




Service Function Chaining to Support Ultra-Low Latency Communication in NFV †

1
Fixed Line Device Engineering, Deutsche Telekom Technik GmbH, 64295 Darmstadt, Germany
2
The School of Electronic Engineering and Computer Science, Queen Mary University of London, London EC1M 6BQ, UK
3
Embedded Systems Department, University of Duisburg-Essen, 47057 Duisburg, Germany
*
Author to whom correspondence should be addressed.
†
This paper is an extended version of our paper published in 2022 IEEE International Conference on Broadband Communications for Next Generation Networks and Multimedia Applications (CoBCom) under the same title.
Electronics 2023, 12(18), 3843; https://doi.org/10.3390/electronics12183843
Submission received: 23 July 2023
/
Revised: 4 September 2023
/
Accepted: 10 September 2023
/
Published: 11 September 2023
(This article belongs to the Special Issue Optical Communications and RF Technologies in Sensor Networks and Multimedia Applications)
Abstract
:Network function virtualization (NFV) has the potential to fundamentally transform conventional network architecture through the decoupling of software from dedicated hardware. The convergence of virtualization and cloud computing technologies has revolutionized the networking landscape, offering a wide range of advantages, including improved flexibility, manageability, and scalability. The importance of network capability in enabling ultra-low latency applications has been greatly amplified in the current era due to the increased demand for emerging services such as autonomous driving, teleoperated driving, virtual reality, and remote surgery. This paper presents a novel and efficient methodology for service function chaining (SFC) in an NFV-enabled network that aims to minimize latency and optimize the utilization of physical network resources, with a specific focus on ultra-low latency applications. In our proposed methodology, we offer flow prioritization and an adjustable priority coefficient factor (µ) to reserve a portion of physical network resources exclusively for ultra-low latency applications in order to optimize the deployment paths of these applications further. We formulate the SFC deployment problem as an integer linear programming (ILP) optimization model. Furthermore, we propose a set of heuristic algorithms that yield near-optimal solutions with minimal optimality gaps and execution times, making them practical for large-scale network topologies. Performance evaluations demonstrate the effectiveness of our proposed methodology in enabling ultra-low latency applications in an NFV-enabled network. Compared to existing algorithms, our proposed methodology achieves notable enhancements in terms of the end-to-end delay (up to 22 percent), bandwidth utilization (up to 28 percent), and SFC acceptance rate (up to 13 percent).
1. Introduction
By separating network functions from specialized hardware and deploying them as virtual network functions (VNFs) on containers, virtual machines, or off-the-shelf hardware, network function virtualization (NFV) has the potential to fundamentally transform traditional network architectures. NFV offers a wide range of advantages, including scalability, flexibility, cost-effectiveness (both in terms of capital and operational expenditures), and accelerated service innovation. These benefits play a vital role in effectively meeting the demands presented by emerging new services. VNFs encompass a diverse range of network services, including but not limited to network address translation, firewalls, traffic analyzers, load balancers, and intrusion detection systems. These network services are implemented as software instances that can be scalable, relocatable, and dynamically orchestrated in response to varying network requirements [1,2,3]. Service function chaining (SFC) plays an essential role in NFV. The term SFC denotes the process of sequentially connecting VNFs in order to create a network service. SFC enables the establishment of service workflows that incorporate multiple VNFs, guaranteeing the orderly passage of traffic through the designated functions as per a pre-established arrangement. NFV and SFC facilitate the dynamic provisioning and management of network services. The inherent flexibility of telecommunication service providers allows them to promptly adapt to evolving demands, efficiently implement services, and effectively utilize available resources [4,5].
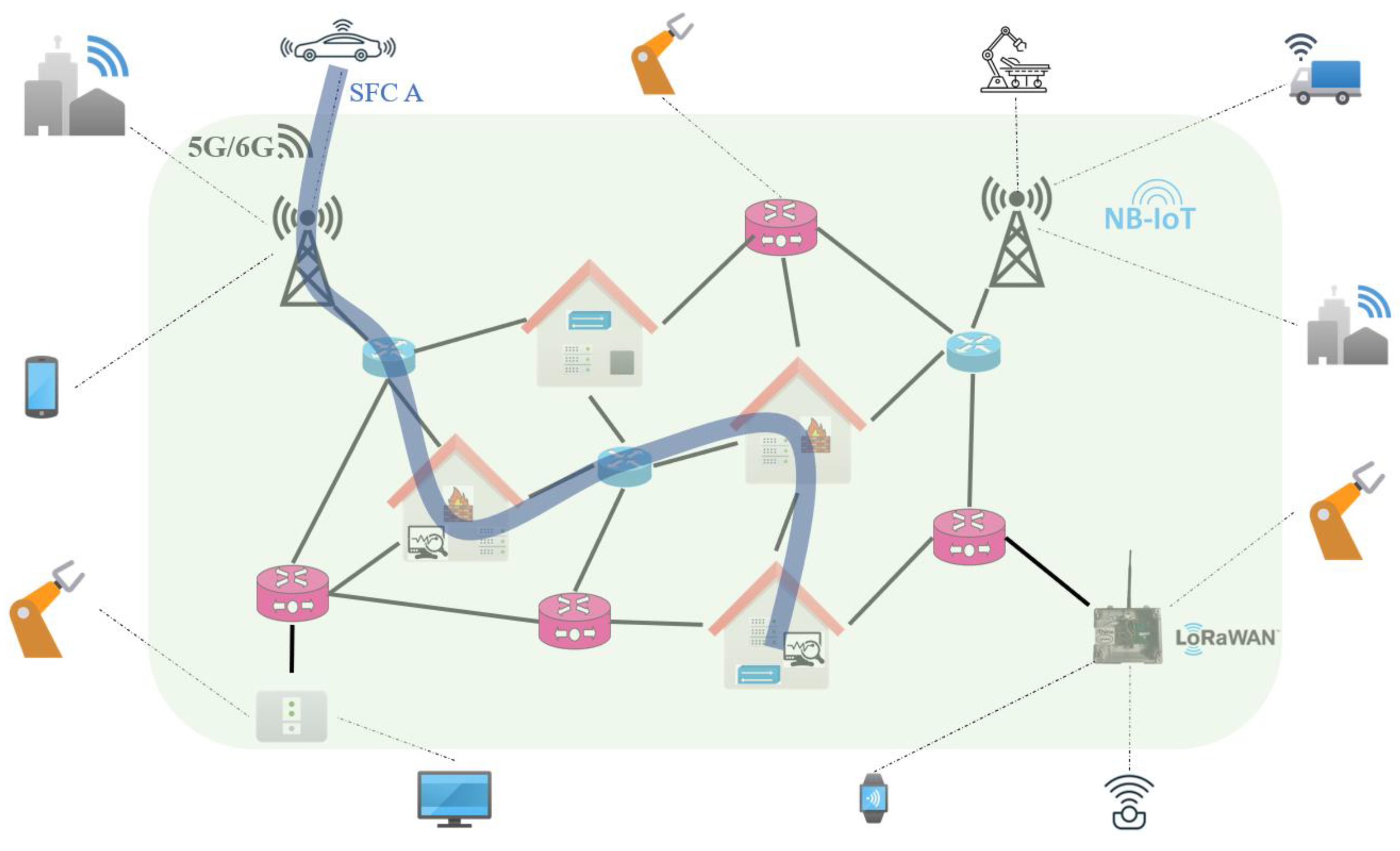
The importance of network capability in facilitating ultra-low latency applications has significantly increased in the current era because of the emergence of new services such as autonomous driving, teleoperated driving, virtual reality, augmented reality, IoT applications, and remote surgery in 5G, 6G, IoT, and fixed-line networks. As seen in Figure 1, the deployment of a network service (referred to as SFC A) entails the utilization of several components and VNFs that necessitate sequential interconnections according to a pre-established arrangement. The efficient provisioning of SFC requests is crucial for enabling ultra-low latency applications and minimizing physical resource consumption. Telecommunication service providers express a notable preference for optimizing the utilization of current physical network resources, including the bandwidth, CPU, and RAM memory, within the network architecture, as opposed to procuring additional physical network resources.
The main objective of our study is to enable ultra-low latency applications in an NFV environment. In order to accomplish this objective, it is necessary to optimize both the latency and physical resource allocation. Therefore, our proposed SFC deployment methodology addresses two primary challenges—the concatenation of various VNFs while taking into account quality of service (QoS) constraints and the efficient allocation of physical network resources through QoS-aware resource management. We propose flow prioritization and physical resource reservation using an adjustable priority coefficient factor (µ) to optimize resource allocation in our proposed methodology. Weighted fairness is used to implement the proposed solution. Weighted fairness is a resource allocation approach that assigns different weights to applications and distributes physical network resources in proportion to these weights. In this study, we assign a minimum of 10% of physical network resources to high-priority flows, meaning that in the presence of high- and low-priority flows, 90% of the physical network resources are shared between high- and low-priority flows, while 10% of physical resources are reserved exclusively for high-priority flows. To this end, high-priority flows have access to the 10% of reserved physical network resources (bandwidth, CPU, and RAM memory) and can obtain more optimal deployment paths. This approach aims to optimize the provisioning paths of high-priority flows and effectively reduce the latency. We also study the impact of variations in physical resource reservation (changing the priority coefficient factor (µ)) in our study in Section 6. Since we reserve a portion of physical network resources only for high-priority flows, we consider the maximum tolerable end-to-end delay not only for high-priority traffic flows but also for low-priority traffic flows in order to minimize the negative impacts on low-priority traffic flows. A comprehensive summary of the contributions made by our research is provided below:
- We propose a novel and efficient SFC embedding methodology that takes into account flow prioritization and physical resource reservation for high-priority flows;
- We formulate the SFC embedding problem as an integer linear programming (ILP) optimization model with the objective of minimizing latency and optimizing the allocation of physical network resources (bandwidth, CPU, and RAM memory);
- We propose a set of heuristic algorithms that achieve near-optimal solutions with a minimal optimality gap and execution time to solve the scalability issue for large-scale network topologies;
- A comprehensive analysis is conducted on the algorithms that are provided. Our proposed algorithms demonstrate improved performance in terms of lower end-to-end delay, enhanced bandwidth utilization, and an increased acceptance rate of ultra-low latency applications.
The paper is structured as follows. A review of the relevant literature is presented in Section 2. Section 3 provides further clarification on the system model. In Section 4, we present the problem formulation as an ILP optimization model. In Section 5, the proposed heuristic algorithm is described. The simulation results are presented in Section 6. We conclude the paper in Section 7.
2. Related Work
Various approaches have been proposed to support low-latency applications, the majority of which take the latency requirements of SFC requests into account and determine the shortest provisioning path possible to enable latency-aware service function chaining. These approaches aim to identify the most efficient provisioning path with respect to end-to-end delay. The studies mentioned above demonstrate differences in several aspects, such as formulation models and graph traversal algorithms. The increasing utilization of ultra-low latency applications has raised the significance and complexity of resolving the SFC embedding problem, thereby demanding further advancements. In the following, we will outline some of the key features of each.
Zhu et al. [6] conducted a study on the topic of delay-aware and resource-efficient service function chaining in an inter-datacenter elastic optical network. The problem was formulated as an ILP optimization model with the objective of minimizing end-to-end delay and resource consumption, including IT resources and bandwidth resources. Subsequently, a delay-aware and load-balancing embedding algorithm was proposed in order to obtain a near-optimal solution. Yu et al. [7] performed a study focused on deterministic latency- or jitter-aware service function chaining in beyond-5G edge fabric. The researchers conducted an investigation into the problem of managing the lifetime of deterministic SFCs in beyond-5G edge fabric. The objective of the study was to maximize the overall profits while ensuring the deterministic latency and jitter of SFC requests. They proposed two SFC deployment algorithms that obtain better performance in terms of the SFC acceptance rate and latency compared with the benchmark algorithm. Yang et al. [8] studied delay-sensitive and availability-aware virtual network function scheduling for NFV, while this paper aims to explore the quantitative modeling of the delay experienced by a flow in both totally ordered and partially ordered SFCs. They investigated delay-sensitive VNF placement and routing problems. They formulated the problem as integer non-linear programming (INLP) and provided a heuristic approach.
Thiruvasagam et al. [9] investigated the reliability-aware, delay-guaranteed, and resource-efficient placement of service function chains in softwarized 5G networks. The authors focused on the problem of placing SFCs in software-defined 5G networks, with an emphasis on ensuring reliability, guaranteeing delay requirements, and optimizing resource utilization. They formulated the problem as an ILP optimization model and provided a heuristic approach to obtain near-optimal results. The study conducted by Sun et al. [10] focused on the orchestration of SFCs in an NFV environment, with an emphasis on achieving low latency rates and resource efficiency. The researchers proposed a deployment optimization algorithm for SFC, referred to as SFCDO. This algorithm was built upon the breadth-first search (BFS) algorithm and aims to identify the shortest path between the source and destination nodes for all SFC requests. Additionally, it prioritizes selecting the path with the fewest hops in order to minimize the overall end-to-end delay. The researchers evaluated the proposed algorithms by analyzing their performance in terms of average end-to-end delay and average bandwidth consumption when handling SFC requests with different lengths and quantities. Alameddine et al. [11] studied low-latency service schedule orchestration in NFV-based networks. The authors tackled the latency-aware service schedule orchestration problem by simultaneously addressing the mapping and scheduling of services to VNFs. The problem was formulated as a mixed-integer linear program (MILP). Harutyunyan et al. [12] examined latency-aware service function chain placement in 5G mobile networks. The problem was defined as an ILP optimization model, aiming to minimize the latency of SFC requests, the cost of service provisioning, and the virtual service function (VSF) migration frequency. The study conducted by Sun et al. [13] examined the cost-effective orchestration of SFC in NFV networks, with a specific focus on low-latency applications. The authors introduced a heuristic algorithm known as closed-loop feedback, which aims to determine the most efficient route for mapping an SFC request, while also considering resource conservation. The algorithm demonstrated superior performance in terms of both the communication latency and deployment time cost compared to two competing algorithms. The authors also conducted an investigation into the provisioning of energy-efficient service function chaining with the aim of facilitating the operation of delay-sensitive applications within an NFV environment, as in [14].
The study conducted by Hmaity et al. [15] focused on the placement of chained VNFs with considerations for latency and capacity. Various heuristic strategies were provided and evaluated in terms of the latency of the links and the processing capacity of the nodes. Tajiki et al. [16] conducted research on service function chaining that was both energy-efficient and QoS-aware (latency-aware) in an SDN-based network. They took into account limitations on the link utilization, server utilization, and maximum tolerable end-to-end delay. The researchers presented an ILP optimization model to address the SFC embedding problem. Additionally, they introduced a series of heuristic algorithms to obtain solutions that are close to optimal. Li et al. [17] introduced a greedy algorithm to address the problem of service mapping. The researchers conducted an analysis of mechanisms for mapping NFV service function chains based on cost and QoS. They put forth a mathematical model aimed at optimizing costs and ensuring QoS. An end-to-end performance analysis for service chaining in a virtualized network was carried out by Fountoulakis et al. [18]. Han et al. [19] offered an algorithm to satisfy the demands of low delays, load balancing, and the efficient utilization of substrate resources in operator networks. In their study, Wang et al. [20] introduced an algorithm based on the Hungarian method to address the problem of SFC embedding. The researchers framed the embedding problem as a problem of weighted graph matching. Pham et al. [21] conducted a study on the subject of traffic-aware and energy-efficient VNF placement for service chaining. Luizelli et al. [22] introduced a heuristic methodology for the placement and chaining of VNFs with the objective of minimizing resource allocation while ensuring the fulfillment of network flow requirements.
In continuation of our investigation conducted in [23,24,25,26], our proposed methodology differs from the aforementioned studies by not only incorporating latency-aware SFC deployment but also by incorporating flow prioritization and distinguishing between ultra-low latency applications and other applications. This distinction is made in order to allocate a portion of the physical network resources (bandwidth, CPU, and RAM memory) exclusively for the purpose of handling high-priority SFC requests associated with ultra-low latency applications. The reservation of physical network resources is accomplished by implementing an adjustable priority coefficient factor (µ) to reserve a portion of the physical network resources, which minimizes the latency and optimizes the allocation of physical resources for high-priority flows exclusively. As a result of the guaranteed allocation of physical network resources, high-priority SFC requests are able to achieve more optimal deployment paths. This, in turn, results in reductions in both end-to-end delays and bandwidth consumption. Achieving optimal outcomes necessitates maintaining an accurate balance between the allocation of physical network resources and the workload associated with high-priority SFC requests. The evaluation of this point is discussed in Section 6. We incorporate the maximum tolerable end-to-end delay for low-priority flows in our optimization model to help reduce the negative effects on low-priority traffic flows.
3. System Model
This section presents a comprehensive overview of our system model, consisting of two primary components—the physical network and the SFC requests. We will provide a more detailed description of these components in the subsequent sections.
3.1. Physical Network
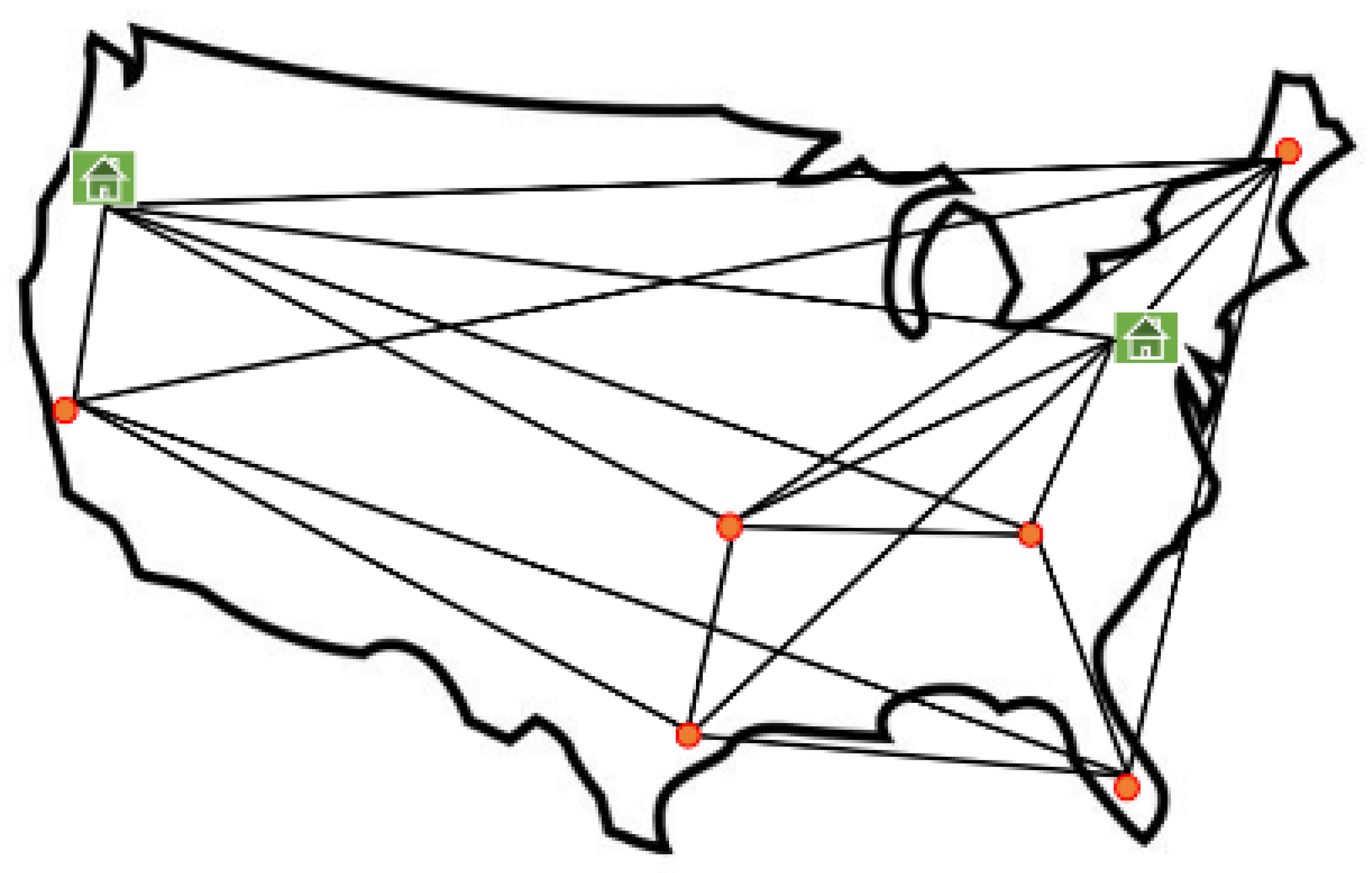
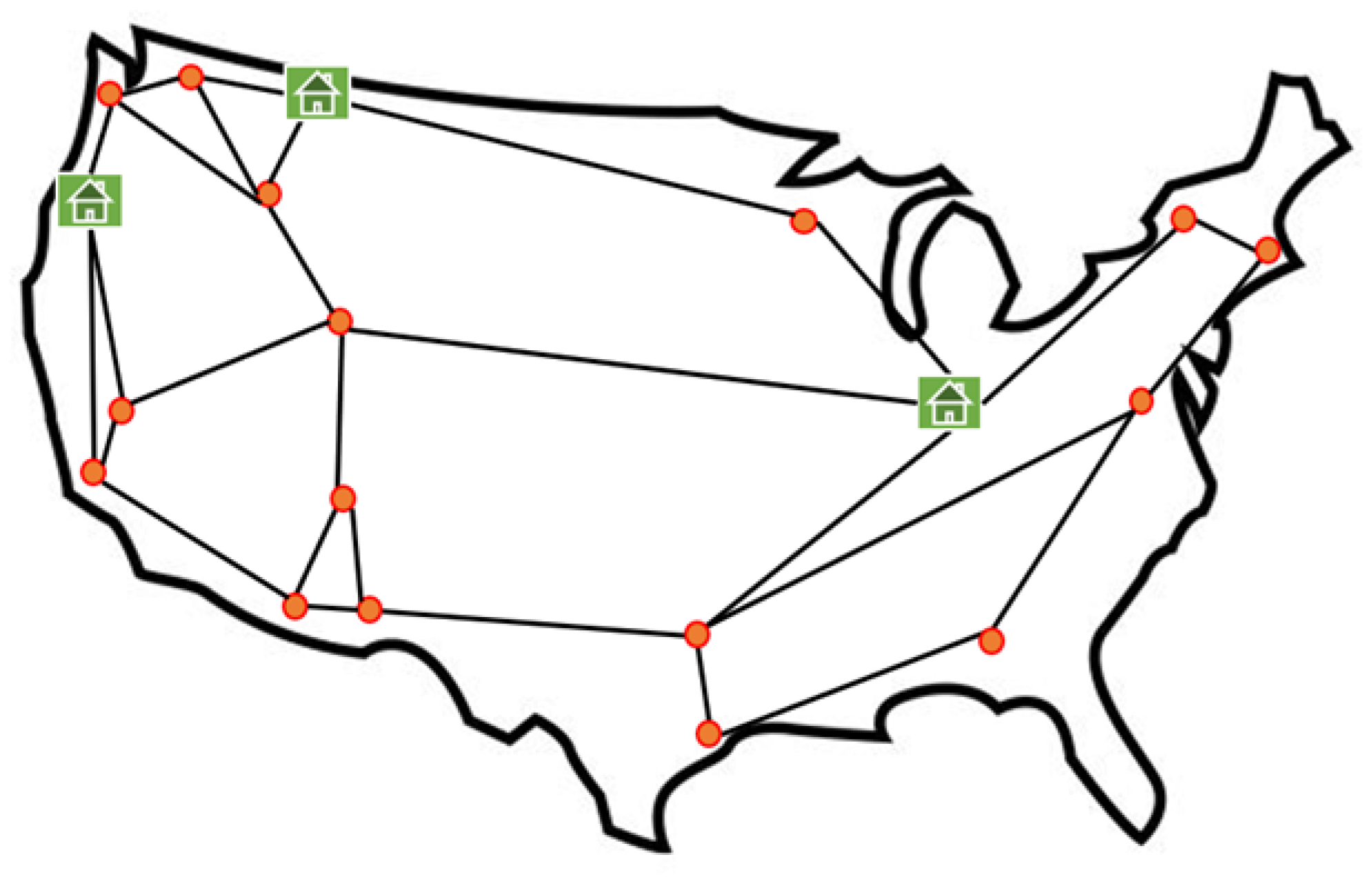
An undirected graph = (,) is used to represent the physical network, where denotes the set of nodes and denotes the set of links. There are two categories of nodes that we take into account. The first category comprises core datacenter nodes (), which are responsible for hosting various VNF types, such as a, b, c, d, and so on. The second category comprises switching nodes (), which only serve the purpose of forwarding traffic to subsequent nodes (, ). To evaluate the effectiveness of our suggested methodology, two distinct network topologies are used in this study. In Section 6.1, we first evaluate the effectiveness of our proposed method using the Gridnet network topology [27]. Then, in Section 6.2, we conduct an evaluation on a bigger network topology known as the EliBackbone network topology in order to determine the effectiveness of our suggested methodology [27]. The Gridnet network topology is presented in Figure 2. The figure depicts CDC nodes as green squares and switching nodes as red circles. These nodes are connected, as shown in the figure, by a link between two nodes.
In our study, the physical network and SFC requests are provided as static inputs [10,28]. We use m and n to represent two nodes (m, n ∈ Np). The parameter denotes the bandwidth capacity of the physical link between node m and node n. Similarly, the parameter denotes the memory capacity of node m, while the parameter represents the CPU capacity of node m. In the present study, it is assumed that the switching nodes () solely perform the function of forwarding traffic to subsequent nodes, without hosting any VNFs. Consequently, it is assumed that the switching nodes do not necessitate substantial CPU and memory capacities. As a result, the CPU and memory capacities of the switching nodes are regarded as infinite.
3.2. Service Function Chain Request
The SFC request f is represented by the following parameters. The symbols and are employed to denote the source and destination of the SFC request f. The matrix represents the necessary VNFs for the SFC request f. In this study, we treat this matrix as a static input. F denotes the total number of SFC requests, while X denotes the total number of VNF tapes (e.g., a, b, c, d). In fact, if the VNF type x is requested for the SFC request f, then equals 1 (0 otherwise). The matrix represents the sequence of required VNFs for all SFC requests, where specifics the required VNF for flow f. It is a matrix with integer values to define the order of each VNF x. Indeed, a VNF with lower index needs to deliver service first. is used to denote the priority of SFC request f. As previously mentioned, we define high-priority SFC requests for ultra-low latency applications ( is 1) and low-priority SFC requests for other applications ( is 0). The parameters denote the required bandwidth, CPU, and memory for each SFC request f, respectively. Finally, denotes the maximum tolerable end-to-end delay of the SFC request f.
4. Problem Formulation (ILP)
Ensuring the fulfillment of a wide range of service level agreements for customers is of the utmost importance for telecommunication service providers. Otherwise, they will lose customers and consequently experience a decline in revenue. Ultra-low latency applications are characterized by their high sensitivity and critical nature, necessitating specialized handling. Hence, it is imperative to have an optimal SFC embedding algorithm. In this section, we present our proposed ILP optimization model for the SFC embedding problem that handles ultra-low latency applications differently from other applications, with the aim of optimizing their QoS and physical resource consumption to a greater extent. The parameters and variables utilized in this paper are comprehensively listed in Table 1.
The physical network is denoted by a matrix in our representation. As previously mentioned, our approach involves assigning two priorities for SFC requests. The high priority is designated for ultra-low latency applications, while the low priority is allocated for other network services. We use an adjustable priority coefficient factor (µ) to employ physical resource reservation (bandwidth, CPU, and RAM memory) for high-priority network services. We make the assumption that the initial priority coefficient factor (µ) is 0.9, meaning that low-priority flows can utilize up to a maximum of 90 percent of physical network resources, and 10 percent of physical network resources are exclusively reserved for high-priority flows. Since we assume that 10 percent of SFC requests are high-priority, we make the decision to start with a 10 percent physical resource reservation for high-priority flows. We will use it as a starting point for our study as we look at the changes to the priority coefficient factor (µ) in Section 6.
Firstly, the necessary constraints on the bandwidth, CPU, and memory utilization of SFC requests are established based on the priority assigned to each SFC request. These constraints are guaranteed as (1)–(6). Constraint (1) guarantees that the bandwidth utilization of SFC requests cannot exceed the physical bandwidth capacity of the link between node m and node n. In this context, F represents the total number of SFC requests in the network, which is considered a static input for the purpose of our analysis. The second constraint ensures that the bandwidth utilization of SFC requests with low priority must not exceed 90 percent (µ) of the physical bandwidth capacity of the link between node m and node n. F′ represents the total number of SFC requests categorized as low priority. The binary variable {0, 1} is employed to denote whether the SFC request f traverses the link (m,n) or not. equals 1 when the SFC request f traverses the link (m,n), and 0 otherwise:
The presence of Constraint (3) guarantees that the amount of CPU resources utilized by SFC requests will not exceed the total CPU capacity of CDC node m. Constraint (4) ensures that the CPU utilization rate of SFC requests with low priority does not exceed 90 percent (µ) of the CPU capacity of CDC node m:
By setting Constraints (5) and (6), the same reasoning used for CPU usage is applied to memory usage on CDC node m. Constraint (5) ensures that the amount of memory consumed by SFC requests will not exceed the total memory capacity of CDC node m. Constraint (6) guarantees that the memory consumption of low-priority SFC requests cannot exceed 90 percent of the total memory capacity of CDC node m. Therefore, 10 percent of the memory capacity on CDC node m is reserved for high-priority SFC requests.
Constraint (7) is designed to ensure that the propagation delay of SFC request f cannot exceed the maximum tolerated end-to-end delay of SFC request f (). Both low-priority and high-priority SFC requests are subject to it. represents the propagation delay on the link connecting node m and node n:
The flow control is ensured by imposing Constraint (8). It is ensured that the links on the deployment path of SFC request f are connected head-to-tail:
In order to ensure that each VNF type x required by SFC request f is supported by the server hosting it, we enforce Constraint (9). The variable is a binary variable. equals 1 when the SFC request f uses VNF type x, which is placed on CDC node m, and 0 otherwise. The matrix identifies the VNF types placed on each CDC node, which is given as an input. If VNF type x is placed on CDC node m, then equals to 1, and 0 otherwise:
Constraint (10) is taken into consideration in order to avoid the occurrence of a loop for SFC request f:
Constraint (11) is implemented to guarantee that the SFC request f successfully traverses a legitimate VNF chain when passing through the nodes:
We define Constraint (12) to make sure that one VNF type x is used by at most one SFC request:
Next, we consider ordering the constraints to enforce an ordered sequence of VNFs to concatenate different VNFs of SFC request f. The matrix ( × × F) is defined as an ordering-aware rerouting matrix. T includes the notion of ordering for the nodes and links appearing in the deployment path. The elements of consist of integer values that are sequentially assigned, beginning with 1. This implies that nodes must be traversed in a specific order:
The matrix denotes the traversal of the SFC request f, wherein it departs from node one in the initial step and proceeds to node four (since the fourth column is one). Subsequently, in the subsequent step, it moves from node four to node two (since the second column in row four is two). Finally, it moves from node two to node three, which is the destination of the SFC request f. The value four in means that SFC request f crossed four nodes to reach its destination. Indeed, specifies the number of previously crossed nodes. The values stored in the matrix are integers and need to be equal to or higher than the corresponding one stored in the rerouting matrix . Hence, Constraint (13) is hereby defined as follows:
We guarantee that becomes zero in the event that equal zero. Hence, we propose Constraint (14):
It is evident that Constraint (14) exhibits non-linearity, necessitating its linearization for incorporation into our optimization model. Given that every SFC request f traverses a maximum of all the nodes, it is possible to alter Constraint (14) to Constraint (15):
The elements of the ordering-aware rerouting matrix for the output links must be zero, corresponding to the destination node. Hence, we apply Constraint (16):
With the exception of the source and destination nodes, when the SFC request f enters a node in its step, it departs from that node in the step. Hence, we propose the inclusion of Constraint (17):
It is imperative to ensure that the SFC requests are successfully transmitted from the source nodes. Hence, we propose the incorporation of Constraint (18):
Finally, in order to force the sequence of VNF chaining, Constraint (19) is implemented. It checks whether the VNFs with higher ordering, i.e., lower index in , are delivered to the SFC request f in one of the crossed servers or not:
In Constraint (19), stores all of the required VNFs with a higher order, i.e., lower index, than . For example, if then . If we assume , then is a member of {2, 3}. Using the same approach as [16], the ordering constraints of the VNFs belonging to a flow are expressed in a different form. Therefore, Constraint (19) is replaced with Constraint (20):
In Constraint (20), if the CDC node m hosts the VNF , then . Therefore, the left side of Constraint (20) considers the step of the CDC node m, and it must be greater than the step of all CDC nodes () hosting a VNF with an index lower than the index of VNF in . By considering the as the index of any VNF in with an index lower than VNF , this means the flow f must pass VNF before . If the CDC node m (I) hosts the VNF , then . Therefore, the right side of Constraint (20) considers the step of the CDC node m (I), and it must be greater than the step of all CDC nodes m hosting a VNF with an index greater than the index of VNF in . If either or is equal to zero, the value of is always lower than (2N−1), then the constraint is fulfilled. Here, and are always lower than (2N−1), since in the worst case the flow crosses all nodes, which means the value of is at most (N − 1) + N. The destination has a flow to itself with a step of at most N + 1. When both and are equal to one, the constraint is satisfied on the condition that the value of is greater than . This means that a CDC node that delivers the lower index VNF is crossed before the CDC nodes that deliver higher index VNFs [16].
In the previous mathematical formulations, we presented the mathematical representation of the SFC embedding problem, where the prioritized SFC requests are treated differently. The priority coefficient factor (µ) is utilized to reserve a portion of the physical network resources (bandwidth, CPU, and RAM memory) exclusively for the use of high-priority flows and to optimize their provisioning paths further. Additionally, the maximum tolerable end-to-end delay of low-priority SFC requests is taken into account to minimize the negative impacts on low-priority flows. The objective function (21) is defined to optimize the provisioning paths of SFC requests with respect to the end-to-end delay. This optimization is subject to Constraints (1)–(13), (15)–(18), and (20).
The objective function (21) obtains the optimal application-aware SFC (OAS) embedding results. It minimizes the number of hops that the flow will cross from source to destination with respect to the end-to-end delay. The OAS is classified as an NP-hard problem due to its mapping to the weight-constrained shortest path problem (WCSPP), which is also recognized as an NP-hard problem [29]. The NP-hard problem refers to a class of computational problems in which the task of obtaining precise numerical solutions for network topologies of a significant scale is highly time-intensive. Hence, in the subsequent section, we present a set of heuristic algorithms aimed at achieving nearly optimal solutions within a reasonable time frame for large-scale network topologies.
5. Heuristic Approach
This section presents a set of heuristic algorithms and relaxed versions that aim to achieve near-optimal results while minimizing the execution time and the optimality gap. These algorithms are designed to be applicable to large-scale network topologies. The algorithms have been specifically designed to produce outcomes with maximum efficiency. Initially, we introduce our proposed heuristic algorithm in Section 5.1, subsequently followed by a discussion of comparable algorithms derived from relevant research studies in Section 5.2 and Section 5.3.
5.1. Fast Application-Aware SFC (FAS) Embedding Algorithm
In our proposed heuristic algorithm, referred to as the fast application-aware SFC (FAS) embedding algorithm, we follow a similar approach as the OAS algorithm (Equation (21)). Specifically, we assign physical network resources (bandwidth, CPU, and RAM memory) based on the priority of each SFC request. This implies that SFC requests with low priority are allowed to utilize a maximum of (µ × physical network resources), while ((1 − µ) × physical network resources) is exclusively reserved for high-priority SFC requests. It is assumed that the initial priority coefficient factor (µ) is 0.9, indicating that low-priority flows can employ a maximum of 90 percent of the physical network resources, while 10 percent of the physical network resources are exclusively allocated for high-priority flows. Given that 10 percent of the SFC requests are high-priority, we make the decision to start with a 10 percent physical resource reservation for high-priority flows. We use it as a starting point for our study as we look at the changes to the priority coefficient factor (µ) in Section 6. This allocation strategy aims to optimize the deployment paths of high-priority SFC requests. The pseudocode for the FAS algorithm is outlined in Algorithm 1.
In line 1, the algorithm is executed for each SFC request (F) in order to derive the optimal deployment paths for the SFC requests. In the second line, a selected path (SP) list is established for the purpose of storing the optimal deployment paths acquired for each SFC request f. In line 3, the source of SFC request f is designated as the current node, thereby establishing the starting point for the algorithm at this particular node. In line 4, the computation of available physical network resources (bandwidth, CPU, and memory) is performed based on the priority assigned to each SFC request f. Further details regarding this process can be found in Algorithms 2 and 3. The purpose of line 5 is to remove the CDC nodes and physical links that are incapable of fulfilling the SFC request f. Lines 6–8 involve the utilization of the Dijkstra algorithm to identify the closest CDC nodes that possess the necessary VNFs for the SFC request f. This identification process is based on the information contained within the VNF ordering matrix W. Once the shortest paths to the CDC nodes that offer the necessary VNFs for the SFC request f have been determined, we proceed with updating the used resources (line 9) and selected path (line 10) accordingly. In the twelfth line, the algorithm determines the shortest path from the final CDC node that supplies the last necessary VNF for SFC request f to the destination node of SFC request f. This information is then used to update the used resources in line 13 and the selected path in line 14. Line 16 returns the optimal deployment paths for the SFC request.
| Algorithm 1: FAS Algorithm |
| Input: = (,) ← Physical Network; , , |
| Output: ← Selected path for SFC request f; |
| 1: for each SFC request f do 2: = empty; 3: CN = Src (f) ← Set source of f as Current Node (CN); 4: Free Resources = Calculate_Free_Resources (Flow f) ← (bandwidth, CPU and memory); 5: Prune (, ← Pruning the CDC nodes and the links, which cannot be used to serve SFC request f; 6: for each VNF x in do 7: Find Nearest CDC Providing x (CN, x) ← Dijkstra; 8: CN = next CDC; 9: Update Used Resources; 10: Update SP; 11: end for 12: Find shortest path from CDC to the Des (flow) ← Dijkstra; 13: Update Used Resources; 14: Update SP; 15: end for 16: return SP; |
Algorithm 2 computes the available physical network resources based on the priority assigned to each SFC request. In the second line of the algorithm, the reduction in used resources (as determined by Algorithm 3) is achieved by subtracting them from 90 percent (based on the initial value of μ, which is 0.9) of the total network capacity, encompassing the bandwidth, CPU, and memory. If the SFC request f possesses high priority, it is permitted to utilize a designated portion of 10 percent of the physical network capacity, as indicated in lines 3–4. If low-priority SFC requests exceed 90 percent of the physical network resources, line 6 sets the free resources value to zero. Line 8 of the algorithm retrieves the free resources.
Algorithm 3 updates the used resources for a given SFC request f based on the priority of the SFC request f. Initially, the algorithm verifies the selected path of SFC request f in lines 1–2. In line 3, if the SFC request f has a high priority, then the algorithm allocates the reserved 10 percent of the network capacity for path deployment. In the event that the allocated 10 percent of the network capacity is insufficient for path deployment, the remaining 90 percent of the network capacity is utilized (line 6). In line 9, if the SFC request f has low priority, the algorithm decreases the required physical network resources only from the 90 percent of the total network capacity. The twelfth line of the algorithm retrieves the utilized resources for the deployment of the SFC request f. By utilizing Algorithms 1–3, we are able to achieve nearly optimal outcomes for our proposed application-aware SFC embedding problem, taking into consideration the priority of each SFC request within a reasonable timeframe.
| Algorithm 2: Calculate_Free_Resources |
| Input: Flow f, |
| Output: Free Resources (Bandwidth, CPU and Memory); |
| 1: Calculate_Free_Resources (Flow f) 2: Free Resources= ( × Network Capacity)—Used Resources; 3: if Flow f has high-priority then 4: Free Resources= Free Resources + ((1 − ) × Network Capacity); 5: end if 6: if Free Resource < 0 then Free Resources= 0; ← Since (1 − )% is reserved for high priority, the Free Resources value for low-priority can become negative. 7: end if 8: return Free Resources; |
| Algorithm 3: Update Used Resources |
| Input: Route, Flow f, |
| Output: Used Resources (Bandwidth, CPU and Memory); |
| 1: Used Reources (Route, Flow f) 2: for each (node m → node n) in Route do 3: if Flow f has high-priority then 4: reduce Required Resources from ((1 − ) × Network Capacity); 5: if ((1 − ) × Network Capacity) < Required Resources 6: then reduce the remaining from ( × Network Capacity); 7: end if 8: else 9: reduce the Required Resources from ( × Network Capacity); 10: end if 11: end for 12: return Used Resources; |
The mathematical computational complexity of our proposed FAS algorithm is as follows. The order of line 1 in Algorithm 1 is O(F), while it is O() for lines 4 and 5 and O(X) for line 6. The order of line 7, which is the Dijkstra algorithm, is O(N × logN + |E|). The order of line 9 is O(N). Therefore, the total computational complexity of the FAS algorithm is in the order of O(F × N × ((N × logN + |E|) + N)) ≈ O(F × × logN + F × N ×|E|).
5.2. Nearest-Service Function-First (NSF) Algorithm
The algorithm proposed by Tajiki et al. [16], known as the nearest service function-First (NSF) algorithm, is employed as a benchmark for comparison. The pseudocode for the NSF algorithm is presented in Algorithm 4. The methodology employed by the researchers involves utilizing a practical approach to identify the nearest server capable of supporting the VNFs within the flow f, in order to provide the desired service. It is worth noting that the NSF method does NOT incorporate prioritization or physical resource allocation in its determination of the most efficient deployment routes. It treats SFC requests in an equal manner. The pseudocode for the NSF algorithm is provided in Algorithm 4. According to the literature cited in reference [16], in order to ensure the effective functioning of this algorithm, it is necessary to input the following parameters. The matrix K specifies the ordering list of required VNFs for each SFC request f. It is imperative to know the starting point and ending point of every SFC request, represented by the parameters “s” and “d”, respectively. The parameter N represents the number of servers within the physical network. The algorithmic iteration in line 1 is performed for each SFC request (F) in order to identify the most efficient deployment paths for SFC requests. The second line of the algorithm generates a selected path (SP) list storing the optimal deployment pathways for each SFC request f. The declaration of the source of the SFC request f in line 3 designates the current node as the starting point, thereby enabling the algorithm to commence its execution from this node. In lines 4–7, the Dijkstra algorithm is utilized to determine the closest server capable of delivering the necessary VNFs for the SFC request f, based on the VNF ordering matrix. Subsequently, the allocated bandwidth resources will be revised in accordance with the selected path (p), as indicated in line 8. Then, the shortest path is located from the most recently formed VNF to the destination node, and that path is added to the selected path in line 10. It is necessary to assess the resources for the total bandwidth usage to date (line 12). Line 14 will return the best possible deployment path that was chosen.
| Algorithm 4: NSF Algorithm |
| Input: K, s, d, N Output: SP ← SP is the Selected Path; 1: for each flow f in F do 2: = empty; 3: CN = s ← CN is the current node; 4: for each VNF k in K do 5: [v, p] = Find_Nearest_Providers (CN, k, N); ← Dijkstra; 6: 7: CN = v; 8: , p); 9: end for 10: p = Shortest_Path (CN, d); ← Dijkstra; 11: 12: , p); 13: end for 14: return SP; |
5.3. Greedy Algorithm
A greedy algorithm is a type of algorithm that aims to solve a problem by iteratively selecting the locally optimal choice at each step. Several studies [13,30,31,32,33,34] have utilized the widely recognized greedy method as a comparative approach for evaluating the SFC deployment problem. While a greedy algorithm is often characterized by its simplicity and efficiency, this does not guarantee the attainment of an optimal solution in all cases. The current best result’s potential to yield the optimal overall outcome is not a matter of concern. The algorithm never undoes a previous choice, even if it was erroneous. It operates in a top-down fashion. This algorithm might not produce the best solution for all problems because it always chooses the best option locally to produce the best outcome globally [35]. In regards to the determination of the most efficient deployment pathways, the greedy algorithm does not incorporate prioritization or physical resource reservation, and it treats SFC requests with equal treatment. The pseudocode of the greedy algorithm is presented in Algorithm 5.
To enable the algorithm to be executed, it is necessary to provide the following set of input parameters. It is imperative to obtain the physical network along with its corresponding physical network resources as the primary input, = (,). Next, we need information on service function chains, including the source and destination of each SFC request, , . We also need to get the VNF ordering matrix . For every SFC request (F), line 1 does an algorithmic loop to determine the best possible deployment route. In the second line, a selected path (SP) list is created in order to maintain a record of the most efficient deployment routes for each SFC request, denoted as f. In line 3, the source of the SFC request f is declared to be the current node, allowing the algorithm to begin here. The objective of line 4 is to remove the CDC nodes and physical links that are unable to fulfill the SFC request f. The greedy algorithm is used in lines 5–7 to find the closest CDC nodes that can supply the necessary VNFs for the SFC request f. The positioning of these nodes is determined by the values contained in the VNF ordering matrix W. Once the shortest distance routes to the CDC nodes, which offer the necessary VNFs for the SFC request f, have been identified, we will proceed to modify both the used resources (line 8) and the selected path (line 9). In line 11, the algorithm determines the most efficient route from the CDC node, which hosts the final necessary VNF, to the destination of the flow. Subsequently, the used resources are updated in line 12, while the selected path is updated in line 13. Line 15 retrieves the optimal deployment paths for the SFC request.
| Algorithm 5: Greedy Algorithm |
| Input: ) ← Physical Network; Output: ← Selected Path for SFC request f; 1: for each SFC request f do 2: = empty; 3: CN = Src (f) ← Set source of f as Current Node (CN); 4: , ← Pruning the CDC nodes and the links, which cannot be used to serve SFC request f; 5: do 6: Find Nearest CDC Providing x (CN, x) ← Greedy; 7: CN = next CDC; 8: Update Used Resources; 9: Update SP; 10: end for 11: Find shortest path from CDC to the Des (flow) ← Greedy; 12: Update Used Resources; 13: Update SP; 14: end for 15: return SP; |
6. Results
We provide the simulation setup and performance assessment results for the proposed algorithms in this section. In this study, we compare the outcomes of the following four embedding algorithms: (a) our proposed OAS algorithm, which uses Equation (21) to obtain exact numerical solutions; (b) our proposed FAS algorithm, which is a heuristic approach to produce results that are close to exact numerical solutions; (c) the NSF algorithm from a related study [16]; (d) the well-known greedy algorithm, which serves as the baseline algorithm. It is important to note that both the NSF algorithm and the greedy algorithm treat all SFC requests equally and do not apply any prioritization or physical resource reservation actions exclusively to high-priority SFC requests. Python was used to execute the simulation, together with the PuLP library and CBC MILP Solver. It was carried out on a machine with 24 GB of RAM and an Intel Core i7-8550U CPU operating at 1.80 GHz to 1.99 GHz. To ensure the effectiveness of our proposed methodology, we used two different network topologies with various scales and capacities. A simulation was conducted, as discussed in Section 6.1, utilizing the Gridnet network topology consisting of 8 nodes. A larger scale network than the Gridnet network topology, the EliBackbone network topology with 19 nodes, was used to run the simulation discussed in Section 6.2.
6.1. Simulation Results Using Gridnet Network Topology
The physical network employed in this test scenario is based on the Gridnet network topology [27], comprising a total of 8 nodes and 18 links. According to the node degree, two nodes are designated as CDC nodes for hosting the VNF instances (see Figure 2). There are six different types of VNFs, which we have defined. Furthermore, each CDC node has the capacity to host a maximum of three different VNF types. The bandwidth capacity between nodes m and n (m, n ∈ Np) is considered to be in the range of 500–1000 Mbps, location-dependent. The CDC node capacities are determined by their network locations, wherein variations in storage and computing capabilities are taken into account. To this end, the memory and CPU capacity of the first CDC node were configured to be 1500 MB and 1500 MIPS, while the second CDC node was allocated 2000 MB and 2000 MIPS, respectively. As previously mentioned, it is assumed that the memory and CPU capacities of switching nodes are infinite. This assumption is based on the fact that switching nodes primarily function to forward traffic to subsequent nodes and do not necessitate significant memory and CPU capacities. The propagation delay of a link (m, n) is determined by the distances between the nodes and the medium type of Gridnet network topology, resulting in a uniform distribution ranging from 2 to 21 milliseconds. As explained before, the initial priority coefficient factor (µ) is assumed to be 0.9 to reserve 10 percent of the physical network resources exclusively for high-priority flows, since 10 percent of the total SFC requests are high priority. The impact of altering this value is also investigated in Section 6. In the context of this simulation framework, a set of 150 SFC requests is generated, with the source and destination nodes being randomly chosen. There is an assumption that 10% of the SFC requests fall within the category of high-priority SFC requests, which remains unchanged when comparing the four methods. The bandwidth (), CPU (, and memory () requirements for each SFC request f are assigned as random numbers within the range (0, 10] [36]. We establish a value of three VNF requests per SFC request, as in [37]. The acceptable upper limit for the end-to-end delay () for each SFC request falls within the range of 50 to 100 milliseconds [36]. To ensure fairness, it is imperative to employ identical simulation parameter settings when conducting a comparative analysis of the OAS, FAS, NSF, and greedy algorithms. In order to achieve this objective, we employ identical simulation configurations for all four algorithms.
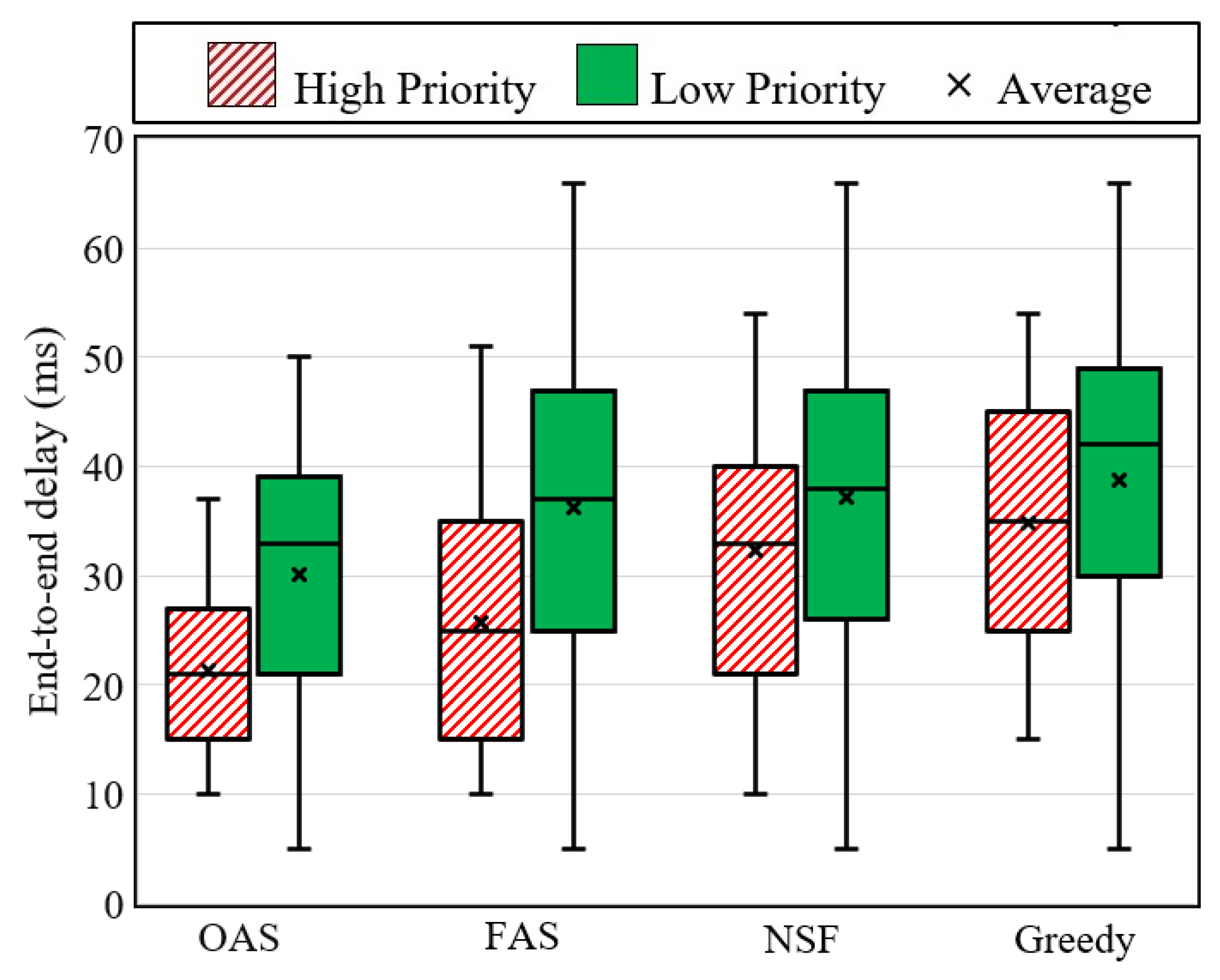
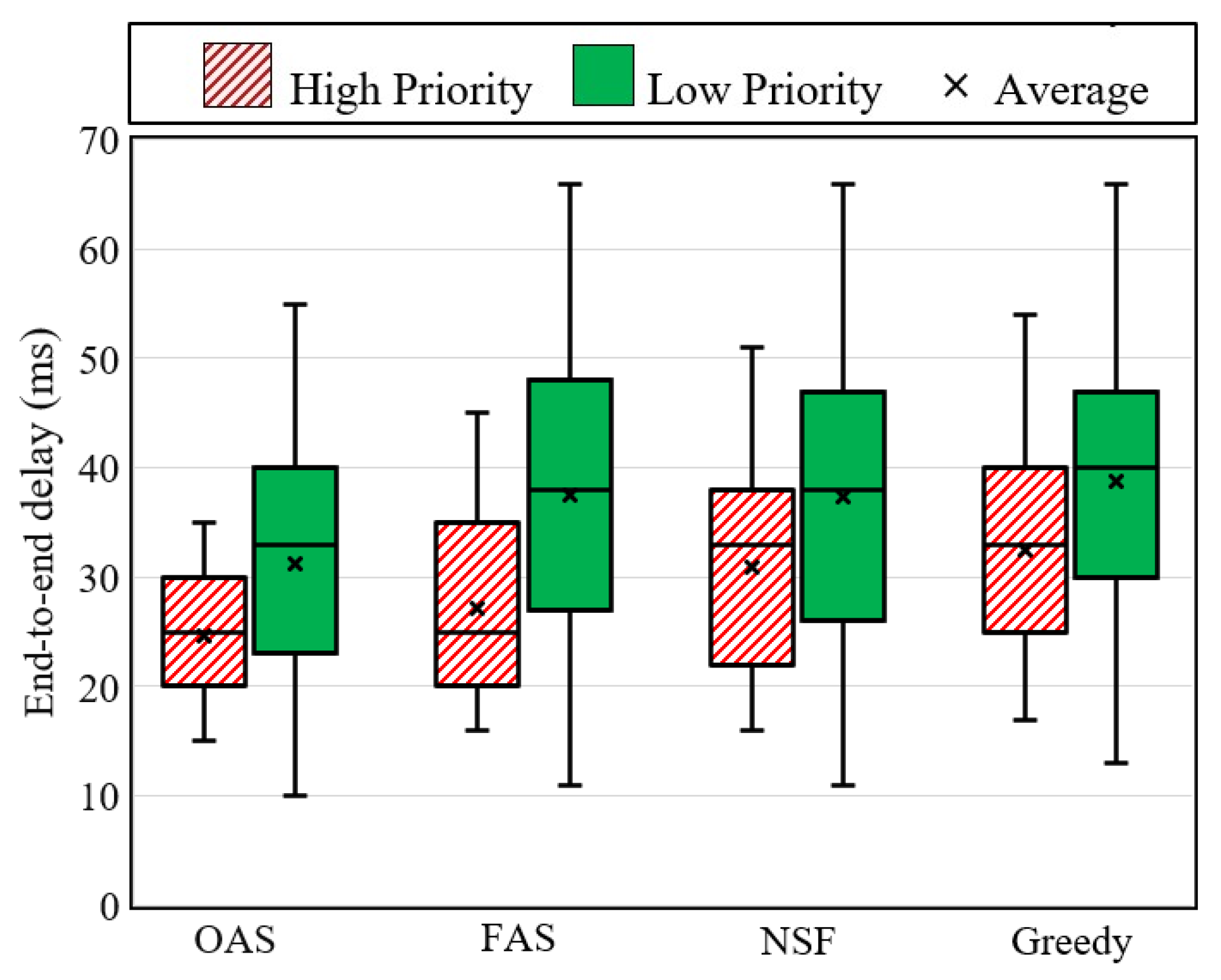
The most significant key performance indicator (KPI) in this investigation is the end-to-end delay. Figure 3 presents the end-to-end delay measurements for the OAS, FAS, NSF, and greedy algorithms. The findings clearly demonstrate that both the OAS and FAS are highly effective in enhancing the average end-to-end delay, particularly for SFC requests with high-priority, in comparison to the NSF and greedy algorithms. In more specific terms, when considering high-priority SFC requests, the OAS and FAS algorithms achieve remarkable reductions of 22 percent and 17 percent, respectively, in the average end-to-end delay in comparison to the greedy algorithm. By allowing ultra-low latency applications to utilize the reserved 10 percent of the physical network resources specifically allocated for high-priority SFC requests, the OAS and FAS algorithms enable more optimized provisioning paths. Furthermore, the results indicate that the average end-to-end delays for low-priority SFC requests remain comparable between the FAS and NSF algorithms. However, the FAS algorithm demonstrates a 2 percent reduction in average end-to-end delay compared to the greedy algorithm, whereas the OAS algorithm exhibits a significant improvement of 15 percent in average end-to-end delay when compared to the greedy algorithm. These findings highlight the significant benefits offered by the OAS and FAS algorithms in reducing end-to-end delay for high-priority SFC requests, thereby enhancing the overall efficiency and performance of ultra-low latency applications.
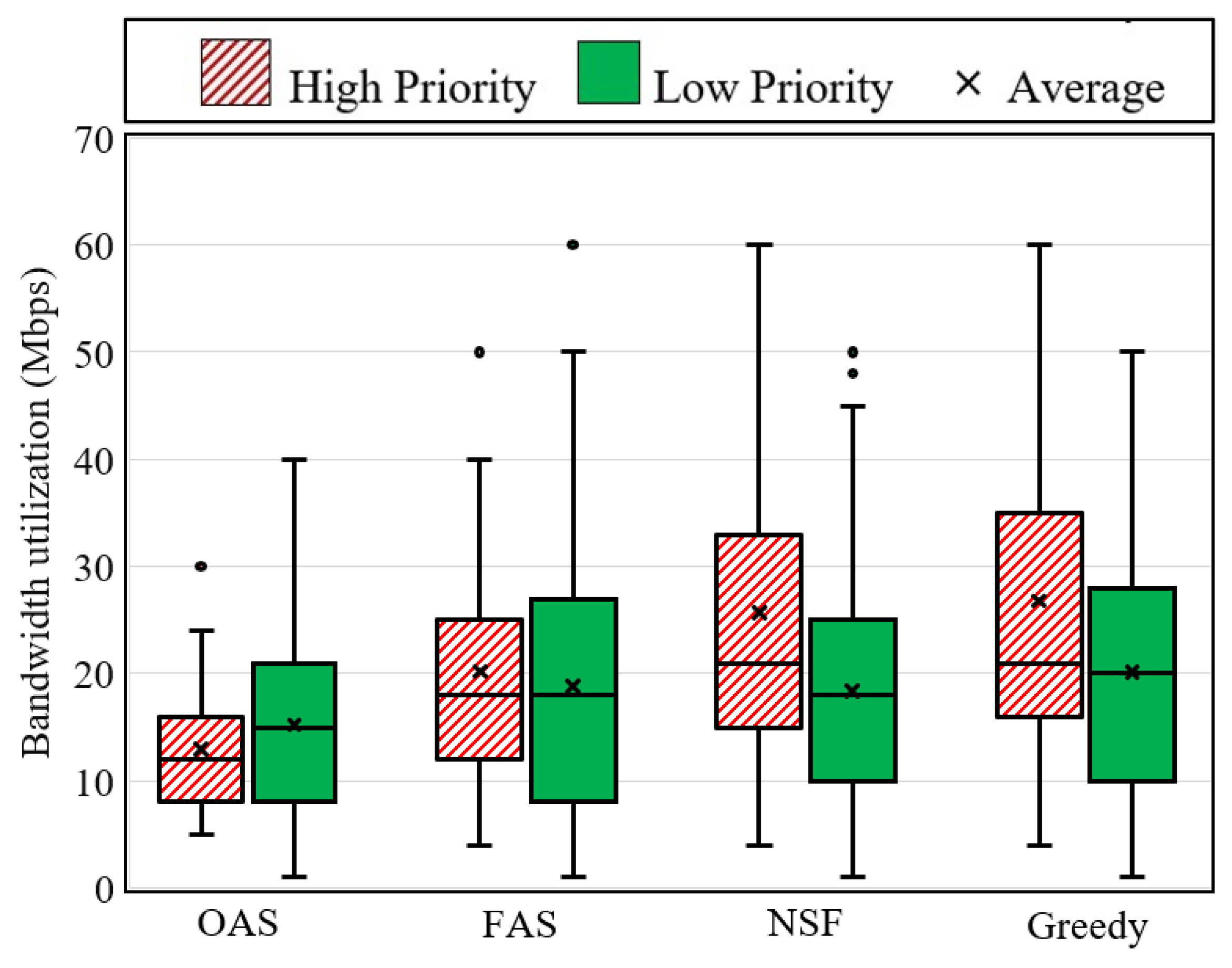
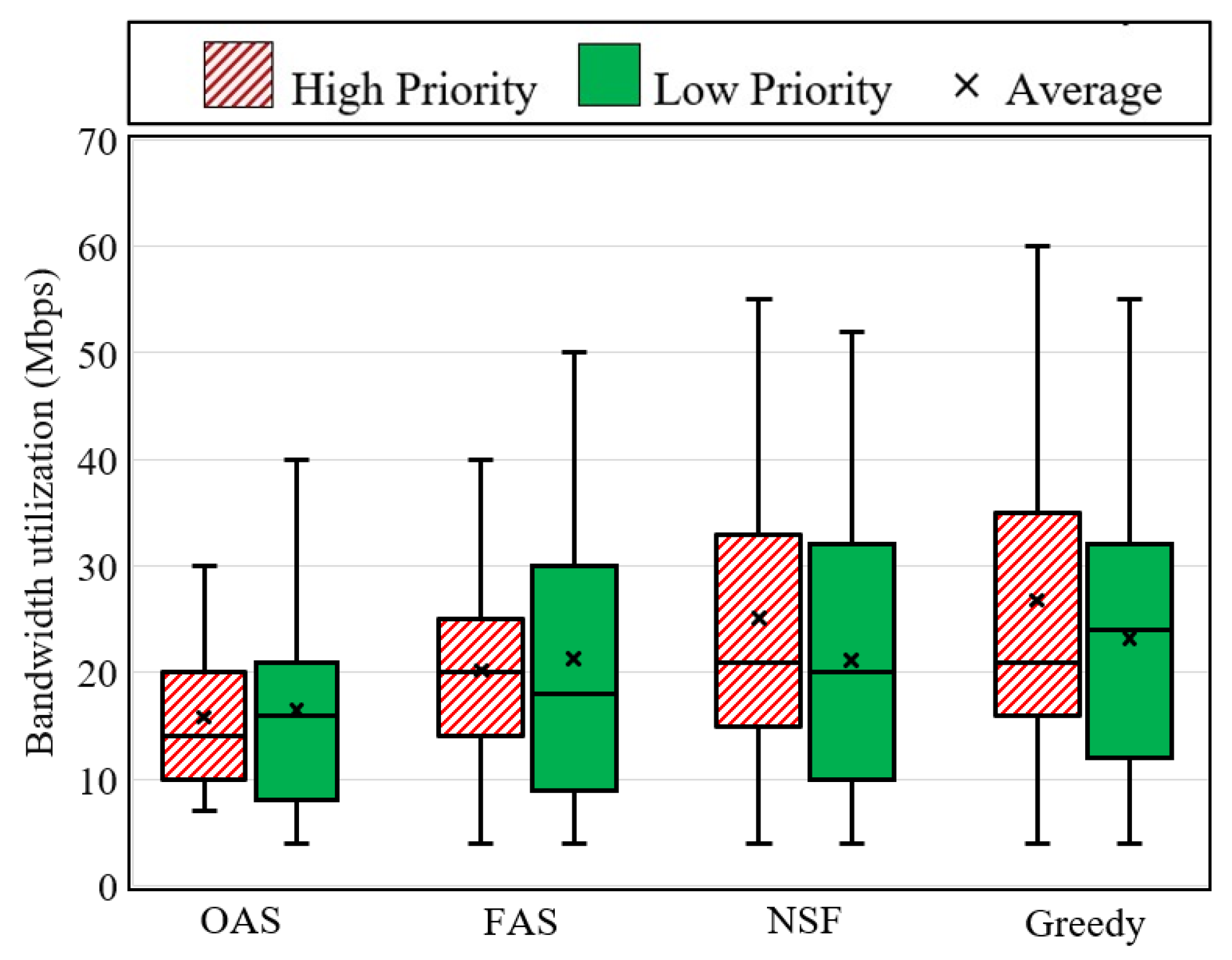
The second key KPI in this investigation is the optimal use of bandwidth resources. Figure 4 depicts the utilization of bandwidth resources in SFC provisioning paths by these four algorithms. The findings indicate that on average both the OAS and FAS algorithms exhibit lower bandwidth utilization rates (28 percent and 24 percent, respectively) compared to the greedy algorithm for high-priority SFC requests. This can be attributed to the fact that the OAS and FAS algorithms employ reserved physical resources, resulting in shorter provisioning paths for high-priority requests, whereas the greedy algorithm may yield locally optimal outcomes that fall short of global optimality. Additionally, the results reveal that on average low-priority SFC requests in the FAS algorithm consume approximately two percent more bandwidth resources compared to the NSF algorithm. This discrepancy arises due to the allocation of reserved physical resources for high-priority SFC requests, which leads to suboptimal deployment paths for low-priority requests. Furthermore, the OAS algorithm exhibits reductions in bandwidth utilization of 10 percent and 12 percent when compared to the NSF and greedy algorithms, respectively. Overall, when considering both priority levels, the OAS algorithm consumes approximately 14 percent less bandwidth resources compared to the greedy algorithm. These findings shed light on the benefits offered by the OAS and FAS algorithms in optimizing bandwidth utilization in SFC provisioning paths, leading to improved resource efficiency and allocation.
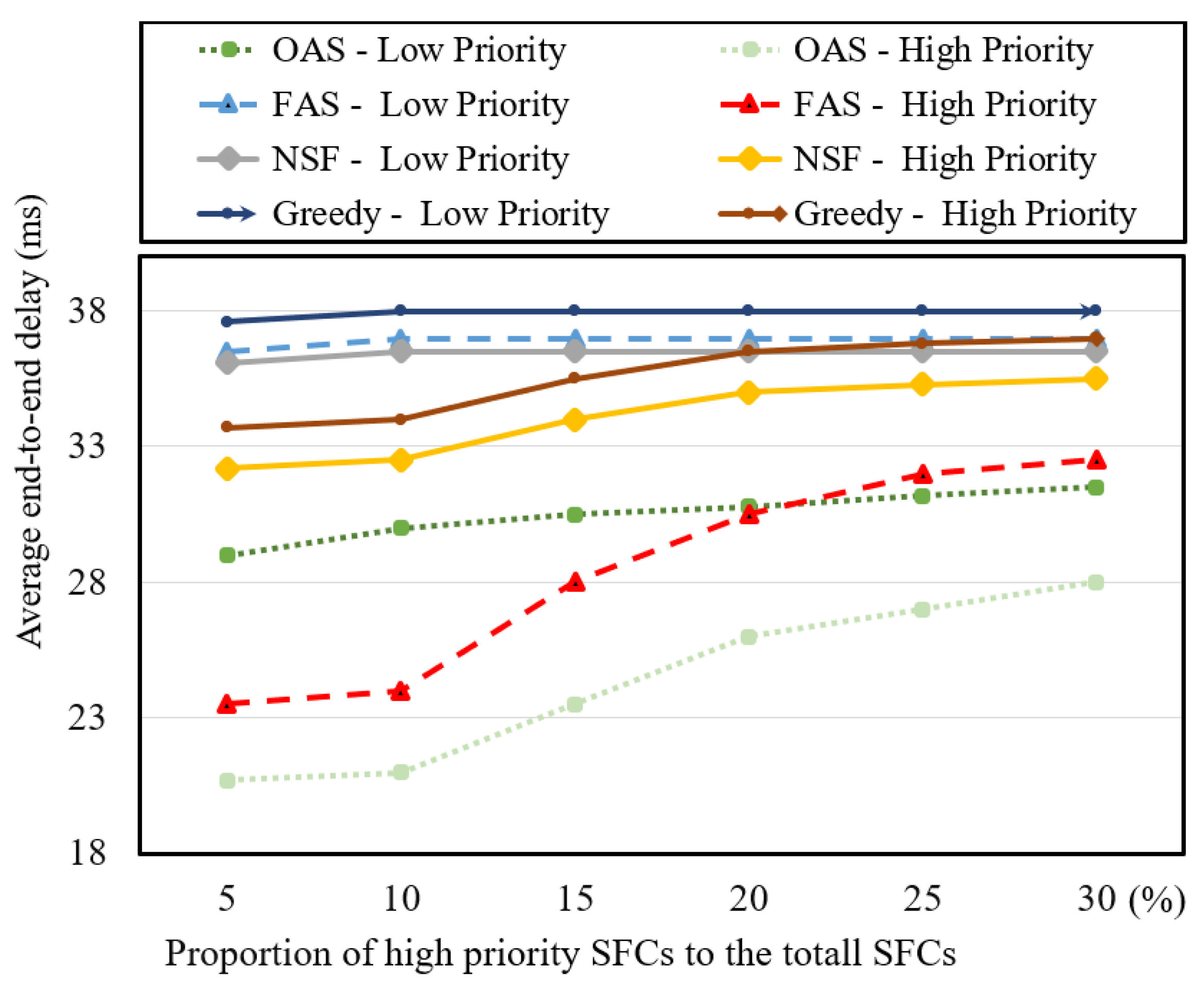
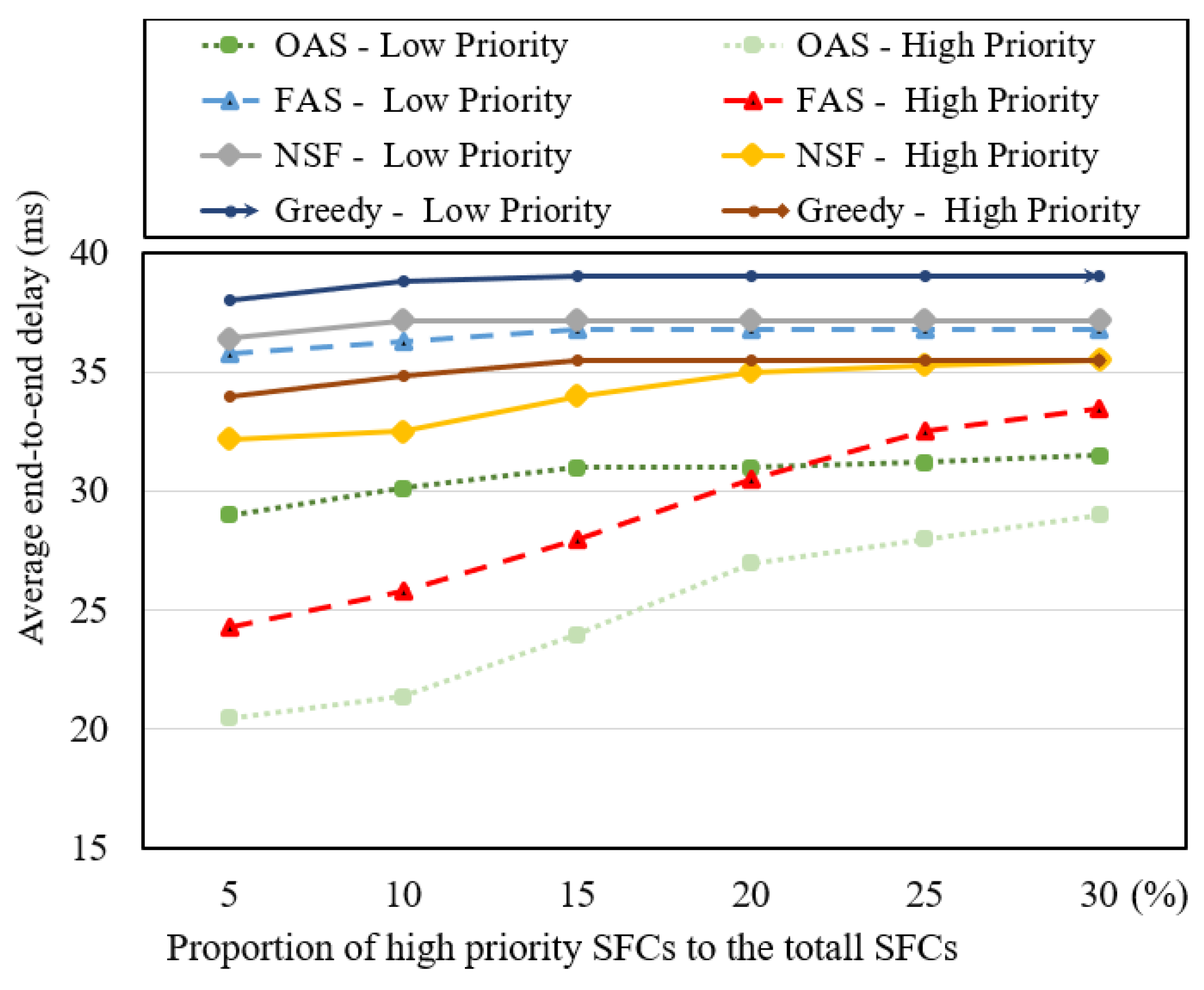
In Figure 5, we examine the average end-to-end delay times of provisioning paths while varying the proportion of high-priority SFC requests relative to the total SFC requests. The results demonstrate that as the proportion of SFC requests designated as high priority increases to up to 10 percent, the OAS and FAS algorithms achieve the lowest average end-to-end delay times compared to the NSF and greedy algorithms for high-priority SFC requests. This improvement can be attributed to the utilization of reserved physical network resources. However, beyond this point, with an increase in the proportion of high-priority SFC requests to up to 30 percent, we observe a significant rise in the average end-to-end delay for high-priority SFC requests in the OAS and FAS algorithms compared to the NSF and greedy algorithms. This occurrence arises due to the complete utilization of the 10 percent of reserved physical resources by a subset of high-priority SFC requests. Consequently, the remaining high-priority SFC requests must utilize the non-reserved physical resources, leading to suboptimal mapping and non-optimal provisioning paths.
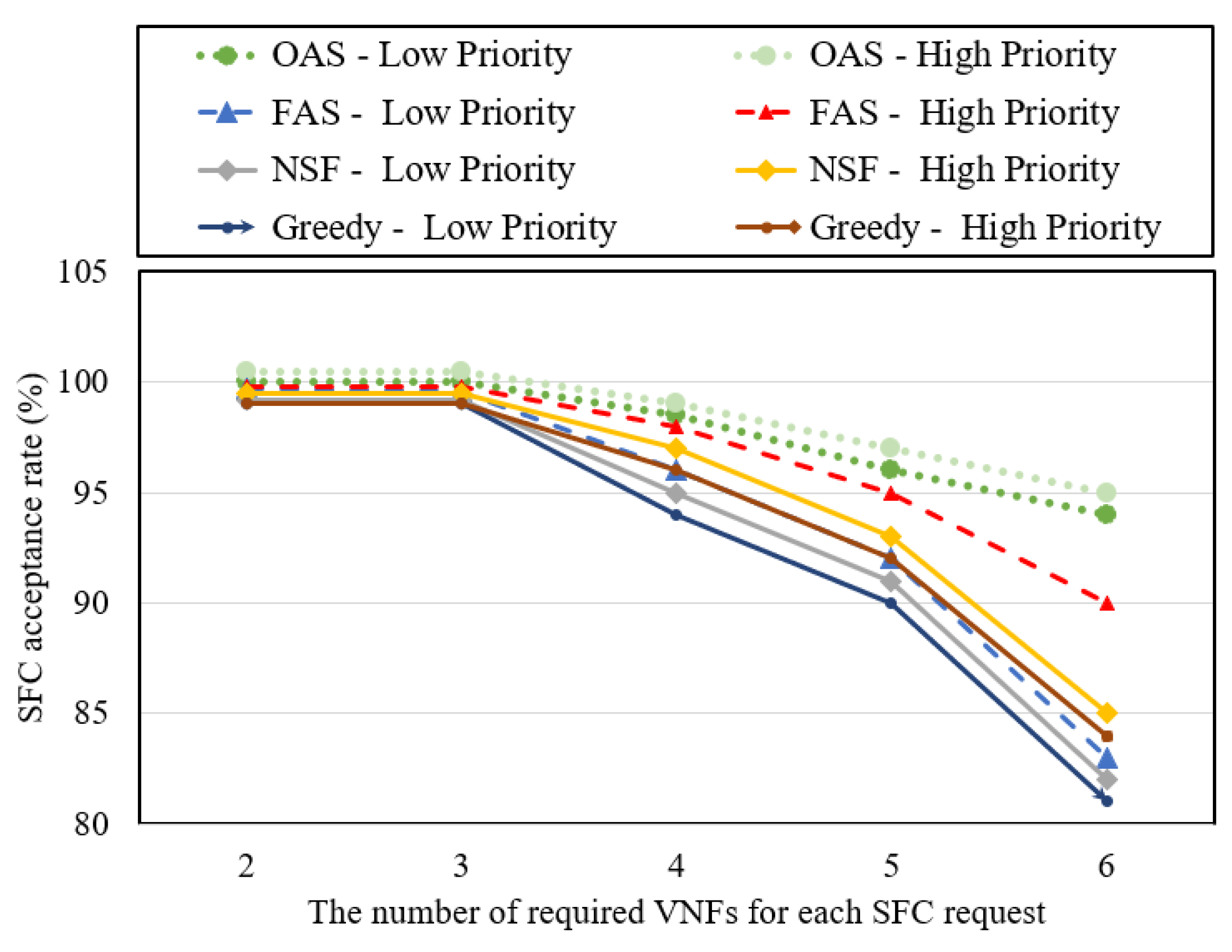
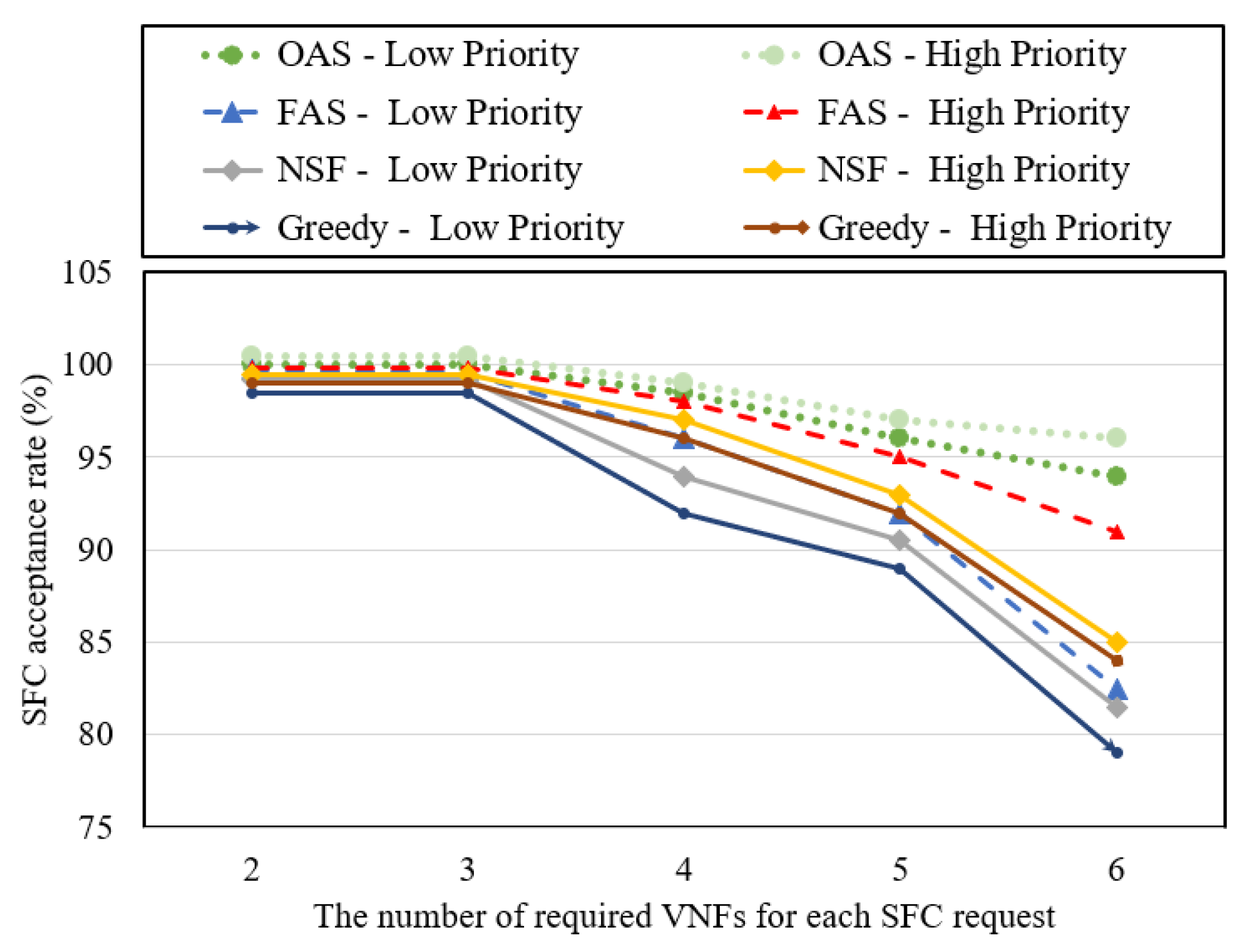
Figure 6 depicts the SFC acceptance rates attained by the aforementioned four algorithms, serving as a measure of their efficacy in mapping SFC requests. The acceptance rate of SFCs refers to the proportion of successfully mapped SFC requests in relation to the overall number of SFC requests. The obtained results reveal a decline in SFC acceptance rates as the number of required VNFs increases for each SFC request. However, it is noteworthy that the OAS and FAS algorithms, which leverage reserved physical resources, exhibit lower reductions in SFC acceptance rates for high-priority SFC requests compared to the NSF and greedy algorithms when encountering an increased number of VNFs. Specifically, when six VNFs are requested per SFC, the acceptance rates for high-priority SFC requests are as follows: OAS (95%), FAS (90%), NSF (85%), greedy (82%). This indicates that the OAS and FAS algorithms are able to mitigate the decline in SFC acceptance rates to a greater extent, emphasizing their effectiveness in handling high-priority SFC requests even with a larger number of VNFs.
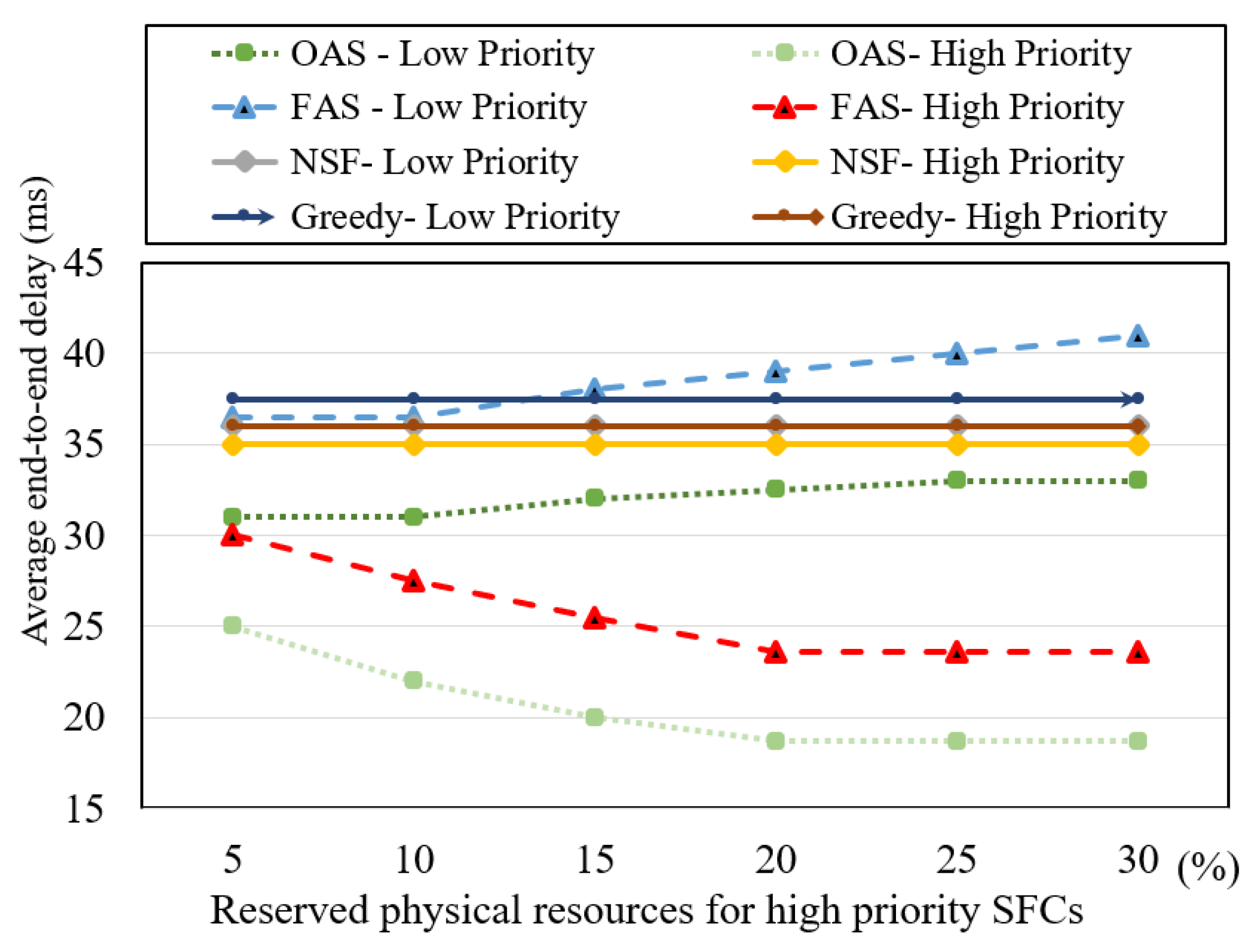
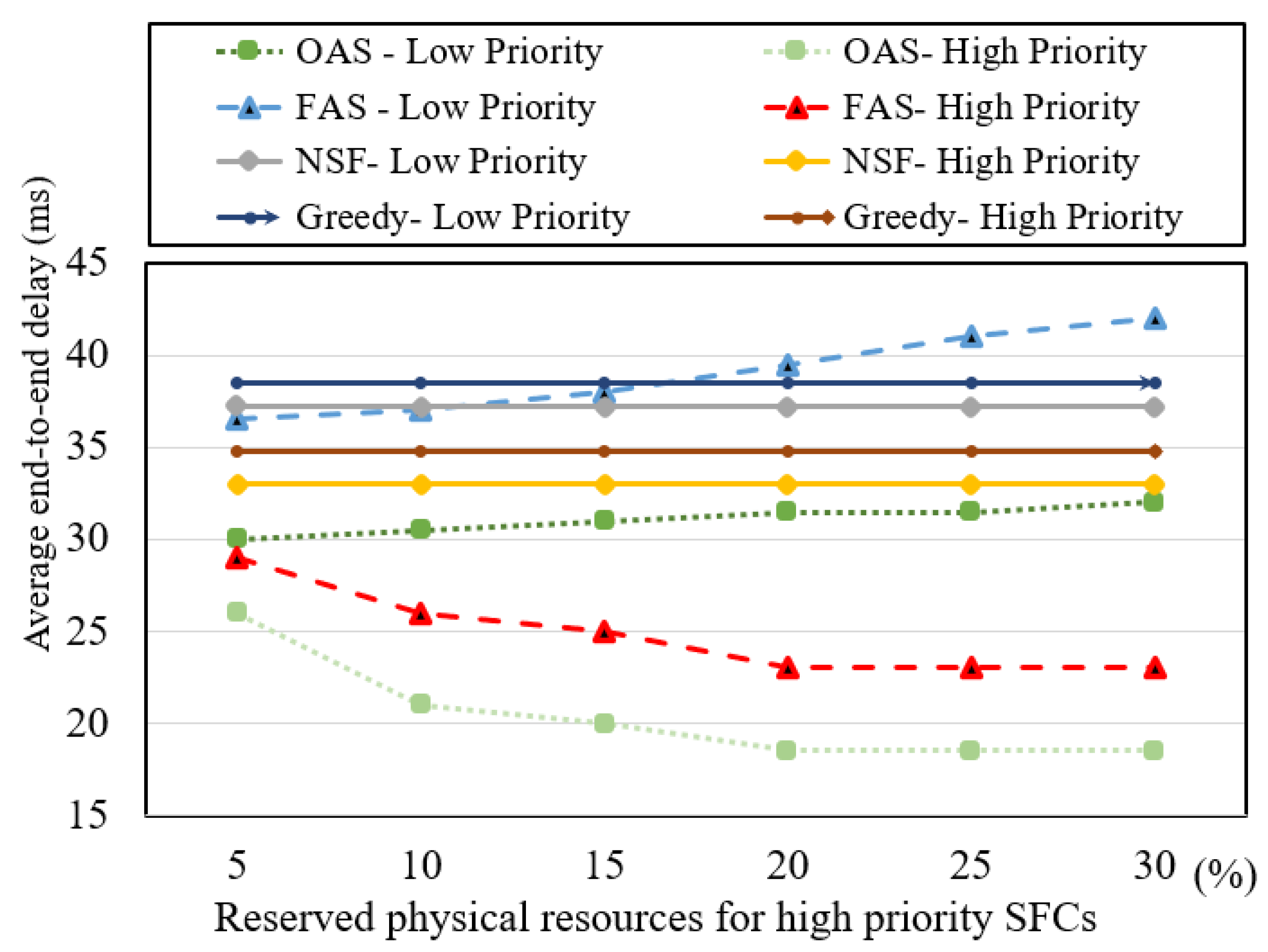
Lastly, as previously mentioned, we analyze the variation of the priority coefficient factor (µ) in our study. The initial priority coefficient factor (µ) chosen was 0.9, resulting in a 10% reservation of physical network resources specifically allocated for high-priority SFC requests. In Figure 7, we examine the average end-to-end delay of SFC provisioning paths while varying the proportion of physical network resources reserved for high-priority SFC requests, as indicated by the priority coefficient factor (µ). The results demonstrate a consistent decline in the average end-to-end delay of high-priority SFC requests for the OAS and FAS algorithms as the proportion of reserved physical resources increases, up to the 20% data point. At this point, the average end-to-end delay reaches its lowest value and remains unchanged as the reserved physical resources are further increased, up to 30 percent. This finding suggests that high-priority SFC requests in this test scenario achieve the most optimal outcomes with a 20% physical resource reservation, and additional physical resource reservations do not impact the provisioning paths.
Contrarily, as anticipated, the average end-to-end delay of low-priority SFC requests for the OAS and FAS algorithms experiences a significant increase after the 15% data point. This is attributable to the greater reservation of physical resources for high-priority SFC requests, resulting in insufficient resources for low-priority requests. Consequently, low-priority SFC requests must select longer paths due to the scarcity of physical resources. The results for the NSF and greedy algorithms remain unaffected by changes in physical resource reservations for high-priority SFC requests, as they operate independently of such reservations. These findings suggest that the incorporation of a dynamic priority coefficient factor (µ) holds the potential to optimize the overall results further. More optimal outcomes can be attained by dynamically modifying the priority coefficient factor (µ) based on the ratio of high-priority flows to total flows and changes in network load. This dynamic adjustment mechanism allows for a flexible and responsive approach, enabling the system to achieve optimal outcomes based on the prevailing conditions and priorities within the network environment. The combination of our proposed approach with existing traffic prediction methodologies, as in [38,39], offers potential for obtaining more optimal outcomes.
6.2. Simulation Results Using EliBackbone Network Topology
In this subsection, using a larger network topology, we assess the effectiveness of our suggested methods. The EliBackbone network topology [26] was selected as the substrate network, as it offers a larger network topology compared to the Gridnet network topology. Figure 8 presents the EliBackbone network topology. The network configuration comprises a total of 19 nodes and 28 links. Within this configuration, three nodes are designated as CDC nodes based on their node degree, serving as hosts for the VNF instances. Additionally, sixteen nodes are designated as switching nodes, responsible for forwarding traffic to subsequent nodes. There are six different types of VNFs, which have been defined. Each CDC node has the capability to support a maximum of three different types of VNFs. We use the following input values in the simulation environment. Depending on the location of the network, it is assumed that each link has a bandwidth capacity of between 500 and 1000 Mbps. CDC nodes are configured with different storage and CPU processing capacities, which are determined by their respective network locations. The first two CDC nodes possess memory capacities of 1500 MB and CPU capacities of 1500 MIPS each. In contrast, the third CDC node has memory and CPU capacities of 2000 MB and 2000 MIPS, respectively. Since switching nodes only transfer network traffic to succeeding nodes and do not require significant amounts of CPU and memory resources, this is what we assume about their resource requirements. We, therefore, treat their CPU and memory as having infinite capacity. The propagation delay of each link is established as a uniform distribution within a range of 2 to 21 milliseconds. This range is determined by factors such as the distances between nodes and the medium type of EliBackbone network topology. Similar to Section 6.1, we assume that the initial priority coefficient factor (µ) is set to 0.9. This implies that low-priority SFC requests are allowed to utilize a maximum of 90 percent of the physical network resources, while 10 percent of the physical network resources are exclusively reserved for embedding high-priority SFC requests. Each SFC request’s bandwidth, CPU, and memory requirements are assumed in this simulation scenario as random values in the range of (0, 10] [36]. To evaluate these four algorithms (OAS, FAS, NSF, and greedy), 200 SFC requests with random source and destination nodes are generated. Ten percent of the SFC requests are assumed to be of high priority, and we consider the first 50% of SFC requests to be of low priority. The number of VNFs requested per SFC request is established as three. The maximum acceptable end-to-end delay () for each SFC request falls within the range of 50 to 100 milliseconds [36]. In order to ensure comparability and fairness, it is imperative to utilize identical simulation parameter settings when conducting algorithm comparisons.
The end-to-end delay rates achieved by these four algorithms (OAS, FAS, NSF, and greedy) are presented in Figure 9. As can be seen, the algorithms we proposed (OAS and FAS) demonstrate significant enhancements in the end-to-end delay of high-priority SFC requests. By utilizing the exclusive allocations of physical network resources for high-priority SFC requests, both the OAS and the FAS algorithms are able to achieve more optimal deployment paths for high-priority flows. In this particular simulation configuration, it was observed that the OAS and FAS algorithms exhibited reductions of 19 and 15 percent, respectively, in the end-to-end delay of high-priority flows when compared to the greedy algorithm. In the case of low-priority flows, both the OAS and the FAS algorithms demonstrated reductions in the average end-to-end delay of 14 and 3 percent, respectively, when compared to the greedy approach. It can be concluded that our proposed methodology is a highly effective approach for facilitating ultra-low latency applications in the context of NFV.
Figure 10 presents the bandwidth usage of the deployment paths utilizing the four algorithms (OAS, FAS, NSF, and greedy). As shown, when compared to the NSF and greedy algorithms, the OAS and FAS algorithms’ physical resource reservations for high-priority flows lead to shorter deployment paths for these flows, and as a result significantly less bandwidth resource utilization for high-priority flows. The greedy algorithm produced the worst results in this simulated environment, because as discussed in Section 5.3 it may produce locally optimal outcomes that are not globally optimal, leading to longer deployment paths and higher bandwidth consumption. In more detail, it was observed that the OAS algorithm and FAS algorithm exhibited reductions of 25% and 20% in bandwidth resource consumption for high-priority SFC requests, while for low-priority flows, reductions of 14% and 3% in bandwidth resource utilization were observed in comparison to the greedy algorithm.
Figure 11 presents an analysis of the average end-to-end delay of provisioning paths while varying the proportion of high-priority SFC requests relative to the total SFC requests. The findings indicate that after the 10% data point, high-priority flows using the OAS and FAS algorithms experience a significant increase in average end-to-end delay. This is because the reserved physical network resources have been used by a number of high-priority SFC requests, and the rest of the high-priority SFC requests must use the non-reserved physical network resources, leading to non-optimal deployment paths and a significant increase in the average end-to-end delay of high-priority flows. This shows that in order to achieve the best results, there needs to be a proper correlation between the quantity of high-priority flows and the physical resources that have been set aside.
Figure 12 shows the SFC acceptance rates that these four algorithms were able to achieve. It represents the ratio of successfully deployed SFC requests to the total number of SFC requests. As presented, the OAS method has a notable acceptance rate for SFC requests of both high and low priority levels, effectively generating precise numerical outcomes. The FAS algorithm achieved a significant acceptance rate for high-priority SFC requests, thereby approaching the desired optimal result. This indicates that the efficient implementation of high-priority SFC requests by the FAS algorithm is made possible through the reservation of physical network resources. In more detail, when a total of six VNFs are requested per SFC, the acceptance rates for SFC requests with high-priority are as follows: the OAS algorithm has a rate of 97%, the FAS algorithm has a rate of 92%, the NSF algorithm has a rate of 85%, and the greedy algorithm has a rate of 83%. This means that the OAS and FAS algorithms are better able to offset the fall in SFC acceptance rates, highlighting their efficiency in managing high-priority SFC requests even with more VNFs.
Last but not least, as stated before, we examine the impact of modifying the priority coefficient factor with a larger network topology. As depicted in Figure 13, the optimization of the deployment path and consequent reduction in average end-to-end delay for high-priority SFC requests by the OAS and FAS algorithms can be achieved by increasing the allocation of reserved physical network resources. As depicted in the graph, the findings indicate a steady decrease in the average end-to-end delay of high-priority SFC requests for the OAS and FAS algorithms as the proportion of allocated physical resources grows, reaching its minimum at the 20% data point. At this point, the average end-to-end delay reaches its minimum value and remains constant while the allocated physical resources are increased, up to a threshold of 30 percent. This means that the best deployment path was reached for all high-priority SFC requests, and reserving additional physical resources only has adverse impacts on low-priority SFC requests. As stated before, by dynamically adjusting the priority coefficient factor (µ) based on the proportion of high-priority flows to total flows and changes in network load, more optimal results can be achieved. The utilization of this dynamic adjustment mechanism facilitates adaptability and agility, empowering the system to attain optimal results by considering the current conditions and priorities inside the network environment. The integration of our suggested methodology with established traffic prediction approaches, as demonstrated in [38,39], has promising prospects for achieving more optimal results.
7. Conclusions
The main objective of this study was to address ultra-low latency communication in an NFV-enabled network. The focus of our investigation was the SFC deployment problem, which is a significant challenge in networks employing NFV with the aim of enhancing the latency and optimizing the bandwidth utilization. In this study, we have introduced a novel and efficient SFC embedding algorithm. Our algorithm aims to achieve two objectives simultaneously—minimizing the latency and optimizing the allocation of physical network resources. By employing a configurable priority coefficient factor (µ) and flow prioritization technique, we successfully improved both the latency and bandwidth consumption compared to the benchmarking algorithms from related studies. To this end, we allocated a specific amount of physical network resources, including bandwidth, CPU, and memory, for the purpose of handling SFC requests that possess a high priority, referred to as ultra-low latency applications, to optimize their provisioning paths. To mitigate potential side effects on low-priority SFC requests, we implemented limitations on the maximum tolerable end-to-end delay for both high- and low-priority SFC requests.
We mathematically formulated the SFC deployment problem as an ILP optimization model, with the aim of obtaining exact numerical solutions. Subsequently, we offered a series of heuristic methodologies and relaxed versions aimed at reducing the time required for execution while maintaining minimal deviation from optimality. This was done in order to address the issue of scalability and ensure the practical applicability of our proposed approach for large-scale network topologies. The performance evaluations provide evidence of the success of our proposed methodology in facilitating ultra-low latency applications in an NFV-enabled network. The performance investigation was carried out on two distinct network topologies of different sizes, utilizing various performance setting elements to verify the effectiveness of our proposed methodology. In contrast to existing algorithms, such as the NSF and greedy algorithms, our proposed methodology demonstrates significant improvements in various performance metrics. To be more specific, the OAS algorithm improved the end-to-end delay (up to 22%), bandwidth usage (up to 28%), and SFC acceptance rate (up to 13%) when compared to the greedy algorithm. Hence, the efficacy of our proposed methodology in facilitating ultra-low latency applications in NFV is evident. In future work, our research will be strengthened by employing a dynamically adjustable priority coefficient factor to adapt the reservation of physical network resources based on the demand for various network services. In addition, we will examine the reliability aspect of SFC requests and incorporate an efficient backup technique with minimal negative impact on the latency for ultra-reliable low-latency communication in an NFV-enabled network.
Author Contributions
Conceptualization, M.M.E.; methodology, M.M.E.; software, M.M.E. and M.M.T.; validation, M.M.E., M.M.T. and G.S.; formal analysis, M.M.E., M.M.T. and G.S.; investigation, M.M.E., M.M.T. and G.S.; resources, M.M.E.; data curation, M.M.E.; writing—original draft preparation, M.M.E.; writing—review and editing, M.M.E., M.M.T. and G.S.; visualization, M.M.E.; supervision, G.S.; project administration, M.M.E. and G.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data sources cited in the text are accessible online.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Mulligan, U. Network Functions Virtualisation (NFV). Available online: https://www.etsi.org/technologies/nfv (accessed on 15 July 2023).
- Adoga, H.U.; Pezaros, D.P. Network Function Virtualization and Service Function Chaining Frameworks: A Comprehensive Review of Requirements, Objectives, Implementations, and Open Research Challenges. Future Internet 2022, 14, 59. [Google Scholar] [CrossRef]
- Sun, J.; Zhang, Y.; Liu, F.; Wang, H.; Xu, X.; Li, Y. A Survey on the Placement of Virtual Network Functions. J. Netw. Comput. Appl. 2022, 202, 103361. [Google Scholar] [CrossRef]
- Bh, D.; Jain, R.; Samaka, M.; Erbad, A. A Survey on Service Function Chaining. J. Netw. Comput. Appl. 2016, 75, 138–155. [Google Scholar] [CrossRef]
- Demirci, S.; Sagiroglu, S. Optimal Placement of Virtual Network Functions in Software Defined Networks: A Survey. J. Netw. Comput. Appl. 2019, 147, 102424. [Google Scholar] [CrossRef]
- Zhu, M.; Gu, J.; Shen, T.; Zhang, J.; Gu, P. Delay-Aware and Resource-Efficient Service Function Chain Mapping in Inter-Datacenter Elastic Optical Networks. J. Opt. Commun. Netw. 2022, 14, 757–770. [Google Scholar] [CrossRef]
- Yu, H.; Taleb, T.; Zhang, J. Deterministic Latency/Jitter-Aware Service Function Chaining Over Beyond 5G Edge Fabric. IEEE Trans. Netw. Serv. Manag. 2022, 19, 2148–2162. [Google Scholar] [CrossRef]
- Yang, S.; Li, F.; Yahyapour, R.; Fu, X. Delay-Sensitive and Availability-Aware Virtual Network Function Scheduling for NFV. IEEE Trans. Serv. Comput. 2022, 15, 188–201. [Google Scholar] [CrossRef]
- Thiruvasagam, P.K.; Kotagi, V.J.; Murthy, C.S.R. A Reliability-Aware, Delay Guaranteed, and Resource Efficient Placement of Service Function Chains in Softwarized 5G Networks. IEEE Trans. Cloud Comput. 2022, 10, 1515–1531. [Google Scholar] [CrossRef]
- Sun, G.; Xu, Z.; Yu, H.; Chen, X.; Chang, V.; Vasilakos, A.V. Low-Latency and Resource-Efficient Service Function Chaining Orchestration in Network Function Virtualization. IEEE Internet Things J. 2020, 7, 5760–5772. [Google Scholar] [CrossRef]
- Alameddine, H.A.; Assi, C.; Kamal Tushar, M.H.; Yu, J.Y. Low-Latency Service Schedule Orchestration in NFV-Based Networks. In Proceedings of the 2019 IEEE Conference on Network Softwarization (NetSoft), Paris, France, 24–28 June 2019; pp. 378–386. [Google Scholar]
- Harutyunyan, D.; Shahriar, N.; Boutaba, R.; Riggio, R. Latency-Aware Service Function Chain Placement in 5G Mobile Networks. In Proceedings of the 2019 IEEE Conference on Network Softwarization (NetSoft), Paris, France, 24–28 June 2019; pp. 133–141. [Google Scholar]
- Sun, G.; Zhu, G.; Liao, D.; Hongfang, Y.; Du, X.; Guizani, M. Cost-Efficient Service Function Chain Orchestration for Low-Latency Applications in NFV Networks. IEEE Syst. J. 2018, 13, 3877–3888. [Google Scholar] [CrossRef]
- Sun, G.; Zhou, R.; Sun, J.; Yu, H.; Vasilakos, A.V. Energy-Efficient Provisioning for Service Function Chains to Support Delay-Sensitive Applications in Network Function Virtualization. IEEE Internet Things J. 2020, 7, 6116–6131. [Google Scholar] [CrossRef]
- Hmaity, A.; Savi, M.; Askari, L.; Musumeci, F.; Tornatore, M.; Pattavina, A. Latency- and Capacity-Aware Placement of Chained Virtual Network Functions in FMC Metro Networks. Opt. Switch. Netw. 2020, 35, 100536. [Google Scholar] [CrossRef]
- Tajiki, M.M.; Salsano, S.; Chiaraviglio, L.; Shojafar, M.; Akbari, B. Joint Energy Efficient and QoS-Aware Path Allocation and VNF Placement for Service Function Chaining. IEEE Trans. Netw. Serv. Manag. 2019, 16, 374–388. [Google Scholar] [CrossRef]
- Li, Y.; Gao, L.; Xu, S.; Ou, Q.; Yuan, X.; Qi, F.; Guo, S.; Qiu, X. Cost-and-QoS-Based NFV Service Function Chain Mapping Mechanism. In Proceedings of the NOMS 2020–2020 IEEE/IFIP Network Operations and Management Symposium, Virtual, 20–24 April 2020; pp. 1–9. [Google Scholar]
- Fountoulakis, E.; Liao, Q.; Pappas, N. An End-to-End Performance Analysis for Service Chaining in a Virtualized Network. IEEE Open J. Commun. Soc. 2020, 1, 148–163. [Google Scholar] [CrossRef]
- Han, X.; Meng, X.; Yu, Z.; Kang, Q.; Zhao, Y. A Service Function Chain Deployment Method Based on Network Flow Theory for Load Balance in Operator Networks. IEEE Access 2020, 8, 93187–93199. [Google Scholar] [CrossRef]
- Wang, M.; Cheng, B.; Li, B.; Chen, J. Service Function Chain Composition and Mapping in NFV-Enabled Networks. In Proceedings of the 2019 IEEE World Congress on Services (SERVICES), Milan, Italy, 8–13 July 2019; Volume 2642-939X, pp. 331–334. [Google Scholar]
- Pham, C.; Tran, N.H.; Ren, S.; Saad, W.; Hong, C.S. Traffic-Aware and Energy-Efficient VNF Placement for Service Chaining: Joint Sampling and Matching Approach. IEEE Trans. Serv. Comput. 2020, 13, 172–185. [Google Scholar] [CrossRef]
- Luizelli, M.C.; da Costa Cordeiro, W.L.; Buriol, L.S.; Gaspary, L.P. A Fix-and-Optimize Approach for Efficient and Large Scale Virtual Network Function Placement and Chaining. Comput. Commun. 2017, 102, 67–77. [Google Scholar] [CrossRef]
- Erbati, M.M.; Schiele, G. Application-and Reliability-Aware Service Function Chaining to Support Low-Latency Applications in an NFV-Enabled Network. In Proceedings of the 2021 IEEE Conference on Network Function Virtualization and Software Defined Networks (NFV-SDN), Heraklion, Greece, 9–11 November 2021; pp. 120–123. [Google Scholar]
- Erbati, M.M.; Tajiki, M.M.; Keshvari, F.; Schiele, G. Service Function Chaining to Support Ultra-Low Latency Communication in NFV. In Proceedings of the 2022 International Conference on Broadband Communications for Next Generation Networks and Multimedia Applications (CoBCom), Graz, Austria, 12–14 July 2022; pp. 1–8. [Google Scholar]
- Erbati, M.M.; Schiele, G. A Novel Reliable Low-Latency Service Function Chaining to Enable URLLC in NFV. In Proceedings of the 2022 IEEE Ninth International Conference on Communications and Networking (ComNet), Hammamet, Tunisia, 1–4 November 2022; pp. 1–8. [Google Scholar]
- Erbati, M.M.; Schiele, G. A Novel Dynamic Service Function Chaining to Enable Ultra-Reliable Low Latency Communication in NFV. In Proceedings of the 2023 17th International Conference on Telecommunications (Con℡), Graz, Austria, 11–13 July 2023; pp. 1–8. [Google Scholar]
- The Internet Topology Zoo. Available online: http://www.topology-zoo.org/ (accessed on 15 July 2023).
- Tajiki, M.M.; Salsano, S.; Chiaraviglio, L.; Shojafar, M.; Akbari, B. Joint Energy Efficient and QoS-Aware Path Allocation and VNF Placement for Service Function Chaining 2018. arXiv 2018, arXiv:1710.02611. [Google Scholar]
- Dumitrescu, I.; Boland, N. Algorithms for the Weight Constrained Shortest Path Problem. Int. Trans. Oper. Res. 2002, 8, 15–29. [Google Scholar] [CrossRef]
- Khoshkholghi, M.A.; Gokan Khan, M.; Alizadeh Noghani, K.; Taheri, J.; Bhamare, D.; Kassler, A.; Xiang, Z.; Deng, S.; Yang, X. Service Function Chain Placement for Joint Cost and Latency Optimization. Mob. Netw. Appl. 2020, 25, 2191–2205. [Google Scholar] [CrossRef]
- Wang, L.; Dolati, M.; Ghaderi, M. CHANGE: Delay-Aware Service Function Chain Orchestration at the Edge. In Proceedings of the 2021 IEEE 5th International Conference on Fog and Edge Computing (ICFEC), Melbourne, Australia, 10–13 May 2021; pp. 19–28. [Google Scholar]
- Yin, X.; Cheng, B.; Wang, M.; Chen, J. Availability-Aware Service Function Chain Placement in Mobile Edge Computing. In Proceedings of the 2020 IEEE World Congress on Services (SERVICES), Beijing, China, 18–23 October 2020; pp. 69–74. [Google Scholar]
- Zhai, D.; Meng, X.; Yu, Z.; Han, X. Reliability-Aware Service Function Chain Backup Protection Method. IEEE Access 2021, 9, 14660–14676. [Google Scholar] [CrossRef]
- Zheng, S.; Ren, Z.; Cheng, W.; Zhang, H. Minimizing the Latency of Embedding Dependence-Aware SFCs into MEC Network via Graph Theory. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–6. [Google Scholar]
- Greedy Algorithms|Brilliant Math & Science Wiki. Available online: https://brilliant.org/wiki/greedy-algorithm/ (accessed on 16 July 2023).
- Pei, J.; Hong, P.; Xue, K.; Li, D. Efficiently Embedding Service Function Chains with Dynamic Virtual Network Function Placement in Geo-Distributed Cloud System. IEEE Trans. Parallel Distrib. Syst. 2019, 30, 2179–2192. [Google Scholar] [CrossRef]
- Pei, J.; Hong, P.; Xue, K.; Li, D. Resource Aware Routing for Service Function Chains in SDN and NFV-Enabled Network. IEEE Trans. Serv. Comput. 2021, 14, 985–997. [Google Scholar] [CrossRef]
- Eramo, V.; Catena, T. Application of an Innovative Convolutional/LSTM Neural Network for Computing Resource Allocation in NFV Network Architectures. IEEE Trans. Netw. Serv. Manag. 2022, 19, 2929–2943. [Google Scholar] [CrossRef]
- Eramo, V.; Lavacca, F.G.; Catena, T.; Salazar, P. Application of a Long Short Term Memory Neural Predictor with Asymmetric Loss Function for the Resource Allocation in NFV Network Architectures. Comput. Netw. 2021, 193, 108104. [Google Scholar] [CrossRef]
Figure 1.
Simplified network architecture.

Figure 2.
Gridnet network topology [27].
Figure 2.
Gridnet network topology [27].

Figure 3.
End-to-end delay rates.

Figure 4.
Bandwidth consumption rates.

Figure 5.
Average end-to-end delay rates over the proportion of high-priority SFCs to the total SFCs.
Figure 5.
Average end-to-end delay rates over the proportion of high-priority SFCs to the total SFCs.

Figure 6.
SFC acceptance rates.

Figure 7.
Average end-to-end delay rates over reserved physical resources.

Figure 8.
EliBackbone network topology [27].
Figure 8.
EliBackbone network topology [27].

Figure 9.
End-to-end delay rates.

Figure 10.
Bandwidth consumption rates.

Figure 11.
Average end-to-end delay over the proportion of high-priority SFCs to the total SFCs.

Figure 12.
SFC acceptance rates.

Figure 13.
Average end-to-end delay over reserved physical resources.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Symbols and variables.
| Symbols | Description |
|---|---|
| The physical network | |
| The set of physical nodes | |
| The set of physical links | |
| The set of switching nodes () | |
| The set of CDC nodes ) | |
| F | The total number of SFC requests (flows) |
| F′ | The total number of low-priority SFC requests (flows) |
| X | The total number of VNF types (e.g., a, b, c, d, etc.) |
| The priority of SFC requests f | |
| The priority coefficient factor for physical resource reservation ( | |
| A binary variable, whether flow f traverses the link (m, n) or not | |
| A binary variable, whether flow f uses VNF type x, which is placed at CDC node m, or not | |
| The total bandwidth capacity of link (m, n) | |
| The total CPU capacity of node m | |
| The total memory capacity of node m | |
| The source node of SFC request f | |
| The destination node of SFC request f | |
| The matrix of required VNFs by SFC request f | |
| The matrix of ordering of VNFs requested by SFC request f | |
| The required bandwidth by SFC request f | |
| The required CPU by SFC request f | |
| The required memory by SFC request f | |
| The maximum tolerated delay by SFC request f | |
| The propagation delay on link (m, n) | |
| The matrix represents the VNF types placed on each CDC node | |
| The matrix T represents the ordering-aware rerouting matrix | |
| Contains all required VNFs with a higher order (i.e., lower index) than |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Erbati, M.M.; Tajiki, M.M.; Schiele, G. Service Function Chaining to Support Ultra-Low Latency Communication in NFV. Electronics 2023, 12, 3843. https://doi.org/10.3390/electronics12183843
AMA Style
Erbati MM, Tajiki MM, Schiele G. Service Function Chaining to Support Ultra-Low Latency Communication in NFV. Electronics. 2023; 12(18):3843. https://doi.org/10.3390/electronics12183843
Chicago/Turabian StyleErbati, Mohammad Mohammadi, Mohammad Mahdi Tajiki, and Gregor Schiele. 2023. "Service Function Chaining to Support Ultra-Low Latency Communication in NFV" Electronics 12, no. 18: 3843. https://doi.org/10.3390/electronics12183843
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.