The Rényi Entropies Operate in Positive Semifields


Department of Signal Theory and Communications, Universidad Carlos III de Madrid, 28911 Leganés, Spain
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Entropy 2019, 21(8), 780; https://doi.org/10.3390/e21080780
Submission received: 31 May 2019
/
Revised: 30 July 2019
/
Accepted: 2 August 2019
/
Published: 8 August 2019
(This article belongs to the Section Information Theory, Probability and Statistics)
Abstract
:We set out to demonstrate that the Rényi entropies are better thought of as operating in a type of non-linear semiring called a positive semifield. We show how the Rényi’s postulates lead to Pap’s g-calculus where the functions carrying out the domain transformation are Rényi’s information function and its inverse. In its turn, Pap’s g-calculus under Rényi’s information function transforms the set of positive reals into a family of semirings where “standard” product has been transformed into sum and “standard” sum into a power-emphasized sum. Consequently, the transformed product has an inverse whence the structure is actually that of a positive semifield. Instances of this construction lead to idempotent analysis and tropical algebra as well as to less exotic structures. We conjecture that this is one of the reasons why tropical algebra procedures, like the Viterbi algorithm of dynamic programming, morphological processing, or neural networks are so successful in computational intelligence applications. But also, why there seem to exist so many computational intelligence procedures to deal with “information” at large.
1. Introduction
Some non-linear algebras like the min-plus semiring [1] have wide application in applications trying to model intelligent behaviour, among other domains [2]. In this paper we fuse ideas from the theory of the means, the abstract algebra of semirings and information theory to propose the following explanation for their ubiquity: that they are in fact the natural algebras in which each of the infinite instances of the Rényi informations [3]:
operate so that applications are “matched” to specific values of the order parameter α. From this starting point, the quasi-genetic, social process of scientific and technological advance selects which value of the parameter is most suited to make a technique work in a particular application.
We will argue in this paper that these non-standard algebras are positive semifields, a special type of semiring with multiplicative inverses but no additive inverses. From the point of view of abstract algebra, recall that a semiring is an algebra whose additive structure is a commutative monoid and whose multiplicative structure is a monoid with multiplication distributing over addition from right and left and an additive neutral element absorbing for ⊗, i.e., [4]. A semiring is commutative if its product is commutative. All semirings considered in this paper are commutative, whence we will drop the qualification altogether. A semiring is zero sum-free if whenever a sum is null all summands are also null, and entire if it has no non-null factors of zero. A semiring is positive if it is zero sum-free and entire [2]. Finally, a semiring is a semifield if there exists a multiplicative inverse for every element —notated as —except the null. All semifields are entire.
In this paper we concern ourselves with positive semifields, e.g., entire, zero sum-free semirings with a multiplicative inverse but no additive inverse (see Section 2.2), whose paragon is the set of non-negative reals with its standard operations . Their scientific and engineering interest lies in the fact that positive semifield applications abound in many areas of research. To cite but a few examples:
- Artificial intelligence (AI) [5] is an extensive field under which applications abound dealing with minimizing costs or maximizing utilities. Semifields and their dual-orderings (see Section 2.2 and Section 2.2.3) provide a perspective to mix these two kinds of valuations.
- Machine learning (ML) [6] makes heavy use of Probability Theory, which is built around the positive semifield of the non-negative reals with their standard algebra and negative logarithms thereof—called log-probabilities or log-likelihoods depending on the point of view—both of which are positive semifields, as shown in Section 2.2, Section 3.1.1, and Section 3.2.1.
- Computational intelligence (CI) [7] makes heavy use of positive semirings in the guise of fuzzy semirings. Although semifields cannot be considered “fuzzy” for several technical reasons, the name is sometimes an umbrella term under which non-standard algebras are included, many of which are semifields, e.g., the morphological semifield of morphological processing and memories, a special case of the semifields in Section 3.1.
- Other applications of positive semifields not related to modeling intelligence include Electrical Network analysis and synthesis (see the example in Section 2.2), queuing theory [8] and flow shop scheduling [1].
To build a basis for our initial conjecture, in methodological Section 2 we revisit a couple of seemingly unrelated observations: First, a simple shifting of the Rényi order parameter makes the connection between these entropies and the weighted Hölder means transparent [9] (Section 2.1). Second, the Rényi procedure to justify the form of the entropy [10] dovetails seamlessly into Pap’s g-calculus [11] as a construction on positive semifields (Section 2.2).
In the results Section 3 we conjoin both observations to support our hypothesis: we first briefly introduce an “entropic” semifield (Section 3.1.1) prior to proving, secondly, how the shifted Rényi entropy takes values in positive semifields, and also how this reflects back on the semifield of positive numbers interpreted as “probabilities” (Section 3.1.2). Third we use the newly defined semifield notation in two application instances: one, to provide an exception-free definition of the means for the extended positive numbers (Section 3.2.2), and two, to rewrite and provide a brief analysis into the Viterbi algorithm in terms of the semifield of max-information (Section 3.2.1). Finally we unfold the argumentation for our conjecture that AI, ML and CI applications are mostly dealing with Rényi entropies of different order (Section 3.3) and we trace some related art spanning the last 70 years (Section 3.4). We end the paper with a discussion of the issues touched upon it and some conclusions.
2. Materials and Methods
2.1. The Shifted Rényi Entropy
We first take the standpoint of information theory. Recall that the weighted power or Hölder mean of order r [12] is defined as
When the geometric mean appears:
Important cases of the means for historical and practical reasons and their relation to the (shifted and original) Rényi entropy are shown in Table 1.
To leverage the theory of generalized means to our advantage, we start with a correction to Rényi’s entropy definition: in [9] a case is made for shifting the original statement from the index that Rényi proposed to . Specifically, the transformation function for the average of surprisals [10] in the Rényi entropy (1) is arbitrary in the parameter chosen for it and we may substitute to obtain the pair of formulas:
Note that the basis of the logarithm is usually not theoretically important. This is what we mean when we use or for an unspecified b.
Consider the extension of the surprisal, or Hartley’s function, to non-negative numbers as
This is an antitone, one-to-one function from onto , with inverse for . It is also the inverse of (3) for . The following definitions are thus obtained:
Definition 1.
Let and be distributions with compatible support. Then the expression of the shifted Rényi entropy , cross-entropy , and divergence are:
Several brief points are worth mentioning in this respect, although the full argument can be followed in [9]:
- The properties of the Rényi entropy, therefore, stem from those of the mean, inversion and the logarithm.
- This is not merely a cosmetic change, since it has the potential to allow the simplification of issues and the discovery of new ones in dealing with the Rényi magnitudes. For instance, since the means are defined for all there cannot be any objection to considering negative values for the index of the shifted entropy. This motivates calling the Rényi spectrum (of entropy).
- The definition makes it also evident that the shifted cross-entropy seems to be the more general concept, given that the shifted entropy and divergence are clearly instances of it.
- Lemma (1) rewrites the entropies in terms of the geometric means which is, by no means, the only rewriting possible. Indeed, some would say that the arithmetic mean is more natural, and this is the program of information theoretic learning [14], where it is explored under the guise of .
- The shifting clarifies the relationship between quantities around the Rényi entropy: given (4), from every measure of information an equivalent average probability emerges. In particular:Definition 2.Let with Rényi spectrum . Then the equivalent probability function of is the Hartley inverse of over all values of
These three quantities—the shifted Rényi entropy, the equivalent probability function, and the information potential—stand in a relationship, as described in Figure 1a, whose characterization is the conducting thread of this paper. In [9] other formulas to convert them into each other are tabulated.
2.2. Positive Semifields
We now retake the point of view of abstract algebra. From the material in Section 2.1 it seems evident that non-negative quantities are important for our purposes. Non-negativity is captured by the concept of zero sum-free semiring mentioned above, but we focus in the slightly less general notion of dioid (for double monoid) [2] where there is an order available that interacts “nicely” with the operations of the algebra.
2.2.1. Complete and Positive Dioids
A dioid is a commutative semiring where the canonical preorder relation— if and only if there exists with —is actually an order . In a dioid the canonical orden relation is compatible with both ⊕ and ⊗ ([2], Chapter 1, Prop. 6.1.7) and the additive zero is always the infimum of the dioid or bottom hence the notation . Dioids are all zero sum-free, that is, they have no non-null additive factors of zero: if then and .
A dioid is complete if it is complete as an ordered set for the canonical order relation, and the following distributivity properties hold, for all ,
In complete dioids, there is already a top element .
A semiring is entire or zero-divisor free if implies or . If the dioid is entire, its order properties justifies calling it a positive dioid or information algebra [2].
2.2.2. Positive Semifields
A semifield, as mentioned in the introduction, is a semiring whose multiplicative structure is a group, where is the function to calculate the inverse such that . Since all semifields are entire, dioids that are at the same time semifields are called positive semifields, of which the positive reals or rationals are a paragon.
Example 1 (Semifield of non-negative reals).
The nonnegative reals are the basis for the computations in Probability Theory and other quantities that are multiplicatively aggregated. The 0 has no inverse hence is incomplete. Consider modeling utilities and costs with this algebra. For utilities 0 acts as a least element—a bottom—and the order is somewhat directed “away” from this element hence the underlying order is , that is to say utilities are to be maximized. But its dual order —intended to model costs, to be minimized—has no bottom (see below), hence applications using, for instance, multiplicative costs and utilities at the same time, will be difficult to carry out in this algebra and notation.
Figure 2 shows a concept lattice of the position of positive semifields within the commutative semirings, as well as the better known collateral families of fields like and distributive lattices like (cfr. ([15], Figure 1)).
In incomplete semifields like the one above, the inverse of the bottom element is the “elephant in the room” to be avoided in computations. Fortunately, semiring theory provides a construction to supply this missing element in semifields [4]. However, the problem with the dual order in the semifield mentioned above suggests that we introduce both completions at the same time through the following theorem (the need for the dotted notation will be made clear after the theorem).
Theorem 1.
For every incomplete positive semifield
- 1.
- There is a pair of completed semifields overwhere and by definition,
- 2.
- In addition to the individual laws as positive semifields, we have the modular laws:the analogues of the De Morgan laws:and the self-dual inequality in the natural order
- 3.
- Further, if is a positive dioid, then the inversion operation is a dual order isomorphism between the dual order structures and with the natural order of the original semifield a suborder of the first structure.
Proof.
For 1, consider obtained by adding a top element to K. The order is extended with , hence the notation ⊤ for this element. In this completed set the definition of the operations are (in this paper, cases in a definition-by-case should be interpreted from top to bottom: this first case to match applies):
with the inversion operation completed by the definition of and . So is the well-known top-completion of a positive semiring ([4], p. 250).
In this construction, inversion is total, injective and surjective in the completed domain , hence a bijection. It is easily seen as an involution , in fact, the inverse for the order-dual . But, the operations in the inverse semifield are given by:
To gain an understanding of the operations, we explore their results on a case-by-case basis. For :
- If then , whence , and symmetrically for . That is, ⊤ is the neutral element of addition and a monoid.
- If , then , whence and symmetrically for . This proves that ⊥ is the maximum element of , to be defined below.
- Otherwise, for , we have ,
while for :
- If then , whence , and symmetrically for b.
- If but , then , whence .
- Otherwise, for , we have .
Note that is a commutative monoid, with commutativity and associativity following from those of . Likewise, is easily proven to be the neutral element of which is a commutative group with commutativity and associativity issuing from those of , whose inverse is the involution . So to prove that the algebra is a semifield we only need to prove the distributive of over , for :
Therefore is another completed semifield issuing from the first one.
For 2, the proof for the De Morgan-like laws is easy from the definion of and : those definitions are actually one half of the laws, e.g., . Inverting and by the involutivity of the inversion , we change and to prove the result. The proof is analogue for the multiplicative law. The dual equalities (12) and the self-dual inequality (14) are just exercises in case analysis.
For 3 we want to find the order for the dual semifield, .
- if , since the natural order is compatible with multiplication we multiply by to obtain whence, by cancellation, , or else , so the order is the dual on inverses.
- We have that , otherwise which asserts that is the “top” of the inverted order. Likewise we read from that , that is is the “bottom” in .
whence . □
This proof provides extensive guide on how to use the notation. Note that:
- The dot notation, from [16], is a mnemonic for where do the multiplication of the bottom and top go:implying that the “lower” addition and multiplication are aligned with the original order in the semifield, e.g., while the “upper” addition and multiplication are aligned with its dual. All other cases remain as defined for ⊕ in the incomplete semifield.
- The case analysis for the operators in the dual semifield allows us to write their definition-by-cases as follows:This is important for calculations, but notice that and only differ in the corner cases.
- The notation to “speak” about these semirings tries to follow a convention reminiscent of that of boolean algebra, where the inversion is the complement ([17], Chapter 12).
- Note that and seem to operate on different “polarities” of the underlying set: if one operates on two numbers, the other operates on their inverses while this is not so for the respective multiplications. This proves extremely important to model physical quantities and other concepts with these calculi (see example below).
Regarding the intrinsic usefulness of completed positive semifields that are not fields—apart from the very obvious but degenerate case of , the booleans—we have the following example used, for instance, in convex analysis and electrical network theory.
Example 2 (Dual semifields for the non-negative reals).
The previous procedure shows that there are some problems with the notation of Example 1, and this led to the definition of the following signatures for this semifield and its inverse in convex analysis [16]:
Both of these algebras are used, for instance, in electrical engineering (EE), the algebra of complete positive reals to carry out the series summation of resistances, and its dual semifield to carry out parallel summation of conductances. With the convention that semiring models resistances, it is easy to see that the bottom element, models a shortcircuit, that the top element models an open circuit (infinite resistance) and these conventions are swapped in the dually-ordered semifield of conductances. Since EE does not use the dotted notation explained in this paper, the formulas required for the multiplication of the extremes:
are not allowed in circuit analysis. In our opinion, this strongly suggests that what is actually being operated with are the incomplete versions of these semifields, and the many problems that EE students have in learning how to properly deal with these values may stem from this fact. Other uses in Economics are detailed in [17].
Example 3 (Multiplicatively and additively idempotent costs and utilities).
Several pairs of such order-dual semirings are known, for instance:
- The completed max-times and min-times semifields.
- The completed max-plus (schedule algebra, polar algebra) and min-plus semifields (tropical algebra).
Note that their additions are all idempotent: a semiring with idempotent addition is simply called an idempotent semiring and it is always positive. These find usage in path-finding algorithms, and some more examples can be found in [2]. The mechanism whereby they are exposed as pairs of dually ordered semifields is explained in Section 2.2.3. For an example of their use in a particular application, see Section 3.2.1.
2.2.3. A Construction for Positive Semifields
There is a non-countable number of semifields obtainable from . Their discovery is probably due to Maslov and collaborators ([18], §1.1.1), but we present here the generalized procedure introduced by Pap and others [11,19,20], but see also Section 3.4.
Construction 1 (Pap’s dioids and semifields).
Let be the semiring of non-negative reals, and consider a strictly monotone generator function g on an interval with endpoints in . Since g is strictly monotone it admits an inverse , so set
- 1.
- the pseudo-addition,
- 2.
- the pseudo-multiplication,
- 3.
- neutral element,
- 4.
- inverse, ,
then,
- 1.
- if g is strictly monotone and increasing increasing such that and , then a complete positive semifield whose order is aligned with that of is:
- 2.
- order-dually, if g is strictly monotone and decreasing such that and , then a complete positive semifield whose order is aligned with that of is
Proof.
Note how in the g-calculus operations are always named with a “pseudo-” prefix, but it does not agree with Semiring Theory practice, hence we drop it. Also, the effect of the type of motonicity of g is to impose the polarity of the extended operations. Remember that the inversion is a dual isomorphism of semifields, so that and . The different notation for the underlying inverse and the inverse in Pap’s construction is introduced so that it can later be instantiated in a number of constructed inverses, as follows.
Our use of Construction 1 is to generate different kind of semifields by providing different generator functions:
Construction 2
(Multiplicative-product real semifields [20]). Consider a free parameter and the function in in Construction 1. For the operations we obtain:
where the basic operations are to be interpreted in . Now,
- if then is strictly monotone increasing whence , , and , and the complete positive semifield generated, order-aligned with , is:
- if then is strictly monotone decreasing whence , , and , and the complete positive semifield generated, order-aligned with , or dually aligned with , is:
Proof.
By instantiation of the basic case. See the details in [21]. □
Note that and . This suggests the following corollary:
Corollary 1.
and are inverse, completed positive semifields.
In particular, consider the cases:
Corollary 2.
In the previous Construction 2,
All these semifields have the same product, and the same “extreme” points, . Their only difference lies in the addition. Sometimes, when only the product is important in an application, the addition remains in the background and we are not really sure in which algebra we are working on. Note also that instead of using the abstract notation for the inversion , since is the paragon originating all other behaviour, we have decided to use the original notation for the inversion in the (incomplete) semifield.
The case where deserves to be commented. To start with, note that for , is aligned with while is aligned with , therefore and are endowed with opposite orderings. Therefore the following lemma is not a surprise.
Lemma 3.
is not a semifield.
Proof.
Recall, that on finite operands . Then we may generalize, due to the associativity of the operation to a vector to . Next, consider , and . From the properties of the means (see also [12], C. 2), it is easy to prove that
By considering and introducing the limits as we have
whence the additive and the multiplicative structures of are the same, so the structure is not even a semiring. Furthermore, when , then whereas . Hence, in particular when, say and we have and the product is clearly not defined. □
3. Results
We are now ready to start presenting a chain of results that leads to our conjecture.
3.1. Entropic Semifields
3.1.1. The Basic Entropic Semifield
The effect of Hartley’s information function is to induce from the set of positive numbers (restricted to the interval) a semifield of the extended reals . To see this, we actually consider it acting on the whole of the non-negative reals of (17) onto the algebra of entropies denoted by .
Theorem 2 (Hartley’s semifields).
The algebra with
obtained from that of positive numbers by Hartley’s information function is a positive semifield that can be completed in two different ways to two mutually dual semifields:
whose elements can be considered as entropic values and operated accordingly.
Proof.
Recall the extension of Hartley’s information function to non-negative numbers in (4), with logarithm base . Since is monotone, it is a generator (function) for Construction 1, with the following addition, multiplication and inversion:
The “interesting” points are transformed as:
The rest follows by Construction 1 and Theorem 1. □
Several considerations are worth stating. First, we have not restricted this dual-order isomorphism to the sub-semiring of probabilities on purpose. Despite this, on our intuitions about amounts of informations hold; we still believe that the “information” in is the highest, whereas the probability of is the smallest.
Second, the notation for the inverse of Hartley’s semifield is a mnemonic to remind that this is a semifield in which the inversion is actually an additive inverse, and consequently the product is an addition.
Third, the order of is aligned with that of , actually a sub-order of it in the abstract algebra sense: same properties on a subset of the original carrier set. But the order of is aligned with the dual order, that of . This has to be taken into consideration in the application of Theorem 1 to the proof of Theorem 2. Corollary 3 makes this difference clear.
Corollary 3.
Hartley’s information function is a dual-order isomorphism of completed positive semifields.
Proof.
In the proof of the previous theorem, note that is monotonically decreasing, entailing that the construction inverts orders in semifields, e.g., and . □
3.1.2. Constructed Entropic Semifields
The next important fact is that Rényi’s modified averaging function and its inverse are also dual isomorphisms of positive semifields. To prove this we make said functions appear in the construction of the semifields as generators.
Theorem 3 (Additive-product real semifields or Entropy semifields).
Let and . Then the algebra whose basic operations are:
can be completed to two dually-ordered positive semifields
whose elements can be considered as emphasized, entropic values and operated accordingly.
Proof.
We build these semifields with a composition of results. The first one is the well known result from the theory of functional means that we choose to cast into the framework of Pap’s g-calculus: the power mean of order r is the pseudo arithmetic-mean with generator and inverse . This was used in Construction 2 to build the semifields of (21) and (22). The second result is Corollary 3, where is proven a dual order isomorphism of semirings.
We next use the composition of functions and its inverse . The latter exists, since it is a composition of isomorphisms and it is a dual order isomorphism, since is order-inverting while is not. That composition is precisely Rényi’s function with inverse , whence:
This composition is strictly increasing when and strictly decreasing when , hence, when applying Construction 1 with it:
- for we get , and
- for we obtain ,
with the extended operations:
□
Note that in these semirings we have: and for .
Moreau’s original proposals [16] are found for and . Further details for compositions of generating functions and other averaging constructions can be found in [22].
Similar to Corollary 2 we have the following:
Proposition 1.
In the semifield construction of Theorem 3
The apparent incongruity of stems from the different origins of each notation: comes from the theory of semirings and is due to the fact that we have forced it to be aligned with which is ultimately motivated by Shannon’s choice of sign for the entropy function [23]. Note that in thermodynamics, this choice of sign is the inverse, that is, negentropy is the privileged concept.
The following corollary is the important result we announced at the beginning of this section.
Corollary 4.
The Rényi entropies in the Rényi spectrum take values in the semifields .
Proof.
We notice that the generating function to use Construction 1 in Theorem 3 is none other than the function to calculate the Rényi non-linear average of (3). Hence the values resulting from Rényi’s entropies belong in that semifield of Theorem 3 with the respective r parameter. □
Therefore Theorem 3 and Corollary 4 state that we have to use semifield algebra when carrying out calculations with entropies, otherwise said, they jointly confer meaning to the statement entropies operate on positive semifields in the title of this paper. An example follows in Section 3.2.1.
3.2. Applications
We would like to clarify further how entropies operate in positive semifields, and, in general, the importance of positive semifields for entropy. For this purpose we present two different applications of the theory of entropic semifields: one shows how to write entropy-processing algorithms in linear (semifield) algebra and the second shows why we cannot avoid positive semifields in entropy definitions, if we want to consider extreme values.
3.2.1. Rewriting the Viterbi Algorithm in Semifields
In this application note we analyze rewriting the Viterbi algorithm [24] in semifield notation, following recent work presented in [25].
Introduction Initially devised as a teaching aid for convolutional codes [24], the “Viterbi” was soon proven to be an optimal algorithm for shortest-path decoding in a specific type of network [26]. When this network comes from the unfolding over time of a Markov chain, it can also be used to recover an “optimal” sequence of states and transition over a generative model for a given sequence of observations [27]. In this natural generalization, it has been applied to text and speech recognition and synthesis, among other cognitively-relevant applications that used to be considered part of “classical” AI but are modernly better tackled with more specialized ML or CI techniques.
Development. Consider a weighted finite automaton of n states over a finite alphabet , defined by
- A starting distribution , where , is the probability of starting at state i.
- A transition matrix W, where is the probability of a transition from state i to state j, and
- An emission distribution , where is the probability of emitting symbol from state .
It is also possible to assign non-null probabilities for definite accepting states, but these can be assimilated to the more general framework used here.
Let be a non-empty string of length T from the free monoid built over that we call the sequence of observations and call the t-th observation. Supposing the sequence of observations to have been generated by the automaton, the purpose of the Viterbi algorithm is to find the best path score over the set of possible generation paths.
This may be done using Bellman’s Principle of Optimality [28] leading to the following recursion for
It is easy to see that this equation can be written in as introduced in (18). First, for any vector , let be a square matrix whose main diagonal is built with the components of , and whose off-diagonal entries are zero. Then we may write (34) in matrix form as
where we have co-opted the scalar lower multiplication to represent also matrix multiplication, as customary in the theory of linear algebra over semirings [4].
To actually solve (35), Hartley’s function is customarily invoked on all the probabilities appearing in (34) (cfr. [25])—often citing the advantages of working on log-probabilities for numeric computing—to obtain
Two remarks are pertinent here. First, a realization already put forward by many researchers [2]: this expression describes a non-linear computation—a minimum score in this case—by means of a linear equation in (19). Second, one of the main ideas put forward in this paper: due to the fact that the original equations dealt with probabilities and the nature of Hartley’s function, (37) is a linear equation on entropies.
Obviously, , hence, call , and , so that (36) can be rewritten in matrix form as
It is also illustrative to see the inclusion of a pruning threshold in this computation by -linear means [25]. By definition so consider the vector and . The problem of thresholding the path computations can be stated as finding such that . The solution to this set of equations is well-known (see e.g., [1], Theorem 3.2.3 of on p. 58): for generic and conformant matrix A and vector we have
Note that for a matrix A with entries, the Cuninghame-Green conjugate is the analogue of the complex conjugate [29], and that the maximal solution takes an analytical form in the dual semifield, in this case .
Then the negative elements of indicate which components need to be pruned. That is, if the individual equations read , setting in at step t for those indices of which are negative actually carries out the pruning.
Discussion What we want to highlight with this application are several facts:
- Actual non-linear computations in the Viterbi algorithm take the form of linear operations over a particular semifield, used here to minimize costs in . This takes the form of a linear matrix equation, an instance of “linear processing” in a non-linear algebra.
- Secondly and more importantly, because of Theorem 3 we know that the values in which the log-probabilities are being operated in the Viterbi are actually the Rényi entropies with index . Hence we conclude that the Viterbi is a quantitative, information entropy-processing algorithm.
- Even such a non-linear process as pruning using a threshold can be characterized and carried out by linear processing in the semifield. This is an instance of the fact that linear operations in process information in (“standard” algebraic) non-linear ways.
Already the authors of [25] provide a geometric construction to characterize the search space associated to the Viterbi as described by equations in terms of half-spaces and their tropical polytopes. Our own work has proven that the spectral spaces for matrices like and are actually complete lattices instead of the better known orthogonal subspaces of the Singular Value Decomposition of matrices in “standard” algebra [15,30]. In fact, the left and right spectral spaces issued form the Singular Value Decomposition show a relation akin to that of extents and intents in Formal Concept Analysis [31]. Further exploration of these issues is left for future work.
Finally, a crucial issue is to realize that the “optimality” of the decoding strategy is prescribed by the algebra being used in the decoding—in the language of this paper, Viterbi is - or -optimal—and this is often based in a-priori considerations on the problem. It follows that several other algorithms can be built with the template of the Viterbi by changing the underlying semifield, but all require that the addition be idempotent, that is ([2], Chapters 1 and 8).
3.2.2. Rewriting the Hölder Means and Rényi Entropies with Semifields
Corollary 4 and Definition 1 suggest that the mean in (2) actually takes values in the positive semifield . The surprisal function would then transform these values into the entropy semifield . However, the expression in Definition 1 does not easily lend itself to accept the extreme values ∞ and 0. Therefore, we propose the following definition for the means in positive semifields:
Definition 3.
Let and . Then in the dual completed semifields issuing from ,
where the case for is only valid when there are no with and .
Justification. To justify this definition, we need to translate the painstakingly developed description of the means in ([12], Chapter II) into complete positive semifield notation to obtain the rewritten means . For that purpose, we will carry out a case-based analysis based in the following set definitions: let n be the dimension of and and the full set of indices on all the components, and let:
be, respectively, the set of indices of zero, finite, and infinite components, and notice that .
Note that the corner cases when are catered to by the reflexivity of the means [12].
In particular, when , if , then and we require that . This entails that the multiplication in (38) for must be the lower multiplication so that
In [12], Chapter II, the existence of is directly disallowed, and, we take the same is the case for . However, the authors later take into consideration the second possibility, so we have decided to include both from the start. For this purpose, consider the case where . Let us first define , which is the only possible definition consistent with our intuitions of an overall weight W for , and notice that . This means we could, in principle, define the normalized weight distribution in two possible ways:
- either ;
- or .
In the first case, if all the weights are null, that is then . For zero coordinates of this poses no problem, but for we find that whence the whole summation is infinite. This does not seem reasonable. On the other hand, in the second case, we have that , as expected.
However, this has too much “annihilating power” for if , considering an such that , then every factor is erased since for is , and the alternative is even less intuitive than the preceding one. Therefore we are forced to choose alternative 1 with the caveat that when all of the weights are null (a strange situation indeed) this does not make sense.
Two points are worth stating:
- The case where is reasoned out by duality, with being dual to , being the dual to , ∞ dual to 0, and the upper multiplication and addition duals to the lower multiplication and addition. In the following we just use this “duality” argument to solve the case for .
- The rest of the cases to analyze essentially have and whence their complements are non-null . This means that the actual summation in (38) is extended to , with and .
Due to Theorem 1 and Construction 1 we know that if and —that is, all non-zero coordinates are finite—then the expressions reduce to those of the classical definition in (2) so that for , that is including .
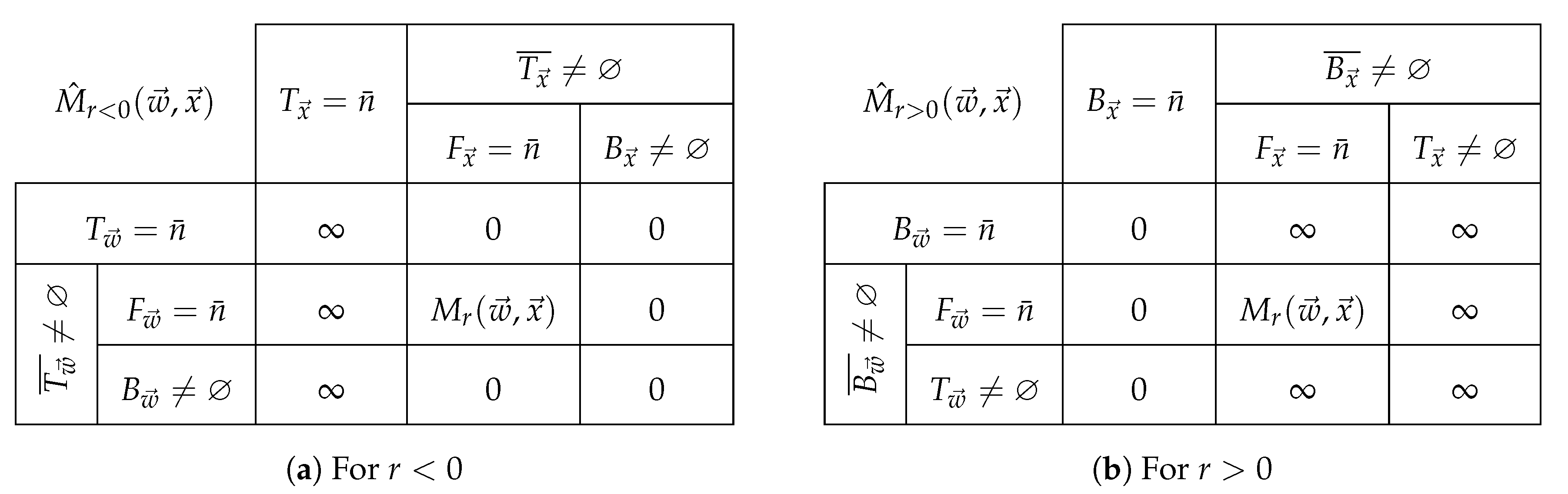
The only cases left to analyze for are those where ∞ appears in either the weights or the quantities on subindices . Notice that if then since cannot be zero, therefore . Likewise, if then and whence the factor and . We have collected all cases for , in Figure 4, along with those for obtained by duality.
Only the case is left for analysis, and recall this is . In [12] this case is treated exceptionally throughout the treatise, and one of the often used alternative expressions for it is leading immediately to where the logaritm has to be interpreted entry-wise.
Recalling that and are order isomorphisms of semifields, this suggests that we are trying to solve the hard problem for in the semifield by using thanks to the properties of the logarithm. However, the addition in is a multiplication so the rules for calculating the weighted means there might be different, considering that might be negative, or, specially, that factors like are actually exponentiations, i.e., they come from factors .
In fact, the clue to suggest the form for this mean comes from information theory and the requirement that , necessary to ignore impossible events with with in the entropy calculation. This can be modeled in our framework by demanding that this multiplication be and to write the geometric mean as:
Note that since the logarithm changes the base semifield for the Figure 4b has to be reinterpreted, along with the sets of subindices: if the components of a vector belong to a semifield with carrier set K, then the index sets have to be defined with respect to the semifield in it. Since the carrier set of is then they read as:
So a table similar to Figure 4b for would have instead of 0. Nevertheless, the exponentiation would bring the mean back to , and entailing that (40) actually follows Figure 4b.
This concludes our justification of the casting of the weighted means into semifield algebra. Note that a single may have and for , a case explicitly addressed in [12]: where is the step function, undefined at
With this formulation we are now capable of describing the Rényi entropies in semifield notation:
Definition 4.
Let and be two distributions with compatible support. Then in the dual completed semifields issuing from , the expression of the Rényi cross-entropy, entropy and divergence are:
Notice that when and the definition of entropy based on the mean and in the semifield expressed are the same, whereas in the other cases there is an extension in the definition which is in agreement with several arbitrary choices made in the definition of the new means, e.g., to comply with the convention extant for entropies. This supports our claim that entropies can be written and operated in semifields.
Since the equivalent probability function is a mean and the means can be expressed in a complete semifield, we have an expression of the former in the complete semifields of reals. Therefore, the expressions for the equivalent probability function and the information potential are:
However, in the definition of the equivalente probability function, and the entropies, we have that which entails some of the cases in Figure 4 are not visited.
3.3. Discussion: A Conjecture on the Abundance of Semifields in AI, ML and CI Applications
We are now in a position to better sustain our main conjecture about the abundance of semifields in science domains that try to model intelligent behaviour:
Conjecture (Pervasiveness of positive semifields in modelling intelligence).
Models and applications in Machine Intelligence—whether AI, ML or CI—operate with information, equivalent probability or proxies thereof, and those calculations are better conceptualized and successfully operated with the adequate dual pairs of positive semifields, especially entropy semifields.
The argument for this conjecture is as follows:
- First, the shifting in definition of the Rényi entropy by in [9] leads to a a straightforward relation (5) between the power means of the probability distribution and the shifted Rényi entropy. For a given probability function or measure the evolution of entropy with resembles an information spectrum . In a procedure reminiscent of defining an inverse transform, we may consider an equivalent probability , which is the Hölder path of , .
- The function used by Rényi to define the generalized entropy, when shifted, is the composition of two functions: Hartley’s information function and the power function of order r, which are monotone and invertible in the extended non-negative reals . They are also bijections:
- The power function is a bijection over of the extended non-negative reals, and
- Hartley’s is a bijection between the extended reals and the extended non-negative reals.
- But in Construction 1 both the power function and Hartley’s prove to be isomorphisms of positive semifields, which are semirings whose multiplicative structure is that of a group, while the additive structure lacks additive inverses. Positive semifields are all naturally ordered and the power function respects this order within the non-negative reals, being an order isomorphism for generic power r. Importantly, positive semifields come in dually-ordered pairs and the expressions mixing operations from both members in the pair are reminiscent of boolean algebras.
- (a)
- The power function with actually generates a whole family of semifields related to emphasizing smaller (with small r) or bigger values (with big r) in the non-negative reals . Indeed, the traditional weighted means are explained by the Construction 2 as being power-deformed aritmetic means, also known as Kolmogorov-Nagumo means with the power function as generators. These, semirings come in dually-ordered pairs for orders r and whose orders are aligned or inverted with respect to that of . Indeed, (Corollaries 1 and 2).
- (b)
- However, Hartley’s function is a dual-order isomorphism, entailing that the new order in the extended reals is the opposite of that on the non-negative reals (Corollary 3). It actually mediates between the (extended) probability semifield and the semifield of informations, notated as a homage to Hartley as (Theorem 2).
- Since the composition of the power mean and Hartley’s information function produces the function that Rényi used for defining his information measures, and this is a dual-order semifield isomorphism, we can see that entropies are actually operated in modified versions of Hartley’s semifields which come in pairs, as all completed positive semifields do (Theorem 3).
- Many of the and semifields appear in domains that model intelligent behaviour. Among a list of applications we list the following:
- In AI, maximizing utilities and minimizing costs is used by many applications and algorithms, e.g., heuristic search, to mimic “informed” behaviour ([5], Chapter 3), decision theory ([5], Chapter 16), uncertainty and probability modelling ([5], Chapters 13–15). In most applications , for multiplicatively-aggregated costs and utilities, and , for additively aggregated ones are being used. Note that both a semifield and its order-dual are needed to express mixed utility-cost expressions, as in electrical network analysis with resistances and conductances.
- In ML, itself is used to model uncertainty as probabilities and as log-probabilities. Sometimes the idempotent versions of these spaces , e.g., and , and , e.g., and , are used, e.g., for A* stack decoding to find best candidates [32]. The Viterbi algorithm operates in , the semifield of max entropies, as required by the application of decoding Markov models ([25], and Section 3.2.1). Although many of the problems and solutions cited above for AI can also be considered as part of ML, a recent branch of ML is solely based upon the Rényi entropy with , [14]. Importantly, recall that every possible Hölder mean can be expressed as the arithmetic mean of a properly exponentiated kernel, whence the importance of this particular Rényi entropy would come.
- In CI, the sub-semifield obtained by the restriction of the operations to appears as a ternary sub-semifield distinct from the Boolean semifield, which in turn appears as a binary sub-semifield of every complete semifield by restricting the carrier set to . As an important example, this ternary sub-semifield, as seen in Proposition 22 and Theorem 3 is pivotal in Spohn’s logical rank theory [33] that essentially leverages the isomorphism of semifields between and the in logical applications.Finally—and also related to signal processing—mathematical morphology and morphological processing need to operate in the dual pair for image processing applications [34].
In our opinion, these facts provide a substantive grounding for our conjecture.
3.4. Historical Notes: The Rise of Positive Semifields
Our first noted appearance of the addition operation of (20) in the context of information is by Barnard [35]. From a system of axioms—typical of the stage of development of Information Theory in those days—it was concluded that for the accumulation of probabilities the only possible functions are the (non-weighted) Kolmogorov-Nagumo (KN) means with , therefore the addition operation is . A special note both prescribed that , since otherwise the function f is not strictly increasing, but cautioned against supposing that is the only possible value.
Rényi explicitly cites the work of Barnard when introducing his information measure [3], and his approach is well-known to have enlightened the relationship between the KN means and entropy. This introduces two considerations:
- From Barnard’s approach, it seems natural to use only in the KN means, and this is what Rényi chose.
- It is more difficult to guess why he decided to place the “origin” of his entropies at Hartley’s () implying the harmonic average, instead of at Shannon’s , related to the geometric average.
Notice there are no modern objections to using [36], and indeed the max-entropy is thoroughly used for specific applications. This led the authors of the present paper to define the shift in the order parameter that clarifies the relationship between the positive semifields in which they are defined vis-à-vis Pap’s g-calculus [9].
In what looks like yet another case of almost simultaneous discovery, the deformed averages of Barnard had been looked into as alternate models of algebra for the modelling of physical phenomena already by Grossman and Katz ([37], and references therein) and Burgin [38]. Due to our inability to gather more than the fundamental mathematics from Burgin’s paper, in Russian, we will review here the former work.
The non-Newtonian Calculus is an apt name by Grossman and Katz [37] to describe the behaviour of a systematic “deformation” of the standard algebra of the real numbers . In this formalism, cast in the notation of this paper, an arithmetic is a complete ordered field whose carrier set is a subset of , and a generator is a one-to-one function whose domain is and whose range is a subset of it. Then the -arithmetic is the complete ordered field obtained from the transformations:
- -zero:
- -unit:
- -addition:
- -subtraction:
- -multiplication:
- -division: for
- -order:
The properties of such -arithmetics, and in particular the integral–differential calculus emanating from them, resemble formally the standard ones, since they operate in complete fields. The avowed intention of the authors is that “they may also be helpful in developing and understanding new systems of measurement that could yield simple physical laws ([37], p. 33).”
Indeed, this has been expanded upon and applied to alternate descriptions of physical phenomena by other authors [39]. The fundamental idea of this application is that the use of standard algebra to provide the “grounding” of integral-differential calculus for the description of physical phenomena is one symmetry (of nature) susceptible of “re-normalization”, e.g., for fractal description in a non-Newtonian calculus [40].
We can see two main differences the approach in [37] as compared to our own.
- First, the motivation for our construction, viz. the modelling of operations on information, is clearly more specialized thant Grossman and Katz’s, as purported in the above-mentioned quote.
- Second, and more importantly, in their framework, as in Barnard’s paper, seems to be assumed monotone, and so the properties of antitone generators and their results (leading to the second half of the dual pair) in Pap’s g-calculus are downplayed.
However, regarding the second point, the order properties of dioids interact very tightly with their operations (see Section 2.2) and we believe this is the reason why Pap found it necessary to distinguish this case in his analysis on generator functions and their domains. As it happens, the resulting structure lacks an additive inverse which dovetails into the intuition that entropies and informations cannot be “(abstractly) subtracted”, hence we consider the construction in this paper more adequate for our purposes.
In any case it would be interesting to follow up on Grossman and Katz’s approach to particular “positive fields”. Since we have already proven that the geometries of their vector spaces are quite different in the, admittedly, extreme case of the idempotent (positive) semifields [15,30], it seems that some reinterpretation of this particular case should be undertaken in their formalism. We leave this for future work.
4. Conclusions
In the context of information measures, we have reviewed the notion of positive semifield—a positive semiring with a multiplicative group structure—distinct from that of the more usual fields with an additive group structure: in positive semirings there are no additive inverses, but there is a “natural order” compatible with addition and multiplication.
Through Pap’s g-calculus and Mesiar and Pap’s semifield Construction, we have related the Hölder means to the shifted Rényi measures of information for pmf , which appear as just the logarithm of the Kolmogorov-Nagumo means in different semifields obtained by ranging the r parameter in . As a fundamental example, we provide the rewriting of the Hölder means in and its dual, which provides the basis for the shifted Renyi entropy, cross-entropy and divergence.
Our avowed intention with this exploration was to provide a conjecture, from an information theoretic point of view, about the abundance of semifield valued quantities in a variety of machine learning and computational intelligence tasks. Namely, that such semifield-valued quantities are being used either directly as Rényi information measures—including Shannon’s—or indirectly as proxies of such. Experimental corroboration of this conjecture would seem to entail some form of constructive theory for intelligence.
Author Contributions
Conceptualization, F.J.V.-A. and C.P.-M.; formal analysis, F.J.V.-A. and C.P.-M.; funding acquisition, C.P.-M.; investigation, F.J.V.-A. and C.P.-M.; methodology, F.J.V.-A. and C.P.-M.; writing—original draft, F.J.V.-A.; writing—review and editing, F.J.V.-A. and C.P.-M.
Funding
This research was funded by the Spanish Government-MinECo project TEC2017-84395-P.
Acknowledgments
This paper evolved from a plenary talk “Why are there so many Semifields in Computational Intelligence?” given at the 9th European Symposium on Computational Intelligence and Mathematics (ESCIM 2017) in Faro (Portugal), October 5th, 2017, to whose organizers we would like to thank for their kind invitation. We would also like to acknowledge the reviewers of previous versions of their paper for their timely criticism and suggestions, and in particular for the references, previously unknown to us, to Burgin’s and Grossman’s and Katz’s work.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | Artificial intelligence |
| CI | Computational intelligence |
| KN | Kolmogorov–Nagumo |
| ML | Machine learning |
References
- Butkovič, P. Max-linear Systems. Theory and Algorithms; Monographs in Mathematics; Springer: Heidelberg, Germany, 2010. [Google Scholar]
- Gondran, M.; Minoux, M. Graphs, Dioids and Semirings. New Models and Algorithms; Operations Research Computer Science Interfaces Series; Springer: Heidelberg, Germany, 2008. [Google Scholar]
- Renyi, A. On measures of entropy and information. In Proceedings of the Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics, Berkeley, CA, USA, 20 June–30 July 1960; University of California Press: Berkeley, CA, USA, 1961; pp. 547–561. [Google Scholar]
- Golan, J.S. Semirings and Their Applications; Kluwer Academic: Dordrecht, The Netherlands, 1999. [Google Scholar]
- Russell, S.J.; Norvig, P. Artificial Intelligence—A Modern Approach, 3rd international ed.; Artificial Intelligence; Prentice Hall: Upper Saddle River, NJ, USA, 2010. [Google Scholar]
- Murphy, K.P. Machine Learning. A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Engelbrecht, A.P. Computational Intelligence. An Introduction; Wiley: Hoboken, NJ, USA, 2002. [Google Scholar]
- Baccelli, F.; Cohen, G.; Olsder, G.; Quadrat, J. Synchronization and Linearity; Wiley: Hoboken, NJ, USA, 1992. [Google Scholar]
- Valverde-Albacete, F.J.; Peláez-Moreno, C. The case for shifting the Renyi entropy. Entropy 2019, 21, 46. [Google Scholar] [CrossRef]
- Renyi, A. Probability Theory; Courier Dover Publications: Mineola, NY, USA, 1970. [Google Scholar]
- Pap, E. g-calculus. In Zbornik Radova Prirodno-Matematichkog Fakulteta. Serija za Matematiku. Review of Research. Faculty of Science. Mathematics Series; University of Novi Sad: Novi Sad, Serbia, 1993; pp. 145–156. [Google Scholar]
- Hardy, G.H.; Littlewood, J.E.; Pólya, G. Inequalities; Cambridge University Press: Cambridge, UK, 1952. [Google Scholar]
- Beck, C.; Schögl, F. Thermodynamics of Chaotic Systems: An Introduction; Cambridge University Press: Cambridge, UK, 1995. [Google Scholar]
- Principe, J.C. Information Theoretic Learning; Information Science and Statistics; Springer: New York, NY, USA, 2010. [Google Scholar]
- Valverde-Albacete, F.J.; Peláez-Moreno, C. The Spectra of irreducible matrices over completed idempotent semifields. Fuzzy Sets Syst. 2015, 271, 46–69. [Google Scholar] [CrossRef]
- Moreau, J.J. Inf-convolution, sous-additivité, convexité des fonctions numériques. J. Math. Pures Appl. 1970, 49, 109–154. (In French) [Google Scholar]
- Ellerman, D.P. Intellectual Trespassing as a Way of Life. Essays in Philosophy, Economics and Mathematics; Rowman & Littlefield Publishers Inc.: Lanham, MD, USA, 1995. [Google Scholar]
- Maslov, V.; Volosov, K. Mathematical Aspects of Computer Engineering; Mir: Moscow, Russia, 1988. [Google Scholar]
- Pap, E.; Ralević, N. Pseudo-Laplace transform. Nonlinear Anal. Theory Methods Appl. 1998, 33, 533–550. [Google Scholar] [CrossRef]
- Mesiar, R.; Pap, E. Idempotent integral as limit of g-integrals. Fuzzy Sets Syst. 1999, 102, 385–392. [Google Scholar] [CrossRef]
- Valverde-Albacete, F.J.; Peláez-Moreno, C. Towards Galois Connections over Positive Semifields. In Information Processing and Management of Uncertainty in Knowledge-Based Systems; Springer International Publishing: Heidelberg, Germany, 2016; CCIS Volume 611, pp. 81–92. [Google Scholar]
- Grabisch, M.; Marichal, J.L.; Mesiar, R.; Pap, E. Aggregation functions: Construction methods, conjunctive, disjunctive and mixed classes. Inf. Sci. 2011, 181, 23–43. [Google Scholar] [CrossRef] [Green Version]
- Shannon, C.E. A mathematical theory of Communication. Bell Syst. Tech. J. 1948, XXVII, 379–423. [Google Scholar] [CrossRef]
- Viterbi, A.J. Error bounds for convolutional codes and an asymptotically optimum decoding algorithm. IEEE Trans. Inf. Theory 1967, 13, 260–269. [Google Scholar] [CrossRef]
- Theodosis, E.; Maragos, P. Analysis of the Viterbi algorithm using tropical algebra and geometry. In Proceedings of the IEEE International Workshop on Signal Processing Advances in Wireless Communications (SPAWC—18), Kalamata, Greece, 25–28 June 2018; pp. 1–5. [Google Scholar]
- Forney, G. The Viterbi algorithm. Proc. IEEE 1973, 61, 268–278. [Google Scholar] [CrossRef]
- Rabiner, L.R. A tutorial on hidden Markov models and selected applications in speech recognition. Proc. IEEE 1989, 77, 257–286. [Google Scholar] [CrossRef]
- Bellman, R.; Kalaba, R. On the role of dynamic programming in statistical communication theory. IRE Trans. Inf. 1957, 3, 197–203. [Google Scholar] [CrossRef]
- Cuninghame-Green, R. Minimax Algebra; Number 166 in Lecture notes in Economics and Mathematical Systems; Springer: Heidelberg, Germany, 1979. [Google Scholar]
- Valverde-Albacete, F.J.; Peláez-Moreno, C. The spectra of reducible matrices over complete commutative idempotent semifields and their spectral lattices. Int. J. Gen. Syst. 2016, 45, 86–115. [Google Scholar] [CrossRef]
- Ganter, B.; Wille, R. Formal Concept Analysis: Mathematical Foundations; Springer: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Paul, D.B. An efficient A* stack decoder algorithm for continuous speech recognition with a stochastic language model. In Proceedings of the workshop on Speech and Natural Language—HLT ’91, Harriman, NY, USA, 23–26 February 1992; Association for Computational Linguistics: Morristown, NJ, USA, 1992; p. 405. [Google Scholar]
- Spohn, W. The Laws of Belief: Ranking Theory and Its Philosophical Applications; Oxford University Press: Oxford, UK, 2012. [Google Scholar]
- Ronse, C. Why mathematical morphology needs complete lattices. Signal Process. 1990, 21, 129–154. [Google Scholar] [CrossRef]
- Barnard, G. The theory of information. J. R. Stat. Soc. Ser. B 1951, 13, 46–64. [Google Scholar] [CrossRef]
- Harremoës, P. Interpretations of Rényi entropies and divergences. Phys. A Stat. Mech. Appl. 2005, 365, 57–62. [Google Scholar] [CrossRef]
- Grossman, M.; Katz, R. Non-Newtonian Calculus; Lee Press: Pigeon Cove, MA, USA, 1972. [Google Scholar]
- Burgin, M. Nonclassical models of the natural numbers. Uspekhi Matemat. Nauk. 1977, 32, 209–210. [Google Scholar]
- Czachor, M. Relativity of arithmetic as a fundamental symmetry of physics. Quantum Stud. Math. Found. 2016, 3, 123–133. [Google Scholar] [CrossRef]
- Czachor, M. Waves along fractal coastlines: from fractal arithmetic to wave equations. Acta Phys. Pol. B 2019, 50, 813–831. [Google Scholar] [CrossRef]
Figure 1.
Schematics of relationship due to entropic isomorphisms. (a) Between shifted entropy-related quantities (from [9]). (b) Between entropy-related domains (see Section 3.1).
Figure 1.
Schematics of relationship due to entropic isomorphisms. (a) Between shifted entropy-related quantities (from [9]). (b) Between entropy-related domains (see Section 3.1).

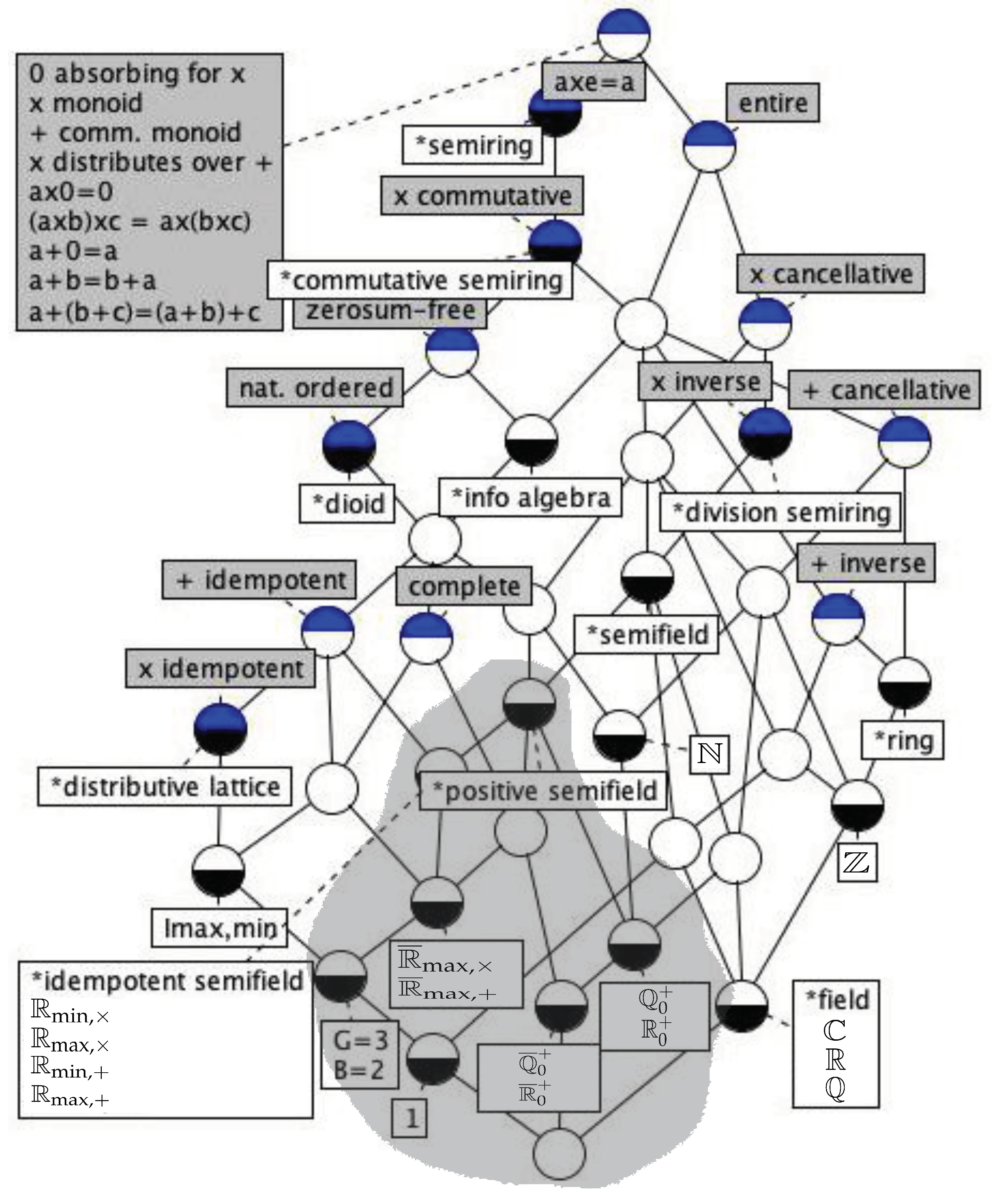
Figure 2.
Lattice of a selection of abstract (leading asterisk, white label) and concrete (white label) commutative semirings and their properties (grey label) mentioned in the text. Adapted from [15]. Each node is a concept of abstract algebra: its properties are obtained from the gray labels in nodes upwards, and its structures from the white labels in nodes downwards. The picture is related to the chosen sets of properties and algebras and does not fully reflect the structure of the class of semirings. We have chosen to highlight positive semifields, like and .
Figure 2.
Lattice of a selection of abstract (leading asterisk, white label) and concrete (white label) commutative semirings and their properties (grey label) mentioned in the text. Adapted from [15]. Each node is a concept of abstract algebra: its properties are obtained from the gray labels in nodes upwards, and its structures from the white labels in nodes downwards. The picture is related to the chosen sets of properties and algebras and does not fully reflect the structure of the class of semirings. We have chosen to highlight positive semifields, like and .

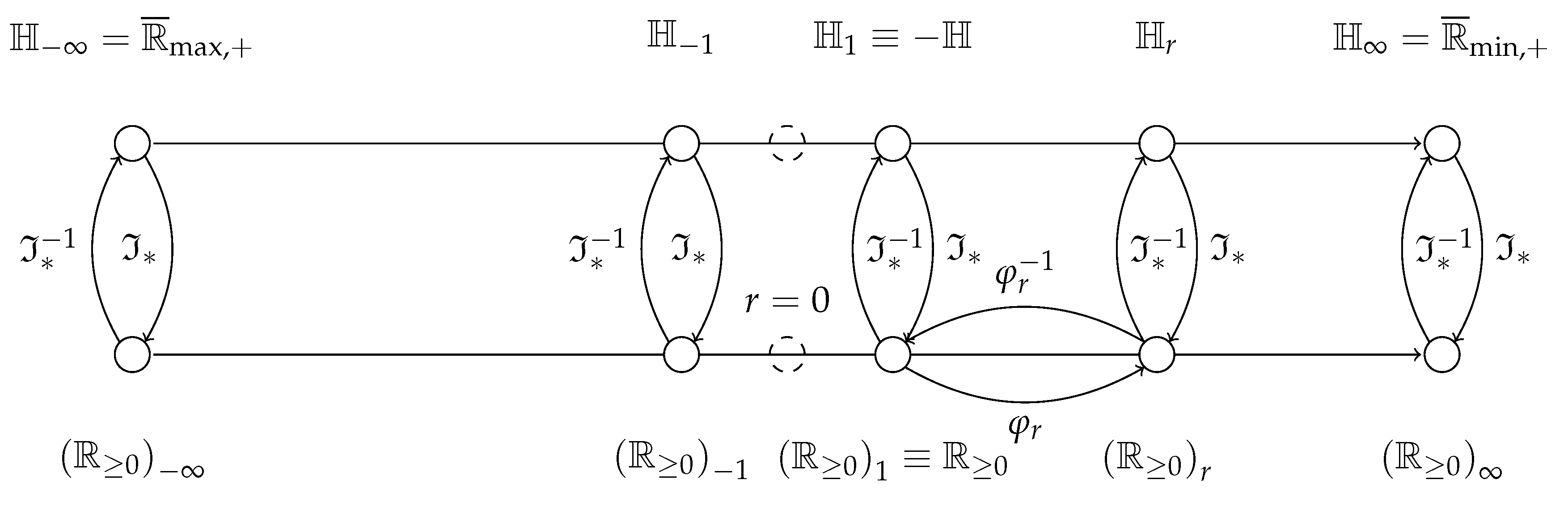
Figure 3.
Domain diagram to interpret the Rényi transformation in the context of the expectations of probabilities and informations. The horizontal axes represent the evolution of parameter r. Notice that for no positive semifields are found (dashed circles). Above lie the entropic semirings, below, the semirings that are deformations of . Between each of these pairs with the same r—where only a few pairs for have been made explicit—mediate Hartley’s information function and its inverse . In the semifields below, only the case for the deformation between and is shown in full.
Figure 3.
Domain diagram to interpret the Rényi transformation in the context of the expectations of probabilities and informations. The horizontal axes represent the evolution of parameter r. Notice that for no positive semifields are found (dashed circles). Above lie the entropic semirings, below, the semirings that are deformations of . Between each of these pairs with the same r—where only a few pairs for have been made explicit—mediate Hartley’s information function and its inverse . In the semifields below, only the case for the deformation between and is shown in full.

Figure 4.
A summary of cases for (a) for and (b) for


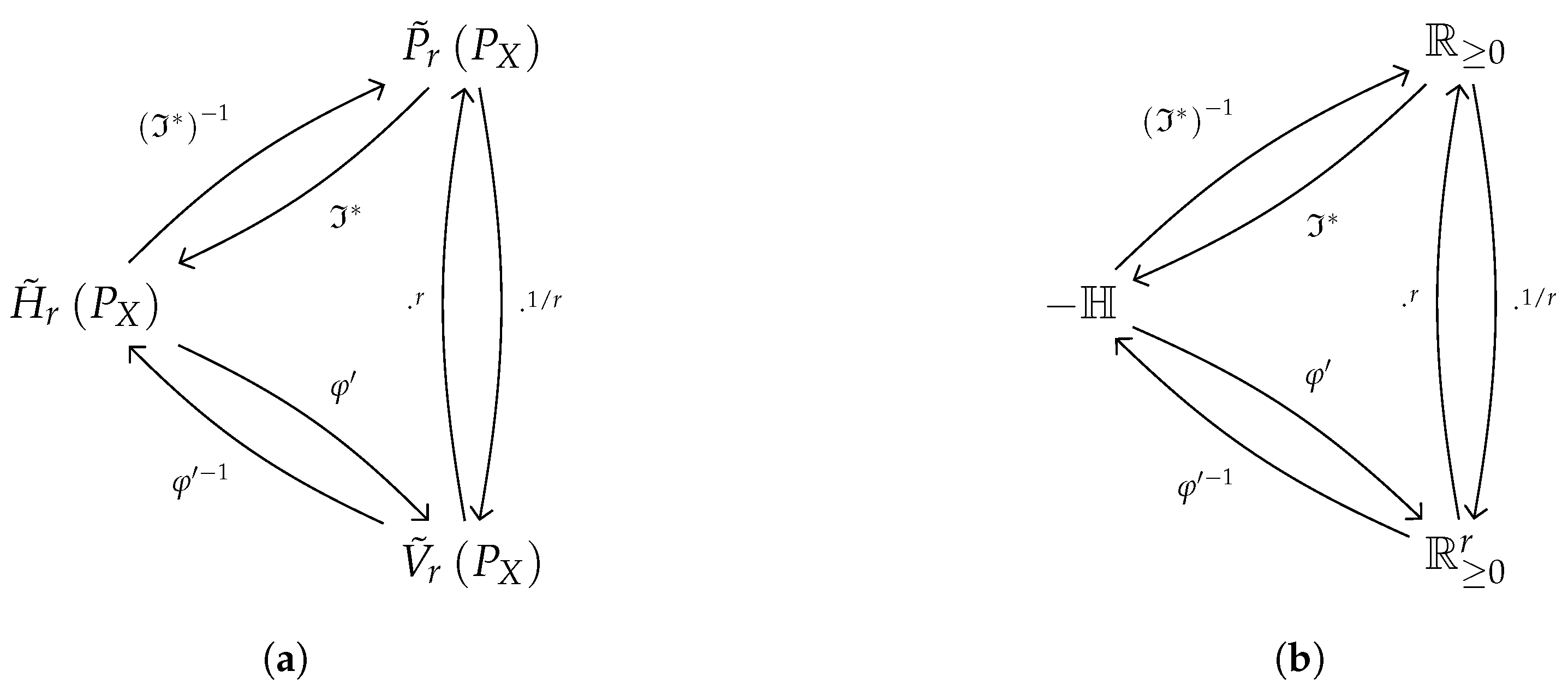{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Relation between the most usual weighted power means, Rényi entropies and shifted versions of them, from [9].
Table 1.
Relation between the most usual weighted power means, Rényi entropies and shifted versions of them, from [9].
| Mean Name | Mean | Shifted Entropy | Entropy Name | r | |
|---|---|---|---|---|---|
| Maximum | min-entropy | ∞ | ∞ | ||
| Arithmetic | Rényi’s quadratic | 2 | 1 | ||
| Geometric | Shannon’s | 1 | 0 | ||
| Harmonic | Hartley’s | 0 | |||
| Minimum | max-entropy |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Valverde-Albacete, F.J.; Peláez-Moreno, C. The Rényi Entropies Operate in Positive Semifields. Entropy 2019, 21, 780. https://doi.org/10.3390/e21080780
AMA Style
Valverde-Albacete FJ, Peláez-Moreno C. The Rényi Entropies Operate in Positive Semifields. Entropy. 2019; 21(8):780. https://doi.org/10.3390/e21080780
Chicago/Turabian StyleValverde-Albacete, Francisco J., and Carmen Peláez-Moreno. 2019. "The Rényi Entropies Operate in Positive Semifields" Entropy 21, no. 8: 780. https://doi.org/10.3390/e21080780
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.