1. Introduction
Due to the advances in Internet and mobile communication technologies, social media platforms, such as Twitter and Facebook, have become essential communication tools and significant sources of emergency information (EI), which can be used to support emergency responses [
1]. During emergencies, such as natural disasters, serious accidents, or terrorist attacks, users of these platforms easily produce various emergency-related information in the form of texts, pictures, and videos, forming user-generated contents (UGCs). Some of these UGCs provide useful information to emergency information management (EIM) professionals for emergency diagnosis and response, including damage severity, rescue needs, or missing persons [
2], and can help allocate resources and improve relief efficiency [
3]. Therefore, classifying and verifying the UGCs of social media platforms can generate useful EI and enable social media to play a more active role in emergency management [
4].
Nevertheless, emergency-related UGCs produced and disseminated on social media platforms have yet to directly assist the on-site rescue activities of emergency management agencies (EMAs) or volunteers [
5]. Despite their wide availability, real-time emergency-related UGCs have varying quality and authenticity due to the heterogenous cognition, motivation, communication skills, emotions, etc., of the authors. Social media platforms are incapable of authenticating all information publishers or all of the information published [
6,
7], making it necessary to develop efficient approaches to extracting reliable and useful EI from social media UGCs after emergency occurrence. The reliable and useful EI allows decision makers to make more rational emergency responses.
Many researchers have tried to mine EI from social media UGCs through machine learning methods [
8,
9,
10]. However, the results end up with unsatisfactory accuracy and reliability, primarily because these methods rely solely on algorithms, ignoring the role of EIM experts’ knowledge or experience [
11]. To mitigate this constraint, this study designed and implemented a machine learning and rule-based integration method (MRIM), which synthesizes machine learning and rule-based classification methods. In this study, we try to answer the following questions: (1) Can the integration of machine learning and rule-based classification be more efficient when extracting useful EI from social media? (2) What characteristics of UGCs affect the performance of the integrated method? (3) How can social media UGCs be better utilized in EIM?
This study focuses specifically on the natural disaster scenario. We tested the integrated method with UGCs on China’s largest microblogging platform—Sina Weibo—on the “July 20 heavy rainstorm in Zhengzhou”. Our results show that this integrated method performs better than pure machine learning methods and pure rule-based methods. We further analyzed how its performance is subject to UGC characteristics and why it encounters misclassification.
Our study enriches the EIM literature by showing the significance and feasibility of integrating UGC characteristics into the machine learning classification process through expert-experience-based rules and extracting useful EI from social media UGCs after an emergency occurs. We also shed light on what characteristics of UGCs impact the performance of the integrated classification method, thus enriching scholarly understanding of how text mining technologies can be designed to more effectively extract EI from social media platforms. Practically, we inform some approaches through which EMAs can incorporate social media UGC analysis into formal EIM.
The rest of this paper comprises four sections. First, we review related research on the utilization of social media in emergencies and extracting information from social media through machine learning methods and rule-based classification methods. We then explain the design of MRIM and present comparative experimental results about its performance. We conclude this paper with discussions about our contributions, limitations, and future research.
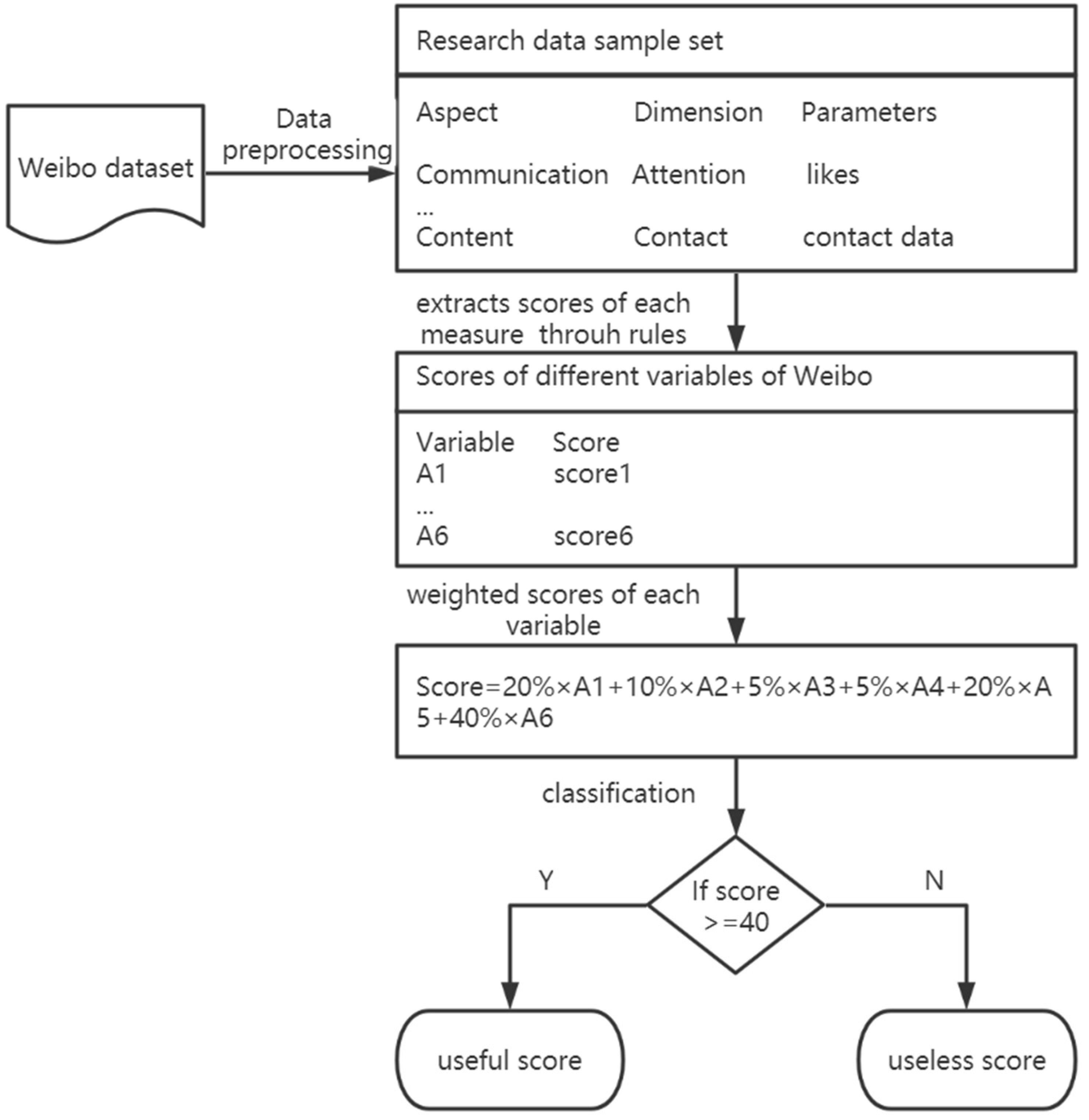
4. Evaluation
4.1. Evaluation of MRIM
4.1.1. Overall Performance
To evaluate the overall performance of MRIM in extracting useful and reliable EI from Weibo microblogs, we performed several comparative experiments on MRIM, pure machine learning, and rule-based methods. For machine learning methods, we used the linear kernel in the SVM algorithm, and we used tenfold cross-validation to test the accuracy of the algorithm. To achieve better generalizability, the SVM algorithm used words with a frequency of three or more and unigram as N-gram vectorization models using the TF-IDF features extraction method.
In the comparative experiments, the method using machine learning alone was named Model 1, the method using rule-based classification alone was called Model 2, and MRIM was named Model 3. The common indicators of classification performance included precision (proportion of correct positive prediction to all positive predictions), recall (proportion of correctly predicted positive to all actually positive), and F-measure. As F-measure is the value that can balance the precision and recall, it was used as the primary comparison measurement.
As shown in
Table 5, MRIM (Model 3, F-measure = 0.831) proposed in this study performed better than the SVM alone (Model 1, F-measure = 0.714) and rule-based alone methods (Model 2, F-measure = 0.750). The recall rates of Model 1 and Model 2 were comparably low, indicating that these two methods could not effectively detect the useful EI from microblogs to support emergency rescue. In contrast, MRIM achieved the best result in terms of F-measure (0.831) and recall rate (0.777). The improvement in the recall rate could better reflect the prospect of MRIM in EIM, as a high recall rate showed that more useful EI could be detected while ensuring the classification accuracy.
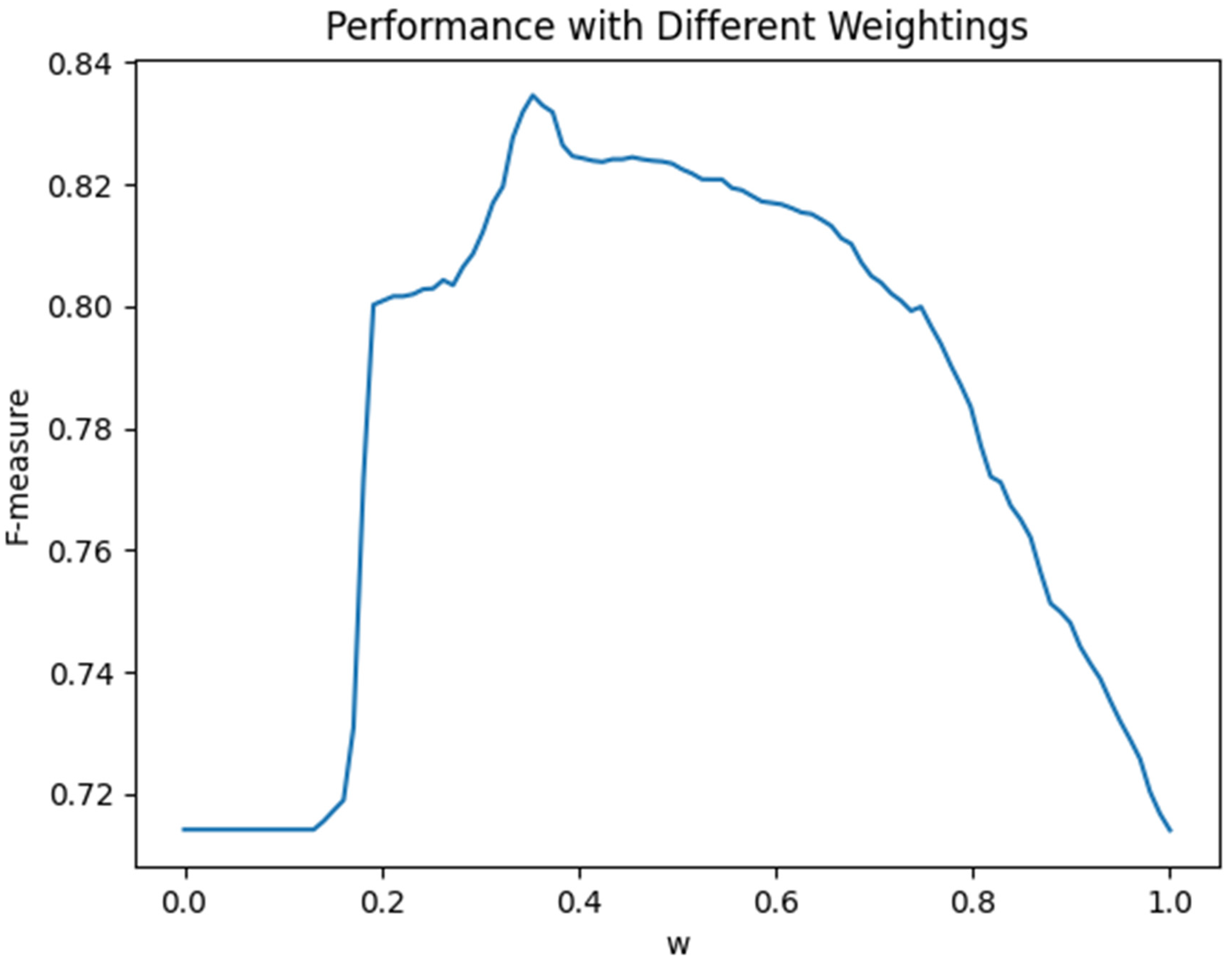
4.1.2. Integration Strategy
According to the integration strategy of MRIM, a microblog will be classified as useful EI when any machine learning and rule-based classification method determines that the microblog is useful. Is there any better way to integrate the classification results? To answer this question, this study attempted to use the score weighting approaches to integrate the scores generated by the two methods.
The score of the machine learning method was based on its classification results. If a microblog was classified as useful, the score would be 100; otherwise, the score would be 0. The score was subsequently combined with the score from the rule-based method to calculate the weighted integrated score of each microblog. If the Integrated_Score was greater than or equal to 40, it would be classified as useful EI. The formula was defined as follows:
In the comparison experiments, the value of
w was adjusted from 0 to 1, and the change in the F-measure was recorded (
Figure 3).
Figure 3 illustrates that the performance of the integrated method was higher than the
SVM alone method (
w = 0) or the rule-based alone method (
w = 1). When the value of
w was set to 0.51, the value of the F-measure reached the peak, which was 0.823 but still lower than MRIM in this study (0.831). This confirms that MRIM has a better integration strategy, which can help us extract as much useful EI from microblogs as possible (with a higher recall rate), and that it behaves robustly during the classification task (with a higher F-measure).
4.1.3. Machine Learning Algorithm
As mentioned above, the SVM algorithm was used in MRIM because it had achieved good results over various text classification tasks [
34], especially when the processing object was short text from social media. One of the main reasons for integrating SVM and rule-based methods is that these two methods complement each other [
38]. The SVM algorithm provides a good classification performance for text mining without considering word order, while the rule-based method integrates human judgment into the classification process by using the rules developed based on expert experience.
To verify whether SVM was indeed the most suitable machine learning algorithm for our dataset, this study compared it with two other popular machine learning algorithms: the naive Bayesian (NB) and decision tree (DT) algorithms. These were chosen because they are suitable for our smaller dataset and further integration. We compared each algorithm and their combinations. In the comparative experiments, we used the integration strategy of MRIM; that is, if any algorithm classified a microblog as useful EI, the integration method would classify the microblog as such.
Table 6 lists the results.
As shown above, the performance of the NB alone method (Model 4, F-measure = 0.656) and the DT alone method (Model 5, F-measure = 0.709) was not as good as that of the SVM alone method (Model 1, F-measure = 0.714), which confirms the superiority of using the SVM algorithm in MRIM.
Table 6 also shows that MRIM (Model 3, F-measure = 0.831) has better performance than the integration methods of NB+SVM (Model 6, F-measure = 0.675) and DT+SVM (Model 7, F-measure = 0.764), indicating that the expert experience provided by the rule-based method is helpful for improving the classification results.
4.2. Influence of Microblog Characteristics on Classification Results
We performed a follow-up study to explore the association between MRIM performance and microblog characteristics. We investigated three aspects of each microblog, including the number of words, the exact address and contact information, and the attention it received.
The number of words in text is important for text mining. It is thus worthwhile to clarify how the number of words affects the performance of MRIM. For this purpose, all microblogs (in total 7979) were divided into ten groups based on the number of words they contained. The first group contained 797 microblogs with the least number of words, the second group focused on 798 microblogs with the second least number of words, and the last group also contained 798 microblogs but with the largest number of words. The SVM alone method and MRIM were applied to each group, and the F-measure values were recorded. The results are shown in
Table 7.
The data in
Table 7 indicate that the more words within a microblog, the more robust the classification performance of both the SVM alone method and MRIM (with F-measure values higher than 0.5). These results imply that microblogs with a small number of words cannot provide enough information. Neither the SVM alone method nor MRIM can complete the information extraction work to a satisfactory level.
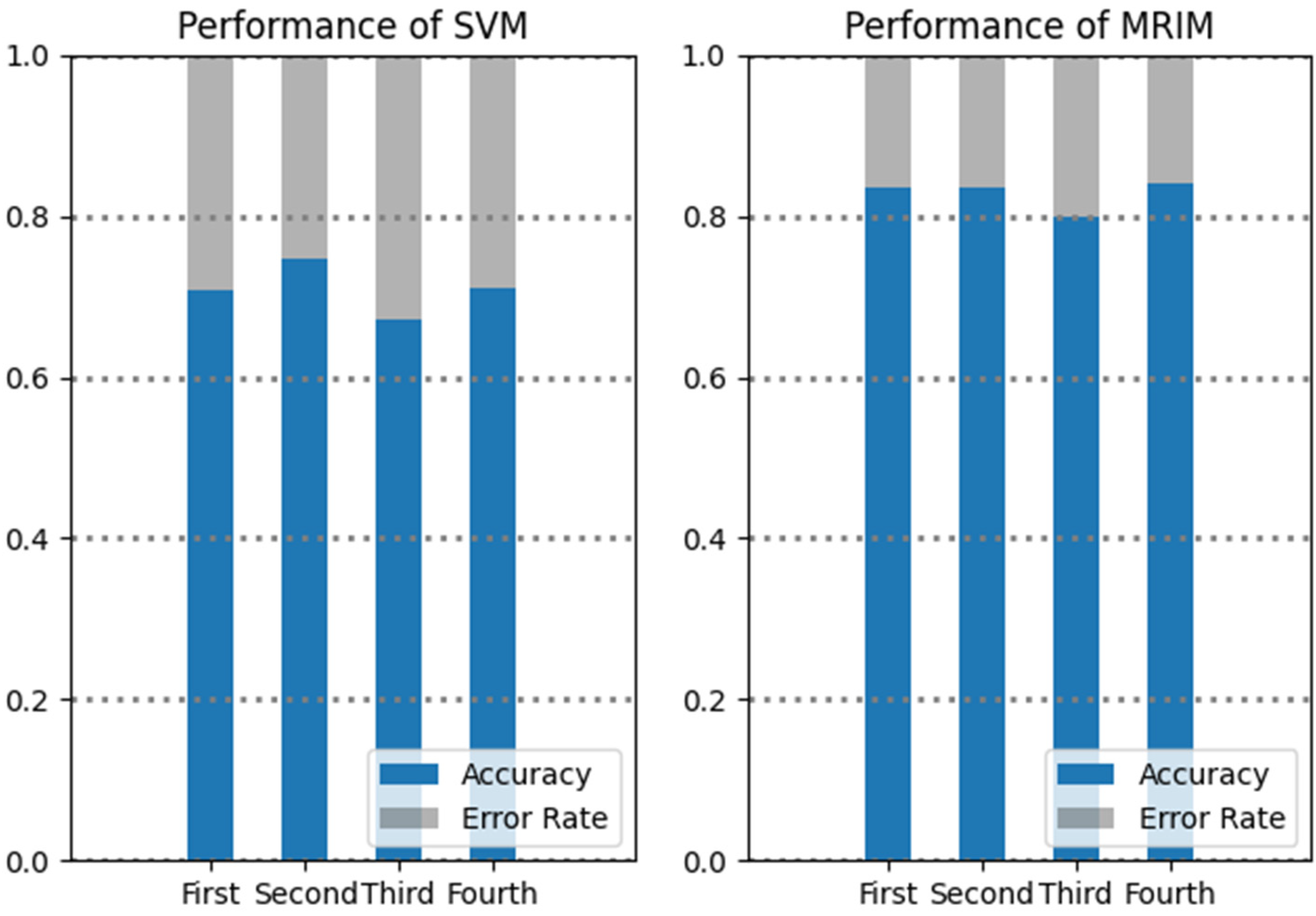
During emergencies, the exact address and contact information can play a crucial role in rescue activities, so they are one of the focuses in EIM. To investigate the impact of exact address and contact information on classification results, we divided all microblogs into four groups according to whether they contained an exact address or contact information. The first group comprised 5461 microblogs containing both an exact address and contact information. The second group comprised 1202 microblogs containing contact information only, and the third comprised 331 microblogs containing exact address information only. The fourth group comprised 985 microblogs containing neither exact address information nor contact information. Again, the SVM alone method and MRIM were applied to each group, and the F-measure values were recorded.
Figure 4 shows the performance of the two methods used on the four groups. We found that MRIM overall performed better than the SVM alone method. However, it is worth noting that both methods had unsatisfactory performance in the third group. A further analysis of the original microblogs of the third group showed that almost 40% of these microblogs had the problem of non-standard writing of exact addresses (abbreviations, regional habits, etc.), and the pattern of word usage was chaotic. Consequently, the keyword-dependent SVM algorithm failed to effectively detect useful EI from microblogs, which also affected the performance of MRIM.
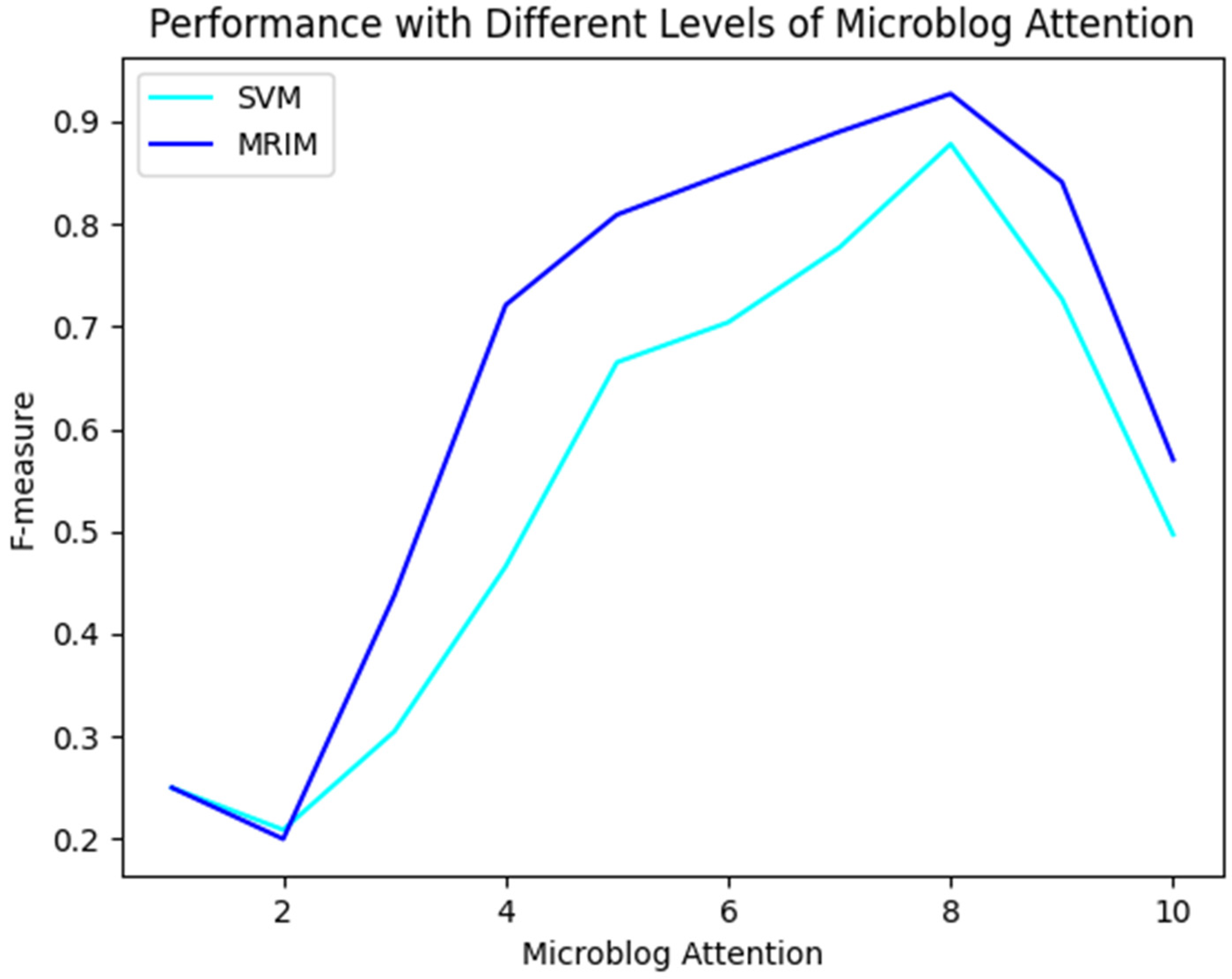
As discussed earlier, the communication characteristics of social media can reflect the effectiveness of UGCs’ content to a certain extent. Therefore, we conducted experiments to study the influence of microblog attention on classification performance. We divided microblogs into ten groups based on the attention they received (measured by the sum of the numbers of likes, comments, and shares). The first group contained 797 microblogs with the smallest amount of attention, the second group focused on 798 microblogs with the second smallest amount of attention, and the last group also contained 798 microblogs but with the largest amount of attention. Both the SVM alone method and MRIM were applied to each group. The variation curves of the F-measure values are shown in
Figure 5, indicating that MRIM performs better than the SVM alone for almost all groups, especially the third to sixth groups. According to previous research and preliminary observation, microblogs that receive more attention are often of higher quality and provide more rational textual expression. All such microblogs should be more accurately detected by the SVM alone method and MRIM. Surprisingly, neither the SVM alone method nor MRIM performed well in the groups that received too much attention, such as the ninth and tenth groups. Following further analysis, we found that about 50% of these microblogs were reports of emergency situations generated by professional media. These microblogs tend to be comprehensive in content and receive a lot of attention. Although they have sufficient information features, they are not able to directly contribute to emergency rescue activities [
53]. Therefore, we should pay more attention to the microblogs posted by individuals and private organizations, especially those generated by victims and bystanders at the scene of an emergency.
4.3. Misclassification Analysis
To improve the classification results of MRIM and lay a foundation for better integration methods, we also identified the reasons for misclassification by MRIM.
We began by performing a detailed analysis of the microblogs that were useless but were mistaken as useful EI. One important finding was that some of these microblogs simply copied the content generated by professional media, which generally provided comprehensive reports on disaster severity and victims. While they could not support emergency rescue actions, their adequate expression and high levels of attention render them easily classified as useful EI. Another important finding was that the classification result of the SVM algorithm was sensitive to missing feature data. The SVM alone method has no strategy to deal with missing values when there are few information features or incomplete vector data in microblogs. Meanwhile, SVM requires the samples to be linearly separable in the feature space, so the quality of the feature space is critical to the performance of SVM. Missing feature data will affect the quality of training results, and all such microblogs may be classified as useful EI by machine learning technology.
We then conducted in-depth analysis of the microblogs that were useful but mistaken as useless EI. There were multiple reasons for their misclassification. First, these microblogs contained informal and colloquial Chinese expressions, which prevented the SVM alone method and MRIM from detecting key information features. Second, the exact addresses and contact information in some useful microblogs were expressed irregularly or even incorrectly, resulting in these valuable information features being incorrectly identified. Finally, some useful microblogs contained fewer words, so their information features were difficult to detect using the classification methods. However, integrating the SVM algorithm and the rule-based method can complement each other, reducing classification errors.
5. Discussion and Conclusions
Social media UGCs produced during emergencies are regarded as informative for supporting emergency responses. However, researchers inadequately explored how useful EI can be efficiently extracted from these UGCs and incorporated into the decision-making process of emergency management. To fill this knowledge gap, this study proposes an extracting method (named MRIM) that integrates a machine learning method (SVM algorithm) and a rule-based classification method. Testing the MRIM on microblog data about the “July 20 heavy rainstorm in Zhengzhou” posted on China’s largest social media platform (Sina Weibo), we found that the MRIM has better EI extraction performance than machine learning alone and rule-based alone methods, and that its performance is associated with specific characteristics of UGCs, including the number of words, the exact address and contact information, and the amount of attention received.
5.1. The Incorporation of Expert Experience Increases the Effectiveness of the Integrated Method
This study adds to the EIM literature by developing a new method integrating machine learning and rule-based classification methods to effectively extract useful EI from social media UGCs. The method, MRIM, builds on prior studies emphasizing the significance of expert experience [
11,
49] and UGC characteristics beyond textual content (e.g., communication characteristics and user characteristics; see [
12,
15,
50,
52]) in the mining of UGCs. It incorporates various UGC characteristics into the classification process through rules developed on the basis of expert experience, significantly outperforming machine learning alone or rule-based alone methods in identifying useful EI from massive UGCs. In terms of the integration strategy of machine learning and the rule-based classification method, we take a more cautious approach: a microblog will be classified as useful EI when any one of the two methods determines that the microblog is useful. This is because rescue efforts in emergencies are so important that we would rather mistakenly extract useless EI than miss out on truly useful EI. In contrast, SVM and other traditional word-based machine learning algorithms underperform because they rely heavily on keywords [
11,
34]. They perform better after integrating rule-based classification methods, suggesting the feasibility of integrating expert experience through rule-based methods into machine learning methods to extract useful EI from social media UGCs.
5.2. The Number of Words, Exact Address and Contact Information, and Users’ Attention Affect the Performance
By identifying which UGC characteristics can heighten classification performance, this study also enriches scholarly understanding of how text mining technologies can be designed to extract EI more effectively. Comparative experiments on the number of words reveal that UGCs with fewer information features significantly degrade the SVM algorithm’s classification performance, confirming that the SVM method is sensitive to missing data in classification tasks [
34]. For particularly short microblogs, the SVM’s reliance on keywords’ co-occurrence is a shortcoming, and other classification methods are required to introduce more clues [
38]. Therefore, researchers need to pay special attention to the use conditions of different classification methods to ensure the classification performance through the complementarity of methods.
While exact address and contact information is often used to seek help or rescue [
12,
27], our results show that the casual writing of exact addresses in UGCs inhibits the performance of machine learning algorithms during classification tasks. Some UGCs have confusing word patterns or text formats, reducing their chances of being recognized by other users [
51], which also prevents our Python programs from identifying addresses and contact information more accurately. Therefore, both MRIM and the SVM alone are unable to effectively detect useful EI from such social media UGCs. This also emphasizes that the key role of address and contact information in emergency response cannot be ignored.
Finally, we found that the SVM algorithms misclassified many UGCs that received a high amount of attention, about 50% of which were comprehensive reports about affected areas and victims generated by official media agencies. This finding is consistent with Kim and Park’s view that official media generally report events more comprehensively but cannot provide instant help in EM [
53]. The ultimate goal of this study is to determine EI that supports emergency rescue activities; therefore, the role of comprehensive reports by official media agencies is minimal and causes disruption.
5.3. The Practical Implications for Better Use of Social Media UGCs in EIM
This study informs EIM practice by showing the promising prospect of using MRIM to efficiently extract EI from the massive number of social media UGCs. Though perceived as important EI sources by EMAs and the public, social media UGCs have not been included in the formal emergency management decision-making procedures due to the daunting data volume and heterogeneous content quality [
5]. Our study suggests that EMAs exploit EI-related UGCs by developing EI mining mechanisms with social media platforms or technology companies. It is also worthwhile for EMAs to stay alert to individual and private organizational users of social media during EIM, paying particular attention to the UGCs generated by individuals at the site of an emergency. They may encourage social media users to post more comprehensive and accurate information, such as precise addresses and contact information. Additionally, social media platforms can implement targeted functions for emergency rescue (e.g., developing templates), guiding users to provide more detailed and accurate information during emergencies.
5.4. Limitations
Our study has three limitations. First, our proposed integrated classification method proved effective in the rainstorm emergency scenario, indicating that this integration idea is generalizable, but its rules are not directly applicable to other types of emergencies. Different emergencies will require different expert experience and judgment rules, requiring integration methods to be customized and tested across scenarios. Second, the integrated method is designed and implemented based on the Weibo platform and thus cannot be directly applied to other social media platforms. However, the main idea of integrating machine learning and rule-based classification can be replicated on similar social media platforms, such as Twitter. Last, the use of the Delphi method in this study was relatively simple and only three experts were invited. We believe it is still necessary to invite more experts to increase the authority of rule-based methods.
5.5. Future Research
Scholars can build on this study to develop new and effective integrated classification methods. The starting point could be using larger datasets in other types of emergencies to verify and strengthen the effectiveness and generalizability of our proposed method. Moreover, researchers can test more characteristics of social media UGCs to explore new approaches that can efficiently and reliably extract EI from UGCs. For instance, they could include temporal and spatial features of UGCs, visual and sound formats (e.g., pictures, videos, emojis), the behavior of users, etc., in classification methods. Finally, given the importance of address information in UGCs for classification performance, it is worthwhile to build a professional address dictionary and develop a more intelligent method to improve address extraction performance.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}