1.3.1. Feature Extraction
Due to the consideration of a general classification task, we consider a classification of single data points (here: pixels) without taking into account neighborhood relations among data points (here: relations within the pixel neighborhood). Accordingly, each pixel in the hyperspectral imagery is typically described by considering spectral features in the form of reflectance values across all spectral bands and concatenating them to a feature vector.
There are also approaches for the classification of hyperspectral imagery which focus on spatial features, where relations within the pixel neighborhood are taken into account. Such spatial features have for instance been presented with morphological profiles [
7] or morphological attribute profiles [
8,
9]. Furthermore, it has been proposed to derive features by sampling spectral information within adaptive pixel neighborhoods [
10] or to derive segment-based features from superpixels [
11,
12,
13]. As spatial features allow describing local image features such as edges, corners and spots, it has also been proposed to efficiently extract texture information preserved in hyperspectral imagery by using local binary patterns and global Gabor filters in a set of selected bands [
14]. In this regard, image features are described using a local neighborhood with a certain size. To take into account spatial image features at multiple scales, an extension towards the use of multiscale texture features has been presented [
15]. Besides, it has been proposed to fuse information from adjacent spectral bands, e.g., by extracting texture features from different direction patterns and thereby not only considering neighboring pixels but also the characteristics across consecutive bands [
16].
A variety of investigations also focuses on spectral unmixing [
17,
18,
19,
20]. There, the objective consists in decomposing the measured spectrum of each pixel into a collection of its constituent spectral signatures (“endmembers”) and a set of corresponding values (“abundances”) indicating the contribution of each spectral signature. Particularly regarding the classification of hyperspectral imagery, where pixels may correspond to a relatively large spatial size, it is likely to have several materials or substances that contribute to the respectively measured spectrum. To decompose the latter into spectral signatures corresponding to various materials or substances, both linear and non-linear (mostly geometrical or statistical) approaches for spectral unmixing have been proposed [
17,
18,
19,
20].
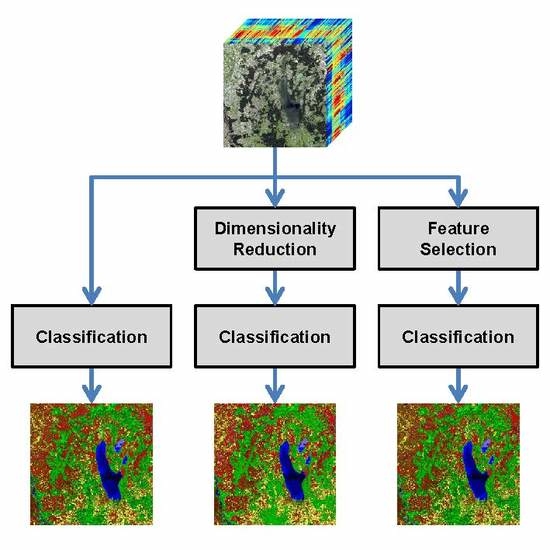
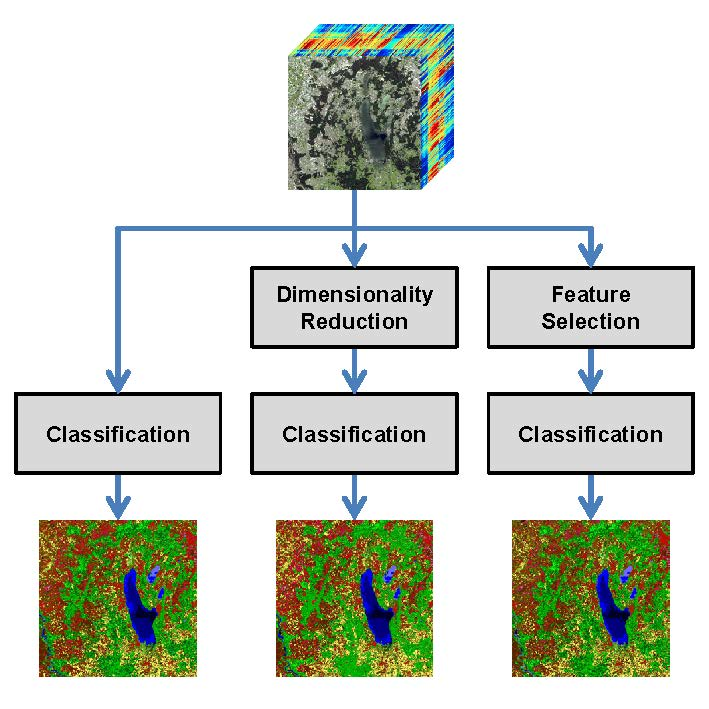
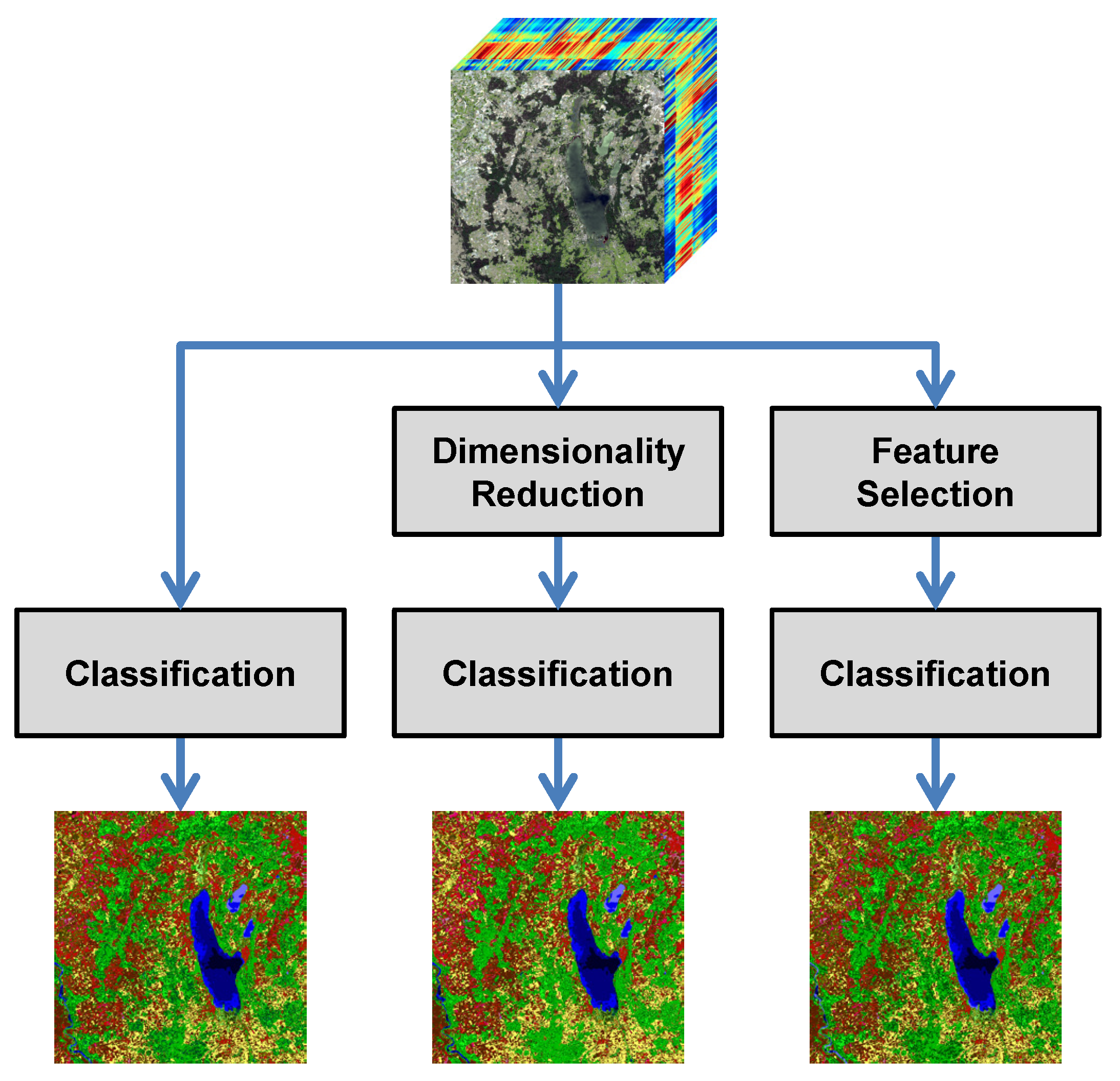
1.3.2. Dimensionality Reduction (DR) vs. Feature Selection (FS)
For many applications, as many features as possible are extracted in the hope to compensate a lack of knowledge about the scene and/or data. Among the extracted features, however, some might be more relevant, whereas others might be less relevant or even redundant. Particularly for the classification of high-dimensional data, one has to take into account the Hughes phenomenon [
21]. According to this phenomenon, an increase of the number of features over a certain threshold decreases the predictive accuracy of a classifier, given a constant number of training examples. In the context of classifying hyperspectral data, the Hughes phenomenon has been reported in [
22,
23]. However, it has also been verified for classification tasks relying only on a relatively small number of features, e.g., in [
24].
To address the Hughes phenomenon, several approaches focus on dimensionality reduction where the objective is to derive a new data representation based on fewer, but potentially better features extracted from the given data representation. In this regard, the most commonly applied techniques are represented by variants of Principal Component Analysis (PCA) [
25], Independent Component Analysis (ICA) [
26,
27], or Linear Discriminant Analysis (LDA) [
28]. These techniques apply linear transformations to map the given feature space (which is spanned by the complete set of hyperspectral bands in our case) to a new space spanned by meta-features. Using such techniques, certain characteristics of the considered data are contained in very few meta-features which are used as the basis for subsequent tasks. While this typically improves both effectiveness and efficiency, derived results hardly allow concluding about relationships with respect to physical properties (as e.g., possible when considering the wavelengths of involved spectral bands).
Consequently, another strategy to address the Hughes phenomenon is followed by feature selection. Here, the objective is to retain the most relevant and most informative features among a set of features, i.e., a subset of the original features, while discarding less relevant and/or redundant features. This, in turn, typically allows gaining predictive accuracy, improving computational efficiency with respect to both time and memory consumption, and retaining meaningful features with respect to the given task [
3,
6]. In general, one may distinguish between supervised and unsupervised feature selection techniques. The supervised techniques can further be sub-categorized into three groups:
Filter-based methods focus on evaluating relatively simple relations between features and classes and possibly also among features. These relations are typically quantified via a score function which is directly applied to the given training data [
4,
6,
24,
29]. Such a classifier-independent scheme typically results in simplicity and efficiency. Many respective methods only focus on relations between features and classes (univariate filter-based feature selection). These relations can be quantified by comparing the values of a feature across all data points with the respective class labels, e.g., via the correlation coefficient [
30], Gini index [
31], Fisher score [
32], or information gain [
33]. This allows ranking the features with respect to their relevance. Other methods take into account both feature-class relations and feature-feature relations (multivariate filter-based feature selection) and can thus be used to remove redundancy to a certain degree. Respective examples are represented by Correlation-based Feature Selection [
34] and the Fast Correlation-Based Filter [
35].
Wrapper-based methods rely on the use of a classifier in order to select features based on their suitability for classification. On the one hand, this may be achieved via Sequential Forward Selection (SFS) where, beginning with an empty feature subset, it is tested which feature can be added so that the increase in performance is as high as possible. Accordingly, classification is first performed separately for each available feature. The feature leading to the highest predictive accuracy is then added to the feature subset. The following steps consist in successively adding the feature that improves performance the most when considering the existing feature subset and the tested feature as input for classification. On the other hand, a classifier may be involved via Sequential Backward Elimination (SBE) where, beginning with the whole feature set, it is tested which feature can be discarded so that the decrease in performance is as low as possible. The following steps consist in successively removing the feature that reduces performance the least. Besides sequential selection, genetic algorithms which represent a family of stochastic optimization heuristics can be involved to select feature subsets [
36].
Embedded methods rely on the use of a classifier which provides the capability to internally select the most relevant features during the training phase of the classifier. Prominent examples in this regard are represented by the AdaBoost classifier [
37] and the Random Forest classifier [
38]. In contrast to wrapper-based methods, the involved classifier has to be trained only once to be able to conclude about the relevance of single features and the computational effort is therefore still acceptable, particularly for the Random Forest classifier which reveals a reasonable computational effort for both training and testing phase.
For more details, we refer to a comprehensive review of feature selection techniques [
3]. Note that many of these techniques require training data with a balanced number of training examples per class as otherwise a bias in feature selection can be expected. From our brief summary, however, it becomes obvious that, particularly for high-dimensional data as given for hyperspectral imagery, applying a wrapper-based method can be extremely time-consuming. For this reason, we do not involve respective techniques in the scope of this paper.
As supervised feature selection via a wrapper-based method or an embedded method relies on the use of a classifier, the selected feature sets strongly depend on the involved classifier and its settings. Furthermore, the feature sets are selected with respect to a particular classification task and therefore depend on the number as well as on the definition of the considered classes. The latter also holds for filter-based methods evaluating relations between features and classes. To avoid such dependencies and hence make feature selection independent of the classifier as well as of the classification task, it seems desirable to conduct unsupervised feature selection which however typically implies an increased computational burden.
Among the unsupervised feature selection techniques, the main objective is represented by a clustering of the input data. In analogy to supervised feature selection, a categorization with respect to filter-based and wrapper-based methods can also be applied for unsupervised feature selection [
39,
40]. In the context of unsupervised feature selection, wrapper-based methods rely on the idea of first applying a clustering algorithm and then evaluating the quality of the derived clustering via cluster validation techniques [
41]. During this process, no external information in the form of corresponding class labels is involved. It has been found that a dynamic number of allowed clusters is to be preferred [
42]. Regarding unsupervised feature selection, relevant features are often selected based on the distribution of their values across the given feature vectors, e.g., by using an entropy measure which allows reasoning about the existence and the significance level of clusters [
43]. A different strategy for unsupervised feature selection relies on assessing the similarity between features and selecting a subset of features that are highly dissimilar from each other [
44,
45,
46,
47], whereby different similarity metrics can be used. Furthermore, the BandClust algorithm [
48] has been proposed which relies on a minimization of mutual information to split the given range of spectral bands into disjoint clusters or sub-bands. A probabilistic model-based clustering approach has been presented in [
49]. Thereby, the parameters of the model are inferred by maximizing the information between data features and cluster assignments. Besides such clustering techniques, the Random Cluster Ensemble (RCE) technique [
50] relies on the variable importance measure used in Random Forests and estimates the out-of-bag feature importance from an ensemble of partitions. Moreover, unsupervised feature selection based on a self-organizing map (SOM) [
51] has been proposed for the analysis of high-dimensional data [
52] and for a case study focusing on the analysis of near-infrared data in terms of a prediction of certain properties of biodiesel fuel [
53]. For a performance evaluation of different unsupervised feature selection methods in the context of analyzing hyperspectral data, we refer to [
47,
54].
A summary of the main characteristics of the different concepts for dimensionality reduction and feature selection is provided in
Table 1.
In this paper, we propose to perform feature selection without taking into account the classification task, i.e., the class labels of the considered data. Accordingly, we focus on unsupervised feature selection only taking into account the characteristics of features which are implicitly preserved in the topology of the given data. To describe these characteristics, we consider the ultrametricity in the data. An important motivation for finding ultrametricity in data is that nearest neighbor search can be carried out very efficiently [
55]. In general, an “ultrametric” is a distance
d which satisfies the strict triangle inequality:
with
x,
y and
z referring to data points. After a
p-adic encoding of data, ultrametric spaces have simpler classification algorithms than their classical counterparts [
56,
57]. This motivates to measure the ultrametricity of very high-dimensional data [
58], and it has been found that they are increasingly ultrametric as their dimension increases. Accordingly, it becomes increasingly easy to find clusters, as the high-dimensional structure is hierarchical in the limit. The results presented in [
58] lead to believe that high-dimensional encoding of data reveals the inherent ultrametric, i.e., hierarchical, structure of data, rather than imposing such on data. In this way, an ultrametric or almost ultrametric encoding of data should lead to better classification results than other data encodings. Thus measures for the ultrametricity of data become crucial.
There are different ways of measuring the ultrametricity of data taken from a metric space such as
. The first such method has been introduced in [
59] and considers the discrepancy between the given metric
d and its subdominant ultrametric which is the unique maximal ultrametric below
d [
60]. It has the problem that it is biased towards the single-link clustering. In this hierarchical clustering method, the similarity of two clusters is the similarity of their most similar elements. This makes single-link clustering suffer from the undesired chaining effect where clusters become almost linear arrangements of points. In order to remedy this effect, Murtagh defines an ultrametricity index which overcomes the chaining effect as the ratio between the number of triangles which are almost isosceles and the number of all triangles in the data [
55]. Furthermore, a clustering based on ultrametric properties is described in [
61].
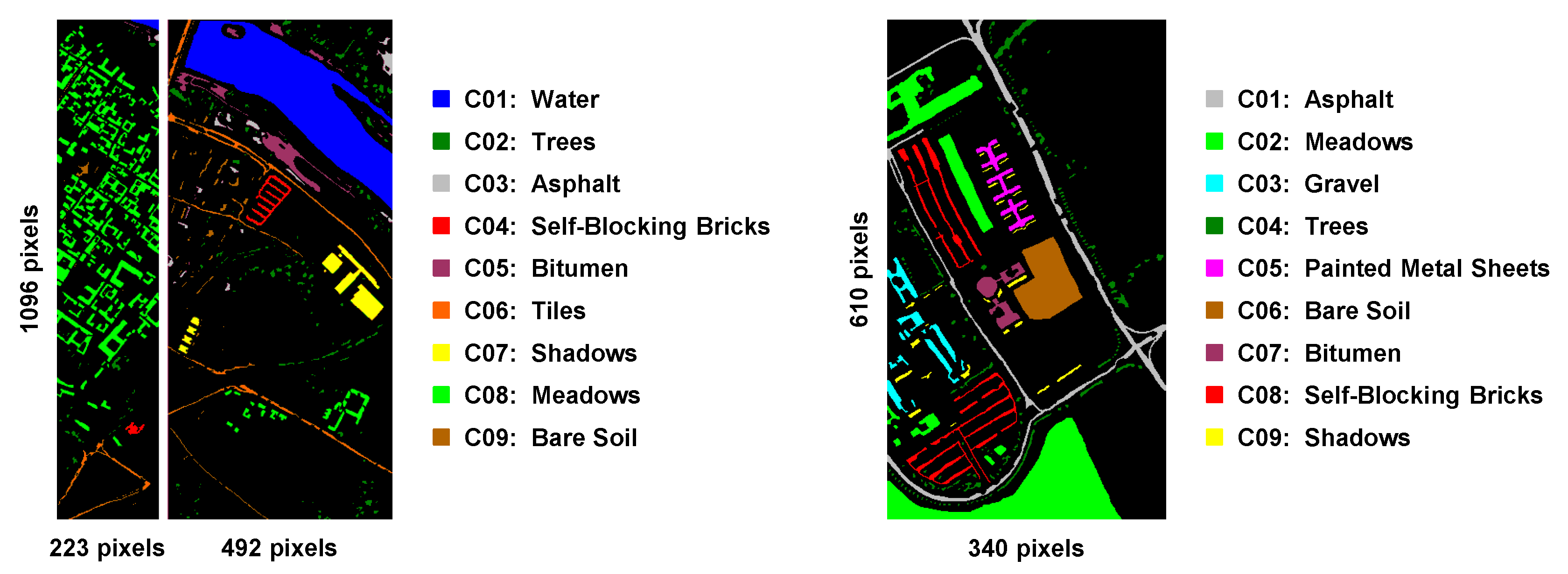
1.3.3. Classification
The derived feature vectors serve as input for classification. For classifying hyperspectral imagery, the classic approach consists in a pixel-wise classification, e.g., by using widely used standard classifiers such as a Support Vector Machine (SVM) or a Random Forest (RF) classifier [
1,
22,
23,
62]. These approaches often yield reasonable classification results, but—due to classifying each pixel individually by only considering the corresponding feature vector—it is not taken into account that the labels of neighboring pixels tend to be correlated.
To account for spatial context in classification and thus conduct spectral-spatial classification, different strategies have been followed. Relying on the results of a pixel-wise classification, it has for instance been proposed to apply a majority voting within watershed segments to achieve a spectral-spatial classification [
63]. Furthermore, approaches for spectral-spatial classification have been presented which consist in a probabilistic SVM-based pixel-wise classification followed by a Markov Random Field (MRF) regularization [
64] or a hierarchical optimization [
65]. A different context model has been used by involving a Conditional Random Field [
11] for spectral-spatial classification. Recently, the use of deep learning techniques for spectral-spatial classification of hyperspectral imagery has been paid increased attention to. In [
66], for instance, a Convolutional Neural Network (CNN) is used which consists of several convolutional layers and pooling layers which allow the extraction of deep spectral-spatial features that are highly discriminant. While the use of such deep features significantly improves the classification results, a CNN involves a huge number of parameters that have to be tuned during the training process. In case of labeled hyperspectral imagery, however, only a rather limited amount of training data is typically available.
A different avenue of research on the classification of hyperspectral imagery focused on the fact that manual annotation in terms of labeling single pixels typically contains highly redundant information for the classification task. Furthermore, due to noise effects, class statistics might not appropriately be represented which in turn results in a decrease of the predictive accuracy of the involved classifier. Accordingly, some investigations focused on selecting training data in a smart way so that a small training set of highly discriminative examples is sufficient to appropriately represent the class boundaries and conduct classification for new examples. In this regard, a popular strategy is followed by Active Learning (AL) [
67,
68] where the main idea consists in training a classifier on a small set of training examples that are well-chosen via an interaction between the user and the classifier. More specifically, the classifier is first trained on a small, but non-optimal set of training examples. The classification of further examples reveals the examples for which the classification result is quite uncertain. For the most uncertain predictions, the user assigns the correct labels so that the respective examples can be included in the training set for reinforcement learning. Thus, the classifier is optimized on well-chosen difficult training examples, and improved generalization capabilities can therefore be expected.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}