4.3. Statistical Properties of Rainfall Clusters
Cluster-wise statistics of the mean rainfall over season are presented in
Table 2. The mean rainfall remains the lowest in cluster III and the highest in cluster IV for each season. It shows the consistent mean of rainfall by the four clusters. In general, cluster III has a small variation and cluster IV has a large variation for each season in the rainfall recognition patterns. The skewness values for all clusters are within the permissible limits of −0.040 to 0.116 for the distribution of data. The results illustrated that the shape of rainfall distribution for the rainfall stations in the Special Region of Yogyakarta was fairly symmetrical due to the values of the skewness being close to zero. The coefficient of variation was obtained by the closest values between each rainfall patterns for all seasons. Cluster II in the inter-monsoon season showed the largest variability of monthly rainfall amounts, at 2.751%. Meanwhile, the lowest coefficient variation was found in the same season with the variation of 2.285% in cluster IV. Kurtosis represents the tails of the distribution of the data and usually it measures the presence of outliers in the distribution. The high values of kurtosis, which is kurtosis >3, shows that the data have heavy tails and contain outliers, while if the kurtosis <3, the data have light tails and contain a lack of outliers. From
Table 2 it clearly shows that all the data in each cluster for all seasons have a lack of outliers due to all the kurtosis values being under 3.
The main features of the clustering results are discussed to verify the distinction between the clusters with respect to their significant locations and the period of monsoon occurrence for the torrential rainfall patterns based on the recommended settings in the previous methodology section. Description of the rainfall patterns refer to range based on Regulation of Head of Meteorology, Climatology, and Geophysics Agency (BMKG), No. KEP.009 of 2010 on Standard Operating Procedures for Implementation of Early Warning, Reporting and Dissemination of Extreme Weather Information [
45]. The distributions of seasonal rainfall data are shown in
Table 3.
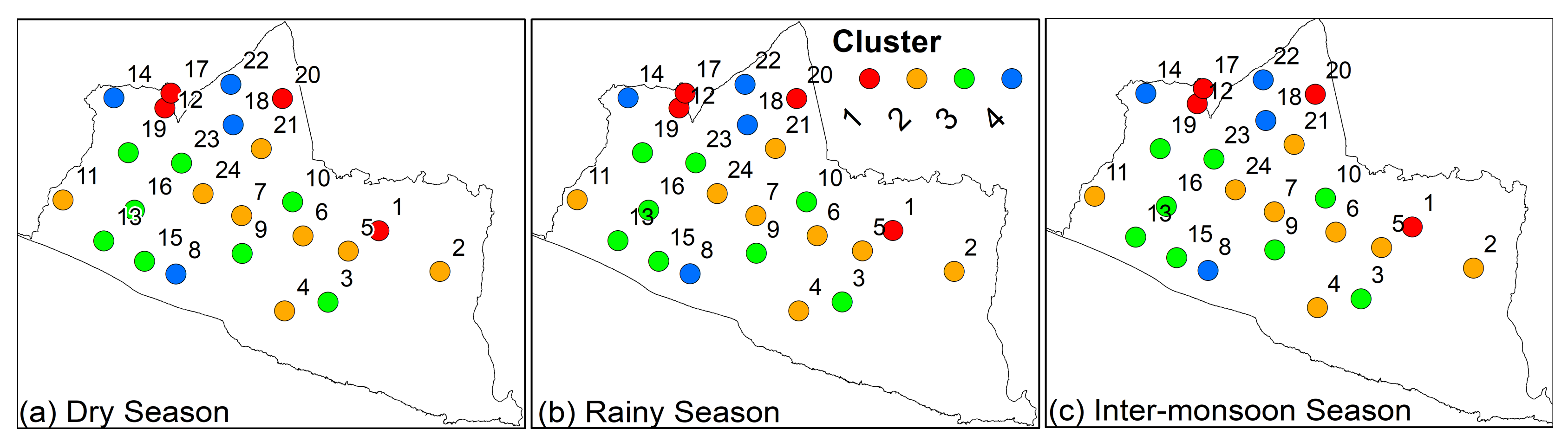
There are four clusters based on careful examination which reveal that the stations in cluster 1 are marked with a red marking, cluster 2 with an orange marking, cluster 3 with a green marking and in cluster 4 with a blue marking, as shown in
Figure 5.
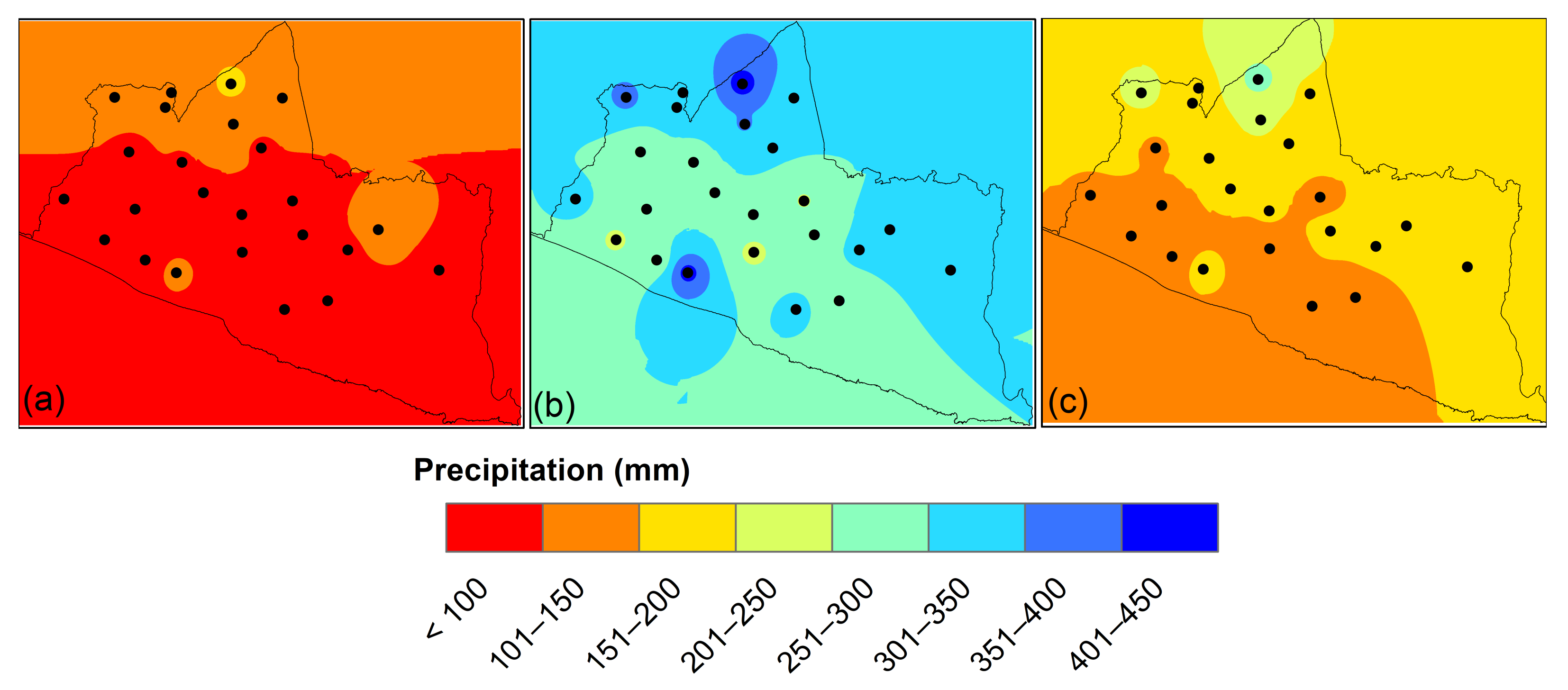
From
Table 3, the rainy season produces the highest average monthly rainfall amount, with a range of rainfall from 284 mm to 424 mm, exhibiting heavy monthly rainfall patterns. For the inter-monsoon season, the value of the highest average monthly rainfall amount in the range of rainfall from 170 mm to 275 mm, classifies this season as having moderate monthly rainfall patterns. The dry season has the least rainfall compared to the rainy season and inter-monsoon season, with the range of rainfall being from 98 mm to 168 mm, classifying the season as having mild monthly rainfall patterns.
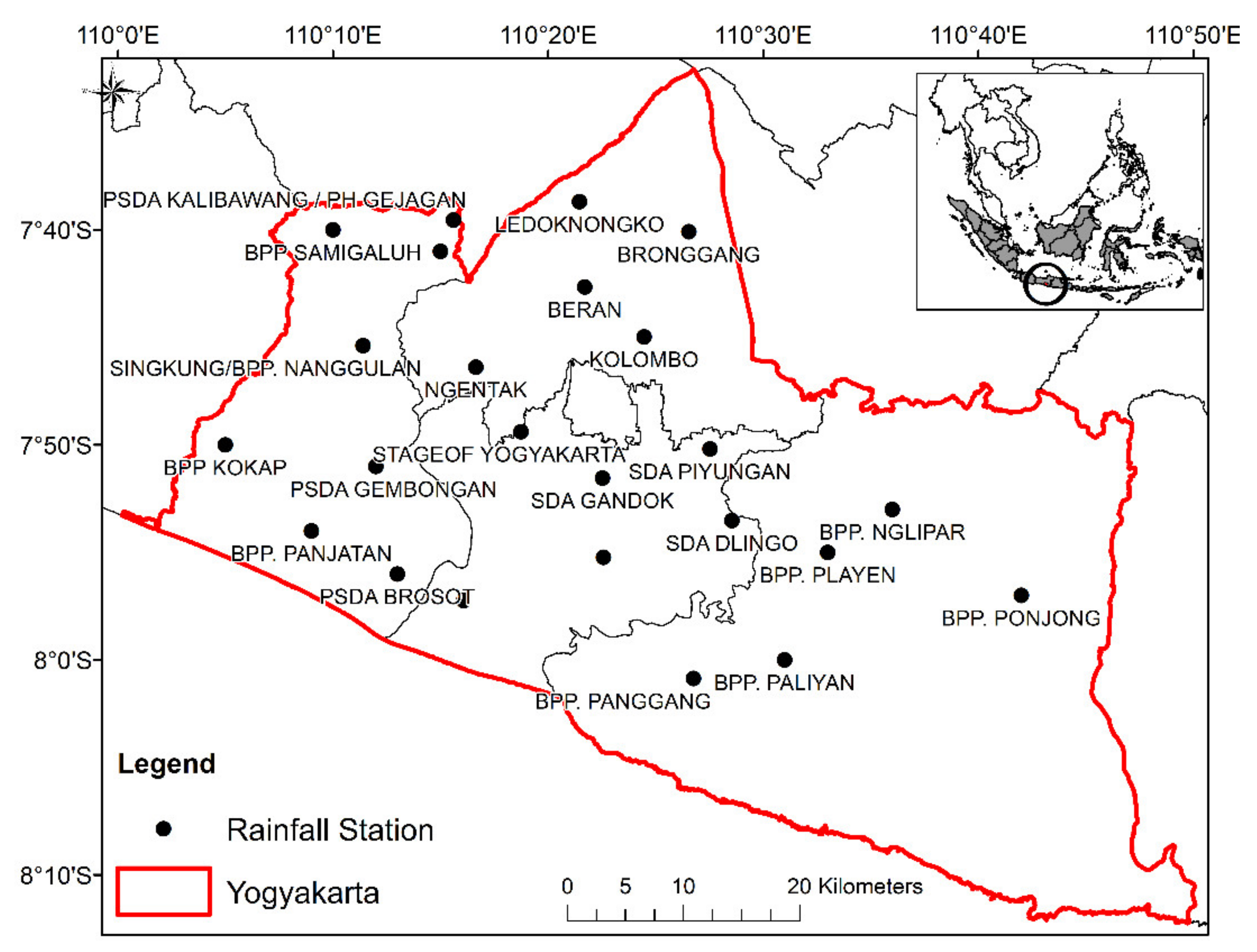
Cluster 1, which is located in the North of Yogyakarta city, shows that the most significant station that produced the highest average monthly rainfall amount is Station 1 for the dry season and the rainy season, while for the inter-monsoon, Station 20 dominates in Cluster 1 for the highest average monthly rainfall amount (
Figure 4). Cluster 2, which extends to the southern parts of Yogyakarta city, shows that the most significant station that produces the highest average monthly rainfall amount is Station 24 for the dry season, and Station 11 for rainy season and Station 21 for the inter-monsoon season.
In Cluster 3, the most significant station, which produces the highest average monthly rainfall amount, is Station 23 for the dry season and the inter-monsoon season, while for the rainy season, Station 16 has the highest average monthly rainfall amount. Lastly, in Cluster 4, the most significant station that produces the highest average monthly rainfall amount is Station 22 in every season.
4.4. Cumulative Percentage of Principal Component Analysis (PCA)
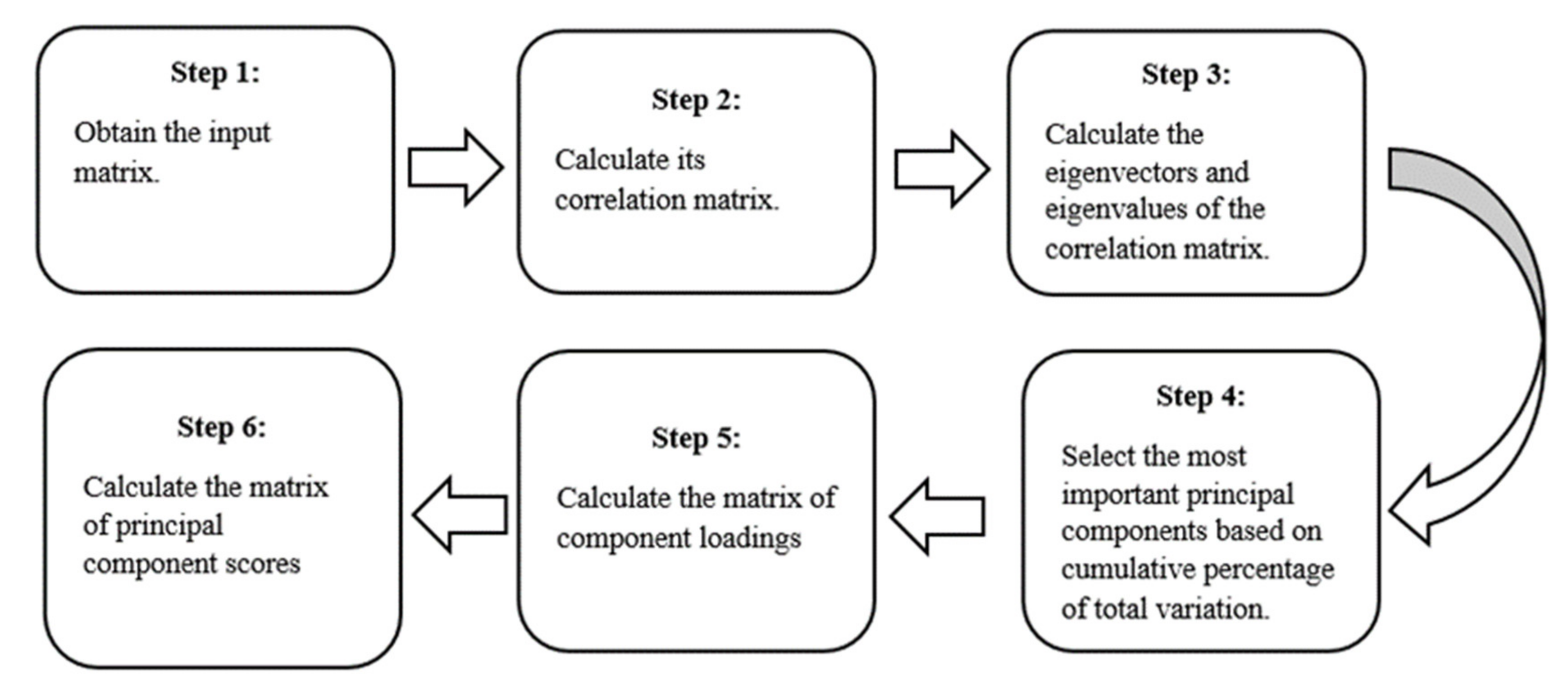
In this section, we will discuss the choice of cumulative percentage to cut off the number of principal components based on the three different seasons. The principal component in this study refers to the new variables that are constructed as linear combinations or mixtures of the initial variables. These combinations are done in such a way that the new variables (i.e., principal components) are uncorrelated and most of the information within the initial variables is squeezed or compressed into the first components.
The monthly average is composed of 12 factors that were analyzed at 75 locations around Thessaly. These variables were found to be linked to each other. Their explanations of the data in terms of a smaller number of uncorrelated variables simplified and structured it in a way that made it easier to comprehend [
46]. This is accomplished through the use of Principal Component Analysis. This was accomplished by identifying 12 linear combinations of the original variables, dubbed principal components, that are mutually uncorrelated, and by calculating the proportion of total variance that each of them could account for.
From
Table 4, we can see clearly that the choice of cumulative percentage of variance will reflect the number of components to retain. It appears that all seasons obtained the same number of components at different levels of cumulative percentages of variations. The selection of a higher cumulative percentage of variation has extracted a greater number of components for each monthly rainfall season in the Special Region of Yogyakarta, Indonesia.
For instance, 10 components and 14 components were retained with PCA at more than 50% and 70% cumulative percentage of variation respectively. However, in identifying rainfall patterns, extracting the correct number of components is crucial because it dictates the rainfall days belonging to the correct grouping patterns. The results showed a significant correlation between principal components and stations such as PCA at Bronggang, Beran and Ledoknongko station, which was high due to the higher elevation near Mount Merapi, Nglipar, Playen and Ponjong, which was also at a high elevation and was borderd by a reservoir area. The eastern and western boarders are highland areas, while in the southern part of the station at Panggang, Paliyan, Kokap and Panjatan, there is a low land area near the Indian Ocean. This result is supported by Dai et al. [
18], who stated that a lesser number of components would be insufficient to identify rainfall patterns when dealing with analysing considerable new patterns of rainfall in a selected region. Meanwhile, the inclusion of too many principal components inflates the importance of noise and results in poorly identified new cluster patterns [
10]. There is no rough guidance for determining the optimal cumulative percentage of variance; however, Jollife [
42] proposed that the optimal cumulative percentage for climatic data can be greater than 70%. This was proved from the previous literature [
19]. Based on the results in
Table 4, the 70% cumulative of variations were obtained by the sufficient components of 14 components for all seasons.
4.5. Principal Component Analysis (PCA)
Every component item and its loadings with a load component over 0.50 was retained in the PCA [
19]. Based on
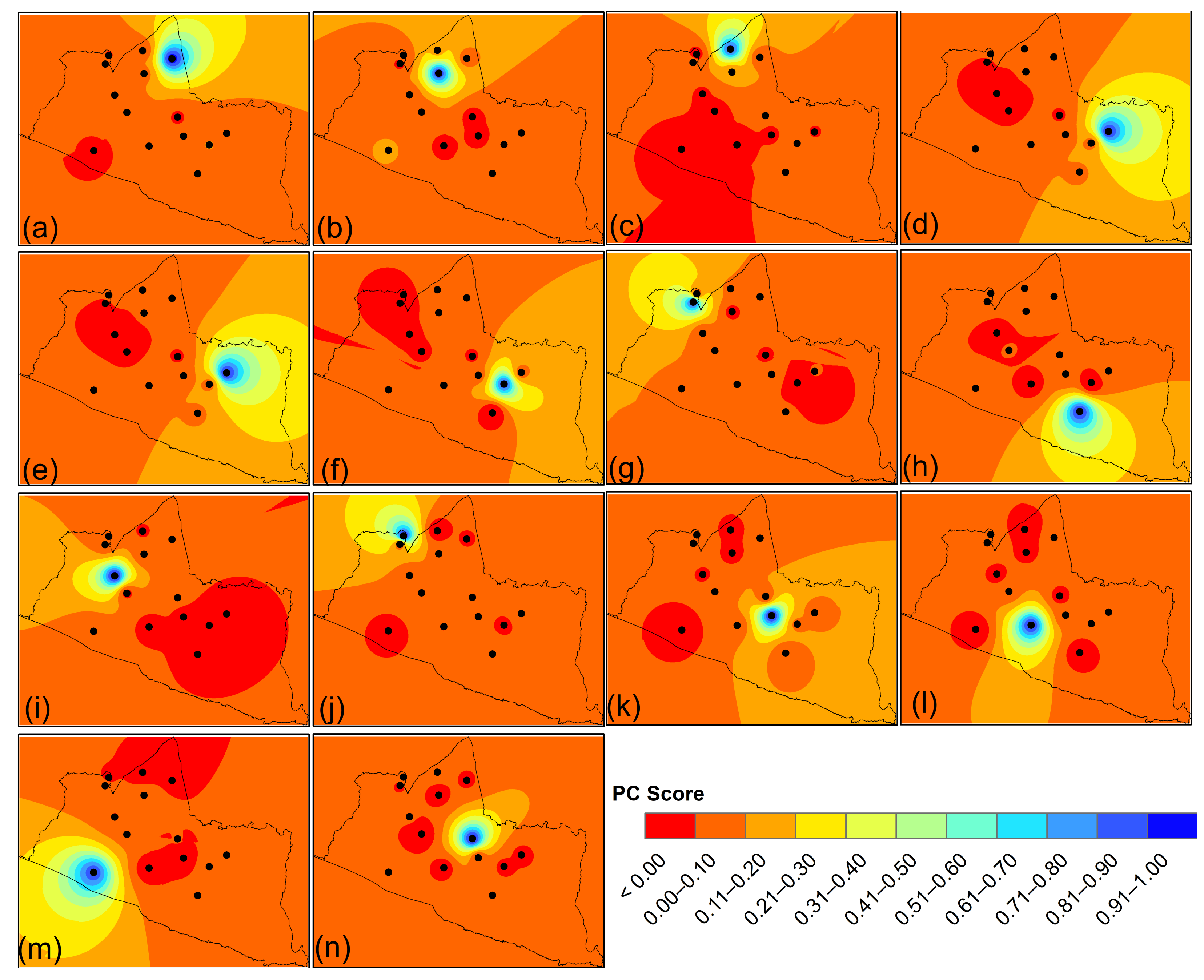
Table 5, one component was retained in PC1 with a load component higher than 0.50: the Station of Bronggang, with a value of 0.972, situated near the hill and on the top of Special Region of Yogyakarta, is the dominant station in PC1. In PC2, the maximum factor loading value of Beran is the dominant station, with a value similar to the BPP.Kalibawang of 0.906. Ledoknongko, PC3, has the maximum load factor with a value of 0.866 near station 20, which is next to two hills. For PC 4, the core of Yogyakarta is Stage of Yogyakarta with the maximum factor loading value of 0.910.
The next PC5 with a dominant station is Station 1, which is situated in the north of the Kulon Progo regency in Cluster 1, with a value of 0.924. Nglipar is superior in PC6, with a factor loading value of 0.879 in the region of Gunung Kidul regency. The highest loading factor rating is PC7, BPP. Kalibawang, with a value of 0.906, is located north of Kulon Progo regency and is close to the hill. The dominant station for PC8 is Paliyan, with a value of 0.919. Ngentak is at 0.981 and its nearest position to Yogyakarta city is the dominant station PC9. The dominant station PC10 is PSDA. Kalibawang, with a value of 0.972, is similar to Bronggang and is located north of the Kulon Progo regency. The dominant station at PC11 is Dlingo, with a value of 0.964, situated close to four hills east of the Bantul regency. The maximum factor loading value of PC12 is 0.931 at Ngetal, which is located in the region of the Bantul regency, south of Yogyakarta city. The dominant station of PC 13 is Brosot, with a value of 0.880, situated near the Indian Ocean. The dominant station of PC14 is Piyungan, with a value of 0.978, situated near the hill east of the Bantul regency.
The largest PC values are found in the north, in the centre of Special Region of Yogyakarta, in the south and east of the Special Region of Yogyakarta, suggesting the highest dry season contribution to overall rainfall. In the northern part of the Special Region of Yogyakarta, strong precipitation in the dry season is attributed to the convective process due to its position close to the hills and the availability of air humidity in the atmosphere, as shown in
Figure 6.
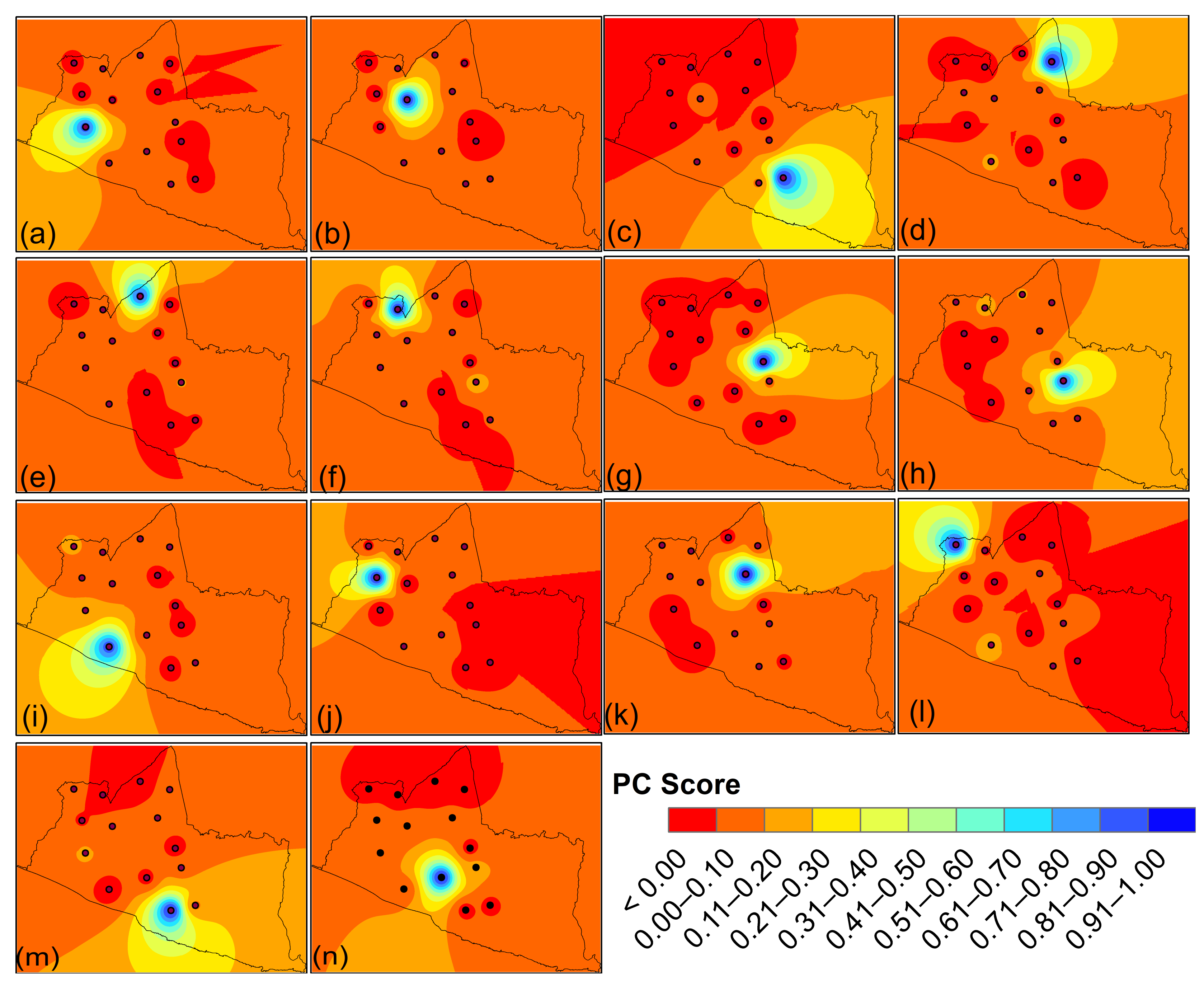
Based on
Table 6, the dominant station in PC1 is Gembongan, with a value of 0.861, which is situated next to Indian Ocean and is also located on the southwest of the Special Region of Yogyakarta. The dominant station of PC2 is Ngentak, with a value of 0.926, which is situated in the lower part of the Bantul regency and close to the Indian Ocean. The dominant station for PC3 is Paliyan, with a factor loading value of 0.934. The dominant station of PC4 is Brongang, near the hill and on the top of the Yogyakarta city, with a value of 0.950. For PC5, the dominant station is Ledoknongko, with a factor loading value of 0.853 and its position is next to Bronggang, which is close to two hills. The dominant station of PC6 is BPP. Kalibawang is situated on the north side of the Kulon Progo regency and is close to the hill, with a value of 0.914.
The dominant station in PC7 is Piyungan, located to the east of the Kulon Progo regency and close to the hill, with a factor loading value of 0.978. The dominant station for PC8 is Dlingo, with a factor loading value of 0.871, situated near four hills east of the Bantul regency. The dominant station in PC9 is Gedongan, with a value of 0.871, positioned close to the city of Yogyakarta. PC10, Singkung, with a value of 0.941, is the dominant station. The dominant station PC11 is Kolombo, which is situated near to Yogyakarta city in the south of the Sleman regency. The dominant station of PC12 is Samigaluh, with a factor loading value of 0.924 on the north side of Kulon Progo regency and close to two hills.
The dominant station of PC13 is Panggang, with a value of 0.937, and is situated south of the Gunung Kidul regency near the Indian Ocean. The dominant station in PC14 is Ngetal, with a factor loading value of 0.954, situated south of the Bantul regency, close to station 23 and near the Indian Ocean. The spatial view of the PC score represented by the Special Region of Yogyakarta region stations reveals that the eastern part of the Special Region of Yogyakarta indicates low rainfall precipitation due to no stations serving in that area. The positive meaning of the PC is in the north, south, and southwest, and in the centre of Yogyakarta as shown in
Figure 7. It indicates that the southern portion is closed to the Indian Ocean during rainy seasons, to the north side of the Special Region of Yogyakarta, and to the center of the Special Region of Yogyakarta, which is closed to the city of Yogyakarta and has the maximum rainfall precipitate.
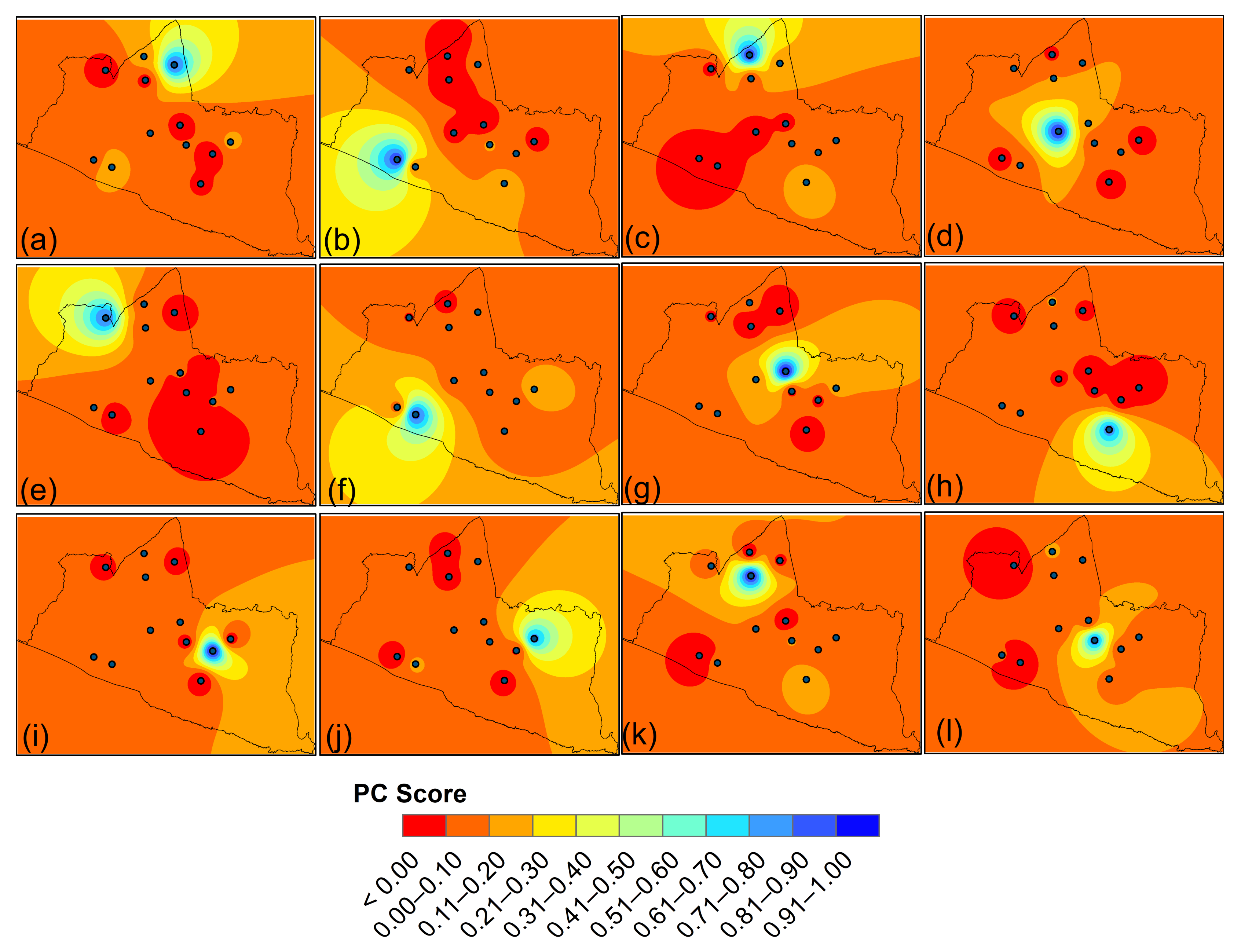
Based on
Table 7 for PC1, the dominant station is Bronggang, with a load factor value of 0.838. It is located on the north side of the city of Yogyakarta and the Sleman regency. The dominant station of PC2 is Brosot, with a value of 0.897, situated near to the Indian Ocean. For PC3, the dominant station is Ledoknongko, situated near Bronggang, which is next to two hills. The dominant station for PC4 is Gandok with a load factor value of 0.943. Station 7 is located in the centre of Bantul regency. The dominant station for PC5 is BPP. Kalibawang, positioned north of the Kulon Progo regency and close to the hill, with the factor loading of 0.811.
The dominant station, PC6, is Gedongan, with a value of 0.856, near to the city of Yogyakarta. Piyungan, with a factor loading value of 0.987, is the dominant station for PC7 and is situated east of the Kulon Progo regency and close to the hill. For PC8, the prevailing station is Paliyan, with a load factor of 0.766. On the west side of the Gunung Kidul regency, PC9, the dominant station is Playen with a factor loading of 0.970. PC10, the dominant station, with a value of 0.755, is in Nglipar, situated north of the Kulon Progo regency. The dominant station of PC11 is Beran, with a factor loading value of 0.932, and its position is near to the city of Yogyakarta. The dominant station PC12 is Dlingo, with a load factor of 0.947 and its position is near four hills east of the Bantul regency.
There is greater rainfall during the season on the north side of Yogyakarta city. The station has represented the positive PC score during the inter-monsoon season, indicating that the region with heavy precipitate rainfall is in the north, the center of the Special Region of Yogyakarta and on the east side, as shown in
Figure 8. The southern region that is closed to the Indian Ocean represents just two stations.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}