
Human Action Recognition from Multiple Views Based on View-Invariant Feature Descriptor Using Support Vector Machines


Abstract
:
1. Introduction
2. Related Works
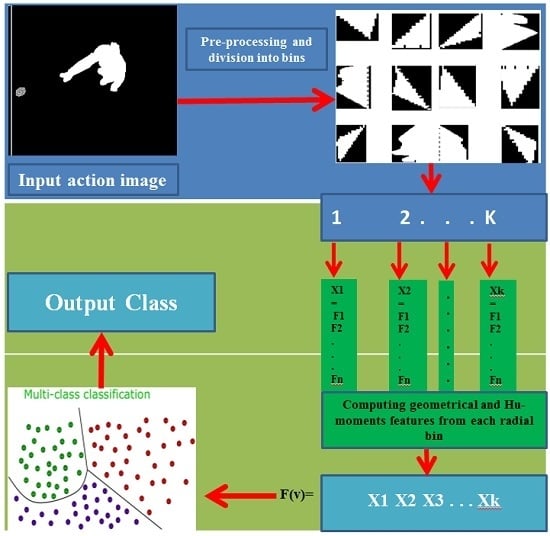
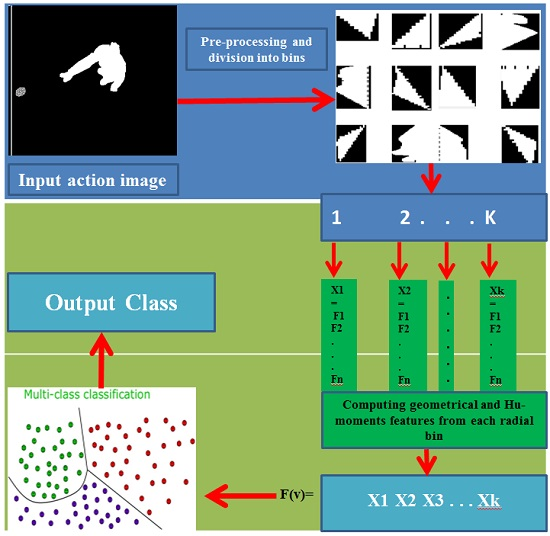
3. Proposed System
| Algorithm 1 |
|
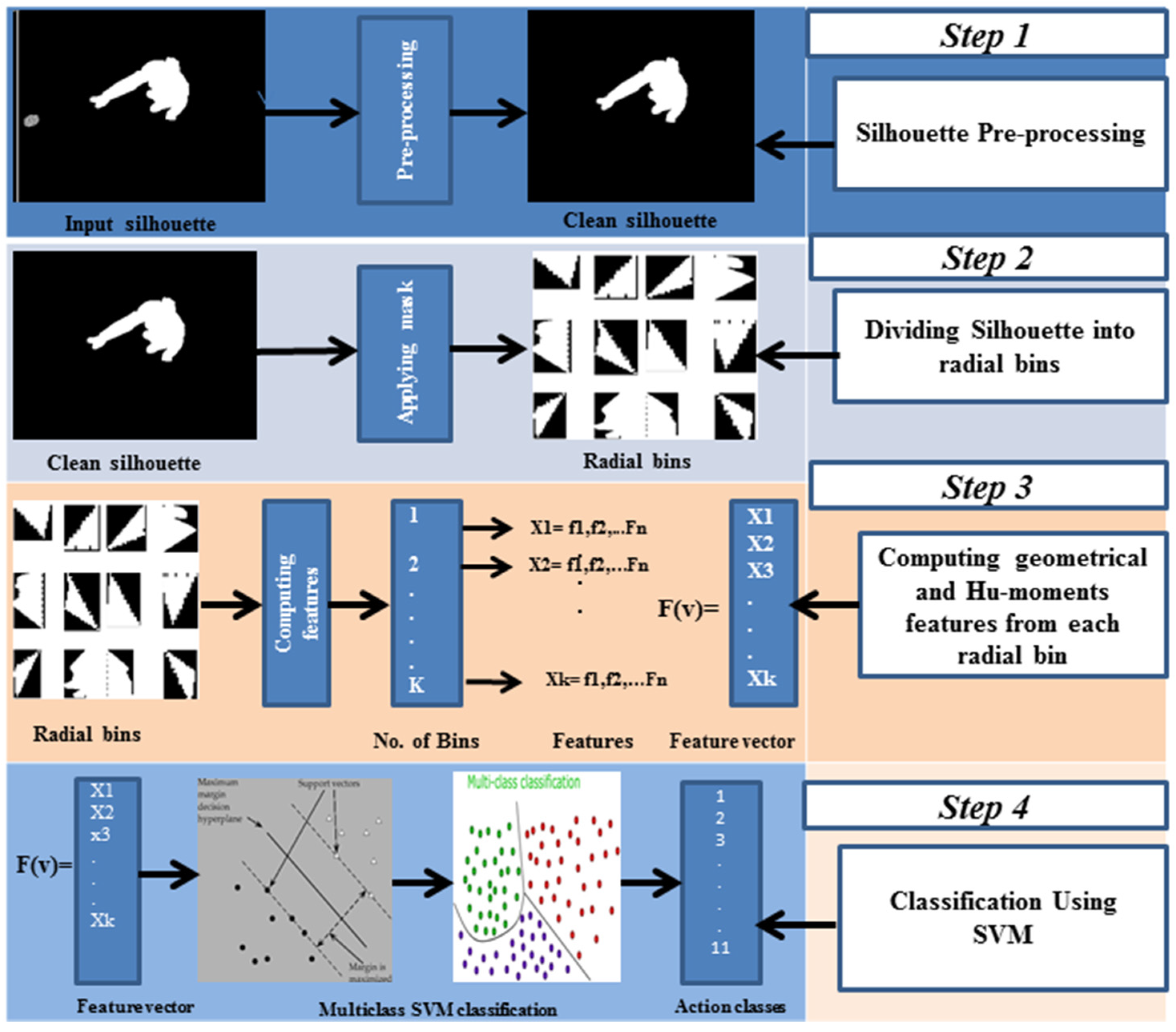
3.1. Pre-Processing
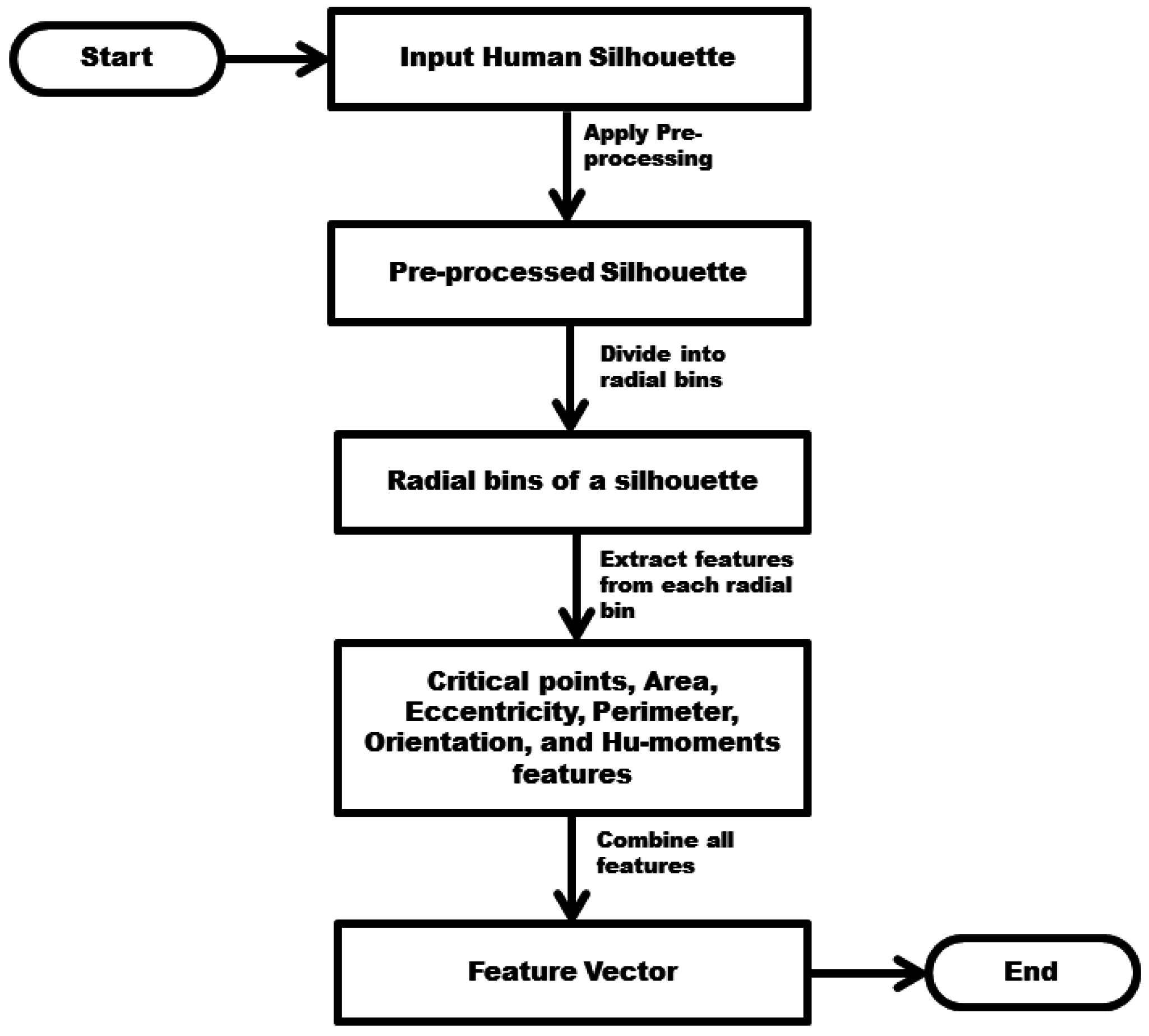
3.2. Multiview Features Extraction and Representation
3.2.1. Region-Based Geometric Features
- (1)
- First of all, we calculate the centroid of a human silhouette using Equation (2), as shown in Figure 3.where
- (2)
- After computing the centroid by Equation (2), a radius of the silhouette is computed.
- (3)
- The silhouette is divided into 12 radial bins with respect to its centroid using a mask; this division has been made with intervals of 30°. These bins are shown in Figure 4.
- (4)
- The following region-based features are computed for each bin of the silhouette.
- (a)
- Critical points: As we move the mask on the silhouette in counter-clockwise direction, a triangle or quadrangle shape is formed in each bin. We compute the critical points (corner points) of each shape and their distances. There can be different numbers of critical points for each shape; therefore, the mean and variance of these points have been computed as features. It gives us 2 × 12 = 24 features for each silhouette.
- (b)
- Area: The simple and natural property of a region is its area. In the case of a binary image, it is a measure of size of its foreground. We have computed the area of each bin, which provides 12 important features for each human silhouette.
- (c)
- Eccentricity: The ratio of the major and minor axes of an object is known as eccentricity [33]. In our case, it is ratio of distance between the major axis and foci of the ellipse. Its value is between 0 and 1, depending upon the shape of the ellipse. If its value is 0, then actually it is a circle; if its value is 1, then it is a line segment. We have computed eccentricity for each of the 12 bins.
- (d)
- Perimeter: This is also an important property of a region. The distance around the boundary of a region can be measured by computing the distance between each pair of pixels. We have computed perimeter of each bin forming a triangle or quadrangle.
- (e)
- Orientation: This is an important property of a region, which specifies the angle between x-axis and major axis of the ellipse. Its value can be between −90° and 90°.
3.2.2. Hu-Moments Invariant Features
3.3. Action Classification with SVM Multiclass Classifier
4. Experimentations
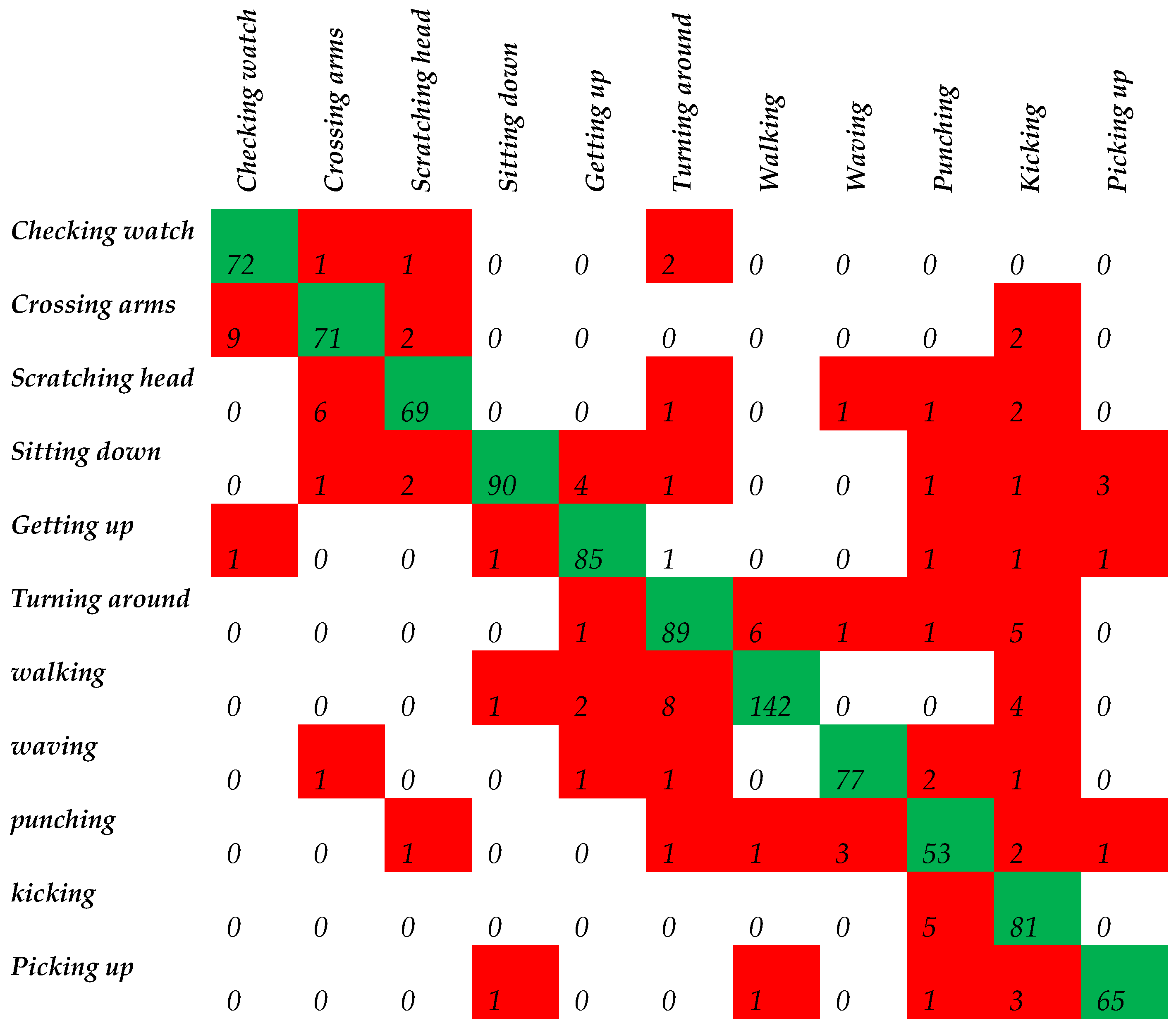
4.1. Evaluation on Multiview Action Recognition Dataset
4.2. Comparison with Similar Methods on IXMAS Dataset
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Poppe, R. A survey on vision-based human action recognition. Image Vis. Comput. 2010, 28, 976–990. [Google Scholar] [CrossRef]
- Aggarwal, J.K.; Ryoo, M.S. Human activity analysis: A review. ACM Comput. Surv. (CSUR) 2011, 43, 16. [Google Scholar] [CrossRef]
- Rudoy, D.; Zelnik-Manor, L. Viewpoint selection for human actions. Int. J. Comput. Vis. 2012, 97, 243–254. [Google Scholar] [CrossRef]
- Saghafi, B.; Rajan, D.; Li, W. Efficient 2D viewpoint combination for human action recognition. Pattern Anal. Appl. 2016, 19, 563–577. [Google Scholar] [CrossRef]
- Holte, M.B.; Tran, C.; Trivedi, M.M.; Moeslund, T.B. Human pose estimation and activity recognition from multi-view videos: Comparative explorations of recent developments. IEEE J. Sel. Top. Signal Proc. 2012, 6, 538–552. [Google Scholar] [CrossRef]
- Holte, M.B.; Moeslund, T.B.; Nikolaidis, N.; Pitas, I. 3D human action recognition for multi-view camera systems. In Proceedings of the 2011 International Conference on 3D Imaging, Modeling, Processing, Visualization and Transmission (3DIMPVT), Hangzhou, China, 16–19 May 2011; pp. 324–329.
- Huang, P.; Hilton, A.; Starck, J. Shape similarity for 3D video sequences of people. Int. J. Comput. Vis. 2010, 89, 362–381. [Google Scholar] [CrossRef]
- Weinland, D.; Ronfard, R.; Boyer, E. Free viewpoint action recognition using motion history volumes. Comput. Vis. Image Underst. 2006, 104, 249–257. [Google Scholar] [CrossRef]
- Slama, R.; Wannous, H.; Daoudi, M.; Srivastava, A. Accurate 3D action recognition using learning on the Grassmann manifold. Pattern Recognit. 2015, 48, 556–567. [Google Scholar] [CrossRef]
- Ali, S.; Shah, M. Human action recognition in videos using kinematic features and multiple instance learning. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 288–303. [Google Scholar] [CrossRef] [PubMed]
- Holte, M.B.; Tran, C.; Trivedi, M.M.; Moeslund, T.B. Human action recognition using multiple views: A comparative perspective on recent developments. In Proceedings of the 2011 Joint ACM Workshop on Human Gesture and Behavior Understanding, Scottsdale, AZ, USA, 28 November–1 December 2011; pp. 47–52.
- Junejo, I.N.; Dexter, E.; Laptev, I.; Perez, P. View-independent action recognition from temporal self-similarities. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 172–185. [Google Scholar] [CrossRef] [PubMed]
- Kushwaha, A.K.S.; Srivastava, S.; Srivastava, R. Multi-view human activity recognition based on silhouette and uniform rotation invariant local binary patterns. Multimedia Syst. 2016. [Google Scholar] [CrossRef]
- Iosifidis, A.; Tefas, A.; Pitas, I. View-invariant action recognition based on artificial neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 412–424. [Google Scholar] [CrossRef] [PubMed]
- Iosifidis, A.; Tefas, A.; Pitas, I. Multi-view action recognition based on action volumes, fuzzy distances and cluster discriminant analysis. Signal Proc. 2013, 93, 1445–1457. [Google Scholar] [CrossRef]
- Wang, L.; Qiao, Y.; Tang, X. Action recognition with trajectory-pooled deep-convolutional descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4305–4314.
- Lei, J.; Li, G.; Zhang, J.; Guo, Q.; Tu, D. Continuous action segmentation and recognition using hybrid convolutional neural network-hidden Markov model model. IET Comput. Vis. 2016, 10, 537–544. [Google Scholar] [CrossRef]
- Gkalelis, N.; Nikolaidis, N.; Pitas, I. View indepedent human movement recognition from multi-view video exploiting a circular invariant posture representation. In Proceedings of the IEEE International Conference on Multimedia and Expo 2009 (ICME 2009), New York, NY, USA, 28 June–3 July 2009; pp. 394–397.
- Weinland, D.; Özuysal, M.; Fua, P. Making Action Recognition Robust to Occlusions and Viewpoint Changes. In Computer Vision–ECCV 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 635–648. [Google Scholar]
- Souvenir, R.; Babbs, J. Learning the viewpoint manifold for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2008 (CVPR 2008), Anchorage, AK, USA, 23–28 June 2008; pp. 1–7.
- Liu, J.; Shah, M. Learning human actions via information maximization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2008 (CVPR 2008), Anchorage, AK, USA, 23–28 June 2008; pp. 1–8.
- Zheng, J.; Jiang, Z.; Chellappa, R. Cross-View Action Recognition via Transferable Dictionary Learning. IEEE Trans. Image Proc. 2016, 25, 2542–2556. [Google Scholar] [CrossRef] [PubMed]
- Nie, W.; Liu, A.; Li, W.; Su, Y. Cross-View Action Recognition by Cross-domain Learning. Image Vis. Comput. 2016. [Google Scholar] [CrossRef]
- Chaaraoui, A.A.; Climent-Pérez, P.; Flórez-Revuelta, F. Silhouette-based human action recognition using sequences of key poses. Pattern Recognit. Lett. 2013, 34, 1799–1807. [Google Scholar] [CrossRef] [Green Version]
- Chaaraoui, A.A.; Flórez-Revuelta, F. A Low-Dimensional Radial Silhouette-Based Feature for Fast Human Action Recognition Fusing Multiple Views. Int. Sch. Res. Not. 2014, 2014, 547069. [Google Scholar] [CrossRef] [PubMed]
- Cheema, S.; Eweiwi, A.; Thurau, C.; Bauckhage, C. Action recognition by learning discriminative key poses. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 1302–1309.
- Ahmad, M.; Lee, S.-W. HMM-based human action recognition using multiview image sequences. In Proceedings of the 18th International Conference on Pattern Recognition 2006 (ICPR 2006), Hong Kong, China, 20–24 August 2006; pp. 263–266.
- Pehlivan, S.; Forsyth, D.A. Recognizing activities in multiple views with fusion of frame judgments. Image Vis. Comput. 2014, 32, 237–249. [Google Scholar] [CrossRef]
- Chun, S.; Lee, C.-S. Human action recognition using histogram of motion intensity and direction from multiple views. IET Comput. Vis. 2016, 10, 250–257. [Google Scholar] [CrossRef]
- Murtaza, F.; Yousaf, M.H.; Velastin, S. Multi-view Human Action Recognition using 2D Motion Templates based on MHIs and their HOG Description. IET Comput. Vis. 2016. [Google Scholar] [CrossRef]
- Hsieh, C.-H.; Huang, P.S.; Tang, M.-D. Human action recognition using silhouette histogram. In Proceedings of the Thirty-Fourth Australasian Computer Science Conference, Perth, Australia, 17–20 January 2011; Australian Computer Society, Inc.: Darlinghurst, Australia, 2011; pp. 213–223. [Google Scholar]
- Rahman, S.A.; Cho, S.-Y.; Leung, M.K. Recognising human actions by analysing negative spaces. IET Comput. Vis. 2012, 6, 197–213. [Google Scholar] [CrossRef]
- Sonka, M.; Hlavac, V.; Boyle, R. Image Processing, Analysis, and Machine Vision; Cengage Learning: Belmont, CA, USA, 2014. [Google Scholar]
- Hu, M.-K. Visual pattern recognition by moment invariants. IRE Trans. Inform. Theory 1962, 8, 179–187. [Google Scholar]
- Huang, Z.; Leng, J. Analysis of Hu’s moment invariants on image scaling and rotation. In Proceedings of the 2010 2nd International Conference on Computer Engineering and Technology (ICCET), Chengdu, China, 6–19April 2010; pp. 476–480.
- Jordan, A. On discriminative vs. generative classifiers: A comparison of logistic regression and naive bayes. Adv. Neural Inform. Proc.g Syst. 2002, 14, 841. [Google Scholar]
- Qian, H.; Mao, Y.; Xiang, W.; Wang, Z. Recognition of human activities using SVM multi-class classifier. Pattern Recognit. Lett. 2010, 31, 100–111. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Vapnik, V.N.; Vapnik, V. Statistical Learning Theory; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Kreßel, U.H.-G. Pairwise classification and support vector machines. In Advances in Kernel Methods; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Platt, J.C.; Cristianini, N.; Shawe-Taylor, J. Large Margin DAGs for Multiclass Classification. Nips 1999, 12, 547–553. [Google Scholar]
- Dietterich, T.G.; Bakiri, G. Solving multiclass learning problems via error-correcting output codes. J. Artif. Intell. Res. 1995, 2, 263–286. [Google Scholar]
- Cheong, S.; Oh, S.H.; Lee, S.-Y. Support vector machines with binary tree architecture for multi-class classification. Neural Inform. Proc.-Lett. Rev. 2004, 2, 47–51. [Google Scholar]
- Hsu, C.-W.; Lin, C.-J. A comparison of methods for multiclass support vector machines. IEEE Trans. Neural Netw. 2002, 13, 415–425. [Google Scholar] [PubMed]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. (TIST) 2011, 2, 27. [Google Scholar] [CrossRef]
- Manosha Chathuramali, K.; Rodrigo, R. Faster human activity recognition with SVM. In Proceedings of the 2012 International Conference on Advances in ICT for Emerging Regions (ICTER), Colombo, Sri Lanka, 12–15 December 2012; pp. 197–203.
- Weinland, D.; Boyer, E.; Ronfard, R. Action recognition from arbitrary views using 3D exemplars. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–20 October 2007; pp. 1–7.
- Reddy, K.K.; Liu, J.; Shah, M. Incremental action recognition using feature-tree. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; pp. 1010–1017.
- Lv, F.; Nevatia, R. Single view human action recognition using key pose matching and viterbi path searching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2007 (CVPR’07), Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8.
- Vitaladevuni, S.N.; Kellokumpu, V.; Davis, L.S. Action recognition using ballistic dynamics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2008 (CVPR 2008), Anchorage, AK, USA, 23–28 June 2008; pp. 1–8.
- Cherla, S.; Kulkarni, K.; Kale, A.; Ramasubramanian, V. Towards fast, view-invariant human action recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops 2008 (CVPRW’08), Anchorage, AK, USA, 23–28 June 2008; pp. 1–8.
- Wu, X.; Xu, D.; Duan, L.; Luo, J. Action recognition using context and appearance distribution features. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 489–496.
- Burghouts, G.; Eendebak, P.; Bouma, H.; Ten Hove, J.M. Improved action recognition by combining multiple 2D views in the bag-of-words model. In Proceedings of the 2013 10th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Krakow, Poland, 27–30 August 2013; pp. 250–255.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Action Name | Index | Action Name |
|---|---|---|---|
| 1 | Checking watch | 7 | Walking |
| 2 | Crossing arms | 8 | Waving |
| 3 | Scratching head | 9 | Punching |
| 4 | Sitting down | 10 | Kicking |
| 5 | Getting up | 11 | Picking up |
| 6 | Turning around | - | - |
| Year | Method | Accuracy (%) |
|---|---|---|
| - | Proposed method | 89.75 |
| 2016 | Chun et al. [29] | 83.03 |
| 2013 | Chaaraoui et al. [24] | 85.9 |
| 2013 | Burghouts et al. [53] | 96.4 |
| 2011 | Wu et al. [52] | 89.4 |
| 2011 | Junejo et al. [12] | 74 |
| 2010 | Weinland et al. [19] | 83.4 |
| 2009 | Reddy et al. [48] | 72.6 |
| 2008 | Liu and Shah [21] | 82.8 |
| 2008 | Cherla et al. [51] | 80.1 |
| 2008 | Vitaladevuni et al. [50] | 87.0 |
| 2007 | Lv and Nevatia [49] | 80.6 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sargano, A.B.; Angelov, P.; Habib, Z. Human Action Recognition from Multiple Views Based on View-Invariant Feature Descriptor Using Support Vector Machines. Appl. Sci. 2016, 6, 309. https://doi.org/10.3390/app6100309
Sargano AB, Angelov P, Habib Z. Human Action Recognition from Multiple Views Based on View-Invariant Feature Descriptor Using Support Vector Machines. Applied Sciences. 2016; 6(10):309. https://doi.org/10.3390/app6100309
Chicago/Turabian StyleSargano, Allah Bux, Plamen Angelov, and Zulfiqar Habib. 2016. "Human Action Recognition from Multiple Views Based on View-Invariant Feature Descriptor Using Support Vector Machines" Applied Sciences 6, no. 10: 309. https://doi.org/10.3390/app6100309