
Integration of Web Processing Services with Workflow-Based Scientific Applications for Solving Environmental Monitoring Problems


Abstract
:1. Introduction
- using resources of a distributed computing environment, in which heterogeneity is increasing every year, and interacting with local resource managers (LRMs) located in the nodes of resources [9],
- developing workflow-based applications, forming a composition of web services provided by different research projects, and executing workflows in a distributed computing environment, which necessitates making access to HPC resources more flexibly and straightforwardly [10],
- implementing other system operations, for example, computation scheduling and distribution of computational load respecting administrative policies of resource provisioning.
2. Proposed Approach: Methods and Tools
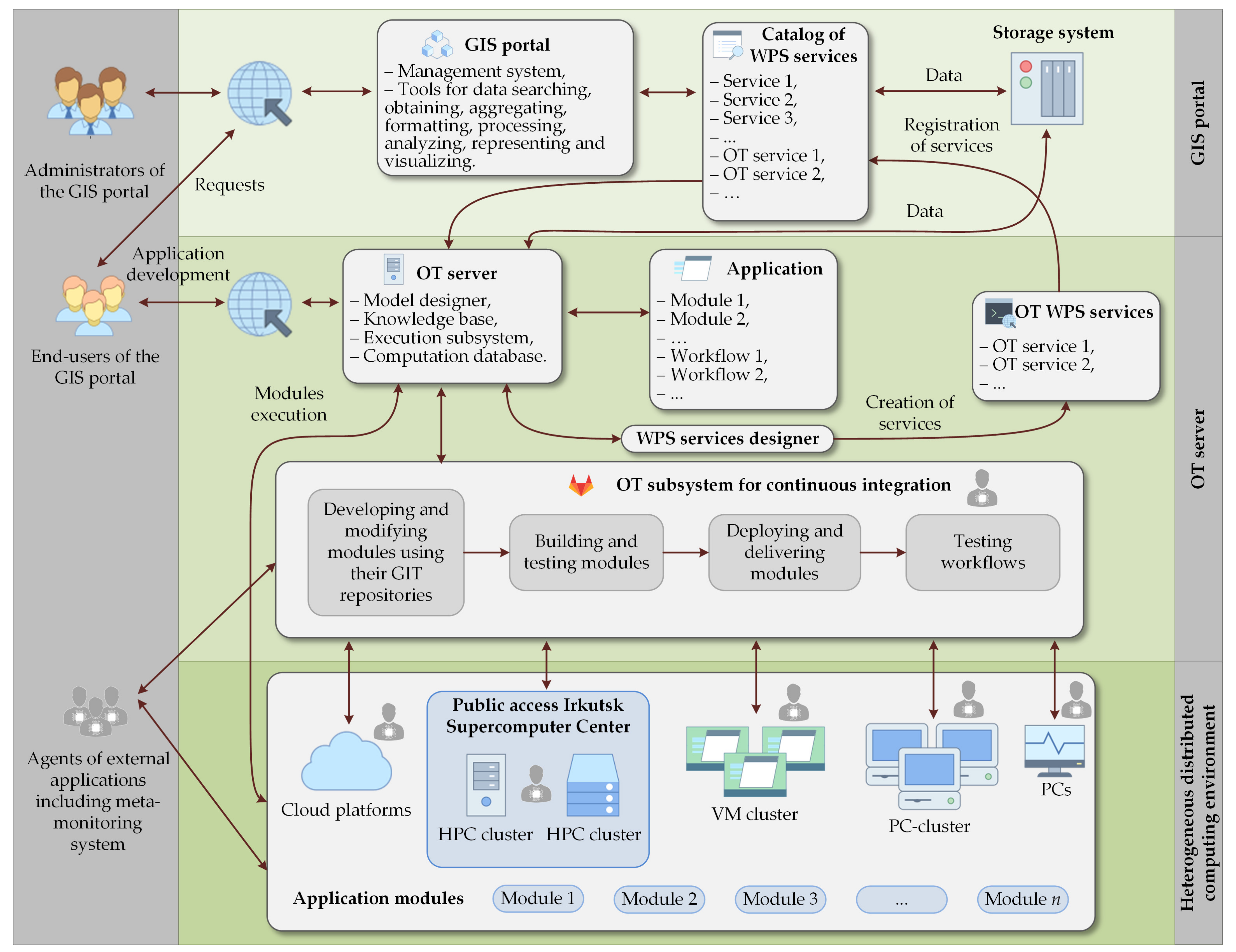
2.1. Automating Creation and Use of WPS Services within GIS Portal
- user web interface,
- subsystem for continuous integration,
- model designer,
- designer of WPS services,
- execution subsystem,
- knowledge base,
- computation database.
- developing or modifying applied modules, as well as their building, deployment, delivery, and testing in resources of the computing environment with means of the OT subsystem for continuous integration,
- describing a computational model that consists of module specifications and relations between modules using the model designer,
- creating workflows on the computational model.
- repository configuration files,
- log files storing operations performed on the repository,
- an index file describing the location of the files,
- end-user files.
- developing and modifying modules using their GIT repositories,
- building and testing modules,
- deploying and delivering modules,
- testing workflows.
- Step 1. The WPS service receives a request from the end-user.
- Step 2. The WPS service checks the input parameters contained in the request. If these parameters are correct, the transition to the next step is performed. Otherwise, it returns an error message to the end-user, and its operation ends.
- Step 3. The WPS service generates an XML file with the request execution status. In addition, it indicates the URL of the XML file, which contains the results of the request execution or the path to the database system in the case of data exchange between modules using text files.
- Step 4. The WPS service implements the following operations: generating a computational job for the OT, calling the computation scheduler, transferring the generated job and input parameters of the request to the scheduler using a specialized API, completing the work.
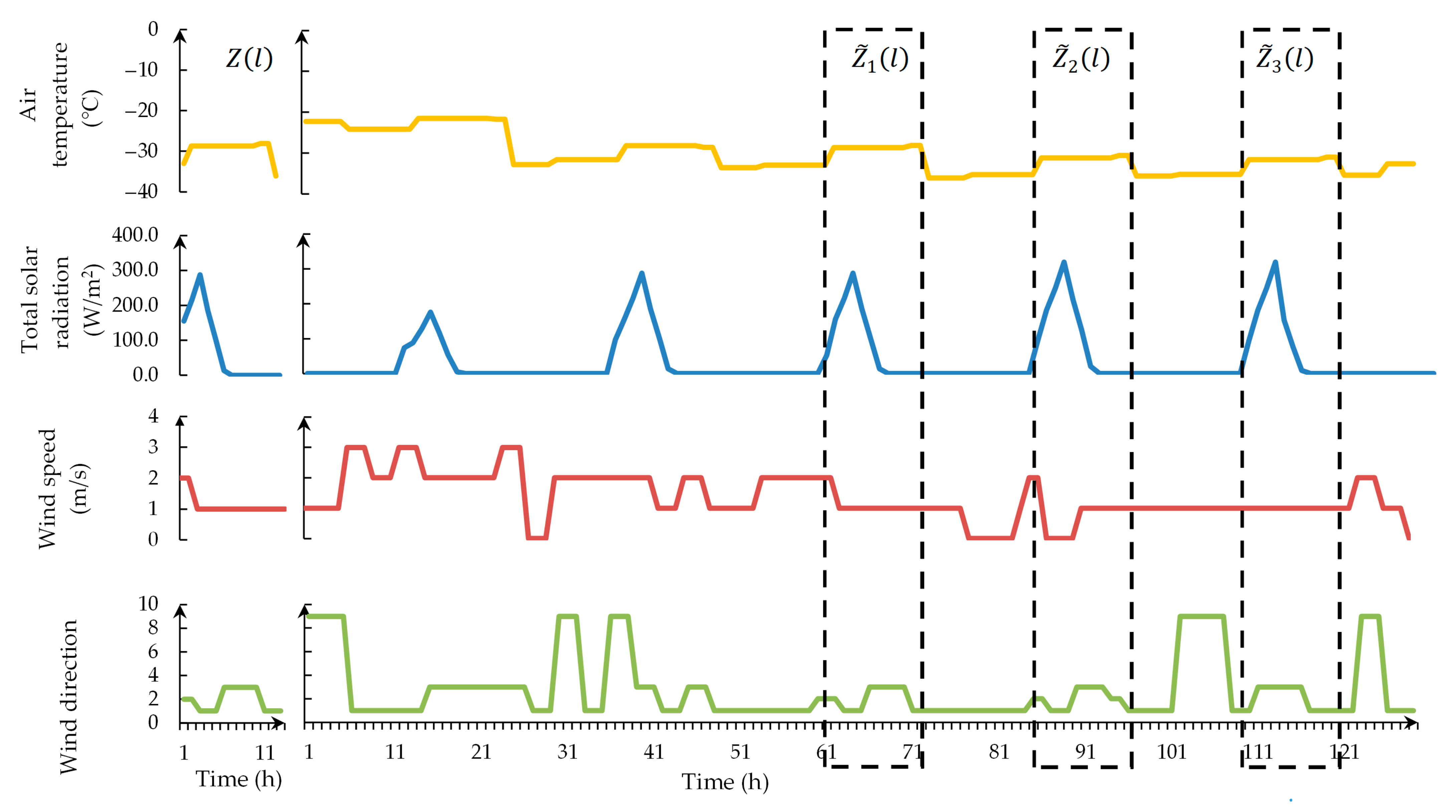
2.2. Technique and Tools for Air Temperature Prediction
| Algorithm 1. Algorithm of the SF operation. |
| 1 function 2 if then 3 return 0; 4 end if 5 if then 6 return 1; 7 else 8 return 0; 9 end if 10 end function |
| Algorithm 2. Algorithm of the PF operation. |
| 1 function 2 ; 3 for from to increment 4 if ( or ) then 5 , , ; 6 if () then 7 ; 8 ; 9 end if 10 end if 11 next ; 12 if () then 13 ; 14 else 15 ; 16 end if 17 return ; 18 end function |
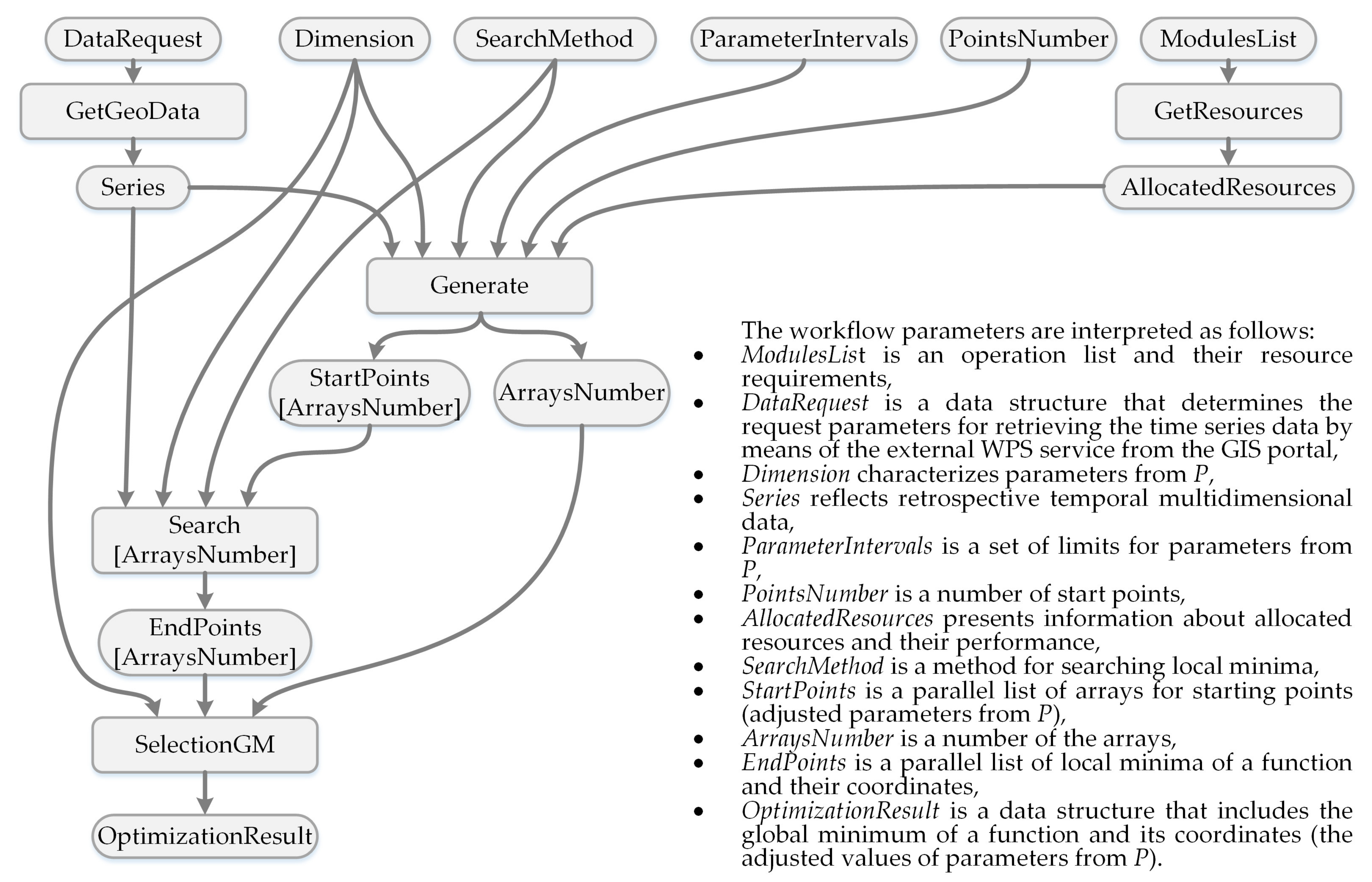
- generating the set of starting points,
- distributing starting points among resources of the computing environment,
- parallel descending from the starting points to the local optima using the Nelder–Mead method,
- selection of the global optimum from .
3. Results and Discussion
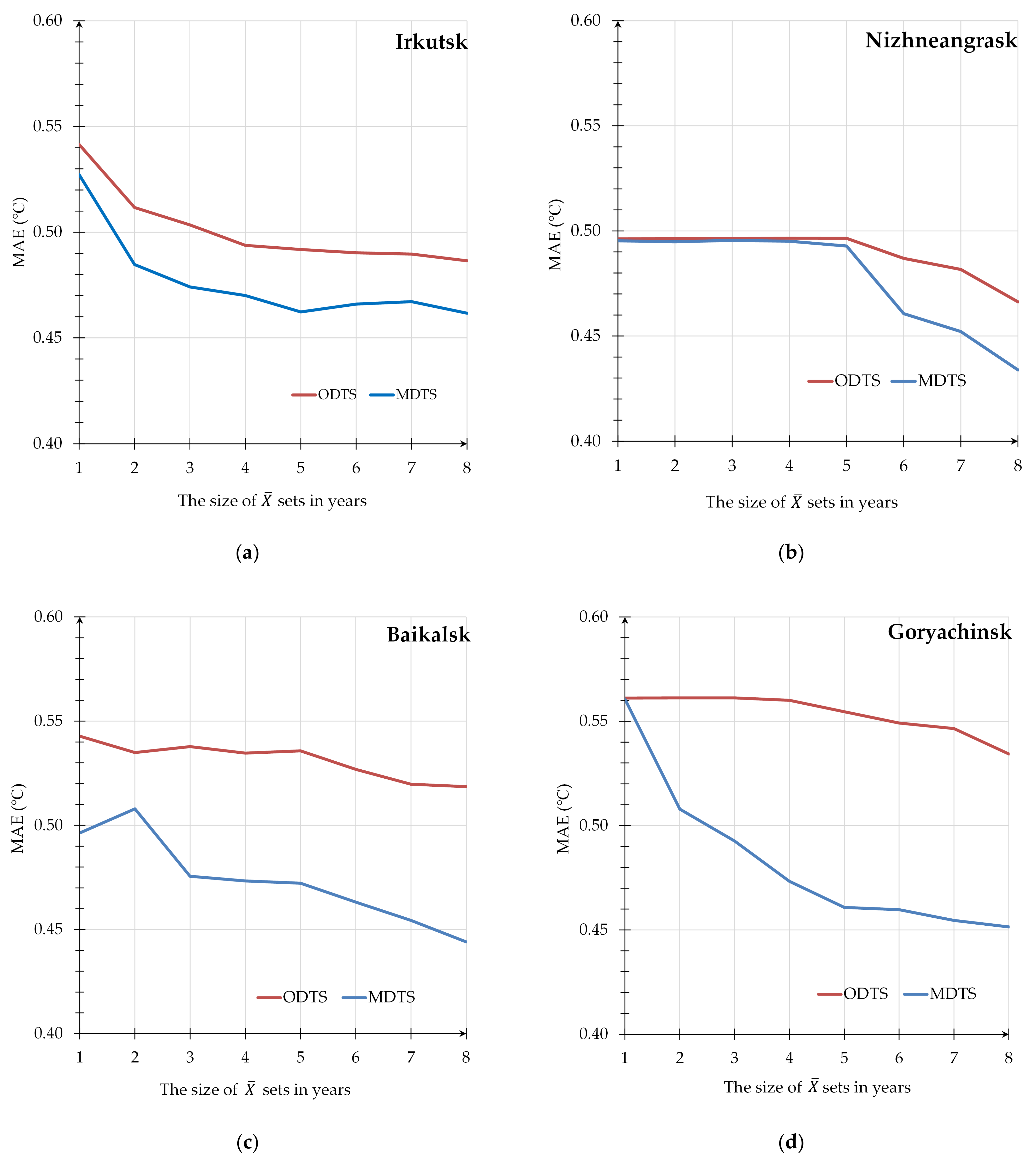
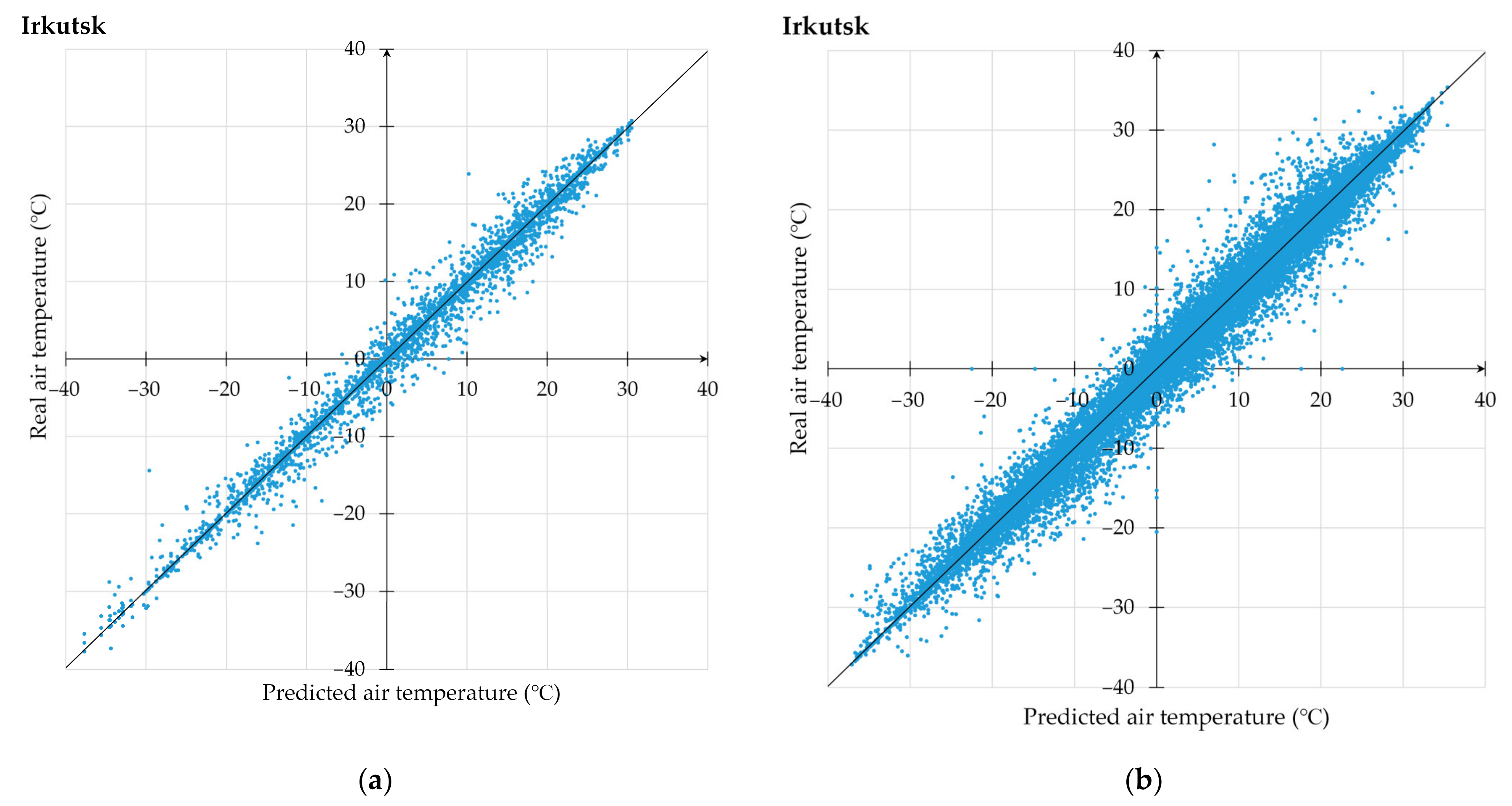
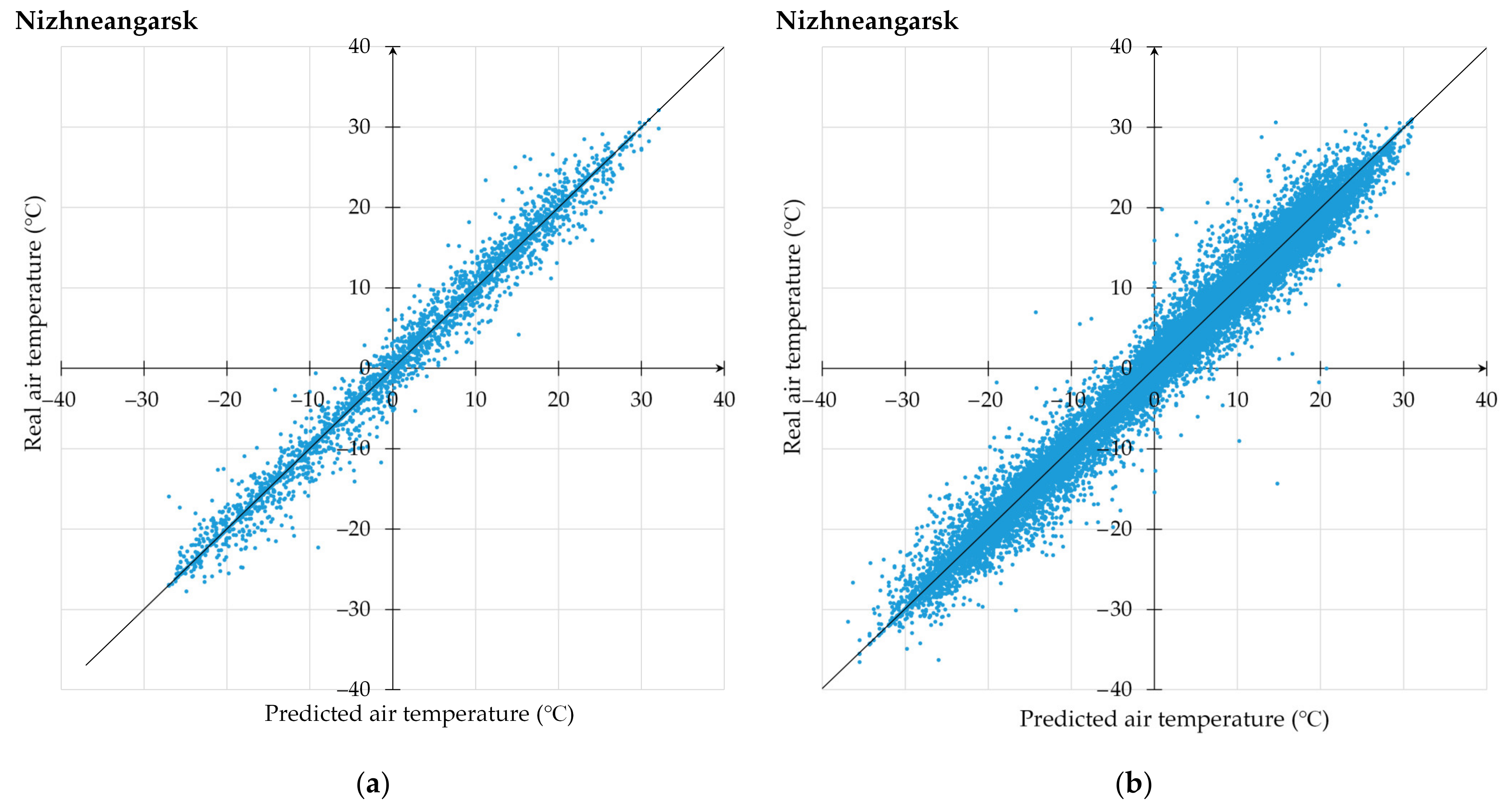
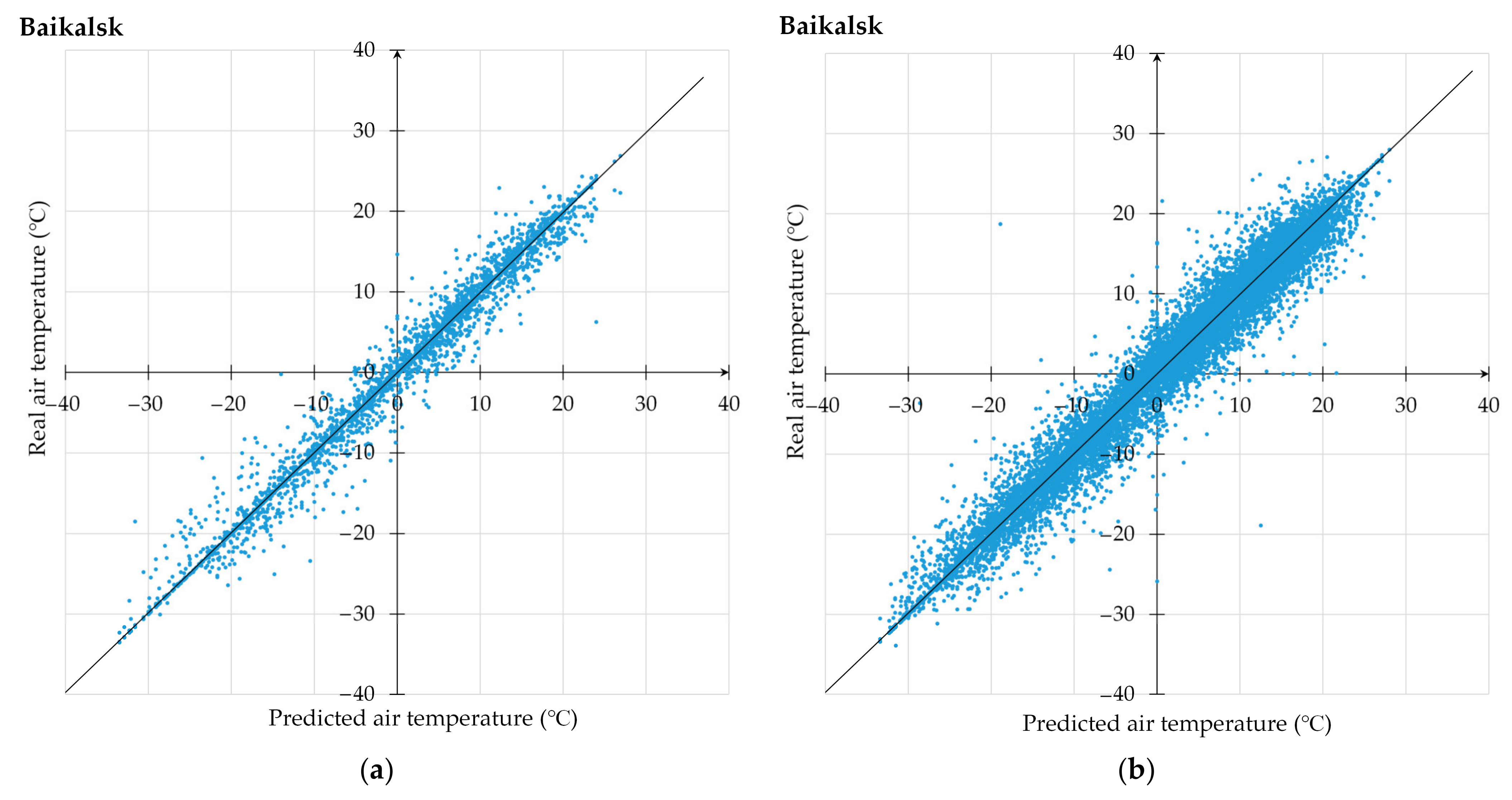
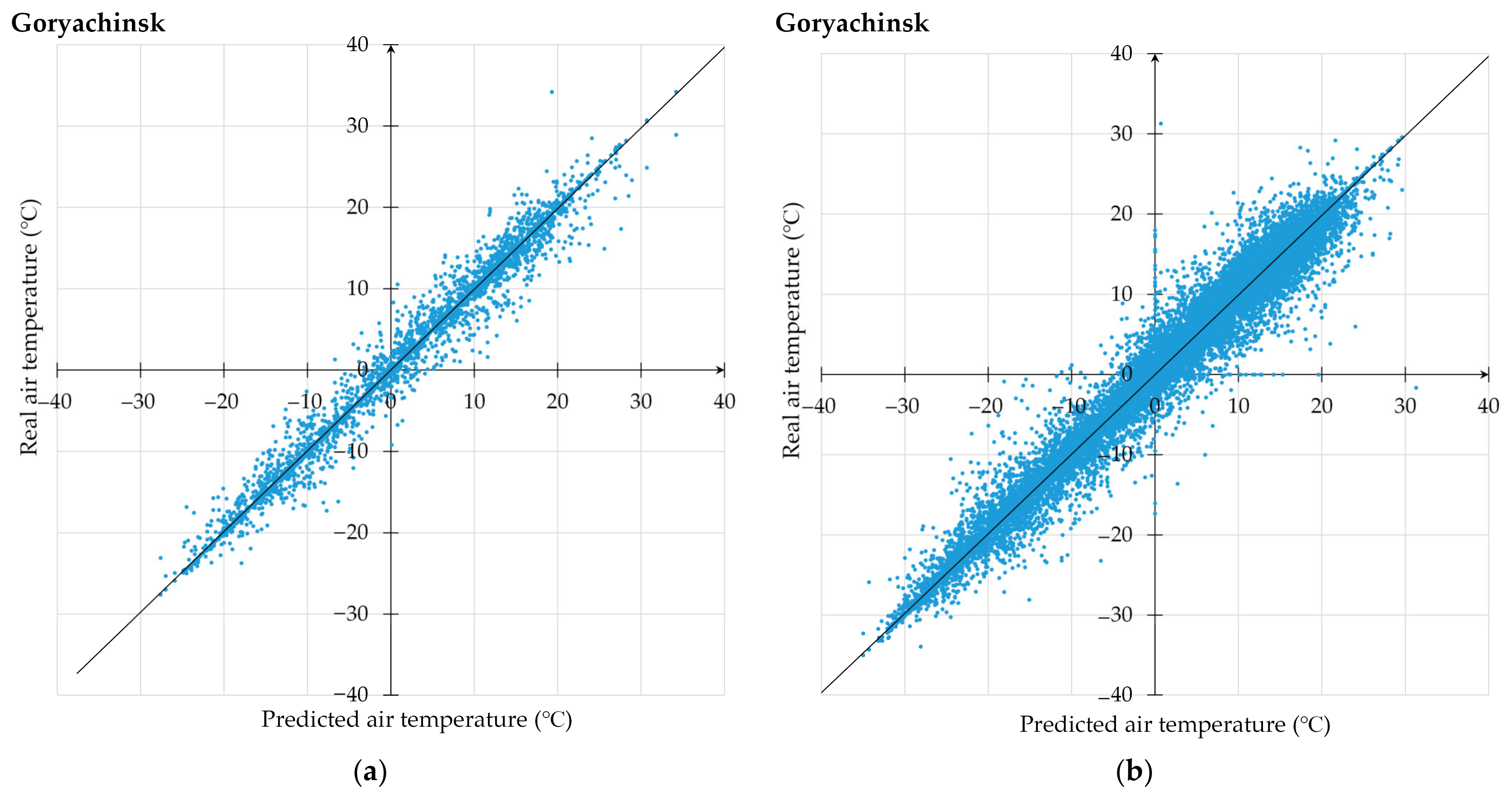
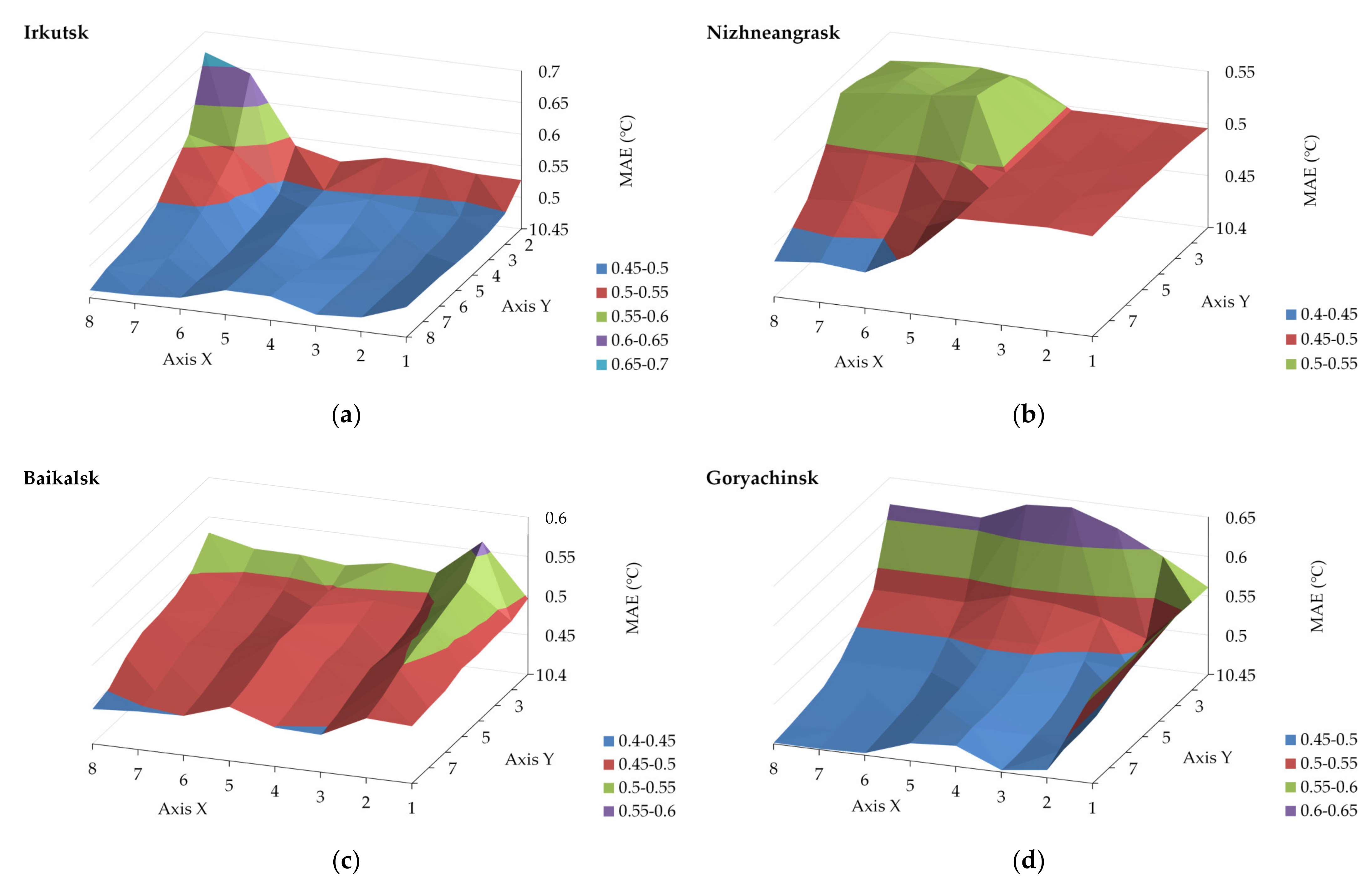
3.1. Proposed Technique Use for Air Temperature Prediction
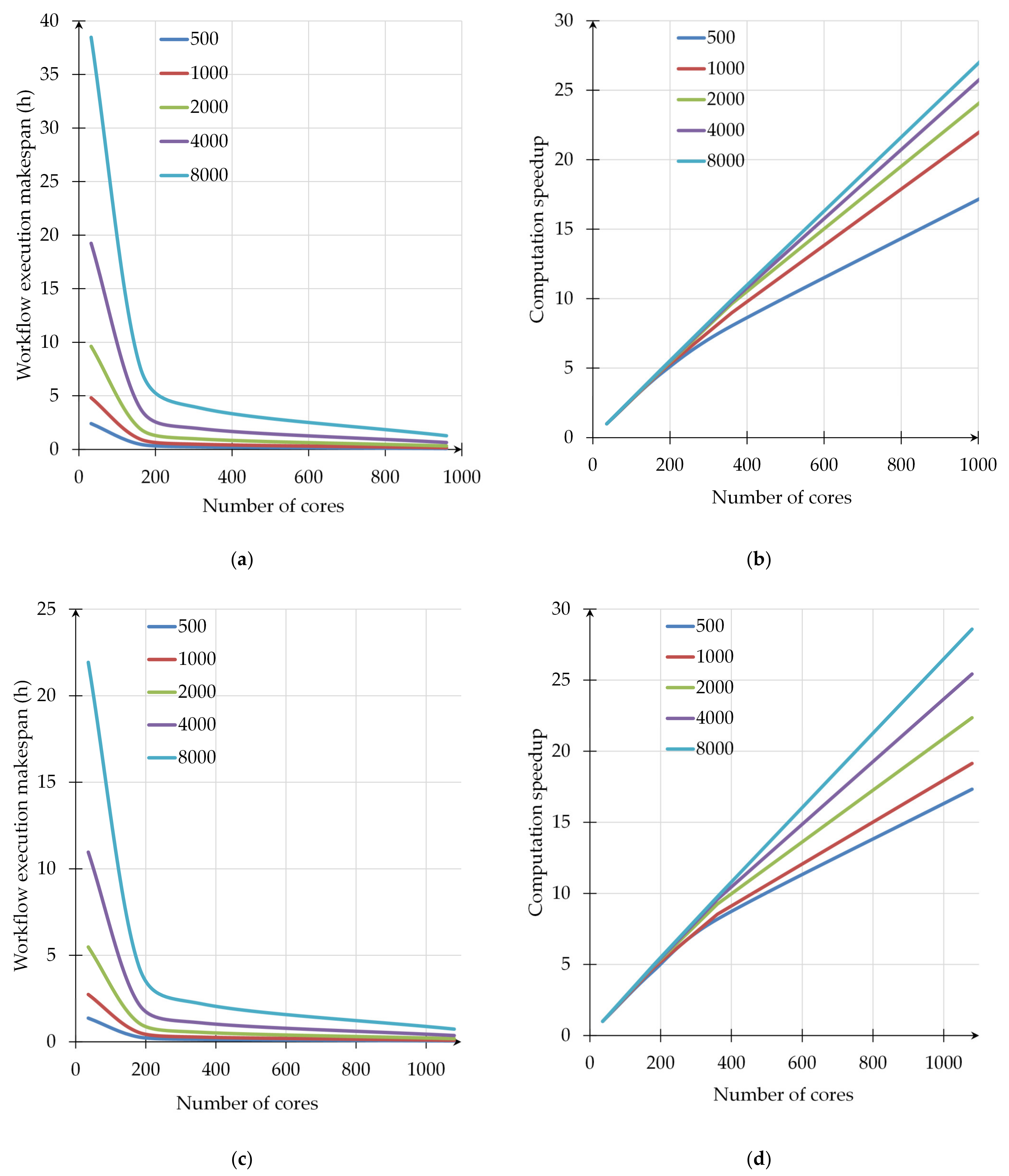
3.2. Comprehensive Analysis of Computational Experiments
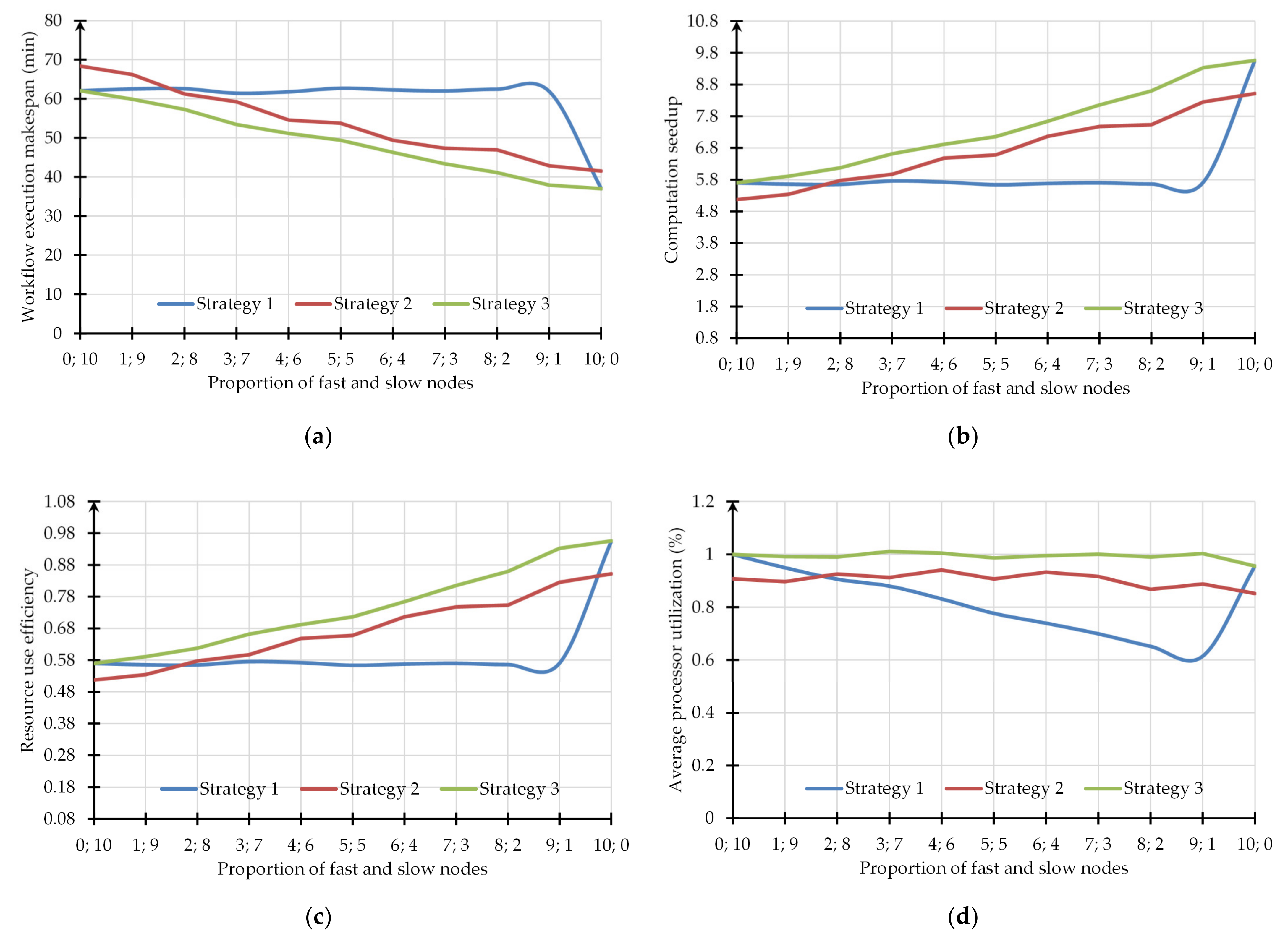
- Launching an equal number of jobs on each node by a user.
- Loading free nodes from the common job queue. This strategy is used in practice by well-known meta-schedulers such as GridWay and Condor DAGMan, as well as LRMs for homogenous resources, for example, LSF [54].
- Launching the number of jobs on each node in proportion to the node’s performance, taking into account the evaluated job execution time on this node. We implemented and applied this strategy in OT using the meta-monitoring system to predict job execution time on nodes represented by agents that took into account the results of the application module testing in these nodes.
- Using at least one slow node negatively affects workflow execution makespan, computation speedup, and resource use efficiency when applying the first strategy. At the same time, values of the average CPU utilization close to 1 were achieved when using the computing environment entirely consisting of homogeneous nodes.
- Within the second strategy, more instances of the module Search were generated. All instances involved queueing before a launch. In addition, it was necessary to transfer data and check the execution status for each instance. Therefore, the second strategy was characterized by more overheads. These overheads were the main contributors to an increase in the workflow execution makespan in comparison with the other strategies.
- The advantages of the third strategy were achieved due to distributing the computational load on resources according to their performance. The demonstrated computation speedup with an increase in the number of used fast nodes and efficiency of their use close to 1 determined the good scalability of distributed computing.
4. Conclusions
- supporting the technology in-memory data grid (IMDG) [55] for applications developed in OT to provide processing spatiotemporal data in the RAM of nodes of the heterogeneous distributed computing environment,
- modifying the meta-monitoring system with respect to automating the identification and partial troubleshooting of faults in operating the system software and hardware to improve the reliability of spatiotemporal data processing based on IMDG.
- developing an additional converter to ensure compatibility with common workflow language (CWL) [56] to prevent re-development of the same workflows and thereby reduce the time of experiments.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Makhonko, N.I.; Belousov, S.A.; Tarasova, E.A.; Plotnikova, Y.A. Information and communication technologies in environmental monitoring of climate change. IOP Conf. Ser. Earth Environ. Sci. 2021, 808, 012045. [Google Scholar] [CrossRef]
- Bychkov, I.V.; Ruzhnikov, G.M.; Hmelnov, A.E.; Fedorov, R.K.; Madzhara, T.I.; Popova, A.K. Digital Monitoring of Lake Baikal and its Coastal Area. In Proceedings of the 2nd Scientific-Practical Workshop Information Technologies: Algorithms, Models, Systems (ITAMS 2019), Irkutsk, Russia, 20 September 2019; CEUR-WS Proc.: Aachen, Germany, 2019; Volume 2463, pp. 13–23. Available online: http://ceur-ws.org/Vol-2463/paper2.pdf (accessed on 29 October 2021).
- Lega, M.; Casazza, M.; Teta, R.; Zappa, C.J. Environmental impact assessment: A multi-level, multi-parametric framework for coastal waters. Int. J. Sust. Dev. Plan. 2018, 13, 1041–1049. [Google Scholar] [CrossRef]
- Paul, P.; Aithal, P.S.; Bhuimali, A.; Kalishankar, T.; Saavedra, M.R.; Aremu, P.S.B. Geo Information Systems and Remote Sensing: Applications in Environmental Systems and Management. Int. J. Manag. Tech. Soc. Sci. 2020, 5, 11–18. [Google Scholar] [CrossRef]
- Fang, S.; Da Xu, L.; Zhu, Y.; Ahati, J.; Pei, H.; Yan, J.; Liu, Z. An integrated system for regional environmental monitoring and management based on internet of things. IEEE Trans. Ind. Inform. 2014, 10, 1596–1605. [Google Scholar] [CrossRef]
- Kussul, N.; Shelestov, A.; Skakun, S. Grid and sensor web technologies for environmental monitoring. Earth Sci. Inform. 2009, 2, 37–51. [Google Scholar] [CrossRef] [Green Version]
- Breunig, M.; Bradley, P.E.; Jahn, M.; Kuper, P.; Mazroob, N.; Rösch, N.; Al-Doori, M.; Stefanakis, E.; Jadidi, M. Geospatial data management research: Progress and future directions. ISPRS Int. Geo-Inf. 2020, 9, 95. [Google Scholar] [CrossRef] [Green Version]
- Lee, C.A.; Gasster, S.D.; Plaza, A.; Chang, C.I.; Huang, B. Recent developments in high performance computing for remote sensing: A review. IEEE J. Sel. Top. Appl. 2011, 4, 508–527. [Google Scholar] [CrossRef]
- Drăgan, I.; Fortiş, T.F.; Iuhasz, G.; Neagul, M.; Petcu, D. Applying self-* principles in heterogeneous cloud environments. In Cloud Computing; Antonopoulos, N., Gillam, L., Eds.; Springer: Cham, Switzerland, 2017; ISBN 978-3-319-85443-4. [Google Scholar]
- Huang, F.; Yang, H.; Tao, J.; Zhu, Q. Universal workflow-based high performance geo-computation service chain platform. Big Earth Data 2020, 4, 409–434. [Google Scholar] [CrossRef]
- The OGF Open Cloud Computing Interface. Available online: http://www.occi-wg.org/doku.php (accessed on 29 October 2021).
- The DMTF Open Virtualization Format. Available online: http://www.dmtf.org/standards/published_documents/DSP0243_1.0.0.pdf (accessed on 29 October 2021).
- The Open Source Geospatial Foundation. Available online: https://www.osgeo.org/ (accessed on 29 October 2021).
- Castronova, A.M. Models as web services using the open geospatial consortium (ogc) web processing service (wps) standard. Environ. Modell. Softw. 2013, 41, 72–83. [Google Scholar] [CrossRef]
- Foerster, T.; Schaeffer, B.; Brauner, J.; Jirka, S. Integrating ogc web processing services into geospatial mass-market applications. In Proceedings of the International Conference on Advanced Geographic Information Systems & Web Services, Cancun, Mexico, 1–7 February 2009; IEEE: New York, NY, USA, 2009; pp. 98–103. [Google Scholar] [CrossRef]
- GeoServer. Available online: http://geoserver.org/ (accessed on 29 October 2021).
- Baranski, B. Grid computing enabled web processing service. In Proceedings of the 6th Geographic Information Days, Münster, Germany, 16–18 June 2008; IfGI Prints: Münster, Germany, 2008; Volume 32, pp. 243–256. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.470.8333&rep=rep1&type=pdf (accessed on 29 October 2021).
- Yue, P.; Zhang, M.; Tan, Z. A geoprocessing workflow system for environmental monitoring and integrated modelling. Environ. Modell. Softw. 2015, 69, 128–140. [Google Scholar] [CrossRef]
- Iosifescu-Enescu, I.; Matthys, C.; Gkonos, C.; Iosifescu-Enescu, C.M.; Hurni, L. Cloud-based architectures for auto-scalable web Geoportals towards the Cloudification of the GeoVITe Swiss academic Geoportal. ISPRS Int. Geo-Inf. 2017, 6, 192. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Jiang, J.; Zhang, H.; Dong, X.; Wang, L.; Ranjan, R.; Zomaya, A.Y. A scalable parallel algorithm for atmospheric general circulation models on a multi-core cluster. Future Gener. Comp. Syst. 2017, 72, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Huang, F.; Tie, B.; Tao, J.; Tan, X.; Ma, Y. Methodology and optimization for implementing cluster-based parallel geospatial algorithms with a case study. Clust. Comput. 2019, 23, 673–704. [Google Scholar] [CrossRef]
- Kang, S.; Lee, K. Auto-Scaling of Geo-Based Image Processing in an OpenStack Cloud Computing Environment. Remote Sens. 2016, 8, 662. [Google Scholar] [CrossRef] [Green Version]
- Sun, Z.; Di, L.; Burgess, A.; Tullis, J.A.; Magill, A.B. Geoweaver: Advanced cyberinfrastructure for managing hybrid geoscientific AI workflows. ISPRS Int. Geo-Inf. 2020, 9, 119. [Google Scholar] [CrossRef] [Green Version]
- Feoktistov, A.; Gorsky, S.; Sidorov, I.; Bychkov, I.; Tchernykh, A.; Edelev, A. Collaborative Development and Use of Scientific Applications in Orlando Tools: Integration, Delivery, and Deployment. Commun. Comput. Inf. Sci. 2020, 1087, 18–32. [Google Scholar] [CrossRef]
- Bychkov, I.; Feoktistov, A.; Gorsky, S.; Edelev, A.; Sidorov, I.; Kostromin, R.; Fereferov, E.; Fedorov, R. Supercomputer Engineering for Supporting Decision-making on Energy Systems Resilience. In Proceedings of the 14th IEEE International Conference on Application of Information and Communication Technologies, Tashkent, Uzbekistan, 7–9 October 2020; IEEE: New York, NY, USA, 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Tchernykh, A.; Bychkov, I.; Feoktistov, A.; Gorsky, S.; Sidorov, I.; Kostromin, R.; Edelev, A.; Zorkalzev, V.; Avetisyan, A. Mitigating Uncertainty in Developing and Applying Scientific Applications in an Integrated Computing Environment. Program. Comput. Soft. 2020, 46, 483–502. [Google Scholar] [CrossRef]
- Bychkov, I.V.; Ruzhnikov, G.M.; Fedorov, R.K.; Khmelnov, A.E.; Popova, A.K. Digital environmental monitoring technology Baikal natural territory. In Proceedings of the 3rd Scientific-Practical Workshop Information Technologies: Algorithms, Models, Systems (ITAMS 2020), Irkutsk, Russia, 3 September 2020; CEUR-WS Proc.: Aachen, Germany, 2020; Volume 2677, pp. 1–7. Available online: http://ceur-ws.org/Vol-2677/paper1.pdf (accessed on 29 October 2021).
- Casanova, H.; Legrand, A.; Zagorodnov, D.; Berman, F. Heuristics for Scheduling Parameter Sweep Applications in Grid Environments. In Proceedings of the 9th Heterogeneous Computing Workshop (HCW) (Cat. No. PR00556), Cancun, Mexico, 1 May 2000; IEEE: New York, NY, USA, 2000; pp. 349–363. [Google Scholar] [CrossRef]
- GridWay Metascheduler. Available online: http://www.gridway.org (accessed on 29 October 2021).
- Tannenbaum, T.; Wright, D.; Miller, K.; Livny, M. Condor—A Distributed Job Scheduler. In Beowulf Cluster Computing with Linux; Sterling, T., Ed.; The MIT Press: Cambridge, MA, USA, 2002; pp. 307–350. [Google Scholar]
- Lientz, B.P.; Swanson, E.B.; Tompkins, G.E. Characteristics of application software maintenance. Commun. ACM 1978, 21, 466–471. [Google Scholar] [CrossRef]
- Chatfield, C. Time-Series Forecasting, 1st ed.; CRC Press: New York, NY, USA, 2000; p. 280. [Google Scholar] [CrossRef]
- De Gooijer, J.G.; Hyndman, R.J. 25 years of time series forecasting. Int. J. Forecast. 2006, 22, 443–473. [Google Scholar] [CrossRef] [Green Version]
- Caissie, D.; St-Hilaire, A.; El-Jabi, N. Prediction of water temperatures using regression and stochastic models. In Proceedings of the 57th Canadian Water Resources Association Annual Congress, Montreal, QC, Canada, 16–18 June 2004; Available online: https://www.researchgate.net/profile/Daniel-Caissie/publication/274071811_Prediction_of_water_temperatures_using_regression_and_stochastic_models/links/551434800cf2eda0df30682a/Prediction-of-water-temperatures-using-regression-and-stochastic-models.pdf (accessed on 29 October 2021).
- Smadi, M.; Mjalli, F. Forecasting Air Temperatures Using Time Series Models and Neural-based Algorithms. J. Math. Stat. 2007, 3, 44–48. [Google Scholar] [CrossRef]
- Sharaff, A.; Roy, S.R. Comparative Analysis of Temperature Prediction Using Regression Methods and Back Propagation Neural Network. In Proceedings of the 2nd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 11–12 May 2018; pp. 739–742. [Google Scholar] [CrossRef]
- Tran, T.T.K.; Bateni, S.M.; Ki, S.J.; Vosoughifar, H. A Review of Neural Networks for Air Temperature Forecasting. Water 2021, 13, 1294. [Google Scholar] [CrossRef]
- Cifuentes, J.; Marulanda, G.; Bello, A.; Reneses, J. Air Temperature Forecasting Using Machine Learning Techniques: A Review. Energies 2020, 13, 4215. [Google Scholar] [CrossRef]
- Smith, B.A.; McClendon, R.W.; Hoogenboom, G. Improving Air Temperature Prediction with Artificial Neural Networks. World Academy of Science, Engineering and Technology. Int. J. Comput. Electr. Autom. Control. Inf. Eng. 2007, 1, 3146–3153. [Google Scholar] [CrossRef]
- Hewage, P.; Behera, A.; Trovati, M.; Pereira, E.; Ghahremani, M.; Palmieri, F.; Liu, Y. Temporal convolutional neural (TCN) network for an effective weather forecasting using time-series data from the local weather station. Soft Comput. 2020, 24, 16453–16482. [Google Scholar] [CrossRef] [Green Version]
- Karevan, Z.; Suykens, J. Transductive LSTM for time-series prediction: An application to weather forecasting. Neural Netw. 2020, 125, 1–9. [Google Scholar] [CrossRef]
- Chevalier, R.F.; Hoogenboom, G.; McClendon, R.W.; Paz, J.A. Support vector regression with reduced training sets for air temperature prediction: A comparison with artificial neural networks. Neural. Comput. Appl. 2011, 20, 151–159. [Google Scholar] [CrossRef]
- Pezeshki, Z.; Mazinani, S.M. Comparison of artificial neural networks, fuzzy logic and neuro fuzzy for predicting optimization of building thermal consumption: A survey. Artif. Intell. Rev. 2019, 52, 495–525. [Google Scholar] [CrossRef]
- Karamizadeh, S.; Abdullah, S.M.; Halimi, M.; Shayan, J.; Rajabi, M.J. Advantage and drawback of support vector machine functionality. In Proceedings of the 2014 international conference on computer, communications, and control technology (I4CT), Langkawi, Malaysia, 2–4 September 2014; pp. 63–65. [Google Scholar] [CrossRef]
- Bhardwaj, S.; Srivastava, S.; Gupta, J. Pattern-Similarity-Based Model for Time Series Prediction. Comput. Intell. 2013, 31, 106–131. [Google Scholar] [CrossRef]
- Dudek, G.; Pełka, P. Pattern similarity-based machine learning methods for mid-term load forecasting: A comparative study. Appl. Soft Comput. 2021, 104, 107223. [Google Scholar] [CrossRef]
- Martí, R.; Resende, M.G.C.; Ribeiro, C.C. Multi-start methods for combinatorial optimization. Eur. J. Oper. Res. 2013, 226, 1–8. [Google Scholar] [CrossRef]
- Nelder, J.A.; Mead, R. A simplex method for function minimization. Comput. J. 1965, 7, 308–313. [Google Scholar] [CrossRef]
- Garey, M.; Johnson, D. Computers and Intractability; W.H. Freeman: San Francisco, CA, USA, 1979; ISBN 0716710447. [Google Scholar]
- Bychkov, I.V.; Oparin, G.A.; Feoktistov, A.G.; Sidorov, I.A.; Bogdanova, V.G.; Gorsky, S.A. Multiagent control of computational systems on the basis of meta-monitoring and imitational simulation. Optoelectron. Instrum. Data Process. 2016, 52, 107–112. [Google Scholar] [CrossRef]
- rp5.ru.Weather Schedule. Available online: https://rp5.ru/ (accessed on 29 October 2021).
- Kostromin, R.; Basharina, O.; Feoktistov, A.; Sidorov, I. Microservice-Based Approach to Simulating Environmentally-Friendly Equipment of Infrastructure Objects Taking into Account Meteorological Data. Atmosphere 2021, 12, 1217. [Google Scholar] [CrossRef]
- Irkutsk Supercomputer Center. Available online: https://hpc.icc.ru/ (accessed on 29 October 2021).
- Estévez Ruiz, E.P.; Caluña Chicaiza, G.E.; Jiménez Patiño, F.R.; López Lago, J.C.; Thirumuruganandham, S.P. Dense Matrix Multiplication Algorithms and Performance Evaluation of HPCC in 81 Nodes IBM Power 8 Architecture. Computation 2021, 9, 86. [Google Scholar] [CrossRef]
- Zhang, H.; Chen, G.; Ooi, B.C.; Tan, K.L.; Zhang, M. In-memory big data management and processing: A survey. IEEE Trans. Knowl. Data Eng. 2015, 27, 1920–1948. [Google Scholar] [CrossRef]
- Common Workflow Language. Available online: https://www.commonwl.org/ (accessed on 29 October 2021).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Air Temperature (°C) | Wind Speed (m/s) | Wind Direction | Total Solar Radiation (W/m2) |
|---|---|---|---|
| −24.2 | 0 | Calm | 74.1 |
| −23.7 | 0 | Calm | 87.8 |
| −22.5 | 0 | Calm | 128.6 |
| −21.5 | 1 | North-West | 176.3 |
| −21.5 | 1 | North-West | 116.2 |
| −21.7 | 2 | North-West | 53.3 |
| −21.9 | 2 | North-West | 4.7 |
| −22.2 | 2 | North-West | 0 |
| Strategy | Number of Launches | Average Execution Time (s) | Total Execution Time (s) | Average Overheads (s) |
|---|---|---|---|---|
| 1 | 10 | 2923.62 | 3819.97 | 33.55 |
| 2 | 100 | 323.17 | 3223.97 | 295.51 |
| 3 | 10 | 2902.05 | 2962.34 | 34.32 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feoktistov, A.; Gorsky, S.; Kostromin, R.; Fedorov, R.; Bychkov, I. Integration of Web Processing Services with Workflow-Based Scientific Applications for Solving Environmental Monitoring Problems. ISPRS Int. J. Geo-Inf. 2022, 11, 8. https://doi.org/10.3390/ijgi11010008
Feoktistov A, Gorsky S, Kostromin R, Fedorov R, Bychkov I. Integration of Web Processing Services with Workflow-Based Scientific Applications for Solving Environmental Monitoring Problems. ISPRS International Journal of Geo-Information. 2022; 11(1):8. https://doi.org/10.3390/ijgi11010008
Chicago/Turabian StyleFeoktistov, Alexander, Sergey Gorsky, Roman Kostromin, Roman Fedorov, and Igor Bychkov. 2022. "Integration of Web Processing Services with Workflow-Based Scientific Applications for Solving Environmental Monitoring Problems" ISPRS International Journal of Geo-Information 11, no. 1: 8. https://doi.org/10.3390/ijgi11010008