
Modeling Risk for CVaR-Based Decisions in Risk Aggregation
1
Department of Mathematics and Statistics, University of Calgary, Calgary, AB T2N 1N4, Canada
2
Gurobi Optimization, LLC, Beaverton, OR 97008, USA
3
Bayes Business School, University of London, London EC1Y 8TZ, UK
*
Author to whom correspondence should be addressed.
J. Risk Financial Manag. 2023, 16(5), 266; https://doi.org/10.3390/jrfm16050266
Submission received: 4 March 2023
/
Revised: 5 May 2023
/
Accepted: 6 May 2023
/
Published: 9 May 2023
(This article belongs to the Special Issue Risk Management and Forecasting Methods in Finance)
Abstract
:Measuring the risk aggregation is an important exercise for any risk bearing carrier. It is not restricted to evaluation of the known portfolio risk position only, and could include complying with regulatory requirements, diversification, etc. The main difficulty of risk aggregation is creating an underlying robust probabilistic model. It is an irrefutable fact that the uncertainty in the individual risks is much lower in its complexity, as compared to modeling the dependence amongst the risks. As a result, it is often reasonable to assume that individual risks are modeled in a robust fashion, while the exact dependence remains unknown, yet some of its traits may be made available due to empirical evidence or “good practice”. Our main contribution is to propose a numerical procedure that enables the identification of the worst possible dependence scenario, when the risk preferences are modeled by the conditional value-at-risk in the presence of dependence uncertainty. For portfolios with two risks, it is known that CVaR ordering coincides with the lower-orthant stochastic ordering of the underlying bivariate distributions. As a by-product of our analysis, we show that no such extensions are possible to higher dimensions.
1. Introduction
Risk aggregation is a well-known strategy to reduce the overall risk held by a financial institution, insurance company, or any other risk bearing carrier. Risk portfolios are often a summation of individual risks (or lines of business) and the risk bearing carrier is usually concerned with evaluating the risk position for this portfolio so that regulatory requirements or business targets (such as diversification, shareholder value management constraints, etc.) are met. Within the insurance and banking industries, there are regulatory requirements that financial institutions need to meet by maintaining an appropriate level of capital at all times. These calculations take into account multiple sources of risk and all other factors that contribute to changes in the company’s balance sheet within a specified period of time. Examples of such regulatory requirements include international Basel II/III banking supervision guidelines (e.g., see BCBS 2016) and the Swiss Solvency Test that applies to all Swiss based insurance and reinsurance companies (e.g., see Swiss Solvency Test 2006), where the risk measurements are performed via the well-known risk measure conditional value-at-risk (CVaR). This risk measure is introduced in the seminal paper of Rockafellar and Uryasev (2000) and has shown clear computational advantage in OR applications.A risk aggregation application in the context of the European Union insurance regulations, known as Solvency II, is given in Asimit et al. (2016).
Many practical situations show that obtaining full knowledge of the dependence amongst a group of observed random variables is a very difficult task. It is an irrefutable fact that when modeling multivariate risks, the estimation error is weighted towards determining the dependence amongst the risks. Common practice has shown that individual risks are estimated with higher confidence as compared to the dependence model between the variables. Unlike estimating individual risks, fitting the dependence model typically presents a great challenge, especially due to data scarcity. As a result, decision makers usually commit to a somewhat arbitrarily chosen parametric model, but these ad hoc choices lead to inadequate evaluations of the overall risk. Therefore, it may be more preferable to use qualitative information about the dependence and use a notion of realistic weakest and strongest dependence models amongst the observed risks instead. For example, knowing that the risks are positively associated would imply that the independence represents the weakest possible dependence, etc. Thus, it is more reasonable to assume that we have reliable models for individual random variables coupled with some partial knowledge of their association.
Many attempts have been made to resolve the problem of risk valuation under uncertainty modeling and more specifically under dependence uncertainty. The literature on this topic is vast and we give only a brief account of the related work. One direction of research typically pursued in the OR literature is to adapt recent methodologies from the so-called robust optimization. For example, in robust portfolio optimization, one typically assumes that a decision maker has some partial information about the joint distribution function amongst the risks. In order to incorporate the uncertainty, several notions of the worst-case risk measure have been proposed. For example, El Ghaoui et al. (2003) and Zymler et al. (2013) discuss this problem in the context of VaR-based optimal portfolio selection. The same problem is investigated in Zhu and Fukushima (2009) and Huang et al. (2010), where decisions are made on the worst-case CVaR; a related insurance setting is discussed in Asimit et al. (2017, 2019) and Balbás et al. (2011), while robust portfolio selection and related topics are addressed in manuscripts like Blanchet et al. (2017) or Fabozzi et al. (2010). Some attention has been devoted to computing bounds on CVaR with moment information. For example, in Bertsimas et al. (2004) sharp explicit bounds are obtained with the first two moments, and in the work of Bertsimas and Popescu (2002), where a more general numerical convex-optimization-based approach is obtained. Recall that robust versions of the above moment-based models may be developed in principle, relying on the so-called robust optimization techniques (e.g., Ben-Tal et al. 2009). Interesting connections between chance-constrained and robust optimization in relation to CVaR are established in Chen et al. (2009). Other risk measures (beyond CVaR) are available in the literature; e.g., the higher-moment risk measure that is investigated in Gómez et al. (2022).
The main contribution of our paper is to propose a method to evaluate sharp lower and upper bounds for the CVaR-based aggregate risk level under dependence uncertainty. Specifically, we assume that bounds on the cumulative multivariate distribution are available, as well as that we have the full knowledge of the individual risk distributions. Here, the partial information about dependence is given by the lower-orthant stochastic ordering type constraints. Arguably, the most practically relevant examples of such types of constraints are the so-called positive and negative quadrant dependence models. The practical advantage of using the above dependence models is that we can test the statistical significance of such properties (see Gijbels and Sznajder 2013). In other words, the validity of restricting the range of possible dependence models may be statistically verified using the observed data. The latter plausible dependence provides us with the main motivation to include lower-orthant type restrictions in our model.
From the methodogical perspective, our numerical method is based on (convex) optimization techniques and specifically, bilinear and linear programming (LP). Interestingly, despite the associated optimization problem being bilinear—and thus non-convex—in nature, we show that the problem’s objective function still retains a strong structural property, namely, it is convex in every argument, and in turn, the convexity provides the basis for efficient computations. Despite a seeming symmetry of the two problems, evaluating the sharp lower bound on CVaR appears to be more of a challenge, as compared to computing the sharp upper bound. This is substantiated by both the complexity analysis of the proposed method, and the numerical results.
It is known that CVaR respects the so-called lower-orthant stochastic ordering for two-dimensional portfolios (chapter 6.2.6 of Denuit et al. (2005)). Yet no similar result has been established or disproved for higher dimensions. As a by-product of our analysis, using elementary LP techniques, we show that no such extensions are possible, and give insights as to why this is the case.
The paper is organized as follows. Section 2 presents our model for determining sharp upper and lower bounds on the CVaR-based aggregate risk level. Section 3 and Section 4 describe the approach used to compute the lower and upper bounds, respectively. Section 5 contains the numerical experiments and analysis, while Section 6 discusses the behaviour of CVaR in multivariate settings under the lower-orthant and other orderings. Our final comments and conclusions are summarized in Section 7.
2. Model Setting
The notation relies on lower case letters for deterministic quantities and capital letters for random variables. Likewise, we use capital letters to denote functions. Bold letters such as and are reserved for deterministic and random vectors, respectively; likewise, we use for vector-valued functions. Capital script letters are used for sets.
Let denote an n-variate random vector, and let be the sum of n possibly dependent risks. The VaR of a generic loss variable Z at confidence level , , represents the -quantile of Z. Mathematically, , where . The CVaR at confidence level , , evaluates the expected loss amount incurred under the worst loss scenarios of Z. The CVaR has multiple formulations in the literature (Acerbi and Tasche 2002), but in the present paper, we only refer to the following representation (Rockafellar and Uryasev 2000),
where is the expectation and .
Let us assume that we have a portfolio consisting of n risks . The cumulative distribution function (c.d.f.) of each individual risk is and is assumed to be known for all , and we write . Moreover, we assume that the dependence between the risks, i.e., the multivariate distribution of , is unknown, but some prior knowledge about the association amongst risks is available. Namely, the set of feasible distributions is given by
where and are some n-dimensional joint c.d.f.’s that define the set of acceptable dependence models. Note that the above assumption provides a lower and upper bound for in the lower-orthant stochastic ordering sense. Recall that two random vectors and in are lower-orthant ordered, written , if for all . It is known that the comonotonic1 dependence gives the sharp upper bound on the c.d.f. with prescribed marginals . Thus, if there is no upper bound specified, without a loss in generality we may set . On the other hand, given the marginals, it is impossible to construct the sharp lower bound on the c.d.f. for . Thus, when the lower bound is not known a priori, it is not so clear what should be used in place of , besides trivial choices.
The main aim of the paper is to compute sharp lower and upper bounds on ,
where . We approximate the solutions to (2) by assuming ’s to be discrete random variables, i.e., by considering a sample of size from our population . Namely, it is assumed that takes the values with equal probability , but we do not know the joint probability amongst the risks, represented by p.m.f.
Note, that if is a continuous compactly supported random vector, one can use the above discretization to approximate its distribution to within the desired accuracy by increasing m. The -equivalent discrete marginal distributions are standardized and assumed to be uniform. This choice is motivated by the common sampling procedure using copulas, if parametric models for the marginal distributions are available. It is also motivated by the practical considerations on availability of historical data. The methods in the paper can be easily adapted to arbitrary marginals. However, this comes at the unnecessary expense of further complicating the notation. The c.d.f. bounds and are represented by discrete vectors and . Likewise, we denote the aggregate risk sample by , , where the multi-index runs over all possible values with . The values of are only partially ordered.
Thus, in order to approximate (2), we need to compute
and
where the multi-index inequalities are interpreted component-wise. Note that the marginal density constraints are stated explicitly as part of the formulation, although, we could absorb these constraints into tighter upper and lower c.d.f. bounds.
3. Computable Lower Bound
3.1. Reduction to Parametric LP
Let us define the value function as
and note that evaluating for a fixed t corresponds to solving an LP problem. This is critical to the design of our computational approach to solving (3), i.e., determining
Since the solution to a moderately sized LP problem can be typically computed in reasonable time, to obtain an initial sense of what range may fall into, one may simply compute a few values for some sample values . We extend this basic idea by combining it with a few more observations that follow. Recall that evaluating corresponds to solving the so-called bilinear optimization problem, which is notoriously difficult, due to the inherent non-convexity of the objective with potentially many local minima.
3.2. Compact Support in t
We now claim that in order to compute , it is unnecessary to perform an exhaustive search over all possible values of .
Theorem 1.
Denote and . Then, the following holds
Proof.
Assume first that : since for all , we have and thus, the value function is increasing for any .
Consider now the case of fixed t, such that . Let denote an optimal probability distribution resolving at t, and denote an optimal probability distribution resolving at . Denoting , we have
where the last identity follows from the feasibility of , namely, , while the next to last inequality follows from being the optimal solution corresponding to t, which in turn implies
Therefore, is decreasing for . Finally, since is a continuous function minimized over a compact set, we can replace inf with min. □
3.3. Key Properties of the Value Function
Since evaluation of the value function can be reduced to an LP with a parametric objective, we can establish the next proposition.
Proposition 1.
The function is a piecewise linear, continuous function, concave on every subinterval , where corresponds to re-indexing of values in non-decreasing order so that for all . Furthermore, has finitely many linear segments.
Proof.
Observe that restricting , we can write with
denoting the partial value function. In turn, determining may easily be recognised as a linear optimization problem in standard minimisation form
Note that is a vector of variables of dimension , is a linear function encoded as matrix with rows and represents the affine equality constraints stated for . The t-parametric objective corresponds to
where we allow a slight abuse of notation when indexing and by the multi-index .
Clearly, is a continuous piecewise linear concave function of t. By enumerating the total number of possible bases, standard LP sensitivity analysis implies that on a given subinterval function , and therefore , consists of at most linear segments. Since we have at most of such subintervals, we conclude that consists of at most linear segments, which also includes two end subintervals and . □
The above bound on the number of linear segments comprising is very crude. Not only do we take a very pessimistic bound on the number of vertices of a very special polytope that describes the feasible probability distributions, we also ignore a special “monotonic” structure in perturbations to the objective vector. Consequently, it is quite natural to expect the number of such segments to be much smaller.
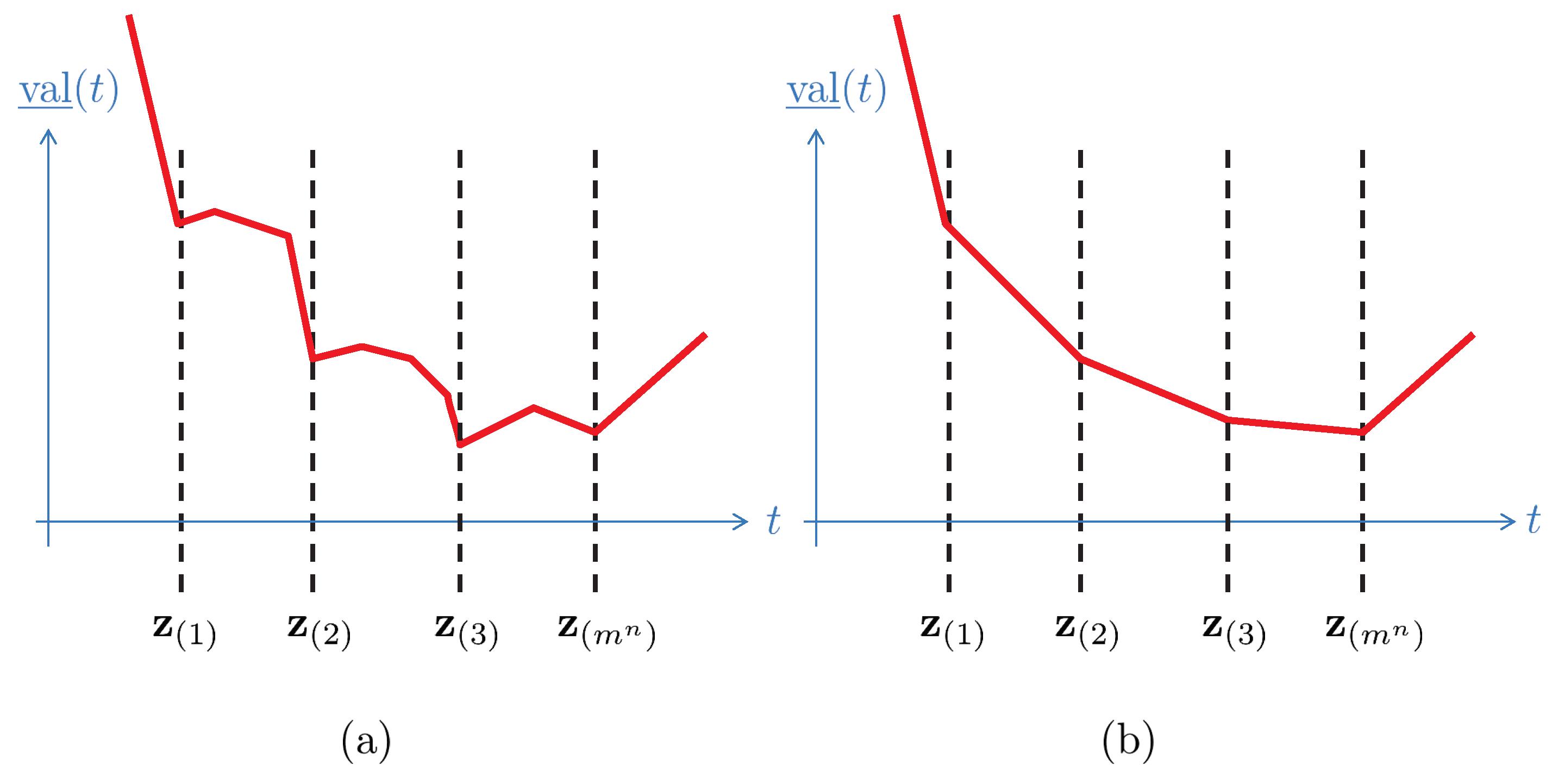
The above proposition, based on classical sensitivity analysis for LP, albeit correct, may be misleading while designing a numerical scheme for minimising . Specifically, the asserted piecewise concavity of may suggest a potential existence of several local minima (see Figure 1a). We remedy this in the next theorem, which gives a complete characterisation of the partial value function. Along the way, we drastically reduce the upper bound on the number of linear segments comprising .
Theorem 2.
The function is continuous, non-negative and non-increasing, satisfying for and for . Moreover, is convex on ℜ and linear on every subinterval .
Proof.
Continuity and the tail-end behaviour of are established in the proof of Proposition 1 and Theorem 1. Examining variational formulation (5), we easily note the non-negativity and monotonicity of the partial value function, with the latter, due to the objective coefficients , being monotone in t. Linearity on follows as a consequence of convexity—to be established shortly—and piecewise concavity in Proposition 1. It remains to show convexity.
We show the convexity property by contradiction. First, introduce
to be the partial value function restricted to a given feasible . Observe that is convex, piecewise linear non-increasing, and its derivative , whenever defined, corresponds to the dot product of with the corresponding sub-vector of , as in (7). Thus, is non-decreasing whenever defined. We also note that as t passes from the interval to , the number of entries, i.e., the non-zeros in , is reduced by at least one.
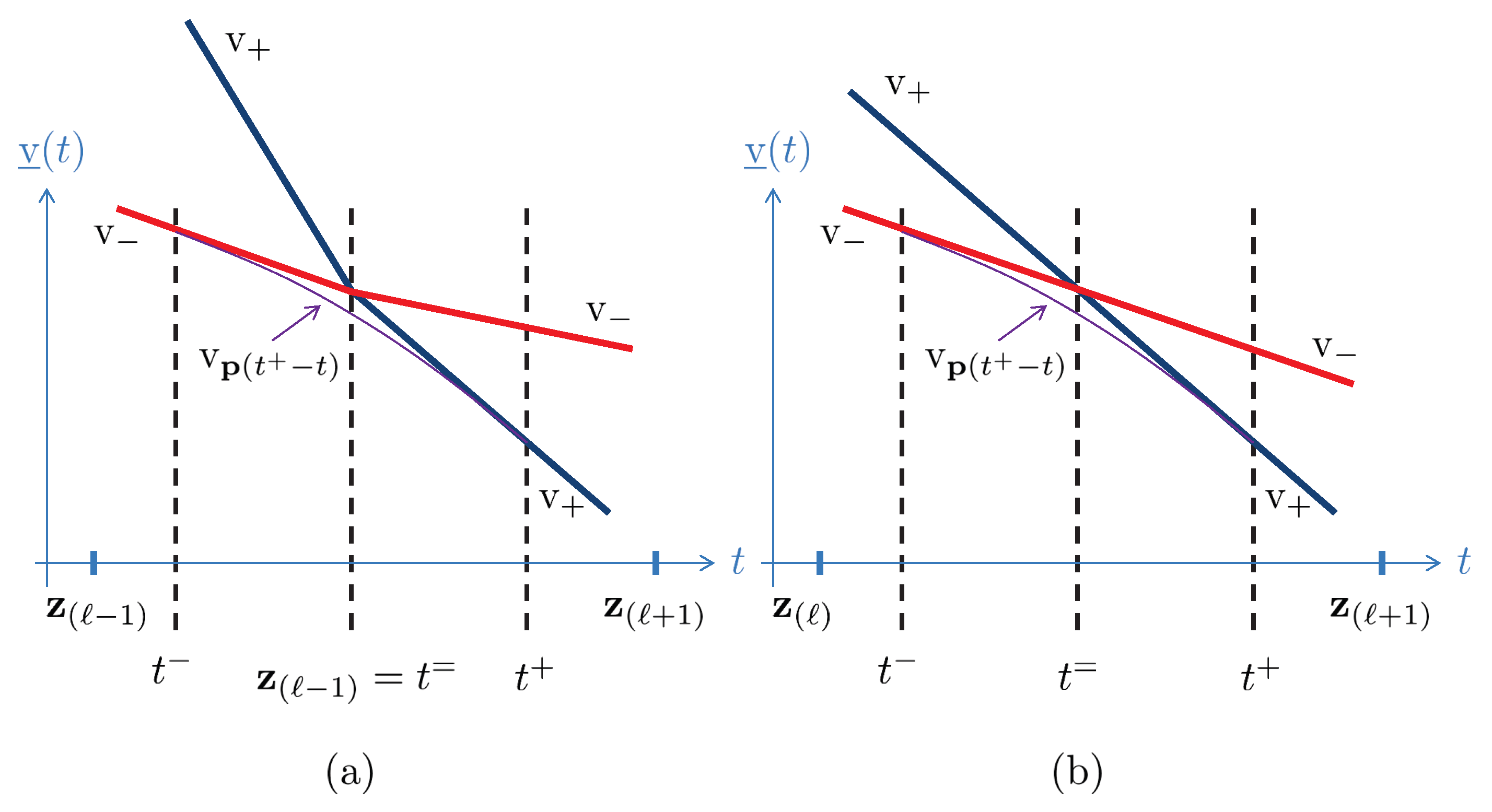
If is strictly concave, there exists a cross-over point , characterized by and the corresponding optimal distributions and , resolving (6) such that , with derivatives satisfying and , where and . Note that and may be chosen close enough to to warrant differentiability of the corresponding piecewise linear on and . Furthermore, without a loss in generality, we may assume that both have either at most one break-point at for some ℓ with and , or no break-point at all with , as can be seen in Figure 2. By re-scaling and shifting t we can also assume and . With the above notation, we have for and for .
Denote . Note that is feasible since the feasible region of (6) is convex. Further, let us examine . By the fundamental theorem of calculus, we obtain
where the inequality is due to the fact that , for all , since ; consequently, carries less probability mass over the support of at as compared to . Since is supposed to be the smallest over all feasible at , the contradiction is conspicuous. This completes the proof. □
3.4. Two Computational Approaches
We now present two computational schemes for computing the sharp lower bound on CVaR given the constraints on the risks’ c.d.f.. The schemes are aimed at illustrating the advantages of exploiting the inherent structure of Problem 3 and range in order of complexity, as well as the perceived numerical efficiency. The latter is further substantiated in Section 5.
3.4.1. Naïve Scheme
Observe that the piecewise concavity of established in Proposition 1 implies that the minimum of the value function may only occur at the end points of each interval . Therefore, it suffices to compute for all and take the minimum value. This gives rise to the naïve scheme.
Clearly, the naïve scheme requires access to an LP solver and runs in finite time. However, it requires solving a large number—namely —of (6)-type optimization problems, where the problem dimensions also grow proportional to . As a result, the procedure may become very computationally expensive for even modest values of m and n. Further effort can be put towards reducing the computational requirements imposed by the naïve scheme. For example, the LP problems for evaluating differ only in the objective function, and thus, may be well-suited for the so-called warm-start techniques, as in simplex-type algorithms. In turn, the use of warm-starting may speed up solution times.
3.4.2. Epigraph Scheme
Unlike the naïve scheme, here we aim to take full advantage of the uncovered convexity of the value function. This not only allows us to greatly reduce the computational efforts required to determine the exact value , but also permits the introduction of an alternative termination criterion when only an approximate answer is required within some given absolute precision .
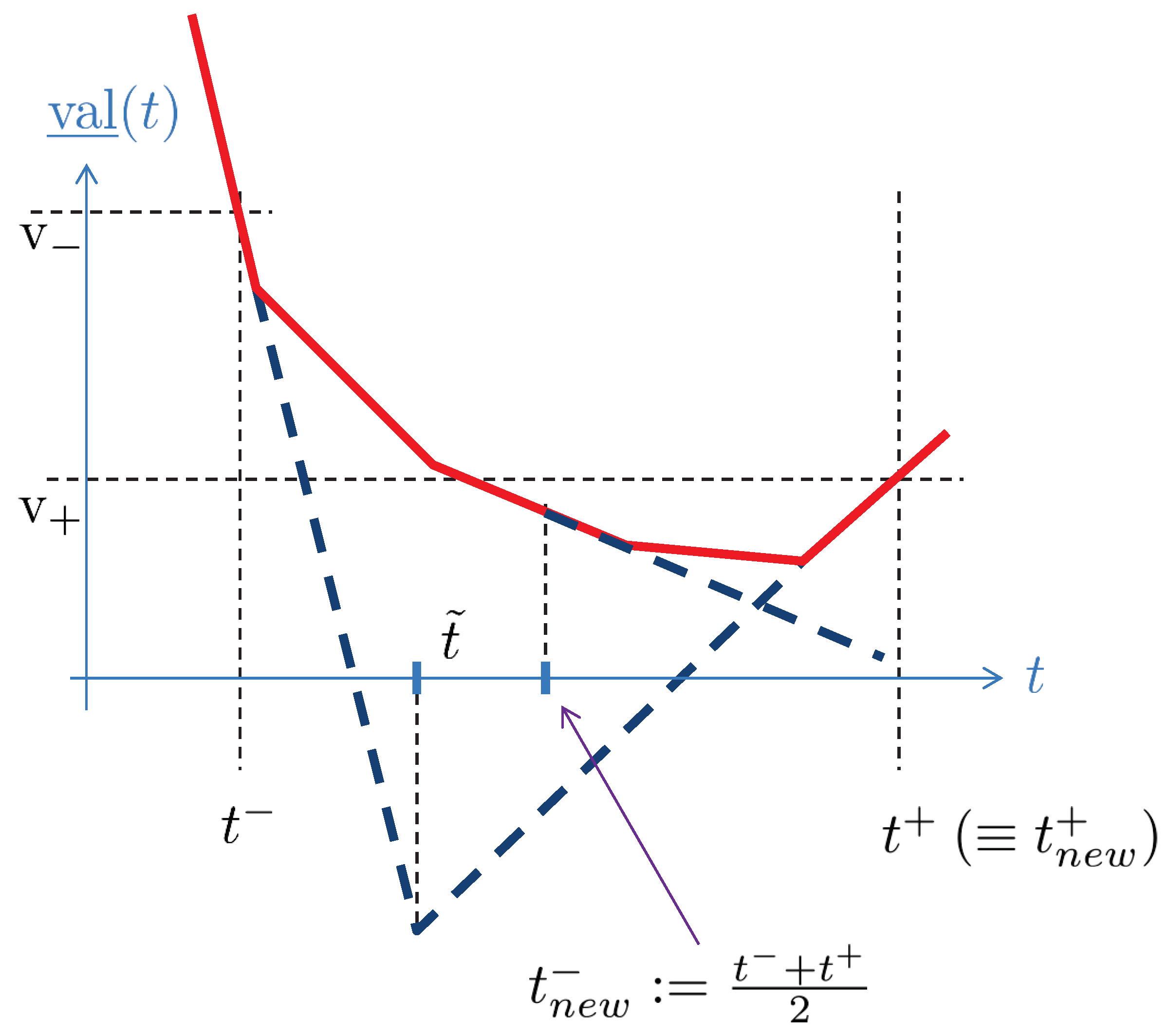
We recall that an epigraph of a convex function can be obtained as an intersection of half-spaces. In the case of a smooth function the half-spaces correspond to tangent hyperplanes, and in the case of non-differentiable functions one may use half-spaces defined by sub-gradients. Thus, given two consecutive values of t with appropriately defined derivatives of , with values and , we know that the minimal value of corresponds to some . In addition, we have , where
is the intersection of the supporting hyperplanes and . This can be seen in Figure 3. To refine the interval and our estimate on , we can take the mid-point of the interval and adjust either or accordingly.
Assuming that the data are given by , and , the scheme may be defined recursively as a function whose declaration is given below using MATLAB notation
and is defined as follows.
- [Input:] , problem data.
- Set ,
- compute and by solving (5), recovering the optimal probability distribution ,
- if then return,
- set with corresponding to as in (7),
- if set ,
- if set ,
- invoke Epigraph().
- [Output:] .
Clearly, in order to obtain , we need to invoke Epigraph() with initial values and . If one desires to terminate the procedure once the absolute precision is reached, such that , it suffices to replace the function termination criteria with .
For the convexity of and its tail behaviour from Theorem 2, we know that the fastest decrease rate of the value function does not exceed and therefore,
Thus, in order to achieve an precision, it suffices to have . In turn, recalling that at every iteration of the scheme the interval is halved, we conclude that the absolute precision can be attained in at most recursive calls, where the dominant work belongs to solving an LP instance of the form (6).
In a nutshell, although the epigraph scheme still relies on solving multiple LP instances in order to recover for fixed n, its worst-case run-time is bounded from above as a polynomial function of the problem input. Furthermore, when an approximate solution is sufficient, one would expect the number of calls to the LP solver to be dramatically less than , as compared to the naïve scheme. We also note that the epigraph procedure is defined recursively only in an attempt to improve clarity of exposition. Clearly, the procedure can be unrolled into if ... else ... statements with no recursion. Just as with the naïve scheme, one may try to take advantage of the warm-starting capabilities of an LP solver in an attempt to speed up the computational times required.
4. Computable Upper Bound
It turns out that despite apparent similarities between Problems (3) and (4), the complexity of evaluating is quite different from that of . Namely, the calculation of is much simpler. We first establish an essential property that is needed for proving the main result of this section.
Proposition 2.
The max-value function , where
is convex in t.
Proof.
For fixed non-negative , the objective function is convex in t. In turn, is obtained by taking a supremum of convex functions , indexed by , and therefore is convex as well as a positive weighted sum of t and . □
Using convexity, we note that the epigraph-based scheme from Section 3.4.2 can readily be adapted to computing the sharp upper bound of . Furthermore, using classical LP duality theory, finding the optimal t value corresponding to minimising may equivalently be reformulated as solving a linear optimization problem. Let
and denote the set of multi-indices corresponding to sums of marginals, including the total probability mass. For simplicity, from now on, we assume that the c.d.f. bounds are consistent with marginals, that is, for all where the marginal index sets are defined as in (8). If not, clearly, the problem of computing is infeasible.
For clarity of exposition, we first slightly modify our formulation of from above. Noting that the lower and upper bound requirements on the c.d.f. are clearly redundant for , they may simply be replaced with more restrictive modified bounds , where
We are now ready to formulate the main result of this section.
Theorem 3.
The upper bound defined in (4) can be computed as follows:
Proof.
Note that for any fixed t, the problem of computing is equivalent to solving its dual
where by strong LP duality, we know that . Furthermore, for any dual-feasible point , by the weak duality property we have
Noting that the dual-feasible region may equivalently be rewritten as stated in the theorem, we finally observe that in order to compute the optimal that satisfies , it suffices to solve the concurrent linear minimisation problem with respect to t and . □
Finally, once the optimal value is known, the corresponding optimal values of can easily be computed by solving for as a linear maximisation problem, if further desired.
5. Numerical Results
In this section, we provide numerical illustrations of our findings from Section 3 and Section 4. First, we gauge how the computational requirements scale up with the problem dimensions and identify one critical bottleneck in Section 5.1. To do this, we compare two ways of implementing our approaches in MATLAB. One primarily relies on CVX with the embedded open-source solver SDPT3, chosen for the sake of simplicity. The other approach uses Gurobi Optimization, LLC (2023) and a direct problem formulation, as a potentially more efficient option. CVX removes the inconvenience of carefully formulating the LP (6) to near-standard form suitable for Gurobi, while potentially sacrificing some of the efficiencies. On the other hand, the user-provided direct specification of the underlying LP may be more of a challenge initially, but potentially gives some computational advantage when solving the problem. Next, we propose an approach that allows us to circumvent one of the main computational obstacles, and illustrate the refined methodology on a real-life inspired example in Section 5.2.
5.1. Verbatim Implementation
Our first goal is to obtain a sense of how the performance of our method scales up with problem dimensions, as well as to gauge if the modeling environment and the LP solver play a role. For this, we use a very modest Alienware laptop with a 2 core Intel i7 U640 CPU running at 1.2 GHz, 4 GB RAM, running Windows 7 x64, MATLAB R2013b, CVX 2.0, and Gurobi 5.5.
Regardless of the approach, we rely on solving (5) or its variant, where the dimensions of the problem grow proportional to —thus, polynomial in m and exponential in n. Specifically, for the standard LP form of the partial value evaluation (6), the number of variables and constraints grow as and , respectively, while the number of non-zeros in the matrix of coefficients describing the affine constraint is roughly .2 Consequently, despite the fact that the fraction of non-zero entries in the matrix of affine coefficients corresponding to (6) decreases exponentially in n, the number of non-zeros still grows very rapidly with the number of risks. For instance, in case of and , one should expect to deal with a matrix containing more than non-zero entries (of one), making solving such problems on a regular computer workstation prohibitively expensive. Even with the availability of super-computing resources, one probably has to resort to very specialized algorithms—e.g., Tardos (1986)—and linear algebra techniques to exploit matrix sparsity structure efficiently for large values of m and n.
In Table 1 we report the average run-times for estimating sharp upper and lower bounds for problems with varying n and m. For this and the other numerical experiments, for each dimension, we generate 30 random problem instances, where sample values are chosen to be uniform between 0 and 1 for simplicity. CVX refers to only using CVX to formulate the LP sub-problem and passes it to a selected solver, while tensor-like notation is used inside the CVX code. CVX+ refers to us formulating the affine constraints of an LP in vectorized form and letting CVX only pass the data to the solver. Direct refers to us both formulating the problem and invoking the Gurobi solver directly, bypassing CVX. When not specified, and .
Our first goal is to understand how the proposed methods scale with dimensions. As expected, the computational cost escalates very rapidly when dimensions m, and especially n, increase. We observe that the run-time heavily depends on the LP solver. For Gurobi, here we used the simplex option, while experimenting with the barrier gave inferior results on this dataset; we suspect that the latter can be attributed to being able to take advantage of a simplex warm-start. Even when no top-of-the-line commercial solver is available, one can compute some bounds with in reasonable time for small values of m.
We also note that, in general using CVX, as opposed to directly formulating the problem and feeding it into a solver, poses some processing time overhead, especially for smaller problems. While formulating the matrix of affine constraints, we rely on MATLAB loops, which may potentially be sped up. Solving with and to within an precision by using the epigraph scheme, MATLAB takes about 100 s to form a single LP matrix of the coefficients in the standard form, while solving all the subsequent LP problems takes roughly another 150 s.
For estimating the lower bound on , between the two schemes, the epigraph-based method is a clear winner over the naïve approach. The solution times grow with n and m (see Table 1 and Table 2), as well as the desired precision (see Table 3b). By comparing the results in Table 2 and Table 4, we conclude that computing the sharp upper bound is generally cheaper, as compared to the lower bound. When computing an exact sharp upper bound, direct LP embedding is preferred.
5.2. Stylized Practice-Inspired Example
Computing CVaR sharp bounds under given marginals and lower-orthant stochastic ordering bounds on joint c.d.f.’s, and in particular sharp lower bound, entails solving a non-convex (bilinear) optimization problem of potentially very high dimensionality. Namely, we seek to determine the extreme values of variables representing the c.d.f. When attempting to scale up the model sizes n and m, we are faced with an obvious memory requirement issue. For instance, solving for in (3) entails formulating a model with over non-zeros that requires almost 1000 GB of RAM if we operate in standard double-precision arithmetic. The RAM requirement grows as and it is reasonable to expect a significant growth in the computational effort required to solve the model as well.
However, it turns out that one could produce a much sparser equivalent representation of lower and upper bound optimization models, allowing solving for sharp bounds with sized models in a reasonable time, i.e., a couple of hours, on a reasonable hardware, i.e., a multi-core station with enough RAM. Next, we present this refined setup, along with a more practical illustration of our approach. The example is partly based on work carried out outside of this manuscript, and has been further stylized to avoid breaching any possible non-disclosure agreements. We focus on the lower bound computation as it is more challenging; the upper bound evaluation can be refined in a similar manner.
Assume an insurance company with a portfolio of three risks, located in (1) New York (NY), (2) Miami (FL) and (3) Houston (TX), for which the policy covers economic damages to certain buildings caused by hurricanes in these regions. The underwriter makes decisions based on the hurricane intensity estimates that in turn are predicted based on an atmospheric internal risk model. If with is the economic damage for the k-th risk in dollars, we know that is , so that the c.d.f. along with the first two moments are
with
resulting in expected losses of USD 1.98 million, USD 10.07 million and USD 4.33 million, respectively. Further, for each risk, the coefficient of variation (CV), a well-known measure of risk, is 1.29, 4.58, and 1.96, so indeed the assets are risky, as expected. A large CV is expected for coverage in more risky regions.
The underwriter has empirical evidence (based on atmospheric observational data) to identify the marginal risk distributions, but does not have the knowledge to create a spatial dependence model across the risks located in different regions. Geographical-dependent ratings would be hardily available even to world-leading rating agencies. Therefore, the underwriter has to rely on the available domain knowledge to come up with aggregate risk estimates based on the best possible information about the risk position.
It is clear that ’s are not negatively associated, and thus, a lower bound on the joint distribution, in terms of the lower-orthant (LO) stochastic ordering, can be given by the independence model,
where is the c.d.f. of . The upper bound on the joint distribution, in terms of LO, assumes that the NY economic damages are independent of the other two, while economic damages from Miami and Houston could be strongly positive dependent, i.e., comonotonic, and therefore
In terms of our CVaR lower bound formulation (3), the above can be encoded via discretizing the individual risks with some fixed m, so that correspond to Pareto distribution sample values or inverse Pareto-c.d.f.’s at mid-points , with
Our objective here is to evaluate the lower bound, specifically, for .
Using a sparse reformulation of (3), which we discuss next, this objective indeed can be achieved in a reasonable computation time, here, in about 2 h, or 7554 s to be precise, yielding mn, corresponding to , with the bound computed to within the relative precision of . For this set of computational experiments we move to a more powerful machine, with an AMD EPYC 7313P 16-core processor and 256 GB RAM, running Ubuntu 22.04. To solve the subsequent LPs, we use Gurobi 10.0.1, where the model was implemented using Gurobi’s Python API, and benchmarked using Python 3.7. We want to emphasize that the chief enabling factor is the sparse reformulation that reduces the number of non-zeros in the model by a square root, e.g., going from to about for , allowing the formulation of the model in RAM as well as permitting vastly faster computations, which is further improved by moving to a powerful computer server. The code can be found on GitHub, as per Zinchenko (2023).
A number of further computational experiments were performed with varying sparsified model dimensions for both n and m and the run-times were recorded. A model with could now be solved in about 550 s, while is the current computational limit for the above machine. The solve time scales super-linearly with the problem dimensions. For lower dimensional models with , as before, the run-times look more favourable; for instance could be solved in 808 s.
The sparse reformulation of (3) is built on a pivotal observation that joint c.d.f.’s can be defined recursively, using inclusion–exclusion formulas. Namely, if we introduce auxiliary variables for the c.d.f. to represent
we can express the c.d.f. bound constraints as upper and lower bounds on , and more critically, define the c.d.f. quantities recursively. Namely, for we have
and for ,
where and is a shorthand notation for and if some sub-index becomes negative, we replace the corresponding c.d.f. entry with 0. This necessitates only 5 and 9 zeros per constraint, respectively, as opposed to an average of in the original model formulation carried out verbatim. To further promote sparsity, the marginals can be reformulated in terms of the c.d.f. auxiliary variables, for instance, for the first risk we can write
Thus, even though we gain another variables in our formulation, the revised non-zero count grows as , as compared to the original . The construction can easily be extended and implemented to any n.
While for , moving beyond becomes prohibitively expensive, an argument can be made that from a practical point of view perhaps this is also not so critical. It is hard to imagine a situation where the empirical marginals are known so precisely that it would necessitate spelling out marginal c.d.f. constraints in finer than granularity. It could also be more important to distill the extreme dependence trends for the unknown multivariate c.d.f. rather than try to zero down on the very last digits of CVaR bounds, and as such, our approach could provide a viable exploratory tool.
6. A Special Case and Its Higher-Dimensional Variants
In this section we investigate the question of whether CVaR ordering may be consistent with the ordering of the underlying distributions for higher-dimensional portfolios, i.e., . We say that two n-dimensional random vectors have identical marginals if for all and . We first provide an alternative proof to a well-known result that CVaR respects the so-called lower-orthant stochastic ordering for (Proposition 6.2.9. of Denuit et al. (2005)).
Theorem 4.
Although the claim may be extended to a wide class of other risk measures, the previously known proofs of the above theorem rely on the fairly exotic techniques from convex analysis. The theorem itself becomes interesting in view of the potential computational savings it may provide, when comparing the aggregate risks of bivariate distributions with identical marginals, satisfying the lower-order stochastic ordering.Let and and be two compactly supported random vectors with identical marginals and corresponding aggregate risks and . If , then for any we have that .
A natural question is whether such an ordering is preserved in higher dimensions, . We show that no such extension exists. In fact, one may argue that even the above result with is unnatural and goes against the intuition of what should happen. To substantiate the latter point of view, we
- give an alternative and self-contained proof of the classical result from Theorem 4,
- state several potential extensions of such a result to higher dimensions, and
- provide counter-examples to show that no such extensions are true for .
6.1. An Alternative Proof for
We start by recalling the inclusion–exclusion type criterion (for example, see Billingsley (1995)), that characterizes a c.d.f.. The criterion ensures that the probability mass accumulated within any hypercube is non-negative, and is commonly referred to as the rectangle inequality.
For fixed n, consider a right-continuous non-decreasing , such that for all , and , F is a c.d.f. if and only if
for all .
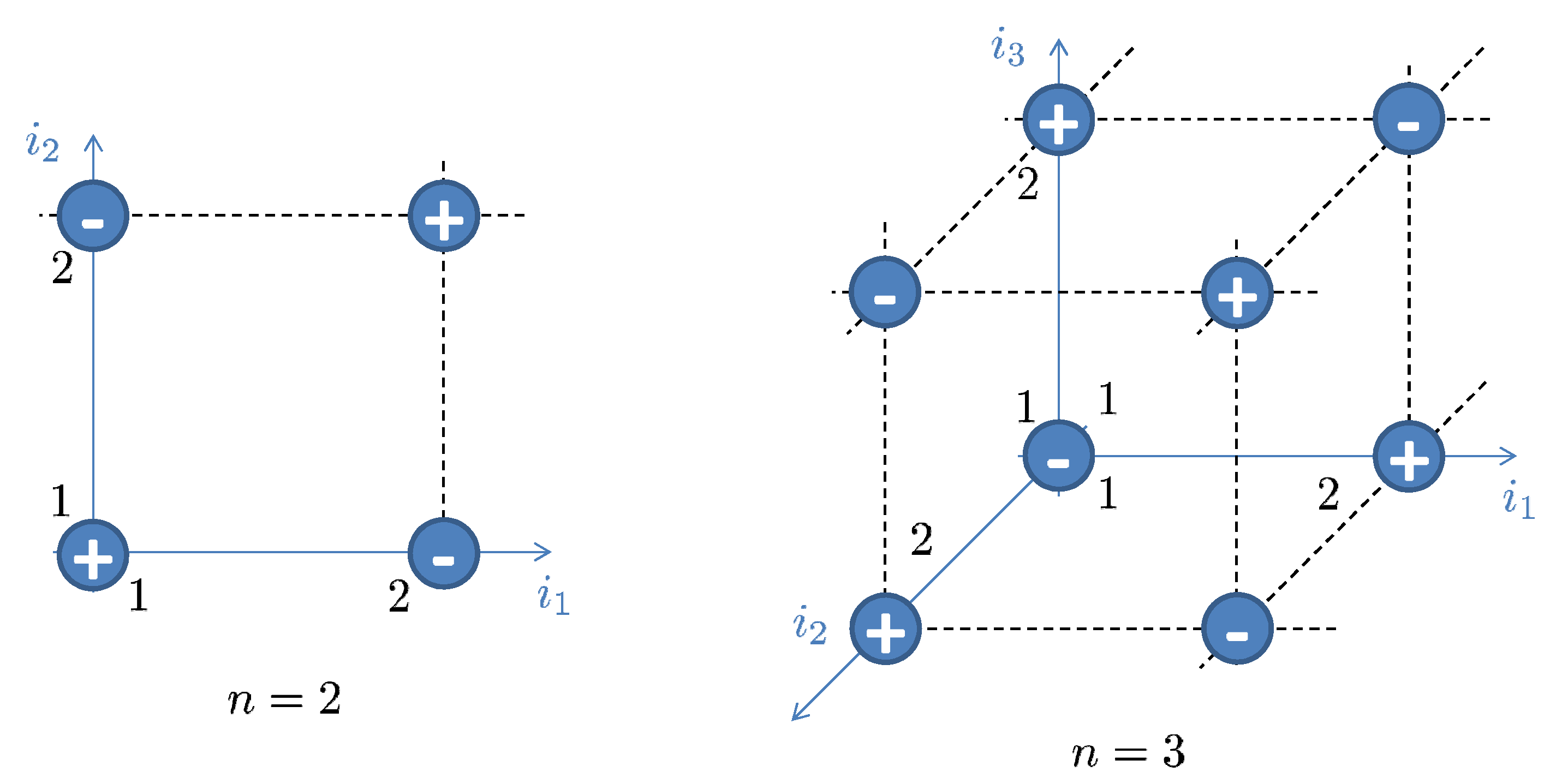
In particular, the rectangle inequality guarantees the existence of a probability mass function (pmf) given a candidate non-decreasing step-like function on . From now on, we consider an n-dimensional discrete random vector with values , , placed on an rectangular grid, and the corresponding pmf . Thus, for the above inequalities become
and for we have
where values correspond to the atoms on the grid, that is, and , with , . The latter expressions can be abridged to
and
introducing . The summation sign pattern for values of F, or equivalently , may be best illustrated graphically, as seen in Figure 4.
The following elementary, yet critical, observation can be made and is given as Proposition 3.
Proposition 3.
The proof of the above proposition, although somewhat tedious, simply relies on accounting for the indices in the summation . We also note that for , the c.d.f. ordering of two distributions with identical marginals is equivalent to the ordering of the survival functions.Along with pmf , consider the c.d.f. and the survival function , defined by the corresponding linear transformations
Then, for any we have
Lemma 1.
Let the two bivariate discrete random variables and have identical marginals and the corresponding c.d.f. . Then, , if and only if .
The proof is a straightforward implication of the inclusion–exclusion type fact that
Finally, we are now able to prove Theorem 4.
Proof of Theorem 4.
The sub-problem (6) can be re-parameterized using the survival function ,
where the survival function bounds may easily be computed applying the inclusion–exclusion type formula similar to that in Lemma 1.
We now make a critical observation, that for all t. From the definition of aggregate risk values , we observe that if and only if the rectangle inequality (9) holds for all
with and any t. Since and , we also have partial ordering of values, namely
The range of all t values may clearly be partitioned into , and . Therefore, there are three possible cases.
- (a)
- : rectangle inequality (9) clearly holds as
- (b)
- : the validity of the rectangle inequality may easily be established by assuming, without a loss in generality, that and considering further sub-cases depending on where the value of t falls with respect to subintervals. For example, if , then , and thus, the rectangle inequality results in positive mass. That is,
- (c)
- : clearly the inequality holds as all values are 0.
Therefore, indeed holds.
To complete the proof, consider problem (11), where and correspond to and , respectively. Due to the non-negativity of the objective coefficients in (11), clearly corresponds to . Similarly, considering a variant of (11) to evaluate the upper bound, we conclude that corresponds to . The fact that completes the proof. □
6.2. A Few Possible Generalizations and Some Counter-Examples
We first provide the definitions of some stochastic ordering and for two multivariate risks we define
- upper-orthant ordering if for all ;
- lower-orthant ordering if for all ;
- concordance ordering if and ;
- persistent ordering if and .
Note that, due to Lemma 1, persistent ordering for results in identical distributions, and is therefore not interesting to be investigated for the bivariate case. Recall from the proof of Theorem 4, that for , the persistence of CVaR ordering relies on the implied upper-orthant stochastic ordering of the respective risks. Consequently, in search of an extension of such a result to , the following question appears to be a natural place to start: Is it true that for trivariate distributions , we have for all , with being the corresponding aggregate risks?
From now on, we fix and the marginals of to be uniform. The key to constructing a counter-example to the above is the failure of the rectangle inequality (10) over values. In turn, this results in a re-parameterized three-dimensional analogue of (11) that has both positive and negative objective coefficients for some suitably chosen t. Specifically, consider the only relevant CVaR estimation values of t that correspond to , in accordance with Theorem 2. We claim that for carefully chosen , we can pick two values and such that , while contains both positive and negative entries. As a consequence of being sign-indeterminant, when estimating with bounds corresponding to the respective distributions , it is natural to expect that we may end up having for some values of as well as for other values of . From here, it may simply suffice to pick “correct” scaling constants in extremal characterisations of .
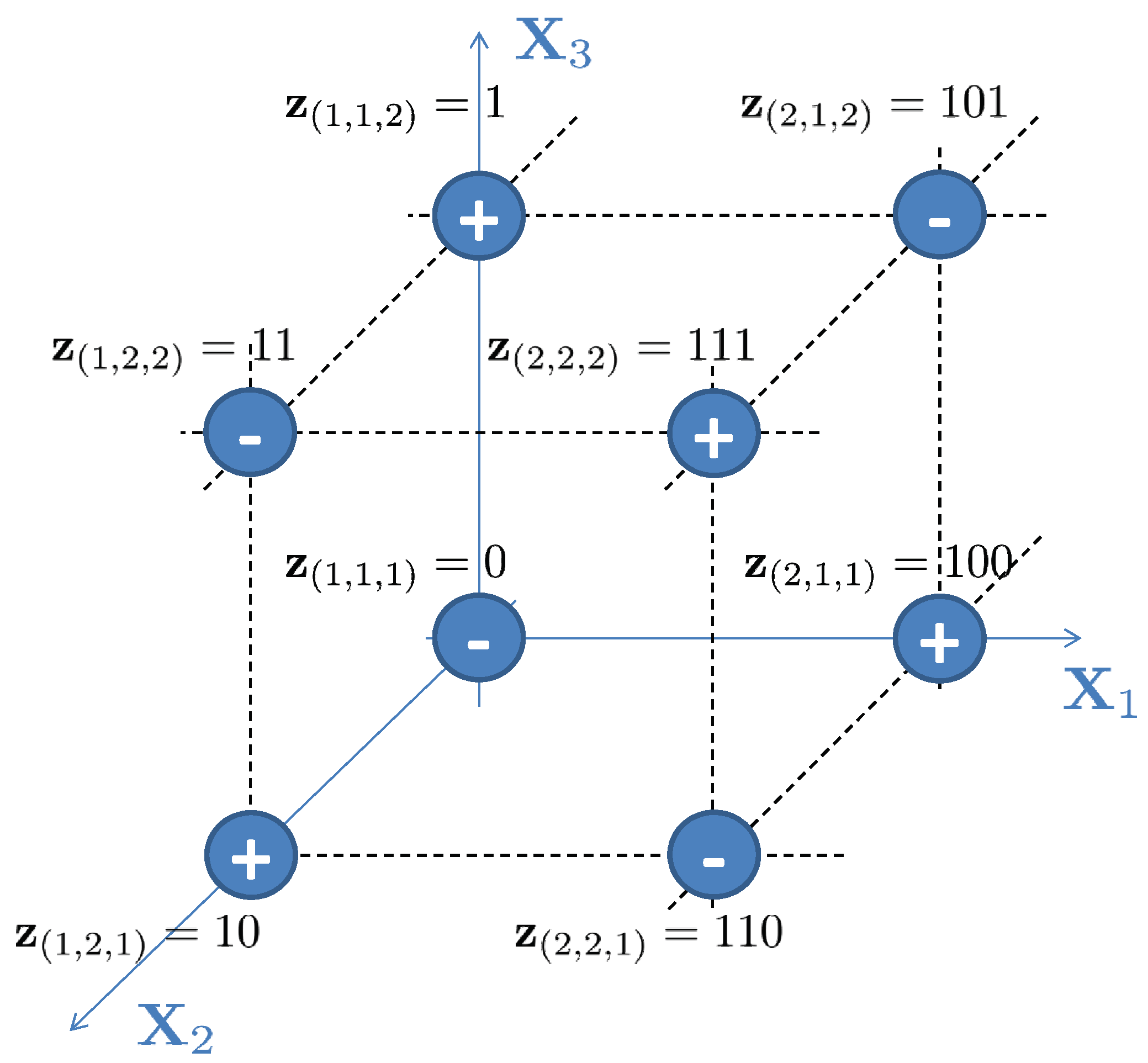
To make this precise, consider the set of risk values for and in Table 5, with aggregate risk values depicted on the hypercube lattice in Figure 5. Take , . Clearly, rectangle inequality (10) holds at and results in negative mass at , due to the fact that .
Now, we can use values to produce a desired counter-example for upper-orthant ordering. To do so, we can form an LP problem to maximize the difference between two partial value-type estimates and . We subject both pmfs and to have identical marginals, and the resulting survival functions and to satisfy the upper-orthant ordering, i.e., . The last problem can be solved for all , to extract an example.
A similar exercise can be carried out for the other stochastic orderings. Thus, for the sake of brevity, we give only a summary of our findings in Table 6 and Table 7. In order to verify the results, it suffices to perform a direct calculation. For instance, with respect to the upper-orthant ordering, observe that takes values 0, 11, 101, and 110, and takes values 1, 10, 100, and 111 all with equal probabilities of one-quarter. Consequently, and . Further, one can verify that holds for any .
Interestingly, counter-examples to lower/upper-orthant and persistent orderings require a distribution supported at vertices of a single hypercube, that is, . On the other hand, the concordant ordering appears to require more degrees of freedom, e.g., . Note that in the latter case, due to the risks being potentially supported on vertices, we present the example in a “sparse” format, as seen in Table 8.
7. Conclusions
The problem of finding the entire spectrum of values for CVaR of a sum of dependent random variables under dependence uncertainty could be approached in various ways. Under restrictive assumptions, analytical approaches are implementable, but the bounds are often loose, and occasionally, not sharp. Even if the sharpness issue is not present, the lower and upper bounds are typically attained under dependence models that are difficult to justify as feasible in practice, especially for portfolios consisting of many risks, since such extreme dependence models are not realistic.
Our contribution is two-fold. Firstly, we provide a first-in-its-class numerical method for constrained CVaR estimation, when the marginal distributions are known while only the bounds are available for the joint distribution. The latter setting is backed up by many observational data, where the dependence structure is rarely computable even if multivariate observational data are available. As a result, the lower and upper sharp bounds of the CVaR-based aggregate risk can be found. We analyse the complexity of the proposed methods for calculating these bounds, as well as substantiate our findings via numerical illustrations. Our approach trivially generalizes to non-uniform marginals. Despite the fact that the computational cost increases very rapidly with the number of risks, we believe that the method may still be used as a viable exploratory tool when dealing with a relatively large risk portfolio. Finally, we show how the run-times may be significantly improved, by exploiting the very special structure of the underlying linear optimization problems at the formulation stage.
Secondly, it is known that CVaR respects the so-called lower-orthant stochastic ordering for two-dimensional portfolios. Yet, no similar result has yet been established or disproved for higher dimensions. As a by-product of our analysis, using elementary LP techniques, we show that no such extensions are possible. Specifically, we construct trivariate counter-examples that demonstrate a lack of aggregate risk monotonicity under upper, lower-orthant, concordant, and persistent stochastic orderings. We also give a self-contained alternative proof for the bivariate risk case, and point out the exact reason why higher-dimensional extensions are not possible.
Author Contributions
The authors contributed equally to this article. All authors have read and agreed to the published version of the manuscript.
Funding
This research was partly funded by Natural Sciences and Engineering Research Council Discovery grant RGPIN/07199-2019.
Data Availability Statement
Data is synthetic, with methodology described in the manuscript.
Acknowledgments
We would like to thank the authors of the free online course CVX 101 (Stephen Boyd and Lieven Vandenberghe) for the invaluable resource that is made open to the public through Stanford University, that helped to sharpen our focus on convexity. We would also like to thank Michael Grant for making the CVX modeling environment freely available to the general public. We would also like to thank the authors of SDPT3 (Kim-Chuan Toh, Michael Todd and Reha Tutuncu) for making their solver publicly available, as well as Gurobi for providing a free academic license for their top-of-the-line LP-MIP solver. The second author would also like to express gratitude to NSERC and PIMS for supporting this piece of research.
Conflicts of Interest
The authors declare no conflict of interest.
| 1 | For a multivariate vector comonotonicity formally is defined as follows: there exists a random vector Z and non-decreasing functions for all such that for all . |
| 2 | Intuitively, on average, for a uniform random integer number between 1 and m, exactly % of integers in are less than or equal to the chosen number. Observing that the c.d.f. constraints have non-zeros at exactly such “lesser” sub-indices along each dimension, a proof can be established by induction. |
References
- Acerbi, Carlo, and Dirk Tasche. 2002. On the Coherence of Expected Shortfall. Journal of Banking and Finance 26: 1487–503. [Google Scholar] [CrossRef]
- Asimit, Alexandru V., Alexandru M. Badescu, Steven Haberman, and Eun-Seok Kim. 2016. Efficient risk allocation within a non-life insurance group under Solvency II Regime. Insurance: Mathematics and Economics 66: 69–76. [Google Scholar] [CrossRef]
- Asimit, Alexandru V., Junlei Hu, and Yuantao Xie. 2019. Optimal Robust Insurance with a Finite Uncertainty Set. Insurance: Mathematics and Economics 87: 67–81. [Google Scholar] [CrossRef]
- Asimit, Alexandru V., Valeria Bignozzi, Ka Chun Cheung, Junlei Hu, and Eun-Seok Kim. 2017. Robust and Pareto Optimality of Insurance Contract. European Journal of Operational Research 262: 720–32. [Google Scholar] [CrossRef]
- Balbás, Alejandro, Beatriz Balbás, and Antonio Heras. 2011. Stable Solutions for Optimal Reinsurance Problems involving Risk Measures. European Journal of Operational Research 214: 796–804. [Google Scholar] [CrossRef]
- BCBS. 2016. Standards. In Minimum Capital Requirements for Market Risk. Basel Committee on Banking Supervision. Basel: Bank for International Settlements, January. [Google Scholar]
- Ben-Tal, Aharon, Laurent El Ghaoui, and Arkadi Nemirovski. 2009. Robust Optimization. Princeton: Princeton University Press. [Google Scholar]
- Bertsimas, Dimitris, and Ioana Popescu. 2002. On the Relation between Option and Stock Prices: A Convex Optimization Approach. Operations Research 50: 358–74. [Google Scholar] [CrossRef]
- Bertsimas, Dimitris, Geoffrey J. Lauprete, and Alexander Samarov. 2004. Shortfall as a Risk Measure: Properties, Optimization and Applications. Journal of Economic Dynamics and Control 28: 1353–81. [Google Scholar] [CrossRef]
- Billingsley, Patrick. 1995. Probability and Measure, 3rd ed. New York: John Wiley and Sons. [Google Scholar]
- Blanchet, Jose, Henry Lam, Qihe Tang, and Zhongyi Yuan. 2017. Applied Robust Performance Analysis for Actuarial Applications. Technical Report, Society of Actuaries. Available online: https://web.stanford.edu/~jblanche/papers/Robust_Actuarial.pdf (accessed on 5 May 2023).
- Chen, Wenqing, Melvyn Sim, Jie Sun, and Chung-Piaw Teo. 2009. From CVaR to Uncertainty Set: Implications in Joint Chance-Constrained Optimization. Operations Research 58: 470–85. [Google Scholar] [CrossRef]
- Denuit, Michel, Jan Dhaene, Marc Goovaerts, and Rob Kaas. 2005. Actuarial Theory for Dependent Risks: Measures, Orders and Models. Chichester: Wiley. [Google Scholar]
- El Ghaoui, Laurent, Maksim Oks, and Francois Oustry. 2003. Worst-case Value-at-risk and Robust Portfolio Optimization: A conic Programming Approach. Operations Research 51: 543–56. [Google Scholar] [CrossRef]
- Fabozzi, Frank J., Dashan Huang, and Guofu Zhou. 2010. Robust Portfolios: Contributions from Operations Research and Finance. Annals of Operations Research 176: 191–220. [Google Scholar] [CrossRef]
- Gijbels, Irène, and Dominik Sznajder. 2013. Positive Quadrant Dependence Testing and Constrained Copula Estimation. Canadian Journal of Statistics 41: 36–64. [Google Scholar] [CrossRef]
- Gómez, Fabio, Qihe Tang, and Zhiwei Tong. 2022. The Gradient Allocation Principle based on the Higher Moment Risk Measure. Journal of Banking & Finance 143: 106544. [Google Scholar]
- Gurobi Optimization, LLC. 2023. Gurobi Optimizer Reference Manual. Available online: https://www.gurobi.com (accessed on 5 May 2023).
- Huang, Dashan, Shushang Zhu, Frank J. Fabozzi, and Masao Fukushima. 2010. Portfolio Selection under Distributional Uncertainty: A Relative Robust CVaR Approach. European Journal of Operational Research 203: 185–94. [Google Scholar] [CrossRef]
- Rockafellar, R. Tyrrell, and Stanislav Uryasev. 2000. Optimization of Conditional Value-at-Risk. Journal of Risk 2: 21–41. [Google Scholar] [CrossRef]
- Swiss Solvency Test. 2006. FINMA SST Technisches Dokument. Available online: https://www.finma.ch/FinmaArchiv/bpv/download/e/SST_techDok_061002_E_wo_Li_20070118.pdf (accessed on 5 May 2023).
- Tardos, Éva. 1986. A Strongly Polynomial Algorithm to Solve Combinatorial Linear Programs. Operations Research 34: 250–56. [Google Scholar] [CrossRef]
- Zhu, Shushang, and Masao Fukushima. 2009. Worst-Case Conditional Value-at-Risk with Application to Robust Portfolio Management. Operations Research 57: 1155–68. [Google Scholar] [CrossRef]
- Zinchenko, Y. 2023. CVaR Engine for a Sharp Lower Bound, GitHub Repository. Available online: https://github.com/yzinchenko/CVaR (accessed on 5 May 2023).
- Zymler, Steve, Daniel Kuhn, and Berç Rustem. 2013. Worst-case Value-at-risk of Nonlinear Portfolios. Management Science 59: 172–88. [Google Scholar] [CrossRef]
Figure 1.
Perceived behavior of : (a) strict piecewise concavity, (b) convexity.

Figure 2.
Hypothetical concavity of : (a) , (b) .

Figure 3.
Epigraph scheme.

Figure 4.
Rectangle inequality summation sign pattern.

Figure 5.
Trivariate aggregate risk values with .


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Average run-time (in seconds) for naïve and epigraph schemes for small size problems with .
Table 1.
Average run-time (in seconds) for naïve and epigraph schemes for small size problems with .
| SDPT3 | Gurobi | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Naïve | Epigraph | Naïve | Epigraph | ||||||||
| n | m | CVX | CVX+ | CVX | CVX+ | CVX | CVX+ | Direct | CVX | CVX+ | Direct |
| 2 | 2 | 2.59 | 2.53 | 6.71 | 6.77 | 1.41 | 1.38 | 0.10 | 6.80 | 6.66 | 0.27 |
| 4 | 9.26 | 8.38 | 17.04 | 16.16 | 4.06 | 3.80 | 0.19 | 8.01 | 7.52 | 0.33 | |
| 6 | 21.85 | 18.49 | 18.79 | 16.85 | 8.76 | 8.03 | 0.36 | 8.28 | 7.40 | 0.38 | |
| 8 | 42.94 | 35.09 | 20.75 | 17.76 | 16.13 | 13.97 | 0.84 | 8.51 | 7.41 | 0.50 | |
| 10 | 77.72 | 61.51 | 22.35 | 18.25 | 26.60 | 22.32 | 1.76 | 9.20 | 7.70 | 0.73 | |
| 12 | 149.49 | 117.61 | 29.06 | 25.27 | 41.82 | 33.68 | 3.57 | 9.95 | 8.17 | 1.11 | |
| 14 | 264.68 | 200.38 | 35.92 | 31.02 | 63.71 | 49.53 | 7.29 | 10.59 | 8.40 | 1.66 | |
| 3 | 3 | 16.05 | 13.67 | 19.68 | 17.10 | 6.51 | 6.11 | 0.29 | 8.04 | 7.59 | 0.37 |
| 4 | 42.80 | 35.11 | 22.57 | 18.86 | 15.36 | 14.05 | 0.83 | 8.46 | 7.70 | 0.53 | |
| 5 | 109.92 | 87.24 | 27.32 | 22.98 | 32.05 | 28.60 | 2.57 | 9.18 | 8.23 | 0.95 | |
| 6 | 299.76 | 224.36 | 39.94 | 33.52 | 61.86 | 53.93 | 8.40 | 10.06 | 8.90 | 1.91 | |
Table 2.
Average run-time (in seconds) for the best lower bound estimation scheme—epigraph-based with direct Gurobi—for small to medium size problems with , with a run-time limit of 15 min.
Table 2.
Average run-time (in seconds) for the best lower bound estimation scheme—epigraph-based with direct Gurobi—for small to medium size problems with , with a run-time limit of 15 min.
| 3 | 6 | 9 | 12 | 15 | 20 | 30 | 40 | 50 | 60 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 0.24 | 0.30 | 0.48 | 0.91 | 1.71 | 4.76 | 28.08 | 93.44 | 240.52 | 543.52 |
| 3 | 0.29 | 1.62 | 16.87 | 114.93 | 600.53 | - | - | - | - | - |
Table 3.
Average run-time (in seconds) for Gurobi-based epigraph scheme with respect to (a) , with , and (b) .
Table 3.
Average run-time (in seconds) for Gurobi-based epigraph scheme with respect to (a) , with , and (b) .
| (a) | (b) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 0.1 | 0.9 | 0.99 | |||||||
| 2 | 20 | 3.47 | 3.93 | 4.21 | 2 | 20 | 3.47 | 3.96 | 4.56 |
| 30 | 20.36 | 23.36 | 25.61 | 30 | 19.24 | 22.29 | 27.53 | ||
| 40 | 68.34 | 74.08 | 85.97 | 40 | 64.46 | 79.07 | 92.04 | ||
| 3 | 6 | 1.16 | 1.37 | 1.46 | 3 | 6 | 1.16 | 1.35 | 1.62 |
| 9 | 11.83 | 13.90 | 14.47 | 9 | 12.22 | 14.14 | 16.84 | ||
| 12 | 77.88 | 95.16 | 100.65 | 12 | 81.13 | 96.21 | 122.45 |
Table 4.
Average run-time (in seconds) for the upper bound using Gurobi-based epigraph and direct LP embedding methods, with , with a run-time limit of 15 min.
Table 4.
Average run-time (in seconds) for the upper bound using Gurobi-based epigraph and direct LP embedding methods, with , with a run-time limit of 15 min.
| Method | 3 | 6 | 9 | 12 | 20 | 30 | 40 | 50 | 60 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Epigraph | 2 | 0.32 | 0.35 | 0.60 | 1.14 | 5.88 | 35.60 | 139.0 | 354.4 | 688.6 |
| Direct LP | 0.05 | 0.07 | 0.13 | 0.33 | 2.64 | 12.05 | 39.2 | 98.4 | 218.1 | |
| Epigraph | 3 | 1.94 | 21.7 | 172.5 | 802.2 | - | - | - | - | - |
| Direct LP | 0.67 | 7.41 | 44.6 | 190.9 | - | - | - | - | - |
Table 5.
Trivariate risk sample values.
| Risk | |||
|---|---|---|---|
| 0 | 100 | 200 | |
| 0 | 10 | 20 | |
| 0 | 1 | 2 |
Table 6.
Cases in which .
| Ordering | i | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0.1 | 1 | 1/4 | - | - | 1/4 | - | 1/4 | 1/4 | - | |
| 2 | - | 1/4 | 1/4 | - | 1/4 | - | - | 1/4 | ||
| 0.9 | 1 | - | 1/4 | 1/4 | - | 1/4 | - | - | 1/4 | |
| 2 | 1/4 | - | - | 1/4 | - | 1/4 | 1/4 | - | ||
| 0.1 | 1 | 1/4 | - | - | 1/4 | - | 1/4 | 1/4 | - | |
| 2 | - | 1/4 | 1/4 | - | 1/4 | - | - | 1/4 |
Table 7.
Cases in which .
| Ordering | i | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0.9 | 1 | 1/4 | - | - | 1/4 | - | 1/4 | 1/4 | - | |
| 2 | - | 1/4 | 1/4 | - | 1/4 | - | - | 1/4 | ||
| 0.1 | 1 | - | 1/4 | 1/4 | - | 1/4 | - | - | 1/4 | |
| 2 | 1/4 | - | - | 1/4 | - | 1/4 | 1/4 | - | ||
| 0.9 | 1 | 1/4 | - | - | 1/4 | - | 1/4 | 1/4 | - | |
| 2 | - | 1/4 | 1/4 | - | 1/4 | - | - | 1/4 |
Table 8.
Trivariate concordant risks with and .
| i | (2,1,1) | (3,1,1) | (2,3,1) | (3,3,1) | (1,2,2) | (2,1,3) | (3,1,3) | (2,3,3) | (3,3,3) |
| 100 | 200 | 120 | 220 | 11 | 102 | 202 | 122 | 222 | |
| 1/6 | - | - | 1/6 | 1/3 | - | 1/6 | 1/6 | - | |
| - | 1/6 | 1/6 | - | 1/3 | 1/6 | - | - | 1/6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Zinchenko, Y.; Asimit, A.V. Modeling Risk for CVaR-Based Decisions in Risk Aggregation. J. Risk Financial Manag. 2023, 16, 266. https://doi.org/10.3390/jrfm16050266
AMA Style
Zinchenko Y, Asimit AV. Modeling Risk for CVaR-Based Decisions in Risk Aggregation. Journal of Risk and Financial Management. 2023; 16(5):266. https://doi.org/10.3390/jrfm16050266
Chicago/Turabian StyleZinchenko, Yuriy, and Alexandru V. Asimit. 2023. "Modeling Risk for CVaR-Based Decisions in Risk Aggregation" Journal of Risk and Financial Management 16, no. 5: 266. https://doi.org/10.3390/jrfm16050266