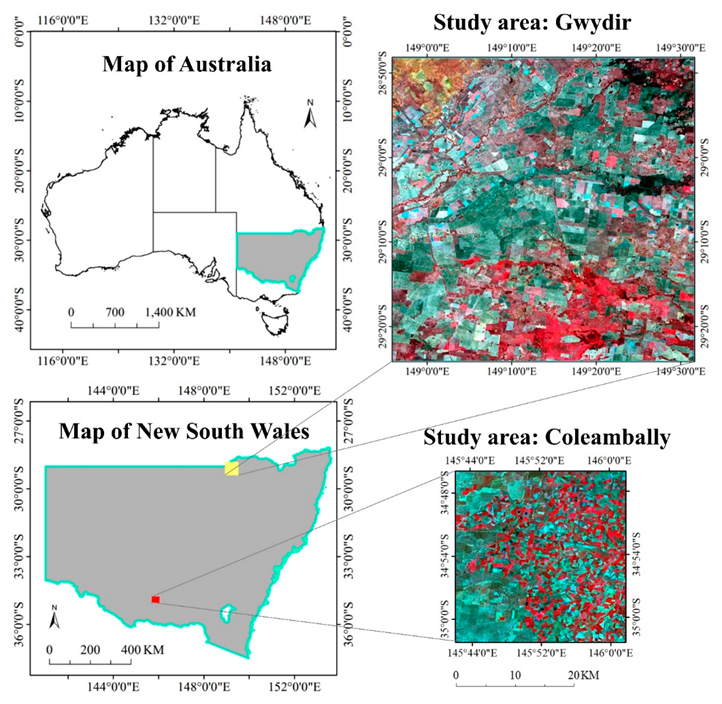
2. Study Area and Datasets
3. Methods
3.1. Five STIF Models
3.1.1. STARFM
3.1.2. UBDF
3.1.3. One-Pair Learning Method
3.1.4. FSDAF
3.1.5. Fit-FC
3.2. Model Parameter Settings and Accuracy Assessment
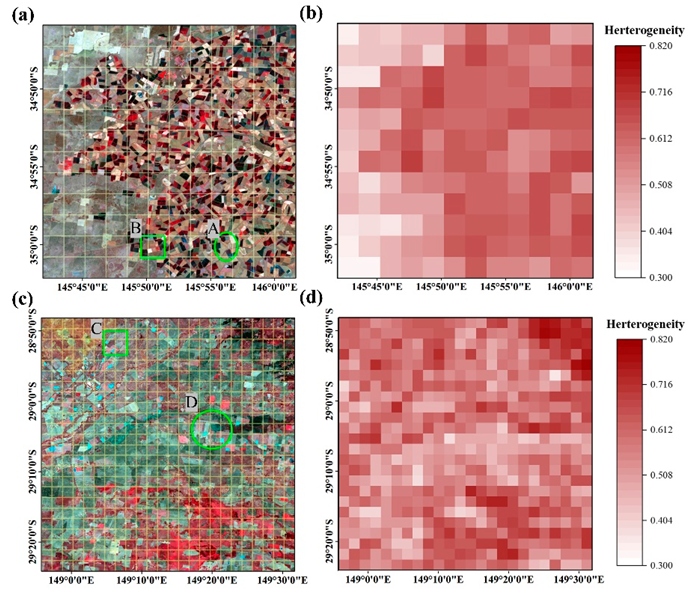
3.3. Spatial Heterogeneity and Temporal Variation Indices
4. Results
4.1. Visual Evaluations
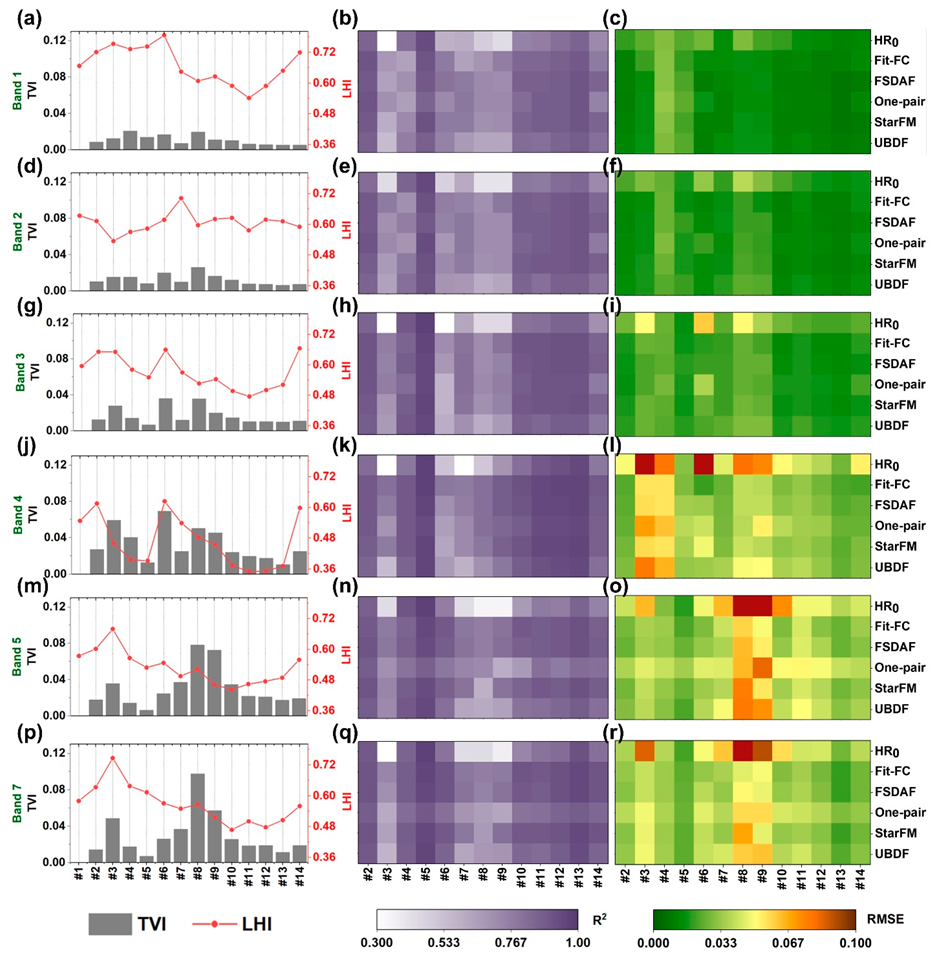
4.2. Scene-Level Accuracy Assessment
4.3. Local-Level Comparisons
5. Discussion
5.1. Model Characteristics and Applicable Situations
5.2. Limitations and Future Directions
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A




References
- Gao, F.; Hilker, T.; Zhu, X.; Anderson, M.; Masek, J.; Wang, P.; Yang, Y. Fusing Landsat and MODIS data for vegetation monitoring. IEEE Geosci. Remote Sens. Mag. 2015, 3, 47–60. [Google Scholar] [CrossRef]
- Hilker, T.; Wulder, M.A.; Coops, N.C.; Linke, J.; McDermid, G.; Masek, J.G.; Gao, F.; White, J.C. A new data fusion model for high spatial-and temporal-resolution mapping of forest disturbance based on Landsat and MODIS. Remote Sens. Environ. 2009, 113, 1613–1627. [Google Scholar] [CrossRef]
- Weng, Q.; Fu, P.; Gao, F. Generating daily land surface temperature at Landsat resolution by fusing Landsat and MODIS data. Remote Sens. Environ. 2014, 145, 55–67. [Google Scholar] [CrossRef]
- Zhu, X.; Cai, F.; Tian, J.; Williams, T.K.-A. Spatiotemporal Fusion of Multisource Remote Sensing Data: Literature Survey, Taxonomy, Principles, Applications, and Future Directions. Remote Sens. 2018, 10, 527. [Google Scholar] [Green Version]
- Zhao, Y.; Huang, B.; Song, H. A robust adaptive spatial and temporal image fusion model for complex land surface changes. Remote Sens. Environ. 2018, 208, 42–62. [Google Scholar] [CrossRef]
- Wang, Q.; Atkinson, P.M. Spatio-temporal fusion for daily Sentinel-2 images. Remote Sens. Environ. 2018, 204, 31–42. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.; Helmer, E.H.; Gao, F.; Liu, D.; Chen, J.; Lefsky, M.A. A flexible spatiotemporal method for fusing satellite images with different resolutions. Remote Sens. Environ. 2016, 172, 165–177. [Google Scholar] [CrossRef]
- Song, H.; Huang, B. Spatiotemporal satellite image fusion through one-pair image learning. IEEE Trans. Geosci. Remote Sens. 2013, 51, 1883–1896. [Google Scholar] [CrossRef]
- Zhu, X.; Chen, J.; Gao, F.; Chen, X.; Masek, J.G. An enhanced spatial and temporal adaptive reflectance fusion model for complex heterogeneous regions. Remote Sens. Environ. 2010, 114, 2610–2623. [Google Scholar] [CrossRef]
- Liu, M.; Liu, X.; Wu, L.; Zou, X.; Jiang, T.; Zhao, B. A modified spatiotemporal fusion algorithm using phenological information for predicting reflectance of paddy rice in southern China. Remote Sens. 2018, 10, 772. [Google Scholar] [CrossRef]
- Wu, P.; Shen, H.; Zhang, L.; Göttsche, F.-M. Integrated fusion of multi-scale polar-orbiting and geostationary satellite observations for the mapping of high spatial and temporal resolution land surface temperature. Remote Sens. Environ. 2015, 156, 169–181. [Google Scholar] [CrossRef]
- Wang, P.; Gao, F.; Masek, J.G. Operational data fusion framework for building frequent Landsat-like imagery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 7353–7365. [Google Scholar] [CrossRef]
- Shen, H.; Wu, P.; Liu, Y.; Ai, T.; Wang, Y.; Liu, X. A spatial and temporal reflectance fusion model considering sensor observation differences. Int. J. Remote Sens. 2013, 34, 4367–4383. [Google Scholar] [CrossRef]
- Roy, D.P.; Ju, J.; Lewis, P.; Schaaf, C.; Gao, F.; Hansen, M.; Lindquist, E. Multi-temporal MODIS–Landsat data fusion for relative radiometric normalization, gap filling, and prediction of Landsat data. Remote Sens. Environ. 2008, 112, 3112–3130. [Google Scholar] [CrossRef]
- Gevaert, C.M.; García-Haro, F.J. A comparison of STARFM and an unmixing-based algorithm for Landsat and MODIS data fusion. Remote Sens. Environ. 2015, 156, 34–44. [Google Scholar] [CrossRef]
- Amorós-López, J.; Gómez-Chova, L.; Alonso, L.; Guanter, L.; Zurita-Milla, R.; Moreno, J.; Camps-Valls, G. Multitemporal fusion of Landsat/TM and ENVISAT/MERIS for crop monitoring. Int. J. Appl. Earth Obs. Geoinf. 2013, 23, 132–141. [Google Scholar] [CrossRef]
- Zurita-Milla, R.; Kaiser, G.; Clevers, J.; Schneider, W.; Schaepman, M. Downscaling time series of MERIS full resolution data to monitor vegetation seasonal dynamics. Remote Sens. Environ. 2009, 113, 1874–1885. [Google Scholar] [CrossRef]
- Zurita-Milla, R.; Clevers, J.G.; Schaepman, M.E. Unmixing-based Landsat TM and MERIS FR data fusion. IEEE Geosci. Remote Sens. Lett. 2008, 5, 453–457. [Google Scholar] [CrossRef]
- Zhukov, B.; Oertel, D.; Lanzl, F.; Reinhackel, G. Unmixing-based multisensor multiresolution image fusion. IEEE Trans. Geosci. Remote Sens. 1999, 37, 1212–1226. [Google Scholar] [CrossRef]
- Huang, B.; Zhang, H. Spatio-temporal reflectance fusion via unmixing: Accounting for both phenological and land-cover changes. Int. J. Remote Sens. 2014, 35, 6213–6233. [Google Scholar] [CrossRef]
- Zhang, W.; Li, A.; Jin, H.; Bian, J.; Zhang, Z.; Lei, G.; Qin, Z.; Huang, C. An enhanced spatial and temporal data fusion model for fusing Landsat and MODIS surface reflectance to generate high temporal Landsat-like data. Remote Sens. 2013, 5, 5346–5368. [Google Scholar] [CrossRef]
- Wu, M.; Niu, Z.; Wang, C.; Wu, C.; Wang, L. Use of MODIS and Landsat time series data to generate high-resolution temporal synthetic Landsat data using a spatial and temporal reflectance fusion model. J. Appl. Remote Sens. 2012, 6, 063507. [Google Scholar]
- Huang, B.; Song, H. Spatiotemporal reflectance fusion via sparse representation. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3707–3716. [Google Scholar] [CrossRef]
- Moosavi, V.; Talebi, A.; Mokhtari, M.H.; Shamsi, S.R.F.; Niazi, Y. A wavelet-artificial intelligence fusion approach (WAIFA) for blending Landsat and MODIS surface temperature. Remote Sens. Environ. 2015, 169, 243–254. [Google Scholar] [CrossRef]
- Liu, X.; Deng, C.; Wang, S.; Huang, G.-B.; Zhao, B.; Lauren, P. Fast and accurate spatiotemporal fusion based upon extreme learning machine. IEEE Geosci. Remote Sens. Lett. 2016, 13, 2039–2043. [Google Scholar] [CrossRef]
- Liu, X.; Deng, C.; Chanussot, J.; Hong, D.; Zhao, B. StfNet: A Two-Stream Convolutional Neural Network for Spatiotemporal Image Fusion. IEEE Trans. Geosci. Remote Sens. 2019. [Google Scholar] [CrossRef]
- Tan, Z.; Yue, P.; Di, L.; Tang, J.J.R.S. Deriving high spatiotemporal remote sensing images using deep convolutional network. Remote Sens. 2018, 10, 1066. [Google Scholar] [CrossRef]
- Song, H.; Liu, Q.; Wang, G.; Hang, R.; Huang, B. Spatiotemporal Satellite Image Fusion Using Deep Convolutional Neural Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 821–829. [Google Scholar] [CrossRef]
- Xu, Y.; Huang, B.; Xu, Y.; Cao, K.; Guo, C.; Meng, D. Spatial and temporal image fusion via regularized spatial unmixing. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1362–1366. [Google Scholar]
- Chen, B.; Huang, B.; Xu, B. A hierarchical spatiotemporal adaptive fusion model using one image pair. Int. J. Digit. Earth 2017, 10, 639–655. [Google Scholar] [CrossRef]
- Emelyanova, I.V.; McVicar, T.R.; Van Niel, T.G.; Li, L.T.; van Dijk, A.I. Assessing the accuracy of blending Landsat–MODIS surface reflectances in two landscapes with contrasting spatial and temporal dynamics: A framework for algorithm selection. Remote Sens. Environ. 2013, 133, 193–209. [Google Scholar] [CrossRef]
- Chen, B.; Huang, B.; Xu, B. Comparison of spatiotemporal fusion models: A review. Remote Sens. 2015, 7, 1798–1835. [Google Scholar] [CrossRef]
- Zhang, F.; Zhu, X.; Liu, D. Blending MODIS and Landsat images for urban flood mapping. Int. J. Remote Sens. 2014, 35, 3237–3253. [Google Scholar] [CrossRef]
- Li, A.; Bo, Y.; Zhu, Y.; Guo, P.; Bi, J.; He, Y. Blending multi-resolution satellite sea surface temperature (SST) products using Bayesian maximum entropy method. Remote Sens. Environ. 2013, 135, 52–63. [Google Scholar] [CrossRef]
- Huang, B.; Zhang, H.; Song, H.; Wang, J.; Song, C. Unified fusion of remote-sensing imagery: Generating simultaneously high-resolution synthetic spatial–temporal–spectral earth observations. Remote Sens. Lett. 2013, 4, 561–569. [Google Scholar] [CrossRef]
- Liao, L.; Song, J.; Wang, J.; Xiao, Z.; Wang, J. Bayesian method for building frequent Landsat-like NDVI datasets by integrating MODIS and Landsat NDVI. Remote Sens. 2016, 8, 452. [Google Scholar] [CrossRef]
- Xue, J.; Leung, Y.; Fung, T. A Bayesian Data Fusion Approach to Spatio-Temporal Fusion of Remotely Sensed Images. Remote Sens. 2017, 9, 1310. [Google Scholar] [CrossRef]
- Ke, Y.; Im, J.; Park, S.; Gong, H. Spatiotemporal downscaling approaches for monitoring 8-day 30 m actual evapotranspiration. ISPRS J. Photogramm. Remote Sens. 2017, 126, 79–93. [Google Scholar] [CrossRef]
- Quan, J.; Zhan, W.; Ma, T.; Du, Y.; Guo, Z.; Qin, B. An integrated model for generating hourly Landsat-like land surface temperatures over heterogeneous landscapes. Remote Sens. Environ. 2018, 206, 403–423. [Google Scholar] [CrossRef]
- Chen, B.; Xu, B. A novel method for measuring landscape heterogeneity changes. Remote Sens. Lett. 2015, 12, 567–571. [Google Scholar] [CrossRef]
- Cheng, Q.; Liu, H.; Shen, H.; Wu, P.; Zhang, L. A spatial and temporal nonlocal filter-based data fusion method. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4476–4488. [Google Scholar] [CrossRef]
- Gao, F.; Masek, J.; Schwaller, M.; Hall, F. On the blending of the Landsat and MODIS surface reflectance: Predicting daily Landsat surface reflectance. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2207–2218. [Google Scholar]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image super-resolution via sparse representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Khan, M.M.; Alparone, L.; Chanussot, J. Pansharpening quality assessment using the modulation transfer functions of instruments. IEEE Trans. Geosci. Remote Sens. 2009, 47, 3880–3891. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Thonfeld, F.; Feilhauer, H.; Braun, M.; Menz, G. Robust Change Vector Analysis (RCVA) for multi-sensor very high resolution optical satellite data. Int. J. Appl. Earth Obs. Geoinf. 2016, 50, 131–140. [Google Scholar] [CrossRef]
- Gao, F.; Anderson, M.C.; Zhang, X.; Yang, Z.; Alfieri, J.G.; Kustas, W.P.; Mueller, R.; Johnson, D.M.; Prueger, J.H. Toward mapping crop progress at field scales through fusion of Landsat and MODIS imagery. Remote Sens. Environ. 2017, 188, 9–25. [Google Scholar] [CrossRef] [Green Version]
- Ke, Y.; Im, J.; Park, S.; Gong, H. Downscaling of MODIS One kilometer evapotranspiration using Landsat-8 data and machine learning approaches. Remote Sens. 2016, 8, 215. [Google Scholar] [CrossRef]
- Dao, P.D.; Mong, N.T.; Chan, H.-P.J.G.; Sensing, R. Landsat-MODIS Image Fusion and Object-based Image Analysis for Observing Flood Inundation in a Heterogeneous Vegetated Scene. Gisci. Remote Sens. 2019. [Google Scholar] [CrossRef]
- Chen, B.; Chen, L.; Huang, B.; Michishita, R.; Xu, B. Dynamic monitoring of the Poyang Lake wetland by integrating Landsat and MODIS observations. ISPRS J. Photogramm. Remote Sens. 2018, 139, 75–87. [Google Scholar] [CrossRef]
- Latifi, H.; Dahms, T.; Beudert, B.; Heurich, M.; Kübert, C.; Dech, S. Synthetic RapidEye data used for the detection of area-based spruce tree mortality induced by bark beetles. Gisci. Remote Sens. 2018, 55, 839–859. [Google Scholar] [CrossRef]
- Liu, M.; Yang, W.; Zhu, X.; Chen, J.; Chen, X.; Yang, L.; Helmer, E. An Improved Flexible Spatiotemporal DAta Fusion (IFSDAF) method for producing high spatiotemporal resolution normalized difference vegetation index time series. Remote Sens. Environ. 2019, 227, 74–89. [Google Scholar] [CrossRef]
- Hilker, T.; Wulder, M.A.; Coops, N.C.; Seitz, N.; White, J.C.; Gao, F.; Masek, J.G.; Stenhouse, G. Generation of dense time series synthetic Landsat data through data blending with MODIS using a spatial and temporal adaptive reflectance fusion model. Remote Sens. Environ. 2009, 113, 1988–1999. [Google Scholar] [CrossRef]
- Onojeghuo, A.O.; Blackburn, G.A.; Wang, Q.; Atkinson, P.M.; Kindred, D.; Miao, Y. Rice crop phenology mapping at high spatial and temporal resolution using downscaled MODIS time-series. Gisci. Remote Sens. 2018, 55, 659–677. [Google Scholar] [CrossRef] [Green Version]
- Fernandez-Beltran, R.; Latorre-Carmona, P.; Pla, F. Single-frame super-resolution in remote sensing: A practical overview. Int. J. Remote Sens. 2017, 38, 314–354. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Coleambally | Gwydir | ||
|---|---|---|---|
| Image No. | Date | Image No. | Date |
| 1 | 08 October 2001 | 1 | 16 April 2004 |
| 2 | 17 October 2001 | 2 | 02 May 2004 |
| 3 | 02 November 2001 | 3 | 05 July 2004 |
| 4 | 09 November 2001 | 4 | 06 August 2004 |
| 5 | 25 November 2001 | 5 | 22 August 2004 |
| 6 | 04 December 2001 | 6 | 25 October 2004 |
| 7 | 05 January 2002 | 7 | 26 November 2004 |
| 8 | 12 January 2002 | 8 | 12 December 2004 |
| 9 | 13 Feberary 2002 | 9 | 28 December 2004 |
| 10 | 22 Feberary 2002 | 10 | 13 January 2005 |
| 11 | 10 March 2002 | 11 | 29 January 2005 |
| 12 | 17 March 2002 | 12 | 14 Feberary 2005 |
| 13 | 02 April 2002 | 13 | 02 March 2005 |
| 14 | 11 April 2002 | 14 | 03 April 2005 |
| 15 | 18 April 2002 | ||
| 16 | 27 April 2002 | ||
| 17 | 04 May 2002 | ||
| STIF Methzods | Number of Classes | Moving Window Size | Number of Similar Pixels | Dictionary Size of the First Layer |
|---|---|---|---|---|
| STARFM | 10 | 31 × 31 Landsat pixels | N/A | N/A |
| UBDF | 6 | 7 × 7 MODIS pixels | N/A | N/A |
| One-pair learning | N/A | N/A | N/A | 1000 (1st layer) 2000 (2nd layer) |
| Fit-FC | N/A | 5 × 5 MODIS pixels in RM 31 × 31 Landsat pixels in SF and RC | 20 | N/A |
| FSDAF | 6 | 31 × 31 Landsat pixels | 20 | N/A |
| Study Site (Landsat Image Size) | Fit-FC | FSDAF | One-Pair Learning (Training/Prediction) | STARFM | UBDF |
|---|---|---|---|---|---|
| Coleambally (1200 × 1200) | 149 | 473 | 952/81 | 207 | 279 |
| Gwydir (2400 × 2400) | 603 | 1864 | 2976/348 | 806 | 1054 |
| Model | Pros | Cons |
|---|---|---|
| Fit-FC | High reflectance accuracy for HL, HH and LH landscapes and image patches Computation efficient | Less accurate for LH landscapes and image patches Less effective in capturing image structure |
| FSDAF | Robust with stable results Good reflectance accuracy for both phenological and land cover type change | Less computation efficient compared to Fit-FC, STARFM and UBDF |
| One-pair learning | Good for large-area land cover type change with shape change Good for capturing image structure | Computationally intensive |
| STARFM | Good reflectance accuracy for heterogeneous landscapes with phenological change More computational efficient than FSDAF, one-pair learning and UBDF | Not suitable for land cover type change, especially with object shape change |
| UBDF | Acceptable reflectance accuracy for heterogeneous landscapes with phenological change | Lowest accuracy among the five models |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, M.; Ke, Y.; Yin, Q.; Chen, X.; Im, J. Comparison of Five Spatio-Temporal Satellite Image Fusion Models over Landscapes with Various Spatial Heterogeneity and Temporal Variation. Remote Sens. 2019, 11, 2612. https://doi.org/10.3390/rs11222612
Liu M, Ke Y, Yin Q, Chen X, Im J. Comparison of Five Spatio-Temporal Satellite Image Fusion Models over Landscapes with Various Spatial Heterogeneity and Temporal Variation. Remote Sensing. 2019; 11(22):2612. https://doi.org/10.3390/rs11222612
Chicago/Turabian StyleLiu, Maolin, Yinghai Ke, Qi Yin, Xiuwan Chen, and Jungho Im. 2019. "Comparison of Five Spatio-Temporal Satellite Image Fusion Models over Landscapes with Various Spatial Heterogeneity and Temporal Variation" Remote Sensing 11, no. 22: 2612. https://doi.org/10.3390/rs11222612