1. Introduction
Disasters and natural hazards require immediate intervention due to their severe negative impacts on human lives and properties, as well as permanent damage to the environment. The robust response and recovery efforts of responders and humanitarian organizations are vital to ensuring a minimum degree of losses and changes to the ecosystem [
1]. Social media platforms have gained importance in the task of disaster classification as the continuous monitoring of content on different online streams can lead to the rapid identification of dangerous situations. The use of such resources helps in providing immediate disaster relief and rescue in critical cases [
2].
Computer vision and deep learning real-time systems have rapidly become essential for active disaster response through tasks including incident identification, irrelevant image filtration, image classification into specific humanitarian categories, and damage severity assessment [
3]. However, due to the complex and varying structures of disaster images, training an accurate and robust disaster classification network requires a large dataset, in addition to balanced sample sizes for each incident type.
1.1. Problem Background
Social media platforms, such as Twitter and Facebook, are considered vital sources of textual and imagery content. Despite extensive research that mainly focuses on textual content to extract useful information, other works have utilized multimodal architectures and enhanced the performance over existing baselines [
4]. However, few studies have focused on the use of imagery content, although past research has proven that imagery content from social media during a disaster can be independently used to develop effective disaster classification frameworks [
5].
The use of disaster-related social media imagery can help identify the spatial relationship between disastrous events and accidents from different angles. If such information is combined with the geographical characteristics of the incident, first aid personnel can be immediately directed to the incident location. This study proposes an approach to gather spatial data from social media platforms and apply image classification to detect disastrous events in real time. If the results are combined with geographical information, this approach can aid first-aid responders in cases of disasters.
In this study, we tackle the task of disaster classification using deep learning techniques with social media-based images. Class imbalance is a common issue in real-world classification problems, where a significant imbalance in the number of training samples between classes causes the learning algorithms to overgeneralize the samples of the majority classes and produce inaccurate network parameters. Certain categories of most disaster classification datasets show skewness in the overall data distribution, which adds to the difficulty of model training. In particular, since deep neural networks (DNNs) need a substantial amount of training data for multi-class problems, most learners tend to exhibit bias towards the majority classes or completely disregard the minority classes. In many problems, the minority group is the class of interest; however, in this current task, all classes of disasters are of equal importance.
Countermeasures against imbalance traditionally include data-level sampling techniques, such as the synthetic minority oversampling technique (SMOTE), which increases the number of class instances by interpolating neighboring points. Alternatively, algorithm-level techniques perform instance weighting or alter the loss function to penalize minority class errors [
6]. However, data-dependent techniques may lead to the overlapping of classes and pose an impracticality for high-dimensional data. Similarly, algorithmic methods face the challenge of selecting an effective cost or penalty that continuously changes based on the domain of the task at hand.
To address the problems associated with traditional countermeasures, synthetic data can be created to mirror the statistical properties of the original dataset. The algorithm used for data generation is a crucial factor that affects the quality of the synthesized data. Data augmentation has become a crucial part of the deep learning process to generate sufficient samples of training data. Prior approaches mainly depend on data warping augmentation methods, including traditional geometric augmentation and color transformations [
7], as well as more novel approaches similar to CutMix augmentation, which replaces regions from training images with patches from others originating from different classes to create additional data [
8]. Although effective at increasing the sample size, these methods only apply simplistic manipulations that fail to produce any new meaningful features.
We conducted experiments to explore the validity of using synthetically generated samples to amplify a training dataset for the task of disaster classification. Generative adversarial networks (GANs) [
9] have been shown to be effective for data augmentation in computer vision tasks. GANs are trained to fit the real distribution of data using a min–max game theory; once the correct distribution is reached, realistic synthetic samples are produced. A basic approach consists of the concurrent training of two models: a generative model to capture the data distribution from input noise and a discriminative model responsible for predicting the probability of a sample belonging to the training data or the generated output.
This work proposes a disaster classification framework that maximizes classification performance by employing a generative network for synthetic disaster data generation in combination with an ensemble learner. This method eliminates the need to collect additional real data samples and aids in making informed decisions, which subsequently improves the results. The key contributions of this paper are summarized as follows: This work produces a comprehensive and balanced disaster classification dataset by training a conditional generative adversarial model. The model is designed to synthesize realistic disaster images determined using both qualitative and quantitative evaluations. This framework aims to provide extensive baselines for the crisis analysis research community.
This work presents a deep learning framework for disaster classification using an ensemble learning approach. Using a new approach for generative augmentation, the framework aids in rapid damage assessment using real-time social media data.
The proposed model has proven to improve the accuracy of disaster classification by up to 11% in comparison to other state-of-the-art research conducted for the same task. These superior results were obtained by training state-of-the-art convolutional architectures using a domain-specific dataset and experimenting with different augmentation methods, such as geometric augmentation, CutMix augmentation, GAN augmentation, and a combination thereof.
1.2. Related Work
Previous research has extensively studied disaster classification. However, the classification of imbalanced datasets that include less frequently occurring disasters, such as droughts and hurricanes, has rarely been studied directly.
1.2.1. Disaster Classification
Due to the lack of labeled images in the domain of disaster classification, recent studies have focused on the collection of disaster data through social media platforms to develop datasets for the research community. These datasets may include disaster images, textual information, or a combination of both.
The earliest publications include the CrisisLex dataset presented by Olteanu et al. [
10], which consists of tweets related to six different disastrous events. As classification results show improvement when the datasets include images of the events, tweets combined with 5000 images are used to classify fires to aid emergency personnel in combating bushfires, with a classification accuracy of 86% [
11]. Yang et al. [
12] described a dataset of geotagged Twitter posts of Hurricane Sandy in 2012, yet the dataset lacks human annotations. Alam et al. [
13] collected CrisisMMD, a large multimodal dataset from Twitter during different natural disasters with three different types of annotations. Other datasets combined and fused satellite imagery with social media content to extract meaningful insights for each disaster type [
14,
15]. Furthermore, the authors in [
2] re-labeled the existing CrisisMMD dataset to detect the type of disaster, informativeness, and damage severity, which was tested for classification against state-of-the-art deep learning models to provide a baseline for future research in similar tasks.
Deep learning pre-trained models have shown positive results when combined with transfer learning. Valdez and Godmalin [
16] created a lightweight convolutional network with two heads to classify disaster images and measure disaster intensity. Hong et al. [
17] conducted a study to identify buildings damaged due to earthquakes using post-disaster aerial images and a proposed CNN that combines global and contextual features to determine the damage levels. Liang et al. [
18] fine-tuned pre-trained convolutional and language models using multimodal inputs of text-image pairs and obtained effective results against multimodal classification benchmarks. Khattar and Quadri [
19] utilized unsupervised domain adaptation to classify unlabeled data of a new disaster using the existing labeled images of relevant disasters.
In this study, we built a balanced disaster dataset, which is a combination of the previously discussed benchmark datasets, and further examples were added using a generative adversarial model for data augmentation to increase the number of samples for under-represented classes.
1.2.2. Generative Augmentation
Since the introduction of the generative adversarial network architecture by Ian Goodfellow and his colleagues in 2014 to produce synthetic visual samples, several variants of the original architecture have been proposed by the research community. A conditional model (cGAN) was proposed to handle multiple classes within the same network. Shahbazi et al. [
20] studied the utilization of pre-trained cGANs to transfer knowledge across classes by injecting a network with a class label for each sample and applying conditional batch normalization. Additionally, the authors in [
21] experimented with non-adversarial loss functions to enhance the quality of generated images. While CycleGAN is used for unpaired image-to-image translation, StyleGAN was designed to apply style transfer to the generated images by separating the high-level attributes of an image, such as pose and identity, and performing scale-specific interpolation operations on the output. Such networks have had a significant impact on areas of computer vision, including image-to-image translation, image generation, and similar domains [
22].
GANs have recently been employed in the field of data augmentation since they can learn the original data distribution and produce similar realistic samples. A conditional GAN was used for multimodal audio-visual emotion recognition to address the class imbalance issue using generators and discriminators for both modalities [
23]. A similar augmentation technique can be applied to medical tasks. Motamed et al. [
24] augmented chest X-rays for the detection of pneumonia and COVID. They demonstrated that the GAN-based approach surpassed the results obtained by traditional augmentation methods in anomaly detection. Rui et al. [
25] designed a Disaster GAN to generate data samples to identify building damage from remote sensing imagery. Additionally, a GAN-based model was used to replace the labor-intensive data collection process for human pose estimation [
26] by entering the original limited dataset into the GAN model along with Gaussian white noise, which produced simulated human pose samples. The remainder of this paper is structured as follows:
Section 2 presents our proposed methodology to enhance the classification results obtained on disaster classification datasets in detail.
Section 3 elaborates on the conducted experiments to produce an effective deep-learning framework for disaster classification.
Section 4 and
Section 5 discuss the results to verify the validity of the proposed framework. Finally,
Section 6 concludes the paper by presenting a summary of the contributions and addressing future work.
2. Methodology
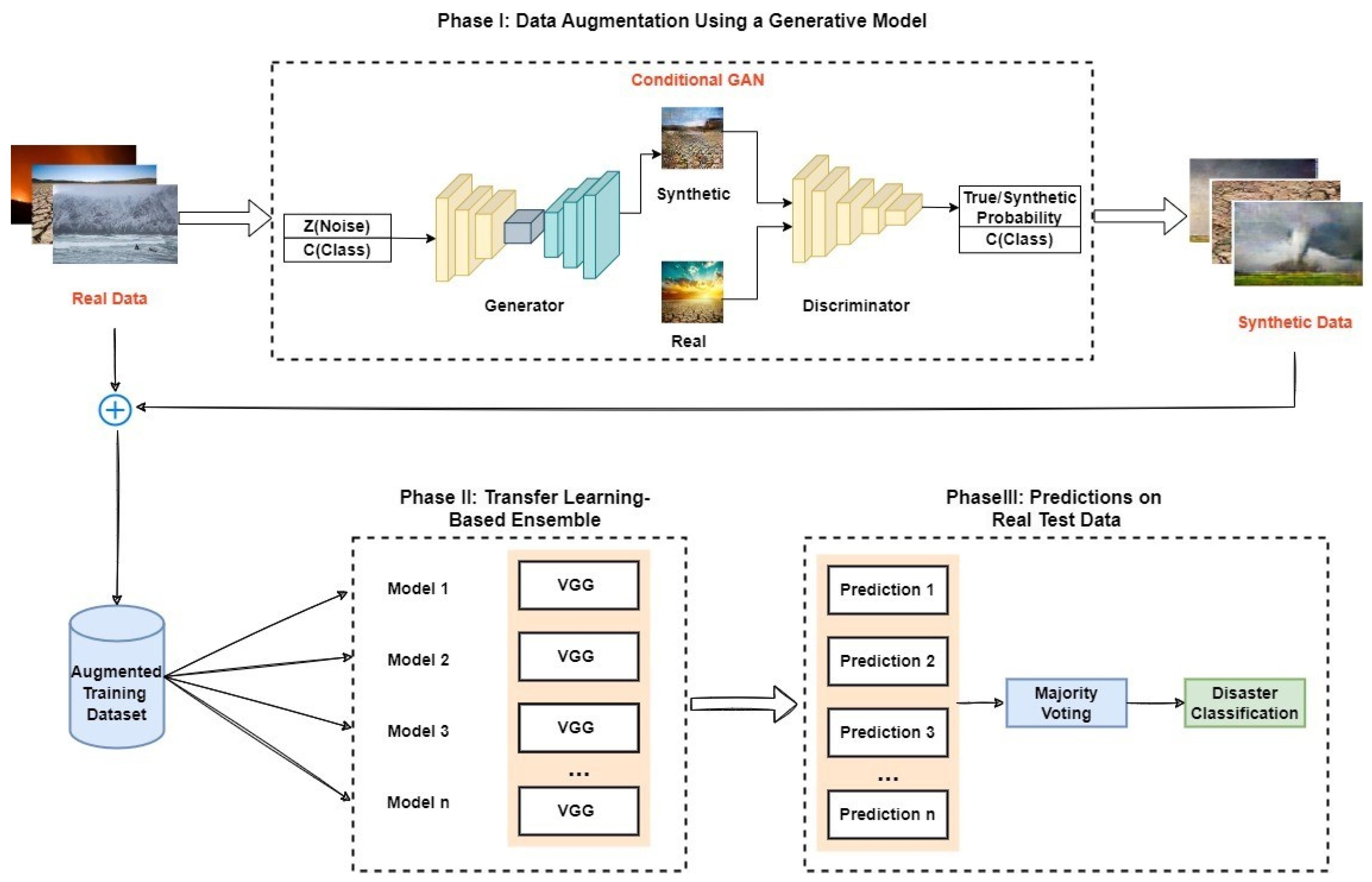
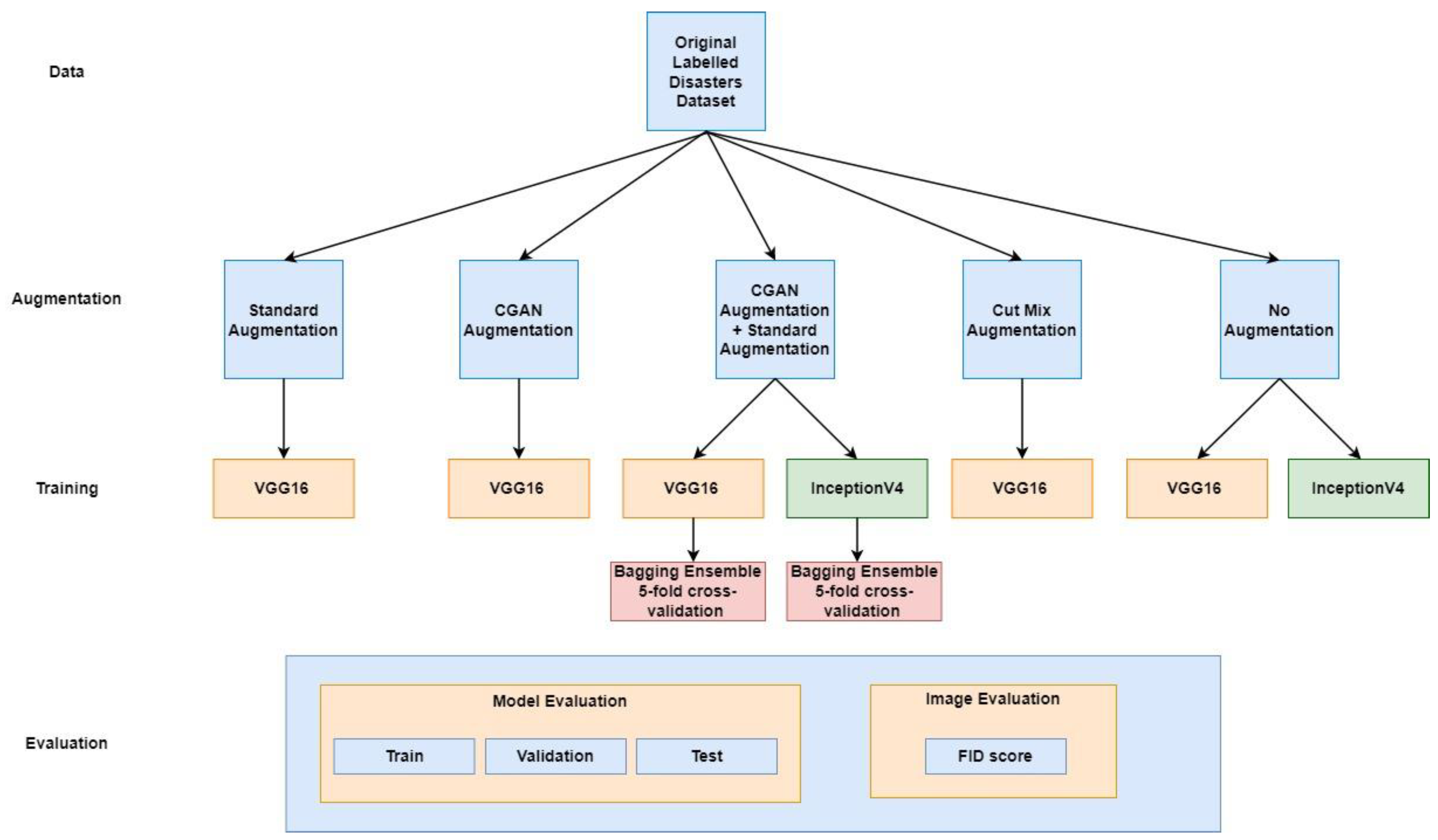
This paper proposes a technique to classify imbalanced disaster data into three main phases, as illustrated in
Figure 1. First, we based our data augmentation on the state-of-the-art conditional GAN architecture to generate fake samples that are as realistic as possible. Once the samples are generated and evaluated using Fréchet Inception Distance and Inception Score [
27], they are used to supplement the training dataset with the augmented information to avoid overfitting. This method eliminates the need to collect additional real data samples and aids in making informed decisions.
Second, we fine-tuned an ensemble of pre-trained VGG16 classifiers to perform disaster classification using the original dataset and the supplemented dataset. We also tested the models’ performance on different types of augmentation. It is to be noted that all testing experimentations were conducted on the same subset of real data samples in order to avoid overfitting and ensure a fair comparison between different models, while the synthetic samples were only used during the training phase.
Hyperparameters are manually set variables to help guide the learning process for each of the implemented architectures. All hyperparameters were obtained after applying a grid search, which defines a search space as a grid of hyperparameter values and evaluates every position in the grid to determine the optimal values.
As ensemble classifiers have the ability to produce performances superior and generally more stable than single models using imagery or textual datasets [
28]. We applied an ensemble learning approach by combining predictions from multiple models trained on different subsets of the data by using bootstrap aggregation (bagging), which applies stratified data resampling with replacement.
Applying stratified random sampling with replacement creates a balanced and reliable representation of each class. After the training phase, in which transfer learning is implemented to gain the advantage of the previously learned weights, each model is ready to output predictions. In the final phase, a majority hard vote is used, where every individual classifier votes for a class with the highest output probability, and the class with the majority votes decides the final prediction.
The following subsections describe the generative model used for augmentation and the deep convolutional classifiers to be trained.
2.1. Data Augmentation
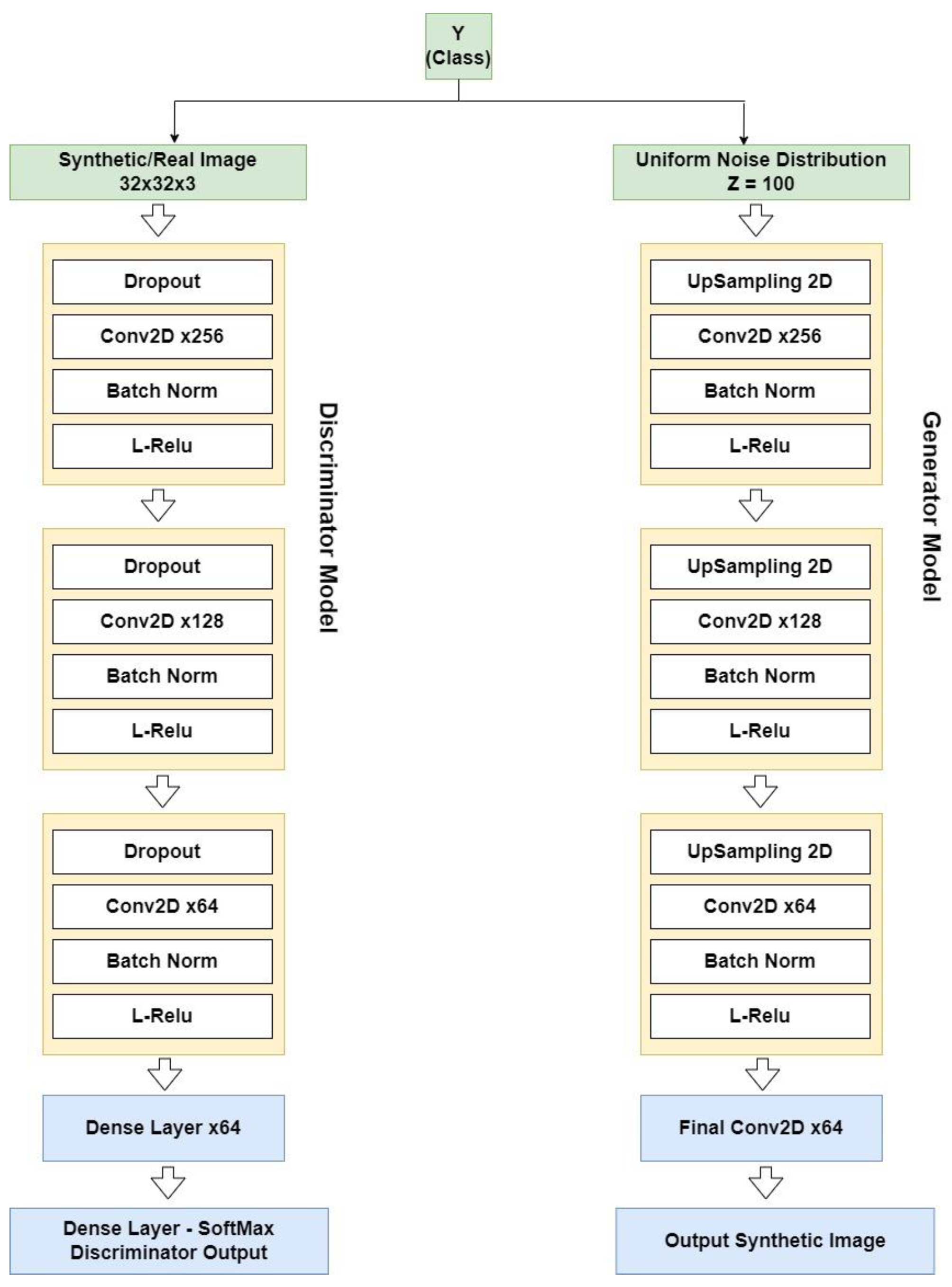
Data generation techniques using over- or under-sampling have proven to be effective for mixed or tabular data. However, GANs have additional merits regarding image generation. Generating high-quality synthetic images eliminates the dependency on a large training dataset. We have described the proposed framework of a disaster conditional GAN with the architecture shown in
Figure 2. The model is conditioned on the class labels of each image to allow the targeted output of the images to be of a given class.
The generator model begins with a uniform noise distribution input that is passed to the first of the three convolution stacks, progressively converting it to a high-dimensional feature vector representing the new image. Batch normalization is used to unify the inputs to prevent all samples from collapsing into a single point. Finally, the model outputs 64 × 64 × 3 images to be passed to the discriminator.
The discriminator is constructed with similar convolutional stacks, followed by final dense layers for classification. Average pooling down samples of the feature vectors are passed to the final fully connected dense layers to progressively map them to a lower-dimensional space for classification by a SoftMax layer. Finally, the model outputs a probability distribution over the class labels, and the most likely prediction is obtained.
2.2. Convolutional Classifiers
Deep learning is a leading approach for information extraction, and convolutional neural networks (CNNs) are commonly used architectures to process multidimensional vectors and achieve highly accurate results [
29]. There are various CNN architectures, where each of the networks differs in terms of the internal layers and techniques used. We opted to use the Inception-V4 and VGG16 architectures since such networks can solve image-based problems while simultaneously reducing the required parameters in comparison to traditional networks. We have briefly described each architecture in the following subsections.
2.2.1. VGG16 Architecture
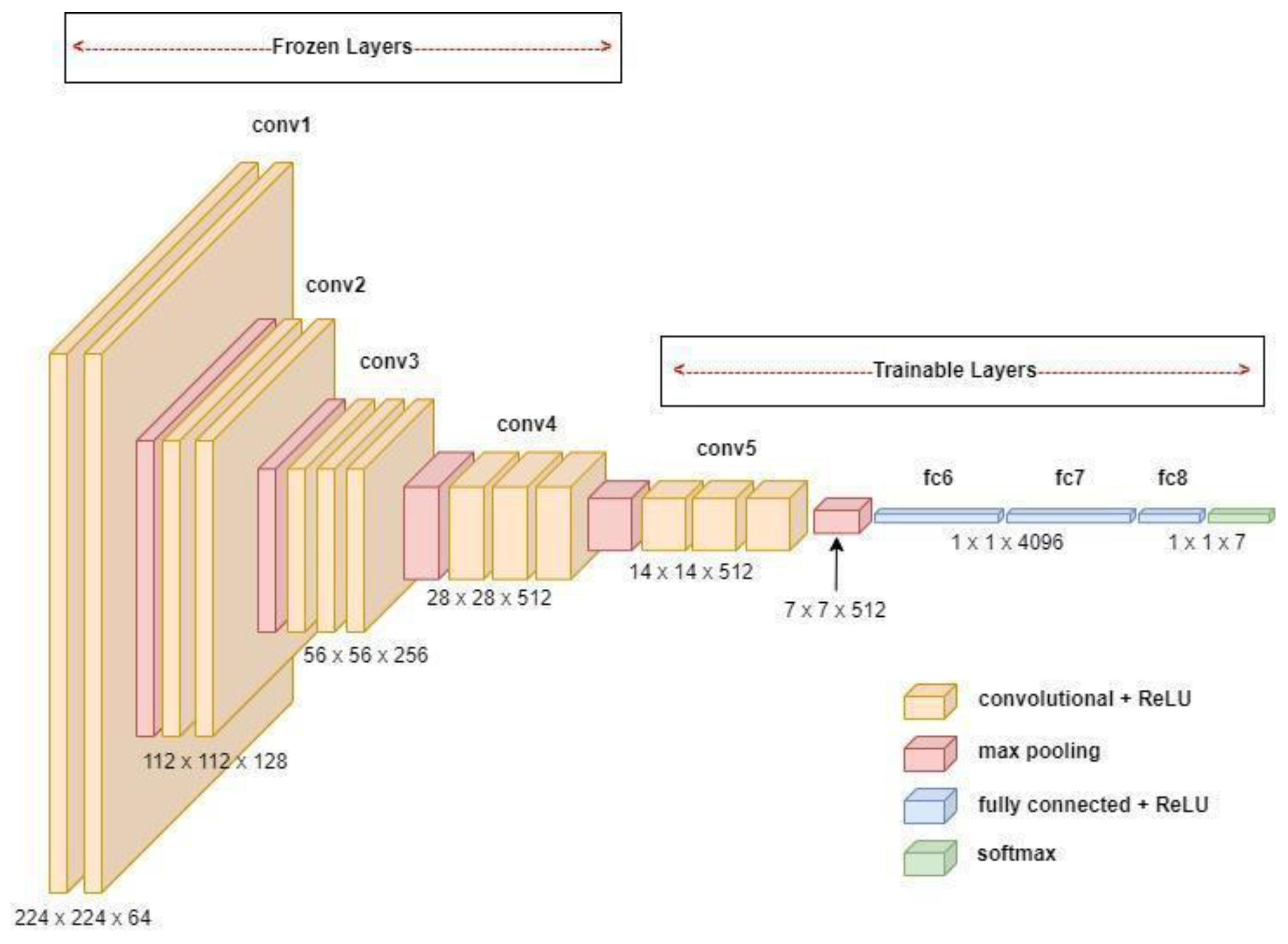
We employed a transfer learning-based approach, which uses the existing weights of a trained model to improve the performance of the targeted domain [
30]. We fine-tuned a VGG16 pre-trained architecture [
31] to adapt it to the task of natural disaster classification using our domain-specific collected dataset. The initial weights of VGG16 pre-trained on the ImageNet dataset, a dataset consisting of 1.2 million RGB images, were used to initialize the model. The architecture used was a 16-layer network composed of convolutional and fully connected layers, as shown in
Figure 3, using only 3 × 3 convolutional layers stacked on top of each other for simplicity. The convolutional blocks were followed by a max pooling layer with stride 2, and the final layers consisted of three hidden layers of 4096 nodes followed by a SoftMax output layer of seven units to represent the class labels.
The model was trained after adding additional classification layers to transfer the parameters from the broad domain to the problem-specific domain. Adam optimizer and SoftMax activation function are used. The learning rate was set to 10−4, the momentum to 0.6, and the maximum number of epochs was set to 100 with an early stopping criterion. The batch size for each epoch was set to 128, as it provided an optimal balance between the training time and model accuracy.
2.2.2. Inception Architecture
The inception architecture, first introduced in 2015 by Szegedy et al. [
32], was employed to be trained and tested for disaster classification. Although the model is relatively small in size in comparison to other state-of-the-art architectures, it provides satisfactory accuracies on the ImageNet dataset. Inception V4 comes as an extension of Inception V3 and Google LeNet modules [
33]. The main aim of the Inception V4 model is to decrease the number of parameters to be trained, thereby decreasing the computational complexity. The architecture is based on the notion of building a wider rather than deeper network by using convolutional filters of different sizes operating on the same level. As the inception architecture is highly tunable, the model consists of three different types of inception blocks, each with different numbers of filters in the various layers, as shown in
Figure 4.
The Inception V4 model is a network of stacked inception modules, followed by a SoftMax layer. Each module has multiple scales containing different kernel sizes. Each filter size extracts different scales of feature maps and propagates the output to the next block. A 1 × 1 convolutional filter is used for dimensionality reduction, while 3 × 3 and 5 × 5 convolutions are applied to achieve optimal feature extraction. Each inception module is followed by a reduction layer to scale the dimensionality of the filter bank to match the depth of the input to the next layer. In terms of the hyperparameters, the network is trained with stochastic gradient descent, momentum, and a decay rate of 0.9. The initial learning rate is set to 0.045 for decaying every 2 epochs.
3. Experimental Settings
In this section, we discuss the original dataset followed by the augmented dataset. We performed a quantitative evaluation of the generated images to verify the quality of the synthesized features. The natural disaster dataset included seven different classes of disasters, each of which had distinct traits. However, two classes showed visible imbalance (hurricane images and drought images). Several state-of-the-art architectures, such as VGG19 and Inception V4, were tested [
34]. To produce an effective classification model, the dataset was first balanced by training a generative adversarial network to produce additional samples for the minority classes.
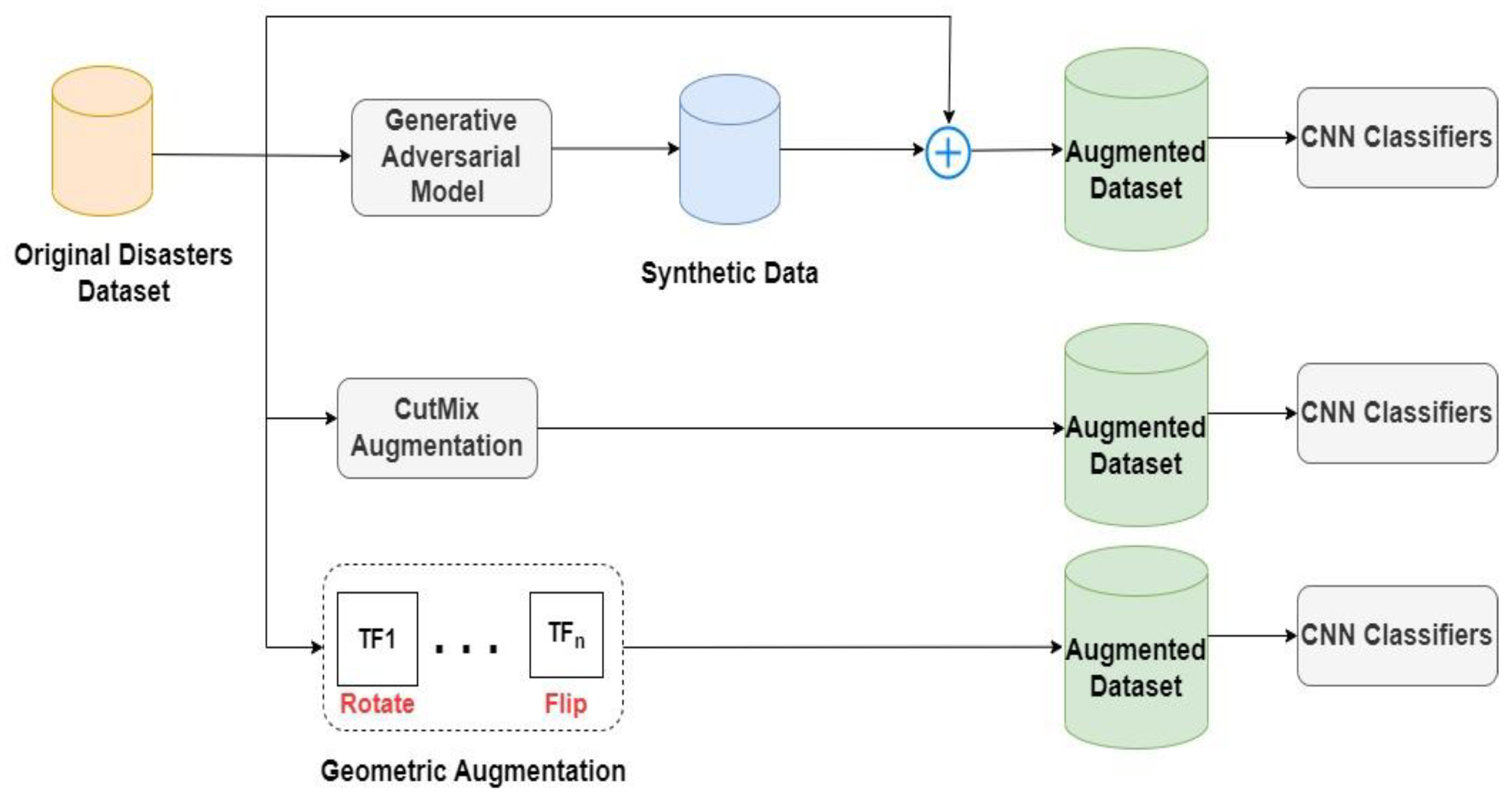
We additionally compared the performance of GAN augmentation to both traditional and CutMix augmentations to verify its superiority, as illustrated by the different augmentation methods applied in
Figure 5.
3.1. Dataset Analysis
A subset of CrisisMMD [
13], a real-world disaster-related dataset collected from Twitter during different natural disasters that took place in 2017, was used as the backbone of our dataset. Although the CrisisMMD dataset was collected several years ago, the samples remain relevant to the current times due to the consistent nature of natural disasters. In fact, the extreme weather events described by such datasets currently have an increasing toll on human and economic status due to the climate changes brought on by more frequent disasters. Additional samples were selected from other recent and publicly available datasets, including the damage identification multimodal dataset [
35] and the damage severity assessment dataset [
36].
The stated datasets consist of a combination of manually annotated tweets and images collected during seven major natural disasters, including earthquakes, hurricanes, wildfires, floods, etc., across different regions of the world. Images concerning certain natural disasters were selected and regrouped into new classes.
Figure 6 shows samples from different classes within the dataset.
Since social media-based data can include irrelevant information, all samples were manually revised and any mistakenly labeled, noisy, or corrupted images were removed from the dataset before the data processing stage.
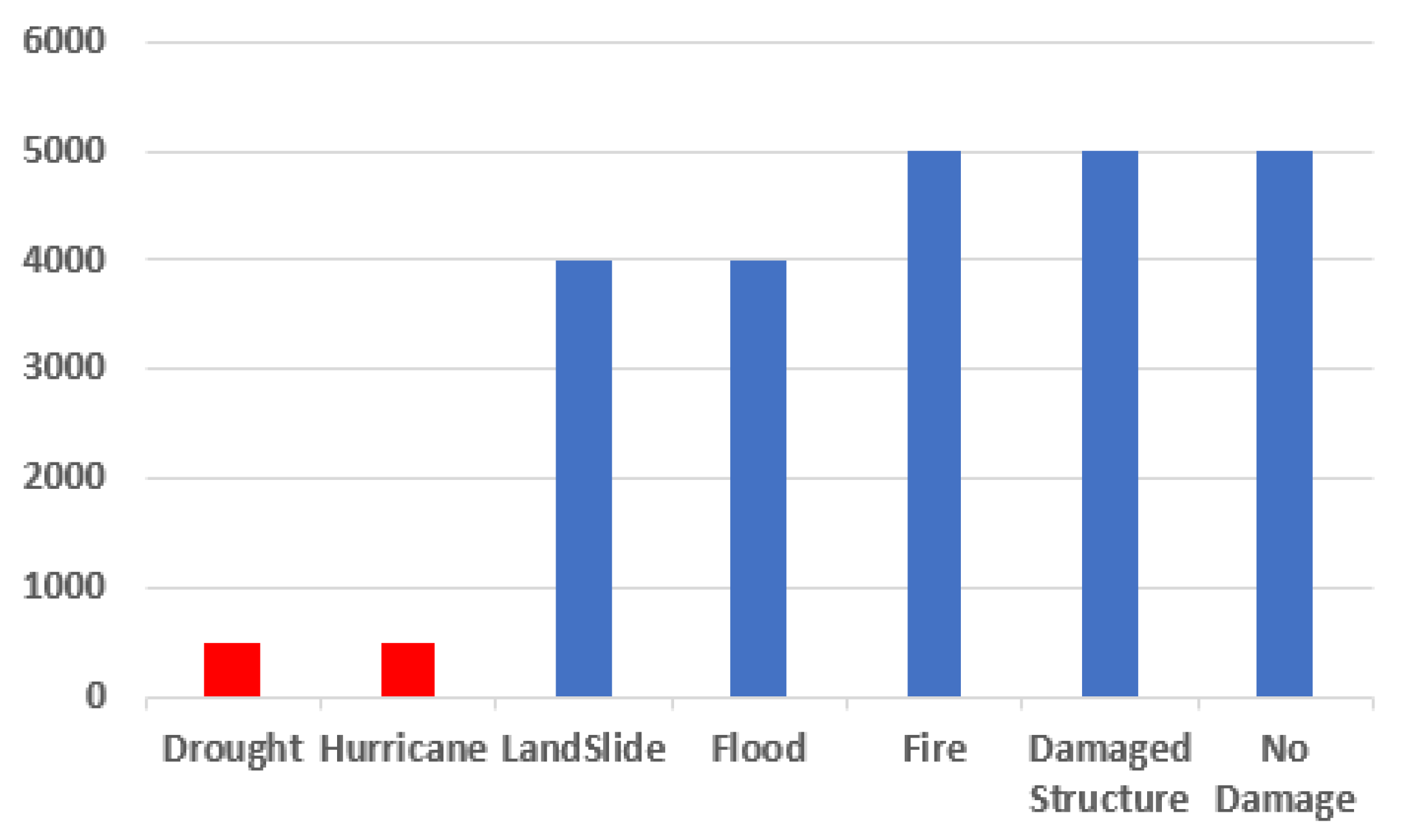
Additionally, text annotations were removed to focus only on the effects of synthetic images on image classification. As shown in
Figure 7, the final dataset exhibits class imbalance in two different classes, which we later eliminated by augmenting the datasets with class-specific synthetic samples.
The imbalance for multi-class classification is represented by the parameter (ρ), which represents the ratio between the number of examples in majority classes and the number of examples in minority classes. The ratio (ρ) can be expressed as follows, where
is a set of examples for each class
[
37].
For the given dataset, an imbalance can be seen for the drought and hurricane classes with an imbalance ratio of 10. Imbalanced classes were selected as inputs to the conditional GAN architecture to produce extra synthetic samples to balance the dataset while maintaining descriptive feature vectors for each class.
3.2. Implementation
The proposed framework was trained using different augmentation methods to determine the efficiency of GAN-based augmentation. After successfully balancing the dataset and verifying the quality of the generated images using inception score calculation, each generated dataset was used to train both the VGG16 and Inception V4 deep learning classifiers. Additionally, ensemble learning by bagging was applied to the best-performing models to further improve the classification results.
Since the introduction of the generative adversarial network architecture in 2014, several variants, including the cGAN model, have been introduced. A cGAN aims to condition the network with additional information, which allows for the generation of class-specific disaster samples after the network is injected with the class labels for each image.
In terms of data generation, the cGAN model was trained with 3000 epochs to generate 5000 new instances for the under-represented classes. Regarding hyper parameters, the Adam optimizer, along with binary cross entropy as a loss function, was used. Leaky Relu was used for activations except for the final layer, which used a Tanh activation. Generator dropout with a probability of 0.2, a learning rate of 0.0002, and a batch size of 4 were applied.
After adding the additional samples to the dataset, the class imbalance ratio was drastically reduced to a ratio of 2.5. It can be seen that the generated data are fairly similar to the true samples, as shown in
Figure 8. After utilizing the synthetically generated data for classification, the results confirm that the generated samples produce similar feature vectors when compared to the true samples and can be used for accurate classification.
Other data augmentation methods of geometric and CutMix augmentation were also applied to the original dataset, and a sample of each method’s output is shown in
Figure 9.
To further evaluate the images generated by the conditional generative network, we applied the inception score method to measure the variation in images and the Fréchet inception distance (FID) evaluation method. The calculation of the FID is based on the features from the last average pooling layer of the inception model.
The equation to calculate the inception score for a set of generated images is as shown below, where
indicates that
is an image sampled from
and
is the KL divergence between the distributions
and
[
38].
The Fréchet inception distance is formulated as follows [
39], where the distance between two Gaussians, real-world data
w(.), and the generated data
(.) were measured using the mean and covariance matrix (
) for each distribution.
We carried out three tests on batches of the generated images and averaged the results to obtain the inception score and FID values for the disaster dataset, as shown in
Table 1.
It is to be noted that the inception and FID scores were only used as a reference to compare subsequent models working on the same task since the disaster classification images were relatively different from the ImageNet samples on which the baseline scores were determined.
Classifiers were trained and tested for every augmentation method in addition to the ensemble classifiers. A summary of the different experimentations is shown in
Figure 10.
4. Results
All the initial experiments used an imbalanced dataset with 24,000 images distributed over seven classes. The final experiments included the GAN-generated images, resulting in a significantly balanced dataset of 29,000 images. All proposed models were implemented using Python, Tensor Flow 2.3.1, and Keras. All training trials were completed on a Jupiter notebook using a local CPU, and the average epoch execution time of 5000 s could be significantly reduced if a GPU-based approach was utilized to speed up computations.
Geometric augmentation that was applied involved image flipping, a 30% zooming rate, and 30% horizontal and vertical shifting. Additionally, the dataset was divided according to common best practices into 70% training, 20% validation, and 10% testing samples with the batch size set to eight samples. Since the validation data provided information that directed the tuning of the model’s hyperparameters and configurations, it was necessary to allocate sufficient validation samples. The test set required the least number of samples, as it measured the final model performance in terms of accuracy. The dataset initially suffered from an imbalance; thus, the majority of samples were directed towards the training set.
The two architectures employed in our experiments were VGG16 and Inception V4, which were evaluated individually using bagging ensembles to improve the resulting predictions by using several differently biased models and obtaining a final majority vote, as described in the previous sections.
In this paper, two hypotheses are evaluated: (1) whether the use of generative models for data augmentation is superior to that of traditional methods; (2) whether the use of an ensemble classifier improves the accuracy of the model for disaster classification.
4.1. Performance Evaluation
To measure the performance of each disaster classification architecture, we employed various performance metrics, such as accuracy, precision, recall, and F1 score, which were calculated as shown:
where
TP represents true positive,
TN true negative,
FP false positive, and
FN false negative.
4.2. Compared Methods
This section discusses the results of each experiment. After testing several classifiers, ensemble learning, and different augmentation methods, the following results were obtained.
Table 2 reports the accuracy (mean ± standard deviation) and macro-averaged results of the validation set for each CNN model, which were used as baseline experiments to show the classification results before adding any method of data augmentation. It is observed that on the baseline dataset, the VGG16 ensemble classifier shows superior results after fine-tuning, with a validation accuracy of 78.2%.
In the following experiments, we mainly focused on the VGG16 ensemble classifier with a fine-tuning approach to train classifiers with different combinations of augmented data, as it was the best-performing learning scheme in all initial experiments. We also observed the performance of the Inception V4-based architecture.
Table 3 shows the macro-averaged results in terms of precision, recall, F1 score, and accuracy of all the experiments performed after augmentation using the three different augmentation techniques. Next, the improvement in performance for each class can be observed, specifically for the initially imbalanced classes. We can see that the original accuracy favors overrepresented classes, which leads to misleading results. To be more specific, the minority and imbalanced classes (drought and hurricane images) benefited the most from GAN augmentation, as we can see that precision and recall were, on average, six times higher after augmentation for drought images and doubled for the hurricane images, as shown in
Table 4.
5. Discussion
This study aimed to produce a deep learning framework for disaster classification that outperforms current state-of-the-art models. The results show that our approach can be used to effectively classify damage incidents. We first compared the performance of different baseline models of inception and VGG19 in terms of accuracy and loss measures for each training and validation set.
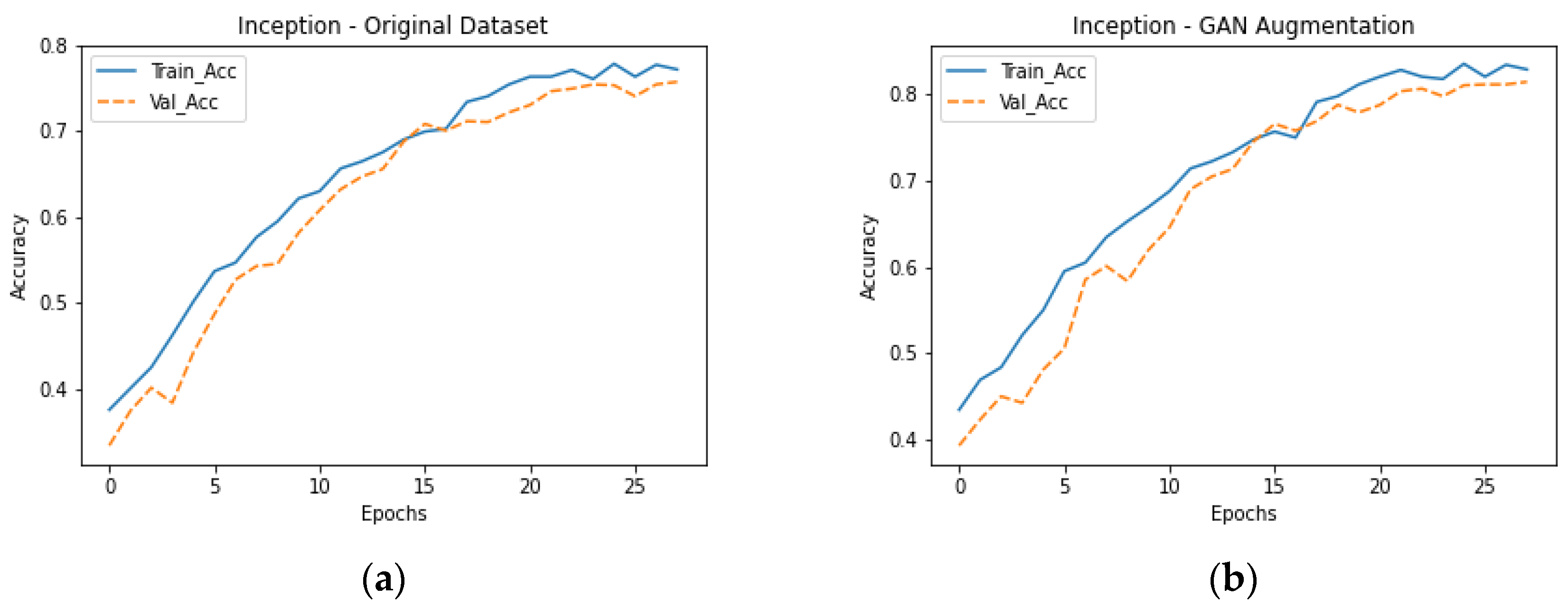
Figure 11 shows that while the inception model is unable to reach the baseline accuracy achieved by the VGG16 model, an average improvement of 9% is detected after applying GAN augmentation. However, the model exhibits signs of overfitting when the number of epochs increases.
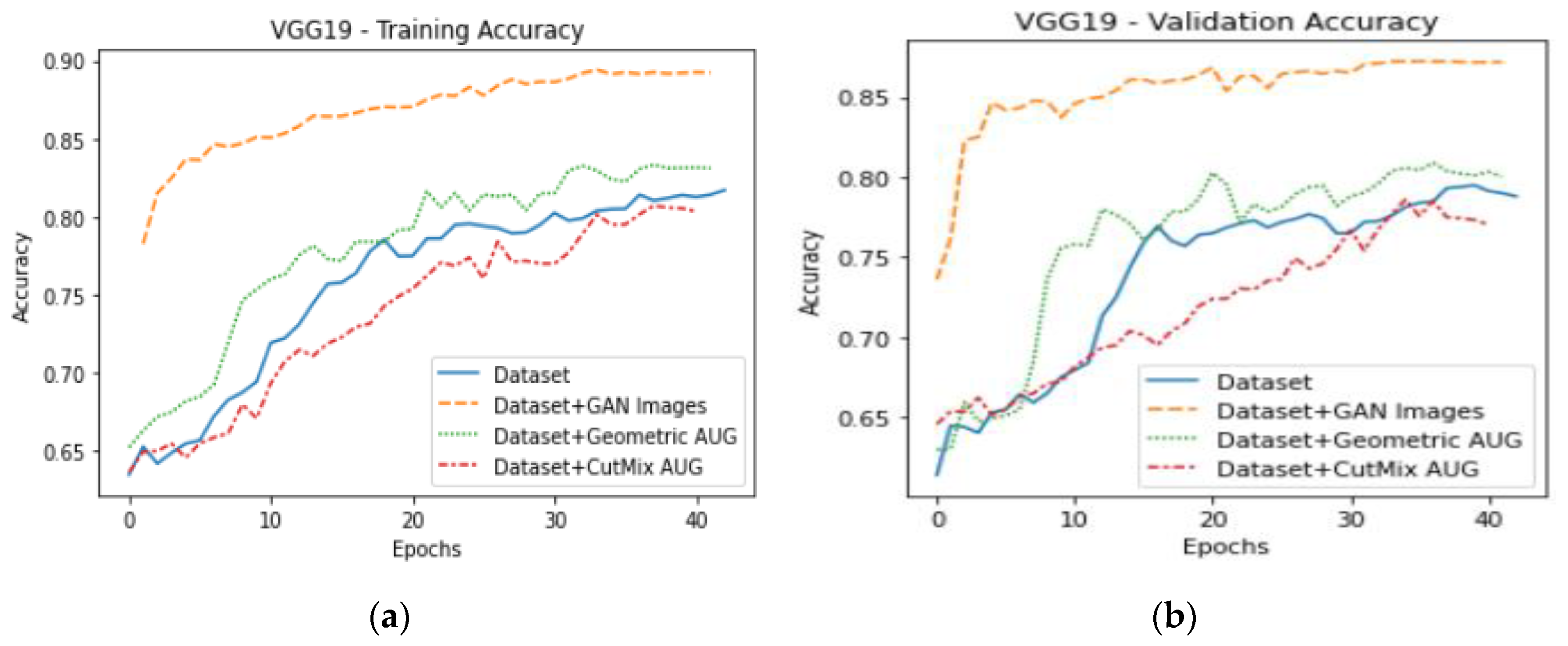
Further experiments focused on the use of the VGG architecture since it provided a noticeably higher performance on the original dataset in comparison to the inception model. After fine-tuning the VGG16 model using a transfer learning approach, the results were obtained for the different types of augmentation.
It can be seen that the baseline model trained on the original unbalanced dataset produced an accuracy of 76.1%. CutMix and geometric augmentation show improvement in accuracy, but they still visibly underperform in comparison to generative adversarial network-based augmentation. After applying GAN augmentation to balance the dataset, the accuracy increases to 86.2%, as shown in
Figure 12.
To further improve the classification results, a deep ensemble learning approach was applied to enhance the model’s generalization ability, which significantly improved the performance over traditional models. Validation accuracy curves showed that using the augmented dataset to train an ensemble VGG classifier with a bagging technique outperformed the previous results using traditional architectures. From the results shown in
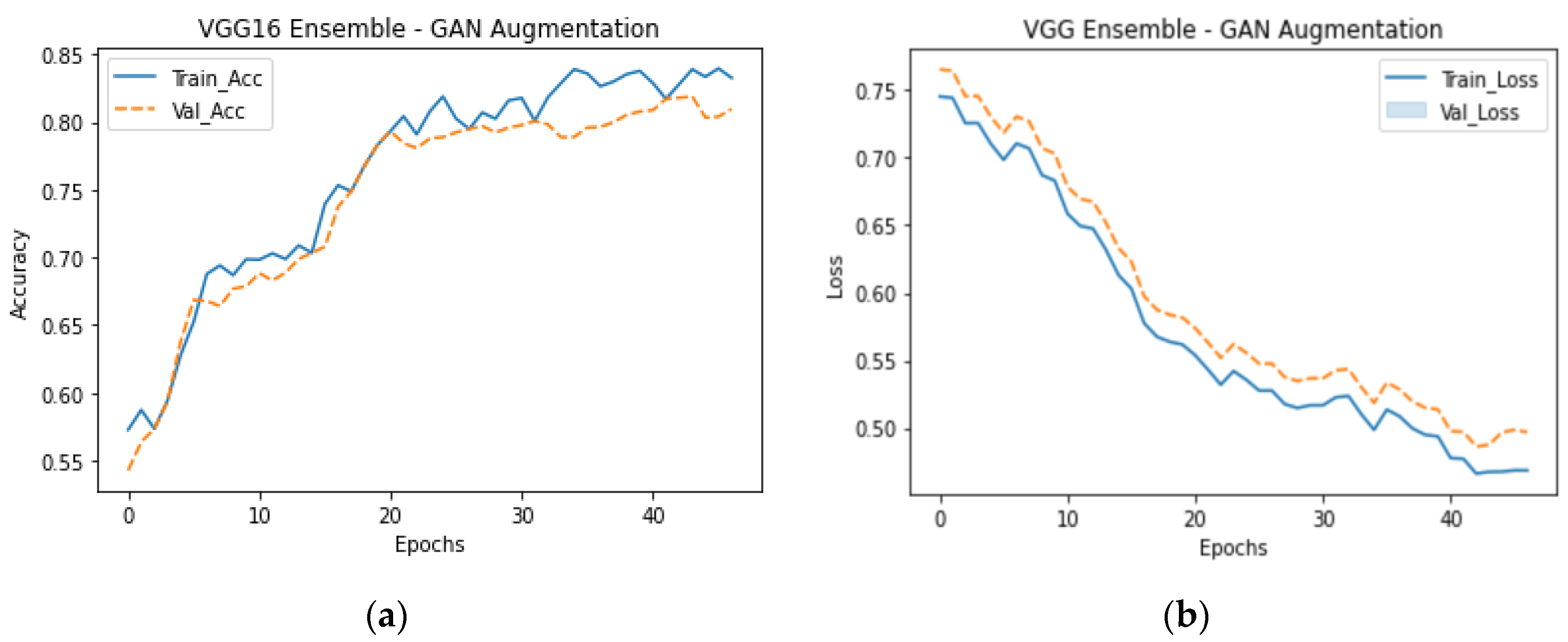
Figure 13, we can observe that the framework reaches a validation accuracy of 88.5%, representing an 11% improvement compared to the original baseline model, which is the highest level of performance achieved on similar disaster datasets.
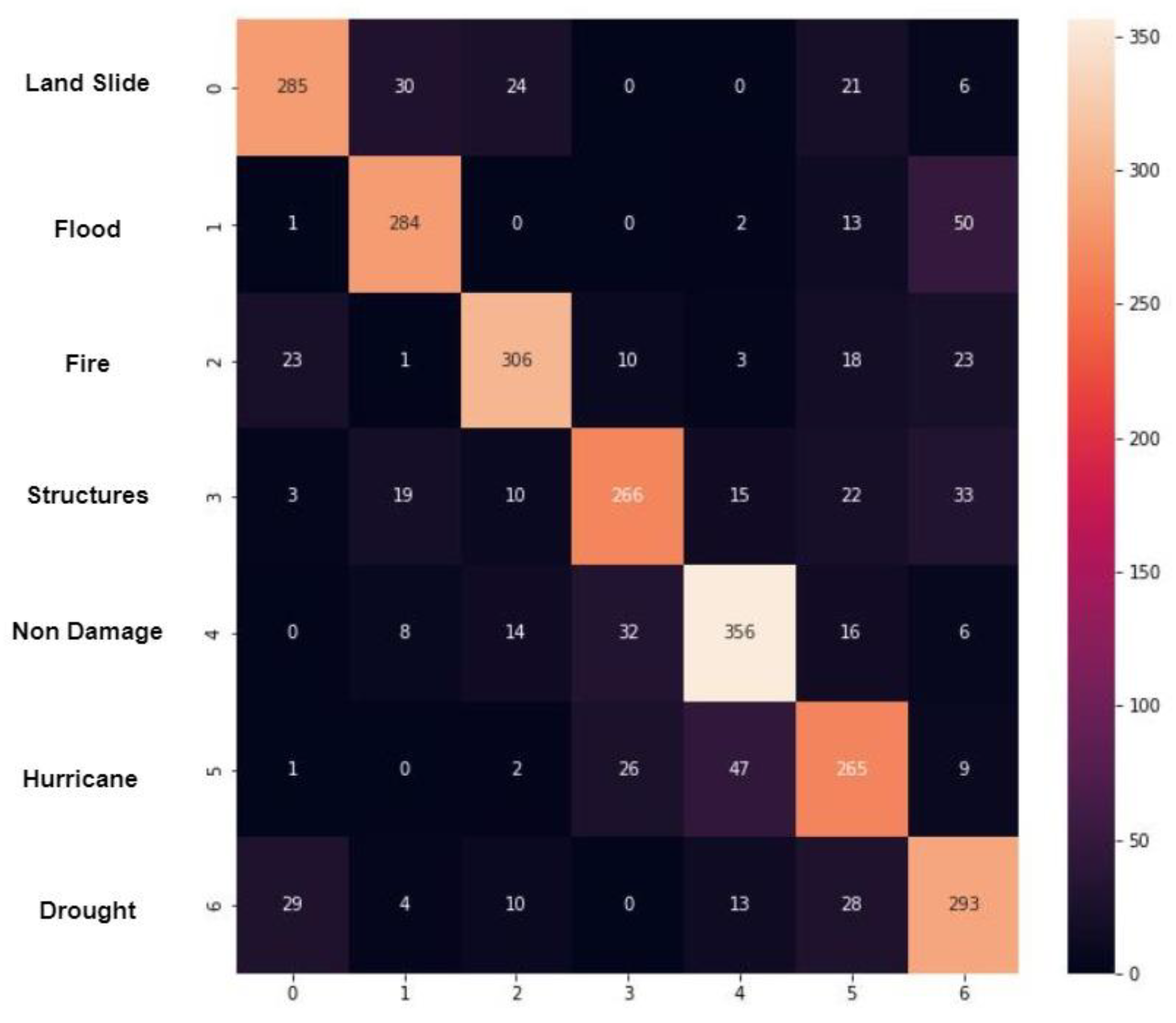
Lastly,
Figure 14 displays the confusion matrix of the best end-to-end model (VGG-based ensemble classifier with geometric and generative data augmentation). The matrix further highlights the improvement in the classification rate for the previously imbalanced classes.
This finding verifies the effectiveness of the ensemble approach in adding bias to each individual model, thereby increasing the overall framework’s generalization ability. We have additionally shown the validity of applying generative data augmentation to balance under-represented classes and improve the performance metrics obtained by different classifiers. In comparison with geometric transformation and CutMix augmentation, the proposed generative method has proven to be superior.
Compared to the traditional data augmentation methods, the model has shown its effectiveness; however, this approach requires a sufficient amount of data in initially unbalanced classes in order to adequately train the GAN model. If the number of samples per class is too small, this approach may not be applicable. The overall classification accuracy for the disaster classification problem showed an average improvement of 11% when the proposed method was applied.
As a result, the proposed framework can be implemented as a real-time disaster monitoring system that accurately and robustly detects the occurrence of any incident and automatically alerts first aid responders. Furthermore, the validity of the generative augmentation approach has been verified, which implies that this framework can be fine-tuned to suit any image classification task in which one or more classes similarly suffer from under-representation.
6. Conclusions
In this paper, we proposed a comprehensive framework for the classification of natural disasters by utilizing insights collected from social media. The initial dataset suffered from a severe class imbalance, which we tackled by training a generative adversarial network to generate high-quality synthetic samples to fortify the original dataset. The quality of the generated image was verified by measuring the inception score and the Fréchet inception distance for each synthetic sample. We conducted extensive experiments and trained an ensemble classifier of VGG16 models by applying a bagging approach. We verified the effectiveness of the proposed ensemble approach in combination with data augmentation by comparing the framework’s performance metrics to those of the traditional convolutional neural models.
The final framework achieved an accuracy of 88.5%, which significantly exceeded the performance of all other approaches for tackling the same task by an average of 11%. This framework can be implemented to collect real-time data across all social media platforms and perform spatial analyses and classifications. As a result, dangerous situations and incidents can be rapidly identified and contained.
The proposed framework could be deployed in a web application to collect social media data in real time and accordingly update the weights of the trained model, thus enhancing its performance. This application could be licensed to institutions and authorities to send alerts in the case of sudden disasters.
Future work can be directed towards investigating the further development of the framework by including multimodal features. We believe that utilizing textual and geographical data describing each disastrous event in combination with disaster images could further improve the classification results.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}