
Estimating the Individual Treatment Effect on Survival Time Based on Prior Knowledge and Counterfactual Prediction

1
Department of Automation, Beijing National Research Center for Information Science and Technology (BNRist), Tsinghua University, Beijing 100084, China
2
MOE Key Laboratory for Bioinformatics, BNRIST Bioinformatics Division, Department of Automation, Tsinghua University, Beijing 100084, China
*
Author to whom correspondence should be addressed.
Entropy 2022, 24(7), 975; https://doi.org/10.3390/e24070975
Submission received: 27 June 2022
/
Revised: 10 July 2022
/
Accepted: 12 July 2022
/
Published: 14 July 2022
(This article belongs to the Special Issue Applications of Entropy in Causality Analysis)
Abstract
:The estimation of the Individual Treatment Effect (ITE) on survival time is an important research topic in clinics-based causal inference. Various representation learning methods have been proposed to deal with its three key problems, i.e., reducing selection bias, handling censored survival data, and avoiding balancing non-confounders. However, none of them consider all three problems in a single method. In this study, by combining the Counterfactual Survival Analysis (CSA) model and Dragonnet from the literature, we first propose a CSA–Dragonnet to deal with the three problems simultaneously. Moreover, we found that conclusions from traditional Randomized Controlled Trials (RCTs) or Retrospective Cohort Studies (RCSs) can offer valuable bound information to the counterfactual learning of ITE, which has never been used by existing ITE estimation methods. Hence, we further propose a CSA–Dragonnet with Embedded Prior Knowledge (CDNEPK) by formulating a unified expression of the prior knowledge given by RCTs or RCSs, inserting counterfactual prediction nets into CSA–Dragonnet and defining loss items based on the bounds for the ITE extracted from prior knowledge. Semi-synthetic data experiments showed that CDNEPK has superior performance. Real-world experiments indicated that CDNEPK can offer meaningful treatment advice.
1. Introduction
In this paper, problems related to the estimation of the Individual Treatment Effect (ITE) on survival time will be discussed. Estimating treatment effects from observational data is an important research topic of causal inference [1]. With the development of personalized healthcare, there has been increasing concern about estimating the Individual Treatment Effect on survival time, which indicates how much an individual could benefit from a pair of treatments in the sense of prolonging survival time [1], and therefore can help a doctor or a patient determine which treatment to select.
To introduce the related concepts and existing works more clearly and concisely, we need to give some notations in this section. Suppose there are patients. For each individual patient with baseline composed of some covariates (e.g., basic information, laboratory tests, and image tests, etc.), let and represent the potential outcomes of a pair of treatments . Since a patient can only receive one actual treatment of the two potential outcomes, the one which cannot be observed is referred to as counterfactual [2]. The Individual Treatment Effect of relative to is defined by [1,2], which is also counterfactual because one of and must be counterfactual. This makes it impossible to learn a model for , i.e., based on historical data, which is useful for predicting the ITE for a new patient before the selecting of treatments.
Representation learning methods [1,3,4,5] are a kind of important method to deal with the counterfactual problem, which divides the historical data of all the patients into two parts, i.e., and for patients who have received treatment and, respectively, with representing the actual treatment patient has received and and representing the observed survival time and the baseline of patient , respectively. Then, in representation learning methods, instead of learning , which encounters the counterfactual problem, based on historical data and based on are learned separately, and for a new patient, the ITE can be predicted by [3].
However, a challenge encountered by representation learning-based ITE estimation is the problem of selection bias caused by confounders, which are defined as the covariates in the baseline affecting both the treatment assignment and the outcome [1,2,6]. An example [3,6] can be used to illustrate the problem. Let and denote taking a drug and not taking a drug, respectively. Suppose that most of the old patients have received treatment and most of the young patients have received treatment , then in this case “age” is a confounder, which makes the data distributions of and not consistent, and therefore further leads to unreliable estimations of for old patients and for young patients.
A common idea to reduce selection bias in representation learning methods for ITE estimation is balancing the confounders. As one of the typical representation learning-based methods for the ITE estimation, the Counterfactual Regression (CFR) method proposed by Shalit et al. [3] uses a fully connected network (FCN) to map into a representation space first. Then, taking the idea of separating the learning for and as mentioned above, the CFR method uses two FCNs to predict and based on and , respectively, and finally optimizes the three FCNs by minimizing a CFR loss function defined as the weighted summation of for , for , and , where the first two items obviously measure the estimation errors for the data from and , respectively, and represents the integral probability metric (IPM) between the probability distributions of and in the representation space, whose minimization means balancing the impact of the confounders on the two distributions in the representation space. As mentioned in [1], the CFR model is also extended to some other improved models, such as those in [6,7]. Additionally, considering the unmeasured confounders, Anpeng Wu et al. propose an instrumental variable-based counterfactual regression method, which can also be regarded as an improvement to the CFR model [5].
ITE estimation methods based on representation learning (including the CFR method mentioned above) face the censoring problem when they are applied to survival time, because the output or denoting survival time in this case will become unavailable (also referred to as censored) if the follow-up of the patient has been lost or patient is still alive before the trial ends [4,8,9]. To make the methods applicable to survival data, Chapfuwa et al. proposed a Counterfactual Survival Analysis (CSA) method [4] which improves CFR by replacing the censored outputs (i.e., the survival times) with the so-called observed censoring times (please refer to the notations in Section 2.1) and revising the corresponding estimation error items in the loss function.
Although balancing the confounders helps to reduce selection bias, the above-mentioned methods cannot discriminate between confounders and non-confounders (i.e., they treat all covariates in the baseline as confounders) and therefore may balance the non-confounders which do not affect the treatment assignment . Shi et al. pointed out that this may lead to a decrease in prediction precision, and proposed the so-called Dragonnet to prevent balancing non-confounders [10]. Besides the three FCNs used in CFR, Dragonnet introduces an FCN to predict the treatment and further incorporates a cross-entropy distance between and in the loss function, whose minimization helps to reduce the influence of the non-confounders in the representation space and therefore helps to prevent them from being balanced [10]. However, unlike CFR and CSA, the Dragonnet method has the demerits of not balancing the confounders and is not applicable to censored survival data.
Besides representation learning methods, there are also other methods for estimating treatment effects on survival time based on machine learning, such as random survival forest (RSF), COX regression, and accelerate failure time (AFT) [11,12,13], etc. In spite of their effectiveness, a common limitation of these kind of methods is they do not balance the confounders, which could lead to selection bias [4].
Actually, besides the above-mentioned methods, Randomized Controlled Trials (RCTs) [14] are always gold standards for treatment effect estimation, in which patients meeting some particular inclusion criteria are selected and randomly assigned to a treatment group and control group; then, the treatment effect is evaluated by comparing the difference between the trial results of the two groups. The RCTs will not face the problem of selection bias because the random allocation of the treatment can guarantee that the baseline distributions in the treatment group and control group are identical. Similarly, there are also Retrospective Cohort Studies (RCSs) for treatment effect estimation [15], in which the data of the treatment and control group are selected from historical data based on inclusion criteria, but RCSs still have the identical baseline distributions in the two groups to avoid selection bias. However, RCTs may not be feasible in many cases, e.g., forcing non-smokers to smoke in an RCT for smoking is against ethics [16]. Even in the cases where RCSs are feasible, the strict inclusion criteria limits the generalizability of RCTs for the patients who cannot be represented by the included ones [17,18], which is also the case for RCSs. These demerits limit the application of RCTs and RCSs.
In spite of their limitations, the conclusions obtained from accomplished RCTs or RCSs can offer valuable qualitative prior knowledge to the counterfactual learning of the ITE, because although the is counterfactual and unavailable for each patient , it can be obtained from the results of RCTs or RCSs where, for patients with a significant treating effect, there is with a high probability, and for patients without a significant treating effect, there is (please refer to Section 4.1 for details). However, although there exists effective methods for treatment effect estimation which introduce prior knowledge, such as [19,20], which incorporates prior knowledge on the relationship between the baseline and treatment , to the best of our knowledge, there is still no method for treatment effect estimation which can take advantage of prior knowledge on the ITE obtained from RCTs or RCSs.
To sum up, there are four problems which need to be considered in the estimation of the ITE on survival time, i.e., (i) how to balance the confounders to reduce selection bias; (ii) how to handle the censored survival data; (iii) how to avoid balancing the non-confounders which may lead to the decrease in prediction precision; and (iv) how to take advantage of prior knowledge on the ITE obtained from RCTs or RCSs.
Considering the situation that the existing methods have proposed solutions to problems (i)–(iii) separately, that none of them take all three problems into consideration in a single method, and that there has been no solution to problem (iv), in this paper, we first propose a new model called CSA–Dragonnet based on CSA and Dragonnet to combine CSA’s solutions to problems (i) and (ii) and Dragonnet‘s solution to problem (iii), and then propose a CSA–Dragonnet with Embedded Prior Knowledge (CDNEPK) to further incorporate the prior knowledge obtained from RCTs or RCSs.
The more important contributions of this paper come from the second part, i.e., the proposing of CDNEPK, which includes: (i) finding a way to express different kinds of prior knowledge extracted from RCTs or RCSs in a unified form; (ii) embedding prior knowledge into the CDNEPK proposed in this paper by inserting counterfactual prediction nets into CSA–Dragonnet, whose output is denoted by , for or 0, and incorporating new loss items into the loss function, which takes advantage of prior knowledge to extract valuable bound information for .
The key novelty of CDNEPK compared to the existing representation learning-based ITE estimation methods lies in the counterfactual prediction introduced in CDNEPK. As explained above, to deal with the difficulty that is counterfactual, i.e., one of and is counterfactual to patient , the existing methods train based on (i.e., that dataset of patients who have actually received treatment ) and based on (i.e., that dataset of patients who have actually received treatment ) separately, both of which have the ground truth outputs (i.e., and , or their corresponding observed censoring times). While in CDNEPK, besides them, for * = 1 and 0, i.e., and are further introduced and trained, which are called the counterfactual prediction because has not actually happened and there are no ground truth data for or . However, as will be explained in Section 4.3, we can extract valuable bound information for the prediction of or from prior knowledge yielded by RCTs and RCSs, so we add the counterfactual prediction nets for and and their corresponding loss items for training to take full advantage of the valuable information offered by prior knowledge.
This paper is organized as follows. Section 2 first defines the notations and gives a brief introduction to CSA and Dragonnet. Then, based on CSA and Dragonnet, CSA–Dragonnet is proposed in Section 3 to handle the problems (i)–(iii) mentioned above simultaneously. In Section 4, we formulate a unified expression of the prior knowledge yielded by RCTs and RCSs and propose CDNEPK with incorporated counterfactual prediction branches and its corresponding loss items. Semi-synthetic data experiments are designed to test the performance of the proposed methods in Section 5. Real-world experiments based on Hepatocellular Carcinoma data covering 1459 patients in China are used to show the potential usage of CDNEPK. Finally, we draw a conclusion in Section 7.
2. Notations and Preliminary
2.1. Notations and Description of Dataset
Throughout the paper, we use the following notations:
- Let or 0 denote two treatments for comparison. For patient , let and represent the potential outcomes of treatment and , respectively; let , , and denote the observed survival time, baseline vector comprising covariates, and the actual treatment patient has received, respectively; let and denote that and are corresponding to an actual treatment (i.e., the observed survival time and the baseline of patient who has received a treatment , or ). For the case where we do not need to refer to the specific value of , we also use and for short.
- Considering the censoring problem, let denote the observed censoring time when is censored, which is defined as “the time up to which we are certain that the event has not occurred” according to [4], where the event refers to death here. To denote and in a unified way, like reference [9], let denote the observed time, which equals when it is available, and is set at when is censored. Similar to the meaning of , we use to denote the observed time of patient who has received an actual treatment . Let indicate that survival time is (is not) censored.
- Let denote the historical dataset of all patients and let represent the historical dataset for patients who have received treatments , with or , where and are the subsets of , with .
- Let denote the prediction of based on and denote the prediction of survival time based on , with or , which is also called factual prediction. While on the contrary, we use to represent a counterfactual prediction, which uses (for a patient who has received ) to predict what will happen if the contrary treatment is adopted (please see Section 4.2 for details).
- Let represent the potential outcome of (with or and call the Individual Treatment Effect of relative to [1]. In this paper, suppose we have historical datasets , , and , and some prior knowledge which can be expressed by for and for (please refer to Section 4.1 for details).
2.2. A Brief Introduction to CSA and Dragonnet
CSA [4] contains seven FCNs, i.e., , , , , , , and . Among them, with as the input is first used to map into a representation space, then and are further fed into two branches to predict and , respectively, with for patients from and for patients from , where denotes the concatenating operation and and are random input vectors. The following CSA loss is minimized in [4] to train the seven FCNs:
where and are used to measure the error between the estimated output and the observed time, which may become more controversial if the survival data is censored, and represents the distance between the distributions of and , which actually reflects the impact of selection bias in the representation space caused by the confounders.
Dragonnet [10] consists of four FCNs, i.e., , , , and . Similar to the CSA model, is still used to map into a representation space; and are used to predict the outcomes for patients from and , respectively. Unlike the CSA model, a new FCN is introduced in Dragonnet to predict the treatment by , and the loss to be minimized is defined by:
where the first two items are estimation errors of the outcomes, is the average cross-entropy distance between and over all patients which reflects the impact of the non-confounders on . So, its minimization helps to reduce the influence of the non-confounders in the representation space and prevents them from being balanced.
From (1) and (2) it can be seen that for the four problems needed to be considered in the estimation of ITE on survival time mentioned in Section 1, the CSA method gives solutions to problem (i) and (ii), i.e., how to balance the confounders to reduce selection bias and how to handle the censored survival times data, and the Dragonnet method gives a solution to problem (iii), i.e., how to avoid balancing the non-confounders which may lead to the decrease in prediction precision.
3. CSA–Dragonnet
As summarized in Section 1, for the ITE estimation, the CFR model [3] is proposed to reduce selection bias by balancing the confounders in the representation space, and the CSA method [4] is proposed by extending CFR to handle the survival data which could be censored. Since CFR does not discriminate between the confounders and the non-confounders, it also balances the non-confounders and leads to a decrease in prediction precision. Hence, Dragonnet is proposed in [10] to reduce the influence of the non-confounders in the representation space and to prevent them from being balanced. However, Dragonnet still suffers from the problems of selection bias and censoring [10]. So in this section, we propose a CSA–Dragonnet based on the CSA model [4] and Dragonnet [10] to combine their advantages.
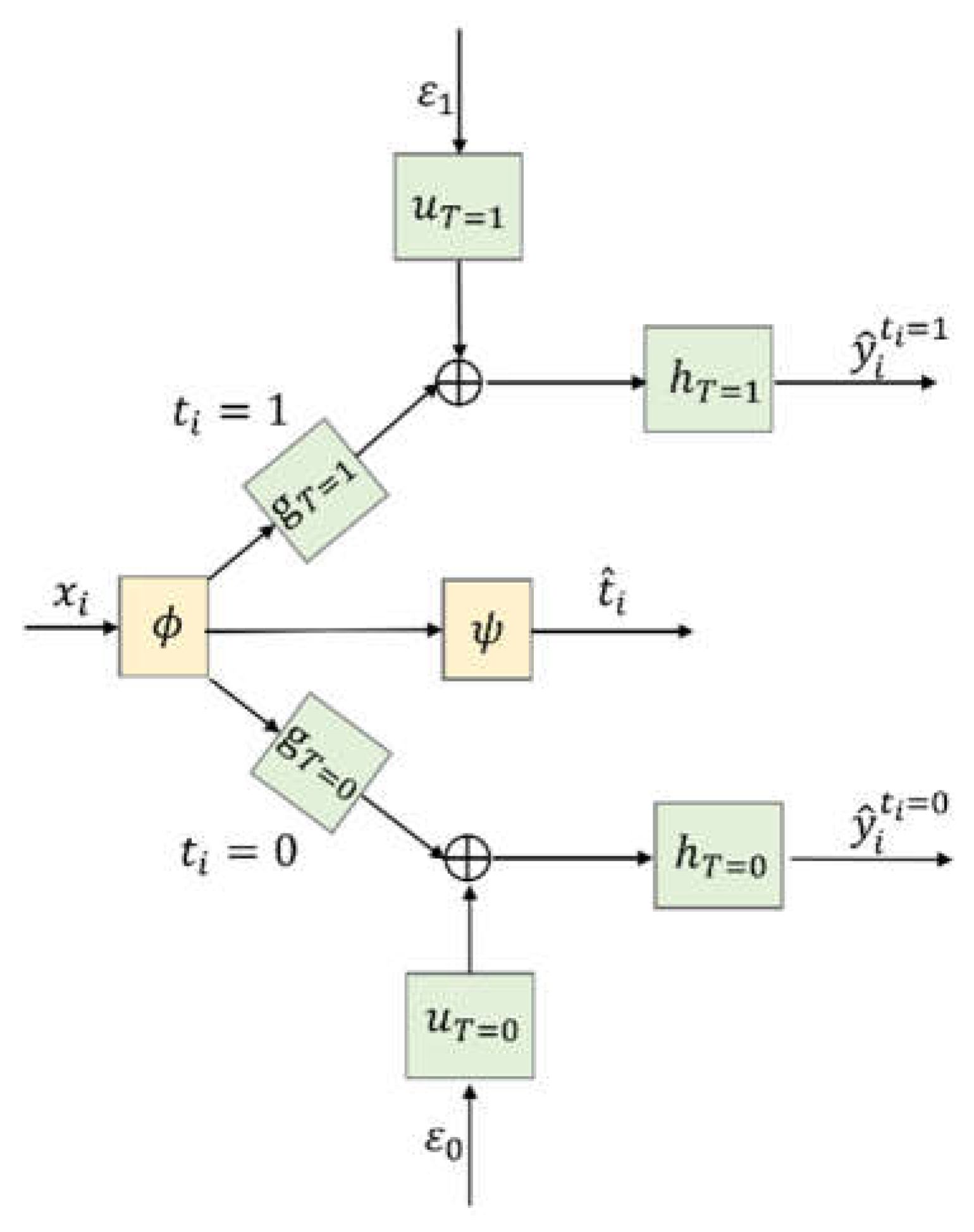
Figure 1 shows the architecture of the proposed CSA–Dragonnet. The CSA–Dragonnet consists of three parts, i.e., (i) as in the CSA [4] and Dragonnet [10] models, the baseline of all patients from is mapped onto a latent representation by an FCN (ii) as in Dragonnet [10], in order to reduce the influence of the non-confounders in the representation space, a single-layered FCN with as the input is used to predict the probability of the treatment, i.e.,; (iii) as in the CSA model [4], in order to predict and , of all the patients are divided into two parts, i.e., for patients from and for patients from , which are further fed into two groups of networks on the top and bottom branches of Figure 1, respectively. In the two branches, , , and (with * = 1 or 0) are all FCNs, and are specially designed random inputs [4], and denotes the concatenating operation rather than summation, i.e., the input of is a vector composed of and . The random inputs and are utilized to introduce some randomness model in the time generation process [4]. Please refer to reference [4] for the details of the non-parametric survival model.
In summary, the whole CSA–Dragonnet is a three-head neural network, in which the inputs include the baseline and two random sources, and the outputs include the predicted probability of the treatment as well as the predicted survival times and . Eight FCNs are involved in the network, among which and are shared networks for all patients, while ,, on the top branch are only applicable to patients with and ,, on the bottom branch are only applicable to patients with . FCNs ,, are defined by Leaky Rectified Linear Unit (Relu) activation functions; FCNs , use Hyperbolic Tangent(tanh) activation functions; FCNs , are defined by exponential activation functions; and is defined by the softmax activation function.
The loss function to train the eight FCNs in CSA–Dragonnet can be defined by combining (1) for CSA and (2) for Dragonnet as follows:
where the last item comes from (2) (i.e., the loss function of Dragonnet) and the other items come from (1) (i.e., the loss function of the CSA method). Please refer to references [21] and [22] for detailed definitions of the IPM distance and cross-entropy distance, respectively.
As explained in Section 1, (i) measures the difference between the impacts of the confounders in the representation space, so minimizing it helps to balance the confounders and reduces selection bias [3,4]; (ii) measures the impact of the non-confounders on , so its minimization helps to reduce the influence of the non-confounders in the representation space and prevents them from being balanced [10]; (iii) as for the first part, since there is and for patients with observed survival time, minimizing the summation of means encouraging to be close to the ground truth, while since and is set as the observed censoring time for patients whose survival times are censored, minimizing the summation of means encouraging to exceed the observed censoring time [4]. Hence, CSA–Dragonnet with the loss can balance the confounders, handle the censored survival data, and avoid balancing the non-confounders simultaneously.
Remark 1.
CSA–Dragonnet is a combination of CSA and Dragonnet. (i) It will reduce to the CSA model [4] if the middle branch for in Figure 1 and the cross-entropy distance in (3) are removed; (ii) CSA–Dragonnet will reduce to Dragonnet if is directly connected to and in the top and bottom branches (i.e.,,,,, and are removed), the IPM distance between the distributions of and is removed, and the first part of is replaced with , which cannot handle censored data.
4. CSA–Dragonnet with Embedded Prior Knowledge (CDNEPK)
4.1. A Unified Expression of the Prior Knowledge Yielded by RCTs and RCSs
As mentioned in Section 1, the results of RCTs or RCSs can offer valuable information about the ITE to counterfactual learning. In the following, two examples are given to illustrate it in detail.
Example 1.
McNamara et al. investigated if advanced Hepatocellular Carcinoma (HCC) patients with liver function in good condition could benefit from “sorafenib” [23] through a systematic review and meta-analysis of 30 related studies based on RCTs or RCSs, which comprised 8678 patients altogether. The conclusion was that patients with Child-Pugh grade A could benefit from “sorafenib” significantly, while the effect of “sorafenib” on patients with Child-Pugh grade B is still controversial [23].
The Child-Pugh (CP) grades mentioned in the conclusion are widely used to describe the liver functional status of a patient [23]. It is determined by a CP score defined as the summation of the scores of five covariates in the baseline listed in Table 1, i.e., the covariate scores of hepatic encephalopathy (HE), ascites (AC), total bilirubin (TBIL), albumin (ALB), and prothrombin time (PT), which are further assigned according to the conditions given in Table 1 [24,25]. More concretely, each row of Table 1 gives the rules for how to assign a score to a corresponding covariate listed in the first column. In addition, a CP score of five or six is also banded into the CP grade A, and a CP score of seven, eight, or nine is banded into the CP grade B [24,25].
Example 2.
Wang et al. investigated whether patients with small HCC could benefit from a hepatectomy through a retrospective control study [26]. A total of 143 patients with HCC were involved in the trial, all of whom satisfied the inclusion criterion of “with single tumor lower than 2 cm, no distant metastasis (DM), no vascular invasion (VI), and no ascites (AC)”. Comparisons between the results of the hepatectomy and control groups showed that the hepatectomy could not significantly extend survival time for patients satisfying the inclusion criterion.
Let denote the potential survival time of patient receiving “sorafenib” (not receiving “sorafenib”), the conclusions in Example 1 actually tell us that if a patient i belongs to the CP grade A, then there is with a high certainty even if the patient was not involved in the meta-analysis conducted by [23]. This prior knowledge offers valuable information on the counterfactual ITE to the patients involved in a representation learning. Similarly, let represent the potential survival time of patient receiving a hepatectomy (not receiving a hepatectomy), we know from Example 2 that if patient meets the condition of “with single tumor lower than 2 cm, no distant metastasis (DM), no vascular invasion (VI), and no ascites”, there is with a high possibility, which is also important prior knowledge for representation learning.
It can be seen that Examples 1 and 2 describe the conditions of the knowledge in different ways. In Example 2, the original covariates in the baseline are directly evaluated in the inclusion criterion, which is common in RCTs or RCSs, while in Example 1, the CP score derived from the original covariates in the baseline is evaluated in the condition. This is also a way of representativeness to express the conditions of the patients, because besides the CP score adopted in Example 1, there are also many other different kinds of scores to measure the initial conditions of the patients related to various diseases, which may influence the further treatment effects, such as the influence of the lung allocation score [27] on lung transplantation [28] and the influence of the renal score [29] on renal cryoablation [30], etc.
In the following, we define a set to denote the group of patients satisfying the two typical kinds of conditions mentioned above in a unified way, i.e.,
where denotes the th element of and (*) is an indicative function which equals 1(0) when the inequality in the brackets holds (does not hold). The number of indicative functions (i.e., ), the weighting coefficients for and , the thresholds , for and , and the set should be determined by the specific conditions of the corresponding knowledge.
Formula (4) can cover both of the two examples given previously. If we let , , , , it is obvious that the group of patients with the CP grade A mentioned in Example 1 can be described by:
where the coefficients and for and l = 1, 2, and 3 can be assigned according to Table 1. For example, it is direct that there are , ; ; =, and . As for Example 2, the group of patients satisfying the inclusion criterion of “with single tumor lower than 2 cm, no distant metastasis (DM), no vascular invasion (VI), and no ascites (AC)” can be directly written as:
where denotes the th element of for .
So, the knowledge obtained in Examples 1 and 2 can be written as , if and , if . Now consider a general situation: suppose we can obtain , if for , and , if for , then let:
where represents the union. The prior knowledge can be finally written as
4.2. Importance of Counterfactual Prediction
As shown in Figure 1, during the training process, when predicting for patient who has really received treatment , CSA–Dragonnet feeds the representation into either the top branch or the bottom branch according to the actual value of , i.e., is only fed into the branch consisting of , , and because the observed time is available for that branch can serve as the ground truth label (when is not censored) or at least as a bound for (when the true survival time is censored) according to the loss (3).
As defined in Notation (4) in Section 2.1, if is fed into another branch composed of , , and , the output is denoted by and is called the counterfactual prediction because the treatment has not happened to patient . The reason why is not calculated in the existing representation methods is that is counterfactual and therefore there is no ground truth information for training the model in that situation.
Now let us discuss what benefit the prior knowledge from formula (8) will bring to the ITE estimation. Although for each patient in the historical dataset, of the two potential outputs and , one must have the corresponding observed time and the other one must be counterfactual, so the knowledge or obviously may offer additional information on the counterfactual potential output, which can be further used as some kind of bound for the counterfactual prediction .
So, in order to take full advantage of the prior knowledge given by RCTs or RCSs, in the following, we will first enhance the CSA–Dragonnet by incorporating counterfactual prediction branches which can output and further by introducing new items into the loss function to guide the training of the counterfactual prediction outputs. We refer to the enhanced method as CSA–Dragonnet with Embedded Prior Knowledge (CDNEPK).
4.3. Architecture of CDNEPK with Incorporated Counterfactual Prediction Branches
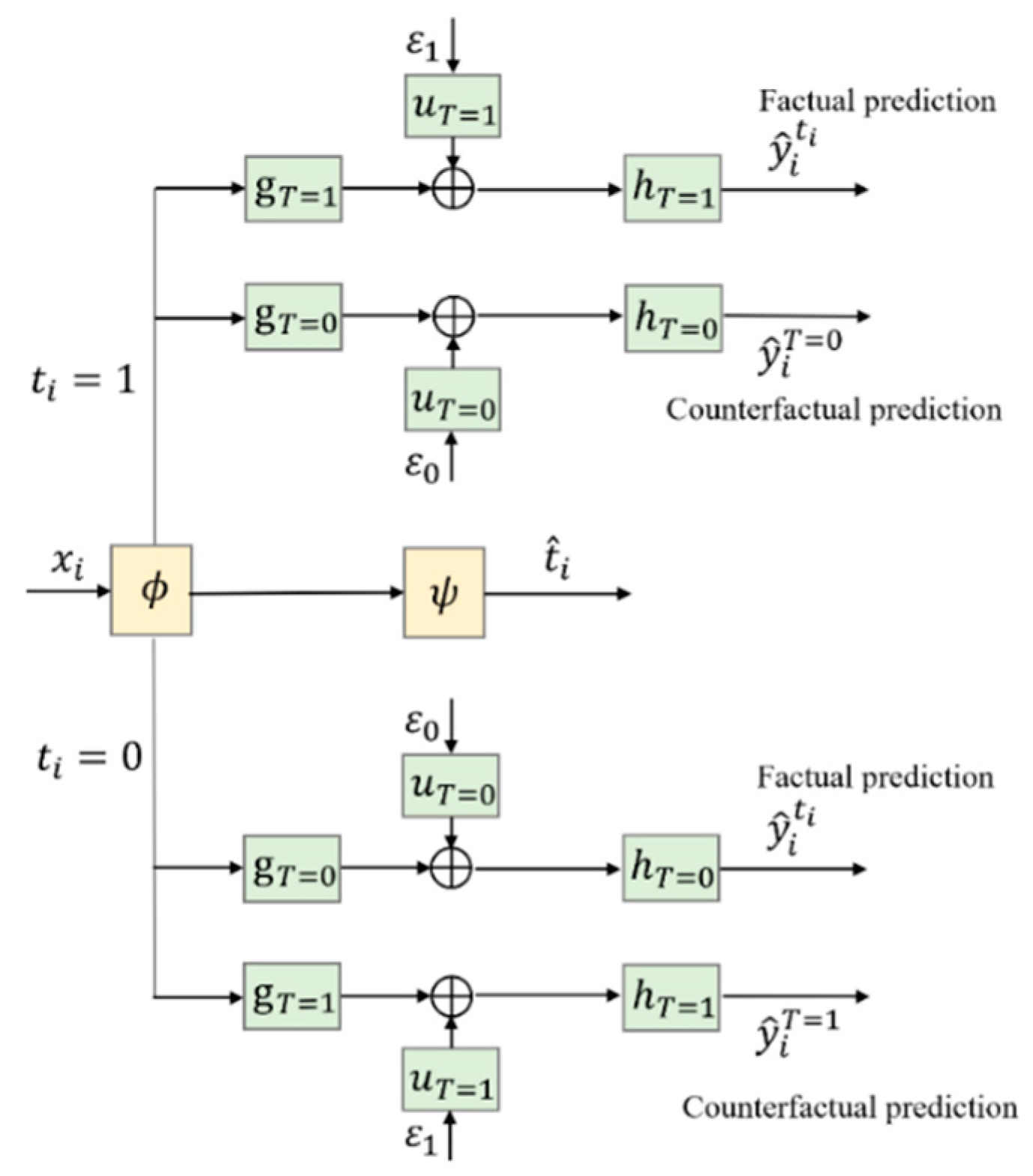
To support the counterfactual prediction, two new branches to predict for and , i.e., and , can be added to CSA–Dragonnet, as shown in Figure 2.
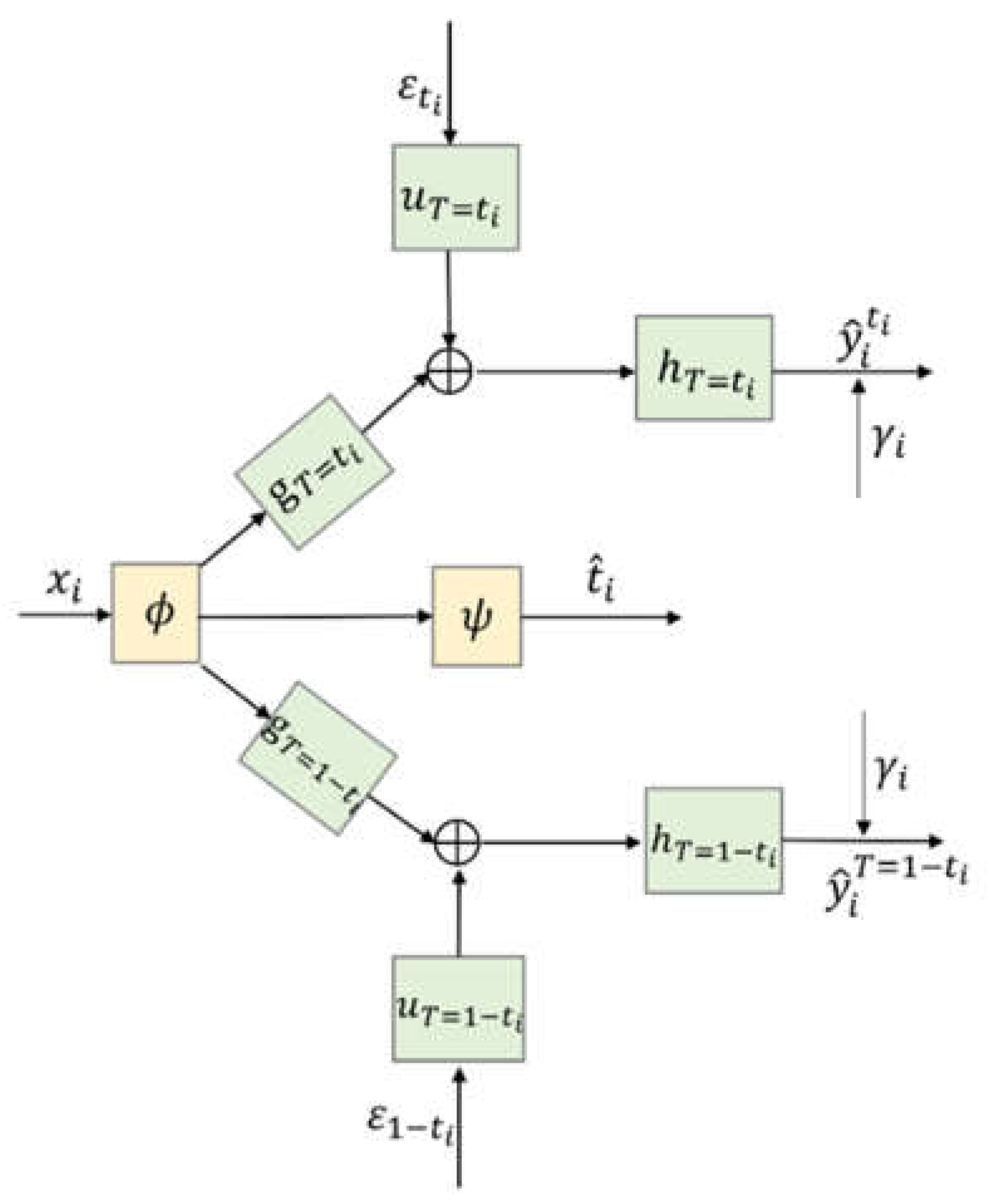
Figure 3 gives a more concise diagram for the CDNEPK, which is equivalent to Figure 2. In Figure 3, the top branch is for factual prediction, which actually combines the calculations in both the top and bottom branches of Figure 1 (or the top and 4th branches of Figure 2) into one branch. Similarly, the bottom branch of Figure 3 is for counterfactual prediction, which combines the 2nd and 5th branches of Figure 2. For convenience, for a patient who has received treatment , we call the top branch of Figure 3 (which consists of , , and the factual prediction branch, and call the bottom branch of Figure 3 (which consists of , , and the counterfactual prediction branch hereafter.
4.4. Loss Items of CDNEPK with Incorporated Prior Knowledge
As explained in Section 4.2, the prior knowledge for and for offers valuable information for the training of the bottom counterfactual prediction branch. In this section, we will discuss how to incorporate this information into the loss function according to different situations of or 0 (i.e., whether patient has actually received the treatment or not), or 1 (i.e., whether the patient’s survival time is censored or not), and or (i.e., whether patient could greatly benefit from the treatment relative to or not according to prior knowledge).
- Patients with prior knowledge ()
- (i)
- , and .
In this case, since the survival time is not censored, we know that of the two potential outputs and in the prior knowledge, has the ground truth observation, i.e., there is and is the true survival time, but is counterfactual. Then, the prior knowledge 0 for is equivalent to , which means can be used as a lower bound of the counterfactual prediction of , or in other words, there should be a constraint for predicting . Let denote the number of patients who belong to , we can define the following loss item:
whose minimization will penalize and favors the satisfaction of the constraint
- (ii)
- , and .
In this case, the survival time is censored, which means at the end of the trial the patient is still alive. So, the observed time must be less than the true survival time (i.e., there is ). Then, of the two potential outputs and ,only has a lower bound instead of the ground truth, and is still counterfactual. Since and 0 lead to > for , we still have the constraint for and therefore can define the loss term by only replacing the in (9) with considering , i.e.,
It is worth mentioning that although is used as the lower bound in both case (i) and case (ii), it is more conservative in this case than in case (i) because of > .
- (iii)
- and .
In this case, has the ground truth , i.e., , with equaling the true survival time, but is counterfactual. So, is equivalent to , which means there is a constraint for with as the upper bound. Then, the loss item can be defined by penalizing as follows:
- (iv)
- , and .
In this case, there is because the survival time is censored, and therefore has a lower bound but is counterfactual. However, it is obvious that and cannot yield any bound information for (and further for based on . So, in this case, the prior knowledge does not offer additional information for the counterfactual model training.
- 2.
- Patients with prior knowledge )
- (i)
- or , and .
In this case, the survival time can be observed, so similar to (1).(i) and (1).(iii), for or , has the ground truth , i.e.,, with equaling the true survival time, but is counterfactual. Then, the prior knowledge for is equivalent to for or . Hence, can serve as the label of the counterfactual predicted survival time , and the loss item can be defined as follows:
where denotes the number of patients who belong to and denotes the number of patients who belong to the intersection of ( or ) and .
- (ii)
- or , and .
In this case, the survival time cannot be observed, so similar to (1). (ii) and (1).(iv), there is for =1 or 0, and is counterfactual. Then, the prior knowledge for is equivalent to . Hence, we have a constraint on the counterfactual predicted survival time with as the lower bound, and we can define the loss item as:
whose minimization will penalize .
4.5. Training Algorithm for CDNEPK
The final loss item for the counterfactual prediction can be defined as the summation of (9)–(13), i.e.,
and the loss function for CDNEPK is finally defined as:
where LCSA-Dragon has been defined in (3). By now, all of the four problems mentioned in Section 1, i.e., (i) balancing the confounders, (ii) handling the censored data, (iii) avoiding balancing the non-confounders, and (iv) taking advantage of prior knowledge have been properly considered in CDNEPK.
The training algorithm of CDNEPK is summarized as the following.
Remark 2.
It is worth noting that Algorithm 1 can also be used for thetraining procedure ofCSA–Dragonnet proposed inSection 3just by replacing the loss function in line four of Algorithm 1 (i.e.,Formula (15))as the loss function of CSA–Dragonnet (i.e.,Formula (3)).
| Algorithm 1: Training algorithm of CDNEPK. |
| Input: Dataset Dall, weighting factors α,β, iteration time c1, batch number c2, batch size b, learning rate r, initial weights of network W; |
| Output: Trained CDNEPK model |
| 1: for i = 1 to c1 do |
| 2: |
| 3: |
| 4: Calculate loss function of jth batch Dj according to Formula (15): |
| 5: Update W by descending its gradient |
| 6: end for |
| 7: end for |
5. Experiments Based on Semi-Synthetic Data
5.1. Data Generating and Experiment Setup
As mentioned in Section 1, the results of RCTs or RCSs can offer valuable information about the ITE to counterfactual learning. In the following, two examples are given to illustrate it in detail.
Based on an ACTG dataset which is given by [31] and contains 2139 HIV patients who received either the treatment of “monotherapy with Zidovudine” or the treatment of “Diadanosine with combination therapy”, [4] proposes the following scheme for generating the semi-synthetic dataset [4].
where the treatment is simulated via a logistic model; and are the average values of AGE and CD40; the potential outcomes and are simulated via the Gompertz-COX model; the survival time equals its corresponding ; the censored time is assumed to follow a lognormal distribution; and the observed time is the minimum of the survival time and the censored time . indicates that survival time is (is not) censored, which is determined by comparing and in the simulation, e.g., if is longer than , is set as 1 [4]. , , , , , , , , , , , contains the parameters of the simulation scheme. The Individual Treatment Effect can be acquired by . It is worth mentioning that (16) can output both of the two potential outcomes and , which is impossible in the real world and can be used to evaluate the performance of a counterfactual learning method which treats as counterfactual and unobservable.
In this section, to generate semi-synthetic data with simulated prior knowledge, we divided all the patients’ baselines covered by the ACTG dataset [31] into four cases, i.e.,
and then by setting the parameters in of (16) properly, generated four different datasets satisfying different conditions, respectively, i.e., , , , and . The final semi-synthetic dataset was obtained by . Through properly selecting the parameters in , among the 2139 patients in , there were 417 patients belonging to or , 668 patients belonging to , and 1054 patients belonging to .
From the viewpoint of evaluating an ITE estimation method based on the dataset , although was generated by the simulation and was known, we treated as counterfactual (not observable) but assumed that there was the prior knowledge or for part of the patients, i.e., there were if and if with a high certainty, where and , and we had no prior knowledge for patients not belonging to or , among which may have randomly varied from negative to positive.
In the experiment, the dataset was randomly divided into the training set, validation set, and test set with a ratio of 70%:15%:15%. As in CSA [4], the FCNs , , , used in CDNEPK and CSA–Dragonnet were two-layer MLPs of 100 hidden units, and the FCNs , used in CDNEPK and CSA–Dragonnet were one-layer MLPs. In addition, all the hidden units in , were characterized by batch normalization and the dropout probability of 𝑝 = 0.2 on all layers. As in Dragonnet [10], the FCN used in CDNEPK and CSA–Dragonnet was a one-layer MLP. Weighting factors , in (3) were set as 1000,100, respectively, which were selected by cross-validation. The iteration time was set as 80 and the batch size was set as 850. An Adam optimizer was used with the learning rate =.
5.2. Experimental Results
We compared our proposed CDNEPK and CSA–Dragonnet with the following methods: (i) CSA [4]; (ii) the accelerate failure time (AFT) model with Weibull distributions [12]; (iii) the random survival forest (RSF) model [13]; and (iv) the COX proportional hazard model [11]. Among them, CSA was introduced in the preliminary, whose settings for the FCNs were identical to those in CDNEPK and CSA–Dragonnet in the simulation. Instead of applying balance representation like the three methods mentioned above, the AFT, RSF, and COX models took the treatment vector as a covariate directly, which led to the limited ability to handle selection bias.
In the experiments, we adopted the PEHE (precision in the estimation of a heterogeneous effect) and the absolute error of the ATE (average treatment effect), which are widely used for assessing the Individual Treatment Effect error [4], and are defined as following, respectively [4]:
It is worth noting that and can only be calculated in simulation experiments where the ground truth is available and they cannot be calculated for real-world data where is counterfactual [4].
Table 2 presents the comparison results among COX, AFT, RSF, CSA, CSA–Dragonnet, and CDNEPK. It can be seen that the COX and AFT models had poorer performance since they adopted linear models and did not consider selection bias. For RSF, although it still suffered from selection bias, its ability to process nonlinear survival data led to the lower and compared to COX and AFT.
CSA, as the baseline method of this paper, dealt with the nonlinearity and selection bias by representation learning and balancing the confounders. It had a significant enhancement compared to COX, AFT, and RSF. Compared to the basis of CSA, the proposed CSA–Dragonnet took the confounder identification into account and improved the performance on and . Furthermore, CDNEPK is proposed to cope with prior knowledge, which is superior to all other methods.
6. Real-World Experiment on Hepatocellular Carcinoma
As the third most fatal cancer for men in the world, Hepatocellular Carcinoma (HCC) has a high mortality rate for patients [32]. Although a hepatectomy is the most effective treatment for HCC, the mortality of some patients after a hepatectomy still remains high and how long a hepatectomy can prolong the survival time of HCC patients still remains controversial [33]. In this section, we utilized CDNEPK to estimate the Individual Treatment Effect for each patient.
The dataset used in this section included records of 1459 patients, which were retrospectively collected from three hospitals in China. Among the 1459 patients, 784 patients were treated with a hepatectomy and the other 675 patients were not treated with liver resection. Basic information, laboratory tests, and imaging tests were included in the patients’ records. The basic information included gender, age, and ECOG-PS score. The laboratory tests consisted of alpha-fetoprotein (AFP), blood tests (i.e., total bilirubin, alanine transaminase, aspartate aminotransferase, and alkaline phosphatase), and hepatitis tests (i.e., HBsAg, HBsAb, HBeAg, HBeAb, HBcAb, and HCVAb). The imaging tests contained tumor numbers, diameters, sites, distant metastasis, vascular invasion, and ascites. All of the above 21 clinical covariates of the baseline and whether a patient had a hepatectomy were included in our final analysis.
In Example 2 we mentioned that HCC patients with a single small tumor cannot benefit from a hepatectomy with a high probability. As for HCC patients in other cases, there are also RCTs or RCSs that focus on whether they could benefit from a hepatectomy. [34] summarizes the results as follows: (i) patients with a single tumor lower than 2 cm, no distant metastasis (DM), no vascular invasion (VI), and no ascites (AC) could not benefit from a hepatectomy significantly;(ii) patients with 2–3 tumors lower than 2 cm, no distant metastasis (DM), no vascular invasion (VI), and no ascites (AC) could not significantly extend survival time from a hepatectomy;(iii) patients with a single tumor between 5–10 cm, no distant metastasis (DM), no vascular invasion (VI), and no ascites (AC) could benefit from a hepatectomy significantly.
Similar to Example 2 of Section 4.1, the results of the RCTs and RCSs given in [34] can be expressed as the following prior knowledge. Let represent the potential survival time of patient receiving a hepatectomy (not receiving a hepatectomy), and we divide all patients’ baselines covered by the HCC dataset [31] into four cases, i.e.,
where
According to Formula (7), there is and .In addition, for patients not belonging to or , we have no prior knowledge, among which may have a wide distribution.
In the experiment, we obtained a trained CDNEPK by using Algorithm 1 of Section 4.5 based on the data of the 1459 HCC patients, in which the settings of CDNEPK were identical to those in Section 5.
A direct usage of the obtained CDNEPK is giving the predicted ITE by for a new patient who has not received treatment yet, where denotes the output of CDNEPK with as the input. This kind of prediction may help a doctor or patient choose the proper treatment. However, the reason why we did not divide the dataset of the 1459 HCC patients into a training set and a test set to show the predicted ITEs for the patients in the test set and evaluate their prediction errors is that the ITE is counterfactual for a patient in the real word data, which means the ground truth data is unavailable for any patient.
In the following, we will show another usage of the obtained CDNEPK, i.e., analyzing the importance of each covariate on the ITE. Based on the obtained CDNEPK, we first calculate for all of the 1459 patients based on their baselines, then build the relationship between the estimated ITE and the baseline by solving the following lasso regression problem:
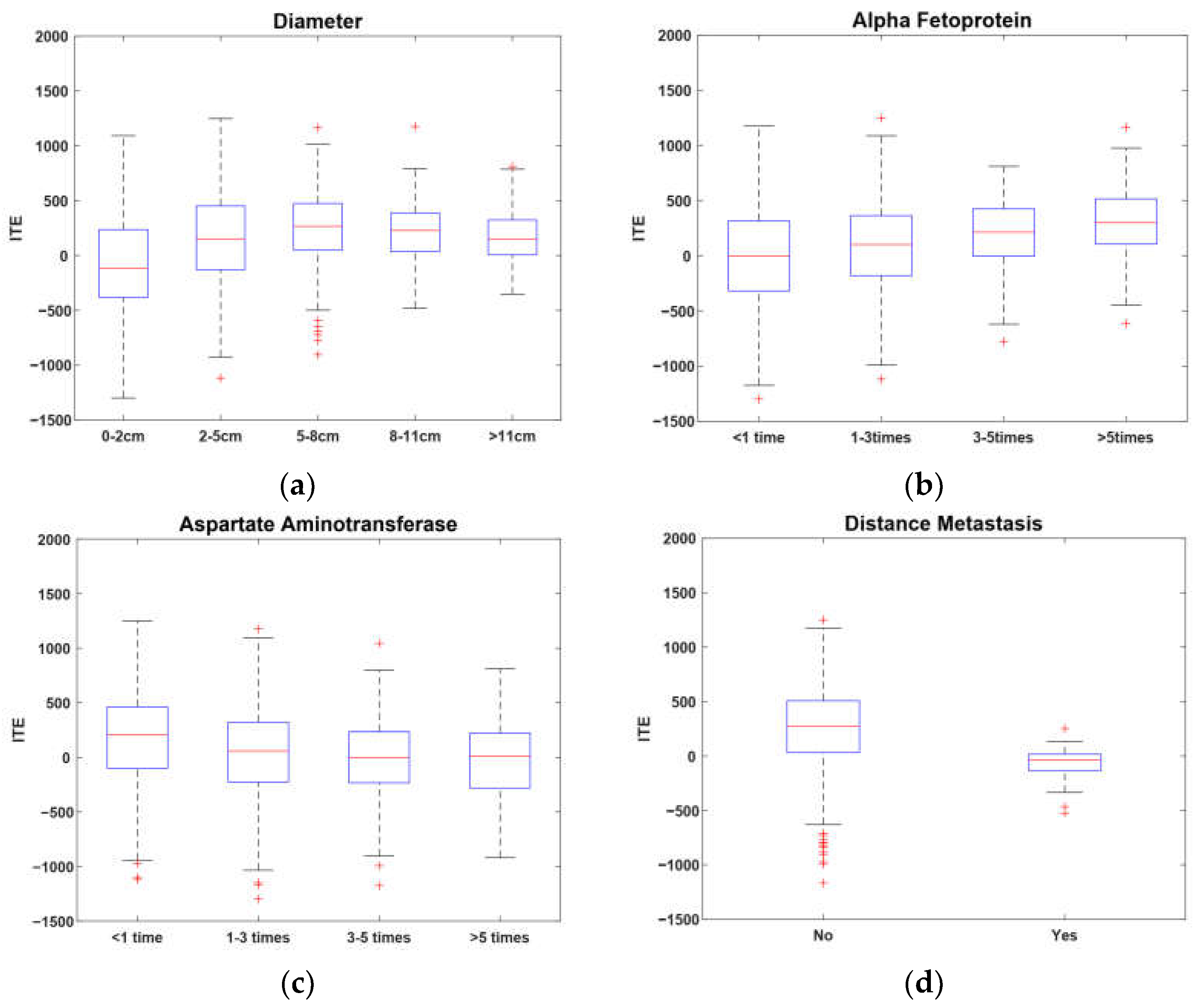
where = and are the regression coefficient vector and weighting factor, respectively. Formula (22) can be solved by the method in [20]. According to the idea of factor analysis [35], it is intuitive that the absolute values of the regression coefficients, i.e., , can reflect the contributions of the covariates of the baseline to the ITE, respectively; i.e., the greater is, the greater the contribution the th covariate has to the ITE. So, through cross-validation, we selected four covariates corresponding to the regression coefficients with the top four greatest absolute values as the key covariates which are most important to the ITE, i.e., tumor diameter, alpha fetoprotein, aspartate aminotransferase, and distant metastasis.
In Figure 4, a box-plot is used to illustrate the relationships between the ITE and the four key covariates. It is apparent from Figure 4a that the ITE increased with the increase in tumor diameter when it was less than 8 cm. In contrast, when the diameter was less than 2 cm, the median was less than zero, which indicates that patients with numbers less than 2 cm may not benefit significantly from a hepatectomy. As a whole, patients with tumors between 5–8 cm could benefit the most from a hepatectomy. Figure 4b indicates that the ITE increased with the increase in alpha fetoprotein, while Figure 4c shows that the ITE decreased with the increase in aspartate aminotransferase. It can be inferred that the benefit of a hepatectomy is positively associated with liver function. Figure 4d shows that patients without distant metastasis had higher benefit ratios than those with distant metastasis in terms of the median and upper quartile. Thus, patients without distant metastasis have a high probability of benefiting from a hepatectomy.
The above example shows that, with CDNEPK, we can utilize observational historical data and prior knowledge to estimate the individual surgical benefit for HCC patients and can further analyze the influence of covariates on the trend of surgical benefits. The results can offer HCC surgeons quantitative information and valuable assistant treatment advice, which can never be obtained by RCT or RCS studies.
7. Conclusions
In this paper, we propose CSA–Dragonnet and CDNEPK to estimate the ITE on survival time from observational data. The key novelty of our methods is that we insert counterfactual prediction nets into CSA–Dragonnet and extract valuable bound information for the counterfactual prediction from the prior knowledge yielded by RCTs and RCS to guide the training of counterfactual outputs. Experiments based on semi-synthetic data and real-world data showed that CDNEPK had the best performance compared to existing methods and that it can provide auxiliary treatment advice for surgeons.
Author Contributions
Conceptualization, Y.Z., H.Y., H.Z. and J.G.; methodology, Y.Z. and H.Y.; investigation, Y.Z.; software, Y.Z.; writing—original draft preparation, Y.Z. and H.Y.; writing—review and editing, Y.Z., H.Y., J.G. and H.Z.; project administration, H.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the National Key Research and Development Program of China under Grant 2021YFB3301200, in part by the National Natural Science Foundation of China under Grant 61933015.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Yao, L.; Chu, Z.; Li, S.; Li, Y.; Gao, J.; Zhang, A. A survey on causal inference. ACM Trans. Knowl. Discov. Data 2021, 15, 1–46. [Google Scholar] [CrossRef]
- Hernán, M.; Robins, J. Causal Inference: What If; Chapman & Hall/CRC: Boca Raton, FL, USA, 2020. [Google Scholar]
- Shalit, U.; Johansson, F.D.; Sontag, D. Estimating individual treatment effect: Generalization bounds and algorithms. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3076–3085. [Google Scholar]
- Chapfuwa, P.; Assaad, S.; Zeng, S.; Pencina, M.J.; Carin, L.; Henao, R. Enabling counterfactual survival analysis with balanced representations. In Proceedings of the Conference on Health, Inference, and Learning, Virtual Event, 8–9 April 2021; pp. 133–145. [Google Scholar]
- Wu, A.; Yuan, J.; Kuang, K.; Li, B.; Wu, R.; Zhu, Q.; Zhuang, Y.; Wu, F. Learning Decomposed Representations for Treatment Effect Estimation. IEEE Trans. Knowl. Data Eng. 2022. [Google Scholar] [CrossRef]
- Imbens, G.; Rubin, D. Causal Inference for Statistics, Social, and Biomedical Sciences: An Introduction; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- Hassanpour, N.; Greiner, R. CounterFactual Regression with Importance Sampling Weights. In Proceedings of the IJCAI, Macao, China, 10–16 August 2019; pp. 5880–5887. [Google Scholar]
- Prinja, S.; Gupta, N.; Verma, R. Censoring in clinical trials: Review of survival analysis techniques. Indian J. Community Med. Off. Publ. Indian Assoc. Prev. Soc. Med. 2010, 35, 217. [Google Scholar] [CrossRef] [PubMed]
- Jenkins, S.P. Survival Analysis; Institute for Social and Economic Research, University of Essex: Colchester, UK, 2005; Volume 42, pp. 54–56, Unpublished Manuscript. [Google Scholar]
- Shi, C.; Blei, D.; Veitch, V. Adapting neural networks for the estimation of treatment effects. In Advances in Neural Information Processing Systems 32; Neural Information Processing Systems Foundation, Inc.: La Jolla, CA, USA, 2019. [Google Scholar]
- Fox, J.; Weisberg, S. Cox Proportional-Hazards Regression for Survival Data. Appendix to an R and S-PLUS Companion to Applied Regression. Available online: https://socialsciences.mcmaster.ca/jfox/Books/Companion-2E/appendix/Appendix-Cox-Regression.pdf (accessed on 23 February 2011).
- Saikia, R.; Barman, M.P. A review on accelerated failure time models. Int. J. Stat. Syst. 2017, 12, 311–322. [Google Scholar]
- Ishwaran, H.; Kogalur, U.B.; Blackstone, E.H.; Lauer, M.S. Random survival forests. Ann. Appl. Stat. 2008, 2, 841–860. [Google Scholar] [CrossRef]
- Hariton, E.; Locascio, J.J. Randomised controlled trials—The gold standard for effectiveness research. BJOG Int. J. Obstet. Gynaecol. 2018, 125, 1716. [Google Scholar] [CrossRef] [Green Version]
- Huang, Y.; Shen, Q.; Bai, H.X.; Wu, J.; Ma, C.; Shang, Q.; Hunt, S.J.; Karakousis, G.; Zhang, P.J.; Zhang, Z. Comparison of radiofrequency ablation and hepatic resection for the treatment of hepatocellular carcinoma 2 cm or less. J. Vasc. Interv. Radiol. 2018, 29, 1218–1225.e1212. [Google Scholar] [CrossRef]
- Mariani, A.W.; Pego-Fernandes, P.M. Observational studies: Why are they so important? Sao Paulo Med. J. 2014, 132, 1–2. [Google Scholar] [CrossRef] [Green Version]
- Cartwright, N. Are RCTs the gold standard? BioSocieties 2007, 2, 11–20. [Google Scholar] [CrossRef] [Green Version]
- Concato, J.; Shah, N.; Horwitz, R.I. Randomized, controlled trials, observational studies, and the hierarchy of research designs. N. Engl. J. Med. 2000, 342, 1887–1892. [Google Scholar] [CrossRef] [Green Version]
- Sauer, B.C.; Brookhart, M.A.; Roy, J.; VanderWeele, T. A review of covariate selection for non-experimental comparative effectiveness research. Pharmacoepidemiol. Drug Saf. 2013, 22, 1139–1145. [Google Scholar] [CrossRef] [PubMed]
- Bloniarz, A.; Liu, H.; Zhang, C.-H.; Sekhon, J.S.; Yu, B. Lasso adjustments of treatment effect estimates in randomized experiments. Proc. Natl. Acad. Sci. USA 2016, 113, 7383–7390. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sriperumbudur, B.K.; Fukumizu, K.; Gretton, A.; Schölkopf, B.; Lanckriet, G.R. On the empirical estimation of integral probability metrics. Electron. J. Stat. 2012, 6, 1550–1599. [Google Scholar] [CrossRef]
- Le, P.B.; Nguyen, Z.T. ROC Curves, Loss Functions, and Distorted Probabilities in Binary Classification. Mathematics 2022, 10, 1410. [Google Scholar] [CrossRef]
- McNamara, M.G.; Slagter, A.E.; Nuttall, C.; Frizziero, M.; Pihlak, R.; Lamarca, A.; Tariq, N.; Valle, J.W.; Hubner, R.A.; Knox, J.J. Sorafenib as first-line therapy in patients with advanced Child-Pugh B hepatocellular carcinoma—A meta-analysis. Eur. J. Cancer 2018, 105, 1–9. [Google Scholar] [CrossRef]
- Turcotte, J.G.; Child III, C.G. Portal Hypertension: Pathogenesis, Management and Prognosis. Postgrad. Med. 1967, 41, 93–102. [Google Scholar] [CrossRef]
- Christensen, E.; Schlichting, P.; Fauerholdt, L.; Gluud, C.; Andersen, P.K.; Juhl, E.; Poulsen, H.; Tygstrup, N. Prognostic value of Child-Turcotte criteria in medically treated cirrhosis. Hepatology 1984, 4, 430–435. [Google Scholar] [CrossRef]
- Wang, J.-H.; Wang, C.-C.; Hung, C.-H.; Chen, C.-L.; Lu, S.-N. Survival comparison between surgical resection and radiofrequency ablation for patients in BCLC very early/early stage hepatocellular carcinoma. J. Hepatol. 2012, 56, 412–418. [Google Scholar] [CrossRef]
- Nathan, S.D. Lung transplantation: Disease-specific considerations for referral. Chest 2005, 127, 1006–1016. [Google Scholar] [CrossRef] [Green Version]
- Russo, M.J.; Iribarne, A.; Hong, K.N.; Davies, R.R.; Xydas, S.; Takayama, H.; Ibrahimiye, A.; Gelijns, A.C.; Bacchetta, M.D.; D’Ovidio, F. High lung allocation score is associated with increased morbidity and mortality following transplantation. Chest 2010, 137, 651–657. [Google Scholar] [CrossRef] [Green Version]
- Kutikov, A.; Uzzo, R.G. The RENAL nephrometry score: A comprehensive standardized system for quantitating renal tumor size, location and depth. J. Urol. 2009, 182, 844–853. [Google Scholar] [CrossRef] [PubMed]
- Sisul, D.M.; Liss, M.A.; Palazzi, K.L.; Briles, K.; Mehrazin, R.; Gold, R.E.; Masterson, J.H.; Mirheydar, H.S.; Jabaji, R.; Stroup, S.P. RENAL nephrometry score is associated with complications after renal cryoablation: A multicenter analysis. Urology 2013, 81, 775–780. [Google Scholar] [CrossRef] [PubMed]
- Hammer, S.M.; Katzenstein, D.A.; Hughes, M.D.; Gundacker, H.; Schooley, R.T.; Haubrich, R.H.; Henry, W.K.; Lederman, M.M.; Phair, J.P.; Niu, M. A trial comparing nucleoside monotherapy with combination therapy in HIV-infected adults with CD4 cell counts from 200 to 500 per cubic millimeter. N. Engl. J. Med. 1996, 335, 1081–1090. [Google Scholar] [CrossRef]
- Yin, L.; Li, H.; Li, A.-J.; Lau, W.Y.; Pan, Z.-Y.; Lai, E.C.; Wu, M.-C.; Zhou, W.-P. Partial hepatectomy vs. transcatheter arterial chemoembolization for resectable multiple hepatocellular carcinoma beyond Milan Criteria: A RCT. J. Hepatol. 2014, 61, 82–88. [Google Scholar] [CrossRef]
- Kaneko, K.; Shirai, Y.; Wakai, T.; Yokoyama, N.; Akazawa, K.; Hatakeyama, K. Low preoperative platelet counts predict a high mortality after partial hepatectomy in patients with hepatocellular carcinoma. World J. Gastroenterol. WJG 2005, 11, 5888. [Google Scholar] [CrossRef]
- Zhou, J.; Sun, H.-C.; Wang, Z.; Cong, W.-M.; Wang, J.-H.; Zeng, M.-S.; Yang, J.-M.; Bie, P.; Liu, L.-X.; Wen, T.-F. Guidelines for diagnosis and treatment of primary liver cancer in China (2017 Edition). Liver Cancer 2018, 7, 235–260. [Google Scholar] [CrossRef] [PubMed]
- Abdi, H.; Williams, L.J.; Valentin, D. Multiple factor analysis: Principal component analysis for multitable and multiblock data sets. Wiley Interdiscip. Rev. Comput. Stat. 2013, 5, 149–179. [Google Scholar] [CrossRef]
Figure 1.
CSA–Dragonnet.

Figure 2.
Introducing counterfactual prediction branches into CSA–Dragonnet.

Figure 3.
Architecture of CDNEPK.

Figure 4.
Key covariates of ITE.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Covariates | Conditions for Covariate Score = 1 | Conditions for Covariate Score = 2 | Conditions for Covariate Score = 3 |
|---|---|---|---|
| hepatic encephalopathy grade | 0 | 1, 2 | 3, 4 |
| ascites grade | 0 | 1 | 2, 3 |
| total bilirubin (g/L) | >0 and <34 | 34~51 | >51 |
| albumin (g/L) | >35 | 28~35 | >0 and <28 |
| prothrombin time (s) | >0 and <4 | 4~6 | >6 |
Table 2.
Quantitative Results.
| COX | 375.33 | 144.65 |
| AFT | 342.71 | 180.08 |
| RSF | 292.78 | 127.29 |
| CSA | 291.49 | 80.34 |
| CSA–Dragonnet | 271.23 | 73.24 |
| CDNEPK | 264.59 | 67.35 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Zhao, Y.; Zhou, H.; Gu, J.; Ye, H. Estimating the Individual Treatment Effect on Survival Time Based on Prior Knowledge and Counterfactual Prediction. Entropy 2022, 24, 975. https://doi.org/10.3390/e24070975
AMA Style
Zhao Y, Zhou H, Gu J, Ye H. Estimating the Individual Treatment Effect on Survival Time Based on Prior Knowledge and Counterfactual Prediction. Entropy. 2022; 24(7):975. https://doi.org/10.3390/e24070975
Chicago/Turabian StyleZhao, Yijie, Hao Zhou, Jin Gu, and Hao Ye. 2022. "Estimating the Individual Treatment Effect on Survival Time Based on Prior Knowledge and Counterfactual Prediction" Entropy 24, no. 7: 975. https://doi.org/10.3390/e24070975
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.