1. Introduction
The diffusion of electronic systems in any kind of environment has laid the foundations for ubiquitous computing. To push the potential of this paradigm to the limit, it was necessary to connect the objects together. For this purpose, the Internet has always provided a standard platform for world connectivity: from the first mobile networks, to the World Wide Web, to the Internet of Things (IoT). IoT enables connections among either objects and objects, or users and objects [
1,
2].
In a context where the number of complex embedded systems is ever increasing, it is necessary to have cutting-edge and powerful technologies that can support this paradigm. Such an example is the development of interfaces combined with objects, such as Radio Frequency Identification (RFID) and Wireless Sensor Networks (WSNs). These technologies represent a valuable example of how information and communication systems have been incorporated, even transparently, into the IoT objects around us. However, these sensing nodes are typically characterized by limited power resources. Therefore, digital signal acquisition and processing must be performed with high efficiency and low power consumption [
3].
Current platforms are the result of generations of systems that have enabled the manipulation of big data: managing authentication, storage, processing, presentation of such information in a clear, efficient, and easy way [
4,
5]. In this context, the IoT paradigm may emerge successfully, since there is a need to overcome the traditional mobile computing scenarios, like smartphones and generic portable devices, and to evolve the idea in a permanent connection of objects to the environment [
6].
The processing capabilities of every computing system are related to the use of energy in the so called “performance per Watt” metrics. Usually, when a system requires higher performances, it uses more energy, even though it is not a rigid rule. Indeed, thanks to novel effective methods and techniques for energy efficiency, the most recent computerized systems can maintain high performances for the same Watt unit [
7]. It could seem that if the factor of performance per Watt does not improve over time, the electrical costs for keeping the systems in an active state would end-up much higher than the price of the hardware [
8,
9].
For some current applications, the problem of energy efficiency is related to the need for equipping sensor nodes with a battery. Although developments on battery capacities could be performed for increasing energy efficiency, the need for replacing low battery duration yet represents an unresolved problem [
9,
10,
11]. In the worst case, the battery cannot be recharged enough. In high-performance processing systems, such as real-time Digital Signal Processing (DSP), this is a big limitation. For this reason, more and more opportunities for the use and development of IoT systems were found during these years. Several promising lines of research, related to energy harvesting [
11] and passive WSNs [
12], represent hot topics to the scientific community.
Due to the implementation of electronic systems in a great variability of scenarios, the need to adapt the various technologies was of primary importance. Research and development advancements concerning this problem never stop. Several issues have been overcome, including the management of the ever-increasing amount of online information. At the same time, developing different physical solutions depends on each specific problem. Programmable Logic Devices (PLDs) can tackle such a kind of problem. PLDs have been used in many contexts for years, especially when high-processing capacity is required. This issue leads to the design of intelligent re-configurable interfaces. Such a goal can be achieved by using Complex PLDs, including Field Programmable Gate Arrays (FPGAs). FPGAs allow the end-user to reprogram them several times and, thanks to their intrinsic structure and storage technologies, represent an ideal compromise between computational power and adaptability [
13]. The peculiarity of this technology is represented by the ability to configure and reconfigure (even at runtime) the logical functioning of the hardware. This involves the creation of partially configurable devices, which can perform multiple functions (even independent of each other) thanks to the possibility of being able to change the configuration of some circuit portions, according to the processing requirements. In such a context, we analyze the possibility of energy efficiency [
14]. The prerequisite for such a hardware interface is the hardware-software co-design, which denotes a design of the final system by means of a cooperative design process between hardware and software, which are strongly linked and adapted to each other [
15].
Using new configuration storage technologies, followed by the development of hardware-specific programming languages, allows for further abstraction levels that significantly simplify the prototyping process on PLDs. Nowadays, the programming standard is represented by the family of Hardware Description Languages (HDLs), such as VHDL and Verilog. Thanks to the great capabilities of such languages, it is possible to create and test architectural hardware without having to change, modify, or physically limit the whole circuit [
16,
17]. In addition, high-level synthesis methods have been created to generate HDL descriptions starting from algorithms coded in software programming languages, such as C or C++. Thanks to the abstraction possibilities provided by these high-level programming languages, logic capabilities considerably overtook the classic functionality of logic devices. Besides the ability to design the entire static design of an FPGA in a simpler and faster way, by means of abstract structures, it is possible to achieve peculiar capabilities, such as partial dynamic reconfiguration. Partial reconfiguration is an advanced technique that allows one to change the configuration of a FPGA at runtime [
18,
19]. The dynamic reconfiguration of systems, which uses functionality to replace configuration data without interrupting its operation, has been provided for many years [
20]. The ultimate goal is to keep most of the area and resources available for more than one hardware module. The design of modules that are built within the FPGA requires that the project is specifically mapped onto the internal hardware [
21]. Reusing the same partition allows for a virtual extension of the chip area. Even though not every FPGA device supports partial reconfiguration, Xilinx
® Inc. (San Jose, CA, USA) has produced several systems that fully support this feature. The complex process of development and control required during runtime limits the feasibility of this technique in many real-world applications.
Xilinx released the Vivado Design Suite that supports both static and partial programming, thus providing a variety of automatic tools and facilities that help the designer in all design phases [
22].
Despite the basic flow for static programming, some steps could be added to design a adaptive system using a dynamic partial reconfiguration technique: a chip region has to be prefigured to make it reconfigurable, setting some parameters by using multiple design implementations. The final product is the total bitstream creation for booting and partial configuration for each module that is to be replaced at runtime. The designer can change this workflow, regardless of the physical structure of the FPGA.
For the development of the proposed DSP system, ZedBoard was used, a board produced by Xilinx in collaboration with Digilent Inc. (Pullman, WA, USA). The on-board chip belongs to the Zynq-7000 family of All Programmable System on Chip (AP SoC), which integrates one of the latest generation of FPGAs in the Programmable Logic (PL) with a dual-core ARM Cortex-A9 (Cambridge, UK) microprocessor in the Processing System (PS) into a single integrated circuit. Its use is especially suitable for applications that require software/hardware functionality. This innovative system enables the analysis of the impact of the use of partial reconfiguration on energy consumption.
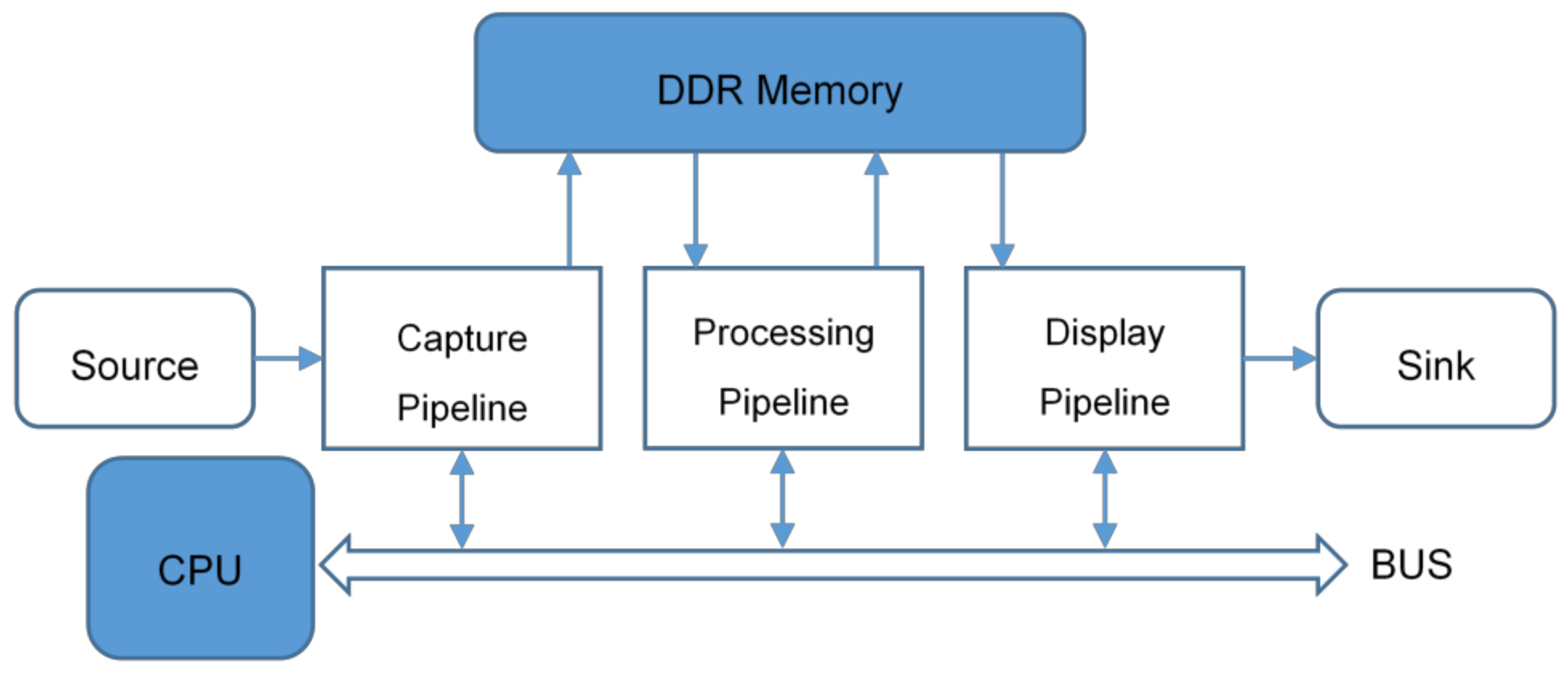
The proposed work is based on the automated DSP of video data streams yielded by a video pattern generator. Filtering can be performed at software-level, as well as at hardware-level, using three different accelerators in the same reconfigurable portion. FPGAs have been designed to generate three pipelines for video stream processing: (i) one for capture, (ii) one for filtering, and (iii) the last one for viewing. At software-level, the CPU controls the data-flow by managing the transfers among the pipelines and Double Data Rate (DDR) memory. It also performs the dynamic loading of the modules that exploit partial reconfiguration. We used the Vivado Design Suite (2017.1, Xilinx Inc., San Jose, CA, USA) during all the steps that led to the final creation of both total and partial bitstreams. A special device configuration unit equipped with the ARM processor allowed for the loading of the partial configuration bitstreams through the Device Configuration (DevC) and Processor Configuration Access Port (PCAP) interfaces. The used operating system is based on Linux and runs on the ARM microprocessor, while the used kernel and the boot loader are provided by Digilent.
The final results show that partial reconfiguration can lead to significant energy efficiency advantages, which are mainly related to low software performances and the idle times of hardware modules.
The paper is structured as follows.
Section 2 outlines the background;
Section 3 analyzes the development environment;
Section 4 describes the proposed reconfigurable system; a case study on DSP is presented in
Section 5;
Section 6 introduces the analytical framework for energy efficiency evaluation, as well as showing and discussing the experimental results; finally, some discussions and conclusive remarks are given in
Section 7 and
Section 8, respectively.
2. Related Works
Dynamic Partial Reconfiguration (DPR) allows one to modify several modules in a static design on the FPGA device and can potentially reduce the number of devices or the device size, thereby reducing both size and power consumption. To date, there have been several works about the partially and dynamically reconfigurable systems. Some of these works have mainly introduced a simple reconfigurable system and focus on the advantages of the proposed dynamic partial reconfiguration design flow. This design type could be exploited in many application fields, for example to meet space requirements in small portable systems, as well as to create a system-on-a-chip with a very high-level of flexibility [
23].
The study on adaptive allocation of limited FPGA resources is also applicable to hardware-accelerated software-defined radios. A system that requires one to either transmit or receive capabilities at any given time, but not both contextually, can switch between the two modes in a fraction of a second using partial reconfiguration. This technology considerably reduces power consumption, which represents a critical issue in portable ground-based applications. A software-defined radio was designed with a reprogrammable Forward Error Correction (FEC) block supporting multiple codecs [
24].
Another work proposes four different techniques to perform DPR, namely: SelectMAP, Serial mode, Joint Test Action Group (JTAG), and Internal Configuration Access Port (ICAP). In the study, each of these techniques is reviewed, evaluated, and tested using a convolutional encoder, i.e., an essential block from a Software Defined Radio (SDR) system [
25].
These architectures generally use a reconfiguration controller for scheduling and allocating total or partial configuration files, named bitstreams. Depending on the complexity of runtime reconfigurations, this controller can be either a simple finite state machine or a microprocessor. The DPR controllers provided by the FPGA vendors rely on software to manage the reconfiguration process. This approach may lead to slow reconfiguration and unpredictable timing. So, an alternative approach was developed for designing an open-source DPR controller specialized for real-time systems. The controller enables a processor to perform reconfiguration in a time-predictable manner and supports different operating modes [
26].
Regarding energy consumption in digital systems, there are two main types of energies that are used: (i) static energy and (ii) dynamic energy. Static current consumption occurs due to intrinsic losses of the transistors, while the dynamic current is used during transistor state switching. A recent study released by Xilinx indicates that, below 0.25 μm (referring to the semiconductor production process), the static energy consumption exponentially increases with every new production process [
27]. This study states that the static component is becoming the largest percentage of the total energy consumption.
The analyses on energy losses of 90 nm FPGAs were performed using detailed device-level simulations. Especially, static energy consumption was found to be directly dependent on the configuration bit values. In addition, this work indicated that the polarity of the inputs/outputs of the circuits has a strong impact on the current consumption. Especially, the authors indicated that in the modern commercial process that uses the CMOS technology, the energy consumption from the elementary structures that compose FPGA devices, such as buffers and multiplexers, is significantly lower when their outputs and inputs are configured in logic 1 versus logic 0 [
27].
On the other hand, the dynamic energy consumption must be also taken into account. Several studies focused on the impact of the clock signal on the overall chip energy consumption. The achieved results show that the clock distribution can contribute up to 22% of the total power. To reduce the consumption of these lines, various solutions were developed, such as clock gating [
28], which allows one to turn certain circuit clocks on or off, or enables clock frequency reduction [
29].
A more interesting breakthrough in these studies implies the use of reconfiguration at runtime. In the past, circuits were proposed in which particular functions were bound to specific regions, allowing for turning-off unnecessary components at runtime [
29]. This class of schemes often requires modification of the FPGA architectures and hardware implementation.
In this work, we will concentrate on energy efficiency techniques that could be applied to existing and commercially available partial dynamically reconfigurable FPGAs, such as Xilinx (all the families of the 7 Series) and Altera Corp. (San Jose, CA, USA) products. In particular, the case of the potential of partial reconfiguration will be treated and analyzed, in order to achieve the maximum balance between computing and dissipated power.
DPR is mainly used to realize adaptive hardware in a dynamic environment. Firstly, it speeds-up hardware algorithms that may be particularly burdensome when running on software platforms. Secondly, it allows one to efficiently use the chip area, so that several hardware modules can be interchanged while the rest of the system continues its execution. Finally, it is possible to implement an energy-saving policy by replacing the inactive modules with other ones that virtually do not dissipate power.
4. The Proposed Reconfigurable System
The system proposed and analyzed in this work is a combination of hardware and software design, developed and implemented using tools, techniques, and components provided by Xilinx and Xylon. One of the main objectives of the paper is the development of a general dynamically and partially reconfigurable infrastructure for the energy efficiency evaluation in dynamic, partially reconfigurable FPGA devices. More specifically, the design methodology for the implemented DSP application was adapted for the ZedBoard device.
This section is divided into two parts: the former explains how a partial reconfiguration hardware design on Vivado Design Suite is created; the latter deals with the software guidelines, explaining the dynamical part of partial reconfiguration process.
4.1. Design Workflow and Implementation
The design workflow for the latest generation systems, like the 7000 Series chip, is developed on the Vivado software suite, which provides a new paradigm of hardware designing. Such software can support the automation of low-level detail management to meet the requirements of the different supported chips. In general, the user should only provide directions for defining the design structure and dealing with floor-planning. The partially reconfigurable design process is similar to the standard stream, but with some additional steps. This particular design flow requires the implementation of multiple configurations that ultimately translate into the creation of total bitstreams, for each configuration, and partial bitstreams, for each reconfigurable module. The amount of the required configurations varies according to the number of modules that need to be implemented. However, all configurations use the same static and routed design, exporting it from the initial configuration and importing it into all the subsequent ones. The detailed description of processing steps involved in a partial reconfiguration project can be retrieved from [
22].
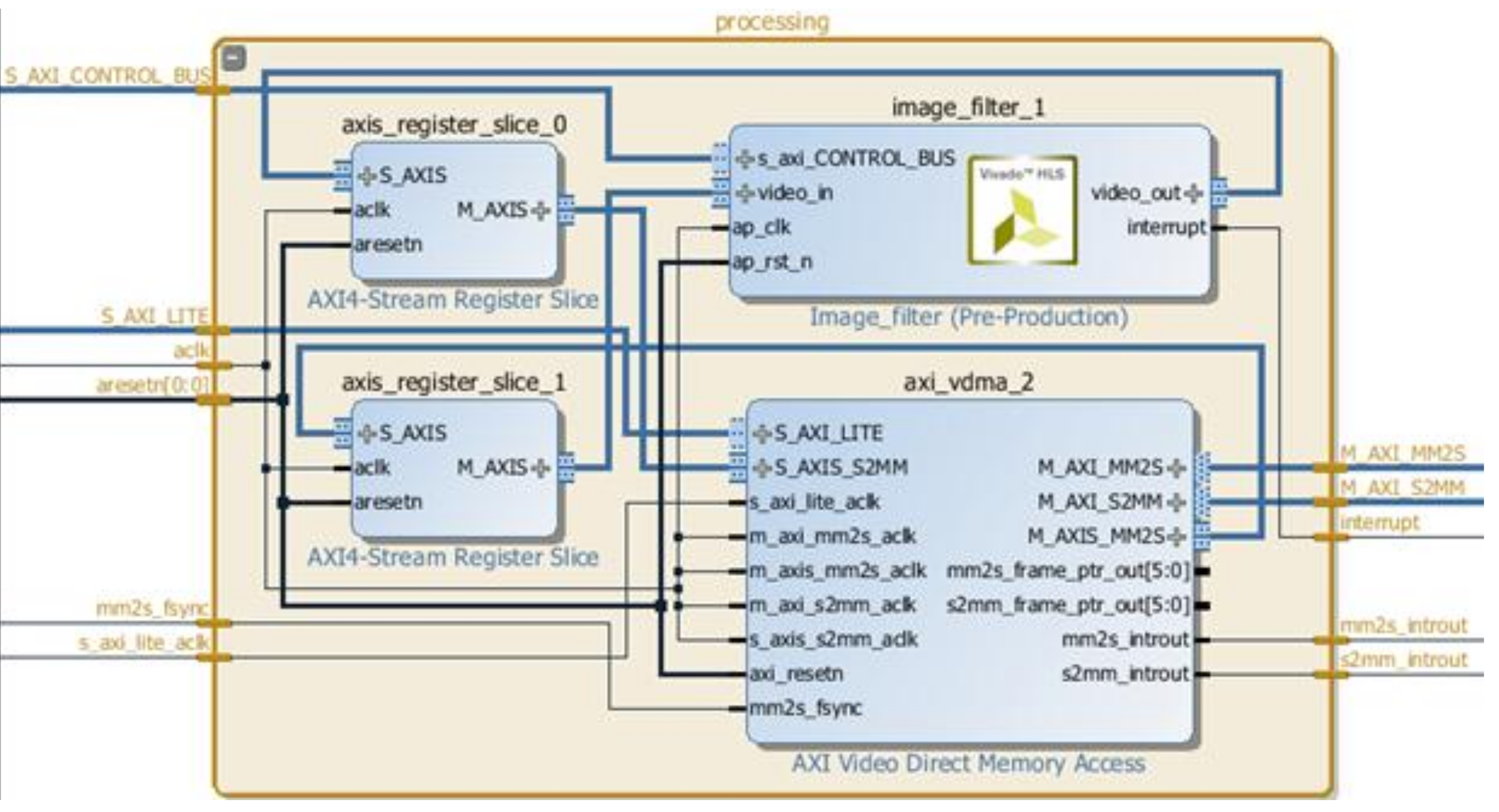
The main contribution of this work regards the development of an infrastructure for the partial dynamic reconfiguration technique. In our case, we used the ZedBoard as target device for our implementation. The design workflow was adapted to consider the common elements and steps to support our analysis. Although the implementation steps can be applied regardless of the target device, thanks also to the Vivado automation processes, the first design step, which is the creation of a block diagram starting from the combination of IP cores, needs to be adapted to each target system. Some IP cores represent specific feature of the target board (e.g., the PS IP Wrapper) and cannot be employed in general design processes. Therefore, the first phase involved the creation of a diagram, wherein the DSP blocks (i.e., video capturing, filtering, and visualization) represented the starting point of the design. Then, the specific blocks of PS, clock, interrupt, and interconnections were added to the make the whole design specialized to the target device. Consequently, device-dependent constraint files were created to bind the design signal line to the board’s physical pins and imported in Vivado. Generally, the constraint files are used during subsequent design phases.
After choosing a reconfigurable target block, the design flow is characterized by synthesis and implementation processes, which are based on the static design flow. The main difference concerns the outline of the portion of the target chip (in our case the PL of the Zynq-7000) that needs to be reconfigurable and starts the process performed by Vivado for the final creation of the partial configuration files.
4.2. Software Guidelines
The configuration process of dynamic partially reconfigurable systems follows the same steps as the classical approach:
After the power-on reset, the boot ROM determines the external memory interface, the boot mode, and encryption status. The ROM uses the DevC Direct Memory Access (DMA) to load the First Stage Boot Loader (FSBL) into the Integrated RAM memory;
The FSBL control is released to the CPU, which configures the PL with the static design bitstream using the PCAP port. The device is now completely configured and working;
The FSBL loads and releases control at the second boot loader (U-boot) that loads the image of the Linux kernel, the binary file tree, and the Linux system root, and finally releases the control to the Linux kernel;
At the end of the boot process, by means of a Bash script, a Linux application is started.
From this moment, the application can use partial bitstreams to modify the logic circuit in the reconfigurable portion, while the rest of the FPGA continues to run. This is accomplished by transferring the partial bitstream from the DDR to the PL through the PCAP. A single configuration engine handles the full configuration, as well as the partial reconfiguration.
The task of loading a partial bitstream in the PL does not require knowledge of the physical location of the reconfigurable module, since the configuration frame address information is included in the partial bitstream. So, it is not possible to dynamically assign the location where the reconfigurable module has to be loaded, because the location is bound with the module during design and implementation steps on Vivado.
At the application-level, reconfiguration is enabled and managed by the
xdevcfg driver provided by Digilent. This driver allows one to perform a complete configuration or partial reconfiguration of the PL. It is built on a virtual file system, where the reconfiguration is performed by writing the bitstream into a certain location of the Linux file system. This operation activates the DMA transfer and blocks the operating system by polling, awaiting an event that indicates the end of the reconfiguration phase. The reconfigurable region is considered as a reconfigurable peripheral, where the only fixed parameter is its range of memory allocations. This peripheral is connected to the ARM via an Advanced eXtensible Interface (AXI) bus interface, while partial bitstreams are already generated and stored on the SD Card mounted onto the Linux file system [
37].
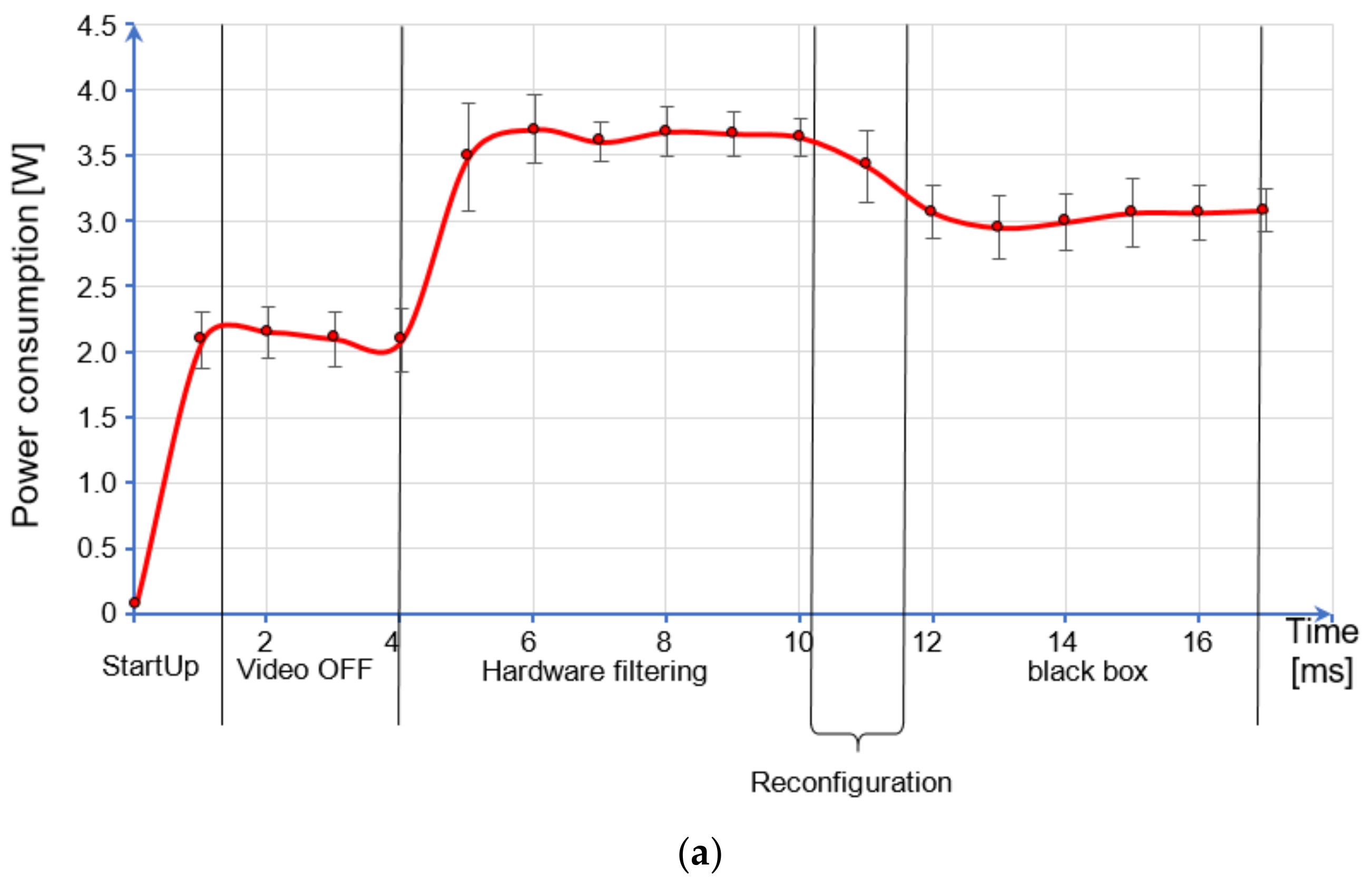
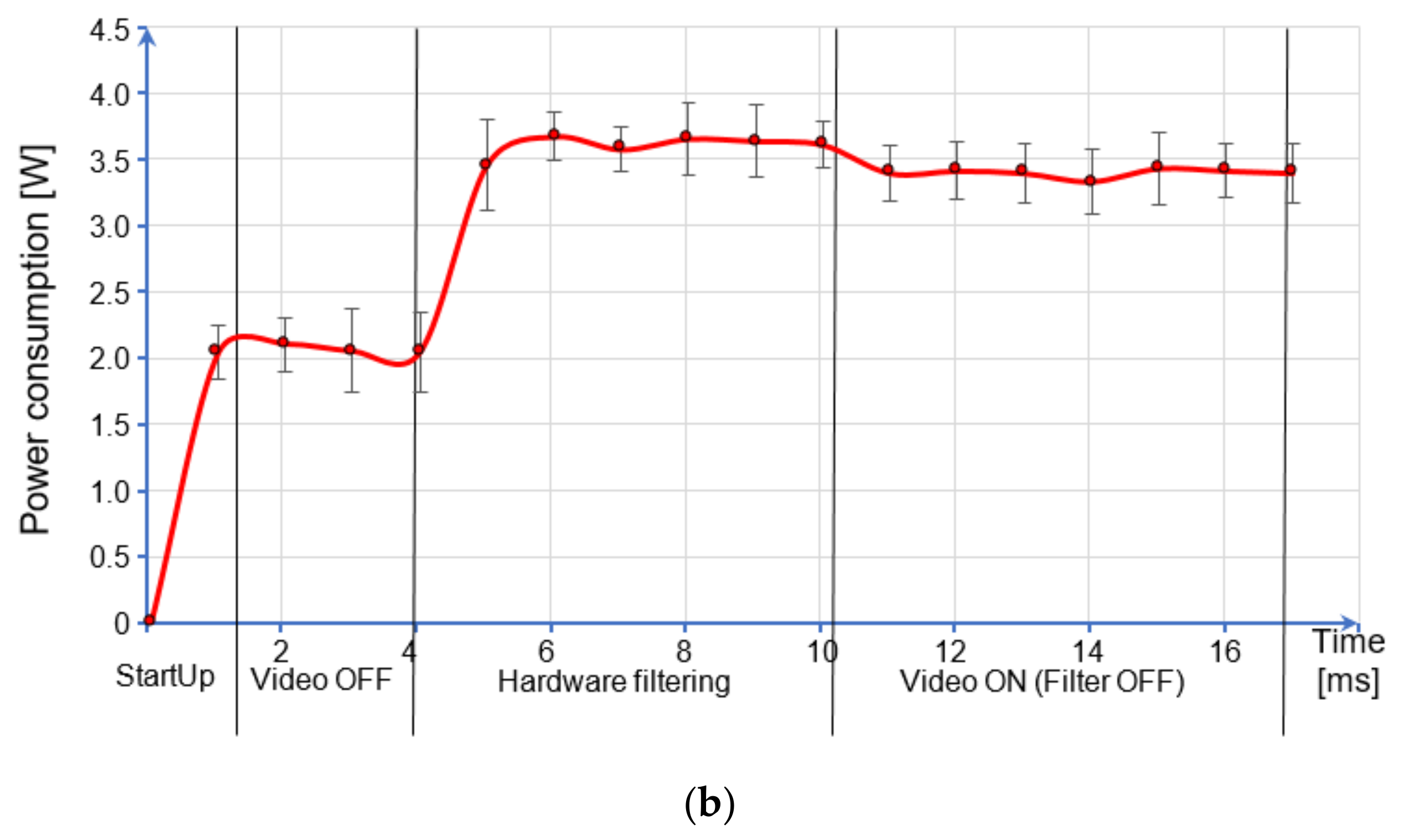
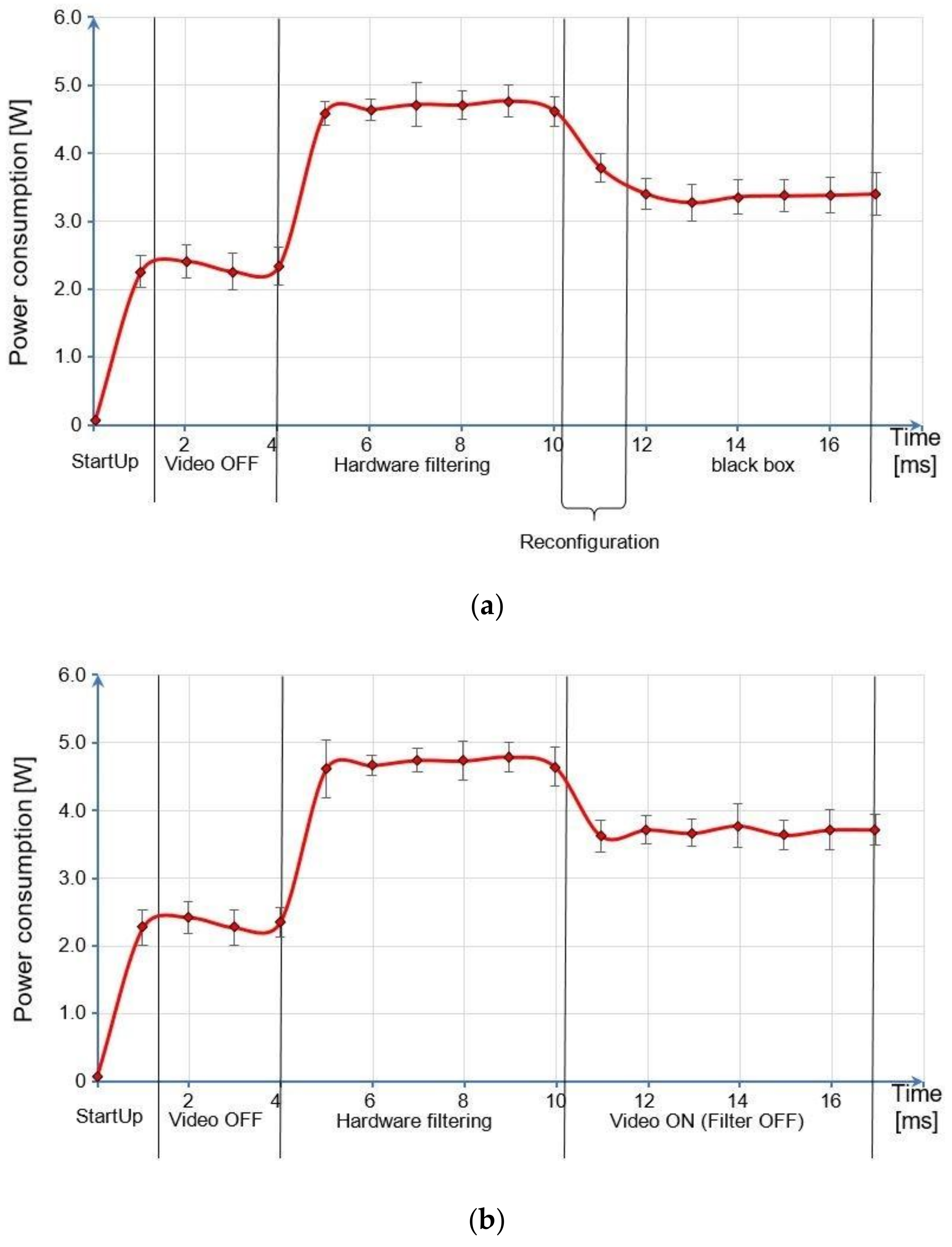
7. Discussion
The proposed case study aims to evaluate which conditions enable the energy efficiency of a dynamic, partially reconfigurable, FPGA-based device. The presented results could be used in the IoT domain, as well as in ubiquitous and edge computing, in which the most of nodes are characterized by limited resources and require high-efficiency and low-power consumption [
48].
Since the 1980s, most embedded systems have used microprocessor-based kits for indoor solutions [
49], which do not require a large amount of processing power. However, in the context of the IoT, the devices need more computational efficiency to appropriately handle multiple flows of information and the related computation. Most of those devices are provided with a reliable connection, a processing core with parallelism feature, a high degree of internal reconfigurability, and adequate power supply sources. Especially, when these power supply sources are batteries that cannot be easily recharged, power-saving is one of the main key aspects. In this case, the high-end FPGA devices, coupled with a high-performance embedded microprocessor, can play a significant role for the goal of energy efficiency [
50]. So, the main point is how the dynamic partial reconfiguration of the latest FPGA devices may be used for this goal.
The work presented in this paper aimed at exploiting a device, which combines an FPGA and a microprocessor in the same chip, to realize a dynamic, partially reconfigurable system and use this paradigm for energy efficiency.
Unlike static systems, a dynamic, partially reconfigurable device can support different hardware modules that can be interchanged at runtime. If some of these modules do not implement logic (i.e., they contain an empty module that is also called a black box), they can be loaded instead of the processing logic so that the portion of the device consumes less energy.
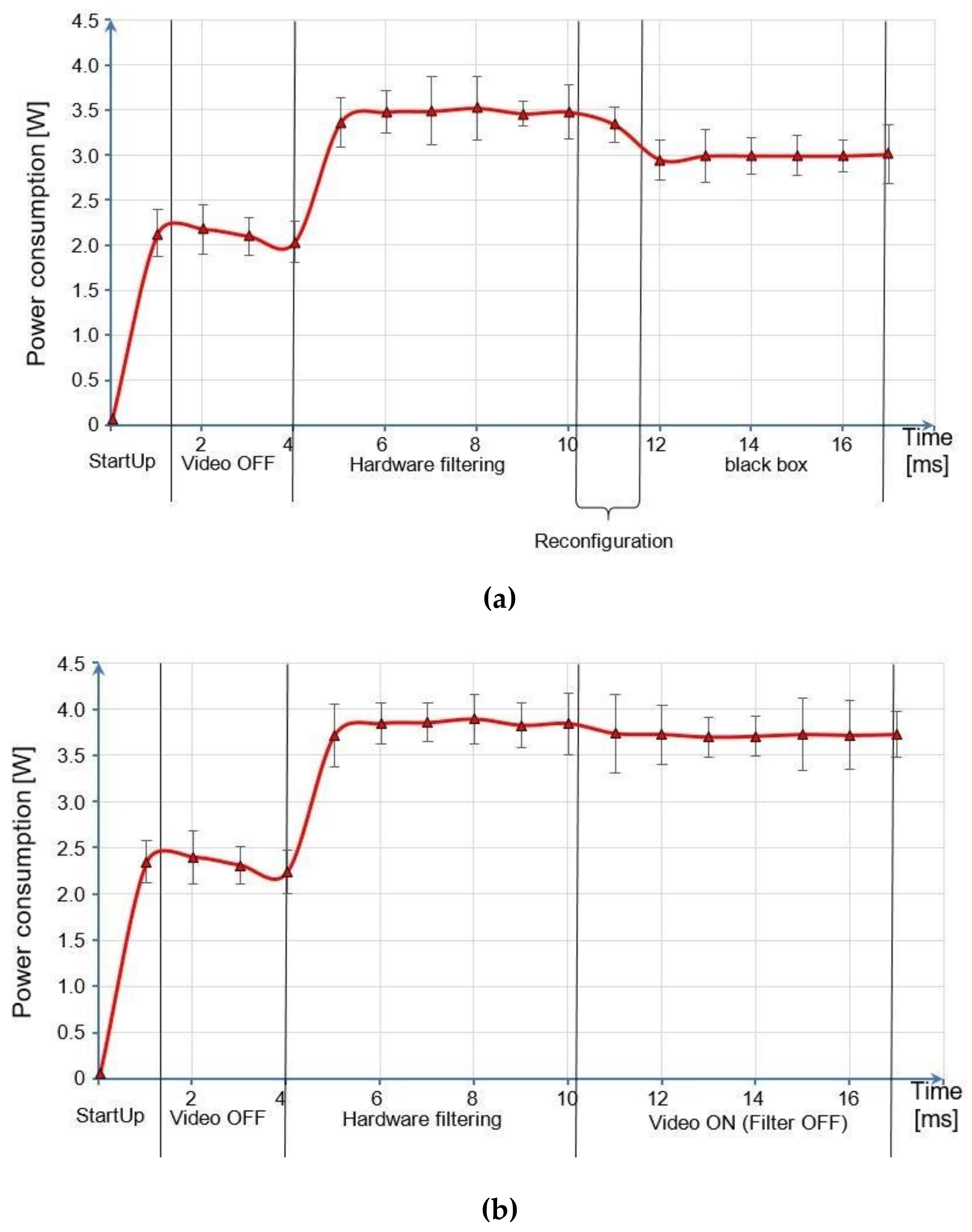
Unfortunately, the configuration process itself introduces a further energy overload. So, the conditions that save energy, using a partially reconfigurable hardware accelerator, have been investigated. We compared the reconfigurable architecture with two different systems: the first one uses the same filters to process the video stream at software-level, while the second one is a non-reconfigurable architecture. For an accurate and concrete evaluation, an analytical framework of the used parameters was provided, which succeeding in generalizing the problem by means of three different aspects:
Quantifying the difference of power consumption between a software and a hardware system, in terms of the power consumption required to perform the same operation using either a microprocessor or an embedded hardware device. This allows one to understand under which timing conditions a dedicated hardware can provide energy-savings compared to the corresponding software implementation;
Evaluating if the energy needed by the management of the reconfiguration process could invalidate the energy saved by the reconfiguration process;
In the specific case of dynamic partial reconfiguration compared to a non-reconfigurable system, assessing if it is possible to achieve a significant benefit using this paradigm.
The estimated timing conditions that allow the dynamic partially reconfigurable process to achieve relevant energy efficiency with respect to the corresponding static architecture are variable and depend on the energy consumption of each reconfigured IP core. The paper presents a deep analysis that links the time between two dynamic partial reconfigurations and the reconfigured core energy consumption for several energy saving rates (25%, 50%, 75%, and 99.9%). Considering the posterize filter, a reconfiguration period of 663 ms enables a 99.9% energy saving rate in a partially reconfigurable device when compared to the same static device with the posterize filter always on. Similar conclusions can be derived for the other filter implementations that have different energy consumption values.
8. Conclusions
The proposed paper investigated under which conditions a partially reconfigurable hardware accelerator can provide energy efficiency for complex processing tasks by introducing a more general analytical framework for a direct comparison between the energy efficiency of a dynamic, partially reconfigurable device and a static non-reconfigurable one. Accordingly, a specific case study was implemented and analyzed on a FPGA based device. Two different solutions were compared to perform the same video processing task using three different filters, namely, posterize, Sobel operator, and FAST. In the first case, the use of software filtering allowed one to achieve CPU performance and consumption, while in the second case the same parameters were measured by loading the hardware filter module. Three main aspects were considered to determine the energy efficiency conditions:
Comparison between the energy ratio and the processing time ratio of the hardware and software cases;
Comparison of the energy saved through partial dynamic reconfiguration and the exceeding energy due to the reconfiguration process;
Comparison between the energy efficiency of the reconfigurable architecture against the static architecture.
By carrying out a set of power consumption measurements, it was shown that for burdensome computational operations, such as in our video processing application, the difference in energy efficiency between software and hardware is considerable. Similar results were achieved for all the three hardware filters, with the highest energy efficiency for the posterize filter reaching a 96.6% saving factor compared to the software version. In the hardware versus software comparison, the CPU has a working frequency higher than the FPGA, but the latter is an ad-hoc specialized architecture and not a general-purpose one. This characteristic led to the low capacity of complex calculations of the microprocessor and greatly increased the latency for processing a frame.
For the second point, it was possible to derive a formula that correlated the idle time of the hardware module with remaining known parameters. The idle time was expressed as a variable to have the freedom to choose the filter deactivation time so that the following estimations are obtained. Using the data collected earlier, it was possible to estimate that the additional energy, introduced by the components that perform the partial reconfiguration, does not invalidate the possibility of energy saving.
For the third point, we introduced an original formulation for investigating the energy efficiency in the case of a partial dynamic reconfiguration system compared to the static version. By relying on FPGA technical characteristics, as well as power consumption measurements, we estimated the timing conditions that allowed the dynamic partially reconfigurable process to achieve relevant energy efficiency with respect to the corresponding static architecture.
In conclusion, under certain timing conditions, a dynamic partially reconfigurable system can achieve a considerable energy saving factor. The main application could be in those solutions that need multiple powerful processing units, such as advanced parallel DSP systems.
Future works will aim to investigate the possibility of changing the reconfigurable area size of the chip at runtime. Exploiting this improvement, the capabilities of the dynamic partial reconfiguration might be extended over the current limits, possibly giving rise to novel techniques for energy efficiency.

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}