
Latent Dirichlet Allocation and t-Distributed Stochastic Neighbor Embedding Enhance Scientific Reading Comprehension of Articles Related to Enterprise Architecture



Abstract
:1. Introduction
2. Background and Related Works
2.1. Enterprise Architecture
2.2. State-of-the-Art Reviews on Enterprise Architecture
2.3. Topic Modeling as a Part of Natural Language Processing
3. Applying Topic Modeling to Enterprise Architecture Research
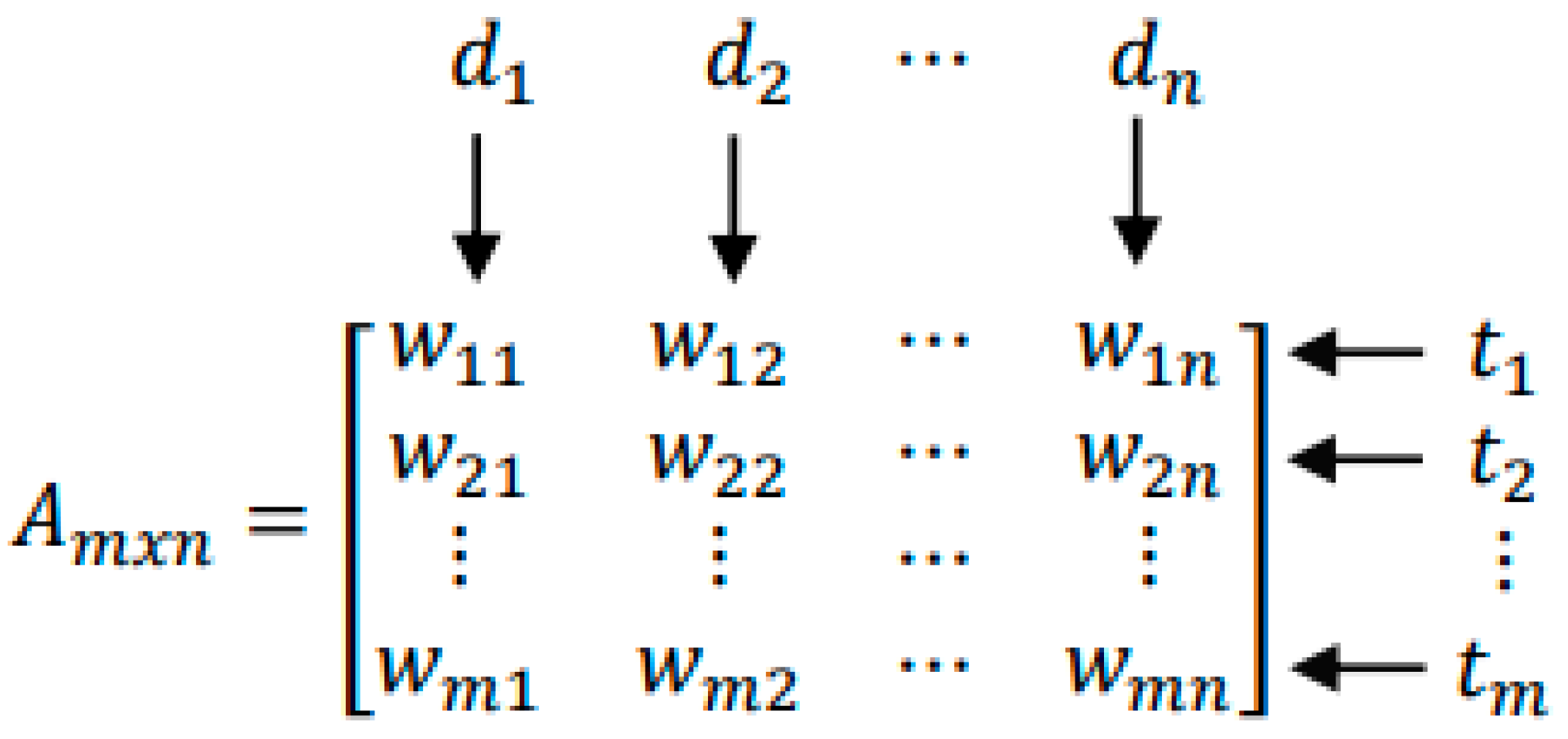
3.1. Topic Modeling Methodology for Literature Reviews
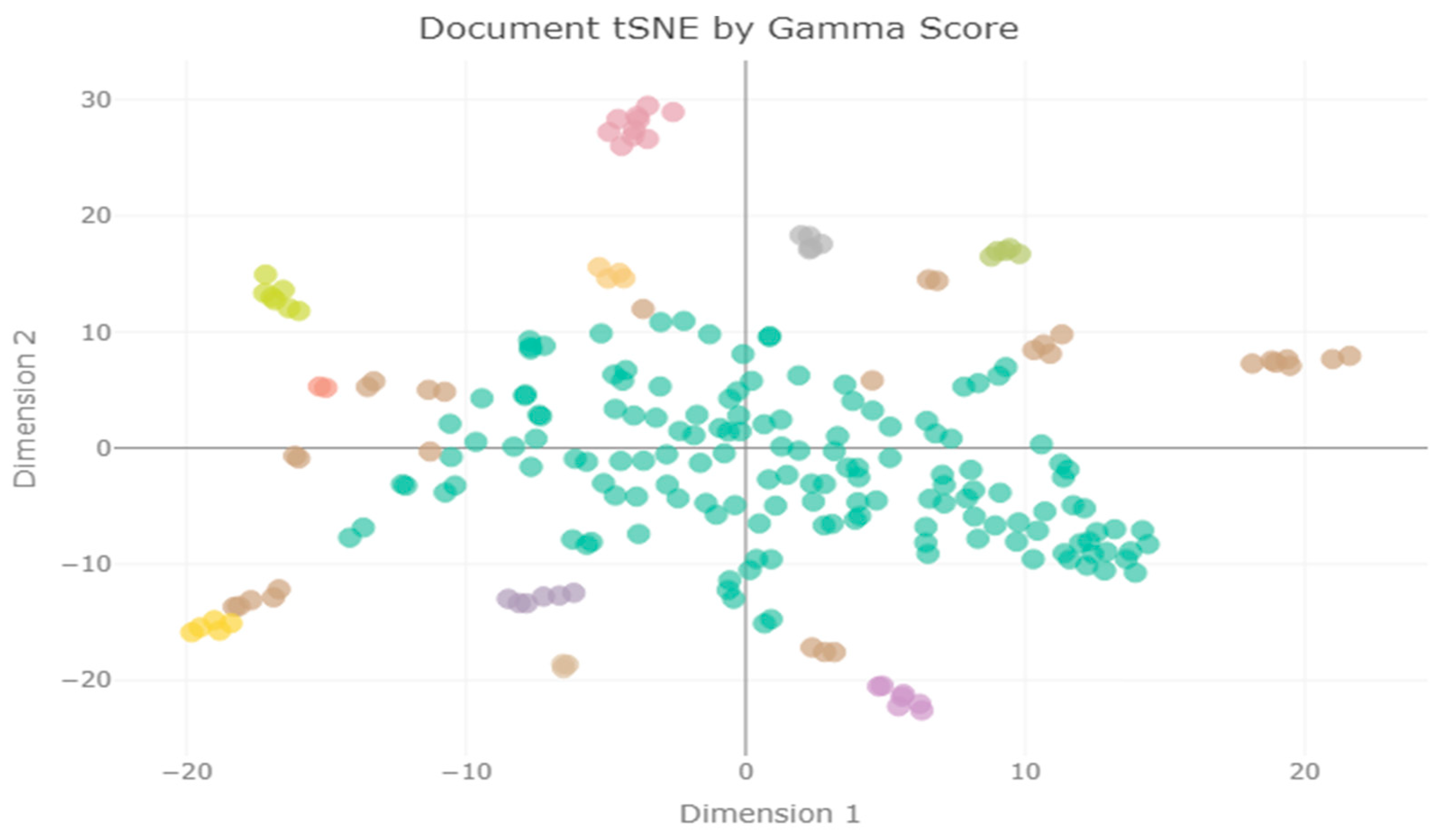
3.2. t-Distributed Stochastic Neighbor Embedding for Topic Model Visualization
3.3. Comparison to the Methodology of Previous Studies
3.4. Information Retrieval: Publication Search and Selection Process
- IEEE Xplore® Digital Library (https://ieeexplore.ieee.org/Xplore/home.jsp)
- ACM Digital Library (https://dl.acm.org/)
- Science Direct–Elsevier (https://www.sciencedirect.com/)
- Springer Link (https://link-springer.com/)
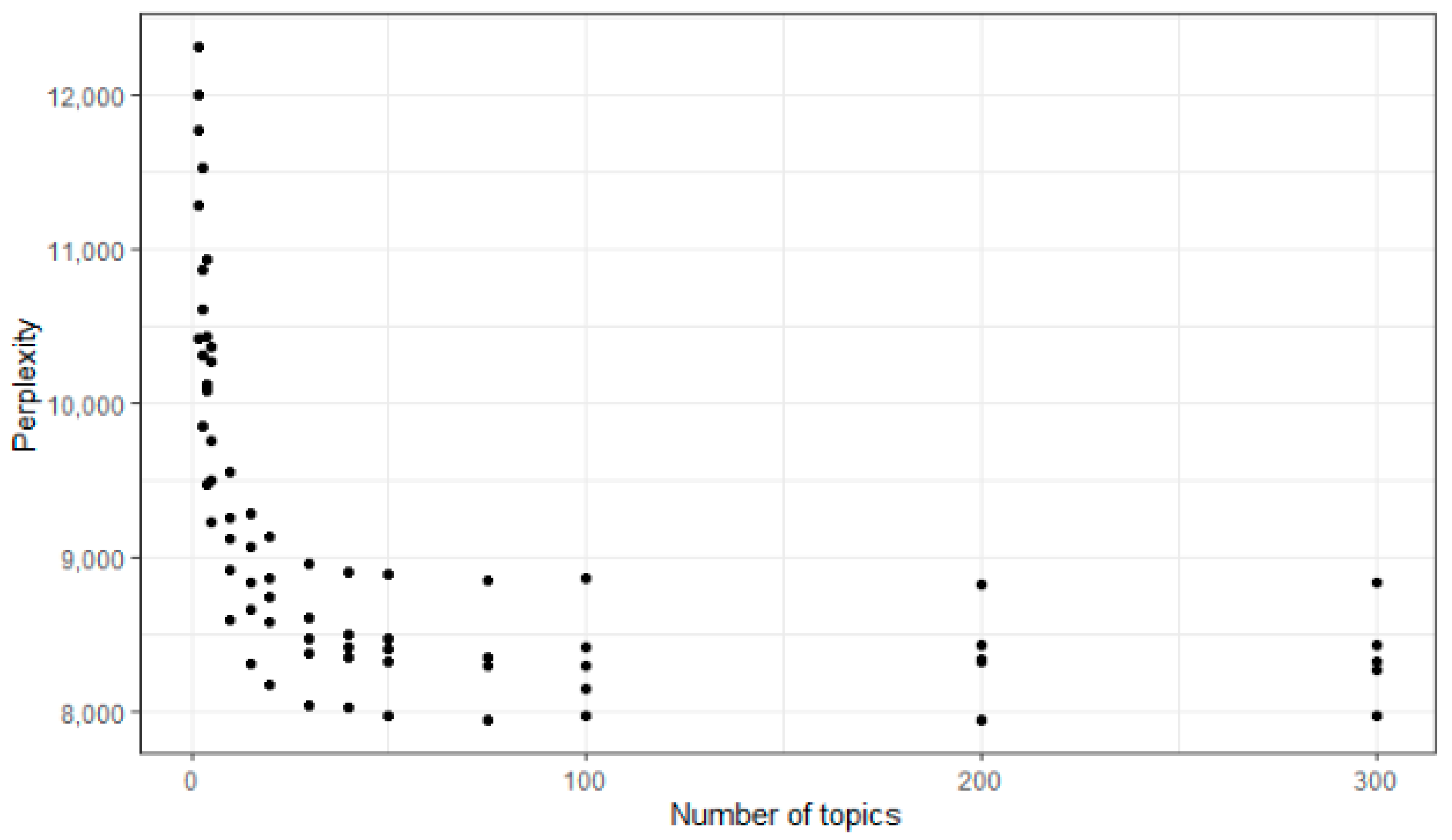
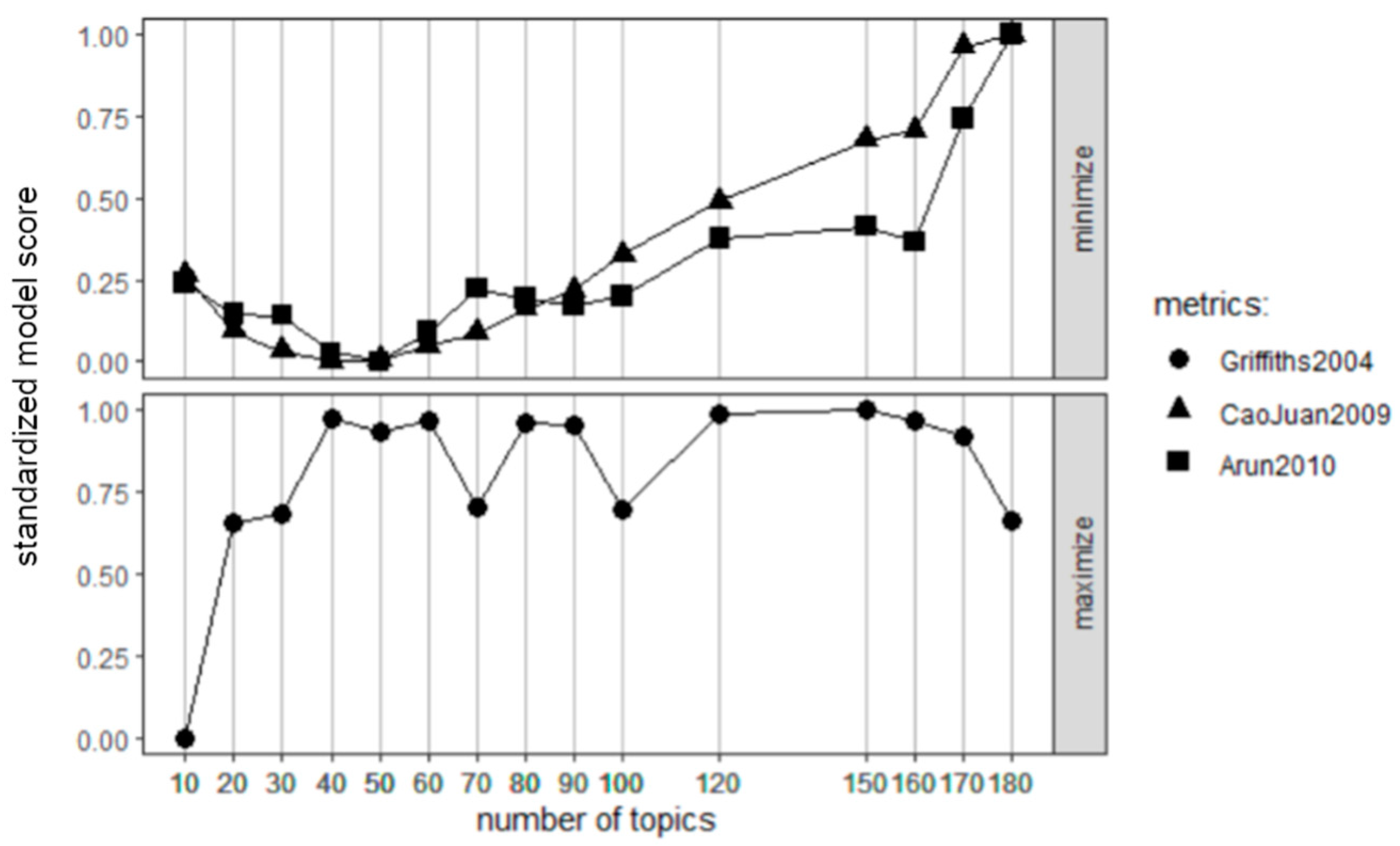
3.5. Application of Algorithm and Parametrization
4. Current Enterprise Architecture Research Trends
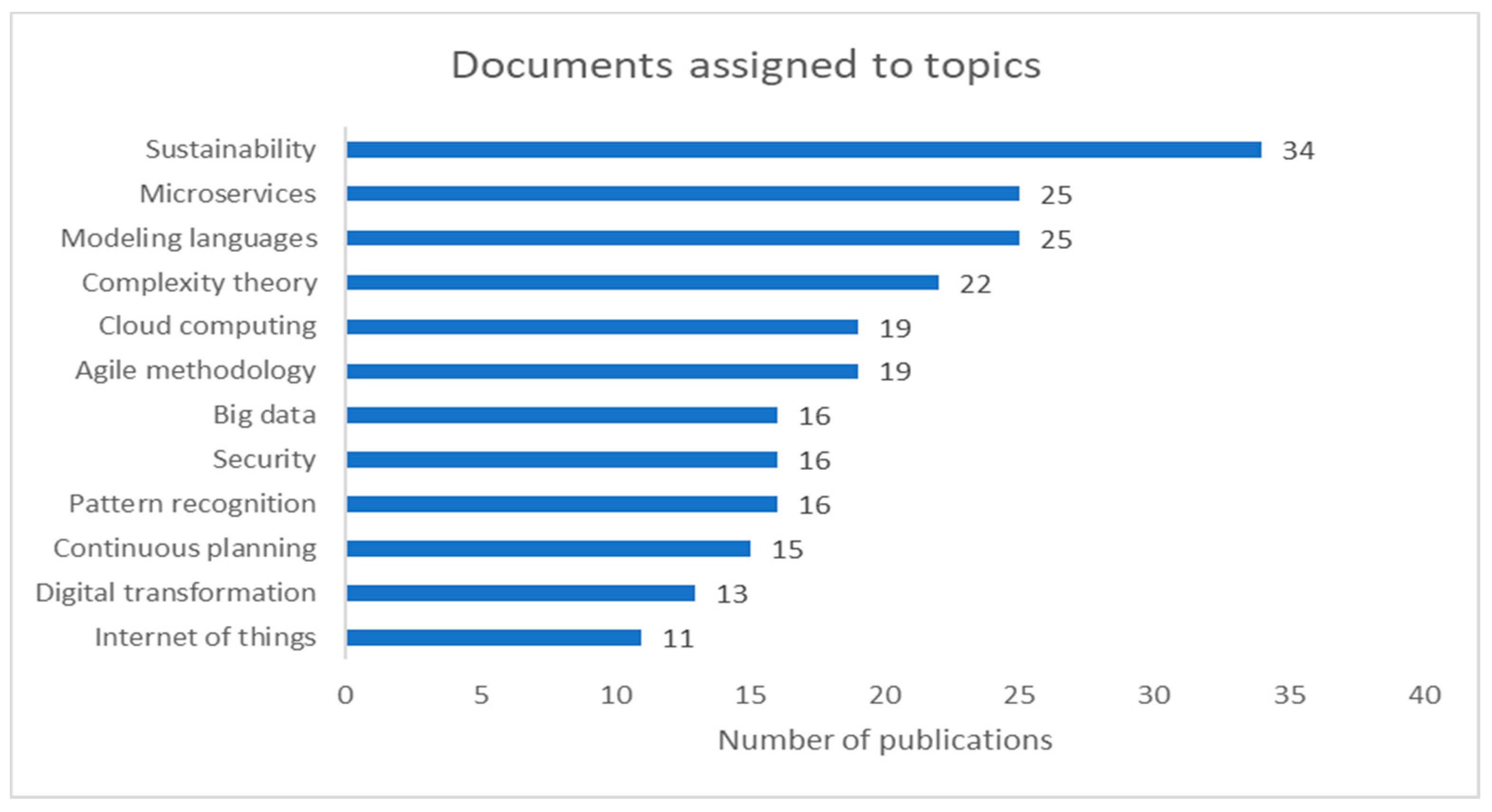
4.1. Identifying and Measuring Current EA Trends
4.2. Significance of Full-Text Mapping and the Deployment of t-SNE in Analyzing EA Trends
4.2.1. Cloud Computing and EA
4.2.2. Sustainability and EA
4.2.3. Digital Transformation and EA
4.2.4. Pattern Recognition and EA
4.2.5. Complexity Theory and EA
4.2.6. Modeling Languages and EA
4.2.7. Big Data and EA
4.2.8. Microservices and EA
4.2.9. Security and EA
4.2.10. Internet of Things and EA
4.2.11. Agile Methodology and EA
4.2.12. Continuous Planning and EA
5. General Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Just, M.A.; Carpenter, P.A.; Woolley, J.D. Paradigms and processes in reading comprehension. J. Exp. Psychol. Gen. 1982, 111, 228–238. [Google Scholar] [CrossRef]
- Abdallah, A.; Abran, A. Enterprise Architecture Measurement: An Extended Systematic Mapping Study. Int. J. Inf. Technol. Comput. Sci. 2019, 11, 9–19. [Google Scholar] [CrossRef] [Green Version]
- Zachman, J. A Framework for Information Systems Architecture. IBM Syst. J. 1987, 38, 276–292. [Google Scholar] [CrossRef]
- Winter, R.; Fischer, R. Essential Layers, Artifacts, and Dependencies of Enterprise Architecture. In Proceedings of the 2006 10th IEEE International Enterprise Distributed Object Computing (EDOCW’06), Hong Kong, China, 16–20 October 2006; p. 30. [Google Scholar]
- Halawi, L.; McCarthy, R.; Farah, J. Where We are with Enterprise Architecture. J. Inf. Syst. Appl. Res. 2019, 12, 4–13. [Google Scholar]
- Gampfer, F.; Jürgens, A.; Müller, M.; Buchkremer, R. Past, current and future trends in enterprise architecture—A view beyond the horizon. Comput. Ind. 2018, 100, 70–84. [Google Scholar] [CrossRef]
- Buchkremer, R.; Demund, A.; Ebener, S.; Gampfer, F.; Jagering, D.; Jurgens, A.; Klenke, S.; Krimpmann, D.; Schmank, J.; Spiekermann, M.; et al. The Application of Artificial Intelligence Technologies as a Substitute for Reading and to Support and Enhance the Authoring of Scientific Review Articles. IEEE Access 2019, 7, 65263–65276. [Google Scholar] [CrossRef]
- Hevner, A.; March, S.; Park, J.; Ram, S. Design science research in information systems. MIS Q. 2004, 28, 75–105. [Google Scholar] [CrossRef] [Green Version]
- Winter, R. Design science research in Europe. Eur. J. Inf. Syst. 2008, 17, 470–475. [Google Scholar] [CrossRef]
- Saint-Louis, P.; Morency, M.C.; Lapalme, J. Defining Enterprise Architecture: A Systematic Literature Review. In Proceedings of the 2017 IEEE 21st International Enterprise Distributed Object Computing Workshop (EDOCW), Quebec City, QC, Canada, 10–13 October 2017; pp. 41–49. [Google Scholar]
- ISO/IEC. Systems and Software Engineering–Architecture Description; IEEE: Piscataway Township, NJ, USA, 2011. [Google Scholar]
- Kitsios, F.; Kamariotou, M. Business strategy modelling based on enterprise architecture: A state of the art review. Bus. Process Manag. J. 2019, 25, 606–624. [Google Scholar] [CrossRef]
- Zhang, M.; Chen, H.; Luo, A. A Systematic Review of Business-IT Alignment Research with Enterprise Architecture. IEEE Access 2018, 6, 18933–18944. [Google Scholar] [CrossRef]
- Ansyori, R.; Qodarsih, N.; Soewito, B. A systematic literature review: Critical success factors to implement enterprise architecture. Procedia Comput. Sci. 2018, 135, 43–51. [Google Scholar] [CrossRef]
- Dumitriu, D.; Popescu, M.A.-M. Enterprise Architecture Framework Design in IT Management. Procedia Manuf. 2020, 46, 932–940. [Google Scholar] [CrossRef]
- Li, L.-S.; Gan, S.-J.; Yin, X.-D. Feedback recurrent neural network-based embedded vector and its application in topic model. J. Embed. Syst. 2017, 2017, 5. [Google Scholar] [CrossRef] [Green Version]
- Horn, N.; Erhardt, M.S.; Di Stefano, M.; Bosten, F.; Buchkremer, R. Vergleichende Analyse der Word-Embedding-Verfahren Word2Vec und GloVe am Beispiel von Kundenbewertungen eines Online-Versandhändlers. In Künstliche Intelligenz in Wirtschaft & Gesellschaft; Springer Fachmedien Wiesbaden: Wiesbaden, Germany, 2020; pp. 559–581. ISBN 9783658295509. [Google Scholar]
- Wang, Y.; Berwick, R.C. On Formal Models for Cognitive Linguistics. In Proceedings of the 11th IEEE International Conference on Cognitive Informatics and Cognitive Computing, Kyoto, Japan, 22–24 August 2012; pp. 7–17. [Google Scholar]
- Fahad, S.K.A.S.A.; Yahya, A.E. Inflectional Review of Deep Learning on Natural Language Processing. In Proceedings of the 2018 International Conference on Smart Computing and Electronic Enterprise, Shah Alam, Malaysia, 11–12 July 2018; pp. 1–4. [Google Scholar]
- Samuel, A.L. Some Studies in Machine Learning Using the Game of Checkers. IBM J. Res. Dev. 1959, 3, 210–229. [Google Scholar] [CrossRef]
- Shubhankar, K.; Singh, A.P.; Pudi, V. A Frequent Keyword-Set Based Algorithm for Topic Modeling and Clustering of Research Papers. In Proceedings of the 2011 3rd Conference on Data Mining and Optimization (DMO), Putrajaya, Malaysia, 28–29 June 2011; pp. 96–102. [Google Scholar]
- Sun, Y.; Han, J.; Gao, J.; Yu, Y. iTopicmodel: Information Network-Integrated Topic Modeling. In Proceedings of the 2009 Ninth IEEE International Conference on Data Mining, Miami Beach, FL, USA, 6–9 December 2009; pp. 493–502. [Google Scholar]
- Hong, L.; Davison, B. Empirical Study of Topic Modeling in Twitter. In Proceedings of the First Workshop on Social Media Analytics, Washington, DC, USA, 25–28 July 2010; pp. 80–88. [Google Scholar]
- Blei, D.; Ng, A.; Jordan, M. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Anwar, W.; Bajwa, I.S.; Choudhary, M.A.; Ramzan, S. An Empirical Study on Forensic Analysis of Urdu Text Using LDA-Based Authorship Attribution. IEEE Access 2018, 7, 3224–3234. [Google Scholar] [CrossRef]
- Haidar, M.A.; Kurimo, M. Lda-Based Context Dependent Recurrent Neural Network Language Model Using Document-Based Topic Distribution of Words. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5730–5734. [Google Scholar]
- Hussain, A.; Tahir, A.; Hussain, Z.; Sheikh, Z.; Gogate, M.; Dashtipour, K.; Ali, A.; Sheikh, A. Artificial intelligence-enabled analysis of UK and US public attitudes on Facebook and Twitter towards COVID-19 vaccinations (Preprint). J. Med. Internet Res. 2020. [Google Scholar] [CrossRef]
- Hao, Y.; Mu, T.; Hong, R.; Wang, M.; Liu, X.; Goulermas, J.Y. Cross-Domain Sentiment Encoding through Stochastic Word Embedding. IEEE Trans. Knowl. Data Eng. 2020, 32, 1909–1922. [Google Scholar] [CrossRef] [Green Version]
- Welbers, K.; Van Atteveldt, W.; Benoit, K. Text analysis in R. Commun. Methods Meas. 2017, 11, 245–265. [Google Scholar] [CrossRef]
- Ooms, J. Pdftools: Text Extraction, Rendering and Converting of PDF Documents. Available online: https://cran.r-project.org/web/packages/pdftools/index.html/ (accessed on 21 April 2021).
- Khanna, P.; Kumar, S.; Mishra, S.; Sinha, A. Sentiment analysis: An approach to opinion mining from twitter data using r. Int. J. Adv. Res. Comput. Sci. 2017, 8, 252–256. [Google Scholar] [CrossRef]
- Suri, P.; Roy, N.R. Comparison between LDA & NMF for Event-Detection from Large Text Stream Data. In Proceedings of the 3rd IEEE International Conference on “Computational Intelligence and Communication Technology” (IEEE-CICT 2017), Ghaziabad, India, 9–10 February 2017; pp. 1–5. [Google Scholar]
- Yaram, S. Machine Learning Algorithms for Document Clustering and Fraud Detection. In Proceedings of the 2016 IEEE International Conference on Data Science and Engineering (ICDSE), Cochin, India, 23–25 August 2016; pp. 1–6. [Google Scholar]
- Feinerer, I. An introduction to text mining in R. Newsl. R Proj. 2008, 8, 19. [Google Scholar]
- Wang, X.; Lee, M.; Pinchbeck, A.; Fard, F.H. Where Does LDA Sit for GitHub? In Proceedings of the 2019 34th IEEE/ACM International Conference on Automated Software Engineering Workshop (ASEW), San Diego, CA, USA, 11–15 November 2019; pp. 94–97. [Google Scholar]
- Hidayat, E.Y.; Firdausillah, F.; Hastuti, K.; Dewi, I.N. Azhari Automatic Text Summarization Using Latent Dirichlet Allocation (LDA) for Document Clustering. Int. J. Adv. Intell. Inform. 2015, 1, 132–139. [Google Scholar] [CrossRef] [Green Version]
- O’Callaghan, D.; Greene, D.; Carthy, J.; Cunningham, P. An Analysis of the Coherence of Descriptions in Topic Modeling. Expert. Syst. Appl. 2015, 42, 5645–5657. [Google Scholar] [CrossRef] [Green Version]
- Xu, A.; Qi, T.; Dong, X. Analysis of the Douban online review of the MCU: Based on LDA topic model. J. Phys. Conf. Ser. 2020, 1437, 012102. [Google Scholar] [CrossRef] [Green Version]
- Huang, L.; Ma, J.; Chen, C. Topic Detection from Microblogs Using T-LDA and Perplexity. In Proceedings of the 2017 24th Asia-Pacific Software Engineering Conference Workshop, Nanjing, China, 4–8 December 2017; pp. 71–77. [Google Scholar]
- Chen, Q.; Yao, L.; Yang, J. Short Text Classification Based on LDA Topic Model. In Proceedings of the 2016 International Conference on Audio, Language and Image Processing (ICALIP), Shanghai, China, 11–12 July 2016; pp. 749–753. [Google Scholar]
- Shiryaev, A.; Dorofeev, A.; Fedorov, A.; Gagarina, L.; Zaycev, V. LDA Models for Finding Trends in Technical Knowledge Domain. In Proceedings of the 2017 IEEE Conference on Russian Young Researchers in Electrical and Electronic Engineering (ElConRus), St. Petersburg and Moscow, Russia, 1–3 February 2017; pp. 551–554. [Google Scholar]
- Shao, J. Linear Model Selection by Cross-Validation. J. Am. Stat. Assoc. 1993, 88, 486–494. [Google Scholar] [CrossRef]
- Pleplé, Q. Perplexity To Evaluate Topic Models. Available online: http://qpleple.com/perplexity-to-evaluate-topic-models/ (accessed on 20 April 2021).
- Slutsky, A.; Hu, X.; An, Y. Tree Labeled LDA: A Hierarchical Model for Web Summaries. In Proceedings of the 2013 IEEE International Conference on Big Data, Silicon Valley, CA, USA, 6–9 October 2013; pp. 134–140. [Google Scholar]
- Jiang, J. Modeling Syntactic Structures of Topics with a Nested HMM-LDA. In Proceedings of the 2009 Ninth IEEE International Conference on Data Mining, Miami Beach, FL, USA, 6–9 December 2009; pp. 824–829. [Google Scholar]
- Jingrui, Z.; Qinglin, W.; Yu, L.; Yuan, L. A Method of Optimizing LDA Result Purity Based on Semantic Similarity. In Proceedings of the 2017 32nd Youth Academic Annual Conference of Chinese Association of Automation (YAC), Hefei, China, 19–21 May 2017; pp. 361–365. [Google Scholar]
- Murzintcev, N. Select Number of Topics for LDA Model. 2019. Available online: https://cran.r-project.org/web/packages/ldatuning/vignettes/topics.html (accessed on 20 April 2021).
- Griffiths, T.; Steyvers, M. Finding Scientific Topics. Proc. Natl. Acad. Sci. USA 2004, 101, 5228–5235. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cao, J.; Xia, T.; Li, J.; Zhang, Y.; Tang, S. A density-based method for adaptive LDA model selection. Neurocomputing 2009, 72, 1775–1781. [Google Scholar] [CrossRef]
- Arun, R.; Suresh, V.; Madhavan, C.V.; Murthy, M.N. On Finding the Natural Number of Topics with Latent Dirichlet Allocation: Some Observations. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Singapore, 11–14 May 2020; pp. 391–402. [Google Scholar]
- Gao, S.; Janowicz, K.; Couclelis, H. Extracting urban functional regions from points of interest and human activities on location-based social networks. Trans. GIS 2017, 21, 446–467. [Google Scholar] [CrossRef]
- Grün, B.; Hornik, K. topicmodels: An R Package for Fitting Topic Models. J. Stat. Softw. 2011, 40, 1–30. [Google Scholar] [CrossRef] [Green Version]
- Meyer, D.; Hornik, K.; Feinerer, I.; Hornik, K.; Meyer, D. Text Mining Infrastructure in R. J. Stat. Softw. 2008, 25, 1–54. [Google Scholar]
- Li, C.; Feng, S.; Zeng, Q.; Ni, W.; Zhao, H.; Duan, H. Mining Dynamics of Research Topics Based on the Combined LDA and WordNet. IEEE Access 2018, 7, 6386–6399. [Google Scholar] [CrossRef]
- Phan, X.-H.; Nguyen, L.-M.; Horiguchi, S. Learning to Classify Short and Sparse Text & Web with Hidden Topics from Large-scale Data Collections. In Proceedings of the 17th international conference on World Wide Web, Beijing, China, 21–25 April 2008; pp. 91–100. [Google Scholar]
- van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Yasaswi, J.; Kailash, S.; Chilupuri, A.; Purini, S.; Jawahar, C.V. Unsupervised learning based approach for plagiarism detection in programming assignments. ACM Int. Conf. Proceeding Ser. 2017, 117–121. [Google Scholar]
- Pezzotti, N.; Thijssen, J.; Mordvintsev, A.; Höllt, T.; Van Lew, B.; Lelieveldt, B.P.F.; Eisemann, E.; Vilanova, A. GPGPU Linear Complexity t-SNE Optimization. IEEE Trans. Vis. Comput. Graph. 2020, 26, 1172–1181. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chang, C.-Y.Y.; Lee, S.-J.J.; Lai, C.-C.C. Weighted word2vec Based on the Distance of Words. In Proceedings of the 2017 International Conference on Machine Learning and Cybernetics, ICMLC 2017, Ningbo, China, 9–12 July 2017; Volume 2, pp. 563–568. [Google Scholar]
- Pezotti, N.; Lelieveldt, B.P.F.; van der Maaten, L.; Hölt, T.; Eisemann, E.; Vilanova, A. Approximated and User Steerable tSNE for Progressive Visual Analytics. IEEE Trans. Vis. Comput. Graph. 2017, 23, 1739–1752. [Google Scholar] [CrossRef] [Green Version]
- Van Der Maaten, L. Accelerating t-SNE using Tree-based Algorithms. J. Mach. Learn. Res. 2015, 15, 3221–3245. [Google Scholar]
- Krijthe, J.; Van Der Maaten, L. Package “Rtsne”. 2018. Available online: https://cran.r-project.org/web/packages/Rtsne/index.html (accessed on 20 April 2021).
- Toomet, O.; Henningsen, A. Sample Selection Models in R: Package sampleSelection. J. Stat. Softw. 2008, 27, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Séaghdha, D. Latent Variable Models of Selectional Preference. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, Uppsala, Sweden, 11–16 July 2010; pp. 435–444. [Google Scholar]
- Allega, P.; Santos, J. Hype Cycle for Enterprise Architecture 2019; Gartner: Stamford, CT, USA, 2019. [Google Scholar]
- Armbrust, M.; Fox, A.; Griffith, R.; Joseph, A.D.; Katz, R. A view of cloud computing. Commun. ACM 2010, 53, 50–58. [Google Scholar] [CrossRef] [Green Version]
- Dillion, T.; Wu, C.; Chang, E. Cloud Computing: Issues and Challenges. In Proceedings of the 2010 24th IEEE International Conference on Advanced Information Networking and Applications, Perth, Australia, 20–23 April 2010; pp. 27–33. [Google Scholar]
- Jadeja, Y.; Modi, K. Cloud Computing—Concepts, Architecture and Challenges. In Proceedings of the 2012 International Conference on Computing, Electronics and Electrical Technologies [ICCEET], Nagercoil, India, 21–22 March 2012; pp. 877–880. [Google Scholar]
- Blosch, M.; Burton, B. Hype Cycle for Enterprise Architecture; Gartner: Stamford, CT, USA, 2017. [Google Scholar]
- Manzhynski, S.; Figge, F. Coopetition for sustainability: Between organizational benefit and societal good. Bus. Strateg. Environ. 2020, 29, 827–837. [Google Scholar] [CrossRef] [Green Version]
- Espahbodi, L.; Espahbodi, R.; Juma, N.; Westbrook, A. Sustainability priorities, corporate strategy, and investor behavior. Rev. Financ. Econ. 2019, 37, 149–167. [Google Scholar] [CrossRef] [Green Version]
- Lapalme, J.; Gerber, A.; Van Der Merwe, A.; Zachman, J.; De Vries, M.; Hinkelmann, K. Exploring the future of enterprise architecture: A Zachman perspective. Comput. Ind. 2016, 79, 103–113. [Google Scholar] [CrossRef] [Green Version]
- Bauer, W.; Hämmerle, M.; Schlund, S.; Vocke, C. Transforming to a hyper-connected society and economy—Towards an “Industry 4.0”. Proceedia Manuf. 2015, 3, 417–424. [Google Scholar] [CrossRef]
- Zimmermann, A.; Schmidt, R.; Sandkuhl, K. Multiple Perspectives of Digital Enterprise Architecture. In Proceedings of the 14th International Conference on Evaluation of Novel Approaches to Software Engineering (ENASE 2019), Crete, Greece, 4–5 May 2019; pp. 547–554. [Google Scholar]
- Korhonen, J.J.; Halen, M. Enterprise Architecture for Digital Transformation. In Proceedings of the 2017 IEEE 19th Conference on Business Informatics, Thessaloniki, Greece, 24–26 July 2017; pp. 349–358. [Google Scholar]
- Zimmermann, A.; Schmidt, R.; Sandkuhl, K.; Jugel, D.; Bogner, J.; Möhring, M. Evolution of Enterprise Architecture for Digital Transformation. In Proceedings of the 2018 IEEE 22nd International Enterprise Distributed Object Computing Workshop, Stockholm, Sweden, 16–19 October 2018; pp. 87–96. [Google Scholar]
- Kaidalova, J.; Sandkuhl, K.; Seigerroth, K. How Digital Transformation affects Enterprise Architecture Management—A case study. Int. J. Inf. Syst. Proj. Manag. 2018, 6, 5–18. [Google Scholar]
- Sapna, R.; Monikarani, H.G.; Mishra, S. Linked Data through the Lens of Machine Learning: An Enterprise View. In Proceedings of the 2019 IEEE International Conference on Electrical, Computer and Communication Technologies (ICECCT), Coimbatore, India, 20–22 February 2019; pp. 1–6. [Google Scholar]
- Schuetz, A.; Widjaja, T.; Kaiser, J. Complexity in Enterprise Architecture: Conceptualization and Introduction of A Measure from a System Theoretic Perspective. In Proceedings of the 21st European Conference on Information Systems, Utrecht, The Netherlands, 5–8 June 2013; pp. 1–12. [Google Scholar]
- Fritscher, B.; Pigneur, Y. Business IT Alignment from Business Model to Enterprise Architecture. In Proceedings of the International Conference on Advanced Information Systems Engineering, London, UK, 20–24 June 2011; pp. 4–15. [Google Scholar]
- Landthaler, J.; Uludag, Ö.; Bondel, G.; Elnaggar, A.; Nair, S.; Matthes, F. A Machine Learning Based Approach to Application Landscape Documentation. In Proceedings of the IFIP Working Conference on The Practice of Enterprise Modeling, Vienna, Austria, 31 October–2 November 2018; pp. 71–85. [Google Scholar]
- Perez-Castillo, R.; Ruiz, F.; Piattini, M.; Ebert, C. Enterprise Architecture. IEEE Softw. 2019, 36, 12–19. [Google Scholar] [CrossRef]
- Lu, L.; Liu, J. The Major Research Themes of Big Data Literature. In Proceedings of the 2016 IEEE International Conference on Computer and Information Technology, Nadi, Fiji, 8–10 December 2016; pp. 586–590. [Google Scholar]
- Veneberg, R.K.; Iacob, M.E.; van Sinderen, M.J.; Bodenstaff, L. Enterprise Architecture Intelligence Combining Enterprise Architecture and Operational Data. In Proceedings of the 2014 IEEE International Enterprise Distributed Object Computing Conference, Ulm, Germany, 1–5 September 2014; pp. 22–31. [Google Scholar]
- Bogner, J.; Zimmermann, A. Towards Integrating Microservices with Adaptable Enterprise Architecture. In Proceedings of the 2016 IEEE 20th International Enterprise Distributed Object Computing Workshop (EDOCW), Vienna, Austria, 5–9 September 2016; pp. 1–6. [Google Scholar]
- Taibi, D.; Lenarduzzi, V.; Pahl, C. Processes, motivations, and issues for migrating to microservices architectures: An empirical investigation. IEEE Cloud Comput. 2017, 4, 22–32. [Google Scholar] [CrossRef]
- Larno, S.; Seppänen, V.; Nurmi, J. Method Framework for Developing Enterprise Architecture Security. Complex Syst. Inform. Model. Q. 2019, 117, 57–71. [Google Scholar] [CrossRef]
- Atzori, L.; Iera, A.; Morabito, G. The internet of things: A survey. Comput. Netw. 2010, 54, 2787–2805. [Google Scholar] [CrossRef]
- Gubbi, J.; Buyya, R.; Marusic, S.; Palaniswami, M. Internet of Things (IoT): A vision, architectural elements, and future directions. Futur. Gener. Comput. Syst. 2013, 29, 1645–1660. [Google Scholar] [CrossRef] [Green Version]
- Schmidt, R.; Möhring, M.; Härting, R.-C.; Reichstein, C.; Neumaier, P.; Jozinovic, P. Industry 4.0—Potentials for Creating Smart Products: Empirical Research Results. In Proceedings of the International Conference on Business Information Systems, Poznań, Poland, 24–26 June 2015; pp. 16–27. [Google Scholar]
- Canat, M.; Català, N.; Jourkovski, A.; Petrov, S.; Wellme, M.; Lagerström, R. Enterprise Architecture and Agile Development Friends or Foes? In Proceedings of the 2018 IEEE 22nd International Enterprise Distributed Object Computing Workshop, Stockholm, Sweden, 16–19 October 2018; pp. 176–183. [Google Scholar]
- Xiong, W.; Carlsson, P.; Lagerström, R. Re-Using Enterprise Architecture Repositories for Agile Threat Modeling. In Proceedings of the 2019 IEEE 23rd International Enterprise Distributed Object Computing Workshop (EDOCW), Paris, France, 28–31 October 2019; pp. 118–127. [Google Scholar]
- Fitzgerald, B.; Stol, K.-J. Continuous software engineering and beyond: Trends and challenges. In Proceedings of the 1st International Workshop on Rapid Continuous Software Engineering, Hyderabad, India, 31 May–7 June 2014; pp. 1–9. [Google Scholar]
- Knight, R.; Rabideau, G.; Chien, S.; Engelhardt, B.; Sherwoord, R. Casper: Space exploration through continuous planning. IEEE Intell. Syst. 2001, 16, 70–75. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic | Methodology of Gampfer et al. [5] | Methodology in This Work |
|---|---|---|
| Input | 3799 documents | 231 documents |
| Input Type | Title and abstract of papers | Full text or papers |
| Method | K-Means Clustering with Davis-Bouldin | Latent Dirichlet Allocation (LDA) |
| Tools | RapidMiner & SAS | R |
| Results | 8 clusters/trends | 12 clusters/trends |
| Result Type | n-to-n relationship between input documents and trends | n-to-1 relationship between input documents and trends |
| Identified Terms | Related Trend/Topic |
|---|---|
| saas, cloud, computing | cloud |
| agile, methodology, adapt | agile/adapt |
| smart, machines | smart |
| framework, big, data, analysis | big data |
| green, bio, sustainable | sustainable |
| entrepreneurial, enterprise, enterpriselevel | entrepreneurial |
| complexity, theory | complexity theory |
| iot, things | internet of things |
| Identified Terms | Related Trend/Topic |
|---|---|
| pattern, fuzzy | pattern recognition |
| security, attack, protection | security |
| saas, cloud, computing | cloud computing |
| sustainable, ecosystem | sustainability |
| complexity, theory | complexity theory |
| archimate, bpmn, modeling | modeling languages |
| digital, transformation, innovation | digital transformation |
| internet, things, sensor | internet of things |
| data, big, veracity | big data |
| release, cycle, development | continuous planning |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Horn, N.; Gampfer, F.; Buchkremer, R. Latent Dirichlet Allocation and t-Distributed Stochastic Neighbor Embedding Enhance Scientific Reading Comprehension of Articles Related to Enterprise Architecture. AI 2021, 2, 179-194. https://doi.org/10.3390/ai2020011
Horn N, Gampfer F, Buchkremer R. Latent Dirichlet Allocation and t-Distributed Stochastic Neighbor Embedding Enhance Scientific Reading Comprehension of Articles Related to Enterprise Architecture. AI. 2021; 2(2):179-194. https://doi.org/10.3390/ai2020011
Chicago/Turabian StyleHorn, Nils, Fabian Gampfer, and Rüdiger Buchkremer. 2021. "Latent Dirichlet Allocation and t-Distributed Stochastic Neighbor Embedding Enhance Scientific Reading Comprehension of Articles Related to Enterprise Architecture" AI 2, no. 2: 179-194. https://doi.org/10.3390/ai2020011